Tämän viikon harjoitustehtävissä tutustuttiin rasterimuotoiseen korkeustietoon pohjautuviin analyyseihin. Paikkatieto-ohjelmistolla korkeusmallista on mahdollista johtaa useita erilaisia johdannaisia, kuten korkeusprofiileja, näkyvyys- ja kaltevuusanalyysejä sekä hydrologisia veden valuntaan liittyviä analyysejä. Tämän kurssikerran harjoituksissa päästiinkin näkemään, miten monenlaista tietoa korkeusmallin pohjalta on mahdollista tuottaa ja mallintaa.
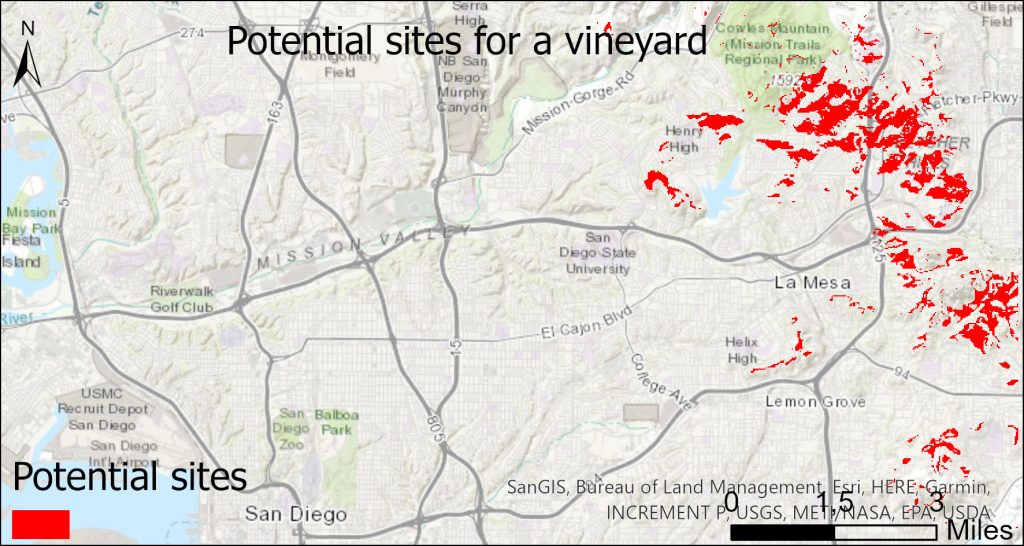
Kurssikerran ensimmäisessä harjoituksessa tehtävänä oli johtaa korkeusmallin avulla tietoa, joka auttaa paikantamaan mahdolliselle viinitarhalle sopivat paikat San Diegossa Kaliforniassa. Optimaalisen sijainnin tulee täyttää seuraavat ehdot: korkeus yli 200 metriä, kaltevuus 1,5–15 % välillä ja rinteen suunta kaakkoon, etelään tai lounaaseen päin.
Harjoituksessa lähtöaineistona toimi jo valmis DEM-korkeusmalli (Digital Elevation Model), joka tarkoittaa x-, y- ja z koordinaatit sisältävää, tunnettuun koordinaatistoon sidottua, maanpinnan korkeusvaihteluita kuvaavaa pintaa. Tässä harjoituksessa käytettävä DEM on rasterimuotoinen korkeusmalli, jossa z-koordinaatti on tallennettu pikselin ominaisuustietoon.
Ensimmäisessä harjoituksessa optimaalisen sijainnin määrittämisessä tarvittiin siis tietoa tarkasteltavan alueen rinteen kaltevuudesta (Slope). Tämän laskeminen onnistuu korkeusmallista peräkkäisten pikseleiden arvojen avulla. Kaltevuus lasketaan solun ja sen naapurisolujen korkeuseron avulla. Alueilla, joilla korkeustieto muuttuu paljon vierekkäisten solujen välillä, saadaan tulokseksi jyrkempi kaltevuus kuin alueilla, joissa korkeus muuttuu tasaisemmin.
Kaltevuustieto kertoo siis korkeuden ja etäisyyden muutoksesta tietyllä tarkastelualueella. ArcGIS paikkatieto-ohjelmistossa tämän kaltevuuden laskenta onnistuu valmiin funktion avulla, ja lopputuloksena saatu kaltevuustieto voidaan ilmoittaa joko kulma-asteina tai prosentteina (prosentti=korkeudenmuutos / etäisyyden muutos x 100). Kaltevuuslaskelmilla on useita eri käyttömahdollisuuksia, ja sen lopputuloksena saadun karttatason avulla on mahdollista jo havainnoida kartoitetun alueen maastonmuotoja.
