
1. Introduction
Project goals
This report for Digital Humanities Project Course II, autumn 2022,
describes the work of the ”genre detection” group. Its undertaking was to explore various XAI (Explainable Artificial Intelligence) techniques, with a view to facilitate the use and further development of ECCO-BERT models. In the project course slides it was put like this: ”Look into explainability, which tokens/sequences/embeddings are influencing the classifier?” This original task evolved into a small-scale review of XAI methods and tools.
We took an different path from the initial path because of the following reason; for the uninitiated, discovering how a model works would simply not fit the scope of this project. At the initial stages, every ounce of information and knowledge we accumulated on the subject of model explainability, the more evident it became that this would require a workload unbearable for the group.
This led us to taking a bird’s eye view of the problem, and deciding that exploring the tools available, their usability and possible ‘low hanging fruit’ (small accomplishments) regarding ECCO-BERT inference would lead to more refined results and a solid foundation for further inquiries into the subject.
To economise the workload, to keep the report at a reasonable size and for ease of using the report we have included a lot of web links to articles, blog posts, etc. in the text, instead of the traditional academic way of citing references.
The data
(The information in this section is mostly from the Detecting Sequential Genre Change in Eighteenth-Century Texts)
The data used both for model training and for predictions comes from Eighteenth Century Collections Online (ECCO). ECCO is a set of 180,000 digitised documents published originally in the eighteenth century, created by the software and education company Gale. These digitised images have been converted into readable text data using Optical Character Recognition (OCR).
ECCO is the largest and most complete source for eighteenth-century text data. The printed works on which it is based range from short pamphlets to full books and collected works, and cover the entire range of popular genres of the eighteenth century.
For the ECCO-BERT model development a data set of documents annotated by human experts with genre labels was created. It contains 30,119 documents corresponding to 5,672 individual works. This was split into 80/10/10 % training, validation (dev) and test sets. The 10 main genres are Arts, Scientific Improvement, Literature, Education, History, Law, Sales Catalogues, Politics, Philosophy and Religion. These are further divided into 43 sub-genres.
In this project, we have concentrated in the test set of the data (3012 documents).
The problem with OCR
The ECCO texts contain a lot of OCR errors. Authors of this article:
Quantifying the impact of dirty OCR on historical text analysis : Eighteenth Century Collections Online as a case study estimate that ”mean precision of ECCO-OCR pages is 0.744, recall is 0.814, and the F1 Score is 0.774”. Furthermore, OCR produces a lot of ”noise characters” for those symbols it cannot recognize. As a result a typical document in the test set looks something like this excerpt from Gulliver’s Travels (document id 0237200500):

A further complication rises from the fact that texts have been ”cleaned” for training the ECCO-BERT models, involving mostly replacing the ”funny” characters with spaces. This results in quite a few words being split in two or more parts.
(Another related matter is that BERT models use Wordpiece tokenization which add another level of complexity to explaining the predictions. These tokenized subwords are a way to ensure some overlap between words that carry some semantic similarity.)
The models
ECCO-BERT models have been trained on the human-annotated subset of ECCO documents described in the preceding section. They are intended for various digital humanities tasks involving the ECCO data, such as
- Generating genre/subgenre labels for all 180 000 ECCO documents, which would be infeasible to do manually.
- Generating genre/subgenre labels for ”text chunks” (described shortly below) within documents, which make it possible to analyze genre changes within a text.
- Also the probabilities predicted for each genre in a text chunk would make it possible to analyze ”mixtures” of genres within a text.
The ECCO-BERT base cased model is available at HuggingFace. It has been trained on the ECCO dataset and is intended for fine-tuning on various tasks that use the ECCO dataset.
Source code is available at GitHub
There are three different ECCO-BERT models:
- ECCO-BERT-Chunk has been trained on whole documents divided into chunks of 510 tokens each to
train the model and predict results, since the maximum input size of ECCO-BERT is 512
tokens (510 input tokens and 2 special tokens expected by the model). The predicted genre probabilities for chunks are averaged for the document. - ECCO-BERT-Seq uses only the first chunk of the document to predict its genre.
- ECCO-BERT-tfidf aims to be a compromise between previous two (ECCO-BERT-Chunk is slow in making predictions due to processing the whole text) by training a linear model on data produced by concatenating the tf-idf features of the full text with the pooling output of ECCO-BERT-Seq.
The reported accuracy for all these three models is around 0.96. There are also separate versions of the models trained for main genre prediction and subgenre prediction. The model were are working with is ECCO-BERT-seq for main genre prediction.
What is Explainable Artificial Intelligence
Explainable artificial intelligence (XAI) is a term for processes and methods that allow users to understand the outputs of machine learning algorithms. XAI is used to describe an AI model, its expected impact and potential biases. It helps characterize model accuracy, fairness, transparency and outcomes in AI-powered decision making. XAI facilitates trust and confidence in AI models and also helps an organization adopt a responsible approach to AI development.
