
Autumn 2023: Section-Level Genre Analysis
Table of Contents
Analysis
Shocking Reader via Extraordinary Language
We discovered a high amount of literature-labeled sections and in books whose main genre is not literature. This intersection raises questions about the fluidity of genre boundaries in 18th-century English texts. The exploration of literature within non-literature labeled books in 18th-century English texts brings us to Terry Eagleton’s perspective. According to Eagleton, “Literature transforms and intensifies ordinary language, deviates systematically from everyday speech” (Eagleton, Literary Theory, 2017, p.2). If we combine it with another theoretical approach, this definition can partially give an answer to the question why authors known for non-literary works chose to use extraordinary language. To understand this choice, we delve into the uses of literature, guided by Rita Felski’s insights. In her book The Use of Literature, Felski outlines four utilities of literature: recognition, enchantment, knowledge, and shock, emphasizing that “the meaning of literature lies in its use…” (Felski, 2008, p.8). To be concise, in our analysis, we focus on the shock aspect of literature.
Shock in Educational Books
The element of shock is used to capture and maintain the reader’s attention, particularly in educational texts. A notable example is a fable in a education labeled book. Traditionally and normally, human readers expect human characters in narratives due to a human-centric approach. However, fables subvert readers’ expectations by using animals as protagonists. This creates an initial shock. This surprising element realized by using literature in education books not only engages the reader but also helps the author to make the effective transmission of the educational message embedded in the text. A great example of this phenomenon is Aesop’s fables.

The fable above is from Aesop’s fables which is classified as Literature by our model. The fable has animal characters, dog and cat. In this particular fable, the choice of a dog and a cat as protagonists is not arbitrary; rather, it serves a strategic purpose. By deviating from the human-centric norm in narrative storytelling, the fable generates a sense of surprise or shock in the reader via extraordinary language. Thus, the message is given to the reader by using such animals in the text.
The relation between literature and history
The blending of literature with other genres extends beyond education, as seen in the relationship between literature and history. Often, historical texts were infused with literary elements, blurring the lines between factual narrative and creative expression. This intermingling presents a challenge for the classifier, which must discern subtle distinctions between these intertwined genres.
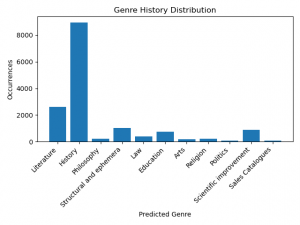
Figure 6.
The chart above shows the genre distribution in books whose main genre is history. Most of the chapters in history books were predicted as history by our model. Literature follows history with more than 2,000 chapters which is a quite number of chapters. However, what is the manifestation of this distribution chart in history labeled books? In this section, we will examine an 18th century book The history of Sir George Ellison in two volumes.

Figure 7.
Figure 7 shows the genre distribution on chapter-level for the aforementioned book. On the left, each dot signifies the chapter’s predicted genre as chapters go on. On the right, overall genre distribution for the book is displayed. The book has 16 chapters. While the book’s main genre is History as the red line demonstrates, our model predicted all chapters as Literature. To explain this interesting distribution in the book, we give further attention to the book and read some chapters from the book.


The images above are pages from the book where the life of Sir George Ellison is narrativized as if it is a literary text. The book can be appreciated as a kind of biographical novel focusing on Ellison’s life. This narrativization of the past puts the text between history and literature genres that can be seen in the signal plot. Thus, the model predicted the genres as literature instead of history.
The relation between literature and education
The intertwining of literature with education further exemplifies the multilayered nature of literature, a phenomenon that we explored through the analysis of specific education labeled books. We found that in education labeled books, literary sections were frequently used for pedagogical purposes.
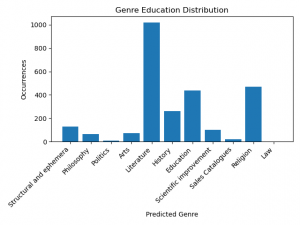
Figure 8.
The bar chart above describes our model’s genre prediction for the chapters in education labeled books overall. Interestingly, the most frequent genre is not education but literature and the genre education is the most frequent third genre. One of the reasons for this might be that the literary texts were used for education purposes. To embody this statement, we will give further examples from specific education labeled books. For instance, in the book The Academic Speaker, the genre distribution in chapter-level can be used to explain the characteristics of the education genre.

