Tämä postaus on jatkoa muutamalle edelliselle postaukselleni, joissa käsittelin pyydystettävyyden mallintamista logistisella regressiomallilla. Ideana ja motivaationa tälle oli se, että käytetyn pyydyksen tehon epäiltiin riippuvan erityisesti veden korkeudesta.
Käsittelin logistista regressiomalli teoreettisesti ja kirjoitin hahmotelmaa siitä, miten malli voitaisiin määritellä BUGS-kielellä. Kuitenkin epäselväksi jäi se, miten prioritieto pyydystettävyydestä saataisiin mukaan malliin. Tämä postaus käsittelee tätä ongelmaa.
Logistinen regressiomalli on muotoa
logit(q) = a + beta[1]*VK +beta[2]*VL + E
VK=veden korkeus, VL=veden lämpötila, E=virhetermi , a= vakiotermi, beta[1] = veden korkeutta vastaava regressiokerroin, beta[2] = veden lämpötilaa vastaava regressiokerroin.
Haluaisimme siis ‘valita’ tämän mallin parametrit niin, että pyydystettävyyden priorijakauma olisi edelleen suurinpiirtein tietty beta-jakauma, kuten aiemminkin. Nyt, koska mallissa pyydystettävyys vaihtelee päivittäin, tarkoittaa tämä oikeastaan sitä, että arvioituna kaikkien päivien yli (tai oikeammin, arvioituna mallin selittäjien jakauman yli), noudattaisi pyydystettävyys haluttua beta-jakaumaa.
Aivan täsmälleen tätä haluttua tulosta emme voi saavuttaa, mutta niin sanotun informatiivisen g-priorin avulla pääsemme hyvin lähelle.
Ratkaistessa todennäköisyys logit-muunnoksesta, saadaan yhtälö
q = exp(x’B) / (1 + exp(x’B) )
jossa X on mallin selittäjät sisältävä matriisi (1, VK, VL) ja B näitä vastaavat kertoimet (a, beta[1], beta[2]).
On näytetty, että jos
B ~ N(b*e, g*n*(X’X)^-1)
ja
x ~ N(u, Z)
missä
b = digamma(a) – digamma(b)
g = [trigamma(a) + trigamma(b)] / p
e = c(1,0,..0) <- p-pituinen vektori
p = parametrien lukumäärä
n = havaintojen lukumäärä
N() = normaalijakauma
x = selittävät muuttujat
niin silloin
exp(x’B) / (1 + exp(x’B) )
vastaa suunnilleen beta-jakaumaa parametrein a ja b.
Tämä siis tarkoittaa, että on mahdollista rakentaa logistinen regressiomalli, jonka priorijakauma vastaa haluttua beta-jakaumaa.
Tämän voi todeta esimerkiksi R-ohjelmiston avulla seuraavasti. Alla olevassa koodissa X on niin kutsuttu design-matrix määriteltynä R-objektina (eli esim matriisi tai data frame, jonka ensimmäinen kolumni on 1, ja toinen ja kolmas esimerkiksi päivittäiset veden korkeudet ja lämpötilat). Koodin ajamiseksi tämä matriisi tulee siis ensin määritellä.
library(MASS)
X <- …
get.bg <- function(alpha, beta, parameters = 3) {
b <- digamma(alpha) – digamma(beta)
g <- trigamma(alpha) + trigamma(beta)
g <- g/parameters
return(c(b = b, g = g))
}
bg <- get.bg(alpha = 3, beta = 50)
Sigma <- bg[[‘g’]]*nrow(X)*solve(t(X) %*% X)
mu <- c(1,0,0)*bg[[‘b’]]
# B noudattaa multinormaalijaumaa, tässä otetaan siitä satunnaisotos
B <- mvrnorm(1000, mu = mu, Sigma = Sigma)
# vektori, jossa todennäköisyyksiä logit-muunnoksesta
p <- apply(B,1,function(bi) {
apply(X,1,function(xi) {
exp(xi%*%bi)/(1+exp(xi%*%bi))
})
})
p <- c(p)
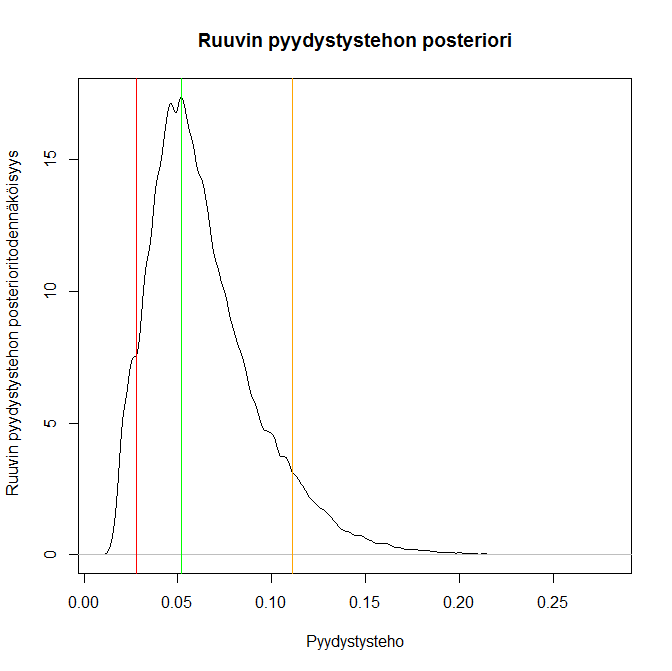
plot(density(p))
Kuvasta nähdään, että tuloksena on haluttu beta(a=3, b=50) jakauma