Jatkan seuraavassa Henrin edellisessä postauksessa tekemää oikeellista havaintoa, jonka mukaan smolttien päivittäisen muuttointensiteetin estimoinnissa ei ole (bayesilaisten periaatteiden vastaisesti) käytetty kaikkea käytössä olevaa asiantuntijatietoa.
Siispä kysymys seuraavassa kuuluu: miten sisällyttää (bayesilaiseen tilastolliseen analyysiin) epävarma, mutta samalla huipukas priori? Oletetaan:
1) että menneen tiedon valossa tiedetään kiinnostuksen kohteena olevan satunnaismuuttujan jakauma varsin huipukkaaksi (yhdellä tai useammalla huipulla) sekä
2) että tämän huipun paikan arvioiminen on varsin epävarmaa.
Toisin sanottuna, että tiedetään ennen aineiston keruuta suuren osan käsiteltävän satunnaismuuttujan todennäköisyysmassasta sijaitsevan jollain varsin kapealla, mutta etukäteen huonohkosti tunnetulla tai jopa täysin tuntemattomalla välillä määrittelyjoukkoa.
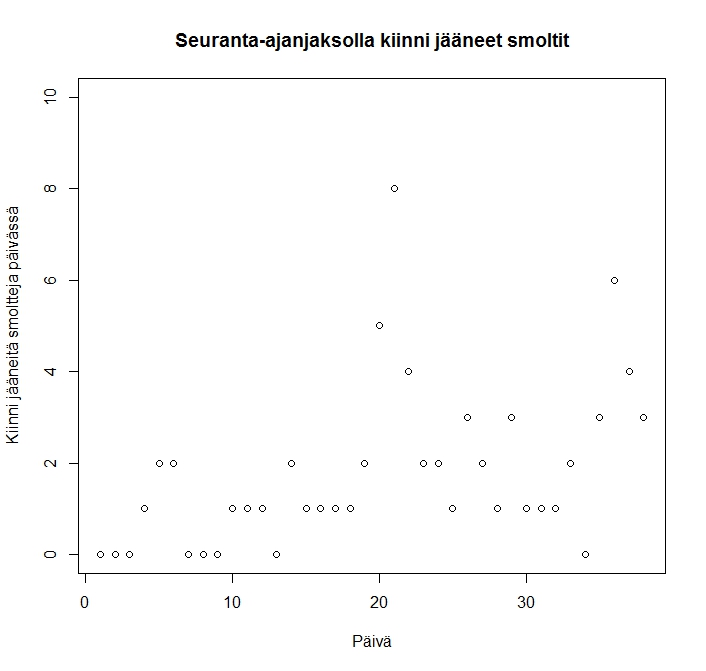
Tämän kaltainen haaste tulee vastaan smolttien muuttomäärien estimoinnissa, kun tilastollisen mallin puitteissa pyritään määrittämään muuttointensiteetin (eli yksittäisen smoltin merelle lähtemisen todennäköisyyden) jakaumaa tarkasteluajanjakson (1,2,3,4…,60) päivien funktiona. Tiedetään nimittäin, että smoltit (sekä taimenen että lohen) muuttavat melko intensiivisissä, mutta ajoitukseltaan paljon vaihtelevissa muuttopiikeissä. Merkittävän lisähaasteen vaellusmäärien päivittäiselle estimoinnille asettaa se, että havaintopiikkejä vaikuttaisi useimmiten olevan useampia (eli että muuttointensiteetin jakauma on multimodaalinen). Esimerkiksi Tornionjoessa tehdyissä riista- ja kalatalouden tutkimuslaitoksen lohismolttien muuttomäärien arvioinneissa on havaittu kolmehuippuisia muuttojakaumia. Myös taimenten vuosittaisissa muuttomäärissä on havaittu kevään ja kesän kuluessa useita melko jyrkkiä huippuja. (RKTL, 2003, 2008, 2009, 2011, 2012, 2013: kiitos näiden tutkimusten esille nostamisesta kuuluu Sara Enbergille! J)
(Kiinnostava kysymys on, mistä tämä multimodaalisuus johtuu? Modaalisuushan on sinänsä varsin ymmärrettävää huomioiden kalojen ryhmäkäyttäytyminen sekä altistuminen samoille ja oletettavasti jokseenkin samankaltaisesti kuhunkin smolttiin vaikuttaville ympäristötekijöille. Mielestäni toistuva useamman moodin havainto kertoo ainakin siitä, ettei muuttoon lähteminen ole kovin yksinkertainen prosessi, joka olisi suoraan riippuvaista esimerkiksi sopivan lämpötilan saavuttamisesta. Sen sijaan muuttoajankohtaan vaikuttavia ehtoja (”selittäviä ympäristötekijöitä”) on joko useita (ja) tai kalat muuttavat muuttohuipun ympärille muodostuneissa ryhmissä, kalojen kunkin ryhmän sisällä jakamien ominaisuuksien perusteella (”selitettävä” muuttuja eli todennäköinen lähtöpäivämäärä ositettu kalan ominaisuuksin vaihteleviin ryhmiin).
