Prepare your cyber-umbrellas, it’s raining data on the 7th day of the hackathon!
After running some algorithms to process data all night, we managed to extract 110k named entities from our 3 subsets (History, Religion, Social Sciences).
Those entities had to prove their worth to be included in our final data. Their first trial was a matching with the DBpedia database to ensure that our name-dropped people had some kind of ID correspondance, like checking passports at the airport (sorry “the coffee man”, you didn’t make it past this trial).
The second trial consisted in the extraction of birthdates from the URI of DBpedia, to see if our entities were old enough to actually be written about in the 18th century, like checking the IDs of people before letting them enter in a disco (sorry Obama, only 200+ years old are admitted this time!).
The 5k names which survived thought that this extremely brutal selection was over but, guess what, it wasn’t. The remaining entities were then presented to the final, indisputable, strict commitee of Veera, Selina and Annika (i.e. the name-dropping police). Jonathan Swift’s lawyers already contacted our team: his popularity in the corpus decreased a lot after this qualitative analysis. I guess we’ll see ya in court, Jo!
Once the struggle to filter the data was over, we started creating new networks, graphs, statistics, wordclouds, and historical gossip (of course) throughout our subset in clusters of time periods.
Ispired by the subject of our project, it’s important for us to name-drop too:
Advertisements in nineteenth century newspapers tell us about how the burgeoning press was used to sell and buy things. They tell us not only about how consumption, commerce and marketization developed in the period, but also point at cultural and technological changes in newspapers as a medium. Our research team consisting of data scientists, linguists and historians came together to the Digital Humanities Hackathon at the University of Helsinki in May 2019 to study advertisements to understand these long-term developments. We used British Library Newspapers (BLN) provided by Gale Engage as a data set to explore and analyse more detailed topics related to advertisements in the press. All images and graphs in this blogpost are drawn from the BLN.
We soon noticed that we can read advertisements closely to identify linguistic features that are typical in advertisements whose goal are to sell particular products. In order to use our data set and to identify computationally these features, we studied advertisements manually and grasped some meaningful features.
It is often hard to differentiate advertisements that are meant to sell products apart from more matter-of-fact announcements such as this ad about a missing dog:
Figure 1: Example of a notification of a lost dog.
To convince readers of the benefits of a particular product, advertisements for selling products seemed to have more adjectives . The study of ads shows a number of features that seem to be typical for advertising language in the nineteenth century. This advertisement for soap in the Hampshire Telegraph and Sussex Chronicle from July 1886 is a good example of this.
Figure 2: Example of ad that displays many characteristic features of nineteenth century textual newspaper advertising.
Some of the features we find most interesting, and that we think can be quantified in a reliable way, are:
1. High levels of adjective use. We found about “absolute Purity”, “Fair White Hands” and “Bright, Clear Complexion”. But it is not only an issue of praising the qualities of the product, but (excessive) adjective use can also be used to mark possible negative consequences of not using a product or things that can be remedied by using the product. Hence we are told that the soap prevents “Redness, Roughness, and Chapping”. Earlier studies have also indicated that ads may include more adjectives than general text. A preliminary quantitative analysis does, however, not suggest that overall proportions of adjectives would be higher in advertisements compared to news text. We acquired a list of adjectives in English from WordNet and then studied the overall frequency of those adjectives in The Morning Post for advertisements and news text separately. The separation into news and advertisements builds on the article segmentation that exists in the metadata. While this metadata does include errors, we did manually evaluate its levels of precision for advertisements and found them to be on average 73 per cent up to 1830 and 87 percent for the period after 1851 (for a description see our Hackathon presentation). For The Morning Post, a conservative daily from London, the adjective share is more or less the same.
Figure 3: Share of adjectives in advertisements and news articles in The Morning Post.
A similar plot about verbs and nouns shows that actually it is the share of verbs and nouns that is smaller in ads compared to news text. What remains to be studied if it is only particular adjectives that are more frequent in ads. Perhaps this has prompted earlier research to emphasize the role of adjectives in ads.
2.Generalizations as a way of defining the audience. Ads often define their audience by providing labels for particular groups that could benefit from a product. In this ad we found out that soap is prepared “for the delicate skin of ladies and children”. In other ads the definition of a target group may be more general, for instance by mentioning that the product is for “everyone”.
3. Quotes or expert opinion as a means to convince buyers. The soap advertisement also uses expert opinions and quotes from content customers to sell products. Both Adelina Patti and Mrs. Langtry assure any reader of the quality of Pears’ soap based on their extensive experience. Performative verbs like “assure” or “recommend” often do this kind of work in advertising texts and seem to be particularly common in certain types of ads, like job advertisements. These appear both when qualified staff is sought, but also when people with higher positions in society recommend staff for others:
Figure 4: Example of using performative verbs in an advertisement.
A particular form of assurance are expert quotes that are used to promote certain products. These seem to have been especially important for advertisements that are related to theatre, books and other complex cultural products, and also in in the soap ad mentioned above. A quantitative analysis would allow to distinguish which products are we more likely to accompany expert statements as a way of persuading potential consumers. However, due to lacking optical character recognition quality, identifying quotes in ads was more unreliable than we had hoped for, so we decided to pursue this possibility later.
4. Repetition. Finally, advertisement text made extensive use of repetition. In the advertisement for Pears’ soap, repetition is used in two ways. First, the brand is mentioned repeatedly in the running text to remind the reader about the soap that is sold “everywhere”. Additionally, “Nice Hands” is repeated eighteen times in the left column of the ad. Here, “Nice Hands” is a selling point, but it also serves a visual purpose. The Morning Post did not include images as a way of distinguishing itself as a conservative and serious newspaper from any papers that were driven by visuals. For the ads, visual repetition like this was a way of bringing forward an ad in the midst of a whole page that might have been cluttered with small textual ads or notices.
And as a means of showing the power of repetition:
Figure 5: Example of repetition in advertisements.
And do not forget that ads did not only repeat the same thing. Sometimes they also wrote the same thing over and over again:
Figure 6: One more example of repetition in advertisements.
