
The last assignment of the course; Introduction to advanced geoinformatics (spring 2021), was to do a final report about an optional topic and data. I chose to do the final report about the air quality and noise pollution that comes from the traffic in the Helsinki metropolitan area. This is an uttermost important topic as it is one of many reasons for premature deaths and other overall health issues. It is expected that poor air quality and noise pollution will only increase in the future if no solution is achieved.
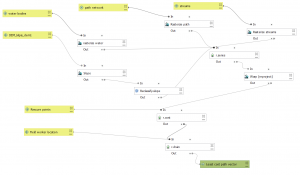
I followed the PPDAC framework as a guideline during the whole process. The framework consists of the problem, the plan, the data, the analysis, and the conclusion. I made this framework prior to the analysis which shows my plan of how to execute the analysis as well as all the inputs (data) and the geoprocessing tools (the analysis) and the desired outputs (conclusion).

Fig 1. The figure shows my PPDAC framework which lists all the inputs, tools, and outputs.
The problem in the analysis was to locate sensitive features within poor air quality zones as well as within zones with noise pollution exceeding the recommended guidelines of decibel (dB) levels. My plan was to create a buffer zone around busy traffic roads in the Helsinki region with each road’s specific traffic amount deciding the range of the buffer zone. After the buffer zone was created, all the sensitive features that fell within the buffer zone would be extracted. The sensitive features were daycare centres, elementary schools, homes for the elderly, and hospitals.
The road network had information in the attribute table of how much traffic travels daily on each road, and the more daily traffic, the poorer the air quality is next to the road. The sensitive features within the buffer zone are accordingly to HSY (Helsinki Region Environmental Services) too closely located to these roads, due to the high amount of pollution from the traffic that could potentially be harmful to the overall health. My plan was also to extract all the sensitive features which fell within a zone with a higher than 53 decibel (dB) which is according to WHOs guidelines above the recommended decibel levels.
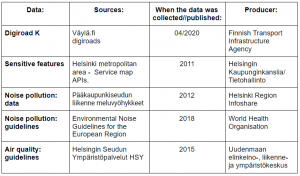
To be able to do this analysis, I used data from many different sources. All my sources have been collected by Finnish municipalities or governmental agencies, so the data is very legitimate. This makes the result of the analysis reliable and accurate. I also followed WHOs noise pollution guidelines “Environmental Noise Guidelines for the European Region” and HSYs air quality guidelines “Air Quality – Minimum and recommended distances for housing and sensitive locations” which are listed in the table below.
Table 1. In the table, there are listed all the sources I used for the assignment, when the data was collected, and who is the producer.
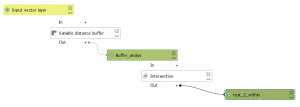
To perform the analysis, I used the graphic builder to build a model that would run the whole process and result in the desired output. I first had to add a new column to the attribute table with the values of the minimum distance from the roads. I had calculated these values using the field calculator. I then used the variable distance buffer tool to create a variable buffer zone with each road’s specific traffic amount deciding the range of the minimum distance buffer zone. When the buffer zone was made around the roads, I used the extract by location tool to see which and the number of sensitive features that fell within the buffer zone. I did also create a layer with the recommended distance from the roads according to HSYs guidelines. I added a new column with the values of the recommended distance to the attribute table and repeated the same analysis.
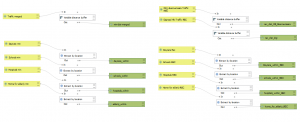
Fig 2. My graphic builder chain at the end of the minimum and recommended distance buffer analysis.
The outcome of the minimum distance analysis showed that only 26 daycare centers, 12 schools, 2 hospitals, and 0 elderly homes of a total of 1483 sensitive features fell within the minimum distance buffer zone. Meaning that these sensitive features are located closer than the allowable distance to a given traffic road because of the poor air quality, according to the HSY report Air Quality – Minimum and recommended distances for housing and sensitive locations. So, the remaining 1443 sensitive features that were in the analysis are located at least the minimum distance from a given road and not affected by traffic pollution and poor air quality to the same extent as those inside the buffer zone.

