Johdanto
Neljännellä viikolla aiheena olivat korkeusmallille tehtävät analyysit ja hydrologinen mallintaminen. Digitaaliset korkeusmallit tarkoittavat digitaalisessa muodossa olevaa havaintoaineistoa tai matemaattista pintaa, joka sisältää x-. y- ja z-koordinaatit ja on sidottu tunnettuun koordinaatistoon. Digitaaliset korkeusmallit kuvaavat maanpinnan korkeusvaihteluita. Erilaisia korkeusmalleja ovat Digital Elevation Model, Digital Terrain Model ja Digital Surface Model. DEM tarkoittaa digitaalista (maanpinnan) korkeusmallia, DTM on yleistermi, joka kattaa kaikki maanpintaa kuvaavat aineistot ja DSM on digitaalinen pintamalli, joka sisältää muun muassa puiden ja rakennusten korkeudet.
Hydrologisessa mallintamisessa lähtökohtana on hydrologisesti korjattu korkeusmalli. Veden virtaus riippuu maan pinnan korkeusvaihteluista, malli kuvaa siis tätä vaihtelua. Hydrologisessa mallinnuksessa Flow Direction -taulukko on tärkeä. Taulukko määrittää virtaussuunnan jokaiselle siinä esiintyvälle ruudulle.
Mahdollisia virtaussuuntia on kahdeksan suhteessa lähimpään ruutuun, jos niitä on enemmän korkeusmalli sisältää ”kuoppia” eli Sinks. Kuopat voivat olla todellisia tai korkeusmallissa olevia virheitä, kuten kurssikirjallisuudessa kerrottiin. Jotta korkeusmallista saadaan hydrologiseen mallinnukseen soveltuva, niin nämä ”kuopat” tulee täyttää Fill -operaation avulla naapurustonsa tasolle.
Ensimmäinen harjoitus
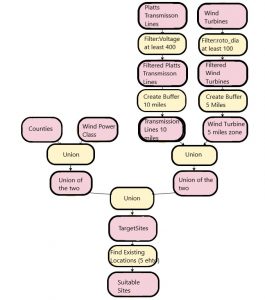
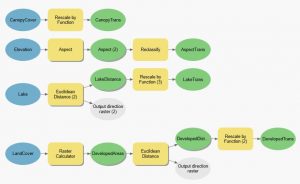
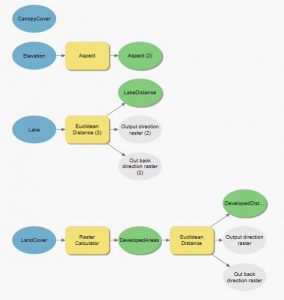
Viikon ensimmäisessä harjoituksessa tuli etsiä viinitarhalle sopiva sijainti. Ehdot viinitarhan sijainnille liittyivät rinteen korkeuteen, jyrkkyyteen ja suuntaan. Tehtävän ensimmäisessä vaiheessa tuli tehdä taas binäärinen soveltuvuusanalyysi, joka oli tuttu jo aiemmilta viikoilta.

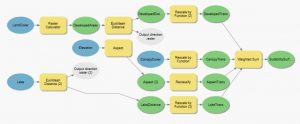
Kuva 1. Ensimmäisen harjoituksen ensimmäisen osat vaiheet.
Kuvassa 1 näkyy harjoituksen ensimmäisen osan vaiheet. Ensin siis tutkittiin rinteen korkeutta ja sen jälkeen valmisteltiin analyysia. Analyysia varten luotiin korkeutta, jyrkkyyttä ja suuntaa kuvaavat tasot, joiden avulla soveltuvuusanalyysi toteutettiin. Yksinkertainen soveltuvuusanalyysi toteutettiin raster calculator -työkalun avulla, jonka seurauksena saatiin tuttuun tapaan jaettua aineisto sopiviin ja ei sopiviin aluesiin.

Kuva 2. Ensimmäisen harjoituksen toisen osan vaiheet.
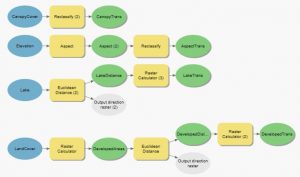
Harjoituksen toisessa vaiheessa työskenneltiin pienemmän alueen kanssa kuin ensimmäisessä vaiheessa, joten aluksi tutkittiin korkeamman resoluution avulla aluetta. Tämän jälkeen aluetta visualisoitiin vinovalovarjosteen avulla, jotta maaston korkeuserot erottuivat paremmin. Varjosteelle lisättiin vielä korkeuskäyrät, jonka jälkeen se viinitarhalle sopivia sijainteja visualisoitiin ja analysoitiin vielä lopuksi 3D:n avulla.
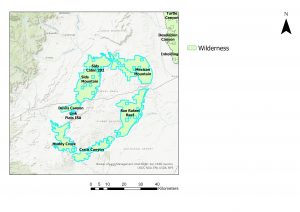
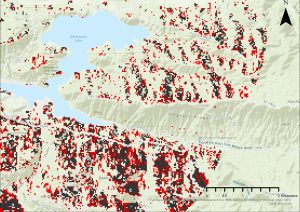
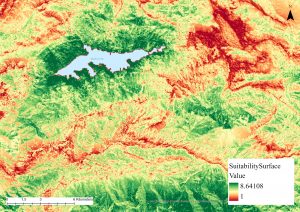
Kuvassa 3 näkyy harjoituksesta kartta, joka esittää viinitarhoille sopivia alueita. Näin jälkikäteen tarkasteltuna kartta voisi olla visuaalisesti vielä hieman parempi. Siitä muun muassa puuttuu kokonaan rinteen suuntaa kuvaavat käyrät, jotka olivat yksi ehdoista, jonka tuli täyttyä sopivan viinitilan alueille.

