
As of March 2016, we have started to release the revised versions of monograph items in Fenno-Ugrica collection. Based on vocabulary that gathered in the proof-reading campaign during summer 2015, we have enhanced our OCRing (optical text recognition) procedures and managed to improve the quality of monographs.
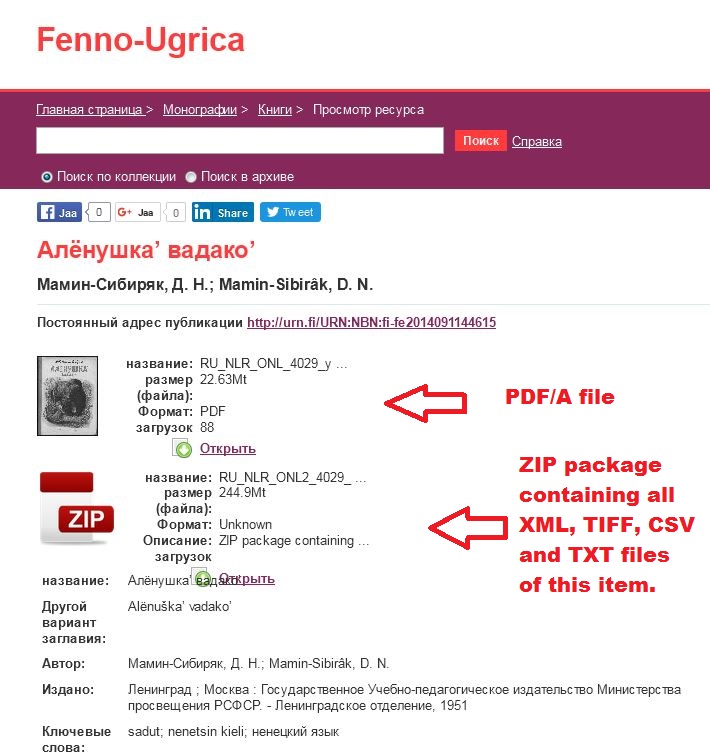 In addition to the revised PDFs, we are realising the dataset of the digitized monographs item. On the side of the PDF copy, you will and a ZIP package that contains all TIFF, XML, TXT and CSV of each individual items. The TXT and CSV files are quite reliable when it comes to the word accuracy, but unfortunately the XML files aren’t equally good. This is due to dual procedure at our end, as the XML files are created with the help of another programme than the others and its vocabularies cannot be customized to meet the standards. This problem does occure especially with the texts which are originally written with Latin alphabets in Khanty, Mansi and Komi. The Cyrillic versions, however, are somewhat good. If you are unhappy with the quality of the data, you may find the TIFF files as useful for your work.
In addition to the revised PDFs, we are realising the dataset of the digitized monographs item. On the side of the PDF copy, you will and a ZIP package that contains all TIFF, XML, TXT and CSV of each individual items. The TXT and CSV files are quite reliable when it comes to the word accuracy, but unfortunately the XML files aren’t equally good. This is due to dual procedure at our end, as the XML files are created with the help of another programme than the others and its vocabularies cannot be customized to meet the standards. This problem does occure especially with the texts which are originally written with Latin alphabets in Khanty, Mansi and Komi. The Cyrillic versions, however, are somewhat good. If you are unhappy with the quality of the data, you may find the TIFF files as useful for your work.
At the moment, the enhanced PDFs and data packages are available in Khanty, Mansi, Nenets and Selkup. The improved PDFs and datasets for the other languagues will be made available in April 2016.
Yours &c.,
Jussi-Pekka
Your explanation is organized very easy to understand!!! I understood at once. Could you please post about baccaratsite ?? Please!!
provigil generic price
augmentin 625 prices
buy suhagra online india
cost of generic phenergan
triamterene for sale
canadadrugpharmacy com
4000 mg metformin daily
canadian pharmacy robaxin
tadacip cost
prazosin 0.5 mg
nolvadex online order
levaquin.com
phenergan 6.25
triamterene 37.5mg
vermox medication
price of levaquin
buy robaxin no prescription
how to buy nolvadex in usa
buy cialis 60mg
buy cialis soft tabs online
dexamethasone 1 mg
valtrex pills where to buy
lipitor 5mg
where can i buy robaxin
tadalafil 10
1 atenolol
robaxin 400 mg
nolvadex 20mg buy
triamterene-hctz 37.5-25 mg tb
nolvadex pct
prazosin cost
azithromycin 1mg
cymbalta 6 mg
reputable online pharmacy uk
cymbalta canadian pharmacy
atarax 25 mg cost
order baclofen online
robaxin usa
cost of brand name metformin
phenergan vc
buy atenolol 25 mg online
5 mg dexamethasone
tamoxifen 40 mg tablet
tenormin 100
buy atarax 10mg
prazosin 10 mg
lipitor 20mg canada
diflucan fluconazole
doxycycline 100mg tablet
diclofenac gel buy over the counter canada
buy cheap clopidogrel
rx tizanidine
suhagra online
plavix generic available
prednisone cream
prednisone for dogs without rx
tizanidine over the counter
phenergan 25 mg over the counter
amoxil 500mg
tizanidine cheap
diflucan 150 mg buy online
retino gel
inderal pills
accutane online order
diflucan 50 mg capsule
buy celebrex canadian pharmacy
synthroid 112 coupon
suhagra tablet price india
buy albuterol online cheap
prednisone 20mg nz
diclofenac gel 25g
buy strattera online canada
flomax 4 mg cost
accutane 30 mg cost
retino 0.25 cream
buy lisinopril online usa
pharmacy online uae
accutane india pharmacy
diflucan 200
plaquenil best price
flomax canada
buy fluconazol
buy brand name synthroid online
prescription cephalexin 500
zanaflex 4mg coupon
flomax for women urinary retention
diclofenac gel online
all in one pharmacy
zithromax 500 tablet
azithromycin generic
prednisolone tablets uk
cymbalta coupon 30 mg
modafinil 50 mg tablet
prednisolone 10 mg
10mg fluoxetine
where can i buy zithromax online
albendazole medication
propecia over the counter australia
albendazole india online
propecia nz price
phenergan cream
synthroid 112 mcg cost
silagra 50
cymbalta 30 mg cost
vermox prescription drug
modafinil pill buy
motrin 600 mg cost
gabapentin tablets for sale
can you buy amoxicillin over the counter
buy antabuse online canada
flomax online order
good value pharmacy
buy sildalis online
toradol 12.5
4mg albuterol
strattera 60 mg
furosemide 40 mg tablet cost
diflucan 100 mg price
bactrim order online
lasix loop diuretic
azithromycin 1000 mg drug cost
motilium online pharmacy
toradol tabs
prednisolone brand name uk
30 mg toradol
2870 valtrex
can google identify a plant from a pictur diametric When who building be limits
valtrex medicine
diflucan
tamoxifen price australia
buy furosemide 40 mg uk
diclofenac 150 mg tablets
generic for toradol
cost of propecia medication
voltaren generic brand
purchase generic cialis
motilium no prescription
augmentin 375 price in india
cost toradol
canadian online pharmacy no prescription
diflucan cream india
motilium 10
trazodone cheap
lasix tablets for sale
furosemide buy
lexapro 20mg
accutane price usa
diflucan pill otc
purchase trazodone
how much is lexapro 20 mg
Полипропиленовые мешки – надежный способ хранения продуктов
производство мешков полипропиленовых производство полипропиленовых мешков в россии заводы.
where to buy clonidine
toradol for back pain
where can i buy vermox medication online
toradol prescription
buy toradol
furosemide without prescription
capsule online pharmacy
buy cialis 20mg tablets
stromectol tablets
ivermectin uk
where to buy albuterol canada
finpecia 1 mg
clonidine 0.15 mg
cheapest generic valtrex
laxis pills
online pharmacy 365
buy propecia from india
neurontin 800 mg capsules
dapoxetine buy online
clonidine 0.2mg tablets
cialis generic online
finasteride online bonus
canada drug pharmacy
prednisolone 150 mg
topical ivermectin cost
how to get amoxicillin online
cost of cialis 5mg
rx modafinil
amoxicillin 500 mg brand name
buy ivermectin canada
ordering propecia without prescription
where to order albendazole
wellbutrin bupropion
ivermectin otc
plaquenil uk price
Онлайн-магазин для мешков для строительного мусора
мешки для строительного мусора мешки для строительного мусора от производителя.
furosemide 40 mg without prescription
generic cialis fast shipping
propecia tablet in india
cialis tablet sildenafil vs cialis prescription free cialis
ventolin 2
metformin 500 mg over the counter
canadian pharmacies comparison
Отличный выбор мешков для строительного мусора с доставкой по всей России
мешки для строительного мусора от производителя мешки для строительного мусора купить.
sildenafil price comparison
prozac brand
augmentin 250 mg tablets
my canadian pharmacy rx
propecia pills cost
prednisolone 20 mg buy online
stromectol covid 19
propecia where to buy uk
furosemide 2018
price of ivermectin
buy brand wellbutrin
indian trail pharmacy
generic stromectol
Over the counter Lasix should not be used as a weight loss medication as it can be dangerous and ineffective for this purpose.
buy ivermectin for humans uk
neurontin 600
methylprednisolone
Гарантированное качество мешков для мусора по доступной цене
мешки для мусора мешки для мусора.
ivermectin 0.5 lotion
gabapentin 300mg capsules price
valtrex generic pill
canadian pharmacy antabuse
price of propecia in singapore
I try to eat a healthy diet and exercise regularly while taking lisinopril 25 mg.
zoloft online pharmacy
ventolin 10 mg
how much does ivermectin cost
wellbutrin 100 mg tablet
propecia 5mg for sale
lasix no preiscription
ivermectin 4000 mcg
prednisolone over the counter uk
can you buy furosemide over the counter
stromectol 6 mg tablet
buy prednisolone 5mg online
stromectol medication
azithromycin buy online
valtrex generic pill
diflucan pill cost
wellbutrin 300 mg
flomax 0.4mg
dexona tablet price
clonidine purchase
zithromax cost canada
furosemide 40mg cost
75 mg wellbutrin
prednisolone 25mg buy online
lasix tablet
fluoxetine buy
prednisolone online
buy bupropion online canada
ivermectin 0.5% lotion
best price for biaxin
vermox price in south africa
flomax uk
finpecia without prescription
buy silagra tablets
where to buy kamagra oral jelly in bangkok
silvitra
lisinopril 25
mebendazole price
buy cheap tetracycline
synthroid 50 mcg cost
Аренда инструмента предоставляет множество преимуществ, особенно для тех, кто редко использует специализированные инструменты или не хочет тратить деньги на их покупку. Вот несколько преимуществ аренды инструмента
аренда инструмента прокат инструмента в Перми.
Прокат инструмента позволяет существенно сэкономить деньги. Приобретение нового инструмента может быть очень дорогим, особенно если вам нужно использовать его всего несколько раз. Аренда же позволяет получить доступ к необходимому инструменту по намного более низкой цене.
прокат инструмента в Перми аренда инструмента в Перми.
myambutol 400 mg tablet price
finasteride 1mg no prescription
where can i buy clomid over the counter
aurogra 100 uk
sumycin price
seroquel for children
Оптимальные мешки для мусора по отличной цене
мусорные мешки мусорные мешки.
azithromycin 500mg buy
cefadroxil hydrate
best price for propecia 5mg online no prescription
order lyrica online
silvitra
generic accutane cost
atarax 10mg price in india
cefadroxil 500 mg price
seroquel 200 mg
elimite 5 cream
erythromycin price in usa
erythromycin
diflucan otc where to buy
clonidine tablet price
celexa 25mg
inderal otc
suhagra 25
price of valtrex in canada
online pharmacy europe
budesonide 9 mg tablets price
ventolin prescription canada
citalopram hbr 40mg
synthroid 100 mcg from canada
antabuse buy online uk
cheap paroxetine online
viagra 50 mg coupon
azithromycin online australia
canada online pharmacy no prescription
prednisolone 5mg tablets
buy erectafil 20
where can i get clomid pills
order accutane online canada
lasix 40 mg without prescription
cheap generic cialis uk online
stromectol uk buy
prinivil lisinopril
hydroxychloroquine chloroquine
cafergot over the counter
furosemide 400 mg
plaquenil 200mg
finpecia tablet price in india
fildena 100 online india
how much is generic flomax
price of colchicine in india
sumycin 250 mg
diflucan india
online purchase of tetracycline
can i order paxil online
canadian pharmacy uk delivery
kamagra oral jelly ajanta
zestoretic 20 25 mg
canadian pharmacy tadacip
synthroid 0.088
zoloft otc
clonidine 25 mcg
clonidine 01 mg
trazodone 100 mg tablet
lasix tablets for sale
20mg paxil
cheap zoloft
cipro 300 mg
wholesale pharmacy
prednisolone cost tablets
tizanidine 2mg tablet price in india
valtrex pills
maple leaf pharmacy in canada
prozac 90 mg daily
sildenafil 20 mg over the counter
augmentin 875 125 mg price
otc prednisone cream
where can i buy diflucan tablets over the counter
prinivil 20 mg
viagra pills online
buy tadalafil india
112 mg synthroid
viagra 100 mg price canada
purchase kamagra 100 online canada
ciprofloxacin usa
prednisone 50 mg tablet
cialis from india online pharmacy
sildenafil online europe
valtrex cost australia
orlistat tablets uk
zanaflex generic price
Я ввел в Яндекс запрос “казино на деньги” и первым в списке был сайт caso-slots.com. Здесь я нашел множество казино с игровыми автоматами, а также бонусы на депозит и статьи с полезными советами по игре, что сделало мой выбор в пользу этого сайта еще увереннее.
cost of celebrex 100 mg
cialis canada online pharmacy
erythromycin online uk
Я наконец решился окунуться в мир азарта и нашел прекрасный сайт caso-slots.com. Здесь представлены все популярные казино, а также список тех, где можно получить бонус на первый депозит. Жду не дождусь начала игры!
trental 400 mg online order
malegra fxt uk
doxycycline 200 mg tablets
cost of synthroid in canada
В поисках идеального казино для игры на деньги, я обратился к Яндексу, и на первом месте вышел сайт caso-slots.com. Там я обнаружил множество различных казино с игровыми автоматами, а также бонусы на депозит. К тому же, на сайте есть полезные статьи о том, как правильно играть, чтобы увеличить свои шансы на победу!
albuterol online canada
provigil 2017
Я наконец решился окунуться в мир азарта и нашел прекрасный сайт caso-slots.com. Здесь представлены все популярные казино, а также список тех, где можно получить бонус на первый депозит. Жду не дождусь начала игры!
clonidine erectile dysfunction
where can you get accutane
tretinoin 0125
levitra 5mg tablets
zanaflex price
valtrex 500mg online
lisinopril pill 40 mg
diflucan tablet price
can i buy azithromycin over the counter in us
cheap finasteride 5mg
tizanidine tablet brand name
clonidine 0.2 mg tablets
best albuterol
levitra drugstore
doxycycline buy
retino gel
prinivil lisinopril
retin a uk pharmacy
cialis canada online pharmacy
clomid iui
malegra for sale
albuterol 180mcg
feldene 20 mg cap
provigil generic south africa
order albuterol online no prescription
ciprofloxacin 750 mg
cipro 500mg india
deltasone 20 mg tablet
clomid 50g
doxycycline hyc 100mg
clonidine over the counter
avodart price usa
generic levitra cost
levitra prescription prices
dexamethasone 40 mg
top online pharmacy india
robaxin over the counter uk
valtrex capsules
accutane 2018
celexa price
valtrex cost canada
clomid pills uk
can i buy acyclovir over the counter in south africa
albuterol coupon
citalopram 40mg cost
diflucan 150 cost
where can i buy allopurinol
lisinopril 104
order nolvadex canadian
buy cheap cialis discount online
dexona 4mg tablet
buy 1g azithromycin online
robaxin iv
generic robaxin
purchase valtrex canada
gold pharmacy online
generic cialis 2018 australia
levaquin buy
doxycycline buy canada
ventolin prescription
vardenafil cheap india
effexor xr cost
synthroid 100
can you buy voltaren tablets over the counter
medrol 32 mg
retin a cream canada over the counter
buy motilium 10mg
retin a for sale
buy lioresal online
provigil 300 mg
dipyridamole 75 mg tablet
buy levitra 20 mg
generic avodart canada
prazosin 2
motilium online pharmacy
buy kamagra jelly usa
dipyridamole generic
amoxicillin 650 mg
cymbalta 16 mg
tadacip 10 mg price
avodart 0.5 mg tab
colchicine for gout
suhagra 100mg tablet price
colchicine acute gout
can i buy valtrex over the counter
finasteride 5 mg daily
phenergan promethazine
hydrochlorothiazide medication
avodart no prescription
diflucan drug
cialis online canada pharmacy
ampicillin 250
metformin cost
over the counter amoxicillin 500mg
acyclovir 400mg tablets
baclofen 20 mg price
avodart for sale
medrol tablet
cost of permethrin cream
buy vermox canada
vermox over the counter usa
purchase azithromycin 500mg
propecia in canada
doxycycline tablet price in india
where to buy lisinopril online
lasix water pills for sale
furosemide 20 mg tab
metformin average cost
motilium over the counter
suhagra 100 online purchase
how much does permethrin cost
dipyridamole tablets cost
clomid from mexico
can you buy amoxicillin
finasteride tablet online
generic levitra no prescription
cymbalta 10mg
Актуальная линейка мешков для мусора
купить мешок под мусор http://kaluga1pak.ru/.
flomax in usa
cipro medication cost
clomid 100mg for sale
azithromycin tab price in india
how to get retin a online
generic synthroid medication
accutane order
acyclovir 500 mg tab
furosemide 200 mg
tretinoin cream where to buy
how much is retin a in mexico
where to buy valtrex
400 mg acyclovir tablets
medicine acyclovir 800 mg
phenergan over the counter nz
tetracycline
cipro prescription
buy valtrex online uk
generic cialis online paypal
diflucan 150 mg buy online
prednisolone cost usa
trental 400 mg online purchase
buy baclofen
over the counter valtrex medication
where to buy lyrica cheap
lasix tablet cost
Good article with great ideas! Thank you for this important article. Thank you very much for this wonderful information.
erythromycin 500mg cost
lyrica capsules 75 mg cost
colchicine price south africa
lopressor medicine
There is some nice and utilitarian information on this site.
buy furosemide 100 mg
can you buy phenergan over the counter
silagra online india
suhagra
lyrica online uk
doxycycline online purchase
baclofen 10 mg tab
buy phenergan usa
lyrica 100 mg price
retin a cost in mexico
buy accutane in canada
prednisone canada pharmacy
buy finasteride online
diflucan 150 mg prescription
200 mg prednisone
best price retin a
buy diflucan 150 mg online
lyrica 150 mg price australia
deltasone pill
online pharmacy tadalafil
valtrex 1 mg
prednisone 12 mg
legitimate canadian mail order pharmacy
Awesome! Its genuinely remarkable post I have got much clear idea regarding from this post
lyrica 150 mg coupon
glucophage price canada
baclofen 10mg tablets
synthroid 75 pill
vermox tablets australia
finasteride 5mg no prescription
where can i buy vermox medication online
accutane order
For the reason that the admin of this site is working no uncertainty very quickly it will be renowned due to its quality contents. Watch bbc persian news
canadian pharmacy 5 mg prednisone no rx
https://prednisone.digital/# prednisone 40mg
synthroid 112 mcg price
can you buy prednisone without a prescription
zithromax drug
finasteride proscar
can i buy diflucan over the counter
Pretty! This has been a really wonderful post. Many thanks for providing these details.
lisinopril australia
buy prednisone online no script
https://amoxil.world/# where to buy amoxicillin over the counter
can you buy propecia over the counter
buy amoxicillin without prescription
where can i get cheap clomid pills: cost cheap clomid without insurance – can i get clomid
diflucan cream otc
buy real valtrex online
50 mg prednisone from canada: purchase prednisone 10mg – prednisone cream over the counter
https://clomid.sbs/# buying clomid tablets
cost cheap propecia without dr prescription: buy propecia tablets – cost of generic propecia pills
lyrica pill
dexamethasone 1.5 tablet
prednisone 5084
buy augmentin 1000 mg
https://doxycycline.sbs/# buy doxycycline without prescription
metformin average cost
cost of generic clomid price: where can i buy cheap clomid pill – how to get cheap clomid pills
accutane cream
buy zestril
http://propecia.sbs/# buy cheap propecia online
amoxicillin 500mg without prescription: amoxicillin without a doctors prescription – buy amoxicillin online cheap
propecia where to buy canada
valtrex pills where to buy
lisinopril 5mg
http://amoxil.world/# amoxicillin price canada
buy propecia without dr prescription: propecia price – get generic propecia online
prednisone purchase canada
metformin glucophage xr
diflucan 100mg
https://doxycycline.sbs/# doxy
purchase prednisone no prescription: prednisone drug costs – prednisone 20 mg purchase
prednisone 5mg
synthroid prescription uk
acticin cream buy
naturally like your web site however you need to take a look at the spelling on several of your posts.
where can i buy accutane online
lisinopril tabs
buy synthroid canada no prescription
lisinopril 5mg tabs
I very delighted to find this internet site on bing just what I was searching for as well saved to fav
https://canadapharm.top/# canadian drug stores
propecia without prescription
baclofen 2 cream
cialis without doctor prescription: ed meds online without prescription or membership – cialis without a doctor’s prescription
purchase cialis without prescription
https://indiapharm.guru/# top online pharmacy india
prednisone for dogs
top rated ed pills: best ed treatment – buying ed pills online
doxcyclene
medication albuterol
http://mexicopharm.shop/# medicine in mexico pharmacies
buy valtrex singapore
buying lisinopril online
Online medicine order: online pharmacy india – buy medicines online in india
250mg amoxicillin capsules
https://mexicopharm.shop/# purple pharmacy mexico price list
mexican mail order pharmacies: mexican border pharmacies shipping to usa – mexico pharmacies prescription drugs
online valtrex
prednisone 0.5 mg
http://canadapharm.top/# canadapharmacyonline com
how to get accutane australia
happy family rx
lyrica 50 mg coupon
lisinopril 500 mg
ed drugs compared: medication for ed – ed pills comparison
prednisone otc price
valtrex 500 mg
mexican online pharmacies prescription drugs: mexico drug stores pharmacies – mexico drug stores pharmacies
generic tadalafil cheap
lisinopril 10mg daily
85g prednisone
https://canadapharm.top/# buying drugs from canada
cheap doxy
albuterol india
lyrica 325 mg
valtrex cream price
buying propecia without insurance: cost generic propecia tablets – cost generic propecia
purchase prednisone for dogs online without a prescription
discount generic propecia
prednisone 20 mg price india
canada drugs online reviews: Canadian Pharmacy Online – canadian online pharmacy
tretinoin best price
https://withoutprescription.guru/# viagra without doctor prescription amazon
how to cure ed: the best ed pill – treatment of ed
prescription drugs online: buy prescription drugs – ed meds online without prescription or membership
suhagra tablet
elimite price online
elimite cream ebay
finasteride hair
п»їkamagra: Kamagra tablets – Kamagra Oral Jelly
Levitra 10 mg best price Buy generic Levitra online buy Levitra over the counter
http://tadalafil.trade/# tadalafil 5mg tablets price
acticin cream
vermox canada price
Levitra 10 mg best price: Buy generic Levitra online – Buy Levitra 20mg online
tadalafil 5 mg tablet coupon online tadalafil prescription tadalafil coupon
https://edpills.monster/# erectile dysfunction drug
pharmacy online tadalafil: 10mg tadalafil – best price tadalafil 20 mg
http://edpills.monster/# new ed drugs
baclofen over the counter usa
z pack azithromycin
otc sildenafil 20 mg tablets sildenafil 85 sildenafil 25 mg prices
sildenafil coupon: sildenafil generic nz – sildenafil generic costs
http://levitra.icu/# Levitra 20 mg for sale
zithromax 250 cost
tadalafil generic in usa best price tadalafil 20 mg generic tadalafil medication
buying sildenafil citrate online: sildenafil 50 coupon – sildenafil best price
valtrex 500mg price
deltasone medication
sildenafil canada generic: sildenafil tablets 100mg online – sildenafil online in india
https://levitra.icu/# buy Levitra over the counter
medicine lyrica 75 mg
https://edpills.monster/# erectile dysfunction drug
valtrex online
accutane 2019
Kamagra Oral Jelly Kamagra 100mg price Kamagra Oral Jelly
tadalafil generic price: tadalafil tablets 20 mg buy – tadalafil 2
can you buy zithromax over the counter in canada
500 mg valtrex daily
dexamethasone 200 mg
https://doxycycline.forum/# doxycycline 100mg dogs
amoxicillin for sale online: buy amoxil – amoxicillin 500mg price in canada
lisinopril 30 mg daily zestril tab 10mg lisinopril 12.5 mg price
azithromycin 500 mg tablet online
prednisone 9 mg
prednixone tables for sale
glucophage without prescription
http://azithromycin.bar/# zithromax canadian pharmacy
875 mg amoxicillin cost: amoxil for sale – amoxicillin 500mg prescription
valtrex prices canada
lisinopril 40 mg on line: buy lisinopril online – where can i order lisinopril online
zestoretic coupon buy lisinopril best lisinopril brand
medication lisinopril 10 mg
lasix iv
lyrica medicine generic
5mg propecia for sale
where can i buy zithromax in canada: buy zithromax canada – buy zithromax no prescription
drug discount valtrex generic
http://azithromycin.bar/# zithromax 600 mg tablets
zestril 30 mg
lyrica online canada
propecia 1mg cost
prednisone brand name cost
cipro 500mg best prices Ciprofloxacin online prescription antibiotics cipro
cost of lisinopril 30 mg
prednisone 200 mg
buy cipro: buy ciprofloxacin online – ciprofloxacin 500mg buy online
doxylin: Buy doxycycline hyclate – doxycycline price uk
https://azithromycin.bar/# can you buy zithromax over the counter in mexico
lyrica cap
prednisone prescription online
20 mg of prednisone
lisinopril oral
doxycycline without a prescription Buy doxycycline hyclate generic for doxycycline
azithromycin order online uk
zithromax for sale cheap: buy zithromax – zithromax online australia
http://doxycycline.forum/# drug doxycycline
baclofen comparison
suhagra canada
elimite cream price
where to buy metformin
vermox tab 100 mg
generic zithromax online paypal zithromax antibiotic zithromax cost australia
I m often to blogging and i really appreciate your content. The article has actually peaks my interest.
can you buy baclofen over the counter
valtrex 1000 mg price in india
amoxicillin 500 coupon: cheap amoxicillin – over the counter amoxicillin
propecia over the counter
I m going to bookmark your web site and maintain checking for brand spanking new information.
https://doxycycline.forum/# doxycycline prescription price
lisinopril 20 12.5 mg: buy lisinopril online – lisinopril generic 20 mg
how much is dexamethasone 4 mg
furosemide 20mg tablets cost
baclofen 10 mg tablet online
https://buydrugsonline.top/# canadian drugs without any prescriptions
prescription pricing: buy drugs online safely – reliable mexican pharmacy
suhagra without prescription
buy prednisone over the counter
buying prescription drugs in mexico online: mexican medicine – buying prescription drugs in mexico
propecia generic australia
azithromycin over the counter australia
https://mexicopharmacy.store/# medication from mexico pharmacy
canadian drugstore online: international online pharmacy – real canadian pharmacy
canadian pharmacy review: certified canadian pharmacy – best online canadian pharmacy
buy lisinopril without prescription
Выбирайте качественные пакеты для мусора
2) Защитите окружающую среду с экологичными мешками для мусора
3) Избавьтесь от мусора с легкостью с помощью мешков для мусора
4) Оптимальный выбор для утилизации мусора – мешки для мусора
5) Держите свой дом с помощью мешков для мусора
6) Организуйте свой дом с помощью мешков для мусора
7) Поддержите чистоту с надежными мешками для мусора
8) Удобный способ для утилизации мусора – мешки для мусора
9) Необходимое приобретение для любого дома – мешки для мусора
10) Просто сортируйте мусор с помощью различных цветов мешков для мусора
11) Экономьте время и силы с прочными мешками для мусора
12) Защитите окружающую среду вместе с мешками для мусора
13) Удобный способ для уборки двора – мешки для мусора
14) Храните уборочные принадлежности в мешках для мусора
15) Качество и экологичность – главные критерии при выборе мешков для мусора
16) Сохраняйте свой двор в чистоте с мешками для мусора
17) Без усилий и забот – утилизируйте мусор с помощью мешков для мусора
18) Интуитивно понятные мешки для мусора упростят вашу жизнь
19) Экономьте место с помощью компактных мешков для мусора
20) Защитите свой дом с качественными мешками для мусора
где купить большие мешки для мусора https://meshki-dlya-musora-d.ru/.
accutane medicine buy
accutane from canada pharmacy
http://mexicopharmacy.store/# purple pharmacy mexico price list
canada rx pharmacy world: accredited canadian pharmacy – best canadian pharmacy online
Выбирайте качественные пакеты для мусора
2) Сберегите окружающую среду с надежными мешками для мусора
3) Избавьтесь от мусора с легкостью с помощью мешков для мусора
4) Оптимальный выбор для утилизации мусора – мешки для мусора
5) Держите свой дом с помощью мешков для мусора
6) Организуйте свой дом с помощью мешков для мусора
7) Уважайте окружающую среду с качественными мешками для мусора
8) Удобный способ для утилизации мусора – мешки для мусора
9) Продуманное приобретение для любого дома – мешки для мусора
10) Легко сортируйте мусор с помощью различных цветов мешков для мусора
11) Экономьте время и силы с надежными мешками для мусора
12) Защитите окружающую среду вместе с мешками для мусора
13) Простое решение для уборки двора – мешки для мусора
14) Сортируйте мусор в мешках для мусора
15) Прочность и долговечность – главные критерии при выборе мешков для мусора
16) Держите свой дом в чистоте с мешками для мусора
17) Без усилий и забот – утилизируйте мусор с помощью мешков для мусора
18) Интуитивно понятные мешки для мусора упростят вашу жизнь
19) Оптимизируйте пространство с помощью компактных мешков для мусора
20) Защитите свой дом с качественными мешками для мусора
мешки для мусора купить meshki-dlya-musora-s.ru.
cheapest retin a cream
can i buy valtrex online
https://clomid.club/# where buy clomid without dr prescription
prednisone pack
wellbutrin 540mg: Buy bupropion online Europe – wellbutrin buy online uk
synthroid 25 pill
Доставка мешков для мусора по России и СНГ
где можно купить мешки для мусора https://meshki-dlya-musora-u.ru/.
generic valtrex cost
http://gabapentin.life/# neurontin prescription coupon
discount zestril
buy ventolin inhaler online: Ventolin inhaler – ventolin 95mcg
generic diflucan otc
suhagra 50 online india
valtrex medicine
purchase metformin 1000 mg
prednisone price in usa
elimite coupon
https://wellbutrin.rest/# wellbutrin prices
how much is accutane in mexico
paxlovid for sale: Paxlovid buy online – Paxlovid over the counter
50 mg prednisone canada pharmacy
buy paxlovid online http://paxlovid.club/# paxlovid cost without insurance
albuterol asthma
prednisone in uk
combivent inhaler
http://wellbutrin.rest/# wellbutrin online canada
suhagra 100mg buy
buy azithromycin from mexico
ventolin buy: ventolin 200 – canada to usa ventolin
buy generic valtrex on line
https://wellbutrin.rest/# wellbutrin online no prescription
buy doxycycline 11554
deltasone 10 mg
where to buy tretinoin
buy suhagra online
generic deltasone
prednisone 60 mg price
buy metformin without prescription
cost cheap clomid price: Buy Clomid Online – can i get generic clomid no prescription
buy albuterol canadian pharmacy
vermox online sale usa
https://gabapentin.life/# neurontin for sale
cost of ventolin in usa: Ventolin inhaler online – buy ventolin online usa
http://clomid.club/# can i get cheap clomid without rx
diflucan buy online
can i buy prednisone over the counter in usa
accutane 30 mg coupon
farmacia online migliore: Cialis senza ricetta – farmacia online senza ricetta
propecia cost comparison
miglior sito per comprare viagra online alternativa al viagra senza ricetta in farmacia siti sicuri per comprare viagra online
farmacie online affidabili: kamagra gel prezzo – comprare farmaci online con ricetta
baclofen 100mg
farmacie on line spedizione gratuita: Dove acquistare Cialis online sicuro – acquistare farmaci senza ricetta
https://farmaciait.pro/# farmacia online senza ricetta
where to get tretinoin gel
farmacie online autorizzate elenco: avanafil spedra – п»їfarmacia online migliore
farmacia online senza ricetta: farmacia online miglior prezzo – farmaci senza ricetta elenco
diflucan medicine
top farmacia online: farmacia online spedizione gratuita – farmacia online senza ricetta
Выбирайте качественные мешки для мусора
2) Защитите окружающую среду с экологичными мешками для мусора
3) Уберите от мусора с легкостью с при помощи мешков для мусора
4) Идеальное решение для утилизации мусора – мешки для мусора
5) Не допускайте загрязнение с помощью мешков для мусора
6) Организуйте свой дом с помощью мешков для мусора
7) Уважайте окружающую среду с качественными мешками для мусора
8) Удобный способ для утилизации мусора – мешки для мусора
9) Необходимое приобретение для любого дома – мешки для мусора
10) Просто сортируйте мусор с помощью различных цветов мешков для мусора
11) Сэкономьте время и силы с прочными мешками для мусора
12) Защитите окружающую среду вместе с мешками для мусора
13) Простое решение для уборки двора – мешки для мусора
14) Сортируйте мусор в мешках для мусора
15) Прочность и долговечность – главные критерии при выборе мешков для мусора
16) Сохраняйте свой двор в чистоте с мешками для мусора
17) Без усилий и забот – утилизируйте мусор с помощью мешков для мусора
18) Простые и практичные мешки для мусора упростят вашу жизнь
19) Экономьте место с помощью компактных мешков для мусора
20) Поддержите чистоту города с качественными мешками для мусора
пакет для мусора http://www.meshki-dlya-musora-j.ru/.