Karkeana esimerkkinä ensin mainitusta voisi olla tilanne, jossa muuttointensiteetin riittävä ehto on riittävän korkea lämpötila, mutta välttämätön ehto sopiva vedenkorkeus. Tällöin vedenkorkeuden vuosittainen vaihtelu kolmessa piikissä voisi selittää kolmihuippuisen muuttointensiteetin jakauman sen jälkeen, kun lämpötilan riittävä ehto on saavutettu. Vastaavasti, jos muuttopäivämäärä riippuu ympäristötekijöiden sijaan tai lisäksi kalan henkilökohtaisista ominaisuuksista, kuten smoltin koosta, smolttien jakautumisesta kutakuinkin kolmeen ryhmien sisällä enemmän kuin välillä vaihtelevaan kokoryhmään selittäisi kolmihuippuisen muuttojakauman.)
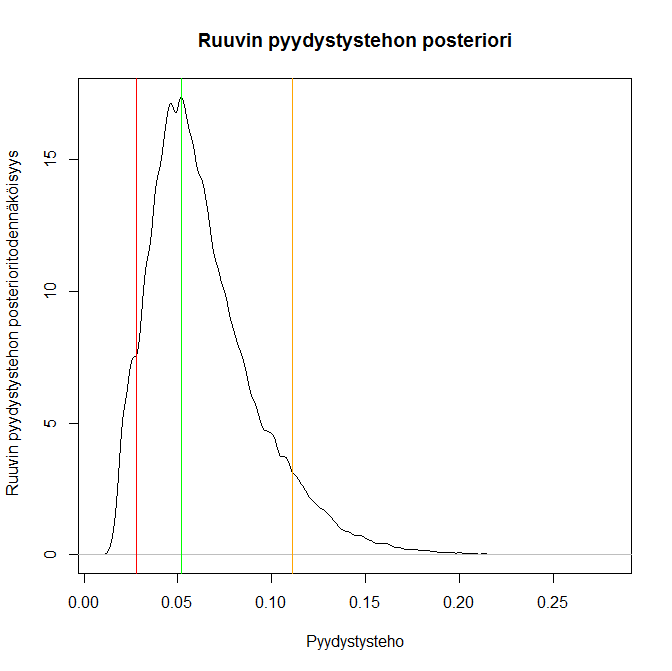
Myös kokonaismuuttomäärien arvioinnin kannalta on varsin tärkeää kyetä estimoimaan, milloin muuttohuippu oikein saavutetaan. Muuttomääriä koskevalla priorivalinnalla on aivan erityisen suuri merkitys juuri silloin, kun havainnointi on vaikeaa, eikä estimointia voida tehdä pelkästään aineistoperusteisesti. Jos (ja meidän tapauksessa kun) yksittäisiä pyydykseen jääviä smoltteja on kovin vähän, on vaihtelu absoluuttisissa pyydykseen jääneiden smolttien havaintomäärissä pientä jopa muuttohuipun ja -suvannon välissä. Kuten mallistamme tiedetään, havaitut muuttomäärät ovat todellisten muuttomäärien ja pyydystettävyyden funktio: jos molemmat näistä selittävistä tekijöistä saavat pieniä arvoja, jää myös pyydykseen keskimäärin vähän kaloja. Tästä seuraavat pienet absoluuttiset havaintomäärien vaihtelut voidaan tällöin virheellisesti arvioida muuttohuipuiksi, varsinkin kun tähän pieneen vaihteluun yhdistetään pyydyksen pyydystettävyyden suuri vaihtelu päivien yli. Vedenkorkeudesta riippuen joinain päivänä ruuvi on pyörinyt, toisina ei. Tietoa siitä, kuinka paljon tämä on vaikuttanut pyydystystehoon, ei ole. Täten pyydystettävyyden vaihtelua ei ole huomioitu vielä yhtään millään tavalla rakentamassamme pyydystettävyyden tilastollisessa mallissa: tämän seurauksena havaintoperusteiset oletukset muuttopiikeistä voisivat selittyä yhtä lailla todellisella muuttomäärien vaihtelulla kuin käytetyn mittausmenetelmän vaihtelulla (jonkinlaisella systemaattisella mittausvirheellä).
