Digital urban spaces of Helsinki seen from Instagram data have high language diversity, the topics of Finnish and English posts differ spatiotemporally and content-wise to some extent and more is discovered in my Master’s thesis. Finnish and English language posts dominate different areas of Helsinki and topics of Finnish posts have connections to everyday life while English topics are influenced by tourists
With ubiquitous internet access and increasing amounts of social media users and content, an ever larger part of social interactions and common discussions are being augmented with digital means of communication. This renders social media data valuable for scientific inquiry in order to understand contemporary societies, cultures, and phenomena. Social media data is being produced constantly in vast quantities and is mostly produced by users living in urban areas. The data produced in social media can have a reference to a real-world location e.g. in the form of a geotag or geographic coordinates enabling spatiotemporal analysis. In order for scientific knowledge to keep up with the quick changes in society and cultures enabled by the internet and social media, social media data sets need to be investigated and doing this requires powerful novel and interdisciplinary methods.
In my thesis, I delved into the digital urban space of Helsinki by applying topic modeling to Finnish and English Instagram posts’ captions from Helsinki. By looking at the topics of Instagram posts made in both English and Finnish languages, my aim was to discover how language affects Instagram topics, the spatiotemporal distributions of these topics and whether linguistic technologies are applicable in geographic research. In order to do all of this, a number of preprocessing steps were required. The language of the posts had to be identified in order to separate Finnish and English posts from another. After this, the caption texts were lemmatized to make LDA topic modeling viable. Lemmatization is a natural language processing technique with which inflected words are returned to their basic ‘dictionary’ form. For topic modeling of morphologically rich languages, such as Finnish, this is a critically important step without which LDA topic modeling would not yield sensible results, but it is recommended for English as well. Then the lemmatized captions were vectorized and fed into an LDA topic model which modeled language-specific topics for the Helsinki area and a few city districts.
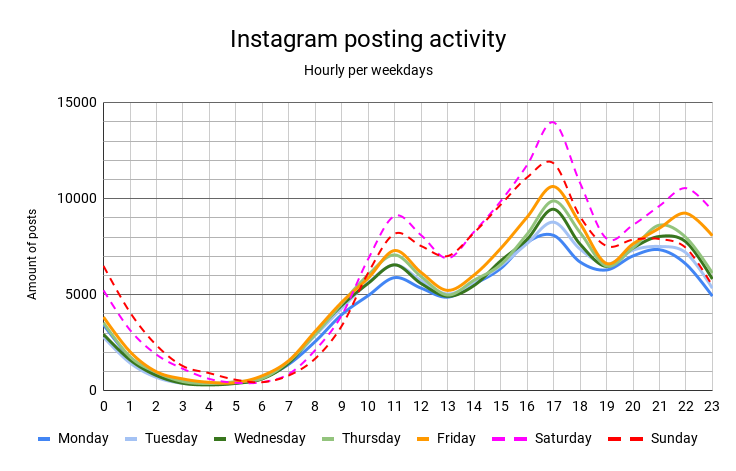
Instagram posting activity in Helsinki follows three-peak rhythmicity.
Plotting the hourly Instagram posting activity by each weekday reveals that Instagram posting frequency in Helsinki follows a three-peak rhythmic structure: peaking at common meal times each day of the week. The temporal structure also shows that Saturdays and Sundays are the most popular days to post on Instagram in Helsinki. These findings hint at a connection between Instagram posting in Helsinki and leisure time activities quite strongly, suggesting Instagram data might be suitable to find out where Instagram users are and what they’re doing on their own time.