Lisäksi sijainnin määrittämiseen tarvittiin tietoa rinteiden suunnasta, ja myös tämän johtaminen onnistuu korkeusmallin pohjalta. Rinteen suunta lasketaan vertaamalla solun korkeutta sen naapurisoluihin. Yleisesti ottaen, jos itään oleva naapurisolu on korkeammalla ja lännessä oleva naapurisolu on matalammalla, solulla on länteen päin oleva näkökohta. Harjoituksessa käytetyt rinteen kaltevuuden (Slope) ja suunnan (Aspect) laskennan työkalut käyttävät siis kumpikin naapurustoanalyysiä. Lopputuloksena syntyvässä karttatasossa rinteen suunta ilmoitetaan myötäpäivään kulkevina asteina välillä 0–360. Nämä numeeriset arvot voidaan liittää kompassin suuntiin niin, että esimerkiksi suoraan itään päin olevien solujen numeerinen arvo on 90 astetta. Tasaisille alueille (joiden kaltevuusarvo on 0) määritetään rinteen suunnaksi -1. (Esri, n.d.)
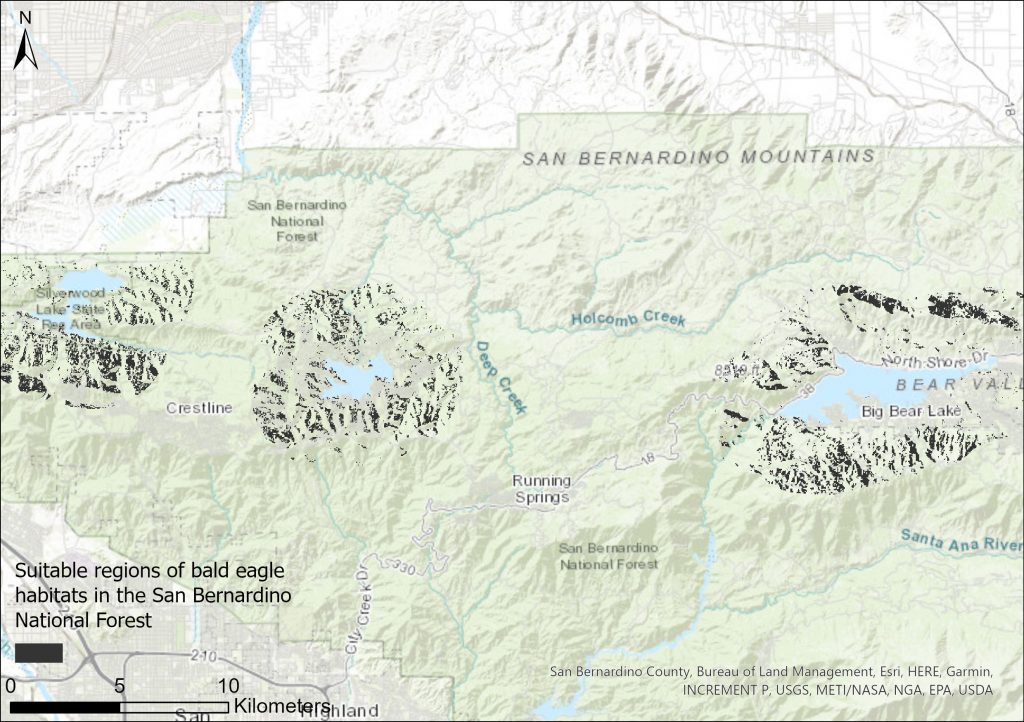
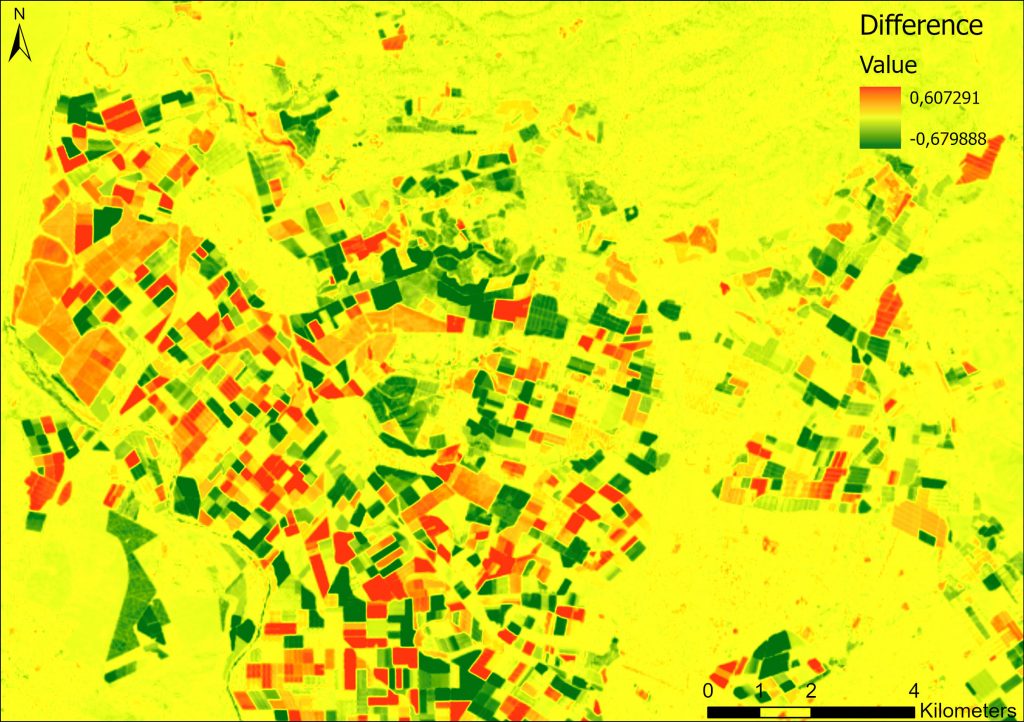
Kun korkeusmallista oli johdettu sekä rinteen kaltevuuteen että suuntaan liittyvä tieto, tuli kaikki kolme karttatasoa vielä yhdistää, jotta voitiin tunnistaa ne pikselit, jotka täyttivät kaikki hakukriteerit. Tämä onnistuu Raster Calculator -työkalulla, jossa on laskuoperaatioiden lisäksi käytettävissä erilaisia loogisia operaattoreita, joiden avulla rasteriaineistosta voidaan tunnistaa operaation ehdot täyttävät solut. Tässä harjoituksessa optimaalisten sijaintien määrittämiseksi operaationa toimi (“sd_elevation” > 200) AND (“sd_slope” >= 1.5) AND (“sd_slope” <= 15) AND (“sd_aspect” >= 112.5) AND (“sd_aspect” <= 247.5) -lauseke, jossa kaikkien ehtojen tulee täyttyä yhtä aikaa.
