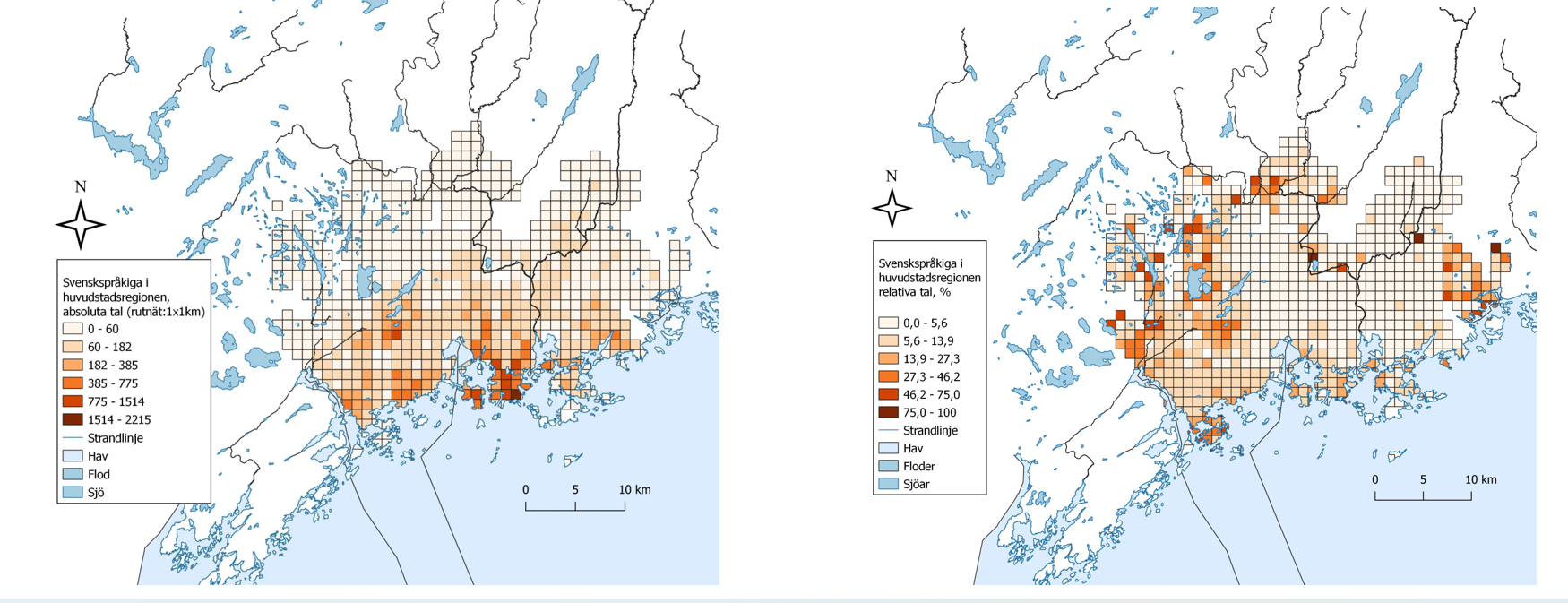
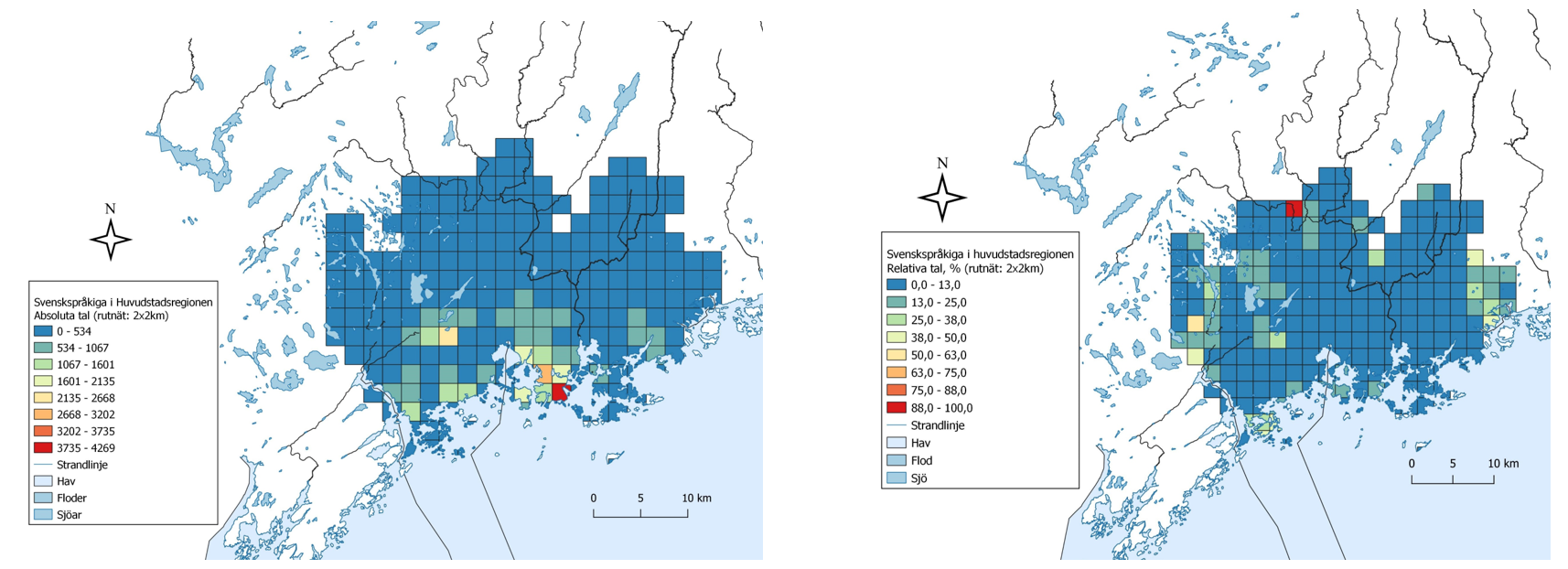
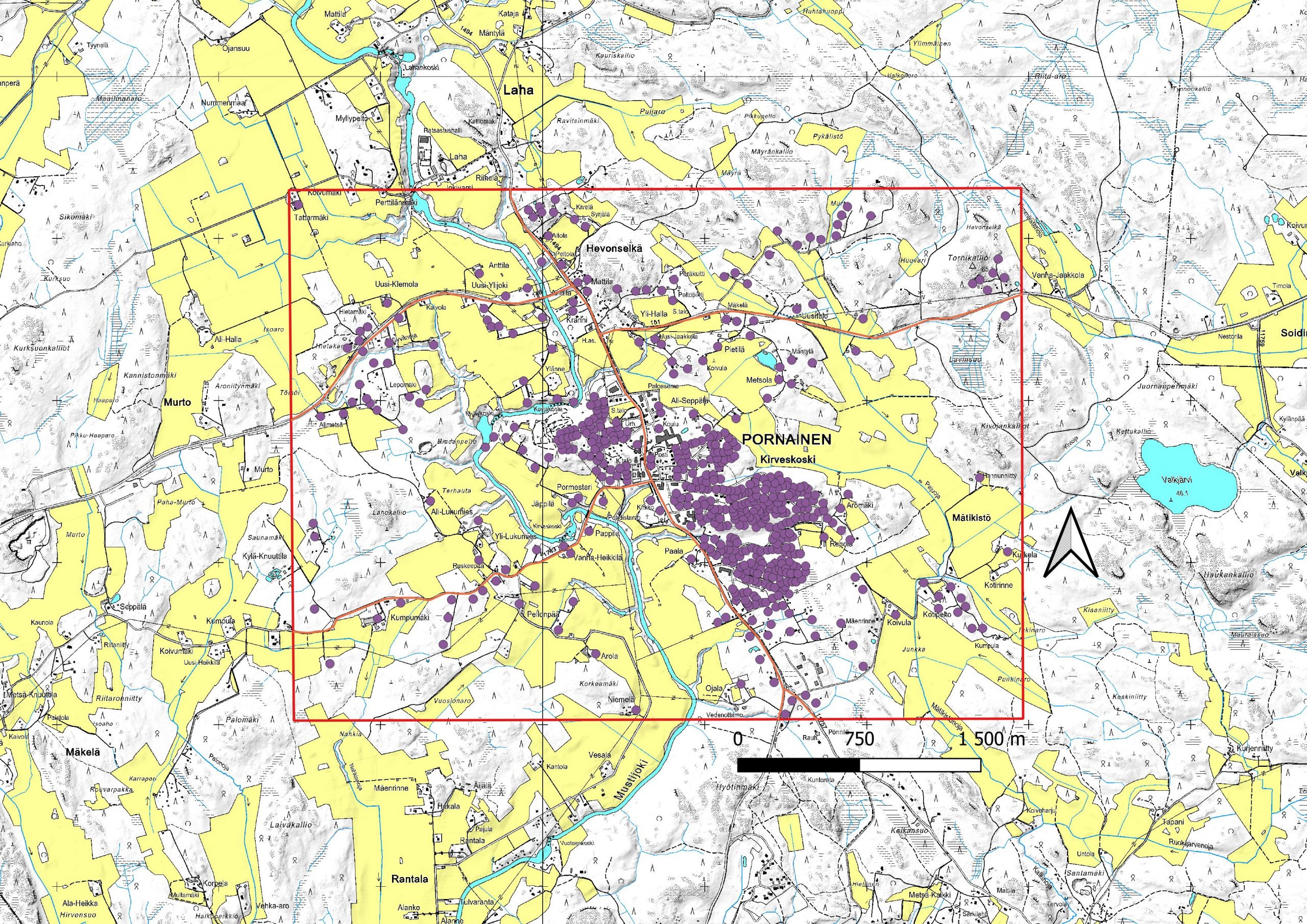
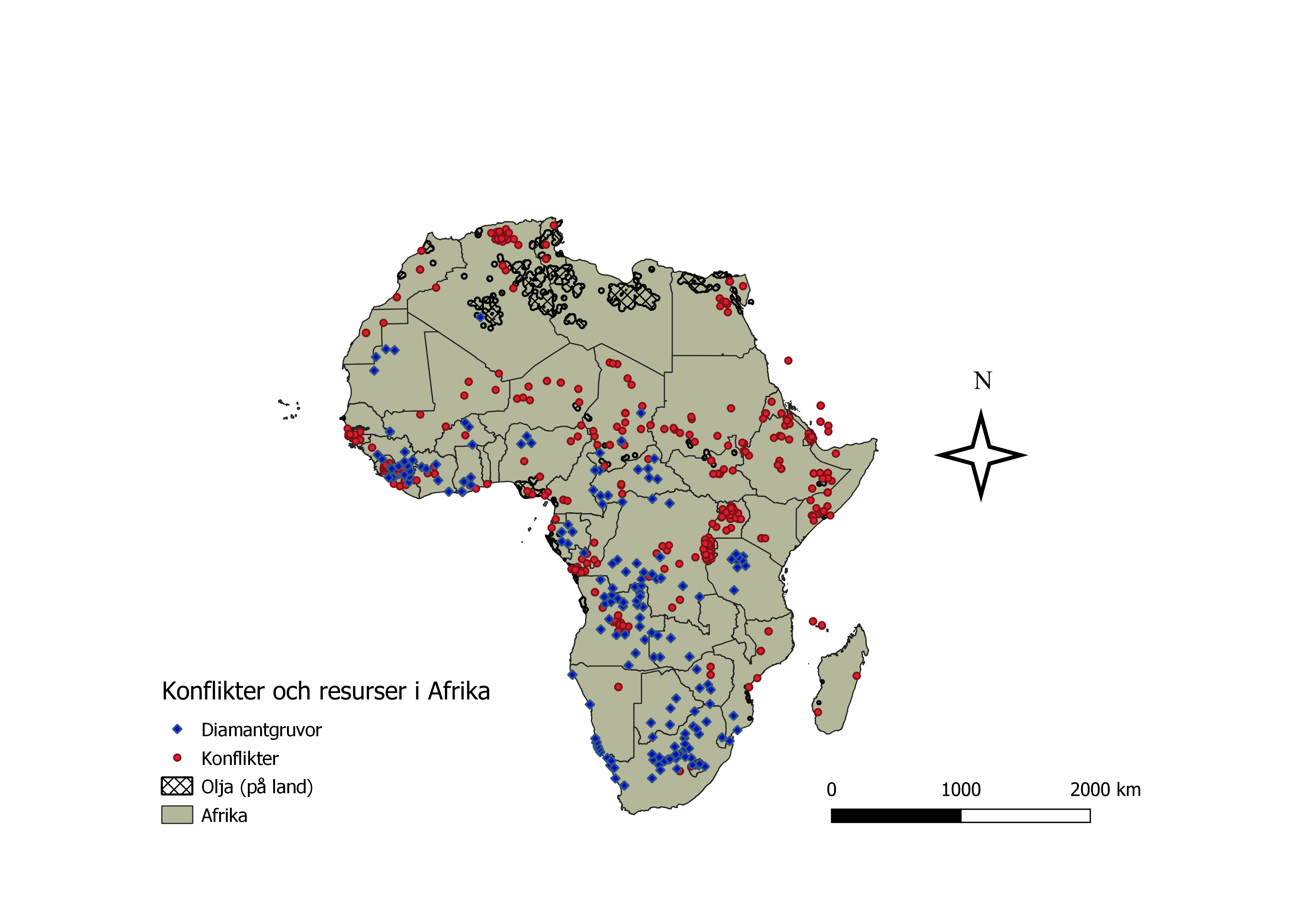
På den femte föreläsningen bekantade jag mig med buffer-verktyget och fick själv klura ut några övningar.
Lite reflektioner om QGIS
Vilka är de centralaste verktygen i QGIS som du anser som hjälpsamma eller du har bra kontroll över? För vilka syften passar de bra för?
Olika select verktyg