Figure 9.
In the plot above, the distribution of the genres in the book whose main genre is education is displayed. Quite interestingly, only one chapter is labeled as Education in the book in its 87 chapters and 78.2% of the chapters were labeled as literature by our model. But is it a mistake done by our model or not? Let’s check two chapters whether it might be true or not.
When we deeply look at the chapters labeled as Literature, it can be observed that the book includes some poems:

The 83th section above has an extraordinary language, as Terry Eagleton suggests, that we can assign the label literature to and the model so. Another example for the book The academic speaker is its tenth chapter labeled as literature by the model:

As can be seen, poems or literary texts were used in education labeled English books in the 18th century. This highlights how literature was employed for educational purposes in the 18th century, serving as a tool for teaching English language.
Structural and Ephemera in Books
Our analysis also extended to the concept of Structural and Ephemera, revealing how even ancillary elements in books contribute to our understanding of genre classification and book composition. In law books, for instance, we observed chapters labeled as ‘Structural and Ephemera’, such as summaries or tables of content. This label appeared frequently in introductory or ancillary sections, where the primary focus was on summarizing or organizing information rather than substantive content. The structural and ephemera label is seen in the books with some specific functions such as table of content, to the reader part, summary, character list, and lastly subscription list.
Table of content
Firstly, the books, especially the long ones, had Structural and Ephemera labeled sections at the beginning. Such chapters aim to list which section starts where.

Figure 10.
The book whose signal chart is above is a scientific improvement labeled book and 86.2% of the chapters were labeled as scientific improvement by the model. However, there are a few exceptions such as the chapter at the beginning of the book labeled as Structural and Ephemera. This chapter can be found below.

The chapter includes information on which chapter starts on which page that is a typical Structural and Ephemera labeled chapter. During our analysis, we found that plenty of books had a table of contents at the beginning which is labeled as Structural and Ephemera, a common trend in books.
Preface/A note to the reader
Another frequently used function of Structural and Ephemera category was to be given additional information to the reader by the author, translator, editor, or publisher. Such chapters, indeed, don’t belong to the primary content but as an extension of the book. For instance, in a 18th century drama book, we encountered such a Structural and Ephemera labeled section usage.

Figure 11.
The second chapter of the book that can be found above is labeled as Structural and Ephemera and its title is “To The Reader”. When we look at its content, it is visible that the chapter is an explanatory passage written by its translator on the drama. We have found such passages written by translators for the books or by writers for books with multiple editions, etc. During these passages, the author gives additional information about the primary content. Thus, Structural and Ephemera category’s another function is to be used giving supplementary details about the book.
Summary
Structural and Ephemera’s other frequent function is similar to Table of Content but instead of the chapter title, it gives a short summary of the chapter in a sentence with the page number. To demonstrate this function, we will use a Law book.

Figure 12.
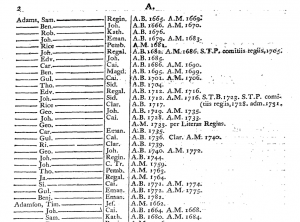
The genre for the book above is Law and 98.5% of all chapters were classified as Law by our model except for just a few chapters. One of those chapters labeled as non law is the first chapter. It has the title “Summaries of the Decisions in this Volume” and is labeled as Structural and ephemera. The chapter starts as:

As it can be seen, the book starts with a list of a summary for the chapters in the book. Since the book consists of 528 pages and 261 chapters in total, it might be hard to find a specific chapter for readers who are interested in only one chapter. Therefore, the book starts with a kind of table of content. This pattern can be observed in different books regardless of their genre if chapter titles are not well enough to explain what the chapter includes. Moreover, we observed that sometimes there might be a Structural and Ephemera labeled chapter at the start of a book with another purpose than we explained above.
Character List
Another frequent function is to give a list of character names that the reader will encounter during the text. We found that this function is only used in books whose main genre is Arts, specifically on drama texts. To exemplify, we will examine a drama book. The book’s main genre is Arts and most of the chapters are labeled as Arts, but the second chapter of the book was labeled as Structural Ephemera by our model and the chapter can be read below:

The inclusion of a character list in the second chapter, classified as ‘Structural Ephemera’ by our model, illustrates a distinctive approach to organizing and presenting dramatic works in 18th-century English literature. This practice not only aids readers in navigating the text but also reflects the genre’s conventions in terms of structure.
Subscription List
The last function we will mention in this paper is subscription list. We found that it was in different books.