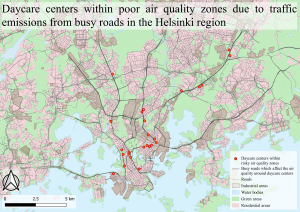
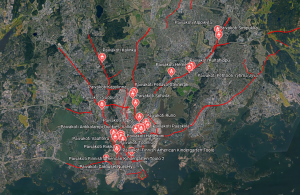
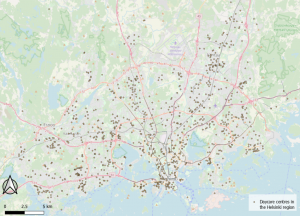
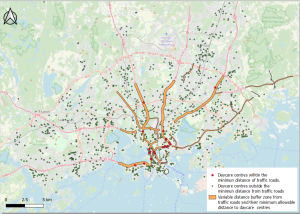
Fig 3. The map shows all the sensitive features within the minimum buffer distance from roads.
While the outcome of the recommended distance analysis shows that 79 daycare centres, 36 schools, 15 elderly homes, and 3 hospitals fell within the recommended distance buffer zone. Even though these sensitive features do not fall within the minimum distance, they are not in an optimal location if considering the health impacts from the pollution. These sensitive features are below the recommended distance but above the minimum distance, making it a “grey-zone”.
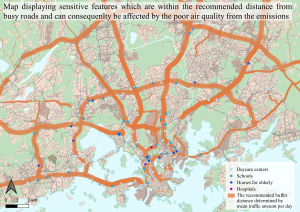
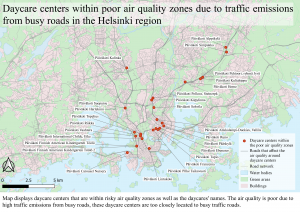
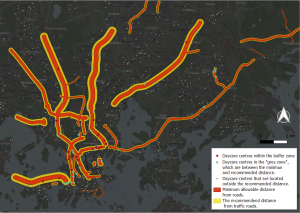
Fig 4. The map shows all the sensitive features within the recommended buffer distance from roads.
When examining figs 3. and 4. a clear pattern can be seen. Most of the sensitive features within the zones are on or within highway ring 3 and with the most focus in the centre of Helsinki. The sensitive features that are the most affected are the daycare centres which have almost as double as many within the sensitive areas as the other sensitive features groups. This is outrageous as daycare centres are for young and undeveloped children that need a safe and healthy environment to grow in.
I did not use the graphic builder to do the noise pollution analysis as it was easier to do it manually with the tools. I started by deleting the fields in the attribute table that had a value below 53 dB so that locations with a decibel over 53 dB would only be visible on the map. Above 53 dB can accordingly to WHOs guideline “Environmental Noise Guidelines for the European Region” be harmful to the health and in this task, I was only interested to see noise polluted areas and which sensitive features fell within. I then used the extract by location tool to extract all those sensitive features that fell within the zone of a higher decibel than 53 dB.
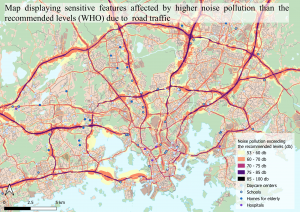
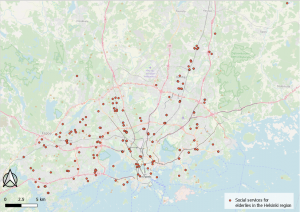
Fig 5. The map shows all areas with noise pollution exceeding 53 dB and the sensitive features within.
Noise pollution due to traffic exceeds recommended levels of 53 dB almost only at greater highways and important traffic roads in the Helsinki metropolitan area. Most of these roads generate an immediate dB level between 75-85 dB right next to the road. The levels of dB rapidly decrease the further away from the road you get. Local factors and variations like buildings, open fields, and specifically built sound barriers also affect the decrease in dB.
There are 184 daycare centres, 43 schools, 20 elderly homes, and 15 hospitals that are within the noise polluted area in the Helsinki metropolitan area out of a total of 1483 sensitive features. This is a legitimate problem as many of the sensitive features which are within the noise polluted areas are also within the poor air quality zone. These sensitive features’ surroundings should immediately be examined and reviewed and solutions to these polluted zones should be achieved at once. Some of these sensitive features could even be potentially moved from the risky areas as it could harm the health of yet undeveloped children and elderly as well as people recovering from an injury. A high amount of pollutions can cause premature deaths and overall health issues as well as social and economic costs (Vieira, J. et al., 2018) and pollution is only expected to increase in the future if no solutions are achieved.
Since pollutions like these are expected to increase in the future, solutions to it are of the uttermost importance. There are different ways to tackle these societal problems, such as nature-based solutions like green-blue infrastructure inspired by nature (Vieira, J. et al., 2018) or strict Air Quality Plans that bring forth a strategy that reduces pollution while is also positive for the economy (Miranda, A. et al.,2015). Local improvements can also be significant in the reduction of local emissions such as speed reduction and street cleaning (Miranda, A. et al.,2015). It is important to define the reasons for pollutions, to be able to solve it. It is not all vehicles that emit large quantities of emissions, the fuel and vehicle type are important variables that need to be considered when reviewing the amount of emissions they emit (Bigazzi, Y. A. & M. Rouleau, 2017). Also, the infrastructure and urban structure and planning are of paramount importance to consider when examining the impacts of pollution. Tightly built high buildings create microclimates that trap pollutions and strengthen them, making the problem even greater.
Due to urbanization and population growth in cities, these societal problem needs to be addressed. These problems could not only lead to an increase in premature death but also to high economic and societal costs in a world that already faces great challenges in the coming decades. Children and the young are the future of this planet and societies so it is very important to protect them from being exposed to pollutants that could potentially harm them. Cities like Helsinki should be front-runners and trendsetters in tackling these societal problems with innovations and new solutions.
References
Vieira, J. et al. (2018) Green spaces are not all the same for the provision of air purification and climate regulation services: The case of urban parks. Environmental Research 160, 306-313.
Bigazzi, Y. A. & M. Rouleau (2017) Can traffic management strategies improve urban air quality? A review of the evidence. Journal of Transport & Health 7, 111-124.
Miranda, A. et al. (2015) Current air quality plans in Europe designed to support air quality management policies.