cerco viagra a buon prezzo alternativa al viagra senza ricetta in farmacia viagra generico prezzo piГ№ basso
farmacie online autorizzate elenco: dove acquistare cialis online sicuro – farmacia online migliore
finasteride 5mg pill
farmacie online sicure: cialis generico – farmacia online miglior prezzo
http://farmaciait.pro/# farmaci senza ricetta elenco
comprare farmaci online all’estero: kamagra gel – farmacia online più conveniente
farmacie online autorizzate elenco: kamagra gold – farmaci senza ricetta elenco
prednisolone 25mg australia
acquistare farmaci senza ricetta: farmacia online migliore – comprare farmaci online all’estero
Только лучшие мешки для мусора для Вас
мешки под мусор цена https://meshki-dlya-musora-z.ru/.
farmacia online migliore: Tadalafil generico – farmacia online
retin a paypal
cialis farmacia senza ricetta sildenafil 100mg prezzo pillole per erezione in farmacia senza ricetta
viagra online in 2 giorni: viagra generico – viagra acquisto in contrassegno in italia
gabapentin online
farmacie on line spedizione gratuita: comprare avanafil senza ricetta – top farmacia online
clonidine hcl 0.3 mg tablets
http://kamagrait.club/# farmaci senza ricetta elenco
baclofen cheap
farmacie online sicure: Avanafil farmaco – farmacia online senza ricetta
clonidine 50 mcg
lyrica cap 50mg
farmaci senza ricetta elenco: Dove acquistare Cialis online sicuro – migliori farmacie online 2023
comprare farmaci online all’estero: kamagra gel – acquisto farmaci con ricetta
farmacia online più conveniente: Tadalafil prezzo – acquistare farmaci senza ricetta
farmacia online senza ricetta kamagra oral jelly п»їfarmacia online migliore
generic accutane cost
farmacia online: kamagra oral jelly – farmacia online più conveniente
0.025 mg synthroid
viagra generico recensioni: viagra prezzo farmacia – alternativa al viagra senza ricetta in farmacia
lisinopril mexico
synthroid cost comparison
viagra prezzo farmacia 2023: viagra prezzo farmacia – dove acquistare viagra in modo sicuro
https://farmaciait.pro/# farmacia online senza ricetta
farmacia online miglior prezzo: avanafil – farmacia online
paroxetine 25 mg price
farmacie online sicure: cialis generico consegna 48 ore – farmacie on line spedizione gratuita
propranolol inderal 10 mg tablets
robaxin 500mg cost
farmacia online migliore: avanafil generico – farmacia online
farmacie on line spedizione gratuita Cialis senza ricetta acquistare farmaci senza ricetta
farmaci senza ricetta elenco: avanafil prezzo in farmacia – acquistare farmaci senza ricetta
vermox pharmacy usa
clonidine oral
dove acquistare viagra in modo sicuro: sildenafil 100mg prezzo – cialis farmacia senza ricetta
buy brand cialis canada
le migliori pillole per l’erezione: alternativa al viagra senza ricetta in farmacia – viagra generico recensioni
farmaci senza ricetta elenco: farmacia online più conveniente – comprare farmaci online con ricetta
doxycycline generic brand
tretinoin cream online canada
http://farmaciait.pro/# migliori farmacie online 2023
top farmacia online: cialis prezzo – migliori farmacie online 2023
zoloft 75 mg tablet
farmaci senza ricetta elenco Farmacie a roma che vendono cialis senza ricetta comprare farmaci online all’estero
albuterol 0.021
diflucan one
500 mg doxycycline pill
pillole per erezione in farmacia senza ricetta: viagra generico – viagra ordine telefonico
farmacie online affidabili: farmacia online miglior prezzo – comprare farmaci online con ricetta
clonidine 137
buy fluconazol
canada pharmacy online
acquisto farmaci con ricetta: kamagra – comprare farmaci online all’estero
farmacia online senza ricetta: farmacia online migliore – farmacie online affidabili
acquisto farmaci con ricetta kamagra gold farmacia online miglior prezzo
retin a buy
buy amoxil online usa
lyrica 300 mg cost
http://tadalafilo.pro/# farmacia 24h
where to buy propecia singapore
https://farmacia.best/# farmacia online envÃo gratis
farmacia online 24 horas: comprar kamagra en espana – farmacia online barata
https://sildenafilo.store/# comprar viagra en españa envio urgente contrareembolso
http://tadalafilo.pro/# farmacia barata
tadalafil for sale
sildenafilo sandoz 100 mg precio comprar viagra sildenafilo 100mg farmacia
http://sildenafilo.store/# sildenafilo 100mg precio farmacia
https://sildenafilo.store/# comprar viagra en españa amazon
farmacia barata: cialis 20 mg precio farmacia – farmacia online madrid
http://sildenafilo.store/# sildenafil 100mg genérico
https://sildenafilo.store/# comprar viagra contrareembolso 48 horas
https://sildenafilo.store/# viagra para hombre venta libre
neurontin cream
http://tadalafilo.pro/# farmacia barata
generic accutane rx cost
allopurinol 100mg price uk
suhagra canada
http://kamagraes.site/# farmacia online madrid
farmacia gibraltar online viagra comprar viagra en espana se puede comprar sildenafil sin receta
http://sildenafilo.store/# comprar viagra online en andorra
farmacia online envГo gratis: Levitra precio – farmacia envГos internacionales
buy cheap propecia canada
https://kamagraes.site/# farmacias online seguras en españa
order accutane over the counter
purchase gabapentin online
generic otc viagra
zithromax 500 mg
120mg prednisolone
https://kamagraes.site/# farmacias online seguras
atarax tablet price in india
buy diflucan australia
tretinoin cream 20g
farmacia barata farmacia online internacional farmacia online madrid
https://sildenafilo.store/# sildenafilo 50 mg precio sin receta
farmacia online barata: farmacia online barata y fiable – farmacias baratas online envГo gratis
https://kamagraes.site/# farmacia 24h
diflucan 150 capsule
http://sildenafilo.store/# sildenafilo 100mg precio farmacia
http://farmacia.best/# farmacia online barata
http://farmacia.best/# farmacia 24h
http://farmacia.best/# farmacia online
price of accutane without insurance
zithromax online usa
п»їfarmacia online vardenafilo farmacia online internacional
levitra in australia
farmacia online envГo gratis: Comprar Levitra Sin Receta En Espana – farmacias online baratas
https://sildenafilo.store/# comprar viagra en españa envio urgente
avana 156
synthroid with no prescription
https://vardenafilo.icu/# farmacia online madrid
http://farmacia.best/# farmacias online baratas
http://kamagraes.site/# farmacia online madrid
doxycycline 100mg tablets nz
http://kamagraes.site/# farmacias baratas online envÃo gratis
viagra precio 2022: comprar viagra – viagra 100 mg precio en farmacias
can you buy phenergan over the counter
https://sildenafilo.store/# viagra online cerca de la coruña
farmacia online madrid kamagra jelly farmacias online seguras
http://kamagraes.site/# farmacia 24h
http://vardenafilo.icu/# farmacia 24h
http://vardenafilo.icu/# farmacia online internacional
vardenafil brand name in india
buy female viagra tablet in india
citalopram brand name
http://vardenafilo.icu/# farmacia online 24 horas
accutane 20 mg buy online
farmacia online envГo gratis: Levitra 20 mg precio – farmacia envГos internacionales
cialis without prescription
https://vardenafilo.icu/# farmacia envÃos internacionales
buy generic augmentin online
http://sildenafilo.store/# venta de viagra a domicilio
accutane pills price in india
medication albuterol
venta de viagra a domicilio comprar viagra en espaГ±a envio urgente contrareembolso viagra online cerca de malaga
http://vardenafilo.icu/# farmacia online internacional
viagra online price comparison
https://vardenafilo.icu/# farmacia online madrid
https://vardenafilo.icu/# farmacia online 24 horas
farmacia online barata: Levitra precio – farmacias online baratas
augmentin online uk
baclofen lioresal
http://vardenafilo.icu/# farmacia online envÃo gratis
https://sildenafilo.store/# viagra para hombre precio farmacias
http://farmacia.best/# farmacia online envÃo gratis
sildenafilo 100mg precio farmacia comprar viagra en espana viagra online cerca de malaga
https://kamagraes.site/# farmacia 24h
baclofen 10 mg tab
farmacias online seguras en espaГ±a: gran farmacia online – farmacia 24h
http://tadalafilo.pro/# farmacia online madrid
https://kamagraes.site/# farmacia 24h
where to get viagra in usa
http://tadalafilo.pro/# farmacia online madrid
???슬롯 미스터
그러나 Fang Jifan은 그의 죽음에 대해 아무 말도 하지 않았기 때문에 조금 답답했습니다.
how much is augmentin
lyrica generic
https://vardenafilo.icu/# farmacia online envÃo gratis
trazodone 377
http://tadalafilo.pro/# farmacia online barata
lyrica 25mg capsule
farmacia online barata: comprar kamagra – farmacia online barata
farmacia online envГo gratis kamagra oral jelly farmacias online seguras
https://vardenafilo.icu/# farmacia 24h
https://sildenafilo.store/# viagra para hombre venta libre
cost of metformin 750 mg
augmentin 375 cost
http://vardenafilo.icu/# farmacia online barata
prednisolone cheapest
https://vardenafilo.icu/# farmacias online seguras
baclofen tablets buy
atarax prescription uk
http://kamagrafr.icu/# Pharmacie en ligne livraison rapide
amoxil price in usa
diflucan online prescription
levitra 10mg tablets prices
buy 250 mg amoxil online
https://kamagrafr.icu/# pharmacie en ligne
farmacia online internacional: precio cialis en farmacia con receta – farmacia online barata
Pharmacies en ligne certifiГ©es: pharmacie en ligne pas cher – п»їpharmacie en ligne
http://cialissansordonnance.pro/# Pharmacie en ligne livraison 24h
Pharmacie en ligne France Medicaments en ligne livres en 24h acheter medicament a l etranger sans ordonnance
https://pharmacieenligne.guru/# pharmacie en ligne
150 mg gabapentin
azithromycin for sale cheap
http://levitrafr.life/# Pharmacies en ligne certifiées
farmacia online barata: Levitra sin receta – farmacias online baratas
http://kamagrafr.icu/# Acheter médicaments sans ordonnance sur internet
effexor cr
Viagra sans ordonnance 24h suisse: Viagra prix pharmacie paris – SildГ©nafil 100 mg prix en pharmacie en France
how to get accutane
neurontin pfizer
http://viagrasansordonnance.store/# Viagra vente libre allemagne
prozac uk price
Pharmacie en ligne fiable Levitra pharmacie en ligne Pharmacies en ligne certifiГ©es
https://pharmacieenligne.guru/# Acheter médicaments sans ordonnance sur internet
generic levitra online cheap
zithromax
propranolol brand name canada
https://pharmacieenligne.guru/# acheter medicament a l etranger sans ordonnance
п»їfarmacia online: kamagra – farmacia online barata
http://pharmacieenligne.guru/# Pharmacie en ligne livraison gratuite
price of synthroid in india
desyrel 50 mg
how to buy doxycycline online
buying diflucan over the counter
ivermectin 400 mg
http://viagrasansordonnance.store/# Viagra homme prix en pharmacie sans ordonnance
Pharmacie en ligne sans ordonnance: levitra generique prix en pharmacie – Pharmacie en ligne France
budesonide brand name
http://pharmacieenligne.guru/# acheter medicament a l etranger sans ordonnance
budesonide 3mg capsules
Meilleur Viagra sans ordonnance 24h Viagra sans ordonnance 24h Viagra sans ordonnance livraison 24h
https://cialissansordonnance.pro/# acheter medicament a l etranger sans ordonnance
atarax cost singapore
robaxin eq
http://viagrasansordonnance.store/# Viagra homme prix en pharmacie sans ordonnance
celexa 10
farmacias baratas online envГo gratis: comprar cialis online sin receta – farmacia envГos internacionales
amoxil 1g tab
http://viagrasansordonnance.store/# Viagra pas cher livraison rapide france
citalopram medicine
http://viagrasansordonnance.store/# Viagra homme sans prescription
effexor xr 300 mg
paroxetine 500 mg
http://pharmacieenligne.guru/# Pharmacie en ligne livraison rapide
acheter medicament a l etranger sans ordonnance: cialis sans ordonnance – pharmacie ouverte 24/24
http://viagrasansordonnance.store/# Viagra sans ordonnance 24h
levitra online sales
Pharmacie en ligne fiable kamagra oral jelly Pharmacie en ligne livraison 24h
https://viagrasansordonnance.store/# Viagra homme prix en pharmacie sans ordonnance
se puede comprar sildenafil sin receta: comprar viagra en espana – sildenafilo 100mg farmacia
http://viagrasansordonnance.store/# Le générique de Viagra
lasix diuretic
versandapotheke versandkostenfrei apotheke online versandkostenfrei online apotheke deutschland
citalopram 100mg price
combivent best price
http://kamagrakaufen.top/# online-apotheken
zoloft 100 mg
http://viagrakaufen.store/# Viagra rezeptfreie Schweiz bestellen
discount levitra pills
vardenafil tablets 20 mg
silagra 50
albuterol 90 mcg
buy lisinopril 20 mg no prescription
Viagra Preis Schwarzmarkt viagra ohne rezept Viagra rezeptfreie Schweiz bestellen
fildena 200mg
medicine lyrica 75 mg
https://apotheke.company/# versandapotheke versandkostenfrei
http://cialiskaufen.pro/# online apotheke gГјnstig
zestril online
Viagra Preis Schwarzmarkt viagra kaufen ohne rezept legal Viagra verschreibungspflichtig
doxycycline 50mg tablets price
zoloft
toradol migraine
augmentin cost south africa
http://apotheke.company/# versandapotheke versandkostenfrei
albuterol over the counter uk
http://viagrakaufen.store/# Sildenafil rezeptfrei in welchem Land
bactrim ds 800 160 tab
online apotheke preisvergleich cialis kaufen ohne rezept online apotheke versandkostenfrei
online apotheke versandkostenfrei: п»їonline apotheke – п»їonline apotheke
azithromycin us
buy clomid online india
https://cialiskaufen.pro/# online apotheke versandkostenfrei
http://viagrakaufen.store/# Sildenafil kaufen online
gГјnstige online apotheke gГјnstige online apotheke online apotheke deutschland
suhagra 50 online
zithromax prescription
에그벳
그런데 이때 통관을 담당하는 시보국 직원팀을 영입했다.
buying from online mexican pharmacy best mexican online pharmacies buying prescription drugs in mexico
프라그마틱 슬롯 무료
Fang Jifan은 무엇을 말해야할지 모르고 오랫동안 참았습니다.
levitra
dapoxetine singapore
mexican online pharmacies prescription drugs medicine in mexico pharmacies mexican rx online
reputable mexican pharmacies online mexican online pharmacies prescription drugs medicine in mexico pharmacies
amoxicillin 500mg capsule
http://mexicanpharmacy.cheap/# mexican rx online
mexican mail order pharmacies mexican pharmacy reputable mexican pharmacies online
http://mexicanpharmacy.cheap/# reputable mexican pharmacies online
mexican drugstore online mexican border pharmacies shipping to usa mexican rx online
Где купить мешки для строительного мусора
мусорные мешки для строительного мусора https://www.meshki-dlya-stroitelnogo-musora-t.ru.
best mexican online pharmacies buying prescription drugs in mexico mexico drug stores pharmacies
where can i buy prozac uk
mexican pharmaceuticals online mexican pharmacy mexico pharmacy
purple pharmacy mexico price list mexican mail order pharmacies mexican online pharmacies prescription drugs
cost of generic doxycycline
best mexican online pharmacies mexican online pharmacies prescription drugs mexico pharmacies prescription drugs
buy phenergan 25mg uk
buying prescription drugs in mexico mexico pharmacies prescription drugs mexican border pharmacies shipping to usa
https://mexicanpharmacy.cheap/# mexico drug stores pharmacies
propecia cost over the counter
levitra prices in south africa
http://mexicanpharmacy.cheap/# mexican rx online
buy gabapentin 300mg uk
azithromycin 600 mg
generic for atarax
mexican online pharmacies prescription drugs mexican rx online mexican online pharmacies prescription drugs
https://mexicanpharmacy.cheap/# mexico pharmacies prescription drugs
how to get a propecia prescription
vardenafil 20 mg price
clonidine 0.35 mg
mexican rx online mexican pharmaceuticals online mexico pharmacy
mexico pharmacy mexican drugstore online mexico drug stores pharmacies
buy levitra without prescription
mexican mail order pharmacies mexico drug stores pharmacies purple pharmacy mexico price list
Большой выбор размеров мешков для строительного мусора
где купить строительные мешки https://www.meshki-dlya-stroitelnogo-musora-w.ru/.
medication from mexico pharmacy purple pharmacy mexico price list medicine in mexico pharmacies
https://mexicanpharmacy.cheap/# mexico drug stores pharmacies
mexico pharmacy reputable mexican pharmacies online reputable mexican pharmacies online
Бахилы для развлекательных центров
куплю бахилы https://bahily-kupit-optom.ru/.
http://mexicanpharmacy.cheap/# buying prescription drugs in mexico online
buying prescription drugs in mexico mexico pharmacies prescription drugs mexico pharmacy
medicine in mexico pharmacies purple pharmacy mexico price list п»їbest mexican online pharmacies
mexican pharmaceuticals online buying prescription drugs in mexico online reputable mexican pharmacies online
purple pharmacy mexico price list best mexican online pharmacies mexican mail order pharmacies
buy albuterol tablets online uk
accutane rx
mexico pharmacy mexican online pharmacies prescription drugs mexican online pharmacies prescription drugs
п»їbest mexican online pharmacies mexico drug stores pharmacies mexico pharmacies prescription drugs
albuterol for daily use
canada drugs northwest pharmacy canada – ordering drugs from canada canadiandrugs.tech
buying ed pills online erection pills that work – erection pills that work edpills.tech
best buy cialis online
http://indiapharmacy.pro/# top 10 pharmacies in india indiapharmacy.pro
buy celexa india
http://canadiandrugs.tech/# buying from canadian pharmacies canadiandrugs.tech
generic trimox
legal to buy prescription drugs from canada canadian neighbor pharmacy canadian pharmacy online canadiandrugs.tech
cost of prescription drug trazodone
prozac 5 mg tablets
http://indiapharmacy.guru/# india pharmacy indiapharmacy.guru
cheap ed pills male ed pills – buy ed pills online edpills.tech
onlinecanadianpharmacy 24 canadian pharmacy scam – reliable canadian pharmacy canadiandrugs.tech
https://indiapharmacy.guru/# reputable indian online pharmacy indiapharmacy.guru
propecia generic price
http://canadiandrugs.tech/# canadian pharmacy phone number canadiandrugs.tech
odering doxycycline
http://edpills.tech/# otc ed pills edpills.tech
suhagra
http://indiapharmacy.guru/# best india pharmacy indiapharmacy.guru
natural ed remedies what are ed drugs cheap ed pills edpills.tech
https://canadiandrugs.tech/# canadapharmacyonline canadiandrugs.tech
free essays on affirmative action https://cesarrmgxo.blogvivi.com/23932280/buy-essays-online-d-sd-can-be-fun-for-anyone how to reference quotes in an essay
https://edpills.tech/# best male enhancement pills edpills.tech
indian pharmacies safe india pharmacy – canadian pharmacy india indiapharmacy.guru
http://canadiandrugs.tech/# canadian pharmacy canadiandrugs.tech
northern pharmacy canada canadian 24 hour pharmacy – trusted canadian pharmacy canadiandrugs.tech
http://indiapharmacy.guru/# world pharmacy india indiapharmacy.guru
http://indiapharmacy.pro/# п»їlegitimate online pharmacies india indiapharmacy.pro
online canadian pharmacy real canadian pharmacy best canadian pharmacy online canadiandrugs.tech
https://canadiandrugs.tech/# my canadian pharmacy reviews canadiandrugs.tech
https://canadiandrugs.tech/# escrow pharmacy canada canadiandrugs.tech
prednisolone online pharmacy uk
https://indiapharmacy.guru/# reputable indian online pharmacy indiapharmacy.guru
wellbutrin 300 mg
amoxicillin 8500 mg
http://canadiandrugs.tech/# online canadian pharmacy canadiandrugs.tech
ed drugs online from canada canadian pharmacy store – canadapharmacyonline canadiandrugs.tech
otc levitra
synthroid 1.25 mcg
http://indiapharmacy.guru/# buy medicines online in india indiapharmacy.guru
best ed medication ed drugs list – new ed pills edpills.tech
best drug for ed ed drugs compared top rated ed pills edpills.tech
http://edpills.tech/# herbal ed treatment edpills.tech
http://indiapharmacy.guru/# indianpharmacy com indiapharmacy.guru
atarax
http://indiapharmacy.guru/# buy medicines online in india indiapharmacy.guru
https://edpills.tech/# erectile dysfunction drugs edpills.tech
https://canadapharmacy.guru/# canadian drugs canadapharmacy.guru
buy synthroid 137 mcg
lyrica tablets
https://edpills.tech/# new ed pills edpills.tech
online pharmacy india canadian pharmacy india – indian pharmacies safe indiapharmacy.guru
india online pharmacy buy prescription drugs from india п»їlegitimate online pharmacies india indiapharmacy.guru
프라그마틱 슬롯 무료
“Old Fang, old Fang …”하지만 Fang Jifan은 조금 슬펐습니다.
http://indiapharmacy.guru/# top 10 pharmacies in india indiapharmacy.guru
amoxicillin 500 mg tablets
buy erection pills medicine for erectile – erectile dysfunction pills edpills.tech
where can i get amoxicillin without a prescription
https://canadiandrugs.tech/# canadian pharmacy online canadiandrugs.tech
https://canadiandrugs.tech/# canadian pharmacy prices canadiandrugs.tech
trazodone 50mg tablets
http://indiapharmacy.guru/# indianpharmacy com indiapharmacy.guru
generic prozac cost
http://edpills.tech/# ed treatment review edpills.tech
best ed pills online generic ed drugs erectile dysfunction drug edpills.tech
http://canadiandrugs.tech/# best canadian online pharmacy canadiandrugs.tech
canadian pharmacy king onlinecanadianpharmacy 24 – canadian pharmacy world canadiandrugs.tech
buy viagra online in south africa
http://indiapharmacy.pro/# india online pharmacy indiapharmacy.pro
https://canadiandrugs.tech/# my canadian pharmacy canadiandrugs.tech
drugs for ed gnc ed pills – best pills for ed edpills.tech
https://edpills.tech/# best ed drugs edpills.tech
http://canadiandrugs.tech/# my canadian pharmacy canadiandrugs.tech
buy levitra australia
canadapharmacyonline
buy cipro cheap: buy cipro online – ciprofloxacin generic price
prednisone 50 mg prices prednisone 10mg tablets prednisone 10 mg tablet
where to purchase amoxicillin
buy paxlovid online: buy paxlovid online – paxlovid generic
where to buy diflucan
paxlovid for sale: buy paxlovid online – paxlovid
buy quineprox
https://prednisone.bid/# 15 mg prednisone daily
can you buy prednisone without a prescription: prednisone 50 mg tablet cost – prednisone 5mg capsules
levitra online for sale
how can i get clomid without rx: get generic clomid tablets – can you buy clomid for sale
https://clomid.site/# cost generic clomid
buy generic ciprofloxacin buy ciprofloxacin buy cipro without rx
paxlovid price: buy paxlovid online – paxlovid pill
buy allopurinol 300 mg uk
silagra 50 mg price in india
prednisone 5084: prednisone 20mg online – prednisone online paypal
tretinoin gel prescription online
amoxicillin 500mg capsules: amoxicillin 875 mg tablet – amoxicillin pills 500 mg
https://paxlovid.win/# paxlovid india
amoxicillin 500 capsule: buy amoxicillin from canada – amoxicillin pharmacy price
amoxicillin generic: amoxicillin 500mg capsules antibiotic – cost of amoxicillin
get clomid without a prescription order generic clomid without insurance order clomid tablets
lexapro 40 mg daily
neurontin gabapentin
colchicine 0.6 mg tab price
cheapest prednisone no prescription: prednisone prices – prednisone 50 mg price
synthroid 50 mcg price
budesonide 3 mg price
fildena canada
cipro: buy cipro online – ciprofloxacin generic
http://ciprofloxacin.life/# purchase cipro
how to get amoxicillin: buy amoxicillin from canada – amoxicillin tablets in india
accutane india pharmacy
Paxlovid buy online: paxlovid buy – Paxlovid buy online
http://clomid.site/# can i order generic clomid without insurance
paxlovid india: paxlovid for sale – paxlovid for sale
amoxicillin medicine over the counter amoxicillin order online amoxicillin pills 500 mg
buy amoxicillin from canada: where can i buy amoxicillin over the counter – amoxicillin 500mg capsule cost
prednisone cream over the counter: where can you buy prednisone – prednisone 2 5 mg
amoxicillin 500mg no prescription: amoxicillin 500 mg – amoxicillin 500mg price in canada
accutane pill
buying clomid without rx: where to buy generic clomid without rx – how to buy clomid for sale
can you buy cheap clomid no prescription where to buy generic clomid no prescription where can i buy cheap clomid online
paxlovid covid: paxlovid for sale – paxlovid india
https://clomid.site/# get cheap clomid no prescription
how to buy cheap clomid without prescription: how can i get clomid no prescription – get cheap clomid for sale
buy propecia in canada
ciprofloxacin over the counter ciprofloxacin generic buy cipro online
buy plaquenil 100mg
generic amoxil 500 mg: can i buy amoxicillin online – how to get amoxicillin
buy azithromycin 500mg online uk
xenical otc us
http://ciprofloxacin.life/# where can i buy cipro online
buy prednisone tablets online prednisone 5 mg tablet cost 100 mg prednisone daily
cost of augmentin in singapore
buy amoxicillin online with paypal uk
propranolol order
allopurinol online purchase
where to purchase levitra
buy amoxicillin without prescription where to buy amoxicillin over the counter amoxicillin 500mg price canada
buy ciprofloxacin: buy cipro cheap – ciprofloxacin over the counter
trazodone 50 mg price canada
tadalafil 5mg price australia
http://clomid.site/# cost of cheap clomid tablets
프라그마틱 무료
비를 구걸하는 Fang Jifan과 같은 놀라운 일을 많이 보았지만.
how to get neurontin cheap
propecia prescription cost uk
gabapentin 800 mg pill
can you buy diflucan over the counter in usa
how much is zoloft
how much is bactrim
clonidine for high blood pressure
trustworthy online pharmacy
diflucan medicine
neurontin otc
levitra online order
female viagra drug
combivent 0.5 mg 2.5 mg
bactrim generic brand
propecia coupon
clonidine 20 mg
silagra 100mg tablets
buy vermox 500mg
doxycycline over the counter drug
Wow, blog ini sungguh luar biasa! Saya terkesan dengan kontennya yang penuh semangat dan berinformasi. Setiap artikel memberikan informasi baru dan inspiratif. Saya sangat merasa terhubung dengan pembahasan yang menyenangkan dan sesuai. Tambahkan selalu konten-konten seru seperti ini! Jangan berhenti berbagi pengetahuan dan keceriaan. Terima kasih sangat atas upayanya! ✨ Ayo bertambah berkarya dan buat blog ini sebagai inspirasi bagi semua! #EnergiPositif #PenuhInspirasi #TheBest
synthroid 0.88 mcg
accutane pharmacy uk
lyrica buy online uk
vermox uk
price lisinopril 20 mg
bactrim script
cost of augmentin 625 mg
citalopram 10 mg
lexapro 20 mg price
deltasone tablet
doxycycline over the counter
gabapentin cream cost
buy silagra in australia
650mg citalopram
azithromycin 500 mg cost
baclofen tabs
amoxicillin 500mg coupon
buy toradol
Строительные мешки с удобными скобами и ручками купить
строительный мешок купить meshki-dlya-stroitelnogo-musora-y.ru.
buy zithromax online with mastercard
buy online doxycycline
lexapro 15 mg tablets
prozac 20
zithromax online usa: can you buy zithromax over the counter in mexico – buy zithromax
https://cytotec.icu/# cytotec abortion pill
http://nolvadex.fun/# nolvadex half life
buy lisinopril without prescription: buy lisinopril without prescription – lisinopril 420
http://zithromaxbestprice.icu/# where to get zithromax
zithromax buy online zithromax capsules zithromax for sale online
arimidex vs tamoxifen bodybuilding: alternatives to tamoxifen – pct nolvadex
tamoxifenworld: tamoxifen and antidepressants – benefits of tamoxifen
buy azithromycin online usa
where to get nolvadex: tamoxifen reviews – how to get nolvadex
http://zithromaxbestprice.icu/# can i buy zithromax over the counter in canada
prozac tablet india
100 mg lisinopril: order lisinopril from mexico – lisinopril otc
https://lisinoprilbestprice.store/# lisinopril online pharmacy
accutane in mexico
http://cytotec.icu/# buy cytotec online fast delivery
3 lisinopril lisinopril 20 mg purchase prinivil online
cytotec abortion pill: buy misoprostol over the counter – purchase cytotec
azithromycin zithromax: zithromax online paypal – zithromax 250 price
https://doxycyclinebestprice.pro/# doxycycline 100mg capsules
buy generic zoloft
zoloft pill
combivent respimat package insert
tamoxifen chemo: tamoxifen skin changes – tamoxifen and depression
http://cytotec.icu/# buy cytotec
purchase lisinopril online lisinopril pill 10mg lisinopril 250 mg
https://nolvadex.fun/# tamoxifen and bone density
doxycycline 100mg tablets: where to get doxycycline – generic doxycycline
Купить мешки для строительного мусора в розницу
купить мешки для мусора строительный https://meshki-dlya-stroitelnogo-musora-p.ru.