Figure 13.
To exemplify, for the book whose signal chart is above, after a preface labeled as History by our model, we encountered a Structural and Ephemera labeled section and then the primary content was labeled as literature in keeping with the book’s main genre. The first page of the second chapter can be seen below:

The section contains the subscription list. While the function changed, the Structural and Ephemera category was heavily used in 18th century books.
The mono-genre aspect of Law
Our other analysis topic for this paper is on Law labeled books. An interesting and generalized pattern for Law labeled books we have found is that the books have a mono-genre aspect, for the most of time.
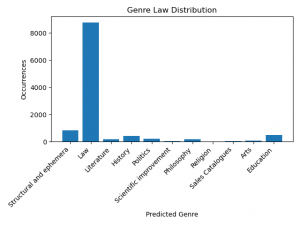
Figure 14.
In all Law labeled books, more than 8,000 chapters are labeled as Law by our model. The next most seen genre in law labeled books is Structural and Ephemera and then Education but none of them compasses more than one thousand chapters in the books. Compared to the other genre plots such as Education or History, the mono-genre aspect of the genre Law requires a special attention to explain.

Figure 15.
The Figure 15 shows an example from the book The Proceedings of a court-martial ‘Taken on the spot.’. The book’s main genre is Law and 81% of all chapters are labeled as law by our model. One of its chapters labeled as Law can be read below.


Figure 16.
Another signal chart for a law book is above. It shares the similar mono-genre aspect with the other law labeled book. Both of them dominantly contain one genre. What we have concluded is that the formality of the genre might restrict the authors to not expand their language as much as other genres such as education allows. This restriction shaped the genre in a way that most of the chapters in law labeled books share dominantly only one genre, which is Law.
Education and Scientific Improvement
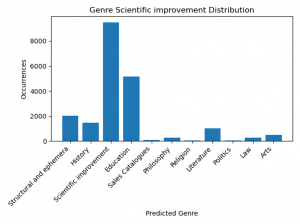
Figure 17.
In 18th century scientific improvement books, we have lots of education labeled sections. Among all genres, it is the second after scientific improvement in the books whose main genre is scientific improvement as can be seen in the plot above. Also, other genres were not as frequent that much compared to Scientific Improvement and Education. In our dataset, we have found that scientific works were often written with educational purpose. This purpose is embodied by a huge leap of education labeled sections in scientific improvement books as one can see in the plot of scientific improvement labeled books. In these books, we see a considerable amount of education labeled sections. For instance, in a book called Elements of algebra whose main genre is Scientific Improvement, 36,4% of all chapters were labeled as Education.

Figure 18.
The second chapter of the book Elements of Algebra is below:

