Hei!
Viimeistä viedään!
Tällä viikolla oli edessä haastava tehdä: suunnitella laskettelukeskuksen toimintoja ArcGISissä itsenäisesti. Jäiks!
Laskettelukeskus vain aloittelijoille – järkeä vai ei?
Aloitin etsimällä laskettelukeskukselle paikkaa Paikkatietoikkunasta. Yhden epäonnistuneen kokeilun jälkeen kohteeksi valikoitui lopulta Sallan alueella oleva Ukerovaara. Ajatuksena olisi siis perustaa Sallaan kilpaileva laskettelukeskus. Ajattelin, että keskuksen kohderyhmää ovat aloittelevat laskettelijat, joten haluan sinne vain erittäin helppoja ja/tai helppoja rinteitä. Keskeinen valintakriteeri oli oikeastaan Ukerovaaran sileän näköiset rinteet, joita voisi olla mukava lasketella. (Alueella on oikeasti myös ojaa ja rakennuksia siellä, minne ajattelin rinteiden laskevan, mutta kuvitellaan tätä harjoitusta varten, että näin ei ole.)
Kun olin ladannut korkeusmalliaineiston alueesta ja avannut sen ArcGISillä, aloin etsimään sopivia rinteitä. Tämä tapahtui Slope-toiminnolla, sekä Reclassify-työkalulla, jonka avulla pystyin luokittelemaan rinteet vaikeusasteen mukaisesti neljään eri luokkaan.
Selvisi, että Ukerovaaralla on hyvin vähän erittäin helppoja rinnekohtia. Keskityin siis vain helppoihin rinteisiin. Keskivaikeita kohtia oli helppojen rinteiden alueella, joten karsitaan nuo kohdat soveltuvuusanalyysilla. Halusin myös rinteiden olevan mahdollisimman tasaisia, eli että rinnesuunta olisi reitillä mahdollisimman samankaltainen (ei siis suuria töyssyjä tms). Soveltuvuusanalyysin kriteereiksi tuli siis:
-alle 25% jyrkkyys, rinnesuunta luode, pohjoinen, länsi (nämä suunnat koska jo rinnevarjostuksesta näkee että tasaisimmat rinteet ovat tällä puolen vaaraa)
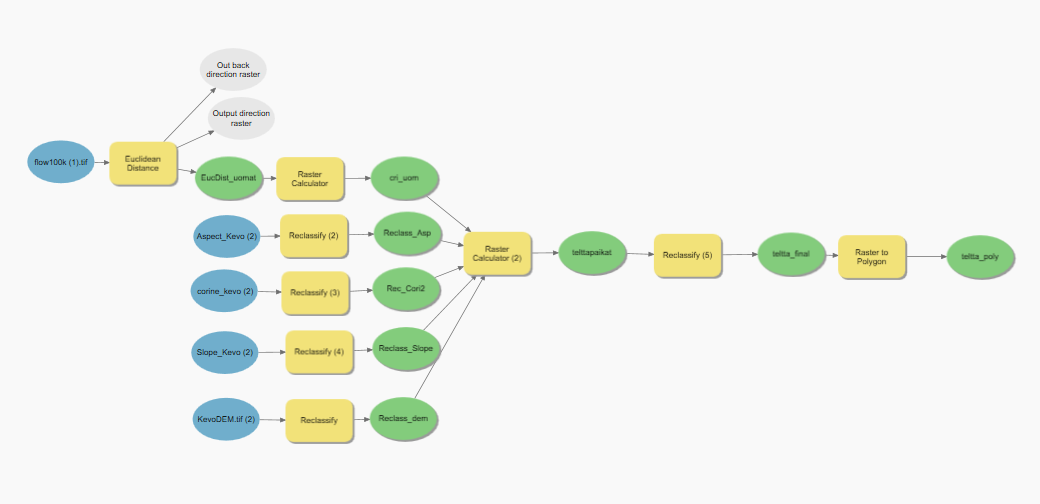
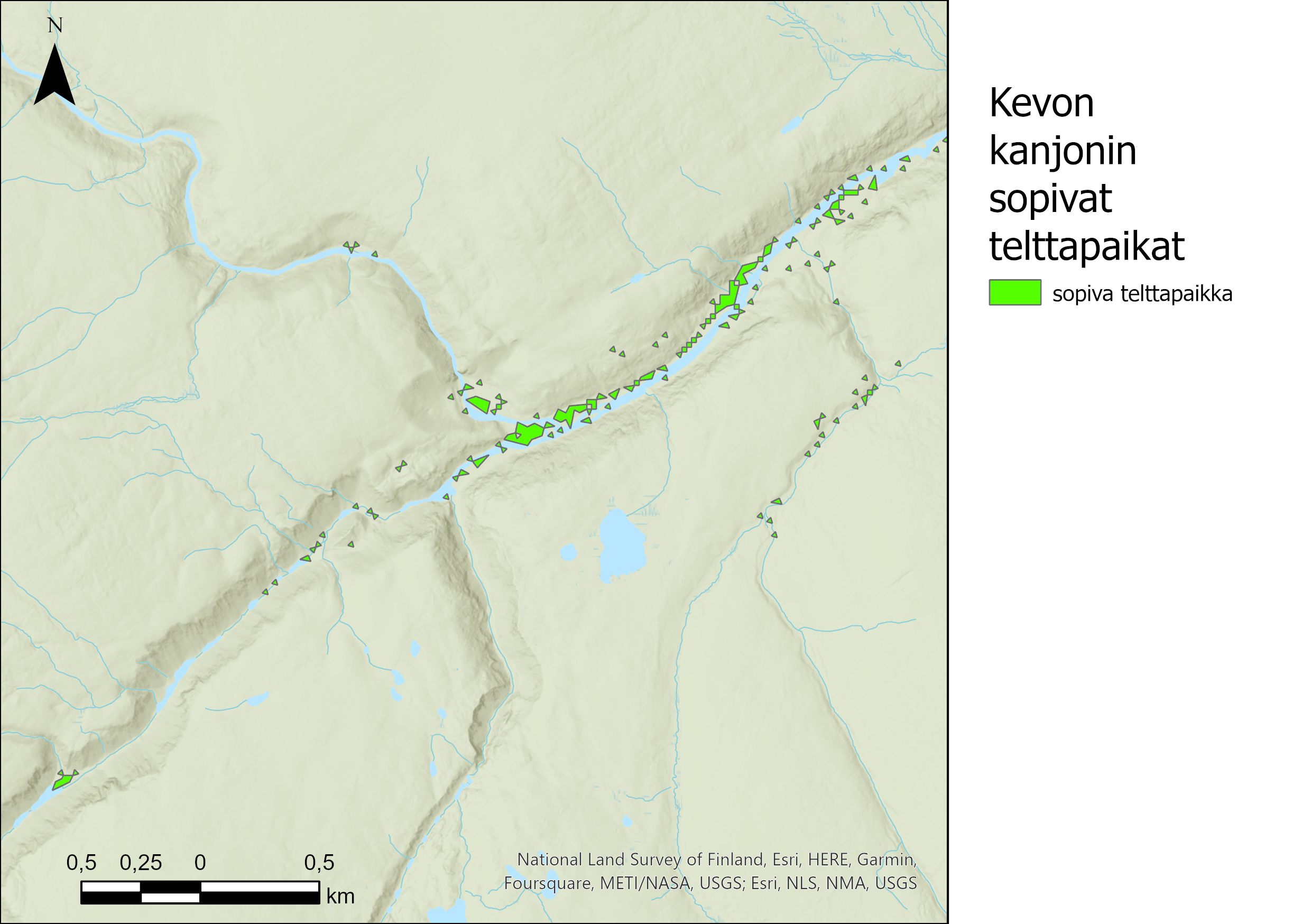
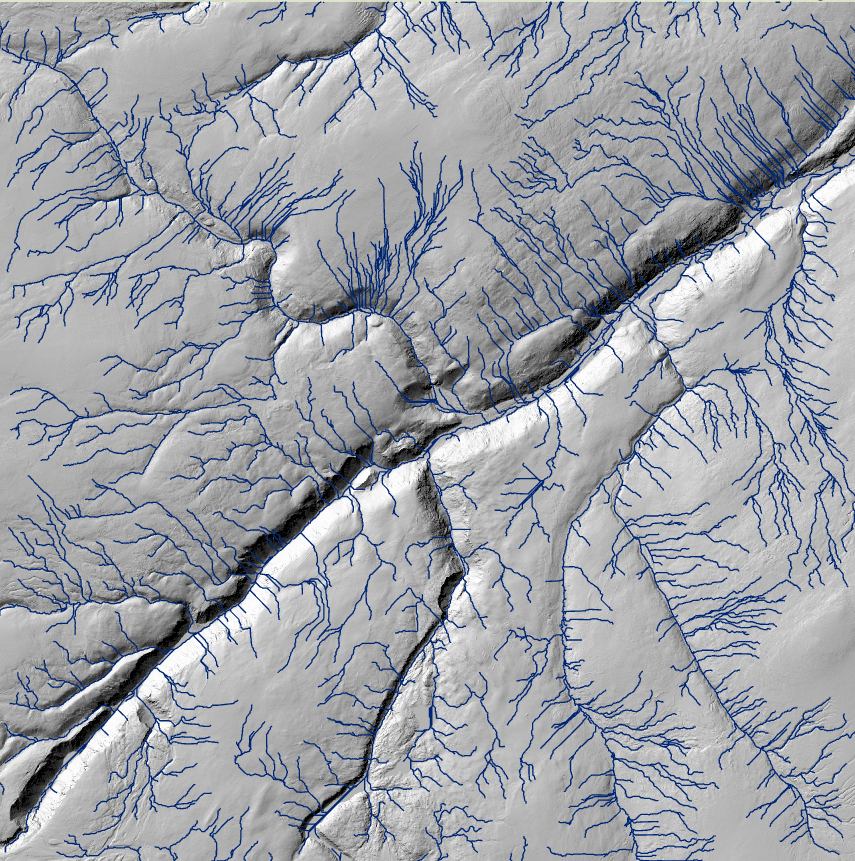
Soveltuvuusanalyysia varten yhdistin kriteerit täyttävät rasterit (Slope ja Aspect) Raster Calculatorilla. Muutin sitten vielä rasterit vielä vektorimuotoon Raster to Polygon-työkalulla. Tuloksena kuvan 1 kuvakaappaus, josta näkyy Ukerovaaran helppojen rinteiden alueet.
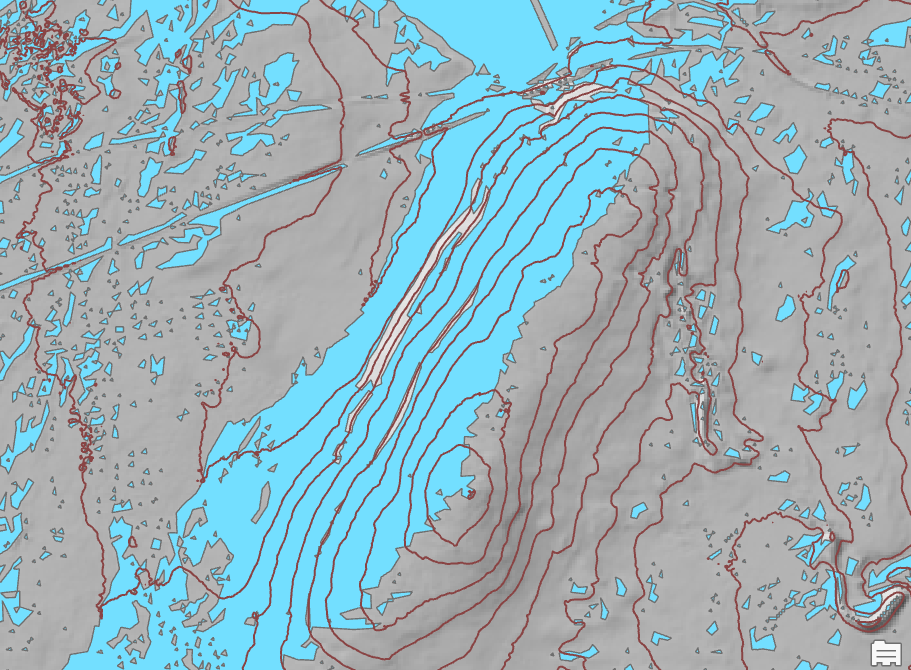
Kuva 1. Ukerovaaran helppojen laskettelurinteiden alueet soveltuvuusanalyysin jälkeen.
