
Having processed the data from one of the two speakers, we’ve experimented with training synthetic voices using Tacotron 2 and FastPitch neural text-to-speech (TTS) frameworks, with good results. As mentioned in the previous entry, the FinSyn corpus contains a wide variety of speaking styles, posing a challenge for synthesis models; if the variation is unaccounted for, the resulting synthetic voices will be unpredictable, either producing speech in average style, or selecting more or less randomly among the styles present in the training corpus.
To account for the stylistic variation, we augmented the model with a reference encoder, which learns to encode the variance of the training data that can not be predicted from text alone. The reference encoder outputs a style embedding , a 128-dimensional vector, which is then used along the input text to synthesize speech. Running the whole corpus through the trained reference encoder, we obtain a view of the latent style embedding space, with second and third principal components of the space visualized below (the first component is related to the duration of the utterance). Each point corresponds to one utterance of the corpus and color corresponds to genre of the text.
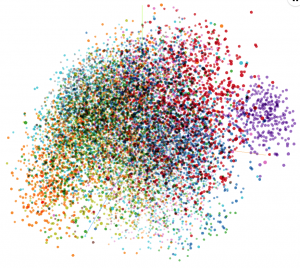
We can see that the genres are not clearly separated, and form a rather continuous space, which is expected; text genres do not completely specify the speaking style, and speaking styles form a multi-dimensional continuum.
To utilize the style embedding space in speech generation, we can, in principle, simply pick a point in that space to obtain speech with a style corresponding to that point. Subjectively, points closest to the center of the space, (average, or neutral style) provide highest quality synthesis. Listen to the following pair, can you determine which one is synthetic?
Ok, especially when listen with the headphones, it is not that difficult. But for us, having worked during earlier speech synthesis paradigms when intelligibilty was still a big concern, the quality is very satisfactory 🙂
Sampling the periphery of the style embedding space still produces fine results:
These were produced using the average embedding point of the respective genres / styles (parliamentary, spontaneous, whisper). To gain further control of the style, we devised a method (paper submitted) to smoothly vary the style, traversing the style space using prosodic characteristics of speech rate, vocal effort, and pitch. Some variants:
The ultimate goal related to our current project would be a system where the synthesis would react in a contextually appropriate fashion, using prosodic and linguistic ques of the dialogue situation to select a suitable speaking style (see: A Hierarchical Predictive Processing Approach to Modelling Prosody).