As can be seen above, the education labeled section is about a scientific topic, algebra; however, the educational purpose is visible in the lines. We found that this pattern is very remarkable in scientific improvement labeled books.
We demonstrated the relation between education and scientific improvement genres in scientific improvement labeled books. One question we had during the project was whether the genre intersection between these two genres is reciprocal or not. In other words, do you have lots of scientific improvement labeled sections in education books or not?
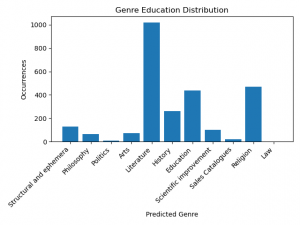
Figure 19.
The figure 19 shows the frequency of genres in education labeled books which answers our question above. In 18th-century English books, the relationship between education and scientific improvement appears asymmetric. This observation is underscored by the predominant genres in education-oriented books. Literature emerges as the most prevalent genre within these texts, followed by religious content. Notably, educational material itself ranks as the third most common genre. Intriguingly, scientific improvement, as revealed in Figure 20, is only the sixth most frequent genre in education labeled books. While this distribution might initially seem surprising to the contemporary readers, it matches with the expectations of educational books from the 18th century.
Richard A. Barney’s book Plots of Enlightenment: Education and the Novel in Eighteenth-Century England contextualizes this phenomenon. Barney claims that educational writings during the Enlightenment were instrumental in shaping a new concept of citizenship that had been emerging (Barney, 1999, p. 8). He suggests that the self is a construct, which can be shaped and influenced by scholarly discourse (Barney, 1999, p. 10). According to him, the Enlightenment Era in England was fundamentally anchored in integrating educational methodologies to drive societal reform (Barney, 1999, p. 11). Then he gives some examples on how educational books were used to train people and specifically minors morally and religiously (Barney, 1999, p.78, 177, 211, 251). However, as Figure 19 showed, the authors used literary texts to educational context. Thus, our findings are consistent with his work in this limited framework. The focus on literature and religion, as opposed to scientific issues, suggests that the educational goals of the time were aligned more with character building and moral instruction than with the dissemination of scientific knowledge.
Problems with the current classifier
Nevertheless, we don’t claim that our model doesn’t have any issues.
Misclassification
As all other classifiers, our model also has a misclassification problem which deviates the results from what it should be.
The book Sailing directions for Bristol and St. George’s channels published in 1799, has an education labeled book. However, the model classified it as scientific improvement.

Moreover, for a section in the book Essays on the trade, commerce, manufactures, and fisheries of Scotland, the actual label is Literature; however, the predicted label is Scientific Improvement.

In a book, A vindication of peaceable Robert Matthews, from the charge of Mrs. Ruscombe’s murder, lately revived against him written by John Casberd in 1681, the Law true-labeled chapter is labeled as Literature.

This might be due to the fact that the section starts with a short explanation of what happened and then it continues with conviction. However, since our model predicts the chapter’s label by considering only the first 512 tokens (510 input tokens and 2 special tokens). it considers only the short summary part which is a narrative part, the model labels the chapter as Literature. This misprediction demonstrates, firstly, a possible problem of the current method, considering only the first 512 tokens. Secondly, it shows the fluency of genres.
Multi language problem
Our model gives wrong predictions for non-English texts, such as French or Latin, since its training data is monolingual, including just English texts. Thus, encountering non-English sections leads to potential misclassifications, impacting the reliability of genre predictions. So, the model’s reliability for non-English text should be taken into consideration. One of the examples is a Latin written book whose main genre is Literature.

Figure 20.
Interestingly, for this book, our model classified more chapters as History than Literature. While this might be interpreted as the intersection of literature and history, the reason is different indeed. To understand this phenomenon, we checked the book pages. What we found was that the book was not, actually, written in English but Latin.

Therefore, the model’s prediction is not reliable for non-English texts. Another example is from a scientific improvement labeled book. For this book, our model didn’t predict any scientific improvement labeled section but education and history.

Figure 21.

However, again, since we didn’t use any Latin text in our training data and the prediction is not reliable.
List problem
Furthermore, in our study, we observed how the format and presentation of text within a book can influence the classifier’s predictions. For instance, chapters in list format, commonly seen in scientific improvement books, often misled the model. The structural format of these lists, typically used for enumerating points or data, was frequently misclassified as ‘Structural and Ephemera’. For instance, a scientific improvement labeled book in our data has four chapters and the model predicted its all genres as Structural and Ephemera.
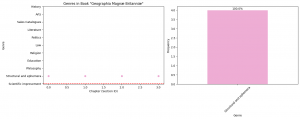
Figure 22.
When we looked at the pages, we found that the page format is a kind of list.
M: Miles – a unit of distance commonly used in the UK.
F: Furlongs – a smaller unit of distance that is equivalent to one-eighth of a mile.

