
Author: Tatu Leppämäki
In a nutshell: A geoparser recognizes place names and locates them in a coordinate space. I explored this topic in my thesis and developed an open source geoparser for Finnish texts: find it in this GitHub repo.
As geographers, we are interested in the spatial aspects of data: where something is located is a prerequisite to the follow-up questions of whys and hows. Of the almost innumerable data sources available online – news articles, social media feeds, digital libraries – a good portion are wholly or partly text-based. Texts and the opinions and sentiments within are often related to space through toponyms (place names). For us humans, it’s very easy to understand a sentence like “I’m enjoying currywurst in Alexanderplatz, Berlin” and the spatial reference there, but geographical information systems process data in unambiguous coordinates. To bridge this gap between linguistic and geospatial information, the text must be analyzed and transformed: in other words, it must be parsed. This is the motivation for the development of geoparsers.
Geoparsing: what and why
Geoparsing can be divided into two sub-tasks: toponym recognition and toponym resolution. In the former, the task is to find toponyms amidst the text flows and in the second, to correctly locate the recognized toponyms. A geoparser wraps this process and outputs structured geodata.
 Geoparsing: a top-level view.
Geoparsing: a top-level view.
Geoparsers, and at least toponym recognition methods, are often exclusively for one language. While English is pretty well covered when it comes to geoparsers (e.g. The Edinburgh Geoparser, GeoTxt, Mordecai), Finnish lacks general-purpose geoparsers to my knowledge. I believe it’s essential that research using geoparsed data can be done with Finnish, which is why I embarked on my thesis. I had two main objectives: (1) understand geoparsing as a task and the methods applied to tackling it and then (2) apply this information to create a geoparser for Finnish texts.
Why would we need geoparsed content? One reason is related to the declining use of geotags, for example the removal of exact geotags from Twitter, and the worsening availability of social media content through open interfaces in general. There’s more need to parse digital content so that it can be applied to succeeding data analysis. And texts can be rich in content: a successfully geoparsed text ties the content (opinions expressed, sentiment or mood analyzed) to a place. This is why geoparsing has been applied to fields ranging from literature studies and history, by geoparsing toponyms in books and historical documents, to disaster management, by tracking these quickly emerging events through geoparsed tweets.
Geoparsing methods
As mentioned, geoparsing is divided into two tasks, toponym recognition and toponym resolution. Recognizing toponyms can be seen as a specific application of Named Entity Recognition (NER), where the task is to find spans of texts that fall into some pre-defined class of interest (see below). In this case, we are only interested in place names. In geoparsing, toponyms can be regarded as something that defines an entity with a location in the world – for example administrative areas, various facilities, roads, and natural features that have been named.
 Example of Named Entity Recognition (NER).
Example of Named Entity Recognition (NER).
Various computational methods, such as writing rule collections, have been applied for toponym recognition. The state-of-the-art relies on machine learning classifiers that try to define whether a word is a toponym given the context it appears in. A specific machine learning technology, artificial neural networks, has proven to be especially potent, both in general Named Entity and toponym recognition. One application of neural algorithms is to train language models with massive crowdsourced textual datasets. Through seeing so many examples, these pre-trained language models gain (limited) understanding of the language they were trained on: this can then be further applied to specific tasks – like toponym recognition!
Toponym resolution deals with resolving the toponyms recognized in the previous step to correct locations. Toponym resolvers traditionally query databases of place names, such as GeoNames, NLS’s Finnish place name database, Who’s on First or OpenStreetMap. These databases are known as gazetteers. Gazetteers contain place names, location information (often as coordinate points), and various attribute information, such as populations of places and their alternate names. If there are matches, the gazetteer query returns candidates, from which the geoparsers then try to solve (disambiguate) the correct location. For example, Helsinki is ambiguous: does it refer to the capital of Finland or the small village in Southwestern Finland?
Often the disambiguation method ranks the candidates to find the most probable pick. There are numerous disambiguation methods, such as selecting the most populous place and minimizing the spatial distance to other places in the same document. The latest advancements are again built on neural methods – many resolvers try to understand the correct candidate from the textual context (like humans do!). This is done by modelling the text surrounding the target toponym and using it as a feature to locate it on the globe.