Or they could include something that is is completely redundant:
Figure 7: Even one more example of repetition in advertisements.
Written by Hyun Jung Kang, Anna Obukhova and Jani Marjanen
Data analysis by Ruben Ros
Bibliography
Leech, Geoffrey N. (1966). English in advertising: A linguistic study of advertising in Great Britain. London: Longmans.
Gotti, Maurizio. (2005). Advertising discourse in eighteenth-century English newspapers. 10.1075/pbns.134.05got.
Lyna, Dries & Damme, Ilja Van (2009) A strategy of seduction? The role of commercial advertisements in the eighteenth-century retailing business of Antwerp, Business History, 51:1, 100-121, DOI: 10.1080/00076790802604475
Miller, George A. (1995). WordNet: A Lexical Database for English. Communications of the ACM Vol. 38, No. 11: 39–41.
Richards, Thomas. (1990). The commodity culture of Victorian England: Advertising and spectacle, 1851–1914. Stanford: Stanford University Press.
During the Digital Humanities Hackathon 2019 in Helsinki our group is researching advertisements in newspapers. This blog post is part of our case study on drug ads. The blog post shows first results and the methods we used. Many of the results raised new question and could open up new interesting research fields.
In the 19th century the first aim of an advertiser was to ensure that his message caught the eye among the vast variety of notices of different kinds in small letters. This meant that the visual presentation of advertisements, and particularly of medical ones, was one of the main tools to attach viewers’ attention in the first place. To sell drugs, companies often used inventive ways to market their products. Apart from addressing certain illnesses or medicines, drugs ads have also reflected gender distinction either with their linguistic styles or visual images as a part of the products’ marketing.
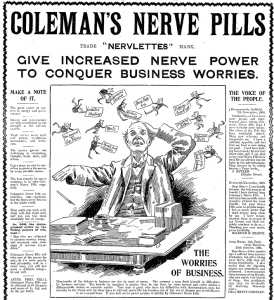
During the Victorian period there were four leading pill-makers who also made the most of the newspaper advertising; James Morison, the creator of Universal Pills, a ‘venerable’ Salopian called Thomas Parr who sold “Parr’s Life Pills” to increase the beauty of women, Thomas Holloway who is also classified as a first world-wide advertiser, and Thomas Beecham who invented “Beecham’s Pills” and claimed to cure “bilious and nervous disorders” 1
One of the most lucrative and deceptive areas of advertising involved the so-called “patent” medicines. Actually, they weren’t patented and they were not really medicine, but rather, exotic concoctions of liquor and narcotics, as noted in the 1900 Puck Magazine illustration above 2. Prior to the regulation of both medicine and advertising in the 1900s by the British government, patent medicines were frequently touted as effective treatments for illnesses as serious as cancer and liver disease. However, many of the pills and syrups were exposed as having no effect or contained dependent ingredients.
Research questions
How are keywords related to gender (women/men) and distributed over time in drug ads?
What adjectives were used in drug ads for women or men?
What kind of illnesses appeared in drug ads for women or men?
What pictures were used in drugs ads for women or men?
Approach / Methods
The following section will line out our approach for using computational methods to gain insights into gender and drug advertisement. The first part lines out a computational approach to extract the words associated with gender in drug advertisement in the newspaper “The Morning Post” in the 19th century (1800 -1900). For the examples and visual advertisements in this blog post we also used other newspapers than “The Morning Post”.
As the programming language for our study we used Python along with an array of complimenting libraries for doing data analysis. As our IDE we used Jupyter notebooks, as they allow for a segmented coding environment where the code runs directly in the browser and is easy to document.
We started by extracting the dataset of advertisements from The Morning Post from the Octavo API (https://app.swaggerhub.com/apis-docs/comhis/octavo/1.3.0#/). In order to do make a local version of the data we created a subset consisting of 40,000 advertisements from each decade. We then tokenized the data by removing all non-alphanumeric characters.
Figure 2: Process of the data analysis.
Microanalysis
To get access to images from the advertisement we used the new Gale Search Engine (http://gdc.galegroup.com). We used the advanced search functionality to get all the hits annotated as “Advertisements”. We then searched for the keywords from our list of medical keywords, and filtered for images. The images were then copied, selected and interpreted.
We also used microanalysis constantly to check the results of the data analysis.
What were the difficulties with the analysis for this case study?
One problem was the under-segmentation of the available advertisements. We then used co-occurrence analysis and vector space analysis to get meaningful results.
As usual when working with historical newspapers, OCR problems potentially affected our analysis.
No visualization of the relationship between original text and data exists. This made it difficult for us to proof the results.
As usual when working with historical newspapers, we had the problem of selection bias. We countered this problem by using one big newspaper where we had a sense of the context.
There are no relative frequencies in the Gale interface
First Results
Pills for women or men?
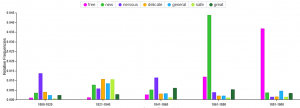
Figure 1 shows the distribution of gender related keywords over time in drug ads in the 19th century. For the analysis we used following keywords (male, men, man, gentlemen, boy, boys, gentlemen, female, girl, woman, women, wife, wifes, females, girls). The figure shows interesting and surprising results at the same time. In the first decades of the 19th century, males dominated in drug ads, even though females were addressed more and more frequently. Between 1860 and 1880, keywords related to men raised again. This surprisingly turned around in between 1880 and 1900. Keywords related to women were mentioned more often than keywords related to men:
Figure 3: Distribution of gender related keywords over time in drug ads.
Gender descriptive language in primarily female and male drug ads?
As men and women have different stereotypes in general, adjectives in advertisements for each gender are used differently. But does this apply also to the 19th century drug ads?
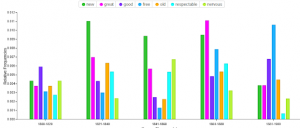
It can be said that there were obvious differences in the use of of adjectives in male or female related drug ads. As seen from the word clouds and figures below, “nervous” as a sign of emotional weakness and “delicate” dominated the female drug ads while “respectable”, or “good” were typical adjectives in male drug ads.