Ett ganska enkelt sätt att få tag på olika saker, t.ex. select area/single feature eller med ett visst värde. Detta verktyg kan vara nödvändigt då tabeller innehåller mycket information som man inte behöver för tillfället. I sin helhet är select en ganska bra funktio med enkla villkor, t.ex. vad är input- och output layer, vilka fält ska användas osv…
Olika join-verktyg
Dessa var lite komplicerade i början, men nödvändiga eftersom man ofta vill jämföra information i ett lager i förhållande till ett annat. Med join attributes (sum)- verktyget kan det vara bra att vara nogrann, och välja vad exakt man vill summarisera.
Grid & Buffer
det var också ganska lätt att förstå grunderna till dessa. Liknande villkor som join- och select verktygen
I samband med femte föreläsningens bullerövning var det dock lite svårt att skapa olika db-nivåer i bufferlagret (Gav upp med övningen). Senare fick jag ändå reda på att ett objekt kan ha flera bufferzoner.
Vad är svårare?
Det svåraste i QGIS enligt mig är att välja vilka verktyg som lämpar sig bäst. Fastän jag använt olika verktyg förut, så kom jag inte ihåg dem så bra när jag gjorde dessa övningar. Antagligen är det bäst med nogranna instruktioner då programmet är nytt för en, medan självständig problemlösning minskar risken för att ens inlärande blir för passivt.
Till vilka syften kan bufferzoner användas?
