Tilastollista päättelyä voidaan harrastaa kahdesta hieman filosofisesti toisistaan poikkeavasta näkökulmasta. Tämä blogi keskittyy ns. Bayeslaisen koulukunnan tarjoamiin menetelmiin. Toinen päättelyn koulukunta on ’perinteisempi’ ja suositumpi frekventistinen päättely. Teoreettisesti ero näiden kahden välillä muodostuu pienestä yksityiskohdasta: Bayes-päättelyssä kiinnostuksen kohteena oleviin mallin parametreihin kiinnitetään todennäköisyysjakauma, kun taas frekventisessä päättelyssä ne ajatellaan tuntemattomiksi, mutta kiinteiksi.
Tämä yksityiskohta osoittautuu hyvin merkitykselliseksi ja määrittelee oikeastaan kaksi hyvin toisistaan poikkeavaa näkökulmaa tilastolliseen päättelyyn. Frekventistisessä näkökulmassa aineiston tuottaneen tilastollisen mallin parametrit ajatelleen siis kiinteiksi, jolloin kaikki käsiteltävä satunnaisuus liittyy itse aineistoon. Aineisto ajatellaan satunnaiseksi leikkimällä sillä mahdollisuudella, että oltaisiin voitu kerätä/havaita myös toisenlaisia aineistoja, mikäli sama koe oltaisiin toistettu samoissa olosuhteissa.
Bayeslaisessa näkökulmassa tilastollisen mallin parametreille kiinnitetään todennäköisyysjakauma, jota päivitetään havaitun aineiston perusteella. Tämä ns. priorijakauma kvantifioi ilmiöön liittyvän enakkotiedon ja siihen liittyvän epävarmuuden. Asetelma on siis päinvastainen kuin frekventistisessä päättelyssä; aineisto on kiinteä ja sen tuottaneen tilastollisen mallin parametrit satunnaisia (epävarmoja).
Tyypillisesti tilastotieteilijöille opetetaan lähinnä pelkästään frekventististä päättelyä. Sellainen asetelma, jossa kaikki onkin toisinpäin aiheuttaa hieman totuttelemista. Olemme esimerkiksi tässä blogissa raportoineet laskentamallimme tuloksia osittain epäselvästi johtuen omalta osaltani kokemattomuudesta analysoida bayslaisen laskentamallin tuloksia. Puutun nyt muutamaan virheelliseen ilmaisuun ja selvennän, mitä yritettiin sanoa ja mitä olisi pitänyt sanoa.
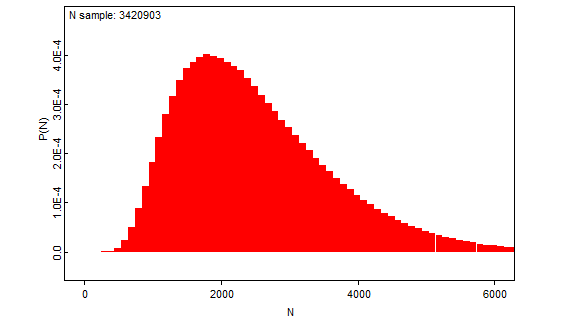
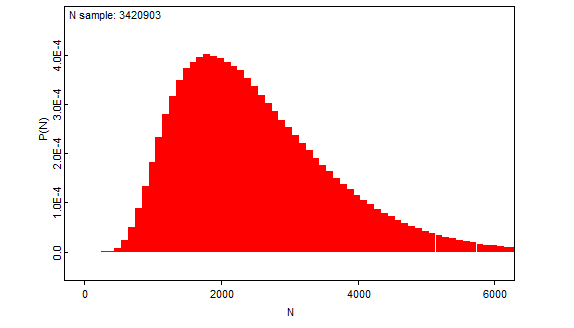
Kokonaismäärän odotusarvon piste-estimaatti
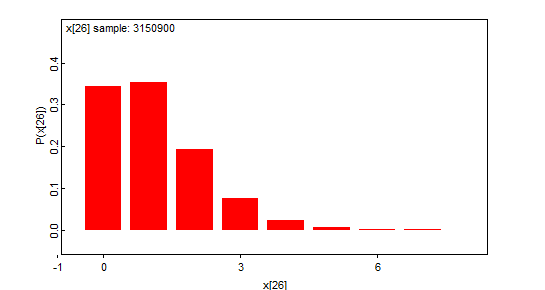
Laskentamallimme tarkoituksena on tuottaa taimenten kokonaismäärän todennäköisyysjakauma. Kun olemme onnistuneet tämän jakauman tuottamaan, on sen odotusarvo meille tunnettu. Käytämme kuitenkin laskennallisia menetelmiä, joten emme aivan täsmälleen pysty tuottamaan haluamaamme jakaumaa, vaan BUGS-ohjelmiston tuottaman estimaatin siitä. On aivan oikein puhua piste-estimaatista, mutta on syytä ymmärtää, että kysymyksessä on estimaatti laskennallisista syistä. Tämä liittyy alempaan kohtaan.
