
Harri Haralds Matulis
Comparison of Six English translations of Lucretius “De rerum natura”
This is a slightly shortened version of full Research Report (26 pages pdf). Full research paper in pdf, Jupyter notebook python code, and other project files can all be found at this GitHub repository – https://github.com/haraldsDev/lucretius-translations-comparison
This project started as a group work, and author would like to thank other group members, Egzona Demaj & Sara al Husaini, especially for discussions which helped to formulate research goals and methodology better, and Petteri Moilanen for the input at the initial stages of research with assembling and pre-processing of the texts!

By artist Job (Onfroy de Bréville, Jacques Marie Gaston), from https://www.oldbookillustrations.com/illustrations/mars-venus/

* * *
1. Introduction and Methodological Approach.
Initial research idea – metric comparison of translations
This was the initial idea of what could be compared between English translations:
“To compare different translations, that would require to slice De Rerum text in smaller, meaningful units. In prose texts usually there is a “sentence-to-sentence” concordance. In poems, to preserve rhyme and meter, sometimes translators relocate words and phrases, but not across limits of one verse (stanza). Although Lucretius text is called Poem, that should be scrutinized – what is the unit in Lucretius: a verse, a paragraph, other. And do translators adhere to it. Furthermore, look at translations, are there some visible, distinct mark indicating a new line / sentence / paragraph which can be used to computationally split the text.”
However, no other translation except 1656en use obvious meter and end-rhymes – therefore another avenues for research had to be found.
Methodological approach to 6 translations comparison
In order to focus on the text itself and inter-textual comparison, a “Roland Barthes type approach” was chosen – that is, to not look at historical, biographical, socio-linguistical sources, references and analyses, but examine the text itself. (Partly such an approach was chosen because of the shortage of time, and the need to focus on one aspect – and this one aspect was: application of computational DH methods for comparison of translations).
In principle it is a valid and often fruitful method to focus on the features of text itself without putting too much emphasis on speculations derived from secondary sources. However, it has to be admitted, that in our research there was a serious hindrance to get completely trustworthy results with this method – our source texts (6 translations) were retrieved from the internet; and it is highly possible that some of the “features” (line-breaks; spelling of certain words; et al) we analyze in the text are later sediments, either by human-directed enhancing / editing of text, or just purely technical glitches introduced in the process of converting and processing text for uploading it to the web.
Some limitations to the method due to impurity of source texts
Here follows a glance at OCR errors in 1656en translation and their manual resolution, which obviously pose some limitations to “pure, a-historical” text analysis method, as the source text is actually not pure.
1656en translation with OCR errors:
Whilst on thy lips his fainting soul is plac’•,
And he within those sacred arms enchac’•;
Let charming accents thy sweet lips i•spi•e,
And for sad Rome an happy peace require;
For whilst our Countrey thus afflicted lies,
With what content oan we Philosophize!
Nor may brave Memmius then wanting be
To th’Publike peace in such perplexitie.
With manual correction of OCR errors:
Whilst on thy lips his fainting soul is plac’d,
And he within those sacred arms enchanc’d;
Let charming accents thy sweet lips inspire,
And for sad Rome an happy peace require;
For whilst our Countrey thus afflicted lies,
With what content oan we Philosophize!
Nor may brave Memmius then wanting be
To th’ Publike peace in such perplexitie.
As this part of research is not concerned with the exact linguistic change over time, the exact display of OCR-wronged words is not crucial, and just a fair effort is done to normalize these 4 words. “Inspire” looks normal, “plac’d” looks like a normal contraction. “enchanc’d” – could be a form of “enchanced”. “Publike” – related to “public”; as there are other Capitalized common words (as opposite to Proper names) before, the “Publike” is preserved with a capital “P”, and also suffix “-e” is preserved at the end – not knowing if such was orthography in 17th century or if it is an OCR-error.
A short description of Lucretius text analyzed in this research
42 lines from Book I, analyzed in translations: – introduction and veneration of Venus – Venus, goddess of love – Venus moves passions and desires in all nature and animal world – Mars, god of war, introduced – Mars desires Venus as others do and reclines over her – narrator asking for good peace for Romans – Memmius cannot devote himself to philosophy during these hard times to Rome.