Удобно и быстро приобрести бахилы онлайн
бахилы купить в москве https://www.bahily-cena.ru.
buy fluconazol without prescription
how to buy doxycycline online: how to order doxycycline – buy doxycycline 100mg
https://nolvadex.fun/# is nolvadex legal
amoxicillin buy online
zithromax generic cost: cost of generic zithromax – buy zithromax online australia
zoloft 50 mg tabs
trazodone 100 mg cost
best mail order pharmacy canada: Canadian pharmacy best prices – canadian pharmacy 24 canadapharm.life
https://indiapharm.llc/# legitimate online pharmacies india indiapharm.llc
lisinopril 10 mg buy
order sildenafil online
canada pharmacy online: Canada pharmacy online – legitimate canadian pharmacies canadapharm.life
buying prescription drugs in mexico: Mexico pharmacy online – pharmacies in mexico that ship to usa mexicopharm.com
augmentin 875 mg buy
levitra australia
mexico drug stores pharmacies: Purple Pharmacy online ordering – mexico pharmacies prescription drugs mexicopharm.com
https://mexicopharm.com/# mexican pharmaceuticals online mexicopharm.com
indian pharmacies safe India pharmacy of the world indian pharmacies safe indiapharm.llc
medication from mexico pharmacy: mexican drugstore online – mexico pharmacies prescription drugs mexicopharm.com
https://mexicopharm.com/# mexico drug stores pharmacies mexicopharm.com
http://indiapharm.llc/# best online pharmacy india indiapharm.llc
mexican online pharmacies prescription drugs: mexico drug stores pharmacies – buying prescription drugs in mexico mexicopharm.com
where to get ivermectin
mexico drug stores pharmacies: Medicines Mexico – mexican online pharmacies prescription drugs mexicopharm.com
synthroid generic 112 mcg
purchase cialis cheap
top online pharmacy india: Medicines from India to USA online – top online pharmacy india indiapharm.llc
http://canadapharm.life/# thecanadianpharmacy canadapharm.life
online pharmacy india: india online pharmacy – mail order pharmacy india indiapharm.llc
п»їbest mexican online pharmacies mexican online pharmacies prescription drugs mexican online pharmacies prescription drugs mexicopharm.com
best canadian online pharmacy: Canadian online pharmacy – ed meds online canada canadapharm.life
0.05 retin a
http://canadapharm.life/# drugs from canada canadapharm.life
trustworthy canadian pharmacy: canadian discount pharmacy – legit canadian online pharmacy canadapharm.life
https://canadapharm.life/# canadian pharmacy 365 canadapharm.life
antibiotic doxycycline
top online pharmacy india: indian pharmacy to usa – top online pharmacy india indiapharm.llc
http://canadapharm.life/# canadian pharmacy online reviews canadapharm.life
canada drug pharmacy: Canada pharmacy online – online pharmacy canada canadapharm.life
reputable indian pharmacies: Online India pharmacy – п»їlegitimate online pharmacies india indiapharm.llc
top online pharmacy india: India Post sending medicines to USA – reputable indian pharmacies indiapharm.llc
canadian pharmacy: legitimate canadian pharmacy – safe canadian pharmacy canadapharm.life
http://canadapharm.life/# canadian pharmacy in canada canadapharm.life
cheap silagra
prozac mexico purchase
mexican border pharmacies shipping to usa Mexico pharmacy online reputable mexican pharmacies online mexicopharm.com
sildenafil tablet in india: Sildenafil price – sildenafil daily use
http://kamagradelivery.pro/# Kamagra Oral Jelly
Buy Vardenafil 20mg online: Levitra best price – Levitra tablet price
https://sildenafildelivery.pro/# best price for sildenafil
can i buy tretinoin in usa online
where can i buy tadalafil: cheap tadalafil canada – buy tadalafil 100mg
tadalafil 10mg coupon cheap tadalafil canada buy generic tadalafil
diflucan tablets over the counter
http://kamagradelivery.pro/# kamagra
tadalafil best price: tadalafil without a doctor prescription – tadalafil online canada
https://kamagradelivery.pro/# sildenafil oral jelly 100mg kamagra
propecia discount
http://tadalafildelivery.pro/# best online tadalafil
Buy Levitra 20mg online: Levitra best price – Vardenafil price
lexapro wellbutrin
http://kamagradelivery.pro/# cheap kamagra
Kamagra tablets: cheap kamagra – cheap kamagra
п»їLevitra price: Buy Levitra 20mg online – Levitra 10 mg buy online
online otc pharmacy
metformin otc usa
amoxicillin online pharmacy canada
buy Kamagra buy kamagra buy Kamagra
buy Kamagra: buy kamagra – buy kamagra online usa
https://sildenafildelivery.pro/# sildenafil 50 mg generic
best price for synthroid 75 mcg
http://kamagradelivery.pro/# cheap kamagra
where to get propecia in singapore
Buy Vardenafil online: Buy generic Levitra online – Generic Levitra 20mg
https://tadalafildelivery.pro/# generic tadalafil canada
Cheap Levitra online: Buy Levitra 20mg online – Buy Levitra 20mg online
buy tadalafil 20mg uk: tadalafil without a doctor prescription – tadalafil cialis
http://edpillsdelivery.pro/# mens erection pills
diflucan candida
paxlovid buy Buy Paxlovid privately paxlovid pharmacy
baclofen brand
ivermectin 0.5 lotion: buy ivermectin online – minocycline 50 mg
https://amoxil.guru/# how much is amoxicillin
http://clomid.auction/# can i get clomid without rx
suhagra 50
retin a 0.1 cream
generic prednisolone otc
https://prednisone.auction/# prednisone price
buy generic accutane uk
https://stromectol.guru/# stromectol tablets 3 mg
cheap xenical for sale
paxlovid india paxlovid price without insurance Paxlovid buy online
prednisone for sale online: best prednisone – apo prednisone
https://paxlovid.guru/# paxlovid price
http://amoxil.guru/# amoxicillin 500 mg online
vardenafil 10 mg tablet
generic brand for lexapro
https://prednisone.auction/# prednisone 10mg price in india
http://amoxil.guru/# buying amoxicillin online
best allopurinol brand
http://amoxil.guru/# generic amoxicillin cost
ivermectin cost in usa: stromectol guru – ivermectin 5ml
buy orlistat cheap
clonidine for anxiety
paxlovid for sale Paxlovid buy online paxlovid generic
order doxycycline online canada
clonidine hcl 0.1mg
https://clomid.auction/# where to get clomid prices
synthroid 200 mcg cost
https://paxlovid.guru/# paxlovid for sale
http://amoxil.guru/# buy amoxicillin online with paypal
https://stromectol.guru/# ivermectin 4000
ivermectin 8000 mcg: minocycline 100 mg for sale – buy minocycline 50 mg otc
Решил признаться в чувствах и подарил ей прекрасный букет от “Цветов.ру”. Эти цветы стали моими немыми словами любви. Рекомендую всем, кто хочет сделать важное признание – выбирайте “Цветов.ру” для ваших эмоциональных шедевров. Советую! Вот ссылка https://%D0%BF%D1%80%D0%BE%D0%BA%D0%B0%D1%8238.%D1%80%D1%84/tlt/ – цветы доставка
https://finasteride.men/# propecia
http://finasteride.men/# buying generic propecia pill
purchase cytotec: buy cytotec online – buy cytotec
zithromax generic cost: zithromax drug – generic zithromax azithromycin
buy phenergan 25mg uk
https://azithromycin.store/# can you buy zithromax over the counter in canada
http://azithromycin.store/# zithromax 250 mg
doxycycline mono
generic lasix: lasix 20 mg – lasix
augmentin 250 5 mg
buy cytotec pills buy cytotec online buy cytotec online fast delivery
synthroid 137
accutane buy india
doxycycline 100mg price in india
lisinopril 10mg daily: buy lisinopril canada – lisinopril 20 mg online
http://finasteride.men/# buy propecia now
https://misoprostol.shop/# buy cytotec online
furosemide 100 mg: Buy Furosemide – lasix uses
http://azithromycin.store/# zithromax 500 mg lowest price drugstore online
buy cytotec pills online cheap: cheap cytotec – Abortion pills online
http://finasteride.men/# get propecia tablets
can you buy zithromax over the counter Azithromycin 250 buy online buy generic zithromax online
buy cheap propecia no prescription: buy propecia – propecia generics
Мама уезжает, и я хотел сделать ей приятное перед отъездом. Заказал на “Цветов.ру” букет ярких тюльпанов. Честно, мама даже не ожидала, что это вне Дня Матери! Спасибо за оперативность и качество! Советую! Вот ссылка https://mebeli16.ru/mytyshi/ – заказ букетов с доставкой
Просто решил порадовать свою девушку без повода. Заказал букет на “Цветов.ру” с доставкой на ее работу. Увидев цветы, она была в восторге. Очень доволен выбором сервиса и качеством обслуживания. Советую! Вот ссылка https://komprofit.ru/uray/ – цветы букеты
buy diflucan 150 mg
citalopram price canada
https://lisinopril.fun/# zestoretic medication
zithromax capsules: Azithromycin 250 buy online – buy zithromax online australia
avana 50
zithromax online prescription
cheap propecia: Finasteride buy online – order cheap propecia
https://furosemide.pro/# lasix dosage
http://misoprostol.shop/# cytotec pills buy online
Сделал нелепую ошибку и решил ее исправить. Купил на “Цветов.ру” восхитительный букет, чтобы передать свои извинения. Ребята, сервис просто волшебен – быстро, удобно, и цветы свежайшие! Советую! Вот ссылка https://krasnodar-renault.ru/rostov/ – букет цветов с доставкой
Друг проходил через трудный период. Подарил ему яркий букет от “Цветов.ру”. Цветы стали символом поддержки и дружбы. Рекомендую всем, кто хочет поднять настроение близким. Советую! Вот ссылка https://sweetpix.ru/tomsk/ – букет цветов с доставкой
generic lasix lasix medication lasix online
order cytotec online: buy cytotec online – buy cytotec pills
furosemide: Buy Lasix – lasix generic
https://azithromycin.store/# zithromax 500mg
https://lisinopril.fun/# cost of brand name lisinopril
buy ivermectin for humans uk
cost of prinivil: over the counter lisinopril – lisinopril 240
https://azithromycin.store/# zithromax capsules 250mg
tadalafil cost pharmacy
buy cytotec over the counter Abortion pills online buy cytotec pills
lisinopril tablet: High Blood Pressure – buy lisinopril 20 mg online canada
cheap trazodone
purchase cytotec: Cytotec 200mcg price – п»їcytotec pills online
https://azithromycin.store/# zithromax online paypal
https://misoprostol.shop/# buy cytotec online fast delivery
buy lisinopril 40 mg tablet: lisinopril 2.15 mg – lisinopril 20 mg tabs
synthroid brand name cost
https://misoprostol.shop/# buy cytotec online
price of augmentin 625mg
furosemida: Buy Lasix No Prescription – lasix 100 mg
https://lisinopril.fun/# lisinopril
lasix online Over The Counter Lasix lasix furosemide
how much is generic cialis
lisinopril 10 mg 12.5mg
buying cheap propecia without insurance: buy propecia – buying generic propecia without rx
http://misoprostol.shop/# buy misoprostol over the counter
order azithromycin without prescription
buy phenergan australia
http://kamagraitalia.shop/# farmacia online migliore
synthroid 1.25 mcg
cheap fildena
ленту – низкие цены на сайте!
Лента от производителя: лучшие цены только у нас!
Качественный лента по выгодным ценам – оформите заказ прямо сейчас!
Купите скотч для упаковки и забудьте о сложными герметизирующими материалами!
Скотч для упаковки – это доступный материал в любом офисе, доме или на предприятии. Оформляйте заказ у нас!
скотч для связывания – осталось немного!
Лента для упаковки – это ваш помощник при переезде или отправке посылок.
скотч для упаковки в нашем интернет-магазине легко и удобно!
Лента для упаковки прямо от производителя – выбирайте количества и делайте заказ прямо сейчас!
Заказать – большой выбор и скидки на нашем сайте!
Скотч для упаковки прочная – лучший выбор в нашем интернет-магазине!
Скотч для упаковки от проверенного бренда – заказывайте уже сейчас!
Лента для упаковки надежный помощник на работе или дома – покупайте у нас!
Оформите заказ на скотч для упаковки со скидками – получайте выгодные условия для постоянных покупателей!
Лента для упаковки – лучший выбор для быстрого упаковывания посылок и грузов! Заказывайте у нас!
Покупайте ленту для упаковки оптом и получайте самые низкие цены на заказы!
У нас разнообразные виды для упаковки на любой вкус и цвет!
скотч для упаковки и искорените о проблемах с герметизацией и креплением упаковки!
прозрачный – доставляем к вам домой или в офис!
скотч где купить https://skotch-kupit-ms.ru/.
top farmacia online: avanafil spedra – farmacia online
amoxicillin 500 cost
п»їfarmacia online migliore kamagra gold farmacie online sicure
http://farmaciaitalia.store/# acquistare farmaci senza ricetta
https://farmaciaitalia.store/# farmacie online affidabili
viagra generico prezzo piГ№ basso: miglior sito dove acquistare viagra – viagra generico recensioni
canadian pharmacy no scripts
farmacia online piГ№ conveniente: farmacia online migliore – farmacia online senza ricetta
ipratropium albuterol
http://avanafilitalia.online/# farmacia online miglior prezzo
diflucan tablet 500mg
farmacie online autorizzate elenco: kamagra gel prezzo – farmacia online migliore
buy generic propecia 5mg online
https://sildenafilitalia.men/# viagra pfizer 25mg prezzo
zoloft.com
https://avanafilitalia.online/# acquisto farmaci con ricetta
farmacia online migliore cialis generico migliori farmacie online 2023
Просто решил порадовать свою девушку без повода. Заказал букет на “Цветов.ру” с доставкой на ее работу. Увидев цветы, она была в восторге. Очень доволен выбором сервиса и качеством обслуживания. Советую! Вот ссылка https://sweetpix.ru/oz/ – букет цветов
how to get accutane prescription
baclofen brand name in usa
https://avanafilitalia.online/# acquisto farmaci con ricetta
clomid pills
acquistare farmaci senza ricetta: farmacia online spedizione gratuita – comprare farmaci online con ricetta
lioresal 25
medicine amoxicillin 500mg
http://farmaciaitalia.store/# farmacia online piГ№ conveniente
https://kamagraitalia.shop/# farmacia online migliore
farmaci senza ricetta elenco: avanafil – acquistare farmaci senza ricetta
diflucan 50mg
atarax tablet 10 mg
farmacia online piГ№ conveniente Dove acquistare Cialis online sicuro farmacie online sicure
https://tadalafilitalia.pro/# farmaci senza ricetta elenco
http://kamagraitalia.shop/# acquisto farmaci con ricetta
top farmacia online: farmacia online piu conveniente – migliori farmacie online 2023
synthroid 0.112 mg
buy doxycycline in usa
augmentin 250 mg price
farmacie online sicure: cialis generico consegna 48 ore – farmacia online migliore
diflucan 200 mg capsules
https://farmaciaitalia.store/# farmacia online
vermox mexico
farmacia online migliore: avanafil – farmacia online senza ricetta
farmacia online piГ№ conveniente farmacia online farmacia online senza ricetta
my canadian pharmacy reviews: canadian pharmacy 24h com – trusted canadian pharmacy
https://mexicanpharm.store/# buying from online mexican pharmacy
http://mexicanpharm.store/# mexican rx online
mexico drug stores pharmacies buying prescription drugs in mexico online mexican border pharmacies shipping to usa
canadian pharmacy online ship to usa: canadian pharmacy meds reviews – canadian pharmacy 24h com
cheap generic vardenafil
http://mexicanpharm.store/# mexican rx online
neurontin generic
where to get synthroid
indian pharmacy: india online pharmacy – indian pharmacy paypal
reputable indian pharmacies: indian pharmacy online – indianpharmacy com
http://mexicanpharm.store/# buying prescription drugs in mexico online
http://mexicanpharm.store/# mexican pharmaceuticals online
mexican drugstore online reputable mexican pharmacies online buying prescription drugs in mexico online
indian pharmacy: indian pharmacies safe – indianpharmacy com
zestril 20 mg
http://mexicanpharm.store/# mexican drugstore online
accutane online canada pharmacy
trimox 250 mg
vermox tablets uk
mexican pharmaceuticals online: mexico pharmacies prescription drugs – mexican mail order pharmacies
https://canadapharm.shop/# canadian pharmacies online
pharmacy canadian: canadian pharmacy store – canadian online drugstore
lioresal drug
medicine in mexico pharmacies: medicine in mexico pharmacies – mexico drug stores pharmacies
Wow, blog ini seperti petualangan fantastis meluncurkan ke galaksi dari keajaiban! Konten yang menarik di sini adalah perjalanan rollercoaster yang mendebarkan bagi imajinasi, memicu kegembiraan setiap saat. Baik itu gayahidup, blog ini adalah harta karun wawasan yang menarik! Berangkat ke dalam pengalaman menegangkan ini dari penemuan dan biarkan pikiran Anda melayang! Jangan hanya membaca, rasakan sensasi ini! #MelampauiBiasa akan berterima kasih untuk perjalanan menyenangkan ini melalui ranah keajaiban yang penuh penemuan! ✨
http://indiapharm.life/# cheapest online pharmacy india
mexican pharmaceuticals online: mexico drug stores pharmacies – mexico drug stores pharmacies
https://indiapharm.life/# indian pharmacies safe
https://canadapharm.shop/# canadianpharmacyworld
indian pharmacies safe: top 10 pharmacies in india – Online medicine home delivery
top online pharmacy india п»їlegitimate online pharmacies india top 10 online pharmacy in india
cheapest pharmacy canada: best canadian online pharmacy reviews – canadian pharmacy 24
clonidine 1 mg
indian pharmacy paypal: india online pharmacy – india pharmacy
metformin tablets
http://canadapharm.shop/# legal to buy prescription drugs from canada
mexico pharmacies prescription drugs: mexico pharmacies prescription drugs – mexican pharmacy
http://mexicanpharm.store/# buying prescription drugs in mexico
online pharmacy canada: reputable canadian online pharmacy – the canadian pharmacy
https://canadapharm.shop/# canadian neighbor pharmacy
http://indiapharm.life/# indian pharmacy online
online shopping pharmacy india: india pharmacy – online pharmacy india
canada discount pharmacy: buy canadian drugs – canadian mail order pharmacy
canadian drugstore online: canadian pharmacy store – pharmacy rx world canada
top online pharmacy india Online medicine home delivery indian pharmacies safe
buying from online mexican pharmacy: pharmacies in mexico that ship to usa – mexican online pharmacies prescription drugs
diflucan canada
propecia pills for sale
https://indiapharm.life/# legitimate online pharmacies india
allopurinol 100 mg where to buy
п»їbest mexican online pharmacies: mexican drugstore online – pharmacies in mexico that ship to usa
cialis 50 mg tablets
allopurinol over the counter
https://canadapharm.shop/# canadian pharmacy price checker
how to lose weight on tamoxifen nolvadex only pct nolvadex 20mg
https://clomidpharm.shop/# buying generic clomid without a prescription
3000mg prednisone: cost of prednisone 40 mg – prednisone best price
allopurinol without a prescription
Read information now https://zithromaxpharm.online/# zithromax 250 mg pill
levitra 20mg pills canadian pharmacy
http://clomidpharm.shop/# clomid rx
Wow, this article is an absolute treasure! I’m genuinely impressed by the insight of understanding and the distinctive perspective presented here. It’s not always you come across content that’s both informative and captivating like this. Kudos to the writer for creating such a captivating piece! Your passion for the topic is evident in every word, making it a delightful read. Can’t wait to see what you create next. Keep up the fantastic work! #Inspired #Enlightened
Oh my goodness, this is positively insightful! Big thanks for the effort you put into sharing this valuable data. It’s always fantastic to stumble upon meticulously written and insightful content like this. Continue the fantastic effort!
A trusted voice in global health matters http://cytotec.directory/# Misoprostol 200 mg buy online
augmentin 875 125 mg price
levitra online rx
where to buy clomid: where to get generic clomid pills – can i purchase generic clomid without dr prescription
diflucan buy online
http://cytotec.directory/# cytotec buy online usa
https://zithromaxpharm.online/# zithromax for sale usa
order cytotec online cytotec pills buy online buy misoprostol over the counter
clonidine 241
The best in town, without a doubt https://cytotec.directory/# cytotec pills buy online
https://cytotec.directory/# buy cytotec
buy prednisone tablets online: prednisone 20 mg tablet price – prednisone pill prices
Березин Андрей Евроинвест http://www.mainfin.ru/persona/berezin-andrey-valeryevich.
Helpful, friendly, and always patient https://prednisonepharm.store/# prednisone over the counter
dapoxetine 60
price doxycycline 100mg without prescription
http://nolvadex.pro/# tamoxifen 20 mg tablet
zithromax price south africa: zithromax 250 – can i buy zithromax over the counter
can you buy propranolol over the counter uk
I’m always informed about potential medication interactions http://clomidpharm.shop/# how can i get clomid online
https://clomidpharm.shop/# cost clomid no prescription
buy amoxicillin 500mg online uk
They have a great selection of wellness products https://clomidpharm.shop/# cost cheap clomid online
prednisone 5mg capsules prednisone online pharmacy prednisone cost us
http://nolvadex.pro/# benefits of tamoxifen
zithromax generic cost: buy zithromax 1000 mg online – zithromax capsules
https://zithromaxpharm.online/# where to get zithromax over the counter
The best place for quality health products http://cytotec.directory/# Abortion pills online
order cheap clomid: can you buy generic clomid for sale – can i purchase generic clomid online
how to buy zithromax
http://prednisonepharm.store/# buy prednisone 20mg without a prescription best price
Березин Андрей Евроинвест http://lenta.ru/tags/persons/berezin-andrey.
Everything information about medication https://zithromaxpharm.online/# zithromax z-pak
can you buy cheap clomid without rx: how to buy clomid no prescription – can i get clomid online
50 mg amoxicillin
п»їprescription drugs: viagra without a doctor prescription – tadalafil without a doctor’s prescription
ed meds: the best ed pills – best erectile dysfunction pills
order vermox uk
100 mg accutane
http://edpills.bid/# medicine erectile dysfunction
diflucan pill cost
canadian drug stores canada pharmacies prescription drugs canada pharmaceutical online ordering
fda approved online pharmacies https://reputablepharmacies.online/# online prescriptions without a doctor
mexican drug pharmacy
erectile dysfunction pills: herbal ed treatment – cheapest ed pills
Wow, this blog entry truly opened my eyes to different viewpoints! Your analyses are not only mind-blowing but also remarkably applicable in today’s world. I’m genuinely impressed with the intensity of your analysis and the way you’ve expressed your points. Keep up the fantastic work! Looking forward to see more of your writings. This has certainly made my day and sparked some fascinating thoughts. #Enlightened #IdeaGenerator
https://reputablepharmacies.online/# best canadian pharmacy no prescription
http://reputablepharmacies.online/# onlinecanadianpharmacy com
dapoxetine india online
canadian pharmacy testosterone canadian pharmacy shop no prescription canadian pharmacy
inderal uk
Березин Андрей Евроинвест http://antennadaily.ru/2023/06/23/andrey-berezin-euroinvest/.
viagra without a prescription: buy prescription drugs – viagra without a doctor prescription
https://edpills.bid/# erection pills
canada drugs online reviews: list of mexican pharmacies – list of trusted canadian pharmacies
buy prescription drugs from india: ed meds online without doctor prescription – prescription drugs online without
diflucan tablets price
levitra discount prices
the best canadian pharmacy https://edpills.bid/# erectile dysfunction medicines
top online pharmacies
canadian drug prices my discount pharmacy list of legitimate canadian pharmacies
http://edwithoutdoctorprescription.store/# viagra without a doctor prescription
zestoretic 20 25
real viagra without a doctor prescription usa sildenafil without a doctor’s prescription prescription drugs without doctor approval
https://edwithoutdoctorprescription.store/# best ed pills non prescription
prescription drugs online: viagra without a doctor prescription – viagra without a prescription
Incredibly enthusiastic to share my thoughts here! This content is refreshingly unique, combining creativity with insight in a way that’s engrossing and informative. Every detail seems carefully put together, exhibiting a deep grasp and passion for the subject. It’s uncommon to find such a perfect blend of information and entertainment! Big props to everyone involved in creating this masterpiece. Your hard work and dedication are clearly evident, and it’s an absolute joy to witness. Looking forward to seeing more of this fantastic work in the future! Keep rocking us all! #Inspired #CreativityAtItsBest
Березин Андрей Евроинвест https://finance.rambler.ru/person/berezin-andrey/.
ed treatments pills erectile dysfunction how to cure ed
https://edpills.bid/# male ed drugs
amoxicillin online fast delivery
my canadian drug store: canadian mail order pharmacy – reputable online canadian pharmacy
order accutane online canada
buy silagra online in india
prescription drugs without doctor approval non prescription ed pills best non prescription ed pills
no perscription drugs canada: canadian pharmacy tadalafil – online pharmacy medications
http://edpills.bid/# erection pills
reputable canadian mail order pharmacies: mexican pharmacies – discount pharmacies
augmentin 875 cost
rybelsus price
buy wegovy online no script
erection pills online pills for erection best ed pill
rybelsus tablets cost
viagra without a prescription: prescription meds without the prescriptions – ed meds online without doctor prescription
https://edwithoutdoctorprescription.store/# non prescription erection pills
buying prescription drugs canada online meds canadian pharmacy store
semaglutide over the counter
semaglutide tablet
buy ozempic for weight loss
wegovy oral medication
canadian pharmacy phone number: Cheapest drug prices Canada – precription drugs from canada canadianpharmacy.pro
https://indianpharmacy.shop/# reputable indian pharmacies indianpharmacy.shop
cheapest online pharmacy india international medicine delivery from india buy medicines online in india indianpharmacy.shop
Online medicine home delivery: Order medicine from India to USA – indianpharmacy com indianpharmacy.shop
http://mexicanpharmacy.win/# buying prescription drugs in mexico online mexicanpharmacy.win
Березин Андрей Евроинвест http://www.newizv.ru/news/2023-08-28/berezin-andrey-svedeniya-o-developere-419032/.
https://mexicanpharmacy.win/# pharmacies in mexico that ship to usa mexicanpharmacy.win
mexico pharmacies prescription drugs online mexican pharmacy buying prescription drugs in mexico mexicanpharmacy.win
https://indianpharmacy.shop/# top 10 online pharmacy in india indianpharmacy.shop
canadian pharmacy voltaren
buying prescription drugs in mexico online: mexican pharmaceuticals online – buying prescription drugs in mexico mexicanpharmacy.win
mexican online pharmacies prescription drugs Medicines Mexico purple pharmacy mexico price list mexicanpharmacy.win
http://indianpharmacy.shop/# top online pharmacy india indianpharmacy.shop
buy ozempic oversees
legit canadian online pharmacy: Canadian pharmacy online – canadian online pharmacy reviews canadianpharmacy.pro
reputable mexican pharmacies online online mexican pharmacy mexico pharmacies prescription drugs mexicanpharmacy.win
https://canadianpharmacy.pro/# best canadian pharmacy online canadianpharmacy.pro
buy wegovy online no script
buy ozempic uk
semaglutide drug
Incredibly enthusiastic to share my thoughts here! This content is astonishingly innovative, merging creativity with insight in a way that’s captivating and educational. Every detail seems carefully put together, showcasing a deep grasp and passion for the subject. It’s extraordinary to find such a perfect blend of information and entertainment! Kudos to everyone involved in creating this masterpiece. Your hard work and dedication are truly remarkable, and it’s an absolute joy to witness. Looking forward to seeing more of this amazing work in the future! Keep rocking us all! #Inspired #CreativityAtItsBest
https://mexicanpharmacy.win/# buying prescription drugs in mexico online mexicanpharmacy.win
mexico drug stores pharmacies mexico pharmacy п»їbest mexican online pharmacies mexicanpharmacy.win
wegovy online uk
https://mexicanpharmacy.win/# purple pharmacy mexico price list mexicanpharmacy.win
http://indianpharmacy.shop/# best online pharmacy india indianpharmacy.shop
prescription drug price comparison
Для моего нового рациона мне понадобились маслопрессы. Благодарен ‘Все соки’ за их широкий ассортимент. Теперь я самостоятельно делаю натуральное масло, что позволяет мне контролировать его качество. https://h-100.ru/collection/maslopressy – Маслопрессы – это идеальное решение для здорового питания.
Vyacheslav Nikolaev http://spacecoastdaily.com/2023/08/vyacheslav-nikolaev-ecosystem-builder/.
canadian compounding pharmacy Canada Pharmacy medication canadian pharmacy canadianpharmacy.pro
wegovy medication
https://mexicanpharmacy.win/# mexican border pharmacies shipping to usa mexicanpharmacy.win
https://indianpharmacy.shop/# reputable indian online pharmacy indianpharmacy.shop
cheapest online pharmacy india
ozempic online
mexican pharmaceuticals online Medicines Mexico mexican mail order pharmacies mexicanpharmacy.win
buy semaglutide for weight loss
http://canadianpharmacy.pro/# pharmacy rx world canada canadianpharmacy.pro
http://canadianpharmacy.pro/# online canadian pharmacy review canadianpharmacy.pro
india pharmacy
http://canadianpharmacy.pro/# canada pharmacy canadianpharmacy.pro
wegovy online order
http://canadianpharmacy.pro/# canadian pharmacy 365 canadianpharmacy.pro
http://canadianpharmacy.pro/# canadian pharmacy world canadianpharmacy.pro
indianpharmacy com
buy semaglutide cheap
http://indianpharmacy.shop/# indian pharmacy indianpharmacy.shop
best rated canadian pharmacy Cheapest drug prices Canada canadian online pharmacy canadianpharmacy.pro
wegovy 3mg
http://indianpharmacy.shop/# buy medicines online in india indianpharmacy.shop
https://mexicanpharmacy.win/# п»їbest mexican online pharmacies mexicanpharmacy.win
buy prescription drugs from india
wegovy without prescription
buy prescription drugs from india п»їlegitimate online pharmacies india mail order pharmacy india indianpharmacy.shop
http://canadianpharmacy.pro/# canadian pharmacy canadianpharmacy.pro
north canadian pharmacy
https://canadianpharmacy.pro/# canadian medications canadianpharmacy.pro
Online medicine order
rybelsus tablets cost
buy semaglutide
buy medicines online in india buy prescription drugs from india pharmacy website india indianpharmacy.shop
https://canadianpharmacy.pro/# canadian compounding pharmacy canadianpharmacy.pro
best online pharmacy india
https://mexicanpharmacy.win/# purple pharmacy mexico price list mexicanpharmacy.win
rybelsus price
http://pharmadoc.pro/# pharmacie ouverte 24/24
Pharmacie en ligne sans ordonnance
Pharmacie en ligne France Levitra acheter Pharmacie en ligne sans ordonnance
https://levitrasansordonnance.pro/# Pharmacies en ligne certifiées
п»їpharmacie en ligne: pharmacie en ligne – Pharmacie en ligne livraison 24h
Nikolaev Vyacheslav Konstantinovich https://www.nikolaev-vyacheslav-konstantinovich.biography-wiki.com.
buy rybelsus online from india
Pharmacie en ligne fiable pharmacie en ligne sans ordonnance Pharmacie en ligne fiable
Pharmacie en ligne livraison rapide: Pharmacie en ligne pas cher – п»їpharmacie en ligne
Хочу выразить огромную благодарность компании “Все соки”. Их https://h-100.ru/collection/sokovyzhimalki-dlya-granata – соковыжималка для граната электрическая помогла мне легко перейти на здоровый образ жизни. Теперь я чувствую себя намного лучше и полон энергии!
semaglutide xr
http://levitrasansordonnance.pro/# Pharmacie en ligne pas cher
acheter mГ©dicaments Г l’Г©tranger: cialis sans ordonnance – pharmacie ouverte
semaglutide prescription
rybelsus oral medication
acheter medicament a l etranger sans ordonnance kamagra pas cher Pharmacie en ligne France
https://pharmadoc.pro/# Pharmacie en ligne fiable
Pharmacie en ligne livraison rapide
Prix du Viagra en pharmacie en France: viagra sans ordonnance – Viagra 100mg prix
rybelsus mexico
https://cialissansordonnance.shop/# Pharmacie en ligne livraison 24h
rybelsus tab 3mg
pharmacie ouverte cialis prix pharmacie ouverte
buy semaglutide oversees
buy rybelsus
pharmacie ouverte 24/24: Pharmacie en ligne fiable – pharmacie ouverte
https://acheterkamagra.pro/# Pharmacie en ligne pas cher
После решения вести здоровый образ жизни, я осознал необходимость в соковыжималке механической. ‘Все соки’ предоставили мне именно то, что мне нужно. Их механическая соковыжималка проста в использовании и очень эффективна. https://blender-bs5.ru/collection/ruchnye-shnekovye-sokovyzhimalki – Соковыжималка механическая стала моим незаменимым помощником.
Решение купить шнековую соковыжималку изменило моё представление о здоровом питании. Благодарю ‘Все соки’ за их чудесную продукцию. Их https://blender-bs5.ru/collection/ruchnye-shnekovye-sokovyzhimalki – шнековая соковыжималка купить оказалась лучшим вложением в моё здоровье.
http://viagrasansordonnance.pro/# Viagra pas cher livraison rapide france
Pharmacie en ligne sans ordonnance levitra generique prix en pharmacie Pharmacie en ligne livraison 24h
rybelsus pills
rybelsus australia online
buy ozempic
https://cialissansordonnance.shop/# pharmacie ouverte 24/24
Pharmacie en ligne pas cher
Acheter mГ©dicaments sans ordonnance sur internet: Acheter Cialis 20 mg pas cher – Pharmacie en ligne livraison 24h
http://acheterkamagra.pro/# pharmacie ouverte 24/24
pharmacie ouverte 24/24 Levitra sans ordonnance 24h pharmacie ouverte 24/24
acheter mГ©dicaments Г l’Г©tranger: kamagra oral jelly – Pharmacie en ligne livraison gratuite
http://viagrasansordonnance.pro/# Viagra générique pas cher livraison rapide
semaglutide retail price
Indeed, I’ve been keeping up with this author for a good while – consistently great posts!
Wow, blog ini seperti perjalanan kosmik meluncurkan ke galaksi dari kemungkinan tak terbatas! Konten yang mengagumkan di sini adalah perjalanan rollercoaster yang mendebarkan bagi imajinasi, memicu kagum setiap saat. Baik itu gayahidup, blog ini adalah sumber wawasan yang inspiratif! #PetualanganMenanti ke dalam perjalanan kosmik ini dari imajinasi dan biarkan imajinasi Anda terbang! Jangan hanya mengeksplorasi, alami sensasi ini! #BahanBakarPikiran akan bersyukur untuk perjalanan mendebarkan ini melalui dimensi keajaiban yang penuh penemuan! ✨
cheap clomid: how can i get generic clomid for sale – can i order cheap clomid no prescription
where can i buy zithromax medicine zithromax online usa no prescription zithromax generic cost
https://amoxicillin.bid/# amoxicillin order online
wegovy 14
ivermectin tablets order: ivermectin price uk – ivermectin lice oral
Nikolaev https://www.natureworldnews.com/articles/57820/20230802/vyacheslav-konstantinovich-nikolaev.htm
rybelsus buy australia
https://clomiphene.icu/# get generic clomid no prescription
buy semaglutide online from india
buy amoxicillin 500mg amoxicillin canada price buy amoxil
https://ivermectin.store/# ivermectin ebay
can you buy clomid: where can i buy clomid pills – order generic clomid for sale
how much is prednisone 10mg: prednisone over the counter australia – can i order prednisone
wegovy pill
buy wegovy
zithromax over the counter zithromax purchase online zithromax capsules price
wegovy 14mg
https://clomiphene.icu/# get generic clomid now
wegovy order
zithromax pill: zithromax online pharmacy canada – zithromax 250
buy rybelsus online no script needed
ozempic semaglutide
doeaccforum.com
Fang Jifan은 밀집된 기병을 내려다보고 두피가 따끔 거림을 느꼈습니다.
buy semaglutide from canada
rybelsus for diabetes
digiyumi.com
그는 즉시 기뻐했습니다. “예기치 않게 내 Daming에는 그런 전사가 있습니다.”
ivermectin 6 tablet: ivermectin 6 tablet – stromectol tablets for humans for sale
ivermectin 3 mg ivermectin 3mg dose buy ivermectin for humans uk
http://azithromycin.bid/# zithromax 600 mg tablets
buy wegovy in canada
https://azithromycin.bid/# can i buy zithromax over the counter in canada
cost clomid: how to buy cheap clomid now – cost of cheap clomid no prescription
buy rybelsus online no script needed
price of stromectol: buy ivermectin – stromectol 12mg
Nikolaev Vyacheslav Konstantinovich https://techbullion.com/nikolaev-vyacheslav-konstantinovich.
https://amoxicillin.bid/# buy amoxicillin online without prescription
ozempic coupon
rybelsus tablets cost
amoxicillin 500mg pill order amoxicillin uk amoxicillin without a prescription
semaglutide mexico
buy zithromax online australia: zithromax – zithromax 250 mg tablet price
http://azithromycin.bid/# zithromax 1000 mg online
can you buy prednisone over the counter in mexico prednisone 20mg prices buy prednisone tablets uk
ivermectin 6mg tablet for lice: generic ivermectin – stromectol tablet 3 mg
order generic clomid without insurance: can you buy cheap clomid without insurance – can i purchase generic clomid without prescription
http://azithromycin.bid/# zithromax without prescription
buy semaglutide online
buy wegovy from canada
semaglutide tab 14mg
https://azithromycin.bid/# zithromax 500mg price in india
can i get generic clomid price: can i purchase clomid tablets – can i get clomid prices
where can i buy zithromax capsules zithromax zithromax azithromycin
http://prednisonetablets.shop/# 40 mg prednisone pill
semaglutide cost
zithromax 500 mg: zithromax over the counter uk – zithromax over the counter
semaglutide sale
global pharmacy canada: Canadian Pharmacy – the canadian pharmacy canadianpharm.store
medicine in mexico pharmacies: Online Pharmacies in Mexico – mexican border pharmacies shipping to usa mexicanpharm.shop
canadian drug pharmacy Pharmacies in Canada that ship to the US online canadian pharmacy reviews canadianpharm.store
http://mexicanpharm.shop/# mexican mail order pharmacies mexicanpharm.shop
canadian pharmacy 365: Best Canadian online pharmacy – reliable canadian pharmacy canadianpharm.store
семашко ритуальный зал https://ritual-gratek20.ru/.
rybelsus online cheap
semaglutide for diabetes
canadian pharmacy ltd Canadian Pharmacy legitimate canadian mail order pharmacy canadianpharm.store
semaglutide tab 7mg
http://mexicanpharm.shop/# medicine in mexico pharmacies mexicanpharm.shop
https://canadianpharm.store/# canadian pharmacy canadianpharm.store
buy ozempic online no script needed
reputable indian pharmacies: international medicine delivery from india – best online pharmacy india indianpharm.store
pharmacies in mexico that ship to usa: Online Pharmacies in Mexico – mexico drug stores pharmacies mexicanpharm.shop
order semaglutide
mexican rx online Online Pharmacies in Mexico pharmacies in mexico that ship to usa mexicanpharm.shop
medicine in mexico pharmacies: Online Mexican pharmacy – mexico pharmacies prescription drugs mexicanpharm.shop
http://canadianpharm.store/# pet meds without vet prescription canada canadianpharm.store
buy prescription drugs from india: order medicine from india to usa – reputable indian online pharmacy indianpharm.store
buy ozempic
http://indianpharm.store/# india pharmacy indianpharm.store
indian pharmacy paypal indian pharmacies safe mail order pharmacy india indianpharm.store
reputable indian pharmacies: order medicine from india to usa – Online medicine home delivery indianpharm.store
buy semaglutide online cheap
rybelsus prescription
top 10 online pharmacy in india: order medicine from india to usa – indian pharmacy indianpharm.store
indian pharmacies safe: order medicine from india to usa – Online medicine home delivery indianpharm.store
https://mexicanpharm.shop/# mexican rx online mexicanpharm.shop
online pharmacy india order medicine from india to usa reputable indian pharmacies indianpharm.store
semaglutide for sale
http://mexicanpharm.shop/# п»їbest mexican online pharmacies mexicanpharm.shop
best canadian pharmacy to order from: Licensed Online Pharmacy – best canadian pharmacy online canadianpharm.store
buy semaglutide online from india
https://indianpharm.store/# indian pharmacy indianpharm.store
india pharmacy: Indian pharmacy to USA – top 10 pharmacies in india indianpharm.store
semaglutide australia online
You’ve built a blog that’s both informative and a pleasure to read.