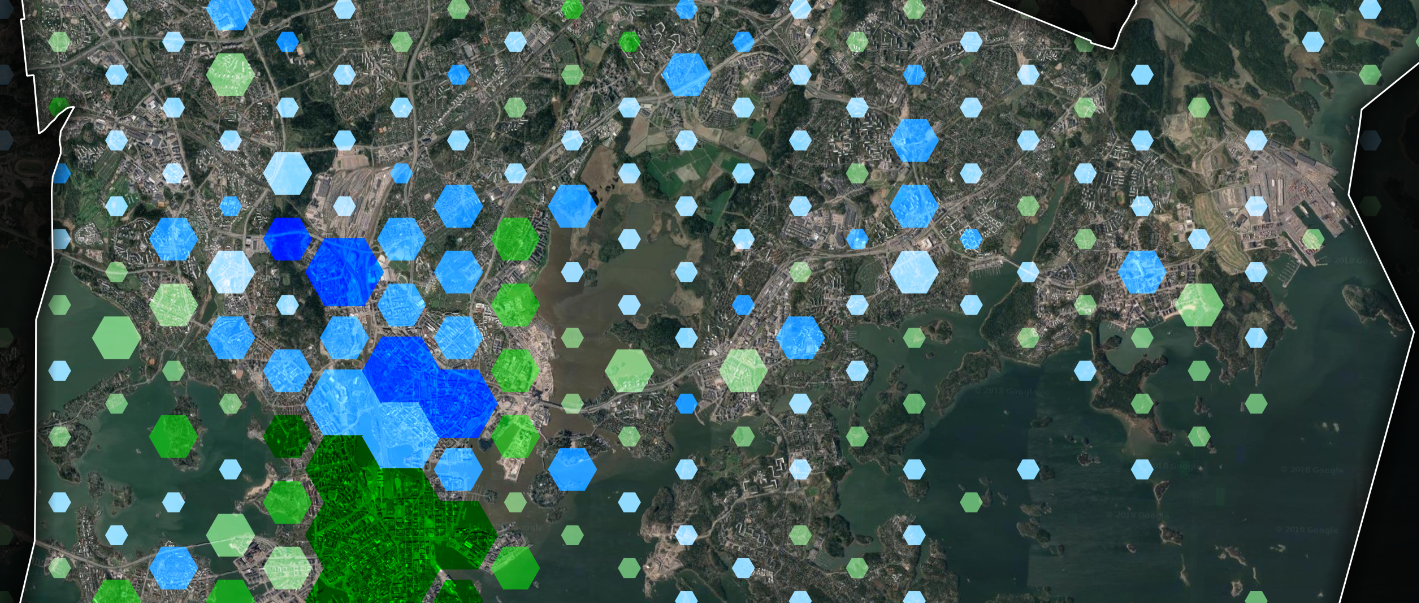
The linguistic landscape of Helsinki from Instagram posts.
To decipher which topics are popular in Finnish and English Instagram posts, the language of the posts was identified revealing the diverse linguistic landscape of Instagram posts in Helsinki. By only focusing on Finnish and English, a lot of knowledge is lost in my analysis, underscoring the importance of a multilingual approach in future work. The geolinguistic division between Finnish and English Instagram posts in Helsinki shows a few key patterns. Firstly, the city center is the area of highest posting intensity, but smaller posting hubs appear along with major transport nodes in Helsinki. Secondly and perhaps more interestingly, central Helsinki is quite clearly divided in two between the languages. Finnish is more popular in areas north of Hakaniemi, while English comes out on top in the southern parts of the center. The main dividing line seems to be Töölönlahti and the small channel connecting Töölönlahti to the Baltic sea, which has historically been the dividing line between the working class in the north and the bourgeoisie in the south. The biggest relative differences between the languages are in peripheral areas with very low post counts suggesting that popular areas for posting are popular for both languages.
Two most common languages of Instagram posts in Helsinki divide the city.
Finnish and English Instagram posts’ topics differ both spatially and temporally at different scales, even though Instagram data was shown to be similar in content and temporal rhythm between the languages. Posts in both languages mostly deal with leisure-related topics, but Finnish topics have several references to everyday life, while English topics do not. Also, Finnish posts didn’t have one numerically dominant topic while as English posts did: ‘morning’. The spatial structure of the topics reflects the complexity of social media content, generality of the topics and the fact that posting location might not specifically relate to the topic of the post. Also, Instagram’s geotagging is based on points-of-interest which introduces slight to moderate spatial inaccuracy into the data as the exact posting coordinates are not recorded. There is, however, some spatial logic to the topics, for instance, the prevalent topic of Suomenlinna island is ‘summer’ for Finnish posts and ‘New Year’ for English posts, topics around the Olympic stadium revolve around sports. Statistically validating the connection between the topic and the underlying geographic region is highly problematic if the topic is very general.
