Lyhyt johdanto kolmannen kurssikerran teemoihin
Kolmannella kurssikerralla jatkettiin edelliseltä viikolta tuttua teemaa eli rasterianalyyseja. Kurssikerran aineistot olivat myös samoja kuin edellisellä viikolla, eli harjoituksissa päästiin taas työskentelemään valkopäämerikotkien pesimäpaikkojen kanssa. Myös oheiskirjallisuus oli sama.

Kuva 1. Tämän näköisille kavereille harjoituksissa selvitettiin optimaalisia pesimäpaikkoja. (kuvan lähde)
Kurssikerran harjoituksissa luotiin niin ksinkertainen kuin painotettu soveltuvuusanalyysi. Kuten jo aiemmin kurssilla tuli ilmi, yksinkertaisessa soveltuvuusanalyysissa aineisto luokitellaan binäärisesti nolliin ja ykkösiin (ei-sopiva – sopiva). Se kertoo siis suoraan annettujen kriteereiden mukaisesti sen, sopiiko tietty alue vaatimuksiin vai ei. Painotetussa soveltuvuusanalyysissä aineisto luokitellaan esimerkiksi asteikolla 1-5, jossa suurimmat numerot tarkoittavat parasta sopivuutta. Painotetun soveltuvuusanalyysin avulla voidaan siis saada aikaan hieman kattavampia ja monipuolisempia analyyseja eri paikkojen soveltuvuudesta annetuille kriteereille.
Ensimmäinen harjoitus
Ensimmäisessä harjoituksessa tarkoituksena oli luoda yksinkertainen soveltuvuusanalyysi optimaalisten kotkien pesimäpaikkojen löytämiseksi. Harjoituksessa käytettiin taas Model Builderia, johon oli siis lisätty työkaluja. Tällä kertaa siihen lisättiin vielä raster calculator -työkalu, jonka avulla pystyttiin yhdistämään tasoja. Tasojen yhdistämisen jälkeen taas muokattiin kartan visuaalista puolta, jotta siitä erotti paremmin sopivat alueet.
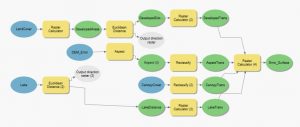
Kuva 2. Ensimmäisen harjoituksen model builder.
Ensimmäisen harjoituksen toisessa vaiheessa tarkastelussa oli sekä sensitivity analysis että error analysis. Sensitivity analysis tarkastelee sitä, miten herkkä soveltuvuusanalyysi on muutoksille, jos sen yhtä parametriä muutetaan. ArcGIS Prossa tämä toteutetaan niin, että ensin muokataan parametriä, jonka jälkeen malli ajetaan ja siitä voi tarkastella mahdollisia muutoksia. Jos muutoksia tapahtuu paljon, niin kyseinen parametri vaikuttaa siis paljon mallin toimintaan.
Error analysis kertoo sen, kuinka paljon lähtöaineisto vaikuttaa mallin toimintaan. Error analysis toteutetaan muokkaamalla esimerkiksi lähtöaineiston arvoja, jonka jälkeen malli taas ajetaan ja mahdolliset muutokset tulevat esille. Itse harjoituksessa näitä harjoiteltiin muokkaamalla aineiston arvoja muun muassa reclassify -työkalun avulla.
Harjoituksessa luotiin kaksi eri tasoa, ErrorDifference ja SuitabilitySurface. Nämä kaksi eri tasoa luotiin, jotta pystyttiin havainnoimaan syntyviä eroja, kun aineiston dataa muokataan yksinkertaisessa soveltuvuusanalyysissa. Keskeinen ero näiden kahden tason välillä on sen, että ErrorDifference -tasossa harvemmat solut lasketaan sopiviksi. Eron takana on selitys siitä, jotta yksinkertaisen soveltuvuusanalyysin solut lasketaan sopiviksi, tulee kaikkien annettujen ehtojen täyttyä. Yksinkertaisessa mallissa ei siis voi olla soluja, jotka ovat soveltuvuuden osalta tasoa ”ihan ok” toisin kuin painotetussa.
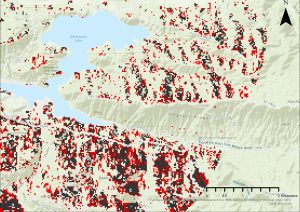
Kuva 3. Ensimmäisen harjoituksen lähennetty kartta, joka visualisoi Suitability Surface ja ErrorDifference -tasojen eroja.
Toinen harjoitus
Jotta eri tasoja voi yhdistää painotetussa soveltuvuusanalyysissa, niin ensin tulee muokata niiden sisältämät datat sopivaksi. Tätä harjoiteltiin tehtävässä kaksi. Sen jälkeen, kun datat oli tarkistettu, niin tehtävässä tuli muokata tasot uudelleenluokittelemalla ne arvoihin 1-10. Tehtävän tarkoitus oli siis valmistella data kolmannessa harjoituksessa toteutettavaa analyysia varten.