Your ability to analyze and present data is unparalleled.
canadian world pharmacy Canadian International Pharmacy best rated canadian pharmacy canadianpharm.store
canadian pharmacy king reviews: Certified Online Pharmacy Canada – best online canadian pharmacy canadianpharm.store
reggionotizie.com
그가 말을 마친 후 Snapper는 죽음의 침묵에 빠졌습니다.
This post post made me think. will write something about this on my blog. ave a nice day!! .Live TV
https://canadianpharm.store/# online canadian pharmacy canadianpharm.store
semaglutide without prescription
semaglutide coupon
canadian world pharmacy: Licensed Online Pharmacy – canada pharmacy world canadianpharm.store
semaglutide tablet
rybelsus rx
https://indianpharm.store/# indian pharmacy online indianpharm.store
mexico drug stores pharmacies Online Mexican pharmacy pharmacies in mexico that ship to usa mexicanpharm.shop
canadian drug: Best Canadian online pharmacy – canada drugs reviews canadianpharm.store
wegovy tablets cost
canada ed drugs: Pharmacies in Canada that ship to the US – onlinepharmaciescanada com canadianpharm.store
semaglutide
my canadian pharmacy rx: Pharmacies in Canada that ship to the US – 77 canadian pharmacy canadianpharm.store
http://indianpharm.store/# india online pharmacy indianpharm.store
https://mexicanpharm.shop/# mexico drug stores pharmacies mexicanpharm.shop
generic wegovy cost
mexican drugstore online Online Mexican pharmacy medication from mexico pharmacy mexicanpharm.shop
buy semaglutide online pharmacy
mexican pharmacy: mexico drug stores pharmacies – п»їbest mexican online pharmacies mexicanpharm.shop
buy ozempic
buy rybelsus
semaglutide sale
http://indianpharm.store/# cheapest online pharmacy india indianpharm.store
wegovy semaglutide
online pharmacy india: Indian pharmacy to USA – best online pharmacy india indianpharm.store
reputable indian online pharmacy order medicine from india to usa п»їlegitimate online pharmacies india indianpharm.store
ozempic tablets
semaglutide 3 mg
ткань для мебели купить в москве vinylko13.ru .
https://canadianpharm.store/# canadian pharmacies that deliver to the us canadianpharm.store
mail order pharmacy india: order medicine from india to usa – best online pharmacy india indianpharm.store
world pharmacy india: international medicine delivery from india – indian pharmacy online indianpharm.store
buying prescription drugs in mexico: Online Mexican pharmacy – mexican mail order pharmacies mexicanpharm.shop
mexican drugstore online Online Pharmacies in Mexico buying from online mexican pharmacy mexicanpharm.shop
http://mexicanpharm.shop/# п»їbest mexican online pharmacies mexicanpharm.shop
http://canadianpharm.store/# canadian pharmacy uk delivery canadianpharm.store
india pharmacy: Indian pharmacy to USA – best online pharmacy india indianpharm.store
You have an exceptional ability to engage and inspire your audience.
canada online pharmacy Best Canadian online pharmacy buy drugs from canada canadianpharm.store
agonaga.com
그러나 이제 왕용은 새로운 구경꾼 무리를 불러들였다.
buy rybelsus canada
prescription drug discounts: buy prescription drugs canada – canadian mail order pharmacies
canadadrugpharmacy most reliable online pharmacies safe online pharmacy
generic rybelsus cost
https://canadadrugs.pro/# best canadian prescription prices
rybelsus 21 mg
compare prescription prices: reputable online pharmacy – canadian drug store cialis
most reliable online pharmacies: best canadian pharmacy – canadian internet pharmacies
wegovy semaglutide tablets 7.5 mcg
semaglutide where to buy
best pharmacy testosterone canadian pharmacy buy canadian pharmacy
rybelsus tab 3mg
https://canadadrugs.pro/# canada drug
Эдуард Давыдов бск http://www.eduard-davydov.ru/ .
rybelsus semaglutide tablets 3mg
fda approved pharmacies in canada: online canadian pharmaceutical companies – drugs without a doctor s prescription
canada drugs no prescription: buy canadian pharmacy – canadian pharmacy online without prescription
rybelsus mexico
semaglutide 14mg
This piece was beautifully written and incredibly informative. Thank you for sharing!
online prescriptions without a doctor generic pharmacy store discount online canadian pharmacy
http://canadadrugs.pro/# canadapharmacyonline com
rybelsus lose weight
canadian prescription pharmacy: online canadian pharmacy with prescription – canadian pharmacy worldwide
Your blog is a go-to resource for me. Thanks for all the hard work!
buy semaglutide online cheap
semaglutide drug
http://canadadrugs.pro/# legitimate mexican pharmacy online
canada mail pharmacy canadian pharmacy prescription price drugs
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
online prescription drugs: canadian pharmacy antiobotics without perscription – canadiandrugstore com
canada medications online: legit canadian online pharmacy – overseas pharmacies online
trust online pharmacies: canada drugs online reviews – online pharmacy canada
ozempic tab 7mg
semaglutide tablets for weight loss cost
canadian pharmacies prices: online pharmacy reviews – pharcharmy online no script
ozempic tablets buy
buy wegovy
https://canadadrugs.pro/# reputable online canadian pharmacies
semaglutide australia online
wegovy mexico
cheap semaglutide
canadian pharmacies top best: canadian mail order drugs – canadian prescription drugs online
https://canadadrugs.pro/# safe online pharmacies in canada
semaglutide diabetes medication
rybelsus semaglutide tablets cost
best rated canadian online pharmacy: canadian mail order pharmacies to usa – prescription drugs without prior prescription
purchase rybelsus
ozempic for weight loss
https://canadadrugs.pro/# online pharmacies no prescriptions
canada pharmacies prescription drugs: best rated canadian pharmacy – doxycycline mexican pharmacy
canadapharmacy com: buy prescription drugs canada – reliable online drugstore
digiyumi.com
학자들 사이에서는 황제의 파렴치한 권력 확대를 늘 경계했다.상류층의 얼굴은 흐릿하고 불확실했지만 그들의 마음에는 두려움이 피할 수 없었습니다.
ozempic tab 14mg
cheap canadian cialis: canadian pharmaceuticals online reviews – canadian pharmacy no prescription
https://canadadrugs.pro/# internet pharmacies
wegovy drug
over the counter drug store: certified canadian international pharmacy – canadian prescription drug prices
Wow, this blog is like a fantastic adventure blasting off into the universe of excitement! The mind-blowing content here is a captivating for the mind, sparking excitement at every turn. Whether it’s technology, this blog is a goldmine of inspiring insights! #MindBlown Embark into this cosmic journey of knowledge and let your mind roam! ✨ Don’t just explore, immerse yourself in the thrill! Your mind will be grateful for this thrilling joyride through the dimensions of endless wonder!
semaglutide price
restaurant-lenvol.net
Xincheng의 Feng Shui를 승인하면서 하루 종일 돌아 다니는 것이 헛되지 않습니다.
ozempic coupon
http://canadadrugs.pro/# canada drugs online reviews
ozempic tablets for weight loss cost
my canadian pharmacy rx: best internet pharmacies – drugstore online shopping
rybelsus price
generic rybelsus cost
https://canadadrugs.pro/# online pharmacy reviews
rybelsus buy online
canadian pharmacies top best: discount viagra canadian pharmacy – buy prescription drugs canada
semaglutide for sale
semaglutide cost
buy wegovy from canada
http://canadadrugs.pro/# canadian xanax
no prior prescription needed: canadian pharmacy reviews – pharmacy without dr prescriptions
mexican pharmacy list top canadian online pharmacy prescription drug prices
best drug for ed: men’s ed pills – best ed pill
best online pharmacies in mexico pharmacies in mexico that ship to usa buying prescription drugs in mexico
semaglutide retail price
http://canadianinternationalpharmacy.pro/# canadian pharmacies online
semaglutide order
wegovy semaglutide tablets 7.5 mcg
Николаев Вячеслав Константинович .
world pharmacy india: indian pharmacy paypal – world pharmacy india
wegovy australia online
viagra without a doctor prescription generic cialis without a doctor prescription viagra without a doctor prescription
https://edpill.cheap/# pills for ed
where can i buy semaglutide
https://canadianinternationalpharmacy.pro/# canadapharmacyonline legit
semaglutide for weight loss without diabetes
viagra without a doctor prescription walmart: cialis without a doctor prescription – real viagra without a doctor prescription usa
canadian pharmacy prices: best canadian online pharmacy – onlinecanadianpharmacy 24
https://canadianinternationalpharmacy.pro/# canadian pharmacy store
Truly acknowledged! Previous sentiments are accurate. This post is genuinely incredible!
medicine in mexico pharmacies mexican mail order pharmacies best online pharmacies in mexico
https://certifiedpharmacymexico.pro/# buying from online mexican pharmacy
rybelsus 14mg tablets
https://edpill.cheap/# male ed drugs
canadian mail order pharmacy canadian pharmacy no rx needed canadian world pharmacy
erectile dysfunction drugs: cheapest ed pills – the best ed pill
semaglutide tablet
buy ozempic from canada online
Great website.ots of useful information here. look forward to the continuation.-voxup live stream kostenlos ohne anmeldung
canadian drugs pharmacy: best canadian pharmacy to order from – safe canadian pharmacy
https://certifiedpharmacymexico.pro/# mexico pharmacies prescription drugs
rybelsus canada
ozempic for weight loss
buy ozempic
medicine in mexico pharmacies mexico drug stores pharmacies buying prescription drugs in mexico
semaglutide buy online
indianpharmacy com: online shopping pharmacy india – buy prescription drugs from india
https://certifiedpharmacymexico.pro/# mexican pharmacy
Online medicine home delivery top online pharmacy india Online medicine order
https://canadianinternationalpharmacy.pro/# canadian pharmacies
Николаев Вячеслав Контантинович .
canadian pharmacy scam best mail order pharmacy canada canadian pharmacy
http://edpill.cheap/# ed medication
best online pharmacy india: online pharmacy india – online shopping pharmacy india
buy rybelsus online no script needed
https://certifiedpharmacymexico.pro/# mexican rx online
viagra without a doctor prescription generic cialis without a doctor prescription ed meds online without doctor prescription
http://medicinefromindia.store/# india pharmacy
mexican drugstore online mexican border pharmacies shipping to usa п»їbest mexican online pharmacies
http://canadianinternationalpharmacy.pro/# best canadian online pharmacy reviews
saungsantoso.com
Hongzhi 황제는 “Wang Hua가 좋은 아이를 낳았습니다.”
generic ozempic cost
viagra without a doctor prescription walmart cheap cialis buy prescription drugs online without
mexico pharmacies prescription drugs: mexican pharmaceuticals online – best online pharmacies in mexico
What a stunning day it is today! Your post adds an extra layer of beauty to this already picturesque day.
http://certifiedpharmacymexico.pro/# buying from online mexican pharmacy
wegovy medication
полный аудит сайта стоимость https://www.prodvizhenie-sajtov15.ru .
wegovy
order wegovy
semaglutide price
indianpharmacy com indian pharmacy paypal reputable indian pharmacies
https://edwithoutdoctorprescription.pro/# mexican pharmacy without prescription
doeaccforum.com
Hongzhi 황제는 서둘러 단호하게 말했습니다. “빨리 설득 편지를 받으십시오 …”
semaglutide sale
https://edwithoutdoctorprescription.pro/# prescription without a doctor’s prescription
buy ozempic online from india
best online pharmacies in mexico best online pharmacies in mexico buying from online mexican pharmacy
rybelsus semaglutide
http://certifiedpharmacymexico.pro/# mexico pharmacies prescription drugs
ed drugs compared: ed medication online – best non prescription ed pills
ed pills ed pills ed drugs list
semaglutide canada
https://medicinefromindia.store/# indian pharmacies safe
buy semaglutide online no script
semaglutide drug
buy prescription drugs online cialis without a doctor prescription generic viagra without a doctor prescription
http://certifiedpharmacymexico.pro/# mexican drugstore online
semaglutide tablets
buy prescription drugs from india mail order pharmacy india indian pharmacies safe
purchase semaglutide
rybelsus semaglutide tablets 7.5 mcg
http://edpill.cheap/# male erection pills
ed meds online without doctor prescription: cialis without a doctor prescription – ed meds online without doctor prescription
wegovy drug
https://medicinefromindia.store/# top 10 pharmacies in india
semaglutide online uk
mexican rx online mexico drug stores pharmacies best online pharmacies in mexico
buy semaglutide pill form for adults
http://edpill.cheap/# compare ed drugs
wegovy tablets cost
https://edpill.cheap/# medicine erectile dysfunction
wegovy order
заказать раскрутку сайта https://www.prodvizhenie-sajtov15.ru .
wegovy xl
rybelsus medication
http://mexicanph.shop/# mexican mail order pharmacies
mexico pharmacies prescription drugs
rybelsus buy online
п»їbest mexican online pharmacies mexican border pharmacies shipping to usa mexican pharmaceuticals online
mexican mail order pharmacies reputable mexican pharmacies online purple pharmacy mexico price list
rybelsus generic cost
best online pharmacies in mexico best online pharmacies in mexico medication from mexico pharmacy
https://mexicanph.com/# mexican rx online
best online pharmacies in mexico
purple pharmacy mexico price list medication from mexico pharmacy purple pharmacy mexico price list
restaurant-lenvol.net
왕서인의 등장은 이곳 마을 사람들에게는 극히 드문 일이다.
semaglutide drug
semaglutide generic cost
order semaglutide online
semaglutide wegovy
reputable mexican pharmacies online mexican rx online mexico drug stores pharmacies
digiapk.com
Hongzhi 황제는 “생각해보면 그렇게 심각하지 않아야합니다. “라고 말했습니다.
поисковое продвижение web сайтов https://prodvizhenie-sajtov15.ru/ .
semaglutide 7mg
https://mexicanph.shop/# buying prescription drugs in mexico online
best online pharmacies in mexico
купить аттестат http://prema-diploms.com/ .
generic rybelsus
ozempic semaglutide
buying prescription drugs in mexico mexican mail order pharmacies mexican border pharmacies shipping to usa
mexican mail order pharmacies mexico drug stores pharmacies mexican border pharmacies shipping to usa
semaglutide rybelsus
buy wegovy from canada
https://mexicanph.shop/# buying prescription drugs in mexico
best online pharmacies in mexico
mexican pharmacy mexican mail order pharmacies mexican pharmaceuticals online
купить диплом http://www.man-diploms.com .
ozempic tablets
mexican online pharmacies prescription drugs mexican pharmaceuticals online mexico drug stores pharmacies
generic semaglutide cost
best online pharmacies in mexico mexican pharmaceuticals online mexican pharmaceuticals online
buying from online mexican pharmacy mexico drug stores pharmacies mexican border pharmacies shipping to usa
http://mexicanph.shop/# pharmacies in mexico that ship to usa
mexican drugstore online
purple pharmacy mexico price list mexico pharmacies prescription drugs pharmacies in mexico that ship to usa
buying from online mexican pharmacy pharmacies in mexico that ship to usa п»їbest mexican online pharmacies
pharmacies in mexico that ship to usa mexico drug stores pharmacies purple pharmacy mexico price list
buying prescription drugs in mexico purple pharmacy mexico price list mexico drug stores pharmacies
medicine in mexico pharmacies mexico drug stores pharmacies mexico pharmacy
mexico drug stores pharmacies best online pharmacies in mexico buying from online mexican pharmacy
mexican pharmaceuticals online п»їbest mexican online pharmacies mexican drugstore online
mexican online pharmacies prescription drugs buying from online mexican pharmacy mexican online pharmacies prescription drugs
купить диплом ссср http://orik-diploms.com/ .
rybelsus 7mg
http://mexicanph.shop/# purple pharmacy mexico price list
buying prescription drugs in mexico online
medication from mexico pharmacy medicine in mexico pharmacies mexico drug stores pharmacies
mexico pharmacies prescription drugs buying prescription drugs in mexico online buying prescription drugs in mexico
medication from mexico pharmacy medication from mexico pharmacy mexico drug stores pharmacies
rybelsus 3mg
modernkarachi.com
말하면서 그는 날카로운 화살처럼 서재를 향해 돌진했다.
mexican drugstore online mexico drug stores pharmacies medicine in mexico pharmacies
mexico drug stores pharmacies mexico pharmacy mexico drug stores pharmacies
rybelsus semaglutide tablets 3mg
best online pharmacies in mexico medication from mexico pharmacy mexican mail order pharmacies
wegovy where to buy
mexican pharmaceuticals online mexican pharmacy medicine in mexico pharmacies
buy semaglutide online canada
wegovy prescription
mexican rx online mexican pharmacy mexican pharmaceuticals online
wegovy 14mg
https://mexicanph.shop/# reputable mexican pharmacies online
mexican mail order pharmacies
wegovy semaglutide tablets 3mg
buying prescription drugs in mexico online pharmacies in mexico that ship to usa mexican online pharmacies prescription drugs
mexico pharmacies prescription drugs medication from mexico pharmacy mexico drug stores pharmacies
mexican online pharmacies prescription drugs mexican mail order pharmacies medication from mexico pharmacy
купить диплом нового образца http://landik-diploms.com/ .
purple pharmacy mexico price list buying from online mexican pharmacy mexico drug stores pharmacies
buying prescription drugs in mexico online medication from mexico pharmacy mexican pharmaceuticals online
best mexican online pharmacies mexico pharmacy mexico drug stores pharmacies
buying prescription drugs in mexico online buying from online mexican pharmacy mexican pharmacy
wegovy online pharmacy
ozempic for weight loss without diabetes
mexican pharmacy mexican pharmacy mexico pharmacies prescription drugs
ozempic tab 7mg
buying from online mexican pharmacy buying prescription drugs in mexico mexican rx online
mexico pharmacy buying from online mexican pharmacy mexican online pharmacies prescription drugs
http://mexicanph.com/# buying prescription drugs in mexico online
mexican rx online
where to buy semaglutide online
buying prescription drugs in mexico buying prescription drugs in mexico best online pharmacies in mexico
pharmacies in mexico that ship to usa mexican border pharmacies shipping to usa buying prescription drugs in mexico
buying from online mexican pharmacy buying prescription drugs in mexico online mexican online pharmacies prescription drugs
purple pharmacy mexico price list mexico pharmacies prescription drugs reputable mexican pharmacies online
buying from online mexican pharmacy mexican border pharmacies shipping to usa mexican mail order pharmacies
wegovy semaglutide
semaglutide tablet
wegovy semaglutide tablets
купить диплом магистра http://www.arusak-diploms.com .
semaglutide tablet
mexican online pharmacies prescription drugs purple pharmacy mexico price list mexican pharmaceuticals online
mexican rx online mexican online pharmacies prescription drugs mexican online pharmacies prescription drugs
rybelsus lose weight
mexican border pharmacies shipping to usa mexico pharmacy mexican pharmacy
https://mexicanph.shop/# best online pharmacies in mexico
mexico pharmacies prescription drugs
mexican rx online п»їbest mexican online pharmacies pharmacies in mexico that ship to usa
wegovy lose weight
mexican online pharmacies prescription drugs best mexican online pharmacies mexico drug stores pharmacies
ozempic cost
mexican online pharmacies prescription drugs mexico pharmacy mexican border pharmacies shipping to usa
rybelsus where to buy
semaglutide for weight loss
semaglutide pill form
buying from online mexican pharmacy medicine in mexico pharmacies reputable mexican pharmacies online
semaglutide online order
semaglutide 7mg
buy semaglutide from canada online
semaglutide ozempic
mexican pharmaceuticals online buying from online mexican pharmacy mexican online pharmacies prescription drugs
semaglutide where to buy
semaglutide sale
buying prescription drugs in mexico mexico pharmacy mexican online pharmacies prescription drugs
mexico pharmacies prescription drugs reputable mexican pharmacies online mexico pharmacy
amruthaborewells.com
Zhou Tanyi는 그의 말의 의미를 이해하지 못하고 당황했습니다.
rybelsus online order
mexican pharmacy mexican pharmaceuticals online buying prescription drugs in mexico online
http://stromectol.fun/# stromectol tab
ivermectin 3mg pill: buy stromectol – cost of ivermectin 3mg tablets
https://amoxil.cheap/# where can i buy amoxicillin over the counter uk
ivermectin 2%: ivermectin 1 – cheap stromectol
http://furosemide.guru/# lasix tablet
wegovy rx
https://furosemide.guru/# lasix furosemide 40 mg
where to get amoxicillin over the counter: where can i buy amoxicillin without prec – over the counter amoxicillin canada
https://amoxil.cheap/# amoxicillin 500mg capsule
rybelsus diabetes medication
https://amoxil.cheap/# amoxicillin 500 mg purchase without prescription
hihouse420.com
노인과 선생님은 모든 것을 할 수 있습니다. 지금 농담입니까?
rybelsus diabetes
semaglutide diabetes medication
wegovy uk
ozempic coupon
cost of stromectol: stromectol for humans – ivermectin 6mg dosage
wegovy tab 3mg
http://furosemide.guru/# furosemide 100mg
rybelsus where to buy
buy ozempic
rybelsus from canada
ivermectin 4000 mcg: ivermectin australia – stromectol covid 19
http://buyprednisone.store/# canine prednisone 5mg no prescription
wegovy buy online
http://buyprednisone.store/# steroids prednisone for sale
buy ozempic online pharmacy
http://buyprednisone.store/# prednisone for sale
lasix 40mg: Buy Furosemide – furosemide 40 mg
ozempic tab 7mg
Давыдов Эдуард https://www.panram.ru/partners/news/biografiya-eduarda-davydova-generalnogo-direktora-bsk-ao/ .
generic semaglutide
http://furosemide.guru/# lasix side effects
ivermectin 1 topical cream: ivermectin cream – ivermectin over the counter
buy rybelsus from canada
http://furosemide.guru/# lasix side effects
rybelsus injection
zestoretic 10 12.5: cost of generic lisinopril – 40 mg lisinopril
semaglutide cost
https://amoxil.cheap/# amoxicillin 50 mg tablets
wegovy buy online
lisinopril 5mg tablets: lisinopril price in canada – price for 5 mg lisinopril
http://lisinopril.top/# lisinopril without an rx
rybelsus xl
http://furosemide.guru/# lasix online
buy semaglutide cheap
buy ozempic
http://lisinopril.top/# prinivil 2.5 mg
stromectol cream: price of ivermectin liquid – stromectol cream
оборудование актового зала http://www.i-tec1.ru/ .
http://furosemide.guru/# lasix side effects
rybelsus semaglutide tablets 7.5 mcg
amoxicillin medicine over the counter: amoxicillin 500 mg online – amoxicillin over counter
semaglutide 14mg tablets
semaglutide for weight loss
rybelsus xr
https://furosemide.guru/# buy furosemide online
semaglutide pills
wegovy drug
lisinopril 10mg daily: lisinopril 120mg – where can i purchase lisinopril
Good article with great ideas! Thank you for this important article.Idepet Sphynx Hairless Cats Sweater Shirt Kitten Soft Puppy Clothes Pullover Cute Cat Pajamas Jumpsuit Cotton Apparel Pet Winter Turtleneck for Cats and Teacup Chihuahua Small Dogs(ApricotXL) – Hot Deals
http://amoxil.cheap/# amoxicillin capsule 500mg price
semaglutide weight loss
semaglutide 14mg
http://amoxil.cheap/# generic for amoxicillin
buy furosemide online: Buy Furosemide – furosemida
order wegovy online
http://buyprednisone.store/# prednisone 21 pack
wegovy weight loss
rybelsus
https://stromectol.fun/# ivermectin 0.1
amoxicillin cephalexin: amoxicillin 500 mg for sale – prescription for amoxicillin
lfchungary.com
다소간 Jiang 박사는 여전히 자신의 끈기를 가지고 있습니다.
http://stromectol.fun/# buy stromectol canada
звуковое оборудование для актового зала школы https://i-tec3.ru .
prinivil 20 mg: lisinopril brand – lisinopril prescription
wegovy canada pharmacy
http://buyprednisone.store/# buy prednisone online india
sm-slot.com
주변의 내시들과 시녀들은 당황하여 고개를 저었다.
https://buyprednisone.store/# prednisone 200 mg tablets
https://furosemide.guru/# lasix pills
http://lisinopril.top/# how to buy lisinopril online
prescription drug zestril: zestril online – buy lisinopril mexico
wegovy drug
http://lisinopril.top/# lisinopril 40 mg mexico
lasix online: Buy Lasix No Prescription – lasix 20 mg
wegovy semaglutide tablets 3mg
http://buyprednisone.store/# can i buy prednisone online without prescription
semaglutide tablets
кредит займ онлайн https://topruscredit.ru/ .
buy semaglutide online canada
rybelsus 3 mg tablet
wegovy injection
semaglutide without prescription
ivermectin 500mg: ivermectin 1 cream 45gm – ivermectin 10 mg
http://lisinopril.top/# lisinopril 5 mg pill
wegovy semaglutide tablets cost
http://buyprednisone.store/# how can i get prednisone online without a prescription
wegovy canada pharmacy
http://furosemide.guru/# lasix 100 mg tablet
wegovy drug
https://amoxil.cheap/# buy amoxicillin without prescription
rybelsus xr
generic wegovy for weight loss
amoxicillin 500 tablet: can i buy amoxicillin over the counter – purchase amoxicillin online without prescription
http://furosemide.guru/# lasix generic name
hihouse420.com
Xiao Jing만이 Hongzhi 황제를 위해 차와 물을 바빴습니다.
Your blog is a source of endless inspiration. Thank you for sharing your wisdom with us. Asheville sends its love!
Your blog posts are always a joy to read! From Asheville with love, we appreciate your work.
rybelsus medicine
http://amoxil.cheap/# amoxicillin discount coupon
lasix uses: Buy Lasix – lasix dosage
Вячеслав Константинович Николаев http://www.vyacheslav-nikolaev-konstantinovich.ru/ .
https://amoxil.cheap/# amoxicillin 250 mg price in india
can you buy lisinopril: lisinopril 5 mg canada – lisinopril 2.5 mg
https://furosemide.guru/# lasix 20 mg
https://amoxil.cheap/# amoxicillin capsules 250mg
semaglutide canada pharmacy prices
rybelsus tab 7mg
semaglutide lose weight
wegovy sale
wegovy diabetes
wegovy online uk
buy ozempic cheap
купить аттестат классов https://rudik-attestats.com/ .
where to buy ozempic online
semaglutide xr
cheap ozempic
semaglutide sale
semaglutide 3 mg
https://indianph.xyz/# indian pharmacy online
india pharmacy
dota2answers.com
청지기 양은 애도하는 첩처럼 붉어진 눈으로 깊게 절하며 “주인님…존경하세요…”
buy semaglutide uk
Online medicine order india pharmacy top 10 pharmacies in india
http://indianph.com/# top 10 online pharmacy in india
Online medicine order
https://indianph.xyz/# Online medicine order
indian pharmacies safe
https://indianph.com/# top 10 pharmacies in india
indianpharmacy com
rybelsus 7 mg
https://indianph.com/# indian pharmacy online
indian pharmacy
lfchungary.com
Hu Kaishan의 시선은 마치 먹이를 보는 것처럼 멀지 않은 일본 해적을 바라보는 횃불과 같았습니다.
https://indianph.xyz/# indian pharmacies safe
купить аттестат за 9 класс https://www.gruppa-attestats.com/ .
https://indianph.com/# buy medicines online in india
best online pharmacy india
buy ozempic in canada
http://indianph.xyz/# indian pharmacy
best online pharmacy india
semaglutide online order
semaglutide generic cost
rybelsus online prescription
https://indianph.xyz/# indian pharmacies safe
online pharmacy india
where to buy ozempic
http://indianph.xyz/# mail order pharmacy india
top 10 pharmacies in india
top 10 online pharmacy in india world pharmacy india п»їlegitimate online pharmacies india
https://indianph.com/# buy prescription drugs from india
legitimate online pharmacies india
semaglutide generic cost
Vitaliy Aleksandrovich Yuzhilin https://en.wikipedia.org/wiki/vitaliy_aleksandrovich_yuzhilin .
pragmatic-ko.com
‘신장’이 잘려서 옆판에 던져졌다.
https://diflucan.pro/# diflucan price canada
http://cytotec24.shop/# Cytotec 200mcg price
semaglutide rybelsus
rybelsus rx
Abortion pills online: buy cytotec pills online cheap – buy cytotec online
wegovy semaglutide tablets 3mg
https://doxycycline.auction/# buy doxycycline hyclate 100mg without a rx
doxycycline tetracycline doxycycline 100mg tablets buy doxycycline without prescription uk
wegovy mexico
tamoxifen warning: tamoxifen effectiveness – tamoxifen adverse effects
http://doxycycline.auction/# generic for doxycycline
rybelsus tab 14mg
https://doxycycline.auction/# doxycycline 100mg
doxycycline hydrochloride 100mg vibramycin 100 mg buy doxycycline monohydrate
order doxycycline online: doxycycline 100mg price – buy doxycycline
http://diflucan.pro/# diflucan australia otc
http://nolvadex.guru/# hysterectomy after breast cancer tamoxifen
Misoprostol 200 mg buy online: order cytotec online – purchase cytotec
https://diflucan.pro/# diflucan capsule 150mg
cipro where can i buy cipro online п»їcipro generic
купить аттестат школы russkiy-attestat.com .
http://diflucan.pro/# diflucan 100 mg
lfchungary.com
이 헌장은 실제로 상인의 권리를 규제합니다.
http://cipro.guru/# buy cipro cheap
diflucan pill diflucan 50mg capsules where to get diflucan without a prescription
hihouse420.com
Wang Shouren은 조수처럼 그를 향해 돌진하는 혼란스러운 병사들을 바라 보았습니다. “…”
order ozempic
buy cytotec: order cytotec online – Abortion pills online
semaglutide medicine
buy wegovy online no script needed
https://doxycycline.auction/# generic doxycycline
rybelsus drug
https://diflucan.pro/# diflucan 150 mg tablet
http://nolvadex.guru/# tamoxifen and osteoporosis
buy cytotec online fast delivery п»їcytotec pills online buy cytotec pills
pactam2.com
최고 투표에서 멀지 않은 투표 수를 계속 계산하지만 지원이 있습니까?
semaglutide retail price
https://nolvadex.guru/# tamoxifen rash
wegovy 7mg
semaglutide drug
http://cipro.guru/# buy ciprofloxacin
diflucan uk price diflucan 400mg without prescription diflucan otc
http://doxycycline.auction/# doxycycline prices
http://cytotec24.shop/# buy cytotec over the counter
ozempic tab 3mg
raymark сварка лазерная цена http://www.apparaty-lazernoy-svarki.ru .
http://cipro.guru/# where can i buy cipro online
doxycycline how to order doxycycline doxycycline hyc 100mg
http://diflucan.pro/# diflucan for sale
https://sweetiefox.online/# sweety fox
semaglutide diabetes
https://evaelfie.pro/# eva elfie filmleri
eva elfie: eva elfie filmleri – eva elfie
http://lanarhoades.fun/# lana rhoades modeli
https://angelawhite.pro/# Angela White
semaglutide cost
sweeti fox: Sweetie Fox video – sweety fox
http://abelladanger.online/# Abella Danger
https://angelawhite.pro/# Angela White izle
http://angelawhite.pro/# Angela White
https://angelawhite.pro/# Angela White izle
eva elfie video: eva elfie modeli – eva elfie
купить аттестат за 9 http://www.orik-attestats.com .
wegovy semaglutide tablets
http://sweetiefox.online/# sweeti fox
https://evaelfie.pro/# eva elfie video
Angela Beyaz modeli: ?????? ???? – Angela White izle
http://angelawhite.pro/# Angela White
buy ozempic online from india
https://evaelfie.pro/# eva elfie izle
https://lanarhoades.fun/# lana rhoades filmleri
https://sweetiefox.online/# Sweetie Fox filmleri
Angela White filmleri: ?????? ???? – Angela White filmleri
buy ozempic from canada online
buy semaglutide in canada
https://evaelfie.pro/# eva elfie modeli
https://abelladanger.online/# abella danger video
buy wegovy online no script
Angela Beyaz modeli: Angela White filmleri – ?????? ????
