
Autumn 2023: Section-Level Genre Analysis
Table of Contents
Materials and Methods
Data and Labeling
All the data used were from the Eighteenth Century Collections Online (ECCO). ECCO is a set of 180,000 digitized documents published originally in the eighteenth century, created by the software and education company Gale. These digitized images have been converted into readable text data by using Optical Character Recognition (OCR).
ECCO is the largest and most complete source for eighteenth-century text data. The printed works on which it is based range from short pamphlets to full books and collected works, and cover the entire range of popular genres of the eighteenth century.
Since we wanted to build a classifier which could find the genres of individual chapters instead of the more common book level genres, we needed chapters of these books that had labels to the genres in addition to the book level labels. There did not exist previously a large data set of annotations for chapter contents, so we built our own data set of 1000 genre annotated chapters by labeling them.
The labeling process involves assigning labels or categories to data points in a dataset. In machine learning and data mining, datasets typically consist of examples or instances, each associated with one or more labels.
The objective of the annotation task was to categorize sections of historical books with genre information. For each section, we had to choose the most appropriate genre label from the ten (10) genres provided. Each label includes a description of its subcategories, enhancing comprehension of the contents within each genre. We labeled the genres into the following categories, which imitated commonly used book level genre labels:
– Arts
– Education
– History
– Law
– Literature
– Politics
– Philosophy
– Religion
– Sales Catalogues
– Scientific Improvement
In addition to these chapters we added a genre “Structural and Ephemera” for chapters that were titles, tables of contents and errata since those did not have any book level genre.
For each section, we were required to carefully research the textual content within that section, disregarding any other text on the page, whether preceding or following, and not relying on the headers. We considered only the text contained within the section, excluding any other text on the page.
In instances where a section was deemed to encompass more than one genre, we labeled it with the most appropriate genre. If both genres were equally significant and distinct, we utilized the special category of data annotation, referred to as “Not sure.”
And specific instructions were provided for labeling non-English text, even if understood, using the category “Can’t tell.” Illustrations and maps should also be labeled as “Can’t tell,” even though there is a confidence that they conform to a particular genre. We also labeled sections as “Can’t tell” for situations, where distinguishing the genre was deemed impossible based on available information, such as very short sections, missing text on the page, or sections containing illustrations.
The category “Not sure” was used for cases where uncertainty arises due to ambiguous text, an inability to assign one clear genre, or a perceived lack of expertise.
During the project, our group of five created the initial set of markings, covering 500 sections (100 sections per person). While marking and discussing the results, we introduced the “Structural and Ephemera” category to the main genres. This addition was prompted by the discovery of books pages containing tables of contents, lists, and publication errors (errata).
In cases where there was doubt about the classification of a section, we rechecked the data using additional questions. After incorporating the “Structural and Ephemera” genre, approximately 1000 documents were annotated and cross-checked, with 200 documents per person and a total of 3000 documents (600 per person).
After the annotation process, we checked if there were any duplicates. That is, the same section has two different genres annotated to it. There were no duplicates found. It appears that the genre given to a specific section is based on the most common label given to each particular section.
It was also noticed that the number of sections labeled as “philosophy” was very low. This would cause issues with the classifier, where it would not predict philosophy. We decided to populate our dataset with “philosophy” sections from the previous years’ dataset.
For the selection of which chapters to be labeled we used Max-Min Diversification sampling method [8]. We chose this method since it adds weight to genres that are less common in ECCO, such as philosophy and arts.
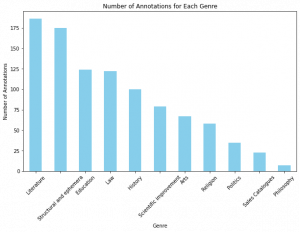
Figure 1. The distribution of different genres in our data
As can be seen from the figure 1 The labels are biased towards the genres “Literature” and “Structural and Ephemera”. with the genres “Sales Catalogues” and “Philosophy” being under-represented in the training data.
To remedy this we added 48 sections labeled “philosophy” from another classification. With this addition Our complete training data set had unique 1177 genre labeled sections from 557 different books. We used these as both our training and testing data.
Additionally we used the classifier on a data set containing 3000 books from major 18th century publishers. We chose this data because it contains hand picked books of known quality. This allowed us to find books with interesting behaviors in relation to our research question.
Classifier
The classifier used for predicting was ECCO-BERT-Seq. It is based on the ECCO-BERT language model. It consists of a transformer encoder and a linear layer which scores different genres. The model takes the 510 first sub-words of a given sample. Since we are examining genres on section level and most of the sections are only 1-5 pages long, this range fits our case well.
The model was fit with our annotated dataset. The dataset was split into training, validation and testing sets. We used “BertForSequenceClassification” as our model, with a pretrained model parameter “TurkuNLP/eccobert-base-cased-v1”. We also set the learning rate to 0.00001, weight decay at 0.01 and the optimizer as AdamW. The model was trained with 10 epochs. The input was the column “section_content”, which describes the written content of a given section. The output was the predicted genre, one of the 11 aforementioned labels.