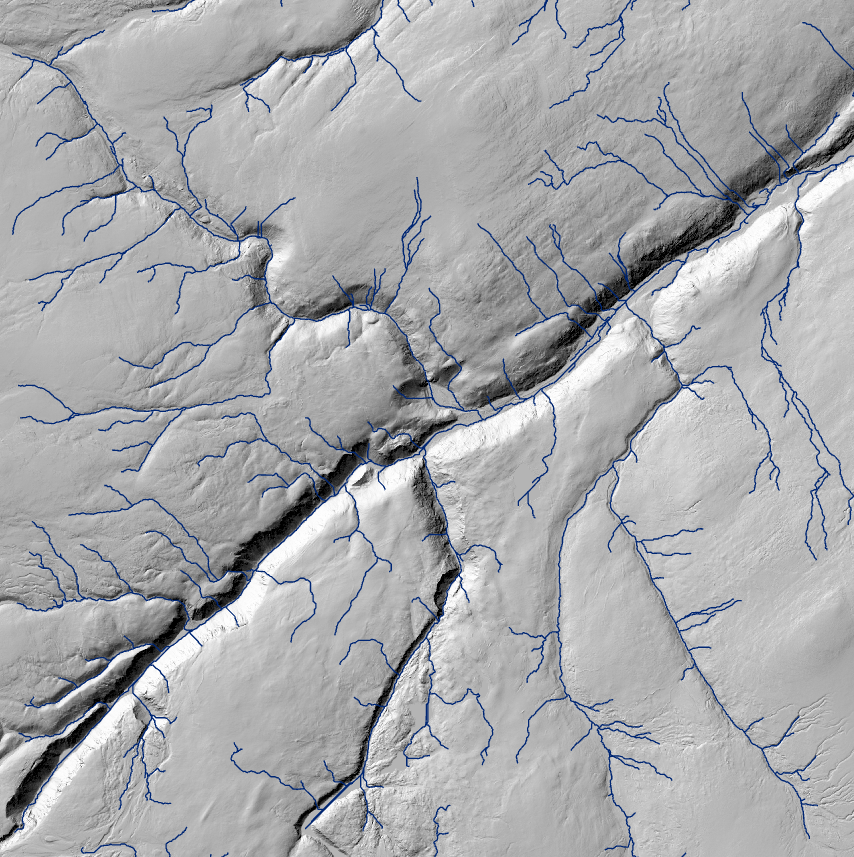
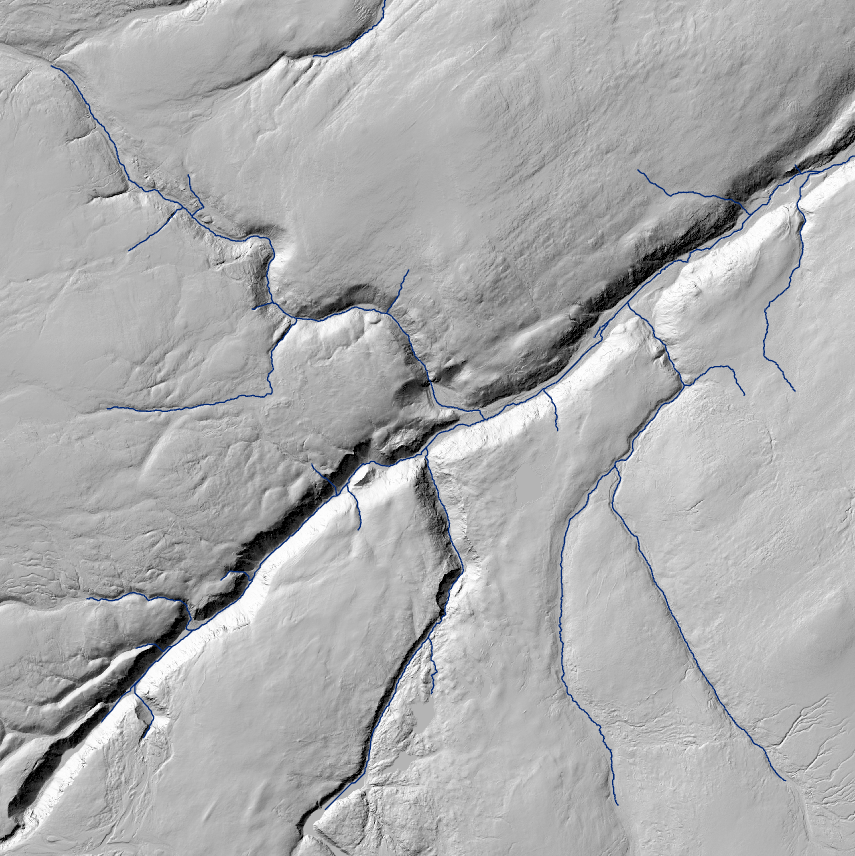
Digitoin kaksi erilaista laskettelureittiä, jotka eivät osu keskivaikeille kohdille. Näytti kuitenkin siltä, että alueen lähellä kulkeva rautatie on aivan turhan lähellä toista reittiä. Oletetaan että reitti ei saisi kulkea vaikkapa alle 100 m päästä rataa, ja tutkitaan bufferianalyysilla, osuuko se tälle vyöhykkeelle. Bufferianalyysi sen paljasti: toinen reiteistä kulkee turhan lähelle rataa. Tämän vuoksi leikataan Clip-analyysillä reittitasoa luodulla bufferilla. Leikatun tason attribuuttitaulukko kertoo, että liian lähellä rataa kulkee 287 metriä laskettelureittiä. Kun tämä vähennetään digitoidun reitin 737:stä metristä, niin jäljelle jää alle 500 metriä reittiä. Täytyy siis todeta, että sijainti tälle helpolle rinteelle on huono, ja vain toinen suunnittelemistani reiteistä voisi toimia.
Lopputuloksena tästä suunnitelmanpoikasesta voi todeta: aloittelijakeskuksen idea ei toimi, ja olisikin järkevää suunnitella Ukerovaaralle keskivaikeitakin rinteitä!
Kuvassa 2 vielä visualisoitu kartta molemmista reiteistä bufferin kanssa.