Many advanced ML techniques, neural networks/deep learning in particular, produce models – commonly called ”black box models” – that are impossible to interpret. Though the model weights (coefficients) are known, no engineer or data scientist can reliably track how – to name an example – a BERT-base Transformers model with 12 layers, 768-dimensional word embeddings and 110 million trainable parameters arrives to a specific prediction. These black box models are trained directly on the data and the developers direct the process only in terms of hyperparameters such as learning rate, choice of optimization algorithm etc.
There are many advantages to understanding how an AI model has led to a specific output. It can help developers ensure that the system is working as expected, it might be necessary to meet regulatory standards, or it might be important in allowing those affected by a decision to challenge or change that outcome. In our case, it is of use to the researchers of 18th century literature, to understand better why e.g. certain chunks of the text are labelled to a given topic. XAI can give insight to labeling even on the word-level.
In the current XAI terminology, we are exploring local/global post-hoc explanations, i.e. we are generating explanations for predictions already made (as opposed to generating explanations simultaneously with the predictions). We are explaining either single predictions (local) or predictions on some kind of average level (global).
The terms explainability and interpretability are often used interchangeably but there is a difference, explained pretty concisely here: ”Interpretability versus explainability”. Simply put, explainability means explaining the model’s behaviour in human terms, whereas with interpretability we explain the model’s predictions in terms of weights, features, parameters etc. In this project, we are not very concerned with these distinctions; we are just reviewing some XAI methods.
2. Bidirectional Encoder Representations from Transformers
Bidirectional Encoder Representations from Transformers (BERT) is a natural language processing (NLP) -model that was developed by Google Research in 2018 (Devlin J. et al. 2018), based on earlier research by the same company (Vaswani A. et al. 2017). BERT is used in various NLP tasks such as machine-translation (e.g. English to French), question answering, guessing the next word in a given sequence or detecting entities from input text (named entity recognition, NER). The advantage of BERT is that unlabelled text is used in the pretraining, which leads to the model learning the scope of a language better, and with less work than previously proposed methods. In addition, BERT can be fine-tuned to multiple tasks without major task-specific constraints (Devlin J. et al. 2018). The BERT-implementation presented in the original paper was pre-trained on 800 million words from a corpus of books and 2,500 million words from the English Wikipedia.
Before the advent of BERT, training of NLP-models for complex tasks such as machine translation was computationally expensive (Vaswani A. et al. 2017). Attention-mechanism, utilized by Recurrent Neural Networks (RNN), was developed to better bind the context of words to inference. RNNs were widely adapted and performed well with small input sizes,, but the sequential nature of the computation meant that no parallelization could be utilized. This constraint is also emphasized by the degrading of performance with longer input texts, where the attention-mechanism can not connect to words over long-distances.
With BERT, a new state-of-the-art was set in machine-translation, with BLEU scoring and computational performance setting new standards.
Implementation
BERT’s comparatively improved performance is attributed to using the well-established attention mechanism, called transformer (Vaswani A. et al. 2017), as well as utilizing novel solutions for smaller training time and better overall performance. For the purpose of keeping the explanations simple, the reader is instructed to look for a more in-depth reference in the original paper (Devlin J. et al. 2018).
Every word/character in a sequence is given a two directional encoding by the neural network. The bidirectional attention of BERT means that the context of words is observed from left-to-right and right-to-left, but not in sequence. BERT was the first model to implement attention in this way. All of the words in the input sequence, of length 512 for example, are encoded as a whole, in contrast to RNN encoding the words sequentially.
BERT is pre-trained in two distinct ways that we have summarized here: In masked,
15% of the words of the input sequence are picked for possible masking; 80% of these are randomly picked to be masked, whereas 10% are changed to random words from the input and 10% are kept as they were. Then, predictions are done on the masked words. This ensures the importance of context (attention) is learnt for every word during training.
The second element to infusing attention to the context of words in the training is the next sentence prediction (NSP), where a set of training sentences (e.g. A, B) are formed by pairing sentences that carry contextual meaning between each other. e.g.:
[CLS] this is an electric car [SEP] it does not use gasoline [SEP].
Then, 50% of the latter sentences are changed to a random sentence, whereas 50% stay the same. Now, predictions for whether B is actually the next sentence is made. This process trains the model to understand sentence relationships, which ”is very beneficial to [question answering] and NLI” (Devlin J. et al. 2018)
3. Our tests with Explainable AI methods
XAI methods have been categorized in many different ways in the literature. For this project, we have chosen the threes families of explanation techniques listed by Atanasova et al., 2020.
Simplification-based methods
This category of methods aims to replace the decision function by a local surrogate model that is structured in a way that it is self-explanatory (an example of a self-explanatory model is linear regression). This approach is embodied in the LIME algorithm, which will be discussed in the next section.
Perturbation-based techniques
In perturbation analysis we test the effect on the neural network output of occluding patches or individual features in the input. Attributions based on Shapley values (also in the next section) are a prominent example of this technique.
Gradient-based techniques
Later in this report, a method called Integrated Gradients is presented, which a widely used gradient based method for explainability. What the gradients of the input and its prediction tell us is the sensitivity of the model to input x at a given point.
The above techniques have been selected partly on theoretical grounds to cover the method families listed in the preceding section, partly on what seemed interesting to us, and partly in consideration of resources (manpower, expertise) available.