2. Preprocessing of source files.
A pre-processing and cleaning of files for analysis
A script file freqlist.sh was written. It lowercases all text, removes specific punctuation and puts every token on a new line. (For punctuation removal an explicit command was used, because the default [:punct:] removed also dashes and hyphens, which was wrong for hyphenated words, such as “ship-bearing” and a few others).
#!/bin/bash
cat $1 |
dos2unix |
tr “[:upper:]” “[:lower:]” |
tr -d “[.,;:()!]” |
tr -s “[:space:]” “\n” > $2
To perform the above listed commands on all source files simultaneously a following Makefile was created:
BOOKS=1656en 1743en 1872en 1886en 1916en 1936en
FREQLISTS=$(BOOKS:%=results/%.tok)
all: $(FREQLISTS)
results/%.tok: tr-files/%.src
bash freqlist.sh $< $@
Here all initial files are saved in a variable BOOKS. Then a freqlist.sh file is executed on every file in the folder <tr-files>, and output is sent as files to folder <results>, preserving the same file names, now with an extension .tok added.
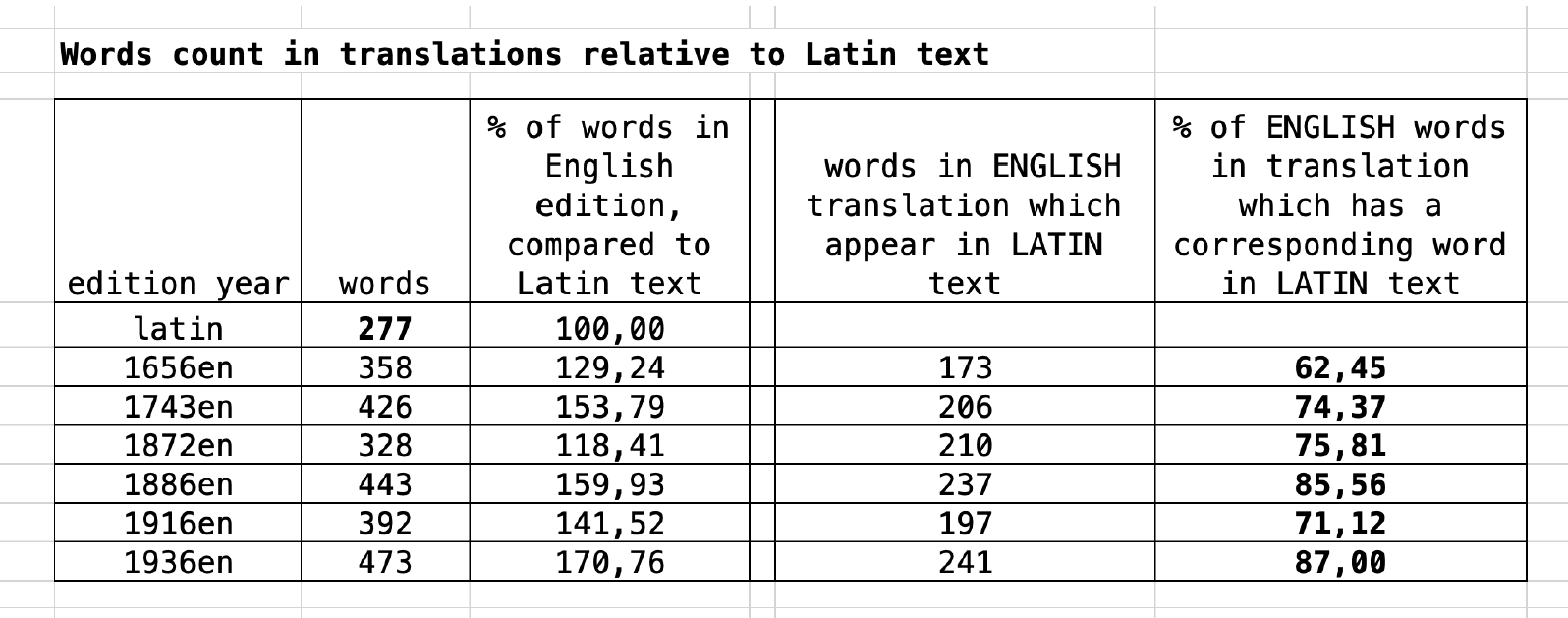
Tokens count in Latin and in English Translations
Greater quantity of tokens in English translations could be attributed to the qualities of English – more articles (the, an, a), prepositions (of), also occasional use of conjunctions (and), where there is not a conjunction in the Latin text.