Koska rasteriaineiston pikselit voivat kuvata vain yhtä muuttujaa ja saada kerrallaan yhden arvon, syntyy operaation lopputuloksena binäärikarttataso, jossa arvon 1 saavat ne kohteet, jotka täyttävät annetun lausekkeen ehdot ja arvon 0 ne kohdat, jotka eivät ole soveltuvia (kuva 1).
Visualisointi helpottaa tiedon tulkitsemista
Optimaalisen viinitarhan visuaalisen tarkastelun helpottamiseksi maastoa haluttiin vielä edelleen tarkastella kolmiulotteisemmin, ja tämän mahdollistaa korkeusmallista johdettu vinovalovarjostus (Hillshade) sekä korkeuskäyrät (Contour).
Vinovalovarjostus (Hillshade) on hyvä keino korostaa maaston korkeuseroja ja tarkastella maaston muotoja hyvin realistisesti (Antikainen, Määttä-Juntunen & Ujanen, 2015, s. 48). Hillshade-työkalulla korkeusmallin kuvaamaa korkeuspintaa valaistaan kuvitteellisella valonlähteellä/auringolla, joka luo valon ja varjon avulla illuusio rinteen suunnasta ja topografiasta. Itse työkalussa voidaan valita sekä valonlähteen suunta (Azimuth) että korkeus (Altitude). Valon tulosuunta ja -korkeus valitaan asteina: suunta määritetään pohjoisesta myötäpäivään (0–360 astetta) ja korkeus horisontista zeniittiin (0–90 astetta) (Antikainen, Määttä-Juntunen & Ujanen, 2015, s. 48). Nämä valinnat vaikuttavat suuresti lopputuloksena syntyvään visualisointiin. Kun valonlähteen sijainti on määritetty, algoritmi käyttää kaltevuutta ja rinteen suuntaa avuksi ja määrittää, kuinka kirkkaasti kukin lähtöaineiston solu valaistaan. Vinovalovarjoste täydentääkin kartan sisältämää korkeusinformaatiota.