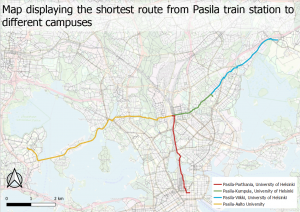
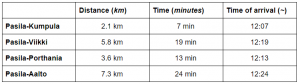
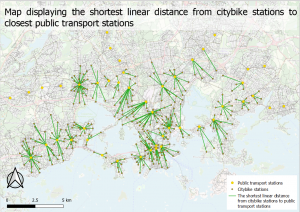

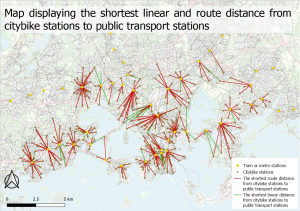




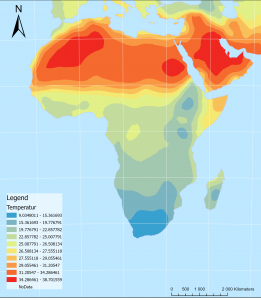 Karta 1. En interpolerad karta över temperaturskillnader i Afrika och Mellan östern. ArcGis PRO.
Karta 1. En interpolerad karta över temperaturskillnader i Afrika och Mellan östern. ArcGis PRO.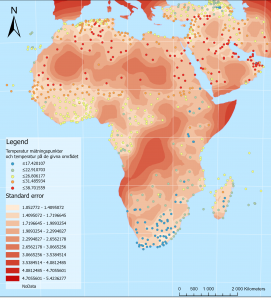 Karta 2. En karta över standardfelen av temperatur gissningarna i den föregående kartan (karta 1.). ArcGis Pro.
Karta 2. En karta över standardfelen av temperatur gissningarna i den föregående kartan (karta 1.). ArcGis Pro.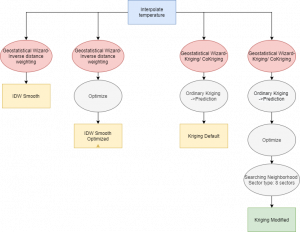
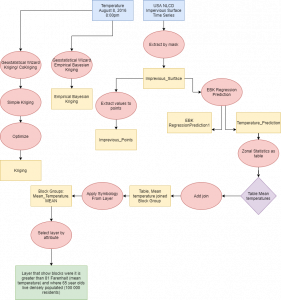
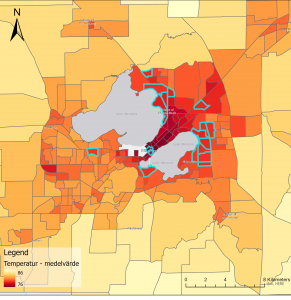 Karta 3. En interpolerad karta över temperaturskillnader i stadsdelar i Madison, Wisconsin samt stadsdelar som har fler än 100 000 invånare som är äldre än 65 år.
Karta 3. En interpolerad karta över temperaturskillnader i stadsdelar i Madison, Wisconsin samt stadsdelar som har fler än 100 000 invånare som är äldre än 65 år. 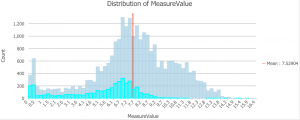 Diagram 1. Ett histogram över syremättnaden i Chesapeake Bay. ArcGis PRO.
Diagram 1. Ett histogram över syremättnaden i Chesapeake Bay. ArcGis PRO.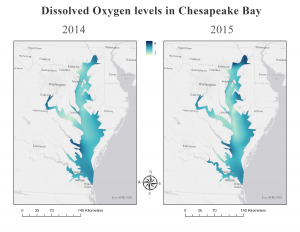 Bild 1. Två kartor som visar syremättnaden i Chesapeake Bay sommaren 2014 och sommaren 2015. ArcGis Pro.
Bild 1. Två kartor som visar syremättnaden i Chesapeake Bay sommaren 2014 och sommaren 2015. ArcGis Pro.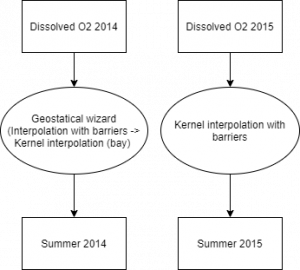

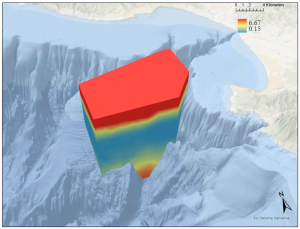 Bild 3. Ett voxel lager som visualiserar syremättnaden i Monterey Bay, Kalifornien. ArcGis Pro.
Bild 3. Ett voxel lager som visualiserar syremättnaden i Monterey Bay, Kalifornien. ArcGis Pro.