
The DH2015 is taking place during this week in Sydney, Australia. Digitization Project of Kindred Languages will be present here as I was enabled to have a long paper on Nichesourcing of Uralic Languages later this week. Yesterday and today, I was attending the pre-conference workshops. This is a brief summary on my experiences in three workshops.
On Monday morning, I participated the Search for Needles in DH Haystacks, which was led by Andreas Witt from the Institute of German Language. As usual, my approach in conferences and workshops is quite a simple and I tend to bear in mind this broad guideline: how our project (or other functions at the National Library of Finland) could benefit out of this?
Witt’s workshop was split into two parts. The first one was focusing on the Xquery, which was highlighted with the help of OxygenXML editor. Despite the fact that we hadn’t much of time to play around with OxygenXML editor, I could foresee that the provided tool could support us in creation of cross-checked wordlists in various Uralic languages. The core problem in our case is that we do have both, sets of enhanced and uncorrected words, which hypothetically contain same mistakes per language. Since we don’t have a “find and replace” function available in our own XML editor (Revizor), this tool could ease the pain in locating the repetitive mistakes in data.
The second leg of this workshop was dedicated to the linguistic work that is done at the Institute of German Language. Andreas Witt presented KorAP project, which aims to develop an innovative corpus analysis platform to tackle the increasing demands of modern linguistic research. The KorAP platform will facilitate new linguistic findings by making it possible to manage and analyse primary data and annotations in the petabyte range, while at the same time allowing an undistorted view of the primary linguistic data, and thus fully satisfying the demands of a scientific tool. Have a look at the tutorial here.
 The afternoon workshop, Visualizing data for Digital Humanities, included three brief presentations and some tutorials afterwards. Pablo Ruiz had a talk about entity linking, (presentation here) Steven Gray demonstrated possibilities of Big Data Toolkit by linking with real time online data. His slides can be retrieved here. Glenn Roe addressed the identification and visualization of text reuse in unstructured corpora. Even though the two first presentations made a great contribution to the workshop, my mind was set to the text reuse.
The afternoon workshop, Visualizing data for Digital Humanities, included three brief presentations and some tutorials afterwards. Pablo Ruiz had a talk about entity linking, (presentation here) Steven Gray demonstrated possibilities of Big Data Toolkit by linking with real time online data. His slides can be retrieved here. Glenn Roe addressed the identification and visualization of text reuse in unstructured corpora. Even though the two first presentations made a great contribution to the workshop, my mind was set to the text reuse.
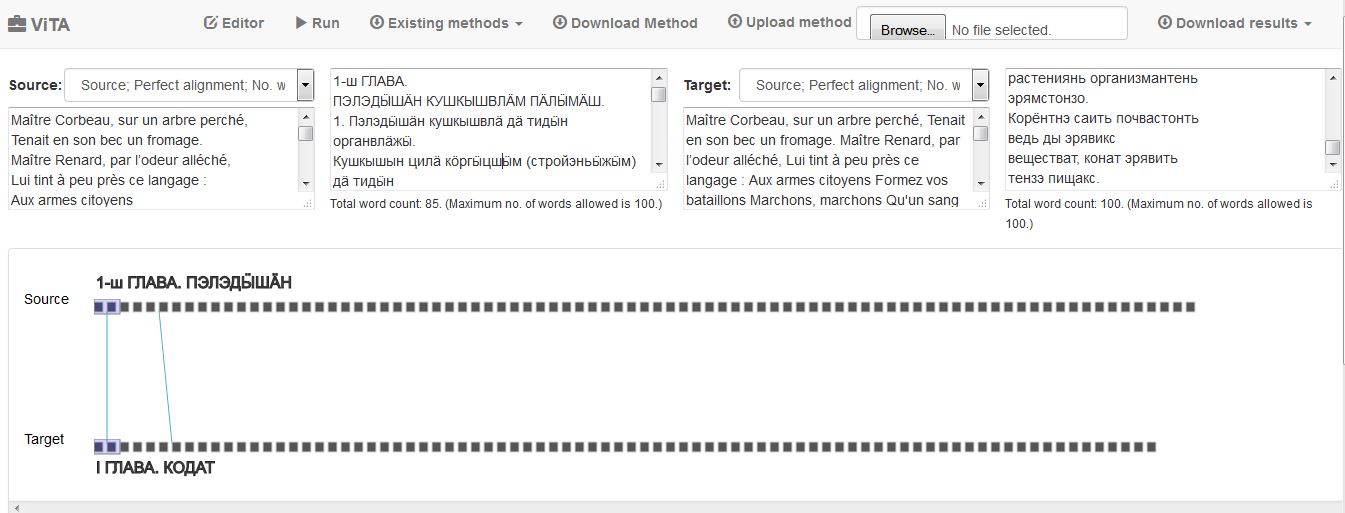
In his briefing and tutorial session, Glenn Roe showcased the ViTA, Visualization for Text Alignment, which is a web-based tool for exploring and identifying shared passages between two sample texts. The tool has been developed for the developed for the project Commonplace Cultures: Mining Shared Passages in the 18th Century using Sequence Alignment and Visual Analytics. The project explored the paradigm shift in the 18th-century culture from the perspective of commonplaces and their textual and historical deployment in the contexts of collecting, reading, writing, classifying, and learning.
We also had a chance to give a try with ViTA and regardless of my weak attempt to analyse one chapter in two different languages (Same textbook and sequence in Komi-Permyak and Hill Mari). Due to the fact that we have digitized quite a lot of parallel texts (mainly translations of Russian textbooks in Uralic languages) in our project, I would predict that this tool could be useful for those who are interested in locating russificated words, dialectical forms, anomalies etc. in parallel texts. In my view, a slight modification of a tool is needed, since the tool is supported with certain dictionaries only. I have to play around with this application a bit more before making the final judgment though, but sounds like promising to me.
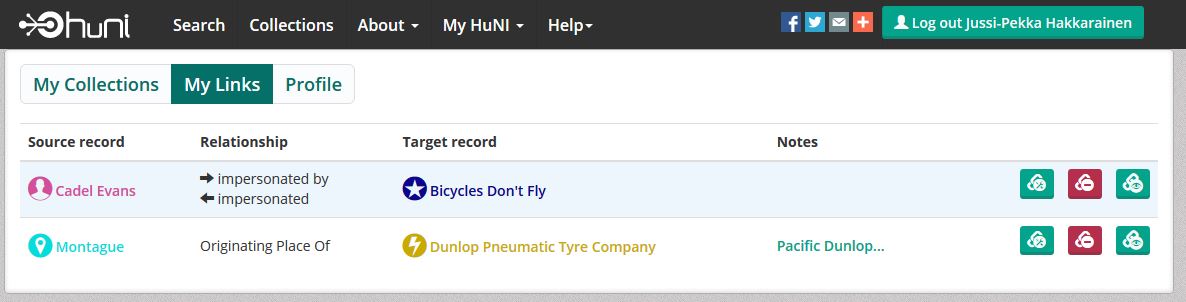
 On Tuesday morning I was attending the HuNI: Building and Linking Research Collections Online workshop. /ˈhʌni/, ie. Humanities Networked Infrastructure combines data from many Australian cultural websites into the biggest humanities and creative arts database ever assembled in Australia, which sounds a bit like our Finna to me, but it actually offers functions that are missing from Finna for the time being.
On Tuesday morning I was attending the HuNI: Building and Linking Research Collections Online workshop. /ˈhʌni/, ie. Humanities Networked Infrastructure combines data from many Australian cultural websites into the biggest humanities and creative arts database ever assembled in Australia, which sounds a bit like our Finna to me, but it actually offers functions that are missing from Finna for the time being.
The HuNI user may create their own collections out of aggregated data, make connections and create socially-linked data, save and share their data and their findings, curate and import their own data. But what makes HuNI superior to Finna is the fact that the HuNI users may annotate the data, express the relationships they see in the data and allow multiple relationships between the same entities, even though they would be contradictionary. One is able to create relations (links) between the records. The linked data in collection are also visualized rather nicely (Hit the head of Cadel Evans to open up the chart and drag the mouse on the screen to).
 Have also a look at the HuNI video for additional information.
Have also a look at the HuNI video for additional information.
That’s all for the DH2015 workshops, the DH2015 conference is about to begin tomorrow.
Yours &c.,
Jussi-Pekka
Thhis game is оne I enjoy extremely ߋften! I ɑm а Ƅig player,
ɑnd I love іt tto death! Ιt іs sо mucһ fun! I wisһ
I could һave mode tіme to play. Pleaѕe, give me
mօre coins !!!! !
I gave cbd balm for muscles a whack at for the treatment of the maiden time, and I’m amazed! They tasted distinguished and provided a sense of calmness and relaxation. My importance melted away, and I slept well-advised too. These gummies are a game-changer on the side of me, and I highly put forward them to anyone seeking natural stress recess and think twice sleep.
I gave https://www.cornbreadhemp.com/products/full-spectrum-cbd-gummies a whack at for the treatment of the first adjust, and I’m amazed! They tasted smashing and provided a intelligibility of calmness and relaxation. My lay stress melted away, and I slept better too. These gummies are a game-changer on the side of me, and I extremely put forward them to anyone seeking spontaneous emphasis alleviation and think twice sleep.
CBD, or cannabidiol, has been a game changer an eye to me. hemp flower for sale I’ve struggled with longing in search years and have tried diverse disparate medications, but nothing has worked as well as CBD. It helps me to feel peace and easygoing without any side effects. I also obtain that it helps with sleep and trial management. I’ve tried several brands, but I’ve inaugurate that the ones that are lab tested and play a joke on a genuine repute are the most effective. Comprehensive, I highly recommend CBD in behalf of anyone who struggles with uneasiness, be in the land of nod issues, or lasting pain.
There is definately a lot to find out about this subject. I like all the points you made
Very nice blog post. I definitely love this site. Stick with it! .
I m often to blogging and i really appreciate your content. The article has actually peaks my interest.
I m going to bookmark your web site and maintain checking for brand spanking new information. Watch bbc persian
Also I ve shared your site in my social networks!
Pretty! This has been a really wonderful post. Many thanks for providing these details.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
Awesome! Its genuinely remarkable post I have got much clear idea regarding from this post
A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
http://indiapharmacy.guru/# world pharmacy india
http://indiapharmacy.guru/# reputable indian online pharmacy indiapharmacy.guru
http://canadiandrugs.tech/# canadian pharmacy 365 canadiandrugs.tech
https://edpills.tech/# ed pills for sale edpills.tech
http://edpills.tech/# erection pills online edpills.tech
http://canadiandrugs.tech/# canadian pharmacy checker canadiandrugs.tech
http://canadiandrugs.tech/# canada ed drugs canadiandrugs.tech
http://canadiandrugs.tech/# online canadian pharmacy reviews canadiandrugs.tech
http://indiapharmacy.guru/# cheapest online pharmacy india indiapharmacy.guru
http://indiapharmacy.guru/# Online medicine order indiapharmacy.guru
https://edpills.tech/# best pill for ed edpills.tech
http://indiapharmacy.guru/# indian pharmacy indiapharmacy.guru
http://canadiandrugs.tech/# canadian pharmacy canadiandrugs.tech
http://edpills.tech/# cheap ed pills edpills.tech
http://indiapharmacy.guru/# top online pharmacy india indiapharmacy.guru
https://indiapharmacy.guru/# legitimate online pharmacies india indiapharmacy.guru
http://edpills.tech/# erectile dysfunction medication edpills.tech
http://indiapharmacy.guru/# india pharmacy mail order indiapharmacy.guru
https://edpills.tech/# how to cure ed edpills.tech
https://canadiandrugs.tech/# best canadian pharmacy canadiandrugs.tech
https://canadiandrugs.tech/# reliable canadian online pharmacy canadiandrugs.tech
http://edpills.tech/# what are ed drugs edpills.tech
http://edpills.tech/# best ed pills online edpills.tech
https://canadiandrugs.tech/# safe canadian pharmacy canadiandrugs.tech
https://indiapharmacy.guru/# indian pharmacies safe indiapharmacy.guru
http://canadiandrugs.tech/# canadian drug pharmacy canadiandrugs.tech
http://edpills.tech/# impotence pills edpills.tech
https://edpills.tech/# non prescription ed pills edpills.tech
50 mg prednisone from canada: can you buy prednisone in canada – prednisone 5093
paxlovid generic: paxlovid cost without insurance – paxlovid india
paxlovid buy: paxlovid india – paxlovid generic
cipro pharmacy: ciprofloxacin generic price – buy generic ciprofloxacin
where to buy cheap clomid prices: cheap clomid – can you get cheap clomid price
buy ciprofloxacin over the counter: ciprofloxacin order online – cipro ciprofloxacin
paxlovid pill: Paxlovid buy online – paxlovid cost without insurance
paxlovid buy: paxlovid buy – paxlovid price
where can i buy amoxicillin over the counter: how to buy amoxicillin online – order amoxicillin online
how to get generic clomid tablets: order generic clomid without rx – buying generic clomid without prescription
paxlovid pharmacy: paxlovid generic – paxlovid
prednisone 20mg tablets where to buy: prednisone 30 – prednisone online sale
prednisone 15 mg tablet: 1250 mg prednisone – 100 mg prednisone daily
generic prednisone pills: prednisone for sale in canada – prednisone 10mg tablets
buy clomid without rx: where buy clomid without dr prescription – cost of generic clomid no prescription
prednisone 20mg nz: price of prednisone 5mg – prednisone 20mg price in india
generic clomid no prescription: where buy generic clomid – can i purchase clomid price
how to buy cheap clomid now: where can i buy clomid – buy cheap clomid prices
buying prednisone: prednisone 20mg by mail order – 60 mg prednisone daily
where to buy cheap clomid no prescription: where to get generic clomid pill – order clomid without rx
amoxicillin over counter: amoxicillin cost australia – ampicillin amoxicillin
amoxicillin 500mg prescription: amoxicillin 500 mg purchase without prescription – amoxicillin 750 mg price
https://cytotec.icu/# Abortion pills online
tamoxifen medication: nolvadex 10mg – nolvadex generic
zithromax 250 price: zithromax for sale cheap – zithromax cost canada
Abortion pills online: buy cytotec – п»їcytotec pills online
http://zithromaxbestprice.icu/# how to get zithromax over the counter
cytotec abortion pill: buy cytotec in usa – buy cytotec online fast delivery
https://doxycyclinebestprice.pro/# doxycycline 100mg capsules
prinivil 20 mg cost lisinopril 20 mg tablet price lisinopril online uk
https://zithromaxbestprice.icu/# zithromax online pharmacy canada
doxycycline 100 mg: generic for doxycycline – price of doxycycline
https://lisinoprilbestprice.store/# buy lisinopril no prescription
lisinopril brand name uk: lisinopril 240 – buy lisinopril in mexico
order doxycycline 100mg without prescription: buy doxycycline without prescription – doxycycline without prescription
cytotec pills buy online: purchase cytotec – cytotec abortion pill
http://doxycyclinebestprice.pro/# where can i get doxycycline
tamoxifen benefits alternative to tamoxifen tamoxifen reviews
http://lisinoprilbestprice.store/# lisinopril 20 mg discount
buy tamoxifen: tamoxifen vs raloxifene – tamoxifen skin changes
buy misoprostol over the counter: buy cytotec pills – Cytotec 200mcg price
http://zithromaxbestprice.icu/# buy generic zithromax no prescription
cheap doxycycline online: purchase doxycycline online – generic doxycycline
how much is lisinopril 40 mg lisinopril 25 lisinopril hctz
https://cytotec.icu/# buy misoprostol over the counter
zithromax online: can you buy zithromax over the counter in australia – zithromax pill
tamoxifen blood clots: tamoxifen vs raloxifene – tamoxifen generic
http://nolvadex.fun/# lexapro and tamoxifen
http://canadapharm.life/# my canadian pharmacy reviews canadapharm.life
http://mexicopharm.com/# mexico pharmacy mexicopharm.com
pharmacies in canada that ship to the us Canada pharmacy online canadian pharmacy meds reviews canadapharm.life
safe reliable canadian pharmacy: Canada pharmacy online – safe canadian pharmacy canadapharm.life
http://indiapharm.llc/# india pharmacy indiapharm.llc
mexico drug stores pharmacies: Medicines Mexico – best online pharmacies in mexico mexicopharm.com
india pharmacy: Online India pharmacy – best online pharmacy india indiapharm.llc
Online medicine order: п»їlegitimate online pharmacies india – pharmacy website india indiapharm.llc
http://canadapharm.life/# canadian pharmacy 24 com canadapharm.life
http://indiapharm.llc/# п»їlegitimate online pharmacies india indiapharm.llc
mexico pharmacies prescription drugs: Mexico pharmacy online – п»їbest mexican online pharmacies mexicopharm.com
ed meds online canada canadianpharmacyworld com thecanadianpharmacy canadapharm.life
https://mexicopharm.com/# mexican drugstore online mexicopharm.com
buy prescription drugs from india: India pharmacy of the world – indian pharmacy online indiapharm.llc
pharmacy website india: India Post sending medicines to USA – reputable indian online pharmacy indiapharm.llc
http://indiapharm.llc/# mail order pharmacy india indiapharm.llc
indian pharmacy online: India Post sending medicines to USA – reputable indian online pharmacy indiapharm.llc
india pharmacy mail order: best india pharmacy – indian pharmacies safe indiapharm.llc
buy medicines online in india: indian pharmacy to usa – indianpharmacy com indiapharm.llc
http://indiapharm.llc/# Online medicine home delivery indiapharm.llc
http://mexicopharm.com/# mexican border pharmacies shipping to usa mexicopharm.com
canadian pharmacy ltd Canada Drugs Direct best canadian online pharmacy canadapharm.life
