
[Lisäys 21.10.2008: OAI-ORE 1.0 on ilmestynyt, ks. lehdistötiedote.]
Nordbibin rahoittama pohjoismainen projekti, jossa Kansalliskirjastokin on mukana, järjesti 22.-23.9. Tukholmassa seminaarin OAI-ORE:sta. Ensimmäisenä päivänä saimme johdatuksen ORE:en, paikalla olivat idean isät Herbert van de Sompel ja Carl Lagoze. Toisena päivänä ohjelmassa oli pienemmän porukan työpaja, jossa mietittiin ORE:n käytännön sovelluksia. Intensiivisen rupeaman jälkeen OAI-ORE:n dokumentaatiota alkaa vähitellen ymmärtää, kylmiltään aivot eivät oikein suostuneet ottamaan sitä vastaan.
Lyhenteen OAI-ORE taustalla ovat sanat Open Archives Initiative – Object Exchange and Reuse. Sitä on nimen mukaisesti kehitetty OAI-hankkeen yhteydessä, jonka tuotoksista paremmin tunnetaan OAI-PMH – Protocol for Metadata Harvesting.
Mitä se OAI-ORE sitten on?
Huomion kohteena ovat kompleksiset objektit, jotka koostuvat useammasta kuin yhdestä tiedostosta. Ottaaksemme selkeän esimerkin, ajatellaan ArXiv.org:ssa julkaistua artikkelia. Tässä on kuva yhdestä:

Oikeastaan tämä ei olekaan kuva artikkelista, vaan sen nimiösivusta eli splash pagesta. Sivulla on bibliografisia tietoja, tiivistelmä sekä linkki itse artikkeliin. Tai paremminkin: linkkejä itse artikkeliin, sillä se on saatavissa myös docx-formaatissa. Lisäksi sivulla on linkkejä artikkelin sitaatiotietoihin ja muihin artikkeliin liittyviin tietoihin.
Oikeastaan siis artikkelin kokonaisuuden muodostavat nimiösivu ja sivut, joihin siltä pääsee linkkien kautta; ei kuitenkaan kaikki, mihin linkit vievät, esim. tuloslistan seuraava artikkeli.
ORE tekee tällaisista yhteenkuuluvista verkkoresursseista yhden olion, joka on konelukuisesti tunnistettavissa. Englanniksi termi on “aggregation”, suomeksi kenties “koonnos”, joka Kielitoimiston sanakirjan mukaan tarkoittaa “kokoamisen tulosta”. Koonnos voisi sisältää vaikkapa “tutkijan julkaisemat artikkelit”, “verkkolehden tänään ilmestyneet artikkelit” tai “tieteellinen artikkeli ja siihen liittyvät tieteellisen datan lähteet”.
Koonnos on olemassa vain käsitteenä – sen muodostavat aineistot saattavat olla eri paikoissa ja hyvin eri tyyppisiä. Mutta mielivaltaisenkin koonnoksen voi määritellä ja kuvailla. Tämän dokumentaation nimi on “resource map” eli aineistokartta.
Siinäpä se ORE oikeastaan olikin: se on tapa
- määritellä mielivaltainen joukko verkkoresursseja kokonaisuudeksi,
- kuvailla joukon rakenne ja suhteet; ja
- antaa sille identiteetti.
Yksi metafora ovat tähtikuviot: ne ovat koonnoksia resursseista, tässä tapauksissa tähdistä; tähtien välillä vallitsevat tietyt suhteet; ja koonnoksella on identiteetti, esim.”Otava”. Eri kulttuureissa koonnokset saattavat poiketa toisistaan, mutta tarkoitus on sama: auttaa hahmottamaan tähtitaivaan informaatiota ja luomaan siihen lisäarvoa.
Taustalla on sitten paljon pohdintaa ja yksityiskohtia. van de Sompel ja Lagoze korostivat toistuvasti sitä, että ORE pyrkii mukautumaan WWW:n tekniseen arkkitehtuuriin ja käyttämään sitä hyväkseen; tämä sisältää myös sen, ettei pyritä kehittämään uusia standardeja tai teknologioita. Myös RDF:ää hyödynnetään runsaasti. Tutustumisen arvoinen on myös Cool URI, jolla on myös käyttöä ORE:ssa; siitä kannattaa ehkä kirjoittaa myöhemmin lisää.
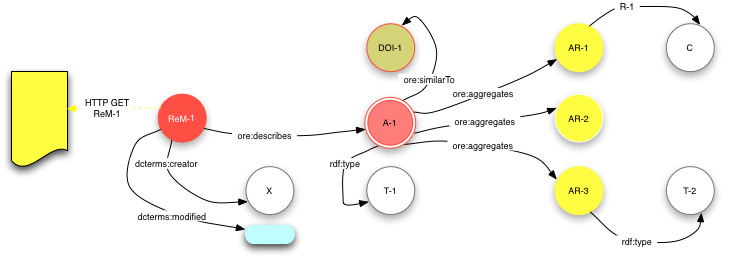
ORE: koonnoskartta, koonnos ja aineistot
On huomattava, että koonnoskarttaa ei välttämättä tuota aineiston julkaisija, vaan aineisto on vapaata riistaa kenen tahansa liittää erilaisiin karttoihin eri tilanteissa. Tukholmassa jo esiteltiin ensimmäisiä versioita työkaluista, joilla koonnoskarttoja voi tehdä helposti.
Koonnoskartan voi esittää (serialisoida) eri tavoin. Koonnoskartttojen löytäminen ja käyttöön saaminen voi perustua erähakuihin (OAI-PMH, SiteMaps, syötteet), joiden avulla siis siirretään suuri määrä tietoa koonnoskartoista kerralla uuteen paikkaan. Syötteet ovat laajasti käytössä, mikä helpottanee myös koonnoskarttojen käyttöönottoa. Kokoelmakartan voi toki esittää myös yksittäin ja ihmislukuisessa muodossa.
Mutta mitä hyötyä tästä kaikesta sitten on? Iso kysymys mielestäni liittyy ORE:n konelukuisuuteen; muuten koonnoskartta ei oikeastaan ole kuin ylevöitynyt linkkilista. Kansalliskirjastoissa ORE on herättänyt mielenkiinota siksi, että sen avulla voitaisiin kehittää aineiston luovuttamista pitkäaikaissäilytykseen toimivina kokonaisuuksina. Tällä hetkellä sen varmistaminen, että esim. päivän lehti todella tulee verkosta kerättyä kokonaan, on joko epävarmaa tai työlästä. Automaattisesti generoituva koonnoskartta voisi välittää tarpeellista informaatiota tarkasti ja ennen kaikkea automaattisesti.
ORE:en on osoitettu kiinnostusta mm. Driver-projektissa, joten siitä todenäköisesti kuullaan vielä etenkin tieteellisen julkaisemisen yhteydessä.