Tusen tack för en bra och intressant kurs Arttu!
The last ride – sjunde krusgången
Förberedelse
Inför den här sista kursgången skulle vi själv förbereda vårt material som vi ville använda. Vi fick själva leta rätt på kartor, material och statistik på precis vad som helst som vi kunde framställa med QGIS. Många använde hela världsdelar, t.ex. Sandra Nystöm och Kasper Mickos, men jag bestämde mig för att hålla mig mitt hemland kärt och experimentera på Finlands kommunala nivå.
Mitt arbete
Som material har jag då alltså valt Finlands kommunala gränser, population i kommunerna, tätortsgraden och ett trafikdata över hur många kollisioner som skett med bil som fordon.
Min första karta som jag producerade föreställer därmed andelen allvarliga bilkollisioner i förhållande till invånarantalet per kommun (bild 1). För att få fram kollisionsandelen så började jag jobba med att dela antalet allvarliga kollisioner med invånarantalet i varje kommun. Det som gav problem var mest de mer simpla sakerna som att försöka flytta data från ett “layer” till ett annat. Jag tror jag förlorade ett helt präktigt antal timmar på att försöka få kolumnen med kollisioner från mitt trafikdata till kommundatat men efter många svordomar så lyckades det och jag kunde utvinna det jag ville få fram.
Det som lite ännu också får mig att fundera på hur bra min första karta är (bild 1) är att ställen där jag skulle ha antagit att andelen krockar skulle varit stort inte alls visar sig vara speciellt utmärkande. Jag trodde att huvudstadsområdet eller de kommuner med stora städer (Tammerfors, Jyväskylä, Lahtis osv.) skulle ha ett större antal bilkollisioner.
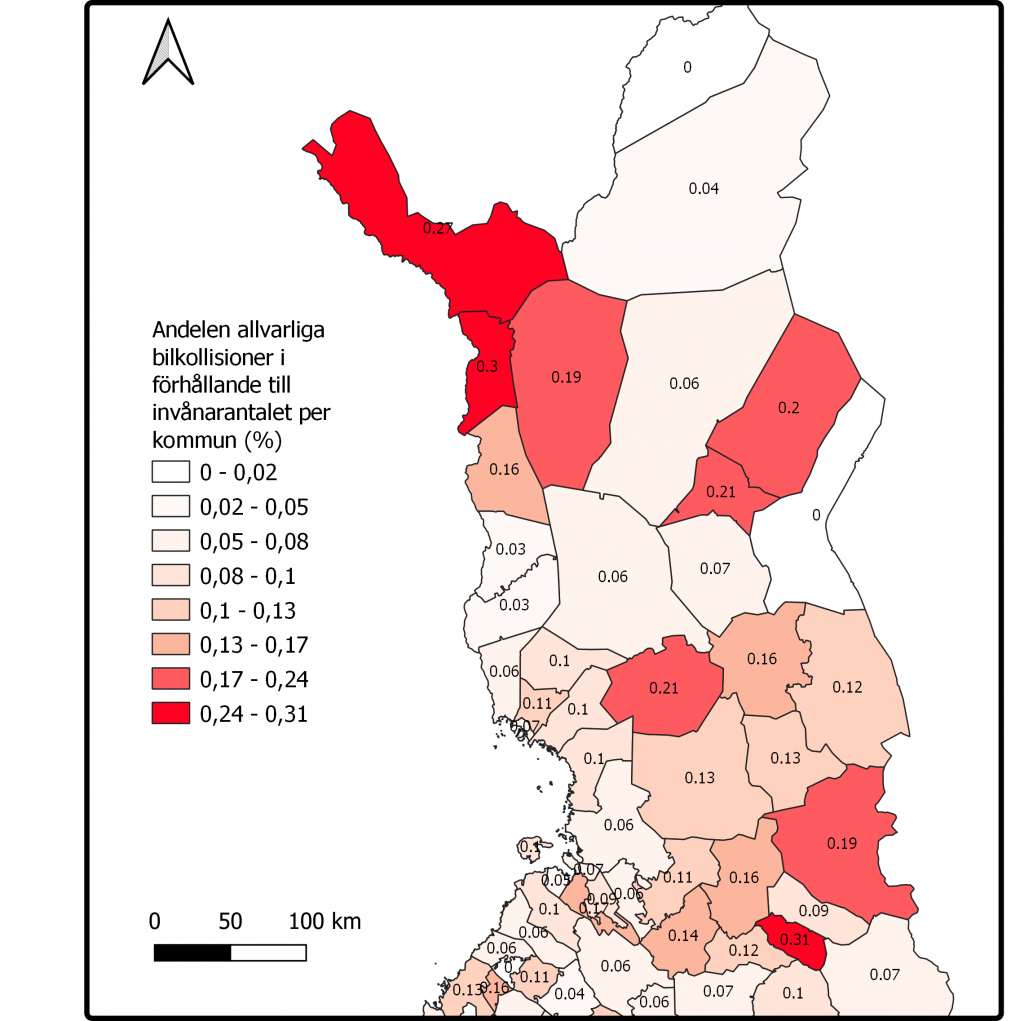
Jag har funderat ut ett par förklaringar till varför mina kartor (bild 1 och bild 2) ser ut som de gör. Den mest sannolika orsaken är att procenten blir mycket högre i kommuner där det inte finns så mycket människor, vilket ju är ganska logiskt eftersom om en kommun har 100 invånare och det sker 20 krockar så är ju andelen 20% medan om en kommun har 10 000 invånare och 200 krockar så är andelen bara 2%. Visserligen så borde ju antalet kollisioner öka i mer tätt bebodda kommuner men t.ex. i Helsingfors där det bor över 600 000 personer men alla har ju inte en bil. Nå oberoende så gjorde jag också en karta som närmare visar norra Finland med kollisionsadelen given i procent på kartan (bild 2). Vad man också bör lägga märke till är att andelen är väldigt låg oberoende var man befinner sig. Majoriteten av värdena ligger under 20% så siffrorna är inte speciellt höga då datat tar i beaktande alla sorters allvarliga kollisioner, vare sig det är mellan flera bilister, utkörningar eller djurkrockar. 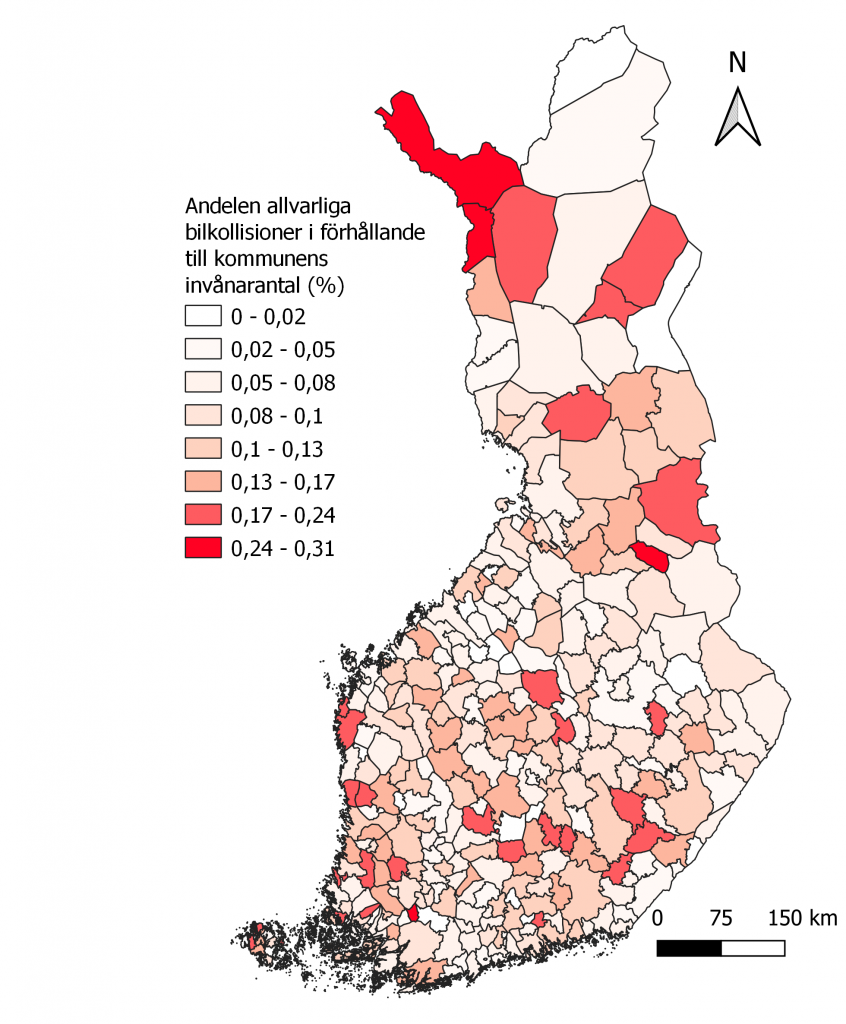
Bild 1: Bilkollisioners andel i förhållande med invånarantal i varje kommun (%), 2019
Tätorter och krockar
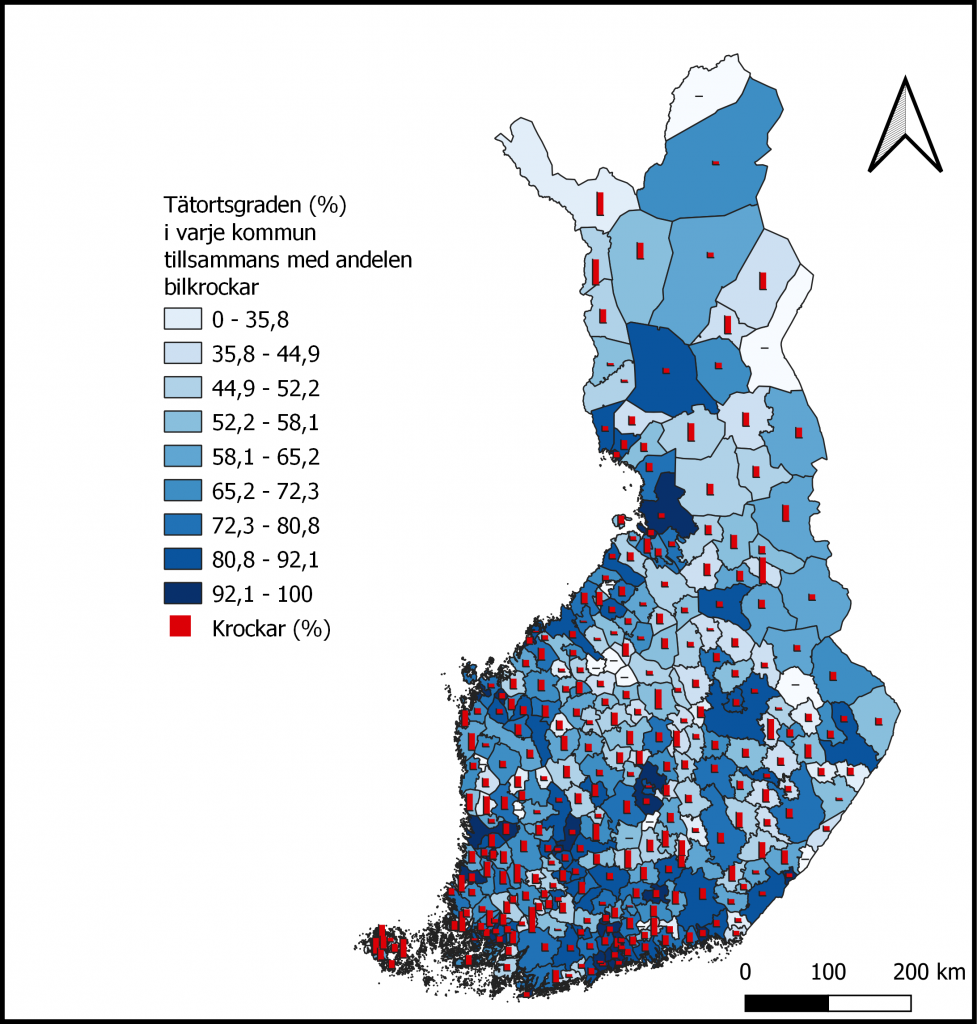
