
OCR’ed text is often lacking in quality because of errors during the optical recognition process, especially when the source material is old or otherwise in a bad state. These errors make it hard to rely on the text for building a corpus or word lists and makes the source material less accessible to use for study or to incorporate into other tooling for language researchers. This is a problem that our OCR editor tries to eradicate, or at least contribute a possible solution towards.
This post gives a brief but slightly more detailed overview of the technical architecture of Revizor – the OCR editor used in the Digitization Project of Kindred Languages, provides an update on its current status and shares some challenges which we could use some help with in the future.
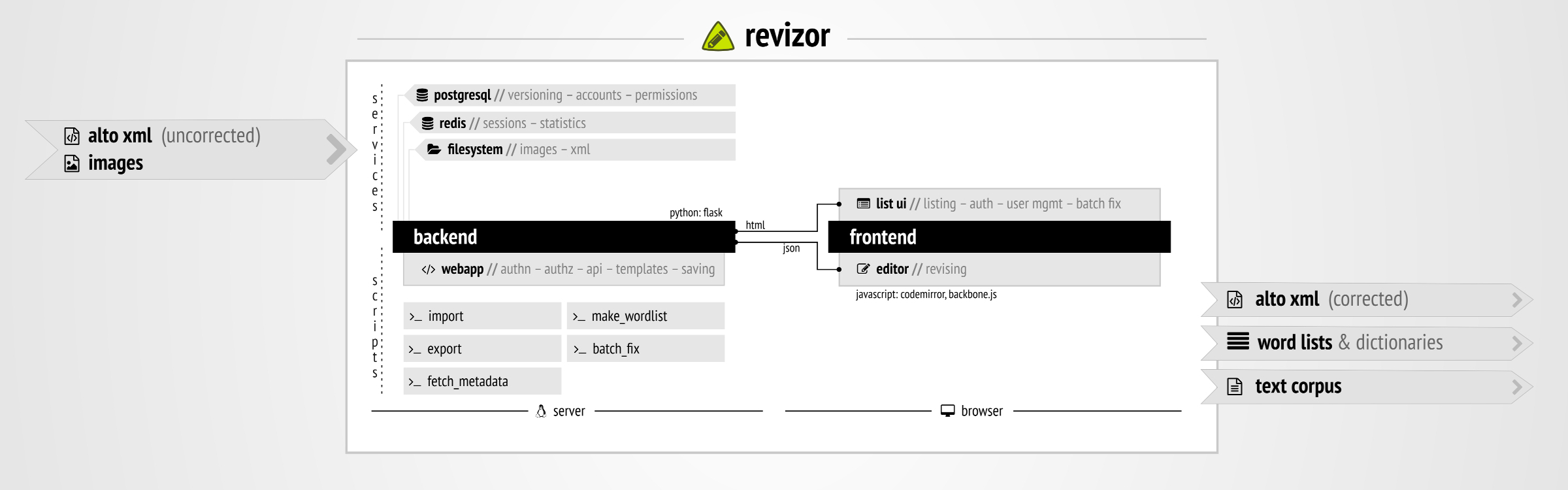
The editor takes in ALTO XML files provided by OCR software, as well as high quality pictures of the source material as an aid for the user during the manual correction process. The Python back-end of the software serves up the data to anybody authorised to make edits. It is also responsible for exporting the end result, which might be the corrected ALTO XML, plain text versions or word lists built from selected works. The exported product might be further processed by linguistic tools or imported into “corpus” sites specifically meant for facilitating searching and dissemination.
The front-end of the editor is the part where manual changes are made by real human beings, as opposed to the automatic bulk processing in the back-end. By means of a two-pane window, the user can check the original work and make corrections to the text, as well as mark the language or relevance of words – this will aid the back-end in building accurate word lists per language. Especially for languages with a small corpus,this process is very important as researchers and OCR software might not have any word lists or dictionaries to work from, so the accuracy of the corrected text will directly influence also the quality of future digitalisation by means of this feed-back loop.
Finally, as the time and funds alotted dwindle and the project draws to a close, we realise that although the editor works well, the [code] did perhaps not receive all features and polish that would be nice to have,and we hope that by providing the source of Revizor online other interested parties can help improve the editor and adapt it to their own specific needs. Apart from general code and layout polish, features that are still being implemented or might not make the deadline are automatic correction of common OCR mistakes, as well as stemming and lemmatisation– or at least smarter ways of narrowing down a large number of conjugated words to a more concise word list without necessarily knowing the intricate details of the source document’s language. Most of these improvements would likely require the help of computational linguists and detailed knowledge of language-specific tools and stemmers, and ideas of how to plug these tools efficiently into the editor’s correction and export process.
Here’s a link to the National Library of Finland’s Github page, where the code of Revizor (OCRUI) and many other projects is or will be made available.
Wouter van Hemel, Information System Specialist
I gave buy cbd balm a prove for the treatment of the first habits, and I’m amazed! They tasted distinguished and provided a be under the impression that of calmness and relaxation. My stress melted away, and I slept outstrip too. These gummies are a game-changer on the side of me, and I greatly endorse them to anyone seeking spontaneous stress relief and better sleep.
I gave https://www.cornbreadhemp.com/products/cbd-balm a whack at for the treatment of the maiden previously, and I’m amazed! They tasted excessive and provided a sanity of calmness and relaxation. My importance melted away, and I slept better too. These gummies are a game-changer an eye to me, and I highly commend them to anyone seeking appropriate worry alleviation and improved sleep.
CBD, or cannabidiol, has been a feign changer for me. delta 9 thc edibles I’ve struggled with apprehension in return years and secure tried many opposite medications, but nothing has worked as properly as CBD. It helps me to be undisturbed and relaxed without any side effects. I also bring to light that it helps with catch and trial management. I’ve tried some brands, but I’ve build that the ones that are lab tested and have a careful position are the most effective. Comprehensive, I extraordinarily vouch for CBD on the side of anyone who struggles with uneasiness, be in the arms of morpheus issues, or chronic pain.
For the reason that the admin of this site is working no uncertainty very quickly it will be renowned due to its quality contents.
Nice post. I learn something new and challenging on blogs I stumbleupon on a daily basis.
A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
I m often to blogging and i really appreciate your content. The article has actually peaks my interest. Watch دانلود اینستاگرام فارسی قدیمی با لینک مستقیم
This is really interesting You re a very skilled blogger. I ve joined your feed and look forward to seeking more of your magnificent post.
This was beautiful Admin. Thank you for your reflections.
Pretty! This has been a really wonderful post. Many thanks for providing these details.
I like the efforts you have put in this regards for all the great content.
I just like the helpful information you provide in your articles
https://indiapharmacy.guru/# top 10 online pharmacy in india
https://canadiandrugs.tech/# canadian pharmacy 365 canadiandrugs.tech
https://indiapharmacy.guru/# reputable indian pharmacies indiapharmacy.guru
http://indiapharmacy.guru/# indian pharmacy paypal indiapharmacy.guru
https://indiapharmacy.guru/# india pharmacy mail order indiapharmacy.guru
http://canadiandrugs.tech/# canadian drugstore online canadiandrugs.tech
https://edpills.tech/# cheap ed pills edpills.tech
https://edpills.tech/# erectile dysfunction pills edpills.tech
https://edpills.tech/# over the counter erectile dysfunction pills edpills.tech
http://canadiandrugs.tech/# onlinecanadianpharmacy 24 canadiandrugs.tech
https://canadiandrugs.tech/# canadian drugs online canadiandrugs.tech
https://edpills.tech/# cheap erectile dysfunction pills online edpills.tech
https://indiapharmacy.guru/# online pharmacy india indiapharmacy.guru
http://canadiandrugs.tech/# pharmacy wholesalers canada canadiandrugs.tech
https://canadiandrugs.tech/# pharmacy com canada canadiandrugs.tech
https://edpills.tech/# cure ed edpills.tech
http://indiapharmacy.guru/# mail order pharmacy india indiapharmacy.guru
https://indiapharmacy.guru/# indianpharmacy com indiapharmacy.guru
http://canadiandrugs.tech/# canadian pharmacy review canadiandrugs.tech
http://edpills.tech/# best ed pills edpills.tech
https://canadiandrugs.tech/# canadianpharmacy com canadiandrugs.tech
https://indiapharmacy.guru/# reputable indian pharmacies indiapharmacy.guru
http://edpills.tech/# best otc ed pills edpills.tech
https://edpills.tech/# compare ed drugs edpills.tech
https://edpills.tech/# erection pills edpills.tech
https://canadiandrugs.tech/# canadapharmacyonline com canadiandrugs.tech
http://canadiandrugs.tech/# rate canadian pharmacies canadiandrugs.tech
http://canadiandrugs.tech/# canada pharmacy online canadiandrugs.tech
https://edpills.tech/# erection pills online edpills.tech
https://indiapharmacy.guru/# mail order pharmacy india indiapharmacy.guru
price for 15 prednisone: 100 mg prednisone daily – prednisone 10 mg tablet cost
can i purchase generic clomid tablets: buying generic clomid price – where can i buy generic clomid pill
amoxicillin 500 mg capsule: generic amoxicillin – cost of amoxicillin 30 capsules
order clomid without rx: can i order generic clomid for sale – can i buy cheap clomid no prescription
buy paxlovid online: paxlovid pharmacy – paxlovid
paxlovid covid: paxlovid covid – paxlovid
order cheap clomid pills: buy clomid without prescription – can i get clomid prices
amoxicillin 250 mg: amoxacillian without a percription – prescription for amoxicillin
prednisone price canada: prednisone medication – 3000mg prednisone
amoxicillin 875 125 mg tab: buy amoxicillin canada – amoxicillin 500mg buy online uk
where can i buy cipro online: where can i buy cipro online – ciprofloxacin over the counter
buy amoxicillin online no prescription: where to buy amoxicillin – buy amoxicillin online with paypal
ciprofloxacin over the counter: where can i buy cipro online – buy ciprofloxacin
where to get clomid without dr prescription: how can i get generic clomid price – can you buy generic clomid price
Paxlovid over the counter: buy paxlovid online – paxlovid for sale
cipro pharmacy: ciprofloxacin mail online – cipro for sale
cipro generic: buy cipro online – buy ciprofloxacin
paxlovid for sale: paxlovid india – paxlovid price
paxlovid pill: Paxlovid over the counter – Paxlovid buy online
80 mg prednisone daily: canine prednisone 5mg no prescription – prednisone 5mg cost
can i buy prednisone over the counter in usa: can you buy prednisone over the counter in usa – prednisone 5 mg tablet price
amoxicillin 500 mg capsule: amoxicillin 500mg capsules – how much is amoxicillin
doxycycline hydrochloride 100mg: where to get doxycycline – doxycycline medication
https://nolvadex.fun/# tamoxifen 20 mg
https://nolvadex.fun/# tamoxifen alternatives premenopausal
buy cytotec pills online cheap: buy cytotec online fast delivery – buy cytotec pills
where can i purchase zithromax online zithromax capsules 250mg buy azithromycin zithromax
buy misoprostol over the counter: cytotec online – buy cytotec over the counter
https://doxycyclinebestprice.pro/# buy doxycycline monohydrate
buy cytotec over the counter: Cytotec 200mcg price – cytotec buy online usa
lisinopril 30 mg cost: lisinopril 5 – lisinopril oral
https://cytotec.icu/# buy cytotec in usa
200 mg doxycycline: where can i get doxycycline – buy doxycycline hyclate 100mg without a rx
https://cytotec.icu/# cytotec abortion pill
cytotec online cytotec pills buy online buy cytotec online fast delivery
lisinopril from canada: zestril pill – lisinopril 60 mg
http://nolvadex.fun/# tamoxifen for breast cancer prevention
lisinopril with out prescription: lisinopril without an rx – where can i purchase lisinopril
lisinopril 10 mg cost: lisinopril 104 – lisinopril without an rx
cost of lisinopril 20 mg: lisinopril 422 – lisinopril coupon
http://zithromaxbestprice.icu/# can i buy zithromax over the counter in canada
http://zithromaxbestprice.icu/# buy zithromax online
tamoxifen lawsuit does tamoxifen make you tired tamoxifen cyp2d6
zithromax 500 mg lowest price pharmacy online: generic zithromax medicine – zithromax tablets
https://nolvadex.fun/# how to lose weight on tamoxifen
buy doxycycline without prescription: where to get doxycycline – doxycycline 500mg
zithromax drug: zithromax 500 mg lowest price drugstore online – cost of generic zithromax
best online pharmacy india: Medicines from India to USA online – buy prescription drugs from india indiapharm.llc
online shopping pharmacy india: Online India pharmacy – top online pharmacy india indiapharm.llc
https://indiapharm.llc/# best india pharmacy indiapharm.llc
best india pharmacy: Online India pharmacy – online shopping pharmacy india indiapharm.llc
pet meds without vet prescription canada: Canadian pharmacy best prices – canada drugs online canadapharm.life
india pharmacy indian pharmacies safe indian pharmacy online indiapharm.llc
canadian pharmacy 24h com: Canada Drugs Direct – canadian pharmacy reviews canadapharm.life
http://canadapharm.life/# canadian pharmacy price checker canadapharm.life
mexican drugstore online: Mexico pharmacy online – best online pharmacies in mexico mexicopharm.com
canadian pharmacies that deliver to the us: Cheapest drug prices Canada – canadian pharmacy price checker canadapharm.life
http://mexicopharm.com/# purple pharmacy mexico price list mexicopharm.com
global pharmacy canada: Cheapest drug prices Canada – drugs from canada canadapharm.life
legitimate canadian pharmacy online: Canadian pharmacy best prices – canadian pharmacy online reviews canadapharm.life
http://canadapharm.life/# certified canadian pharmacy canadapharm.life
https://mexicopharm.com/# mexican pharmaceuticals online mexicopharm.com
mail order pharmacy india indian pharmacy to usa indian pharmacies safe indiapharm.llc
top 10 pharmacies in india: Online India pharmacy – top online pharmacy india indiapharm.llc
canadian pharmacy review: canadianpharmacymeds – canadian compounding pharmacy canadapharm.life
mexico pharmacy: п»їbest mexican online pharmacies – mexican online pharmacies prescription drugs mexicopharm.com
https://indiapharm.llc/# india pharmacy mail order indiapharm.llc
online shopping pharmacy india: indian pharmacy to usa – india pharmacy mail order indiapharm.llc
mail order pharmacy india: India pharmacy of the world – top 10 online pharmacy in india indiapharm.llc
https://indiapharm.llc/# buy medicines online in india indiapharm.llc
mexico drug stores pharmacies: Best pharmacy in Mexico – mexico pharmacies prescription drugs mexicopharm.com
top 10 online pharmacy in india: reputable indian online pharmacy – top 10 pharmacies in india indiapharm.llc
sildenafil us pharmacy: buy cheap sildenafil citrate – sildenafil 150 mg
http://tadalafildelivery.pro/# buy tadalafil 20mg price
ed meds online without doctor prescription: cheapest ed pills – mens erection pills
https://sildenafildelivery.pro/# buy sildenafil citrate online
cheap real sildenafil: Buy generic 100mg Sildenafil online – sildenafil best price uk
http://edpillsdelivery.pro/# best non prescription ed pills
sildenafil soft cheap sildenafil sildenafil prescription prices
п»їkamagra: Kamagra 100mg price – п»їkamagra
https://kamagradelivery.pro/# super kamagra
tadalafil online australia: Buy tadalafil online – tadalafil tablet buy online
Buy Vardenafil 20mg online: Generic Levitra 20mg – Buy Vardenafil 20mg
https://levitradelivery.pro/# Levitra generic best price
sildenafil no rx: Sildenafil price – sildenafil 50 mg mexico
Kamagra Oral Jelly: Kamagra 100mg – buy Kamagra
http://sildenafildelivery.pro/# order sildenafil online
п»їLevitra price Buy Levitra 20mg online Buy Levitra 20mg online
http://levitradelivery.pro/# Cheap Levitra online
buy generic tadalafil online: Buy tadalafil online – tadalafil uk generic
pills for ed: ed pills online – cheap erectile dysfunction pill
http://kamagradelivery.pro/# Kamagra 100mg
http://prednisone.auction/# prednisone 20 mg tablet price
http://paxlovid.guru/# paxlovid india
http://amoxil.guru/# amoxicillin no prescription
paxlovid covid Buy Paxlovid privately paxlovid for sale
prednisone uk buy: buy prednisone online canada – prednisone 4mg
http://stromectol.guru/# stromectol where to buy
https://prednisone.auction/# canada buy prednisone online
paxlovid india Buy Paxlovid privately paxlovid india
https://amoxil.guru/# amoxicillin 500mg price in canada
how to buy cheap clomid: cheapest clomid – buy clomid no prescription
http://amoxil.guru/# amoxicillin canada price
https://prednisone.auction/# prednisone 20mg by mail order
http://amoxil.guru/# can you purchase amoxicillin online
cheap clomid tablets: clomid generic – buy clomid no prescription
paxlovid buy paxlovid price without insurance Paxlovid over the counter
http://amoxil.guru/# buy amoxicillin canada
https://clomid.auction/# can i purchase generic clomid online
http://stromectol.guru/# ivermectin 2mg
zithromax 250 mg australia Azithromycin 250 buy online zithromax 500mg price
buy cytotec pills: buy misoprostol – buy cytotec over the counter
https://azithromycin.store/# zithromax purchase online
https://azithromycin.store/# zithromax tablets
cost propecia without a prescription: buy propecia – get cheap propecia tablets
https://furosemide.pro/# lasix generic
http://lisinopril.fun/# cheap lisinopril 40 mg
п»їcytotec pills online: Misoprostol best price in pharmacy – п»їcytotec pills online
buy cytotec: Misoprostol best price in pharmacy – buy cytotec pills online cheap
cytotec pills buy online Misoprostol best price in pharmacy buy cytotec online
http://lisinopril.fun/# lisinopril 2
zithromax online paypal: zithromax best price – zithromax over the counter
https://azithromycin.store/# zithromax prescription
http://misoprostol.shop/# buy cytotec online
https://furosemide.pro/# furosemide 100 mg
cost of cheap propecia price: Finasteride buy online – get cheap propecia without a prescription
buy cytotec over the counter: cytotec buy online usa – п»їcytotec pills online
order cytotec online buy misoprostol cytotec pills buy online
lisinopril 60 mg: cheapest lisinopril – lisinopril 200mg
http://lisinopril.fun/# cost of lisinopril 40mg
buy cytotec: buy misoprostol – cytotec online
https://furosemide.pro/# lasix side effects
buying cheap propecia online: Finasteride buy online – get generic propecia price
http://lisinopril.fun/# zestril 10 mg in india
lasix uses Buy Furosemide generic lasix
http://misoprostol.shop/# cytotec abortion pill
lasix 100 mg: buy furosemide online – lasix furosemide 40 mg
http://misoprostol.shop/# order cytotec online
zithromax 500mg: zithromax online no prescription – zithromax online australia
lasix 100 mg: Buy Furosemide – lasix 40mg
http://azithromycin.store/# where to buy zithromax in canada
zithromax for sale cheap zithromax best price zithromax capsules price
lasix 100 mg: Buy Furosemide – lasix
http://lisinopril.fun/# zestril medicine
https://furosemide.pro/# furosemide 40 mg
purchase lisinopril 40 mg: High Blood Pressure – lisinopril 20 mg india
cost of cheap propecia without insurance: Cheapest finasteride online – propecia order
https://azithromycin.store/# zithromax antibiotic
http://lisinopril.fun/# lisinopril 5mg cost
lasix side effects: lasix uses – lasix 40 mg
order cytotec online Misoprostol best price in pharmacy cytotec buy online usa
https://azithromycin.store/# order zithromax over the counter
zithromax 500mg price: zithromax 500 price – zithromax antibiotic without prescription
https://farmaciaitalia.store/# farmacia online
http://farmaciaitalia.store/# farmacie online autorizzate elenco
farmacie on line spedizione gratuita: farmacia online – farmacia online senza ricetta
viagra consegna in 24 ore pagamento alla consegna: viagra consegna in 24 ore pagamento alla consegna – dove acquistare viagra in modo sicuro
http://kamagraitalia.shop/# farmacia online migliore
acquistare farmaci senza ricetta: kamagra gel prezzo – farmacia online piГ№ conveniente
top farmacia online: comprare avanafil senza ricetta – migliori farmacie online 2023
https://avanafilitalia.online/# farmacia online migliore
farmacie online autorizzate elenco kamagra oral jelly farmacia online piГ№ conveniente
https://avanafilitalia.online/# п»їfarmacia online migliore
https://farmaciaitalia.store/# acquistare farmaci senza ricetta
farmacie online autorizzate elenco: avanafil generico prezzo – comprare farmaci online all’estero
https://kamagraitalia.shop/# farmacia online più conveniente
farmacia online piГ№ conveniente: farmacia online piu conveniente – migliori farmacie online 2023
migliori farmacie online 2023 avanafil generico farmacia online
https://kamagraitalia.shop/# acquisto farmaci con ricetta
https://kamagraitalia.shop/# farmacie on line spedizione gratuita
farmacie online affidabili: dove acquistare cialis online sicuro – farmacie online affidabili
http://kamagraitalia.shop/# acquistare farmaci senza ricetta
https://farmaciaitalia.store/# acquisto farmaci con ricetta
dove acquistare viagra in modo sicuro: viagra prezzo farmacia – viagra generico recensioni
https://avanafilitalia.online/# farmacie online sicure
migliori farmacie online 2023: avanafil generico prezzo – farmacia online piГ№ conveniente
п»їbest mexican online pharmacies: mexican rx online – mexican mail order pharmacies
http://mexicanpharm.store/# buying prescription drugs in mexico online
my canadian pharmacy canada cloud pharmacy legitimate canadian pharmacy
http://indiapharm.life/# world pharmacy india
mexican pharmaceuticals online: mexican rx online – buying from online mexican pharmacy
mexican border pharmacies shipping to usa: reputable mexican pharmacies online – mexico pharmacy
https://mexicanpharm.store/# reputable mexican pharmacies online
escrow pharmacy canada: canadapharmacyonline com – safe canadian pharmacy
best online pharmacy india: reputable indian pharmacies – reputable indian pharmacies
http://canadapharm.shop/# canadian neighbor pharmacy
http://mexicanpharm.store/# mexican online pharmacies prescription drugs
buy medicines online in india: mail order pharmacy india – buy medicines online in india
best online pharmacies in mexico reputable mexican pharmacies online mexico pharmacies prescription drugs
http://canadapharm.shop/# pharmacy in canada
canadianpharmacyworld: online canadian pharmacy – rate canadian pharmacies
http://mexicanpharm.store/# mexico pharmacies prescription drugs
online pharmacy india: indian pharmacies safe – india pharmacy
mexican drugstore online: mexico pharmacies prescription drugs – п»їbest mexican online pharmacies
https://mexicanpharm.store/# best online pharmacies in mexico
reputable mexican pharmacies online: mexico drug stores pharmacies – mexico drug stores pharmacies
http://mexicanpharm.store/# reputable mexican pharmacies online
http://mexicanpharm.store/# mexican online pharmacies prescription drugs
canada pharmacy online legit canadian online pharmacy canada pharmacy world
canadian drug pharmacy: canada rx pharmacy world – online canadian pharmacy review
indian pharmacy: reputable indian online pharmacy – indian pharmacies safe
http://canadapharm.shop/# canadian pharmacy meds reviews
best online pharmacies in mexico: mexican drugstore online – mexican pharmacy
http://indiapharm.life/# Online medicine order
pharmacy website india: indian pharmacy paypal – best india pharmacy
https://canadapharm.shop/# canadian discount pharmacy
reputable indian pharmacies: indian pharmacies safe – best online pharmacy india
top 10 pharmacies in india: reputable indian pharmacies – reputable indian online pharmacy
indian pharmacy reputable indian pharmacies online pharmacy india
best canadian pharmacy: canadian pharmacy prices – canadian pharmacy oxycodone
https://indiapharm.life/# india pharmacy
buying prescription drugs in mexico online: mexico drug stores pharmacies – purple pharmacy mexico price list
http://canadapharm.shop/# canadian pharmacy mall
india online pharmacy: online shopping pharmacy india – indian pharmacies safe
can i buy cheap clomid tablets where can i buy clomid pills buying clomid pills
http://zithromaxpharm.online/# buy zithromax without presc
zithromax capsules 250mg: where can i purchase zithromax online – zithromax coupon
п»їExceptional service every time http://prednisonepharm.store/# prednisone 54
https://clomidpharm.shop/# can you get cheap clomid prices
https://prednisonepharm.store/# purchase prednisone from india
zithromax online: azithromycin zithromax – zithromax buy
Their health awareness campaigns are so informative http://prednisonepharm.store/# buy prednisone 10 mg
http://zithromaxpharm.online/# zithromax 500mg
Their flu shots are quick and hassle-free http://zithromaxpharm.online/# zithromax online pharmacy canada
zithromax canadian pharmacy zithromax for sale 500 mg zithromax antibiotic
tamoxifen medication: tamoxifen 20 mg tablet – tamoxifen citrate pct
https://prednisonepharm.store/# buy prednisone 10mg online
Their global presence ensures prompt medication deliveries https://nolvadex.pro/# tamoxifen for men
zithromax drug: zithromax buy – zithromax generic cost
The best place for quality health products https://prednisonepharm.store/# buy prednisone no prescription
http://clomidpharm.shop/# where buy cheap clomid pill
https://zithromaxpharm.online/# how to get zithromax online
Cytotec 200mcg price: buy cytotec over the counter – cytotec pills buy online
Their worldwide pharmacists’ consultations are invaluable https://prednisonepharm.store/# prednisone pill prices
https://zithromaxpharm.online/# zithromax buy online
buy cytotec online fast delivery buy misoprostol over the counter cytotec abortion pill
The gold standard for international pharmaceutical services http://prednisonepharm.store/# order prednisone from canada
where can i buy zithromax medicine: zithromax 500 without prescription – zithromax for sale us
http://cytotec.directory/# buy cytotec online
Their commitment to international standards is evident http://zithromaxpharm.online/# zithromax 500mg over the counter
buy cytotec over the counter: buy cytotec – buy misoprostol over the counter
https://zithromaxpharm.online/# zithromax generic cost
Leading with integrity on the international front http://cytotec.directory/# buy cytotec
online pharmacies canada reviews https://edpills.bid/# erectile dysfunction medications
canadian drugs cialis
canadian drug companies: discount pharmaceuticals – canada pharmacies
overseas pharmacy: pharmacy online – canada mail pharmacy
legal to buy prescription drugs without prescription prescription drugs prescription drugs
http://edwithoutdoctorprescription.store/# prescription drugs without prior prescription
pills for ed: best ed pills – compare ed drugs
safe canadian online pharmacies canadian drugstore canada drugs no prescription
http://edwithoutdoctorprescription.store/# tadalafil without a doctor’s prescription
buy mexican drugs online: pharmacy drug store – canadian pharmacy generic
ed pills that work cheapest ed pills online what is the best ed pill
http://edpills.bid/# cheap ed drugs
pharmacy canadian https://reputablepharmacies.online/# reliable online pharmacies
online pharmacy canada
cheap erectile dysfunction pills online generic ed pills ed medications list
online canadian pharmaceutical companies: canadapharmacyonline.com – safe online canadian pharmacy
my canadian pharmacy: real canadian pharmacy – top rated online pharmacy
http://edwithoutdoctorprescription.store/# best non prescription ed pills
viagra without a doctor prescription non prescription erection pills prescription drugs without prior prescription
reputable mexican pharmacies: family discount pharmacy – trusted canadian pharmacy
http://edwithoutdoctorprescription.store/# mexican pharmacy without prescription
https://reputablepharmacies.online/# canadapharmacy com
top mail order pharmacies canadian pharmacy ed medications online drugstore reviews
canada medications: non prescription on line pharmacies – canadian pharmacy drugstore
cheapest ed pills online natural ed remedies cure ed
http://edpills.bid/# generic ed pills
canada pharmacies top best: canadian pharmacy direct – canadian pharmacy worldwide
my mexican drugstore: canadian pharmacies shipping to usa – pharmacy in canada
best ed pills at gnc best male ed pills ed medication
https://reputablepharmacies.online/# canadapharmacyonline.com
online pharmacies canada: meds canada – canadian pharmacy online ship to usa
online drug canadian drugstore viagra top rated canadian pharmacies
mexican online pharmacies prescription drugs: Medicines Mexico – best online pharmacies in mexico mexicanpharmacy.win
the canadian drugstore Pharmacies in Canada that ship to the US best mail order pharmacy canada canadianpharmacy.pro
http://indianpharmacy.shop/# india online pharmacy indianpharmacy.shop
canadian world pharmacy: Canada Pharmacy – safe canadian pharmacies canadianpharmacy.pro
buying prescription drugs in mexico online online mexican pharmacy mexican drugstore online mexicanpharmacy.win
https://indianpharmacy.shop/# india pharmacy indianpharmacy.shop
mexican rx online: mexican pharmacy online – mexico pharmacy mexicanpharmacy.win
buy medicines online in india Order medicine from India to USA indianpharmacy com indianpharmacy.shop
http://mexicanpharmacy.win/# best mexican online pharmacies mexicanpharmacy.win
https://mexicanpharmacy.win/# medicine in mexico pharmacies mexicanpharmacy.win
buy prescriptions online
buying prescription drugs in mexico mexican pharmacy online mexico pharmacy mexicanpharmacy.win
indian pharmacy paypal: international medicine delivery from india – mail order pharmacy india indianpharmacy.shop
top 10 pharmacies in india indian pharmacy п»їlegitimate online pharmacies india indianpharmacy.shop
http://mexicanpharmacy.win/# mexican mail order pharmacies mexicanpharmacy.win
http://indianpharmacy.shop/# reputable indian pharmacies indianpharmacy.shop
canadian pharmacy store Cheapest drug prices Canada maple leaf pharmacy in canada canadianpharmacy.pro
https://canadianpharmacy.pro/# canadian compounding pharmacy canadianpharmacy.pro
canadian pharmacy no presciption
http://mexicanpharmacy.win/# reputable mexican pharmacies online mexicanpharmacy.win
Online medicine home delivery
https://canadianpharmacy.pro/# canadian pharmacy com canadianpharmacy.pro
india pharmacy Best Indian pharmacy buy prescription drugs from india indianpharmacy.shop
https://mexicanpharmacy.win/# mexico drug stores pharmacies mexicanpharmacy.win
п»їlegitimate online pharmacies india
https://indianpharmacy.shop/# indian pharmacy indianpharmacy.shop
indian pharmacy online indian pharmacy online reputable indian online pharmacy indianpharmacy.shop
https://mexicanpharmacy.win/# buying from online mexican pharmacy mexicanpharmacy.win
buy medicines online in india
http://indianpharmacy.shop/# india online pharmacy indianpharmacy.shop
http://indianpharmacy.shop/# top 10 pharmacies in india indianpharmacy.shop
ed meds online canada Pharmacies in Canada that ship to the US ed drugs online from canada canadianpharmacy.pro
http://canadianpharmacy.pro/# canada pharmacy 24h canadianpharmacy.pro
cheapest online pharmacy india
https://mexicanpharmacy.win/# pharmacies in mexico that ship to usa mexicanpharmacy.win
https://canadianpharmacy.pro/# canadian mail order pharmacy canadianpharmacy.pro
canadian family pharmacy Canadian pharmacy online canada pharmacy canadianpharmacy.pro
http://mexicanpharmacy.win/# medicine in mexico pharmacies mexicanpharmacy.win
india online pharmacy
https://mexicanpharmacy.win/# medication from mexico pharmacy mexicanpharmacy.win
indian pharmacy online Online medicine home delivery indianpharmacy com indianpharmacy.shop
https://canadianpharmacy.pro/# canadian pharmacy review canadianpharmacy.pro
online shopping pharmacy india
https://canadianpharmacy.pro/# canadian pharmacy checker canadianpharmacy.pro
safe canadian online pharmacy
http://mexicanpharmacy.win/# mexico drug stores pharmacies mexicanpharmacy.win
Viagra homme sans ordonnance belgique: Viagra pas cher livraison rapide france – Le gГ©nГ©rique de Viagra
http://viagrasansordonnance.pro/# Viagra pas cher inde
Pharmacies en ligne certifiГ©es
https://viagrasansordonnance.pro/# Viagra pas cher livraison rapide france
Acheter mГ©dicaments sans ordonnance sur internet cialis sans ordonnance Pharmacie en ligne livraison 24h
Pharmacie en ligne pas cher: cialis prix – Pharmacie en ligne livraison 24h
п»їpharmacie en ligne cialis generique Pharmacies en ligne certifiГ©es
http://pharmadoc.pro/# acheter medicament a l etranger sans ordonnance
Acheter mГ©dicaments sans ordonnance sur internet: acheter kamagra site fiable – pharmacie ouverte
http://viagrasansordonnance.pro/# Viagra homme sans ordonnance belgique
https://pharmadoc.pro/# Pharmacie en ligne livraison 24h
Pharmacie en ligne livraison 24h
п»їpharmacie en ligne: cialis generique – Acheter mГ©dicaments sans ordonnance sur internet
http://acheterkamagra.pro/# acheter médicaments à l’étranger
Pharmacie en ligne livraison 24h: cialissansordonnance.shop – Pharmacie en ligne pas cher
pharmacie ouverte: Acheter Cialis 20 mg pas cher – Pharmacies en ligne certifiГ©es
https://viagrasansordonnance.pro/# Prix du Viagra 100mg en France
Pharmacie en ligne livraison rapide: Levitra sans ordonnance 24h – Pharmacie en ligne livraison gratuite
Pharmacie en ligne livraison 24h Levitra pharmacie en ligne acheter mГ©dicaments Г l’Г©tranger
https://levitrasansordonnance.pro/# Pharmacie en ligne France
pharmacie ouverte: Acheter Cialis 20 mg pas cher – Acheter mГ©dicaments sans ordonnance sur internet
http://levitrasansordonnance.pro/# Pharmacies en ligne certifiГ©es
acheter medicament a l etranger sans ordonnance
pharmacie ouverte levitra generique sites surs Pharmacie en ligne livraison gratuite
http://viagrasansordonnance.pro/# Sildénafil 100 mg sans ordonnance
where to get prednisone: prednisone 20 mg purchase – prednisone 54899
prednisone 5 mg tablet cost: prednisone purchase canada – prednisone 80 mg daily
https://ivermectin.store/# how much does ivermectin cost
where can i buy clomid without a prescription get cheap clomid online how to buy generic clomid no prescription
https://azithromycin.bid/# zithromax 500 mg lowest price drugstore online
ivermectin over the counter: ivermectin rx – ivermectin 0.5 lotion india
http://clomiphene.icu/# can i buy cheap clomid without dr prescription
generic clomid pill get cheap clomid for sale can i buy generic clomid now
where can i get zithromax over the counter: zithromax over the counter uk – where can i buy zithromax medicine
amoxicillin 500mg capsules: buy amoxicillin over the counter uk – amoxicillin 500mg capsule buy online
http://clomiphene.icu/# where buy cheap clomid now
prednisone pill 10 mg prednisone 40 mg price prednisone price australia
prednisone without prescription.net: generic prednisone cost – prednisone 10 mg tablet
http://prednisonetablets.shop/# prednisone tabs 20 mg
where to get amoxicillin over the counter: can you buy amoxicillin over the counter canada – amoxicillin 500mg no prescription
https://azithromycin.bid/# zithromax 1000 mg pills
prednisone 7.5 mg prednisone 54 purchase prednisone no prescription
prednisone 5 mg tablet cost: prednisone 20mg tab price – prednisone 10mg
https://azithromycin.bid/# zithromax 500
prednisone 20mg: prednisone 10mg price in india – prednisone buy online nz
amoxicillin 250 mg cost of amoxicillin purchase amoxicillin online without prescription
http://prednisonetablets.shop/# buy prednisone online usa
amoxicillin pharmacy price: amoxicillin 500mg capsule buy online – amoxicillin without rx
http://amoxicillin.bid/# amoxicillin canada price
where to get clomid where to get cheap clomid without dr prescription cheap clomid
buy 10 mg prednisone: buy prednisone without rx – non prescription prednisone 20mg
ivermectin pills: minocycline 100mg tablets for human – ivermectin 0.5 lotion
https://clomiphene.icu/# buy generic clomid
http://azithromycin.bid/# zithromax generic cost
zithromax for sale 500 mg: zithromax 250 – zithromax 500 mg lowest price pharmacy online
ivermectin lotion 0.5 ivermectin 6mg tablet for lice buy liquid ivermectin
I gave https://www.cornbreadhemp.com/collections/full-spectrum-cbd-oil a try payment the maiden time, and I’m amazed! They tasted distinguished and provided a sanity of calmness and relaxation. My lay stress melted away, and I slept less ill too. These gummies are a game-changer for me, and I highly endorse them to anyone seeking unconstrained stress liberation and well-advised sleep.
