
Text Variation Explorer
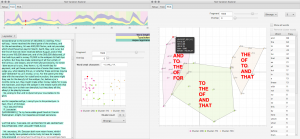 Exploratory data analysis is like graphical detective work – it forces us to notice things that we never expected to see. Text Variation Explorer (TVE) is our interactive exploration tool aimed for graphical detective work. With TVE, it is possible to make variation in text corpora visible and fingerprint writing styles. We are currently working on the second version of TVE, which provides enhanced visualization options as well as improvements on handling corpus metadata. The latest version, which comes bundled with the Parsed Corpus of Early English Correspondence (PCEEC), can be downloaded below.
Exploratory data analysis is like graphical detective work – it forces us to notice things that we never expected to see. Text Variation Explorer (TVE) is our interactive exploration tool aimed for graphical detective work. With TVE, it is possible to make variation in text corpora visible and fingerprint writing styles. We are currently working on the second version of TVE, which provides enhanced visualization options as well as improvements on handling corpus metadata. The latest version, which comes bundled with the Parsed Corpus of Early English Correspondence (PCEEC), can be downloaded below.
- Download TVE2 (zip file, extract to use)
- TVE2 manual
- Key to the PCEEC metadata included in TVE2
Khepri
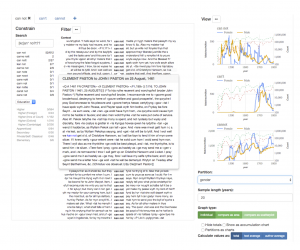 A modular view-based tool for exploring (historical sociolinguistic) data.
A modular view-based tool for exploring (historical sociolinguistic) data.
- Digital Humanities Conference 2016 Publication
- Digital Humanities Conference 2016 Presentation
- Test site
- GitHub repository
FiCa
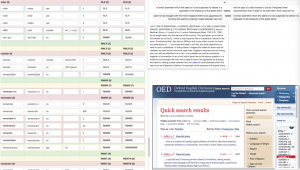 A user interface for quickly filtering and categorizing complicated data based on contextual information.
A user interface for quickly filtering and categorizing complicated data based on contextual information.
NATAS Python library
This library will have methods for processing historical English corpora, especially for studying neologisms. The first functionalities to be released relate to normalization of historical spelling and OCR post-correction.