Kuva 3. Ensimmäisen harjoituksen kartta, josta näkyy viinitarhoille sopivat alueet.
Toinen harjoitus
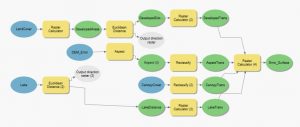
Viikon toisessa harjoituksessa mallinnettiin pintavesien valuntaa, jossa lähtökohtana oli hydrologisesti korjattu korkeusmalli (eli DEM). Harjoituksessa käytettiin ArcGIS Pro:n Tasks -ominaisuutta. Omaisuuteen on automaattisesti luokiteltu työvaiheet, joten niihin tulee vain sijoittaa tarvittavat tiedot. Ominaisuutta käytettiin viisi kertaa, työvaiheet, joita tämän ominaisuuden avulla käytetiin näkyvät kuvista 4, 5, 6 ja 7. Työvaiheet aloitettiin aina samalla Create unit hydrograph at outlet -vaiheella. Lisäsin kuviin työvaiheiden oikealle puolelle myös tasojen nimet, jotka syntyivät työkalujen käytön seurauksena.
Toisen harjoituksen työvaiheet
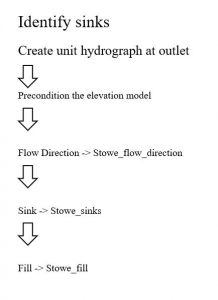
Kuva 4. Toisen harjoituksen ensimmäisen vaiheen työvaiheet.
Ensin siis valmisteltiin digitaalinen korkeusmalli muun muassa täyttämällä löydetyt ”kuopat”, kuten kuvasta X näkee. Digitaalinen korkeusmalli on oivallinen työkalu, kun halutaan ymmärtää maan ominaisuuksia, kuten esimerkiksi virtaussuuntia ja jyrkkyyttä. Mallia voidaan hyödyntää myös moniin eri tarkoituksiin, kuten kurssikirjallisuudessa kerrottiin (Saraf, Choudhury, Roy, Sarma, Vijay & Choudhury, 2004). Tämän jälkeen tarkasteltiin veden virtaussuuntia ja alueita, johon se todennäköisimmin kerääntyy. Lisäksi tässä vaiheessa mitattiin matka Little Riverin ja sen hetkisen outlet pointin välillä.

Kuva 5. Toisen harjoituksen toisen vaiheen työvaiheet.
Kolmannessa vaiheessa mitattiin sitä, kuinka nopeasti vesi virtaa tutkitulle alueelle. Tätä mitattiin rinteen jyrkkyyden avulla. Loppuvaiheessa vielä muokattiin veden virtausnopeuksia, koska valmiit arvot olivat epärealistisia.

Kuva 6. Toisen harjoituksen kolmannen vaiheen työvaiheet.
Kolmannessa vaiheessa huomattiin se, että vesi virtaa nopeimmin lähellä ojia (streams). Neljännessä vaiheessa mitattiin sitä, kauanko vedellä kestää virrata halutulle alueelle mistä tahansa kartan alueelta. Loppuvaiheessa muokattiin virtausnopeutta kuvaavan rasteridatan tietoja, koska se sisälsi todella paljon yksittäisiä arvoja. Uudelleenluokittelun avulla helpotettiin siis tulevan analyysin tekemistä.
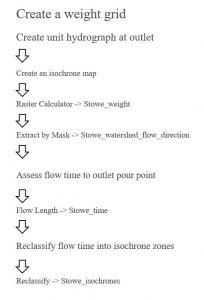
Kuva 7. Toisen harjoituksen neljännen vaiheen työvaiheet.
Viimeisessä eli viidennessä vaiheessa luotiin taulukko, josta näkee veden korkeuden sen laskupisteen kohdalla sateen aikana. Taulukkoa voi siis hyödyntää siihen, että tulvia voidaan ennustaa ja niihin voidaan varautua mahdollisimman hyvin.

Kuva 8. Toisen harjoituksen viimeiset työvaiheet.
Taulukko 1. Toisen harjoituksen lopputulos, eli taulukko joka esittää veden korkeutta.


Kuva 9. Lopun kevennys, tältä harjoitus kaksi näytti kesken työskentelyn.



 Kuva 1. Harjoituksen 1 kartta.
Kuva 1. Harjoituksen 1 kartta.