Figure 4: Word cloud of most frequent adjectives in drug ads related to women in the 19th centuryFigure 5: Word cloud of most frequent adjectives in drug ads related to men in the 19th century
Figure 6: Most frequent adjectives in drug ads related to women between 1800 and 1900Figure 7: Most frequent adjectives in drug ads related to men between 1800 and 1900
Although the adjective “nervous” dominated the drug advertisements for women, it also occurred in the male context within the seven most frequently used adjectives.
Pills for diseases of the nervous system for women:
Figure 8: Graphic (London, England), Saturday, March 10, 1888.
Pills for diseases of the nervous system for men:
Figure 9. The Penny Illustrated Paper (London, England), Saturday, December 15, 1906, Vol. 92, Issue 2377.Figure 10. The Penny Illustrated Paper (London, England), Saturday, August 13, 1898, Vol. 75, Issue 1942.
It is very interesting that the use of the word “nervous” in women’s advertisements was less common after 1860, but this development did not occur in men’s drug advertising.
A closer look into the drug advertisements has given possible solutions for this development. It may be that pills for nervousness did not longer have the same market in the new era of psychological treatment. In addition, the word neurosis became more frequent in the English language in the 1860s onwards. And neurosis is often tied to the process of medicalization of psychological issues. Nervous disorders in female related ads did more and more appear in other contexts than drug selling. For example, in the context of electro-therapy:
Figure 11: Morning Post (London, England), Tuesday, March 20, 1888, Issue 36116,
Different sexes, different (amount of) diseases?
Another noteworthy point of the gender-relevant content of drug ads was the distribution of genders according to the illnesses. Female images were primarily used for the diagnoses related to nerves or anxiousness as a reference to their being more emotional, whereas male figures were used in the context of severe diseases like cardiovascular conditions 3 or rheumatism.
Figure 12: Illnesses appearing in drug ads for men between 1800 to 1900.Figure 13: Illnesses appearing in drug ads for women between 1800 to 1900.
Even at first glance it becomes clear that drug ads for men and women are linked to diseases in ratio 25:9 respectively. The two graphs have only asthma, bile, colds, and plaints in common. Drug ads for men contained a long list of various serious illnesses like rheumatism, pulmonary diseases, epilepsy, scurvy, dyspepsia, deafness etc. while ads for women addressed “soft diseases” like heartburn or colds.
It is necessary to note that out of the common health issues, asthma is mentioned mostly in female related drug ads, whereas it is very slight for males throughout the whole century.
Gender stereotypes in visualized drug advertisements in the 19th century?
Drug advertisements of the period in question put a prominent accent on the featuring human figures; often women, sometimes men and in a few cases children, and each of them represented in different styles – mostly patterned on cultural stereotypes and standards.
Images in drug advertisements started to surface after 1850. Before 1850, hardly any images were used to advertise pills or waters (liquid medicines, e.g. syrup). “Parr’s Life Pills”, an example of patent medicines marketed as cure-alls, was one of the companies using pictures in the advertisements already in the 1850s. Parr’s advertisement is showing a large group of people with Parr himself in the centre shooting with a crossbow displaying his own strength and healthiness while others, mostly females, are admiring him.
Also Holloway’s pills is using visualized ads in the 1850s. Just like Parr, Holloway used a large group of people as an image, putting a male in the center again, possibly just like Parr showing himself?
Figure 14. Ipswich Journal (Ipswich, England), Friday, September 9, 1853, Issue 6018.Figure 15. Northern Star (1838) (Leeds, England), Saturday, February 23, 1850, Issue 644.
While drug ads in the 1850s where showing specific scenes involving figures in action, drug ads of the late 19th century were illustrated with static female figures (Figures 17 and 18) but again men in action (Figures 19 and 20). Drug advertisements in the 1880s till mid 1890s were dominated by female images, whereas the opposite sex became more frequent after 1895.
When it comes to facial expressions, women are shown calmer and serious while men are more natural and ambitious:
Figure 18. Right: The Penny Illustrated Paper (London, England), Saturday, July 24, 1909, Vol. 98, Issue 2513.Figure 19. Left: Western Mail (Cardiff, Wales), Wednesday, March 7, 1900, Issue 9605.
Written by Sarah Oberbichler, Khanim Garayeva, and Kalle Kusk Gjetting
Data analysis by Ruben Ros
Edited by Ilona Pikkanen
↑1 Turner, Ernest Sackville. The Shocking History of Advertising, Great Britain 1965. pp. 61-64; Advertisement for Beecham’s Pills, in: https://www.bl.uk/collection-items/advertisement-for-beechams-pills, 21.05.2019. ↑2 History of Advertising Regulation in Communication Law and Ethics. An open-content course for Radford University COMS 400 Students and others [https://revolutionsincommunication.com/law/?page_id=730], 21.05.2019. ↑3 Wanda Leppard, Shirley Matile Ogletree, and Emily Wallen, Gender Stereotyping in Medical Advertising:
Much Ado About Something? in: Sex Roles (1993), 29/llH2, pp. 1.
We are now more than half-way into the hackathon. The hump is embodied by an interim presentation on the group’s progress in the afternoon.
In the morning, we extracted subsets of the data containing keywords, and utilised collaborative data verification technology (i.e. the group eyeballing through a Google Sheet) to check results
The keyword of the day is “keywords”. We extracted keywords for each title, then use them to discover patterns for the topic clustering.
