
Spring 2023: Traces of Macbeth: A Study of Text Reuse
Table of Contents
Materials and methods
Data collection and processing
We mainly utilized the Shakespeare text reuse dataset (Rosson et al., 2023) by the Helsinki Computational History Group. It is a subset of the Eighteenth Century Collections Online (ECCO) and Early English Books Online (EEBO-TCP), consisting of text reuses connected to the works of William Shakespeare. Crucially, the data includes the textual content of the reuse instances, allowing for natural language processing (NLP) techniques to enable a deep semantic understanding of the textual reuse landscape.
From this dataset, we queried for reuses of Macbeth specifically. After some trials and errors, we obtained roughly 44 thousand instances of reuse connected to Macbeth.
Text correction with GPT-3.5
However, after a process of discovery and analysis, we found that there are numerous problems with both the content and the structure of the data. Regarding the content of reuses, most of the passages contain OCR errors, to the point of them being intelligible.
This problem can either severely decrease the accuracy of most types of natural language processing (NLP) techniques, or prevent them from working altogether. To address this problem, we turn to one of the most popular advanced large language models called GPT-3.5 (Brown et al., 2020), also known as ChatGPT. The model is trained on a massive corpus of books, news articles, websites, etc, and this corpus certainly includes Macbeth itself. Our hypothesis is that the model memorized the data it trained on (Chang et al., 2023), so much so that it can recall individual passages of Macbeth on demand. We then experimented with the capability of GPT-3.5 to fix any OCR or spelling errors. One example is given below.
Given that our hypothesis is validated, we use GPT-3.5 to correct the text reuses at scale. The prompt is simple:
[{“role”: “system”, “content” : “You fix bad-quality OCR from Macbeth. Reply with ONLY the corrected text in quotes.”}, {“role”: “user”, “content” : f”<{text}>”}]
The computation took 16 hours when parallelized over 12 cpu threads, and cost ~10€ of OpenAI credits. We manually went through some samples of corrections made by GPT and judged that they were sufficiently “clean” for NLP analysis.
Additionally, we found that the Macbeth data seems to include many near duplicates of the same reuse. Near duplicates, because reused passages of the duplicates were not identical but extremely similar. We filtered these duplicates by taking the reuses from one target ‘document id’ and removing the reuses that would start at the exact same location in that document id. After these steps, we arrived at 22 thousand samples of GPT-corrected text reuse passages connected to Macbeth.
Data visualization and topic modeling
Now, we can start answering the research questions prompted in the beginning. For the first two questions,
“How were the versions quoted throughout the century?”
“Who reused Macbeth and how?”
We can visualize crucial metadata information, such as the versions of Macbeth included in the dataset, the texts and the authors that borrow Macbeth, and the geography of the reuses. For each dimension, we can look at different angles, such as time and places, that give us rich perspectives. One of the most important statistics that we use is the count of reuse instances. By inspecting the number of reuses, e.g. authors, target texts, and publication places, we can identify the important characteristics of the Macbeth reuse landscape.
Clustering similar passages
“What kinds of [Macbeth] passages were reused” is a monumental, multifaceted question that we tried to answer next. It requires that we dive into the textual content of the reuses and extract insights at scale. Thus, we would need to group together all the passages that are from the same act and scene in Macbeth. Additionally, grouping the reuses in this way allows us to investigate if different authors are reusing the same passages from Macbeth.
The clustering process was done in three parts: passage encoding (TF-IDF), calculating a passage distance matrix, and applying a clustering algorithm (HDBSCAN). TF-IDF (short for term frequency–inverse document frequency) is a text encoding algorithm that explicitly calculates a weighted importance value for each word in a corpus with respect to the other documents (in our case passages) in the corpus. The encoding of a single passage is a vector of values corresponding to the words in the passage; the vector has the same length as the vocabulary of the corpus. Since HDBSCAN is a density-based clustering algorithm, which clusters data points based on a distance metric, we precompute a distance matrix from our passage encodings. We use cosine distance as the metric since it is generally applicable for similar NLP tasks.