Matching tokens from Latin text in each of English translations and percentage:
And this is how the Excel file of Latin text and 6 English translations looked like:
![]()
3. Analysis of linguistic and semantic choices in 6 translations
3.1. Six telling case studies
3.1.1. “navigerum” – influence of previous translations?
That was not a central question of research, however, it is interesting to see if translators use earlier translations or at least consult them – and can we deduce answer to this question by just comparing texts. All in all, the differences where so great between translations, that it could be said with certainty that all of them are independent, self-sustainable translations, even if translators where familiar with previous translations. From 42 lines containing 277 tokens (in Latin), there was just one occasion where English translations where very similar, although the form used was not an obvious choice. That refers to Latin words “navigerum” (14 token nr) and “frugiferentis” (17 token nr), which in 4 of 6 translations are translated with a hyphenated compound, e.g “ship-bearing”, see below.
Not elsewhere in the analyzed fragment such hyphenated forms occur. (0 denotes that there was no corresponding word in that English translation)
| 01_latin_order | 02_latin_tokens | 03_eng_direct_tokens | 1656_en | 1743_en | 1872_en | 1886_en | 1916_en | 1936_en |
| 14 | navigerum | Ship-bearing | ship-bearing | bearing | ship-bearing | ship-carrying | 0 | carries |
| 15 | quae | who | 0 | 0 | 0 | 0 | 0 | that |
| 16 | terras | earth | earth | earth | lands | lands | lands | land |
| 17 | frugiferentis | fruitbearing | corn-bearing | fruitful | corn-bearing | corn-bearing | fruitful | bears |
3.1.2. Favoni & genitabilis
| 01_latin_order | 02_latin_tokens | 03_eng_direct_tokens | 1656_en | 1743_en | 1872_en | 1886_en | 1916_en | 1936_en |
|
65 |
genitabilis | of (adj sg masc gen) | genial | genial | 0 | birth-favoring | procreant | teeming |
| 66 | aura | wind, air (in motion), a breeze, wind | 0 | winds | breathe | breeze | blow | wind |
| 67 | favoni | the west wind (Favonius) | west | western | zephyrs | favonius | west | west |
The slightly different translations of “genitabilis”, showing the rich variety of English. “Favoni” is interesting as it is a proper name in Latin, however, only one of translators choose to preserve the Latin form with an added suffix “Favonius”, while all other opt for translation “west-”, and one even allude to “zephyrs”.
3.1.3. Verbs and nouns – treated differently
| 01_latin_order | 02_latin_tokens | 03_eng_direct_tokens | 1656_en | 1743_en | 1872_en | 1886_en | 1916_en | 1936_en |
| 81 | ferae | a wild beast, wild animal | savage | savage | untamed | wild | wild | wild |
| 82 | pecudes | cattle | bruits | beasts | herds | herds | herds | beasts |
| 83 | persultant | to leap about, range through | jump | frisk | bound | bound | leap | bound |
| 84 | pabula | fodder, pasturage, grass | meads | fields | pastures | pastures | fields | pastures |
| 85 | laeta | joyful, cheerful, glad, | flowry | cheerful | glad | glad | happy | fat |
An example showing that nouns are translated with a variety of synonyms centering around the same root meaning – whereas verbs function as more independent entities, able to work in different contexts – therefore, there is not so close a “family resemblance” relationship between the verbs used to translate the same Latin token.
3.1.4. Adverbs – not much of a choice for translators
| 01_latin_order | 02_latin_tokens | 03_eng_direct_tokens | 1656_en | 1743_en | 1872_en | 1886_en | 1916_en | 1936_en |
| 124 | quae | because | since | since | since | since | since | since |
| 125 | quoniam | because (for) | 0 | 0 | 0 | 0 | 0 | 0 |
| 126 | rerum | things | 0 | 0 | 0 | 0 | 0 | things |
| 127 | naturam | nature | nature | nature’s | nature | 0 | cosmos | nature |
| 128 | sola | alone | sole | alone | alone | sole | alone | alone |
| 129 | gubernas | govern | reign | govern | rulest | mistress | guidest | pilot |
This example shows several characteristic features. First, the 2 tokens “quae quoniam” of Latin is translated by 1 in English, and here it (adverb) is similar to all translators. That tells that adverbs as function words are much more limited and translators cannot bend language to their taste when it comes to adverbs – which express a specific relationship. Rather interesting is the omission of “rerum” in all translations but one – that signalizes that all translators see “rerum” as an appendix to “naturam” rather than as an independent word bearing meaning. Translation of “gubernas” is furthermore interesting not only because of the wide variety of verb synonyms givens, bet also the noun form “mistress” used in 1886_en translation to translate the verb. Such interchanges between parts of speech are not uncommon.
3.1.5. Mars or Mavors
The following excerpt is telling in the attitude towards translating Latin proper name “Mars / Mavors” and his adjective “armipotens”:
| 01_latin_order | 02_latin_tokens | 03_eng_direct_tokens | 1656_en | 1743_en | 1872_en | 1886_en | 1916_en | 1936_en |
| 200 | belli | war | wars | war | war | war | battle | war |
| 201 | fera | beast | direful | bloody | 0 | savage | savage | wild |
| 202 | moenera | 0 | 0 | tumults | 0 | works | works | works |
| 203 | mavors | Mars | mars | mars | mars | mavors | mars | mavors |
| 204 | armipotens | in arms powerful | 0 | armipotent | potent | lord | puissant | lord |
| 205 | regit | to rule, to govern | lord | rules | rules | controls | rules | guides |
The nowadays accepted form in English is “Mars”. However, looking at 6 variants chosen by translators, actually the older translations use form “Mars” whilst 1886_en and 1936_en adhere to Latin form “Mavors”. If the opposite were true, then there could be made some speculations about gradual appearance of form “Mars” in English use. However, here it makes one pose the question – do more contemporary translations wanted to keep the original form of Latin for the sake of giving the authentic feeling of the text?
Such questions cannot be answered without background research of the topic – showing the potential of the computational methods in humanities (to find questions!), but also highlighting the importance of close reading and domain knowledge which help answer these questions!
“Armipotens” translations here show all the spectrum of translators’ choices when rendering a compound word which is fully meaningful in source language while direct translation might be incongruous in the target language – omitting it, transcribing the Latin with amendment of the suffix (“armipotent”), simplifying and keeping the essential part (“potent”), translating with an equivalent English term (“lord”), or providing an adequate but niche and foreign sounding translation (“puissant”).
3.1.6. “corpore sancto” – holy body, sacred arms, or heavenly limbs?
Some interesting commentaries about this passage where Lucretius describes lustful desires of Mars and him advancing on Venus. The scene is very erotic, full of passion, and although it is done in a godly way – with some restraint both on part of Venus and Mars – the depiction of desire is necessary for Lucretius as that is the gist of the passage: forces of war (Mars) and love (Venus) in an equilibrium as a necessary condition for procreation of anything.
Taking into account that translations were made to English language and to society living by Christian morality, where fleshly desires were frowned upon, it is interesting to see how translators chose to translate “corpore sancto”. The direct translation would be “holy body”. However, as “holy body” is often associated with body of Christ, some of translators choose different depictions, such as “sacred arms”, “heavenly limbs”, “sacred form”, “sacred limbs”.
| 01_latin_order | 02_latin_tokens | 03_eng_direct_tokens | 1656_en | 1743_en | 1872_en | 1886_en | 1916_en | 1936_en |
| 240 | tuo | on your | 0 | thy | 0 | thy | 0 | thy |
| 241 | recubantem | reclining | 0 | cling | recumbent | reposing | reclined | leans |
| 242 | corpore | body | arms | limbs | form | body | body | limbs |
| 243 | sancto | holy | sacred | heavenly | sacred | holy | holy | sacred |
| 244 | circum | round, around | 0 | round | 0 | about | round | 0 |
3.2. AGREEMENT – on what words translators agree most.
3.2.1. Untranslated words by all translators
The next section looks at unused (0/6 occurences) or very-little-used (1/6 occurences) words which are in Latin text but are not used / translated to English text – similarly for all or most of translations.
| 01_latin_order | 02_latin_tokens | 03_eng_direct_tokens | Nr of occurences in English translations | |
| 18 | concelebras | celebrate | 0 | |
| 57 | ac | and (from atque) | 0 | |
| 97 | quamque | and how | 0 | |
| 119 | ut | that | 0 | |
| 125 | quoniam | because (for) | 0 | |
| 134 | dias | dea, of deity | 0 | |
| 135 | in | in | 0 | |
| 157 | conor | try | 0 | |
| 170 | rebus | things | 0 | |
| 179 | ut | in | 0 | |
| 231 | eque | NaN | 0 | |
| 232 | tuo | yours | 0 | |
| 251 | funde | to pour out, to shed | 0 | |
| 261 | hoc | here, in this place | 0 | |
| 15 | quae | who | 1 | |
| 126 | rerum | things | 1 | |
| 142 | neque | nothing | 1 | |
| 144 | quicquam | anything | 1 | |
| 147 | studeo | studying | 1 | |
| 164 | in | in | 1 | |
| 227 | in | in | 1 | |
| 238 | tu | you | 1 | |
| 255 | incluta | celebrated,
famous, glorious |
1 | |
Reflections on groups of non-translated (0 or 1) words:
(1) prepositions and conjunctions – the sense of the sentence in English can often be expressed without these or they are unnecessary in English, or there are no equivalent in English.
(2) “dias” – used as an address of Venus, often in a repeated form in Latin, for which just a single address is kept in the English phrase.
(3) “rerum”, “rebus” – in phrase “rerum natura”, apparently treated as non-semantic addendum to the “rerum” and omitted in English by translators.
(4) “concelebras”, “conor”, “funde”, “studeo”, “incluta” – more research needed to conclude why these words were predominantly omitted in translation. Also, it cannot be ruled out that an incorrect translation to “03_eng_direct_tokens” was created (by the author of this research paper, because of insufficient Latin knowledge) and therefore some words were not spotted, although there might have been a corresponding English word in some translations.
3.2.2. Identically translated words by all or most translators.
| 01_latin_ order | 02_latin_ tokens | 03_eng_ direct_ tokens | Word in English Translations | How many of 6 translators use this word |
| 3 | hominum | human | men | 6 |
| 4 | divomque | godly | gods | 6 |
| 7 | venus | Venus | venus | 6 |
| 31 | dea | goddess | goddess | 6 |
| 43 | tellus | the earth, globe | earth | 6 |
| 45 | flores | a blossom, flower | flowers | 6 |
| 102 | maria | seas | seas | 6 |
| 124 | quae | because | since | 6 |
| 131 | sine | without | without | 6 |
| 136 | luminis | of light | light | 6 |
| 151 | quos | whom | which | 6 |
| 152 | ego | I | i | 6 |
| 186 | ac | and | and | 6 |
| 192 | tu | you | thou | 6 |
| 256 | pacem | peace | peace | 6 |
| 55 | nam | for | for | 5 |
| 61 | diei | day (sg, masc gen) | day | 5 |
| 69 | primum | the first, first | first | 5 |
| 78 | tua | yours, of you (adj sg fem abl) | thy | 5 |
| 109 | avium | birds | birds | 5 |
| 162 | dea | goddess | goddess | 5 |
| 249 | ore | mouth | lips | 5 |
Reflection on groups of words with great AGREEMENT:
(1) nouns,
(2) certain conjunctions and prepositions,
(3) use of pronouns at certain phrases are identical for translations.
3.3. DIVERSITY – on what words translators differ most.
Here is a list of words, where there is a great diversity between translators – 6 or 5 different versions.