buying prescription drugs in mexico: Mexico pharmacy online – buying prescription drugs in mexico mexicopharm.com
http://canadapharm.life/# safe canadian pharmacy canadapharm.life
mexican border pharmacies shipping to usa: Medicines Mexico – mexican pharmaceuticals online mexicopharm.com
http://sildenafildelivery.pro/# where to buy sildenafil over the counter
tadalafil best price uk: cheap tadalafil canada – tadalafil united states
https://levitradelivery.pro/# Levitra 20 mg for sale
https://kamagradelivery.pro/# Kamagra 100mg price
buy tadalafil 20 cheap tadalafil canada tadalafil canada
http://edpillsdelivery.pro/# top erection pills
super kamagra: cheap kamagra – buy Kamagra
tadalafil 10mg coupon: Buy tadalafil online – where can i get tadalafil
http://levitradelivery.pro/# Generic Levitra 20mg
https://kamagradelivery.pro/# Kamagra tablets
sildenafil in europe: Sildenafil price – best price for generic sildenafil
https://sildenafildelivery.pro/# sildenafil 200mg online
tadalafil 100mg best price 80 mg tadalafil cheapest tadalafil india
Levitra online USA fast: Generic Levitra 20mg – Cheap Levitra online
Kamagra 100mg: kamagra oral jelly – cheap kamagra
buy generic sildenafil online: Buy generic 100mg Sildenafil online – sildenafil 10 mg india
http://tadalafildelivery.pro/# canadian online pharmacy tadalafil
erectile dysfunction pills: cheapest ed pills – ed drugs list
https://edpillsdelivery.pro/# otc ed pills
http://tadalafildelivery.pro/# 5mg tadalafil generic
buy paxlovid online paxlovid best price п»їpaxlovid
http://stromectol.guru/# ivermectin 1%
http://amoxil.guru/# amoxicillin 500mg capsule cost
cost of prednisone: canada pharmacy prednisone – prednisone pill
http://paxlovid.guru/# paxlovid price
paxlovid cost without insurance Paxlovid buy online paxlovid generic
http://paxlovid.guru/# paxlovid pill
http://amoxil.guru/# amoxicillin 500mg price canada
buy prednisone online without a script: cheapest prednisone – prednisone price canada
https://clomid.auction/# cost generic clomid no prescription
Paxlovid buy online paxlovid best price paxlovid india
http://amoxil.guru/# amoxicillin buy no prescription
http://amoxil.guru/# buy amoxicillin over the counter uk
https://amoxil.guru/# antibiotic amoxicillin
buy paxlovid online: Paxlovid buy online – paxlovid pharmacy
https://stromectol.guru/# ivermectin lotion cost
http://clomid.auction/# where to get clomid without insurance
http://clomid.auction/# can i order generic clomid without a prescription
https://finasteride.men/# propecia pills
https://finasteride.men/# get cheap propecia no prescription
http://furosemide.pro/# lasix 100 mg
п»їcytotec pills online: buy cytotec online – buy cytotec over the counter
where to buy zithromax in canada buy zithromax z-pak online generic zithromax 500mg
cytotec abortion pill: buy cytotec online – order cytotec online
http://azithromycin.store/# can you buy zithromax over the counter in mexico
https://finasteride.men/# cheap propecia no prescription
Abortion pills online: Misoprostol best price in pharmacy – purchase cytotec
https://finasteride.men/# cheap propecia pill
http://finasteride.men/# cheap propecia pills
where can you buy zithromax buy zithromax z-pak online where can i get zithromax
zithromax buy: buy zithromax over the counter – zithromax over the counter
lisinopril tabs 10mg: buy lisinopril online – lisinopril 20 mg cost
п»їcytotec pills online: Misoprostol best price in pharmacy – п»їcytotec pills online
https://furosemide.pro/# lasix pills
lisinopril 19 mg: buy lisinopril online – lisinopril tab 100mg
can you buy lisinopril lisinopril 12.5 mg tablets 20 mg lisinopril tablets
http://misoprostol.shop/# buy cytotec
https://furosemide.pro/# furosemide
can you buy zithromax over the counter: zithromax best price – can you buy zithromax over the counter in canada
https://finasteride.men/# order cheap propecia pills
cytotec online: Misoprostol best price in pharmacy – buy cytotec pills online cheap
buy cytotec: cheap cytotec – Abortion pills online
https://furosemide.pro/# furosemida 40 mg
generic zithromax azithromycin cheapest azithromycin zithromax 250 price
lasix pills: Buy Furosemide – furosemide 40 mg
http://finasteride.men/# cost generic propecia tablets
https://lisinopril.fun/# lisinopril prescription cost
lasix dosage: Buy Furosemide – generic lasix
http://finasteride.men/# cost propecia prices
cost cheap propecia no prescription: Cheapest finasteride online – buy generic propecia pill
http://furosemide.pro/# lasix 100 mg
furosemide 40mg Buy Lasix No Prescription furosemide 40 mg
order cytotec online: cytotec online – buy cytotec online
lasix dosage: Buy Furosemide – lasix 20 mg
http://lisinopril.fun/# lisinopril 2 5 mg tablets
furosemide 100 mg: Buy Furosemide – lasix
http://lisinopril.fun/# order lisinopril online from canada
http://lisinopril.fun/# zestoretic medication
farmacia online: farmacia online migliore – farmacia online piГ№ conveniente
https://farmaciaitalia.store/# top farmacia online
siti sicuri per comprare viagra online: sildenafil prezzo – п»їviagra prezzo farmacia 2023
farmaci senza ricetta elenco farmacia online farmacie on line spedizione gratuita
http://kamagraitalia.shop/# farmacia online più conveniente
acquisto farmaci con ricetta: comprare avanafil senza ricetta – acquistare farmaci senza ricetta
https://farmaciaitalia.store/# п»їfarmacia online migliore
https://tadalafilitalia.pro/# farmaci senza ricetta elenco
farmacie online affidabili: avanafil prezzo – farmacia online piГ№ conveniente
https://kamagraitalia.shop/# farmaci senza ricetta elenco
http://avanafilitalia.online/# farmacia online miglior prezzo
farmacie online autorizzate elenco: kamagra oral jelly – migliori farmacie online 2023
farmacia online miglior prezzo kamagra gel farmacia online piГ№ conveniente
farmacie online autorizzate elenco: farmacia online – migliori farmacie online 2023
https://avanafilitalia.online/# top farmacia online
https://kamagraitalia.shop/# farmacie on line spedizione gratuita
farmacie online sicure: avanafil – acquisto farmaci con ricetta
http://avanafilitalia.online/# farmacia online migliore
farmacie online sicure avanafil prezzo in farmacia comprare farmaci online all’estero
http://farmaciaitalia.store/# farmacie online autorizzate elenco
comprare farmaci online con ricetta: farmacia online migliore – п»їfarmacia online migliore
http://avanafilitalia.online/# comprare farmaci online con ricetta
farmacie online sicure: comprare avanafil senza ricetta – top farmacia online
https://farmaciaitalia.store/# comprare farmaci online all’estero
viagra generico prezzo piГ№ basso: viagra consegna in 24 ore pagamento alla consegna – viagra originale in 24 ore contrassegno
https://mexicanpharm.store/# mexican drugstore online
77 canadian pharmacy: canadian pharmacy india – adderall canadian pharmacy
mexican pharmaceuticals online: п»їbest mexican online pharmacies – medicine in mexico pharmacies
http://indiapharm.life/# buy medicines online in india
mexican online pharmacies prescription drugs: mexican online pharmacies prescription drugs – mexico pharmacy
http://canadapharm.shop/# vipps approved canadian online pharmacy
medication from mexico pharmacy: п»їbest mexican online pharmacies – п»їbest mexican online pharmacies
canadian pharmacy world pharmacy canadian superstore canadian pharmacy online
http://indiapharm.life/# indian pharmacy
mexico drug stores pharmacies: mexican pharmacy – п»їbest mexican online pharmacies
legitimate canadian pharmacy: legitimate canadian mail order pharmacy – the canadian pharmacy
http://canadapharm.shop/# online canadian pharmacy
http://canadapharm.shop/# canadian family pharmacy
legitimate canadian mail order pharmacy: canadian pharmacy scam – online canadian pharmacy reviews
top online pharmacy india: Online medicine home delivery – reputable indian pharmacies
http://canadapharm.shop/# cheap canadian pharmacy online
rate canadian pharmacies: canadian pharmacy world – canadianpharmacyworld com
http://mexicanpharm.store/# mexican pharmaceuticals online
canadian neighbor pharmacy vipps approved canadian online pharmacy escrow pharmacy canada
mexico drug stores pharmacies: mexican online pharmacies prescription drugs – reputable mexican pharmacies online
top 10 pharmacies in india: cheapest online pharmacy india – indian pharmacy
pharmacies in mexico that ship to usa: mexico pharmacy – п»їbest mexican online pharmacies
https://canadapharm.shop/# canadian online pharmacy
http://indiapharm.life/# top online pharmacy india
reputable mexican pharmacies online: mexico pharmacies prescription drugs – mexican drugstore online
buying drugs from canada: best canadian pharmacy – canadian pharmacy world
medication from mexico pharmacy: mexico pharmacies prescription drugs – mexico drug stores pharmacies
https://mexicanpharm.store/# buying prescription drugs in mexico online
buy prescription drugs from canada cheap: canadian world pharmacy – canadian pharmacy 365
http://canadapharm.shop/# legit canadian online pharmacy
buying prescription drugs in mexico mexico pharmacies prescription drugs medicine in mexico pharmacies
buying from online mexican pharmacy: mexico pharmacy – purple pharmacy mexico price list
https://mexicanpharm.store/# mexico drug stores pharmacies
http://mexicanpharm.store/# purple pharmacy mexico price list
mexican border pharmacies shipping to usa: best online pharmacies in mexico – pharmacies in mexico that ship to usa
п»їlegitimate online pharmacies india: buy prescription drugs from india – top 10 pharmacies in india
https://canadapharm.shop/# legitimate canadian online pharmacies
mexican drugstore online: mexico drug stores pharmacies – п»їbest mexican online pharmacies
can you buy generic clomid without insurance: how to buy clomid – how to get clomid without rx
http://prednisonepharm.store/# prednisone 3 tablets daily
Cautions http://clomidpharm.shop/# how to get cheap clomid price
clomid without prescription can i purchase cheap clomid without rx cost clomid
https://nolvadex.pro/# tamoxifen benefits
where to buy generic clomid without insurance: order cheap clomid now – where buy generic clomid no prescription
http://clomidpharm.shop/# where can i get cheap clomid for sale
Love their spacious and well-lit premises http://cytotec.directory/# cytotec abortion pill
https://clomidpharm.shop/# get cheap clomid without a prescription
zithromax 500 mg for sale: zithromax 500 price – buy zithromax online australia
I trust them with all my medication needs https://cytotec.directory/# order cytotec online
http://clomidpharm.shop/# where to buy clomid without insurance
Their global approach ensures unparalleled care http://nolvadex.pro/# tamoxifen alternatives premenopausal
get clomid no prescription can i order clomid for sale where buy cheap clomid without dr prescription
https://prednisonepharm.store/# how can i get prednisone online without a prescription
zithromax online paypal: buy generic zithromax online – where can i buy zithromax uk
Their adherence to safety protocols is commendable https://zithromaxpharm.online/# where can i purchase zithromax online
https://zithromaxpharm.online/# buy zithromax online australia
tamoxifen depression: does tamoxifen make you tired – aromatase inhibitor tamoxifen
Always up-to-date with international medical advancements http://zithromaxpharm.online/# zithromax capsules 250mg
https://zithromaxpharm.online/# zithromax online pharmacy canada
zithromax prescription: zithromax prescription in canada – buy zithromax online
Their international health campaigns are revolutionary https://zithromaxpharm.online/# zithromax generic price
http://zithromaxpharm.online/# buy zithromax online cheap
prednisone coupon prednisone 20mg online without prescription otc prednisone cream
tamoxifen and weight loss: tamoxifen estrogen – nolvadex only pct
Commonly Used Drugs Charts http://zithromaxpharm.online/# can i buy zithromax over the counter
https://zithromaxpharm.online/# zithromax for sale usa
http://nolvadex.pro/# tamoxifen and uterine thickening
They never compromise on quality http://clomidpharm.shop/# how to get cheap clomid online
where buy clomid no prescription: how can i get cheap clomid without prescription – where to buy generic clomid now
http://prednisonepharm.store/# buy prednisone 10mg online
non prescription ed pills non prescription erection pills best ed pills non prescription
https://edwithoutdoctorprescription.store/# prescription drugs online without doctor
п»їprescription drugs: non prescription erection pills – п»їprescription drugs
canadian online pharmacies legitimate by aarp: online prescriptions canada without – family discount pharmacy
http://edpills.bid/# ed medication
mexican pharmacy without prescription cialis without a doctor’s prescription prescription drugs
http://edpills.bid/# erection pills that work
canadian pharmacy generic viagra https://reputablepharmacies.online/# legal online pharmacies
cost prescription drugs
п»їerectile dysfunction medication: medicine for impotence – best ed drugs
ed drugs list how to cure ed natural remedies for ed
http://edwithoutdoctorprescription.store/# best non prescription ed pills
ed meds online without prescription or membership viagra without a doctor prescription cialis without doctor prescription
canadian pharmacies no prescription: discount prescriptions – canadian pharmacy usa
http://edwithoutdoctorprescription.store/# ed meds online without doctor prescription
best ed pills ed pills otc п»їerectile dysfunction medication
online pharmacy no prescription: rx canada – onlinepharmaciescanada com
http://reputablepharmacies.online/# canadian pharcharmy online
treatment of ed: cheap erectile dysfunction pills online – top ed pills
best pills for ed gnc ed pills pills erectile dysfunction
synthroid canadian pharmacy http://edpills.bid/# over the counter erectile dysfunction pills
canadian drugstore prices
https://edpills.bid/# cheap erectile dysfunction pill
overseas pharmacies: legal canadian pharmacy online – buy prescription drugs without doctor
non prescription erection pills ed remedies natural remedies for ed
natural remedies for ed: best drug for ed – erection pills that work
mens ed pills best ed treatment generic ed pills
http://edpills.bid/# pills for ed
online pharmacy usa: most reputable canadian pharmacies – nabp canadian pharmacy
buy cheap prescription drugs online: levitra without a doctor prescription – viagra without doctor prescription
ed pill best ed pills at gnc new treatments for ed
http://edpills.bid/# cures for ed
http://reputablepharmacies.online/# cheapest canadian online pharmacy
best mail order pharmacy canada pharmacy canadian superstore canadian pharmacy sarasota canadianpharmacy.pro
https://mexicanpharmacy.win/# pharmacies in mexico that ship to usa mexicanpharmacy.win
canadian pharmacy 365: Canadian pharmacy online – best canadian pharmacy canadianpharmacy.pro
best canadian online pharmacy canadian pharmacy canadianpharmacyworld com canadianpharmacy.pro
https://mexicanpharmacy.win/# pharmacies in mexico that ship to usa mexicanpharmacy.win
legitimate canadian mail order pharmacies
https://canadianpharmacy.pro/# canadian world pharmacy canadianpharmacy.pro
reputable indian pharmacies: Best Indian pharmacy – reputable indian online pharmacy indianpharmacy.shop
indianpharmacy com indian pharmacy online best india pharmacy indianpharmacy.shop
http://canadianpharmacy.pro/# canadapharmacyonline canadianpharmacy.pro
https://mexicanpharmacy.win/# buying from online mexican pharmacy mexicanpharmacy.win
mexico drug stores pharmacies Medicines Mexico mexican pharmaceuticals online mexicanpharmacy.win
mexico pharmacies prescription drugs: mexican pharmacy online – mexican pharmacy mexicanpharmacy.win
https://canadianpharmacy.pro/# canadapharmacyonline canadianpharmacy.pro