TF-IDF and HDBSCAN were deliberately chosen for this clustering task. TF-IDF was chosen over more advanced (semantic) encodings because we wanted to ensure that passage encoding only contains information about the literal words in each passage. HDBSCAN was chosen because it is an effective unsupervised method for clustering with very few hyperparameters (McInnes, Healy & Astels, 2017). Most clustering algorithms require that the number of clusters is specified before clustering, but HDBSCAN is designed to infer the number of clusters from the data. This is ideal because we don’t know how many groups of similar passages to expect.
From 22k passages, the clustering process found around ~400 clusters, and ~8k unique passages. These results were manually validated by inspecting the clustered passages.
Passage embeddings visualization
Given 22 thousand reuse passages, how do we make sense of it all? An intuitive way is to visualize these passages semantically by mapping them to a vector space. Similar to word embeddings, the distance in this passage embedding space should encode the semantic similarity between the sentences. However, this task is not trivial, as Macbeth reuse passages are long, with antiquated language, which directly impacts the performance of NLP techniques that are pre-trained on predominantly modern English data.
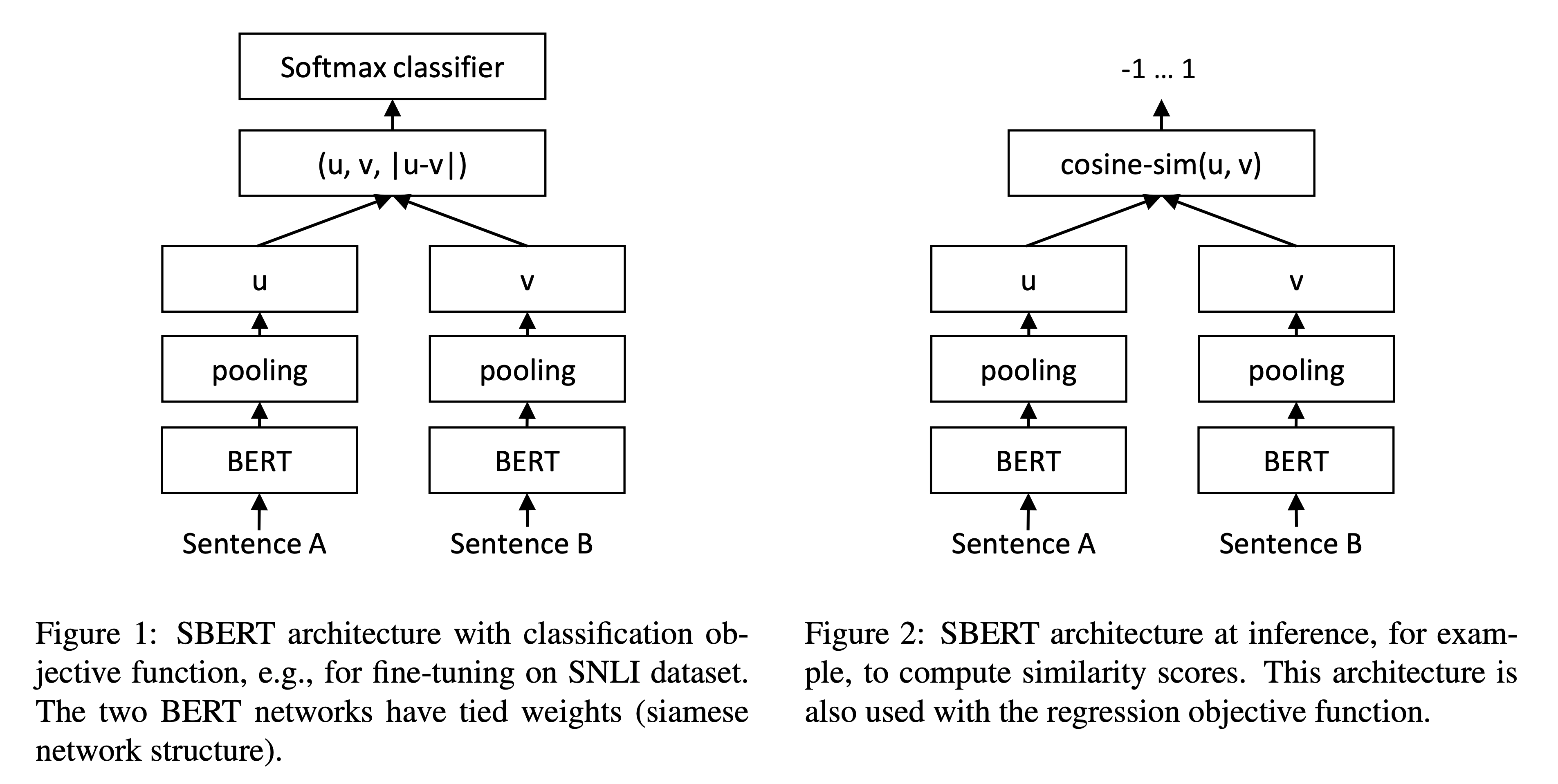
One of the prime candidates for this task is the BERT language model (Devlin et al., 2018). It is one of the state-of-the-art encoder-only language models that can generate highly contextual embeddings. However, it is not trained on any task that is ‘aligned’ with the semantic similarity task—critical for our embedding application. Consequently, studies (Reimers & Gurevych, 2019; Ethayarajh, 2019). have shown that BERT embeddings underperform classical methods such as GloVe.
A solution is Sentence-BERT (Reimers & Gurevych, 2019). It is a BERT-based architecture that explicitly models the semantic similarity task using siamese and triplet network architectures. As a result, it can derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. The authors evaluated SBERT on semantic textual similarity and SentEval tasks and showed that it outperformed vanilla BERT as well as state-of-the-art methods.
Now that we have found a method for embedding text reuse passages, we can proceed to visualize the landscape of Macbeth’s text reuses. Since the SBERT embeddings are high-dimensional, we perform dimension reduction using Uniform Manifold Approximation and Projection (UMAP). UMAP can preserve both the local and the global structure of data, thus producing low-dimensional embeddings that are visually informative.
Topic modeling
