
”You should act like every measurement you start is going to continue forever, but the people in charge of the measurements and data flow would move on to different tasks the next week,” says Pasi Kolari, university researcher at the University of Helsinki. In this blog interview, Kolari, who works as a data liaison for SMEAR stations (Station for Measuring Ecosystem-Atmosphere Relations), sheds light on the real life challenges of collecting, processing and opening data. The article is part of the Think Open article series on open science research infrastructures.
(Tämä artikkeli on saatavilla myös suomeksi.)
Text: Tanja Lindholm, Mika Holopainen & Siiri Fuchs
Finland is one of the leading countries in atmospheric science. One major project has been the establishment of SMEAR (Station for Measuring Ecosystem-Atmosphere Relations) stations and the research carried out at them.
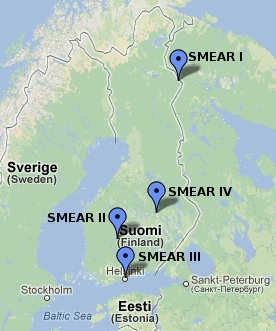
The planning of the first station started in 1989 with professors Pertti Hari and Markku Kulmala. The first station was established in 1991 to Värriö Subarctic Research Station and the next in 1995 to Hyytiälä forestry field station. Today there are a total of seven stations, four in Finland, one in Estonia and two in China.
The stations gather information on different ecosystem-atmosphere interactions. For example, the SMEAR II station measures data from over 1200 different variables, including aerosol concentrations, their physical, optical and chemical properties, photosynthesis and different soil properties. From this data have come at least a hundred PhD theses and a couple of thousand scientific articles published since 1991. Publications and theses have focused on, for example, forest carbon sequestration and transpiration and evaporation, different soil processes, nitrogen usage and circulation in different parts of the ecosystem.
SMEAR stations are also part of the ICOS (Integrated Carbon Observation System) network. ICOS is a European research infrastructure which focuses on producing consistent long-term data on atmospheric greenhouse gases and ecosystem carbon balance.
University researcher Pasi Kolari works at the Institute for Atmospheric and Earth System Research (INAR) at the Faculty of Science and handles different assignments involving SMEAR data. We asked what it takes to handle huge amounts of data, what kind of processes are included, and what happens to data in different steps of the process.
Pasi Kolari
|
How did you come to work with SMEAR, and what is your current role?