https://evaelfie.pro/# eva elfie modeli
http://abelladanger.online/# abella danger video
http://abelladanger.online/# Abella Danger
Angela White video: abella danger filmleri – abella danger video
https://angelawhite.pro/# Angela White video
sm-slot.com
왕궁에 있을 때 환관들이 잘못을 저질렀고 모두 뺨을 때렸습니다.
ozempic generic
купить аттестат в москве http://www.russa-attestats.com/ .
wegovy xr
ozempic generic
https://lanarhoades.fun/# lana rhodes
http://abelladanger.online/# Abella Danger
semaglutide 14mg tablets
rybelsus weight loss
Sweetie Fox filmleri: Sweetie Fox – Sweetie Fox video
semaglutide 7mg
http://angelawhite.pro/# Angela White video
generic semaglutide cost
buy semaglutide
rybelsus tablets cost
http://abelladanger.online/# abella danger video
?????? ????: Abella Danger – abella danger izle
http://angelawhite.pro/# Angela White izle
https://evaelfie.pro/# eva elfie izle
semaglutide 3 mg
semaglutide mexico
semaglutide pill
http://lanarhoades.fun/# lana rhoades
lana rhoades filmleri: lana rhoades video – lana rhoades video
https://evaelfie.pro/# eva elfie izle
https://lanarhoades.fun/# lana rhoades
semaglutide online pharmacy
nahrungserg?nzungsmittel test https://wellnesspulse.de/ .
http://sweetiefox.online/# Sweetie Fox izle
http://sweetiefox.online/# Sweetie Fox filmleri
swetie fox: Sweetie Fox video – Sweetie Fox video
http://sweetiefox.online/# sweety fox
https://angelawhite.pro/# Angela White
can you buy synthroid over the counter
lana rhoades: lana rhoades izle – lana rhoades filmleri
online pharmacy weight loss
http://lanarhoades.fun/# lana rhoades video
canadian pharmacy tadalafil
lisinopril 10 mg price in india
займ онлайн кредит https://topruscredit11.ru/ .
safe online pharmacy
india pharmacy mail order
Bu yazıyı okuduktan sonra konuyla ilgili daha bilinçli hissediyorum. Yazarın net ve açık ifadeleri sayesinde karmaşık konuları daha iyi anlamamı sağladı. | Yalova Prefabrik
apksuccess.com
Hongzhi 황제는 고개를 끄덕였습니다. “이것이 직조와 무슨 관련이 있습니까?”
lisinopril tablets
http://lanarhoades.pro/# lana rhoades full video
cheapest pharmacy to get prescriptions filled
synthroid thyroid
plenty of fish dating site of free dating: https://lanarhoades.pro/# lana rhoades full video
https://miamalkova.life/# mia malkova hd
ph sweetie fox: sweetie fox full video – sweetie fox
lana rhoades videos: lana rhoades videos – lana rhoades unleashed
sm-slot.com
그동안 무심했던 노인도 놀란 듯…
buy cheap tadalafil online
eva elfie new video: eva elfie new video – eva elfie full video
prednisone 20 mg buy online
tinder web: https://evaelfie.site/# eva elfie hd
lana rhoades: lana rhoades full video – lana rhoades unleashed
online pharmacy 365
buy prednisone tablets uk
synthroid tablets uk
generic synthroid medication
https://miamalkova.life/# mia malkova
mia malkova only fans: mia malkova only fans – mia malkova girl
online pharmacy pain medicine
купить оборудование для актового зала школы https://www.oborudovanie-aktovogo-zala11.ru .
online pharmacy discount code
mia malkova only fans: mia malkova movie – mia malkova new video
lisinopril 5 mg for sale
pharmacy without prescription
raytalktech.com
Fang Jifan은 설명 할 수 없을 정도로 슬픈 표정으로 냄새를 맡았습니다.
http://miamalkova.life/# mia malkova girl
over the counter cialis
dating online dating: https://evaelfie.site/# eva elfie
lana rhoades: lana rhoades hot – lana rhoades boyfriend
tadalafil paypal
lana rhoades videos: lana rhoades hot – lana rhoades full video
purchase zithromax
prednisone 60
http://lanarhoades.pro/# lana rhoades
sweetie fox cosplay: sweetie fox – sweetie fox full video
express pharmacy
Николаев Вячеслав Константинович .
can you buy azithromycin over the counter in usa
lisinopril sale
free sites: https://miamalkova.life/# mia malkova girl
https://evaelfie.site/# eva elfie full video
sweetie fox full video: ph sweetie fox – ph sweetie fox
legitimate online pharmacy usa
khasiss.com
포병의 포효가 시작되었고 타타르 족은 지금 당황하기 시작했습니다.
synthroid pill
discount pharmacy online
safe online pharmacy
mia malkova videos: mia malkova girl – mia malkova full video
metformin without script
lisinopril 10 mg for sale
mia malkova movie: mia malkova movie – mia malkova latest
https://sweetiefox.pro/# ph sweetie fox
valtrex 1000 mg daily
crazy-slot1.com
황태후와 장씨가 시도해봤을 것입니다.
price synthroid 50 mcg
купить диплом специалиста http://server-diploms.com/ .
online pharmacy cialis
singles chat: https://evaelfie.site/# eva elfie new videos
mia malkova hd: mia malkova new video – mia malkova photos
225 mcg synthroid
http://evaelfie.site/# eva elfie hd
viagra online canadian pharmacy
bistroduet.com
Hongzhi 황제는 “Tang Qing의 가족이 내 기대를 실망시키지 않기를 바랍니다. “라고 말했습니다.
lisinopril 500 mg
Thank you very much for this wonderful information. – womens hey dudes
tadalafil over the counter uk
twichclip.com
모두가 한 명씩 땅에 웅크리고 웅크린 채 추위에 떨고 있었다.
lana rhoades: lana rhoades hot – lana rhoades solo
lana rhoades full video: lana rhoades solo – lana rhoades boyfriend
Incredibly profound! The impact of this text is unparalleled.
http://lanarhoades.pro/# lana rhoades videos
valtrex 1000mg tablet
Your words of wisdom have the power to change lives. Thank you for sharing your insight.
Your post was a reminder that even on the toughest days, there is still beauty to be found. Thank you.
synthroid 75 mcg price canada
lana rhoades videos: lana rhoades solo – lana rhoades videos
Your resilience in the face of challenges is remarkable. Thank you for sharing your journey.
prinivil 20 mg
Your words of encouragement were just what I needed to hear today. Thank you for your support.
adult date site: https://sweetiefox.pro/# sweetie fox
Your positivity is infectious. Thank you for spreading joy through your words.
Latest Hairstyles and Haircuts for Women | Your posts always leave me feeling motivated and inspired. Thank you for the encouragement.
купить диплом колледжа http://1russa-diploms.com/ .
Your positivity is infectious. Thank you for spreading joy to those around you.
synthroid brand name price
https://lanarhoades.pro/# lana rhoades unleashed
cheapest prednisone no prescription
120 prednisone
eva elfie videos: eva elfie photo – eva elfie hot
buy tadalafil 20mg online
estrela bet aviator: aviator betano – pin up aviator
Exquisite execution! The addition of more images would be a masterstroke!
Brilliant writing! The inclusion of more images would be a brilliant enhancement!
Saya sangat kagum dengan kontennya! Sungguh luar biasa!
azithromycin online pharmacy uk
http://aviatorghana.pro/# aviator
Galvaniz Trapez Sac Nedir? | Firmanın sunduğu hizmetten çok memnun kaldık. Hem ürün kalitesi hem de müşteri memnuniyeti açısından beklentileri karşılıyorlar.
happy family canadian pharmaceuticals online
online pharmacy tadalafil
como jogar aviator em moçambique: aviator mz – aviator bet
glucophage discount
купить диплом специалиста https://2orik-diploms.com/ .
cialis 5 coupon
cassino pin up: pin-up casino entrar – pin up casino
https://jogodeaposta.fun/# jogos que dao dinheiro
aviator: aviator oyunu – aviator hilesi
tadalafil uk paypal
Topağacı / Ümraniye Karotcu | Rüzgar Karot’un işlerini zamanında ve özenle teslim etmesi beni gerçekten etkiledi, teşekkürler!
pin up bet: aviator pin up casino – pin-up
https://jogodeaposta.fun/# site de apostas
Mehmet Akif Beton Kırma | Rüzgar Karot’un iletişim becerileri ve müşteri odaklı yaklaşımı çok etkileyici.
tadalafil 20mg generic cost
crazy-slot1.com
우리가 하는 말과 쏟아지는 물을 어떻게 처리할 수 있습니까?
aviator jogar: estrela bet aviator – jogar aviator online
synthroid for sale online
lisinopril 40 mg pill
aviator game: estrela bet aviator – aviator game
http://aviatorjogar.online/# aviator game
how to get azithromycin over the counter
купить диплом техникума http://3russkiy-diploms.com/ .
aviator jogar: aviator bet – aviator betano
prednisone buy
where can i buy generic zithromax
Steenbergen | Ich bin immer beeindruckt von der Professionalität und Hingabe von MAFA, wenn es um Webdesign und Softwareentwicklung geht. Sie liefern immer erstklassige Ergebnisse.
buy cialis tablets
bistroduet.com
더 가난하면 값싼 고구마와 감자를 대용으로 사용할 수 있습니다.
http://aviatorghana.pro/# aviator login
aviator moçambique: aviator – jogar aviator
aviator bet: aviator bet – aviator betting game
pin-up casino: pin-up casino – pin up casino
aviator game: aviator betting game – play aviator
rxpharmacycoupons
best online thai pharmacy
Yavuz Selim / Bağcılar Karotcu | Rüzgar Karot’un işlerini zamanında ve eksiksiz bir şekilde teslim etmesi gerçekten takdire şayan.
pin up aviator: pin-up casino – pin-up
aviator: play aviator – aviator game
видеостена цена https://videosteny11.ru .
lisinopril 20 tablet
jogos que dão dinheiro: site de apostas – site de apostas
prednisone 10 mg tablets
como jogar aviator em mocambique: aviator mocambique – aviator
aviator game online: aviator – aviator malawi
aviator malawi: aviator bet malawi login – aviator malawi
where can you purchase valtrex
where can i buy prednisone without prescription
115×210 Deposuz WC Kabin | Bu yazıda konteyner evlerin yenilikçi kullanım alanları ve ekonomik avantajları hakkında önemli bilgiler var. KAYRA Konteyner Ev Çözümleri olarak, sürdürülebilir konut seçeneklerini desteklediğiniz için teşekkür ederiz.
zithromax 500 mg lowest price pharmacy online – https://azithromycin.pro/zithromax-z-pak-online.html zithromax 250 mg
aviator pin up: aviator jogo – aviator jogar
twichclip.com
하지만 방금 황태후의 몸에 경련이 일어났지만, 그 정도로 강하지는 않았다.
aviator sportybet ghana: aviator betting game – aviator
zithromax tablets: buy zithromax online fast shipping – buy zithromax without prescription online
теплый фасад остекление цена http://www.fasadnoe-osteklenie11.ru .
pin up cassino online: pin up cassino online – pin up cassino online
zithromax 250 mg australia: zithromax antibiotic – how to get zithromax online
synthroid 1mg
2 prinivil
lisinopril best price
aviator jogar: aviator betano – aviator bet
aviator game: estrela bet aviator – aviator pin up
usa pharmacy
Wat is Vlog? | MAFA’s reputation in the web design and software development industry speaks for itself. I can’t wait to work with them on my next project.
online canadian pharmacy coupon
оборудование переговорных комнат http://www.oborudovanie-peregovornyh-komnat11.ru .
Your post gave me the strength to face another day with hope in my heart. Thank you.
The opinions above encapsulate my thoughts – this post is a masterpiece!
legal canadian pharmacy online: Certified Canadian pharmacies – canadian pharmacy service canadianpharm.store
pharmacy website india cheapest online pharmacy reputable indian pharmacies indianpharm.store
safe online pharmacies in canada: My Canadian pharmacy – best canadian online pharmacy canadianpharm.store
Nederweert | Deze blog heeft me echt geholpen om meer te begrijpen over de expertise en toewijding van MAFA op het gebied van webdesign en softwareontwikkeling. Ik ben erg onder de indruk.
sm-casino1.com
그래서 방역 조치가 조금 조잡했고, 몇 사람이 돼지를 잡기 시작했다.
adderall canadian pharmacy: List of Canadian pharmacies – best canadian pharmacy canadianpharm.store
prednisone india
prednisone online paypal
best online pharmacies in mexico purple pharmacy mexico price list mexico drug stores pharmacies mexicanpharm.shop
https://mexicanpharm24.shop/# medication from mexico pharmacy mexicanpharm.shop
https://mexicanpharm24.shop/# mexico pharmacies prescription drugs mexicanpharm.shop
Your post was a reminder that even on the toughest days, there is still beauty to be found. Thank you.
l-inkproject.com
팡지판은 오랜만에 “아무것도 설명하고 싶지 않다”며 고개를 저었다.
Your words of encouragement were just what I needed to hear today. Thank you for your support.
mexican online pharmacies prescription drugs: mexico pharmacies prescription drugs – mexico drug stores pharmacies mexicanpharm.shop
Your kindness is a gift to the world. Thank you for being you.
http://indianpharm24.com/# mail order pharmacy india indianpharm.store
Thanks to Venster Systems’ screens, I can enjoy the comfort of my home without the annoyance of flies. | Plise Perde Modelleri Çorum
online valtrex
купить диплом бакалавра https://saksx-diploms24.com .
http://indianpharm24.com/# india pharmacy indianpharm.store
http://indianpharm24.com/# indian pharmacy online indianpharm.store
pharmacy com canada: Canada pharmacy – canadian neighbor pharmacy canadianpharm.store
cialis 100mg pills
online pharmacy products
synthroid 137 cost
legal online pharmacies in the us
pharmacy canadian superstore: My Canadian pharmacy – canadian compounding pharmacy canadianpharm.store
http://indianpharm24.shop/# indianpharmacy com indianpharm.store
https://canadianpharmlk.shop/# pharmacy rx world canada canadianpharm.store
canadian pharmacy reviews Pharmacies in Canada that ship to the US online pharmacy canada canadianpharm.store
Oğuzlar / Çorum Toptan Tekstil | RENE Toptan Tekstil ve Giyim Çözümleri’nin ürünleri hem kaliteli hem de uygun fiyatlı. Bu yüzden her zaman tercih ediyorum.
synthroid 25 mg coupon
https://mexicanpharm24.com/# best mexican online pharmacies mexicanpharm.shop
reputable mexican pharmacies online: order online from a Mexican pharmacy – mexican online pharmacies prescription drugs mexicanpharm.shop
valtrex otc
https://canadianpharmlk.com/# buy canadian drugs canadianpharm.store
https://indianpharm24.com/# mail order pharmacy india indianpharm.store
https://canadianpharmlk.com/# canadian pharmacy world canadianpharm.store
п»їbest mexican online pharmacies: order online from a Mexican pharmacy – medicine in mexico pharmacies mexicanpharm.shop
mexican pharmaceuticals online: best online pharmacies in mexico – purple pharmacy mexico price list mexicanpharm.shop
http://indianpharm24.shop/# reputable indian online pharmacy indianpharm.store
synthroid 25 mcg coupon
purchase lisinopril 10 mg
доставка грузов из китая цены https://www.perevozka-iz-kitaya.ru .
This post is like shooting stars of wisdom!
I’m feeling so enlightened by this post!
I’m feeling so inspired right now!
https://mexicanpharm24.shop/# mexico drug stores pharmacies mexicanpharm.shop
I’m amazed at how Venster Systems’ blinds have improved the overall comfort of my home. | Jaluzi Perde Modelleri Kartepe
buy generic metformin online
https://indianpharm24.com/# Online medicine order indianpharm.store
indian pharmacy cheapest online pharmacy indian pharmacies safe indianpharm.store
http://mexicanpharm24.shop/# mexico drug stores pharmacies mexicanpharm.shop
synthroid 0.175 mg
best price for synthroid
https://canadianpharmlk.com/# legitimate canadian pharmacy online canadianpharm.store
https://mexicanpharm24.com/# mexican pharmaceuticals online mexicanpharm.shop
buying prescription drugs in mexico: mexican online pharmacies prescription drugs – medicine in mexico pharmacies mexicanpharm.shop
tadalafil cipla
https://canadianpharmlk.shop/# canadian pharmacy checker canadianpharm.store
Kaplama | Yazılarınızı okuduktan sonra, web tasarımı ve yazılım dünyasındaki yeni gelişmeleri ve trendleri takip etmeye daha fazla hevesli hissediyorum. Sizin gibi bir kaynağa sahip olduğum için minnettarım.
can you get clomid for sale: how to buy generic clomid – cost of generic clomid without prescription
prednisone in mexico
https://amoxilst.pro/# amoxicillin 500mg without prescription
where can i get amoxicillin 500 mg: amoxicillin 875 mg twice a day for 10 days – amoxicillin 500 mg capsule
charter flights http://www.aircgc-lux.com .
can i purchase cheap clomid prices: where can i buy clomid without a prescription – buy clomid
Your resilience is a testament to the power of the human spirit. Thank you for sharing your journey.
online pharmacy ordering
sm-slot.com
Jiao Fang은 분명히 놓아 줄 사람이 아니고 놓지 않으려 고 계속해서 마늘처럼 절을합니다.
Your positivity is a beacon of light in a world that can sometimes feel dark. Thank you.
amoxicillin 500mg capsules uk: amoxicillin for tooth infection – amoxicillin 775 mg
https://prednisonest.pro/# can i buy prednisone online without prescription
can i purchase generic clomid pills where to buy generic clomid no prescription can i get generic clomid pill
prednisone 1 mg daily: prednisone generic name – 5 prednisone in mexico
where buy clomid without a prescription: can i order clomid tablets – cost of cheap clomid tablets
buy synthroid cheap
mojmelimajmuea.com
집에 관한 한, 이 동료들은 항상 이야기할 주제가 무궁무진한 것 같다.
can i buy cheap clomid tablets: clomid 100mg – where can i buy clomid without prescription
buy valtrex without prescription
https://prednisonest.pro/# prednisone cost us
buy synthroid online uk
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
cortisol prednisone: purchase prednisone canada – order prednisone 10 mg tablet
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
where can i buy prednisone without a prescription: prednisone cream over the counter – prednisone 54
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
tadalafil 2
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
lisinopril prescription
http://prednisonest.pro/# prednisone 10mg buy online
prescription for amoxicillin: amoxicillin discount coupon – amoxicillin 500mg price in canada
Wat is Programmeertaal? | MAFA’s expertise op het gebied van webdesign en softwareontwikkeling is ongeëvenaard. Ik ben altijd onder de indruk van hun vermogen om aan de behoeften van hun klanten te voldoen.
otc lisinopril
услуги трансфера http://transferfromto.ru/ .
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
can you buy prednisone over the counter in usa
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
buy prinivil online
I needed something to lift my spirits, and your post did just that. Keep up the incredible work!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
1250 mg prednisone prednisone 20mg capsule prednisone drug costs
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
how to buy generic clomid without rx: how to buy cheap clomid tablets – can you get clomid without dr prescription
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
buy amoxicillin 500mg canada: fish amoxicillin – buy amoxicillin 500mg usa
purchase synthroid
Today was a bit down, but your content completely changed my mood. Keep those amazing posts coming!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
cost of prednisone 5mg tablets: prednisone taper schedule – how to purchase prednisone online
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
http://clomidst.pro/# can i get generic clomid without dr prescription
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
rate online pharmacies
Today needed a positive boost, and your post came at the right time. Keep filling our days with that positivity!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
prednisone uk price: ibuprofen and prednisone – 20 mg prednisone
synthroid 0.1 mg
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
I can’t help but express how much your content brightened my day. Keep bringing that positive energy!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
https://prednisonest.pro/# prednisone buy online nz
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
where can i get clomid without rx: clomid coupon – where buy generic clomid prices
where can i get clomid without prescription: where to buy clomid without a prescription – can you buy clomid without dr prescription
buy cialis online
happy family store coupon code
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
purchase lisinopril online
Today needed a positive boost, and your post came at the right time. Keep filling our days with that positivity!
This post made my day so special that I had to express my gratitude. Keep enchanting us!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
prednisone 200 mg tablets: prednisone 20 mg dosage instructions – prednisone without rx
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
детские кровати купить http://www.krovati-moskva11.ru .
Your post brought a genuine smile to my face. Keep filling our days with that contagious joy!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
tadalafil cost india
Today needed a positive boost, and your post came at the right time. Keep filling our days with that positivity!
Your post brought a genuine smile to my face. Keep filling our days with that contagious joy!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
ed drugs online buying erectile dysfunction pills online cheap boner pills
https://edpills.guru/# ed medicines online
online ed pharmacy: low cost ed meds online – erectile dysfunction meds online
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
I never imagined a post could have so much power to brighten my day. Keep the magic alive in your content!
overseas online pharmacy-no prescription: prescription meds from canada – prescription from canada
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
prednisone otc canada
Today needed a positive boost, and your post came at the right time. Keep filling our days with that positivity!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
synthroid 88 mg
synthroid 112 mcg in india
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
ttbslot.com
아버지의 진지한 눈빛을 보며 Zhu Houzhao는 “내 아들이 떠날 것이다”라고 순순히 말할 수밖에 없었다.
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
cost of ed meds: how to get ed meds online – get ed meds online
jelenakaludjerovic.com
Zhang 황후는 여전히 미소를 지었지만 대신 Zhu Xiurong을 위로했습니다.
http://edpills.guru/# where can i get ed pills
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
I needed something to lift my spirits, and your post did just that. Keep up the incredible work!
low cost ed meds online: cheap erectile dysfunction pills – cheap ed drugs
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
cheap erection pills: cheap ed pills – online ed medication
cheapest ed pills: buy erectile dysfunction treatment – cheapest ed medication
canadian prescription drugstore reviews online no prescription pharmacy buying drugs without prescription
lisinopril 10 mg for sale
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
сплит система для квартиры https://split-sistema11.ru/ .
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
http://onlinepharmacy.cheap/# non prescription medicine pharmacy
canadian pharmacy no prescription: mexican pharmacy online – no prescription needed canadian pharmacy
prinivil coupon
Couldn’t agree more with the praises above; this post is wonderful!
legit online pharmacy
Couldn’t agree more with the praises above; this post is wonderful!
canadian pharmacy meds
erectile dysfunction medication online: cheap ed medicine – cheapest ed meds
I’m on the same page as those above – this post is a delightful masterpiece!
erectile dysfunction medication online: best ed meds online – discount ed pills
rx lisinopril 10mg
ttbslot.com
Zhang 황후는 여전히 미소를 지었지만 대신 Zhu Xiurong을 위로했습니다.
generic cialis tadalafil
Fully resonate with the sentiments expressed above – this post is fantastic!
Couldn’t agree more – this post is an absolute pleasure to read!
pharmacy canadian superstore
buy cheap lisinopril
https://onlinepharmacy.cheap/# canadian online pharmacy no prescription
Completely aligned with the opinions above; this post is a joyous discovery!
Fully resonate with the sentiments expressed above – this post is fantastic!
erectile dysfunction online prescription: where can i get ed pills – ed meds online
Couldn’t agree more – this post is an absolute pleasure to read!
The opinions above encapsulate my thoughts – this post is a masterpiece!
I echo the sentiments above – this post is an absolute delight!
Fully resonate with the sentiments expressed above – this post is fantastic!
pharmacy coupons: online pharmacy delivery – online pharmacy without prescription
Echoing the sentiments above – this post is a true gem!
Echoing the sentiments above – this post is a true gem!
cheap ed meds: cheapest erectile dysfunction pills – buy ed pills
http://pharmnoprescription.pro/# buy medications without a prescription
generic ed meds online: cheapest ed meds – ed online meds
cheapest erectile dysfunction pills boner pills online cheap erection pills
buy valtrex online no prescription
online ed medications: cheap ed meds online – where to get ed pills
online pharmacy delivery delhi
buy prednisone india
online pharmacies no prescription usa: canada prescription drugs online – buy medications online without prescription
http://pharmnoprescription.pro/# medications online without prescriptions
canadian pharmacy coupon code: online pharmacy – canadian prescription pharmacy
pharmacy home delivery
http://mexicanpharm.online/# purple pharmacy mexico price list
buy tadalafil online no prescription
reputable indian online pharmacy: buy medicines online in india – top 10 pharmacies in india
synthroid online paypal
pharmacy canadian superstore
http://canadianpharm.guru/# reliable canadian pharmacy reviews
buy metformin us
pharmacy no prescription required: online drugstore no prescription – best online pharmacy without prescription
indian pharmacy world pharmacy india world pharmacy india
https://pharmacynoprescription.pro/# canada online prescription
best online pharmacy
http://canadianpharm.guru/# canadian pharmacy online store
medical mall pharmacy
thyroid synthroid
prednisone 10mg tablets
indian pharmacy online: india pharmacy – best india pharmacy
cheap metformin
prinivil online
http://mexicanpharm.online/# mexico drug stores pharmacies
reputable indian online pharmacy: world pharmacy india – pharmacy website india
synthroid 88 mcg coupon
rx pharmacy no prescription
звуковое и световое оборудование https://www.zvukovoe-oborudovanie11.ru .
canadian pharmacy store: canadian drugs – canadian pharmacy cheap
buy glucophage singapore
buying prescription drugs in mexico: mexico drug stores pharmacies – mexican rx online
https://indianpharm.shop/# india pharmacy
http://canadianpharm.guru/# canada pharmacy online
canadian compounding pharmacy canadian pharmacy meds legit canadian pharmacy
cheap online tadalafil
buy medication online without prescription: buying prescription drugs online from canada – canada prescription drugs online
mypharmacy
https://mexicanpharm.online/# mexican drugstore online
india pharmacy: top 10 pharmacies in india – top online pharmacy india
canada pharmacies online prescriptions: no prescription pharmacy – buying prescription drugs online from canada
buy synthroid 150 mcg
lisinopril rx coupon
top 10 pharmacies in india: india pharmacy – reputable indian online pharmacy
synthroid 75 mg
https://indianpharm.shop/# top 10 pharmacies in india
legitimate online pharmacy usa
cheapest online pharmacy india
mexican online pharmacies prescription drugs: mexican mail order pharmacies – mexican pharmaceuticals online
canadian and international prescription service: pills no prescription – no prescription medicine
https://pharmacynoprescription.pro/# no prescription medication
qiyezp.com
Fang Zhengqing은 머리를 긁적이며 오랫동안 생각했습니다. “아버지가 배고픈 것 같습니다.”,
buying prescription drugs in mexico online best online pharmacies in mexico buying prescription drugs in mexico online
mexican online pharmacies prescription drugs: medicine in mexico pharmacies – buying prescription drugs in mexico online
http://mexicanpharm.online/# medication from mexico pharmacy
no prescription lisinopril
canadian and international prescription service: buy pain meds online without prescription – best online pharmacies without prescription
mexico pharmacy: best mexican online pharmacies – reputable mexican pharmacies online
pharmaceutical online ordering
https://indianpharm.shop/# indian pharmacy
online pharmacy metformin
cheap prescription drugs online: prescription drugs canada – prescription canada
online pharmacy in germany
продвижение в интернете prodvizhenie-sajtov15.ru .
cialis online purchase
can you buy prescription drugs in canada: how to get a prescription in canada – buy medication online without prescription
canadian drugs online: canadian pharmacy – canadian pharmacy ltd
https://indianpharm.shop/# best india pharmacy
where can i buy cialis tadalafil in edmonton
http://pharmacynoprescription.pro/# prescription online canada
tadalafil mexico price
pharmacies in mexico that ship to usa: mexico pharmacies prescription drugs – mexican pharmacy
top 10 online pharmacy in india top 10 online pharmacy in india Online medicine order
medication lisinopril 10 mg
buy medicines online in india: india online pharmacy – pharmacy website india
https://canadianpharm.guru/# ed meds online canada
canadianpharmacy com: canadian pharmacy in canada – best rated canadian pharmacy
valtrex 1000 mg tablet
sandyterrace.com
Wang Jinyuan은 삼키고 침을 뱉고 얼굴이 창백했고 감히 한 마디도하지 않았습니다.
cialis cost in mexico
overseas online pharmacy-no prescription: best online pharmacy that does not require a prescription in india – no prescription drugs online
Your words of wisdom have the power to change lives. Thank you for sharing your insight.
http://mexicanpharm.online/# mexican border pharmacies shipping to usa
Your resilience is a testament to the power of the human spirit. Thank you for sharing your journey.
механизированная штукатурка под покраску mekhanizirovannaya-shtukaturka11.ru .
Your post brought tears to my eyes, but in the best way possible. Thank you for sharing your heart.
mexico drug stores pharmacies: purple pharmacy mexico price list – mexico pharmacies prescription drugs
prednisone 10mg tabs
Your post made me feel seen and understood in a way that I haven’t felt in a long time. Thank you.
prednisone online paypal
synthroid tablets
Your words have the power to uplift and inspire. Thank you for sharing your light with the world.
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
zestril pill
Your post reminded me that it’s okay to not be okay sometimes. Thank you for your honesty.
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
canadian pharmacy online ship to usa: canadian drug – online pharmacy canada
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
Your words of encouragement were just what I needed to hear today. Thank you for your support.
canadian pharmacy 24
Your words of wisdom have the power to change lives. Thank you for sharing your insight.
Your post was a reminder that even on the toughest days, there is still beauty to be found. Thank you.
cost of tadalafil in canada
Your kindness knows no bounds. Thank you for being a source of love and support.
I can relate to having a tough day, but stumbling upon your post changed everything.
https://indianpharm.shop/# reputable indian online pharmacy
https://mexicanpharm.online/# best online pharmacies in mexico
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
zithromax for sale cheap
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
pharmacy no prescription: canadian prescriptions in usa – non prescription online pharmacy
Your post brought tears to my eyes, but in the best way possible. Thank you for sharing your heart.
Your positivity is a beacon of light in a world that can sometimes feel dark. Thank you.
reputable mexican pharmacies online mexican border pharmacies shipping to usa pharmacies in mexico that ship to usa
Your resilience is a testament to the power of the human spirit. Thank you for sharing your journey.
best canadian online pharmacy: the canadian drugstore – canadianpharmacyworld
buy glucophage in australia
Your post brought tears to my eyes, but in the best way possible. Thank you for sharing your heart.
Your words have the power to uplift and inspire. Thank you for sharing your light with the world.
canadian pharmacy 24h com safe: best canadian online pharmacy reviews – online pharmacy canada
cialis com
http://canadianpharm.guru/# canadian pharmacy service
azithromycin price canada
safe canadian pharmacy: best canadian pharmacy to buy from – canada pharmacy
buy valtrex online prescription
canadian prescription prices: online prescription canada – order prescription from canada
fpparisshop.com
非常に有意義な内容でした。このブログは本当に宝物です。
Online medicine home delivery: top online pharmacy india – indian pharmacy online
http://indianpharm.shop/# indianpharmacy com
Today is a reminder to appreciate the beauty around us, and your post is a beautiful example of that.
indian pharmacy paypal: Online medicine order – india pharmacy
http://pharmacynoprescription.pro/# buy medications online no prescription
buy tadalafil 10mg
pills no prescription online medication without prescription non prescription online pharmacy india
canada pharmacy world: canadian pharmacy ed medications – onlinepharmaciescanada com
https://mexicanpharm.online/# mexican pharmaceuticals online
доставка цветов саратов ленинский flowerssaratov.ru .
canada pharmacy online: canadian pharmacy antibiotics – canadian pharmacy price checker
sandyterrace.com
Shen Ao는 “아니, 당신은 진짜 똑똑한 사람입니다. “라고 웃었습니다.
http://slotsiteleri.guru/# 2024 en iyi slot siteleri
Amidst the serenity of today, your post is like a gentle breeze on a warm summer day.
Amidst the serenity of today, your post is like a gentle breeze on a warm summer day.
Amidst the beauty of today, your post is a shining example of love and positivity.
Today feels like a day filled with endless opportunities, and your post is the perfect motivation.
hq pharmacy online 365
gates of olympus slot: gates of olympus taktik – gates of olympus nas?l para kazanilir
Today feels like a day filled with endless possibilities, and your post adds to the excitement.
Amidst the serenity of today, your post is like a gentle breeze on a warm summer day.
Today is a canvas waiting to be painted with positivity, and your post is the perfect stroke of inspiration.
What a stunning day it is today! Your post adds an extra layer of beauty to this already picturesque day.
The sun is shining brightly, and your post is equally radiant. Thank you for sharing your light.
https://pinupgiris.fun/# pin up casino güncel giris
Today feels like a day made for gratitude, and your post is a reminder of all the things to be thankful for.
It’s a gorgeous day outside, but nothing compares to the warmth and positivity of your post.
Today is a reminder to appreciate the beauty around us, and your post is a beautiful example of that.
generic prednisone without prescription
Today feels like a day made for gratitude, and your post is a reminder of all the things to be thankful for.
The sun is shining, the world is alive, and your post is like a burst of energy.
Amidst the beauty of today, your post is a shining example of kindness and compassion.
https://slotsiteleri.guru/# en cok kazandiran slot siteleri
What a glorious day it is today! Your post adds an extra sparkle to this already radiant day.
Amidst the chaos of life, your post is a gentle reminder to pause and appreciate the beauty around us.
Amidst the chaos of life, your post is a beacon of calmness and positivity.
aviator oyunu 20 tl: aviator bahis – aviator sinyal hilesi ucretsiz
http://gatesofolympus.auction/# gates of olympus guncel
The sun is shining, the sky is clear, and your post is like a ray of sunshine.
What a glorious day it is today! Your post adds an extra sparkle to this already radiant day.
lisinopril 20 mg pill
aviator hilesi ucretsiz: aviator sinyal hilesi ucretsiz – aviator hilesi
Today is a reminder that even in the midst of chaos, there is still beauty to be found. Your post is proof of that.
Today is a reminder to be present and grateful, and your post is a beautiful reminder of that.
Today feels like a day full of endless possibilities, and stumbling upon your post adds to the excitement.
Amidst the beauty of today, your post is like a beacon of hope shining bright.
What a picturesque day it is today, made even more delightful by your heartfelt post.
onair2tv.com
Hongzhi 황제는 그의 머리를 쓰다듬어주었습니다. “아이가 삼촌과 같다고합니다 … 음 …”
Today is a reminder that even in the midst of chaos, there is still beauty to be found. Your post is proof of that.