| 01_
latin _order |
02_latin
_tokens |
03_eng_
direct_ tokens |
1656 | 1743 | 1872 | 1886 | 1916 | 1936 | uniques |
| 42 | daedala | skilful / Daedalus | th’inamel’d | art | plastic | manifold | daedal | quaint | 6 |
| 59 | patefactast | to lay open, open | brings | leads | unlocks | disclosed | comes | revealed | 6 |
| 113 | incutiens | strike | infuse | inspiring | infusing | striking | kindling | strike | 6 |
| 129 | gubernas | govern | reign | govern | rulest | mistress | guidest | pilot | 6 |
| 219 | suspiciens | looking up | bending | back | looking | upturned | backward | pillowing | 6 |
| 250 | loquellas | speech, words, chatter | accents | eloquence | words | discourse | syllables | petition | 6 |
| 252 | petens | seek, look for | require | implore | Imploring | asking | win | seeking | 6 |
| 260 | agere | to act, lead, move | philosophize | write | pursue | think | attend | set | 6 |
| 263 | tempore | times | whilst | times | hours | day | season | time | 6 |
| 6 | alma | nourishing | NaN | sweet | benignant | increase-giving | dear | life-giver | 5 |
| 26 | visitque | to look, view | beholding | view | behold | beholds | NaN | look | 5 |
| 41 | suavis | sweet, agreeable, grateful | sweet | sweetest | NaN | sweet-smelling | scented | sweet-scented | 5 |
| 66 | aura | wind, air (in motion), a breeze, wind | NaN | winds | breathe | breeze | blow | wind | 5 |
| 91 | capta | captivated, taken | NaN | pleased | captive | prisoner | seized | enchained | 5 |
| 106 | rapacis | rapid, current, rapacious | rapid | swiftest | NaN | sweeping | swift | tearing | 5 |
| 118 | efficis | succeed (you) | NaN | drives | causest | constrainest | bringest | makest | 5 |
| 123 | propagent | propagate, teem, | renews | propagate | renewal | continue | NaN | renew | 5 |
| 138 | exoritur | arise | NaN | rise | arise | rises | risen | comes | 5 |
| 233 | pendet | hang, suspend | plac’d | hangs | suspends | reclines | NaN | lies | 5 |
| 241 | recubantem | reclining | NaN | cling | recumbent | reposing | reclined | leans | 5 |
| 1 | aeneadum | Aenea | romes | rome | romans | aeneadae | rome | aeneas’s | 5 |
| 44 | summittit | puts forth | submit | affords | spreads | puts | bears | puts | 5 |
| 49 | ponti | the sea / bridge | seas | sea’s | ocean | sea | deep | ocean | 5 |
| 76 | perculsae | throw down, overturn, | touch | strikes | smit | smitten | smit | thrilled | 5 |
| 85 | laeta | joyful, cheerful, glad, | flowry | cheerful | glad | glad | happy | fat | 5 |
| 108 | domos | houses | roosts | forests | home | homes | homes | haunts | 5 |
| 114 | blandum | soothing, seductive | soft | tender | gentle | fond | lure | fond | 5 |
| 141 | laetum | happy | frolick | gay | joyous | glad | joyful | glad | 5 |
| 146 | sociam | be with, friend, associate, | ayde | companion | companion | helpmate | co-partner | helper | 5 |
| 169 | excellere | excell in | excell | grace | excel | peer | peerless | grace | 5 |
| 206 | in | in | on | in | upon | into | to | upon | 5 |
| 220 | tereti | round | round | long | rounded | shapely | full | shapely | 5 |
| 264 | iniquo | uneven, unjust, evil, wicked | afflicted | sad | adverse | trouble | troublous | trouble | 5 |
| 275 | communi | common, societal, of society | publike | common | common | general | civic | state | 5 |
| 277 | saluti | welfare, health | peace | good | weal | weal | cause | fortunes | 5 |
Reflection on groups of words with great DIVERSITY:
(1) verbs – verb translation often truly differs amongst them; this means that the action can be expressed with many differing verbs still keeping close semantic distance to the original.
(2) nouns (loquellas, saluti) – these nouns are usually parts of larger noun phrases, where the sense is acquired by translating all of the phrase, and often it is done not by direct word-to-word translation, but finding some corresponding phrase in English.
(3) adjectives (daedala, alma, suavis, laeta) – translations are close in meaning, having synonymic relationship, sometimes even derived from the same root with different suffixes and embellishments.
3.4. Comparison of word order deviations in 6 translations relative to Latin
To analyze the differences between original Latin text and translation, one of the aspects was “word order” – does the English translations preserve the word order that is in Latin? There are several reasons to preserve and to not preserve. Reasons for – translation is a reflection of the original, therefore it should be as close to the original as possible. Against – sometimes to preserve the idea, flow and feeling of the original you have to transgress from the original in order to recreate that idea, flow and feeling in the target language. Nevertheless, looking at 6 translations it should be possible to compare which of them keeps closer to the original and which deviate more.
However, this analysis was complicated by the fact, that English translations have much more tokens than Latin original – therefore, if we start with indexing both texts and then comparing the position of similar tokens (in Latin and in English),the further text progresses, the greater the distance; e.g. if the last token in Latin is number 277, then in English it is 328 at least (1872en) and 473 at most (1936en).