The level of intrigue featured in the 18th century history circles #spoilers
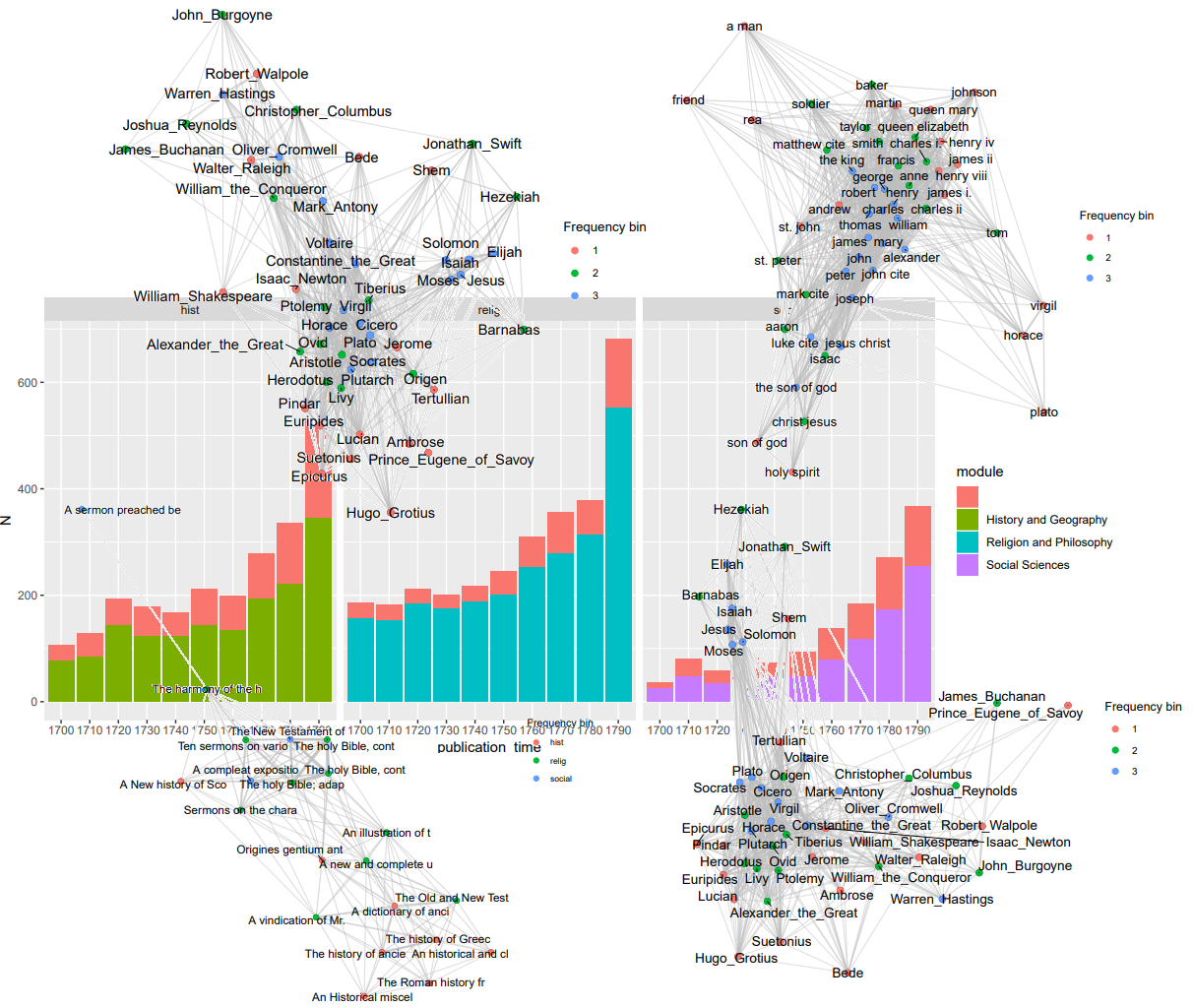
In the later half of the day, we also got the top named entities mentioned in publications, decade-by-decade. The idea is that books of a similar nature would refer to a similar set of entities. Some colourful and fabulous graphs for the topics are coming up in the very near future.
Presenting some initial results, with impressive visual effects
At 4pm, it’s presentation time. Each group gave an update on the progress and presented intermediary results. Saving the best for the last, our very animated presentation drew the day towards a highlighted close.
Well, the working day, that is. At 6pm, we all headed to the marvelous main building of the university — as an annual tradition for each iteration of the hackathon — to wine and dine at the archive where collections of theses on Fennistics were enshrined.
Social evening at the Morphological Archive in the main building of the university at the Senate Square
Afterwards also as a tradition, the socialising continues on at the aptly named “Thirsty Scholar”, with a beer garden and a view of the Helsinki Dome.
This blog post was written by David Rosson, graduate-to-be of a double-master’s program in Human-Computer Interaction at TU Berlin and Aalto University.
“Let’s think the unthinkable, let’s do the undoable. Let us prepare to grapple with the ineffable itself, and see if we may not eff it after all.”
― Douglas Adams, Dirk Gently’s Holistic Detective Agency
Fundamental questions & a theoretical framework
Having thought about these key issues of our research, we constructed a four-layered model that represents notions about the past and the future.
The past is “what really happened”, everything that has ever happened up until this point in time. The past is objective — however, we cannot get directly to the past — it is unreachable.
History is “what we think happened”. History is our tool to talk about the past. When we think about the past, we are creating history. History is subjective — as soon as we talk about the past, we can never be objective. It is also selective — history is only a tiny fraction of the past, of everything that ever happened. History is a narrative about the past influenced by morals, ideology, politics and ideas. History can be both concrete (“historical facts”) and abstract (theories, ideologies, etc.)
Political discourse is “what we talk should have happened” and “what we talk should happen”. It is even more subjective and selective. It is, amongst other things, the way we talk and express ideas about the past and future.
3.1. Regarding the past, political discourse on the one hand draws and builds on our idea of the past, what we call “our history”. One’s ideas of the past influence and inform one’s political discourse. On the other hand, political discourse also influences other people’s ideas of the past, their view of history.
3.2. Regarding the future, political discourse builds on history to construct and envision a specific idea of the future.
4. The future is “what we think, plan, hope and fear will happen”. It is everything that could ever happen from this point in time onwards. It is also subjective and selective. The future is a concept: a narrative we construct about the thihgs that will happen, influenced by our morals, ideologies, politics and ideas. Just like history allows us to construct countless different narratives about the past, talking about the future offers endless different versions that can be proposed.
Although we speak about the past and the future, we stay at present therefore our narrative is framed by the context — in our case, political.
There also would be various connections between the past and the future: the past might be something great or disastrous and we might avoid or repeat it. According to this, the ideas about the relations between the past and the future could be the following:
We should learn on mistakes on the past in order to avoid them in future.