Korkeussuhteiden havainnoinnin helpottamiseksi karttaesitykseen lisättiin myös korkeuskäyrät. Ne luodaan korkeustiedon pohjalta Contour-työkalun avulla, jonka loppuloksena syntyy vektorimuotoinen viiva-aineisto, jossa yksi viiva kuvaa absoluuttista korkeustietoa eli korkeuden samanarvonkäyrää (Antikainen, Määttä-Juntunen & Ujanen, 2015, s. 49). Pakollisia valintoja työkalussa on vain korkeuskäyrien tasoero eli käyräväli, mutta työkalun avulla voi lisäksi määrittää jonkun tietyn lähtökorkeuden (Base contour), josta korkeuskäyriä aletaan piirtämään (Antikainen, Määttä-Juntunen & Ujanen, 2015, s. 49).
Lopputuloksena syntyy korkeutta kuvaavat samanarvonkäyrät, jotka visualisoivat, miten korkea maasto on kyseisessä kohdassa. Korkeuskäyrät helpottavat siis korkeustiedon visualisointia sekä kartan tulkitsemista. Näitä samanarvonkäyriä voidaan korkeuden kartoittamisen lisäksi käyttää myös, minkä tahansa jatkuvista arvoista koostuvan pinnan kartoittamiseen, kuten sadannan tai ilmanpaineen.
Näkyvyysanalyysi tuo lisätietoa maisemasta
Harjoituksessa lisäkriteeriksi lisättiin, että mahdolliselta viinitarholta tulisi olla myös näkymä läheiseen Murrayn tekojärveen. Tämän hahmottamiseksi harjoituksessa suoritettiin näkyvyysanalyysi (Viewshed), jonka algoritmi tunnistaa lähtöaineistona toimivasta korkeusmallirasterista ne solut, jotka voidaan nähdä määritetystä havainnointipisteestä.
Näkyvyys lasketaan arvioimalla solujen korkeudet paikallisten horisonttien löytämiseksi. Paikallisen horisontin ulkopuolella olevat alueet voidaan sitten arvioida sen määrittämiseksi, ovatko ne näkyvissä vai eivät, ja jos on, edustavatko ne kauempana olevaa paikallista horisonttia. Viewshed-työkalu voi ottaa huomioon myös muita tekijöitä, kuten tarkkailijan korkeuden, käyttämällä erityisiä määritteitä, jotka voidaan lisätä tarkkailupisteen ominaisuustietoihin. (Esri, n.d.)
Harjoituksessa havainnointipisteenä käytettiin tekojärven keskelle lisättyä pistettä, josta käsin maisemaa tarkasteltiin. Lopputuloksena syntyi uusi rasteri karttataso, jossa kartan solut saivat arvot 0 = ei näy tai 1 = näkyy tarkastelupisteeltä. Tätä analyysiä olisi voinut vielä edelleen jatkaa suorittamalla karttatasoille lokaalin päällekkäisoperaation. Kertomalla yhteen sekä optimaalista viinitarhan sijaintia että tekojärven näkyvyysaluetta kuvavat binääriset karttatasot, olisi lopputuloksena saatu ne pikselit, joissa lopulta nämä kaikki ehdot olisivat täyttyneet. Mutta tämänkin lisäksi optimaalisen viinitarhan sijainnin määritämisessä, olisi lisäksi tarvittu tietoa muistakin muuttujista kuten auringon säteilystä tai etäisyydestä läheisiin teihin.