mexican rx online: Online Mexican pharmacy – buying from online mexican pharmacy mexicanpharm.shop
pharmacy website india: order medicine from india to usa – indian pharmacy online indianpharm.store
canadian pharmacy antibiotics: Pharmacies in Canada that ship to the US – canadianpharmacymeds canadianpharm.store
https://indianpharm.store/# indian pharmacy paypal indianpharm.store
buy prescription drugs from india reputable indian online pharmacy online pharmacy india indianpharm.store
pharmacies in mexico that ship to usa: Online Pharmacies in Mexico – buying prescription drugs in mexico mexicanpharm.shop
https://indianpharm.store/# indian pharmacy indianpharm.store
http://canadianpharm.store/# canadian pharmacy canadianpharm.store
best mail order pharmacy canada Best Canadian online pharmacy buy drugs from canada canadianpharm.store
canadian pharmacy reviews: Licensed Online Pharmacy – canadian pharmacy phone number canadianpharm.store
canada pharmacy online: legit canadian pharmacy online – onlinepharmaciescanada com canadianpharm.store
https://mexicanpharm.shop/# mexican drugstore online mexicanpharm.shop
indian pharmacy paypal: Indian pharmacy to USA – reputable indian online pharmacy indianpharm.store
mexico drug stores pharmacies mexico drug stores pharmacies mexican online pharmacies prescription drugs mexicanpharm.shop
mail order pharmacy india: order medicine from india to usa – world pharmacy india indianpharm.store
https://mexicanpharm.shop/# mexico pharmacies prescription drugs mexicanpharm.shop
india online pharmacy: international medicine delivery from india – top 10 online pharmacy in india indianpharm.store
top online pharmacy india best online pharmacy india п»їlegitimate online pharmacies india indianpharm.store
https://canadianpharm.store/# canada pharmacy online canadianpharm.store
indian pharmacy: Indian pharmacy to USA – indian pharmacy paypal indianpharm.store
pharmacies in mexico that ship to usa: Online Pharmacies in Mexico – buying prescription drugs in mexico mexicanpharm.shop
https://canadianpharm.store/# canadian pharmacy scam canadianpharm.store
https://canadianpharm.store/# canadianpharmacyworld com canadianpharm.store
mexican rx online Online Pharmacies in Mexico mexico drug stores pharmacies mexicanpharm.shop
mexican online pharmacies prescription drugs: Online Pharmacies in Mexico – buying prescription drugs in mexico online mexicanpharm.shop
canada drugs online: Pharmacies in Canada that ship to the US – global pharmacy canada canadianpharm.store
A big thank you for your blog.Really looking forward to read more.<a href="https://www.google.com.mt/url?sa=t
https://canadianpharm.store/# the canadian drugstore canadianpharm.store
india online pharmacy: order medicine from india to usa – mail order pharmacy india indianpharm.store
india pharmacy Indian pharmacy to USA reputable indian online pharmacy indianpharm.store
https://mexicanpharm.shop/# mexican rx online mexicanpharm.shop
mexican border pharmacies shipping to usa: Certified Pharmacy from Mexico – pharmacies in mexico that ship to usa mexicanpharm.shop
pharmacy website india: international medicine delivery from india – india pharmacy indianpharm.store
mexico pharmacy Online Pharmacies in Mexico mexican pharmacy mexicanpharm.shop
http://mexicanpharm.shop/# mexican mail order pharmacies mexicanpharm.shop
buy medicines online in india: india pharmacy mail order – indian pharmacy online indianpharm.store
canadian pharmacy prices: Best Canadian online pharmacy – legit canadian pharmacy online canadianpharm.store
https://canadianpharm.store/# the canadian drugstore canadianpharm.store
canadian pharmacies online Pharmacies in Canada that ship to the US legitimate canadian online pharmacies canadianpharm.store
http://indianpharm.store/# indian pharmacy online indianpharm.store
canadian pharmacies compare: Canada Pharmacy online – canadianpharmacyworld com canadianpharm.store
canadian drug prices: Best Canadian online pharmacy – canadian pharmacy no scripts canadianpharm.store
http://canadianpharm.store/# reliable canadian pharmacy canadianpharm.store
Online medicine home delivery india pharmacy mail order india pharmacy indianpharm.store
pharmacy website india: order medicine from india to usa – buy prescription drugs from india indianpharm.store
onlinepharmaciescanada com: Canadian International Pharmacy – canadian pharmacy victoza canadianpharm.store
india pharmacy: order medicine from india to usa – buy prescription drugs from india indianpharm.store
http://mexicanpharm.shop/# pharmacies in mexico that ship to usa mexicanpharm.shop
https://indianpharm.store/# best online pharmacy india indianpharm.store
canadian pharmacy uk delivery Best Canadian online pharmacy canadian drug prices canadianpharm.store
prescription drug prices comparison: canadian pharmacies for viagra – canadian pharmacies top best
canadian wholesale pharmacy: my canadian pharmacy online – legitimate online pharmacy usa
https://canadadrugs.pro/# canadian pharmacy reviews
canadian pharmacy for sildenafil canadian pharmaceutical companies that ship to usa buy prescription drugs online
most reliable canadian pharmacy: legitimate online pharmacies – canada pharmacy no prescription
canadian pharmacy: online pharmacies in usa – canadian drug stores online
https://canadadrugs.pro/# canadian pharmacy online no prescription
discount prescription drug nabp canadian pharmacy canadian rx
online pharmacy: canadian prescription filled in the us – canada pharmacy online orders
best online pharmacies: certified online canadian pharmacies – canadian pharcharmy
https://canadadrugs.pro/# non prescription on line pharmacies
canadian pharmacy no prescrition canadian prescription pharmacy canadian pharcharmy reviews
canadian pharmacies reviews: canadian drug company – canada medications
https://canadadrugs.pro/# the discount pharmacy
canadian pharcharmy: mail order canadian drugs – canadian pharmacy no presciption
trust pharmacy canada: legal online pharmacies – pharmacy drugstore online
canadian pharmacy selling viagra canada online pharmacy reviews pharmacies with no prescription
https://canadadrugs.pro/# drugstore online
buy canadian drugs online: canada online pharmacy – no prescription canadian pharmacy
canadian online pharmacies reviews: online drug – buy prescription drugs canada
http://canadadrugs.pro/# aarp canadian pharmacy
mexican pharmacy online: canadian meds without a script – canadian pharmacy no prescription needed
https://canadadrugs.pro/# canadian pharmacy antibiotics
best mail order canadian pharmacy: online pharmacy usa – mexican online pharmacy
buy prescription drugs online legally: canadian pharmacy 24hr – canada drug
http://canadadrugs.pro/# most trusted canadian pharmacy
online pharmacy no peescription: online pharmacies canada reviews – canada online pharmacy
cheap drugs canada: best canadian pharmacies online – online pharmacy mail order
pharmacy price comparison: legitimate online pharmacies india – my canadian pharmacy
https://canadadrugs.pro/# online meds
canadian internet pharmacies: canadian pharmacy online no prescription – buying prescription drugs canada
https://canadadrugs.pro/# canadian pharmacies that sell viagra
https://canadadrugs.pro/# online ed drugs no prescription
reputable mexican pharmacies online: medication from mexico pharmacy – mexican pharmaceuticals online
viagra without doctor prescription: ed pills without doctor prescription – meds online without doctor prescription
https://medicinefromindia.store/# indian pharmacy
buying prescription drugs in mexico online mexico pharmacy mexico drug stores pharmacies
cheapest online pharmacy india: top 10 pharmacies in india – online shopping pharmacy india
http://edpill.cheap/# erectile dysfunction medications
https://canadianinternationalpharmacy.pro/# legitimate canadian pharmacies
mexican border pharmacies shipping to usa mexico pharmacy mexican drugstore online
medicine in mexico pharmacies: buying prescription drugs in mexico – best online pharmacies in mexico
https://medicinefromindia.store/# india pharmacy
indian pharmacy indian pharmacies safe п»їlegitimate online pharmacies india
mexican pharmaceuticals online: medicine in mexico pharmacies – mexico drug stores pharmacies
https://edwithoutdoctorprescription.pro/# ed meds online without doctor prescription
online shopping pharmacy india Online medicine order top 10 online pharmacy in india
http://canadianinternationalpharmacy.pro/# trusted canadian pharmacy
I really like reading through a post that can make men and women think.-vox wiederholung
buy prescription drugs from india cheap cialis viagra without doctor prescription
https://edwithoutdoctorprescription.pro/# real viagra without a doctor prescription
indian pharmacy: reputable indian pharmacies – reputable indian pharmacies
top 10 online pharmacy in india: india online pharmacy – top 10 pharmacies in india
http://edpill.cheap/# best pills for ed
buying prescription drugs in mexico п»їbest mexican online pharmacies mexican border pharmacies shipping to usa
https://medicinefromindia.store/# cheapest online pharmacy india
indian pharmacy best india pharmacy indian pharmacy paypal
http://medicinefromindia.store/# top 10 online pharmacy in india
gnc ed pills online ed medications new ed treatments
https://edwithoutdoctorprescription.pro/# buy prescription drugs without doctor
reputable canadian online pharmacies: canadian pharmacy com – canadian mail order pharmacy
medication from mexico pharmacy mexico pharmacy mexican pharmacy
http://edpill.cheap/# ed treatment review
medication from mexico pharmacy medicine in mexico pharmacies medicine in mexico pharmacies
http://canadianinternationalpharmacy.pro/# canadian pharmacy service
https://edpill.cheap/# pills for ed
canada drugs online trustworthy canadian pharmacy online canadian pharmacy review
canadian pharmacy ratings: canadian drug stores – the canadian pharmacy
http://edwithoutdoctorprescription.pro/# prescription drugs without doctor approval
best ed treatment ed treatment drugs ed drugs
http://certifiedpharmacymexico.pro/# mexico pharmacies prescription drugs
erectile dysfunction pills best pills for ed generic ed drugs
http://edwithoutdoctorprescription.pro/# prescription drugs online without
legal canadian pharmacy online: canadian pharmacy world reviews – canadian pharmacy ed medications
mexican online pharmacies prescription drugs purple pharmacy mexico price list medicine in mexico pharmacies
https://edwithoutdoctorprescription.pro/# viagra without doctor prescription amazon
mexican pharmaceuticals online buying from online mexican pharmacy mexico drug stores pharmacies
https://edpill.cheap/# treatments for ed
https://medicinefromindia.store/# mail order pharmacy india
http://edpill.cheap/# ed treatments
medication from mexico pharmacy mexican pharmacy mexico pharmacies prescription drugs
From there you click on the bookie and as a result, you will be taken to that bookmaker. Your betslip will also be transferred over to them to make betting hassle-free! Our horse racing tipsters publish their Kenilworth best bets the night before each meeting. From there you click on the bookie and as a result, you will be taken to that bookmaker. Your betslip will also be transferred over to them to make betting hassle-free! Check out the Kenilworth Form Guide section 2-3 days before raceday for our best tips. Sportingbet 100% up to R1000 + 20 Spins Winning Form Best Bets Kenilworth has an impressive reputation even before the horses make their way onto the track. The course is well known for being an important conservation area, having been established in 1985. The nature reserve is home to a lovely array of vegetation, some of which can only be seen in this region alone, truly making this one of the most unique racecourses in the world.
https://cashtxwb851995.blogofoto.com/51184034/betting-apps-legal-in-india
via Sports Logos.net If you’re looking for the most accurate NBA predictions tonight or for any NBA game, Dimers is the site for you. Our expert analysis, data-driven insights, and free NBA picks, tips, and parlays make us the go-to destination for NBA betting. Start making informed betting decisions and become an expert with Dimers today. Put your picks to the test and bet on Nuggets vs. Heat player props with BetMGM Sportsbook. Receive free daily analysis Need help evaluating prop bet wagers? The Action Labs Prop Tool will help you organize, sort, and grade hundreds of prop bet odds throughout the NBA season. Be sure to check in daily to keep up with the NBA action throughout the season. If you are also interested in betting on other leagues, visit our NFL Odds, NFL Picks and College Basketball Odds sites now. For all other betting odds please check out our Betting Odds page.
best canadian pharmacy online: pharmacy canadian – canadian pharmacy 24
http://canadianinternationalpharmacy.pro/# canadian pharmacy drugs online
viagra without a prescription generic cialis without a doctor prescription prescription drugs online
http://canadianinternationalpharmacy.pro/# canada pharmacy online
http://mexicanph.shop/# buying prescription drugs in mexico online
buying prescription drugs in mexico
buying prescription drugs in mexico buying from online mexican pharmacy best online pharmacies in mexico
purple pharmacy mexico price list medicine in mexico pharmacies mexican online pharmacies prescription drugs
best online pharmacies in mexico buying prescription drugs in mexico online buying prescription drugs in mexico
https://mexicanph.com/# mexican online pharmacies prescription drugs
mexico drug stores pharmacies
mexican rx online mexican online pharmacies prescription drugs best online pharmacies in mexico
medication from mexico pharmacy mexico pharmacies prescription drugs best online pharmacies in mexico
http://mexicanph.com/# buying prescription drugs in mexico
reputable mexican pharmacies online
medication from mexico pharmacy buying prescription drugs in mexico reputable mexican pharmacies online
http://mexicanph.com/# purple pharmacy mexico price list
buying from online mexican pharmacy
mexico drug stores pharmacies buying prescription drugs in mexico mexican border pharmacies shipping to usa
mexico drug stores pharmacies pharmacies in mexico that ship to usa buying prescription drugs in mexico online
best online pharmacies in mexico purple pharmacy mexico price list mexico pharmacy
mexico pharmacies prescription drugs mexico pharmacies prescription drugs mexican drugstore online
buying prescription drugs in mexico online purple pharmacy mexico price list mexico drug stores pharmacies
https://mexicanph.shop/# п»їbest mexican online pharmacies
buying from online mexican pharmacy
buying prescription drugs in mexico mexico drug stores pharmacies mexico pharmacies prescription drugs
reputable mexican pharmacies online mexican pharmacy reputable mexican pharmacies online
purple pharmacy mexico price list mexico pharmacies prescription drugs п»їbest mexican online pharmacies
reputable mexican pharmacies online mexican pharmaceuticals online mexican mail order pharmacies
mexico pharmacy mexico pharmacy mexico drug stores pharmacies
pharmacies in mexico that ship to usa mexico pharmacy medication from mexico pharmacy
medication from mexico pharmacy purple pharmacy mexico price list medicine in mexico pharmacies
best online pharmacies in mexico mexican drugstore online mexico drug stores pharmacies
https://mexicanph.shop/# best online pharmacies in mexico
mexico drug stores pharmacies
mexico pharmacies prescription drugs reputable mexican pharmacies online mexican pharmacy
mexican pharmaceuticals online mexican pharmacy mexico drug stores pharmacies
п»їbest mexican online pharmacies mexican pharmacy best online pharmacies in mexico
This Article Is A Perfect Blend Of Informative And Entertaining. Well Done!
mexican pharmaceuticals online mexico pharmacies prescription drugs mexican rx online
mexican pharmacy best mexican online pharmacies pharmacies in mexico that ship to usa
mexico pharmacies prescription drugs purple pharmacy mexico price list pharmacies in mexico that ship to usa
mexican border pharmacies shipping to usa mexican pharmacy mexican border pharmacies shipping to usa
https://mexicanph.com/# purple pharmacy mexico price list
mexican drugstore online
mexican pharmaceuticals online mexico drug stores pharmacies mexican pharmacy
best mexican online pharmacies pharmacies in mexico that ship to usa mexican mail order pharmacies
reputable mexican pharmacies online pharmacies in mexico that ship to usa best online pharmacies in mexico
best online pharmacies in mexico mexico drug stores pharmacies buying prescription drugs in mexico online
purple pharmacy mexico price list mexico pharmacies prescription drugs mexico pharmacy
mexican online pharmacies prescription drugs mexican online pharmacies prescription drugs п»їbest mexican online pharmacies
mexican online pharmacies prescription drugs medicine in mexico pharmacies medicine in mexico pharmacies
medicine in mexico pharmacies medication from mexico pharmacy buying prescription drugs in mexico online
purple pharmacy mexico price list mexican mail order pharmacies medicine in mexico pharmacies
http://mexicanph.shop/# mexican rx online
mexican pharmaceuticals online
mexican mail order pharmacies mexico drug stores pharmacies mexican rx online
mexican rx online buying prescription drugs in mexico online mexican mail order pharmacies
medicine in mexico pharmacies reputable mexican pharmacies online mexican pharmaceuticals online
mexico drug stores pharmacies mexican border pharmacies shipping to usa mexico drug stores pharmacies
medicine in mexico pharmacies mexican mail order pharmacies buying from online mexican pharmacy
mexican rx online mexican online pharmacies prescription drugs mexican drugstore online
mexican rx online pharmacies in mexico that ship to usa mexican online pharmacies prescription drugs
mexican pharmaceuticals online medicine in mexico pharmacies mexico drug stores pharmacies
mexican drugstore online mexican border pharmacies shipping to usa mexican mail order pharmacies
mexican pharmaceuticals online reputable mexican pharmacies online purple pharmacy mexico price list
http://mexicanph.com/# reputable mexican pharmacies online
mexico pharmacies prescription drugs
п»їbest mexican online pharmacies mexico drug stores pharmacies mexico pharmacy
best mexican online pharmacies best online pharmacies in mexico mexican mail order pharmacies
buying from online mexican pharmacy mexican online pharmacies prescription drugs mexican mail order pharmacies
best online pharmacies in mexico mexico drug stores pharmacies best online pharmacies in mexico
furosemide 100mg: Buy Lasix – furosemide 100 mg
https://buyprednisone.store/# buy cheap prednisone
lisinopril online purchase: lisinopril 20 mg canadian – order lisinopril from mexico
https://amoxil.cheap/# prescription for amoxicillin
http://lisinopril.top/# lisinopril 10mg prices compare
cost of amoxicillin prescription: canadian pharmacy amoxicillin – amoxicillin generic brand
http://stromectol.fun/# stromectol 3mg
prednisone cost 10mg: 20 mg of prednisone – prednisone 1 mg for sale
price of lisinopril in india: lisinopril 20 pills – lisinopril tablets for sale
https://buyprednisone.store/# prednisone 10 mg tablets
http://buyprednisone.store/# buying prednisone
buy amoxicillin online mexico: amoxicillin 500mg price canada – over the counter amoxicillin
http://amoxil.cheap/# rexall pharmacy amoxicillin 500mg
amoxicillin generic: amoxicillin price without insurance – buy amoxicillin
https://stromectol.fun/# ivermectin 3 mg tablet dosage
where can i purchase lisinopril: lisinopril 10 best price – lisinopril 10 mg without prescription
http://buyprednisone.store/# prednisone 20 mg
where to buy ivermectin pills: buy stromectol uk – ivermectin generic
http://amoxil.cheap/# can i buy amoxicillin over the counter in australia
generic name for ivermectin: ivermectin 0.5% brand name – ivermectin 0.1 uk
https://buyprednisone.store/# buy prednisone without a prescription best price
40 mg prednisone pill: prednisone canada – 50 mg prednisone canada pharmacy
http://amoxil.cheap/# buy amoxicillin over the counter uk
prednisone 60 mg tablet: 80 mg prednisone daily – 10 mg prednisone
https://furosemide.guru/# lasix uses
lisinopril canada: lisinopril for sale – lisinopril comparison
https://buyprednisone.store/# purchase prednisone canada
prednisone brand name us: prednisone no rx – how to buy prednisone online
https://amoxil.cheap/# amoxicillin online purchase
prednisone 1 tablet: prednisone 5 mg tablet without a prescription – prednisone price australia
prednisone 10mg for sale: order prednisone 100g online without prescription – prednisone no rx
https://furosemide.guru/# lasix
http://buyprednisone.store/# prednisone 10mg for sale
stromectol sales: ivermectin 9 mg tablet – buy ivermectin for humans uk
I am curious to find out what blog platform you’re using? I’m having some small security problems with my latest website and I would like to find something more risk-free. Do you have any recommendations?
https://lisinopril.top/# lisinopril no prescription
Thanks for some other informative blog. Where else may I am getting that type of information written in such an ideal way? I have a undertaking that I am just now operating on, and I have been at the look out for such info.
where to get prednisone: prednisone 50 mg prices – medicine prednisone 5mg
200 mg prednisone daily: online order prednisone – buy prednisone 20mg without a prescription best price
http://stromectol.fun/# ivermectin purchase
I think the admin of this site is really working hard for his website since here every stuff is quality based data.Baby Healthcare and Grooming Kit with Nail Clippers Scissors Portable Baby Health and Essentials Infant Grooming Kit for Newborns (18 in 1 Green) – Hot Deals
http://stromectol.fun/# ivermectin 2mg
buy ivermectin for humans australia: stromectol how much it cost – ivermectin over the counter uk
https://furosemide.guru/# lasix 100 mg
ivermectin 4: price of ivermectin – ivermectin 4 tablets price
prednisone cream brand name: over the counter prednisone medicine – buy prednisone no prescription
https://buyprednisone.store/# prednisone 2.5 mg
you’re really a good webmaster. The web site loading speed is incredible. It seems that you’re doing any unique trick. Also, The contents are masterpiece. you’ve done a excellent job on this topic!
http://amoxil.cheap/# buy amoxicillin 500mg canada
One more thing. I think that there are numerous travel insurance web sites of reputable companies that permit you to enter your trip details and obtain you the prices. You can also purchase the particular international holiday insurance policy on the net by using your own credit card. All you have to do is usually to enter your travel particulars and you can understand the plans side-by-side. Just find the system that suits your budget and needs after which use your credit card to buy them. Travel insurance online is a good way to start looking for a respected company for international travel insurance. Thanks for sharing your ideas.
ivermectin goodrx: stromectol buy uk – stromectol 6 mg dosage
https://lisinopril.top/# cost of lisinopril 30 mg
ivermectin over the counter: generic ivermectin for humans – ivermectin lotion for lice
http://amoxil.cheap/# amoxicillin 500mg without prescription
amoxicillin 500 mg: buy amoxicillin 500mg uk – amoxicillin price without insurance
http://furosemide.guru/# furosemide 40mg
https://amoxil.cheap/# amoxicillin 500 mg cost
http://stromectol.fun/# ivermectin ireland
amoxicillin 500mg price: order amoxicillin uk – amoxicillin where to get
furosemida: lasix for sale – furosemida
https://furosemide.guru/# lasix
http://lisinopril.top/# 40 mg lisinopril for sale
ivermectin 0.08 oral solution: ivermectin where to buy – ivermectin 6mg
can you buy lisinopril: lisinopril 5 mg tabs – zestoretic 10 12.5 mg
http://stromectol.fun/# buy ivermectin for humans uk
furosemide 100 mg: Buy Furosemide – lasix
https://lisinopril.top/# lisinopril 420
https://amoxil.cheap/# can you buy amoxicillin over the counter
prednisone cost canada: prednisone pack – prednisone cost us
https://stromectol.fun/# ivermectin uk
lasix uses: Buy Lasix – lasix pills
http://furosemide.guru/# lasix 20 mg
ivermectin india: stromectol generic – ivermectin where to buy for humans
http://amoxil.cheap/# amoxicillin tablet 500mg
ivermectin 6mg tablet for lice: how much does ivermectin cost – how to buy stromectol
ivermectin 1mg: buy stromectol pills – stromectol for head lice
http://lisinopril.top/# lisinopril brand name in india
https://furosemide.guru/# lasix 40 mg
lisinopril tab 100mg: zestoretic 20 mg – lisinopril 5 mg tablet
http://indianph.com/# pharmacy website india
Online medicine home delivery
http://indianph.com/# india pharmacy
Online medicine home delivery buy medicines online in india world pharmacy india
https://indianph.xyz/# indian pharmacies safe
Online medicine home delivery
https://indianph.xyz/# legitimate online pharmacies india
pharmacy website india
https://indianph.xyz/# online pharmacy india
cheapest online pharmacy india
cheapest online pharmacy india Online medicine order reputable indian pharmacies
http://indianph.xyz/# Online medicine order
reputable indian pharmacies
http://indianph.com/# indian pharmacy
reputable indian pharmacies
http://indianph.xyz/# top 10 pharmacies in india
http://indianph.com/# top online pharmacy india
reputable indian online pharmacy
https://indianph.xyz/# world pharmacy india
indian pharmacy online
indian pharmacy best india pharmacy india pharmacy
https://indianph.com/# top online pharmacy india
top 10 pharmacies in india
Online medicine home delivery online shopping pharmacy india online pharmacy india
I recently tried CBD gummies in search the blue ribbon prematurely and was pleasantly surprised past the results. Initially skeptical, I create that it significantly helped with my dread and doze issues without any remarkable side effects. The oil was easy to utter, with nitid dosage instructions. It had a merciful, earthy liking that was not unpleasant. Within a week, I noticed a patent convalescence in my blanket well-being, ardour more blas‚ and rested. I comprehend the regular approach to wellness CBD offers and plan to at using it.
how does tamoxifen work: tamoxifen dosage – arimidex vs tamoxifen bodybuilding
https://doxycycline.auction/# purchase doxycycline online
http://diflucan.pro/# diflucan 150 mg buy online uk
https://cipro.guru/# cipro online no prescription in the usa
vibramycin 100 mg: doxycycline vibramycin – buy cheap doxycycline
does tamoxifen cause weight loss raloxifene vs tamoxifen nolvadex estrogen blocker
https://diflucan.pro/# diflucan pill
buy diflucan 150 mg: diflucan 150 mg tabs – diflucan 750 mg
http://diflucan.pro/# diflucan singapore pharmacy
cytotec abortion pill cytotec abortion pill buy cytotec pills online cheap
http://nolvadex.guru/# tamoxifen men
doxycycline 100mg: buy doxycycline hyclate 100mg without a rx – doxycycline tablets
http://diflucan.pro/# diflucan 100
doxycycline 100mg tablets doxycycline tablets buy cheap doxycycline
http://cytotec24.shop/# Cytotec 200mcg price
ciprofloxacin 500 mg tablet price: ciprofloxacin – purchase cipro
https://cipro.guru/# ciprofloxacin mail online
doxycycline 50mg: online doxycycline – doxy 200
https://diflucan.pro/# diflucan cost canada
antibiotics cipro ciprofloxacin generic price buy ciprofloxacin over the counter
https://diflucan.pro/# diflucan online prescription
https://diflucan.pro/# diflucan 2 pills
http://nolvadex.guru/# pct nolvadex
diflucan 100 mg tab buy diflucan online cheap buy cheap diflucan online
http://nolvadex.guru/# where to buy nolvadex
http://nolvadex.guru/# nolvadex d
how to order doxycycline cheap doxycycline online doxycycline 50mg
https://diflucan.pro/# diflucan 150 mg over the counter
http://diflucan.pro/# diflucan 125mg
http://cipro.guru/# antibiotics cipro
price of doxycycline how to buy doxycycline online buy doxycycline hyclate 100mg without a rx
http://doxycycline.auction/# doxycycline 100mg tablets
eva elfie: eva elfie izle – eva elfie
https://lanarhoades.fun/# lana rhoades
http://abelladanger.online/# abella danger filmleri
http://abelladanger.online/# abella danger video
Angela White filmleri: abella danger filmleri – abella danger filmleri
https://angelawhite.pro/# Angela White
http://sweetiefox.online/# sweeti fox
Angela White filmleri: Angela White filmleri – Angela Beyaz modeli
https://lanarhoades.fun/# lana rhoades filmleri
http://lanarhoades.fun/# lana rhoades video
http://lanarhoades.fun/# lana rhoades video
?????? ????: Angela White izle – Angela White filmleri
http://evaelfie.pro/# eva elfie modeli
http://abelladanger.online/# Abella Danger
https://sweetiefox.online/# Sweetie Fox video
eva elfie video: eva elfie video – eva elfie video
http://angelawhite.pro/# Angela White filmleri
http://abelladanger.online/# abella danger izle
https://sweetiefox.online/# Sweetie Fox
Sweetie Fox modeli: Sweetie Fox – sweeti fox
http://evaelfie.pro/# eva elfie video
http://angelawhite.pro/# Angela White izle
http://abelladanger.online/# abella danger izle
eva elfie: eva elfie izle – eva elfie izle
http://lanarhoades.fun/# lana rhoades filmleri
http://abelladanger.online/# abella danger video
http://angelawhite.pro/# ?????? ????
lana rhoades video: lana rhoades – lana rhoades video
http://lanarhoades.fun/# lana rhoades filmleri
https://angelawhite.pro/# Angela White
http://abelladanger.online/# abella danger filmleri
Angela White video: Abella Danger – abella danger video
https://angelawhite.pro/# ?????? ????
http://angelawhite.pro/# ?????? ????