Multimodaalista muuttomäärien jakaumaa ei voida approksimoida millään esittämistämme tilastollisista malleista: tasajakaumamalli olettaa muuttomäärän tasaiseksi (huiputtomaksi) päivien funktiona, lognormaalijakauma olettaa yhden huipun saavutettavan tarkasteluajanjakson alkupäässä, normaali keskellä. Mikään ei kuitenkaan estä sovittamasta mitä tahansa muuttojakaumaa halutulla tavalla kuvaava funktiota, kunhan tämä täyttää todennäköisyysjakauman määritelmän summautuen yhteen yli määrittelyjoukkonsa eli 60 havaintopäivän. Yksi vaihtoehto olisi useamman asteen polynomifunktio. Jonkinlainen kenties helpommin hahmotettavissa oleva approksimaatio käytössä olevan prioritiedon mallintamiseksi saattaisi olla osittaa määrittelyjoukko oletettuihin ”moottohuippuryhmiin” (kuten kolmeen osaan), sovittaa kuhunkin näistä väleistä välin päätepisteisiin katkaistu ja melko huipukas normaalijakauma ja normalisoida saadut tulokset sellaisella vakiolla, joka varmistaa y-arvojen summautumisen yhteen koko 60 päivää kattavassa määrittelyjoukossa.
Miten määrittelyjoukkon ositteiden keskipisteet eli muuttohuiput sitten määritettäisiin? Muuttohuippujen paikkaan (eli seurantajakson ajankohtaan) liittyvää epävarmuutta voitaisiin ainakin vähentää estimoimalla huippukohtaa malliperusteisesti. Bohlin ym. (1993: kiitos tämän tutkimuksen esille nostamisesta kuuluu Mikko Hynniselle) havaitsivat, että muuttopiikin sijoittumiseen vaikuttaa 1) (vuosittaisen) smoltin (keskimääräinen) pituus, 2) vedenkorkeus sekä erityisesti vedenkorkeuden muutos, 3) lämpötila sekä erityisesti lämpötilan muutos (viikon takaisesta) ja 4) edellisen vuoden kalakannan kasvu. Näillä tekijöillä Bohlin ym. kykenivät selittämään 47% prosenttia päivittäisten muuttotodennäköisyyksien varianssista.
Periaatteessa meillä olisi käytettävissä kerättyä seurantatietoa 3 ensin mainitusta tekijästä; neljännestäkin tietoa luulisi olevan saatavilla. Muuttointensiteetin jakauman estimointi mainituilla selittävillä muuttujilla on siis harkitsemisen arvoinen asia. Tällaisellakin (polynomiaalisella regressio)mallilla jäisi kuitenkin edelleen oletettavasti selittämättä suurin osa smolttien muuttoon lähtötodennäköisyyden päivittäisestä vaihtelusta, minkä lisäksi ei voitaisi tietenkään mennä takuuseen siitä, että lounais-Ruotsissa tehdyt havainnot siirtyvät sellaisenaan Vantaanjoen kaikin puolin varsin erityislaatuiseen muuttotilanteeseen. Siksi tällaiseenkin regressiomallivalintaan tulisi suhtautua terveellä skeptisyydellä kuitenkin samanaikaisesti ymmärtäen, että kaikki käytössä oleva tieto olisi syytä estimoinnissa myös hyödyntää: lähes täydelliseen a priori tietämättömyyteen perustuva malli on peräti virheellinen (ja tehoton), jos a priori tieto on oikeasti olemattoman sijaan ainoastaan heikkoa.
Muuttomäärien jakaumaa koskeva arvio on vaikutusvaltainen kokonaismääriä estimoitaessa. Tämän voi havaita tarkastelemalla eri mallivalintojen posterioriestimaatteja Vantaanjoen smolttien muuttomääristä (ks. tämän päivän tulospostaus kolmella mallilla). Tästä seuraa yhdessä mallivalintaan liittyvän edellä esitellyn epävarmuuden kanssa, että vuosittaisen muuttomäärän totaalin posterioriestimaattia johtaessa olisi järkevää käyttää melko useaa mallia, joiden yli posterioriestimaatit sitten keskiarvoistettaisiin painottamalla lähtökohtaisesti perustelluimpina pidettyjä malleja suuremmilla prioritodennäköisyyksillä.
Tästä voitaneen luvata tulevan pian lisäpäivityksiä, so stay tuned.