Simplification-based methods: LIME
Local interpretable model-agnostic explanations (LIME), introduced by Ribeiro (Ribeiro et al. 2016), explains individual predictions by training local surrogate models. A thorough exposition of the method can be found in Christoph Molnar’s Interpretable Machine Learning web book.
- Select the data point/prediction you want to explain.
- Create perturbations of the data point and get predictions for these new points. With text classification, perturbations is are produced by leaving out words of the original text.
- Weight the new points according to their proximity to the original.
- Train an interpretable (linear) model on this data.
- Explain the prediction by interpreting the local model in terms of its weights. (Bigger coefficient means a more important feature.)
LIME has been implemented in several software packages; we used lime Python package. Its documentation can be found at Read the Docs and source code at GitHub
Using the software with ECCO text chunks proved problematic. Trying to generate a LIME explanation for a full-length text chunk (512 tokens) caused Puhti Jupyter sessions to crash with and ”out of memory” error, even with 64 gigabytes of RAM.
To circumvent this, I was forced to use a shortened version of the text. A demo notebook can be found at genre detection GitHub repo. Here we will just demonstrate the output of the package.
The explain\_instance method of LimeTextExplainer class of lime.lime\_text module returns an explanation object that contains the most influential features in terms of predicted genre probability. There are a few option available (see documentation and the demo notebook) but in our example we’ve generated explanation only for the correct genre (Religion). The explanation looks like this (a formatted printout):
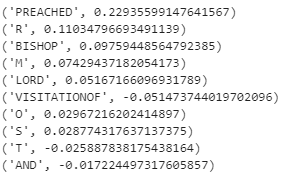
The explanation contains the words that had the biggest absolute (positive or negative) effect on the classes predicted probability, in descending order of the size of the absolute effect. For our test case, the actual genre is Religion, and at least some attributions make sense. Here’s the package’s visualization of the same data:
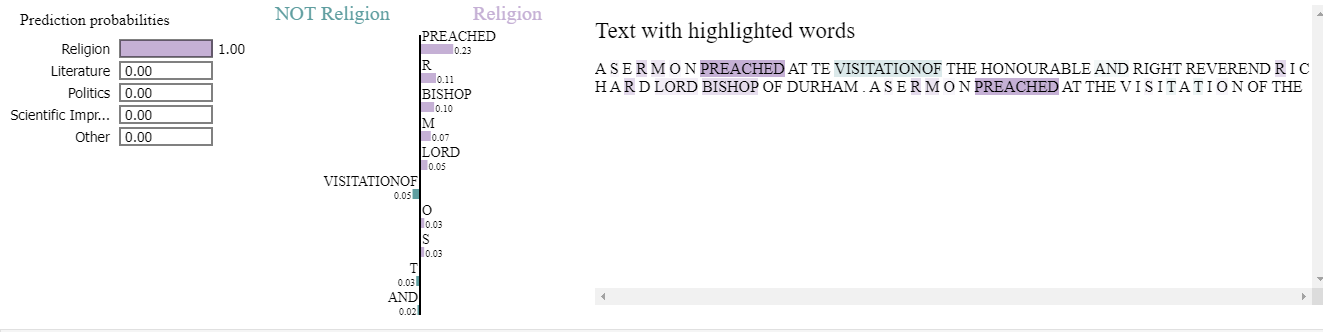
For further examples of the usage, see the demo notebook.
Pros and cons
For a discussion of theoretical (dis)advantages of the method, we refer the reader to the Interpretable Machine Learning chapter on LIME. Our experiences with the lime package can be summed up as follows:
Pros:
-
- Easy to use.
- The method/package is pretty popular, so there’s a lot of resources (of varying quality) in the web.
- Conceptually pretty easy to understand.
Cons:
-
- The ”out of memory” problem: the explain\_instance method crashes constantly with longer inputs.
- There is only one type of visualization and it doesn’t handle displaying explanations for multiple (more than two) classes gracefully.
- Only local explanations. One could of course aggregate the explanations for words – e.g. compute the average – for a global explanation but as the a new surrogate model with new coefficients is created for every text, we are not sure how useful or theoretically justifiable that would be.
Simplification-based methods: ECCO
ECCO provides the user with a handful on tools to explore the inner workings of transformers language models. With scientific backing on all of the XAI-methods utilized by ECCO, the tool is prone to offer insight into the decision making of a model. With development in stage alpha, some features are not yet available for BERT-models. The users is directed to glimpse at ECCO for a summary of the visualizations not covered in the next paragraph.
The method we explored is called non negative matrix factorization. This method is alike to principal component analysis, where high dimensional data is reduced to a given number principal components (eigenvectors). In its essence, dimensionality reduction is a way to make simplifactions of high-dimensional data, for the purpose of e.g. visualizations. As is pointed out before, the neural network of ECCO-BERT has a large amount of neurons and weights. With concepts such as non-negative matrix factorization (NMF), we can shed some light on how different groups of neurons activate between particular layers.
