
One of the main data processing steps before making use of novel data sources (e.g. Twitter data) for better understanding social processes and phenomena is the detection of users’ origins – be it at country, municipality or neighborhood level. This allows us to know whose Tweets in some geographical area (say, in a certain city or a neighborhood) we investigate. The most basic way is to distinguish locals from non-locals when examining mobility and activity locations of people. A more advanced analysis would require knowledge about origin countries in tourism studies and origin neighborhoods in segregation studies, for example.
This data processing step is also a prerequisite for cross-border mobility research – we need to know origins of people in order to categorize and analyze movements across country borders extracted from geotagged Tweets. Hence, it is the priority for our cross-border project. See, for example, the recent recent cross-border mobility analysis in the case of the Greater Region of Luxembourg from the MSc thesis by Samuli Massinen.
For analyzing cross-border mobility between Finland and Estonia, we first collected publicly available geotagged Tweets from Twitter Streaming API. We also got additional data from prof. Matthew Zook and Ate Poorthuis who collect Twitter data via the DOLLY project at Uni Kentucky. For extracting individual mobility trajectories and analyzing movements between Finland and Estonia, we used the Twitter Search API to collect Tweet histories (up to 3200 latest Tweets) for each Twitter user who had geotagged a Tweet in Finland and Estonia at least once. Finally, we collected digital traces of roughly 80,000 Twitter users (public accounts) between 2012 and 2019. Using Samuli’s algorithm to detect the country of origin, we found that some 34,000 Twitter users live in Finland.
Now we were excited to know where the Finnish Twitter users in our sample come from and does their spatial distribution at municipality level make sense. So, we slightly modified Samuli’s algorithm to detect their origin municipality in Finland and mapped the result. To evaluate our results, we applied simple regression model to estimate population derived from Twitter data and compared it with the official residential statistics at municipality level (Figure 1).
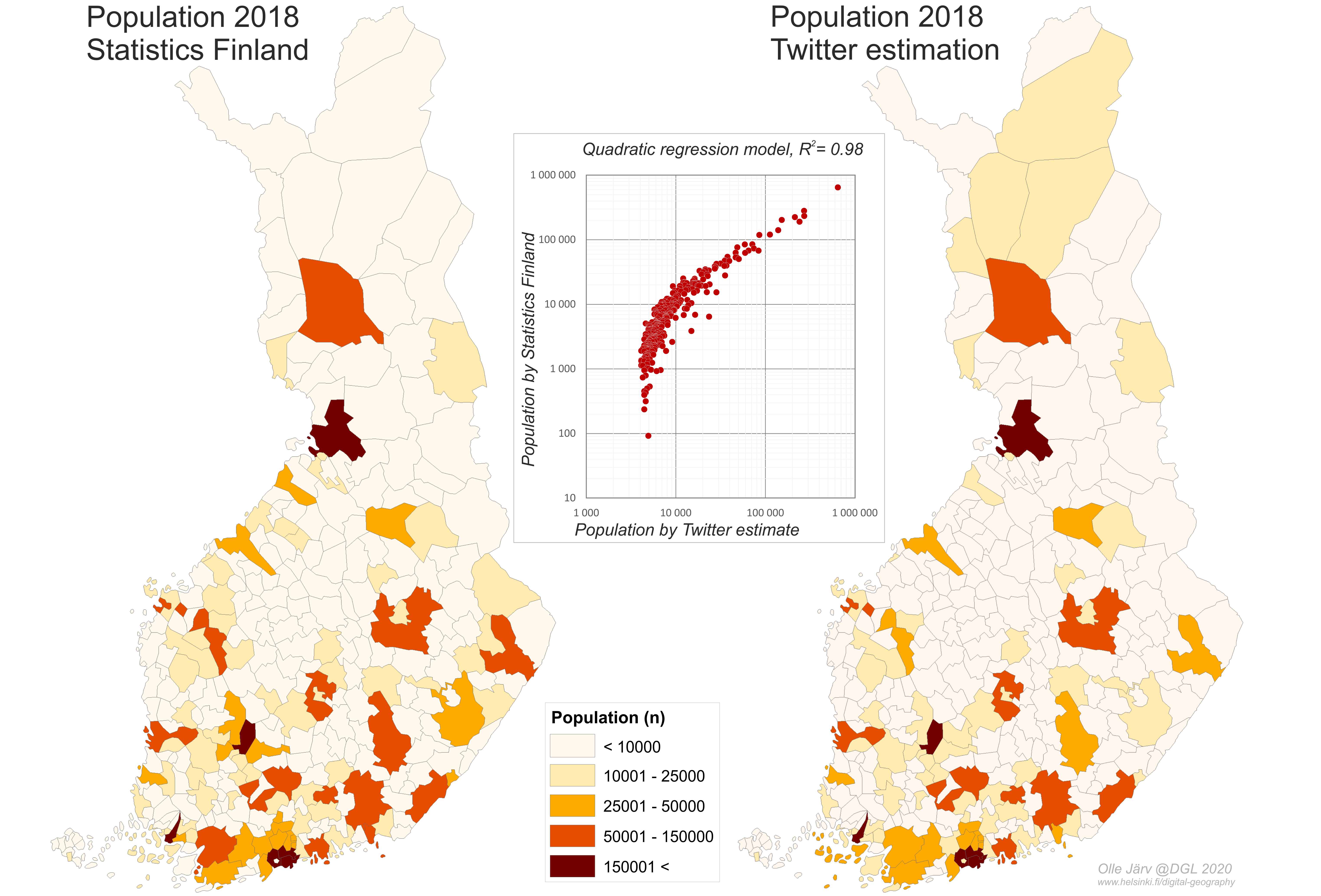
Figure 1. The comparison of Finnish population distribution by municipality between the official residential register by Statistics Finland and population estimation based on Twitter data using quadratic regression model.
What can we see from the comparison?
First, the positive side. The population estimation from Twitter at municipality level has very high correlation with the official residential registration statistics – the correlation coefficient is 0.98! This is a great outcome and gives the confidence to continue using the data extracted from Twitter for national scale analyses. In particular, given the applied simplistic modelling, there is a huge potential to further develop estimation models. For example, one could now evaluate domestic tourism between different regions or examine the network of central cities with their catchment areas based on people’s mobility derived from Tweets.
