“You ask, what is our aim? I can answer in one word: Victory.” (Winston Churchill)
00:29 — Poster completed. ? This very productive last hackathon day starts by us sending our sophisticated poster to the organizers, after hours of rearranging pictures and discussing content.

09:15 — Hot preparation phase. ? On time, the group gets together at 9:15 in the morning to work out the missing steps of our battle plan. The final presentation is completed by 13:00 and we even have time for the rehearsal.
13:20 — We’re live (streaming)! ? The moment of truth is approaching. We listen to the presentations of the Brexit and Parliament groups and have some digital humanities yoga exercises. Then the time has come.
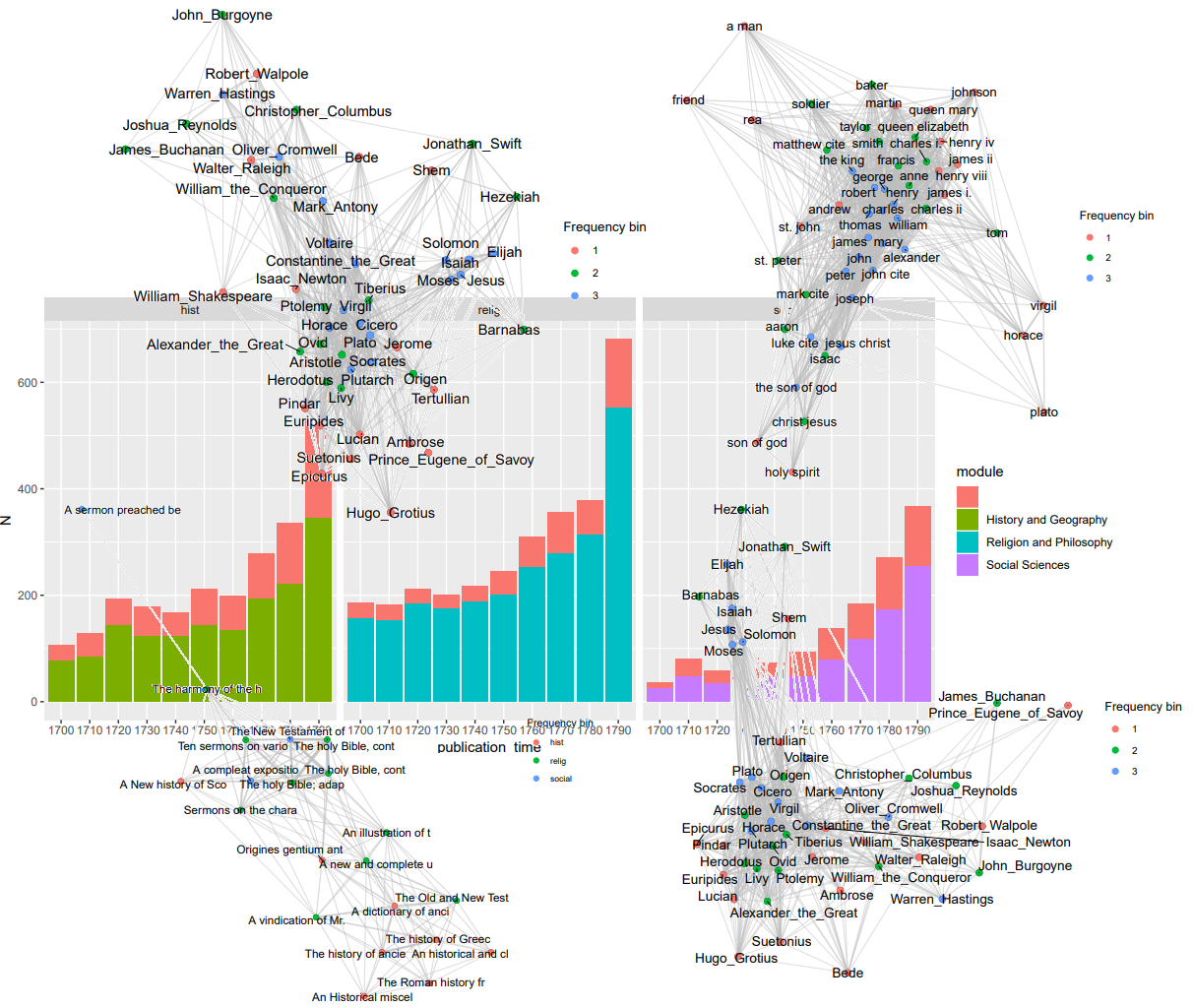
15:00 — Finally presenting. ? All the blood, sweat and tears of the past ten days are unifying in this one final presentation. The whole team stands in front of the DHH19 audience and we are ready to share our findings with the rest of the world. Not only have we found answers to our research questions, but we basically revealed a new path for identifying genres based on named entities. Plus, we received valuable feedback that can be included in subsequent examinations.
16:15 — Wine and poster session. ? The Newspapers group has finished with their presentation as well and we pass over to the poster session. Wine and snacks create a pleasant atmosphere that facilitates an open discussion of results, questions and philosophical concepts with external visitors, but also amongst participants.
#teamspirit @ poster
18:00 — Socializing. ? In company of countless thirsty scholars, we recapitulated this last day at the “Thirsty Scholar”. Later on, some very persistent individuals of the #genreandstyle group experienced authentic Finnish karaoke, joining in to classical Finnish songs with complex character combinations.
Conclusion. In the end, the Digital Humanities Hackathon 2019 meant a lot more than “just another hackathon” to us. We received all the essential resources for our project (data, rooms, technical equipment, coffee (!) and experts) and it was up to us to employ them rationally. From this perspective, the Digital Humanties Hackathon was also part of an extensive learning process about the other group members as well as yourself and about how to communicate and coordinate in such an interdisciplinary and diverse environment.
Therefore, we would like to say “thank you” to the organizers, sponsors, participants and everyone else who was involved in making this event possible. We hope, to see you again someday (DHH20?) and are looking forward to exchanging sentimental memories.
This blog post was written by Sophie Schneider (@BibWiss), who graduated in library science (B.A.) at Potsdam University of Applied Sciences. She intends to enroll in a master programme in information science for the upcoming semester.