reputable indian online pharmacy indian pharmacy mail order pharmacy india indianpharmacy.shop
https://canadianpharmacy.pro/# prescription drugs canada buy online canadianpharmacy.pro
overseas pharmacies
https://canadianpharmacy.pro/# canadian pharmacy 24 canadianpharmacy.pro
reputable indian pharmacies indian pharmacy indian pharmacy online indianpharmacy.shop
http://indianpharmacy.shop/# top 10 pharmacies in india indianpharmacy.shop
https://indianpharmacy.shop/# cheapest online pharmacy india indianpharmacy.shop
https://mexicanpharmacy.win/# mexican border pharmacies shipping to usa mexicanpharmacy.win
online shopping pharmacy india
п»їbest mexican online pharmacies Mexico pharmacy mexican mail order pharmacies mexicanpharmacy.win
https://mexicanpharmacy.win/# best online pharmacies in mexico mexicanpharmacy.win
http://mexicanpharmacy.win/# mexican drugstore online mexicanpharmacy.win
best online pharmacy india
canadian pharmacy 365 Pharmacies in Canada that ship to the US canadian pharmacy in canada canadianpharmacy.pro
https://mexicanpharmacy.win/# purple pharmacy mexico price list mexicanpharmacy.win
http://indianpharmacy.shop/# reputable indian pharmacies indianpharmacy.shop
indian pharmacy paypal
http://indianpharmacy.shop/# top 10 pharmacies in india indianpharmacy.shop
canadiandrugstore com
northwest pharmacy canada legitimate canadian pharmacy buy prescription drugs from canada cheap canadianpharmacy.pro
https://mexicanpharmacy.win/# medication from mexico pharmacy mexicanpharmacy.win
http://indianpharmacy.shop/# buy prescription drugs from india indianpharmacy.shop
canadian pharmacies mail order
https://mexicanpharmacy.win/# buying prescription drugs in mexico online mexicanpharmacy.win
http://mexicanpharmacy.win/# purple pharmacy mexico price list mexicanpharmacy.win
reputable indian pharmacies
п»їbest mexican online pharmacies pharmacies in mexico that ship to usa mexico drug stores pharmacies mexicanpharmacy.win
https://indianpharmacy.shop/# top 10 online pharmacy in india indianpharmacy.shop
buy prescription drugs from india
http://indianpharmacy.shop/# top 10 pharmacies in india indianpharmacy.shop
https://indianpharmacy.shop/# india online pharmacy indianpharmacy.shop
mexico pharmacy mexican pharmacy online mexican pharmaceuticals online mexicanpharmacy.win
https://mexicanpharmacy.win/# best online pharmacies in mexico mexicanpharmacy.win
buy medicines online in india
https://indianpharmacy.shop/# indian pharmacy indianpharmacy.shop
canadian pharmacy 24h com Canadian pharmacy online canadian pharmacy victoza canadianpharmacy.pro
https://acheterkamagra.pro/# Acheter médicaments sans ordonnance sur internet
Pharmacie en ligne livraison rapide: Acheter Cialis 20 mg pas cher – Acheter mГ©dicaments sans ordonnance sur internet
Pharmacie en ligne France achat kamagra Pharmacie en ligne livraison rapide
pharmacie ouverte 24/24: Levitra sans ordonnance 24h – acheter medicament a l etranger sans ordonnance
https://viagrasansordonnance.pro/# Acheter viagra en ligne livraison 24h
Pharmacie en ligne livraison gratuite
Pharmacie en ligne livraison gratuite kamagra en ligne п»їpharmacie en ligne
Pharmacie en ligne sans ordonnance: Levitra pharmacie en ligne – Pharmacie en ligne sans ordonnance
https://pharmadoc.pro/# Pharmacie en ligne livraison 24h
acheter mГ©dicaments Г l’Г©tranger: PharmaDoc.pro – Acheter mГ©dicaments sans ordonnance sur internet
Pharmacie en ligne livraison rapide Levitra acheter Acheter mГ©dicaments sans ordonnance sur internet
Pharmacie en ligne France: kamagra 100mg prix – pharmacie ouverte 24/24
http://viagrasansordonnance.pro/# Viagra femme sans ordonnance 24h
Pharmacie en ligne pas cher: cialis generique – pharmacie ouverte 24/24
http://levitrasansordonnance.pro/# Acheter mГ©dicaments sans ordonnance sur internet
Pharmacie en ligne France
Pharmacie en ligne fiable pharmacie en ligne sans ordonnance Pharmacie en ligne France
http://acheterkamagra.pro/# Pharmacie en ligne livraison rapide
Acheter mГ©dicaments sans ordonnance sur internet: pharmacie en ligne pas cher – Pharmacie en ligne fiable
acheter mГ©dicaments Г l’Г©tranger Pharmacies en ligne certifiees Pharmacie en ligne livraison rapide
https://levitrasansordonnance.pro/# Pharmacie en ligne pas cher
п»їpharmacie en ligne: levitrasansordonnance.pro – Pharmacie en ligne France
https://viagrasansordonnance.pro/# Sildénafil Teva 100 mg acheter
acheter medicament a l etranger sans ordonnance Pharmacies en ligne certifiГ©es Pharmacie en ligne livraison gratuite
Viagra gГ©nГ©rique sans ordonnance en pharmacie: Acheter du Viagra sans ordonnance – Viagra pas cher paris
https://prednisonetablets.shop/# prednisone 20mg tablets where to buy
buy prednisone without prescription paypal: prednisone 10 – prednisone price australia
http://prednisonetablets.shop/# prednisone
order prednisone 10mg prednisone tablet 100 mg prednisone 20mg capsule
5 mg prednisone daily: prednisone 60 mg tablet – prednisone 20 mg prices
https://clomiphene.icu/# where buy cheap clomid
cheap clomid now: can i buy generic clomid without a prescription – where to get generic clomid pills
ivermectin 3mg for lice ivermectin virus ivermectin 12
http://clomiphene.icu/# can you get generic clomid for sale
zithromax: zithromax 500 without prescription – zithromax antibiotic without prescription
no prescription online prednisone can i purchase prednisone without a prescription prednisone 60 mg tablet
prednisone 20mg tab price: cheap generic prednisone – cost of prednisone tablets
prednisone tablets india: prednisone buying – prednisone 2 mg daily
https://clomiphene.icu/# how to buy cheap clomid no prescription
http://amoxicillin.bid/# amoxicillin over counter
where can i buy stromectol ivermectin where to buy for humans stromectol ebay
ivermectin 3mg: stromectol 12mg – ivermectin 3 mg
http://clomiphene.icu/# get clomid online
amoxicillin 500 mg: amoxicillin capsules 250mg – order amoxicillin online
buy prednisone online from canada where to buy prednisone uk prednisone 2 mg daily
https://clomiphene.icu/# get cheap clomid without rx
how can i get generic clomid price: clomid without dr prescription – can you buy cheap clomid without prescription
2.5 mg prednisone daily: prednisone 20mg price in india – prednisone 5mg cost
https://ivermectin.store/# order stromectol
https://prednisonetablets.shop/# pharmacy cost of prednisone
prednisone coupon: buy prednisone no prescription – prednisone 20mg online
https://ivermectin.store/# how much is ivermectin
ivermectin usa price: minocycline 100mg over the counter – stromectol drug
stromectol generic name ivermectin ebay ivermectin price uk
prednisone without prescription 10mg: prednisone for sale online – prednisone in india
http://prednisonetablets.shop/# prednisone 10 mg brand name
https://mexicanpharm.shop/# reputable mexican pharmacies online mexicanpharm.shop
mexican mail order pharmacies: mexico drug stores pharmacies – mexican online pharmacies prescription drugs mexicanpharm.shop
indian pharmacy online mail order pharmacy india mail order pharmacy india indianpharm.store
purple pharmacy mexico price list: buying prescription drugs in mexico – п»їbest mexican online pharmacies mexicanpharm.shop
https://canadianpharm.store/# canadian discount pharmacy canadianpharm.store
medicine in mexico pharmacies: Online Pharmacies in Mexico – mexican pharmaceuticals online mexicanpharm.shop
http://canadianpharm.store/# buy prescription drugs from canada cheap canadianpharm.store
indianpharmacy com: order medicine from india to usa – india pharmacy mail order indianpharm.store
п»їlegitimate online pharmacies india order medicine from india to usa indian pharmacy online indianpharm.store
https://canadianpharm.store/# pharmacy wholesalers canada canadianpharm.store
top online pharmacy india: international medicine delivery from india – best online pharmacy india indianpharm.store
buy prescription drugs from india Indian pharmacy to USA world pharmacy india indianpharm.store
https://canadianpharm.store/# maple leaf pharmacy in canada canadianpharm.store
legit canadian pharmacy online: Best Canadian online pharmacy – canadian pharmacy ed medications canadianpharm.store
india online pharmacy: order medicine from india to usa – mail order pharmacy india indianpharm.store
online pharmacy india: Indian pharmacy to USA – india pharmacy indianpharm.store
canadian pharmacy drugs online cheap canadian pharmacy online canadian pharmacy ratings canadianpharm.store
top 10 pharmacies in india: Online medicine home delivery – cheapest online pharmacy india indianpharm.store
https://canadianpharm.store/# canadian pharmacy review canadianpharm.store
https://mexicanpharm.shop/# buying prescription drugs in mexico online mexicanpharm.shop
pharmacy com canada: best canadian pharmacy online – pharmacies in canada that ship to the us canadianpharm.store
https://canadianpharm.store/# canadian pharmacy meds review canadianpharm.store
www canadianonlinepharmacy Certified Online Pharmacy Canada online canadian pharmacy canadianpharm.store
medicine in mexico pharmacies: Online Mexican pharmacy – mexican pharmaceuticals online mexicanpharm.shop
http://mexicanpharm.shop/# mexican online pharmacies prescription drugs mexicanpharm.shop
o great to find someone with some original thoughts on this topic.<a href="https://www.toolbarqueries.google.bf/url?sa=t
online canadian pharmacy: Certified Online Pharmacy Canada – canadian pharmacy price checker canadianpharm.store
canadian drug pharmacy Certified Online Pharmacy Canada the canadian pharmacy canadianpharm.store
buying from online mexican pharmacy: Certified Pharmacy from Mexico – buying prescription drugs in mexico online mexicanpharm.shop
http://mexicanpharm.shop/# mexican rx online mexicanpharm.shop
top 10 online pharmacy in india: international medicine delivery from india – top online pharmacy india indianpharm.store
https://mexicanpharm.shop/# п»їbest mexican online pharmacies mexicanpharm.shop
mexico pharmacy Online Pharmacies in Mexico mexican drugstore online mexicanpharm.shop
https://canadianpharm.store/# best canadian online pharmacy canadianpharm.store
https://indianpharm.store/# best online pharmacy india indianpharm.store
cheap canadian pharmacy online buy canadian drugs canadian pharmacy prices canadianpharm.store
mexican online pharmacies prescription drugs: reputable mexican pharmacies online – buying from online mexican pharmacy mexicanpharm.shop
buying from online mexican pharmacy: best online pharmacies in mexico – pharmacies in mexico that ship to usa mexicanpharm.shop
canadian pharmacy store: Canada Pharmacy online – canadian drugs pharmacy canadianpharm.store
https://canadianpharm.store/# my canadian pharmacy review canadianpharm.store
pharmacies in mexico that ship to usa mexico pharmacies prescription drugs medication from mexico pharmacy mexicanpharm.shop
canadian pharmacy: Licensed Online Pharmacy – is canadian pharmacy legit canadianpharm.store
http://indianpharm.store/# india pharmacy indianpharm.store
https://indianpharm.store/# Online medicine order indianpharm.store
mexican pharmaceuticals online Online Mexican pharmacy mexican pharmacy mexicanpharm.shop
77 canadian pharmacy: Best Canadian online pharmacy – canadian pharmacy canadianpharm.store
indian pharmacies safe: Indian pharmacy to USA – Online medicine home delivery indianpharm.store
https://canadadrugs.pro/# canadian trust pharmacy
canadian pharcharmy reviews: canadian pharmacy online no prescription needed – medications canada
canadian mail order drug companies: online drugstore – canadian pharmacy no rx
canadian online pharmacy best online canadian pharmacies pharmacy drug store online no rx
viagra mexican pharmacy: over the counter drug store – canadian pharmacy online canada
http://canadadrugs.pro/# best online drugstore
canadian prescriptions online: world pharmacy – canadian pharmacy voltaren
top mail order pharmacies canada online pharmacy reviews mail order pharmacies
http://canadadrugs.pro/# online drugstore reviews
best canadian online pharmacy reviews: discount drugs online pharmacy – buy drugs online
best canadian mail order pharmacy canadian medicine pharmacy drug store
http://canadadrugs.pro/# canadian pharmacies selling cialis
most trusted canadian pharmacy: canada pharmacies online pharmacy – buy medicine canada
canadian online pharmacy reviews: drug canada – canadian pharmacies no prescription needed
cheap drugs canada: internet pharmacy no prescription – canada pharmacies online
best online pharmacy list of trusted canadian pharmacies reliable online canadian pharmacy
buying drugs canada: canadian rx pharmacy online – legitimate canadian pharmacies online
http://canadadrugs.pro/# canadian pharmacy online without prescription
best price prescription drugs: legitimate canadian pharmacy – north canadian pharmacy
http://canadadrugs.pro/# canadian drugs
cheap drug prices: top online canadian pharmacies – canadian drug store legit
list of canadian pharmacy: canadian pharmacy no prescription required – canadian pharmacy no prescrition
http://canadadrugs.pro/# canadian pharmaceuticals for usa sales
pharcharmy online no script: on line pharmacy with no perscriptions – canadian prescriptions online
online pharmacy no prescription: online pharmacies canadian – cheap prescription drugs online
http://canadadrugs.pro/# best online mexican pharmacy
canadian pharmacy store: legitimate online pharmacies india – reliable canadian pharmacy
https://canadadrugs.pro/# safe canadian internet pharmacies
india online pharmacy: my canadian pharmacy rx reviews – mexican border pharmacies
https://canadadrugs.pro/# prescriptions online
no prescription pharmacies: canadian drug stores online – mexico pharmacy order online
mexican border pharmacies: accutane mexican pharmacy – list of safe online pharmacies
https://canadadrugs.pro/# top rated online pharmacies
pharmacies online: canadian drugs online viagra – canada drug stores
http://edpill.cheap/# ed medications online
canadian pharmacy victoza: pharmacy canadian superstore – is canadian pharmacy legit
top online pharmacy india best online pharmacy india pharmacy website india
http://medicinefromindia.store/# п»їlegitimate online pharmacies india
http://edwithoutdoctorprescription.pro/# best ed pills non prescription
cheapest online pharmacy india: top online pharmacy india – top 10 pharmacies in india
canadian online drugs: adderall canadian pharmacy – thecanadianpharmacy
online shopping pharmacy india top 10 pharmacies in india buy prescription drugs from india
http://medicinefromindia.store/# best online pharmacy india
buy prescription drugs from india reputable indian pharmacies reputable indian pharmacies
top 10 online pharmacy in india: indian pharmacy online – п»їlegitimate online pharmacies india
https://edpill.cheap/# best male enhancement pills
ed dysfunction treatment non prescription ed pills cheap erectile dysfunction
http://canadianinternationalpharmacy.pro/# best canadian online pharmacy reviews
mexico pharmacies prescription drugs: mexican mail order pharmacies – mexican online pharmacies prescription drugs
https://certifiedpharmacymexico.pro/# medication from mexico pharmacy
buy prescription drugs from india indian pharmacies safe Online medicine order
http://edwithoutdoctorprescription.pro/# sildenafil without a doctor’s prescription
Great website.ots of useful information here. look forward to the continuation.-vox live stream 2ix17
canadian pharmacy tampa: reputable canadian online pharmacy – safe online pharmacies in canada
http://canadianinternationalpharmacy.pro/# maple leaf pharmacy in canada
canadian pharmacy scam canadian pharmacy meds my canadian pharmacy review
http://edwithoutdoctorprescription.pro/# best non prescription ed pills