Geoparsing Finnish texts
Languages are not alike and any geoparsing methods developed (rules written or machine learning classifiers trained) for other languages often can’t be applied to Finnish as-is, because they exploit the features of their target language. Finnish, like many other languages including Estonian and Turkish, tend to conjugate words to a whole different extent than English. This means that the toponyms recognized are not in their lemmas, or base forms (in Turku – Turussa), which in turn means they’re challenging to resolve: only the base forms are saved in gazetteers, after all. An additional processing step of transforming the conjugated toponyms to base forms, called lemmatization, is therefore needed. Lemmatization adds a source of error not present in English geoparsing.
In addition, Finnish lacks ground-truth datasets, which are crucial to understand how well a geoparser performs, what types of errors they make, and to train new classifiers. To enable these, I and two annotators created two test sets for Finnish geoparsing. They are publicly available here. One of these consists of news articles (n=42) and the other of tweets (n=980). Basically, each toponym and the corresponding location information in the form of a coordinate pair from GeoNames gazetteer is marked. See how the toponyms are distributed below: most of them fall in Finland.
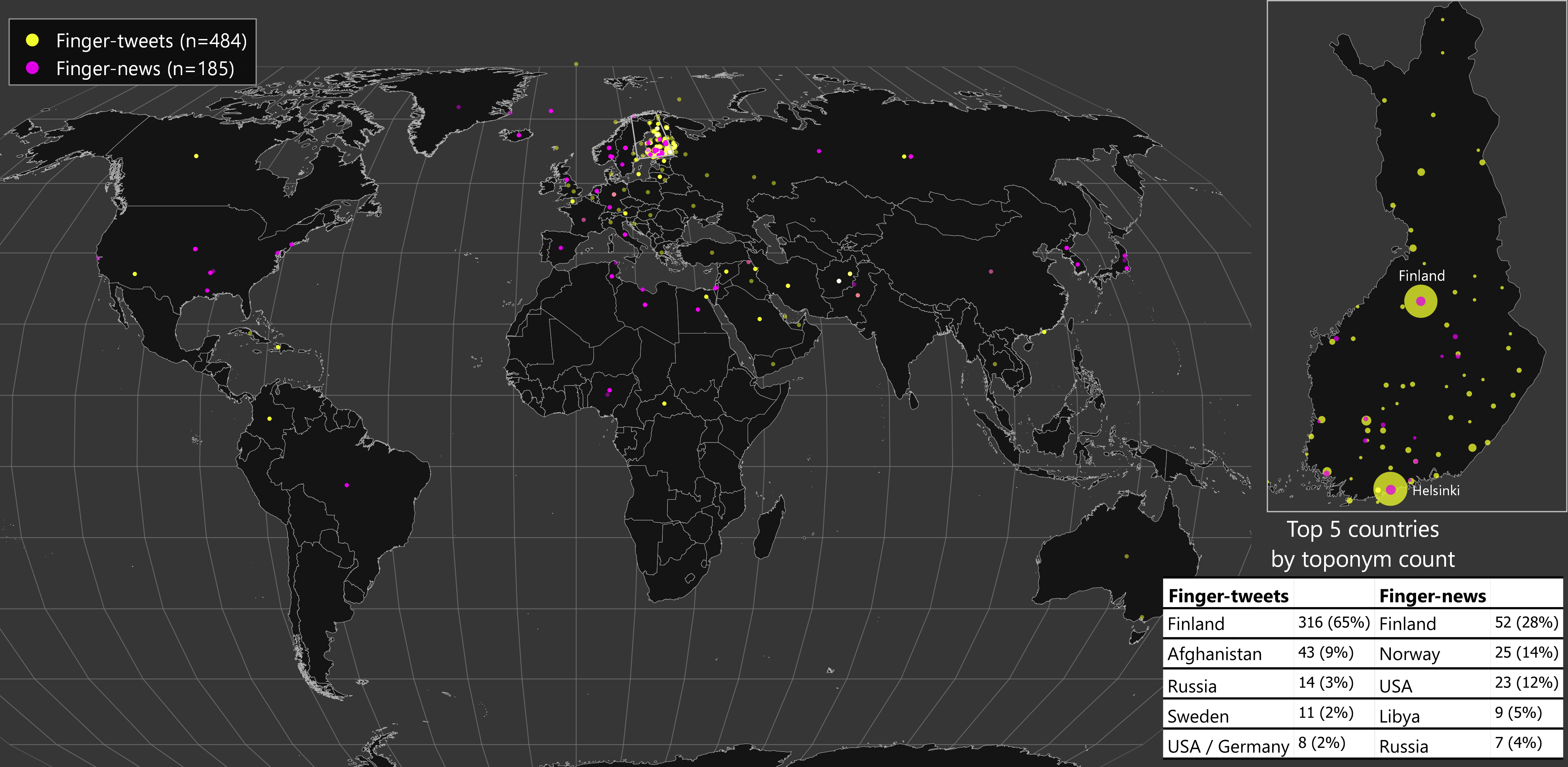 Distribution of toponyms in the two corpora.