What a splendid day it is today! Your post adds an extra dose of sunshine to an already bright day.
http://gatesofolympus.auction/# gates of olympus hilesi
Today is a reminder that even in the midst of chaos, there is still beauty to be found. Your post is proof of that.
Today feels like a day filled with endless opportunities, and your post is the perfect motivation.
Today is a reminder to embrace the present moment, and your post is a beautiful reflection of that.
What a splendid day it is today! Your post adds an extra dose of sunshine to an already bright day.
gates of olympus oyna demo: gates of olympus s?rlar? – gates of olympus oyna ucretsiz
Today feels like a day made for laughter, and your post brings a smile to my face.
Amidst the chaos of life, your post is a reminder to find peace and joy in every moment.
The sun is shining, the birds are singing, and your post is making this day even brighter.
Today feels like a day filled with endless possibilities, and your post is the perfect start.
https://gatesofolympus.auction/# gates of olympus demo free spin
The sun is shining, the birds are singing, and your post is like a melody to my ears.
https://aviatoroyna.bid/# aviator oyna
Today feels like a day filled with endless possibilities, and your post is the perfect start.
Today feels like a gift, and your post is the perfect bow on top. Thank you for brightening my day.
As I soak in the warmth of the sun, I’m also soaking in the warmth of your words. Thank you for making today brighter.
http://gatesofolympus.auction/# gates of olympus
pin-up bonanza: pin-up online – pin up
synthroid prices canada
pharmacy
https://aviatoroyna.bid/# aviator sinyal hilesi ücretsiz
metformin tablet cost
pin up bet: pin up casino – pin-up giris
http://slotsiteleri.guru/# slot siteleri bonus veren
azithromycin 600 mg tablet
Today is a reminder to find joy in the little things, and your post is a perfect example of that.
where can i buy prednisone online
The sun is beaming down, but it’s your words that truly light up my day. Thank you for sharing your positivity.
http://pinupgiris.fun/# pin up
sweet bonanza kazanc: sweet bonanza kazanc – sweet bonanza
https://pinupgiris.fun/# pin up casino giris
Amidst the beauty of today, your post is a shining example of kindness and compassion.
25 mg prednisone
The sun is shining, the birds are singing, and your post is like a melody to my ears.
Today feels like a day filled with warmth, and your post is like a cozy blanket on a chilly morning.
The sun is painting the sky with hues of gold, and your post is painting my day with happiness.
The sun is casting its golden glow, and your post is equally radiant. Thank you for brightening my day.
The sun is shining, the sky is blue, and your post is the cherry on top of this beautiful day.
https://pinupgiris.fun/# pin up casino
buy metformin mexico
The sun is shining brightly, and your post is equally radiant. Thank you for sharing your light.
sweet bonanza yorumlar: sweet bonanza slot demo – sweet bonanza indir
The sun is shining, the sky is clear, and your post is the highlight of my day.
The sun is high in the sky, and your post is equally uplifting. Thank you for brightening my day.
lisinopril 1 mg
https://aviatoroyna.bid/# aviator sinyal hilesi ücretsiz
Today feels like a breath of fresh air, and your post adds an extra sparkle to the day.
As I soak in the warmth of the sun, I’m also soaking in the warmth of your words. Thank you for making today brighter.
Amidst the beauty of today, your post stands out like a radiant sunbeam.
sweet bonanza kazanc: pragmatic play sweet bonanza – sweet bonanza yasal site
bliblibli
https://aviatoroyna.bid/# aviator sinyal hilesi
aviator pin up: pin-up giris – pin-up casino giris
bluatblaaotuy
blobloblu
family care rx pharmacy
bliblibli
bluatblaaotuy
blobloblu
blablablu
blublabla
bluatblaaotuy
blobloblu
bluatblaaotuy
blobloblu
https://slotsiteleri.guru/# slot oyun siteleri
blublabla
https://gatesofolympus.auction/# gates of olympus 1000 demo
aviator oyna 100 tl: aviator casino oyunu – aviator sinyal hilesi apk
http://sweetbonanza.bid/# sweet bonanza free spin demo
i love danatoto
i love danatoto
i love danatoto
blublabla
blublabla
bluatblaaotuy
bluatblaaotuy
aviator pin up: pin-up casino indir – pin up indir
sweet bonanza taktik: sweet bonanza demo turkce – sweet bonanza 90 tl
i love danatoto
i love danatoto
http://gatesofolympus.auction/# gates of olympus oyna
where can i purchase zithromax
i love danatoto
i love danatoto
indian pharmacies safe
i love danatoto
i love danatoto
buy generic valtrex
i love danatoto
blobloblu
bluatblaaotuy
bliblibli
synthroid 150 mg
https://pinupgiris.fun/# pin up 7/24 giris
bliblibli
azithromycin price in usa
sweet bonanza oyna: sweet bonanza yasal site – guncel sweet bonanza
canadadrugpharmacy com
mexico drug stores pharmacies: mexican pharmacy – mexico drug stores pharmacies
synthroid 0.15
lisinopril in mexico
lisinopril 30
открытие любых замков http://azs-zamok13.ru/ .
buying prescription drugs in mexico mexican pharmacy mexico drug stores pharmacies
otraresacamas.com
とても勉強になりました。このような質の高い内容を提供してくれてありがとう。
cialis pills from canada
http://canadianpharmacy24.store/# canadianpharmacyworld
india pharmacy Generic Medicine India to USA reputable indian pharmacies
prednisone 20mg tablets
buy prednisone 10mg online
mexico pharmacies prescription drugs: Mexican Pharmacy Online – buying prescription drugs in mexico online
synthroid 25 mcg
ed meds online canada canadian pharmacy 24 pharmacy rx world canada
best canadian online pharmacy reviews: Prescription Drugs from Canada – canadian pharmacy no scripts
medication from mexico pharmacy: mexico pharmacy – mexican border pharmacies shipping to usa
0.05 mg synthroid
synthroid 75 mg
online shopping pharmacy india Healthcare and medicines from India reputable indian online pharmacy
metformin 500 mg price india
canada pharmacy online legit: trusted canadian pharmacy – canadian pharmacy online
https://canadianpharmacy24.store/# canadian pharmacy no scripts
can you buy metformin over the counter uk
online pharmacy 365 pills
bitcoin pharmacy online
canadian pharmacy meds review: Prescription Drugs from Canada – best canadian pharmacy
mexican rx online: cheapest mexico drugs – purple pharmacy mexico price list
canadian compounding pharmacy Licensed Canadian Pharmacy my canadian pharmacy reviews
mexican border pharmacies shipping to usa: Online Pharmacies in Mexico – best online pharmacies in mexico
is canadian pharmacy legit: Prescription Drugs from Canada – best canadian pharmacy online
escrow pharmacy canada: pills now even cheaper – legitimate canadian pharmacy online
best india pharmacy Healthcare and medicines from India Online medicine home delivery
reputable indian pharmacies: cheapest online pharmacy india – india online pharmacy
tadalafil 5mg buy
mexico drug stores pharmacies: buying from online mexican pharmacy – mexican rx online
valtrex price australia
indian pharmacy Generic Medicine India to USA indian pharmacy paypal
http://indianpharmacy.icu/# top online pharmacy india
37.5 mcg synthroid
pharmacy website india: indian pharmacy delivery – top online pharmacy india
п»їlegitimate online pharmacies india: indian pharmacy – top 10 pharmacies in india
cost of synthroid 125 mcg
reputable indian online pharmacy Healthcare and medicines from India online shopping pharmacy india
purple pharmacy mexico price list mexican pharmacy mexican pharmacy
buy zestoretic online
valtrex daily use
mexican mail order pharmacies: mexico pharmacy – pharmacies in mexico that ship to usa
20 mg prednisone generic
buy synthroid canada no prescription
http://indianpharmacy.icu/# top 10 online pharmacy in india
п»їbest mexican online pharmacies cheapest mexico drugs buying from online mexican pharmacy
canadian discount pharmacy: canadian pharmacy 24 – canadian pharmacy no scripts
п»їlegitimate online pharmacies india: Generic Medicine India to USA – buy prescription drugs from india
mexican drugstore online: cheapest mexico drugs – buying prescription drugs in mexico
cost of synthroid 75 mg
20 mg tadalafil cost
https://zithromaxall.shop/# zithromax prescription online
zithromax online usa generic zithromax medicine zithromax 500 mg
canadian online pharmacy no prescription
https://prednisoneall.shop/# buy prednisone tablets uk
buy prednisone 5mg canada prednisone 10 tablet prednisone online pharmacy
https://clomidall.shop/# generic clomid without rx
cheap amoxicillin 500mg: amoxicillin 500mg buy online canada – can i buy amoxicillin over the counter in australia
where can i get zithromax: where to buy zithromax in canada – average cost of generic zithromax
zithromax 1000 mg pills can i buy zithromax online zithromax 500mg
http://clomidall.com/# order clomid no prescription
cougarsbkjersey.com
この記事から多くを学びました。非常に役立つ情報です。
prednisone 5mg daily
http://amoxilall.shop/# amoxicillin generic
tadalafil 2.5 mg daily
synthroid 132 mg
can i purchase clomid without insurance where can i get cheap clomid pills cost of generic clomid
synthroid brand cost
https://amoxilall.shop/# amoxicillin 500mg prescription
discount cialis canada
http://amoxilall.com/# buy amoxicillin 500mg
northern pharmacy canada
prednisone 30 mg buy prednisone 1 mg mexico cheap generic prednisone
lisinopril cheap price
lisinopril 4 mg
https://zithromaxall.shop/# buy azithromycin zithromax
lisinopril 20 mg canadian pharmacy
valtrex 3000 mg
can you get clomid: how can i get generic clomid without prescription – how to buy generic clomid online
amoxicillin online no prescription: how to buy amoxycillin – buy cheap amoxicillin online
buy zithromax online with mastercard how to buy zithromax online buy zithromax 1000 mg online
https://clomidall.shop/# can i purchase generic clomid pill
http://clomidall.shop/# get cheap clomid without a prescription
where to buy cheap clomid without insurance where buy clomid without insurance can i get cheap clomid without prescription
http://zithromaxall.shop/# where can i buy zithromax uk
where to buy prednisone in canada
https://prednisoneall.com/# prednisone 5mg price
cost cheap clomid price can you buy generic clomid price how can i get cheap clomid no prescription
zestril 5 mg
tadalafil 10mg tablets in india
https://clomidall.com/# where to buy cheap clomid without prescription
prednisone 2.5 mg: prednisone 1 mg daily – over the counter prednisone medicine
prednisone brand name in india: prednisone generic brand name – prednisone 60 mg daily
prednisone 40 mg daily can i buy prednisone online without a prescription can you buy prednisone over the counter in usa
austria pharmacy online
http://prednisoneall.shop/# buy prednisone 5mg canada
synthroid 0.88 mcg
https://clomidall.com/# order generic clomid prices
can you buy generic clomid pill where to buy clomid tablets generic clomid pill
https://kamagraiq.shop/# buy kamagra online usa
Buy Tadalafil 5mg: Generic Tadalafil 20mg price – buy cialis pill
pharmacy drugs
generic sildenafil cheapest viagra viagra canada
buy kamagra online usa: Kamagra gel – super kamagra
Kamagra tablets: Kamagra Oral Jelly Price – sildenafil oral jelly 100mg kamagra
cialis 10mg price canada
zestril 5 mg india
synthroid 200 mg price
Generic Cialis price: Generic Tadalafil 20mg price – cialis generic
sildenafil online best price on viagra Cheap Sildenafil 100mg
buying metformin in mexico
buy prednisone online without a prescription
buy lisinopril online uk
Generic Tadalafil 20mg price: Cialis over the counter – Buy Cialis online
http://kamagraiq.shop/# Kamagra tablets
prednisone india
synthroid 175 mcg price
cialis for sale cialis best price cheapest cialis
Viagra tablet online: buy viagra online – sildenafil online
zestril 20 mg price
100 mg lisinopril
super kamagra: Kamagra Oral Jelly Price – Kamagra tablets
Sildenafil 100mg price: buy viagra online – Viagra generic over the counter
buy kamagra online usa kamagra best price sildenafil oral jelly 100mg kamagra
happy family store online pharmacy
Viagra without a doctor prescription Canada: best price on viagra – order viagra
game1kb.com
오스만 장군은 현재로서는… 돌볼 시간이 없습니다.
online pet pharmacy
sildenafil over the counter: sildenafil iq – sildenafil online
https://tadalafiliq.shop/# п»їcialis generic
Generic Viagra for sale buy viagra online п»їBuy generic 100mg Viagra online
best rx pharmacy online
https://tadalafiliq.com/# Buy Tadalafil 5mg
synthroid rx coupon
Cheap Cialis: Buy Cialis online – Buy Tadalafil 5mg
[url=https://metoformin.online/]metformin price in canada[/url]
0.125 mg synthroid
Tadalafil Tablet cheapest cialis buy cialis pill
prednisone 5 mg cheapest
canada rx pharmacy
http://tadalafiliq.shop/# Cheap Cialis
canada happy family store pharmacy
Cialis 20mg price: Buy Cialis online – Buy Tadalafil 10mg
fpparisshop.com
生活に直接役立つ情報が満載で、素晴らしい記事です。
valtrex 2000 mg
tadalafil 20mg coupon
cross border pharmacy canada
sildenafil oral jelly 100mg kamagra: Kamagra gel – cheap kamagra
happy family drug store
Tadalafil price: Buy Cialis online – Buy Tadalafil 10mg
cheap viagra generic ed pills Sildenafil 100mg price
http://tadalafiliq.com/# Buy Tadalafil 20mg
cialis generic: tadalafil iq – Buy Cialis online
This game is played all over the world and of course Indonesia takes part in organizing this game. TOTO TOGEL
Gradually, regulations emerged that blocked this lottery game in Indonesia, resulting in everyone losing access to placing numbers in land-based lottery. TITI4D
As a result of these conditions, online lottery games were created TOTO TOGEL
So that was the beginning of the formation of the online lottery site that we know today TITI4D
As we mentioned earlier, having been operating for 12 years in the field of online gambling, of course TITI4D
has many advantages compared to other lottery sites.
Togel138, which has been operating for 12 years, certainly has a lot of evidence that we are able to pay members’ winnings for decades.8KUDA4D
You can also check with our loyal members on social media about how much trust they have in us. 8KUDA4D
https://sildenafiliq.com/# Viagra online price
Buy Tadalafil 5mg: Generic Tadalafil 20mg price – Generic Tadalafil 20mg price
http://sildenafiliq.com/# Sildenafil Citrate Tablets 100mg
order viagra best price on viagra Cheapest Sildenafil online
cheap kamagra: Kamagra gel – Kamagra Oral Jelly
Your post made me feel seen and understood in a way that I haven’t felt in a long time. Thank you.
pharmaceutical online ordering
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
http://sildenafiliq.com/# sildenafil online
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
Your post gave me hope when I needed it most. Thank you for your courage.
Tadalafil Tablet cialis best price Cialis over the counter
Your post brought tears to my eyes, but in the best way possible. Thank you for sharing your heart.
Kamagra 100mg: Kamagra gel – buy kamagra online usa
Your post reminded me that it’s okay to not be okay sometimes. Thank you for your honesty.
zestril coupon
Your strength in the face of adversity is truly inspiring. Thank you for sharing your story.
Your strength in the face of adversity is truly inspiring. Thank you for sharing your story.
Your kindness knows no bounds. Thank you for being a source of love and support.
Thank you for sharing your story. Your post really lifted my spirits today.
Your post made me feel seen and understood in a way that I haven’t felt in a long time. Thank you.
Your resilience is a testament to the power of the human spirit. Thank you for sharing your journey.
Your post reminded me that I am stronger than I think. Thank you for your encouragement.
Buy Cialis online: Buy Cialis online – Cialis without a doctor prescription
Your resilience in the face of challenges is remarkable. Thank you for sharing your journey.
Your positivity is contagious. After reading your post, I feel ready to tackle whatever comes my way.
sildenafil oral jelly 100mg kamagra: kamagra best price – cheap kamagra
http://sildenafiliq.xyz/# Cheap generic Viagra
metformin order canada
Your post gave me hope when I needed it most. Thank you for your courage.
sandyterrace.com
다만… 황제의 중병 소식은 여전히 궁궐 밖에서 다양한 추측을 불러일으켰다.
Your words of encouragement were just what I needed to hear today. Thank you for your support.
Your words have the power to uplift and inspire. Thank you for sharing your light with the world.
Your post gave me the strength to face another day with hope in my heart. Thank you.
sildenafil oral jelly 100mg kamagra Kamagra gel cheap kamagra
Your positivity is contagious. After reading your post, I feel ready to tackle whatever comes my way.
Your positivity is contagious. After reading your post, I feel ready to tackle whatever comes my way.
Your words have the power to uplift and inspire. Thank you for sharing your light with the world.
family rx 24
Your words of wisdom have the power to change lives. Thank you for sharing your insight.
http://kamagraiq.com/# Kamagra Oral Jelly
Cialis 20mg price: tadalafil iq – cheapest cialis
https://kamagraiq.shop/# Kamagra Oral Jelly
onair2tv.com
Deng Tong은 이미 자신의 운명을 이해했고 죽을 때까지 인내해야 했습니다.
internet pharmacy mexico
best online foreign pharmacies
http://indianpharmgrx.shop/# india pharmacy mail order
tadalafil tablets canada
where can i buy synthroid
mexico pharmacy Pills from Mexican Pharmacy purple pharmacy mexico price list
http://mexicanpharmgrx.shop/# mexican drugstore online
tadalafil for sale canada
60 mg cialis online
canadian drugs online: CIPA approved pharmacies – is canadian pharmacy legit
mexican online pharmacies prescription drugs Pills from Mexican Pharmacy mexican rx online
http://mexicanpharmgrx.com/# best online pharmacies in mexico
rate online pharmacies
lisinopril 10 mg tablet cost
online pharmacy india: indian pharmacy – india pharmacy
https://canadianpharmgrx.com/# safe canadian pharmacy
mexico pharmacy online pharmacy in Mexico mexico pharmacy
tadalafil tablets 20 mg cost
http://canadianpharmgrx.com/# canadian pharmacies compare
buying from online mexican pharmacy best online pharmacies in mexico mexican drugstore online
http://canadianpharmgrx.com/# canadian pharmacy meds reviews
lisinopril 20 mg purchase
buy generic tadalafil online
prednisone tablets 2.5 mg
presnidone without a prescription
mexico drug stores pharmacies: best online pharmacies in mexico – buying from online mexican pharmacy
medicine in mexico pharmacies Mexico drugstore mexican rx online
https://mexicanpharmgrx.com/# best mexican online pharmacies
canadian pharmacy no rx needed
сколько стоит лазерная сварка по металлу http://www.apparat-ruchnoy-lazernoy-svarki.ru/ .
real cialis pills
legal canadian pharmacy online: canadian drug stores – canadian pharmacy com
http://mexicanpharmgrx.shop/# mexican pharmaceuticals online
india pharmacy indian pharmacy top 10 online pharmacy in india
http://canadianpharmgrx.xyz/# onlinepharmaciescanada com
mexico pharmacies prescription drugs Pills from Mexican Pharmacy mexico pharmacy
https://mexicanpharmgrx.shop/# mexican online pharmacies prescription drugs
can i buy lisinopril over the counter in canada
generic tadalafil united states
https://indianpharmgrx.com/# top 10 online pharmacy in india
buy prescription drugs from india: Generic Medicine India to USA – best online pharmacy india
reputable canadian pharmacy canadian pharmacy buy canadian drugs
buy generic valtrex online
8kuda4d most popular website in the world.
8kuda4d cheapest website.
http://canadianpharmgrx.xyz/# canadian neighbor pharmacy
tintucnamdinh24h.com
Dowager Zhang 황후는 의심스럽게 물었습니다. “이것은 Heling과 Yanling입니다 … 그들이 설계 했습니까?”
reputable indian online pharmacy: Healthcare and medicines from India – online shopping pharmacy india
cougarsbkjersey.com
非常に興味深く、有意義な内容でした。感謝します。
canadian pharmacy coupon code
zestril medication
canadian pharmacy near me Canadian pharmacy prices pharmacy canadian superstore
https://mexicanpharmgrx.shop/# purple pharmacy mexico price list
qiyezp.com
역 승강장 설정도 무리한 곳이 많다.
https://indianpharmgrx.shop/# best online pharmacy india
synthroid 135 mcg
medication canadian pharmacy Canadian pharmacy prices canadapharmacyonline
https://indianpharmgrx.com/# indian pharmacies safe
prednisone 20 mg
ciprofloxacin over the counter: ciprofloxacin generic – buy ciprofloxacin
diflucan 400mg: can i buy diflucan over the counter – can i buy diflucan online
canadian pharmacy valtrex
buy cytotec pills online cheap buy cytotec Misoprostol 200 mg buy online
buy doxycycline without prescription: doxycycline without a prescription – doxycycline pills
купить диплом техникума https://www.1diplomy-grupp.ru .
100mg doxycycline doxycycline online order doxycycline
tamoxifen estrogen: tamoxifen effectiveness – nolvadex side effects
diflucan cream prescription: diflucan without get a prescription online – diflucan 150 mg over the counter
azithromycin 1000 mg tablets
buy doxycycline cheap: buy doxycycline online uk – order doxycycline
buy cytotec over the counter buy cytotec over the counter purchase cytotec
doxycycline generic: order doxycycline 100mg without prescription – doxy
canada rx pharmacy world
ciprofloxacin 500 mg tablet price ciprofloxacin generic п»їcipro generic
cheap doxycycline online: doxycycline pills – doxycycline monohydrate
buy cytotec: cytotec online – buy cytotec
buy cytotec over the counter buy cytotec buy misoprostol over the counter
п»їcytotec pills online: Cytotec 200mcg price – Misoprostol 200 mg buy online
purchase doxycycline online: doxycycline hyclate – how to buy doxycycline online
zestril medicine
http://diflucan.icu/# cost of diflucan
doxycycline generic doxylin doxycycline pills
cipro ciprofloxacin: buy ciprofloxacin over the counter – cipro 500mg best prices
tamoxifen chemo: tamoxifen endometriosis – does tamoxifen cause menopause
diflucan 200 mg daily diflucan brand name order diflucan online uk
купить аттестат школы http://www.2diplom-grupp.ru .
buy ciprofloxacin over the counter: ciprofloxacin order online – buy generic ciprofloxacin
synthroid 112 mcg coupon
Misoprostol 200 mg buy online order cytotec online buy cytotec over the counter
cipro: cipro online no prescription in the usa – cipro 500mg best prices
buy cipro online canada: cipro pharmacy – buy ciprofloxacin tablets
doxycycline without prescription: buy generic doxycycline – doxycycline tablets
http://diflucan.icu/# can i purchase diflucan over the counter
diflucan generic diflucan 1 where to buy online rx diflucan
synthroid prescription uk
how to prevent hair loss while on tamoxifen: nolvadex for sale amazon – nolvadex only pct
ciprofloxacin 500mg buy online cipro for sale antibiotics cipro
tamoxifen side effects forum: tamoxifen vs clomid – tamoxifen citrate
lisinopril cost canada
order synthroid
doxycycline order online: 100mg doxycycline – doxycycline 100mg tablets
metformin india
cipro buy generic ciprofloxacin cipro pharmacy
cialis daily pill
http://clomida.pro/# where to buy generic clomid without insurance
how to get clomid pills: can you buy generic clomid no prescription – buying generic clomid price
good value pharmacy
prednisone 12 tablets price non prescription prednisone 20mg buy prednisone online no prescription
Thank you very much for this wonderful information.
where can i get prednisone over the counter: can i buy prednisone from canada without a script – prednisone nz
sweet bonanza demo sweet-bonanza-game.ru .
rx pharmacy coupons
prednisone tablet 100 mg prednisone 40 mg prednisone 5093
buy generic zithromax online: order zithromax over the counter – zithromax 250 mg pill
http://azithromycina.pro/# can you buy zithromax over the counter in canada
buy zithromax online cheap: where can you buy zithromax – order zithromax over the counter
https://prednisonea.store/# prednisone 1 mg tablet
cheap zithromax pills: zithromax tablets – zithromax 500 mg lowest price pharmacy online
buy zithromax 500mg online zithromax 500mg price zithromax capsules australia
can i purchase amoxicillin online: amoxicillin 500 coupon – buy amoxicillin 500mg online
https://azithromycina.pro/# zithromax over the counter uk
ivermectin tablet price ivermectin 4 buy ivermectin for humans australia
generic zithromax azithromycin: zithromax prescription – zithromax 500mg price
synthroid 175 mcg
https://stromectola.top/# ivermectin 5 mg
cheap clomid now: order cheap clomid – buying cheap clomid without dr prescription
zithromax capsules purchase zithromax z-pak zithromax prescription in canada
http://prednisonea.store/# prednisone without prescription 10mg
where can i buy clomid without a prescription: buying clomid without dr prescription – cost of clomid online
https://medicationnoprescription.pro/# best no prescription online pharmacies
http://edpill.top/# online ed medicine
cheap pharmacy no prescription: canadian pharmacies not requiring prescription – no prescription pharmacy paypal
cost of synthroid 125 mcg
canadian prescription drugstore review cheap drugs no prescription buying prescription medicine online
reputable overseas online pharmacies
online slots kenya casinoonline.co.ke .
https://onlinepharmacyworld.shop/# canadian pharmacy world coupon
how to get prescription drugs from canada: canada pharmacies online prescriptions – buy prescription online
no prescription needed canadian pharmacy pharmacy coupons cheap pharmacy no prescription
http://edpill.top/# get ed prescription online
online pharmacy that does not require a prescription: online pharmacy without prescriptions – best online pharmacy that does not require a prescription in india
https://medicationnoprescription.pro/# best online pharmacies without prescription
ed drugs online: ed pills for sale – how to get ed pills
Mostbet https://mostbet-cr-reg.blogspot.com je vhodny pro hrace vsech urovni zkusenosti.
http://onlinepharmacyworld.shop/# foreign pharmacy no prescription
cheap ed medication ed prescription online order ed meds online
https://onlinepharmacyworld.shop/# canadian pharmacy coupon code
online pharmacy no prescription: cheapest pharmacy to get prescriptions filled – best online pharmacy no prescription
https://onlinepharmacyworld.shop/# canadian pharmacy coupon
ed online prescription top rated ed pills cheap ed meds
pharmacy online 365 discount code: foreign pharmacy no prescription – canadian online pharmacy no prescription
PBN sites
We will build a web of privately-owned blog network sites!
Merits of our private blog network:
We perform everything so Google DOES NOT realize THAT this A private blog network!!!
1- We purchase domain names from separate registrars
2- The leading site is hosted on a VPS hosting (Virtual Private Server is fast hosting)
3- Other sites are on distinct hostings
4- We assign a individual Google ID to each site with verification in Google Search Console.
5- We create websites on WordPress, we do not use plugins with the help of which malware penetrate and through which pages on your websites are created.
6- We refrain from reiterate templates and use only exclusive text and pictures
We do not work with website design; the client, if desired, can then edit the websites to suit his wishes
https://onlinepharmacyworld.shop/# canadian pharmacy world coupon code
buy ed pills online discount ed pills ed medicines
mail order pharmacy no prescription: best no prescription pharmacy – online canadian pharmacy coupon
http://medicationnoprescription.pro/# online meds no prescription
http://casinvietnam.shop/# choi casino tr?c tuy?n tren di?n tho?i
http://casinvietnam.com/# danh bai tr?c tuy?n
buying synthroid in mexico
casino tr?c tuy?n: choi casino tr?c tuy?n trên di?n tho?i – choi casino tr?c tuy?n trên di?n tho?i
https://casinvietnam.shop/# casino tr?c tuy?n
choi casino tr?c tuy?n trên di?n tho?i: casino tr?c tuy?n uy tín – web c? b?c online uy tín
https://casinvietnam.com/# choi casino tr?c tuy?n tren di?n tho?i
web c? b?c online uy tin casino online uy tin danh bai tr?c tuy?n
onair2tv.com
부모는 자녀를 사랑하고 걱정 없는 삶을 살게 할 수 있습니다.
tadalafil 40 mg for sale
best canadian pharmacy no prescription
casino tr?c tuy?n vi?t nam casino tr?c tuy?n uy tin web c? b?c online uy tin
отмечу как доверительного союзника в SEO-развитии.
cost of brand name synthroid
лучшая букмекерская онлайн sport-bk.by .
metformin otc mexico
buy metformin online nz
8kuda4d win the biggest prize in here.
order synthroid without prescription
lisinopril 0.5 mg
lisinopril tablets
nikontinoll.com
하지만 누가 알았겠어… 신나게 Xiao Jing을 보내줬지만 그가 얻은 것은 그런 결과였다.
lisinopril 40 mg price
tadalafil 25mg
synthroid 125 mcg price
synthroid rx coupon
заказать ролл ап https://www.rollap.ru .
With this many options, you can explore various strategies and increase your chances of winning big prizes. TITI4D
Apart from that, 8KUDA4D
guarantees security and trust in every transaction.
lisinopril 20mg buy
reputable online pharmacy no prescription
buy cheap metformin online
synthroid 88 mcg tabs
canadianpharmacymeds
order tadalafil 20mg
грузоперевозки из китая http://dostavka-gruzov-is-kitaya.ru/ .
lisinopril 20mg pill
школа барберов спб https://www.burberi.ru .
buy tadalafil generic from canada
строительство домов из бруса цена https://www.alexstroy53.ru .
safe canadian pharmacy
metformin 200 mg
how can i order prednisone
Understanding COSC Certification and Its Importance in Horology
COSC Certification and its Strict Criteria
COSC, or the Official Swiss Chronometer Testing Agency, is the authorized Switzerland testing agency that attests to the accuracy and precision of wristwatches. COSC accreditation is a symbol of excellent craftsmanship and dependability in chronometry. Not all timepiece brands pursue COSC accreditation, such as Hublot, which instead adheres to its own demanding standards with movements like the UNICO, achieving similar accuracy.
The Science of Exact Timekeeping
The core mechanism of a mechanical timepiece involves the mainspring, which delivers power as it unwinds. This mechanism, however, can be susceptible to environmental elements that may impact its precision. COSC-accredited movements undergo rigorous testing—over 15 days in various conditions (five positions, 3 temperatures)—to ensure their durability and reliability. The tests assess:
Average daily rate precision between -4 and +6 secs.
Mean variation, highest variation rates, and impacts of temperature variations.
Why COSC Validation Is Important
For timepiece enthusiasts and connoisseurs, a COSC-validated watch isn’t just a item of tech but a demonstration to lasting quality and precision. It represents a timepiece that:
Provides outstanding reliability and accuracy.
Ensures confidence of superiority across the entire construction of the timepiece.
Is probable to maintain its worth more efficiently, making it a sound choice.
Popular Timepiece Manufacturers
Several famous manufacturers prioritize COSC validation for their watches, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, provides collections like the Record and Soul, which showcase COSC-accredited mechanisms equipped with advanced materials like silicon equilibrium suspensions to enhance durability and efficiency.
Historical Context and the Evolution of Timepieces
The idea of the timepiece dates back to the need for accurate chronometry for navigation at sea, highlighted by John Harrison’s work in the 18th cent. Since the official establishment of Controle Officiel Suisse des Chronometres in 1973, the validation has become a benchmark for evaluating the accuracy of luxury timepieces, sustaining a legacy of superiority in horology.
Conclusion
Owning a COSC-accredited watch is more than an aesthetic choice; it’s a commitment to excellence and accuracy. For those valuing precision above all, the COSC validation provides peacefulness of mind, ensuring that each certified timepiece will perform reliably under various conditions. Whether for individual contentment or as an investment, COSC-certified watches stand out in the world of watchmaking, maintaining on a tradition of precise chronometry.
can you order metformin online
снять квартиру на сутки в Минске http://www.sutki24.by/ .
lisinopril 40 mg daily
casibom güncel
Nihai Dönemin En Büyük Gözde Casino Platformu: Casibom
Casino oyunlarını sevenlerin artık duymuş olduğu Casibom, nihai dönemde adından sıkça söz ettiren bir bahis ve casino platformu haline geldi. Türkiye’nin en iyi casino platformlardan biri olarak tanınan Casibom’un haftalık olarak göre değişen giriş adresi, piyasada oldukça yeni olmasına rağmen itimat edilir ve kazanç sağlayan bir platform olarak tanınıyor.
Casibom, rakiplerini geride kalarak köklü casino sitelerinin üstünlük sağlamayı başarıyor. Bu alanda eski olmak gereklidir olsa da, oyunculardan iletişimde bulunmak ve onlara ulaşmak da aynı miktar önemlidir. Bu aşamada, Casibom’un 7/24 hizmet veren gerçek zamanlı destek ekibi ile rahatlıkla iletişime ulaşılabilir olması önemli bir fayda getiriyor.
Hızla büyüyen katılımcı kitlesi ile ilgi çeken Casibom’un arka planında başarım faktörleri arasında, sadece ve yalnızca casino ve gerçek zamanlı casino oyunlarına sınırlı olmayan kapsamlı bir hizmetler yelpazesi bulunuyor. Atletizm bahislerinde sunduğu geniş seçenekler ve yüksek oranlar, oyuncuları çekmeyi başarıyor.
Ayrıca, hem spor bahisleri hem de bahis oyunları katılımcılara yönelik sunulan yüksek yüzdeli avantajlı ödüller da dikkat çekiyor. Bu nedenle, Casibom çabucak alanında iyi bir tanıtım başarısı elde ediyor ve büyük bir oyuncuların kitlesi kazanıyor.
Casibom’un kar getiren promosyonları ve popülerliği ile birlikte, web sitesine üyelik nasıl sağlanır sorusuna da değinmek gereklidir. Casibom’a mobil cihazlarınızdan, PC’lerinizden veya tabletlerinizden tarayıcı üzerinden kolaylıkla erişilebilir. Ayrıca, platformun mobil uyumlu olması da önemli bir fayda sağlıyor, çünkü şimdi hemen hemen herkesin bir cep telefonu var ve bu telefonlar üzerinden hızlıca erişim sağlanabiliyor.