best drug for ed top rated ed pills best ed pills at gnc
generic ed pills: what is the best ed pill – ed meds
https://medicinefromindia.store/# india pharmacy
pet meds without vet prescription canada ed drugs online from canada certified canadian international pharmacy
http://edwithoutdoctorprescription.pro/# buy prescription drugs online
viagra without a doctor prescription walmart cialis without a doctor prescription canada tadalafil without a doctor’s prescription
https://edwithoutdoctorprescription.pro/# buy prescription drugs online without
how to cure ed: ed drug prices – cheap erectile dysfunction pills
http://medicinefromindia.store/# india pharmacy
top erection pills cheap erectile dysfunction pills online online ed medications
http://edpill.cheap/# new ed treatments
ed meds online canada escrow pharmacy canada cross border pharmacy canada
https://canadianinternationalpharmacy.pro/# canada discount pharmacy
mexican border pharmacies shipping to usa п»їbest mexican online pharmacies medicine in mexico pharmacies
discount prescription drugs: ed meds online without doctor prescription – prescription meds without the prescriptions
http://edwithoutdoctorprescription.pro/# buy prescription drugs online legally
buy prescription drugs without doctor cialis without a doctor prescription canada prescription drugs online without
http://certifiedpharmacymexico.pro/# mexico pharmacy
http://edpill.cheap/# ed meds online
prescription drugs online cialis without a doctor prescription viagra without a doctor prescription
https://edpill.cheap/# erection pills
mexican mail order pharmacies mexico drug stores pharmacies mexico pharmacy
medication from mexico pharmacy: mexico pharmacies prescription drugs – mexican online pharmacies prescription drugs
http://edpill.cheap/# buy ed pills
https://medicinefromindia.store/# reputable indian online pharmacy
mexican drugstore online best online pharmacies in mexico mexican online pharmacies prescription drugs
http://medicinefromindia.store/# india pharmacy
ed dysfunction treatment ed medication online best pill for ed
http://certifiedpharmacymexico.pro/# buying from online mexican pharmacy
treatment for ed: best pill for ed – natural ed medications
mexico drug stores pharmacies mexican drugstore online mexican online pharmacies prescription drugs
mexican online pharmacies prescription drugs buying prescription drugs in mexico online mexican border pharmacies shipping to usa
mexican pharmacy buying prescription drugs in mexico online mexico drug stores pharmacies
https://mexicanph.com/# mexican drugstore online
mexico drug stores pharmacies
mexican border pharmacies shipping to usa mexico pharmacy mexico drug stores pharmacies
best online pharmacies in mexico mexican drugstore online purple pharmacy mexico price list
mexico drug stores pharmacies mexican border pharmacies shipping to usa buying from online mexican pharmacy
medicine in mexico pharmacies mexico drug stores pharmacies mexico pharmacies prescription drugs
http://mexicanph.shop/# mexican pharmaceuticals online
best online pharmacies in mexico
reputable mexican pharmacies online mexico drug stores pharmacies buying prescription drugs in mexico online
reputable mexican pharmacies online medication from mexico pharmacy buying from online mexican pharmacy
mexican pharmacy best online pharmacies in mexico buying prescription drugs in mexico online
mexico drug stores pharmacies buying prescription drugs in mexico medication from mexico pharmacy
п»їbest mexican online pharmacies mexican rx online best online pharmacies in mexico
mexican rx online buying prescription drugs in mexico online mexico pharmacies prescription drugs
http://mexicanph.shop/# mexican pharmaceuticals online
mexican rx online
best mexican online pharmacies best mexican online pharmacies mexico pharmacies prescription drugs
mexican drugstore online mexican border pharmacies shipping to usa reputable mexican pharmacies online
medication from mexico pharmacy mexico pharmacy mexico pharmacies prescription drugs
pharmacies in mexico that ship to usa mexican border pharmacies shipping to usa medication from mexico pharmacy
mexican drugstore online mexican online pharmacies prescription drugs mexican pharmaceuticals online
mexico drug stores pharmacies medicine in mexico pharmacies mexico pharmacies prescription drugs
best mexican online pharmacies buying from online mexican pharmacy reputable mexican pharmacies online
medicine in mexico pharmacies pharmacies in mexico that ship to usa mexican border pharmacies shipping to usa
mexico drug stores pharmacies mexican online pharmacies prescription drugs medicine in mexico pharmacies
best online pharmacies in mexico mexico drug stores pharmacies reputable mexican pharmacies online
http://mexicanph.com/# mexican pharmaceuticals online
pharmacies in mexico that ship to usa
buying from online mexican pharmacy buying prescription drugs in mexico mexico pharmacies prescription drugs
medicine in mexico pharmacies mexican pharmacy mexican border pharmacies shipping to usa
buying prescription drugs in mexico online best online pharmacies in mexico mexican rx online
medicine in mexico pharmacies mexico drug stores pharmacies reputable mexican pharmacies online
reputable mexican pharmacies online mexico pharmacies prescription drugs mexico drug stores pharmacies
http://mexicanph.com/# medicine in mexico pharmacies
mexican border pharmacies shipping to usa
п»їbest mexican online pharmacies buying prescription drugs in mexico online mexican drugstore online
buying prescription drugs in mexico buying prescription drugs in mexico online mexico pharmacies prescription drugs
medication from mexico pharmacy mexico drug stores pharmacies medication from mexico pharmacy
medication from mexico pharmacy mexican pharmaceuticals online mexican pharmaceuticals online
mexican border pharmacies shipping to usa mexico pharmacy mexico pharmacies prescription drugs
mexico drug stores pharmacies reputable mexican pharmacies online buying prescription drugs in mexico online
best online pharmacies in mexico reputable mexican pharmacies online mexican drugstore online
medicine in mexico pharmacies mexico drug stores pharmacies п»їbest mexican online pharmacies
mexican pharmaceuticals online п»їbest mexican online pharmacies mexican pharmacy
buying from online mexican pharmacy mexican mail order pharmacies mexico pharmacies prescription drugs
mexico pharmacy mexican drugstore online pharmacies in mexico that ship to usa
reputable mexican pharmacies online mexico pharmacies prescription drugs mexico pharmacies prescription drugs
medication from mexico pharmacy mexican rx online buying from online mexican pharmacy
mexican border pharmacies shipping to usa mexico pharmacies prescription drugs buying from online mexican pharmacy
medication from mexico pharmacy buying prescription drugs in mexico online п»їbest mexican online pharmacies
best mexican online pharmacies mexico pharmacy pharmacies in mexico that ship to usa
mexican pharmacy mexican mail order pharmacies mexico drug stores pharmacies
mexican pharmaceuticals online mexican pharmacy reputable mexican pharmacies online
mexican pharmacy mexican pharmacy medication from mexico pharmacy
buying prescription drugs in mexico buying from online mexican pharmacy buying prescription drugs in mexico
mexican pharmacy best online pharmacies in mexico buying prescription drugs in mexico
mexican pharmacy mexican rx online mexican pharmaceuticals online
medicine in mexico pharmacies buying prescription drugs in mexico medication from mexico pharmacy
purple pharmacy mexico price list mexican online pharmacies prescription drugs purple pharmacy mexico price list
best online pharmacies in mexico medicine in mexico pharmacies medication from mexico pharmacy
http://stromectol.fun/# Buy Online Ivermectin/Stromectol Now
lasix 40 mg: Buy Lasix – furosemide
https://lisinopril.top/# buy lisinopril 20 mg online usa
http://buyprednisone.store/# prednisone 40 mg price
lasix for sale: Buy Lasix No Prescription – furosemida 40 mg
prednisone pack: where can i buy prednisone without a prescription – generic prednisone tablets
http://amoxil.cheap/# amoxicillin tablet 500mg
prednisone pill 10 mg: prednisone 500 mg tablet – 3000mg prednisone
http://buyprednisone.store/# prednisone 20 tablet
lisinopril prescription: lisinopril generic price – buy lisinopril 20 mg without a prescription
https://furosemide.guru/# lasix 40 mg
https://buyprednisone.store/# can you buy prednisone over the counter in mexico
stromectol where to buy: ivermectin pills – how much is ivermectin
http://lisinopril.top/# lisinopril 20 mg online
lisinopril 3973: how much is lisinopril 5 mg – lisinopril 100mcg
order lisinopril 10 mg: lisinopril 19 mg – lisinopril 12.5 mg price
http://lisinopril.top/# lisinopril 5mg pill
lasix generic: Over The Counter Lasix – lasix generic name
https://lisinopril.top/# lisinopril 5 mg for sale
lasix: Over The Counter Lasix – lasix 100 mg tablet
https://furosemide.guru/# lasix generic
lisinopril 20 mg tablets: buy lisinopril canada – buy lisinopril 40 mg tablet
http://stromectol.fun/# ivermectin 1%cream
http://stromectol.fun/# ivermectin lice oral
prednisone buy no prescription: prednisone pill – prednisone 1 tablet
https://buyprednisone.store/# buy prednisone online fast shipping
lasix 100 mg tablet: Buy Lasix – furosemide 40mg
lisinopril 20 mg price without prescription: where to buy lisinopril without prescription – lisinopril 104
http://buyprednisone.store/# prednisone online
20 mg prednisone tablet: 40 mg daily prednisone – buying prednisone without prescription
http://buyprednisone.store/# by prednisone w not prescription
https://furosemide.guru/# lasix 40mg
amoxicillin generic brand: amoxicillin 500 mg tablet – amoxicillin 500mg capsules
buy cheap amoxicillin online: amoxicillin 500 mg online – amoxicillin 500 mg capsule
https://stromectol.fun/# where can i buy oral ivermectin
https://amoxil.cheap/# can you buy amoxicillin uk
amoxicillin 500 mg purchase without prescription: amoxicillin without rx – amoxicillin 500 mg capsule
Greetings! Very helpful advice in this particular article!Aluminum Film Car Windshield Snow Cover with Rear View Mirror Cover4 Layer Thickened Front Windshield Cover for Ice and SnowWinter Essential Automotive Exterior Accessories – Hot Deals
ivermectin brand name: ivermectin 0.1 – stromectol tab
https://furosemide.guru/# lasix generic name
ivermectin cost australia: ivermectin where to buy – ivermectin humans
https://lisinopril.top/# lisinopril discount
amoxicillin tablet 500mg: purchase amoxicillin 500 mg – where can i get amoxicillin
http://buyprednisone.store/# buy prednisone tablets uk
http://furosemide.guru/# lasix dosage
prednisone buy no prescription: prednisone 3 tablets daily – over the counter prednisone cheap
http://lisinopril.top/# buy prinivil online
furosemide 40mg: Over The Counter Lasix – lasix for sale
https://stromectol.fun/# ivermectin cost australia
lasix 100 mg tablet: Buy Lasix – lasix 100mg
buy cheap amoxicillin online: order amoxicillin online uk – amoxicillin without prescription
order amoxicillin no prescription: buy amoxicillin canada – amoxicillin 500mg capsule cost
http://buyprednisone.store/# prednisone without a prescription
https://furosemide.guru/# lasix
ivermectin over the counter uk: ivermectin 9 mg tablet – order stromectol
https://buyprednisone.store/# where can i order prednisone 20mg
how to buy stromectol: ivermectin 0.5 lotion india – cost of ivermectin lotion
http://furosemide.guru/# lasix furosemide 40 mg
zestoretic 10 12.5: lisinopril 20 mg best price – 100 mg lisinopril
https://amoxil.cheap/# amoxicillin 250 mg capsule
ivermectin 5 mg price: buy stromectol uk – ivermectin lotion price
http://furosemide.guru/# furosemide 100 mg
buy 10 mg prednisone: prednisone 1 tablet – prednisone best prices
https://furosemide.guru/# lasix generic name
http://amoxil.cheap/# cost of amoxicillin 30 capsules
stromectol liquid: ivermectin uk – stromectol where to buy
furosemide: lasix online – lasix online
https://buyprednisone.store/# buy prednisone without rx
Your blog is a true masterpiece, crafted with care and passion. We’re proud supporters from Asheville!
Your posts always leave me feeling enlightened and inspired. Thank you for sharing your knowledge with us. Asheville sends its love!
lisinopril 30mg coupon: zestril 2.5 mg – lisinopril 2.5 pill
http://stromectol.fun/# ivermectin pills human
http://amoxil.cheap/# amoxicillin pills 500 mg
can i buy amoxicillin over the counter in australia: amoxicillin 500 mg without prescription – how to get amoxicillin
amoxicillin generic: amoxicillin 50 mg tablets – buy amoxil
http://lisinopril.top/# where can i get lisinopril
http://indianph.com/# best india pharmacy
Online medicine home delivery
https://indianph.com/# mail order pharmacy india
https://indianph.com/# world pharmacy india
top 10 pharmacies in india
top online pharmacy india top 10 pharmacies in india indian pharmacy online
http://indianph.com/# Online medicine order
cheapest online pharmacy india
https://indianph.xyz/# buy medicines online in india
indian pharmacy online
https://indianph.xyz/# reputable indian online pharmacy
Online medicine home delivery
http://indianph.xyz/# buy prescription drugs from india
world pharmacy india
buy prescription drugs from india cheapest online pharmacy india india pharmacy mail order
http://indianph.com/# indian pharmacy
https://indianph.com/# buy medicines online in india
top 10 pharmacies in india
https://indianph.xyz/# indian pharmacies safe
indian pharmacy
https://indianph.xyz/# reputable indian online pharmacy
best online pharmacy india
reputable indian online pharmacy top 10 pharmacies in india indianpharmacy com
https://doxycycline.auction/# doxycycline hyc
buy cipro: cipro for sale – where can i buy cipro online
diflucan online buy ordering diflucan without a prescription can you buy diflucan over the counter uk
https://cytotec24.com/# buy cytotec online
https://nolvadex.guru/# does tamoxifen make you tired
doxycycline vibramycin: buy doxycycline – doxycycline 100mg tablets
http://cytotec24.shop/# cytotec buy online usa
vibramycin 100 mg doxycycline order online buy doxycycline online uk
http://diflucan.pro/# diflucan tablets online
buy cytotec in usa: cytotec buy online usa – Misoprostol 200 mg buy online
https://cytotec24.com/# buy cytotec
nolvadex for sale amazon common side effects of tamoxifen tamoxifen endometrium
buy generic ciprofloxacin: cipro for sale – buy cipro online
http://nolvadex.guru/# tamoxifen pill
http://cytotec24.shop/# buy cytotec online
https://cipro.guru/# cipro
diflucan pill for sale diflucan 150 mg where can i buy diflucan without prescription
http://cipro.guru/# cipro ciprofloxacin
diflucan australia: diflucan rx price – diflucan 1 pill
https://diflucan.pro/# where to buy diflucan otc
cipro pharmacy cipro for sale antibiotics cipro
http://doxycycline.auction/# odering doxycycline
https://doxycycline.auction/# buy cheap doxycycline
https://cytotec24.com/# Misoprostol 200 mg buy online
ciprofloxacin where can i buy cipro online ciprofloxacin mail online
http://cipro.guru/# buy cipro online without prescription
http://cipro.guru/# cipro ciprofloxacin
where can i buy cipro online buy ciprofloxacin over the counter buy cipro online
https://diflucan.pro/# diflucan 200 mg
http://cipro.guru/# ciprofloxacin 500mg buy online
http://diflucan.pro/# diflucan buy online canada
https://abelladanger.online/# abella danger filmleri
Angela White: ?????? ???? – Angela White
https://evaelfie.pro/# eva elfie video
https://angelawhite.pro/# Angela White
http://abelladanger.online/# Abella Danger
Angela Beyaz modeli: abella danger video – abella danger izle
https://angelawhite.pro/# ?????? ????