We should not repeat out experience from the past.
We should stay on the way we stood for years.
We should restore our past we lost in future.
Some findings from the corpus of speeches
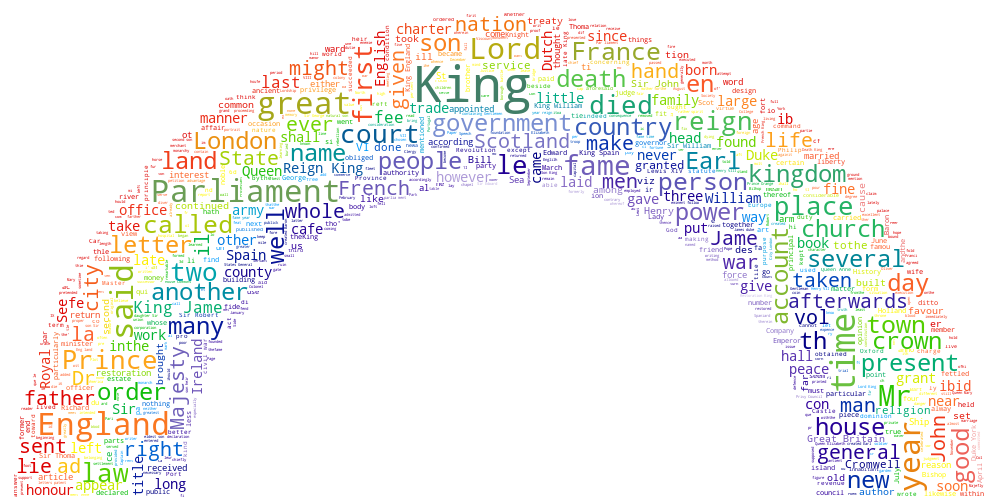
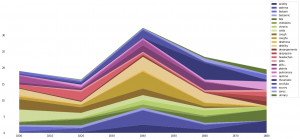
We also did some analysis of the corpus in order to find which words MPs use while speaking about the past and the future.
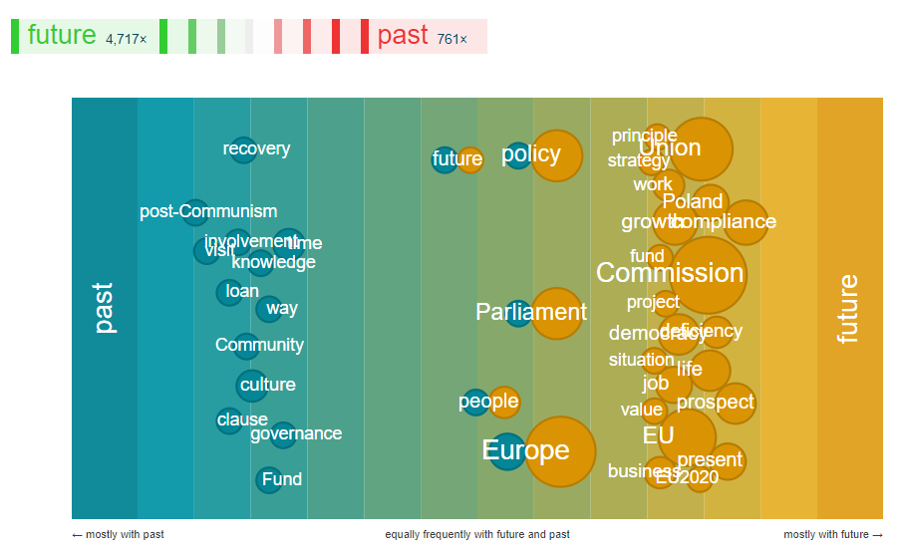
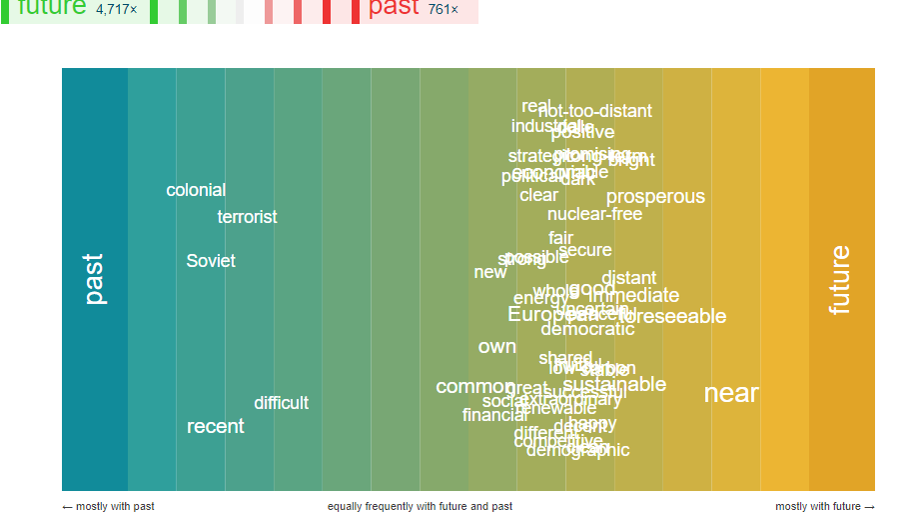
The notions related with the past are, for example, knowledge, recovery, culture, post-Communism and such notions as principle, prospect, strategy, situation are connected with the future. There are also some ideas that lie between tha past and the future.