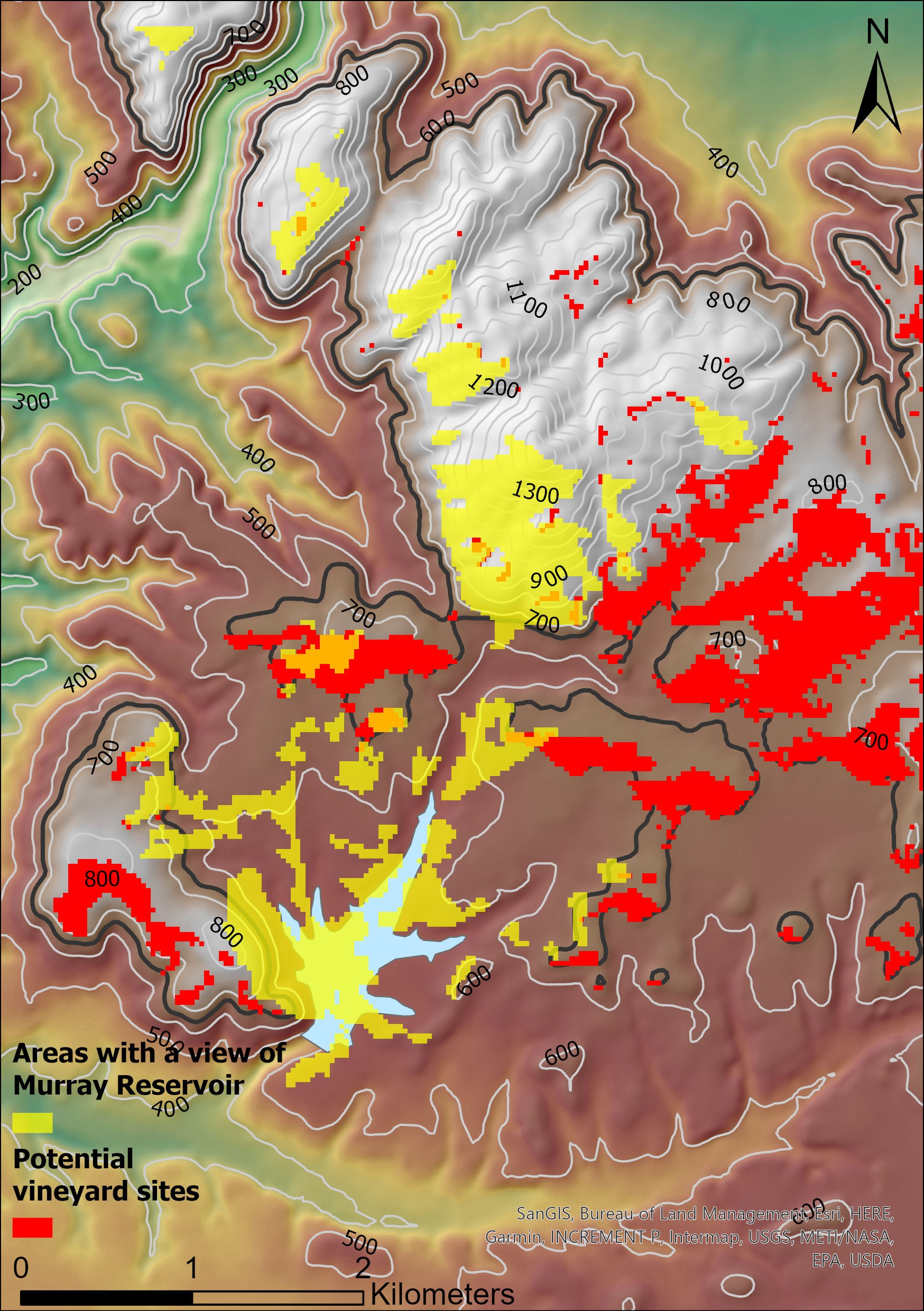
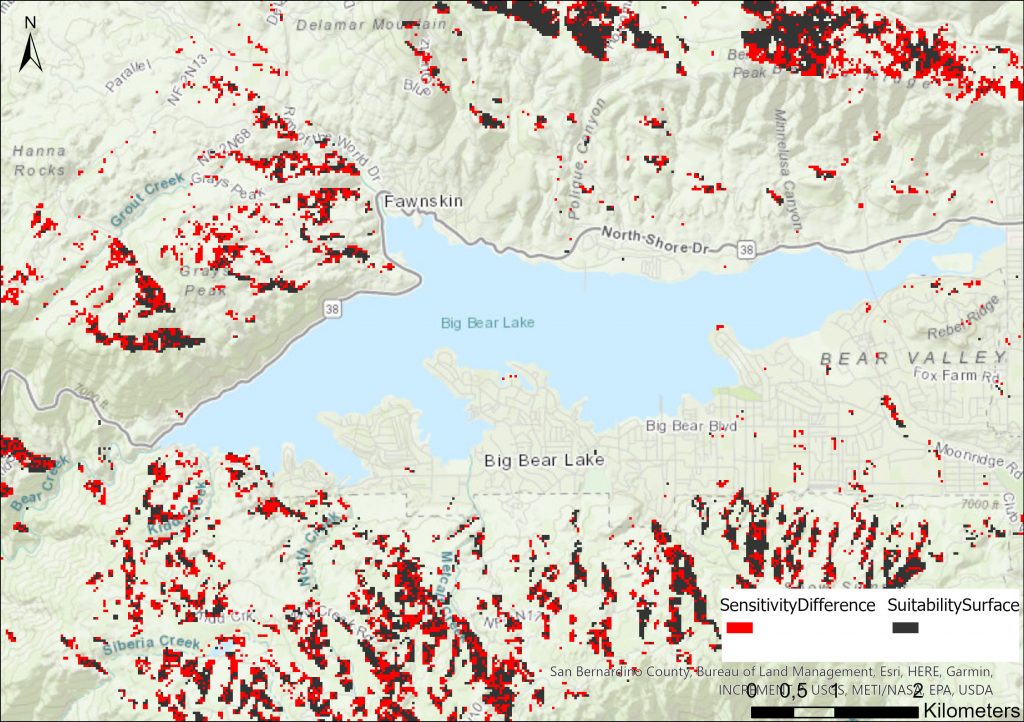
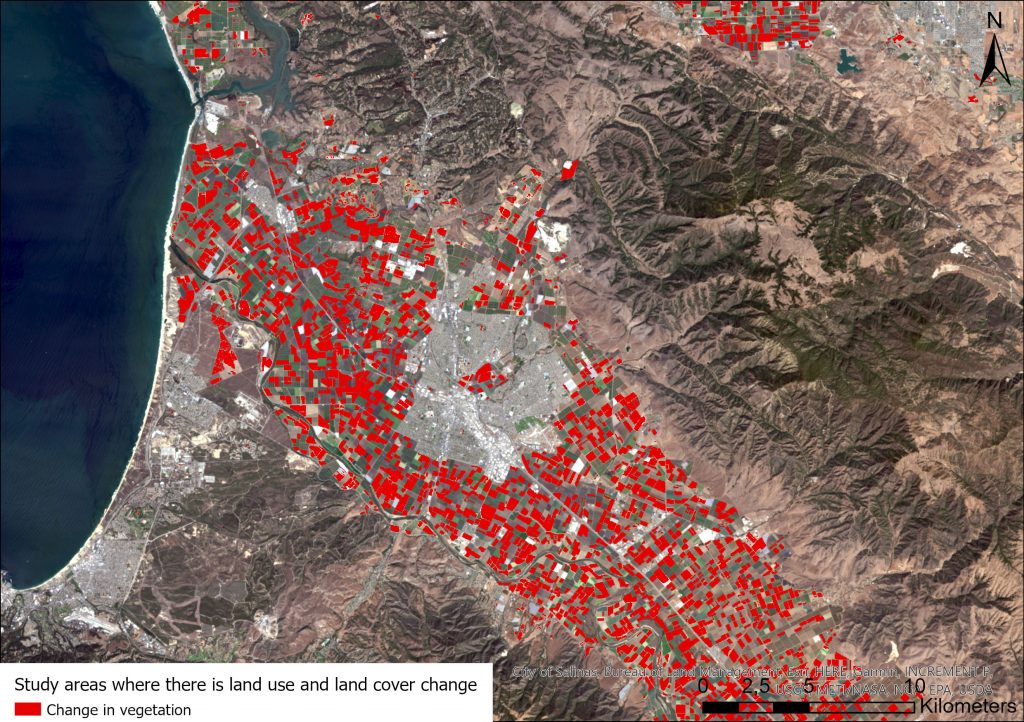
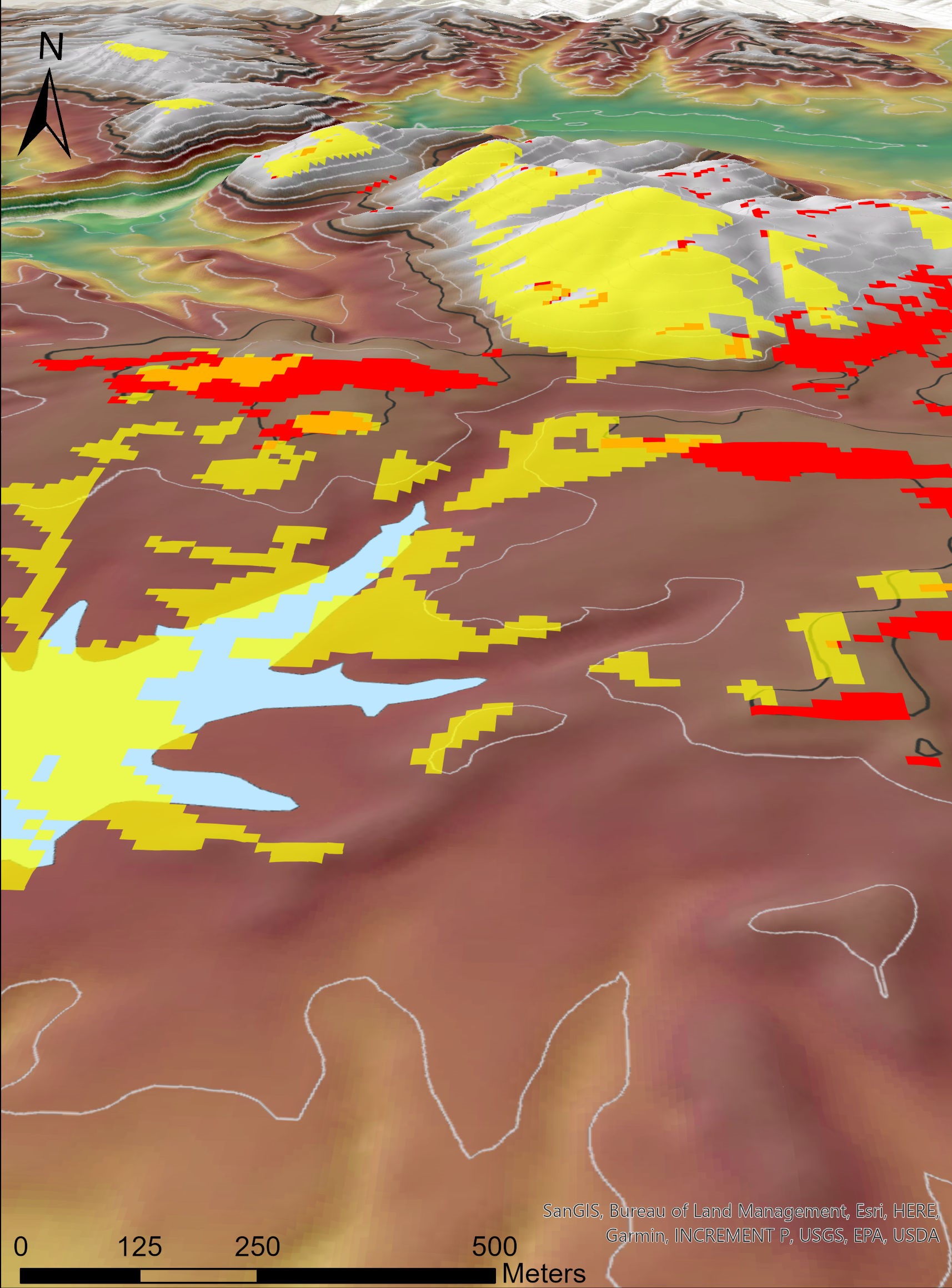
Tässä harjoituksessa tyydyttiin nyt tarkastelemaan näitä eri karttatasoja päällekkäin (kuva 2) ja arvioimaan optimaalisia sijainteja visuaalisen analyysin avulla. Lisäksi lopuksi analyysin tulokset viimeisteltiin vielä muutamalla 2D kartta 3D esitykseksi (kuva 3).
Tässä harjoituksessa tärkeäksi muodostui käytettävän lähtöaineiston laatu ja tarkkuus. Rasteriaineistoa käsitellessä aineiston tarkkuudella, spatiaalisella resoluutiolla, on muun muassa merkitystä sille, miten tarkkoja mallinnuksia ja analyysejä aineistosta on mahdollista tehdä. Toinen tekijä, joka vaikuttaa johdettujen rasterien laatuun, on naapuriruutujen määrä. Rasterin sisäpuolella olevilla soluilla on kahdeksan välitöntä naapuriruutua, mutta reunalla olevilla soluilla on vain viisi ja kulmasoluilla vain kolme vierekkäistä ruutua. Koska rinteen suuntaan ja jyrkkyyteen liittyvät analyysit käyttävät hyväkseen naapuriruutujen tietoja eli laskevat reuna- ja kulmasolujen arvot, analyysien luotettavuus on heikompi rasteriaineiston reuna- ja kulmasoluille, koska naapurisoluja on vähemmän. Tämä rajoitus tulee erityisesti tärkeäksi tarkasteltaessa johdetun rasteriaineiston reunalla olevia kohteita tai kun johdettuja rasteripintoja halutaan yhdistää.