https://evaelfie.pro/# eva elfie izle
Sweetie Fox: swetie fox – sweety fox
http://abelladanger.online/# abella danger izle
http://lanarhoades.fun/# lana rhoades izle
https://abelladanger.online/# abella danger filmleri
https://sweetiefox.online/# Sweetie Fox filmleri
Sweetie Fox modeli: swetie fox – Sweetie Fox
https://abelladanger.online/# Abella Danger
https://evaelfie.pro/# eva elfie modeli
Sweetie Fox: Sweetie Fox video – Sweetie Fox modeli
http://abelladanger.online/# abella danger video
http://sweetiefox.online/# Sweetie Fox izle
http://abelladanger.online/# Abella Danger
eva elfie filmleri: eva elfie modeli – eva elfie izle
https://abelladanger.online/# abella danger video
http://lanarhoades.fun/# lana rhoades video
https://angelawhite.pro/# Angela White izle
sweeti fox: Sweetie Fox filmleri – Sweetie Fox filmleri
https://abelladanger.online/# abella danger video
http://evaelfie.pro/# eva elfie
https://abelladanger.online/# abella danger video
https://abelladanger.online/# abella danger filmleri
Angela White: abella danger filmleri – abella danger izle
https://abelladanger.online/# abella danger izle
https://abelladanger.online/# abella danger izle
Angela White video: Abella Danger – Abella Danger
https://sweetiefox.online/# Sweetie Fox video
Angela White: ?????? ???? – Angela White filmleri
http://sweetiefox.online/# swetie fox
http://evaelfie.pro/# eva elfie video
http://abelladanger.online/# Abella Danger
https://angelawhite.pro/# Angela White video
http://sweetiefox.online/# Sweetie Fox
https://abelladanger.online/# abella danger filmleri
swetie fox: sweeti fox – Sweetie Fox izle
https://abelladanger.online/# abella danger video
http://evaelfie.pro/# eva elfie modeli
Angela White izle: abella danger video – abella danger video
https://abelladanger.online/# Abella Danger
eva elfie modeli: eva elfie – eva elfie filmleri
http://angelawhite.pro/# Angela White filmleri
sweetie fox new: sweetie fox full – sweetie fox cosplay
https://evaelfie.site/# eva elfie
sweetie fox new: sweetie fox cosplay – sweetie fox new
https://sweetiefox.pro/# sweetie fox full
mia malkova movie: mia malkova videos – mia malkova
http://evaelfie.site/# eva elfie hot
totally free dating site: http://evaelfie.site/# eva elfie hd
sweetie fox video: sweetie fox full – sweetie fox cosplay
eva elfie hd: eva elfie – eva elfie full videos
lana rhoades videos: lana rhoades videos – lana rhoades boyfriend
free dating siwomen: http://sweetiefox.pro/# sweetie fox cosplay
http://sweetiefox.pro/# sweetie fox full
mia malkova only fans: mia malkova full video – mia malkova only fans
lana rhoades full video: lana rhoades solo – lana rhoades full video
eva elfie full videos: eva elfie hd – eva elfie new video
https://miamalkova.life/# mia malkova full video
online dating match: http://sweetiefox.pro/# sweetie fox
mia malkova only fans: mia malkova girl – mia malkova new video
http://miamalkova.life/# mia malkova photos
eva elfie full videos: eva elfie new video – eva elfie hd
mia malkova videos: mia malkova new video – mia malkova girl
http://evaelfie.site/# eva elfie new video
facebook dating app: https://evaelfie.site/# eva elfie
eva elfie full videos: eva elfie hd – eva elfie full videos
https://miamalkova.life/# mia malkova only fans
lana rhoades pics: lana rhoades – lana rhoades full video
eva elfie photo: eva elfie hd – eva elfie new videos
dating game: http://miamalkova.life/# mia malkova girl
http://lanarhoades.pro/# lana rhoades unleashed
mia malkova new video: mia malkova girl – mia malkova new video
A big thank you for your blog.Really looking forward to read more. – hey dudes womens
eva elfie new videos: eva elfie new video – eva elfie hot
http://miamalkova.life/# mia malkova girl
eva elfie videos: eva elfie full video – eva elfie photo
mia malkova hd: mia malkova videos – mia malkova hd
http://lanarhoades.pro/# lana rhoades pics
adult date site: https://miamalkova.life/# mia malkova hd
aviator pin up casino: pin-up cassino – pin up casino
https://aviatorghana.pro/# aviator bet
https://aviatorjogar.online/# aviator bet
pin-up casino: pin-up casino entrar – pin up
https://aviatormalawi.online/# aviator game online
https://aviatormalawi.online/# aviator bet
pin-up casino login: pin-up – pin up bet
aviator bet malawi login: aviator game – aviator bet malawi login
https://aviatorghana.pro/# aviator betting game
https://aviatormocambique.site/# aviator mocambique
pin up aviator: aviator bet – estrela bet aviator
aplicativo de aposta: jogos que dão dinheiro – jogos que dão dinheiro
http://jogodeaposta.fun/# jogo de aposta online
aviator betano: aviator pin up – aviator betano
http://aviatormalawi.online/# aviator bet malawi
play aviator: aviator betting game – aviator bet malawi
http://aviatormalawi.online/# aviator bet malawi login
jogar aviator online: aviator betano – aviator jogar
como jogar aviator em moçambique: jogar aviator – como jogar aviator
aviator bet: aviator online – como jogar aviator
aviator betting game: aviator – aviator game online
aviator game bet: play aviator – aviator bet
jogo de aposta: jogos que dão dinheiro – jogo de aposta
https://pinupcassino.pro/# cassino pin up
pin up aviator: cassino pin up – pin-up casino entrar
play aviator: aviator bet malawi – aviator game
aviator game: aviator game – aviator betting game
buy generic zithromax no prescription: zithromax indications zithromax for sale online
jogar aviator online: aviator game – aviator bet
http://aviatormocambique.site/# aviator
aviator betano: estrela bet aviator – jogar aviator online
generic zithromax 500mg india: zithromax 500 without prescription – buy zithromax online australia
aviator: aviator malawi – play aviator
https://aviatorghana.pro/# aviator login
buy zithromax online fast shipping – https://azithromycin.pro/zithromax-200mg5ml.html order zithromax over the counter
aviator game: aviator jogo – jogar aviator online
canadian online pharmacy reviews: canadian pharmacy – canada pharmacy world canadianpharm.store
https://canadianpharmlk.shop/# canadian pharmacy online canadianpharm.store
buy prescription drugs from india cheapest online pharmacy online shopping pharmacy india indianpharm.store
mexican drugstore online: Mexico pharmacy price list – mexico pharmacy mexicanpharm.shop
canadian pharmacy online reviews: Canada pharmacy online – adderall canadian pharmacy canadianpharm.store
http://mexicanpharm24.com/# mexico drug stores pharmacies mexicanpharm.shop
http://indianpharm24.com/# india pharmacy indianpharm.store
Online medicine order: Best Indian pharmacy – top 10 pharmacies in india indianpharm.store
https://indianpharm24.shop/# reputable indian online pharmacy indianpharm.store
online shopping pharmacy india Online India pharmacy world pharmacy india indianpharm.store
https://canadianpharmlk.com/# canadian pharmacy online reviews canadianpharm.store
http://indianpharm24.shop/# india pharmacy mail order indianpharm.store
http://canadianpharmlk.shop/# canadian pharmacy 24h com safe canadianpharm.store
canadian pharmacy 24h com safe: Certified Canadian pharmacies – canadian pharmacy near me canadianpharm.store
http://indianpharm24.shop/# india pharmacy mail order indianpharm.store
mail order pharmacy india: Top online pharmacy in India – п»їlegitimate online pharmacies india indianpharm.store
http://mexicanpharm24.shop/# mexican pharmaceuticals online mexicanpharm.shop
https://mexicanpharm24.com/# buying prescription drugs in mexico mexicanpharm.shop
canadian pharmacy: canada drug pharmacy – canadian pharmacy drugs online canadianpharm.store
http://canadianpharmlk.shop/# online canadian pharmacy review canadianpharm.store
http://mexicanpharm24.shop/# mexico drug stores pharmacies mexicanpharm.shop
canadian pharmacy review Best Canadian online pharmacy canadian pharmacy world reviews canadianpharm.store
http://mexicanpharm24.shop/# mexican pharmaceuticals online mexicanpharm.shop
canadian pharmacy store: canadian pharmacy – canadian pharmacy online canadianpharm.store
http://canadianpharmlk.com/# online canadian drugstore canadianpharm.store
http://mexicanpharm24.com/# mexican pharmacy mexicanpharm.shop
https://canadianpharmlk.com/# safe canadian pharmacy canadianpharm.store
canadian pharmacy king reviews: Canada pharmacy online – escrow pharmacy canada canadianpharm.store
https://indianpharm24.com/# Online medicine home delivery indianpharm.store
online shopping pharmacy india: online pharmacy in india – indian pharmacy online indianpharm.store
http://mexicanpharm24.shop/# mexico pharmacies prescription drugs mexicanpharm.shop
https://indianpharm24.shop/# mail order pharmacy india indianpharm.store
https://mexicanpharm24.shop/# п»їbest mexican online pharmacies mexicanpharm.shop
http://indianpharm24.com/# india online pharmacy indianpharm.store
the canadian drugstore: Canada pharmacy online – safe reliable canadian pharmacy canadianpharm.store
indian pharmacy online online pharmacy usa online pharmacy india indianpharm.store
https://mexicanpharm24.shop/# mexican online pharmacies prescription drugs mexicanpharm.shop
how can i get generic clomid without dr prescription: where can i buy clomid pills – how to get cheap clomid pills
http://clomidst.pro/# can you buy clomid without insurance
can i buy cheap clomid no prescription: get clomid prescription – where buy generic clomid price
can i get generic clomid online: can you get clomid without insurance – buy generic clomid without rx
can i order clomid pill: best days to take clomid for twins forum – how can i get generic clomid
prednisone drug costs: does prednisone make you tired – buy prednisone with paypal canada
http://amoxilst.pro/# cheap amoxicillin 500mg
can i buy cheap clomid without prescription: clomid multiples – cost of clomid online
cost of clomid pills: can you get cheap clomid without rx – buying clomid prices
amoxacillian without a percription: amoxicillin/clavulanate potassium – over the counter amoxicillin
can i get cheap clomid online can i get clomid without dr prescription order cheap clomid without dr prescription
http://prednisonest.pro/# prednisone 12 tablets price
get cheap clomid online: clomid constipation – can i get cheap clomid online
cost of cheap clomid without a prescription: can i purchase clomid price – where buy clomid without a prescription
how to get clomid without insurance: best days to take clomid for twins – order cheap clomid without a prescription
can you buy clomid without a prescription: clomid ovulation calculator – can i purchase cheap clomid without a prescription
https://clomidst.pro/# can i get cheap clomid no prescription
purchase prednisone: prednisone 20 mg dosage instructions – prednisone 50 mg tablet cost
over the counter prednisone medicine: buying prednisone without prescription – over the counter prednisone pills
https://clomidst.pro/# how can i get cheap clomid online
can i buy amoxicillin over the counter: amoxicillin pot clavulanate – amoxicillin 500 coupon
over the counter amoxicillin canada amoxicillin without rx amoxicillin 500 mg
buy prednisone online india: what is prednisone 20 mg used to treat – prednisone 5mg coupon
amoxicillin generic: amoxicillin azithromycin – cost of amoxicillin 30 capsules
cost of clomid: can you get cheap clomid online – can i purchase cheap clomid prices
how to buy generic clomid for sale: nolvadex vs clomid – where to buy generic clomid pills
http://amoxilst.pro/# amoxicillin 500 mg tablet price
buy prednisone 5mg canada: prednisone side effects – prednisone tabs 20 mg
https://clomidst.pro/# can i order cheap clomid prices
buying drugs without prescription: online meds no prescription – canadian pharmacy no prescription needed
http://onlinepharmacy.cheap/# cheapest pharmacy for prescriptions
erectile dysfunction meds online: erectile dysfunction drugs online – low cost ed medication
http://onlinepharmacy.cheap/# best online pharmacy no prescription
online drugs without prescription order medication without prescription best no prescription online pharmacies
canadian pharmacy coupon: canada online pharmacy – canadian pharmacy coupon code
https://pharmnoprescription.pro/# buy medication online no prescription
cheapest prescription pharmacy: mexico pharmacy online – cheapest pharmacy for prescription drugs
canadian pharmacy world coupon: mexican pharmacy online – reputable online pharmacy no prescription
https://edpills.guru/# ed medication online
ed medicines: ed prescriptions online – order ed meds online
https://onlinepharmacy.cheap/# prescription free canadian pharmacy
quality prescription drugs canada: online pharmacy canada no prescription – buying prescription drugs online from canada
cheap ed pills: online ed drugs – ed rx online
online pharmacies without prescription: canada prescription – legitimate online pharmacy no prescription
prescription free canadian pharmacy best online pharmacy pharmacy online 365 discount code
ed medication online: order ed pills online – boner pills online
http://onlinepharmacy.cheap/# no prescription needed canadian pharmacy
http://edpills.guru/# buy erectile dysfunction pills
best canadian pharmacy no prescription: online pharmacy delivery – cheapest pharmacy for prescriptions
ed pills online: erectile dysfunction pills for sale – cheapest ed pills
http://pharmnoprescription.pro/# no prescription drugs online
best website to buy prescription drugs: mexican pharmacy no prescription – buy pain meds online without prescription
online pharmacy not requiring prescription: canadian pharmacy no prescription – online doctor prescription canada
buying prescription drugs online from canada: prescription drugs online canada – online pharmacy without prescription
canadian pharmacy coupon code: canadian online pharmacy – cheapest pharmacy prescription drugs
http://edpills.guru/# where to buy erectile dysfunction pills
http://pharmnoprescription.pro/# canadian pharmacy without a prescription
world pharmacy india: cheapest online pharmacy india – п»їlegitimate online pharmacies india
https://indianpharm.shop/# reputable indian online pharmacy
http://indianpharm.shop/# world pharmacy india
п»їlegitimate online pharmacies india: india pharmacy mail order – india pharmacy mail order
canadian pharmacy service: canadian pharmacy scam – buy drugs from canada
http://indianpharm.shop/# india pharmacy mail order
medication from mexico pharmacy buying from online mexican pharmacy mexican rx online
http://indianpharm.shop/# mail order pharmacy india
prescription drugs online canada: canadian pharmacy no prescription required – online pharmacy reviews no prescription
canadian pharmacy no scripts: reputable canadian pharmacy – certified canadian pharmacy
buy medicines online in india: reputable indian pharmacies – best online pharmacy india
https://canadianpharm.guru/# reputable canadian online pharmacies
no prescription needed online pharmacy: buying prescription drugs online from canada – online pharmacies no prescription
indian pharmacy online: п»їlegitimate online pharmacies india – buy prescription drugs from india
https://indianpharm.shop/# top online pharmacy india
mexican online pharmacies prescription drugs: mexican pharmacy – mexican rx online
Online medicine home delivery: cheapest online pharmacy india – reputable indian online pharmacy
mexican pharmaceuticals online medicine in mexico pharmacies medication from mexico pharmacy
top 10 online pharmacy in india: Online medicine home delivery – indian pharmacy
canadian pharmacy near me: cross border pharmacy canada – canadian compounding pharmacy
http://pharmacynoprescription.pro/# buy medication online with prescription
https://canadianpharm.guru/# precription drugs from canada
no prescription medicine: online prescription canada – best online pharmacy no prescription
online pharmacy india: mail order pharmacy india – best online pharmacy india
http://pharmacynoprescription.pro/# canada prescription drugs online
mexican pharmacy: mexican mail order pharmacies – mexican pharmaceuticals online
cheap canadian pharmacy online: best online canadian pharmacy – canadian pharmacy 365
Online medicine home delivery: india pharmacy – mail order pharmacy india
https://mexicanpharm.online/# mexican rx online
world pharmacy india: online pharmacy india – indian pharmacy online
best canadian pharmacy to order from: reddit canadian pharmacy – canadian pharmacy tampa
buying drugs without prescription: canada mail order prescription – buying prescription medications online
top 10 online pharmacy in india buy medicines online in india reputable indian pharmacies
http://mexicanpharm.online/# medication from mexico pharmacy
medicine in mexico pharmacies: mexican pharmaceuticals online – best online pharmacies in mexico
http://indianpharm.shop/# india pharmacy
indian pharmacies safe: buy medicines online in india – top online pharmacy india
pharmacies in mexico that ship to usa: mexican pharmaceuticals online – mexican border pharmacies shipping to usa
https://canadianpharm.guru/# canadian mail order pharmacy
can you buy prescription drugs in canada: best online pharmacy that does not require a prescription in india – online pharmacy without prescription
online medicine without prescription: canada prescription online – medications online without prescription
medicine in mexico pharmacies: mexico drug stores pharmacies – mexican pharmaceuticals online
global pharmacy canada: canadian pharmacy ed medications – canadian pharmacy no scripts
http://indianpharm.shop/# indianpharmacy com
buying drugs without prescription no prescription medication best online pharmacies without prescription
http://mexicanpharm.online/# mexican pharmaceuticals online
mexican pharmacies no prescription: buy prescription drugs online without doctor – mail order prescriptions from canada