The book is a navigation book including the distance between the places. However, the model couldn’t draw a good line between scientific improvement genre and Structural and Ephemera category for such list formatted pages.
Another book is an education labeled book. However, again, all of the chapters were labeled as Structural and Ephemera by our model.
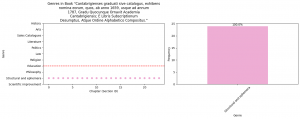
Figure 23.
The page is from the book whose signal chart is above. As it can be seen, the page is in list format. The format continues in almost all pages in the book which misled our model.
Such misclassifications highlight the need for more sophisticated text analysis techniques that can discern content beyond its structural presentation or building a model with more data.
Distant reading and close reading methods for validation analysis
In this research project, where the main aim lies in the section-level genre analysis of 18th-century English texts using BERT, we examine several questions. These include assessing the extent to which a book, labeled as a particular genre, genuinely aligns with that classification. We also explore how to quantify the presence of genre shifts and transformations in labeled texts and determine the percentage of genres within a single genre. These investigations are based on results obtained from testing the data of the ECCO-BERT-Seq classifier, utilizing the ECCO-BERT language model. Our findings have resulted in genre predictions across 11 categories.
Empirically, it has been found that the model shows more accurate results when using filtered data, as OCR-noise makes it difficult to predict genres.
The genres that the classifier predicts more accurately are those characterized by specific structures in their texts. Additionally, the model demonstrates accuracy in classifying the religious genre, possibly attributed to the distinctive vocabulary found in religious texts.Furthermore, good prediction accuracy applies to the religious genre, which may indicate the effectiveness of predictions characterized by a particular frequency of specific vocabulary compared to other genres.
The most challenging genres to recognize are philosophy and politics because they are ambiguous and often can be classified as overlapping. The model may not have enough data and special markers that would enable clearer classification of a section of text.
What markers can help identify overlapping genres such as philosophy and politics, literature and history, or literature and arts?
Since the classifier is sensitive to structural texts, the most likely logical conclusion would be to specify indicators that would help the model determine the structure used in writing different types of texts in the 18th century. There is a strong likelihood that specific themes and genres are associated with narrative points and certain rhythmic footprints in the text. Most likely, a text written for a public speech will be more rhythmically structured to give it a clearer perceptual framework.
But if the genres overlap, how can we establish that a section-level text belongs to philosophy in one case and to a political genre in another? Where do we attribute a text from the section if it could be labeled as both genres: philosophical and political? How do we determine the genre category in such cases? Similarly, how can we distinguish between literature and arts genres?
The most optimal indicators for determining the structure of a text of a certain genre within the framework of our study may involve stylometric analysis of the text within the section after classification with labeled genres. Stylometry can help identify subtle patterns and characteristics within the text that may not be immediately apparent through traditional methods.
If we extract the data obtained after prediction, including the first 50 words and the last 50 words of the section with a given genre, we can combine the methods of distance reading according to Moretti “Distant Reading” (2013) and traditional close reading. This allows us to check our understanding of the resulting text and manually determine its genre. We can then compare our definition with the classifier’s prediction and confirm the hypothesis that the classifier labels genres as a human annotator would.
Our aim is not to redefine the genre of the classifier after manual testing, but to understand what additional computational methods and tools we can use to further improve the model’s performance.
When utilizing stylometry, we cannot expect all the necessary parameters for determining the genre to be concentrated on one linguistic level. Therefore, it is better to take into account all layers, including syntax, punctuation usage, word frequency, sentence length, rhythmic repetition of words at the beginning and end of sentences, form, semantics, and other linguistic elements to unveil unique patterns associated with different genres of writing styles.
But, as each parameter requires careful testing to find the optimal approach, in this study, we will only begin to consider various stylometric parameters. Next, we’ll examine the punctuation frequency of each section with the predicted genre from the book with interesting behavior after analyzing the signal plots.
While analyzing the signal plots from the books after the classifier’s genres, we tried to take a look at some of the books and detect any interesting behaviors or patterns during the classification:

Figure 24. Plotting signals of genres from the book “The carmelite A tragedy, by Richard Cumberland, Esq. Adapted for theatrical representation, as performed at the Theatre-Royal, Drury-Lane. Regulated from the prompt-books, by permission of the managers.”
Figure 24 illustrates the distribution of genres and specifies that the main genre is “Аrts.”In terms of percentage, the classifier determines that in the book with the main genre being “Arts”, 25% of annotated sections are identified by the model as “Arts.” Section-wise, the book consists of 62.5%, identified as “Literature,” and 12.5% as “Structural and Ephemera.” It includes eight (8) genre-predicted chapters, with five (5) predicted as “Literature”, two (2) as “Arts”, and one (1) as “Structural and Ephemera.”
Let’s examine the textual data extracted from each section after genre annotation by the model:


Figure 25. First 50 words extraction from each section of the book.