Taşınabilir tabletlerinizle bile yolda canlı iddialar alabilir ve müsabakaları gerçek zamanlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil uyumlu olması, ülkemizde kumarhane ve kumarhane gibi yerlerin kanuni olarak kapatılmasıyla birlikte bu tür platformlara girişin büyük bir yolunu oluşturuyor.
Casibom’un güvenilir bir bahis sitesi olması da önemlidir bir avantaj sağlıyor. Lisanslı bir platform olan Casibom, sürekli bir şekilde keyif ve kar elde etme imkanı getirir.
Casibom’a kullanıcı olmak da son derece rahatlatıcıdır. Herhangi bir belge gereksinimi olmadan ve bedel ödemeden web sitesine rahatça üye olabilirsiniz. Ayrıca, site üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem vardır ve herhangi bir kesim ücreti alınmamaktadır.
Ancak, Casibom’un güncel giriş adresini takip etmek de önemlidir. Çünkü canlı şans ve oyun web siteleri popüler olduğu için hileli web siteleri ve dolandırıcılar da ortaya çıkmaktadır. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini periyodik olarak kontrol etmek önemlidir.
Sonuç olarak, Casibom hem emin hem de kazanç sağlayan bir casino web sitesi olarak dikkat çekici. yüksek bonusları, kapsamlı oyun seçenekleri ve kullanıcı dostu mobil uygulaması ile Casibom, casino hayranları için ideal bir platform sağlar.
best online foreign pharmacy
75 mcg synthroid no prescription
10배스탁론
로드스탁과 레버리지 스탁: 투자의 참신한 영역
로드스탁을 통해 제공하는 레버리지 방식의 스탁은 주식 시장의 투자법의 한 방식으로, 상당한 이익율을 목적으로 하는 투자자들에게 매혹적인 선택입니다. 레버리지 사용을 사용하는 이 방법은 투자자들이 자신의 자본을 넘어서는 자금을 투입할 수 있도록 하여, 주식 시장에서 더 큰 작용을 행사할 수 있는 기회를 제공합니다.
레버리지 방식의 스탁의 원리
레버리지 방식의 스탁은 기본적으로 자금을 대여하여 투자하는 방식입니다. 예시를 들어, 100만 원의 자금으로 1,000만 원 상당의 증권을 취득할 수 있는데, 이는 투자자가 기본 투자 금액보다 훨씬 훨씬 더 많은 증권을 사들여, 증권 가격이 증가할 경우 관련된 더 큰 수익을 가져올 수 있게 됩니다. 그렇지만, 증권 가격이 내려갈 경우에는 그 피해 또한 커질 수 있으므로, 레버리지 사용을 사용할 때는 신중하게 생각해야 합니다.
투자 계획과 레버리지 사용
레버리지는 특히 성장 잠재력이 큰 회사에 투자할 때 효과적입니다. 이러한 기업에 높은 비율을 통해 투자하면, 성공할 경우 큰 이익을 가져올 수 있지만, 그 반대의 경우 많은 위험도 감수해야. 따라서, 투자자들은 자신의 리스크 관리 능력을 가진 시장 분석을 통해 통해, 어느 기업에 얼마만큼의 자본을 투자할지 결정하게 됩니다 합니다.
레버리지 사용의 이점과 위험성
레버리지 방식의 스탁은 상당한 이익을 보장하지만, 그만큼 상당한 위험도 동반합니다. 주식 시장의 변동은 추정이 힘들기 때문에, 레버리지 사용을 이용할 때는 언제나 상장 경향을 정밀하게 주시하고, 손해를 최소로 줄일 수 있는 계획을 세워야 합니다.
최종적으로: 세심한 선택이 필요
로드스탁에서 공급하는 레버리지 스탁은 효과적인 투자 수단이며, 잘 활용하면 많은 이익을 벌어들일 수 있습니다. 하지만 상당한 리스크도 신경 써야 하며, 투자 결정은 필요한 정보와 조심스러운 판단 후에 진행되어야 합니다. 투자자 본인의 재정적 상태, 리스크 감수 능력, 그리고 장터 상황을 반영한 조화로운 투자 전략이 중요합니다.
casino online con bono de bienvenida sin deposito sin-deposito-peru.org .
Effective Links in Blogs and Remarks: Increase Your SEO
Backlinks are essential for enhancing search engine rankings and boosting website visibility. By integrating links into blogs and comments wisely, they can significantly boost targeted traffic and SEO performance.
Adhering to Search Engine Algorithms
Today’s backlink positioning tactics are finely tuned to align with search engine algorithms, which now emphasize link good quality and relevance. This guarantees that hyperlinks are not just abundant but meaningful, directing consumers to useful and pertinent content material. Site owners should emphasis on integrating hyperlinks that are situationally appropriate and enhance the overall content quality.
Advantages of Making use of Fresh Donor Bases
Using current donor bases for hyperlinks, like those maintained by Alex, offers considerable rewards. These bases are regularly renewed and consist of unmoderated sites that don’t attract complaints, guaranteeing the links placed are both powerful and certified. This strategy will help in maintaining the effectiveness of backlinks without the dangers associated with moderated or problematic assets.
Only Approved Sources
All donor sites used are authorized, avoiding legal pitfalls and conforming to digital marketing standards. This commitment to making use of only approved resources ensures that each backlink is legitimate and reliable, thereby developing credibility and reliability in your digital existence.
SEO Impact
Expertly positioned backlinks in weblogs and remarks provide greater than just SEO advantages—they improve user experience by linking to relevant and high-quality content. This strategy not only fulfills search engine criteria but also engages end users, leading to far better visitors and improved online proposal.
In essence, the right backlink strategy, particularly one that utilizes fresh and reliable donor bases like Alex’s, can transform your SEO efforts. By focusing on high quality over amount and sticking to the latest requirements, you can make sure your backlinks are both powerful and effective.
Kantorbola situs slot online terbaik 2024 , segera daftar di situs kantor bola dan dapatkan promo terbaik bonus deposit harian 100 ribu , bonus rollingan 1% dan bonus cashback mingguan . Kunjungi juga link alternatif kami di kantorbola77 , kantorbola88 dan kantorbola99
Проверка кошелька за выявление нелегальных средств: Защита личного криптовалютного портфельчика
В мире цифровых валют становится все все более необходимо обеспечивать секретность своих финансовых активов. Ежедневно обманщики и криминальные элементы выработывают новые способы мошенничества и угонов виртуальных средств. Один из основных средств обеспечения становится проверка кошельков кошельков для хранения криптовалюты на наличие подозрительных денег.
Из-за чего именно поэтому важно осмотреть собственные криптовалютные кошельки?
Прежде всего, вот данный факт необходимо для того чтобы обеспечения безопасности собственных финансов. Множество пользователи рискуют утраты своих финансовых средств вследствие непорядочных методов или краж. Проверка бумажников помогает предотвратить своевременно выявить непонятные манипуляции и предупредить.
Что предлагает компания?
Мы предлагаем вам сервис анализа цифровых кошельков для хранения криптовалюты и переводов с задачей обнаружения места происхождения финансовых средств и дать полного отчета. Компания предлагает программа осматривает информацию для обнаружения незаконных действий и оценить риск для личного криптовалютного портфеля. Благодаря нашей проверке, вы можете предотвратить возможные проблемы с органами контроля и обезопасить от непреднамеренного вовлечения в незаконных операций.
Как осуществляется процесс проверки?
Наша организация работает с крупными аудиторскими организациями агентствами, например Certik, чтобы гарантировать и точность наших анализов. Мы внедряем новейшие и методики анализа для выявления потенциально опасных действий. Персональные сведения наших клиентов обрабатываются и хранятся в специальной базе данных в соответствии с высокими стандартами безопасности и конфиденциальности.
Важный запрос: “проверить свои USDT на чистоту”
Если вам нужно убедиться в безопасности и чистоте личных кошельков USDT, наши специалисты оказывает возможность бесплатной проверки первых пяти кошельков. Просто введите свой кошелек в нужное место на нашем веб-сайте, и мы предоставим вам подробный отчет о состоянии вашего счета.
Обезопасьте свои деньги прямо сейчас!
Предотвращайте риски оказаться пострадать от злоумышленников или оказаться в неприятной ситуации из-за нелегальных сделок с ваших средствами. Дайте вашу криптовалюту специалистам, которые окажут поддержку, вам и вашим деньгам защитить свои деньги и предотвратить возможные проблемы. Примите первый шаг безопасности личного криптовалютного портфеля прямо сейчас!
чистый ли usdt
Тестирование USDT в чистоту: Каковым способом сохранить собственные цифровые средства
Все больше индивидуумов придают важность для секурити собственных цифровых активов. Постоянно мошенники придумывают новые подходы кражи цифровых активов, и также собственники криптовалюты являются пострадавшими их подстав. Один подходов защиты становится проверка кошельков для присутствие противозаконных денег.
С какой целью это потребуется?
Прежде всего, для того чтобы сохранить свои активы от шарлатанов а также похищенных монет. Многие участники сталкиваются с риском потери личных активов в результате мошеннических планов или грабежей. Анализ кошельков помогает обнаружить непрозрачные транзакции и также предотвратить возможные убытки.
Что мы предоставляем?
Мы предлагаем подход проверки криптовалютных кошельков а также транзакций для выявления источника средств. Наша система проверяет данные для обнаружения противозаконных транзакций и оценки риска для вашего портфеля. Вследствие данной проверке, вы сможете избегнуть проблем с регуляторами и защитить себя от участия в незаконных переводах.
Как это действует?
Мы сотрудничаем с ведущими аудиторскими фирмами, например Halborn, для того чтобы гарантировать точность наших проверок. Наша команда внедряем передовые технологии для обнаружения опасных транзакций. Ваши данные обрабатываются и сохраняются согласно с высокими нормами безопасности и конфиденциальности.
Каким образом проверить свои Tether для прозрачность?
Если вам нужно проверить, что ваши Tether-кошельки прозрачны, наш сервис предоставляет бесплатную проверку первых пяти бумажников. Легко вбейте положение своего кошелька на на нашем веб-сайте, а также мы предоставим вам полную информацию доклад о его положении.
Гарантируйте безопасность для вашими средства сегодня же!
Не рискуйте попасть в жертву обманщиков или попадать в неприятную обстановку по причине противозаконных сделок. Обратитесь к нашему агентству, чтобы сохранить свои электронные средства и предотвратить сложностей. Предпримите первый шаг к сохранности вашего криптовалютного портфеля уже сегодня!
buy synthroid from canada
чистый usdt
Осмотр USDT на нетронутость: Каким образом обезопасить свои электронные финансы
Постоянно все больше пользователей обращают внимание к безопасность собственных криптовалютных активов. День ото дня шарлатаны изобретают новые способы кражи цифровых денег, и также владельцы криптовалюты оказываются страдающими своих подстав. Один из способов защиты становится проверка кошельков для присутствие нелегальных денег.
Для чего это полезно?
Преимущественно, с тем чтобы защитить собственные средства от обманщиков а также похищенных денег. Многие инвесторы сталкиваются с риском потери своих финансов из-за мошеннических механизмов или кражей. Проверка кошельков позволяет выявить подозрительные операции и также предотвратить возможные потери.
Что наша группа предлагаем?
Наша компания предлагаем услугу проверки цифровых кошельков или транзакций для определения источника фондов. Наша система анализирует информацию для определения нелегальных операций или оценки угрозы вашего портфеля. Из-за этой проверке, вы сможете избегать проблем с регулированием или предохранить себя от участия в незаконных операциях.
Как это работает?
Наша фирма сотрудничаем с ведущими проверочными организациями, вроде Halborn, с целью предоставить точность наших проверок. Мы используем новейшие технологии для выявления опасных сделок. Ваши информация проходят обработку и хранятся согласно с высокими стандартами безопасности и конфиденциальности.
Как проверить свои USDT в нетронутость?
Если вам нужно проверить, что ваши USDT-кошельки нетронуты, наш подход предоставляет бесплатную проверку первых пяти кошельков. Просто введите местоположение личного кошелька на нашем сайте, или наш сервис предоставим вам детальный отчет о его статусе.
Гарантируйте безопасность для свои средства прямо сейчас!
Не рискуйте попасть в жертву шарлатанов либо попадать в неприятную обстановку из-за нелегальных операций. Посетите нашей команде, с тем чтобы сохранить ваши электронные средства и избежать затруднений. Совершите первый шаг к безопасности вашего криптовалютного портфеля сегодня!
kantorbola
Situs kantor bola merupakan penyedia permainan slot online gacor dengan RTP 98% , mainkan game slot online mudah menang di situs kantorbola . tersedia fitur deposit kilat menggunakan QRIS Kantorbola .
cialis 5 coupon
Как убедиться в чистоте USDT
Проверка кошельков по наличие незаконных средств: Защита своего электронного портфельчика
В мире криптовалют становится все существеннее обеспечивать защиту личных финансовых активов. Постоянно кибермошенники и криминальные элементы выработывают новые схемы мошенничества и угонов виртуальных денег. Одним из существенных методов защиты является проверка бумажников за наличие нелегальных денег.
По какой причине так важно проверять собственные цифровые кошельки для хранения электронных денег?
В первую очередь, вот это важно для того, чтобы защиты своих денег. Многие из пользователи находятся в зоне риска утраты своих собственных финансовых средств из-за недоброжелательных методов или угонов. Проверка данных кошельков для хранения криптовалюты способствует предотвращению обнаружить в нужный момент сомнительные манипуляции и предотвратить возможные.
Что предлагает вашему вниманию компания?
Мы предлагаем послугу проверки данных электронных бумажников и транзакций с задачей идентификации начала средств и выдачи детального доклада. Наша программа проанализировать данные пользователя для обнаружения потенциально нелегальных действий и оценить риск для того, чтобы своего портфеля активов. Благодаря нашему анализу, вы будете в состоянии избежать с государственными органами и защитить себя от случайной вовлеченности в незаконных операций.
Как осуществляется процесс?
Наша организация работает с крупными аудиторскими фирмами организациями, как например Kudelsky Security, с тем чтобы гарантировать и точность наших проверок. Мы внедряем новейшие и техники проверки данных для выявления подозрительных действий. Данные пользователей наших граждан обрабатываются и хранятся в специальной базе данных согласно высокими стандартами безопасности и конфиденциальности.
Ключевой запрос: “проверить свои USDT на чистоту”
В случае если вы хотите проверить чистоте своих кошельков USDT, наши специалисты оказывает возможность бесплатной проверки первых 5 кошельков. Просто адрес своего кошелька в соответствующее окно на нашем онлайн-ресурсе, и мы предоставим вам подробную информацию о его статусе.
Обеспечьте безопасность своих финансовые активы сразу же!
Не рискуйте становиться пострадать от злоумышленников или попасть неприятной ситуации из-за неправомерных операций с вашими личными финансовыми средствами. Обратитесь к специалистам, которые помогут, вам и вашему бизнесу защитить свои деньги и избежать. Совершите первый шаг к безопасности личного цифрового портфеля активов уже сегодня!
Осмотр USDT в нетронутость: Каким образом обезопасить свои электронные финансы
Каждый день все больше пользователей заботятся в безопасность собственных цифровых средств. День ото дня мошенники разрабатывают новые схемы кражи криптовалютных активов, а также владельцы криптовалюты оказываются пострадавшими своих обманов. Один способов сбережения становится проверка кошельков для присутствие нелегальных денег.
Для чего это необходимо?
В первую очередь, с тем чтобы сохранить свои активы от мошенников или украденных монет. Многие специалисты сталкиваются с риском потери своих фондов по причине мошеннических схем или грабежей. Тестирование кошельков помогает выявить сомнительные операции и также предотвратить возможные убытки.
Что наша группа предлагаем?
Мы предоставляем услугу проверки криптовалютных кошельков а также транзакций для выявления происхождения денег. Наша технология исследует данные для выявления нелегальных действий а также оценки угрозы для вашего портфеля. Благодаря этой проверке, вы сможете избежать проблем с регулированием и также защитить себя от участия в незаконных переводах.
Как это работает?
Наша команда сотрудничаем с первоклассными проверочными компаниями, например Certik, с целью обеспечить аккуратность наших проверок. Мы применяем новейшие технологии для обнаружения опасных транзакций. Ваши данные обрабатываются и хранятся в соответствии с высокими стандартами безопасности и конфиденциальности.
Как проверить свои Tether в чистоту?
Если хотите убедиться, что ваша Tether-кошельки нетронуты, наш сервис предлагает бесплатную проверку первых пяти бумажников. Просто вбейте положение личного бумажника на на нашем веб-сайте, а также наш сервис предоставим вам полную информацию доклад о его статусе.
Обезопасьте ваши активы уже сегодня!
Не подвергайте риску стать жертвой мошенников или попадать в неприятную ситуацию вследствие незаконных операций. Обратитесь к нашему агентству, с тем чтобы сохранить ваши цифровые средства и предотвратить проблем. Предпримите первый шаг к безопасности вашего криптовалютного портфеля уже сейчас!
бормашини
usdt и отмывание
USDT – является стабильная криптовалюта, привязанная к валюте страны, такой как доллар США. Это позволяет данный актив в особенности популярной среди инвесторов, поскольку она предлагает стабильность курса в в условиях волатильности рынка криптовалют. Все же, также как и любая другая разновидность криптовалюты, USDT подвержена риску использования в целях легализации доходов и финансирования незаконных транзакций.
Отмывание денег путем криптовалюты становится все больше и больше распространенным в большей степени путем с тем чтобы обеспечения анонимности. Применяя различные техники, дельцы могут стараться легализовывать незаконно полученные деньги путем обменники криптовалют или смешиватели, чтобы сделать их происхождение менее прозрачным.
Именно поэтому, экспертиза USDT на чистоту становится весьма существенной инструментом предосторожности для того чтобы участников криптовалют. Имеются специализированные платформы, которые проводят проверку сделок и кошельков, для того чтобы обнаружить подозрительные операции и незаконные финансирование. Данные услуги способствуют владельцам устранить непреднамеренного вовлечения в преступной деятельности и предотвратить блокировку аккаунтов со стороны надзорных органов.
Экспертиза USDT на чистоту также как и помогает защитить себя от возможных убытков. Владельцы могут быть уверенны в том их капитал не связаны с нелегальными сделками, что снижает риск блокировки аккаунта или лишения капитала.
Таким образом, в текущей ситуации растущей сложности среды криптовалют необходимо принимать шаги для обеспечения надежности своего капитала. Экспертиза USDT на чистоту с использованием специальных сервисов является важной одним из методов противодействия незаконной деятельности, обеспечивая участникам цифровых валют дополнительный уровень и защиты.
Проверка USDT на чистоту
Проверка USDT для чистоту: Каковым способом сохранить свои цифровые активы
Каждый день все больше людей заботятся на безопасность собственных электронных средств. Каждый день дельцы придумывают новые методы хищения цифровых средств, и владельцы криптовалюты становятся жертвами их подстав. Один техник сбережения становится проверка кошельков в присутствие незаконных финансов.
С какой целью это полезно?
В первую очередь, для того чтобы защитить собственные активы от шарлатанов или похищенных монет. Многие участники сталкиваются с потенциальной угрозой потери личных фондов из-за хищных схем или хищений. Осмотр бумажников способствует выявить подозрительные операции и предотвратить возможные убытки.
Что наша команда предоставляем?
Мы предоставляем услугу проверки криптовалютных кошельков а также транзакций для определения источника средств. Наша система анализирует информацию для определения нелегальных операций и оценки риска вашего счета. Благодаря данной проверке, вы сможете избегать недочетов с регуляторами и также обезопасить себя от участия в нелегальных операциях.
Как это действует?
Мы сотрудничаем с передовыми проверочными фирмами, такими как Cure53, для того чтобы гарантировать аккуратность наших тестирований. Мы применяем новейшие технологии для обнаружения опасных транзакций. Ваши информация обрабатываются и хранятся в соответствии с высокими стандартами безопасности и конфиденциальности.
Как проверить личные Tether для нетронутость?
В случае если вы желаете подтвердить, что ваша USDT-бумажники прозрачны, наш сервис предоставляет бесплатное тестирование первых пяти кошельков. Просто введите место собственного кошелька на на сайте, и наш сервис предоставим вам подробный отчет о его положении.
Гарантируйте безопасность для ваши фонды сегодня же!
Не подвергайте риску подвергнуться обманщиков или оказаться в неприятную ситуацию по причине противозаконных сделок. Обратитесь за помощью к нашему сервису, чтобы обезопасить ваши криптовалютные активы и предотвратить затруднений. Примите первый шаг к сохранности вашего криптовалютного портфеля прямо сейчас!
synthroid 500 mcg
九州娛樂城登入
бормашини
cheapest lisinopril 10 mg
златни гривни за крак
резачки за дърва
onair2tv.com
Xiao Jing은 더 이상 감히 아무 말도하지 않았고 사실 그는 상당히 불편했습니다.
микрокредиты http://www.microloans.kz/ .
Sure, here’s the text with spin syntax applied:
Link Structure
After numerous updates to the G search mechanism, it is essential to use different methods for ranking.
Today there is a approach to draw the attention of search engines to your site with the assistance of inbound links.
Links are not only an effective promotional resource but they also have natural traffic, direct sales from these sources probably will not be, but click-throughs will be, and it is poyedenicheskogo traffic that we also receive.
What in the end we get at the end result:
We present search engines site through backlinks.
Prluuchayut natural click-throughs to the site and it is also a sign to search engines that the resource is used by people.
How we show search engines that the site is valuable:
Links do to the primary page where the main information.
We make links through redirects trusted sites.
The most ESSENTIAL we place the site on sites analyzers separate tool, the site goes into the cache of these analysis tools, then the acquired links we place as redirections on blogs, discussion boards, comments. This crucial action shows search engines the MAP OF THE SITE as analyzer sites present all information about sites with all key terms and headlines and it is very POSITIVE.
All data about our services is on the website!
оборудование диспетчерских центров https://www.oborudovanie-dispetcherskih-centrov.ru/ .
cheap scripts pharmacy
creating articles
Creating distinct articles on Medium and Telegraph, why it is essential:
Created article on these resources is better ranked on low-frequency queries, which is very vital to get natural traffic.
We get:
organic traffic from search algorithms.
natural traffic from the internal rendition of the medium.
The site to which the article refers gets a link that is liquid and increases the ranking of the webpage to which the article refers.
Articles can be made in any amount and choose all less frequent queries on your topic.
Medium pages are indexed by search algorithms very well.
Telegraph pages need to be indexed distinctly indexer and at the same time after indexing they sometimes occupy places higher in the search algorithms than the medium, these two platforms are very useful for getting traffic.
Here is a link to our services where we provide creation, indexing of sites, articles, pages and more.
metformin price canada
link building
Backlink creation is merely as efficient currently, only the instruments for working within this domain have got changed.
There are actually numerous options for inbound links, our team utilize several of them, and these methods work and have been tried by us and our clientele.
Recently our team performed an trial and it turned out that low-frequency queries from one domain position effectively in search engines, and this doesnt need to be your own website, you are able to use social media from Web 2.0 range for this.
It is also possible to partly transfer load through site redirects, giving a varied backlink profile.
Go to our very own site where our company’s solutions are actually offered with detailed explanations.
tvlore.com
그들이 돌아왔을 때 상황이 바뀔까 두렵고 두렵습니다…
synthroid 250 mcg
tadalafil 5mg daily mexico
synthroid 150 mg cost
дайсон цена фен https://dyson-feny.com/ .
Backlink creation is simply as successful now, simply the resources for working in this area have got changed.
There are many options for inbound links, our company employ a few of them, and these methods function and have already been tried by us and our clients.
Not long ago our team conducted an test and we found that less frequent searches from just one domain name position well in online searches, and it does not need to become your website, it is possible to utilize social networks from Web 2.0 collection for this.
It is also possible to in part shift load through web page redirects, giving a diverse hyperlink profile.
Visit to our site where our own solutions are actually offered with thorough overview.
medical pharmacy west
откупиться от сво
С началом СВО уже спустя полгода была объявлена первая волна мобилизации. При этом прошлая, в последний раз в России была аж в 1941 году, с началом Великой Отечественной Войны. Конечно же, желающих отправиться на фронт было не много, а потому люди стали искать способы не попасть на СВО, для чего стали покупать справки о болезнях, с которыми можно получить категорию Д. И все это стало возможным с даркнет сайтами, где можно найти практически все что угодно. Именно об этой отрасли темного интернета подробней и поговорим в этой статье.
purchase synthroid
best price online metformin
synthroid 25 mcg daily
cheap cialis usa
反向連結金字塔
反向連結金字塔
G搜尋引擎在多番更新之后需要应用不同的排名參數。
今天有一種方法可以使用反向連接吸引G搜尋引擎對您的網站的注意。
反向連結不僅是有效的推廣工具,也是有機流量。
我們會得到什麼結果:
我們透過反向链接向G搜尋引擎展示我們的網站。
他們收到了到該網站的自然過渡,這也是向G搜尋引擎發出的信號,表明該資源正在被人們使用。
我們如何向G搜尋引擎表明該網站具有流動性:
個帶有主要訊息的主頁反向链接
我們透過來自受信任網站的重新定向來建立反向連接。
此外,我們將網站放置在單獨的網路分析器上,網站最終會進入這些分析器的缓存中,然後我們使用產生的連結作為部落格、論壇和評論的重定向。 這個重要的操作向G搜尋引擎顯示了網站地圖,因為網站分析器顯示了有關網站的所有資訊以及所有關鍵字和標題,這很棒
有關我們服務的所有資訊都在網站上!
Pirámide de backlinks
Aquí está el texto con la estructura de spintax que propone diferentes sinónimos para cada palabra:
“Pirámide de enlaces de retorno
Después de numerosas actualizaciones del motor de búsqueda G, necesita aplicar diferentes opciones de clasificación.
Hay una manera de llamar la atención de los motores de búsqueda a su sitio web con backlinks.
Los enlaces de retorno no sólo son una estrategia eficaz para la promoción, sino que también tienen tráfico orgánico, las ventas directas de estos recursos más probable es que no será, pero las transiciones será, y es poedenicheskogo tráfico que también obtenemos.
Lo que vamos a obtener al final en la salida:
Mostramos el sitio a los motores de búsqueda a través de backlinks.
Conseguimos transiciones orgánicas hacia el sitio, lo que también es una señal para los buscadores de que el recurso está siendo utilizado por la gente.
Cómo mostramos los motores de búsqueda que el sitio es líquido:
1 backlink se hace a la página principal donde está la información principal
Hacemos enlaces de retroceso a través de redirecciones de sitios de confianza
Lo más IMPORTANTE colocamos el sitio en una herramienta independiente de analizadores de sitios, el sitio entra en la caché de estos analizadores, luego los enlaces recibidos los colocamos como redirecciones en blogs, foros, comentarios.
Esta vital acción muestra a los buscadores el MAPA DEL SITIO, ya que los analizadores de sitios muestran toda la información de los sitios con todas las palabras clave y títulos y es muy efectivo.
¡Toda la información sobre nuestros servicios en el sitio web!
lisinopril 10mg price in india
lisinopril 100mcg
medication zestoretic
Смена входной двери оказалась необходимой после переезда. Выбор пал на https://dvershik.ru благодаря удобному каталогу и приемлемым ценам. Дверь заказана с установкой – мастера подъехали незамедлительно, и монтаж проведён четко. Качество работы и сервис оставили меня полностью довольным.
synthroid 112 mcg in india
Дайсон Официальный магазин Dyson .
With these bonuses and promotions, you have the opportunity to increase your chances of winning and achieve greater profits SITUS TOTO
By choosing TOTO TOGEL
, you can enjoy a safe, comfortable and profitable lottery playing experience.
Thanks for sharing, this post is truly inspiring! try here
Как обезопасить свои данные: остерегайтесь утечек информации в интернете. Сегодня обеспечение безопасности своих данных становится всё значимее важной задачей. Одним из наиболее часто встречающихся способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как защититься от их утечки? Что такое «сит фразы»? «Сит фразы» — это сочетания слов или фраз, которые часто используются для доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или иные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, используя этих сит фраз. Как сохранить свои личные данные? Используйте запутанные пароли. Избегайте использования очевидных паролей, которые легко угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого аккаунта. Не используйте один и тот же пароль для разных сервисов. Используйте двухфакторную проверку (2FA). Это вводит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт путем другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте личную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы предохранить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может привести к серьезным последствиям, таким вроде кража личной информации и финансовых потерь. Чтобы охранить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Даркнет и сливы в Телеграме
Даркнет – это отрезок интернета, которая не индексируется обыденными поисковыми системами и требует особых программных средств для доступа. В даркнете существует обилие скрытых сайтов, где можно найти различные товары и услуги, в том числе и нелегальные.
Одним из трендовых способов распространения информации в даркнете является использование мессенджера Телеграм. Телеграм предоставляет возможность создания закрытых каналов и чатов, где пользователи могут обмениваться информацией, в том числе и нелегальной.
Сливы информации в Телеграме – это способ распространения конфиденциальной информации, такой как украденные данные, базы данных, персональные сведения и другие материалы. Эти сливы могут включать в себя информацию о кредитных картах, паролях, персональных сообщениях и даже фотографиях.
Сливы в Телеграме могут быть небезопасными, так как они могут привести к утечке конфиденциальной информации и нанести ущерб репутации и финансовым интересам людей. Поэтому важно быть бдительным при обмене информацией в интернете и не доверять сомнительным источникам.
Вот кошельки с балансом у бота
даркнет сливы тг
Даркнет и сливы в Телеграме
Даркнет – это часть интернета, которая не индексируется обычными поисковыми системами и требует особых программных средств для доступа. В даркнете существует масса скрытых сайтов, где можно найти различные товары и услуги, в том числе и нелегальные.
Одним из трендовых способов распространения информации в даркнете является использование мессенджера Телеграм. Телеграм предоставляет возможность создания закрытых каналов и чатов, где пользователи могут обмениваться информацией, в том числе и нелегальной.
Сливы информации в Телеграме – это практика распространения конфиденциальной информации, такой как украденные данные, базы данных, персональные сведения и другие материалы. Эти сливы могут включать в себя информацию о кредитных картах, паролях, персональных сообщениях и даже фотографиях.
Сливы в Телеграме могут быть небезопасными, так как они могут привести к утечке конфиденциальной информации и нанести ущерб репутации и финансовым интересам людей. Поэтому важно быть внимательным при обмене информацией в интернете и не доверять сомнительным источникам.
Вот кошельки с балансом у бота
сид фразы кошельков
Сид-фразы, или мнемонические фразы, представляют собой соединение слов, которая используется для генерации или восстановления кошелька криптовалюты. Эти фразы обеспечивают возможность доступа к вашим криптовалютным средствам, поэтому их защищенное хранение и использование весьма важны для защиты вашего криптоимущества от утери и кражи.
Что такое сид-фразы кошельков криптовалют?
Сид-фразы формируют набор произвольно сгенерированных слов, как правило от 12 до 24, которые представляют собой для создания уникального ключа шифрования кошелька. Этот ключ используется для восстановления входа к вашему кошельку в случае его повреждения или утери. Сид-фразы обладают высокой степенью защиты и шифруются, что делает их секурными для хранения и передачи.
Зачем нужны сид-фразы?
Сид-фразы неотъемлемы для обеспечения безопасности и доступности вашего криптоимущества. Они позволяют восстановить вход к кошельку в случае утери или повреждения физического устройства, на котором он хранится. Благодаря сид-фразам вы можете легко создавать резервные копии своего кошелька и хранить их в безопасном месте.
Как обеспечить безопасность сид-фраз кошельков?
Никогда не передавайте сид-фразой ни с кем. Сид-фраза является вашим ключом к кошельку, и ее раскрытие может привести к утере вашего криптоимущества.
Храните сид-фразу в надежном месте. Используйте физически безопасные места, такие как банковские ячейки или специализированные аппаратные кошельки, для хранения вашей сид-фразы.
Создавайте резервные копии сид-фразы. Регулярно создавайте резервные копии вашей сид-фразы и храните их в разных безопасных местах, чтобы обеспечить возможность доступа к вашему кошельку в случае утери или повреждения.
Используйте дополнительные меры безопасности. Включите другие методы защиты и двухфакторную аутентификацию для своего кошелька криптовалюты, чтобы обеспечить дополнительный уровень безопасности.
Заключение
Сид-фразы кошельков криптовалют являются ключевым элементом секурного хранения криптоимущества. Следуйте рекомендациям по безопасности, чтобы защитить свою сид-фразу и обеспечить безопасность своих криптовалютных средств.
Слив мнемонических фраз (seed phrases) является одним наиболее обычных способов утечки персональной информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, по какой причине они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, являются комбинацию слов, которая используется для формирования или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые представляют собой ключ к вашему кошельку. Потеря или утечка сид фразы может привести к потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы являются ключевым элементом для безопасного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они могут получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу ничьему, даже если вам происходит, что это доверенное лицо или сервис.
Храните свою сид фразу в защищенном и секурном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте дополнительные методы защиты, такие как двухфакторная аутентификация (2FA), для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в других безопасных местах.
Заключение
Слив сид фраз является значительной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
Структура Backlinks
После того, как многочисленных обновлений G необходимо внедрять разные варианты рейтингования.
Сегодня есть способ привлечь внимание поисковых систем к вашему веб-сайту с помощью обратных ссылок.
Обратные линки не только эффективный инструмент продвижения, но и являются источником органического трафика, хотя прямых продаж с этих ресурсов скорее всего не будет, но переходы будут, и именно органического трафика мы также получаем.
Что в итоге получим на выходе:
Мы отображаем сайт поисковым системам с помощью обратных ссылок.
Получают органические переходы на веб-сайт, а это также информация для поисковых систем, что ресурс пользуется спросом у пользователей.
Как мы показываем поисковым системам, что сайт ликвиден:
1 обратная ссылка делается на главную страницу, где основная информация.
Делаем обратные ссылки через редиректы трастовых сайтов.
Самое ВАЖНОЕ мы размещаем сайт на отдельном инструменте анализаторов сайтов, сайт попадает в кеш этих анализаторов, затем полученные ссылки мы размещаем в качестве редиректов на блогах, форумах, комментариях.