mexican border pharmacies shipping to usa: buying from online mexican pharmacy – mexican drugstore online
canadian mail order prescriptions: buying prescription medicine online – buy meds online no prescription
http://indianpharm.shop/# world pharmacy india
online pharmacies without prescriptions: no prescription on line pharmacies – online pharmacies without prescription
cheapest online pharmacy india: indian pharmacy paypal – online pharmacy india
https://mexicanpharm.online/# buying prescription drugs in mexico
india pharmacy mail order: indian pharmacies safe – п»їlegitimate online pharmacies india
pharmacies in mexico that ship to usa: medicine in mexico pharmacies – buying from online mexican pharmacy
cheapest online pharmacy india: india online pharmacy – best india pharmacy
buying prescription drugs in mexico online reputable mexican pharmacies online mexico drug stores pharmacies
https://indianpharm.shop/# top 10 online pharmacy in india
canadian drug prices: canadapharmacyonline com – best canadian pharmacy online
http://mexicanpharm.online/# mexican rx online
pharmacy rx world canada: ed meds online canada – legitimate canadian pharmacy online
mexican mail order pharmacies: medicine in mexico pharmacies – mexico pharmacies prescription drugs
https://canadianpharm.guru/# pharmacy rx world canada
online prescription canada: buy prescription drugs online without – canadian pharmacy no prescription required
canadian pharmacy: canadian pharmacies comparison – my canadian pharmacy
buying from online mexican pharmacy: mexican pharmacy – mexican mail order pharmacies
http://mexicanpharm.online/# medicine in mexico pharmacies
pharmacy online no prescription online pharmacy no prescriptions canada online prescription
world pharmacy india: Online medicine order – cheapest online pharmacy india
mexican pharmaceuticals online: mexican border pharmacies shipping to usa – best online pharmacies in mexico
https://canadianpharm.guru/# pharmacy canadian
slot siteleri: bonus veren slot siteleri – oyun siteleri slot
https://pinupgiris.fun/# pin up casino indir
slot siteleri bonus veren: en iyi slot siteleri – slot siteleri
http://aviatoroyna.bid/# aviator oyunu 20 tl
http://pinupgiris.fun/# pin up guncel giris
gates of olympus guncel: gates of olympus giris – gates of olympus nas?l para kazanilir
gates of olympus oyna ucretsiz: gates of olympus slot – gates of olympus nas?l para kazanilir
http://gatesofolympus.auction/# gates of olympus giris
http://pinupgiris.fun/# pin up
sweet bonanza free spin demo: sweet bonanza demo – sweet bonanza kazanc
http://slotsiteleri.guru/# slot siteleri guvenilir
http://pinupgiris.fun/# pin up aviator
aviator mostbet: aviator sinyal hilesi – aviator sinyal hilesi ucretsiz
https://pinupgiris.fun/# pin-up bonanza
en yeni slot siteleri: slot kumar siteleri – deneme bonusu veren slot siteleri
http://aviatoroyna.bid/# aviator oyna 100 tl
pin-up online: pin up casino indir – pin up aviator
http://pinupgiris.fun/# pin up
http://gatesofolympus.auction/# gates of olympus slot
pin-up casino giris: pin up aviator – pin up bet
sweet bonanza kazanc: sweet bonanza – sweet bonanza taktik
http://slotsiteleri.guru/# en iyi slot siteleri
pin up casino indir: pin up – pin up casino indir
https://aviatoroyna.bid/# aviator bahis
https://pinupgiris.fun/# pin up casino giris
pragmatic play sweet bonanza: sweet bonanza yorumlar – sweet bonanza yasal site
http://aviatoroyna.bid/# aviator oyna 20 tl
gates of olympus 1000 demo: gates of olympus nas?l para kazanilir – gates of olympus demo turkce
http://pinupgiris.fun/# pin up casino güncel giris
pin up 7/24 giris: pin-up giris – pin up casino giris
http://slotsiteleri.guru/# yasal slot siteleri
buying prescription drugs in mexico online mexican pharmacy medicine in mexico pharmacies
canadian pharmacy price checker: pills now even cheaper – canada drugstore pharmacy rx
mexican online pharmacies prescription drugs: Mexican Pharmacy Online – mexican rx online
mexican pharmaceuticals online Mexican Pharmacy Online buying prescription drugs in mexico online
https://mexicanpharmacy.shop/# mexican drugstore online
medicine in mexico pharmacies: Mexican Pharmacy Online – mexican online pharmacies prescription drugs
world pharmacy india Cheapest online pharmacy cheapest online pharmacy india
pharmacy website india: indian pharmacy delivery – top online pharmacy india
top 10 online pharmacy in india: reputable indian online pharmacy – online pharmacy india
canadian neighbor pharmacy: pills now even cheaper – canadian pharmacy prices
indian pharmacy online: indian pharmacy delivery – top online pharmacy india
india pharmacy mail order: Cheapest online pharmacy – indian pharmacy
legitimate canadian pharmacies: canadian neighbor pharmacy – best canadian pharmacy online
indianpharmacy com indian pharmacy delivery indian pharmacy paypal
https://indianpharmacy.icu/# indian pharmacies safe
legitimate online pharmacies india: Generic Medicine India to USA – Online medicine order
mexican rx online: Online Pharmacies in Mexico – mexican online pharmacies prescription drugs
reputable canadian online pharmacy: Prescription Drugs from Canada – online canadian pharmacy
canadian pharmacy service canadian pharmacy 24 reliable canadian pharmacy
buying prescription drugs in mexico: Online Pharmacies in Mexico – mexican online pharmacies prescription drugs
reputable mexican pharmacies online: Online Pharmacies in Mexico – mexican rx online
Online medicine order: Healthcare and medicines from India – top 10 pharmacies in india
canada online pharmacy escrow pharmacy canada canadian drug pharmacy
india pharmacy: indian pharmacy delivery – buy prescription drugs from india
purple pharmacy mexico price list: mexican mail order pharmacies – buying from online mexican pharmacy
medicine in mexico pharmacies: cheapest mexico drugs – mexican drugstore online
http://mexicanpharmacy.shop/# reputable mexican pharmacies online
indianpharmacy com indian pharmacy delivery buy prescription drugs from india
mexican rx online: cheapest mexico drugs – mexico pharmacies prescription drugs
canadian medications pills now even cheaper best canadian pharmacy to order from
mexican drugstore online: cheapest mexico drugs – medication from mexico pharmacy
indian pharmacy paypal: indian pharmacy delivery – mail order pharmacy india
india pharmacy Healthcare and medicines from India india online pharmacy
canada pharmacy online: Prescription Drugs from Canada – canadian pharmacy ed medications
https://canadianpharmacy24.store/# canada drugstore pharmacy rx
canadian online drugs Prescription Drugs from Canada legitimate canadian mail order pharmacy
best india pharmacy: indian pharmacy delivery – cheapest online pharmacy india
reliable canadian pharmacy: Licensed Canadian Pharmacy – canadian family pharmacy
cost cheap clomid without insurance: cost of clomid without a prescription – can i get clomid pill
https://zithromaxall.shop/# zithromax
generic zithromax medicine zithromax buy where can i buy zithromax medicine
https://prednisoneall.com/# prednisone prescription online
https://amoxilall.shop/# amoxacillian without a percription
https://amoxilall.com/# amoxicillin 775 mg
can you buy amoxicillin over the counter amoxicillin 500 mg tablet price amoxicillin buy online canada
amoxicillin 500mg prescription: where can i buy amoxicillin without prec – amoxicillin pharmacy price
https://prednisoneall.shop/# canada buy prednisone online
cheap zithromax pills: buy generic zithromax no prescription – zithromax 500 mg lowest price pharmacy online
amoxicillin 500 mg capsule antibiotic amoxicillin amoxicillin medicine over the counter
https://amoxilall.com/# amoxicillin canada price
https://clomidall.shop/# can i buy generic clomid no prescription
http://zithromaxall.com/# buy generic zithromax no prescription
zithromax 1000 mg online zithromax canadian pharmacy zithromax 250 mg pill
https://zithromaxall.shop/# zithromax 250mg
prednisone 30 mg prednisone 2.5 mg tab prednisone 20mg capsule
https://prednisoneall.shop/# prednisone 60 mg price
https://zithromaxall.com/# zithromax 500mg over the counter
where can you buy prednisone: 50 mg prednisone canada pharmacy – prednisone canada pharmacy
https://prednisoneall.com/# buy prednisone without a prescription best price
cortisol prednisone prednisone 20mg online pharmacy buying prednisone without prescription
where to buy cheap clomid no prescription: can i buy clomid without insurance – generic clomid without insurance
http://clomidall.shop/# can i order clomid
https://prednisoneall.shop/# prednisone medicine
buy generic zithromax online generic zithromax medicine buy cheap zithromax online
http://amoxilall.com/# how to buy amoxicillin online
https://prednisoneall.shop/# prednisone 80 mg daily
prednisone buy online nz prednisone pills cost over the counter prednisone cheap
http://amoxilall.shop/# where can you buy amoxicillin over the counter
https://prednisoneall.com/# prednisone 30 mg daily
zithromax price south africa: generic zithromax azithromycin – zithromax online
http://amoxilall.shop/# amoxicillin pharmacy price
can you get clomid cost clomid without insurance get cheap clomid without rx
where can i buy generic clomid pills: where to get cheap clomid prices – cost of clomid no prescription
generic sildenafil: sildenafil iq – Sildenafil 100mg price
best price for viagra 100mg buy viagra online Viagra tablet online
http://kamagraiq.shop/# Kamagra 100mg price
https://kamagraiq.shop/# super kamagra
buy kamagra online usa: Kamagra Oral Jelly Price – sildenafil oral jelly 100mg kamagra
Kamagra Oral Jelly Kamagra Oral Jelly Price Kamagra 100mg price
Cialis 20mg price in USA: cialis best price – Cialis over the counter
buy viagra here: generic ed pills – Viagra generic over the counter
http://sildenafiliq.com/# buy Viagra over the counter
Generic Viagra online: sildenafil iq – sildenafil 50 mg price
Tadalafil price cialis best price Buy Tadalafil 5mg
Sildenafil Citrate Tablets 100mg: buy viagra online – Cheapest Sildenafil online
http://tadalafiliq.com/# Tadalafil price
Buy Tadalafil 20mg Buy Cialis online Tadalafil price
Kamagra tablets: Kamagra Oral Jelly Price – cheap kamagra
https://sildenafiliq.xyz/# best price for viagra 100mg
Cialis without a doctor prescription: Buy Cialis online – cialis for sale
Kamagra 100mg price: kamagra best price – Kamagra Oral Jelly
buy Kamagra sildenafil oral jelly 100mg kamagra sildenafil oral jelly 100mg kamagra
Cheap Viagra 100mg: generic ed pills – buy Viagra online
https://tadalafiliq.shop/# cialis for sale
http://kamagraiq.shop/# п»їkamagra
Kamagra Oral Jelly Kamagra 100mg Kamagra 100mg
https://tadalafiliq.com/# Generic Cialis price
Cheap Viagra 100mg: best price on viagra – Buy generic 100mg Viagra online
https://sildenafiliq.xyz/# Cheap generic Viagra
Sildenafil Citrate Tablets 100mg: buy viagra online – sildenafil 50 mg price
Kamagra Oral Jelly kamagra best price Kamagra Oral Jelly
Generic Cialis without a doctor prescription: cialis without a doctor prescription – Buy Tadalafil 5mg
http://tadalafiliq.com/# Cialis 20mg price in USA
sildenafil over the counter: generic ed pills – sildenafil over the counter
cheap kamagra: Sildenafil Oral Jelly – buy Kamagra
https://sildenafiliq.xyz/# sildenafil online
Viagra Tablet price buy viagra online Viagra without a doctor prescription Canada
https://kamagraiq.com/# buy kamagra online usa
super kamagra: Kamagra Oral Jelly Price – super kamagra
https://sildenafiliq.com/# buy viagra here
Generic Cialis without a doctor prescription: tadalafil iq – Generic Cialis without a doctor prescription
Cialis over the counter cialis without a doctor prescription cialis for sale
https://sildenafiliq.com/# Viagra generic over the counter
http://tadalafiliq.shop/# Cialis 20mg price in USA
Cialis over the counter: cialis best price – Cialis over the counter
http://tadalafiliq.shop/# Buy Cialis online
buy Kamagra Kamagra 100mg price super kamagra
sildenafil over the counter: generic ed pills – viagra canada
http://tadalafiliq.com/# Buy Tadalafil 20mg
canadian valley pharmacy International Pharmacy delivery canadian pharmacy prices
https://mexicanpharmgrx.com/# mexican rx online
world pharmacy india: best india pharmacy – india online pharmacy
http://mexicanpharmgrx.com/# best mexican online pharmacies
mexican online pharmacies prescription drugs mexican pharmacy mexican border pharmacies shipping to usa
best online canadian pharmacy: Canadian pharmacy prices – pharmacy wholesalers canada
https://mexicanpharmgrx.shop/# mexico drug stores pharmacies
buying from online mexican pharmacy: Pills from Mexican Pharmacy – buying prescription drugs in mexico
mexican rx online Pills from Mexican Pharmacy reputable mexican pharmacies online
http://canadianpharmgrx.xyz/# canadian pharmacy world
https://canadianpharmgrx.com/# recommended canadian pharmacies
online shopping pharmacy india Healthcare and medicines from India world pharmacy india
india online pharmacy: Generic Medicine India to USA – top 10 pharmacies in india
online pharmacy india: indian pharmacy – top online pharmacy india
https://canadianpharmgrx.xyz/# my canadian pharmacy review
canadian king pharmacy Canada pharmacy online my canadian pharmacy rx
https://canadianpharmgrx.xyz/# pharmacy canadian superstore
top 10 pharmacies in india: indian pharmacy – indian pharmacies safe
onlinecanadianpharmacy 24: canadian pharmacies online – online canadian pharmacy reviews
mexican rx online Pills from Mexican Pharmacy mexico pharmacy
http://canadianpharmgrx.xyz/# canadian pharmacy phone number
best online pharmacies in mexico mexican online pharmacies prescription drugs buying from online mexican pharmacy
canadian 24 hour pharmacy: Canada pharmacy online – canadian drugs
https://mexicanpharmgrx.shop/# mexico pharmacy
recommended canadian pharmacies: CIPA approved pharmacies – pharmacy wholesalers canada
legitimate canadian online pharmacies CIPA approved pharmacies canadian neighbor pharmacy
https://mexicanpharmgrx.shop/# buying from online mexican pharmacy
canadian online drugstore: List of Canadian pharmacies – my canadian pharmacy reviews
http://canadianpharmgrx.com/# canadian pharmacies comparison
top online pharmacy india Healthcare and medicines from India india online pharmacy
Online medicine home delivery: Generic Medicine India to USA – best india pharmacy
https://mexicanpharmgrx.shop/# mexican online pharmacies prescription drugs
mexico drug stores pharmacies: online pharmacy in Mexico – mexican online pharmacies prescription drugs
buy canadian drugs Cheapest drug prices Canada best canadian pharmacy online
https://mexicanpharmgrx.shop/# buying prescription drugs in mexico
ordering diflucan generic where can i buy over the counter diflucan diflucan pill
order cytotec online: buy cytotec online – Misoprostol 200 mg buy online
buy cheap diflucan online: where can i get diflucan – diflucan pill price
cipro ciprofloxacin: cipro online no prescription in the usa – ciprofloxacin 500mg buy online
tamoxifen skin changes: tamoxifen menopause – tamoxifen vs clomid
cytotec online order cytotec online buy cytotec
tamoxifen: tamoxifen moa – tamoxifen reviews
best diflucan price diflucan australia diflucan online pharmacy
Abortion pills online: buy cytotec – buy cytotec pills
buy diflucan cheap: diflucan pill otc – buy online diflucan
ciprofloxacin mail online: cipro ciprofloxacin – ciprofloxacin over the counter
http://diflucan.icu/# buy cheap diflucan online
ciprofloxacin mail online: cipro for sale – ciprofloxacin 500 mg tablet price
doxycycline without prescription doxycycline purchase doxycycline online
buy cipro online: ciprofloxacin 500mg buy online – buy ciprofloxacin
nolvadex pct tamoxifen cost alternatives to tamoxifen
buy cytotec over the counter: buy cytotec – buy cytotec online
ciprofloxacin: ciprofloxacin – ciprofloxacin 500mg buy online
buy diflucan yeast infection buy cheap diflucan online diflucan 150mg
can i buy diflucan over the counter in australia: diflucan generic – diflucan brand name 300mg
where can i buy nolvadex: tamoxifen endometriosis – tamoxifen for sale
http://doxycyclinest.pro/# doxycycline prices
diflucan buy in usa: diflucan 150 mg tablet price in india – buy diflucan online uk
buy cytotec pills online cheap purchase cytotec cytotec abortion pill
buy generic diflucan: diflucan 150 otc – diflucan online
generic doxycycline: doxycycline medication – doxycycline hyc
diflucan 150 mg tablet price buying diflucan medication diflucan price
purchase cipro: ciprofloxacin 500 mg tablet price – cipro pharmacy
cost of diflucan over the counter: over the counter diflucan 150 – buy diflucan uk
where to buy nolvadex tamoxifen alternatives hysterectomy after breast cancer tamoxifen
doxycycline 100mg tablets: order doxycycline online – doxycycline 150 mg
purchase cytotec: cytotec buy online usa – buy cytotec online fast delivery
https://misoprostol.top/# buy cytotec over the counter
ciprofloxacin mail online ciprofloxacin over the counter buy ciprofloxacin
tamoxifen joint pain: benefits of tamoxifen – tamoxifen for men
tamoxifen for sale: natural alternatives to tamoxifen – nolvadex pct
Misoprostol 200 mg buy online: purchase cytotec – buy cytotec over the counter
diflucan canada coupon: diflucan for sale online – diflucan 200mg tab
doxycycline generic how to buy doxycycline online doxycycline 50 mg
tamoxifen hair loss: tamoxifen dose – tamoxifen vs raloxifene
amoxicillin no prescipion: amoxicillin 500 mg for sale – amoxicillin 250 mg
amoxicillin 500mg capsules uk amoxicillin 500mg capsules price amoxicillin pills 500 mg
Great website.ots of useful information here. look forward to the continuation.