Hydrologinen mallintaminen ja hydrografi-diagrammin luominen
Kurssikerran toisessa harjoituksessa tutustuttiin korkeusmallin pohjalta tehtäviin hydrologisiin mallinnuksiin. Tavoitteena oli arvioida veden virtausnopeutta ja tulvahuipun ajallista jakaumaa hypoteettisen tulvatapahtuman aikana Stowessa, Vermontissa mahdollisten tulvavahinkojen ehkäisemiseksi.
Harjoituksessa veden virtauksen mallintaminen aloitettiin korjaamalla korkeusmallissa olevia kuoppia, jotka voivat olla todellisia tai sitten korkeusmallissa olevia virheitä. “Kuopat” ovat pikseleitä, joiden kaikki naapuriruudut ovat sitä korkeamalla, ja tästä johtuen virtauksen mallintamisessa vesi ei pääse virtaamaan niistä eteenpäin. Tämä voi aiheuttaa virheitä mallinnuksessa, ja näiden kuoppien tunnistaminen sekä täyttäminen ovat tärkeä osa aineiston alkuvalmistelua. Kuoppia muodostavien pikselien täyttäminen tapahtuu paikkatieto-ohjelmistossa nostamalla näiden solujen korkeusarvot vähintään samalle tasolle yhden naapurisolun kanssa (Holopainen ym., 2015, s. 84).
Kun korkeusmallin kuopat on täytetty, onnistuu virtaussuunnan määrittäminen D8-virtaussuunta-algoritmin avulla (Holopainen ym., 2015, s. 134). Virtaussuunta määrittyy maksimaalisen korkeusarvon muutoksen mukaan jokaiselle ruudulle, ja veden virtauksen mallien avulla voidaan päätellä, mihin naapuriruutuun vesi siitä virtaa (Holoainen ym., 2015, s. 84). Lopputuloksena syntyy virtaussuuntagridi, jonka avulla pystytään edelleen määrittämään jokiverkon uomat sekä vapaasti valitun pisteen yläpuolinen valuma-alue (Holopainen ym., 2015, s. 134). Harjoituksessa virtaussuuntagridiä käytettiinkin tarkastelun kohteena olevan Little River -joen purkupisteen yläpuolisen valuma-alueen määrittämiseksi.
Alueen virtaaman aikakäyrän määrittämiseksi tarvittiin lisäksi tietoa valuma-alueen veden virtausnopeudesta sekä kerääntymisajasta alajuoksulla sijaitsevaan purkupisteeseen (kuva 4). Näiden avulla voidaan ennustaa, missä ajassa vesi virtaa valuma-alueella ja saavuttaa purkupisteen mahdollisen rankkasateen jälkeen.

Valuma-alueen topografia- ja korkeustietojen pohjalta pystyttiin siis johtamaan useita pintavaluntaan liittyviä muuttujia ja mallintamaan veden virtausta hypoteettisen tulvatilanteen sattuessa. Näiden tietojen pohjalta pystyttiin luomaan virtaaman aikakäyrä (kuva 5), joka kuvaa veden virtausnopeutta (m2/s) ja tulvahuipun ajallista jakautumista tarkastellulla Little River purkupisteellä. Tämän perusteella tarkastellussa uomassa on yksi korkea tulvahuippu ja se saavutetaan 4 tuntia sateen jälkeen.

Lähteet
Antikainen, H., Määttä-Juntunen, H. & Ujanen, J. (2015). GIS-analyysimenetelmät ArcGIS 10.2.1 -ohjelmistolla. Oulun yliopiston maantieteen laitoksen opetusmoniste no. 43. Haettu 27.11.2020 osoitteesta http://jultika.oulu.fi/files/isbn9789526207889.pdf
Esri. (n.d.). Terrain Analysis Using ArcGIS Pro.
Holopainen, M., Tokola, T., Vastaranta, M., Heikkilä, J., Huitu, H., Laamanen, R. & Alho, P. (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7. Haettu 27.11.2020 osoitteesta http://hdl.handle.net/10138/166765