Efter att jag tillverkat min första karta så fick jag idén att ta reda på om tätortsgraden kan ge en bidragande förklaring till varför vissa kommuner har en högre krockprocent än andra kommuner (bild 3). Igen en gång var svårigheten att föra över data från en layer till en annan och med mild irritation så fick jag arbetet avklarat och igen en gång tycker jag att mitt resultat blev helt annorlunda än vad jag förväntat mig. Datat visar en rolig trend där antalet krockar verkar öka då tätortsgraden sjunker. Kort och koncist: personer som bor på landsbygden verkar vara sämre chaufförer än personer som bor i tätorter, eller rättare sagt så förekommer det fler kollisioner i kommuner med lägre tätortsgrad. Datat visar ju inte vem som körde eller varifrån kusken kom ifrån, bara var olyckan skett.
Trenden är ändå intressant men om den är helt verklighetstroende är svårt att säga. Antagligen så blir resultaten lite dumma eftersom jag valt att jämföra krockar med individantal från första början. Jag skulle kanske ha bordat laga en “heatmap” istället för att man bättre skulle kunna urskilja var det sker mest olyckor men det blev hur det blev.
Avslut
Det här var alltså den sista kursgången i det här givande ämnet som kallas geoinformatikens metoder. Det här har varit en mycket bra och intressant kurs. Antagligen så gillade jag den här kursen också lika mycket som “tiedon esittäminen maantieteessä” kurssen för att den innehöll så mycket datoranvändning, och jag gillar att syssla med datorer. Det som jag fortfarande lite saknar med den här kursen är övning. En del saker känns ännu ganska svåra när det kommer till att försöka manipulera och redigera mina attributtabeller, speciellt då jag vill försöka flytta data från en attributtabell till en annan men det är väl bara så att man måste lära sig det bättre på egen hand.
Källor:
Tilastokeskus, Kuntien avainluvut 1987-2019, hämtad 29.3.2021: https://pxnet2.stat.fi/PXWeb/pxweb/fi/Kuntien_avainluvut/Kuntien_avainluvut__2021/kuntien_avainluvut_2021_aikasarja.px/?rxid=444223df-f91c-4479-891f-5dcd50b983d2
Tilastokeskus, Tieliikenneonnettomuuksissa kuolleet ja loukkaantuneet alueittain tienkäyttäjäryhmän, iän ja sukupuolen mukaan vuosina 2003-2021, Hämtad 29.3.2021: https://tieliikenneonnettomuudet.stat.fi/PXWeb/pxweb/fi/Tieliikenneonnettomuudet/Tieliikenneonnettomuudet__1_Tienkayttajat/010_tienk_tau_101.px/
Sandra Nyströms blogg, hämtad 29.3.2021: https://blogs.helsinki.fi/nystroms/2021/03/05/seitsemas-ja-viimeinen-kurssikerta/
Kasper Mickos blogg, hämtad 29.3.2021: https://blogs.helsinki.fi/kmickos/2021/03/08/kurssiviikko-7-on-tamakin-s-tyomaa/
Vecka 6, Trygghet och jordskalv
Interpolation
Den här kursgången började med att vi använde oss av data som samlats insamlats av kursen deltagare, mestadels från Helsingfors. Det data vi använde oss av var trygghet på en skala 1-5 där 1 är otrygg och 5 är trygg. Vi Interpolerade ett passligt stort område så att alla datapunkter rymdes med och på det sättet skapade vi en sort “heat map” över helsingfors (Bild 1). Interpolering är en av de lättare verktygen som inte kräver alldeles för svåra funktioner för att använda, 5/5.