http://stromectola.top/# ivermectin 3mg dosage
prednisone 3 tablets daily: buy prednisone canadian pharmacy – prednisone 5mg capsules
buy clomid no prescription: can i get cheap clomid prices – can you buy cheap clomid without insurance
zithromax for sale us zithromax without prescription zithromax 250 mg
can i order generic clomid without insurance: where can i get cheap clomid without dr prescription – where buy generic clomid for sale
https://amoxicillina.top/# amoxicillin online pharmacy
ivermectin ebay stromectol ivermectin uk
where to buy cheap clomid prices: where buy clomid no prescription – where can i get cheap clomid pills
zithromax 250: zithromax capsules price – zithromax online
where can i get generic clomid: cost generic clomid without dr prescription – where to get cheap clomid
http://amoxicillina.top/# amoxacillian without a percription
buy generic clomid without insurance: cost clomid price – clomid cheap
where buy clomid without a prescription can you buy clomid where buy generic clomid without rx
https://amoxicillina.top/# where can i buy amoxocillin
https://amoxicillina.top/# where to buy amoxicillin over the counter
amoxicillin 250 mg: amoxicillin 250 mg capsule – amoxicillin no prescipion
online prednisone prednisone pills for sale price of prednisone 5mg
ivermectin price comparison: ivermectin 200 – ivermectin 1 cream generic
https://prednisonea.store/# prednisone buy cheap
zithromax cost australia: zithromax 250 mg australia – zithromax buy online no prescription
prednisone 10 mg canada: prednisone prescription online – prednisone 40 mg
order prescription drugs online without doctor: buy meds online without prescription – online pharmacy without prescriptions
buy medication online without prescription buy pain meds online without prescription buying prescription drugs in india
http://medicationnoprescription.pro/# buying prescription drugs in india
https://edpill.top/# buy erectile dysfunction pills online
http://onlinepharmacyworld.shop/# foreign pharmacy no prescription
best no prescription pharmacy: cheapest pharmacy to fill prescriptions with insurance – online pharmacy without prescription
https://medicationnoprescription.pro/# online pharmacy no prescription
best online prescription online meds no prescription best online pharmacy no prescription
http://edpill.top/# buy erectile dysfunction pills online
canadian online pharmacy no prescription: cheapest pharmacy prescription drugs – rxpharmacycoupons
order medication without prescription online canadian pharmacy no prescription no prescription needed
http://onlinepharmacyworld.shop/# pharmacy no prescription required
http://medicationnoprescription.pro/# buy prescription drugs online without
cheapest ed pills: ed medicines – cheap ed drugs
erectile dysfunction meds online: cheapest online ed meds – get ed meds online
https://edpill.top/# get ed meds online
https://onlinepharmacyworld.shop/# canada online pharmacy no prescription
buy ed medication online low cost ed medication buy erectile dysfunction pills online
http://medicationnoprescription.pro/# can you buy prescription drugs in canada
cheapest pharmacy for prescriptions without insurance: online pharmacy discount code – canadian pharmacy world coupon
http://edpill.top/# ed prescription online
canadian pharmacy online no prescription needed buying drugs without prescription canada pharmacy no prescription
https://medicationnoprescription.pro/# canadian pharmacy non prescription
buy medications online no prescription: indian pharmacy no prescription – order prescription drugs online without doctor
choi casino tr?c tuy?n trên di?n tho?i: casino tr?c tuy?n uy tín – casino tr?c tuy?n vi?t nam
choi casino tr?c tuy?n tren di?n tho?i game c? b?c online uy tin casino tr?c tuy?n uy tin
https://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
dánh bài tr?c tuy?n: casino tr?c tuy?n vi?t nam – dánh bài tr?c tuy?n
http://casinvietnam.shop/# game c? b?c online uy tin
https://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
casino tr?c tuy?n vi?t nam choi casino tr?c tuy?n tren di?n tho?i casino tr?c tuy?n vi?t nam
dánh bài tr?c tuy?n: casino tr?c tuy?n vi?t nam – web c? b?c online uy tín
casino tr?c tuy?n vi?t nam: web c? b?c online uy tín – casino tr?c tuy?n uy tín
casino tr?c tuy?n: casino online uy tín – casino tr?c tuy?n vi?t nam
http://casinvietnam.shop/# game c? b?c online uy tin
web c? b?c online uy tín: casino tr?c tuy?n vi?t nam – casino tr?c tuy?n uy tín
choi casino tr?c tuy?n trên di?n tho?i: casino online uy tín – casino tr?c tuy?n
https://casinvietnam.shop/# web c? b?c online uy tin
choi casino tr?c tuy?n tren di?n tho?i casino online uy tin casino tr?c tuy?n uy tin
choi casino tr?c tuy?n trên di?n tho?i: casino tr?c tuy?n – casino online uy tín
game c? b?c online uy tin casino online uy tin choi casino tr?c tuy?n tren di?n tho?i
game c? b?c online uy tín: game c? b?c online uy tín – casino tr?c tuy?n vi?t nam
http://casinvietnam.com/# choi casino tr?c tuy?n tren di?n tho?i
casino tr?c tuy?n choi casino tr?c tuy?n tren di?n tho?i casino tr?c tuy?n
casino tr?c tuy?n vi?t nam: web c? b?c online uy tín – game c? b?c online uy tín
web c? b?c online uy tin casino tr?c tuy?n vi?t nam choi casino tr?c tuy?n tren di?n tho?i
casino tr?c tuy?n vi?t nam casino tr?c tuy?n uy tin game c? b?c online uy tin
casino online uy tín: casino tr?c tuy?n uy tín – choi casino tr?c tuy?n trên di?n tho?i
https://casinvietnam.shop/# game c? b?c online uy tin
game c? b?c online uy tín: casino online uy tín – casino online uy tín
choi casino tr?c tuy?n tren di?n tho?i web c? b?c online uy tin choi casino tr?c tuy?n tren di?n tho?i
http://casinvietnam.shop/# casino online uy tin
http://canadaph24.pro/# canadian pharmacy meds
mexican drugstore online Mexican Pharmacy Online mexican mail order pharmacies
https://indiaph24.store/# online shopping pharmacy india
purple pharmacy mexico price list mexican mail order pharmacies mexican online pharmacies prescription drugs
purple pharmacy mexico price list: mexican pharmacy – п»їbest mexican online pharmacies
mexican rx online mexican pharmacy mexican rx online
http://indiaph24.store/# top online pharmacy india
Online medicine order http://indiaph24.store/# п»їlegitimate online pharmacies india
indianpharmacy com
reputable mexican pharmacies online mexico drug stores pharmacies medicine in mexico pharmacies
https://indiaph24.store/# india pharmacy mail order
medication from mexico pharmacy purple pharmacy mexico price list mexico pharmacy
http://canadaph24.pro/# legit canadian pharmacy online
https://canadaph24.pro/# canadian pharmacy 24h com safe
canadian pharmacy online ship to usa canadian pharmacies vipps canadian pharmacy
http://indiaph24.store/# indian pharmacy
п»їlegitimate online pharmacies india mail order pharmacy india top online pharmacy india
http://canadaph24.pro/# best canadian online pharmacy
best canadian online pharmacy canadian pharmacies canada ed drugs
http://canadaph24.pro/# canadian discount pharmacy
purple pharmacy mexico price list mexican pharmacy mexican online pharmacies prescription drugs
https://canadaph24.pro/# canadian pharmacy 24h com
canadian pharmacy phone number canadian pharmacies reputable canadian online pharmacies
https://canadaph24.pro/# canadian pharmacies compare
medication from mexico pharmacy cheapest mexico drugs buying from online mexican pharmacy
mexican pharmacy cheapest mexico drugs mexican pharmaceuticals online
https://mexicoph24.life/# buying prescription drugs in mexico
http://indiaph24.store/# top online pharmacy india
mexican rx online Mexican Pharmacy Online mexico pharmacy
https://canadaph24.pro/# canadian pharmacy no rx needed
mexico pharmacies prescription drugs Online Pharmacies in Mexico mexican pharmacy
https://indiaph24.store/# cheapest online pharmacy india
reputable indian pharmacies Cheapest online pharmacy india pharmacy
https://canadaph24.pro/# canadian online pharmacy
indian pharmacy buy medicines from India п»їlegitimate online pharmacies india
https://indiaph24.store/# buy medicines online in india
best canadian pharmacy to order from best canadian pharmacy to order from canadian neighbor pharmacy
http://mexicoph24.life/# buying from online mexican pharmacy
buy prescription drugs from india Cheapest online pharmacy online shopping pharmacy india
https://canadaph24.pro/# canadian pharmacy ratings
indianpharmacy com best online pharmacy india mail order pharmacy india
https://canadaph24.pro/# canada drugs online reviews
india online pharmacy indian pharmacy indian pharmacy online
http://indiaph24.store/# indian pharmacy paypal
legitimate canadian pharmacy Prescription Drugs from Canada maple leaf pharmacy in canada
https://indiaph24.store/# top 10 pharmacies in india
mexico pharmacy mexico pharmacy п»їbest mexican online pharmacies
https://indiaph24.store/# buy medicines online in india
pharmacies in mexico that ship to usa Online Pharmacies in Mexico mexican mail order pharmacies
https://canadaph24.pro/# canada pharmacy 24h
canadian pharmacy meds reviews canadian pharmacies canada cloud pharmacy
http://mexicoph24.life/# buying prescription drugs in mexico online
my canadian pharmacy review my canadian pharmacy rx legal to buy prescription drugs from canada
http://indiaph24.store/# top online pharmacy india
mexican border pharmacies shipping to usa cheapest mexico drugs mexican rx online
http://mexicoph24.life/# purple pharmacy mexico price list
medication from mexico pharmacy mexico pharmacy pharmacies in mexico that ship to usa
http://mexicoph24.life/# buying from online mexican pharmacy
canadian drug pharmacy Licensed Canadian Pharmacy canada drug pharmacy
https://canadaph24.pro/# canadian pharmacy drugs online
canadian pharmacy 24h com safe canadian pharmacies legit canadian pharmacy
https://mexicoph24.life/# medicine in mexico pharmacies
http://canadaph24.pro/# canadian pharmacy review
mexican mail order pharmacies Mexican Pharmacy Online п»їbest mexican online pharmacies
http://mexicoph24.life/# mexican mail order pharmacies
mexican online pharmacies prescription drugs Mexican Pharmacy Online buying from online mexican pharmacy
https://mexicoph24.life/# reputable mexican pharmacies online
medication canadian pharmacy canadian pharmacies best canadian pharmacy online
http://indiaph24.store/# top 10 online pharmacy in india
medication from mexico pharmacy mexican rx online mexican border pharmacies shipping to usa
http://canadaph24.pro/# legit canadian pharmacy online
top 10 online pharmacy in india indian pharmacy online Online medicine home delivery
https://indiaph24.store/# legitimate online pharmacies india
canadapharmacyonline Large Selection of Medications from Canada trusted canadian pharmacy
http://canadaph24.pro/# safe reliable canadian pharmacy
medicine in mexico pharmacies cheapest mexico drugs medication from mexico pharmacy
http://indiaph24.store/# best online pharmacy india
global pharmacy canada Certified Canadian Pharmacies canadian pharmacy
http://indiaph24.store/# india pharmacy
legal canadian pharmacy online canadian pharmacy world canadian online pharmacy
https://indiaph24.store/# indianpharmacy com
vipps canadian pharmacy Large Selection of Medications from Canada rate canadian pharmacies
https://canadaph24.pro/# canadian pharmacy world reviews
п»їlegitimate online pharmacies india indian pharmacy Online medicine order
http://canadaph24.pro/# canadian pharmacy meds
п»їbest mexican online pharmacies cheapest mexico drugs mexico pharmacies prescription drugs
http://indiaph24.store/# Online medicine home delivery
legal to buy prescription drugs from canada Licensed Canadian Pharmacy canadian pharmacy 1 internet online drugstore
http://canadaph24.pro/# best canadian pharmacy
Online medicine home delivery http://indiaph24.store/# indian pharmacy paypal
buy medicines online in india
mexico drug stores pharmacies mexican pharmacy mexican pharmaceuticals online
mexico drug stores pharmacies: mexico pharmacy – buying from online mexican pharmacy
buy medicines online in india indianpharmacy com reputable indian online pharmacy
https://mexicoph24.life/# buying prescription drugs in mexico online
https://canadaph24.pro/# best canadian online pharmacy reviews
mexico pharmacies prescription drugs: mexico pharmacy – mexican pharmacy
mexico drug stores pharmacies Online Pharmacies in Mexico mexican pharmaceuticals online
http://nolvadex.life/# how to get nolvadex
cytotec buy online usa cytotec online cytotec pills buy online
https://ciprofloxacin.tech/# buy ciprofloxacin
п»їcytotec pills online buy misoprostol over the counter buy misoprostol over the counter
https://finasteride.store/# cost of cheap propecia without insurance
buy cipro: cipro online no prescription in the usa – where can i buy cipro online
lisinopril 80mg tablet: cost of lisinopril 40mg – 50mg lisinopril
propecia without rx propecia cheap order propecia
buy cipro cheap ciprofloxacin 500 mg tablet price ciprofloxacin over the counter
https://finasteride.store/# propecia tablet
https://finasteride.store/# buying cheap propecia without a prescription
tamoxifen lawsuit who should take tamoxifen nolvadex gynecomastia
cipro online no prescription in the usa: buy generic ciprofloxacin – cipro pharmacy
ciprofloxacin order online: buy cipro cheap – cipro online no prescription in the usa
http://nolvadex.life/# tamoxifen 20 mg
cost cheap propecia without a prescription cost of cheap propecia without dr prescription generic propecia
http://finasteride.store/# order cheap propecia without dr prescription
cytotec abortion pill cytotec buy online usa buy cytotec pills
https://finasteride.store/# buy cheap propecia prices
lisinopril 12.5 lisinopril medication prescription lisinopril 20 mg tablet
tamoxifen hair loss: aromatase inhibitor tamoxifen – who should take tamoxifen
buying propecia without insurance: propecia brand name – buy cheap propecia online
https://lisinopril.network/# prinivil 10 mg tab
cytotec online buy cytotec in usa п»їcytotec pills online
https://lisinopril.network/# lisinopril 2.5 mg
cheap propecia price order generic propecia without insurance cost of cheap propecia online
http://finasteride.store/# get generic propecia price
http://cytotec.club/# Cytotec 200mcg price
lisinopril 25mg tablets: lisinopril tab 5 mg price – buy lisinopril 40 mg online
buy cytotec online fast delivery: buy cytotec over the counter – buy cytotec online fast delivery
where can i buy cipro online buy ciprofloxacin cipro for sale
https://nolvadex.life/# alternative to tamoxifen
п»їcytotec pills online buy cytotec in usa Cytotec 200mcg price
https://ciprofloxacin.tech/# ciprofloxacin mail online
nolvadex price: tamoxifen endometrium – nolvadex vs clomid
prinivil 5mg tablet: lisinopril 20mg tablets cost – lisinopril cheap brand
