The challenges – as well as the opportunities – of open data are affecting more and more researchers, and regardless of the discipline, the same questions come up again and again: Can I open the research data I have collected? What does it require? How to deal with sensitive material? In March 2021, the University of Helsinki’s Data Support, in cooperation with data repositories, organized a webinar that brought together researchers and data management experts from various fields. The webinar focused on what it takes to open data and how open materials can be used. This blog post sums up the event.
Text: Juuso Ala-Kyyny & Tanja Lindholm
 Many funders and organisations demand opening the research data. Opening the data is still unfamiliar for many researchers and the help and support needed is not always available. This leads into a mismatch that creates false rumours around the subject as well as fears.
Many funders and organisations demand opening the research data. Opening the data is still unfamiliar for many researchers and the help and support needed is not always available. This leads into a mismatch that creates false rumours around the subject as well as fears.
This was one of the main reasons why University of Helsinki’s Data Support wanted to organize a webinar, What it takes: open your research data, that took place on 25th of March 2021. Internationally linked representatives of Finnish service providers gave practical insights to what opening data is all about as well as what it takes. Webinar gathered 114 participants from a wide variety of Finnish research organizations.
This blog article summarizes the main content of the webinar, since there is no recording available. PDF files of the presentations can also be found in the summaries. And if you are really busy, here’s a very short summary of what it takes to open your data:
- While being just one phase in the research lifecycle, opening data needs to be considered at different stages of the research process and already from the planning stage.
- Opening data takes time and resources; it is needed for the process of opening the data e.g. agreements, metadata, storing.
- Opening data needs support and structures built by institutions and funders – researchers must not be left alone.
Here are the sections of this blog article:
- Opening sensitive data in life science
- Language Bank data – how to open and how to use
- Opening data requires planning and resources
- Opening data requires support for researchers
- Data as open and as easy to use as possible
- Discussion – about planning research and choosing repository
Opening sensitive data in life science
Opening sensitive data is not an easy task, and not even always possible. There is also detailed legislation that one needs to take into account. CSC – IT Center for Science offers some services and help for sensitive data in life science (see also a blog post about CSC services).
Francesca Morello from CSC introduced the Federated EGA (European Genome-phenome Archive), which is the European network for genome-phenome data. It promotes the sharing of genetic and phenotypic data for restricted research purposes according to EU’s General Data Protection Regulation (GDPR). CSC is the contact point for the EGA network in Finland.
Morello gave an detailed example of how FEGA’s system works from researcher’s perspective: how to sign up, what agreements are needed, what file formats are suitable etc. In all cases of data storing and sharing, metadata plays a key role since it determines how the data can be used.
”Data is stored and kept permanently at CSCs servers in Finland, but the metadata is shared through European network hence it can be found and re-used by other scientists”, Morello says.
Morello pointed out that the process of opening the data – from signing up to storing the data – might take several weeks of time, and a researcher should be prepared for this. However, CSC offers support for customizing the process (servicedesk@csc.fi).
One question that came up in a discussion was about data curation: Is FEGA data curated?
”Federated EGA (like the central EGA archive) is not curated. However, there are very strict standards required during the submission process. There is a minimal amount of metadata that the user as to fill in using the submitter portal (a user interface that simplifies the metadata submission). If the user does not fill in the minimal requirements, the submission is not accepted and can not be validated against central EGA servers. Also the data needs to be in specific format and this is also verified at the time of submission.”
- Here you can find Francesca Morello’s presentation: ”Sensitive Data Services: Federated EGA”.
Language Bank data – how to open and how to use
Many researchers in the humanities are already familiar with the Language Bank of Finland (Kielipankki) services. Researcher of the month interviews give a good idea about the uses of Language Bank services.
Mietta Lennes from Language Bank highlighted practicalities related to storing and sharing data as well as how to utilize open materials. She also brought up what guidance is available related to for example personal data.
Lennes mentioned how Language Bank also gathers data from other sources – i.e. plenary sessions of the Parliament of Finland – for research use. And as a part of international CLARIN ERIC network researchers can utilize all material from CLARIN community.
Language Bank data are different types of text- and speech data, i.e. text documents and voice and video files or recordings. When opening the data, a researcher is required to offer proper descriptions of the data (metadata) and necessary agreements (e.g. informed consent agreement). Language Bank has also listed different kind of tools in their webpages to help a researcher to open and use data. There is also wide variety of training, guides and guidance available (fin-clarin@helsinki.fi).