NMF’s works in the following, very generalized manner: The data X is factorized into two matrices U, V, that try to replicate the original data. The similarity of proposed factorizations of data is compared against the original data, minimizing the difference of this comparison. A comprehensive review on the topic is written by \cite{6165290}. Our use is straightforward, input k for how many factorizations to produce and whether the neural network activations should be pinpointed between certain layers.
Pictured below, the activations through the whole network factorized in to 18 components/factors:

Pros:
-
-
- Easy to use.
- Scientific basis on factorization/dimensionality reduction of connections.
- Great documentation with examples and mathematical proofs
- Intuitive design makes interpretation of results easy and straightforward
-
Cons:
-
-
- As the library is still in its ALPHA stage, only NMF is supported for ECCO-BERT.
- Trial and error is needed to find good number of components for factorizations.
-
Perturbation-based techniques: Shapley values and SHAP values
The Shapley value is originally a solution concept in cooperative game theory, introduced by Lloyd Shapley in 1951. To each cooperative game it assigns a unique distribution (among the players) of a total surplus generated by the coalition of all players. ”Shapley Values – A Gentle Introduction” offers a readable and concise explanation of the concept and its application in ML:
”Shapley was studying cooperative game theory when he created this tool. However, it is easy to transfer it to the realm of machine learning. […] The Shapley value tells us how much impact each element has on the prediction, or (more precisely) how much each feature moves the prediction away from the average prediction.”
And further:
”In 2017, Lundberg and Lee published a paper titled A Unified Approach to Interpreting Model Predictions. They combined Shapley values with several other model explanation methods to create SHAP values (SHapley Additive exPlanations) and the corresponding shap library.
If you want to create Shapley values for your model, chances are you will actually generate SHAP values – indeed, in our research, we couldn’t find a library implementing Shapley values. This is great as SHAP takes all the benefits of Shapley values and improves upon many negatives.”
The SHAP package and other SHAP-based methods
In the abstract of SHAP-Based Explanation Methods: A Review for NLP Interpretability}{SHAP-Based Explanation Methods: A Review for NLP Interpretability} by Mosca et al. (2022), the authors state:
”The SHapley Additive exPlanations (SHAP) framework is considered by many to be a gold standard for local explanations thanks to its solid theoretical background and general applicability.”
The article lists over 30 ”available Shapley- and SHAP-based methods”, plus we have found some others. Here we shall examine the original, and still the most popular, implementation – the shap package which is documented at Read the Docs and at GitHub.
The workflow with the shap package and a BERT model consists of three steps:
- Create the \textbf{shap.explainer} object with the transformers.pipeline.
- Generate expalnations by feeding the texts to the explainer.
- Visualize the results. They can also be saved by e.g. the pickle module.
A BERT multi-class model example of the workflow can be found
here at Read the Docs. Though there are half a dozen different plots available with the package, with text classification seems that only text (force) and bar plots are commonly used. They are explained thoroughly here. Here we’ll just demonstrate a couple of visualizations of the ECCO data. The code is in the notebook SHAP\_demo.ipynb in our
As generating the SHAP values can be time-consuming, we generated those for the whole test set as a Puhti batch job (took about 4 hours). Scripts used for the purpose can be found at our.. you guessed it.
Text plot, a.k.a. force plot, ”shows an explanation of a string of text using coloring and interactive labels. The output is interactive HTML and you can click on any token to toggle the display of the SHAP value assigned to that token.”
Here is an example: the first two text chunks of the test set, interactivity not included as this is a screen capture:

For further inspection we refer the reader to demos and documentation listed above.
Bar plots are useful for displaying aggregations of SHAP values over the dataset or a subset of it. Here we have a plot of the 10 most influential (in terms of average impact) tokens with regard to class “Politics”:

What both types of visualization show is that the impact of individual tokens are very small. The test set contains over 37 thousand unique tokens and the attributions get dispersed over them, which make the SHAP values not very informative.
Pros and cons
Pros:
-
- Like stated above, SHAP is a very popular; lots of users and contributors.
- A theoretically ”sound” approach.
- Global explanations available through aggregations of SHAP values.
Cons:
- Not really designed for large texts where each word is a feature.
- SHAP values and their aggregations do not seem to contain much useful information about the basis of the model decisions.
Gradient-based techniques: Integrated gradients/Transformers Interpret
Gradient-based methods compute the gradient of the output with regard to input and use it to assign feature importance.
Integrated Gradients (IG), introduced in a 2017 paper, Axiomatic Attribution for Deep Networks, explains by integrating the gradient of a function (direction of greatest change)
along some trajectory in input space connecting some root point ẍ to the data point x. IG aims to explain the relationship between a model’s predictions in terms of its features. It has many use cases including understanding feature importances, identifying data skew, and debugging model performance.
IG satisfies two important requirements for an attribution method:
- Sensitivity: If an input feature affects the prediction probability, it should have an attribution value not equal to 0.
- Implementation invariance: If two different neural networks provide the same predicted probability for an input, the attribution values should be the same.
IG has become a popular interpretability technique due to its broad applicability to any differentiable model (e.g. images, text, structured data), ease of implementation, theoretical justifications, and computational efficiency relative to alternative approaches that allows it to scale to large networks and feature spaces such as images.