Figure 26. Last 50 words extraction from each section of the book.
We extracted the model’s prediction data, which included the first 50 words and last 50 words of each section in a given genre. We can manually check what text is included in each section. We can also extract any specified number of words from each section for subsequent stylometric testing, or extract the entire text of a section (we will do this later to determine the punctuation frequency of each section).
However, the first paragraph consists of two sections, zero (0) and one (1). We will consider punctuation frequency in these sections separately, as hypothetically, they could have different genre labels. Additionally, we will examine the second (2) section with the predicted genre “Structural and Ephemera“, which includes a list of characters. As for the eighth (8) section, annotated as the ‘Arts’ genre and containing noise within the section, we will also test it for punctuation frequency to understand whether the punctuation characteristic of the text can influence the annotation of the sections or not.
Obviously, the classification “Structural and Ephemeral” is correct, since it presents a list of actors.
The main genre of the book is also correctly defined. In terms of models, 62.5% of the book’s content falls into the “Literature” genre.
Let’s look at the remaining 25%, which the model classifies as “Arts”. In the third section (3), the annotator can classify a literary text as both the “Arts” and “Literature” genres based on the first 50 and last 50 words, especially if clear annotation criteria are lacking.
Although the eighth (8) section is classified as “Arts”, a manual inspection of the text (close reading) reveals the presence of noise. It follows that the model is attempting to classify the section, perhaps by including punctuation parameters in the section analysis.
The result of book annotation indicates that even unfiltered data does not interfere with the classification of the main genre of the book.
To understand, deepen the features of text data, let’s apply stylometric tools and try to identify some patterns to find out whether punctuation data influences the classification of sections or not.
We can try to analyze the text data in each predicted section by counting the frequency of punctuation, as it is a critical layer for understanding stylistic features, emphasis and rhythm, genre differences, attribution, and text structure analysis.
Since we are just beginning to look for some patterns and indicators to determine the structure of fuzzy and overlapping genres, we can begin the experiment by analyzing the punctuation frequency of each predicted genre segment to confirm or refute the hypothesis of the influence of punctuation frequency on genre choice.
Punctuation footprint
The punctuation analysis is mainly carried out with a view to better understand the meaning of the different types of texts. Punctuation is believed to play the role of ‘assisting the written language in indicating those elements of speech that cannot be conveniently set down on paper: chiefly the pause, pitch and stress in speech’ (Markwardt, 1942: 156). While many linguists link punctuation with intonation, the reality is more intricate – punctuation marks can impact orthography, morphology, syntactic relations, semantic information, and even influence the structure of the text. Rong W., Kun S. (2018)
In this study, we will attempt to compare the frequency of punctuation within each section and identify possible patterns or similar quantitative characteristics of sections that have been assigned the same genre categories by the classifier.
We will try to identify the punctuation footprint of each predicted genre.
Punctuation frequencies in the predicted genre “Literature”
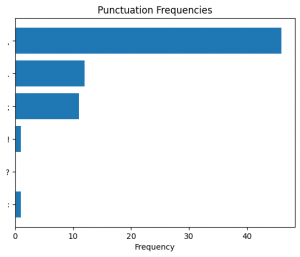
Figure 27. Punctuation frequency in the first (0) section predicted as “Literature.”
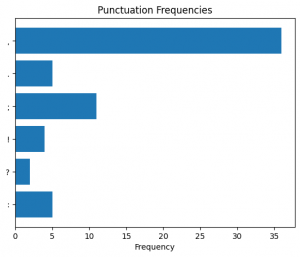
Figure 28. Punctuation frequency in the first (1) section predicted as “Literature.”
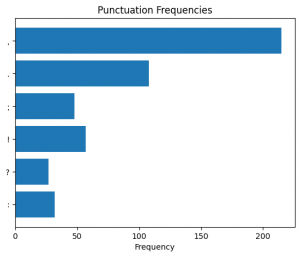
Figure 29. Punctuation frequency in the fourth (4) section predicted as “Literature”.
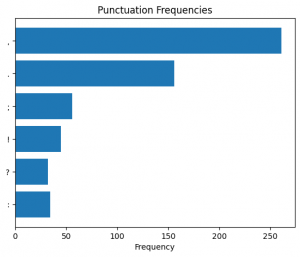
Figure 30. Punctuation frequency in the fifth (5) section predicted as “Literature”.
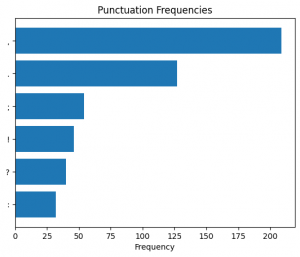
Figure 31. Punctuation frequency in the sixth (6) section predicted as “Literature”.
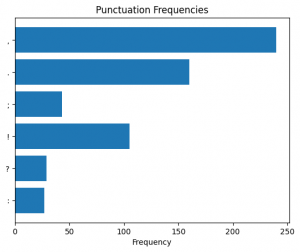
Figure 32. Punctuation frequency in the seventh (7) section predicted as “Literature”.
Punctuation frequencies in the predicted genre “Arts”