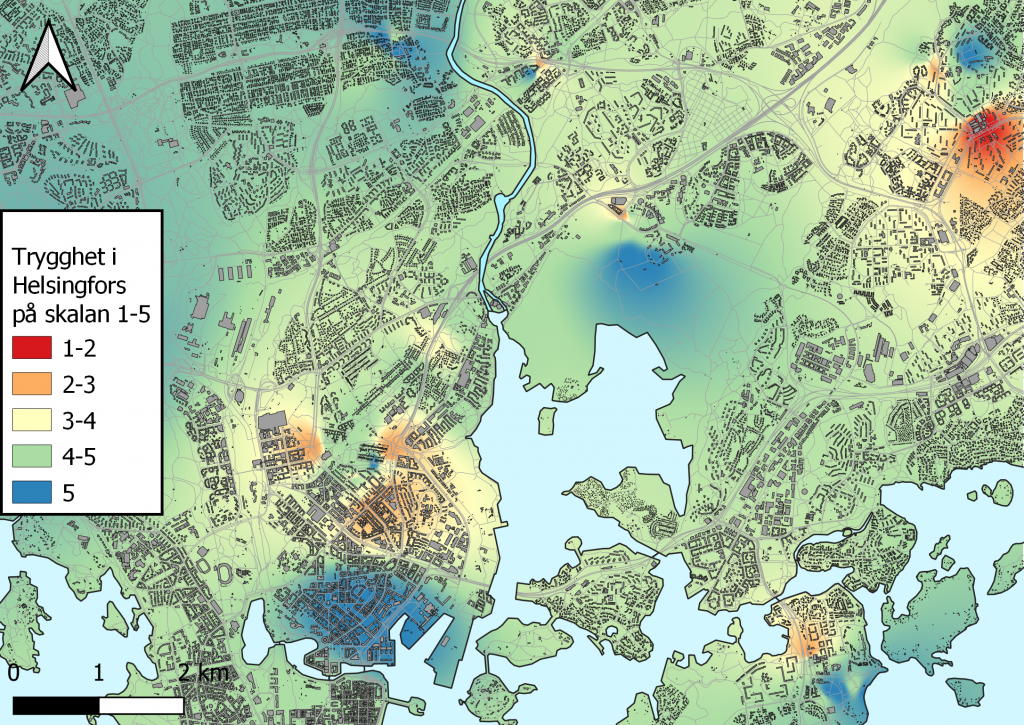
Hasarder
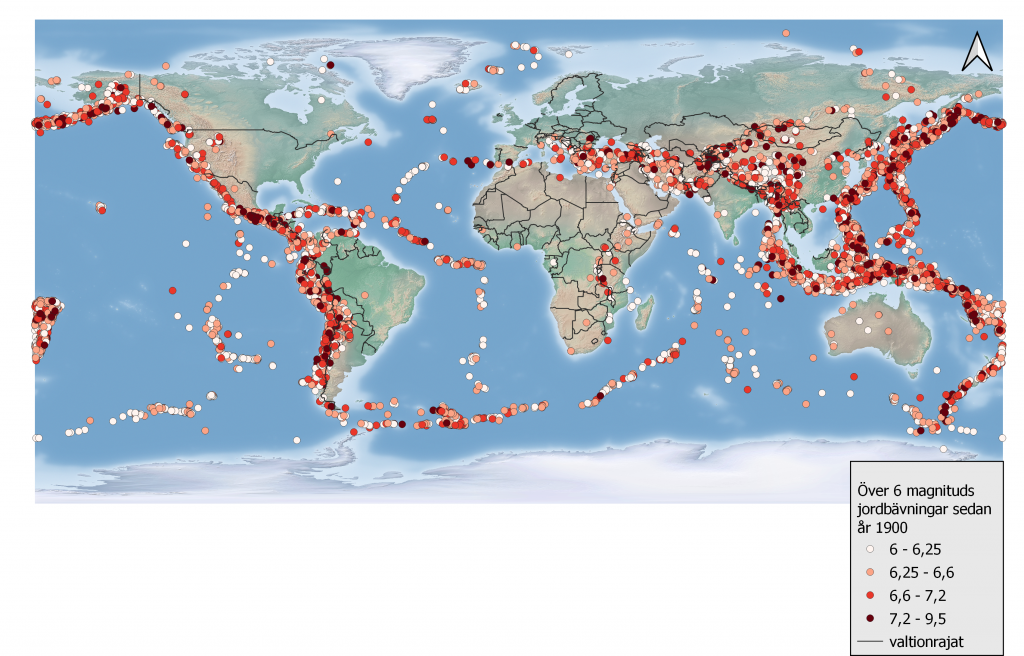
Till följande började vi med lektionens verkliga uppgifter som gick ut på att använda oss av olika data från webben över olika hasarder (jordbävningar, tsunamier, vulkanutbrott) och av dem framställa kartor som man skulle kunna använda inom undervisningen (Bild 2-5).
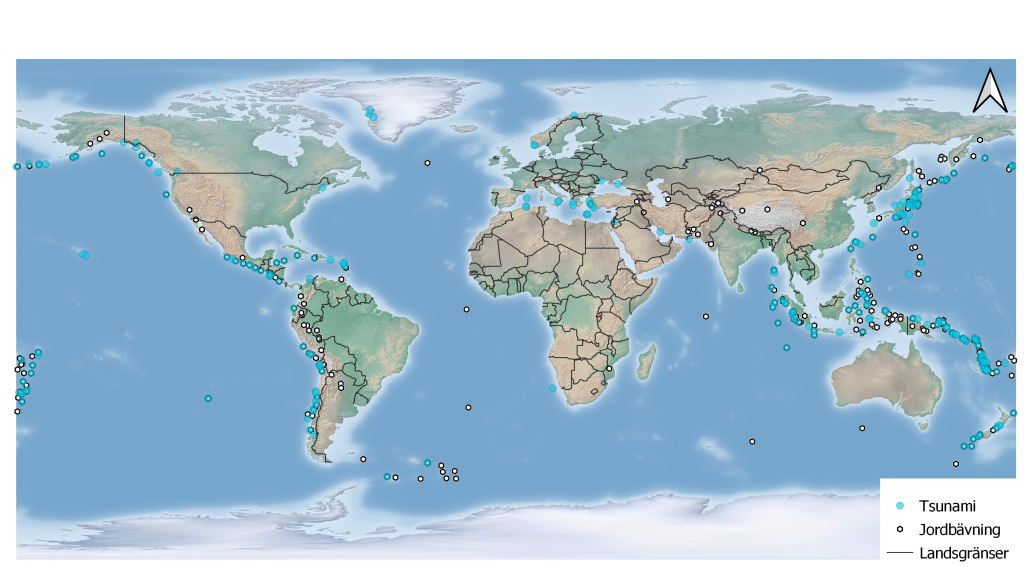
Det var inte så svårt att söka data eftersom webbsidorna USGS och NCEI är ganska lätta att navigera. Man bara väljer vilken typ av hasard man vill kolla upp och definierar variabler enligt eget tycke, t.ex. år, plats eller status. Datat laddades ned antingen som .csv eller .tsv filer vilket betyder att man måste vara lite extra noggrann då man för in datat i QGIS. Man måste välja koordinater och se till att man använder sig av rätt avskiljare (komma, punkt, semikolon, etc.) för att skapa rätt data. Efter det är allt ganska “smooth sailing” och man kan redigera datat hur man vill för att framställa t.ex. en karta över hur jordbävningar och tsunamier korrelerar mellan åren 2000 och 2021 (Bild 2).