Transformers Interpret package is included here as an example of Intergrated Gradients on account of being mentioned in section 4.2 of the article A Practical guide on Explainable AI Techniques applied on Biomedical use case applications (Bennetot et al. 2021). To quote:
The Transformer-Interpret tool has the advantage of relying on two well documented packages and frameworks (e.g.,
Captum and HuggingFace Transformers). It provides simple methods to explain most common natural language processing
tasks performed by Transformer models, such as sequence classification, zero-shot classification, and question answering.
The default attribution method used by Transformer-Interpret is Integrated Gradients (IG). Integrated Gradients visualize the importance of the input feature in the model’s prediction. To do so, IG computes the integral of gradients with respect to inputs along the path from a given baseline to input.
An introductory article written by the creator of the package can be found here. There is also a repo at GitHub.
An example notebook transformers\_interpret\_demo.ipynb can be found in out GitHub repository.
An example of an ECCO- BERT text chunk visualization: first three texts of the test set
![]()
And here are the attribution scores for the first 10 words and top 10 words for the first text:
![]()
Some explanations and observations:
-
- Green means the token has increased the predicted probability, red means decreased. The deeper the color, the bigger the impact.
- The \textbf{Attribution score} displayed is the sum of individual word attribution scores.
- Though the prediction probabilities are about the same (the viz uses rounding) for the texts, attribution scores vary a lot. We are not sure how to interpret the differences.
- Despite diligent googling, we haven’t been able to figure out what \textbf{Attribution label} means.
- The attributions are computed on subword level (BERT’s WordPiece tokenization). You could of course ”manually” merge the subword tokens and their scores. Also multiple occurrences of a token get each an individual score (see ”Commons” in the first text).
- These values actually make some sense; ”PARLIAMENTARY” and ”Commons” – Politics, ”PERFORMED” – Arts, ”LETTERS” and ”WRITTEN” – Education.
Pros and cons
Pros:
-
- Easy to use.
- Neat visualizations and intuitive design
- Some of the attribution scores make human sense..
Cons:
-
-
- Unclear how to interpret different score magnitudes or aggregate the results.
- Poorly documented
- Doesn’t seem to include many ”convenience features”, e.g. showing attribution scores in ascending/descending order
- Also seems there are no explanations available on the global level.
- Not many contributors, nor many users.
- Basically just a convenience wrapper around Captum. You might just as well learn to use that.
-
The Language Interpretability Tool (LIT)
LIT was presented in 2020 by researchers from Google. The paper The Language Interpretability Tool:
Extensible, Interactive Visualizations and Analysis for NLP Models explains how LIT brings together well-founded and widely used interpretability methods under one API. The developers have built LIT in a model-agnostic way, while providing API’s simple enough to be easily implemented on existing work. The design principles of flexibility, extensibility and modularity are ensured in this way.
Our initial tests of LIT have been contradicting the aims and wishes of the developers. The UI is crisp looking, but at the same time, a bit daunting when many of the methods covered in this report have been concentrated in one tool. That said, it is useful for the scientist/analyst who knows what to look for to have every feasible tool in one place.
Next some demonstrations of a BERT-model’s interpretations of multi-class data:
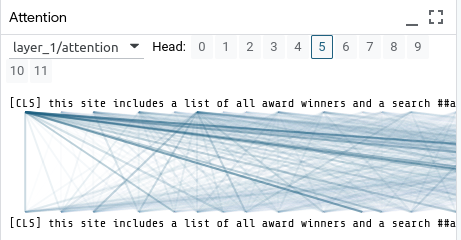
Presented in the picture above is one of the simplest widgets in the LIT arsenal, the attention visualization. Here, one can select any on the 12 multi-heads of the BERT model, and see on different levels the long-distance attention span of the transformer model. Further knowledge of the interplay between words in the English language and insight into the effects of these connections on sentence level would ease interpreting this visualization.
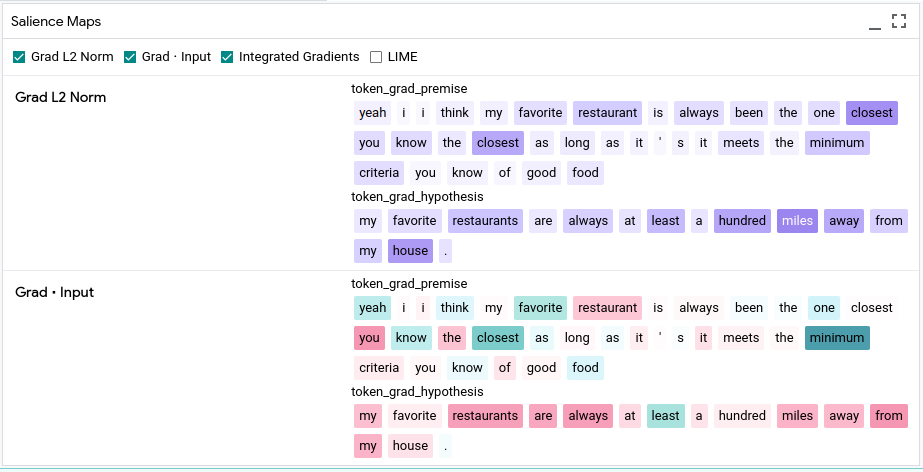
The next widget is the array of salience maps. With the checkboxes in the upper row, one can select from three gradient based methods and LIME. The salience maps below emphasize the effect of words on the prediction, similar to those seen on other methods in this report.