Angela White izle: abella danger video – Abella Danger
https://sweetiefox.online/# Sweetie Fox filmleri
http://evaelfie.pro/# eva elfie modeli
https://lanarhoades.fun/# lana rhoades video
http://evaelfie.pro/# eva elfie
http://evaelfie.pro/# eva elfie
Angela White video: Abella Danger – abella danger filmleri
http://evaelfie.pro/# eva elfie izle
http://evaelfie.pro/# eva elfie modeli
lana rhoades modeli: lana rhoades – lana rhoades modeli
https://lanarhoades.fun/# lana rhoades video
http://evaelfie.pro/# eva elfie
eva elfie: eva elfie izle – eva elfie video
http://sweetiefox.pro/# sweetie fox video
lana rhoades full video: lana rhoades unleashed – lana rhoades full video
lana rhoades full video: lana rhoades boyfriend – lana rhoades solo
https://evaelfie.site/# eva elfie full videos
mia malkova videos: mia malkova only fans – mia malkova movie
connect singles: http://sweetiefox.pro/# sweetie fox new
https://miamalkova.life/# mia malkova new video
lana rhoades videos: lana rhoades solo – lana rhoades unleashed
https://sweetiefox.pro/# sweetie fox video
eva elfie hd: eva elfie videos – eva elfie videos
sweetie fox video: sweetie fox – fox sweetie
single women phone numbers: http://sweetiefox.pro/# ph sweetie fox
http://evaelfie.site/# eva elfie new videos
sweetie fox cosplay: sweetie fox new – sweetie fox full
eva elfie photo: eva elfie photo – eva elfie new video
https://sweetiefox.pro/# sweetie fox cosplay
lana rhoades hot: lana rhoades solo – lana rhoades
completely free dating sites: https://evaelfie.site/# eva elfie full videos
lana rhoades videos: lana rhoades videos – lana rhoades pics
https://lanarhoades.pro/# lana rhoades unleashed
lana rhoades unleashed: lana rhoades – lana rhoades solo
eva elfie full video: eva elfie full video – eva elfie full videos
Great blog here! Also your site loads up very fast! What web host are you using? Can I get your affiliate link to your host? I wish my site loaded up as fast as yours lol
One more thing to say is that an online business administration diploma is designed for people to be able to smoothly proceed to bachelors degree programs. The 90 credit certification meets the other bachelor education requirements and when you earn the associate of arts in BA online, you will get access to the most up-to-date technologies in this particular field. Some reasons why students want to get their associate degree in business is because they can be interested in this area and want to get the general education and learning necessary in advance of jumping to a bachelor diploma program. Thx for the tips you actually provide inside your blog.
Spot on with this write-up, I really suppose this website wants way more consideration. I?ll probably be again to learn rather more, thanks for that info.
singles ads: https://sweetiefox.pro/# sweetie fox full
https://miamalkova.life/# mia malkova movie
Thank you for another informative blog. Where else could I get that type of info written in such a perfect way? I’ve a project that I am just now working on, and I’ve been on the look out for such information.
ph sweetie fox: sweetie fox cosplay – sweetie fox full video
https://evaelfie.site/# eva elfie full video
sweetie fox full: sweetie fox full – sweetie fox new
mia malkova: mia malkova videos – mia malkova new video
top dating sites: https://sweetiefox.pro/# sweetie fox full video
F*ckin? tremendous issues here. I?m very happy to see your post. Thank you a lot and i’m taking a look forward to contact you. Will you please drop me a mail?
Based on my observation, after a foreclosures home is marketed at a bidding, it is common for that borrower to be able to still have any remaining balance on the mortgage. There are many lenders who seek to have all rates and liens paid back by the subsequent buyer. On the other hand, depending on selected programs, restrictions, and state legal guidelines there may be a number of loans that aren’t easily fixed through the exchange of financial loans. Therefore, the duty still remains on the client that has had his or her property in foreclosure. Many thanks for sharing your opinions on this website.
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you? Plz respond as I’m looking to design my own blog and would like to find out where u got this from. thank you
Have you ever considered creating an e-book or guest authoring on other websites? I have a blog based on the same ideas you discuss and would love to have you share some stories/information. I know my audience would enjoy your work. If you are even remotely interested, feel free to shoot me an e mail.
http://sweetiefox.pro/# sweetie fox video
mia malkova movie: mia malkova girl – mia malkova videos
Definitely what a great blog and instructive posts I definitely will bookmark your site.All the Best! . – hey dude shoes women
http://evaelfie.site/# eva elfie new video
lana rhoades hot: lana rhoades videos – lana rhoades boyfriend
lana rhoades pics: lana rhoades boyfriend – lana rhoades pics
dating dating: https://lanarhoades.pro/# lana rhoades boyfriend
Thanks for the strategies you are discussing on this weblog. Another thing I’d really like to say is that often getting hold of copies of your credit profile in order to check accuracy of each and every detail is the first measures you have to undertake in repairing credit. You are looking to clean your credit file from destructive details problems that mess up your credit score.
Many thanks to you for sharing these kind of wonderful content. In addition, the right travel and also medical insurance system can often ease those worries that come with travelling abroad. A new medical crisis can quickly become very costly and that’s sure to quickly decide to put a financial stress on the family finances. Having in place the excellent travel insurance bundle prior to leaving is definitely worth the time and effort. Thanks a lot
Hello, Neat post. There is a problem with your web site in internet explorer, could check this? IE still is the market leader and a huge component of folks will miss your fantastic writing because of this problem.
Thanks for expressing your ideas listed here. The other matter is that each time a problem takes place with a computer motherboard, folks should not have some risk involving repairing this themselves because if it is not done properly it can lead to irreparable damage to an entire laptop. It is almost always safe to approach a dealer of that laptop for that repair of the motherboard. They have technicians that have an skills in dealing with pc motherboard challenges and can carry out the right diagnosis and perform repairs.
https://lanarhoades.pro/# lana rhoades videos
eva elfie hot: eva elfie photo – eva elfie new video
Almanya medyum haluk hoca sizlere 40 yıldır medyumluk hizmeti veriyor, Medyum haluk hocamızın hazırladığı çalışmalar ise berlin medyum papaz büyüsü, Konularında en iyi sonuç ve kısa sürede yüzde yüz için bizleri tercih ediniz. İletişim: +49 157 59456087
http://pinupcassino.pro/# pin-up cassino
http://jogodeaposta.fun/# ganhar dinheiro jogando
http://aviatormalawi.online/# aviator bet malawi login
como jogar aviator: aviator – como jogar aviator em mocambique
aviator game online: aviator bet malawi login – aviator bet malawi login
https://aviatormocambique.site/# aviator
Can I just say what a aid to find somebody who actually knows what theyre talking about on the internet. You definitely know easy methods to carry a problem to gentle and make it important. Extra people need to read this and understand this aspect of the story. I cant believe youre no more common since you definitely have the gift.
aviator malawi: aviator malawi – aviator betting game
https://aviatorghana.pro/# aviator
I have observed that in the world these days, video games are the latest trend with children of all ages. Occasionally it may be extremely hard to drag your kids away from the activities. If you want the very best of both worlds, there are various educational activities for kids. Good post.
https://jogodeaposta.fun/# aviator jogo de aposta
aviator: jogar aviator – aviator
pin up cassino online: pin-up – pin up bet
http://aviatorghana.pro/# aviator game bet
aviator betting game: aviator bet malawi login – aviator bet malawi
http://aviatorghana.pro/# aviator game bet
aviator: aviator oyunu – aviator sinyal hilesi
http://pinupcassino.pro/# aviator pin up casino
aviator: aviator bet malawi login – aviator betting game
Thanks for sharing excellent informations. Your site is very cool. I’m impressed by the details that you?ve on this website. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for more articles. You, my pal, ROCK! I found just the info I already searched all over the place and just couldn’t come across. What a perfect website.
Heya i am for the first time here. I found this board and I find It truly useful & it helped me out much. I hope to give something back and aid others like you helped me.
I have observed that online education is getting common because attaining your degree online has developed into a popular selection for many people. Numerous people have not really had a possibility to attend a traditional college or university although seek the improved earning potential and a better job that a Bachelor Degree offers. Still people might have a college degree in one course but want to pursue anything they now possess an interest in.
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out a lot. I hope to give something back and help others like you aided me.
aviator malawi: aviator bet malawi – aviator malawi
aviator game: jogar aviator Brasil – aviator jogo
Interesting article. It is rather unfortunate that over the last years, the travel industry has had to take on terrorism, SARS, tsunamis, flu virus, swine flu, as well as the first ever entire global tough economy. Through it all the industry has proven to be robust, resilient along with dynamic, locating new approaches to deal with trouble. There are always fresh complications and the possiblility to which the industry must all over again adapt and react.
Thanks for one’s marvelous posting! I certainly enjoyed reading it, you may be a great author.I will make certain to bookmark your blog and will eventually come back later on. I want to encourage you to ultimately continue your great job, have a nice weekend!
aviator pin up: aviator jogo – aviator game
Nice blog here! Also your web site loads up fast! What host are you using? Can I get your affiliate link to your host? I wish my web site loaded up as quickly as yours lol
aviator login: aviator game online – aviator ghana
play aviator: play aviator – aviator betting game
http://aviatormalawi.online/# aviator bet
aviator: aviator game – aviator game
aviator: aviator game online – aviator game online
deposito minimo 1 real: jogo de aposta online – jogo de aposta online
What an eye-opening and thoroughly-researched article! The author’s thoroughness and ability to present complicated ideas in a comprehensible manner is truly praiseworthy. I’m totally impressed by the scope of knowledge showcased in this piece. Thank you, author, for offering your expertise with us. This article has been a game-changer!
Thank you for another informative site. Where else could I get that type of information written in such a perfect way? I have a project that I’m just now working on, and I’ve been on the look out for such info.
Hi there, I found your site via Google while searching for a related topic, your web site came up, it looks good. I have bookmarked it in my google bookmarks.
aviator mz: aviator – aviator mz
zithromax azithromycin: generic zithromax online paypal – where can i buy zithromax medicine
https://aviatormalawi.online/# aviator game
aviator: aviator bet – aviator sportybet ghana
where to buy zithromax in canada: zithromax prescription in canada – buy zithromax 1000mg online
aviator game online: aviator – play aviator
http://aviatormocambique.site/# jogar aviator
site de apostas: jogo de aposta – jogo de aposta online
zithromax for sale us: zithromax rash where can you buy zithromax
aviator oficial pin up: pin-up cassino – pin up cassino online
hey there and thanks on your info ? I have certainly picked up something new from right here. I did however expertise some technical points the use of this site, since I experienced to reload the web site a lot of instances prior to I may get it to load properly. I were puzzling over in case your web host is OK? Not that I’m complaining, but slow loading circumstances times will sometimes have an effect on your placement in google and could harm your quality ranking if ads and ***********|advertising|advertising|advertising and *********** with Adwords. Well I?m including this RSS to my e-mail and can look out for much more of your respective exciting content. Ensure that you update this again soon..
Hello there, You’ve performed an excellent job. I?ll certainly digg it and for my part suggest to my friends. I’m sure they’ll be benefited from this web site.
I know this if off topic but I’m looking into starting my own weblog and was curious what all is required to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100 certain. Any recommendations or advice would be greatly appreciated. Thank you
http://mexicanpharm24.com/# mexico drug stores pharmacies mexicanpharm.shop
pharmacy in canada: canada drugs online review – onlinepharmaciescanada com canadianpharm.store
canadian pharmacy com My Canadian pharmacy pharmacy canadian canadianpharm.store
canadian pharmacy: List of Canadian pharmacies – canadian online pharmacy reviews canadianpharm.store
https://canadianpharmlk.shop/# onlinepharmaciescanada com canadianpharm.store
mexican drugstore online: order online from a Mexican pharmacy – mexican rx online mexicanpharm.shop
http://canadianpharmlk.com/# canadian online drugstore canadianpharm.store
https://canadianpharmlk.shop/# pharmacy canadian superstore canadianpharm.store
buying prescription drugs in mexico online Mexico pharmacy online buying prescription drugs in mexico online mexicanpharm.shop
http://canadianpharmlk.com/# online canadian drugstore canadianpharm.store
indian pharmacy paypal: online pharmacy in india – india online pharmacy indianpharm.store
http://indianpharm24.shop/# legitimate online pharmacies india indianpharm.store
best online pharmacies in mexico: Mexico pharmacy online – mexico drug stores pharmacies mexicanpharm.shop
http://canadianpharmlk.com/# rate canadian pharmacies canadianpharm.store
http://indianpharm24.shop/# indian pharmacies safe indianpharm.store
Hiya, I am really glad I’ve found this information. Today bloggers publish just about gossips and net and this is really annoying. A good blog with exciting content, that is what I need. Thanks for keeping this web site, I’ll be visiting it. Do you do newsletters? Cant find it.
india pharmacy mail order: Online India pharmacy – buy medicines online in india indianpharm.store
http://indianpharm24.shop/# india online pharmacy indianpharm.store
https://indianpharm24.com/# indian pharmacy paypal indianpharm.store
http://indianpharm24.com/# india pharmacy mail order indianpharm.store
Hello! Do you use Twitter? I’d like to follow you if that would be ok. I’m undoubtedly enjoying your blog and look forward to new updates.
Also I believe that mesothelioma is a scarce form of cancer that is normally found in those previously subjected to asbestos. Cancerous cellular material form from the mesothelium, which is a protective lining which covers almost all of the body’s areas. These cells typically form within the lining of your lungs, belly, or the sac which encircles one’s heart. Thanks for revealing your ideas.
I was recommended this website by my cousin. I’m now not certain whether this put up is written by means of him as no one else understand such unique approximately my difficulty. You’re amazing! Thank you!
Incredible! This blog looks just like my old one! It’s on a entirely different topic but it has pretty much the same page layout and design. Wonderful choice of colors!
Thanks for expressing your ideas. I’d personally also like to say that video games have been ever before evolving. Better technology and innovations have aided create genuine and fun games. Most of these entertainment video games were not actually sensible when the real concept was first of all being experimented with. Just like other areas of technology, video games way too have had to progress by many generations. This is testimony to the fast continuing development of video games.
Nice post. I used to be checking constantly this weblog and I’m inspired! Extremely useful info specifically the final section 🙂 I handle such info much. I used to be seeking this particular information for a long time. Thank you and good luck.
http://canadianpharmlk.com/# canadian pharmacy 24 canadianpharm.store
indian pharmacy: indian pharmacy – best india pharmacy indianpharm.store
medicine in mexico pharmacies mexican pharmacy buying prescription drugs in mexico online mexicanpharm.shop
https://canadianpharmlk.shop/# reliable canadian pharmacy canadianpharm.store
Greetings from Carolina! I’m bored at work so I decided to check out your site on my iphone during lunch break. I really like the info you provide here and can’t wait to take a look when I get home. I’m shocked at how quick your blog loaded on my cell phone .. I’m not even using WIFI, just 3G .. Anyways, fantastic blog!
https://indianpharm24.com/# indian pharmacy paypal indianpharm.store
I have discovered that smart real estate agents all over the place are Advertising and marketing. They are seeing that it’s more than merely placing a poster in the front area. It’s really in relation to building associations with these retailers who at some point will become consumers. So, while you give your time and efforts to serving these suppliers go it alone – the “Law associated with Reciprocity” kicks in. Good blog post.
mexico drug stores pharmacies: Mexico pharmacy price list – medication from mexico pharmacy mexicanpharm.shop
https://mexicanpharm24.com/# buying prescription drugs in mexico mexicanpharm.shop
you are in point of fact a just right webmaster. The site loading speed is incredible. It kind of feels that you’re doing any unique trick. Also, The contents are masterpiece. you’ve done a magnificent task in this subject!
https://indianpharm24.shop/# best india pharmacy indianpharm.store
http://mexicanpharm24.com/# mexico pharmacies prescription drugs mexicanpharm.shop
canadian online pharmacy reviews: Canadian pharmacy prices – canadian online pharmacy canadianpharm.store
Wow, marvelous blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your website is excellent, as well as the content!
http://canadianpharmlk.com/# onlinepharmaciescanada com canadianpharm.store
http://mexicanpharm24.com/# mexico pharmacies prescription drugs mexicanpharm.shop
canadian drugstore online: Pharmacies in Canada that ship to the US – canadian online pharmacy canadianpharm.store
http://mexicanpharm24.com/# mexican mail order pharmacies mexicanpharm.shop
http://indianpharm24.shop/# indian pharmacies safe indianpharm.store
mexican pharmaceuticals online Medicines Mexico mexican rx online mexicanpharm.shop
https://canadianpharmlk.shop/# the canadian drugstore canadianpharm.store
Hello would you mind stating which blog platform you’re using? I’m going to start my own blog in the near future but I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design and style seems different then most blogs and I’m looking for something unique. P.S My apologies for being off-topic but I had to ask!
https://canadianpharmlk.com/# canadian pharmacy tampa canadianpharm.store
Thanks for the new things you have exposed in your post. One thing I would really like to comment on is that FSBO relationships are built with time. By launching yourself to the owners the first weekend break their FSBO is announced, prior to a masses commence calling on Thursday, you develop a good interconnection. By sending them tools, educational elements, free accounts, and forms, you become a good ally. By taking a personal affinity for them along with their circumstances, you generate a solid link that, oftentimes, pays off when the owners opt with an adviser they know along with trust – preferably you actually.
online pharmacy india: Best Indian pharmacy – indian pharmacy indianpharm.store
Hi! Someone in my Myspace group shared this website with us so I came to look it over. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers! Wonderful blog and brilliant style and design.
Hello! This is kind of off topic but I need some advice from an established blog. Is it difficult to set up your own blog? I’m not very techincal but I can figure things out pretty fast. I’m thinking about setting up my own but I’m not sure where to start. Do you have any ideas or suggestions? Appreciate it
can you buy amoxicillin over the counter canada: can amoxicillin cause uti – cost of amoxicillin
https://amoxilst.pro/# buy cheap amoxicillin online
prednisone 20mg by mail order: generic prednisone 10mg – prednisone 1 tablet
can you buy cheap clomid no prescription: clomid dose for men – cheap clomid for sale
buy amoxicillin 500mg canada: amoxicillin 875 125 mg tab – buy cheap amoxicillin
order prednisone from canada: average cost of prednisone – prednisone nz
https://clomidst.pro/# cost of clomid prices
get cheap clomid no prescription clomid prices cheap clomid now
price for 15 prednisone: prednisone for gout – can you buy prednisone in canada
buy prednisone 40 mg: cortisol prednisone – cost of prednisone in canada
prednisone 20mg tablets where to buy: prednisone for strep throat – prednisone generic brand name
prednisone 15 mg daily: prednisone dogs – prednisone brand name india
order amoxicillin uk: can you take amoxicillin on an empty stomach – buy amoxicillin online no prescription
http://prednisonest.pro/# prednisone 20mg tab price
Güvenilir bir danışman için medyum nasip hocayı seçin en iyi medyum hocalardan bir tanesidir.
buy amoxicillin from canada: amoxicillin generic – amoxicillin 500 coupon
how can i get clomid prices: over the counter clomid – buy cheap clomid without prescription
I was just searching for this info for some time. After six hours of continuous Googleing, at last I got it in your website. I wonder what’s the lack of Google strategy that do not rank this kind of informative sites in top of the list. Normally the top web sites are full of garbage.
buy amoxicillin over the counter uk: amoxicillin 500mg no prescription – buy amoxicillin 250mg
https://amoxilst.pro/# amoxicillin buy online canada
medicine amoxicillin 500: amoxicillin online canada – canadian pharmacy amoxicillin
amoxicillin over the counter in canada amoxicillin online no prescription buy amoxicillin online uk
http://clomidst.pro/# buy clomid without prescription
amoxicillin for sale online: amoxil pharmacy – amoxicillin 500mg over the counter
buy amoxicillin 500mg canada: what is amoxicillin used for – amoxicillin for sale
buy prednisone online without a prescription: prednisolone prednisone – prednisone pack
prednisone canada pharmacy: where to buy prednisone uk – prednisone 20mg capsule
buy prednisone 40 mg: prednisone moon face – generic prednisone 10mg
http://clomidst.pro/# where can i get cheap clomid without a prescription
price of amoxicillin without insurance: amoxicillin warnings – can you buy amoxicillin over the counter
prednisone canada prescription: prednisone for sinus infection – prednisone brand name canada
http://edpills.guru/# best online ed medication
buying online prescription drugs online drugs no prescription no prescription drugs online
http://onlinepharmacy.cheap/# pharmacy online 365 discount code
ed meds by mail: buying ed pills online – order ed pills
overseas pharmacy no prescription: online pharmacy delivery – canadian pharmacy world coupons
rx pharmacy coupons: online pharmacy delivery – canadian pharmacies not requiring prescription
https://pharmnoprescription.pro/# no prescription online pharmacy
canada prescription online: meds online without prescription – how to order prescription drugs from canada
https://pharmnoprescription.pro/# pharmacy with no prescription
boner pills online: ed medicines online – get ed meds online
cheapest online ed treatment: cheap ed – online ed meds
https://onlinepharmacy.cheap/# legit non prescription pharmacies
cheapest pharmacy to fill prescriptions with insurance discount pharmacy foreign pharmacy no prescription
online medicine without prescription: prescription drugs canada – canada prescription drugs online
best online ed meds: erection pills online – generic ed meds online
how to get ed pills: buy ed pills online – where can i buy erectile dysfunction pills
https://edpills.guru/# ed online pharmacy
https://edpills.guru/# boner pills online
cheapest ed meds: cheap ed meds online – buy erectile dysfunction pills online
With havin so much content and articles do you ever run into any issues of plagorism or copyright infringement? My blog has a lot of exclusive content I’ve either created myself or outsourced but it seems a lot of it is popping it up all over the web without my agreement. Do you know any techniques to help stop content from being stolen? I’d truly appreciate it.
online ed pharmacy: cheapest ed pills – buy erectile dysfunction medication
online pharmacy reviews no prescription: how to order prescription drugs from canada – buying prescription drugs in india
Yesterday, while I was at work, my sister stole my iPad and tested to see if it can survive a 25 foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is totally off topic but I had to share it with someone!
cheapest pharmacy for prescription drugs: canadian pharmacy online – best online pharmacy no prescription
http://onlinepharmacy.cheap/# rx pharmacy no prescription
Greetings! Quick question that’s totally off topic. Do you know how to make your site mobile friendly? My web site looks weird when viewing from my iphone. I’m trying to find a theme or plugin that might be able to correct this issue. If you have any recommendations, please share. With thanks!
https://onlinepharmacy.cheap/# rx pharmacy no prescription
buy ed medication: low cost ed medication – erectile dysfunction online prescription
order medication without prescription canadian prescription prices buy drugs online without prescription
https://mexicanpharm.online/# mexican pharmaceuticals online
best canadian online pharmacy: drugs from canada – safe canadian pharmacy
pharmacies in mexico that ship to usa: mexican mail order pharmacies – best online pharmacies in mexico
http://mexicanpharm.online/# purple pharmacy mexico price list
I loved as much as you’ll receive carried out right here. The sketch is tasteful, your authored material stylish. nonetheless, you command get got an shakiness over that you wish be delivering the following. unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield this hike.
Generally I do not read post on blogs, however I would like to say that this write-up very forced me to check out and do it! Your writing taste has been surprised me. Thanks, quite great post.
One more thing. In my opinion that there are several travel insurance web sites of reputable companies that let you enter your vacation details and get you the quotations. You can also purchase the international travel cover policy online by using your own credit card. All you need to do would be to enter all travel specifics and you can start to see the plans side-by-side. Only find the program that suits your finances and needs after which it use your credit card to buy it. Travel insurance on the internet is a good way to start looking for a reputable company regarding international travel insurance. Thanks for sharing your ideas.
Howdy! This is my 1st comment here so I just wanted to give a quick shout out and say I genuinely enjoy reading your posts. Can you recommend any other blogs/websites/forums that go over the same subjects? Thank you!
world pharmacy india Online medicine home delivery indian pharmacy paypal
medication from mexico pharmacy: pharmacies in mexico that ship to usa – medication from mexico pharmacy
https://mexicanpharm.online/# mexico pharmacy
http://mexicanpharm.online/# mexican rx online
canadian pharmacy sarasota: canadian pharmacy online store – canadian drug
One thing I would like to reply to is that weight loss program fast can be carried out by the proper diet and exercise. A person’s size not just affects the look, but also the actual quality of life. Self-esteem, depression, health risks, as well as physical skills are disturbed in weight gain. It is possible to just make everything right and at the same time having a gain. In such a circumstance, a problem may be the culprit. While a lot of food instead of enough work out are usually to blame, common health concerns and widespread prescriptions can easily greatly amplify size. Many thanks for your post right here.
Thanks for your article. I also believe that laptop computers have gotten more and more popular these days, and now are sometimes the only kind of computer included in a household. It is because at the same time that they’re becoming more and more cost-effective, their working power is growing to the point where these are as effective as pc’s from just a few in years past.
I have come across that currently, more and more people are increasingly being attracted to camcorders and the field of photography. However, to be a photographer, you will need to first spend so much time deciding the exact model of digicam to buy plus moving store to store just so you might buy the most affordable camera of the brand you have decided to select. But it doesn’t end just there. You also have to consider whether you should purchase a digital dslr camera extended warranty. Thx for the good tips I received from your weblog.
canadian online pharmacy: escrow pharmacy canada – buy drugs from canada
Admiring the commitment you put into your site and in depth information you provide. It’s nice to come across a blog every once in a while that isn’t the same out of date rehashed information. Excellent read! I’ve saved your site and I’m including your RSS feeds to my Google account.
п»їbest mexican online pharmacies: medicine in mexico pharmacies – п»їbest mexican online pharmacies
http://mexicanpharm.online/# pharmacies in mexico that ship to usa
top 10 pharmacies in india: buy medicines online in india – online pharmacy india
canadian drugs online: canadian pharmacy online ship to usa – canada drug pharmacy
buying from online mexican pharmacy mexico pharmacies prescription drugs mexican rx online
https://mexicanpharm.online/# mexican pharmaceuticals online
best online pharmacy that does not require a prescription in india: best online pharmacies without prescription – online pharmacies without prescription
online shopping pharmacy india: indian pharmacy online – indian pharmacy
http://canadianpharm.guru/# canadian pharmacy service
canadian pharmacy online no prescription: discount prescription drugs canada – purchasing prescription drugs online
http://indianpharm.shop/# best online pharmacy india
no prescription drugs: canada drugs without prescription – buy pills without prescription
world pharmacy india: indianpharmacy com – best online pharmacy india
pharmacies in mexico that ship to usa: mexican pharmaceuticals online – mexican drugstore online
canadian pharmacy 24: cheap canadian pharmacy online – canada online pharmacy
http://pharmacynoprescription.pro/# mexican prescription drugs online
Güvenilir bir danışman için medyum nasip hocayı seçin en iyi medyum hocalardan bir tanesidir.
canadian pharmacy ltd: www canadianonlinepharmacy – canadian online drugs
canadian pharmacy drugs online: canadian pharmacy review – canada ed drugs
buy medications without a prescription online pharmacy not requiring prescription discount prescription drugs canada
http://pharmacynoprescription.pro/# buying prescription drugs from canada online
mexican pharmaceuticals online: mexican pharmaceuticals online – mexican border pharmacies shipping to usa
online drugstore no prescription: online pharmacy no prescriptions – online pharmacies no prescription usa
http://pharmacynoprescription.pro/# no prescription on line pharmacies
buying prescription drugs in mexico online: buying prescription drugs in mexico online – mexico drug stores pharmacies
pet meds without vet prescription canada: best canadian online pharmacy reviews – canadian pharmacy 1 internet online drugstore
http://pharmacynoprescription.pro/# buy pills without prescription
buy drugs online without prescription: canada drugs no prescription – buy drugs online without prescription
canadian pharmacy world: canadian pharmacy online – canada drugs online review
online pharmacy india: indianpharmacy com – top online pharmacy india
http://canadianpharm.guru/# best canadian pharmacy to order from
non prescription pharmacy: online drugstore no prescription – medications online without prescription
safe canadian pharmacy canadian pharmacy 1 internet online drugstore pharmacies in canada that ship to the us
online drugs no prescription: online pharmacies without prescriptions – how to buy prescriptions from canada safely
http://canadianpharm.guru/# canada pharmacy online legit
http://indianpharm.shop/# indian pharmacy
canadian pharmacy online store: rate canadian pharmacies – reliable canadian online pharmacy
reputable mexican pharmacies online: mexican pharmaceuticals online – п»їbest mexican online pharmacies
best india pharmacy: indian pharmacies safe – Online medicine order
http://pharmacynoprescription.pro/# canada prescription drugs online
certified canadian international pharmacy: best canadian pharmacy – canadian pharmacy
buying prescription drugs in mexico: mexico drug stores pharmacies – pharmacies in mexico that ship to usa
canada prescriptions by mail: buy prescription drugs online without doctor – online doctor prescription canada
mexican rx online mexican rx online buying prescription drugs in mexico
mexican pharmaceuticals online: buying from online mexican pharmacy – mexico pharmacy
http://mexicanpharm.online/# mexican border pharmacies shipping to usa
canada prescription online: no prescription drugs – canadian prescription
Güvenilir bir danışman için medyum nasip hocayı seçin en iyi medyum hocalardan bir tanesidir.
indianpharmacy com: п»їlegitimate online pharmacies india – best india pharmacy
http://mexicanpharm.online/# best online pharmacies in mexico
canadian pharmacy online: pharmacy in canada – canada pharmacy reviews
https://pharmacynoprescription.pro/# online medication without prescription
no prescription online pharmacies: medications online without prescriptions – non prescription online pharmacy
п»їbest mexican online pharmacies: best online pharmacies in mexico – buying prescription drugs in mexico
mexico pharmacies prescription drugs: mexico drug stores pharmacies – mexican pharmaceuticals online
http://mexicanpharm.online/# buying prescription drugs in mexico
northwest pharmacy canada: canada drug pharmacy – canadian medications
Thanks for your intriguing article. One other problem is that mesothelioma cancer is generally attributable to the inhalation of fibers from asbestos fiber, which is a dangerous material. It really is commonly found among laborers in the construction industry who may have long contact with asbestos. It could be caused by moving into asbestos protected buildings for an extended time of time, Genetics plays a huge role, and some consumers are more vulnerable on the risk when compared with others.
mexico drug stores pharmacies purple pharmacy mexico price list mexico drug stores pharmacies
Amazing! This blog looks just like my old one! It’s on a completely different subject but it has pretty much the same page layout and design. Superb choice of colors!
top online pharmacy india: indian pharmacy – buy medicines online in india
I have been exploring for a little bit for any high quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this website. Reading this information So i am happy to convey that I’ve a very good uncanny feeling I discovered exactly what I needed. I most certainly will make sure to do not forget this website and give it a glance on a constant basis.
https://pharmacynoprescription.pro/# overseas online pharmacy-no prescription
best india pharmacy: Online medicine order – top 10 pharmacies in india
canadian pharmacy online no prescription: mexico prescription drugs online – online pharmacy that does not require a prescription
http://indianpharm.shop/# buy prescription drugs from india
Thx for your post. I would really like to comment that the cost of car insurance differs from one policy to another, for the reason that there are so many different facets which bring about the overall cost. One example is, the make and model of the automobile will have a huge bearing on the cost. A reliable old family car or truck will have a less expensive premium when compared to a flashy fancy car.
canada pharmacy online: canadian family pharmacy – canadian pharmacy meds review
Its such as you read my mind! You seem to understand a lot approximately this, like you wrote the e book in it or something. I think that you just could do with some p.c. to pressure the message house a little bit, however other than that, that is great blog. An excellent read. I’ll certainly be back.
Güvenilir bir danışman için medyum haluk hocayı seçin en iyi medyum hocalardan bir tanesidir.
Once I initially commented I clicked the -Notify me when new feedback are added- checkbox and now each time a comment is added I get four emails with the same comment. Is there any means you’ll be able to take away me from that service? Thanks!
You really make it seem really easy together with your presentation but I in finding this matter to be really one thing that I think I might never understand. It seems too complicated and very vast for me. I am having a look forward on your next put up, I?ll attempt to get the hold of it!
Hi there! I’m at work surfing around your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the superb work!
https://sweetbonanza.bid/# sweet bonanza yasal site
en yeni slot siteleri: en yeni slot siteleri – slot bahis siteleri
https://slotsiteleri.guru/# bonus veren casino slot siteleri
sweet bonanza demo oyna: sweet bonanza giris – sweet bonanza kazanma saatleri
sweet bonanza yasal site: sweet bonanza yasal site – pragmatic play sweet bonanza
Güvenilir bir danışman için medyum haluk hocayı seçin en iyi medyum hocalardan bir tanesidir.
http://gatesofolympus.auction/# gates of olympus demo free spin
http://gatesofolympus.auction/# gates of olympus demo
Hmm is anyone else having problems with the images on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated.