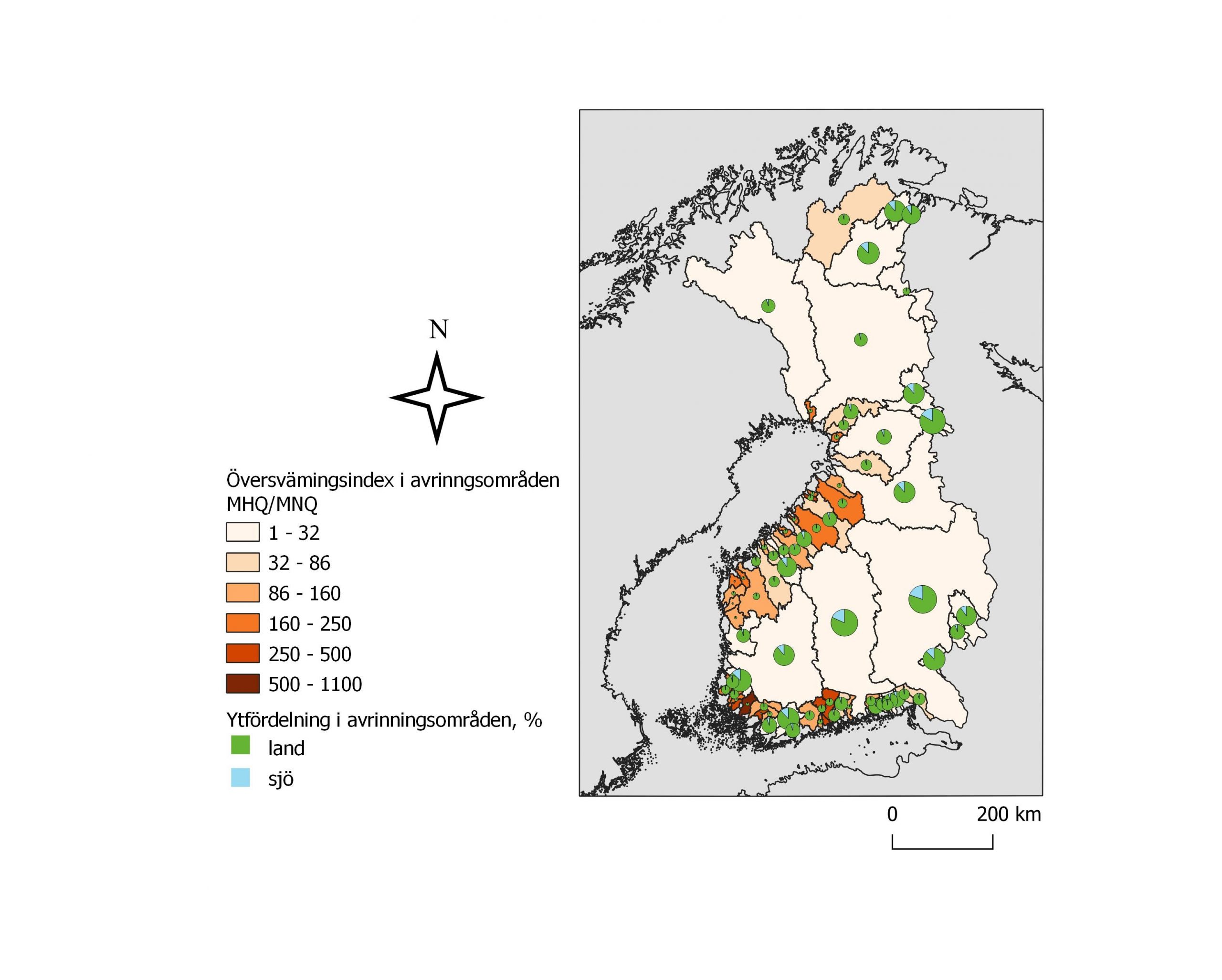
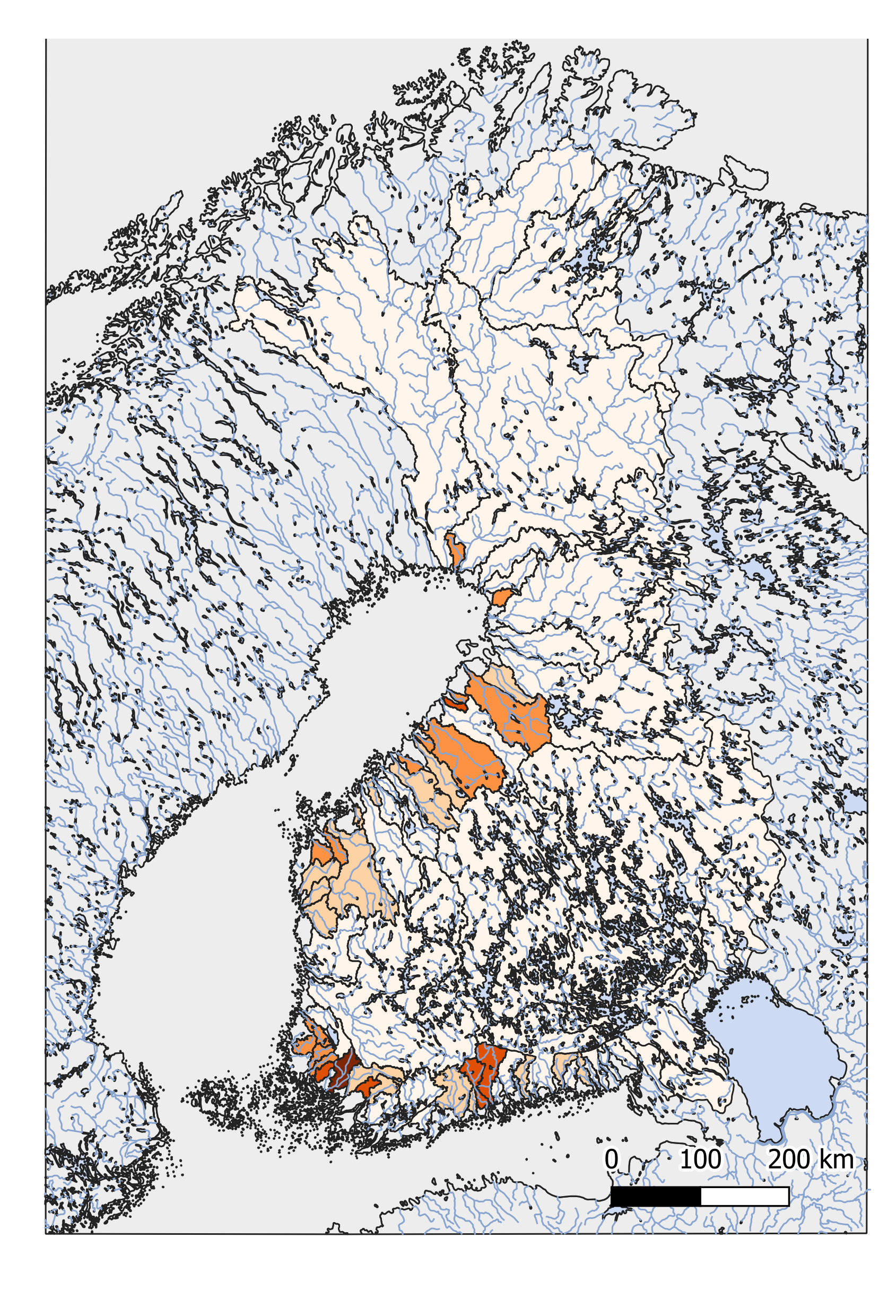
I övningarna användes bufferverktyget för att beräkna bl.a. befolkning och byggnader inom ett visst område. Buffer-verktyget kunde även anpassas till kursens tidigare övningar, t.ex. hur många bor nära vattendrag som löper risk för översvämming, genom att buffra vattendraget.
Vilka faktorer påverkar hurdana problem som kan lösas med hjälp av QGIS? Hurdana gränser lägger t.ex. programmet, använda materialen eller användaren till analysen?
QGIS gränser: Jag har lagt märke till att programmet kan sluta fungera om man i misstag skriver en ogiltig räknefunktion.
Använda Materialen: Kan innehålla fel som ger fel resultat, kan göra kartframställingar felaktiga.
Användaren: man gör lätt små fel, t.ex. fel id i attributfälten.
Hur framskred uppgifterna?
Fastän jag fick utmana mina kunskaper i de självständiga övningarna, så skedde det också att jag jag gjorde dem mer komplicerade än vad de egentligen var. Det svåraste var att skapa bullersträckan i flygfältsövningen, eftersom man i princip måste göra något helt nytt. Jag tror att experimentella övningar där man själv måste skapa nästan allt ändå är de mest lärorika.
Medan jag gjorde övningarna tänkte jag inte riktigt på saken, men Armida tog upp i sitt inlägg att statistics-panel gjorde det lätt att få fram statistik och jämförelser. Jag tror att denna funktion kommer att vara till användning i framtiden.
Referenser
Wanström, A. (2024) Bufferointi ja reflektio viikko 5. Gissful thinking. University of Helsinki blogging platform. 15.02.2024. https://blogs.helsinki.fi/armida/2024/02/15/bufferointi-ja-reflektointi-viikko-5/ [20.02.2024]