What are the chemical compounds responsible for the refined flavours of high-quality chocolate? Researchers have already started working on the molecular recipe for this irresistible treat.
Chocolate might be the most universally favoured treat in the world, where tons and tons are indulged yearly, thanks to its unique flavour profile and versatility. Despite that, we know little about the molecular development of its sensory qualities or what makes chocolate of different origins and varieties distinct from one another.
A group of researchers has attempted to analyse six specialty chocolates, divided into specific pairs of sensory attributes: acidic-fruity, cocoa-like – roasty and floral-astringent. The samples went through various extraction processes to isolate odour-active from flavour-active compounds. These compounds, also known as odourants and tastants, are directly responsible for our perceptions of smell and taste. One of the methods used even mimics human nasal activities during consumption, which is crucial for the chemical release of odourants. Researchers used certain molecules’ previously known sensory effects to compare the flavour pairs’ final amount of odourants and tastants.
Everyone who prefers Granny Smith apples to Honey Crunch knows the apparent distinction between origins and varieties of apples. This cognition can also be applied to cocoa beans, whose taste varies from delicate flower notes to unpleasant bitterness. This flavour diversity, however, does not guarantee the consistency required for mass-produced chocolate – so big corporations resort to blending beans from different sources. While scientists conducted past analyses with industrially produced chocolate, this study stands out for the novel use of single-origin chocolate in coordination with the Cocoa of Excellence (CoEx) program. CoEx acknowledges the cocoa quality and endorses the diversity neglected by large businesses. Their biennial award promises global recognition to top-quality cocoa producers worldwide, and the winning chocolate is chosen based on an official set of quality and flavour guidelines. Consequently, the results of this study can provide an essential basis for standard sensory assessment of superior cocoa and chocolate.

The hypothesis was that the presence, or lack thereof, of known flavour-active compounds, reveals differences in molecular compositions of chocolate with different flavour profiles. From a general knowledge standpoint, the higher the concentration, the more intense sensation our senses can perceive. The minimum detectable amounts are called odour and taste thresholds. This phenomenon has a biological advantage. Sensory cells react to large amounts of essential substances while being much more stringent towards potentially dangerous compounds (which, more often than not, are accompanied by unpleasant flavour). Thus, to conclude the full sensory effect of the samples chocolate, researchers calculated the ratio of each dose over the responding threshold (DoT). The molecules are subsequently matched to its aroma extract dilution analysis (AEDA) – a procedure for evaluating the potency of odourants.
The impact of molecules on sensory perception turns out not to be so linear.
Looking deep into the molecular clusters of acidic-fruity chocolate, it was soon evident that none of the fruity-smelling compounds alone is responsible for the sensory distinction. The samples show visible variation concentrations of known esters under the same flavour description. What baffled the researchers even more was the presence of roasty odour compounds in this group. With some of the acidic-fruity chocolate samples further divided into specific fruit notes of brown fruits or dried fruits, the initial goal to interpret chocolate flavours on a molecular level becomes even more tangled. According to the DoT parameters, one ester may have an additional effect for brown fruit odour even at concentrations below the threshold.
Moreover, acetic acid, known for its pungent scent and sour taste, seemed to be the main responsible for the group samples’ acidity due to its highest DoT factors. On the other hand, the presence of citric acid and lactic acid, two other sour-tasting acids, in the chocolate implies that the combination of all these acids evokes the acidic flavour perception – collectively instead of individually.
Similar results were also observed from two other groups. The most abundant odourants in the cocoa-like – roasty group weren’t described as such during AEDA. Some floral-smelling odourants also appear more in this group than in the supposedly floral-astringent one. This eccentricity suggests possible interactions between flavour- and odour-active compounds. It is a fine-tuned collaboration – key molecular compounds dancing hand in hand gracefully to the melody of fine flavours.
The researchers believe that their study demonstrates for the first time how diversity in dark chocolate flavour develops under a microscopic gaze. Using the results, producers can optimise quality based on the selection of raw materials and processing. Nevertheless, we are far from grasping the nuances of chocolate flavours and even further from recreating its magic in our kitchen laboratory.
Hân Đỗ
Source:
DOI: 10.1021/acs.jafc.2c04166







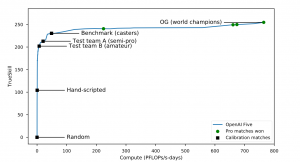
 fig2 : A team fight in Dota 2
fig2 : A team fight in Dota 2