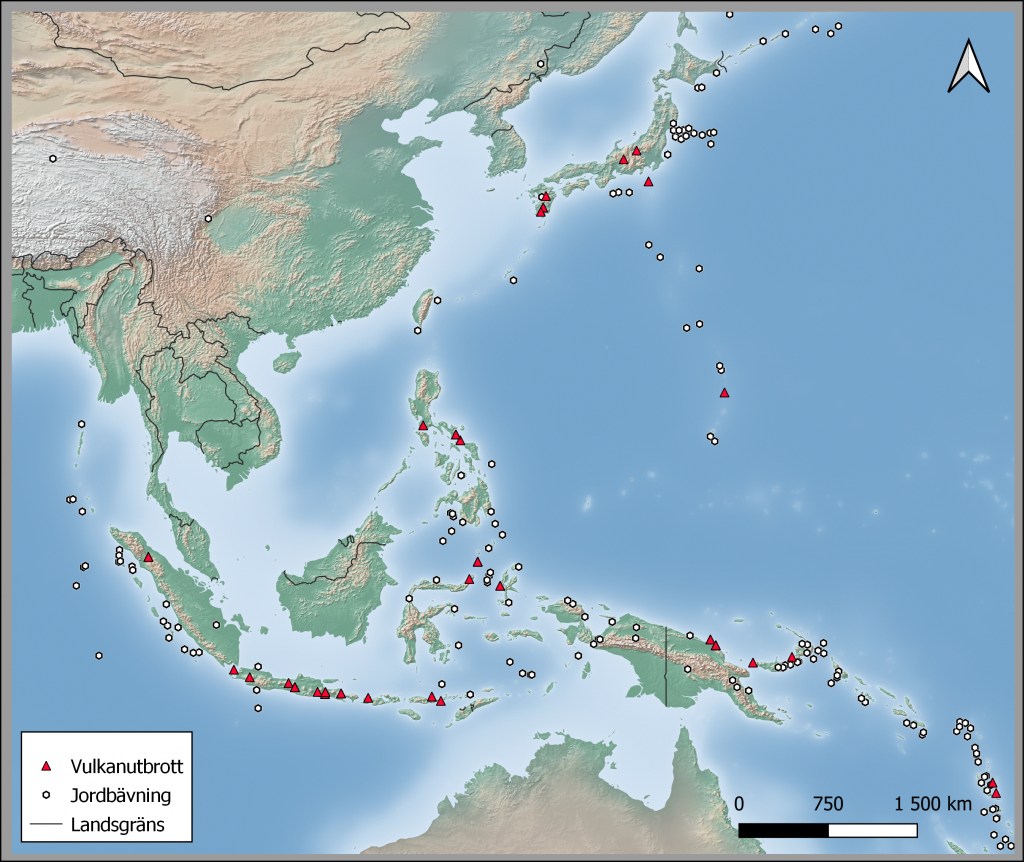
Aningen besvärligt ännu är att få QGIS att lyda när man vill få fram specifikt data med många variabler som endast jordbävningar mellan åren 2000-2021 av en minsta magnitud av 7 och sedan kombinera det datat med vulkanutbrott (Bild 3). Jag lagade inte själv desto fler och mer invecklade variabler men om man har kunskapen så kan man i princip jämföra vad som helst. Aino Schulz lagade väldigt bra kartor med olika variabler som magnituder, dödsoffer och positionering.
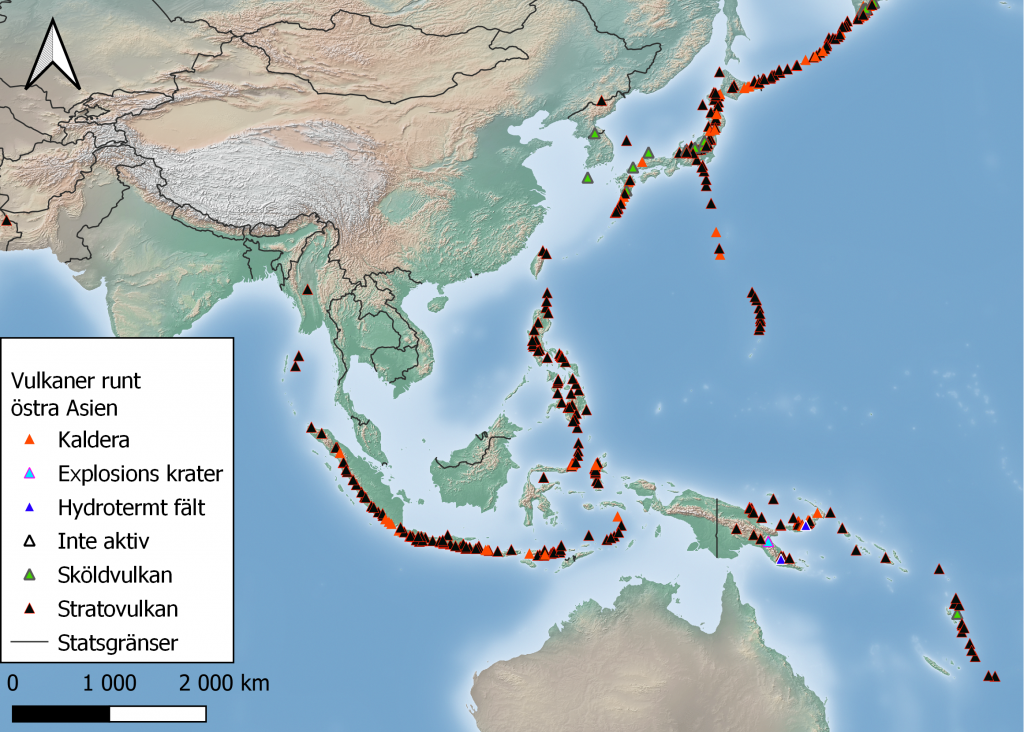
Som en liten bonus gjorde jag en karta över några olika typer av vulkaner som haft utbrott (eruption) i Sydostasien för att jag tyckte det såg fint ut (Bild 4).
Källor:
Aino Schulz blogg, hämtad 3.3.2021: https://blogs.helsinki.fi/scsc/2021/03/01/24-2-2021-maa-202-luento-ja-itsenaistehtava/
USGS, science for a changing wordl, Earthquake Hazards Program: https://earthquake.usgs.gov/earthquakes/search/
NCEI, National Centers for Enviromental Information, Natural Hazards: https://www.ngdc.noaa.gov/hazel/view/hazards/volcano/loc-data?region=13#
Vecka 5 #Ragequit
Den här veckans uppgift gick som allra längst ut på att självständigt försöka tillämpa de kunskaper vi lär oss hittills genom 3 självständiga uppgifter som inte direkt såg allt för komplicerade ut vid första titten men efter att jag börjat komma längre in på uppgifterna så blev det allt mer tydligt att det var ganska svårt, tungt och segt att ta sig framåt.
Lektionen så börja vi med vårt tidigare data över Borgnäs dit vi ritat in vägar och hus. Vi gjorde en buffertzon vid vägarna och tog en noggrannare titt på vilka hus som låg innanför buffertzonen. Idén bakom buffrandet var att få en aning av förståelse för hur man kan använda sig av buffertzoner i t.ex. stadsplanering eller liknande.