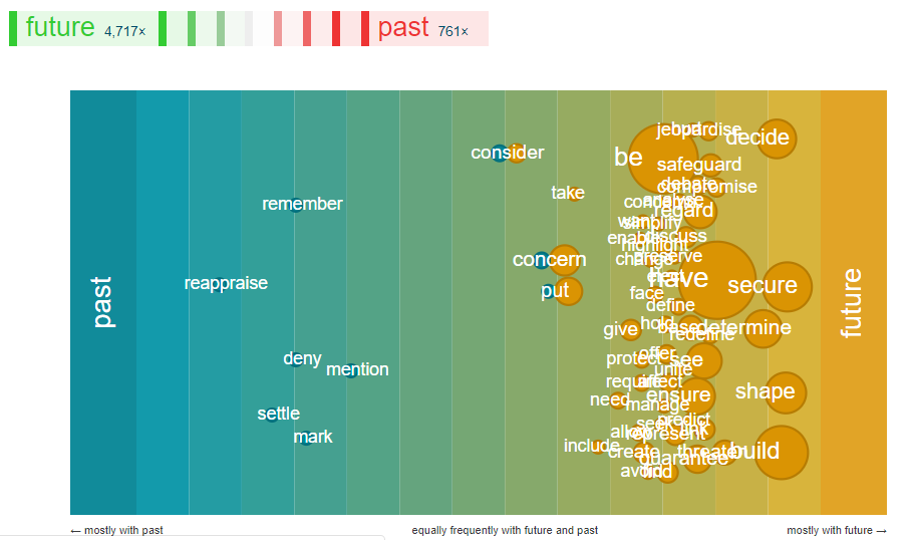
The verb map shows what can we do while speaking about the past and the future.
The last image illustrates the most common adjectives in the speeches about the past and the future.
Another day of Hackathoning is nearing its end, and the Genre and Style (tweeting @GenreAndStyle)group is operating at full speed. Our NER (named-entity recognition) approach is providing us with data to analyze as well as a great deal of choices to make. Today we’ve been looking at the names recognised in our subsets of the ECCO data. We are using external databases (mainly DBpedia) to verify names from the list of entities, which includes a rather large variety of strings — it is 18th century text OCR’d from various microfilm copies, after all. The goal for today has been to create preliminary networks to look at, and that was accomplished in the afternoon. Tomorrow we will among other things try to incorporate another subset of data to compare the NER profiles of the datasets.
From the perspective of a DH novice, the week has been wonderful and bewildering. Many aspects of the research we are doing seem enticing, but the time limits and intensity of the hackathon largely deny the possibility to immerse in a technical area one is not acquainted with. However, the discussions and planning sessions (as well as the input of friendly visiting Hackathon researchers) present a wonderful opportunity to bridge together research interests, types of data, and humanities substance on the one hand, and computational and digital methods on the other. Furthermore, the interesting task of visualizing and communicating the crucial message and findings of the project are yet ahead of us (visualization in particular being an aspect of data sciencish research I am personally not well-versed in). The Hackathon is certainly an experience I would recommend to all driven humanists.
18th century writers can have a thing or to teach to pseudonimity-seeking Social Media aspirants
Hopefully we will be able to really immerse ourselves with the results of our entity linking efforts before the week reaches its end. Inspecting the content of our object of study, historical texts, in depth and in all its interactions is after all what many of us aim for.
Yours Sincerely,
Gentleman Who Has Made Reading His Diversion Upwards Of Twenty-eight Years
This blog post was written by Aleksi Jalavala, an MA student at the University of Helsinki, who is pushing himself into new territories at the Hackathon as well as in studies in Digital Humanities in general.
Now it’s time to present the data we work with in order to show you how huge our plans and intentions.
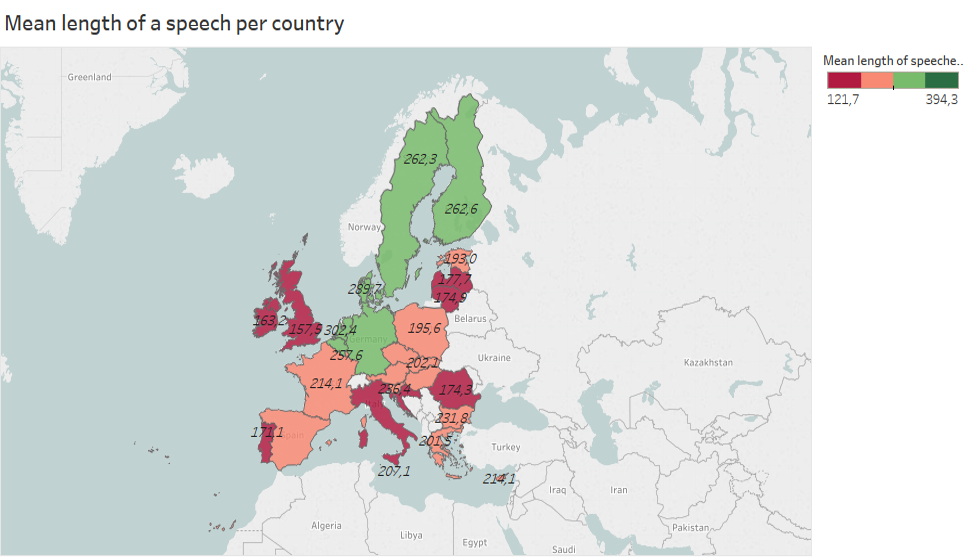
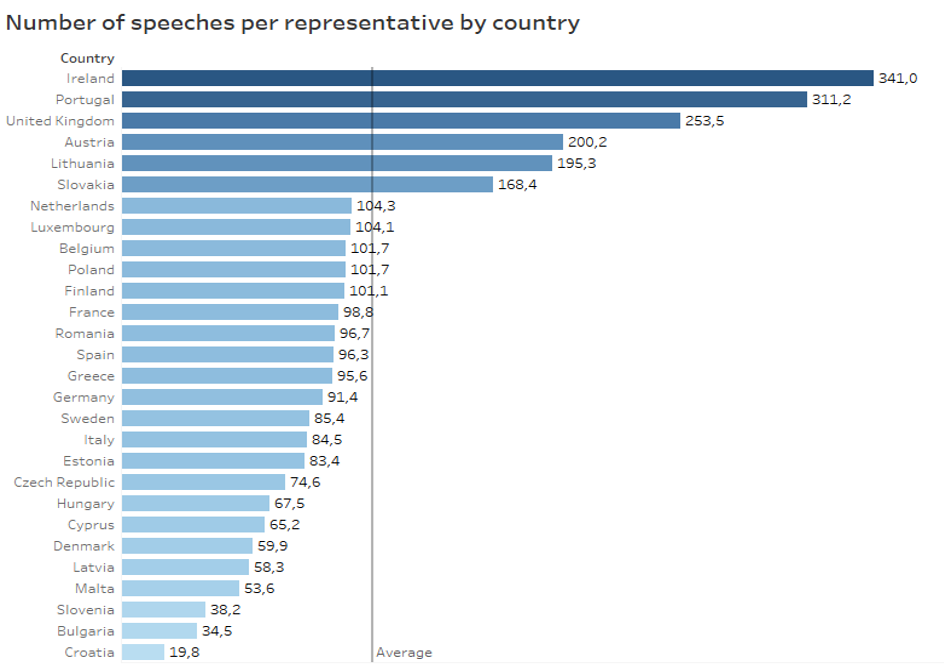
So, what we have? We explore the linked Open Dataset with data from and about the European Parliament (EP): the parliamentary debates translations from 1999 till 2017. It includes 247,955 dociments with the length from 121 to 394 words. All of them also contain metadata such as a name of speaker, country, date of birth, gender, function.