In the webinar discussion part, one important question was raised: Do you need the participants’ consent to be able to open the data?
”You cannot give advice that fits all kind of datasets – you have to think about case by case. But there is a difference between a legal basis of getting consent according to the GDPR and an ethical consent in which you simply ask for a permission i.e. to make a recording. In both cases, you still need to inform research subjects: you have to give them information on how you are about to process the data and, how you are about to distribute the data. This is what we require”, Lennes says.
- Here you can find Mietta Lennes’ presentation:
”Kielipankki – as open as possible”.
Opening data requires planning and resources

In his presentation, Tuomas Alaterä took the audience to a postmodern medieval story, where a knight-researcher rode the path of opening data, encountering dragons in disguise of metadata, data sharing and sensitive data and getting help with a mystical ”FSD” spell.
FSD, or the Finnish Social Science Data Archive (Tietoarkisto) is one of the oldest Finnish research infrastructures. As research data infrastructures, social science data archives date back to the 1960s. FSD was also the first in Finland to receive Core Trust Seal, a standard repository certification. FSD is a thematic repository for the human sciences.
The data stored in the FSD archive must meet the quality requirements related to both the metadata and the access rights – agreements are a crucial part of the process because they define i.e. who has the right to use the data. FSD’s Data Management Guidelines will help the researcher in the process.
Services of FSD are free for a researcher. However, Alaterä stresses that a researcher should allocate enough time and other resources to prepare the data for archiving.
”The research project itself should have resources to organise, clean up and process the data for deposit. But we will not charge for our services.”
One important aspect is that the process of opening the data does not start at the end of the project. According to Alaterä, it is important to acknowledge the question around opening data at the beginning of the research.
”Think about archiving and reuse already when planning the research project. This will tremendously help with many mundane issues like which formats to use, how to document, how to organize the actual files and how much resources there are needed for the data deposit.”
- Here you can find Tuomas Alaterä’s presentation: ”Finnish Social Science Data Archive (FSD)”.
Opening data requires support for researchers
Kari Lahti from Luomus (Natural History Museum) approached the themes of the webinar from two perspectives: from the challenges’ and from the benefits’ point of view based on the experience from the Finnish Biodiversity Information Facility (FinBIF) and its Laji.fi online portal, one-stop shop for biodiversity data.
So, what it takes to open your data? It takes different actions from key actors – researchers, repositories, research institutions and funders. According to Lahti, researcher needs to know at least what practicalities and legislation there is, related to opening the data.
”Researcher should recognize the basics of FAIR principles, should aspire to open their data, should know what their domain specific data model is, and should seek for help from data stewards”, Lahti says.
Understanding FAIR principles and requirements applies to all actors, and Lahti stresses researcher support for data management.
”Institutions should invest in data stewards to support the work of researches – this is crucial. Funders should support the institutions in data stewardship building, for instance by earmarking 5–10 percent of research funding.”
In ”Good news” part, Lahti lists benefits of open data, based on the usage statistics gathered from Laji.fi (started 2016). The use of the Laji.fi has increased rapidly, which has also been reflected in the number of research done with the data as well as data citations.
- Here you can find Kari Lahti’s presentation: ”A View From Biodiversity Informatics Domain”.
Data as open and as easy to use as possible
Journalist and biologist Jouni Tikkanen turned attention to the utilization of open data. In his work at Suomen Luonto magazine (Finnish Nature), he has used regularly for example the data from Laji.fi.
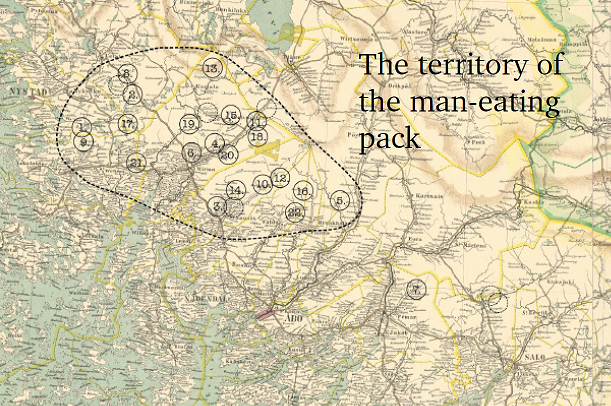
In his latest book Lauma (2019), Tikkanen writes about wolves that presumably killed several children between 1880–1881 in Turku area, Finland. To get a picture of the man-eater wolf pack territory, he built a map combining various data sources:
- old maps: The National Library (digitalized, open access)
- news: The National Library (digitalized, open access)
- letters: The National Archive (not digitalized)
- parish register: Suomen Sukuhistoriallinen Yhdistys (Finland’s Family History Association) (digitalized, a yearly subscription needed)
- modern maps: The National Land Survey (mostly open access, online)
In addition to this, Tikkanen got help from people working at the University of Helsinki to get access on the articles behind paywalls.