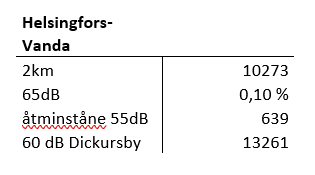
Första självständiga uppgiften gick ut på att just laga en buffertzon för start- och landningsbanorna vid Malms flygfält. Zonerna skulle bli repsektive 1km och 2km från banorna och sedan skulle vi beräkna hur många människor som bor innanför dessa buffertzoner som representerade “bullerzoner” eller “oljudsområden” från överpasserande flygtrafik. En stor miss som skedde var att jag läste instruktionerna dåligt och istället för Malm så började jag vid Helsingfors-Vanda flygplats. Nåväl efter att missen blev avklarad så var det ganska enkelt att räkna personer innanför bullerområdena och uppgiftens andra del som utspelade sig vid Helsingfors-Vanda flygfält var också relativt enkel eftersom båda uppgifterna i stor sett handlade om att använda olika “Select” kommandon för att sedan kunna räkna antal. Inga större problem. Den sista delen av första uppgiften med “Stationer” innehöll också tillämpandet av bufferzoner och sedan att räkna antal personer innanför dem så “Select” fuktionen funkade riktigt bra här också.
Uppgift 2 med tätorter gick också smidigt ända tills den allra sista delen som gick ut på att ta reda på hur många tätortsområden som hade en större andel än 10%, 20% och 30% utländska invånare. Den biten klarade jag inte fast jag försökte i nästan 3 timmar med att klippa, klistra och räkna. Defeat.
Det som jag uppenbart inte kan i QGIS är att använda attributdata på ett bra, smidigt och lätt sätt. Jag lyckas nog komma fram till rätt resultat men vägen dit tar oändlig tid och är ineffektiv för jag behärskar inte de olika räknesätten som finns i QGIS, t.ex. hur man kan ta en kolumn från ett data och lägga in det i ett annat.
Hela den här uppgiften gjorde mig arg, irriterad, trött och utmattad och jag kan bara inte förstå hur till exempel Jonathan Loo klarat av andra uppgiftens sista del med utländska personer.
#ragequit
Sist men inte minst så försökte jag mig på att göra den sista tredje uppgiften och valde VVS/LVI datat över vilka byggnader som skulle behöva genogå rörmokeri. Efter att jag börjat behandla datat bestämde sig QGIS för att vägra jobba mera varje gång jag försökte öppna en attributtavla så jag avslutade därmed utan att göra den sista delen. Lauri Silvennoinens fina rasterkarta och tabeller ger mig dock en god idé till hur den sista uppgiften borde se ut.



Källor:
Jonathan Loos blogg, hämtad 28.2.2021: https://blogs.helsinki.fi/joloo/2021/02/25/de-sjalvstandiga-uppgifterna/
Lauri Silvennoinens blogg, hämtad 28.2.2021: https://blogs.helsinki.fi/laurisil/2021/02/24/koko-kone-bufferoi/
Fjärde veckan
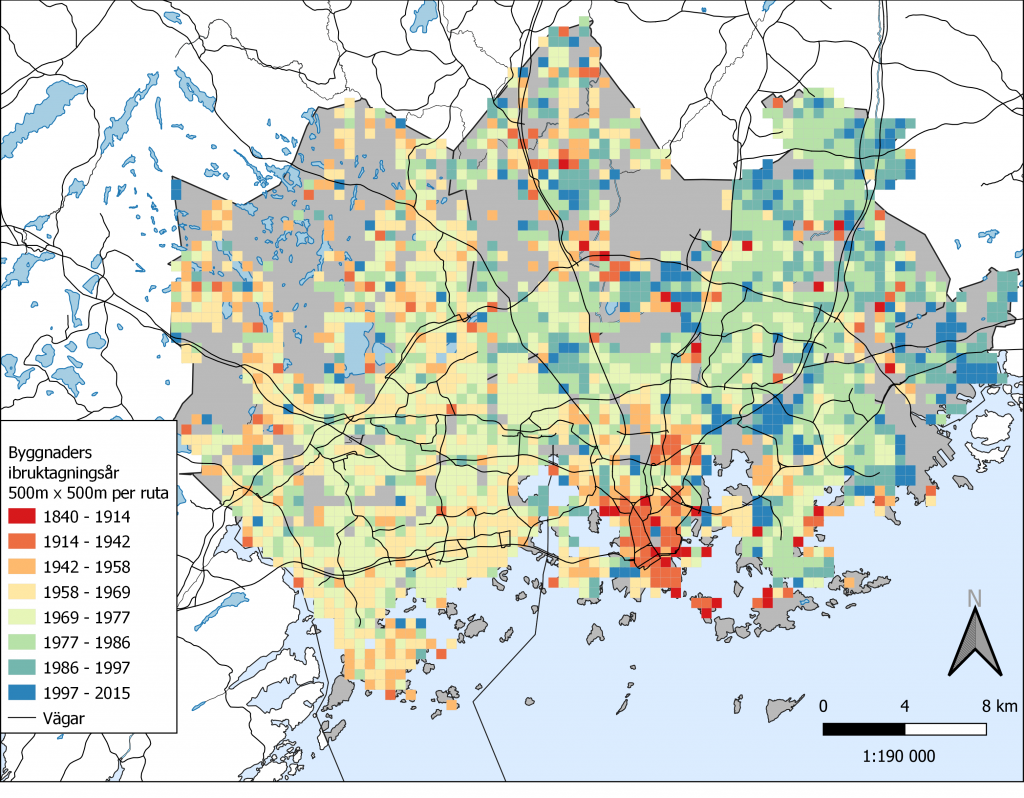
Den här veckans uppgifter gick bland annat ut på att utforska rasterdata och försöka framställa lite eget data från givna databaser. Vi framställde till att börja med ett rutnätverk över en karta på huvudstadsregionen. Vårt egna rutnät bestod av 1km x 1km stora rutor som vi manuellt bestämde vilket område de skulle täcka, i det här fallet vår ursprungliga karta över huvudstadsregionen.
Iden bakom det hela var att regiondatat i sig självt innehöll info om byggnader och deras invånare. Tanken är att kunna utrycka en viss information inom en ruta där t.ex. en ruta kan innehålla fyra byggnader i vilka det bor x-antal människor i olika åldrar och med olika ursprung. Då kan man framställa ett rutdata som beskriver en viss egenskap och dess mängd i varje ruta. I den ursprungliga uppgiften vi gjorde på lektionen visualiserade vi andelen svenskspråkiga i varje område.
Bild 1 föreställer mitt egna försök där jag valt att visualisera byggnadernas medelålder i varje ruta. Tanken är att man kan se på kartan var det finns mer gamla byggnader och på vilka ställen det förekommer nyare byggnader. Själv valde jag att rutorna skulle vara 500m x 500m för att få en mer exakt bild och jag hade en del jobb med att gallra bort vissa rader i det originala datat för att de inte hade årtal och på såvis beskrivits som 99999999 men jag kom runt problemen med lite enkelt googlande och genom att pröva mig fram. Slutresultatet syns ju på bild 1 och jag funderade nog på hur bilden skulle kunna förbättras så jag tillade ett av de vägnätsdata som fanns att tillgå.
Rutstorleken tycker jag är ganska bra men jag är ännu lite osäker om jag borde haft fler punkter/färger så att fler tidsintervall kommit bättre fram.