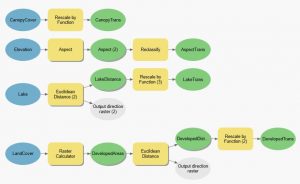
Kuva 4. Toisen harjoituksen jälkeinen model builder. Huomioitavaa seuraavaan tehtäväään verrattuna yksittäiset tasot.
Kolmas harjoitus
Kolmannessa harjoituksessa päästiin käyttämään tätä aiemmin muokattua dataa yhdistämällä luodut tasot yhdeksi tasoksi. Tasot yhdistettiin Weighted Sum -työkalun avulla. Työkalu lisättiin Model Builderiin ja aiemmat tasot yhdistettiin siihen. Tämän jälkeen Model Builder taas ajettiin, jolloin se lisäsi kartalle SuitabilitySurface nimisen tason, jota hieman muokkaamalla pystytiin kartalta näkemään valkopäämerikotkien optimaaliset pesimäpaikat. Optimaalisimpia paikkoja kartan (kuva 5) perusteella olivat Big Bear -järven ympäristö sekä kartan alareunan alueet.
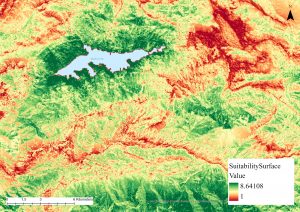
Kuva 5. Kolmannen harjoituksen kartta, joka esittää soveliaita pesimäpaikkoja. Kuten legenda osoittaa, tumman vihreät paikat ovat parhaita ja tumman punaiset huonoimpia.
Harjoituksen loppupuolella aineistolle tehtiin vielä omat mallit sensitivity ja error -analyyseille. Sensitivity analyysin avulla voidaan nähdä vaikutukset lopputulokseen, kun muokataan luodun mallin parametrejä. Jos tuloksista on havaittavissa suuria eroja, niin malli on voimakkaasti sensitiivinen muokatulle parametrille. Error analyysissa taas voidaan havaita mahdollisten lähtöaineiston virheiden vaikutukset lopputulokseen.
Itse harjoituksessa luotuja malleja ja niiden vaikutuksia havainnoitiin liikuttamalla mallien synnyttämiä lopputuloksia toistensa päällä swipe-työkalun avulla. Lopputuloksissa harjoituksessa luotujen mallien välillä ei esiintynyt suuria vaihteluita. Tästä voi siis päätellä esimerkiksi sen, että lähtöaineisto oli hyvä eikä sisältänyt suuria virheitä.
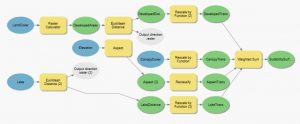
Kuva 6. Kolmannen harjoituksen lopullinen model builder.
Ensimmäisen ja kolmannen harjoituksen model builderit ovat hyvin lähellä toisiaan, kuten kuvista 2 ja 6 näkee. Suurimpana erona on se, että kolmannessa harjoituksessa käytettiin uudelleenluokittelua raster calculator -työkalun sijaan. Myös viimeinen työkalu on eri harjoitusten välillä. Kolmannessa harjoituksessa tehtiin painotettu soveltuvuusanalyysi, joten työkaluna on weighted sum eikä raster calculator, kuten aiemmassa tehtävässä.
Rasteriaineistojen lyhyt yhteenveto
Viikon kaksi ja kolme harjoituksista lyhyesti tiivistetysti voisia sanoa, että rasteriaineistojen kanssa työskennellessä tärkeä tehtävä ennen analyyseja on muokata rasteriaineistot toisilleen sopiviksi. Rasteriaineistoihin liittyvässä oheiskirjallisuudessa puhuttiin rasteriaineistojen rekisteröimisestä, joka tarkoittaa sitä, että aineistot pakotetaan kohdakkain. (Holopainen ym., 2015, s.53). Rekisteröimisen avulla rasterisaineistot saadaan samaan koordinaatistoon. Tämä on tärkeää, koska analyyseista muodostuvien rasteriaineistojen koordinaatistot ovat riippuvaisia lähtöaineiston koordinaattijärjestelmästä.
Myös lähtöaineisto tulee valita sekä tarkastaa huolella esimerkiksi sen mahdollisten virheiden vuoksi. Tähän voi käyttää esimerkiksi harjoituksista tuttua error analyysiä. Myös rasteriaineistojen solujen tiedot tulee tarkastaa niiden koordinaatiston lisäksi. Esimerkiksi mahdollinen solun arvon puuttuminen vaikuttaa analyysien lopputulokseen.
Lähteet
Holopainen et al. (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7.