We have speeches in original language and its English translation provided with the date and the link to the video.
Our main interest focuses on the concepts of the past and the future and the way they are represented in the speeches. To start, we counted the number of mentions of these concepts: MPs expessed ideas about the future 30771 times and only 9214 they spoke about the past.
During the Digital Humanities Hackathon our group is researching data collected from Twitter. Our data consists of all the tweets, retweets and mentions connected to the hashtag #Brexit from time period starting from 26 February to 15 April 2019.
The timeline for our data is interesting since the 29 March was the original date United Kingdom was supposed to leave European Union, but as we all know that did not happen. This means we have a possibility to look in detail something that failed to happen and how people reacted to it on this particular social media platform.
One important thing to remember when doing research with data like this is that you need to know your data, how it was collected and what are its limitations. Twitter represents only one social media among others – not everyone uses it.
We only have people from certain demographics of general population and even the Twitter users who participate in the political discussion on Twitter and who knows if they share their true feelings as openly as they would in “real life” on social media.
Problem with using singular hashtag as a parameter for collecting data is that hashtags are always self-selected markers and not all Twitter users add them in their tweets. In our case there could also be other hashtags connected to Brexit as a phenomenon that are used individually without the addition of #Brexit. This sets certain limitations to interpreting our data.
Digital humanities methods have great advantages for doing fast and big research, but there is still something the computer cannot achieve. For example, yesterday Heng and Faiz were identifying the gender of 577 MP members manually because there wasn’t a good program that could detect the gender accurately by the twitter username.
Besides, the bigger the data is, the messier the data could be. It is easy to obtain big size of data, but the data could also have low reliability without close manual checking. We for example, have to vary of bot activity relating to political discussion. Bigger and faster is not always better, and we need to find a balance between quantity and quality when doing digital humanities.
With data coming from social media there are also ethical questions to be solved and thought about. Because Twitter data contains so much personal information from users, sharing the original datasets with your research would be highly unethical. What kind of information can we use, what is too personal? This means that anonymisation of usernames, tweets and other critical information is extremely important and a lot of time needs to be dedicated to these practices.
Written by Minna Turunen MA student of the Cultural Heritage program at the University of Helsinki and Heng Gong MA student of English studies at the University of Helsinki.
The Newspapers group studies the relationship between advertising and journalistic ideals in the nineteenth century. Our team consists of students in computer science, history and literature from Italy, Azerbaijan, the Netherlands, Kazakhstan, South Korea, Pakistan, France, Russia, Denmark, Ecuador and Finland.
Bolivia Erazo did her doctoral studies in cultural history at the University of Turku, Finland. In her monograph, she examined the coming of sound cinema to Quito, Ecuador in the late 1920s and early 1930s. In general, she is interested in media history.
Khanim Garayeva is a first year PhD student of the English Literary Studies in the University of Szeged, Hungary. Her main research area is the Historiographic Metafiction in the Contemporary British Literature, however, DH is her another academic focus.
Kalle Kusk Gjetting is an Information Studies student from Aarhus University. His main interest is mixed-method approaches within both humanities and computer science.
Zafar Hussain is a Data Science master student at university of Helsinki. He is a researcher at computational history group, University of Helsinki. His research interests include bridging the gap between humanities and computer science.
Hyun Jung Kang is a PhD student at University of Paris Nanterre. Her main research interests lies in the area of computational linguistics and its application to the behavioral and social sciences. Her current research focuses on opinion mining of online reviews written in French. But she is looking forward to doing linguistic analysis in other subjects such as digital humanities and forensic science.
Sarah Oberbichler is a postdoctoral researcher and works at the Department of Contemporary History at the University of Innsbruck. She is currently working in two projects on digital newspapers and digital archives. Her research interests are European and regional contemporary history, migration history, media, and digital humanities.
Anna Obukhova is a Russian Language and Literature student in the University of Helsinki. She is interested in discourse analysis, corpus linguistics and language of newspapers.
Nejma Omari is a PhD student at Paul Valery Montpellier III University. She is currently preparing a doctoral thesis in french literature and digital humanities under the supervision of Marie-Eve Therenty. She works on the relationship between newspapers and literature, collection of articles and media culture in the 19th century.
Anastasia Pustozerova is a Master student in Vienna University of Technology. She is doing research in machine learning, currently working on privacy techniques in ml.
Ruben Ros is a student of History at Utrecht University. He is interested in DH and conceptual history and previously worked as an intern in the Helsinki Computational History Group.
Our team leaders
Antoine Doucet is a tenured Full Professor at the L3i laboratory of the University of La Rochelle since 2014. He obtained a PhD in computer science from the University in Helsinki in 2005, and holds a French habilitation (HDR) since 2012. Antoine’s main research interests lie in the fields of information retrieval (structured and semi-structured) and natural language processing.
Axel Jean-Caurant is a postdoctoral researcher at the University of La Rochelle. His main interests concern digital humanities, word embeddings and information access. He is currently working on a project about digital newspapers.