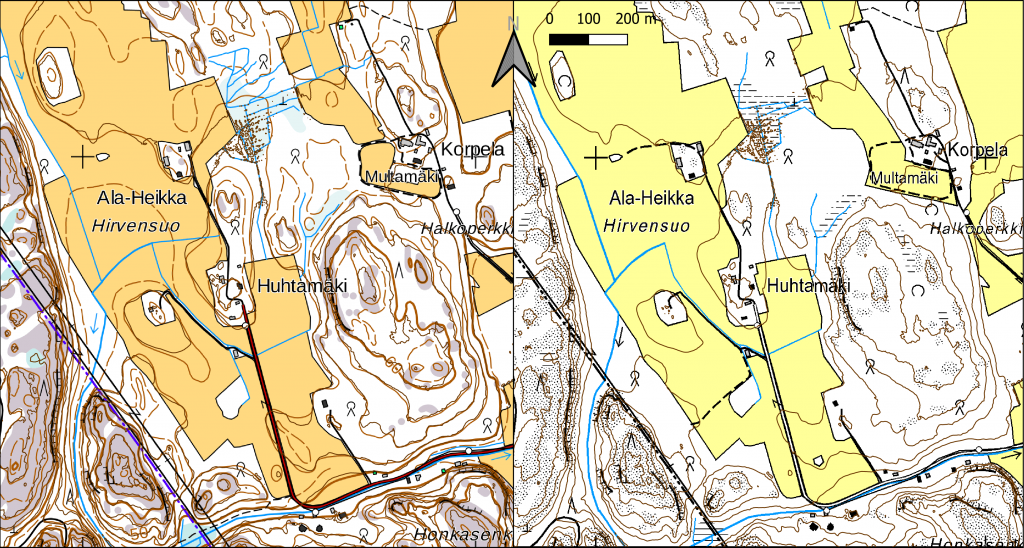
I kursgångens andra uppgift skapade vi egna höjdkurvor från ett givet rasterdata där vi använde oss av terrängskuggning från fyra olika bitar av områden över Borgnäs med omnejd.
Vi fogade samman de här fyra olika bitarna till en enda snygg helhet och skapade egna höjdkurvor för dem genom att använda ett verktyg vid namn “Contour” där jag använde mig av ett mellanrum på 5m för varje representation av stigning i terrängen som man kan se på bild 2.
Till höger på bilden syns mina egna tillverkade höjdkurvor och till vänster är ett kartbotten, hämtat från Lantmäteriverket med sina tillverkade höjdkurvor. Den tydligaste skillnaden är att Lantmäteriverkets karta har märkt sina höjdkurvor med en siffra som jag själv saknar på min karta. Lantmäteriets grundkarta är också mer exakt än min egna då de verkar ha använt en noggrannare skala för kurvorna än jag själv vilket är en poäng som också Johnatan Loo poängterat i sin blogg om att Lantmäteriverkets hljdkurvor ör mer avrundade eftersom deras karta är längre bearbetad för att göra den lättare att läsa.
Källor:
Jonathan Loos blogg. Hämtad 17.02.2021: https://blogs.helsinki.fi/joloo/2021/02/15/raster-och-rutor/
Tredje kursgången
Den här gången i vår kurs hade vi som uppgift att kombinera data från olika källor till en helhet i QGIS. Allt gick ut på att klara av att kombinera och konfigurera de olika data vi hade att tillgå för att sedan kunna framställa och presentera det på ett snyggt vis.
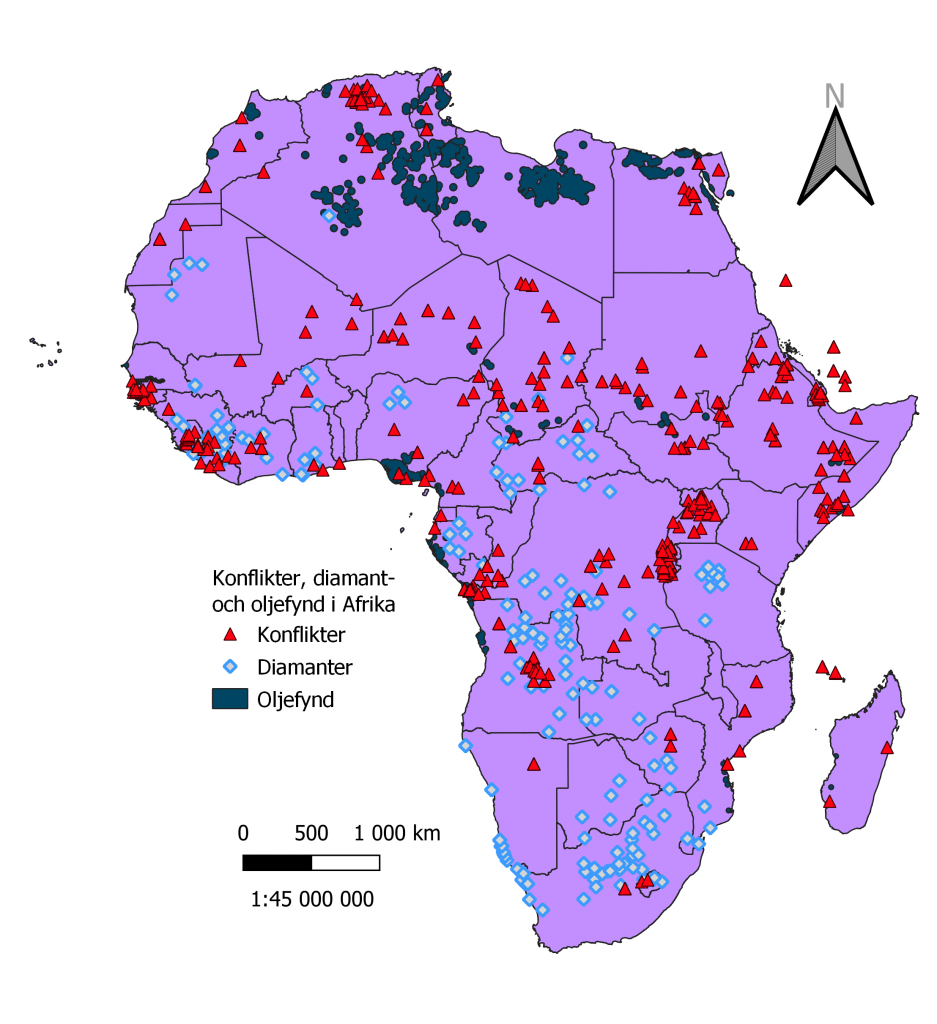
Som man kan se i bild 1 och bild 2 så har vi använt oss av ett data över Afrika. Från början var verkade datat snyggt indelat men vid närmare åsyn så var det indelat i fler kategorier och fält än vad som var nödvändigt, t.ex. så hade vissa länder flera rader data än vad som var nödvändigt så alla rader med data som hörde till samma nation bands ihop till en enda rad.
Som extra data hade vi oljefynd, diamantfynd och konflikter i länderna och vi försökte finna en möjlig relation mellan konflikter och de två andra variablerna och man kan se resultatet i bild 1 där varje symbolerna och färgerna representerar respektive variabler. T.ex. så har både Libyen och Algeriet många oljefynd men Libyen har inga konflikter medan Algeriet har ett stort antal. På samma sätt kan man se hur det på sina ställen verkar finnas ett samband mellan dessa naturresurser och konflikter, som också Saara Nurminen konstaterat i sin bloggtext.