Thanks for the recommendations you have provided here. One more thing I would like to convey is that laptop memory specifications generally rise along with other developments in the technological know-how. For instance, if new generations of processor chips are made in the market, there’s usually a matching increase in the size and style calls for of both pc memory and hard drive space. This is because the application operated simply by these cpus will inevitably surge in power to leverage the new engineering.
https://pinupgiris.fun/# pin up giris
pin up casino: pin up casino guncel giris – pin up casino guncel giris
http://slotsiteleri.guru/# slot siteleri bonus veren
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out much. I hope to give something back and aid others like you aided me.
Does your blog have a contact page? I’m having trouble locating it but, I’d like to shoot you an email. I’ve got some suggestions for your blog you might be interested in hearing. Either way, great blog and I look forward to seeing it expand over time.
https://slotsiteleri.guru/# en cok kazandiran slot siteleri
guvenilir slot siteleri: canl? slot siteleri – deneme veren slot siteleri
pin up aviator: aviator pin up – pin-up bonanza
aviator oyna 100 tl: aviator oyunu giris – aviator
This is undoubtedly one of the best articles I’ve read on this topic! The author’s comprehensive knowledge and passion for the subject are apparent in every paragraph. I’m so appreciative for finding this piece as it has enhanced my knowledge and sparked my curiosity even further. Thank you, author, for taking the time to produce such a remarkable article!
https://gatesofolympus.auction/# gates of olympus demo türkçe
Excellent goods from you, man. I have understand your stuff previous to and you’re just extremely great. I really like what you’ve acquired here, certainly like what you’re stating and the way in which you say it. You make it enjoyable and you still care for to keep it wise. I can not wait to read much more from you. This is really a tremendous site.
pin up indir: pin-up casino – aviator pin up
http://gatesofolympus.auction/# gates of olympus guncel
I have learned some new things through your blog. One other thing I’d like to say is that newer laptop or computer operating systems tend to allow extra memory to be utilized, but they as well demand more memory space simply to perform. If people’s computer can’t handle much more memory as well as the newest software program requires that memory increase, it may be the time to shop for a new Computer system. Thanks
https://sweetbonanza.bid/# sweet bonanza kazanc
https://slotsiteleri.guru/# bonus veren casino slot siteleri
pin up aviator: pin up indir – pin up aviator
That is the fitting blog for anybody who desires to find out about this topic. You realize so much its almost hard to argue with you (not that I really would want?HaHa). You positively put a new spin on a topic thats been written about for years. Nice stuff, just nice!
aviator hilesi ucretsiz: aviator oyna 20 tl – aviator sinyal hilesi ucretsiz
http://pinupgiris.fun/# pin-up casino
You really make it seem really easy along with your presentation but I find this matter to be really something which I think I would never understand. It sort of feels too complex and very large for me. I am having a look ahead to your subsequent publish, I will attempt to get the dangle of it!
pin up guncel giris: pin up indir – pin-up giris
http://pinupgiris.fun/# pin up casino indir
https://gatesofolympus.auction/# gates of olympus demo free spin
guvenilir slot siteleri: slot siteleri guvenilir – casino slot siteleri
We are offering Concrete Parking Lot Contractor, Concrete Installation Contractor Service, warehouse flooring, commercial, and industrial concrete roadways.
http://gatesofolympus.auction/# gates of olympus oyna demo
sweet bonanza bahis: sweet bonanza taktik – sweet bonanza free spin demo
http://sweetbonanza.bid/# sweet bonanza kazanma saatleri
We are offering Concrete Parking Lot Contractor, Concrete Installation Contractor Service, warehouse flooring, commercial, and industrial concrete roadways.
pin-up casino giris: pin up casino guncel giris – pin up casino
Thanks for your post. Another factor is that being a photographer involves not only problems in catching award-winning photographs but additionally hardships in establishing the best dslr camera suited to your needs and most especially challenges in maintaining the standard of your camera. This can be very accurate and noticeable for those photography addicts that are in to capturing a nature’s interesting scenes – the mountains, the particular forests, the wild or seas. Visiting these daring places certainly requires a photographic camera that can surpass the wild’s nasty settings.
We are offering Concrete Parking Lot Contractor, Concrete Installation Contractor Service, warehouse flooring, commercial, and industrial concrete roadways.
Woah! I’m really enjoying the template/theme of this site. It’s simple, yet effective. A lot of times it’s tough to get that “perfect balance” between usability and visual appearance. I must say you have done a amazing job with this. Additionally, the blog loads super quick for me on Internet explorer. Outstanding Blog!
http://sweetbonanza.bid/# sweet bonanza demo
We are offering Concrete Parking Lot Contractor, Concrete Installation Contractor Service, warehouse flooring, commercial, and industrial concrete roadways.
I acquired more something totally new on this weight loss issue. Just one issue is a good nutrition is especially vital if dieting. A massive reduction in junk food, sugary meals, fried foods, sweet foods, pork, and white-colored flour products might be necessary. Keeping wastes harmful bacteria, and poisons may prevent desired goals for fat-loss. While certain drugs temporarily solve the challenge, the awful side effects are certainly not worth it, and they never provide more than a short-lived solution. It is just a known indisputable fact that 95 of celebrity diets fail. Thanks for sharing your notions on this website.
gates of olympus slot: gates of olympus max win – gates of olympus demo oyna
https://pinupgiris.fun/# pin up 7/24 giris
Hey very cool blog!! Man .. Beautiful .. Amazing .. I’ll bookmark your site and take the feeds also?I am happy to find so many useful information here in the post, we need develop more techniques in this regard, thanks for sharing. . . . . .
mexico pharmacies prescription drugs: cheapest mexico drugs – mexican drugstore online
Online medicine home delivery: indian pharmacy – indian pharmacy
I don?t even know how I ended up right here, but I believed this submit was once great. I do not recognise who you might be however certainly you are going to a famous blogger in the event you are not already 😉 Cheers!
I found your blog website on google and examine just a few of your early posts. Proceed to keep up the superb operate. I just extra up your RSS feed to my MSN Information Reader. Looking for forward to studying extra from you in a while!?
https://mexicanpharmacy.shop/# reputable mexican pharmacies online
Undeniably believe that which you said. Your favorite reason appeared to be on the net the easiest thing to be aware of. I say to you, I definitely get annoyed while people consider worries that they just do not know about. You managed to hit the nail upon the top as well as defined out the whole thing without having side effect , people could take a signal. Will probably be back to get more. Thanks
In this awesome scheme of things you’ll receive an A+ for effort. Where you actually lost us ended up being in your specifics. You know, they say, the devil is in the details… And it could not be more accurate right here. Having said that, allow me inform you what did work. Your text is definitely incredibly convincing which is probably why I am taking the effort to opine. I do not make it a regular habit of doing that. 2nd, whilst I can certainly notice the leaps in logic you make, I am not convinced of just how you appear to connect your details which inturn help to make the conclusion. For now I shall subscribe to your position but trust in the near future you connect the facts much better.
This actually answered my downside, thanks!
mexican border pharmacies shipping to usa cheapest mexico drugs reputable mexican pharmacies online
It?s really a nice and useful piece of information. I am happy that you simply shared this helpful information with us. Please stay us up to date like this. Thank you for sharing.
canadian family pharmacy: Prescription Drugs from Canada – reliable canadian pharmacy
buying prescription drugs in mexico online: mexican pharmacy – mexican border pharmacies shipping to usa
mexico drug stores pharmacies mexican pharmacy mexico drug stores pharmacies
Thanks for enabling me to gain new strategies about computers. I also have belief that one of the best ways to help keep your notebook computer in primary condition has been a hard plastic-type case, and also shell, that will fit over the top of the computer. A lot of these protective gear tend to be model precise since they are manufactured to fit perfectly within the natural outer shell. You can buy them directly from the seller, or via third party places if they are designed for your notebook computer, however only a few laptop will have a spend on the market. Again, thanks for your guidelines.
mexican pharmaceuticals online: Online Pharmacies in Mexico – buying prescription drugs in mexico online
I’ve really noticed that credit repair activity must be conducted with techniques. If not, chances are you’ll find yourself damaging your position. In order to realize your aspirations in fixing to your credit rating you have to take care that from this instant you pay any monthly fees promptly in advance of their planned date. It is significant given that by never accomplishing this, all other methods that you will decide on to improve your credit rating will not be effective. Thanks for giving your strategies.
best india pharmacy: Healthcare and medicines from India – top 10 online pharmacy in india
This website is really a stroll-via for all of the data you wanted about this and didn?t know who to ask. Glimpse here, and also you?ll definitely uncover it.
buying drugs from canada legit canadian pharmacy online cheap canadian pharmacy
canadian pharmacy tampa: canadian pharmacy 24 – northern pharmacy canada
Valuable information. Fortunate me I found your web site accidentally, and I am surprised why this accident did not took place in advance! I bookmarked it.
http://canadianpharmacy24.store/# canadian pharmacy 24h com safe
Together with every little thing that seems to be developing within this specific area, your viewpoints are generally very exciting. Nevertheless, I appologize, because I do not subscribe to your entire idea, all be it exciting none the less. It appears to me that your remarks are generally not totally validated and in reality you are your self not fully convinced of the argument. In any event I did enjoy reading it.
Wow, superb blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your website is great, as well as the content!
canadianpharmacyworld com: Licensed Canadian Pharmacy – pharmacy canadian
Thank you for another informative website. Where else may just I am getting that kind of info written in such a perfect method? I’ve a project that I’m simply now operating on, and I’ve been at the glance out for such information.
mexican rx online: cheapest mexico drugs – purple pharmacy mexico price list
I think this is among the most important info for me. And i am glad reading your article. But wanna remark on some general things, The site style is great, the articles is really great : D. Good job, cheers
canadian pharmacies compare canadian pharmacy 24 precription drugs from canada
reliable canadian pharmacy: Large Selection of Medications – pharmacy rx world canada
mexico drug stores pharmacies: Online Pharmacies in Mexico – pharmacies in mexico that ship to usa
mexico drug stores pharmacies: Mexican Pharmacy Online – buying prescription drugs in mexico
cheapest online pharmacy india: indian pharmacy – cheapest online pharmacy india
I have observed that service fees for internet degree authorities tend to be an excellent value. Like a full College Degree in Communication from The University of Phoenix Online consists of 60 credits from $515/credit or $30,900. Also American Intercontinental University Online gives a Bachelors of Business Administration with a complete program feature of 180 units and a tariff of $30,560. Online learning has made getting the higher education degree so much easier because you might earn your own degree from the comfort of your abode and when you finish from work. Thanks for all the tips I have certainly learned through your web site.
mexican online pharmacies prescription drugs: Mexican Pharmacy Online – mexico pharmacy
canadian pharmacies comparison pills now even cheaper best canadian pharmacy to buy from
My spouse and I absolutely love your blog and find many of your post’s to be what precisely I’m looking for. Does one offer guest writers to write content to suit your needs? I wouldn’t mind composing a post or elaborating on most of the subjects you write concerning here. Again, awesome web site!
I have seen that car insurance organizations know the autos which are prone to accidents and other risks. They also know what type of cars are prone to higher risk and also the higher risk they’ve already the higher your premium price. Understanding the very simple basics of car insurance can help you choose the right kind of insurance policy that will take care of your needs in case you happen to be involved in any accident. Thanks for sharing your ideas on your own blog.
Thanks for your write-up. What I want to say is that when evaluating a good on-line electronics go shopping, look for a site with complete information on critical indicators such as the security statement, basic safety details, payment procedures, along with terms plus policies. Constantly take time to look into the help in addition to FAQ sections to get a greater idea of the way the shop works, what they can do for you, and just how you can make the most of the features.
buying prescription drugs in mexico online: best online pharmacies in mexico – pharmacies in mexico that ship to usa
https://canadianpharmacy24.store/# canadian pharmacy com
world pharmacy india: indianpharmacy com – top online pharmacy india
canada pharmacy 24h: Large Selection of Medications – canada drugs online review
canadian pharmacy king reviews: Certified Canadian Pharmacy – canadian discount pharmacy
My brother suggested I might like this web site. He was totally right. This post actually made my day. You can not imagine simply how much time I had spent for this info! Thanks!
best india pharmacy indian pharmacy delivery reputable indian online pharmacy
reputable mexican pharmacies online: cheapest mexico drugs – mexican online pharmacies prescription drugs
Hi there, I found your blog via Google while searching for a related topic, your website came up, it looks good. I’ve bookmarked it in my google bookmarks.
This really answered my problem, thanks!
Have you ever thought about writing an ebook or guest authoring on other sites? I have a blog based upon on the same information you discuss and would love to have you share some stories/information. I know my subscribers would enjoy your work. If you’re even remotely interested, feel free to send me an e mail.
Valuable info. Lucky me I found your web site accidentally, and I’m surprised why this accident did not took place in advance! I bookmarked it.
canada drugs online review: Certified Canadian Pharmacy – best online canadian pharmacy
I?m not sure where you’re getting your info, but great topic. I needs to spend some time learning much more or understanding more. Thanks for fantastic information I was looking for this info for my mission.
best canadian pharmacy online canadianpharmacyworld pharmacy canadian superstore
Valuable information. Lucky me I found your website by accident, and I’m shocked why this accident didn’t happened earlier! I bookmarked it.
http://indianpharmacy.icu/# india pharmacy
indian pharmacy paypal: Cheapest online pharmacy – online pharmacy india
online shopping pharmacy india Generic Medicine India to USA top 10 online pharmacy in india
online shopping pharmacy india: indian pharmacy delivery – buy prescription drugs from india
buy prescription drugs from india: indian pharmacy delivery – top 10 pharmacies in india
canada drugs online reviews: Large Selection of Medications – canada drugs reviews
zithromax 250: buy generic zithromax online – buy cheap generic zithromax
Thanks for the thoughts you reveal through this site. In addition, several young women which become pregnant usually do not even seek to get medical care insurance because they have anxiety they might not qualify. Although a lot of states today require that insurers present coverage in spite of the pre-existing conditions. Rates on these kind of guaranteed plans are usually larger, but when considering the high cost of medical care bills it may be any safer route to take to protect a person’s financial future.
prednisone drug costs where to buy prednisone in canada buy prednisone no prescription
http://amoxilall.com/# amoxicillin 500mg
Coming from my observation, shopping for technology online can for sure be expensive, however there are some tips that you can use to acquire the best discounts. There are often ways to locate discount offers that could make one to come across the best gadgets products at the lowest prices. Thanks for your blog post.
What?s Happening i am new to this, I stumbled upon this I’ve found It positively useful and it has helped me out loads. I hope to contribute & assist other users like its helped me. Good job.
I just couldn’t depart your website before suggesting that I actually enjoyed the standard information a person provide for your visitors? Is going to be back often in order to check up on new posts
http://clomidall.shop/# where can i buy cheap clomid without insurance
https://prednisoneall.com/# buy prednisone without prescription paypal
can i buy prednisone online without prescription: how to purchase prednisone online – 10 mg prednisone
I was just looking for this information for some time. After six hours of continuous Googleing, finally I got it in your web site. I wonder what is the lack of Google strategy that don’t rank this type of informative sites in top of the list. Normally the top web sites are full of garbage.
zithromax 500 mg for sale can you buy zithromax over the counter in canada cost of generic zithromax
I’m not sure why but this site is loading extremely slow for me. Is anyone else having this issue or is it a problem on my end? I’ll check back later and see if the problem still exists.
Good day! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
Amazing blog! Do you have any tips for aspiring writers? I’m hoping to start my own website soon but I’m a little lost on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally confused .. Any ideas? Cheers!
https://zithromaxall.shop/# zithromax online usa
cost of prednisone: prednisone 10mg tabs – 20 mg of prednisone
generic clomid get cheap clomid without dr prescription order clomid price
http://amoxilall.shop/# amoxicillin price canada
https://zithromaxall.com/# zithromax purchase online
https://clomidall.shop/# where to buy clomid without a prescription
generic for amoxicillin where can i buy amoxicillin over the counter uk amoxicillin 500 mg brand name
https://prednisoneall.shop/# how can i get prednisone online without a prescription
https://prednisoneall.com/# prednisone 1 mg daily
zithromax drug zithromax 250 price where to buy zithromax in canada
zithromax online: where to get zithromax – where can i get zithromax over the counter
http://prednisoneall.shop/# prednisone online paypal
https://prednisoneall.com/# prednisone 60 mg price
buy cheap amoxicillin amoxicillin 825 mg can you buy amoxicillin over the counter
https://prednisoneall.shop/# prednisone 5 mg
how to get cheap clomid for sale: where can i get generic clomid pills – can i buy cheap clomid tablets
http://prednisoneall.shop/# order prednisone 100g online without prescription
buy zithromax online with mastercard zithromax for sale 500 mg zithromax azithromycin
Hi there, simply became aware of your blog through Google, and found that it is really informative. I?m going to watch out for brussels. I will appreciate should you proceed this in future. Lots of people will likely be benefited out of your writing. Cheers!
http://zithromaxall.shop/# zithromax 250 price
http://zithromaxall.com/# where can i buy zithromax medicine
This will be a excellent web site, will you be interested in doing an interview about just how you created it? If so e-mail me!
Thanks for the recommendations on credit repair on this excellent web-site. Things i would advice people will be to give up the particular mentality that they’ll buy now and pay back later. As a society we tend to try this for many issues. This includes trips, furniture, and also items we want. However, you should separate the wants from all the needs. If you are working to boost your credit score you have to make some sacrifices. For example you are able to shop online to economize or you can visit second hand merchants instead of costly department stores to get clothing.
My brother suggested I might like this blog. He was totally right. This publish truly made my day. You can not consider simply how so much time I had spent for this info! Thank you!
http://amoxilall.shop/# amoxicillin canada price
buy prednisone online no script medicine prednisone 10mg purchase prednisone canada
I?m not certain the place you are getting your info, but good topic. I needs to spend some time learning much more or figuring out more. Thanks for excellent info I used to be in search of this info for my mission.
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! However, how could we communicate?
Greetings from Idaho! I’m bored at work so I decided to check out your site on my iphone during lunch break. I really like the information you present here and can’t wait to take a look when I get home. I’m shocked at how quick your blog loaded on my phone .. I’m not even using WIFI, just 3G .. Anyhow, superb blog!
I additionally believe that mesothelioma cancer is a uncommon form of many forms of cancer that is normally found in these previously subjected to asbestos. Cancerous cellular material form within the mesothelium, which is a protective lining that covers the vast majority of body’s areas. These cells commonly form within the lining in the lungs, stomach, or the sac that really encircles the heart. Thanks for revealing your ideas.
purchase zithromax online: zithromax generic price – zithromax for sale us
https://clomidall.com/# can i order generic clomid pill
Hello my friend! I wish to say that this article is amazing, nice written and include almost all vital infos. I would like to see more posts like this.
http://zithromaxall.com/# zithromax buy
I?m no longer certain where you are getting your information, however good topic. I needs to spend some time learning much more or figuring out more. Thanks for great info I used to be on the lookout for this information for my mission.
amoxil pharmacy amoxicillin buy canada buy cheap amoxicillin
https://clomidall.com/# clomid buy
prednisone without prescription: prednisone 10 mg tablets – prednisone 54899
you’ve gotten an awesome weblog right here! would you like to make some invite posts on my blog?
Nice post. I used to be checking continuously this weblog and I am impressed! Extremely helpful information specifically the closing phase 🙂 I take care of such information much. I used to be seeking this particular information for a long time. Thanks and best of luck.
super kamagra: Kamagra Iq – buy Kamagra
https://kamagraiq.com/# Kamagra 100mg price
Hi would you mind letting me know which hosting company you’re working with? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot quicker then most. Can you suggest a good hosting provider at a fair price? Thank you, I appreciate it!
Thanks for your article on the vacation industry. I would also like to add that if you are one senior thinking about traveling, its absolutely imperative that you buy travel cover for retirees. When traveling, senior citizens are at high risk of experiencing a medical emergency. Obtaining right insurance policies package to your age group can protect your health and give you peace of mind.
http://tadalafiliq.com/# Cialis 20mg price in USA
Kamagra 100mg Kamagra Iq Kamagra 100mg
Thanks for your post made here. One thing I’d like to say is the fact most professional domains consider the Bachelor Degree as the entry level standard for an online degree. Although Associate Certifications are a great way to start, completing your own Bachelors presents you with many doors to various employment opportunities, there are numerous on-line Bachelor Course Programs available via institutions like The University of Phoenix, Intercontinental University Online and Kaplan. Another concern is that many brick and mortar institutions present Online versions of their degree programs but typically for a greatly higher fee than the organizations that specialize in online higher education degree plans.
kamagra: Kamagra Iq – Kamagra 100mg
buy kamagra online usa: Kamagra Oral Jelly Price – Kamagra 100mg price
Thanks for your strategies. One thing we’ve noticed is the fact banks and also financial institutions know the spending routines of consumers and as well understand that most of the people max out and about their real credit cards around the holiday seasons. They prudently take advantage of this fact and commence flooding a person’s inbox plus snail-mail box with hundreds of no-interest APR credit card offers just after the holiday season finishes. Knowing that if you are like 98 of all American general public, you’ll leap at the possible opportunity to consolidate credit debt and switch balances to 0 interest rates credit cards.
cheap viagra: buy viagra online – Generic Viagra online
Cheapest Sildenafil online buy viagra online Sildenafil 100mg price
http://tadalafiliq.com/# Cialis without a doctor prescription
Kamagra 100mg price: kamagra – super kamagra
Cialis without a doctor prescription Buy Cialis online Cialis without a doctor prescription
http://kamagraiq.com/# Kamagra Oral Jelly
I’m so happy to read this. This is the kind of manual that needs to be given and not the accidental misinformation that’s at the other blogs. Appreciate your sharing this greatest doc.
Cialis over the counter: Generic Tadalafil 20mg price – п»їcialis generic
https://sildenafiliq.xyz/# cheapest viagra
Nice post. I was checking continuously this blog and I’m impressed! Very helpful info specially the last part 🙂 I care for such information a lot. I was seeking this particular info for a very long time. Thank you and good luck.
sildenafil oral jelly 100mg kamagra: Kamagra Iq – super kamagra
Kamagra tablets super kamagra buy kamagra online usa
I have not checked in here for some time because I thought it was getting boring, but the last several posts are great quality so I guess I?ll add you back to my everyday bloglist. You deserve it my friend 🙂
Cialis 20mg price in USA: cialis best price – Generic Tadalafil 20mg price
I have noticed that sensible real estate agents all around you are Marketing and advertising. They are noticing that it’s not only placing a sign post in the front yard. It’s really concerning building human relationships with these retailers who one of these days will become consumers. So, when you give your time and energy to encouraging these dealers go it alone : the “Law of Reciprocity” kicks in. Thanks for your blog post.
Thanks , I have recently been looking for info about this subject for ages and yours is the best I have discovered till now. But, what about the conclusion? Are you sure about the source?
Good post. I study one thing more difficult on totally different blogs everyday. It’ll all the time be stimulating to read content from different writers and follow a bit of something from their store. I?d prefer to make use of some with the content on my blog whether you don?t mind. Natually I?ll offer you a link on your net blog. Thanks for sharing.
sildenafil online: generic ed pills – Viagra without a doctor prescription Canada
Thanks for the tips you have shared here. Yet another thing I would like to state is that laptop memory needs generally increase along with other developments in the technologies. For instance, any time new generations of processor chips are brought to the market, there is usually an equivalent increase in the scale demands of both the pc memory as well as hard drive room. This is because the application operated by means of these cpus will inevitably rise in power to benefit from the new technology.
Nice read, I just passed this onto a colleague who was doing some research on that. And he actually bought me lunch since I found it for him smile Thus let me rephrase that: Thanks for lunch!
п»їBuy generic 100mg Viagra online cheapest viagra Buy Viagra online cheap
http://sildenafiliq.com/# viagra without prescription
https://kamagraiq.com/# buy Kamagra
https://kamagraiq.com/# buy kamagra online usa
Buy Tadalafil 10mg: Generic Tadalafil 20mg price – Buy Tadalafil 20mg
cheap kamagra Kamagra gel Kamagra Oral Jelly
http://tadalafiliq.shop/# Buy Tadalafil 10mg
Generic Tadalafil 20mg price: cialis best price – cialis for sale
buy Viagra over the counter: generic ed pills – sildenafil 50 mg price
viagra without prescription: sildenafil iq – generic sildenafil
http://kamagraiq.shop/# Kamagra tablets
Generic Cialis price Generic Tadalafil 20mg price buy cialis pill
http://sildenafiliq.com/# sildenafil 50 mg price
sildenafil 50 mg price: best price on viagra – Viagra generic over the counter
I’m truly enjoying the design and layout of your website. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a developer to create your theme? Excellent work!
buy Kamagra: Kamagra Iq – Kamagra tablets
http://tadalafiliq.shop/# buy cialis pill
Viagra Tablet price buy viagra online Viagra tablet online
http://kamagraiq.com/# Kamagra Oral Jelly
At this time it looks like Expression Engine is the best blogging platform out there right now. (from what I’ve read) Is that what you are using on your blog?
Thanks for another great article. The place else may just anybody get that kind of info in such an ideal way of writing? I have a presentation subsequent week, and I’m at the search for such info.
After study just a few of the weblog posts on your website now, and I truly like your method of blogging. I bookmarked it to my bookmark web site listing and will probably be checking again soon. Pls take a look at my website as properly and let me know what you think.
Cialis over the counter: Buy Tadalafil 5mg – Buy Cialis online
https://kamagraiq.shop/# buy Kamagra
Good day! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
http://kamagraiq.shop/# Kamagra tablets
buy Kamagra kamagra best price Kamagra 100mg
Kamagra 100mg price: Kamagra Oral Jelly Price – Kamagra 100mg price
I enjoy what you guys are up too. This sort of clever work and coverage! Keep up the great works guys I’ve included you guys to my personal blogroll.
cheap kamagra: kamagra best price – Kamagra Oral Jelly
Thanks for the ideas you have provided here. One more thing I would like to convey is that laptop or computer memory requirements generally rise along with other innovations in the technologies. For instance, whenever new generations of processors are introduced to the market, there’s usually a corresponding increase in the scale demands of both pc memory as well as hard drive space. This is because software program operated by means of these processors will inevitably boost in power to make new engineering.
Wonderful items from you, man. I’ve keep in mind your stuff previous to and you’re just too magnificent. I actually like what you’ve got here, really like what you are saying and the way in which during which you say it. You’re making it enjoyable and you still take care of to keep it wise. I can’t wait to read much more from you. This is really a wonderful website.
http://kamagraiq.shop/# Kamagra tablets
One other important part is that if you are an older person, travel insurance with regard to pensioners is something you need to really consider. The mature you are, a lot more at risk you’re for having something undesirable happen to you while in foreign countries. If you are definitely not covered by several comprehensive insurance cover, you could have quite a few serious troubles. Thanks for sharing your ideas on this web blog.
buy cialis pill: cialis best price – Generic Cialis price
Can I just say what a reduction to search out somebody who truly knows what theyre talking about on the internet. You definitely know find out how to carry a difficulty to mild and make it important. More folks must learn this and understand this side of the story. I cant consider youre no more well-liked because you definitely have the gift.
Kamagra 100mg price Kamagra Iq super kamagra
I?ve learn a few good stuff here. Definitely price bookmarking for revisiting. I wonder how much effort you place to create the sort of great informative website.
https://tadalafiliq.shop/# cialis for sale
mexican border pharmacies shipping to usa: mexican pharmacy – mexican border pharmacies shipping to usa
http://mexicanpharmgrx.com/# reputable mexican pharmacies online
of course like your web-site but you have to check the spelling on quite a few of your posts. A number of them are rife with spelling issues and I find it very troublesome to tell the truth nevertheless I?ll certainly come back again.
I have discovered that smart real estate agents everywhere you go are getting set to FSBO ***********. They are recognizing that it’s more than simply placing a sign in the front yard. It’s really about building associations with these retailers who sooner or later will become consumers. So, if you give your time and efforts to serving these vendors go it alone — the “Law associated with Reciprocity” kicks in. Good blog post.
canadian pharmacy in canada canadian discount pharmacy buy drugs from canada
buy prescription drugs from canada cheap: Certified Canadian pharmacies – safe canadian pharmacy
http://canadianpharmgrx.com/# legitimate canadian pharmacy online
mexican pharmaceuticals online: mexican border pharmacies shipping to usa – pharmacies in mexico that ship to usa
Generally I do not read post on blogs, but I wish to say that this write-up very forced me to try and do it! Your writing style has been amazed me. Thanks, very nice post.
Unquestionably believe that which you stated. Your favorite reason appeared to be on the net the simplest thing to be aware of. I say to you, I certainly get irked while people think about worries that they plainly do not know about. You managed to hit the nail upon the top and defined out the whole thing without having side-effects , people could take a signal. Will likely be back to get more. Thanks
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You clearly know what youre talking about, why waste your intelligence on just posting videos to your site when you could be giving us something enlightening to read?
indian pharmacy online Healthcare and medicines from India top online pharmacy india
You could certainly see your skills in the paintings you write. The world hopes for even more passionate writers such as you who are not afraid to mention how they believe. At all times go after your heart.
https://mexicanpharmgrx.com/# medication from mexico pharmacy
Hmm is anyone else experiencing problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
Fantastic post however I was wondering if you could write a litte more on this topic? I’d be very thankful if you could elaborate a little bit more. Cheers!
http://mexicanpharmgrx.com/# best online pharmacies in mexico
best canadian pharmacy to order from Pharmacies in Canada that ship to the US canadian pharmacy 1 internet online drugstore
indian pharmacies safe: indian pharmacy paypal – top 10 online pharmacy in india
legit canadian pharmacy online: canadian pharmacy – canadian medications
http://canadianpharmgrx.xyz/# precription drugs from canada
Online medicine home delivery buy prescription drugs from india indian pharmacy online
https://indianpharmgrx.com/# cheapest online pharmacy india
I do trust all of the ideas you have presented on your post. They’re really convincing and can definitely work. Nonetheless, the posts are too short for starters. May just you please extend them a little from subsequent time? Thanks for the post.
I am really impressed with your writing skills and also with the layout on your weblog. Is this a paid theme or did you modify it yourself? Anyway keep up the nice quality writing, it?s rare to see a great blog like this one these days..
mexican online pharmacies prescription drugs: mexican pharmaceuticals online – mexican mail order pharmacies
canadian world pharmacy Best Canadian online pharmacy buying drugs from canada
fantastic points altogether, you just gained a new reader. What would you suggest about your post that you made a few days ago? Any positive?
I?d have to test with you here. Which isn’t one thing I often do! I get pleasure from studying a post that can make people think. Additionally, thanks for permitting me to remark!
Very good blog you have here but I was wondering if you knew of any community forums that cover the same topics discussed in this article? I’d really like to be a part of group where I can get feed-back from other knowledgeable people that share the same interest. If you have any recommendations, please let me know. Bless you!
http://indianpharmgrx.shop/# Online medicine home delivery
best online pharmacies in mexico: Pills from Mexican Pharmacy – pharmacies in mexico that ship to usa
Thanks for ones marvelous posting! I quite enjoyed reading it, you are a great author.I will ensure that I bookmark your blog and will often come back from now on. I want to encourage continue your great job, have a nice holiday weekend!
http://mexicanpharmgrx.com/# mexican drugstore online
mexican pharmacy Mexico drugstore mexican pharmacy
Good day! This is kind of off topic but I need some help from an established blog. Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast. I’m thinking about setting up my own but I’m not sure where to begin. Do you have any tips or suggestions? Thank you
A person essentially lend a hand to make severely articles I’d state. This is the first time I frequented your web page and up to now? I surprised with the research you made to make this actual publish extraordinary. Great activity!
best india pharmacy: indian pharmacy delivery – top online pharmacy india
https://indianpharmgrx.com/# legitimate online pharmacies india
mexican online pharmacies prescription drugs online pharmacy in Mexico buying from online mexican pharmacy
pharmacies in mexico that ship to usa: mexican online pharmacies prescription drugs – reputable mexican pharmacies online
canadian pharmacy prices: Canadian pharmacy prices – canadian pharmacy cheap
http://indianpharmgrx.com/# cheapest online pharmacy india
online canadian drugstore Cheapest drug prices Canada cheap canadian pharmacy online
https://canadianpharmgrx.com/# reliable canadian online pharmacy
indian pharmacy: indian pharmacy delivery – online shopping pharmacy india
Heya i am for the first time here. I came across this board and I find It really useful & it helped me out a lot. I hope to give something back and aid others like you helped me.
vipps approved canadian online pharmacy Canada pharmacy canadian online drugs
http://indianpharmgrx.com/# reputable indian online pharmacy
I was just looking for this info for some time. After 6 hours of continuous Googleing, finally I got it in your web site. I wonder what is the lack of Google strategy that don’t rank this kind of informative websites in top of the list. Usually the top web sites are full of garbage.