”I started in 2000 as a usual graduate student and later as a PhD student. My tasks were, for example, dealing with some measuring components that I later on used in my master’s and PhD theses. I also did some modelling where I needed other data as well. At that time it was quite common that people would sit on their data (sharing was yet to come), so the easiest method was to gather raw data from our data servers and process the data myself.”
”Gradually, I started delivering data for others as well. At the beginning of the 2010s, when ICOS was being planned, my position as a data contact person was made official. Nowadays I do everything from calibrating the measuring equipment to data management planning. I produce end user data (mainly from SMEAR I and II), document the measurements and data they produce, maintain the end user database, publish and deliver the same data all over the world as well as give advice on data management planning for technicians and researchers working with SMEAR data.”
The first station has gathered data for already 28 years. How much raw data has accumulated during this time, where is the data kept, and how is it backed up?
”SMEAR stations produce a few terabytes of data every year, so roughly one standard PC hard drive gets full every month. Big stations, like SMEAR II, produce more data, but mostly the amount of data at stations depend on what kind of instruments there are, for example, some online mass spectrometers produce a terabyte of data in a year. Most of the data is copied immediately to University or campus servers, where backups are made regularly. We have also started to use Datacloud, a new cloud service at the University.”
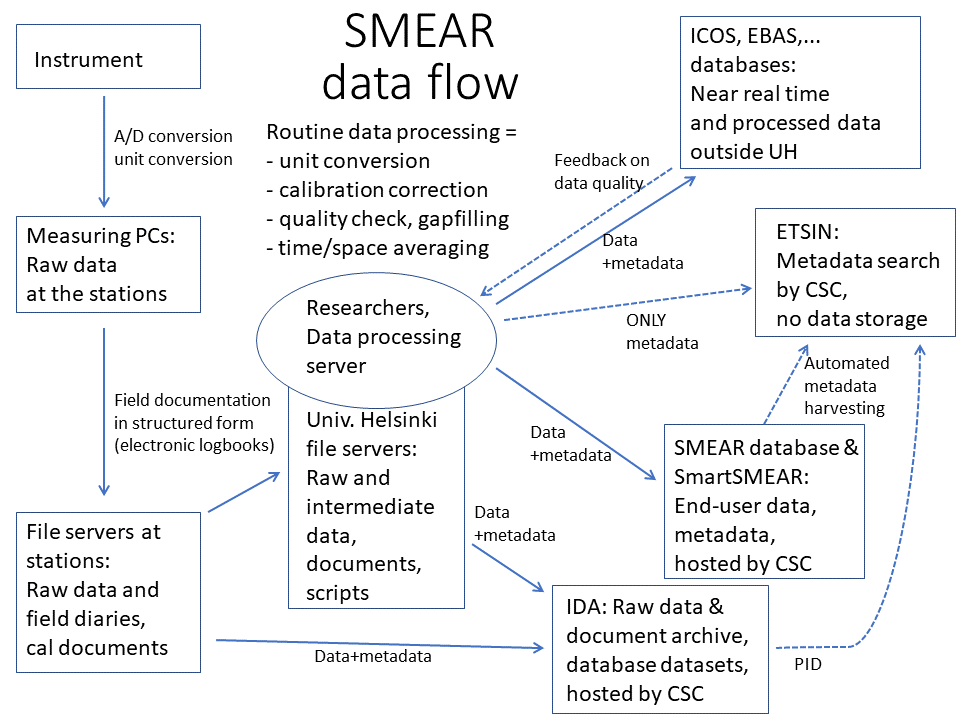
The journey from raw to end user data is long. What does it take?
”Above all it needs labour in measurement maintenance, documentation in the field as well as the refining of end user metadata from field documents. The documentation of end user data requires understanding of the measurements and data user needs, as well as general knowledge in data management. The actual processing of data into a usable form for the end user is small measured in working hours, since the process is automated by running computational codes on computing servers several times a day. Of course, the produced data has to be checked, and the maintenance of computational codes is quite laborious.”
Since the first SMEAR station was founded before the digital age, the methods have likely changed. Can this be seen, for example, in the documentation, or are there new joint practices between the stations? Have you caught something later that should have been documented that would have been beneficial?
”Data management at the SMEAR stations is quite variable. Transferring files and centralising the online processing of the data are pretty much the only common practices between the stations. In the nineties, we made our own common data collection software, but later on a new generation of technicians replaced this with new software. However, the notebooks at different stations still vary. At the beginning of 2010s, some researchers still had paper notebooks. SMEAR II and its satellites started to use electronic notebooks (elog software) in 2015. For data collected in short-term campaigns that does not end up in a SMEAR database, there is no common practice for processing or publishing the data. I hope that good practices from research infrastructure will spread also to other parts of data management. Positive attitudes from researchers and technicians towards data management are needed.”
Documentation has been made from the perspective of the measurer when it should have been done from the perspective of the end user. Many end users have never even visited the station, or they use the data for completely different purposes from the original intention.
”The biggest flaw in the old documentation is that it concentrates on small technical issues – and at the same time the most important information for the end user, such as what is measured, where it is measured and when, is missing. Documentation has been made from the perspective of the measurer when it should have been done from the perspective of the end user. Many end users have never even visited the station, or they use the data for completely different purposes from the original intention. In addition, it would have been beneficial to make some kind of general yearly document to describe what is generally done at the stations and how the environment has changed through time.”
SMEAR data has been opened in many places (e.g., ICOS, ETSIN, PAS). What challenges has this brought for metadata, and are there any differences between the repositories? Is there a need for common metadata standards at the European Union or other levels?
”Reinventing the wheel is one of the biggest downsides of opening the data. All projects and infrastructures want to develop their own file formats, metadata standards and input systems. There is no interest in what other projects or infrastructures have done or if the data the project uses has already been collected by some other project or infrastructure. This leads to a situation where the same data and metadata is sent to different places in different formats. In this sense, it would be more beneficial if funders paid more attention not to enabling overlapping data collection, but rather to supporting efforts to find metadata and data in other databases and repositories.”
Reinventing the wheel is one of the biggest downsides of opening the data. All projects and infrastructures want to develop their own file formats, metadata standards and input systems.

SMEAR data has been broadly used in different research. Can you follow who uses the data and how? Do different repositories create statistics about the data usage, e.g., data citation and the amount of downloads?
”From the AVAA service we can follow how much data has been downloaded from the SMEAR database, but not how much it has been used, for example, in scientific publications. Data usage can be followed by harvesting persistent identifiers given to the data, for example at Etsin, from journal articles. With the same principle, downloads can be followed from other international databases and Zenodo. So far, we have estimated the amount of data usage roughly from download amounts and collaborative publications. More intelligent harvesting of the data has not been applied since the proper tools for this are lacking.”
Do you know how much SMEAR data has been used outside of your research group, and if so, has it generated unexpected collaborations?
”We don’t have exact information from outside users, but probably thousands of users over time. Open data has created a lot of larger and smaller collaboration, mainly joint data analysis publications. However, there have been cases where the new data users have wanted to visit SMEAR stations and take measurements with their own equipment, or they have invited our researchers to their stations. Some collaboration proposals have come outside of the usual research community, for example, researchers using remote sensing data have used our long-term data or wanted to make their own measurements at a certain location. Perhaps these cases can be called unexpected. We also promote our stations and data actively at conferences and different types of meetings.”
Open data has created a lot of larger and smaller collaboration, mainly joint data analysis publications.
Has there been any challenges regarding opening research data?

”As mentioned earlier, the poor documentation of the old data has been the biggest challenge, but it is doable as long as one has the energy to get the information from the SMEAR veterans. The biggest problem is researchers who refuse to understand the benefits of opening research data – that we not only produce data for ourselves, but for the whole scientific community.”
”We do not really have any way to force someone to open their data. Some are afraid that opening the data means that you give up your rights to the data and that the original authorship of the data is somehow lost. This is really not a problem when you explain that the name of the original data producer follows the data to the end of the world, while other data users cite the original dataset correctly.”
Some are afraid that opening the data means that you give up your rights to the data and that the original authorship of the data is somehow lost.
If you could start the SMEAR project from the top, what you would do differently, and what would get your specific attention?
”You should act like every measurement you start is going to continue forever, but the people in charge of the measurements and data flow would move on to different tasks the next week. All documentation should be done for others, not for yourself.”
Article series on Open Science infrastructures: