
How book genres and their components evolved: An examination with Contextualized Topic Model
This report describes an experimental work of the “genre” group within the Digital Humanities Project Course 2022, ECCO (Eighteenth Century Collections Online[1]) database used to investigate the genre evolution of English publications during the century. It reveals several computational challenges and proposed solutions to processing an OCR-ed, large-scale, textual archive and implementing document categorization with Contextualized Topic Modeling (CTM). Furthermore, we highlight several genre patterns (frequency and association) that were consistent or changing through the temporal timeframes, with implications on the historical, social and intellectual motivation behind them.
-
Research question and objectives
“Genre” has been a fundamental yet developing concept in literary history and information retrieval. The word “genre” dates back from 1770 in the French language[2] and commonly used for the categorization of art, music or literature[3]. The concept is central to organizing human communication and knowledge as different systems of genres have been developed and deployed for libraries and bibliographical collections through ancient and modern times (Zhang, L., & Lee, H. , 2013[4]). Categorisation of genres, therefore, is historically dominated by rule-based approach and is seen as an annotation task for humans, while recent works in computational linguistics also seek to automate such decisions. Existing categorisations may adequately serve specific purposes for which they are designed for, though it is also important to note that hidden inconsistencies and overgeneralizations exist (Berglund, K., 2021[5]; Starks, D., Lewis, M., 2003[6]) and may become prevalent as archives grow by time and encompass works unbounded by larger geographical and temporal context.
Our motivation lies within a data-driven approach to understanding genre patterns and exploring how it can be meaningful for the literary and historical study of genre. Genres can be dynamic and undertake multiple changes over time, which static categorisation cannot fully capture. Using genre patterns as a guideline opens up a different set of interpretation to genre evolution and potentially extends theoretical implications. We therefore set our research questions as follow:
To what extent does the concentration of patterns evolve over time within genres?
More specifically, we aim to investigate which genres gain more popularity over time and which genres cease to exist (if any). Over time, we expect that some genres would tend to become more specified whereas others would be merged into bigger or more general “concepts”. A secondary aim would be to explore if there are any clear interrelations between genres?
On the methodological side, our work fits in the development of computational methods for recognizing patterns in large-scale data. Existing unsupervised models and most recently topic modeling provides powerful implementation vehicles for our work. Such an approach can also be examined or evaluated within the context of genre categorisation in comparison to the annotation and supervised approach.
-
Data, Preparation and Exploration
- Data
The ECCO dataset, originally created by software and education company Gale, consists of 180,000 digitized documents published originally in the eighteenth century with text converted to readable data using automated optical character recognition (OCR). The genre annotation of 10 main categories and 43 fine-grained subcategories of 30,119 documents made by (Jibing, Z., Yann, C., Iiro, R,, Filip, G., Mikko, T., and Rohit, B., 2022) is also taken into consideration in result comparison.

Table 1. Main categories and sub-categories in document annotation by Jinbing, Z., Yann, C., Iiro, R,, Filip, G., Mikko, T., and Rohit, B. (2022). Appendix A.1 - Data Exploration
Data exploration was the first step into understanding how to address our research questions. Firstly, we only focused on the ECCO dataset metadata to see the distribution of books when it comes to genres. Below, you can find book counts by genre, highlighting that there is clear unbalance in the representation of the different genres in the dataset; literature has around 10000 whereas politics, education, sales catalogs, philosophy and law combined would have less books in total. A similar analysis has also been conducted using the subgenres.
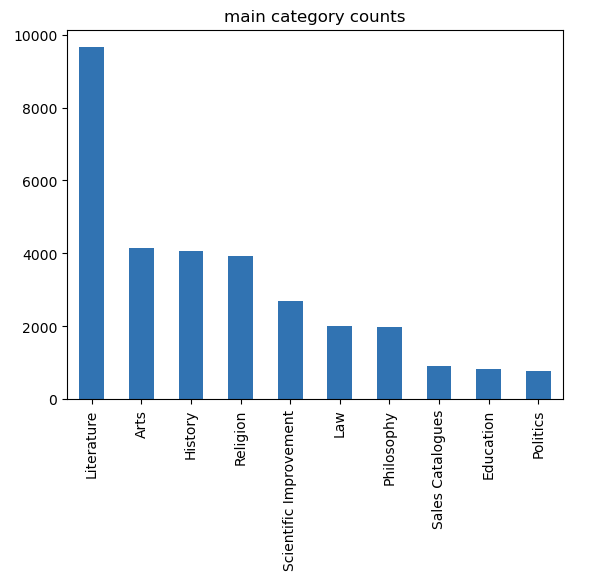
Figure 1A. Numbers of documents in each main category as annotated by by Jibing, Z., Yann, C., Iiro, R,, Filip, G., Mikko, T., and Rohit, B. (2022) 
Figure 1B. Numbers of documents in each subcategory as annotated by by Jibing, Z., Yann, C., Iiro, R,, Filip, G., Mikko, T., and Rohit, B. (2022) Second, we looked at how the book counts vary over time to see if some decades would be excluded from the analysis due to the lack of enough data. Most decades had at least 1000 books, with an average of 2580 books. The only decades with less books were 1680, 1700, 1710 and 18000. The decades provided are lower bounds (so 1680 represents 1680-1689).
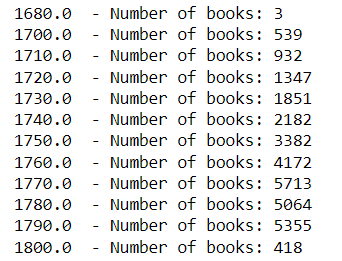
Figure 2. Numbers of documents in each decade Dashboards are made using Puhti geoconda module & Panel library to provide way for Humanities people to work with data exploration without coding with several features as:
- Interactive data browser interface
- Fetches needed text only after click, no need to keep data in memory
While the dashboard only enables selective manual text analysis, the works from this offer a complementary tool for no-code exploration and strengthen our motivations to investigate co-occurrence of genres within temporal frames and recognizing dominance of some sub-categories over others (example: sub-category 29 for religion).
- Data
- First Approach – ClusteringTwo main components for a model are feature extraction and the classification algorithm. The model represents data points with numerical values or vectors as features, and performs clustering based on single/several layers of linear/non-linear mathematical functions. In the case of our document clustering model, we experimented with several methods of representing document chunks (i.e. word2vec, sentence2vec, pre-trained contextualized embeddings) and different algorithm architectures (i.e DBSCAN, Topic Modeling).
- Data
Our first approach was using clustering models to find if it is possible to clusterize the data in such a way that the documents from each genre are grouped together. Also, once we found the clusters, see how the distribution of decades is inside each cluster, and find insights from them.The process started by preprocessing the training texts. It included lowercase the text, replaced jumps in lines and clean characters and numbers. After that, we joined our training data with the metadata, so we could have the publication year, place and authors id. Then again, we performed a merge with tables in the MariaDB database, specifically the tables ECCO_CORE and ECCO_DOCUMENT_PARTS, so that we could extract the part of the document that we wanted and the language. The next step was to filter the data, to have just documents in English and just the body part of them. The reasoning behind this was that there were documents of different languages, and that would make it difficult to preprocess vectors. And also, we realized that usually document parts that are not the body, for example the headers, contain multiple characters and punctuations, that are not useful and require more time and resources to be cleaned up, but they don’t provide enough information.Following, we tokenize the texts, to eliminate stop words and short tokens. After that, we used Word2Vec to create new vectors of the tokens that we have. We created vectors of size 100 and they are created based on the Word2Vec already trained vectors. We could experiment and see that the similarity between vectors, to find similar ones, worked. These vectors are just for each word, but we needed the vectors for documents. We created a pipeline to take the vectors of the tokens of a document, and then average them to get the new whole document vectors.
- ModelThe model that we used was DBSCAN. It stands for Density-based spatial clustering of applications with noise. Basically, it comes from the idea that we are able to identify clusters based on density. If there is a dense concentration of points in a plane, we as humans can identify the clusters. It will find three different kinds of points. First, some core points, then reachable points and at last, noise points. If a point is density reachable, then it must be part of the cluster. If it can not be reached, then it is classified as noise. In contrast with other clustering methods, like K-Means, DBSCAN does not need a fixed K hyperparameter, which is the number of clusters. By itself it will find the clusters in the data. But it still needs two hyperparameters, the distance 𝝴 and the minimum number of points required to consider a group of points a cluster.
We found out that the model is very sensitive to the two hyperparameters. At the beginning, we trained a DBSCAN model with the Word2Vec vectors, and the model classified almost all of them as noise, and just grouped together very few instances. To solve this issue, we had two options, tweak the distance hyperparameter or normalize the vectors, so we could compare them better. We actually did both, but the first option was hard to analyze. As clustering is an unsupervised method, after each run, we had to evaluate the distribution of clusters, see if we have less noise, but we still needed to interpret each cluster. The second option was to normalize the document vectors. We use UMAP for this.
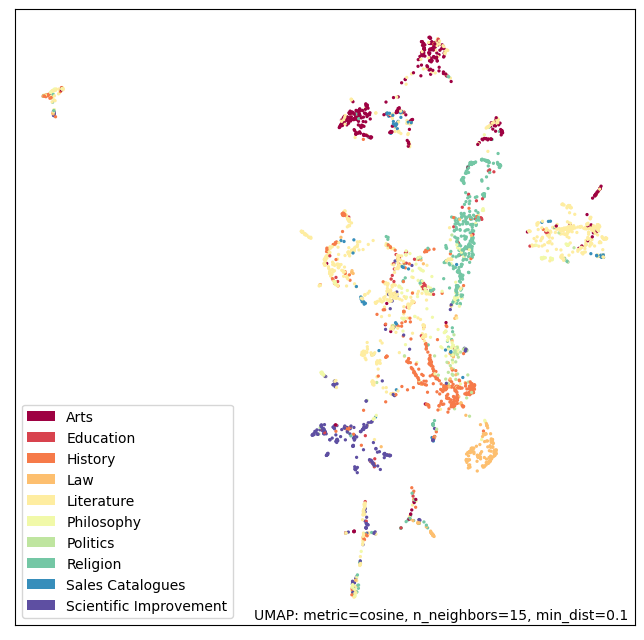
Figure 3. Distribution of annotate genres in clusters generated by UMAP UMAP is a dimensionality reduction method, like PCA. For this plot we reduced the vectors to 2 dimensions using cosine distance. We can see that there are clear clusters for Arts and Scientific Improvement. But for the rest of genres it is hard to identify a pattern or specific cluster. For example, the Literature genre is combined with many other genres, and it is scattered all around the plot. This is to be expected, since Literature is broad and not tied-up to just one specific topic. Religion also looks broad and can be related to multiple other genres.
The 2 dimensions were used just to be able to plot the results, but they are not the only or best dimension to reduce our data. We created a pipeline to reduce the dimensionality and then use HDBSCAN to cluster the resulting embeddings. We did not work further with this experiment, since we moved to topic modeling. It remains as future work.
- Data
- Experimenting with Topic ModelsContextualized Topic Modeling (CTM) developed by Bianchi, F., Terragni, S., & Hovy, D. (2021) is later selected for the main pipeline. It allows focus on underlying patterns that constitute genres, and can be adapted easily to explore the temporal evolution of genres with detected patterns. We based such patterns on “topics” in CTM, where a topic is defined as a set of closely related words using the whole corpus. One advancement in CTM compared to traditional neural topic models is the usage of SBERT pre-trained contextualized word embeddings to empower Bag-of-Words (BoW) document representations, which is proven to produce topics with higher coherence and easier to interpret (Bianchi, F., Terragni, S., & Hovy, D. , 2021). We experimented with different versions of CTM (ZeroShotTM, CombinedTM and SuperCTM) and based our analysis on the results of ZeroShotTM.

Figure 4. Architecture of Contextualized Topic Models by Bianchi, F., Terragni, S., & Hovy, D. (2021) - ZeroShot Model
- ModelAs stated previously, topic models a traditional representation of bag-of-words. They suffer from not being able to handle words that are not in the original bag and they are fixed to a specific vocabulary, therefore, they can only work for one language [5].
To address the problem with conventional topic models, it is necessary to incorporate the contextual information to the model input, for this purpose one could try using state-of-art contextual embeddings and give the embeddings as input to a conventional topic model, there are many pre-trained models available for generating contextual embeddings. Alternatively, one could adapt an advanced, ready to use model family that does exactly the same but in more coherent way and has more solid theoretical foundation, most importantly, the model family offers numerous methods that help with, eg. preprocessing. The model family described above is the model we ended up using, and it is called Contextualized Topic Models(CTM), it combines state-of-art contextual embeddings with a LDA topic modeling architecture, and it is able to get the topics coherently. CTM models, as it is illustrated in Figure 4, combine both contextual embeddings, from unprocessed document corpus, and BOW representation, from preprocessed documents, to generate inputs for the topic model, thus capturing contextual information. When testing, it is sufficient for the model to only transform the test dataset to contextual embedding form as input in our case, as the model has ability to handle unseen language and missing words, the BOW representation is not used, this feature shortens running time when testing, but also sacrificing overall coherence within topics, as results from our ZeroShot TM model might differ from CombinedTM model, which should produce a better result with pure english data, but the latter one is not feasible due to our data and computing environment. A version using the CombinedTM model would be implemented as future work.
Our data comes in multiple languages and also contains multiple misspelled words and characters. ZeroShot TM is capable of dealing with these situations, that is why we choose to use it.
- Preprocessing
The implementation of preprocessing consisted in two steps. First, we applied standard cleaning by lower case and cleaned basic jumps of lines. Then, tokenize the text and eliminate all tokens that are less than 3 characters and stopwords. That is the first step. Then, with the help of the Contextualized Topic Models library, another preprocessing step is applied. The white space pre-processes lowercase again, then eliminates all punctuations, removes stop words and vectorizes the documents as a Bag of Words. In this case, it was very helpful a set of stop words from the tutors that have worked on this project. At the beginning there were many topics that did not make any sense, with words that are random or are just weird characters in old versions of the language. This set that was given to us, removes all of those characters and there was a big improvement in the topics.
- Decades ModelsWe decided to create a different model for each decade. Since we tried with just one model overall, it is hard to see if there is a pattern over time, and see the incidence of each topic. We selected only the decades between 1720-1800 (8 decades), since they are the ones that have enough documents. From each decade, we selected the body of 1000 English documents from and divided them into a train set (800 documents) and a test set (200 documents). Topic models do not accept full topics, they only take documents with at most 128 tokens. This is why we decided to divide each document into chunks of 128 tokens and use all of the chunks for the training. The distribution of the genres in each decade is consistent in the sampling. All models were trained using 20 epochs. We did not use GPU for training. The specifications of the sessions during training were:
- 8 Cores
- 32 GB Memory
- 512 GB Local Disk
- ModelAs stated previously, topic models a traditional representation of bag-of-words. They suffer from not being able to handle words that are not in the original bag and they are fixed to a specific vocabulary, therefore, they can only work for one language [5].
- Combined Topic ModelCombinedTM is the standard model provided by the same authors of the ZeroShot and the SuperCTM models. It is supposedly more coherent, allowing for higher limits for the number of components compared to the ZeroShot model. However, this comes at the cost of higher computations. One common feature of all the models mentioned above is that they all utilize in-memory training.
For training the CombinedTM model, identical preprocessing to the ZeroShot model was used. That being said, the experiments were not successful because the model ran out of memory whenever a higher number of components than 10 was used, which is the primary reason for experimenting with this model. As a result, CombinedTM was not a feasible approach.
- SuperCTM ModelSuperCTM, short for supervised CTM, is an extension to the previous models that adds supervision. In SuperCTM, labels are added to the training data, which guides the behavior of the clustering algorithm. Internally, a one-hot vector is made out of the provided labels, which then acts as additional information about the data. It should be noted that this is not exactly the standard way of supervision, which means having the target values in the training set. Rather, the labels are an additional data point for an unsupervised clustering method.
One way to use SuperCTM would be to manually label a subset of training data and use that as a seed for the clustering algorithm. An iterative method would also be possible, where the results are examined after initial clustering, new labels are added based on the results, and a new clustering is initiated. For our work, we used the pre-made categorization to examine if the clustering would result in a closer match to that categorization, compared to the other models.
- ZeroShot Model
-
Results & Analysis
- Topic Clusters
Most topics have the same structure. At least 9 or 8 topics are really close together and usually the topic #10, or the one that is further from the others which contains outliers and tokens that do not have significant topical meaning.
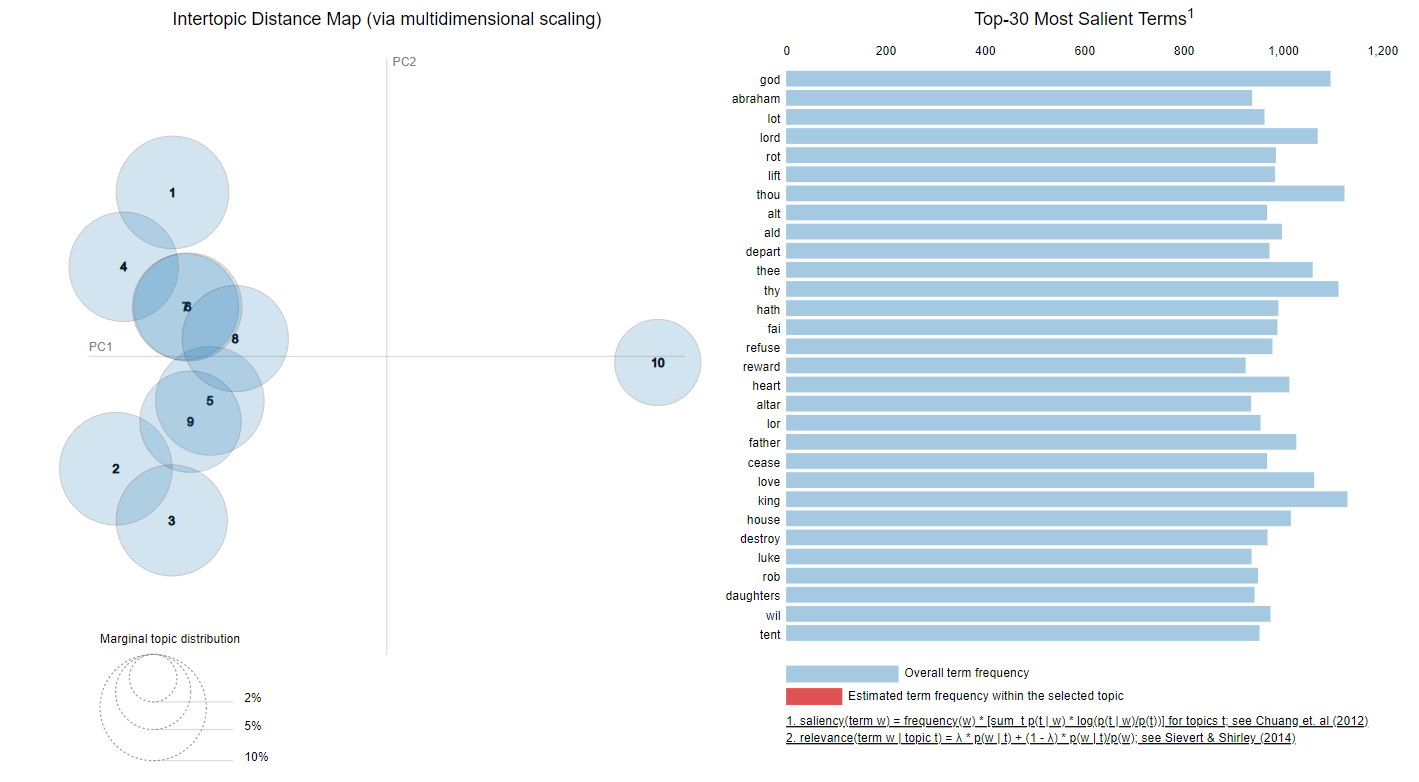
Figure 5. Topics of the 1790 model 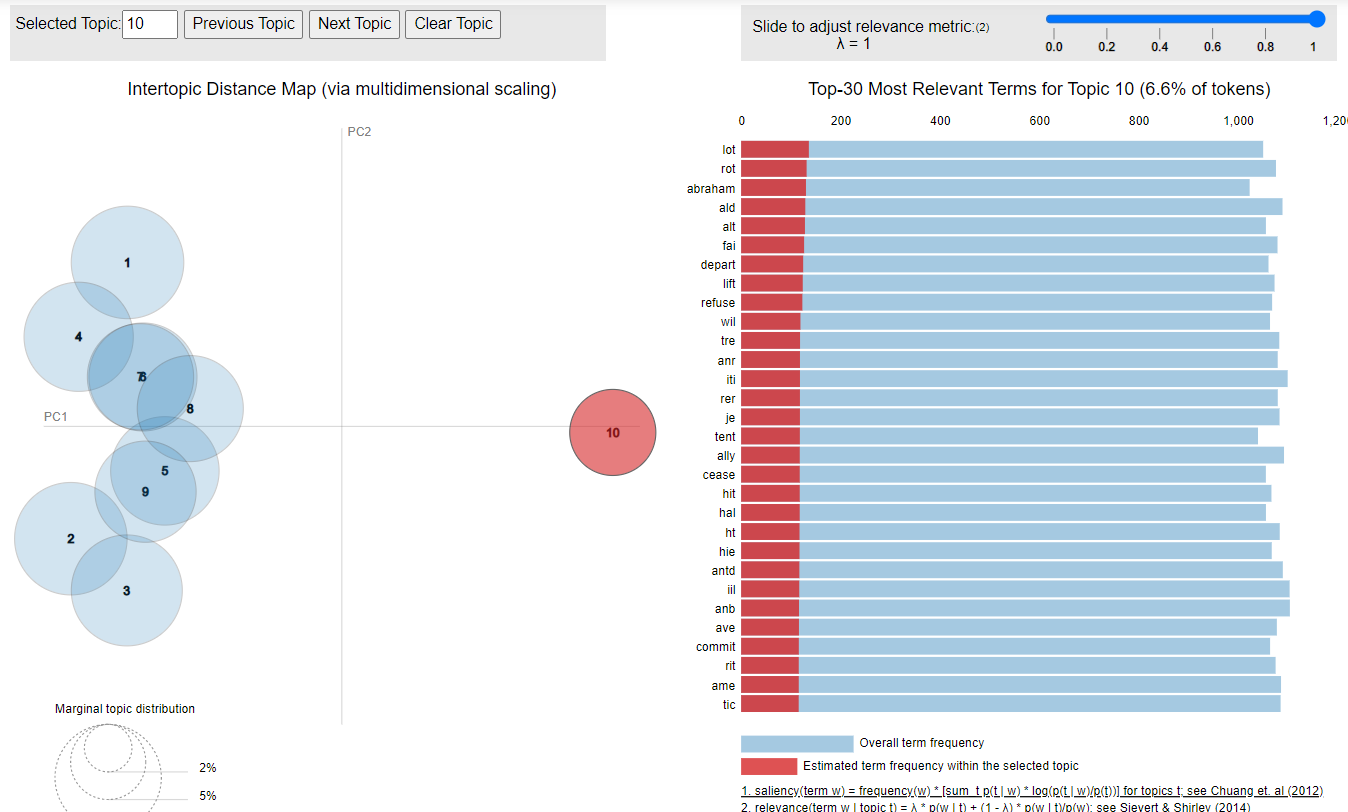
Figure 6. Topic #10 of the 1790 model 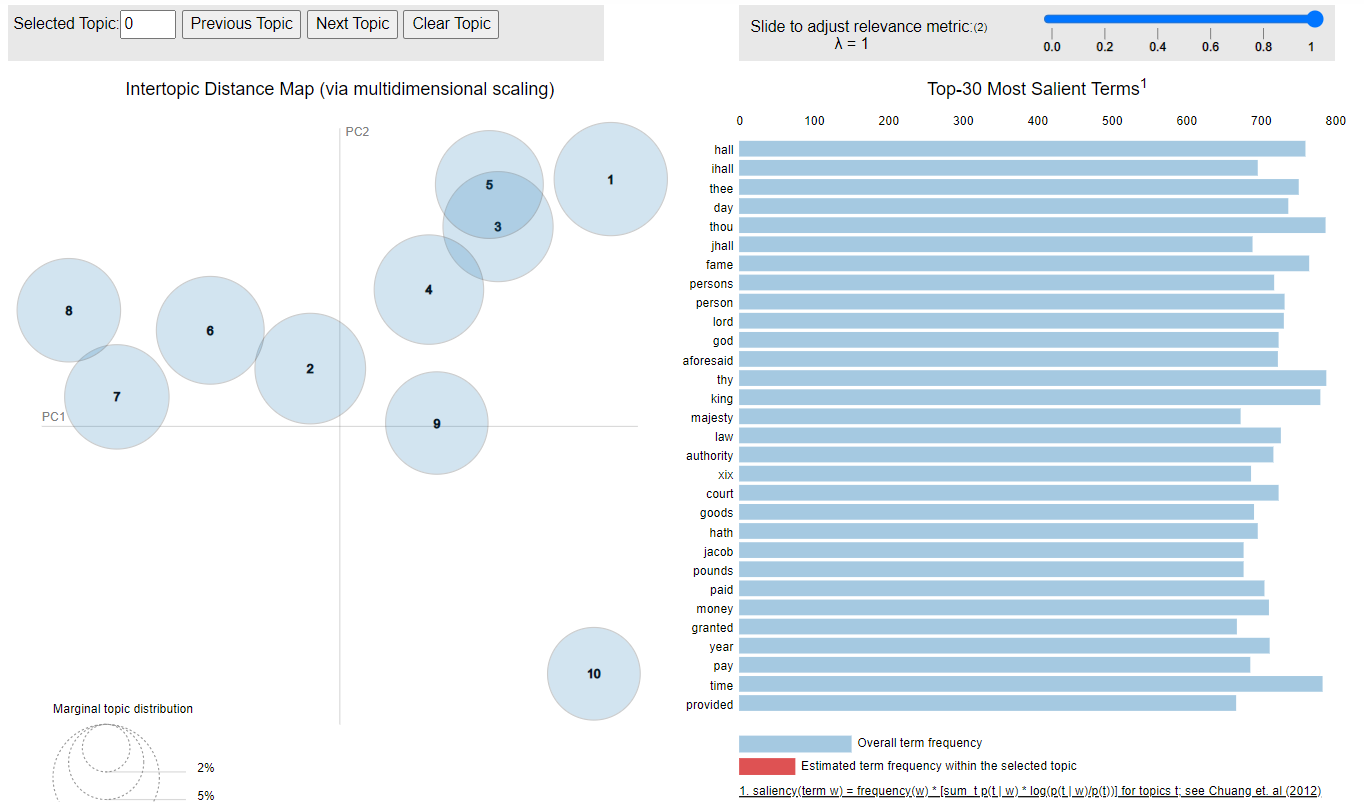
Figure 7. Topics of the 1780 model In this case, the topics are more spread out, not so close to each other, but there is still one topic that contains the outliers. Spread-out topics allow us to differentiate them better, they are a clearer central topic. But when they are close together we can also see the relationship between topics. For example, how closely related are the ideas behind government, the state, and the church.
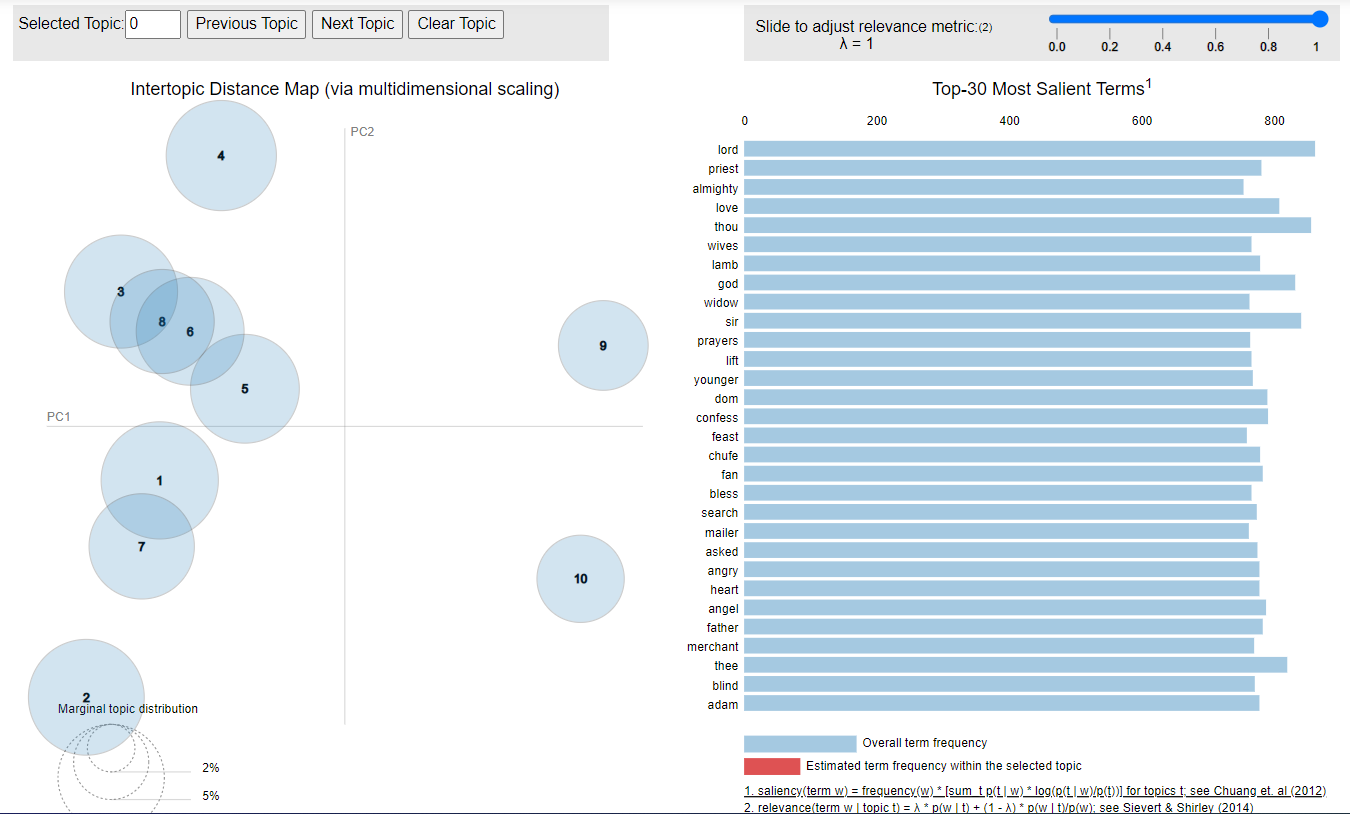
Figure 8. Topics of the 1770 model 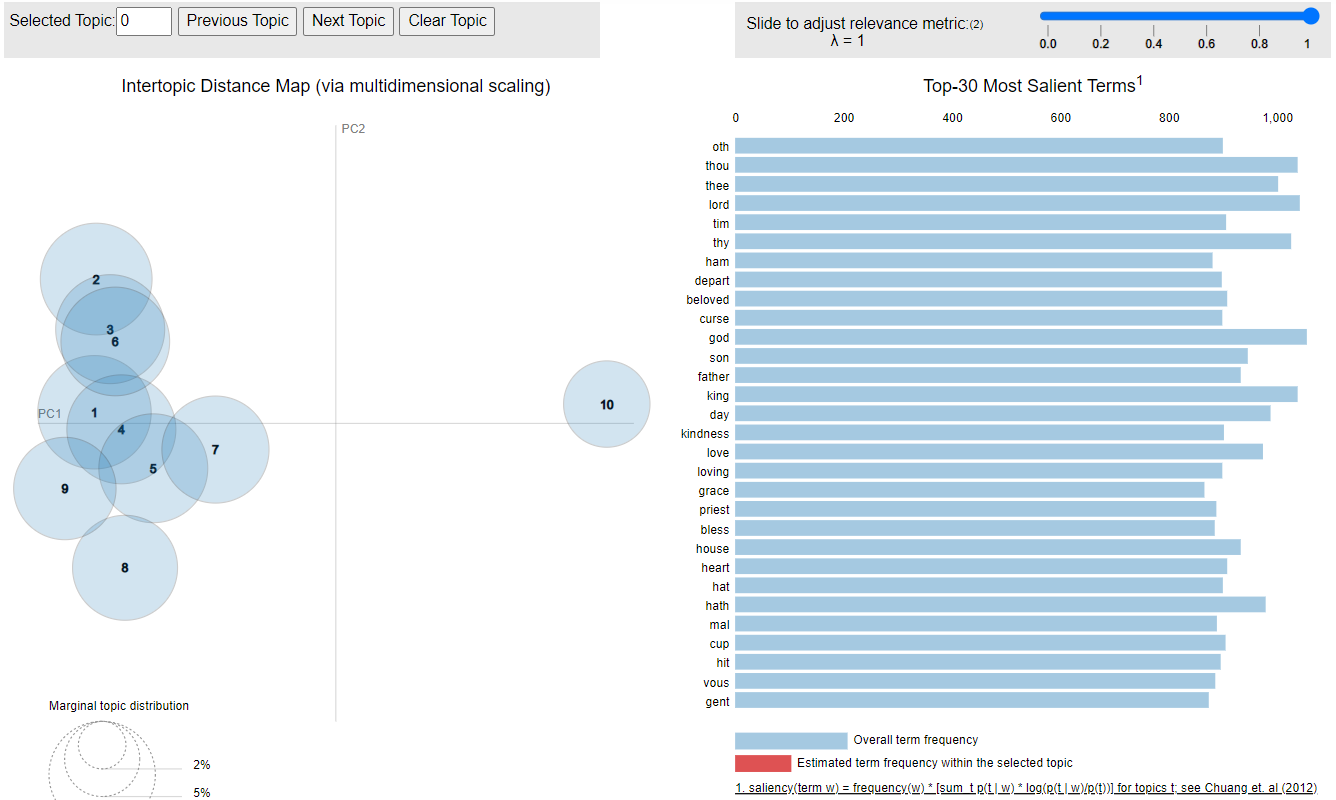
Figure 9. Topics of the 1740 model This is one of the hardest to analyze. Topic #10 contains normal words, not just weird tokens, but it does not represent any central idea. The rest of the topics are so close together that it is difficult to separate them.
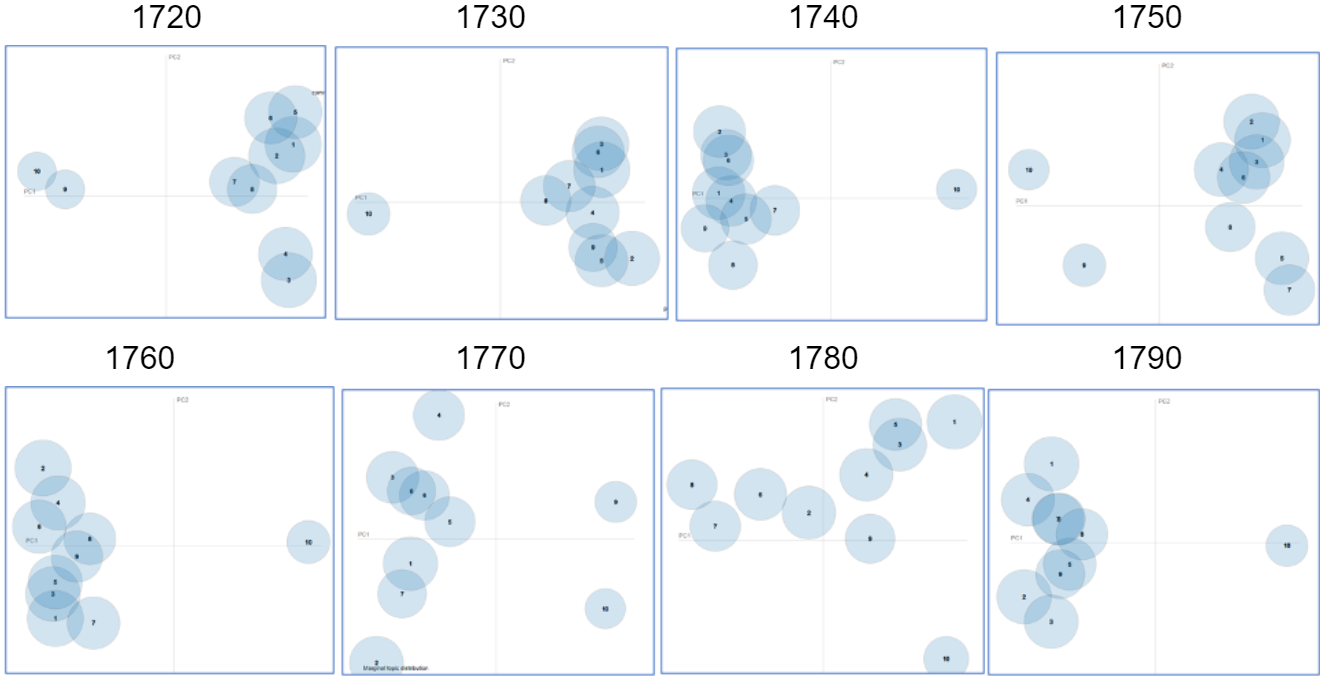
Figure 10. Clusters of topics in 8 decades from 1720-1790 While it can be observed that genre boundaries might have become clearer over time with strong distinction during 1770-1780, further investigation and empirical evidence is necessary for stronger inference, especially on what constitutes for boundaries in the result and if they correlate with genre as boundaries topics are not equal to topics.
- Comparing topics to pre-labeled categoriesWe compared our topic clusters to the previous categorization of genres to see how well they match. For the comparisons we considered the documents from the decade 1720. The topics were compared with whole documents. First we combined the predictions of document chunks to whole document predictions by taking the average of chunk predictions for each document. Then the most probable topic for each document is considered the predicted topic.
A comparison can be made between our predicted topics and the genres by seeing how the documents are distributed within them. We can plot a confusion matrix where each cell is the number of documents within a certain topic and genre.
Figure 11. Confusion matrix between predicted topics and previous genres for decade 1720. The predicted topics seem to have some connection to the genre categorization. Looking at the confusion matrix, the documents within a predicted topic are usually clustered to only a few genres, rather than scattered randomly. However, they don’t match the genres exactly. For example, documents within the “Romance” topic are split between Literature and Art categories. This might indicate an interesting split of subtopics in “Romance”.
To further analyze the connection, we can map our predicted topics to the genres. For each of the predicted topics, a best fit is determined by a genre. The best fit is determined by taking the most common genre within the documents predicted to a certain topic. This results in a mapping from predicted topics to the previous genre categorization.
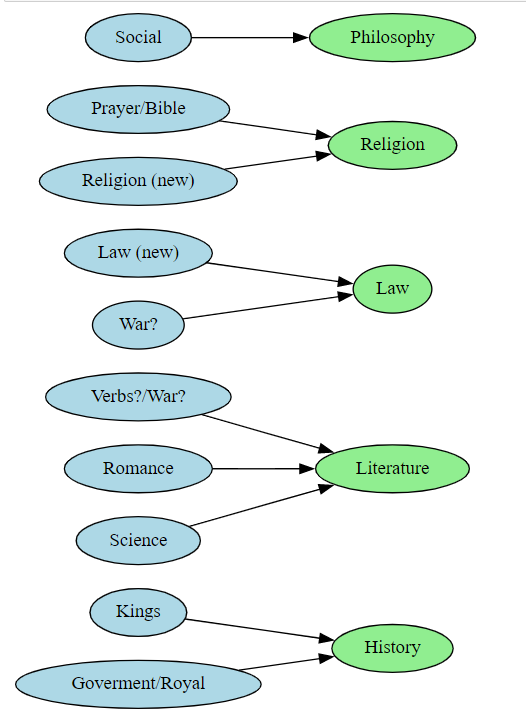
Figure 12. Mapping from predicted topics to the previous categories for decade 1720 The mapping does make semantic sense. For example the “Prayer” and “Religion” topics get mapped to the Religion genre. A lot of the predicted topics seem to get mapped to the same genre according to the best fit. For example, “Verbs?/War?”, “Romance” and “Science” get mapped to Literature. It might be that our topic modeling picked up differences within single genres more than differences between the genres.
After the mapping we can determine a simple accuracy score between the previous genre categorization and our topics which are mapped to the genres. For the ZeroShotTM model that we focused our analysis on, the accuracy score was 58%. What keeps the accuracy score rather low is the fact that many topics are split pretty evenly between few different genres, so the documents in the one that isn’t the best-fit mapping get treated as a mismatch in the accuracy score.
Additionally, in the SuperCTM model that we tested, labels are given to the data to guide the clustering algorithm. For our test, we used the previously done genre categorization as labels to the data. If the labeling provides benefits, it would make sense that the predicted topics match the genre categorization better. To test this hypothesis, we also ran the accuracy score to the predicted topics from the SuperCTM model. The accuracy score was 65%. So we can see that the labeling seems to help the clustering method, but only by a modest amount.
- Ad-hoc labeling and a humanistic perspective of genre componentsThe first real task that involves a qualitative humanities approach is annotating the topics that we have. Since annotation is a subjective measure depending on annotators, we had two different people annotate the topics, ensuring better accuracy and less variance. The annotated topics are below.

Table 2. Labeled topics after cross-annotator agreement A couple of things immediately emerged as interesting:
- Topics are not as specific as genres and one topic can be associated with multiple different genres, as well as be multifaceted, giving more strength to the interdisciplinarity argument of texts.
- As mentioned in the results portion, some topics are labeled as N/A either because the words do not make any sense, or they do make sense but not all together. Those topics are also very often separated from other topics.
- The topics change decade by decade, there are some that stay strong throughout the entire century (religion) and some that don’t appear much outside of a couple incidences (medicine).
With the annotated topics, we proceed to look at association among different topics and analyze the underlying reasons. Strong associations are observed between: 1) religion and love, 2) parliament and trade, or country affairs in general, 3) philosophy, mankind and nature. One other thing that struck me as interesting is that war tends to be a separate topic from the others, lightly associated with country affairs but other than that, it stays to the side.
As briefly mentioned before, we can observe that religion is one of the most common topics in the annotations. This trend continues throughout the entire century and in each decade there is at least one topic correlated with religion, at times appearing more frequently than once. This is in line with historical religious happenings – 20th century historian Sydney E. Ahlstrom recognizes the 18th century as a period of ‘great international Protestant upheaval’[8], which is symbolic to religion’s importance at this time. In England, all of this came after the 1689 Toleration Act, which was supposed to provide commoners with the right to religious freedom. 17th century’s turmoil in this sphere had made people want to live in peace and love with religion in the following 100 years – which English methodism provided under their major rule of ‘God is love’[9]. This is therefore one of the explanations behind our finding of religion and love appearing closely together on several of our decade topic models – if God was equal to love in the methodist ideals, words that related to both of those topics were similar.
Before discussing our other strongly associated topics, it is important to note that love is not the only topic that’s interrelational to religious themes. Because of its abundance in the 18th century, religion has paired up with many other themes, one of which is law. This association can be traced back to the notion that, as Randall McGowen states in his work, “For much of the eighteenth century, fundamental notions of criminal justice were as likely to be articulated within the frame of Christian theology as in secular legal terms. Divine justice was the normative model for human justice.”[10] The author suggests that it’s difficult to separate law in the 18th century from religious rules, which explains their close association within our analyzed topics.
Our next interesting association comes in the form of nature, mankind and philosophy. In this case, the cross relation is between three topics rather than two, because it is difficult to separate them cleanly. The 18th century was the era of the Enlightenment, which is loosely considered “the era of philosophy”. One of the main concepts of Enlightenment’s philosophy was to focus on the way human intelligence grasps nature. According to the Stanford Encyclopedia of Philosophy, some of the greatest scientists and philosophers of the time such as Newton, wanted to prove that natural science should exist outside of political and religious dogmas and be its own entity, the power of which humans can harness through various means[11]. Enlightenment ideals revolved around humans and ways to make their lives better, through the intelligence perspective and new scientific discoveries, to their social lives and connections with others. It is therefore no wonder these three topics relate to each other greatly in many texts and are the core of the philosophical point of view.
Having analyzed religion and philosophy, one can notice that there is not much connection between these two themes in our topic models. This can be attributed to the role of Enlightenment philosophy that we have established – since this period was all about setting mankind and their development via intelligence as the main point, religion was not considered as vital to it as it had been in previous centuries. The main ‘threat’ to religion was materialism, the philosophical ideology that everything that we know and experience is rooted in physical objects, not ideas[12]. Materialism, as well as atheism that was supported by Diderot and propagated by d’Holbach[11] were some of the core Enlightenment philosophies, and with them falling so far from religious practices, so did the topics in the text, which resulted in them not being correlated greatly in our model.
One interesting thing is there is a topic that only shows up in the later decades of the 1700s, and that is medicine. Mitchell et al. in their study of the history of anatomy in England write about how not even anatomy was very well researched before the 17th century, as that is when books from abroad started appearing in English, and the 18th century was a period of gruesome anatomical experiments on prisoners[13]. As this was a very contested issue, not much is written about it nor connected to other genres or topics, assumingly out of respect.
Lastly, we want to point out the significance of war and its lack of associations on the topic model. In most decades, war seems to be an outlier that is far away from topics on the model, while the others are more clustered together. This is a pattern pretty specific to the themes we have deemed to be war-like. The explanation lies in the importance of warfare texts in the 18th century. According to John Richardson’s Literature and War in the Eighteenth Century[14], it is not that the topic was scarce, but rather – there was no major works on war or any topics that would be connected to it. It looks on the outside that no one wrote about war in the 18th century, but the truth simply lies in the obscurity of texts and literature surrounding it.
These intertopical patterns do not stop here and they are abundant depending on the context and timeframe analyzed. These are just a few select examples of topic relationships that were interesting to us and that we could find solid background explanations for. To conclude our humanities analysis, we would like to acknowledge how our model shows just how high the interdisciplinarity of 18th century texts is, and that they are not a monolith by any means, showcasing that they evolve and change over time.
- Visualizations
The different topic models will return a probability of a text belonging to each topic. That posed an interesting question about how to interpret those probabilities. With visualization we were able to analyze further the results of the models.

Figure 13. Genre prediction for chunks in A collection of psalms and hymns by John Wesley This first example is a way of visualizing the data. The x-axis is the chunk, and for each chuck, the model predicts a probability for each topic. So each chunk will have 10 points in the vertical line, according to the probability value. We can see that for this document, it is hard to see which ones are the main topics. Most chunks have a high probability of a topic called NA. NA topics usually contain outliers and common words, they don’t represent any specific topic. But inside the NA value, there are also a high density of green points that represent a Love/Religion topic. It makes sense, since this document is a collection of psalms and hymns.

Figure 14. Genre prediction for chunks in Hamlet by William Shakespeare This next document is a portion of Hamlet. The main cluster of topics is between Verbs?/War? and War?. There are small sets of chunks which have a high probability of topic Prayer/Bible, these differ from the rest, since the probability for them is really high, above 70%.
The NA topics are not noise, but they are harder to analyze, since all chunks will have some probability of NA just because they contain common words that were not filtered during the preprocessing. A visualization was made to filter the probability of NA, to improve the quality of visualizations.

Figure 15. Genre prediction for chunks of sampled publications in 1740s The plot presents big gaps, which are usually filled with the NA values. Most of them are just chunks that do not represent a lot to determine the topic of the overall document.

Figure 16. Genre prediction for chunks of sampled publications in 1750s 
Figure 17. Genre prediction for chunks of sampled publications in 1760s These visualizations were made with the test sets of each decade. There are clear clusters of chunks that represent a given topic. This is helpful for our topic. Originally we wanted to clusterize and then analyze the genres inside the clusters. Now, we can see underlying topics in the documents and also analyze how they behave according to the original annotated genre.

Figure 18. Genre prediction for chunks in six publications in 1790s This is a set of 6 documents from 1790 and has the original genre as ‘Law’. They all contain two main topics. The orange one, which is Law, and then green, which represents the Parliament. This means that the topics are consistent with the original topic for this model.

Figure 19. Genre prediction for document 1412400103, which has the main genre “law”. In the Figure 19, horizontal axis refers to the number of chunks, vertical axis refers to probability between 0 and 1, note that the probability is truncated and therefore only showing probabilities larger than 0.3. The patterns are covered with patches to better visualize their existence. The trained models work exceedingly well with law related documents, which might be explained by the fact that law documents often contain a relatively specific set of sentences and words.
- Topic Clusters
-
Conclusions
- To what extent does the concentration of patterns evolve over time within genres?
Due to the previous work associated with genre intersectionality, our initial research question was centered around genres. However, since we ended up using an unsupervised topic modeling approach, we talk about topics or themes more than about specific genres. This has given us more freedom of fitting different texts to different topics and seeing the interdisciplinarity of texts easier than with set genres.
With that distinction made, we can focus on our main research question. By generating topic models decade by decade and cross-annotating the topics from bags of words, we notice several patterns throughout the century. We see that certain topics end up closer together than others, such as religion with love or mankind with philosophy, indicating a strong link between them within texts. Some topics show up only a couple of times, and are secluded from the rest, such as war. - Which genres gain more popularity over time and which genres cease to exist (if any)?
As we only look at the 18th century, it is difficult to truly quantify whether a genre ceases to exist just looking at one period of time in history. Rather than ceasing to exist, we can focus on genres that show up later in the century more prominently, such as medicine. This finding implies that historically, events and happenings have caused a specific topic or theme to rise in popularity, and while analyzing, we can determine what caused it and how it relates to the other topics at hand. Some topics, such as religion, stay consistently at the top of the popularity trend throughout the century, which signifies their importance in this time period in history and society. - Are there clear interrelations between genres?
Some topics seem to relate to each other more closely than others for a longer period of time. Examples of those that we have discussed are love with religion, parliament with trade or country affairs, as well as nature, philosophy and mankind altogether. There are other important relations that show up in our analysis that we also paid attention to, such as religion with law, that are significant within their history and relationship to each other, and looking into those relationships can provide important historical and societal context as to why they coexist.
- To what extent does the concentration of patterns evolve over time within genres?
-
Future Work
- Decadal CombinedTM
Based on the discussion earlier, the main issue with CombinedTM was the fact that the model ran out of memory during the training phase. This experiment was conducted before the decision of modularizing the training using the different decades. It would be interesting to see if training the CombinedTM model becomes feasible when only using a subset of the books for a certain decade instead of the training with the whole period.
- Clustering with UMAP and HDBSCAN
We tried the DBSCAN clustering algorithm, but did not work on it further. It still remains as a possible solution. The key to this approach is to normalize the vectors, and reduce their dimension with UMAP, so they are comparable between them. And then apply an optimized model in HDBSCAN.
- Further developed case study for specific genre or topic
Several large patterns are observed from algorithm-detected topics, further research can dive deeper into the temporal evolution of such patterns: Are associations between several topics static or dynamic? What are the main components of such associations? Do they change over time and what are possible causes behind it. For example, religion was prominent in many publications through several decades, closely co-occurred with the love theme but separated from romance and seemingly one major area for law documents. One may continue to explore the change in intellectual roles of religion in religious books to other genres with religion-related texts, possibly in how religious topics occur across different book genres over time and develop further interpretations for such shifts. It is important to note that analysis can be extended considering multiple perspectives from what has been done in this report. The relation of law and religion themes can be interpreted within the context of divine justice as normative model of human justice, while the pattern of religious issues like selective religious intolerance to be addressed by law [15] also emerged as seen in several works such as The Spirits of Laws (Montesquieu, 1748).
- Genre as an intellectual concept and a social construct
As our research focuses on genre as a system of categorizing knowledge, we also experimented many different patterns of knowledge categorisation across documents and within documents. This preliminary work can be extended to collect more evidence about what constitutes a genre, boundaries between genres and certain shifts in how such they were defined through a particular historical period. We note that detecting topical patterns based on lexical behavior remains a major approach to computational study of genres, but also suggest further historical data on genre categories should be taken into account in future analysis. Continuing from the view of genre as a social construct relative to temporal/geographical factors, further comparative studies may deepen our understanding of genres within specific historical and social context.
- Decadal CombinedTM
-
Reflection of Learning and individual work
- Eli: I took care of reading up on prior work on this topic, initial data exploration from the humanities perspective, annotating final topics and last but not least, analyzing our findings as a humanist. Initially, I did not think this project sounded too difficult, but I struggled to find my place in it all. I discovered that splitting the work between people while still ensuring that everyone is in touch with everyone else and understands what is going on is a difficult task, and it requires heavy, constant communication. My specific part was not too hard to do alone, as it mostly consisted of finding relevant research and books that have covered our topics and then combining it all together in a cohesive analysis. But this project was not something to do alone – we were all responsible for each other, and that’s what was challenging. I learned a lot when it comes to good communication and good planning, and I am sure I will use this knowledge further on in my life, as I know I still have a lot to learn and reflect on. As for the project itself, I believe it ended up working out nicely and there are certain things that we have discovered that are very interesting and would be a good basis for other research in the future, whether it is humanists, computer scientists or, like us, an interdisciplinary group. I hope that many people can get something valuable out of our work.
- Sebastian: 1) Work on the database connection and exploration. During this phase, I looked for the data documentation, credentials for connection, and then connected both in my local machine and in puhti to the database. Then, explore the tables and see which ones provide the information that we need. 2) In a second step, I worked on the DBSCAN clustering method. I first faced the problem of how to convert the text data into vectors that could be used by a clustering algorithm. I decided to use the Word2Vec pre-trained vectors. 3) Planning. Together with Bo, we planned how we were going to implement the Topic Models. 4) Work in the Zero Shot Topic Models. I implemented the original pipeline for treating the data, then sampled it so that each decade model had the same number of documents, and then trained all 8 models. After the training, I saved the models and the vocabulary, so we could use them to just make inferences over the models. 5) Visualization. With the trained models, I used the library of contextualized topic modeling to visualize the different topics in two dimensions and then, after the proposed visualization implementation by Bo, I added the sampling, so we could see a grid of different documents from the same original Genre and/or Decade. 6) Post the report on the blog post. We had troubles with the data from the beginning and during the preprocessing phase. And I think that is good, since projects usually do not have perfect data. This project helped me implement necessary pipelines that as Data Scientist, we need to know how to do. The project also made me realize the importance of quick and efficient pivoting. From the beginning the tutors and professors told us to have B and C plans, in case plan A didn’t work out. And that was the case, we had to pivot, and I would like to pivot quicker and earlier. It took us a lot of time to change from clustering to topic models. If we have done it in time, we could have worked more on the topic models, and maybe try different implementations. I think it learned a lot about NLP and Topic Models. I haven’t used them before and I had to review the literature and existing libraries so I could implement and train the models. This project allowed me to implement technologies I was not familiar with and learn from my colleagues who have used them.
- Toni: I started my work by exploring the data and trying out the Non-negative matrix factorization clustering model. Very quickly it became evident that the size of the data was going to be a challenge. It was a first project for me which required working with huge data sets to this degree. Because of the huge data set, I tried to use the Dask parallelizing library to help with the clustering, but it proved somewhat inadequate. Later on we pivoted to using more modern libraries, CTM to be exact, which are built on top of Pytorch, which seems to be the better solution overall.
From my initial work, I moved the usable parts of my code to a general source file, to be used by others elsewhere. A habit I tried to follow through the course. I also took the effort to clean my notebooks, so that they would be readable to others.
Later on I picked up on the CTM models others had built and did some additional work on those, including trying out the SuperCTM version of the library. I also implemented methods to compare our predicted topics to the categories which existed from previous work. This included combining the chunk predictions to a prediction of a single document, figuring out the best mapping of predicted topics to the pre-existing categories and calculating accuracy score between them. The other part of my work focused on trying to help the students from humanities background to get easier access to the data, including a dashboard which enables the browsing of the text documents, and also a simple code which zips a subset of the texts to a downloadable format. I also created visualizations of our results, including a bar chart visualizing our topics per decade used in the final presentation, and a confusion matrix and topic mapping comparing our topics to the pre-existing categories. During the course I learned a lot about new clustering methods for text-based data, including a new appreciation of the need to figure out how to work with large data sets. I also learned about working with an interdisciplinary group, including the need to pay attention to how different aspects of a project will be communicated. - Bo: This is the very first data science project course that deals with actual research I have ever had, and as our group is focusing on text data, I had opportunities to learn much in all aspects from hands-on NLP methods to practices of conducting research as a group. At the beginning, I spent most of the time I planned for the project on the configurations. I got myself familiarized with CSC computational resources, I read through the documentation of using Puhti and IDA and tried different ways to build connection to Puhti. At the first I tried accessing Puhti with the web interface and checking the data under ECCO_SOURCE directory, after trying several times doing this, I found that the interface is prone to crush or get stuck whenever a large sized directory is being accessed, and that after the interface getting stuck the session could not be closed, I had no choice but to wait for the task to be processed by the computing node I accessed. It took me a while to develop myself an executable workflow with the interface, as I learned to access directories with a login/computing node I opened. As I no longer have trouble with using Puhti, I started experimenting with the data and topic models. In the first group meetings, I suggested to use LDA as our primary topic modeling tool, I then implemented a plain LDA model and did experiments with a small subset sampled from ECCO_SOURCE, when the number of topics is fixed, the resulting doc-to-topic probability distributions are mostly flat, indicating that the model had low accuracy when clustering. While Sebastian and Tony tried other topic modeling methods like DBSCAN and NMF, we were provided an effective model family, CTM models. After discussions we agreed on switching to the CTM approach, as the models are able to capture contextual information with SBERT pre-trained embeddings and can leverage both Bow and SBERT embeddings together with preprocessed and unprocessed documents to model the topics. The per decade models are then trained by Sebastian. With the trained models I have implemented a within book genre visualization method for other group members, which is based on chunk level topic predictions, a co-occurrence pattern between topics can be then examined by our humanity experts.