Rich as the previous visualization is, something is still amiss. There is no organization and characterizations of the different areas within this semantic distribution. In turn, it is difficult to have a sense of what this distribution means in the literary analysis context. Fortunately, a tool that exactly addresses our needs is topic modeling. Topic modeling is a time-tested machine learning technique for extracting clusters along with their representative words from large unstructured sets of documents. Using topic modeling, we can assign passages (circles in our visualization) to clusters, as well as give literary interpretations to those clusters.
There are many ways to perform topic modeling such as LDA and ZeroShotTM. Yet, a recent paper by Zhang et al. (2022) showed that clustering on top of the UMAP dimensionality reduction—what we have done so far—can achieve competitive results with state-of-the-art methods. Subsequently, we followed the clustering method by tuning the hyperparameters appropriately, then extracted the topic words using the TFIDF x IDF_i index proposed by the authors. Now, we can finally visualize the full landscape of Macbeth text reuse:
However, clusters and topic words as they are do not provide us with good insights. We need to give thematic interpretations to the clusters, characterizing and contextualizing them with respect to Macbeth. To do this, humanities students worked alongside ChatGPT to make sense of the topic clusters and topic words. The results are fascinating, and we shall explore them further in the ‘Analysis’ section.
Framing in target texts and intertextuality analysis
We analyzed the intertextuality of the target texts from two angles: topical and lexical. To limit the scope of this analysis, we used the 1711 edition of Macbeth and the target texts that are linked to it. Lexically, the similarity is measured by the Jaccard bag distance between the reuse pair’s full text. The more overlapping vocabulary, the higher the lexical similarity. Topically, the similarity is measured by the Janson-Shannon distance between the topic distribution of the reuse pair’s context. The context is the combination of upper and lower snippets around the target text, which are the same length (see the figure below). This way, the measurement of topical similarity between the reuse pairs disentangles with the lexical: the analyzed snippet does not include the reuse text, therefore the lexically similar part would not contribute to the topical similarity.

More specifically, we used the following open source tools for computation: Mullen’s (2020) textreuse package in R for lexical similarity, and Řehůřek & Sojka’s (2010) Gensim for topic modeling and topical similarity.