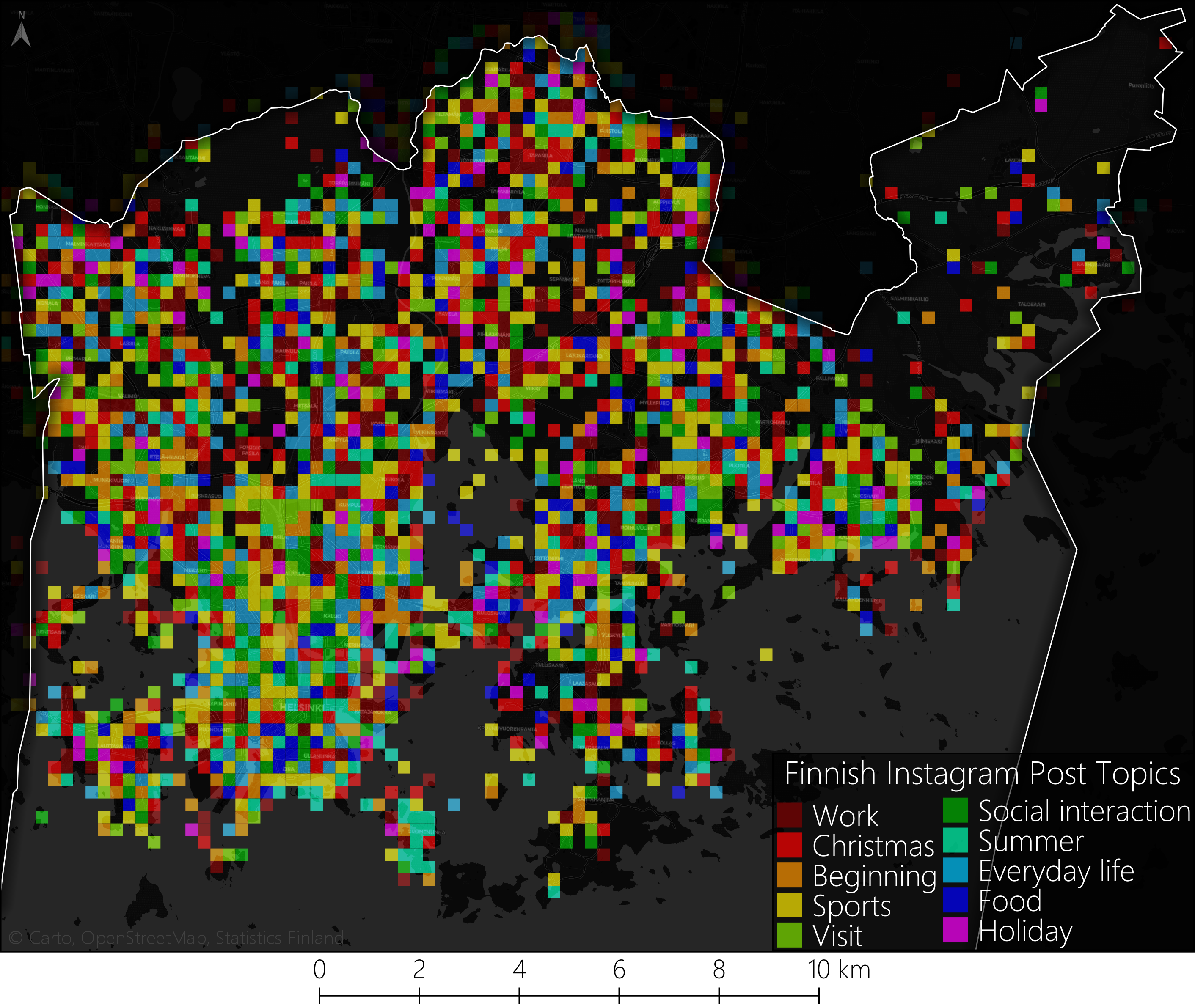
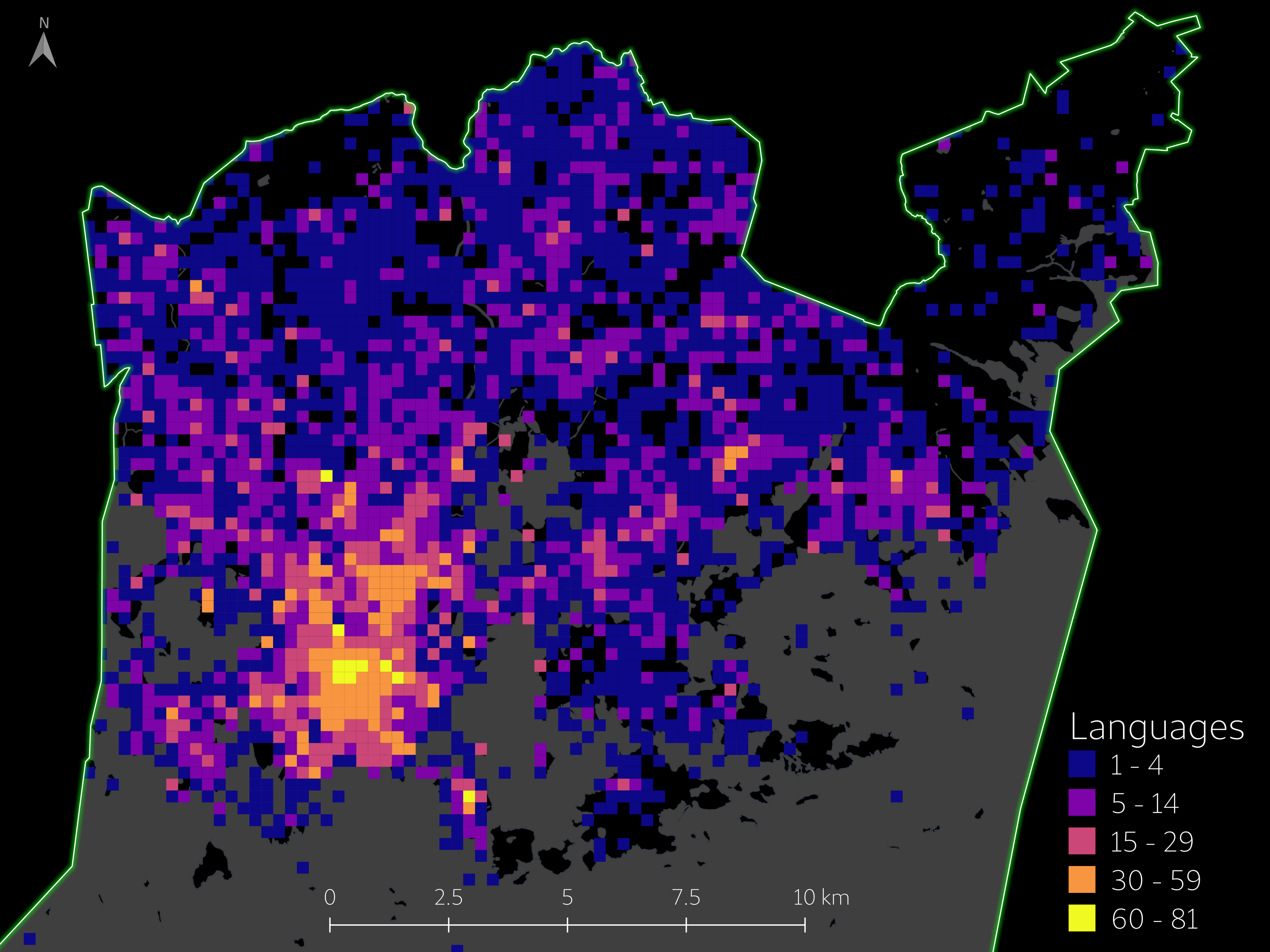
Topics of Finnish Instagram posts in Helsinki aggregated into a 250-meter grid.
The topics become more specific at city district level which is to be expected with the limited spatial extent of a city district. However, at the city district level, the POI-based location structure becomes more problematic due to the aggregation of posts under POIs. At the city district scale, English topics have clearer references to touristic sights in the city districts suggesting a presence of tourists or at least sightseeing as an activity in the data set. Finnish topics, however, maintain a connection to everyday life with topics like “work”, “family” and “everyday life” and touristic sights are not mentioned.
There are a few things to consider when doing research with social media data. First, social media posts are often about subjects the user considers positive creating a positivity bias into the data. Second, results from social media analyses only represent the users of its particular social media platform and finding out to what extent this group represents the population as a whole is difficult. Third, the locational accuracy of posts isn’t in all cases very good, because geo-tagging functionality can be based on fixed points-of-interest and not to the actual coordinates of the user at the time of posting. This means that large amounts of posts can be and are aggregated on to commonly named points-of-interest. For instance, “Helsinki, Finland” was one of the most popular location names in the data and surprisingly consisted of numerous different points across Helsinki. Fourth, social media posts are multilingual and most of the tools for content analysis have been developed for English and most of social media research deal with English content. Including minor languages into the analysis would ensure a broader and less biased understanding of what is going on in social media. Fifth, social media companies are constantly developing and changing their APIs making access to data and reproducibility depend on the whims of social media corporations. Regardless of these error elements and limitations, social media data can be a very fruitful data set for scientific analyses of the city and (some of) its people.
Tuomas Väisänen
Here’s the link to my Master’s Thesis (only in Finnish)