LIT also provides the discrete probability distribution over the possible class-labels, visualizes the embeddings of inputs in 3d space and gives other metrics on the inference of the model. All in all, LIT provides easy access to centralized explainability analyzing, but with the downside of being clearly built with tensorflow models in mind. Although promoted as model-agnostic, utilising the tool with a pytorch model has not worked out for the writer. The documentation for the tool is quite easy to understand, but as the examples use a dataset that is in a format ready to use for tensorflow, this data pre-processing has to be done with some constraints from LIT on any custom data and model one wants to use.
Pros and cons
Pros:
-
- Centralized.
- Easier to handle larger inputs than with other compared methods
- The ability to compare multiple datapoints and their interpretations simultaneously
- Tech. support and extensive use is almost a guarantee a the tool is made by google.
Cons:
-
-
- Documentation and examples rely heavily on tensorflow
- Although LIT includes multiple tools, the view gets easily cluttered
-
Other XAI methods, not tested by us
Here we’ve listed XAI techniques and software packages which we encountered but didn’t have the time to look into. The section contains also links to articles that might be worth perusing.
Layer-wise Relevance Propagation
LRP provides an explanation of a neural network’s output in terms of its input. For example, in image classification, the explanation would be a map of which pixels in the image contribute to the prediction and to what extent. A couple of papers on the subject:
Layer-Wise Relevance Propagation: An Overview
Towards Best Practice in Explaining Neural Network Decisions with LRP
Transformer Interpretability Beyond Attention Visualization
According to this paper
…we propose a novel way to compute relevancy for Transformer networks. […] We benchmark our method on very recent visual Transformer networks, as well as on a text classification problem, and demonstrate a clear advantage over the existing explainability methods.
The source code can be found at GitHub. This one seems also to built on Captum.
Captum
Captum is an ”open source, extensible library for model interpretability built on PyTorch… Captum helps ML researchers more easily implement interpretability algorithms that can interact with PyTorch models. It also allows researchers to quickly benchmark their work against other existing algorithms available in the library.”
Seems a professional project that has a lot of contributors and recent updates at GitHub, which is not always the case with these projects. Definitely worth a look.
AI Explainability 360
AI Explainability 360 by IBM Research Trusted AI is an ”extensible open source toolkit [that] can help you comprehend how machine learning models predict labels by various means throughout the AI application lifecycle.”
\newpage
\subsubsection{Papers, blogs, etc.}
AI Ethics Tool Landscape: ”This open source and plain-text project provides a taxonomy for the existing tool landscape for ethical and trustworthy Artificial Intelligence (AI).” A bit wider scope than ours, but the explainability is in there.
A Survey of the State of Explainable AI for Natural Language Processing in ACL Anthology 2020.
On the Explainability of Natural Language Processing Deep Models on ACM Computing Surveys.
Explainability Methods for
Transformer-based Artificial Neural Networks: a Comparative Analysis. Some guy’s CS Master’s thesis on the subject.
Improving text classification with transformers and layer normalization: ”Our proposed method adds layer normalization and dropout layers to a transformer-based language model, which achieves better classification results than using a transformer-based language alone with imbalanced classes.” The ECCO classes (genres) are imbalanced so this might be worth a look.
4. Conclusions
 In the above sections, tools have been displayed, their use explained and some pros and cons listed. Let us address the usability of all the tools tested by us. In short, most of the can be taken to use without heavy pre-processing or customization of data/the model. As such, the quality of documentation was also very good, with most of the tools, therefore utilizing these XAI tools is straightforward.
In the above sections, tools have been displayed, their use explained and some pros and cons listed. Let us address the usability of all the tools tested by us. In short, most of the can be taken to use without heavy pre-processing or customization of data/the model. As such, the quality of documentation was also very good, with most of the tools, therefore utilizing these XAI tools is straightforward.
However, some challenges lie between outputting explanations and making sound conlusions. As was the case with most tools, the rather large size of the chunk has the affect that words that “explain” the workings of the model in a given case, e.g. the classification of a set of words to the ten main classes, tend to have small impacts to any given class. It seems that we cannot pinpoint classification decision making to single words, and if we could, we do not know how to visualize this with the tools used.
This point is also tied to the training data having quite a large amount of singular characters, which pop out in the explanations but when observed in context, have no understandable relevance to the classification given to the chunk.