Personally speaking, what I’ve learnt the most from the project is how data science research in practice looks and what and how different phases are involved in a research project. In this project, I observed that we had human interaction based decision making in nearly all phases; we do clustering, we observe the result, we conduct experts, we do necessary correction and repeat the procedure to finally get the results, and even after this the results, clearly, needs human interpretation, therefore there could be many human based factors in a research project, it is not all about data. Additionally, I am really happy to get myself familiarized with NLP based workflow, and after the project I found my interest in NLP related works and applications of data science in humanity subjects, as it is clear for me to see what I am researching on. Finally, I wish we could have more time to work with the current results and to improve our models, to better explore the overall pattern of subgenres, but as compromises are made and our time is limited, it is also a lesson for me; probably we should have set our goal to answer less questions, so we could have more time to work with each question.
- Hany: My work was primarily based on the first half of the course regarding initial planning, coming up with research questions and exploratory analysis. When the groups were formed and we were assigned the genres group, I think we spent a significant amount of time just trying to figure out what we’re supposed to do. I spent a bit of time exploring what the data is, what we can and what we cannot get from the data. Following the initial look, I worked on formulating our research question(s) as well as a few secondary questions. My part was also to conduct the exploratory data analysis, which was partly done before the research proposal presentation. I tried to explore if we can subdivide our problem and focus on the decadal variation, which we ultimately did. Additionally, at first, I attempted the use of multiple spell checkers/correction tools to try and improve the quality of the text itself. It is obvious that the higher quality your input, the higher quality your output is and in this case, looking at the input texts was quite disappointing due to the amount of typos/mistakes. Multiple spell checkers were used varying significantly in quality. Unfortunately, due to the length of our texts, spell checkers, even though they produced great results, were not feasible. When it came to model training and development later on, I worked on the CombinedTM model, as an upgrade to our Zero-Shot model. At that point, the training procedure was already prepared by Sebastian and I mainly adjusted some of the parameters in the training data and model to train the CombinedTM model. Essentially, the model was used to allow for a higher number of components, but whenever that was attempted, the model would run out of memory crashing the machine. That being said, it is worth noting that this model was implemented before we did the decadal division so it is likely to train successfully if only focusing on a certain decade instead of the whole dataset, which is a future work idea. Finally, when it comes to the project, I would say that the takeaway for me from this course is flexibility and importance of planning. We encountered a few technical difficulties, and I would say we only overcame them because of how flexible and open to change everyone was. That being said, I noticed that there was some miscoordination with members in the team, including myself at times, not knowing how they can contribute positively since division of work was not very clear. Also, we almost never met in person to discuss the project which I believe would have made a large difference, especially when it comes to communication and coordination of tasks so that no 2 people are essentially repeating the same task on their own.
- Duong: It has been a long and challenging project with takeaway from both the intellectual and organizational ends. For me, I paid attention to the larger conceptualization of our work including the written proportion of it in this report, some analysis on genre boundaries along with future development for research in this area, and from time to time formed critical stances to NLP implementation as methodology for our research questions. Overall, our team has been working hard with different technical experiments, trying out potential approaches in both distant reading with visualization and unsupervised NLP models. There were several things I learnt from this approach. First, the collaboration between data science majors and humanities in making exploratory visualisation needs to take place during both idea creation and graph interpretation. When interpreting graphs we occasionally came back to confirm basic aspects of it such as what are the data points, what do different axises with measurements mean, and discussed what primary knowledge we can understand from the graphs. Second, to frame research questions into implementation task requires many discussions. For example comparison between the results of our unsupervised model and genre annotations by previous work has been brought up and pivoted from the beginning as one potential approach to understand genres in relation to their underlying topical patterns, and to evaluate the outcome of our clustering/topic models. However, we only had a more fine-grained implementation of this approach when more analysis elements came into play such as visualisation of detected chunk topics within one document or compared against the ad-hoc annotations, which can and should have been discussed earlier. On the otherhand, experimenting with several technical implementations could leave our research pipeline scattered, and hardly held together with also a rather large group. I encouraged data science teammates to discuss overlaps of their individual work, especially on their pivots of different NLP models. Another area that I would have worked on more is to keep different research directions clearer so we could formulate methods and implementations in a more organized manner. This part is not only important as our self-awareness as a group, but also essential to have more rigorous research pipeline. All in all, I am extremely grateful being able to work along with students who have strong interests and eagerness to experiment different things in research. I will keep in mind the takeaways pointed out above and continue working to find my own approach to multidisciplinary collaborative DH projects in the future.
-
References
[1] https://www.gale.com/intl/primary-sources/eighteenth-century-collections-online
[2] https://www.etymonline.com/word/genre
[3] https://www.merriam-webster.com/dictionary/genre
[4] Zhang, L., & Lee, H. (2013). The Role of Genre in the Bibliographic Universe. Advances In Classification Research Online, 23(1), pp. 38-45. doi:10.7152/acro.v23i1.14236
[5] Berglund, K. (2021) “Genres at work: A holistic approach to genres in book publishing,” European Journal of Cultural Studies, 24(3), pp. 757–776. Available at: https://doi.org/10.1177/13675494211006097.
[6] Starks, D. and Lewis, M. (2003) ‘The annotated bibliography’, Australian Review of Applied Linguistics, 26(2), pp. 101–117. doi:10.1075/aral.26.2.07sta.
[7] Federico Bianchi, Silvia Terragni, Dirk Hovy, Debora Nozza, and Elisabetta Fersini. 2021. Cross-lingual Contextualized Topic Models with Zero-shot Learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1676–1683, Online. Association for Computational Linguistics.
[8] Ahlstrom, S.E., (1972), A Religious History of the American People. New Haven and London: Yale University Press, p. 263
[9] Methodist Agenda (1999), CALLED TO LOVE AND PRAISE – The Nature of the Christian Church in Methodist Experience and Practice, https://www.methodist.org.uk/media/1993/fo-statement-called-to-love-and-praise-1999.pdf, accessed 09.05.2023.
[10] McGowen, R. (1987), “He Beareth Not the Sword in Vain”: Religion and the Criminal Law in Eighteenth Century England, Eighteenth-Century Studies , Winter, 1987-1988, Vol. 21, No. 2, pp. 192-211. The Johns Hopkins University Press, https://www.jstor.org/stable/pdf/2739104.pdf.
[11] Enlightenment, Stanford Encyclopedia of Philosophy, 2010, https://plato.stanford.edu/entries/enlightenment/, accessed 10.05.2023.
[12] Materialism, Open Edu, https://www.open.edu/openlearn/history-the-arts/history-art/the-enlightenment/content-section-4.2, accessed 10.05.2023.
[13] Mitchell PD, Boston C, Chamberlain AT, Chaplin S, Chauhan V, Evans J, Fowler L, Powers N, Walker D, Webb H, Witkin A. The study of anatomy in England from 1700 to the early 20th century. J Anat. 2011 Aug;219(2):91-9. doi: 10.1111/j.1469-7580.2011.01381.x. Epub 2011 Apr 18. PMID: 21496014; PMCID: PMC3162231. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3162231/.
[14] Richardson, J. (2013), Literature and War in the Eighteenth Century, Oxford Handbooks Editorial Board, https://academic.oup.com/edited-volume/43514/chapter/364247985, accessed 10.05.2023.
[15] Bandoch, J. (2015) ‘Montesquieu’s selective religious intolerance in of the spirit of the laws’, Political Studies [Preprint]. doi:10.1111/1467-9248.12174.