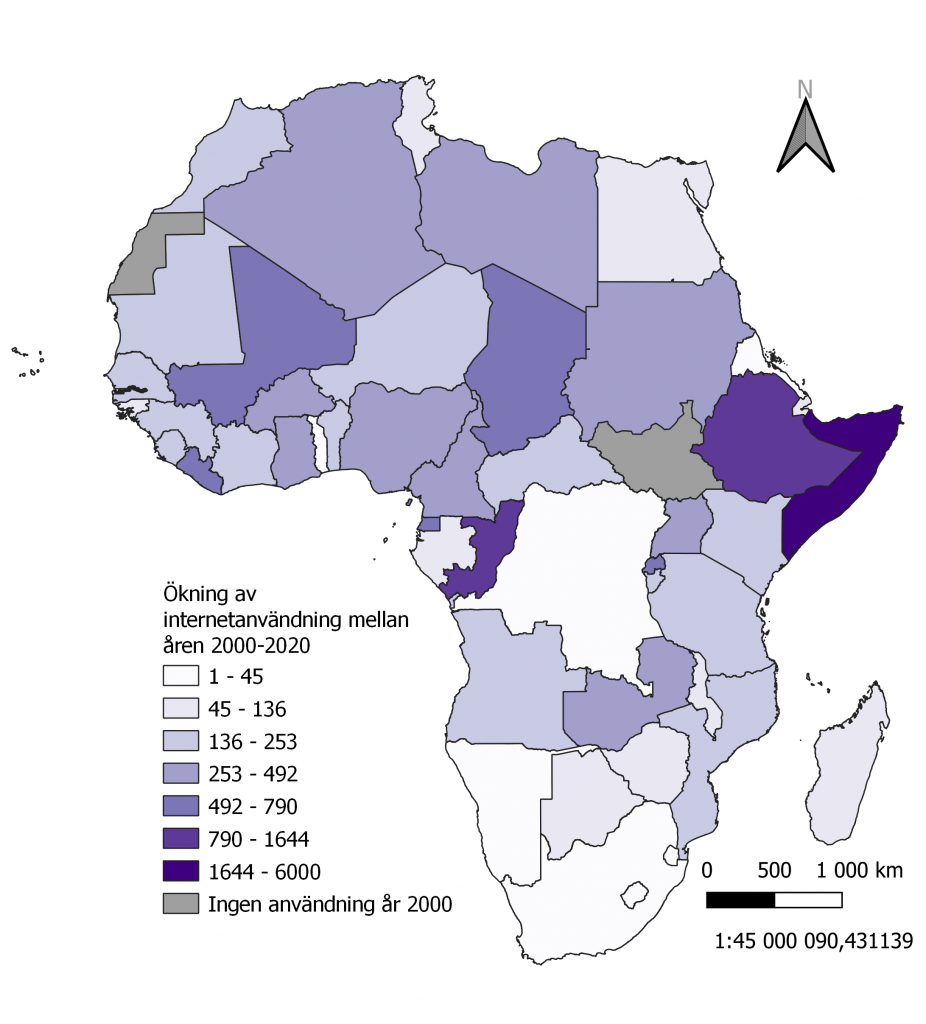
Den andra saken som jag behandlade gällande Afrika-datat var en helt extern fil med uppgifter för internätsanvändning i de olika nationerna som man kan se på bild 2. Datat representerar hur stor ökning av internätanvänding som de olika länderna genomgott mellan åren 2000 och 2020. Man kan se tydligt hur nätanvändingen ökat i vissa länder medan andra så har den knappt stigit alls. Lite missvisande med denna karta är att den inte berättar utgångsläget för hur stor nätanvändningen var år 2000 så man kan tro att t.ex. Sydafrika inte använder sig av internät alls för att ökningen varit så liten men sanningen är att Sydafrika är en av de största nätanvändarna i Afrika och redan hade ett enormt antal användare år 2000 vilket gör att ökningen är så liten.
Den sista delen som hör till kursgången var hemuppgiften där vi tog reda på översvämningsindexet (det högsta uppmätta värdet subtraherat med det lägsta under ett år) för olika ställen i Finland med hjälp av data för avrinningsområdet i Finland. Kartan jag framställde visar då alltså på vilka ställen i Finland som det svämmar över som mest i jämförelse med hur stor andel av sjöar det finns i området. Föga förvånande visar kartan att de ställen som består av väldigt få sjöar verkar svämma över mer än deras motpart.
En god insikt som Jonathan Loo gjort i sin blogg är att när man framställer datat för sjöarnas storlek/antal i områdena och visualiserar dem så varierar den andelen beroende på hur sjöarna räknades i datat beroende på om man ställt in det efter “intersects, contains,overlaps” eftersom sjöarna räknas på olika sätt då.

Källor:
Saara Nurminens blogg: https://blogs.helsinki.fi/saaranur/2021/02/08/kolmas-kurssikerta/
Jonathan Loos blogg: https://blogs.helsinki.fi/joloo/2021/02/09/kombinationen-av-data/
Andra veckans uppgift
Den här veckans uppgifter fick oss att fundera på hur olika kartprojektioner kan ge en förvrängd bild av verkligheten, beroende på vad man vill framföra som form av visuell data. Det uppstår alltid problem när man vill avbilda en rund sfär som en 2-dimensionell bild och det vanliga är att kartan förvränger storlek, vinklar eller former.
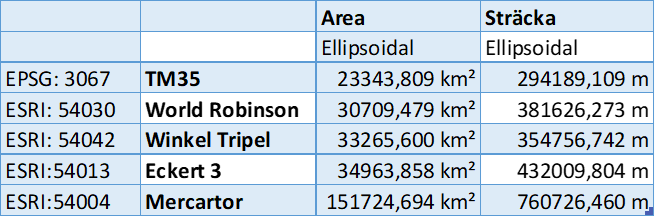
Tabell 1. representerar den här skillnaden mellan projektioner. Som data har jag helt slumpmässigt valt en yta och en sträcka som båda är gjorda i TM35 projektionen i Finland och arean visar ca 23344 km² medan sträckan ligger vid ca 294189 m. I tabellen syns sedan vad den valda arean och sträckan förvrängs till då man byter mellan olika projektioner, här bör man lägga märke till att alla projektioner som använts, förutom TM35, är världskartor så förvrängningen blir desto större.
Bild 1. är sen än visuell representation av hur de olika projektionerna luras. Bilden är i form av TM35 och färgerna representerar förvrängningen. Man kan se att ju längre norrut man tittar desto mer förvrängd är bilden i de andra projektionerna. Trots att färgernas gränser inte verkar flytta sig märkvärt så bör man lägga märke till hur stor förvrängningen är, Mercartor befinner sig mellan 3,95 och 8,26 vilket är en massiv förvrängning medan t.ex. Robinson är en mindre förvrängning mellan 1,185 och 1,416.
Det här gör att det är ganska viktigt att hålla reda på vilken typ av kartprojektion som man använder för att det som man vill visa hålls verklighetstroget till sitt syfte, men andra ord ska man hålla reda på vilken projektion man använder när som också Saara Nurminen skriver i sitt blogginlägg.
Källor: Saara Nurminens blogg: https://blogs.helsinki.fi/saaranur/2021/01/29/toinen-kurssikerta/
Den första hemuppgiften
Efter att vi blivit introducerade till QGIS under första lektionen så har vi fått som uppgift att framställa en egen analys ifrån ett data som kunde fås från Maa-202:s egna Moodle-sida.