To remedy the above challenges, we feel that ECCO (the XAI method) can offer a more broad view to the model’s decision making. Despite being still in early development, ECCO is a promising XAI-tool with the use of non-negative matrix factorization. Our tests with different fully connected layers and different k’s for number of factorizations resulted in “groupings” that are semantically sound. We feel that this XAI-method can shed light into larger flows of decision making, and would therefore give more profound explanations of the model than fine-grained, single token. To emphasize this, the following three pictures demonstrate what we see as sound decision making:

In here, two things are immediately to be noticed: first, the fifth factorisation colourised in dark red is concentrated approximately in the middle of the text chunk. Many neuronal models “focus” on different parts of the input, be it text, images, or such. Looking at other factors, it can be quickly seen that these positionally oriented groupings cover the whole chunk. The second point to take notice of are the words in this set; pursuant, refuting, truth, fundamental constitution and so on. Words, that can be easily connected to law and matters concerning it. Lets look at another factor:

“…abuses and ill pra[ct]ices committed” and “…abuses, ill pra[c]tices, and intolerable exactions…”. Again, a factor the can be seen connected to legal proceedings. In the last example, multiple legally-themed sentences and words are highlighted as belonging to a factor:

“…taken into custody…”, “…being committed prisoner to the Tower of London…” and “…brought to the bar…” all relate to actions revolving around an person accused of criminal wrongdoing.
Here we stop looking into what factorization has to offer and conclude that with ECCO it can be confirmed that the model ECCO-BERT involves sentences and words semantically essential to the classes it outputs as predictions. It is left to the reader to have a look at our GitHub repository and start making their own inferences on what further use and insight ECCO can offer to ECCO-BERT.
Summary
Due to limited time available and this being our first dive into XAI, our results and conclusions are very tentative. Still, they might be summarized as follows:
- ECCO gives assurance that the model decision making seems to be sound. ECCO does this based on larger input than any other XAI method can handle, hence ECCO is the most suitable for large-scale explainability inference. Further testing is encouraged to find out the sentences/types of words that consistently affect genre detection.
- None of the methods we tried produced much actionable intelligence on the importance of specific tokens w.r.t. the model’s predictions. The main reasons for this were probably the length of text chunks and the very large vocabulary plus the OCR fails of the data set.
- It might be worth looking into OCR correction and tuning the text cleanup in pre-processing as ways to improve the models.
- Another aspect that we didn’t have time to look into was the effect of word positions on the prediction. As most documents contain some kind of introduction or introduce the main concepts early, the early words of the first chunk might be the most decisive. This is also implied by the fact that the accuracy of ECCO-BERT-Seq model is within a .01 margin with the best ECCO-BERT models. ECCO can offer tools into this analysis.
- Demo notebooks and the article/webpage links might be useful for someone just starting with XAI for text classifification.
The work done here can be used as a prototype for other analysis: If one were to look into decision making in another downstream task, such as in the work of the text reuse group, our work can be utilized with simply changing the training data and model to match that of the task at hand. Otherwise, as long as the model utilizes transformers, the XAI-methods covered by us are applicabble. For example, if certain sentences/phrases pop up consistently in connection to a given genre, then maybe using these as input to the text-reuse algorithm could offer insight into the historical importance and evolution of these words/sentences.
As a sidenote, since the model seemed to detect persons names and dates (as separate factors with ECCO), it seems that the model is already showing named entity recognition (NER) capabilities without explicitly been trained with data labelled to that task.
5. Learning outcomes, project organization etc.
Petteri’s learning outcomes
First of all, I learned quite a bit about Expalainable AI, especially in the context of text classification, especially about its limitations. The lack of time and expertise prevented delving deeper into matters, but there are several problem areas that seem interesting:
- Explainability of neural networks in terms neuron activations, weights etc. Is it feasible or the best way to go about XAI in any case?
- Explaining text classification in a meaningful way when texts are ”long” (whatever that is). Most examples found in the literature, websites, blogs etc. employ very short texts (typically 10-30 words).
- The poor accuracy of OCR with digital archives like the ECCO collections. One assumes that some work have been done to rectify it, but I didn’t have the time to research the topic.
On the technical side, I had to refresh my memories regarding PyTorch, Transformers, Linux and GitHub. I also learned the basics of using Puhti: the web interface, resource quotas, the batch job system etc.
There were a couple of obstacles there: I could not start Jupyter sessions on Puhti for two weeks in September because my Jupyter environment had somehow gotten corrupted. After a fortnight of email exchanges, the Helpdesk guy suggested I remove a hidden directory named .jupyter in my home directory. That helped but the scars remain… The 10 GB disk quota per user was also a bin inconvenient at times.
As for the project work, it has reinforced my previous experiences that in this kind of project, it is best to concentrate on what you are doing yourself and not to worry too much about the others. It will all come together at some point, though maybe not in the way you originally envisioned… Also, you at some point of the project, you’re transported from the state of ”we’ve got loads of time” to the state ”we have no time left!” with no intermediate state in between…
The genre detection/XAI angle was quite technologically oriented and the people involved were all Data Science majors, so I did not really learn much about digital humanities per se. I did a bit of reading on the subject and the field seems to be very wide and diverse nowadays:
Along with the digital archives, quantitative analyses, and tool-building projects that once characterized the field, DH now encompasses a wide range of methods and practices: visualizations of large image sets, 3D modeling of historical artifacts, ‘born digital’ dissertations, hashtag activism and the analysis thereof, alternate reality games, mobile makerspaces, and more. In what has been called ‘big tent’ DH, it can at times be difficult to determine with any specificity what, precisely, digital humanities work entails.