Distribution of toponyms in the two corpora.
Finger: the Finnish geoparser
The main output of my thesis is a geoparser for Finnish texts, named Finger (FINnish GeoparsER). Finger is written in Python. My guiding principle was to make Finger an useful exploration of Finnish texts. To be useful, the program must be openly shared, easily understandable, and installable. I also decided to rely on ready-made libraries (such as NLP library spaCy and Pandas for data analysis as to not re-invent the wheel.
![]() From the user’s point-of-view, Finger simply accepts a list of input texts and outputs a table (a Pandas DataFrame) where each recognized toponym has been lemmatized and then resolved to lat-lon coordinate points. It should be kept in mind that any of these steps can and often will fail. Under the hood, the toponym recognizer in Finger is based on a neural language model fine-tuned for general Named Entity Recognition. Only the relevant location entities are collected and further processed by Finger. The pipeline is implemented in spaCy except for the lemmatization (based on the Voikko library). Finally, the online version of GeoNames gazetteer is queried with the lemmatized toponym and the primary candidate returned by the query is accepted.
From the user’s point-of-view, Finger simply accepts a list of input texts and outputs a table (a Pandas DataFrame) where each recognized toponym has been lemmatized and then resolved to lat-lon coordinate points. It should be kept in mind that any of these steps can and often will fail. Under the hood, the toponym recognizer in Finger is based on a neural language model fine-tuned for general Named Entity Recognition. Only the relevant location entities are collected and further processed by Finger. The pipeline is implemented in spaCy except for the lemmatization (based on the Voikko library). Finally, the online version of GeoNames gazetteer is queried with the lemmatized toponym and the primary candidate returned by the query is accepted.
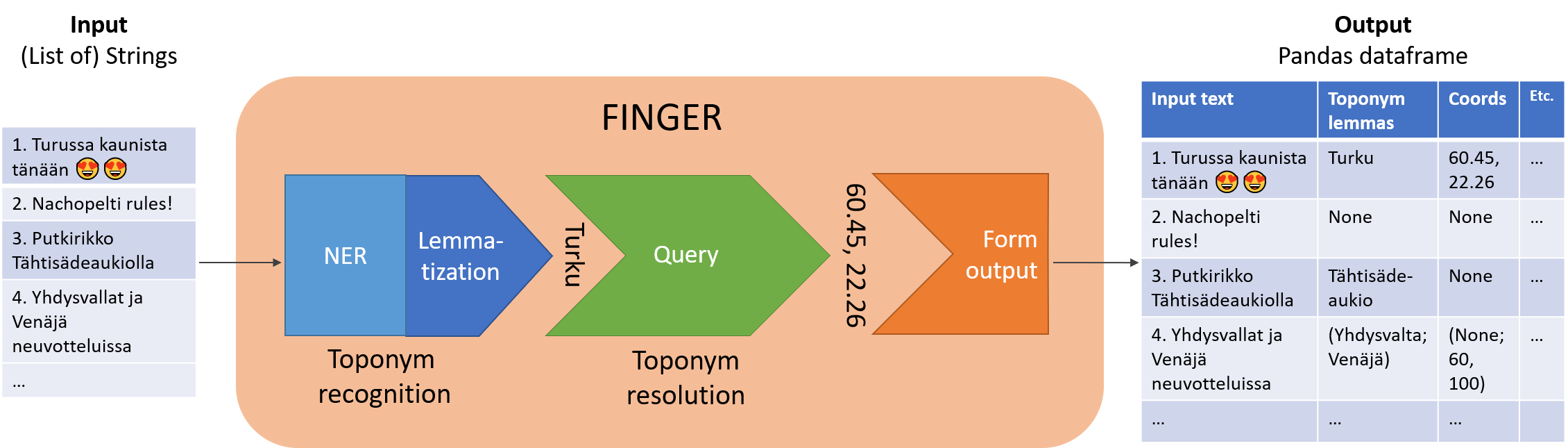 How Finger works?