For each epoch iteration using batch size of 8, the model was trained with the entire training dataset, and then validated. After fitting the model, we ran the predictions using the test dataset, and compared them to the true values that we had annotated. Accuracy of the prediction was the main driver of the model’s performance.
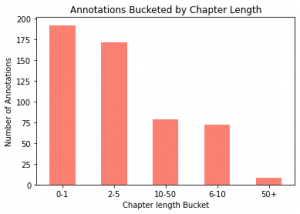
Figure 2. distribution of different chapter lengths in our data
Model analysis
We considered two different models:
- A model trained with filtered data
- A model trained without filtering the data
The filtering of the data relates to removing section contents with high amounts of OCR noise. To filter, we used a simple regex formula which removes words that include more than five special characters. The code removed OCR noises such as “——–” or “.l.o.v.e.” but didn’t delete all noisy words such as “majefty” (implies to “majesty”). The model then outputted a table of precision, recall, and F1 score for each label, as well as the accuracy of the model.
Model 1 (trained with filtered data) achieved an accuracy of 0.8421 and F1 macro of 0.8004, while model 2 (with unfiltered data) achieved an accuracy of 0.7730 and F1 macro of 0.6971. Model 1 clearly performed better. This is due to the OCR noise causing difficulties for predicting: different genres contained the same description since the OCR noise format was similar. By filtering out the noisy data, the model was more accurately able to distinguish between genres. The table below describes the evaluation metrics of the model:
| Genre | Precision | Recall | F1 |
| Arts | 0.714 | 0.833 | 0.769 |
| Education | 0.893 | 0.806 | 0.847 |
| History | 0.879 | 0.829 | 0.853 |
| Law | 0.784 | 0.906 | 0.841 |
| Literature | 0.827 | 0.827 | 0.827 |
| Philosophy | 0.714 | 0.500 | 0.588 |
| Politics | 0.714 | 0.455 | 0.556 |
| Religion | 0.889 | 0.960 | 0.923 |
| Sales Catalogues | 1.000 | 0.750 | 0.857 |
| Scientific Improvement | 0.826 | 0.826 | 0.826 |
| Structural and Ephemera | 0.889 | 0.949 | 0.918 |
The model performs well in certain genres, particularly religion, structural and ephemera, and sales catalogues. However, there are areas where the model could improve, specifically in the philosophy and politics genres, which have lower scores across all three metrics. The overall accuracy and macro-average F1-Score suggest that the model performs well overall.
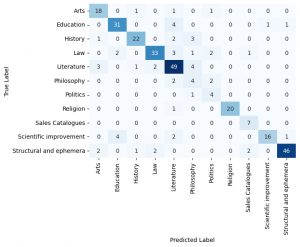
Figure 3. The model’s accuracy across the different genres. The values depict the percentage at which the labels are predicted correctly
The model started with a high loss value, but decreased as we progressed through the training loop. It achieved good performance with 10 epochs, and additional epochs introduced overfitting, and deteriorated the results.
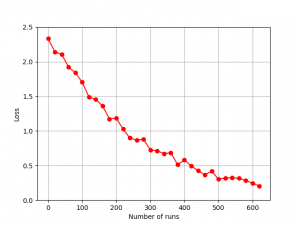
Figure 4. The loss curve for our model
Confusion matrix analysis:
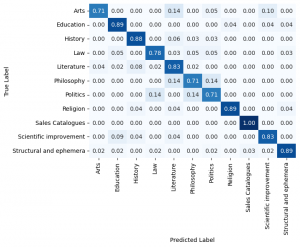
Figure 5. Confusion matrix for the model. The diagonals represent correct predictions, with the rest being misclassifications.
Figure 5 shows us the confusion matrix for the training process. As would be expected with an accuracy of 0.8 the predicted labels match the actual labels quite well. However this matrix indicates that the misclassifications are not random, but instead follow logical patterns.
The genres that the classifier is getting right most of the time are those that have specific structures in their texts. These would be the tables of contents from “structural and ephemera” or the lengthy dialogues from law depositions. For the good classification accuracy the reason could be that religious texts have a distinct vocabulary compared to the other texts.
The two genres that had the worst classification accuracy were philosophy and politics. The reason for this is two fold. First even with the additional data points for philosophy these two genres still had relatively few observations. Second these genres do not have clear structural elements that would distinguish them from the other genres, in fact these two genres have elements that closely resemble the other genres styles. For example it is quite common that political texts are written from the point of view of characters or that philosophical texts have historical discussions. This is evident in the fact that the genre “Sales Catalogues”, which has clearer structures in its texts, has much better classification accuracy compared to these two genres.
Overall this confusion matrix shows that the classifier is labeling the genres in a way that a human annotator might. It gets the “easy” genres right with high probability and it struggles when the genre is ambiguous or does not have clear structural elements with which to make the classifications. However when the classifier makes an error it still gives a label to a genre that is related to the actual genre. A fact that gives confidence to the conclusion that we make in this report.