But in my admittedly uninformed view, DH worksflows of this type (meaning ECCO and projects using its data) do not necessarily differ that much from the general data science workflow; you plan your project, you obtain your data, you probably preprocess it, explore it, analyze it with regard to your problem/research question and you communicate the results.
Akseli’s learning outcomes
When the course kicked off, I was eager to learn more about the English language and how the use of data science, machine learning in particular, can be of use to discovering new findings. However, I found the topics revolving around text reuse to be hard-to-grasp and therefore I decided to concentrate on XAI. My learning objectives were:
- discovering new and efficient methods for visualizing the inner-workings of transformer models and
- to better understand ECCO or any transformer-language model
- to hone group-working skills (in a new, interdisciplinary setting)
Initial difficulties were the kind that one encounters in every project; unfamiliar pipelines, strange errors and bugs when trying to run code and the like. For me, the largest difficulty was the inability to utilize Puhti to its fullest, and since the model files /data/any processing that gets stored in memory easily gets quite large, using Puhti was the only viable option to really ”crunch those numbers”. It was therefore great that Petteri could get his implementations of the computationally more heavy functionalities runnings, so that I could concentrate on XAI methods that run simply in notebooks.
Project organization/sharing of work was distributed quite evenly during the first few weeks, but then I (A) struggled to produce results with the XAI-methods I had selected to explore. This quickly led to Petteri keeping us above the water while I did not “carry my weight” of the work. Eventually this passed and I got back on the right track, but without Petteri’s great work and consistent producing of results, we might have ended up with much smaller results. Petteri did most of the trials with the XAI-methods (I did LIT and ECCO) and wrote over half of the report.
I do feel that I have learned about the choices one can make regarding XAI-solutions, and should similar tasks appear in the future, I know what pitfalls to be wary of. I also learnt about the importance of meetings and setting substantial goals; especially in a project such as ours, where we are not building new software or functionalities (that could be seen as solid tasks/goalposts towards which to head on to), it is vital to keep the constant exchange of thoughts and ideas flowing.
5. References
Zhang, J., Ryan, Y. C., Rastas, I., Ginter, F., Tolonen, M., & Babbar, R. (2022, December). Detecting Sequential Genre Change in Eighteenth-Century Texts. In Proceedings of the Computational Humanities Research Conference 2022. CEUR-WS. org.
Molnar, C. (2022). Interpretable Machine Learning:
A Guide for Making Black Box Models Explainable (2nd ed.).
christophm.github.io/interpretable-ml-book/
Atanasova, P., Simonsen, J. G., Lioma, C., and Augenstein, I. (2020). A diagnostic study of
explainability techniques for text classification. In Proceedings of the 2020 Conference on
Empirical Methods in Natural Language Processing (EMNLP), pages 3256–3274, Online.
Association for Computational Linguistics.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2018). Bert: Pre-training of deep
bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Klein, L. and Gold, M. (2016). Digital humanities: The expanded field.
Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. Advances in neural information processing systems, 30.
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016). ” why should i trust you?” explaining
the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international
conference on knowledge discovery and data mining, pages 1135–1144.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L.,
and Polosukhin, I. (2017). Attention is all you need. Advances in neural information
processing systems, 30.
Mosca, E., Szigeti, F., Tragianni, S., Gallagher, D., & Groh, G. (2022, October). SHAP-Based Explanation Methods: A Review for NLP Interpretability. In Proceedings of the 29th International Conference on Computational Linguistics (pp. 4593-4603).
Sundararajan, M., Taly, A., & Yan, Q. (2017, July). Axiomatic attribution for deep networks. In International conference on machine learning (pp. 3319-3328). PMLR.
Bennetot, A., Donadello, I., El Qadi, A., Dragoni, M., Frossard, T., Wagner, B., … & Diaz Rodriguez, N. A Practical Guide on Explainable Ai Techniques Applied on Biomedical Use Case Applications. Available at SSRN 4229624.
Wang, Y.-X. and Zhang, Y.-J. (2013). Nonnegative matrix factorization: A comprehensive
review. IEEE Transactions on Knowledge and Data Engineering, 25(6):1336–1353
Hill, M. J., & Hengchen, S. (2019). Quantifying the impact of dirty OCR on historical text analysis: Eighteenth Century Collections Online as a case study. Digital Scholarship in the Humanities, 34(4), 825-843.
Tenney, I., Wexler, J., Bastings, J., Bolukbasi, T., Coenen, A., Gehrmann, S., … & Yuan, A. (2020). The language interpretability tool: Extensible, interactive visualizations and analysis for NLP models. arXiv preprint arXiv:2008.05122.
Chefer, H., Gur, S., & Wolf, L. (2021). Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 782-791).
Remmer, E. (2022). Explainability Methods for Transformer-based Artificial Neural Networks:: a Comparative Analysis.
Rodrawangpai, B., & Daungjaiboon, W. (2022). Improving text classification with transformers and layer normalization. Machine Learning with Applications, 10, 100403.