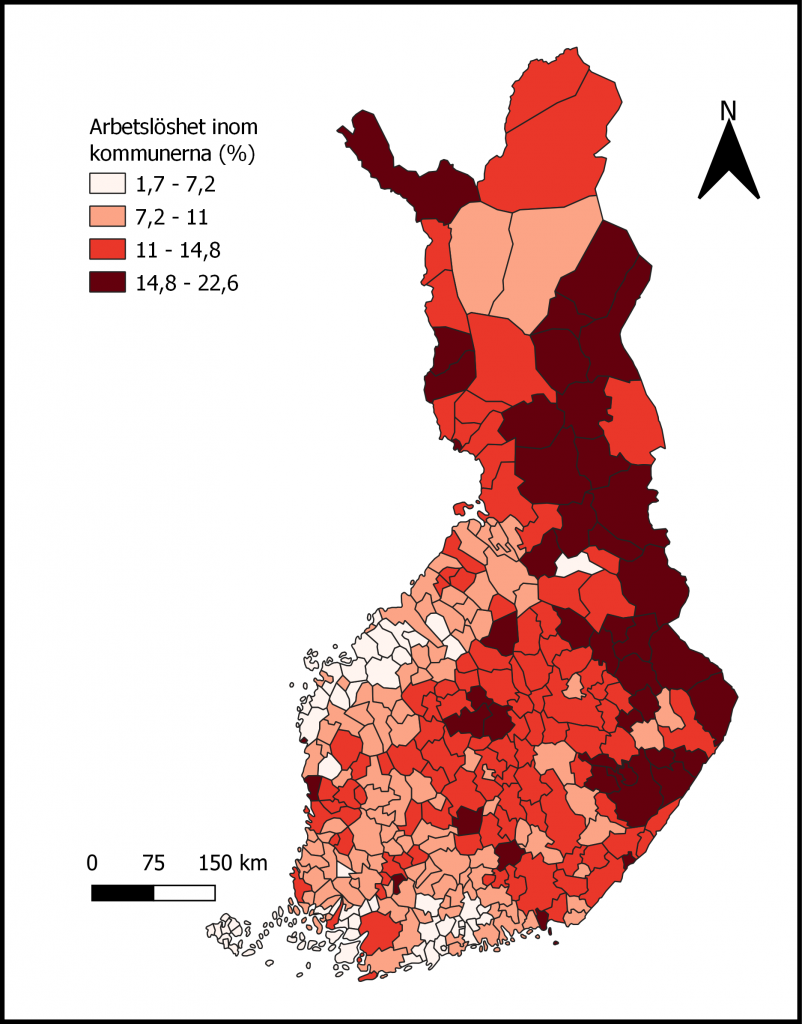
Jag valde själv som uppgift att framställa en version av hur arbetslösheten återspeglas i kommunerna som man kan se i Bild 1.
Tillvägagångsättet var ganska enkelt eftersom jag långt följde samma mönster som vi använt då vi skapade analysen över hur mycket kväve (N) som hörde till utsläppen runt Östersjön. Visserligen var det inte riktigt så enkelt att komma ihåg alla knep och sätt som jag trodde att det skulle vara men med hjälp av föreläsningens inspelade video kom jag igen på rätt väg med uppgiften.
Jag anser att resultatet blev riktigt bra där färgskalan jag använde går från vitt till mörkröd och är passande seriös då själva ämnet, arbetslöshet, är ett ganska tungt vägande ämne och kanske till och med aningen känsligt. Min egna mening är att det är ganska enkelt att se i vilka kommuner som arbetslösheten är hög/låg men jag skulle kanske ha kunnat använda fler klasser som kunnat visa en ännu mer exakt bild över arbetslöshetsmängden men jag är rädd för att kartan skulle blivit otydlig då.
Det svåraste med hela uppgiften var att få en bra uppfattning om hur en blogg skall skrivas och se ut så efter lite tänkande bestämde jag mig för att söka inspiration från mina kurskamraters bloggar, Sandra och Santeri, vilket gav mej den insikt som jag behövde för att få igång en blogg.
Källor:
Sandra Nystöms blogg https://blogs.helsinki.fi/nystroms/
Santeri Saarinens blogg https://saarinengeoinformatiikka.blogspot.com/2021/01/1-kurssikerta.html
Första intrycket
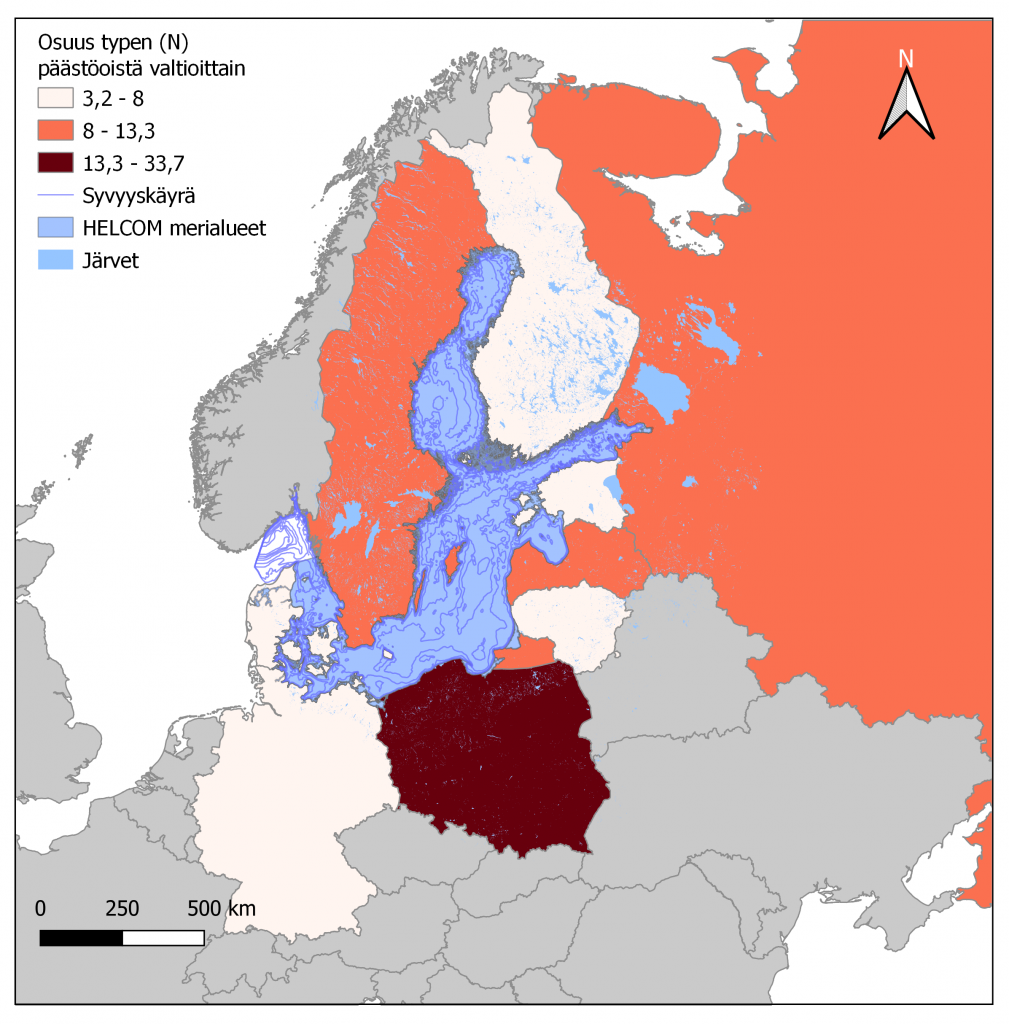
Som första post i min blog om geoinformatik har jag torrövat enligt direktiven som vi fick under vår allra första kursgång. Kort och gott introducerades vi in i den fina världen av geoinformatik tillsammans med programmet QGIS som vi kommer att använda för att behandla olika typer av kartor samt data.
Vår första riktiga övning gick ut på att lära oss de mest grundliga och nödvändiga funktionerna i QGIS. Som man kan se på bilden som hör till detta inlägg bearbetade vi ett delområde av Europa från färdigt givet data. Datat i sig självt behandlade kväveutsläpp (N) från länder son ligger vid Östersjön. Ju mörkare röd färg ett land har desto större del kväve slipper ut som förorening av det totala mängden utsläpp ifrån samma stat.