Second, the challenge. The exceptionally high concentration of Twitter users in the capital city of Helsinki compared to other municipalities is a challenge for the regression model – basically, it is an outlier in the model. According to our approach, 33% of all origins are located in Helsinki, although the proportion of Finnish population living in Helsinki is only 12% according to the residential register. We were able to minimize the over representation of Helsinki to some extent by using the best fit quadratic regression, instead of simple linear regression model (R2 = 0.83). In both models we also weighted Twitter data with age and gender according to Twitter users’ profile, but this increased the model performance marginally.
The city of Helsinki as an outlier can be explained by two issues, at least: 1) certain (other than age and gender related) social group using Twitter is more represented in Helsinki than in other municipalities; 2) information extraction from Twitter data (data enrichment) has not yet taken into account the detection of work locations – one of the main anchor points in our daily lives. Luckily, these issues can be tackled in future by advancing the data enrichment. For the former, one could enrich data to provide additional background attributes to profile Twitter users. One could also weight Twitter data with the proportion of higher education and/or university students in a municipality. For the latter issue, one could apply the framework of the anchor point model by Ahas et al. (2010) to reveal both the home and work (school) locations to better pinpoint residential locations. Currently, we believe that our simplistic model has assigned many Twitter users’ residential locations to Helsinki who actually are commuting from the Helsinki wider metropolitan area to Helsinki for work.
In conclusion, this comparison gives us confidence that we can detect users’ origins from social media data, and that we can use it as one background attribute in our work-in-progress cross-border mobility analysis between Finland and Estonia. We also continue with the origin detection algorithm development. Stay tuned!
Kunnittaisia todellisia väestömääriä v. 2018 kuvaavassa kartassa on virhe Seinäjoen kohdalla. Kaupunki on merkitty yhtä luokkaa pienemmäksi kuin todellisuudessa. (Seinäjoella oli v. 2018 lopussa n. 63 000 asukasta. 60 000 as).
Hei! Kiitos todella tarkasta huomiosta. Lähtöaineistot ja tulokset on oikeita, mutta on harmittavasti käynyt niin, että kuvakollaasin viilauksen yhteydessä kartat ovat menneet vaihtoon. Päivitin kuvan ja nyt kartat ja otsikot täsmää. Kiitos vielä tästä kommentista. T. Olle