How Finger works?
Finger uses out-of-the-box methods: a general-purpose named entity recognizer and a simple gazetteer query. Are they enough for this task? To test that, I evaluated the system’s performance against the tweet and news datasets: the closer the geoparser performs to the human marked ground-truth, the better. The results are presented in full in the thesis, but I found that the majority of toponyms were correctly recognized and then resolved on both datasets. News articles and tweets differ in length and often in the level of formality, but Finger performed about equally on both. For the first version of the program, these results are promising.
Caveats
While I’m excited to develop and share this work, there are a number of cautions one should consider before using data output by Finger and other geoparsers. Some of these are listed below.
First, Finger doesn’t currently geoparse documents, but all the toponyms within. In other words, if there are three toponyms in a tweet, Finger doesn’t try to distill the geographical target area of the tweet, but rather just attempts to correctly geoparse toponyms in the text. This point is especially relevant if geoparsing is used for geolocating people, e.g. through social media posts. An additional analysis step is needed for the so-called document geoparsing.
Second, the point coordinates returned by Finger can be a poor representation of the actual locations. For example, what does a point tell of the extents of Canada? Because the input texts are unstructured, it’s to be expected that the output data is multi-scale: it ranges from fine-grained, such as a single facility, to coarse, such as a continent. Though location information expressed as coordinate points appear deceptively precise and uniform, the user should carefully consider which spatial analyses are appropriate (e.g. point pattern analyses) and at what scale. Moreover, when is Canada treated as a location and when is it a geo-political entity? Such ambiguity is frequently present in language, for example in Canada signed the Paris agreement. The user should be aware of what the geoparser considers a location.
Third, as with all data and methods, critical user oversight is needed when using Finger. The toponym recognizer is expected to make some errors, both falsely marking non-toponyms and omitting real toponyms. The toponym resolver similarly leaves some toponyms unresolved and falsely locates others. Method advancements can quell these problems but never eliminate them. Finger output can for example be a starting point for gathering georeferenced data, which is followed by user supervision. I imagine user input is especially useful for geoparsing challenging texts, like those with colloquialisms and historical documents.
Conclusion and what comes next
In my thesis, I focused on understanding and developing a method for geoparsing Finnish texts. Data is produced in huge quantities every second, but heaps of it are initially unstructured, which creates the need for tools like Finger. My hope is that geoparsing will prove to be a useful method not only for geographers looking to access new sources of geodata but for all researchers interested in spatial linkages in texts. While I have some ideas on how to further improve Finger, Finnish geoparsing needs to be advanced through case studies to truly test its usefulness (for example, see the sports facility application by Koivisto). For my part, I’ll continue working on geoparsing under the ongoing MOBICON project as a PhD researcher at the Digital Geography Lab. If you’re interested in the concept, Finger and the other resources are openly available (see source code and installation instructions in this repository). See also the full thesis: ”Developing a Finnish geoparser for extracting location information from unstructured texts”.
The thesis was supervised by Tuuli Toivonen (Professor in Geoinformatics, Univ. of Helsinki) and Tuomo Hiippala (Assistant Professor in English Language and Digital Humanities, Univ. of Helsinki). Both supervisors and the author are members of the Digital Geography Lab, an interdisciplinary research team focusing on spatial Big Data analytics for fair and sustainable societies.