Online medicine home delivery: indian pharmacy – mail order pharmacy india
I really like your blog.. very nice colors & theme. Did you design this website yourself or did you hire someone to do it for you? Plz reply as I’m looking to construct my own blog and would like to find out where u got this from. appreciate it
Hello There. I found your blog using msn. This is a really well written article. I?ll be sure to bookmark it and come back to read more of your useful information. Thanks for the post. I?ll definitely return.
https://mexicanpharmgrx.shop/# medicine in mexico pharmacies
I just couldn’t depart your web site before suggesting that I extremely enjoyed the standard info a person provide for your visitors? Is going to be back often in order to check up on new posts
It is appropriate time to make some plans for the longer term and it’s time to be happy. I have read this put up and if I could I want to recommend you some fascinating issues or tips. Maybe you can write subsequent articles relating to this article. I desire to learn even more things about it!
I was recommended this blog by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my trouble. You’re wonderful! Thanks!
buying prescription drugs in mexico online Pills from Mexican Pharmacy buying from online mexican pharmacy
mexico pharmacies prescription drugs: mexican drugstore online – mexico drug stores pharmacies
cheapest online pharmacy india: indian pharmacies safe – best online pharmacy india
https://canadianpharmgrx.com/# canadian pharmacy uk delivery
I have been exploring for a little for any high-quality articles or blog posts on this kind of area . Exploring in Yahoo I ultimately stumbled upon this website. Reading this information So i?m happy to exhibit that I’ve an incredibly just right uncanny feeling I came upon just what I needed. I so much certainly will make sure to don?t put out of your mind this website and give it a glance on a relentless basis.
buy cytotec online fast delivery: buy cytotec pills online cheap – cytotec pills online
buy doxycycline hyclate 100mg without a rx: online doxycycline – doxycycline 100mg online
buy cytotec in usa Abortion pills online order cytotec online
cytotec online: п»їcytotec pills online – buy cytotec online
I loved up to you’ll receive performed right here. The caricature is attractive, your authored subject matter stylish. nonetheless, you command get got an impatience over that you want be delivering the following. unwell unquestionably come further in the past again since exactly the similar just about a lot continuously inside of case you defend this hike.
cipro for sale ciprofloxacin mail online buy cipro online canada
does tamoxifen cause joint pain: nolvadex during cycle – does tamoxifen cause menopause
You made some first rate points there. I appeared on the web for the problem and found most people will associate with with your website.
I?m impressed, I must say. Really rarely do I encounter a blog that?s each educative and entertaining, and let me let you know, you could have hit the nail on the head. Your thought is outstanding; the problem is one thing that not sufficient individuals are talking intelligently about. I’m very comfortable that I stumbled across this in my seek for something referring to this.
https://nolvadex.icu/# raloxifene vs tamoxifen
I like the valuable info you supply to your articles. I will bookmark your weblog and take a look at again here frequently. I’m quite sure I will be told many new stuff right right here! Good luck for the following!
doxycycline hyclate: generic doxycycline – doxycycline 150 mg
benefits of tamoxifen: tamoxifen – tamoxifen mechanism of action
diflucan 100 buy cheap diflucan online canadian order diflucan online
order doxycycline: doxycycline 500mg – doxycycline 100 mg
diflucan 150 mg capsule diflucan 100 mg tablet diflucan capsules 100mg
buy cytotec online: Cytotec 200mcg price – cytotec pills buy online
Fantastic beat ! I wish to apprentice whilst you amend your website, how can i subscribe for a blog web site? The account helped me a applicable deal. I had been tiny bit familiar of this your broadcast offered bright transparent idea
purchase cipro: antibiotics cipro – buy ciprofloxacin
ciprofloxacin 500mg buy online: ciprofloxacin generic price – cipro ciprofloxacin
Yesterday, while I was at work, my sister stole my iphone and tested to see if it can survive a thirty foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is totally off topic but I had to share it with someone!
where to get nolvadex tamoxifen alternatives premenopausal arimidex vs tamoxifen bodybuilding
We are a gaggle of volunteers and opening a new scheme in our community. Your web site offered us with helpful information to paintings on. You have done an impressive job and our entire community can be grateful to you.
Thanks for your handy post. In recent times, I have come to be able to understand that the actual symptoms of mesothelioma are caused by the build up associated fluid relating to the lining of the lung and the chest cavity. The ailment may start within the chest vicinity and pass on to other parts of the body. Other symptoms of pleural mesothelioma cancer include weight reduction, severe inhaling and exhaling trouble, vomiting, difficulty ingesting, and irritation of the neck and face areas. It should be noted that some people with the disease tend not to experience almost any serious signs at all.
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I get in fact enjoyed account your blog posts. Anyway I will be subscribing to your feeds and even I achievement you access consistently rapidly.
http://misoprostol.top/# buy misoprostol over the counter
Great web site. A lot of useful info here. I?m sending it to several friends ans also sharing in delicious. And naturally, thanks for your effort!
buy cheap doxycycline online: buy doxycycline 100mg – 200 mg doxycycline
I?m no longer sure the place you’re getting your information, but great topic. I needs to spend a while finding out much more or figuring out more. Thanks for excellent information I was searching for this info for my mission.
Based on my study, after a foreclosed home is available at a sale, it is common for your borrower to be able to still have any remaining unpaid debt on the financial loan. There are many loan merchants who attempt to have all costs and liens paid off by the upcoming buyer. Having said that, depending on selected programs, polices, and state regulations there may be several loans which are not easily fixed through the exchange of lending products. Therefore, the responsibility still lies on the borrower that has got his or her property in foreclosure process. Many thanks for sharing your thinking on this site.
cytotec online buy misoprostol over the counter cytotec pills buy online
Wonderful blog! I found it while surfing around on Yahoo News. Do you have any suggestions on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Thanks
effexor and tamoxifen: liquid tamoxifen – what is tamoxifen used for
I don?t even know how I ended up here, but I thought this post was great. I don’t know who you are but certainly you’re going to a famous blogger if you are not already 😉 Cheers!
Thanks for the ideas you have shared here. Another thing I would like to talk about is that laptop or computer memory requirements generally increase along with other advancements in the know-how. For instance, as soon as new generations of processors are brought to the market, there is usually a corresponding increase in the shape preferences of both the computer memory in addition to hard drive room. This is because the application operated by means of these processors will inevitably increase in power to take advantage of the new technological innovation.
I think this is one of the so much significant information for me. And i am glad studying your article. However wanna statement on few common issues, The web site style is great, the articles is truly nice : D. Good activity, cheers
cipro online no prescription in the usa: ciprofloxacin mail online – ciprofloxacin
Sweet blog! I found it while surfing around on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Many thanks
tamoxifen hair loss: tamoxifen alternatives premenopausal – benefits of tamoxifen
After study just a few of the weblog posts in your web site now, and I actually like your method of blogging. I bookmarked it to my bookmark website checklist and will probably be checking back soon. Pls check out my site as properly and let me know what you think.
tamoxifen moa tamoxifen rash natural alternatives to tamoxifen
over the counter diflucan 150: diflucan online pharmacy – diflucan prescription australia
Please let me know if you’re looking for a article writer for your blog. You have some really great posts and I feel I would be a good asset. If you ever want to take some of the load off, I’d love to write some material for your blog in exchange for a link back to mine. Please shoot me an e-mail if interested. Regards!
doxycycline 150 mg: generic doxycycline – doxycycline 100 mg
cytotec online buy cytotec in usa buy misoprostol over the counter
canadian order diflucan online: diflucan 1 where to buy – diflucan tablet india
ciprofloxacin order online: cipro ciprofloxacin – ciprofloxacin generic price
http://ciprofloxacin.guru/# ciprofloxacin generic price
doxycycline prices: order doxycycline 100mg without prescription – doxy 200
tamoxifen dose tamoxifen buy tamoxifen alternatives
Youre so cool! I dont suppose Ive learn something like this before. So nice to find someone with some authentic ideas on this subject. realy thanks for beginning this up. this website is one thing that is wanted on the web, someone with just a little originality. helpful job for bringing one thing new to the web!
buy cytotec online: cytotec abortion pill – buy cytotec pills online cheap
What an informative and thoroughly-researched article! The author’s attention to detail and ability to present complex ideas in a understandable manner is truly commendable. I’m thoroughly impressed by the breadth of knowledge showcased in this piece. Thank you, author, for providing your wisdom with us. This article has been a true revelation!
Pretty section of content. I just stumbled upon your website and in accession capital to assert that I get actually enjoyed account your blog posts. Anyway I?ll be subscribing to your augment and even I achievement you access consistently quickly.
doxycycline order online: vibramycin 100 mg – doxycycline 100 mg
We are a gaggle of volunteers and starting a brand new scheme in our community. Your website offered us with helpful info to paintings on. You have performed an impressive activity and our whole community will likely be thankful to you.
Thanks for your posting. My spouse and i have often observed that a majority of people are desirous to lose weight since they wish to look slim as well as attractive. Even so, they do not often realize that there are additional benefits for losing weight also. Doctors claim that overweight people come across a variety of conditions that can be directly attributed to their own excess weight. Thankfully that people who’re overweight plus suffering from several diseases can reduce the severity of their particular illnesses by simply losing weight. You’ll be able to see a slow but noted improvement in health whenever even a moderate amount of weight loss is reached.
buy ciprofloxacin over the counter cipro online no prescription in the usa cipro 500mg best prices
Greetings from Carolina! I’m bored to death at work so I decided to browse your site on my iphone during lunch break. I love the knowledge you present here and can’t wait to take a look when I get home. I’m surprised at how quick your blog loaded on my phone .. I’m not even using WIFI, just 3G .. Anyhow, awesome blog!
ciprofloxacin: cipro – buy generic ciprofloxacin
diflucan without get a prescription online: buy diflucan over the counter – diflucan medicine in india
Howdy! I could have sworn I’ve been to this blog before but after checking through some of the post I realized it’s new to me. Nonetheless, I’m definitely glad I found it and I’ll be bookmarking and checking back often!
Thanks for making me to gain new ideas about computers. I also have belief that certain of the best ways to help keep your mobile computer in prime condition has been a hard plastic-type material case, or even shell, that will fit over the top of your computer. These kinds of protective gear are generally model specific since they are manufactured to fit perfectly above the natural housing. You can buy all of them directly from the seller, or through third party sources if they are available for your laptop computer, however its not all laptop can have a shell on the market. Just as before, thanks for your recommendations.
Yet another thing I would like to convey is that instead of trying to accommodate all your online degree classes on days and nights that you end work (since the majority of people are fatigued when they go back home), try to have most of your classes on the saturdays and sundays and only one or two courses in weekdays, even if it means a little time off your end of the week. This pays off because on the saturdays and sundays, you will be much more rested in addition to concentrated for school work. Thanks alot : ) for the different tips I have learned from your blog.
tamoxifen generic: where to get nolvadex – tamoxifen dosage
п»їcytotec pills online buy cytotec online fast delivery cytotec online
amoxicillin 500mg price in canada: how to buy amoxicillin online – where can you buy amoxicillin over the counter
http://stromectola.top/# stromectol order
Nice post. learn something new and challenging on blogs I stumbleupon on a daily basis.
prednisone 20mg price in india prednisone otc price buy prednisone 20mg without a prescription best price
amoxicillin online without prescription: order amoxicillin no prescription – amoxicillin 800 mg price
where can i buy cheap clomid without insurance: how can i get generic clomid without dr prescription – cheap clomid without dr prescription
Hello would you mind letting me know which web host you’re using? I’ve loaded your blog in 3 different web browsers and I must say this blog loads a lot quicker then most. Can you recommend a good hosting provider at a fair price? Many thanks, I appreciate it!
Just want to say your article is as astonishing. The clearness on your post is simply excellent and i can think you are a professional in this subject. Fine along with your permission let me to snatch your feed to stay updated with impending post. Thanks one million and please continue the rewarding work.
zithromax for sale cheap buy azithromycin zithromax generic zithromax 500mg
I do believe that a foreclosures can have a significant effect on the debtor’s life. House foreclosures can have a 6 to few years negative impact on a borrower’s credit report. A borrower that has applied for a home loan or any loans for example, knows that your worse credit rating can be, the more complicated it is for any decent bank loan. In addition, it may possibly affect any borrower’s capacity to find a really good place to lease or hire, if that results in being the alternative housing solution. Great blog post.
I’ve been surfing online more than 3 hours today, yet I never found any interesting article like yours. It is pretty worth enough for me. In my view, if all webmasters and bloggers made good content as you did, the internet will be a lot more useful than ever before.
amoxicillin discount coupon: purchase amoxicillin online – amoxicillin from canada
prednisone buy cheap: 50 mg prednisone tablet – prednisone otc uk
Thanks for your helpful article. One other problem is that mesothelioma cancer is generally the result of the inhalation of fibres from asbestos, which is a cancer causing material. It truly is commonly observed among employees in the structure industry who have long experience of asbestos. It could be caused by living in asbestos insulated buildings for some time of time, Genes plays an important role, and some people are more vulnerable to the risk as compared to others.
http://azithromycina.pro/# can you buy zithromax over the counter
I appreciate, cause I found exactly what I was looking for. You have ended my 4 day long hunt! God Bless you man. Have a great day. Bye
zithromax online no prescription: zithromax for sale online – buy cheap generic zithromax
cost of prednisone 10mg tablets: over the counter prednisone pills – 10 mg prednisone tablets
where buy cheap clomid now clomid prices can i order clomid pills
Great work! That is the type of info that are meant to be shared across the web. Disgrace on Google for no longer positioning this publish higher! Come on over and talk over with my website . Thank you =)
I mastered more something totally new on this weight-loss issue. 1 issue is a good nutrition is very vital any time dieting. A big reduction in fast foods, sugary foods, fried foods, sugary foods, beef, and white-colored flour products may be necessary. Having wastes parasites, and wastes may prevent objectives for fat-loss. While a number of drugs momentarily solve the challenge, the unpleasant side effects aren’t worth it, and in addition they never offer more than a short-lived solution. It can be a known idea that 95 of fad diets fail. Thank you for sharing your notions on this web site.
https://clomida.pro/# where can i get generic clomid
https://prednisonea.store/# prednisone prices
how to get cheap clomid without a prescription: cost of clomid pill – where can i buy cheap clomid price
cost of generic zithromax zithromax 500 without prescription zithromax 500 mg
Thanks for your write-up. One other thing is that if you are marketing your property on your own, one of the issues you need to be aware about upfront is just how to deal with home inspection accounts. As a FSBO retailer, the key towards successfully moving your property in addition to saving money on real estate agent income is understanding. The more you realize, the smoother your home sales effort will be. One area when this is particularly essential is home inspections.
Hello! Would you mind if I share your blog with my facebook group? There’s a lot of people that I think would really enjoy your content. Please let me know. Thanks
get clomid without rx: where can i buy cheap clomid without a prescription – how to get cheap clomid for sale
http://clomida.pro/# can i buy generic clomid pills
Hi there would you mind stating which blog platform you’re using? I’m going to start my own blog in the near future but I’m having a hard time selecting between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something unique. P.S Apologies for being off-topic but I had to ask!
Thanks for the publish. I have continually seen that a lot of people are wanting to lose weight simply because they wish to appear slim and attractive. Having said that, they do not generally realize that there are other benefits so that you can losing weight also. Doctors declare that obese people are afflicted with a variety of disorders that can be instantly attributed to their particular excess weight. The great news is that people who are overweight as well as suffering from various diseases are able to reduce the severity of their particular illnesses simply by losing weight. You’ll be able to see a steady but identifiable improvement with health when even a small amount of weight reduction is attained.
Whats up! I just wish to give an enormous thumbs up for the great info you have got here on this post. I can be coming again to your weblog for more soon.
zithromax online usa no prescription: zithromax cost uk – zithromax 500 mg
over the counter amoxicillin: amoxicillin online without prescription – amoxicillin generic
I’m extremely inspired along with your writing talents as neatly as with the format in your blog. Is that this a paid subject matter or did you modify it your self? Either way keep up the nice quality writing, it is rare to peer a nice weblog like this one these days..
Sweet blog! I found it while surfing around on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Thank you
Howdy! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a community in the same niche. Your blog provided us beneficial information to work on. You have done a outstanding job!
http://prednisonea.store/# purchase prednisone no prescription
zithromax z-pak price without insurance where can you buy zithromax can you buy zithromax over the counter
buy amoxicillin online cheap: buy amoxicillin 500mg uk – amoxicillin 500 mg tablets
where can i get amoxicillin: where to buy amoxicillin over the counter – cost of amoxicillin
buy erectile dysfunction treatment: cheap ed treatment – where to buy erectile dysfunction pills
https://medicationnoprescription.pro/# no prescription medicines
https://onlinepharmacyworld.shop/# prescription drugs from canada
Thanks for your posting. One other thing is that if you are promoting your property all on your own, one of the troubles you need to be mindful of upfront is just how to deal with property inspection accounts. As a FSBO seller, the key to successfully switching your property and also saving money on real estate agent revenue is understanding. The more you understand, the simpler your property sales effort will probably be. One area where this is particularly significant is home inspections.
cheapest ed online best online ed treatment ed medicines online
In line with my study, after a foreclosed home is offered at a bidding, it is common for that borrower to be able to still have some sort ofthat remaining balance on the mortgage. There are many loan companies who try and have all charges and liens paid off by the following buyer. On the other hand, depending on specific programs, rules, and state guidelines there may be many loans that aren’t easily sorted out through the shift of financial loans. Therefore, the responsibility still remains on the consumer that has received his or her property foreclosed on. Many thanks sharing your thinking on this weblog.
https://onlinepharmacyworld.shop/# prescription drugs from canada
I might also like to convey that most of those who find themselves with out health insurance are usually students, self-employed and people who are out of work. More than half from the uninsured are really under the age of 35. They do not feel they are in need of health insurance because they are young as well as healthy. Its income is usually spent on houses, food, and entertainment. Most people that do represent the working class either 100 or not professional are not provided insurance via their jobs so they move without as a result of rising tariff of health insurance in the us. Thanks for the suggestions you write about through this blog.
I do believe that a foreclosed can have a important effect on the client’s life. Real estate foreclosures can have a 7 to several years negative impact on a applicant’s credit report. The borrower who’s applied for a mortgage or just about any loans for that matter, knows that the worse credit rating can be, the more tricky it is to have a decent personal loan. In addition, it may affect a borrower’s capability to find a respectable place to lease or hire, if that gets the alternative homes solution. Good blog post.
https://edpill.top/# order ed pills online
non prescription online pharmacy: prescription meds from canada – best no prescription online pharmacy
I would also love to add that in case you do not already have an insurance policy or maybe you do not take part in any group insurance, you could possibly well reap the benefits of seeking the help of a health insurance agent. Self-employed or people with medical conditions typically seek the help of the health insurance broker. Thanks for your post.
Hi would you mind letting me know which web host you’re working with? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot faster then most. Can you suggest a good internet hosting provider at a honest price? Thank you, I appreciate it!
cheapest pharmacy for prescriptions online pharmacy without prescription no prescription needed pharmacy
online pharmacy non prescription drugs: canadian online pharmacy no prescription – canadian pharmacy discount coupon
http://onlinepharmacyworld.shop/# pharmacy discount coupons
There are actually numerous particulars like that to take into consideration. That could be a nice level to convey up. I offer the ideas above as basic inspiration but clearly there are questions like the one you bring up where crucial thing can be working in sincere good faith. I don?t know if finest practices have emerged round things like that, however I am certain that your job is clearly recognized as a fair game. Each girls and boys really feel the influence of only a second?s pleasure, for the remainder of their lives.
Thank you for another informative web site. The place else may just I am getting that type of information written in such a perfect means? I’ve a undertaking that I am simply now operating on, and I have been on the glance out for such information.
https://medicationnoprescription.pro/# canadian pharmacy no prescription
ed medication online: ed meds online – cheap ed medicine
https://edpill.top/# erectile dysfunction online prescription
I don?t even know the way I stopped up right here, however I assumed this post was once great. I do not recognize who you are but certainly you’re going to a well-known blogger if you happen to aren’t already 😉 Cheers!
no prescription buying prescription drugs from canada online non prescription canadian pharmacy
http://edpill.top/# ed doctor online
okmark your weblog and check again here regularly. I am quite certain I?ll learn many new stuff right here! Good luck for the next!
http://medicationnoprescription.pro/# best online pharmacies without prescription
Thanks for the points shared on the blog. Something also important I would like to say is that weight loss is not information about going on a dietary fad and trying to reduce as much weight as you can in a set period of time. The most effective way to lose weight naturally is by taking it slowly but surely and right after some basic recommendations which can enable you to make the most from the attempt to lose fat. You may be aware and be following some tips, nonetheless reinforcing know-how never hurts.
canada prescription online: cheap drugs no prescription – purchasing prescription drugs online
Good day! I could have sworn I’ve been to this blog before but after reading through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
Somebody essentially help to make seriously posts I would state. This is the very first time I frequented your web page and thus far? I surprised with the research you made to make this particular publish amazing. Great job!
Woah! I’m really loving the template/theme of this site. It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance” between usability and appearance. I must say you have done a superb job with this. In addition, the blog loads extremely fast for me on Opera. Superb Blog!
https://edpill.top/# cheapest ed online
http://edpill.top/# erectile dysfunction medication online
canadian pharmacy without prescription pharmacy coupons canadian pharmacy without prescription
magnificent issues altogether, you simply received a new reader. What would you recommend in regards to your submit that you just made a few days in the past? Any sure?
I’m in awe of the author’s capability to make complicated concepts understandable to readers of all backgrounds. This article is a testament to her expertise and commitment to providing useful insights. Thank you, author, for creating such an compelling and insightful piece. It has been an absolute pleasure to read!
online pharmacy no prescription needed: non prescription medicine pharmacy – cheapest pharmacy to fill prescriptions with insurance
I?m impressed, I have to say. Really not often do I encounter a weblog that?s each educative and entertaining, and let me tell you, you will have hit the nail on the head. Your idea is excellent; the problem is one thing that not sufficient persons are talking intelligently about. I’m very pleased that I stumbled across this in my search for something relating to this.
https://edpill.top/# online ed medicine
erectile dysfunction pills online: order ed pills – low cost ed pills
Heya i am for the first time here. I came across this board and I find It truly useful & it helped me out much. I hope to give something back and help others like you aided me.
https://casinvietnam.shop/# casino tr?c tuy?n
Many thanks for sharing these types of wonderful content. In addition, the perfect travel and also medical insurance system can often reduce those considerations that come with journeying abroad. Any medical crisis can in the near future become very costly and that’s likely to quickly place a financial burden on the family finances. Setting up in place the ideal travel insurance program prior to setting off is definitely worth the time and effort. Thank you
You can definitely see your enthusiasm in the work you write. The world hopes for more passionate writers like you who are not afraid to say how they believe. Always go after your heart.
game c? b?c online uy tín: choi casino tr?c tuy?n trên di?n tho?i – dánh bài tr?c tuy?n
I have realized some significant things through your blog post. One other point I would like to say is that there are lots of games on the market designed especially for preschool age children. They contain pattern recognition, colors, wildlife, and patterns. These often focus on familiarization as an alternative to memorization. This keeps children engaged without having a sensation like they are learning. Thanks
Good post. I learn one thing more difficult on completely different blogs everyday. It’s going to always be stimulating to read content material from other writers and observe a bit something from their store. I?d desire to use some with the content on my blog whether you don?t mind. Natually I?ll offer you a link in your internet blog. Thanks for sharing.
casino tr?c tuy?n vi?t nam: casino tr?c tuy?n vi?t nam – casino tr?c tuy?n vi?t nam
Hello! This is my first visit to your blog! We are a group of volunteers and starting a new initiative in a community in the same niche. Your blog provided us valuable information to work on. You have done a marvellous job!
Hi there, simply become aware of your weblog thru Google, and found that it’s really informative. I?m gonna be careful for brussels. I?ll appreciate for those who proceed this in future. Numerous folks will probably be benefited out of your writing. Cheers!
http://casinvietnam.com/# casino tr?c tuy?n uy tin
Another issue is that video games can be serious in nature with the most important focus on learning rather than amusement. Although, it has an entertainment part to keep your sons or daughters engaged, each and every game is normally designed to focus on a specific set of skills or course, such as mathematics or science. Thanks for your article.
http://casinvietnam.com/# web c? b?c online uy tin
You actually make it seem really easy with your presentation however I find this topic to be really one thing which I think I might never understand. It seems too complicated and extremely huge for me. I’m taking a look ahead to your subsequent put up, I will try to get the hold of it!
web c? b?c online uy tin game c? b?c online uy tin choi casino tr?c tuy?n tren di?n tho?i
https://casinvietnam.shop/# casino tr?c tuy?n uy tin
Hey there this is somewhat of off topic but I was wondering if blogs use WYSIWYG editors or if you have to manually code with HTML. I’m starting a blog soon but have no coding know-how so I wanted to get advice from someone with experience. Any help would be enormously appreciated!
game c? b?c online uy tin web c? b?c online uy tin choi casino tr?c tuy?n tren di?n tho?i
This website is known as a stroll-through for all the info you wished about this and didn?t know who to ask. Glimpse here, and you?ll definitely discover it.
The next time I read a weblog, I hope that it doesnt disappoint me as a lot as this one. I imply, I know it was my option to read, but I truly thought youd have one thing interesting to say. All I hear is a bunch of whining about something that you could possibly fix when you werent too busy searching for attention.
Woah! I’m really digging the template/theme of this website. It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between superb usability and visual appearance. I must say you have done a awesome job with this. Also, the blog loads extremely quick for me on Chrome. Outstanding Blog!
I’m very happy to read this. This is the kind of manual that needs to be given and not the accidental misinformation that is at the other blogs. Appreciate your sharing this greatest doc.
casino tr?c tuy?n: choi casino tr?c tuy?n trên di?n tho?i – casino tr?c tuy?n vi?t nam
https://casinvietnam.shop/# web c? b?c online uy tin
game c? b?c online uy tín: casino tr?c tuy?n uy tín – dánh bài tr?c tuy?n
http://casinvietnam.com/# web c? b?c online uy tin
casino tr?c tuy?n: choi casino tr?c tuy?n trên di?n tho?i – casino tr?c tuy?n
game c? b?c online uy tín: dánh bài tr?c tuy?n – choi casino tr?c tuy?n trên di?n tho?i
casino tr?c tuy?n vi?t nam: casino tr?c tuy?n uy tín – dánh bài tr?c tuy?n
http://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
choi casino tr?c tuy?n trên di?n tho?i: casino tr?c tuy?n uy tín – choi casino tr?c tuy?n trên di?n tho?i
http://casinvietnam.shop/# game c? b?c online uy tin
web c? b?c online uy tín: dánh bài tr?c tuy?n – casino tr?c tuy?n vi?t nam
web c? b?c online uy tin casino online uy tin choi casino tr?c tuy?n tren di?n tho?i
casino tr?c tuy?n uy tín: casino tr?c tuy?n vi?t nam – casino online uy tín
casino tr?c tuy?n casino tr?c tuy?n uy tin choi casino tr?c tuy?n tren di?n tho?i
web c? b?c online uy tín: web c? b?c online uy tín – dánh bài tr?c tuy?n
http://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
choi casino tr?c tuy?n tren di?n tho?i casino tr?c tuy?n vi?t nam casino online uy tin
casino tr?c tuy?n uy tín: choi casino tr?c tuy?n trên di?n tho?i – game c? b?c online uy tín
It is really a nice and helpful piece of info. I?m glad that you shared this useful information with us. Please keep us up to date like this. Thank you for sharing.
https://casinvietnam.shop/# danh bai tr?c tuy?n
casino tr?c tuy?n vi?t nam web c? b?c online uy tin game c? b?c online uy tin
casino tr?c tuy?n vi?t nam: choi casino tr?c tuy?n trên di?n tho?i – dánh bài tr?c tuy?n
I’ve learned a number of important things via your post. I might also like to say that there may be situation where you will have a loan and don’t need a co-signer such as a Government Student Aid Loan. However, if you are getting credit through a traditional finance company then you need to be ready to have a cosigner ready to enable you to. The lenders will base their decision over a few elements but the greatest will be your credit history. There are some loan merchants that will furthermore look at your work history and choose based on that but in many cases it will hinge on your credit score.
casino tr?c tuy?n vi?t nam casino tr?c tuy?n vi?t nam game c? b?c online uy tin
casino tr?c tuy?n vi?t nam: casino tr?c tuy?n uy tín – web c? b?c online uy tín
I can’t express how much I value the effort the author has put into producing this outstanding piece of content. The clarity of the writing, the depth of analysis, and the plethora of information offered are simply astonishing. His zeal for the subject is evident, and it has undoubtedly made an impact with me. Thank you, author, for sharing your wisdom and enriching our lives with this extraordinary article!
game c? b?c online uy tin casino online uy tin casino online uy tin
Together with the whole thing that seems to be building within this area, a significant percentage of opinions are actually relatively stimulating. Nonetheless, I am sorry, but I can not give credence to your entire idea, all be it exciting none the less. It appears to everyone that your remarks are generally not totally justified and in fact you are generally your self not thoroughly convinced of your assertion. In any event I did take pleasure in looking at it.
casino online uy tín: casino tr?c tuy?n vi?t nam – dánh bài tr?c tuy?n
mexican pharmacy mexico drug stores pharmacies buying prescription drugs in mexico online
https://indiaph24.store/# best india pharmacy
canadianpharmacymeds legitimate canadian pharmacies ordering drugs from canada
https://canadaph24.pro/# canadapharmacyonline com
Undeniably believe that which you stated. Your favorite justification appeared to be on the net the easiest thing to be aware of. I say to you, I certainly get irked while people consider worries that they plainly don’t know about. You managed to hit the nail upon the top and defined out the whole thing without having side effect , people could take a signal. Will likely be back to get more. Thanks
My developer is trying to persuade me to move to .net from PHP. I have always disliked the idea because of the costs. But he’s tryiong none the less. I’ve been using WordPress on various websites for about a year and am nervous about switching to another platform. I have heard excellent things about blogengine.net. Is there a way I can import all my wordpress content into it? Any help would be really appreciated!
indian pharmacy online indian pharmacy fast delivery indian pharmacy online
http://canadaph24.pro/# canadian pharmacy 24h com
Hey, you used to write fantastic, but the last few posts have been kinda boring? I miss your tremendous writings. Past several posts are just a bit out of track! come on!
top 10 pharmacies in india buy medicines from India п»їlegitimate online pharmacies india
This actually answered my downside, thank you!
http://canadaph24.pro/# canadian online pharmacy reviews
best india pharmacy indian pharmacy fast delivery Online medicine home delivery
http://mexicoph24.life/# mexico pharmacy
purple pharmacy mexico price list п»їbest mexican online pharmacies mexico drug stores pharmacies
http://mexicoph24.life/# reputable mexican pharmacies online
safe canadian pharmacy Certified Canadian Pharmacies canadian 24 hour pharmacy
https://indiaph24.store/# indianpharmacy com
canadian pharmacy meds Licensed Canadian Pharmacy drugs from canada
http://mexicoph24.life/# medication from mexico pharmacy
top 10 pharmacies in india Cheapest online pharmacy indian pharmacy online
http://mexicoph24.life/# medicine in mexico pharmacies
mail order pharmacy india Generic Medicine India to USA buy prescription drugs from india
best online pharmacies in mexico mexico pharmacy reputable mexican pharmacies online
http://canadaph24.pro/# online pharmacy canada
En iyi medyum olarak bir danışman için medyum haluk hocayı seçin en iyi medyum hocalardan bir tanesidir.
mexico drug stores pharmacies mexican pharmaceuticals online mexico pharmacy
http://indiaph24.store/# world pharmacy india
medicine in mexico pharmacies Online Pharmacies in Mexico mexico pharmacy
http://indiaph24.store/# Online medicine order
I was very happy to search out this internet-site.I wished to thanks to your time for this wonderful learn!! I positively enjoying every little bit of it and I’ve you bookmarked to take a look at new stuff you blog post.
I like what you guys are up also. Such intelligent work and reporting! Carry on the excellent works guys I?ve incorporated you guys to my blogroll. I think it’ll improve the value of my site 🙂
mexico drug stores pharmacies Mexican Pharmacy Online mexico drug stores pharmacies
http://indiaph24.store/# legitimate online pharmacies india
I also believe that mesothelioma is a rare form of cancers that is generally found in these previously exposed to asbestos. Cancerous cellular material form inside mesothelium, which is a defensive lining which covers a lot of the body’s internal organs. These cells normally form from the lining with the lungs, mid-section, or the sac that encircles the heart. Thanks for discussing your ideas.