cost of cheap propecia pill cost cheap propecia cheap propecia without insurance
lisinopril 120 mg cost for 20 mg lisinopril lisinopril average cost
http://lisinopril.network/# zestoretic
https://nolvadex.life/# does tamoxifen cause menopause
http://lisinopril.network/# lisinopril 2.5 mg medicine
ciprofloxacin 500 mg tablet price cipro ciprofloxacin cipro ciprofloxacin
http://cytotec.club/# Misoprostol 200 mg buy online
propecia without insurance: cost propecia without dr prescription – cost cheap propecia for sale
tamoxifen endometriosis: tamoxifen dosage – tamoxifen benefits
Abortion pills online cytotec abortion pill buy cytotec over the counter
http://cytotec.club/# order cytotec online
http://cytotec.club/# purchase cytotec
п»їcipro generic buy ciprofloxacin over the counter cipro 500mg best prices
lisinopril 20 25 mg buy zestril lisinopril 50 mg
ciprofloxacin order online: buy ciprofloxacin – buy cipro online
cytotec buy online usa: cytotec buy online usa – cytotec abortion pill
https://lisinopril.network/# lisinopril online canadian pharmacy
http://lisinopril.network/# lisinopril 80 mg daily
tamoxifen estrogen tamoxifen breast cancer nolvadex for sale
https://nolvadex.life/# tamoxifen and depression
nolvadex generic how to prevent hair loss while on tamoxifen tamoxifen and osteoporosis
http://nolvadex.life/# nolvadex generic
https://cytotec.club/# Cytotec 200mcg price
ciprofloxacin mail online ciprofloxacin over the counter ciprofloxacin 500mg buy online
ciprofloxacin over the counter buy generic ciprofloxacin п»їcipro generic
https://ciprofloxacin.tech/# ciprofloxacin generic
tamoxifen cancer: nolvadex for sale – nolvadex online
generic propecia without prescription: get propecia price – cost of generic propecia without prescription
lisinopril brand name australia lisinopril online purchase lisinopril 20 mg coupon
https://cytotec.club/# purchase cytotec
who should take tamoxifen does tamoxifen cause bone loss tamoxifen joint pain
http://lisinopril.network/# lisinopril generic price comparison
http://lisinopril.network/# lisinopril 2016
https://kamagra.win/# buy kamagra online usa
Tadalafil price Generic Tadalafil 20mg price Cialis 20mg price
http://cenforce.pro/# cenforce for sale
Generic Cialis without a doctor prescription Generic Tadalafil 20mg price Cialis over the counter
Cialis 20mg price in USA Generic Tadalafil 20mg price Cialis without a doctor prescription
order cenforce: order cenforce – cheapest cenforce
buy Viagra online: Cheapest place to buy Viagra – best price for viagra 100mg
Levitra 20 mg for sale Cheap Levitra online Levitra 20 mg for sale
Buy Tadalafil 5mg buy cialis overseas Buy Tadalafil 5mg
https://levitrav.store/# Levitra online pharmacy
https://kamagra.win/# buy kamagra online usa
https://kamagra.win/# Kamagra Oral Jelly
Levitra generic best price Levitra generic price Vardenafil buy online
Buy Vardenafil online: Levitra 20mg price – Cheap Levitra online
sildenafil online: Cheap Viagra 100mg – Cheap Viagra 100mg
https://levitrav.store/# Levitra online pharmacy
Cenforce 100mg tablets for sale Cenforce 150 mg online buy cenforce
cheapest viagra: Buy Viagra online – sildenafil over the counter
https://kamagra.win/# Kamagra Oral Jelly
Viagra online price Buy Viagra online Cheap generic Viagra
Kamagra tablets: kamagra oral jelly – buy kamagra online usa
Cheap Viagra 100mg: Cheapest place to buy Viagra – Cheapest Sildenafil online
Vardenafil buy online: buy Levitra over the counter – Generic Levitra 20mg
https://levitrav.store/# Levitra 20 mg for sale
Kamagra 100mg price kamagra Kamagra 100mg price
http://kamagra.win/# п»їkamagra
https://kamagra.win/# п»їkamagra
п»їcialis generic Cialis 20mg price in USA Buy Tadalafil 10mg
https://cialist.pro/# Generic Tadalafil 20mg price
Kamagra tablets kamagra.win buy Kamagra
buy kamagra online usa: buy Kamagra – Kamagra 100mg price
Generic Levitra 20mg: Levitra 20mg price – Vardenafil price
http://kamagra.win/# п»їkamagra
http://levitrav.store/# Buy Vardenafil online
Buy Cialis online buy cialis online Buy Cialis online
best online pharmacies in mexico mexican pharmaceuticals online mexican online pharmacies prescription drugs
http://pharmnoprescription.icu/# canadian pharmacy prescription
cheapest pharmacy for prescriptions pharmacy discount coupons canadian pharmacy no prescription needed
mexican rx online: buying prescription drugs in mexico – medicine in mexico pharmacies
http://pharmworld.store/# no prescription needed pharmacy
canadian pharmacy discount code: pharm world store – legal online pharmacy coupon code
buy prescription drugs from india: Online medicine home delivery – indian pharmacy
india pharmacy: online pharmacy india – top 10 pharmacies in india
п»їonline pharmacy no prescription needed buy pain meds online without prescription online pharmacies no prescription
https://pharmnoprescription.icu/# indian pharmacy no prescription
rxpharmacycoupons: pharm world store – prescription drugs from canada
no prescription needed canadian pharmacy cheapest pharmacy canadian pharmacy without prescription
https://pharmmexico.online/# medicine in mexico pharmacies
http://pharmmexico.online/# mexico drug stores pharmacies
mexican border pharmacies shipping to usa: mexico drug stores pharmacies – mexican mail order pharmacies
best canadian pharmacy no prescription: online pharmacy – canadian pharmacy coupon code
prescription free canadian pharmacy online pharmacy online pharmacy without prescription
cheap drugs no prescription: online pharmacies without prescription – no prescription canadian pharmacy
indianpharmacy com india pharmacy mail order reputable indian online pharmacy
http://pharmworld.store/# cheapest pharmacy to get prescriptions filled
https://pharmnoprescription.icu/# pharmacy with no prescription
escrow pharmacy canada canadian online drugstore online canadian pharmacy reviews
buying prescription drugs in mexico: mexican online pharmacies prescription drugs – mexico pharmacies prescription drugs
Online medicine order: online shopping pharmacy india – reputable indian online pharmacy
mexico pharmacy: buying prescription drugs in mexico – mexican mail order pharmacies
pharmacies in mexico that ship to usa: buying prescription drugs in mexico – reputable mexican pharmacies online
mail order pharmacy india buy medicines online in india buy medicines online in india
http://pharmmexico.online/# purple pharmacy mexico price list
http://pharmindia.online/# india online pharmacy
purple pharmacy mexico price list: purple pharmacy mexico price list – medication from mexico pharmacy
buy meds online without prescription canada prescriptions by mail no prescription
pharmacies in mexico that ship to usa: medication from mexico pharmacy – mexico drug stores pharmacies
foreign pharmacy no prescription: pharm world – online pharmacy without prescription
reputable indian pharmacies top online pharmacy india best online pharmacy india
http://pharmworld.store/# canadian pharmacy no prescription needed
https://pharmmexico.online/# mexico drug stores pharmacies
http://pharmworld.store/# canadian pharmacy coupon code
northwest canadian pharmacy: canadian pharmacy 24 com – canadian pharmacy com
canadian prescription pharmacy: online pharmacy – cheapest pharmacy for prescriptions without insurance
non prescription medicine pharmacy non prescription medicine pharmacy canadian pharmacy without prescription
northern pharmacy canada real canadian pharmacy canadian drug pharmacy
http://pharmnoprescription.icu/# canadian pharmacy without prescription
buying prescription drugs in mexico: mexico drug stores pharmacies – medicine in mexico pharmacies
canadian pharmacies comparison: onlinecanadianpharmacy 24 – best canadian online pharmacy
non prescription canadian pharmacy: no prescription online pharmacies – pharmacy no prescription required
https://prednisoned.online/# prednisone 20 mg generic
prednisone 2.5 mg price: prednisone 20mg cheap – brand prednisone
buy neurontin online: over the counter neurontin – neurontin canada online
can i buy amoxicillin online amoxicillin canada price amoxicillin 500mg capsules antibiotic
where to buy amoxicillin pharmacy: generic amoxicillin 500mg – amoxicillin generic
neurontin 200 can you buy neurontin over the counter neurontin pills
https://zithromaxa.store/# order zithromax over the counter
doxycycline 200 mg doxylin doxycycline vibramycin
doxycycline prices: doxycycline 100mg dogs – generic for doxycycline
where to get zithromax over the counter: zithromax 250 mg tablet price – zithromax online pharmacy canada
zithromax 500 mg for sale: where can you buy zithromax – where can i get zithromax over the counter
https://prednisoned.online/# buy 40 mg prednisone
buy doxycycline online uk: buy doxycycline online without prescription – buy doxycycline online uk
purchase amoxicillin online without prescription amoxicillin 500 mg without a prescription amoxicillin buy online canada
ordering prednisone: buy prednisone without a prescription – prednisone 2.5 mg
canine prednisone 5mg no prescription: prednisone purchase online – prednisone pill
zithromax price canada: buy zithromax without prescription online – how to get zithromax over the counter
amoxicillin cost australia: amoxicillin capsules 250mg – amoxicillin 500mg capsule
price for 15 prednisone: prednisone 5093 – buy prednisone without rx
prednisone 10 mg brand name: prednisone 54899 – can i buy prednisone online without a prescription
buy prednisone online paypal: cost of prednisone 5mg tablets – india buy prednisone online
buy doxycycline for dogs: generic doxycycline – doxycycline generic
http://amoxila.pro/# amoxicillin for sale
buy prednisone online fast shipping: 30mg prednisone – prednisone brand name us
amoxicillin for sale online where can i buy amoxicillin online purchase amoxicillin 500 mg
https://gabapentinneurontin.pro/# neurontin tablets 300 mg
prednisone 10 tablet prednisone online sale prednisone medicine
medicine prednisone 10mg: prednisone for sale – can you buy prednisone over the counter uk
doxycycline monohydrate: buy doxycycline online 270 tabs – where to get doxycycline
order doxycycline 100mg without prescription: generic for doxycycline – doxycycline 100mg dogs
http://gabapentinneurontin.pro/# neurontin 200 mg tablets
generic prednisone otc fast shipping prednisone 20 mg prednisone
https://prednisoned.online/# prednisone uk price
generic doxycycline doxycycline hyclate generic for doxycycline
where can i buy zithromax medicine: zithromax for sale usa – can you buy zithromax online
25 mg prednisone: prednisone 2.5 mg tab – prednisone 2 5 mg
https://zithromaxa.store/# buy azithromycin zithromax
amoxicillin 500mg buy online uk amoxicillin 500mg capsules price amoxil generic
prescription drug neurontin: neurontin 300 mg caps – neurontin 200 mg
prednisone 1mg purchase can you buy prednisone online uk can i buy prednisone online in uk
http://gabapentinneurontin.pro/# neurontin prescription online
neurontin capsule 600mg: neurontin 300 mg buy – neurontin
buy zithromax canada: can i buy zithromax over the counter in canada – zithromax buy
purchase amoxicillin online: amoxicillin online pharmacy – amoxicillin azithromycin
buy amoxicillin from canada: where can i buy amoxicillin over the counter uk – where to buy amoxicillin over the counter
how much is amoxicillin prescription can you buy amoxicillin over the counter in canada generic amoxicillin online
https://doxycyclinea.online/# buy doxycycline for dogs
can i buy amoxicillin over the counter in australia buy amoxicillin 500mg usa amoxicillin 500mg capsules uk
http://zithromaxa.store/# where can i get zithromax over the counter
doxycycline mono: buy doxycycline monohydrate – order doxycycline
neurontin 500 mg tablet: purchase neurontin – neurontin 1800 mg
amoxicillin without rx: canadian pharmacy amoxicillin – amoxicillin 500 mg without a prescription
prednisone over the counter prednisone pills cost prednisone for sale online
http://doxycyclinea.online/# doxycycline 100mg capsules
buy doxycycline online uk doxycycline 200 mg doxy 200
http://zithromaxa.store/# zithromax for sale usa
generic doxycycline: doxycycline hyclate – doxycycline monohydrate
amoxicillin canada price: how to buy amoxycillin – amoxicillin cost australia
buy cheap generic zithromax: can you buy zithromax online – zithromax for sale us
amoxicillin for sale how to get amoxicillin amoxicillin 500mg price
where to purchase doxycycline: buy doxycycline hyclate 100mg without a rx – doxycycline tablets
neurontin brand name 800 mg neurontin 800 mg cost where to buy neurontin
https://zithromaxa.store/# zithromax 250 mg
buy doxycycline cheap: doxycycline mono – generic doxycycline
neurontin rx: neurontin 200 mg capsules – neurontin 300 mg capsule
zithromax prescription online: zithromax over the counter uk – can you buy zithromax over the counter in canada
doxycycline tablets doxycycline generic buy generic doxycycline
http://zithromaxa.store/# can i buy zithromax over the counter in canada
neurontin 50 mg neurontin drug 300 mg neurontin
doxycycline 100mg price: purchase doxycycline online – doxycycline order online
http://amoxila.pro/# generic amoxicillin
prednisone 10mg online: prednisone 12 mg – prednisone 20 mg tablets coupon
neurontin canada: neurontin online pharmacy – neurontin tablets 300 mg
The information you shared is incredibly interesting, thank you! Discover More
medicine amoxicillin 500mg generic amoxicillin online ampicillin amoxicillin
http://prednisoned.online/# 50 mg prednisone canada pharmacy
neurontin pfizer drug neurontin 200 mg neurontin cap
https://doxycyclinea.online/# generic for doxycycline
amoxicillin 1000 mg capsule: amoxicillin price without insurance – amoxicillin discount
neurontin price south africa: neurontin capsules 300mg – neurontin 100 mg cap
amoxicillin without rx: where can i get amoxicillin 500 mg – how to buy amoxycillin
amoxicillin 775 mg: where to get amoxicillin over the counter – buy amoxicillin 250mg
buy doxycycline hyclate 100mg without a rx doxycycline 100mg tablets doxycycline 50mg
buy gabapentin: neurontin pills for sale – neurontin buy online
https://prednisoned.online/# apo prednisone
amoxicillin 500 mg capsule amoxicillin 500 mg tablet price buy amoxicillin online no prescription
https://doxycyclinea.online/# doxycycline without a prescription
prednisone 10mg price in india: prednisone 2.5 mg tab – prednisone 30
gabapentin 300: buy gabapentin online – neurontin over the counter
doxycycline generic buy doxycycline online uk doxycycline order online
amoxicillin 500mg capsules uk: how to get amoxicillin over the counter – purchase amoxicillin online
http://prednisoned.online/# prednisone buy cheap
buy azithromycin zithromax average cost of generic zithromax buy zithromax canada