Therefore, to make such analysis sensible, texts were aligned sentence-to-sentence. This was not straightforward task for several reasons – the punctuation in Latin original is sometimes ambiguous – commas, full-stops and other marks are not so common as in contemporary language, and sometimes it was not with absolute certainty to say where one sentences ends and the next starts. Because of that some “chunks” for alignment were shorter (10-15), and one was longer (40), while the median was around 20-25 words for fragment.
For the purposes of analysis Latin text was cut in 12 “fragments” and English text was aligned to them. Of 12 fragments 6 are cut on a full-stop, 1 on a colon, 3 on a comma, 2 on a semicolon. Cut between fragments 2 and 3 are in the middle of the line, all other cuts are at the end of line. In fragment 9 there are 2 sentences, first of them ends with a full-stop, second is cut at a semicolon. Fragment 11 also contains 2 sentences, as in 1743en translation these sentences are intertwined and cannot be separated.
Some reflections on word order deviation in translations
Looking at 6 barcharts, and taking in consideration that English fragments were proportionally longer than Latin, there are few points to bear in mind: (1) the propensity of English positions to grow as translation sentences get longer – that explains partly why the distribution of English is more to the plus (+) side of deviation; (2) negative (–) deviation can be obtained not from the very start of the fragment, as English word cannot correspond to the Latin word of previous sentence – this further adds to the larger deviation towards plus (+) side.
![]()
(1) for the last 4 translations the deviation interval is from -5 to +15 (with a few outliers). For the first two translation the interval is greater.
(2) for the 1743en translation there is a cluster of words at interval (+15, +20). That can, perhaps, be explained with the fact that 1743en translation preserves the meter and rhymes at the end of lines and for that purpose some reposition of phrases was done.
(3) the highest peak in all 6 graphs is around position 0, which tells that all translations are following the Latin word order to some extent. For translations 1656en and 1936en the 0 position is almost twice as common (27 occurrences) as the next most frequent value (14, 16 occurrences). Whereas for 1743en and 1916en the values around 0 position (-1, 0, +1) are more evenly spread out.
4. Conclusions
- Initial idea to compare meter and rhyme was not doable, as there was not enough meter and rhyme preserved in 6 translations.
- Method of “ahistorical reading” of texts in principle gave good results, although some precautions about results should be kept, as texts worked with were not source files, therefore possibly altered versions.
- A decision to analyze closely 42 lines of original and 6 translations proved to be very, very time consuming close reading. And although the results obtained were interesting, with lacking total scientific rigor (because of working with copies not sources), it was more a learning process than results-oriented.
- Very different tokens count in Latin and English revealed some surprising facts – English texts were 29% to 70% longer than Latin original. However, English words having a corresponding word in Latin text was varying from 62% to 87%. Thus, it can be said that translations were quite far away from original if we look at word-to-word level, while on the semantic level all of the translations created a sufficient level of coherency and correspondence.
- Close reading linguistic, stylistic and semantic analysis revealed important aspects of different treatment of different parts of speech in translations – nouns and adjectives very translated most closely, while translation of verbs provided the greatest variance. This, perhaps, reveal an interesting feature about the way we use language – nouns are more mono-semantic, while verbs acquire their meaning depending on the context.
- Different treatment of proper names and their translation was encountered, however, there cannot be drawn conclusive summary about practices from such a short text. However, it was several times noted that later editions are using more archaic forms and vice versa. More research would be necessary to state is that because of individual taste of translators or because of prevailing conventions of the era.
- Comparison of word order deviation in translations relative to Latin original was very time consuming, but results were rather undecided. First major obstacle to meaningful analysis was radically larger tokens count in English (29% to 70% more). It made impossible to align both texts as “parallel texts”. A decision was made to align on sentence-to-sentence level. This was quite hard because of ambiguous punctuation in Latin, and decisions of translators to occasionally transgress borders of sentences. Looking at calculations derived from comparison of sentences (or parts of sentences), the result stated the obvious – that most words tend to occur at 0, -1 or +1 positions – or, to put in another way, that translators largely adhere to the original word order. However, where there were deviations it was almost impossible to tell do they derive from individual decisions of translator to transpose the word order, or because of larger tokens amount in English text.
5. Appendices – see in the full PDF version at GitHub repository!