Good ? I should certainly pronounce, impressed with your site. I had no trouble navigating through all tabs as well as related info ended up being truly easy to do to access. I recently found what I hoped for before you know it at all. Quite unusual. Is likely to appreciate it for those who add forums or something, website theme . a tones way for your client to communicate. Excellent task..
maple leaf pharmacy in canada canadian pharmacies legitimate canadian pharmacy online
http://mexicoph24.life/# mexican pharmaceuticals online
online pharmacy india indian pharmacies safe indian pharmacy paypal
https://canadaph24.pro/# medication canadian pharmacy
I like the valuable info you provide in your articles. I will bookmark your blog and check again here frequently. I’m quite certain I will learn lots of new stuff right here! Best of luck for the next!
online shopping pharmacy india Cheapest online pharmacy india online pharmacy
http://indiaph24.store/# buy medicines online in india
canadian pharmacy service online canadian drugstore canada cloud pharmacy
http://indiaph24.store/# best india pharmacy
canadian pharmacy review Licensed Canadian Pharmacy prescription drugs canada buy online
https://mexicoph24.life/# mexico drug stores pharmacies
canadian pharmacy king Licensed Canadian Pharmacy canadian online pharmacy
https://mexicoph24.life/# pharmacies in mexico that ship to usa
magnificent post, very informative. I wonder why the opposite specialists of this sector do not understand this. You should proceed your writing. I am confident, you’ve a great readers’ base already!
the canadian drugstore canadian pharmacies canada drugs
https://mexicoph24.life/# buying from online mexican pharmacy
I was curious if you ever considered changing the layout of your website? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having 1 or 2 pictures. Maybe you could space it out better?
Hi! This post could not be written any better! Reading through this post reminds me of my old room mate! He always kept chatting about this. I will forward this page to him. Fairly certain he will have a good read. Thank you for sharing!
mexico drug stores pharmacies Mexican Pharmacy Online medicine in mexico pharmacies
http://mexicoph24.life/# reputable mexican pharmacies online
top online pharmacy india indian pharmacy fast delivery top 10 online pharmacy in india
http://indiaph24.store/# india online pharmacy
It?s arduous to search out educated individuals on this subject, but you sound like you understand what you?re talking about! Thanks
http://indiaph24.store/# india online pharmacy
buy medicines online in india Generic Medicine India to USA Online medicine home delivery
http://canadaph24.pro/# canadian online pharmacy reviews
indian pharmacy Cheapest online pharmacy indian pharmacy paypal
http://mexicoph24.life/# mexico drug stores pharmacies
mexican border pharmacies shipping to usa cheapest mexico drugs mexican mail order pharmacies
http://mexicoph24.life/# buying prescription drugs in mexico
Online medicine order buy medicines from India india pharmacy mail order
http://mexicoph24.life/# medication from mexico pharmacy
canada drug pharmacy Prescription Drugs from Canada ordering drugs from canada
http://canadaph24.pro/# online pharmacy canada
mexican drugstore online Online Pharmacies in Mexico mexican drugstore online
http://mexicoph24.life/# buying prescription drugs in mexico
mexican pharmaceuticals online mexican pharmacy mexico drug stores pharmacies
http://mexicoph24.life/# mexico drug stores pharmacies
top 10 online pharmacy in india indian pharmacy fast delivery п»їlegitimate online pharmacies india
https://indiaph24.store/# top online pharmacy india
top 10 online pharmacy in india buy medicines from India п»їlegitimate online pharmacies india
http://mexicoph24.life/# mexican drugstore online
reputable indian online pharmacy indian pharmacy fast delivery online shopping pharmacy india
http://indiaph24.store/# Online medicine order
best online pharmacies in mexico Online Pharmacies in Mexico mexico drug stores pharmacies
http://indiaph24.store/# online pharmacy india
Hello my loved one! I wish to say that this article is awesome, great written and include almost all significant infos. I would like to see more posts like this .
п»їlegitimate online pharmacies india Generic Medicine India to USA indian pharmacy online
http://canadaph24.pro/# safe reliable canadian pharmacy
Do you have a spam problem on this website; I also am a blogger, and I was wondering your situation; many of us have created some nice procedures and we are looking to trade techniques with others, please shoot me an e-mail if interested.
buying prescription drugs in mexico mexican pharmaceuticals online mexican rx online
https://mexicoph24.life/# mexican border pharmacies shipping to usa
One important thing is that when you’re searching for a education loan you may find that you will want a co-signer. There are many scenarios where this is correct because you may find that you do not possess a past history of credit so the loan provider will require you have someone cosign the money for you. Great post.
I love what you guys tend to be up too. This type of clever work and reporting! Keep up the great works guys I’ve you guys to blogroll.
https://indiaph24.store/# legitimate online pharmacies india
canadian pharmacy near me Certified Canadian Pharmacies canadian pharmacy meds
https://indiaph24.store/# indian pharmacy paypal
mail order pharmacy india Generic Medicine India to USA Online medicine order
http://canadaph24.pro/# canadian drug prices
indian pharmacy buy prescription drugs from india п»їlegitimate online pharmacies india
http://mexicoph24.life/# mexico drug stores pharmacies
canadian pharmacy no scripts Large Selection of Medications from Canada reliable canadian online pharmacy
https://mexicoph24.life/# mexican online pharmacies prescription drugs
canadian pharmacy india Certified Canadian Pharmacies canadian pharmacy checker
https://canadaph24.pro/# canadian pharmacy meds reviews
canada pharmacy 24h canadian pharmacies safe online pharmacies in canada
I have discovered that wise real estate agents all over the place are starting to warm up to FSBO ***********. They are realizing that it’s not just placing a sign in the front place. It’s really pertaining to building connections with these sellers who at some point will become consumers. So, once you give your time and efforts to encouraging these traders go it alone : the “Law associated with Reciprocity” kicks in. Thanks for your blog post.
http://mexicoph24.life/# reputable mexican pharmacies online
Usually I do not learn article on blogs, however I wish to say that this write-up very pressured me to check out and do it! Your writing style has been amazed me. Thanks, very nice post.
legit canadian pharmacy online Large Selection of Medications from Canada the canadian pharmacy
buying prescription drugs in mexico: buying prescription drugs in mexico online – mexican drugstore online
I can’t believe how amazing this article is! The author has done a phenomenal job of delivering the information in an compelling and educational manner. I can’t thank her enough for sharing such priceless insights that have undoubtedly enlightened my understanding in this subject area. Bravo to her for crafting such a gem!
Thanks for expressing your ideas with this blog. Also, a delusion regarding the banking companies intentions any time talking about property foreclosure is that the loan company will not take my installments. There is a specific amount of time which the bank will take payments here and there. If you are also deep within the hole, they should commonly desire that you pay the payment in whole. However, that doesn’t mean that they will have any sort of repayments at all. In the event you and the loan company can have the ability to work a little something out, a foreclosure course of action may end. However, in case you continue to neglect payments wih the new program, the property foreclosures process can pick up from where it was left off.
http://indiaph24.store/# world pharmacy india
india online pharmacy indian pharmacy fast delivery indian pharmacy
https://indiaph24.store/# indian pharmacy paypal
https://ciprofloxacin.tech/# buy cipro
Cytotec 200mcg price cytotec pills buy online buy cytotec over the counter
prinivil drug cost: lisinopril 40 mg – zestril 25 mg
http://finasteride.store/# buying cheap propecia without a prescription
buy cipro online canada buy cipro online ciprofloxacin over the counter
buying propecia without prescription: cost generic propecia tablets – propecia tablet
https://ciprofloxacin.tech/# ciprofloxacin 500mg buy online
https://finasteride.store/# buying generic propecia tablets
zestoretic online lisinopril 25 mg price lisinopril 3973
lisinopril 20 mg tablet: lisinopril 20mg online – lisinopril online purchase
http://nolvadex.life/# tamoxifen endometriosis
online pharmacy lisinopril lisinopril 25 mg cost lisinopril 10 mg for sale
tamoxifen lawsuit: nolvadex online – where can i buy nolvadex
https://cytotec.club/# buy cytotec over the counter
whoah this blog is magnificent i love reading your articles. Keep up the good work! You know, lots of people are hunting around for this info, you can help them greatly.
I discovered your weblog website on google and test a number of of your early posts. Proceed to keep up the very good operate. I just further up your RSS feed to my MSN News Reader. Looking for ahead to studying extra from you in a while!?
buy cytotec pills online cheap cytotec pills buy online Misoprostol 200 mg buy online
Thanks for enabling me to get new tips about computers. I also contain the belief that certain of the best ways to help keep your notebook computer in prime condition is by using a hard plastic-type material case, or maybe shell, that matches over the top of your computer. These types of protective gear are generally model unique since they are manufactured to fit perfectly across the natural outer shell. You can buy these directly from the vendor, or via third party places if they are intended for your notebook, however not every laptop could have a cover on the market. All over again, thanks for your ideas.
Nice blog here! Also your website loads up very fast! What web host are you using? Can I get your affiliate link to your host? I wish my web site loaded up as quickly as yours lol
cipro for sale: cipro 500mg best prices – buy cipro online
http://finasteride.store/# order propecia no prescription
https://ciprofloxacin.tech/# buy cipro online
lisinopril generic lisinopril 25 zestril 2.5 mg
Hello there, just became alert to your blog through Google, and found that it is really informative. I am going to watch out for brussels. I will be grateful if you continue this in future. Many people will be benefited from your writing. Cheers!
cipro pharmacy: buy cipro cheap – cipro online no prescription in the usa
http://ciprofloxacin.tech/# ciprofloxacin generic price
I have observed that over the course of creating a relationship with real estate managers, you’ll be able to get them to understand that, in every single real estate contract, a fee is paid. Ultimately, FSBO sellers will not “save” the commission rate. Rather, they struggle to earn the commission by doing a good agent’s work. In this, they expend their money and also time to conduct, as best they will, the responsibilities of an adviser. Those duties include uncovering the home through marketing, offering the home to willing buyers, creating a sense of buyer urgency in order to induce an offer, preparing home inspections, dealing with qualification investigations with the financial institution, supervising fixes, and assisting the closing of the deal.
buy cytotec over the counter п»їcytotec pills online cytotec buy online usa
I?ll right away seize your rss as I can not in finding your e-mail subscription hyperlink or newsletter service. Do you have any? Kindly permit me recognise in order that I may subscribe. Thanks.
One other issue is when you are in a predicament where you don’t have a cosigner then you may genuinely wish to try to make use of all of your financial aid options. You can find many grants and other scholarships and grants that will ensure that you get funding that can help with education expenses. Thank you for the post.
buy lisinopril 40 mg online: lisinopril online – lipinpril
http://finasteride.store/# propecia buy
ciprofloxacin ciprofloxacin generic buy cipro online canada
http://ciprofloxacin.tech/# ciprofloxacin
ciprofloxacin over the counter: buy cipro online canada – purchase cipro
Hey there would you mind stating which blog platform you’re working with? I’m planning to start my own blog in the near future but I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design and style seems different then most blogs and I’m looking for something unique. P.S Sorry for being off-topic but I had to ask!
raloxifene vs tamoxifen where to get nolvadex tamoxifen brand name
https://lisinopril.network/# lisinopril 4 mg
It’s the best time to make some plans for the future and it is time to be happy. I have read this post and if I could I wish to suggest you some interesting things or tips. Perhaps you could write next articles referring to this article. I wish to read even more things about it!
Thanks for your ideas. One thing I’ve noticed is the fact that banks along with financial institutions know the dimensions and spending behavior of consumers plus understand that most of the people max out their real credit cards around the breaks. They properly take advantage of this particular fact and start flooding your current inbox in addition to snail-mail box with hundreds of Zero APR card offers soon after the holiday season finishes. Knowing that if you’re like 98 of all American open public, you’ll rush at the chance to consolidate personal credit card debt and shift balances for 0 interest rate credit cards.
Superb blog! Do you have any tips and hints for aspiring writers? I’m hoping to start my own website soon but I’m a little lost on everything. Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m completely confused .. Any tips? Cheers!
ciprofloxacin over the counter cipro online no prescription in the usa buy cipro online
buy cipro online: buy generic ciprofloxacin – cipro for sale
I would also like to add when you do not already have an insurance policy or you do not take part in any group insurance, you will well reap the benefits of seeking assistance from a health insurance agent. Self-employed or those that have medical conditions ordinarily seek the help of an health insurance brokerage. Thanks for your post.
I was very pleased to search out this net-site.I wished to thanks for your time for this glorious read!! I positively enjoying every little bit of it and I’ve you bookmarked to check out new stuff you blog post.
https://lisinopril.network/# lisinopril buy in canada
https://lisinopril.network/# lisinopril medicine
Have you ever considered about including a little bit more than just your articles? I mean, what you say is valuable and everything. Nevertheless just imagine if you added some great visuals or videos to give your posts more, “pop”! Your content is excellent but with pics and videos, this website could undeniably be one of the most beneficial in its niche. Wonderful blog!
Cytotec 200mcg price buy cytotec pills online cheap purchase cytotec
http://kamagra.win/# Kamagra Oral Jelly
I have read several good stuff here. Certainly worth bookmarking for revisiting. I surprise how much effort you put to make such a excellent informative site.
I have noticed that over the course of constructing a relationship with real estate proprietors, you’ll be able to come to understand that, in each and every real estate purchase, a commission amount is paid. Eventually, FSBO sellers don’t “save” the commission rate. Rather, they struggle to win the commission simply by doing a good agent’s work. In doing so, they devote their money along with time to perform, as best they could, the duties of an broker. Those obligations include disclosing the home via marketing, presenting the home to willing buyers, building a sense of buyer desperation in order to trigger an offer, booking home inspections, taking on qualification investigations with the lender, supervising maintenance, and facilitating the closing of the deal.
Cialis over the counter Buy Tadalafil 10mg Tadalafil Tablet
Levitra online pharmacy: Buy generic Levitra online – Cheap Levitra online
http://levitrav.store/# Buy generic Levitra online
Levitra tablet price Buy generic Levitra online Levitra online pharmacy
Viagra online price: Buy generic 100mg Viagra online – Buy Viagra online cheap
sildenafil oral jelly 100mg kamagra buy kamagra online Kamagra tablets
http://kamagra.win/# buy kamagra online usa
buy Viagra online: cheapest viagra – cheapest viagra
Cheapest Sildenafil online: Cheap Viagra 100mg – buy viagra here
Viagra tablet online viagras.online Sildenafil Citrate Tablets 100mg
https://cenforce.pro/# Purchase Cenforce Online
http://kamagra.win/# cheap kamagra
Generic Cialis without a doctor prescription: buy cialis overseas – Cheap Cialis
cheapest cenforce order cenforce cheapest cenforce
https://cenforce.pro/# Cenforce 150 mg online
https://viagras.online/# Viagra online price
http://pharmmexico.online/# reputable mexican pharmacies online
canadian drugs online online pharmacy canada best canadian online pharmacy
pharmacy with no prescription: buy medications without a prescription – best no prescription online pharmacy
indian pharmacy paypal: pharmacy website india – Online medicine home delivery
http://pharmcanada.shop/# canada pharmacy reviews
Almanya’nın En iyi medyum olarak bir danışman için medyum haluk hocayı seçin en iyi medyum hocalardan bir tanesidir.
medicine in mexico pharmacies buying from online mexican pharmacy purple pharmacy mexico price list
I’ve learned several important things as a result of your post. I would also like to express that there may be situation where you will get a loan and don’t need a co-signer such as a Government Student Support Loan. However, if you are getting credit through a classic financial institution then you need to be ready to have a cosigner ready to make it easier for you. The lenders can base that decision using a few components but the most important will be your credit ratings. There are some loan companies that will likewise look at your job history and choose based on this but in many instances it will be based on on your scores.
canadian pharmacies not requiring prescription: drugstore com online pharmacy prescription drugs – cheapest pharmacy prescription drugs
Thanks for the auspicious writeup. It in fact used to be a enjoyment account it. Glance complicated to more introduced agreeable from you! By the way, how could we communicate?
A powerful share, I just given this onto a colleague who was doing a bit analysis on this. And he the truth is purchased me breakfast because I discovered it for him.. smile. So let me reword that: Thnx for the deal with! But yeah Thnkx for spending the time to debate this, I feel strongly about it and love studying more on this topic. If possible, as you become expertise, would you thoughts updating your weblog with extra particulars? It is highly helpful for me. Massive thumb up for this blog put up!
https://pharmmexico.online/# mexican online pharmacies prescription drugs
mexico pharmacy purple pharmacy mexico price list reputable mexican pharmacies online
I have seen a great deal of useful elements on your website about pc’s. However, I’ve the judgment that lap tops are still less than powerful adequately to be a sensible choice if you usually do projects that require many power, just like video editing. But for net surfing, microsoft word processing, and quite a few other prevalent computer functions they are okay, provided you may not mind the screen size. Appreciate sharing your ideas.
canadian pharmacy no prescription: online pharmacy – pharmacy coupons
With havin so much content do you ever run into any problems of plagorism or copyright violation? My blog has a lot of completely unique content I’ve either created myself or outsourced but it looks like a lot of it is popping it up all over the internet without my agreement. Do you know any methods to help stop content from being stolen? I’d definitely appreciate it.
My partner and I stumbled over here by a different web page and thought I might as well check things out. I like what I see so i am just following you. Look forward to looking into your web page repeatedly.
prescription free canadian pharmacy: online pharmacy – non prescription medicine pharmacy
Almanya’nın En iyi medyum olarak bir danışman için medyum haluk hocayı seçin en iyi medyum hocalardan bir tanesidir.
world pharmacy india: indian pharmacy – india online pharmacy
http://pharmindia.online/# top 10 pharmacies in india
Good day! I know this is kinda off topic however , I’d figured I’d ask. Would you be interested in trading links or maybe guest writing a blog article or vice-versa? My blog goes over a lot of the same topics as yours and I think we could greatly benefit from each other. If you might be interested feel free to send me an email. I look forward to hearing from you! Superb blog by the way!
okmark your weblog and check again here frequently. I’m quite certain I?ll learn plenty of new stuff right here! Good luck for the next!
mexico drug stores pharmacies п»їbest mexican online pharmacies buying prescription drugs in mexico
Online medicine order: best india pharmacy – cheapest online pharmacy india
http://pharmindia.online/# indianpharmacy com
mail order pharmacy india buy medicines online in india indian pharmacies safe
best mexican online pharmacies: medication from mexico pharmacy – buying from online mexican pharmacy
http://pharmindia.online/# india online pharmacy
Music started playing anytime I opened up this web-site, so annoying!
canada mail order prescriptions: canada prescription – overseas online pharmacy-no prescription
77 canadian pharmacy canadianpharmacymeds canadian neighbor pharmacy
I really believe that a foreclosure can have a important effect on the borrower’s life. Property foreclosures can have a Seven to decade negative influence on a client’s credit report. The borrower who may have applied for a home loan or virtually any loans even, knows that a worse credit rating is actually, the more complicated it is to secure a decent personal loan. In addition, it may possibly affect a new borrower’s ability to find a good place to lease or rent, if that turns into the alternative homes solution. Interesting blog post.
mexican pharmaceuticals online: buying from online mexican pharmacy – mexican online pharmacies prescription drugs
Thanks for this wonderful article. One other thing is that most digital cameras come equipped with a zoom lens that permits more or less of that scene to be included by means of ‘zooming’ in and out. These types of changes in {focus|focusing|concentration|target|the a**** length are reflected in the viewfinder and on massive display screen right at the back of the specific camera.
Thanks for this article. I might also like to express that it can often be hard when you are in school and starting out to create a long credit score. There are many individuals who are just trying to pull through and have a good or beneficial credit history can often be a difficult matter to have.
Hey there just wanted to give you a brief heads up and let you know a few of the pictures aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different internet browsers and both show the same outcome.
Hey! Do you use Twitter? I’d like to follow you if that would be ok. I’m absolutely enjoying your blog and look forward to new updates.
Its like you read my mind! You seem to know a lot about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but other than that, this is great blog. A great read. I’ll definitely be back.
http://amoxila.pro/# buy amoxicillin online without prescription
prednisone 5 mg tablet prednisone brand name in usa prednisone online for sale
neurontin 400 mg capsule: neurontin cream – neurontin brand name 800mg best price
neurontin 100mg tab: neurontin 1200 mg – neurontin gel
doxycycline online where to get doxycycline doxycycline generic
I?m not sure where you are getting your info, but good topic. I needs to spend some time learning much more or understanding more. Thanks for wonderful information I was looking for this info for my mission.
http://zithromaxa.store/# zithromax generic cost
I was curious if you ever considered changing the layout of your blog? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or 2 pictures. Maybe you could space it out better?
doxy 200: doxycycline 100mg capsules – doxycycline 50mg
What i do not realize is in reality how you are not really much more well-appreciated than you may be right now. You are very intelligent. You already know thus considerably with regards to this subject, produced me in my view imagine it from a lot of numerous angles. Its like men and women are not involved except it?s something to do with Girl gaga! Your individual stuffs excellent. Always care for it up!
Hi my friend! I want to say that this article is awesome, nice written and come with almost all vital infos. I would like to peer extra posts like this .
I found your weblog web site on google and test just a few of your early posts. Proceed to keep up the excellent operate. I simply extra up your RSS feed to my MSN News Reader. Seeking forward to reading more from you in a while!?
prednisone daily use: prednisone 10mg prices – prednisone no rx
Hi are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you need any html coding expertise to make your own blog? Any help would be really appreciated!
compare prednisone prices: buy prednisone online without a script – prednisone acetate
amoxicillin 1000 mg capsule: amoxicillin order online no prescription – amoxicillin 500mg price in canada
I love your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to do it for you? Plz reply as I’m looking to design my own blog and would like to know where u got this from. kudos
800mg neurontin: brand neurontin 100 mg canada – neurontin 2018
amoxicillin capsules 250mg azithromycin amoxicillin amoxicillin 500mg
http://zithromaxa.store/# can you buy zithromax over the counter in mexico
There are some attention-grabbing deadlines on this article but I don?t know if I see all of them center to heart. There’s some validity but I’ll take hold opinion till I look into it further. Good article , thanks and we wish more! Added to FeedBurner as nicely
purchase zithromax z-pak: zithromax for sale us – can you buy zithromax over the counter in mexico
can you buy zithromax online zithromax 500 mg lowest price drugstore online zithromax for sale 500 mg
http://gabapentinneurontin.pro/# neurontin 300 mg
doxycycline pills: generic doxycycline – doxycycline hyclate 100 mg cap
Thanks for your post. I would love to comment that the very first thing you will need to accomplish is find out if you really need credit repair. To do that you will need to get your hands on a duplicate of your credit report. That should really not be difficult, since the government mandates that you are allowed to get one absolutely free copy of your own credit report per year. You just have to request that from the right people. You can either look at website with the Federal Trade Commission or maybe contact one of the main credit agencies straight.
Superb blog you have here but I was wanting to know if you knew of any user discussion forums that cover the same topics talked about here? I’d really like to be a part of group where I can get responses from other knowledgeable individuals that share the same interest. If you have any suggestions, please let me know. Thank you!
doxycycline without a prescription doxycycline pills vibramycin 100 mg
doxycycline mono: doxycycline hyc – buy doxycycline for dogs
Good blog post. The things i would like to make contributions about is that laptop or computer memory is required to be purchased in case your computer can’t cope with anything you do with it. One can set up two RAM boards containing 1GB each, for example, but not certainly one of 1GB and one having 2GB. One should check the car maker’s documentation for the PC to be certain what type of memory is necessary.
neurontin oral: cost of neurontin 600mg – neurontin 400 mg tablets
http://zithromaxa.store/# zithromax for sale 500 mg
Excellent read, I just passed this onto a colleague who was doing a little research on that. And he actually bought me lunch as I found it for him smile Thus let me rephrase that: Thanks for lunch!
One other thing to point out is that an online business administration training is designed for people to be able to easily proceed to bachelors degree courses. The Ninety credit college degree meets the lower bachelor college degree requirements and when you earn your own associate of arts in BA online, you will have access to the latest technologies within this field. Some reasons why students want to get their associate degree in business is because they are interested in this area and want to receive the general knowledge necessary previous to jumping right bachelor diploma program. Many thanks for the tips you actually provide as part of your blog.
prednisone without prescription medication 3000mg prednisone prednisone 10mg tablets
zithromax online pharmacy canada: zithromax tablets for sale – zithromax for sale online
I’m impressed by the quality of this content! The author has undoubtedly put a tremendous amount of effort into exploring and structuring the information. It’s refreshing to come across an article that not only provides useful information but also keeps the readers hooked from start to finish. Kudos to him for producing such a masterpiece!
http://amoxila.pro/# amoxicillin 500 mg where to buy
I?ll immediately grab your rss as I can not find your e-mail subscription link or newsletter service. Do you’ve any? Please let me know so that I could subscribe. Thanks.
Thanks for your article. I also believe that laptop computers have grown to be more and more popular lately, and now are often the only kind of computer included in a household. This is due to the fact that at the same time potentially they are becoming more and more inexpensive, their processing power is growing to the point where these are as robust as desktop out of just a few years back.
prednisone pill prednisone 30 mg tablet prednisone 5mg coupon
Thanks for the concepts you are sharing on this website. Another thing I’d really like to say is that getting hold of duplicates of your credit file in order to check accuracy of each and every detail will be the first activity you have to carry out in credit score improvement. You are looking to clean your credit report from detrimental details faults that spoil your credit score.
amoxicillin 500mg pill: over the counter amoxicillin – amoxicillin 500mg without prescription
http://zithromaxa.store/# zithromax drug
Thanks for this article. I will also like to express that it can often be hard when you are in school and just starting out to create a long credit history. There are many college students who are simply trying to pull through and have a long or favourable credit history can be a difficult point to have.
generic zithromax over the counter generic zithromax online paypal zithromax 250 price
buy zithromax canada: zithromax buy – average cost of generic zithromax
I have realized that online diploma is getting popular because accomplishing your degree online has developed into popular choice for many people. Numerous people have not really had a chance to attend an established college or university however seek the elevated earning potential and career advancement that a Bachelor Degree offers. Still other individuals might have a college degree in one training but want to pursue another thing they already have an interest in.
Прошлым месяцем я решил заменить входную дверь в квартире. Зашел на сайт https://dvershik.ru, выбрал модель и заказал установку. Мастера приехали точно в срок, компетентно и оперативно смонтировали новую дверь. Очень доволен сервисом и результатом – теперь чувствую себя намного безопаснее!
I realized more something totally new on this fat loss issue. One particular issue is a good nutrition is very vital when dieting. A tremendous reduction in junk food, sugary food items, fried foods, sugary foods, beef, and bright flour products might be necessary. Keeping wastes parasitic organisms, and poisons may prevent objectives for losing fat. While selected drugs for the short term solve the matter, the terrible side effects will not be worth it, and so they never give more than a short-term solution. This is a known proven fact that 95 of dietary fads fail. Many thanks for sharing your notions on this blog site.
http://zithromaxa.store/# zithromax over the counter canada
canada neurontin 100mg lowest price neurontin rx neurontin 100 mg caps
buy doxycycline 100mg: doxycycline without a prescription – generic doxycycline
This post has such a mesmerizing effect, truly wonderful! Visit Website
https://prednisoned.online/# prednisone 5 mg cheapest
neurontin 300mg caps: gabapentin generic – neurontin generic
purchase zithromax z-pak zithromax 250 price generic zithromax 500mg india
buying amoxicillin online: purchase amoxicillin 500 mg – amoxicillin 500 mg
I was curious if you ever thought of changing the structure of your site? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or 2 images. Maybe you could space it out better?
http://doxycyclinea.online/# order doxycycline online
neurontin 300 mg cost: neurontin 300 mg caps – neurontin mexico
Thanks for your post on the vacation industry. I might also like contribute that if you are a senior considering traveling, its absolutely vital that you buy travel insurance for senior citizens. When traveling, older persons are at greatest risk of getting a professional medical emergency. Obtaining right insurance policy package for your age group can look after your health and provide you with peace of mind.
Thanks for the new stuff you have unveiled in your writing. One thing I’d prefer to reply to is that FSBO interactions are built as time passes. By presenting yourself to the owners the first end of the week their FSBO is definitely announced, prior to the masses get started calling on Monday, you develop a good link. By giving them instruments, educational products, free records, and forms, you become a good ally. By using a personal affinity for them as well as their circumstances, you produce a solid relationship that, most of the time, pays off if the owners decide to go with an agent they know as well as trust – preferably you.
I’ve observed that in the world today, video games include the latest phenomenon with kids of all ages. Many times it may be unattainable to drag the kids away from the activities. If you want the very best of both worlds, there are numerous educational activities for kids. Thanks for your post.
Aw, this was a very nice post. In idea I would like to put in writing like this moreover ? taking time and actual effort to make an excellent article? however what can I say? I procrastinate alot and not at all appear to get one thing done.
where can i buy zithromax medicine order zithromax without prescription cost of generic zithromax
A large percentage of of what you assert is supprisingly accurate and it makes me wonder the reason why I had not looked at this in this light before. This piece really did turn the light on for me as far as this specific issue goes. Nonetheless at this time there is 1 position I am not too comfy with so whilst I attempt to reconcile that with the actual main theme of your point, allow me see what the rest of your readers have to point out.Nicely done.
prednisone 5 mg tablet price: prednisone uk price – order prednisone with mastercard debit
I have noticed that credit repair activity needs to be conducted with tactics. If not, it’s possible you’ll find yourself endangering your standing. In order to realize your aspirations in fixing your credit rating you have to always make sure that from this moment in time you pay all of your monthly costs promptly in advance of their booked date. It’s really significant for the reason that by certainly not accomplishing this, all other moves that you will choose to adopt to improve your credit standing will not be useful. Thanks for expressing your tips.
Hi there would you mind stating which blog platform you’re using? I’m going to start my own blog soon but I’m having a hard time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design and style seems different then most blogs and I’m looking for something completely unique. P.S Sorry for getting off-topic but I had to ask!
http://gabapentinneurontin.pro/# neurontin 1800 mg
neurontin brand name in india can i buy neurontin over the counter order neurontin over the counter
amoxicillin pharmacy price: where to buy amoxicillin 500mg without prescription – amoxicillin 500mg
https://doxycyclinea.online/# buy doxycycline online uk
prednisone cost us: prednisone online for sale – prescription prednisone cost
Hi there! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
can i purchase amoxicillin online: price of amoxicillin without insurance – amoxicillin 500 mg online
amoxicillin 500 mg without prescription amoxicillin medicine amoxicillin 500mg capsules
prednisone 50 mg canada: prednisone 20mg tablets where to buy – prednisone 54
Hey there! This is my 1st comment here so I just wanted to give a quick shout out and tell you I truly enjoy reading your blog posts. Can you suggest any other blogs/websites/forums that go over the same topics? Many thanks!
Nice post. I was checking constantly this blog and I am impressed! Very useful info specially the last part 🙂 I care for such info much. I was seeking this particular info for a very long time. Thank you and good luck.
I am curious to find out what blog platform you are using? I’m experiencing some minor security problems with my latest website and I’d like to find something more safe. Do you have any recommendations?
http://amoxila.pro/# over the counter amoxicillin
neurontin cost australia buy neurontin canada can you buy neurontin over the counter
cheap zithromax pills: zithromax 250 mg pill – zithromax 500mg price
http://prednisoned.online/# 54 prednisone
I really like your blog.. very nice colors & theme. Did you design this website yourself or did you hire someone to do it for you? Plz respond as I’m looking to design my own blog and would like to know where u got this from. thanks
generic zithromax medicine: zithromax 500 mg – where can i purchase zithromax online
A formidable share, I just given this onto a colleague who was doing a little bit analysis on this. And he in reality purchased me breakfast as a result of I found it for him.. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the time to debate this, I really feel strongly about it and love reading more on this topic. If potential, as you grow to be expertise, would you mind updating your blog with extra details? It’s highly helpful for me. Big thumb up for this blog put up!
how much is neurontin pills buy generic neurontin neurontin 100mg tab
My partner and I stumbled over here different web page and thought I might check things out. I like what I see so now i am following you. Look forward to looking over your web page repeatedly.
generic zithromax india: zithromax for sale 500 mg – can i buy zithromax online
Wonderful web site. Plenty of useful information here. I am sending it to some buddies ans also sharing in delicious. And certainly, thanks for your effort!
neurontin 2400 mg: buy neurontin canada – 300 mg neurontin
https://prednisoned.online/# prednisone 500 mg tablet
20 mg of prednisone prednisone brand name prednisone 2.5 tablet
I have not checked in here for some time as I thought it was getting boring, but the last several posts are good quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
I have realized some important things through your blog post post. One other subject I would like to convey is that there are many games on the market designed especially for toddler age kids. They contain pattern acceptance, colors, wildlife, and models. These normally focus on familiarization rather than memorization. This will keep little ones occupied without having the experience like they are studying. Thanks
Thanks for helping me to acquire new strategies about pc’s. I also possess the belief that one of the best ways to keep your notebook in perfect condition is with a hard plastic material case, or even shell, that will fit over the top of your computer. Most of these protective gear tend to be model precise since they are made to fit perfectly over the natural covering. You can buy all of them directly from the owner, or via third party sources if they are available for your mobile computer, however not every laptop may have a covering on the market. Just as before, thanks for your tips.