Tikkanen’s presentation highlighted the process of utilizing information in various ways from information seeker’s point of view (e.g. search interface, information about access rights) and illustrated how information seeking proceeds from one source of information to another.
Tikkanen’ presentation also concretizes the unpredictable potential of open material – the beauty of the unknown.
”My case for open access data is that publishers of data never know what can be the relevant point of views. So, it’s better to make the data as open as possible. And I would also like to say, that you should always think about a user – not only a researcher who is depositing data. You should make it as easy as possible to use the data. And it is much easier to use the data, if you can find it from one place, like from Finna or some other portal”, Tikkanen says.
- Here you can find Jouni Tikkanen’s presentation: ”Why open access?”
Discussion – about planning research and choosing repository
What do you need to take into account already at the beginning of the research, if you want to open the data while publishing?
Mietta Lennes: ”The most important thing is to think about it thoroughly in advance. Often people think they are too afraid of archiving personal data, and of course, you have to have good grounds for archiving the data with identifiers. You need to have safeguards and proper security measures. But there are also many cases where it doesn’t make sense to anonymise the data. And especially in language data sets it’s often even impossible to remove all the identifiers and then you cannot promise research subjects that you will anonymise the data completely. So, you have to think how you can meet halfway, what is really necessary and what is reasonable. You have to think also threats: what if something leaks, would it hurt someone? After all this consideration, you might be still able to open – at least part of – the data.”
Kari Lahti: ”We are in the very beginning of this kind of culture, but it would be really useful to think about opening the data in advance. We have now an experience where a funder requires data to be deposited in our repository. And they have to start the negotiations from the very beginning – e.g. what is the data format and data model – to make it easy to share the data and you don’t have data in your hands that is incompatible with the repository’s requirements. When we speak about opening data quickly, the planning is crucial.
Tuomas Alaterä: ”I would like to add one point from FSD’s point of view: we curate the data, check the anonymity of the data and risks involved on behalf of the researcher. The data controller is usually a researcher or a research group, and if we feel confident that this can be opened, then a researcher should feel fairly confident as well. If there is a risk, we should notice it and there are services in place if something comes up. We also check the data already in the archive in case new technologies reveal some identifying information in ways that were not known at the time of archiving.”
How important it is to choose right repository?
Tuomas Alaterä: ”Ideally, metadata travels. So it should not be that important that the data is in one certain place. You can find it in common catalogues; minimum set of FSD metadata can be found in Finna, and then you end up in Aila where you can find more detailed information.”
Kari Lahti: ”Big issue here is, are we talking about metadata or the data itself.”
Mietta Lennes: ”I would go for the most sustainable repository you can find, the repository that has long-term funding, is well established and well-known, so that you don’t have to worry about your data being dumped in a few years.
Francesca Morello: ”The journal may have very specific requirements for a researcher to publish the data, but the services are not ready yet and you cannot publish sensitive data. Who will help you then? That is a very complicated question.”
Kari Lahti: ”I also wonder who is responsible for finding the right repository. Is it domain specific institution? They should be aware and they should inform researchers: if you have data in our discipline, here are repositories you should use. And if funders require a researcher to open data, do they understand the requirements? We should think about the whole governance issue here, who is responsible and, who is advising and what. Very recently, I learned about this data stewardship that could be really good. University of Helsinki could establish domain specific data stewards who could understand and help researchers in these issues.”
Tuomas Alaterä: ”There are also research groups from different institutions working together, and it is not always clear whose responsibility it is to provide support for the group. So, it could be very beneficial for the data stewardship to have a network of collaboration and you don’t have to repeat this in each institution with limited resources.”