Jani Marjanen is a postdoctoral researcher at the Helsinki Computational History Group, University of Helsinki. He is a trained historian who has focused on the development of the publich sphere and the theory and method of conceptual history.
Jean-Philippe Moreux joined the BnF in 2012 as OCR and digital publishing formats expert and is now Gallica scientific advisor. In addition to being a member of the ALTO Editorial Board, he currently works on all heritage digitization programs and research projects (NLP, text and data mining, OCR, etc.) BnF participated to, as well as on the application of research results to digital libraries.
Dr. Ilona Pikkanen works at the Research Department of the Finnish Literature Society. Her research interests include the comparative, long-term study of historiography and historical fiction.
Our European Parliament team is a group of students and researchers competent in computer science, political science, linguistic, media studies. We are from Finland, Germany, Russia, Croatia, Austria.
Aleksandra Konovalova
I have graduated from Saint Petersburg State University with MA in Applied Linguistics and worked for 2 years as a Linguist. My main goal is to understand and to learn how to use my skills more effectively in the field of Digital Humanities and to continue work in this field.
Daria Ustyuzhanina
I am a senior lecturer in the department of journalism and literary studies of Siberian federal University, Krasnoyarsk, Russia. I also work on my PhD thesis on social creativity in the online sphere. My research interests include such topics as media, education, data visualization in journalism.
Ellimaija Tanskanen
I did my bachelor’s degree at the university of Helsinki majoring in French language studies and I am starting a master’s degree in communications. My interest in cross-disciplinarity and digital methods applied to languages and humanities led me to the hackathon. My goal is to learn more about different research methods and working in a pluridisciplinary team on a research project.
Gabrielle Mantell
I am a master’s student in European and Nordic Studies at the University of Helsinki. My current research focuses on the use of computational and memetic propaganda within the context of global politics. I hold a MA in Science and Security from King’s College London and a BA in International Relations from Mount Holyoke College. I have also worked in the tech industry as a UX researcher, focusing on human-computer interaction. My research interests include computational international relations, machine learning and geopolitics.
Gerlinde Theunissen
I am a Erasmus Mundus Master student in Public Policy, Political Economy and Development Studies at the Erasmus University Rotterdam and the IBEI in Barcelona. My background is in Political Science and Public Administration at the University Konstanz and the University Leiden and my current interest is in social policies, socio-economic inequalities, gender inequality, border studies and migration. Curious about comparative social research methods brought me to the Hackathon and I am eager to explore various methods to analyse political speeches and debates.
Iuliia Nikolaenko
I work as a trainee in Digital Russia Studies network and I’m an exchange student in the University of Helsinki Social Sciences Faculty. I currently study in Master’s program “Comparative Social Research” at Higher School of Economics, Moscow. My research interests implement such topics as media, ideology, mechanisms of social opinion forming and computational linguistics.
Stefan Hechl
I am an MA student in contemporary history at the University of Innsbruck (Austria), currently working on my thesis on Austrian nation building in historical newspapers. Since 2018, I have been working in the H2020 project NewsEye, which is attempting to improve access to digitised newspaper archives across Europe. This was my first contact with digital humanities and led to my interest in the Helsinki Hackathon. My main goal is to learn more about methods of digital humanities and data science and to share my knowledge of humanities research with people working in computer science.
Suhas Thejaswi
I am a computer science PhD Student at Aalto University. My research work involve design and analysis of algorithms for its complexity, scalability and parallelization potential, furthermore applying these algorithms for large-scale data analysis. I am curious to explore how to apply theoretical methodologies for the analysis of political debates and its applications in digital humanities.
Team leaders
Fredrik Norén
Fredrik Norén is PhD in media and communication and work as a first assistant researcher at Humlab, the center for digital humanities at Umeå University. In his dissertation ”The Future Belongs to the Information Officers”: The Formation of Governmental Information in Sweden 1965–1975 (2019) Norén investigated how governmental information was debated and practiced in the borderland between different societal spheres. His research is primarily focused on media historical perspectives on governmental communication, and on the use of digital methods to analyze large-scale text collections. Recent publications include ”Distant reading the history of Swedish film politics in 4500 governmental SOU reports” (Scandinavian Journal of Cinema, 2017) and ”Urban catastrophe and sheltered salvation: The media system of Swedish civil defence, 1937–1960” (Media History, 2018). He is currently part of a large scale text analysis project called Welfare State Analytics that will analyze the Swedish society 1945–1990 through massive text collections connected to politics, media an culture.

































 Bolivia Erazo did her doctoral studies in cultural history at the University of Turku, Finland. In her monograph, she examined the coming of sound cinema to Quito, Ecuador in the late 1920s and early 1930s. In general, she is interested in media history.
Bolivia Erazo did her doctoral studies in cultural history at the University of Turku, Finland. In her monograph, she examined the coming of sound cinema to Quito, Ecuador in the late 1920s and early 1930s. In general, she is interested in media history.









 Axel Jean-Caurant is a postdoctoral researcher at the University of La Rochelle. His main interests concern digital humanities, word embeddings and information access. He is currently working on a project about digital newspapers.
Axel Jean-Caurant is a postdoctoral researcher at the University of La Rochelle. His main interests concern digital humanities, word embeddings and information access. He is currently working on a project about digital newspapers.
 Jean-Philippe Moreux joined the BnF in 2012 as OCR and digital publishing formats expert and is now Gallica scientific advisor. In addition to being a member of the ALTO Editorial Board, he currently works on all heritage digitization programs and research projects (NLP, text and data mining, OCR, etc.) BnF participated to, as well as on the application of research results to digital libraries.
Jean-Philippe Moreux joined the BnF in 2012 as OCR and digital publishing formats expert and is now Gallica scientific advisor. In addition to being a member of the ALTO Editorial Board, he currently works on all heritage digitization programs and research projects (NLP, text and data mining, OCR, etc.) BnF participated to, as well as on the application of research results to digital libraries.