Odotusarvon piste-estimaatin 95% luottamusväli
Luottamusväli on frekventistisen päättelyn termi. Frekventistisessä päättelyssä 95% luottamusväli tarkoittaa, että muodostettu väli sisältää todellisen parametrin arvon 95 kertaa sadasta, perustuen sellaiseen mielikuvitusleikkiin, jossa kerätään vastaavia aineistoja ja muodostetaan uusia välejä. Tällä nimikkeellä olemme raportoineet kokonaismäärään liittyviä todennäköisyysvälejä (Näistä käytetään Bayeslaisessa analyysissa joskus termiä uskottavuusväli, engl. credible interval), eli sellaisia välejä, joiden sisällä kokonaismäärä on 95% todennäköisyydellä.
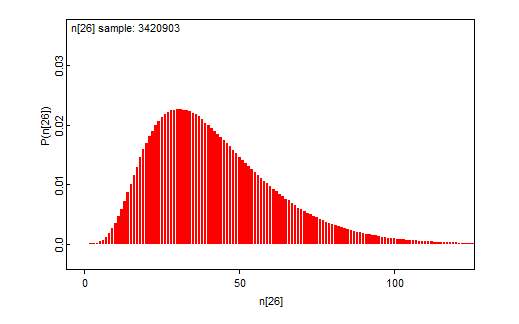
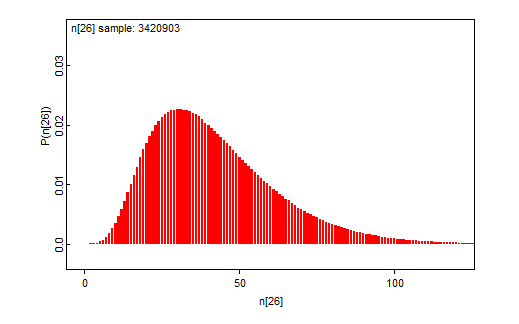
Vaikkakin oletettavasti lukijat ovat tienneet mitä näillä luvuilla on tarkoitettu, on niiden kohdalla tarkalleen ottaen tehty paha virhe liittyen edellisen kohdan huomioihin. Kuten todettu, liittyy odotusarvon piste-estimaattiin laskennallista epävarmuutta, joka on tunnettua, sillä laskentaohjelmistot kuten BUGS raportoivat samplaykseen liittyvän epävarmuuden (MCMC error), joka kunkin tunnusluvun kohdalla kuvaa siihen liittyvää laskennallista epävarmuutta. Tämä epävarmuus voitaisiin (ja kuuluisikin) raportoida, jolloin voitaisiin esimerkiksi kertoa piste-estimaattiin liittyvä 95% todennäköisyysväli (uskottavuusväli). Tämä väli on kuitenkin aivan eri asia, kuin mallin antama todennäköisyysväli kokonaismäärälle, sillä piste-estimaatin todennäköisyysvälissä kysymyksessä on parametriin liittyvä laskennallinen epävarmuus, ei mallin epävarmuus.
Raportoimamme luvut ovat siis olleet kokonaismäärän 95% todennäköisyysvälejä – välejä, joiden sisällä kokonaismäärä on mallimme mukaan 95% todennäköisyydellä.