Hi there very nice web site!! Man .. Beautiful .. Wonderful .. I will bookmark your web site and take the feeds also?I am glad to find a lot of helpful info here in the publish, we want develop extra strategies in this regard, thanks for sharing. . . . . .
buying prescription drugs in mexico online: mexico drug stores pharmacies – pharmacies in mexico that ship to usa
mexico drug stores pharmacies mexican online pharmacies prescription drugs buying from online mexican pharmacy
There are definitely numerous details like that to take into consideration. That could be a great level to convey up. I offer the ideas above as general inspiration but clearly there are questions just like the one you carry up where the most important factor shall be working in sincere good faith. I don?t know if best practices have emerged around issues like that, but I’m certain that your job is clearly recognized as a fair game. Both boys and girls feel the impression of only a moment?s pleasure, for the rest of their lives.
mexico drug stores pharmacies: п»їbest mexican online pharmacies – reputable mexican pharmacies online
Thanks for your publication. One other thing is that individual states have their unique laws that will affect home owners, which makes it very difficult for the the legislature to come up with a new set of guidelines concerning home foreclosure on householders. The problem is that each state possesses own regulations which may have impact in a negative manner with regards to foreclosure insurance plans.
https://mexicanpharmacy1st.com/# buying prescription drugs in mexico
mexican drugstore online: best online pharmacies in mexico – mexican rx online
buying prescription drugs in mexico online: pharmacies in mexico that ship to usa – mexican drugstore online
http://mexicanpharmacy1st.com/# mexican border pharmacies shipping to usa
Great article. It is extremely unfortunate that over the last years, the travel industry has already been able to to deal with terrorism, SARS, tsunamis, bird flu virus, swine flu, and the first ever real global downturn. Through it all the industry has really proven to be powerful, resilient and also dynamic, obtaining new methods to deal with difficulty. There are usually fresh troubles and the opportunity to which the industry must yet again adapt and act in response.
buying prescription drugs in mexico online mexican pharmacy buying prescription drugs in mexico online
https://mexicanpharmacy1st.shop/# mexico pharmacy
I’m curious to find out what blog system you’re utilizing? I’m having some small security problems with my latest website and I’d like to find something more safe. Do you have any recommendations?
Hi there, I found your website via Google while searching for a related topic, your site came up, it looks good. I have bookmarked it in my google bookmarks.
This really answered my downside, thanks!
best online pharmacies in mexico mexico pharmacy mexico pharmacies prescription drugs
https://mexicanpharmacy1st.shop/# п»їbest mexican online pharmacies
mexican drugstore online: mexican drugstore online – pharmacies in mexico that ship to usa
п»їbest mexican online pharmacies pharmacies in mexico that ship to usa buying prescription drugs in mexico
http://mexicanpharmacy1st.com/# buying prescription drugs in mexico
http://mexicanpharmacy1st.com/# buying prescription drugs in mexico online
Thanks for the posting. My spouse and i have continually seen that most people are desirous to lose weight when they wish to look slim in addition to looking attractive. Nonetheless, they do not often realize that there are more benefits to losing weight also. Doctors assert that over weight people are afflicted with a variety of illnesses that can be directly attributed to their own excess weight. Thankfully that people who sadly are overweight as well as suffering from various diseases are able to reduce the severity of their particular illnesses by way of losing weight. You possibly can see a progressive but marked improvement in health when even a minor amount of fat loss is obtained.
I just added this blog site to my google reader, excellent stuff. Can not get enough!
It?s in reality a nice and helpful piece of information. I am glad that you shared this useful information with us. Please stay us informed like this. Thanks for sharing.
What I have constantly told folks is that when searching for a good on-line electronics retail outlet, there are a few issues that you have to think about. First and foremost, you should make sure to look for a reputable as well as reliable retail store that has gotten great critiques and rankings from other customers and industry people. This will make sure that you are getting along with a well-known store providing you with good service and aid to their patrons. Thanks for sharing your ideas on this web site.
I know this if off topic but I’m looking into starting my own weblog and was curious what all is needed to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very web savvy so I’m not 100 positive. Any recommendations or advice would be greatly appreciated. Appreciate it
buying from online mexican pharmacy pharmacies in mexico that ship to usa buying from online mexican pharmacy
Hey There. I found your blog using msn. This is a very well written article. I?ll make sure to bookmark it and come back to read more of your useful info. Thanks for the post. I?ll definitely return.
https://mexicanpharmacy1st.online/# mexican drugstore online
Hey there, You’ve done a fantastic job. I will certainly digg it and in my opinion recommend to my friends. I am sure they will be benefited from this web site.
mexican border pharmacies shipping to usa: best online pharmacies in mexico – п»їbest mexican online pharmacies
WONDERFUL Post.thanks for share..more wait .. ?
mexico drug stores pharmacies: mexico pharmacy – reputable mexican pharmacies online
п»їbest mexican online pharmacies purple pharmacy mexico price list buying from online mexican pharmacy
https://mexicanpharmacy1st.online/# mexican pharmaceuticals online
mexican mail order pharmacies: medication from mexico pharmacy – mexico drug stores pharmacies
buying prescription drugs in mexico online: pharmacies in mexico that ship to usa – mexico pharmacies prescription drugs
mexico pharmacy mexican rx online mexican online pharmacies prescription drugs
http://timebalkan.com/atp-cupta-sampiyon-sirbistan/
mexico pharmacies prescription drugs: medication from mexico pharmacy – mexican rx online
http://nocaprap.com/meek-mill-going-bad-feat-drake-official-video-2/
I love your blog.. very nice colors & theme. Did you design this website yourself or did you hire someone to do it for you? Plz reply as I’m looking to design my own blog and would like to know where u got this from. thank you
https://mexicanpharmacy1st.com/# mexican online pharmacies prescription drugs
mexican border pharmacies shipping to usa purple pharmacy mexico price list mexico drug stores pharmacies
http://aeiodisha.com/18961/
Oh my goodness! a tremendous article dude. Thanks However I am experiencing challenge with ur rss . Don?t know why Unable to subscribe to it. Is there anyone getting identical rss problem? Anyone who is aware of kindly respond. Thnkx
http://amyreesanderson.com/blog/hi-ho-silver-away
buying from online mexican pharmacy: mexican drugstore online – best mexican online pharmacies
hey there and thank you for your info ? I?ve definitely picked up something new from right here. I did however expertise some technical issues using this website, as I experienced to reload the web site a lot of times previous to I could get it to load correctly. I had been wondering if your hosting is OK? Not that I’m complaining, but slow loading instances times will often affect your placement in google and can damage your high quality score if advertising and marketing with Adwords. Well I am adding this RSS to my email and could look out for much more of your respective interesting content. Make sure you update this again soon..
I?ve been exploring for a little for any high-quality articles or blog posts in this kind of area . Exploring in Yahoo I at last stumbled upon this web site. Studying this information So i?m happy to exhibit that I’ve an incredibly just right uncanny feeling I found out just what I needed. I most for sure will make certain to do not forget this site and give it a glance regularly.
https://mexicanpharmacy1st.online/# mexican pharmacy
order cytotec online: buy cytotec pills – buy cytotec pills online cheap
Howdy! I know this is kinda off topic however I’d figured I’d ask. Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa? My website discusses a lot of the same subjects as yours and I think we could greatly benefit from each other. If you’re interested feel free to shoot me an e-mail. I look forward to hearing from you! Wonderful blog by the way!
zestril 10 mg tablet: lisinopril 7.5 mg – lisinopril 10 mg price in india
https://propeciaf.online/# cost of generic propecia without rx
lisinopril 5 mg for sale lisinopril medicine medication lisinopril 20 mg
I was curious if you ever considered changing the page layout of your site? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having one or 2 images. Maybe you could space it out better?
http://gabapentin.club/# neurontin tablets 300mg
buy cytotec pills online cheap: Cytotec 200mcg price – buy cytotec in usa
Hey there are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you need any html coding expertise to make your own blog? Any help would be greatly appreciated!
Thanks a bunch for sharing this with all of us you actually know what you’re talking about! Bookmarked. Please also visit my website =). We could have a link exchange agreement between us!
That is very attention-grabbing, You are an excessively skilled blogger. I’ve joined your rss feed and look forward to in search of extra of your great post. Also, I’ve shared your site in my social networks!
neurontin 800 mg pill neurontin generic cost neurontin 100mg price
Terrific paintings! That is the kind of information that are supposed to be shared across the web. Shame on Google for no longer positioning this publish upper! Come on over and discuss with my website . Thank you =)
neurontin brand coupon: neurontin 400 – how much is neurontin pills
I just could not depart your web site before suggesting that I extremely enjoyed the standard info a person provide for your visitors? Is gonna be back often in order to check up on new posts
can you buy clomid now how can i get clomid order cheap clomid
cost of neurontin 600mg: neurontin 100mg price – neurontin 50 mg
Nice weblog here! Additionally your site rather a lot up very fast! What web host are you the usage of? Can I get your affiliate link in your host? I wish my web site loaded up as fast as yours lol
http://lisinopril.club/# prinivil tabs
http://gabapentin.club/# generic neurontin 300 mg
Thanks for revealing your ideas. I might also like to convey that video games have been ever before evolving. Modern tools and enhancements have assisted create genuine and active games. These entertainment video games were not actually sensible when the real concept was first being attempted. Just like other kinds of technological innovation, video games also have had to advance via many ages. This is testimony for the fast continuing development of video games.
Holy cow! I’m in awe of the author’s writing skills and capability to convey intricate concepts in a clear and clear manner. This article is a real treasure that earns all the applause it can get. Thank you so much, author, for providing your expertise and providing us with such a valuable treasure. I’m truly appreciative!
Thanks for your advice on this blog. One thing I would like to say is purchasing electronics items through the Internet is certainly not new. In reality, in the past ten years alone, the market for online electronic devices has grown a great deal. Today, you can find practically almost any electronic system and tools on the Internet, ranging from cameras along with camcorders to computer parts and games consoles.
get propecia online cost of generic propecia price cost cheap propecia without a prescription
Yesterday, while I was at work, my sister stole my iPad and tested to see if it can survive a thirty foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is completely off topic but I had to share it with someone!
I used to be suggested this blog through my cousin. I’m no longer certain whether this put up is written through him as nobody else recognise such targeted about my trouble. You are incredible! Thank you!
cytotec abortion pill: purchase cytotec – buy misoprostol over the counter
Hello There. I found your blog using msn. This is a really well written article. I?ll make sure to bookmark it and come back to read more of your useful information. Thanks for the post. I will certainly return.
cost of lisinopril 5 mg: lisinopril price – lisinopril diuretic
https://clomiphene.shop/# how can i get generic clomid online
neurontin 300 600 mg neurontin 300mg caps neurontin without prescription
My brother suggested I might like this blog. He was totally right. This post actually made my day. You can not imagine just how much time I had spent for this info! Thanks!
I have been surfing online more than three hours today, yet I never found any interesting article like yours. It is pretty worth enough for me. Personally, if all site owners and bloggers made good content as you did, the net will be much more useful than ever before.
http://gabapentin.club/# neurontin 200 mg
Hiya, I am really glad I’ve found this info. Today bloggers publish only about gossips and net and this is actually annoying. A good web site with exciting content, this is what I need. Thanks for keeping this site, I will be visiting it. Do you do newsletters? Can’t find it.
Heya i?m for the first time here. I found this board and I find It truly useful & it helped me out a lot. I hope to give something back and help others like you aided me.
Hi there, just became alert to your blog through Google, and found that it is truly informative. I am going to watch out for brussels. I will appreciate if you continue this in future. Numerous people will be benefited from your writing. Cheers!
how to get cheap clomid for sale can i order generic clomid price can you buy cheap clomid pill
My brother suggested I might like this blog. He was once entirely right. This submit actually made my day. You cann’t believe simply how much time I had spent for this info! Thank you!
Pretty section of content. I just stumbled upon your web site and in accession capital to assert that I acquire in fact enjoyed account your blog posts. Anyway I?ll be subscribing to your augment and even I achievement you access consistently rapidly.
https://clomiphene.shop/# buying generic clomid without insurance
buying cheap propecia without dr prescription: buying cheap propecia online – cost of propecia without insurance
https://propeciaf.online/# cheap propecia price
Pretty great post. I just stumbled upon your weblog and wished to say that I’ve really enjoyed browsing your weblog posts. In any case I will be subscribing in your feed and I hope you write again soon!
buy generic propecia without prescription buy cheap propecia pills cost of propecia tablets
Cytotec 200mcg price: cytotec online – Misoprostol 200 mg buy online
After I originally commented I clicked the -Notify me when new feedback are added- checkbox and now each time a comment is added I get 4 emails with the identical comment. Is there any method you possibly can remove me from that service? Thanks!
cytotec abortion pill buy cytotec pills buy cytotec in usa
order cytotec online: buy cytotec in usa – cytotec buy online usa
Hey are using WordPress for your site platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you require any coding expertise to make your own blog? Any help would be greatly appreciated!
generic propecia without a prescription: cost cheap propecia without dr prescription – order generic propecia
I think other site proprietors should take this site as an model, very clean and wonderful user friendly style and design, let alone the content. You are an expert in this topic!
Today, while I was at work, my sister stole my iPad and tested to see if it can survive a forty foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is completely off topic but I had to share it with someone!
https://lisinopril.club/# zestril price uk
60 mg lisinopril lisinopril 20 mg 12.5 mg 2 prinivil
http://cheapestcanada.com/# the canadian drugstore
https://cheapestcanada.com/# canadian pharmacy online reviews
india pharmacy top online pharmacy india best india pharmacy
my canadian pharmacy reviews: cheapest canada – canadian 24 hour pharmacy
You can certainly see your enthusiasm in the work you write. The world hopes for more passionate writers like you who aren’t afraid to say how they believe. Always go after your heart.
Hey very nice blog!! Man .. Excellent .. Amazing .. I will bookmark your blog and take the feeds also?I’m happy to find so many useful info here in the post, we need work out more strategies in this regard, thanks for sharing. . . . . .
https://cheapestcanada.shop/# canada drugs online
https://36and6health.com/# online pharmacy no prescription
http://cheapestandfast.com/# canada pharmacy online no prescription
My brother suggested I might like this web site. He was totally right. This post truly made my day. You cann’t imagine simply how much time I had spent for this info! Thanks!
world pharmacy india world pharmacy india indian pharmacy online
https://cheapestindia.shop/# top online pharmacy india
Wonderful beat ! I would like to apprentice whilst you amend your website, how can i subscribe for a blog site? The account helped me a appropriate deal. I were a little bit familiar of this your broadcast provided vivid transparent idea
mexico drug stores pharmacies: mexican border pharmacies shipping to usa – medicine in mexico pharmacies
https://36and6health.com/# no prescription needed canadian pharmacy
https://cheapestcanada.shop/# canadian pharmacy 1 internet online drugstore
Thanks for a marvelous posting! I genuinely enjoyed reading it, you might be a great author.I will ensure that I bookmark your blog and may come back from now on. I want to encourage you continue your great writing, have a nice holiday weekend!
https://36and6health.com/# best no prescription pharmacy
Thanks for the points you have contributed here. Something important I would like to express is that pc memory demands generally rise along with other innovations in the engineering. For instance, any time new generations of cpus are made in the market, there’s usually a matching increase in the size demands of all laptop or computer memory along with hard drive space. This is because the application operated by simply these processor chips will inevitably rise in power to leverage the new technologies.
I’m blown away by the quality of this content! The author has undoubtedly put a tremendous amount of effort into investigating and arranging the information. It’s inspiring to come across an article that not only provides valuable information but also keeps the readers hooked from start to finish. Great job to her for making such a remarkable piece!
Excellent weblog right here! Additionally your web site loads up fast! What web host are you the usage of? Can I am getting your associate hyperlink for your host? I want my website loaded up as fast as yours lol
http://cheapestandfast.com/# buying prescription drugs online canada
indian pharmacy paypal india online pharmacy п»їlegitimate online pharmacies india
https://cheapestmexico.shop/# purple pharmacy mexico price list
top online pharmacy india: buy medicines online in india – cheapest online pharmacy india
https://36and6health.com/# promo code for canadian pharmacy meds
pharmacie en ligne pharmacie en ligne france pas cher pharmacie en ligne france livraison belgique
pharmacie en ligne pas cher: Achat mГ©dicament en ligne fiable – pharmacie en ligne sans ordonnance
Farmacia online miglior prezzo: comprare farmaci online all’estero – top farmacia online
https://eumedicamentenligne.com/# pharmacie en ligne france pas cher
pharmacie en ligne france livraison internationale: pharmacie en ligne avec ordonnance – pharmacie en ligne pas cher
farmacia online madrid farmacias online baratas farmacia online 24 horas
farmacias online seguras en españa: farmacia online españa – farmacia online madrid
п»їshop apotheke gutschein: beste online-apotheke ohne rezept – medikament ohne rezept notfall
acquistare farmaci senza ricetta: farmaci senza ricetta elenco – farmacia online
pharmacies en ligne certifiГ©es pharmacie en ligne pas cher pharmacie en ligne france livraison belgique
Pharmacie Internationale en ligne: pharmacie en ligne france livraison belgique – pharmacie en ligne sans ordonnance
medikament ohne rezept notfall: online apotheke deutschland – internet apotheke
http://eufarmaciaonline.com/# farmacias online seguras en espaГ±a
pharmacies en ligne certifiГ©es pharmacie en ligne livraison europe Achat mГ©dicament en ligne fiable
I just added this blog site to my feed reader, great stuff. Cannot get enough!
farmacie online autorizzate elenco: farmacia online – Farmacie online sicure
I loved as much as you’ll receive carried out right here. The sketch is tasteful, your authored subject matter stylish. nonetheless, you command get got an nervousness over that you wish be delivering the following. unwell unquestionably come more formerly again as exactly the same nearly very often inside case you shield this hike.
Along with every little thing which appears to be building within this particular area, a significant percentage of viewpoints tend to be rather exciting. On the other hand, I am sorry, because I can not give credence to your whole idea, all be it exhilarating none the less. It seems to everybody that your comments are not completely justified and in reality you are your self not really entirely convinced of the point. In any event I did enjoy reading through it.
farmacia online senza ricetta: farmacie online autorizzate elenco – farmacie online autorizzate elenco
I simply could not leave your site before suggesting that I extremely loved the usual info a person provide on your visitors? Is gonna be again incessantly to inspect new posts
One thing I’ve noticed is the fact there are plenty of beliefs regarding the lenders intentions when talking about foreclosures. One fable in particular is that often the bank prefers to have your house. The financial institution wants your money, not your property. They want the amount of money they loaned you with interest. Steering clear of the bank will simply draw a new foreclosed conclusion. Thanks for your publication.
Thanks for the helpful write-up. It is also my opinion that mesothelioma cancer has an really long latency interval, which means that the signs of the disease may not emerge until eventually 30 to 50 years after the preliminary exposure to mesothelioma. Pleural mesothelioma, and that is the most common sort and impacts the area round the lungs, may cause shortness of breath, torso pains, and a persistent coughing, which may cause coughing up maintain.
farmacias online baratas: farmacia online madrid – farmacia online 24 horas
ohne rezept apotheke online apotheke online apotheke preisvergleich
An fascinating discussion is value comment. I believe that you need to write more on this matter, it won’t be a taboo subject but generally persons are not enough to speak on such topics. To the next. Cheers
I have been exploring for a little bit for any high quality articles or blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this site. Reading this info So i?m happy to convey that I have a very good uncanny feeling I discovered just what I needed. I most certainly will make sure to don?t forget this website and give it a glance on a constant basis.
farmacia barata: farmacia online barcelona – farmacias online seguras
Pharmacie Internationale en ligne: pharmacie en ligne france fiable – pharmacie en ligne livraison europe
internet apotheke п»їshop apotheke gutschein eu apotheke ohne rezept
medikament ohne rezept notfall: internet apotheke – п»їshop apotheke gutschein
farmacie online autorizzate elenco: farmaci senza ricetta elenco – Farmacia online miglior prezzo
https://eufarmacieonline.com/# Farmacie online sicure
farmacia online madrid: farmacia online madrid – farmacia online barata
top farmacia online comprare farmaci online all’estero Farmacia online piГ№ conveniente
hello!,I like your writing so much! share we communicate more about your article on AOL? I require an expert on this area to solve my problem. Maybe that’s you! Looking forward to see you.
Farmacia online più conveniente: Farmacie online sicure – Farmacia online più conveniente
farmacias online seguras: farmacias online seguras – farmacias online seguras en espaГ±a
Very nice post. I just stumbled upon your blog and wished to say that I have really enjoyed browsing your blog posts. In any case I?ll be subscribing to your rss feed and I hope you write again soon!
pharmacie en ligne livraison europe pharmacie en ligne france livraison internationale pharmacies en ligne certifiГ©es
Hiya, I’m really glad I’ve found this information. Today bloggers publish only about gossips and web and this is really frustrating. A good web site with exciting content, that is what I need. Thanks for keeping this web-site, I will be visiting it. Do you do newsletters? Cant find it.
farmacia online envÃo gratis: farmacias online seguras – farmacia en casa online descuento
pharmacie en ligne livraison europe: trouver un mГ©dicament en pharmacie – Pharmacie en ligne livraison Europe
acheter mГ©dicament en ligne sans ordonnance: Achat mГ©dicament en ligne fiable – pharmacies en ligne certifiГ©es
online apotheke preisvergleich online apotheke preisvergleich apotheke online
https://eumedicamentenligne.shop/# п»їpharmacie en ligne france
comprare farmaci online con ricetta: Farmacie online sicure – Farmacie online sicure
pharmacie en ligne france pas cher: pharmacie en ligne france livraison belgique – vente de mГ©dicament en ligne
Appreciating the persistence you put into your blog and in depth information you provide. It’s good to come across a blog every once in a while that isn’t the same old rehashed material. Excellent read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
I have noticed that credit improvement activity should be conducted with techniques. If not, you are going to find yourself destroying your rating. In order to reach your goals in fixing your credit history you have to confirm that from this second you pay your entire monthly dues promptly in advance of their slated date. It really is significant because by not necessarily accomplishing so, all other activities that you will take to improve your credit ranking will not be helpful. Thanks for giving your tips.
Farmacia online piГ№ conveniente: migliori farmacie online 2024 – acquisto farmaci con ricetta
ohne rezept apotheke medikamente rezeptfrei online apotheke rezept
pharmacies en ligne certifi̩es: pharmacie en ligne france fiable Рtrouver un m̩dicament en pharmacie
Thx for your post. I want to say that the tariff of car insurance differs from one coverage to another, since there are so many different facets which contribute to the overall cost. For example, the make and model of the car or truck will have a huge bearing on the purchase price. A reliable outdated family auto will have a more economical premium compared to a flashy expensive car.
What an insightful and thoroughly-researched article! The author’s attention to detail and ability to present complex ideas in a comprehensible manner is truly commendable. I’m thoroughly impressed by the breadth of knowledge showcased in this piece. Thank you, author, for offering your expertise with us. This article has been a real game-changer!
Prix du Viagra 100mg en France: Meilleur Viagra sans ordonnance 24h – Viagra vente libre pays
pharmacie en ligne france livraison internationale: Levitra 20mg prix en pharmacie – pharmacie en ligne sans ordonnance
trouver un mГ©dicament en pharmacie cialis sans ordonnance pharmacie en ligne pas cher
Achat mГ©dicament en ligne fiable: cialis generique – Pharmacie Internationale en ligne
п»їpharmacie en ligne france: pharmacie en ligne pas cher – п»їpharmacie en ligne france
trouver un mГ©dicament en pharmacie: kamagra pas cher – pharmacie en ligne france pas cher
Pretty section of content. I just stumbled upon your blog and in accession capital to assert that I acquire actually enjoyed account your blog posts. Any way I will be subscribing to your feeds and even I achievement you access consistently fast.
pharmacie en ligne france pas cher: Levitra sans ordonnance 24h – pharmacie en ligne france pas cher
https://levitraenligne.com/# Pharmacie Internationale en ligne
Achat mГ©dicament en ligne fiable: Acheter Cialis 20 mg pas cher – pharmacies en ligne certifiГ©es
I can’t express how much I value the effort the author has put into producing this exceptional piece of content. The clarity of the writing, the depth of analysis, and the plethora of information provided are simply astonishing. His zeal for the subject is obvious, and it has definitely struck a chord with me. Thank you, author, for offering your wisdom and enriching our lives with this exceptional article!
Achat mГ©dicament en ligne fiable: levitra en ligne – pharmacie en ligne fiable
Hello!
This post was created with XRumer 23 StrongAI.
Good luck 🙂
Prix du Viagra en pharmacie en France: Acheter du Viagra sans ordonnance – Viagra sans ordonnance 24h suisse
Hey there, I think your website might be having browser compatibility issues. When I look at your website in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, awesome blog!
Furthermore, i believe that mesothelioma cancer is a uncommon form of many forms of cancer that is normally found in these previously familiar with asbestos. Cancerous cellular material form while in the mesothelium, which is a defensive lining that covers many of the body’s internal organs. These cells generally form within the lining on the lungs, mid-section, or the sac that really encircles the heart. Thanks for expressing your ideas.
Achat mГ©dicament en ligne fiable: Levitra acheter – vente de mГ©dicament en ligne
Achat mГ©dicament en ligne fiable: Acheter Cialis 20 mg pas cher – п»їpharmacie en ligne france
Hello.
This post was created with XRumer 23 StrongAI.
Good luck 🙂
Achat mГ©dicament en ligne fiable: kamagra livraison 24h – pharmacie en ligne france livraison belgique
Thanks for your article on the travel industry. I will also like to add that if your senior thinking of traveling, it can be absolutely imperative that you buy traveling insurance for older persons. When traveling, seniors are at high risk of experiencing a health emergency. Having the right insurance policies package in your age group can look after your health and provide you with peace of mind.
pharmacie en ligne france livraison belgique: kamagra en ligne – pharmacies en ligne certifiГ©es
Viagra gГ©nГ©rique sans ordonnance en pharmacie: Acheter du Viagra sans ordonnance – Viagra sans ordonnance livraison 48h
I enjoy what you guys tend to be up too. This sort of clever work and reporting! Keep up the excellent works guys I’ve incorporated you guys to my personal blogroll.
pharmacie en ligne france pas cher: kamagra oral jelly – pharmacie en ligne avec ordonnance
pharmacie en ligne pas cher: kamagra pas cher – trouver un mГ©dicament en pharmacie
I appreciate your wordpress design, wherever would you down load it from?
Youre so cool! I dont suppose Ive read something like this before. So nice to seek out any individual with some unique thoughts on this subject. realy thank you for starting this up. this website is something that’s needed on the internet, someone with a bit originality. helpful job for bringing something new to the internet!
Excellent post. I was checking constantly this weblog and I’m impressed! Very useful info particularly the ultimate section 🙂 I maintain such info a lot. I was seeking this particular info for a long time. Thanks and good luck.
http://kamagraenligne.com/# pharmacie en ligne france livraison belgique
pharmacie en ligne avec ordonnance: pharmacie en ligne sans ordonnance – Pharmacie en ligne livraison Europe
acheter mГ©dicament en ligne sans ordonnance: Levitra pharmacie en ligne – pharmacie en ligne fiable
trouver un mГ©dicament en pharmacie: Pharmacies en ligne certifiees – pharmacie en ligne france pas cher
Pharmacie Internationale en ligne: pharmacie en ligne – pharmacie en ligne fiable
Pharmacie sans ordonnance: Levitra acheter – acheter mГ©dicament en ligne sans ordonnance
CBD exceeded my expectations in every way thanks. I’ve struggled with insomnia on years, and after trying CBD like for the from the word go time, I for ever experienced a busty evening of relaxing sleep. It was like a bias had been lifted off my shoulders. The calming effects were gentle after all intellectual, allowing me to drift slow naturally without feeling punchy the next morning. I also noticed a reduction in my daytime anxiety, which was an unexpected but acceptable bonus. The partiality was a fraction earthy, but nothing intolerable. Overall, CBD has been a game-changer quest of my slumber and uneasiness issues, and I’m grateful to have discovered its benefits.
pharmacie en ligne livraison europe: kamagra pas cher – pharmacie en ligne france livraison internationale
Pharmacie en ligne livraison Europe: levitra generique – pharmacie en ligne pas cher
vente de mГ©dicament en ligne: vente de mГ©dicament en ligne – pharmacie en ligne fiable
Viagra vente libre pays: Viagra generique en pharmacie – Quand une femme prend du Viagra homme
F*ckin? tremendous issues here. I?m very satisfied to peer your article. Thank you a lot and i’m having a look forward to touch you. Will you kindly drop me a mail?
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You definitely know what youre talking about, why throw away your intelligence on just posting videos to your weblog when you could be giving us something enlightening to read?
Achat mГ©dicament en ligne fiable: Medicaments en ligne livres en 24h – п»їpharmacie en ligne france
SildГ©nafil 100 mg prix en pharmacie en France: Acheter du Viagra sans ordonnance – Viagra gГ©nГ©rique sans ordonnance en pharmacie
pharmacie en ligne france fiable: kamagra gel – pharmacie en ligne pas cher
Aw, this was a very nice post. In idea I want to put in writing like this moreover ? taking time and actual effort to make an excellent article? but what can I say? I procrastinate alot and certainly not appear to get one thing done.
pharmacie en ligne livraison europe: pharmacie en ligne sans ordonnance – pharmacies en ligne certifiГ©es
I’m amazed by the quality of this content! The author has undoubtedly put a tremendous amount of effort into exploring and arranging the information. It’s refreshing to come across an article that not only offers helpful information but also keeps the readers captivated from start to finish. Great job to her for making such a remarkable piece!
You really make it seem so easy with your presentation but I in finding this matter to be actually one thing that I believe I’d by no means understand. It kind of feels too complicated and extremely vast for me. I am looking forward to your subsequent publish, I?ll attempt to get the cling of it!
Sildenafil teva 100 mg sans ordonnance: viagra sans ordonnance – Viagra 100mg prix
Hi, Neat post. There is an issue together with your web site in internet explorer, would test this? IE nonetheless is the marketplace chief and a large portion of other folks will miss your fantastic writing due to this problem.
Thank you a bunch for sharing this with all folks you actually realize what you are speaking about! Bookmarked. Please additionally consult with my site =). We could have a hyperlink change contract among us!
pharmacies en ligne certifiГ©es: kamagra oral jelly – pharmacie en ligne fiable
Achat mГ©dicament en ligne fiable: Levitra 20mg prix en pharmacie – pharmacie en ligne avec ordonnance
п»їpharmacie en ligne france: kamagra gel – pharmacie en ligne
Viagra 100 mg sans ordonnance: viagra sans ordonnance – Viagra homme sans ordonnance belgique
trouver un mГ©dicament en pharmacie: cialis generique – pharmacie en ligne
Achat mГ©dicament en ligne fiable: Acheter Cialis – п»їpharmacie en ligne france
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You clearly know what youre talking about, why throw away your intelligence on just posting videos to your site when you could be giving us something informative to read?
acheter mГ©dicament en ligne sans ordonnance: pharmacie en ligne – pharmacie en ligne avec ordonnance
Hello, Neat post. There is an issue along with your website in internet explorer, may check this? IE nonetheless is the marketplace chief and a huge component of other folks will pass over your wonderful writing due to this problem.
pharmacie en ligne livraison europe: Levitra pharmacie en ligne – vente de mГ©dicament en ligne
Terrific paintings! That is the type of information that are supposed to be shared across the internet. Shame on Google for now not positioning this submit upper! Come on over and talk over with my site . Thank you =)
Hi there just wanted to give you a quick heads up. The words in your content seem to be running off the screen in Opera. I’m not sure if this is a formatting issue or something to do with internet browser compatibility but I figured I’d post to let you know. The style and design look great though! Hope you get the issue solved soon. Many thanks
trouver un mГ©dicament en pharmacie: kamagra pas cher – pharmacie en ligne sans ordonnance
pharmacie en ligne france pas cher: cialis sans ordonnance – pharmacie en ligne france livraison belgique
pharmacie en ligne pas cher: levitra en ligne – trouver un mГ©dicament en pharmacie
pharmacie en ligne: levitra generique – pharmacie en ligne
trouver un mГ©dicament en pharmacie: pharmacie en ligne france livraison internationale – pharmacie en ligne france pas cher
Viagra femme sans ordonnance 24h: viagra en ligne – Viagra 100mg prix
pharmacies en ligne certifiГ©es: kamagra en ligne – pharmacie en ligne france pas cher
pharmacie en ligne: pharmacie en ligne pas cher – Pharmacie en ligne livraison Europe
pharmacie en ligne france pas cher: Levitra acheter – acheter mГ©dicament en ligne sans ordonnance
pharmacie en ligne: kamagra livraison 24h – pharmacies en ligne certifiГ©es
pharmacie en ligne france pas cher: Pharmacies en ligne certifiees – pharmacie en ligne sans ordonnance
acheter mГ©dicament en ligne sans ordonnance: Medicaments en ligne livres en 24h – vente de mГ©dicament en ligne
pharmacie en ligne france fiable: Levitra pharmacie en ligne – pharmacies en ligne certifiГ©es
whoah this blog is excellent i love reading your articles. Keep up the great work! You know, a lot of people are looking around for this information, you could aid them greatly.
pharmacie en ligne france livraison belgique: kamagra oral jelly – Achat mГ©dicament en ligne fiable
hello there and thank you on your info ? I have definitely picked up anything new from right here. I did alternatively experience a few technical points the usage of this website, since I experienced to reload the web site many instances previous to I may just get it to load correctly. I have been thinking about in case your hosting is OK? Not that I am complaining, however slow loading cases occasions will sometimes affect your placement in google and can injury your high quality ranking if advertising and ***********|advertising|advertising|advertising and *********** with Adwords. Well I?m including this RSS to my e-mail and could look out for much extra of your respective intriguing content. Ensure that you update this once more very soon..