Figure 33. Punctuation frequency in the third (3) section predicted as “Arts.”
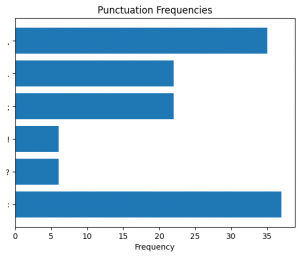
Figure 34. Punctuation frequency in the eighth (8) section predicted as “Arts”
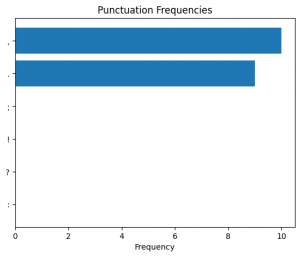
Punctuation frequencies in the predicted genre “Structural and Ephemera”
To compare the values, we took six meanings of punctuation marks: comma, period, question mark, exclamation mark, colon, semicolon and checked their cosine similarity between sections with similar predicted genre and different predicted genre.
In our analysis, we employ the cosine similarity measure to study the punctuation frequency patterns. This measure is a tool in understanding the degree of alignment in punctuation usage between different sections. By comparing the cosine similarity values, we gain insights into the extent of similarity or dissimilarity in the punctuation frequency patterns across various sections.
In the context of our analysis, a cosine similarity close to 1 suggests high similarity in punctuation usage between sections, while a value closer to 0 indicates less similarity. This similarity measure helps us understand how closely the punctuation frequency patterns align between different sections.
Cosine similarity between sections alternately:
Section 0 and Section 1 = 0.9806503580922247
Section 1 and Section 2 = 0.7806569878153415
Section 2 and Section 3 = 0.9495059401644016
Section 3 and Section 4 = 0.9625170995133123
Section 4 and Section 5 =0.9938777893743037
Section 5 and Section 6 =0.9848271003157376
Section 6 and Section 7 = 0.9814162217183454
Section 7 and Section 8 = 0.7787270596461574
Cosine similarity between sections 2 and 8
“Structural and Ephemera” and “Arts”(noisy):
Section 2 and Section 8 = 0.6756920506126546
Cosine similarity between sections 8 and 7:
“Arts” (noisy) and “Literature”
Section 8 and Section 7 = 0.7787270596461574
Cosine similarity between sections 8 and 3 “Arts”:
Section 8 and Section 3 = 0.813066578926062
Can the model incorporate punctuation frequency as a signal at some layer? Additionally, why did it categorise the noise, consisting of letters and punctuation marks with an entropic distribution, as the “Arts” genre in this specific case? Was it influenced by the numerical coefficient, where the difference between periods and commas closely resembled the coefficient of the “Arts” section? Alternatively, was this decision based on the residual principle? If certain parameters to determine a portion of the text are absent, does the model default to categorise the main category?