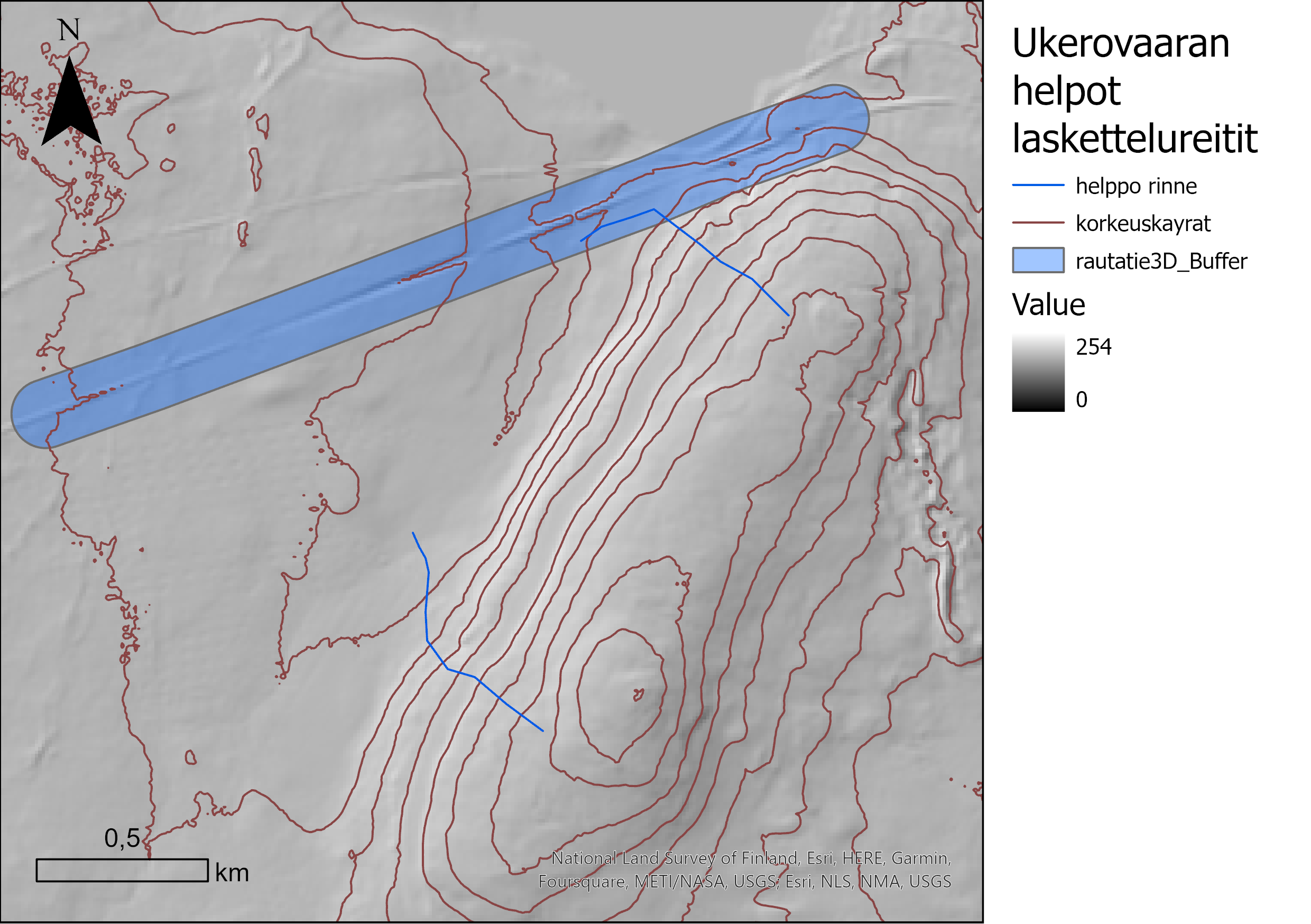
Kuva 2. Ukerovaaran suunnitellut helpot laskettelureitit.
Loppusanat
Tällä kurssilla on tullut niin paljon asiaa niin lyhyessä ajassa, että on ollut vaikeaa sisäistää tietoa sujuvaa itsenäistä työskentelyä varten. Siksi keskityin tässä tehtävässä mahdollisimman yksinkertaiseen analyysiin – tämäkin tehtävä oli minulle hyvin haastava. Oli vaikeaa keksiä mielekkäitä analyysejä, joita tässä olisi ollut järkevää soveltaa. Tehtävää hidasti sekin, että yritin ensin huonosti valitulla alueella, ja toisella yrityksellä Ukerovaarankin kanssa aloitin monia kohtia uudelleen alusta, kun en ihan hahmottanut, mitä olisi pitänyt tehdä. En siis sanoisi geoinformatiikan taitojani hyviksi: geoinformatiikka on aina ollut opinnoissa minulle vaikeinta. Toisaalta tällä kurssilla on ollut itselleni helpompiakin viikkoja, ja myös oppimisen iloa on mahtunut mukaan.