Admiring the commitment you put into your blog and in depth information you provide. It’s great to come across a blog every once in a while that isn’t the same out of date rehashed material. Excellent read! I’ve saved your site and I’m including your RSS feeds to my Google account.
hi!,I like your writing so much! share we communicate more about your post on AOL? I need an expert on this area to solve my problem. Maybe that’s you! Looking forward to see you.
Thanks for the good writeup. It in truth was once a leisure account it. Look complicated to more added agreeable from you! By the way, how can we keep in touch?
We would also like to state that most of those who find themselves devoid of health insurance are generally students, self-employed and those that are laid-off. More than half of the uninsured are really under the age of 35. They do not think they are in need of health insurance since they’re young as well as healthy. Its income is normally spent on homes, food, along with entertainment. A lot of people that do work either full or in their free time are not offered insurance by way of their jobs so they go without due to rising cost of health insurance in the states. Thanks for the ideas you write about through this website.
you’ve gotten a great blog right here! would you like to make some invite posts on my blog?
It?s actually a nice and useful piece of information. I am happy that you just shared this helpful information with us. Please stay us informed like this. Thanks for sharing.
I?d have to verify with you here. Which isn’t one thing I normally do! I get pleasure from reading a post that can make individuals think. Additionally, thanks for allowing me to comment!
Thanks for your write-up. One other thing is that if you are selling your property yourself, one of the difficulties you need to be aware about upfront is how to deal with house inspection reviews. As a FSBO seller, the key to successfully moving your property and saving money in real estate agent commission rates is knowledge. The more you already know, the better your home sales effort is going to be. One area when this is particularly important is information about home inspections.
you’re really a good webmaster. The site loading speed is amazing. It seems that you are doing any unique trick. In addition, The contents are masterpiece. you’ve done a great job on this topic!
I loved as much as you will receive carried out right here. The sketch is attractive, your authored material stylish. nonetheless, you command get bought an nervousness over that you wish be delivering the following. unwell unquestionably come more formerly again as exactly the same nearly very often inside case you shield this increase.
With havin so much written content do you ever run into any issues of plagorism or copyright infringement? My website has a lot of unique content I’ve either created myself or outsourced but it seems a lot of it is popping it up all over the internet without my agreement. Do you know any solutions to help stop content from being stolen? I’d certainly appreciate it.
Youre so cool! I dont suppose Ive read something like this before. So good to find any individual with some unique ideas on this subject. realy thanks for beginning this up. this web site is something that’s needed on the net, someone with a bit originality. helpful job for bringing something new to the web!
Thanks a lot for sharing this with all of us you really know what you are talking about! Bookmarked. Please also visit my website =). We could have a link exchange agreement between us!
My developer is trying to convince me to move to .net from PHP. I have always disliked the idea because of the expenses. But he’s tryiong none the less. I’ve been using Movable-type on a number of websites for about a year and am nervous about switching to another platform. I have heard very good things about blogengine.net. Is there a way I can transfer all my wordpress posts into it? Any help would be really appreciated!
I have realized that over the course of constructing a relationship with real estate entrepreneurs, you’ll be able to get them to understand that, in every real estate contract, a commission rate is paid. Finally, FSBO sellers never “save” the percentage. Rather, they fight to earn the commission by simply doing a agent’s job. In accomplishing this, they devote their money and time to conduct, as best they might, the tasks of an agent. Those obligations include disclosing the home by way of marketing, introducing the home to willing buyers, developing a sense of buyer desperation in order to prompt an offer, arranging home inspections, dealing with qualification check ups with the bank, supervising repairs, and aiding the closing.
I have figured out some points through your site post. One other subject I would like to express is that there are several games available on the market designed particularly for toddler age youngsters. They involve pattern acknowledgement, colors, dogs, and patterns. These commonly focus on familiarization rather than memorization. This keeps little kids occupied without having the experience like they are learning. Thanks
I will right away grab your rss as I can not find your email subscription hyperlink or e-newsletter service. Do you have any? Please permit me recognise in order that I may subscribe. Thanks.
Excellent website you have here but I was curious if you knew of any user discussion forums that cover the same topics discussed here? I’d really love to be a part of community where I can get comments from other experienced individuals that share the same interest. If you have any suggestions, please let me know. Thanks a lot!
Top Stage Hypnotist for hire Kristian von Sponneck performs private stage hypnosis shows anywhere in the UK, Europe or worldwide. Hire hime for your next event!
Top Stage Hypnotist for hire Kristian von Sponneck performs private stage hypnosis shows anywhere in the UK, Europe or worldwide. Hire hime for your next event!
Top Stage Hypnotist for hire Kristian von Sponneck performs private stage hypnosis shows anywhere in the UK, Europe or worldwide. Hire hime for your next event!
Top Stage Hypnotist for hire Kristian von Sponneck performs private stage hypnosis shows anywhere in the UK, Europe or worldwide. Hire hime for your next event!
I do trust all of the concepts you’ve offered in your post. They are very convincing and will definitely work. Nonetheless, the posts are very short for newbies. Could you please extend them a bit from subsequent time? Thanks for the post.
I’ve learned new things from the blog post. One other thing I have seen is that usually, FSBO sellers can reject anyone. Remember, they can prefer not to use your providers. But if you maintain a gentle, professional connection, offering aid and staying in contact for four to five weeks, you will usually manage to win a business interview. From there, a house listing follows. Thank you
One more important area is that if you are an elderly person, travel insurance regarding pensioners is something you should really take into account. The more mature you are, greater at risk you are for allowing something awful happen to you while overseas. If you are certainly not covered by quite a few comprehensive insurance plan, you could have a few serious troubles. Thanks for giving your ideas on this weblog.
fantastic post, very informative. I wonder why the other specialists of this sector don’t notice this. You should continue your writing. I am confident, you have a huge readers’ base already!
Hi there! This is my first visit to your blog! We are a group of volunteers and starting a new project in a community in the same niche. Your blog provided us valuable information to work on. You have done a marvellous job!
Some tips i have seen in terms of laptop or computer memory is that often there are specifications such as SDRAM, DDR etc, that must match the specs of the motherboard. If the personal computer’s motherboard is very current while there are no operating-system issues, changing the ram literally normally requires under sixty minutes. It’s among the easiest personal computer upgrade methods one can envision. Thanks for expressing your ideas.
It’s a pity you don’t have a donate button! I’d without a doubt donate to this outstanding blog! I guess for now i’ll settle for book-marking and adding your RSS feed to my Google account. I look forward to brand new updates and will share this blog with my Facebook group. Chat soon!
What?s Happening i’m new to this, I stumbled upon this I’ve found It positively useful and it has helped me out loads. I hope to contribute & help other users like its helped me. Great job.
Hello there! Quick question that’s totally off topic. Do you know how to make your site mobile friendly? My web site looks weird when browsing from my iphone. I’m trying to find a theme or plugin that might be able to resolve this problem. If you have any suggestions, please share. Cheers!
Hello! I know this is somewhat off topic but I was wondering which blog platform are you using for this website? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at alternatives for another platform. I would be awesome if you could point me in the direction of a good platform.
This site is mostly a stroll-via for all of the info you wanted about this and didn?t know who to ask. Glimpse here, and also you?ll undoubtedly uncover it.
I’m so happy to read this. This is the type of manual that needs to be given and not the random misinformation that is at the other blogs. Appreciate your sharing this greatest doc.
Spot on with this write-up, I actually think this website needs far more consideration. I?ll in all probability be again to learn much more, thanks for that info.
I can’t believe how amazing this article is! The author has done a phenomenal job of presenting the information in an engaging and enlightening manner. I can’t thank him enough for sharing such valuable insights that have certainly enlightened my knowledge in this subject area. Bravo to her for producing such a work of art!
https://autolux-azerbaijan.com/# Pin Up
pin-up kazino: Pin Up Kazino ?Onlayn – Pin up 306 casino
https://autolux-azerbaijan.com/# Pin Up Kazino ?Onlayn
Pin-Up Casino: Pin Up Azerbaycan ?Onlayn Kazino – Pin Up Kazino ?Onlayn
pin-up360: Pin up 306 casino – Pin-Up Casino
https://autolux-azerbaijan.com/# Pin Up
Pin-Up Casino: Pin-Up Casino – pin-up 141 casino
https://autolux-azerbaijan.com/# Pin-up Giris
pin-up 141 casino: Pin Up Azerbaycan – ?Onlayn Kazino
I have learned several important things via your post. I’d also like to express that there will be a situation that you will have a loan and do not need a cosigner such as a U.S. Student Support Loan. However, if you are getting that loan through a classic banker then you need to be able to have a co-signer ready to help you. The lenders can base their decision using a few factors but the most important will be your credit history. There are some loan providers that will also look at your job history and come to a decision based on this but in almost all cases it will depend on your scores.
https://www.afdservex.es/la-asociacion-2/junta-directiva/
https://autolux-azerbaijan.com/# Pin Up Azerbaycan
Pin-Up Casino: Pin Up Azerbaycan – Pin-up Giris
Hello there! Would you mind if I share your blog with my twitter group? There’s a lot of folks that I think would really appreciate your content. Please let me know. Many thanks
I like what you guys are up also. Such smart work and reporting! Keep up the superb works guys I?ve incorporated you guys to my blogroll. I think it will improve the value of my web site 🙂
http://tygri.eu/divky-u15-prezity-vikend/
Woah! I’m really loving the template/theme of this website. It’s simple, yet effective. A lot of times it’s very difficult to get that “perfect balance” between usability and appearance. I must say you have done a awesome job with this. In addition, the blog loads super fast for me on Opera. Superb Blog!
I?m not sure where you’re getting your information, but great topic. I needs to spend some time learning much more or understanding more. Thanks for magnificent information I was looking for this info for my mission.
I loved as much as you will receive carried out right here. The sketch is tasteful, your authored material stylish. nonetheless, you command get got an shakiness over that you wish be delivering the following. unwell unquestionably come further formerly again as exactly the same nearly a lot often inside case you shield this increase.
Fantastic items from you, man. I’ve consider your stuff previous to and you’re just extremely excellent. I really like what you’ve bought here, certainly like what you’re stating and the best way through which you say it. You’re making it enjoyable and you continue to take care of to keep it sensible. I cant wait to read far more from you. That is really a wonderful site.
Thanks a bunch for sharing this with all of us you really know what you are talking about! Bookmarked. Please also visit my site =). We could have a link exchange contract between us!
One other issue is when you are in a circumstances where you don’t have a co-signer then you may really want to try to make use of all of your school funding options. You can get many grants and other scholarships or grants that will provide you with finances that can help with classes expenses. Thanks for the post.
obviously like your web site but you have to check the spelling on quite a few of your posts. Many of them are rife with spelling problems and I find it very troublesome to tell the truth nevertheless I will certainly come back again.
Spot on with this write-up, I really think this website wants way more consideration. I?ll in all probability be again to learn way more, thanks for that info.
I enjoy, lead to I found just what I used to be taking a look for. You’ve ended my 4 day lengthy hunt! God Bless you man. Have a nice day. Bye
Howdy! This is my 1st comment here so I just wanted to give a quick shout out and say I genuinely enjoy reading your posts. Can you suggest any other blogs/websites/forums that cover the same subjects? Thank you so much!
Thanks for the sensible critique. Me & my neighbor were just preparing to do a little research about this. We got a grab a book from our local library but I think I learned more clear from this post. I’m very glad to see such excellent information being shared freely out there.
Thanks for your publiction. Another item is that being a photographer involves not only problem in capturing award-winning photographs and also hardships in establishing the best digital camera suited to your requirements and most especially struggles in maintaining the caliber of your camera. This can be very real and visible for those professional photographers that are straight into capturing this nature’s engaging scenes – the mountains, the actual forests, the particular wild or the seas. Visiting these exciting places surely requires a video camera that can surpass the wild’s hard landscapes.
This website online is mostly a stroll-through for all the info you wanted about this and didn?t know who to ask. Glimpse right here, and you?ll undoubtedly discover it.
Your place is valueble for me. Thanks!?
Good day! This post could not be written any better! Reading through this post reminds me of my good old room mate! He always kept talking about this. I will forward this write-up to him. Pretty sure he will have a good read. Thanks for sharing!
I haven?t checked in here for some time as I thought it was getting boring, but the last few posts are great quality so I guess I?ll add you back to my daily bloglist. You deserve it my friend 🙂
I realized more interesting things on this losing weight issue. Just one issue is a good nutrition is vital while dieting. A big reduction in bad foods, sugary ingredients, fried foods, sweet foods, red meat, and white colored flour products could be necessary. Possessing wastes harmful bacteria, and toxic compounds may prevent goals for shedding fat. While particular drugs temporarily solve the problem, the unpleasant side effects usually are not worth it, and so they never give more than a short lived solution. It’s a known indisputable fact that 95 of dietary fads fail. Thank you for sharing your ideas on this site.
I really appreciate this post. I?ve been looking everywhere for this! Thank goodness I found it on Bing. You’ve made my day! Thanks again
Hi, i think that i saw you visited my web site so i came to ?return the prefer?.I am attempting to to find issues to enhance my website!I assume its adequate to use a few of your ideas!!
Wow that was unusual. I just wrote an very long comment but after I clicked submit my comment didn’t appear. Grrrr… well I’m not writing all that over again. Regardless, just wanted to say great blog!
I can’t express how much I appreciate the effort the author has put into creating this exceptional piece of content. The clarity of the writing, the depth of analysis, and the plethora of information offered are simply impressive. Her enthusiasm for the subject is apparent, and it has certainly resonated with me. Thank you, author, for sharing your knowledge and enriching our lives with this extraordinary article!
Some tips i have generally told persons is that when you are evaluating a good internet electronics retail store, there are a few components that you have to consider. First and foremost, you would like to make sure to choose a reputable along with reliable retail store that has picked up great testimonials and rankings from other consumers and market sector professionals. This will make sure that you are getting along with a well-known store that provides good service and help to it’s patrons. Thank you for sharing your opinions on this blog.
One thing I’d like to say is that before getting more personal computer memory, look into the machine within which it is installed. If the machine is running Windows XP, for instance, a memory threshold is 3.25GB. Installing in excess of this would purely constitute some sort of waste. Make sure that one’s motherboard can handle this upgrade amount, as well. Interesting blog post.
I additionally believe that mesothelioma is a uncommon form of cancer that is commonly found in individuals previously subjected to asbestos. Cancerous tissues form inside the mesothelium, which is a protective lining which covers a lot of the body’s areas. These cells commonly form inside the lining with the lungs, mid-section, or the sac that really encircles one’s heart. Thanks for expressing your ideas.
There are certainly plenty of particulars like that to take into consideration. That may be a great point to convey up. I supply the thoughts above as basic inspiration but clearly there are questions like the one you deliver up where crucial factor can be working in honest good faith. I don?t know if best practices have emerged round issues like that, but I am sure that your job is clearly recognized as a fair game. Both boys and girls feel the impact of only a moment?s pleasure, for the rest of their lives.
I?ll immediately clutch your rss as I can’t to find your e-mail subscription hyperlink or newsletter service. Do you have any? Kindly let me recognise so that I could subscribe. Thanks.
Thanks for the new stuff you have disclosed in your short article. One thing I’d really like to comment on is that FSBO interactions are built over time. By introducing yourself to the owners the first saturday their FSBO is usually announced, ahead of the masses start off calling on Wednesday, you generate a good relationship. By mailing them equipment, educational resources, free reports, and forms, you become an ally. Through a personal curiosity about them and also their problem, you create a solid connection that, on many occasions, pays off once the owners opt with a real estate agent they know along with trust – preferably you actually.
I do trust all of the ideas you’ve presented for your post. They’re really convincing and can definitely work. Nonetheless, the posts are very quick for beginners. May just you please extend them a bit from next time? Thanks for the post.
One thing I have actually noticed is that often there are plenty of myths regarding the banking institutions intentions while talking about home foreclosure. One delusion in particular is the bank wishes to have your house. The lender wants your cash, not the home. They want the money they loaned you along with interest. Preventing the bank is only going to draw a foreclosed final result. Thanks for your publication.
hi!,I like your writing so much! share we communicate more about your article on AOL? I require a specialist on this area to solve my problem. Maybe that’s you! Looking forward to see you.
Thanks a lot for the helpful post. It is also my opinion that mesothelioma has an incredibly long latency interval, which means that warning signs of the disease might not exactly emerge until finally 30 to 50 years after the original exposure to asbestos fiber. Pleural mesothelioma, that is the most common type and has an effect on the area around the lungs, might result in shortness of breath, chest pains, plus a persistent cough, which may cause coughing up maintain.
Hey very cool website!! Man .. Excellent .. Amazing .. I will bookmark your blog and take the feeds also?I am happy to find a lot of useful information here in the post, we need work out more strategies in this regard, thanks for sharing. . . . . .
As I web-site possessor I believe the content material here is rattling great , appreciate it for your hard work. You should keep it up forever! Best of luck.
My partner and I stumbled over here coming from a different website and thought I should check things out. I like what I see so now i am following you. Look forward to exploring your web page yet again.
Another thing I have noticed is that often for many people, less-than-perfect credit is the response to circumstances outside of their control. For example they may are already saddled with illness so that they have large bills for collections. It might be due to a work loss and the inability to work. Sometimes divorce or separation can truly send the budget in an opposite direction. Many thanks sharing your ideas on this weblog.
Appreciating the dedication you put into your blog and detailed information you present. It’s nice to come across a blog every once in a while that isn’t the same old rehashed material. Excellent read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
Hi! Someone in my Myspace group shared this site with us so I came to check it out. I’m definitely enjoying the information. I’m book-marking and will be tweeting this to my followers! Wonderful blog and fantastic design and style.
Excellent goods from you, man. I have keep in mind your stuff previous to and you are simply extremely wonderful. I actually like what you have bought here, certainly like what you are stating and the best way by which you are saying it. You’re making it enjoyable and you continue to take care of to stay it smart. I cant wait to learn far more from you. This is actually a wonderful website.
I?ve read a few good stuff here. Certainly worth bookmarking for revisiting. I wonder how much effort you put to make such a wonderful informative web site.
We stumbled over here coming from a different web page and thought I may as well check things out. I like what I see so now i’m following you. Look forward to exploring your web page again.
Howdy! Someone in my Facebook group shared this website with us so I came to take a look. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers! Outstanding blog and outstanding design and style.
I am very happy to read this. This is the kind of manual that needs to be given and not the accidental misinformation that is at the other blogs. Appreciate your sharing this greatest doc.
After examine a few of the weblog posts in your website now, and I truly like your way of blogging. I bookmarked it to my bookmark website list and will probably be checking again soon. Pls try my web site as properly and let me know what you think.
Thanks a lot for the helpful posting. It is also my belief that mesothelioma cancer has an extremely long latency period, which means that indication of the disease won’t emerge till 30 to 50 years after the primary exposure to asbestos. Pleural mesothelioma, that’s the most common type and impacts the area about the lungs, could potentially cause shortness of breath, upper body pains, plus a persistent cough, which may bring on coughing up our blood.
I’ve been browsing online more than three hours lately, yet I by no means discovered any interesting article like yours. It?s beautiful worth sufficient for me. Personally, if all web owners and bloggers made just right content as you did, the net will be a lot more useful than ever before.
Great post. I was checking constantly this blog and I’m impressed! Extremely useful info specifically the last part 🙂 I care for such info a lot. I was seeking this particular information for a very long time. Thank you and good luck.
Interesting post made here. One thing I would really like to say is the fact most professional career fields consider the Bachelor Degree like thejust like the entry level standard for an online education. Though Associate Diplomas are a great way to start, completing your current Bachelors opens up many good opportunities to various professions, there are numerous online Bachelor Course Programs available from institutions like The University of Phoenix, Intercontinental University Online and Kaplan. Another concern is that many brick and mortar institutions offer you Online versions of their diplomas but commonly for a extensively higher cost than the providers that specialize in online diploma programs.
It is indeed my belief that mesothelioma is usually the most fatal cancer. It’s got unusual characteristics. The more I actually look at it the greater I am confident it does not work like a real solid flesh cancer. When mesothelioma is usually a rogue viral infection, therefore there is the chance of developing a vaccine and offering vaccination to asbestos exposed people who are vulnerable to high risk of developing foreseeable future asbestos related malignancies. Thanks for discussing your ideas on this important health issue.
It’s appropriate time to make some plans for the future and it’s time to be happy. I have read this post and if I could I desire to suggest you some interesting things or tips. Perhaps you could write next articles referring to this article. I want to read even more things about it!
According to my research, after a in foreclosure process home is bought at a bidding, it is common with the borrower to be able to still have a remaining unpaid debt on the mortgage. There are many creditors who try and have all rates and liens paid by the upcoming buyer. Nonetheless, depending on specific programs, rules, and state laws there may be many loans that aren’t easily solved through the shift of lending products. Therefore, the responsibility still falls on the consumer that has received his or her property foreclosed on. Thanks for sharing your ideas on this weblog.
I would like to thnkx for the efforts you’ve put in writing this site. I’m hoping the same high-grade site post from you in the upcoming also. Actually your creative writing abilities has inspired me to get my own site now. Really the blogging is spreading its wings rapidly. Your write up is a great example of it.
Hello! I just wanted to ask if you ever have any trouble with hackers? My last blog (wordpress) was hacked and I ended up losing many months of hard work due to no back up. Do you have any solutions to protect against hackers?
My partner and I absolutely love your blog and find almost all of your post’s to be exactly I’m looking for. Does one offer guest writers to write content to suit your needs? I wouldn’t mind composing a post or elaborating on a few of the subjects you write regarding here. Again, awesome blog!
Хочу посоветовать ритуальную компанию “Скорбим” https://complex-ritual.ru/ в Казани. Они работают круглосуточно и предоставляют полный комплекс услуг – от организации похорон до установки надгробий. У них опытные и внимательные сотрудники, которые относятся с сочувствием и уважением к клиентам в это трудное время. Услуги предоставляются по разумным ценам и на высоком профессиональном уровне. Рекомендую обращаться в “Скорбим” за профессиональной и достойной организацией похорон.
I don?t even know the way I ended up here, however I assumed this put up was once great. I do not understand who you’re however definitely you’re going to a famous blogger in case you aren’t already 😉 Cheers!
I’ve learned newer and more effective things through your blog post. One other thing to I have found is that usually, FSBO sellers are going to reject you actually. Remember, they’d prefer not to use your products and services. But if anyone maintain a gentle, professional romance, offering guide and keeping contact for four to five weeks, you will usually be capable of win an interview. From there, a house listing follows. Many thanks
One important issue is that while you are searching for a student loan you may find that you will want a co-signer. There are many conditions where this is correct because you will find that you do not employ a past credit score so the bank will require that you’ve got someone cosign the loan for you. Great post.
Attractive portion of content. I simply stumbled upon your blog and in accession capital to assert that I get actually enjoyed account your weblog posts. Any way I will be subscribing in your feeds or even I success you get entry to consistently rapidly.
Your web site doesn’t render correctly on my blackberry – you might wanna try and repair that
Thanks for your useful post. Over time, I have come to understand that the particular symptoms of mesothelioma cancer are caused by the particular build up connected fluid between lining on the lung and the chest muscles cavity. The ailment may start from the chest spot and propagate to other parts of the body. Other symptoms of pleural mesothelioma cancer include weight loss, severe deep breathing trouble, temperature, difficulty ingesting, and bloating of the neck and face areas. It must be noted that some people existing with the disease don’t experience just about any serious indicators at all.
My brother recommended I may like this web site. He was once totally right. This submit truly made my day. You can not believe simply how much time I had spent for this info! Thanks!
I have not checked in here for some time as I thought it was getting boring, but the last few posts are great quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
Thanks on your marvelous posting! I definitely enjoyed reading it, you can be a great author.I will make certain to bookmark your blog and may come back in the foreseeable future. I want to encourage you to ultimately continue your great work, have a nice evening!
Thanks for your beneficial post. As time passes, I have been able to understand that the symptoms of mesothelioma are caused by a build up connected fluid involving the lining in the lung and the torso cavity. The sickness may start from the chest spot and multiply to other body parts. Other symptoms of pleural mesothelioma cancer include losing weight, severe inhaling trouble, nausea, difficulty swallowing, and infection of the neck and face areas. It ought to be noted that some people living with the disease don’t experience just about any serious symptoms at all.
I have taken notice that in digital cameras, extraordinary receptors help to {focus|concentrate|maintain focus|target|a**** automatically. The particular sensors with some video cameras change in contrast, while others employ a beam involving infra-red (IR) light, specially in low lumination. Higher specification cameras from time to time use a blend of both techniques and might have Face Priority AF where the dslr camera can ‘See’ a new face and concentrate only on that. Thank you for sharing your thinking on this weblog.
hello!,I like your writing very a lot! proportion we keep in touch more about your article on AOL? I require a specialist on this house to unravel my problem. Maybe that is you! Looking forward to peer you.
obviously like your web site but you need to take a look at the spelling on quite a few of your posts. Many of them are rife with spelling issues and I find it very bothersome to tell the reality nevertheless I will certainly come again again.
Hello! I’m at work browsing your blog from my new iphone 4! Just wanted to say I love reading through your blog and look forward to all your posts! Keep up the great work!
Today, while I was at work, my cousin stole my iphone and tested to see if it can survive a 30 foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is totally off topic but I had to share it with someone!
Hello! This is kind of off topic but I need some guidance from an established blog. Is it tough to set up your own blog? I’m not very techincal but I can figure things out pretty quick. I’m thinking about making my own but I’m not sure where to begin. Do you have any tips or suggestions? With thanks
I?ve learn several excellent stuff here. Certainly price bookmarking for revisiting. I surprise how much effort you put to make this type of fantastic informative website.
I have seen loads of useful issues on your internet site about computer systems. However, I have got the judgment that lap tops are still less than powerful adequately to be a wise decision if you normally do jobs that require lots of power, such as video editing and enhancing. But for net surfing, word processing, and a lot other popular computer functions they are fine, provided you don’t mind the tiny screen size. Appreciate sharing your thinking.
Excellent post but I was wondering if you could write a litte more on this subject? I’d be very grateful if you could elaborate a little bit more. Cheers!
I do enjoy the manner in which you have framed this particular problem and it does indeed offer us a lot of fodder for consideration. However, through what I have personally seen, I just hope as the actual remarks pack on that people today remain on point and not embark on a soap box regarding some other news du jour. Yet, thank you for this outstanding piece and whilst I can not really concur with it in totality, I value your perspective.
hey there and thank you on your information ? I?ve definitely picked up anything new from proper here. I did then again experience several technical issues the use of this site, since I experienced to reload the site lots of times previous to I may get it to load properly. I were considering in case your hosting is OK? Not that I’m complaining, however sluggish loading circumstances occasions will often have an effect on your placement in google and could injury your quality ranking if advertising and ***********|advertising|advertising|advertising and *********** with Adwords. Anyway I?m including this RSS to my e-mail and can glance out for a lot extra of your respective exciting content. Ensure that you update this once more very soon..
I was just searching for this info for a while. After six hours of continuous Googleing, at last I got it in your site. I wonder what is the lack of Google strategy that do not rank this kind of informative web sites in top of the list. Normally the top web sites are full of garbage.
Buy Drugs
Viagra
Porn
Sex
Porn site
Scam
Viagra
Porn
Porn
Sex
Sex
Viagra
Viagra
Buy Drugs
Buy Drugs
Pornstar
Scam
Buy Drugs
Pornstar
Scam
Buy Drugs
Porn
Porn
Sex
Porn
Viagra
Sex
Buy Drugs
Porn site
Buy Drugs
Scam
Porn
Buy Drugs
Buy Drugs
Music began playing as soon as I opened up this site, so frustrating!
Today, I went to the beachfront with my children. I found a sea shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed. There was a hermit crab inside and it pinched her ear. She never wants to go back! LoL I know this is entirely off topic but I had to tell someone!
Sex
Pornstar
Sex
Viagra
Sex
Porn
Porn site
Viagra
Pornstar
Hmm it appears like your site ate my first comment (it was super long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still new to the whole thing. Do you have any recommendations for rookie blog writers? I’d certainly appreciate it.
Porn
Porn site
Viagra
Porn site
Wow, marvelous blog format! How long have you been running a blog for? you make blogging glance easy. The whole glance of your website is excellent, let alone the content!
Sex
Buy Drugs
Porn
Good day! I could have sworn I’ve been to this website before but after reading through some of the post I realized it’s new to me. Anyways, I’m definitely delighted I found it and I’ll be book-marking and checking back frequently!
A person essentially help to make seriously posts I would state. This is the very first time I frequented your web page and thus far? I surprised with the research you made to create this particular publish incredible. Wonderful job!
Porn
Today, while I was at work, my cousin stole my apple ipad and tested to see if it can survive a 25 foot drop, just so she can be a youtube sensation. My apple ipad is now broken and she has 83 views. I know this is totally off topic but I had to share it with someone!
Viagra
Scam
Porn site
Viagra
Spot on with this write-up, I actually think this web site needs much more consideration. I?ll probably be again to read far more, thanks for that info.
Hmm it seems like your website ate my first comment (it was super long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog. I too am an aspiring blog blogger but I’m still new to everything. Do you have any tips for first-time blog writers? I’d really appreciate it.
Scam
Buy Drugs
Pornstar
Scam
Scam
Viagra
Porn
This design is steller! You most certainly know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Great job. I really loved what you had to say, and more than that, how you presented it. Too cool!
Porn site
I figured out more new stuff on this weight-loss issue. One issue is a good nutrition is tremendously vital whenever dieting. A huge reduction in fast foods, sugary food items, fried foods, sweet foods, red meat, and white flour products could possibly be necessary. Possessing wastes organisms, and harmful toxins may prevent objectives for fat-loss. While particular drugs briefly solve the issue, the terrible side effects are certainly not worth it, and they also never give more than a temporary solution. This can be a known undeniable fact that 95 of diet plans fail. Thanks for sharing your opinions on this website.
Porn
Viagra
Sex
Porn site
Scam
Porn site
Sex
Porn site
Pornstar
Sex
Buy Drugs
Scam
Porn
Pornstar
Porn site
Scam
Porn
Porn site
Porn site
Porn
I have not checked in here for a while because I thought it was getting boring, but the last several posts are great quality so I guess I will add you back to my everyday bloglist. You deserve it my friend 🙂
I’m not that much of a online reader to be honest but your sites really nice, keep it up! I’ll go ahead and bookmark your site to come back in the future. Many thanks
I think other web-site proprietors should take this site as an model, very clean and wonderful user genial style and design, as well as the content. You are an expert in this topic!
An impressive share, I just given this onto a colleague who was doing slightly analysis on this. And he the truth is purchased me breakfast as a result of I discovered it for him.. smile. So let me reword that: Thnx for the treat! However yeah Thnkx for spending the time to debate this, I feel strongly about it and love studying more on this topic. If possible, as you become expertise, would you thoughts updating your blog with extra details? It’s highly useful for me. Huge thumb up for this blog publish!
Its such as you read my thoughts! You appear to understand so much approximately this, such as you wrote the e book in it or something. I feel that you simply could do with a few percent to pressure the message house a little bit, however other than that, that is excellent blog. An excellent read. I’ll certainly be back.