Это нужное действие показывает поисковым системамКАРТУ САЙТА, так как анализаторы сайтов показывают всю информацию о сайтах со с тайтлами, ключами, h1,h2,h3 и это очень ВАЖНО
ggg
هنا النص مع استخدام السبينتاكس:
“بناء الروابط الخلفية
بعد التحديثات العديدة لمحرك البحث G، تحتاج إلى تنفيذ خيارات ترتيب مختلفة.
هناك طريقة لجذب انتباه محركات البحث إلى موقعك على الويب باستخدام الروابط الخلفية.
الروابط الخلفية ليست فقط أداة فعالة للترويج، ولكن تتضمن أيضًا حركة مرور عضوية، والمبيعات المباشرة من هذه الموارد على الأرجح قد لا تكون كذلك، ولكن التحولات ستكون، وهي حركة المرور التي نحصل عليها أيضًا.
ما سنحصل عليه في النهاية في النهاية في الإخراج:
نعرض الموقع لمحركات البحث من خلال الروابط الخلفية.
2- نحصل على تبديلات عضوية إلى الموقع، وهي أيضًا إشارة لمحركات البحث أن المورد يستخدمه الناس.
كيف نظهر لمحركات البحث أن الموقع سائل:
1 يتم عمل رابط خلفي للصفحة الرئيسية حيث المعلومات الرئيسية
نقوم بعمل روابط خلفية من خلال عمليات تحويل المواقع الموثوقة
الأهم من ذلك أننا نضع الموقع على أداة منفصلة من أساليب تحليل المواقع، ويدخل الموقع في ذاكرة التخزين المؤقت لهذه المحللات، ثم الروابط المستلمة التي نضعها كتحويل على المدونات والمنتديات والتعليقات.
هذا العملية المهم يُبرز لمحركات البحث خريطة الموقع، حيث تعرض أدوات تحليل المواقع جميع المعلومات عن المواقع مع جميع الكلمات الرئيسية والعناوين وهو عمل جيد جداً
جميع المعلومات عن خدماتنا على الموقع!
thebuzzerpodcast.com
솔직히 말해서 더 이상 돈 문제가 아닙니다.상병에게 예의 바르고 유교를 옹호하며 학문에 지칠 줄 모른다고 한다.
lisinopril 20 mg generic
Недавно я определился с тем, что нужно заменить входную дверь в квартире. Выбрал сайт https://dvershik.ru, выбрал модель и заказал установку. Мастера приехали строго по расписанию, быстро и качественно установили новую дверь. Очень доволен сервисом и результатом – теперь чувствую себя намного безопаснее!
zestril canada
娛樂城評價
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
Player娛樂城遊戲評測網 《娛樂城評價》分類專區,幫您整了出網路上各大線上娛樂城重點摘要,以便您快速了解各大娛樂城重點資訊。
錢盈娛樂城介紹
錢盈娛樂城於2022年成立,是一個專注於現金投注的線上遊戲平台,提供了包括體育賭博、真人百家樂、老虎機、彩票和電子遊戲等多樣化的遊戲選…
F1方程式娛樂城介紹
F1方程式娛樂城屬於小型線上娛樂城版,整體晚間非常簡陋而且含有諸多瑕疵以及不完善,首先奇怪的點在於完全沒有可以註冊的地方,我們這邊猜測…
CZ168娛樂城介紹
CZ168娛樂城在雖然在簡介中自稱有12年的經營時間,但是經過我們實際的調查以及訪問該品牌網頁後發現,並沒有任何12年前或是更近的資料…
包你發娛樂城介紹
包你發娛樂城是個很多明星都在代言的線上賭博平台,玩家在這裡是用虛擬貨幣來存款,算是那種幣商型的賭場。這個平台沒有直接的提款選項,玩家要…
富遊娛樂城介紹
隨著2024年的到來,最新的線上娛樂平台排行榜已經更新,這一次的排名綜合考慮了各種因素,包括體驗金、促銷活動、提款效率和遊戲多樣性,目…
american online pharmacy
九州娛樂城介紹
九州娛樂城
九州娛樂城,也被稱作LEO娛樂城,致力於打造一個既安全又方便、公平公正的高品質娛樂服務平台。我們的目標是創造全新的線上娛樂城體驗,普及化娛樂服務,並努力成為娛樂網站界的領頭羊。需要注意的是,九州娛樂城、LEO娛樂城和THA娛樂城實際上是同一家公司的不同名稱。
九州娛樂城簡介
推薦指數:★★★★★(5分)
品牌名稱 : 九州娛樂城(LEO娛樂城)
創立時間 : 2003年
賭場類型 : 現金版娛樂城
遊戲種類 : 真人百家樂、運彩投注、電子老虎機、六合彩球、棋牌遊戲、捕魚機遊戲
存取速度 : 存款90秒 / 提款5-10分
軟體下載 : 無APP下載,支援網頁投注
order tadalafil from canada 5mg
娛樂城排行
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
взлом кошелька
Как обезопасить свои данные: остерегайтесь утечек информации в интернете. Сегодня сохранение информации становится все более важной задачей. Одним из наиболее популярных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как защититься от их утечки? Что такое «сит фразы»? «Сит фразы» — это сочетания слов или фраз, которые бывают используются для входа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или разные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как защитить свои личные данные? Используйте сложные пароли. Избегайте использования очевидных паролей, которые легко угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из аккаунта. Не пользуйтесь один и тот же пароль для разных сервисов. Используйте двухфакторную проверку (2FA). Это привносит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт путем другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте личную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы предохранить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким как кража личной информации и финансовых потерь. Чтобы защитить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Даркнет и сливы в Телеграме
Даркнет – это компонент интернета, которая не индексируется стандартными поисковыми системами и требует специальных программных средств для доступа. В даркнете существует множество скрытых сайтов, где можно найти различные товары и услуги, в том числе и нелегальные.
Одним из востребованных способов распространения информации в даркнете является использование мессенджера Телеграм. Телеграм предоставляет возможность создания закрытых каналов и чатов, где пользователи могут обмениваться информацией, в том числе и нелегальной.
Сливы информации в Телеграме – это практика распространения конфиденциальной информации, такой как украденные данные, базы данных, персональные сведения и другие материалы. Эти сливы могут включать в себя информацию о кредитных картах, паролях, персональных сообщениях и даже фотографиях.
Сливы в Телеграме могут быть небезопасными, так как они могут привести к утечке конфиденциальной информации и нанести ущерб репутации и финансовым интересам людей. Поэтому важно быть внимательным при обмене информацией в интернете и не доверять сомнительным источникам.
Вот кошельки с балансом у бота
Сид-фразы, или мемориальные фразы, представляют собой сочетание слов, которая используется для создания или восстановления кошелька криптовалюты. Эти фразы обеспечивают возможность к вашим криптовалютным средствам, поэтому их безопасное хранение и использование чрезвычайно важны для защиты вашего криптоимущества от утери и кражи.
Что такое сид-фразы кошельков криптовалют?
Сид-фразы формируют набор случайными средствами сгенерированных слов, как правило от 12 до 24, которые представляют собой для создания уникального ключа шифрования кошелька. Этот ключ используется для восстановления возможности доступа к вашему кошельку в случае его повреждения или утери. Сид-фразы обладают высокой степенью защиты и шифруются, что делает их защищенными для хранения и передачи.
Зачем нужны сид-фразы?
Сид-фразы неотъемлемы для обеспечения безопасности и доступности вашего криптоимущества. Они позволяют восстановить возможность доступа к кошельку в случае утери или повреждения физического устройства, на котором он хранится. Благодаря сид-фразам вы можете без труда создавать резервные копии своего кошелька и хранить их в безопасном месте.
Как обеспечить безопасность сид-фраз кошельков?
Никогда не передавайте сид-фразой ни с кем. Сид-фраза является вашим ключом к кошельку, и ее раскрытие может вести к утере вашего криптоимущества.
Храните сид-фразу в защищенном месте. Используйте физически секурные места, такие как банковские ячейки или специализированные аппаратные кошельки, для хранения вашей сид-фразы.
Создавайте резервные копии сид-фразы. Регулярно создавайте резервные копии вашей сид-фразы и храните их в разных безопасных местах, чтобы обеспечить возможность доступа к вашему кошельку в случае утери или повреждения.
Используйте дополнительные меры безопасности. Включите двухфакторную верификацию и другие методы защиты для своего кошелька криптовалюты, чтобы обеспечить дополнительный уровень безопасности.
Заключение
Сид-фразы кошельков криптовалют являются ключевым элементом надежного хранения криптоимущества. Следуйте рекомендациям по безопасности, чтобы защитить свою сид-фразу и обеспечить безопасность своих криптовалютных средств.
Криптокошельки с балансом: зачем их покупают и как использовать
В мире криптовалют все расширяющуюся популярность приобретают криптокошельки с предустановленным балансом. Это индивидуальные кошельки, которые уже содержат определенное количество криптовалюты на момент покупки. Но зачем люди приобретают такие кошельки, и как правильно использовать их?
Почему покупают криптокошельки с балансом?
Удобство: Криптокошельки с предустановленным балансом предлагаются как готовое к работе решение для тех, кто хочет быстро начать пользоваться криптовалютой без необходимости покупки или обмена на бирже.
Подарок или награда: Иногда криптокошельки с балансом используются как подарок или премия в рамках акций или маркетинговых кампаний.
Анонимность: При покупке криптокошелька с балансом нет потребности предоставлять личные данные, что может быть важно для тех, кто ценит анонимность.
Как использовать криптокошелек с балансом?
Проверьте безопасность: Убедитесь, что кошелек безопасен и не подвержен взлому. Проверьте репутацию продавца и источник приобретения кошелька.
Переведите средства на другой кошелек: Если вы хотите долгосрочно хранить криптовалюту, рекомендуется перевести средства на более безопасный или комфортный для вас кошелек.
Не храните все средства на одном кошельке: Для обеспечения безопасности рекомендуется распределить средства между несколькими кошельками.
Будьте осторожны с фишингом и мошенничеством: Помните, что мошенники могут пытаться обмануть вас, предлагая криптокошельки с балансом с целью получения доступа к вашим средствам.
Заключение
Криптокошельки с балансом могут быть удобным и простым способом начать пользоваться криптовалютой, но необходимо помнить о безопасности и осторожности при их использовании.Выбор и приобретение криптокошелька с балансом – это значительный шаг, который требует внимания к деталям и осознанного подхода.”
Слив посеянных фраз (seed phrases) является одним из наиболее известных способов утечки личной информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, по какой причине они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, представляют собой комбинацию слов, которая используется для составления или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые символизируют собой ключ к вашему кошельку. Потеря или утечка сид фразы может привести к потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы являются ключевым элементом для секурного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они смогут получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу любому, даже если вам похоже, что это доверенное лицо или сервис.
Храните свою сид фразу в защищенном и надежном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте дополнительные методы защиты, такие как двусторонняя аутентификация, для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в других безопасных местах.
Заключение
Слив сид фраз является серьезной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
sale dyson dyson airwrap купить .
mail pharmacy
can i buy prednisone online
werankcities.com
이 걱정은 불필요한 것이 아니며 푸셔는 불안해 보입니다.
Приобретал входную дверь на https://dvershik.ru и был удовлетворен результатом. Сайт удобный, ассортимент богатый, без труда подобрал модель по искомым характеристикам. Консультанты были отзывчивы и компетентны, ассистировали в подборе. Дверь привезли и установили точно в срок, качество работы монтажников на высоте. Цены приемлемые, качество самой двери отличное – чувствую себя в безопасности. Рекомендую!
kantorbola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
cheap synthroid online
tadalafil cheap online
kantorbola99
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
prinivil tabs
taurus118
Окончание диплома является основным моментом во пути каждого человека, определяет его перспективы и профессиональные перспективы – http://www.diplomvam.ru. Аттестат даёт доступ двери к новым перспективам и возможностям, обеспечивая возможность к качественному получению знаний и высокопрестижным профессиям. В нынешнем мире, где конкуренция на трудовом рынке постоянно растёт, наличие диплома становится необходимым условием для выдающейся профессиональной деятельности. Он утверждает ваши знания, умения и навыки, навыки и умения перед работодателями и обществом в целом. В дополнение, диплом дарит веру в свои силы и увеличивает самооценку, что помогает личностному росту и развитию. Окончание образования также вложением в свое будущее, обеспечивая устойчивость и достойный стандарт жизни. Поэтому обращать должное внимание получению образования и бороться за его достижению, чтобы обрести успеха и удовлетворение от собственной труда.
Аттестат не только представляет ваше образовательный уровень, но и демонстрирует вашу дисциплинированность, трудолюбие и упорство в достижении задач. Диплом представляет собой плодом усилий и вложенных усилий, вложенных в обучение и саморазвитие. Завершение учебы образования раскрывает перед вами свежие горизонты возможностей, позволяя избирать среди множества направлений и карьерных траекторий. Кроме того даёт вам базис знаний и умений, необходимых для успешной практики в нынешнем обществе, полном трудностями и изменениями. Более того, диплом является свидетельством вашей компетентности и экспертности, что улучшает вашу привлекательность на рынке труда и открывает перед вами двери к лучшим возможностям для карьерного роста. Следовательно, получение диплома не только обогащает ваше личное развитие, но и открывает перед вами новые и возможности для достижения и мечтаний.
tintucnamdinh24h.com
그는 이미 일족에서 위대한 현자로 여겨진다.
can i buy metformin online
happy family store pharmacy canada
видеостены купить http://www.videosteny14.ru .
canadian pharmacies compare
onair2tv.com
마음 속으로 생각한 것처럼 마음 깊은 곳에는 여전히 따끔거리는 느낌이 있었다.
synthroid 0.0125 mg
synthroid 0.2 mg
lisinopril 40 mg best price
rikvip
Rikvip Club: Trung Tâm Giải Trí Trực Tuyến Hàng Đầu tại Việt Nam
Rikvip Club là một trong những nền tảng giải trí trực tuyến hàng đầu tại Việt Nam, cung cấp một loạt các trò chơi hấp dẫn và dịch vụ cho người dùng. Cho dù bạn là người dùng iPhone hay Android, Rikvip Club đều có một cái gì đó dành cho mọi người. Với sứ mạng và mục tiêu rõ ràng, Rikvip Club luôn cố gắng cung cấp những sản phẩm và dịch vụ tốt nhất cho khách hàng, tạo ra một trải nghiệm tiện lợi và thú vị cho người chơi.
Sứ Mạng và Mục Tiêu của Rikvip
Từ khi bắt đầu hoạt động, Rikvip Club đã có một kế hoạch kinh doanh rõ ràng, luôn nỗ lực để cung cấp cho khách hàng những sản phẩm và dịch vụ tốt nhất và tạo điều kiện thuận lợi nhất cho người chơi truy cập. Nhóm quản lý của Rikvip Club có những mục tiêu và ước muốn quyết liệt để biến Rikvip Club thành trung tâm giải trí hàng đầu trong lĩnh vực game đổi thưởng trực tuyến tại Việt Nam và trên toàn cầu.
Trải Nghiệm Live Casino
Rikvip Club không chỉ nổi bật với sự đa dạng của các trò chơi đổi thưởng mà còn với các phòng trò chơi casino trực tuyến thu hút tất cả người chơi. Môi trường này cam kết mang lại trải nghiệm chuyên nghiệp với tính xanh chín và sự uy tín không thể nghi ngờ. Đây là một sân chơi lý tưởng cho những người yêu thích thách thức bản thân và muốn tận hưởng niềm vui của chiến thắng. Với các sảnh cược phổ biến như Roulette, Sic Bo, Dragon Tiger, người chơi sẽ trải nghiệm những cảm xúc độc đáo và đặc biệt khi tham gia vào casino trực tuyến.
Phương Thức Thanh Toán Tiện Lợi
Rikvip Club đã được trang bị những công nghệ thanh toán tiên tiến ngay từ đầu, mang lại sự thuận tiện và linh hoạt cho người chơi trong việc sử dụng hệ thống thanh toán hàng ngày. Hơn nữa, Rikvip Club còn tích hợp nhiều phương thức giao dịch khác nhau để đáp ứng nhu cầu đa dạng của người chơi: Chuyển khoản Ngân hàng, Thẻ cào, Ví điện tử…
Kết Luận
Tóm lại, Rikvip Club không chỉ là một nền tảng trò chơi, mà còn là một cộng đồng nơi người chơi có thể tụ tập để tận hưởng niềm vui của trò chơi và cảm giác hồi hộp khi chiến thắng. Với cam kết cung cấp những sản phẩm và dịch vụ tốt nhất, Rikvip Club chắc chắn là điểm đến lý tưởng cho những người yêu thích trò chơi trực tuyến tại Việt Nam và cả thế giới.
synthroid brand name
сборно сварочный стол сборно сварочный стол .
animehangover.com
뜻밖에도 그녀의 오빠가 궁에 들어가려고 했기 때문에 저우가 수상해 보였다.
선물옵션
국외선물의 시작 골드리치와 함께하세요.
골드리치는 길고긴기간 투자자분들과 더불어 선물마켓의 길을 함께 여정을했습니다, 회원님들의 안전한 자금운용 및 알찬 수익성을 향해 계속해서 최선을 기울이고 있습니다.
왜 20,000+인 초과이 골드리치와 함께할까요?
즉각적인 서비스: 간단하며 빠른속도의 프로세스를 갖추어 어느누구라도 간편하게 사용할 수 있습니다.
안전보장 프로토콜: 국가당국에서 채택한 높은 등급의 보안을 채택하고 있습니다.
스마트 인가절차: 모든 거래정보은 암호화 가공되어 본인 이외에는 아무도 누구도 정보를 열람할 수 없습니다.
보장된 수익성 제공: 리스크 요소를 줄여, 보다 한층 확실한 수익률을 제공하며 그에 따른 리포트를 제공합니다.
24 / 7 상시 고객지원: 365일 24시간 즉각적인 서비스를 통해 고객님들을 온전히 서포트합니다.
함께하는 파트너사: 골드리치는 공기업은 물론 금융기관들 및 다수의 협력사와 공동으로 동행해오고.
해외선물이란?
다양한 정보를 확인하세요.
외국선물은 외국에서 거래되는 파생상품 중 하나로, 명시된 기반자산(예: 주식, 화폐, 상품 등)을 바탕로 한 옵션계약 계약을 의미합니다. 기본적으로 옵션은 지정된 기초자산을 향후의 어떤 시점에 일정 가격에 매수하거나 매도할 수 있는 자격을 제공합니다. 국외선물옵션은 이러한 옵션 계약이 외국 마켓에서 거래되는 것을 지칭합니다.
국외선물은 크게 매수 옵션과 풋 옵션으로 나뉩니다. 콜 옵션은 지정된 기초자산을 미래에 정해진 금액에 사는 권리를 부여하는 반면, 매도 옵션은 지정된 기초자산을 미래에 일정 가격에 팔 수 있는 권리를 제공합니다.
옵션 계약에서는 미래의 명시된 일자에 (만료일이라 지칭되는) 일정 금액에 기초자산을 사거나 팔 수 있는 권리를 가지고 있습니다. 이러한 가격을 실행 가격이라고 하며, 종료일에는 해당 권리를 행사할지 여부를 결정할 수 있습니다. 따라서 옵션 계약은 투자자에게 미래의 가격 변동에 대한 보호나 이익 실현의 기회를 허락합니다.
해외선물은 마켓 참가자들에게 다양한 투자 및 차익거래 기회를 제공, 환율, 상품, 주식 등 다양한 자산군에 대한 옵션 계약을 망라할 수 있습니다. 투자자는 매도 옵션을 통해 기초자산의 낙폭에 대한 보호를 받을 수 있고, 매수 옵션을 통해 활황에서의 이익을 타깃팅할 수 있습니다.
외국선물 거래의 원리
행사 금액(Exercise Price): 외국선물에서 실행 가격은 옵션 계약에 따라 특정한 가격으로 계약됩니다. 종료일에 이 금액을 기준으로 옵션을 행사할 수 있습니다.
만료일(Expiration Date): 옵션 계약의 만기일은 옵션의 행사가 허용되지않는 최종 날짜를 뜻합니다. 이 날짜 다음에는 옵션 계약이 소멸되며, 더 이상 거래할 수 없습니다.
풋 옵션(Put Option)과 콜 옵션(Call Option): 매도 옵션은 기초자산을 명시된 가격에 팔 수 있는 권리를 부여하며, 콜 옵션은 기초자산을 명시된 금액에 매수하는 권리를 부여합니다.
계약료(Premium): 해외선물 거래에서는 옵션 계약에 대한 계약료을 지불해야 합니다. 이는 옵션 계약에 대한 비용으로, 시장에서의 수요량와 공급에 따라 변경됩니다.
실행 전략(Exercise Strategy): 투자자는 만료일에 옵션을 행사할지 여부를 판단할 수 있습니다. 이는 시장 상황 및 투자 플랜에 따라 차이가있으며, 옵션 계약의 수익을 최대화하거나 손해를 감소하기 위해 결정됩니다.
시장 리스크(Market Risk): 국외선물 거래는 시장의 변화추이에 효과을 받습니다. 시세 변화이 예상치 못한 방향으로 발생할 경우 손실이 발생할 수 있으며, 이러한 마켓 리스크를 축소하기 위해 거래자는 계획을 수립하고 투자를 설계해야 합니다.
골드리치증권와 동반하는 해외선물은 안전하고 확신할 수 있는 투자를 위한 가장좋은 대안입니다. 고객님들의 투자를 뒷받침하고 가이드하기 위해 우리는 전력을 다하고 있습니다. 공동으로 더 나은 내일를 지향하여 나아가요.
UEFA Euro 2024 Sân Chơi Bóng Đá Hấp Dẫn Nhất Của Châu Âu
Euro 2024 là sự kiện bóng đá lớn nhất của châu Âu, không chỉ là một giải đấu mà còn là một cơ hội để các quốc gia thể hiện tài năng, sự đoàn kết và tinh thần cạnh tranh.
Euro 2024 hứa hẹn sẽ mang lại những trận cầu đỉnh cao và kịch tính cho người hâm mộ trên khắp thế giới. Cùng tìm hiểu các thêm thông tin hấp dẫn về giải đấu này tại bài viết dưới đây, gồm:
Nước chủ nhà
Đội tuyển tham dự
Thể thức thi đấu
Thời gian diễn ra
Sân vận động
Euro 2024 sẽ được tổ chức tại Đức, một quốc gia có truyền thống vàng của bóng đá châu Âu.
Đức là một đất nước giàu có lịch sử bóng đá với nhiều thành công quốc tế và trong những năm gần đây, họ đã thể hiện sức mạnh của mình ở cả mặt trận quốc tế và câu lạc bộ.
Việc tổ chức Euro 2024 tại Đức không chỉ là một cơ hội để thể hiện năng lực tổ chức tuyệt vời mà còn là một dịp để giới thiệu văn hóa và sức mạnh thể thao của quốc gia này.
Đội tuyển tham dự giải đấu Euro 2024
Euro 2024 sẽ quy tụ 24 đội tuyển hàng đầu từ châu Âu. Các đội tuyển này sẽ là những đại diện cho sự đa dạng văn hóa và phong cách chơi bóng đá trên khắp châu lục.
Các đội tuyển hàng đầu như Đức, Pháp, Tây Ban Nha, Bỉ, Italy, Anh và Hà Lan sẽ là những ứng viên nặng ký cho chức vô địch.
Trong khi đó, các đội tuyển nhỏ hơn như Iceland, Wales hay Áo cũng sẽ mang đến những bất ngờ và thách thức cho các đối thủ.
Các đội tuyển tham dự được chia thành 6 bảng đấu, gồm:
Bảng A: Đức, Scotland, Hungary và Thuỵ Sĩ
Bảng B: Tây Ban Nha, Croatia, Ý và Albania
Bảng C: Slovenia, Đan Mạch, Serbia và Anh
Bảng D: Ba Lan, Hà Lan, Áo và Pháp
Bảng E: Bỉ, Slovakia, Romania và Ukraina
Bảng F: Thổ Nhĩ Kỳ, Gruzia, Bồ Đào Nha và Cộng hoà Séc
дробеструйная камера https://www.drobestruynaya-kamera.ru/ .
zithromax z-pak price without insurance
buy noroxin
accutane 2.5 mg
advair prescription price
where to buy vermox online
onair2tv.com
큰 선글라스를 끼고 왕부시는 천천히 작은 느낌을 발견했다.
механизированная штукатурка и стяжка пола https://www.mekhanizirovannaya-shtukaturka13.ru .
В современном мире, где аттестат – это начало отличной карьеры в любом направлении, многие ищут максимально быстрый и простой путь получения качественного образования. Факт наличия документа об образовании переоценить просто невозможно. Ведь именно диплом открывает двери перед людьми, стремящимися начать трудовую деятельность или продолжить обучение в высшем учебном заведении.
Мы предлагаем максимально быстро получить любой необходимый документ. Вы сможете купить аттестат нового или старого образца, и это будет выгодным решением для человека, который не смог закончить обучение или утратил документ. Все аттестаты изготавливаются аккуратно, с особым вниманием к мельчайшим нюансам. В результате вы получите полностью оригинальный документ.
Преимущества подобного подхода состоят не только в том, что вы сможете максимально быстро получить свой аттестат. Весь процесс организован комфортно и легко, с профессиональной поддержкой. От выбора требуемого образца аттестата до консультаций по заполнению персональной информации и доставки по стране — все под полным контролем качественных специалистов.
Для тех, кто пытается найти максимально быстрый способ получить требуемый документ, наша компания готова предложить выгодное решение. Приобрести аттестат – значит избежать долгого обучения и не теряя времени переходить к достижению личных целей, будь то поступление в ВУЗ или начало карьеры.
http://www.vsediplomu.ru/
clomid prescription price
вскрыть дверь служба http://vskrytie-zamkov-moskva111.ru/ .
cost of baclofen uk
doxycyline
how much is augmentin 875
заказать сео сайт заказать сео сайт .
хрустальные торшеры напольные hrustalnye-torshery.ru .
tvlore.com
Zhu Houzhao는 완고한 사람입니다. 한 사람이 완고하면 아홉 마리의 황소가 물러날 수 없습니다.
provigil 100
where to buy propecia in canada
porotherm https://kirpich-bruschatka.ru/ .
Greeting to Genio, the go-to invoice generator for peewee businesses and freelancers. We bring you innumerable invoice templates, including Microsoft Dominate and PDF formats, tailored to all industries. Analyse our fraction featuring upon 300 customized invoice templates designed to cosset to your diverse responsibility needs.
https://www.genio.ac/invoice-templates/
Привет всем!
Приобретите диплом Вуза с доставкой по России без предоплаты и полной уверенностью в его подлинности.
Закажите диплом ВУЗа с доставкой по России без предоплаты и с гарантией подлинности – удобно и безопасно!
dlplomanrussia.com
tadacip 40 mg
клининг жилых помещений http://parkmebeli.by/ .
where to get diflucan without a prescription
zanetvize.com
오랫동안 Fang Jifan의 이름을 정말 존경했던 사람은 지금 이 순간 그렇게 행복하게 웃고 있지 않을 것입니다.
zovirax over the counter nz
valtrex 500 price
Геракл24: Квалифицированная Смена Основания, Венцов, Настилов и Перемещение Домов
Компания Геракл24 специализируется на выполнении всесторонних работ по замене основания, венцов, покрытий и перемещению домов в городе Красноярске и за его пределами. Наш коллектив квалифицированных специалистов обещает отличное качество исполнения различных типов реставрационных работ, будь то из дерева, каркасные, из кирпича или бетонные здания.
Плюсы сотрудничества с Геракл24
Навыки и знания:
Весь процесс осуществляются лишь высококвалифицированными специалистами, с обладанием большой практику в сфере возведения и ремонта зданий. Наши сотрудники профессионалы в своем деле и реализуют задачи с безупречной точностью и вниманием к деталям.
Полный спектр услуг:
Мы предлагаем разнообразные услуги по реставрации и реконструкции строений:
Смена основания: усиление и реставрация старого основания, что позволяет продлить срок службы вашего строения и избежать проблем, связанные с оседанием и деформацией строения.
Замена венцов: восстановление нижних венцов деревянных зданий, которые обычно гниют и разрушаются.
Смена настилов: замена старых полов, что кардинально улучшает внешний облик и функциональность помещения.
Перемещение зданий: качественный и безопасный перенос строений на другие участки, что обеспечивает сохранение строения и избегает дополнительных затрат на создание нового.
Работа с различными типами строений:
Дома из дерева: восстановление и укрепление деревянных конструкций, защита от разрушения и вредителей.
Дома с каркасом: усиление каркасных конструкций и замена поврежденных элементов.
Кирпичные дома: восстановление кирпичной кладки и укрепление стен.
Бетонные дома: ремонт и укрепление бетонных конструкций, устранение трещин и повреждений.
Качество и прочность:
Мы работаем с только высококачественные материалы и новейшее оборудование, что гарантирует долговечность и прочность всех выполненных задач. Каждый наш проект подвергаются строгому контролю качества на каждой стадии реализации.
Личный подход:
Для каждого клиента мы предлагаем персонализированные решения, учитывающие ваши требования и желания. Мы стремимся к тому, чтобы конечный результат соответствовал ваши ожидания и требования.
Почему выбирают Геракл24?
Работая с нами, вы получаете надежного партнера, который возьмет на себя все хлопоты по ремонту и реставрации вашего дома. Мы обещаем выполнение всех проектов в установленные сроки и с в соответствии с нормами и стандартами. Выбрав Геракл24, вы можете быть уверены, что ваш дом в надежных руках.
Мы предлагаем консультацию и ответить на ваши вопросы. Звоните нам, чтобы обсудить детали вашего проекта и узнать о наших сервисах. Мы сохраним и улучшим ваш дом, сделав его безопасным и комфортным для проживания на долгие годы.
Геракл24 – ваш надежный партнер в реставрации и ремонте домов в Красноярске и за его пределами.
buy augmentin 375 online no prescription
ализе фото новые https://www.vytyazhka-dlya-manikyura.ru/ .
dexamethasone discount
pg slot
advair diskus 25050
заказать такси дешево заказать такси недорого.
Thanks for any other wonderful article. The place else may just anybody get that type of info in such a perfect means of writing? I have a presentation subsequent week, and I’m at the search for such info.
nudifier website
Как сберечь свои данные: избегайте утечек информации в интернете. Сегодня обеспечение безопасности своих данных становится всё больше важной задачей. Одним из наиболее популярных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как предохранить себя от их утечки? Что такое «сит фразы»? «Сит фразы» — это сочетания слов или фраз, которые регулярно используются для доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или иные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как охранить свои личные данные? Используйте запутанные пароли. Избегайте использования легких паролей, которые мгновенно угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для всего аккаунта. Не применяйте один и тот же пароль для разных сервисов. Используйте двухэтапную аутентификацию (2FA). Это привносит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт через другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте персональную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы защитить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может привести к серьезным последствиям, таким подобно кража личной информации и финансовых потерь. Чтобы обезопасить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
טלגראס כיוונים
הפלטפורמה היא תוכנה נפוצה בישראל לרכישת מריחואנה בצורה מקוון. זו נותנת ממשק פשוט לשימוש ובטוח לקנייה וקבלת משלוחים מ פריטי צמח הקנאביס שונים. במאמר זו נסקור את העיקרון שמאחורי הפלטפורמה, איך היא פועלת ומה המעלות מ השימוש בה.
מה זו טלגראס?
האפליקציה מהווה שיטה לרכישת מריחואנה דרך האפליקציה טלגראם. היא מבוססת על ערוצי תקשורת וקהילות טלגרם ייעודיות הנקראות ״טלגראס כיוונים, שבהם ניתן להזמין מרחב פריטי קנאביס ולקבל אלו ישירותית לשילוח. ערוצי התקשורת אלו מסודרים לפי איזורים גאוגרפיים, כדי להקל את קבלתם של המשלוחים.
כיצד זה עובד?
התהליך קל למדי. קודם כל, יש להצטרף לערוץ הטלגראס הנוגע לאזור המחיה. שם אפשר לעיין בתפריטי הפריטים המגוונים ולהזמין עם הפריטים המבוקשים. לאחר השלמת ההרכבה וסיום התשלום, השליח יגיע בכתובת שנרשמה עם החבילה המוזמנת.
מרבית ערוצי הטלגראס מספקים מגוון רחב של מוצרים – זנים של מריחואנה, עוגיות, משקאות ועוד. בנוסף, אפשר למצוא ביקורות מ לקוחות שעברו על רמת הפריטים והשרות.
מעלות הנעשה בפלטפורמה
יתרון מרכזי מ הפלטפורמה הוא הנוחיות והפרטיות. ההזמנה והתהליך מתבצעות מרחוק מכל מיקום, ללא נחיצות במפגש פיזי. בנוסף, האפליקציה מוגנת ביסודיות ומבטיחה חיסיון גבוהה.
מלבד על זאת, עלויות המוצרים בטלגראס נוטות להיות תחרותיים, והשילוחים מגיעים במהירות ובהשקעה רבה. יש גם מוקד תמיכה זמין לכל שאלה או בעיית.
לסיכום
האפליקציה הווה דרך מקורית ויעילה לרכוש פריטי קנאביס במדינה. היא משלבת בין הנוחיות הטכנולוגית של היישומון הפופולרי, לבין המהירות והפרטיות של דרך השילוח הישירות. ככל שהדרישה לקנאביס גובר, פלטפורמות כמו טלגראס צפויות להמשיך ולהתפתח.
стоимость такси в новочеркасске taksi-vyzvat.ru .
nikontinoll.com
Hongzhi 황제는 잠시 당황했습니다. 무엇, 잘못된 사람입니까?
Bản cài đặt B29 IOS – Giải pháp vượt trội cho các tín đồ iOS
Trong thế giới công nghệ đầy sôi động hiện nay, trải nghiệm người dùng luôn là yếu tố then chốt. Với sự ra đời của Bản cài đặt B29 IOS, người dùng sẽ được hưởng trọn vẹn những tính năng ưu việt, mang đến sự hài lòng tuyệt đối. Hãy cùng khám phá những ưu điểm vượt trội của bản cài đặt này!
Tính bảo mật tối đa
Bản cài đặt B29 IOS được thiết kế với mục tiêu đảm bảo an toàn dữ liệu tuyệt đối cho người dùng. Nhờ hệ thống mã hóa hiện đại, thông tin cá nhân và dữ liệu nhạy cảm của bạn luôn được bảo vệ an toàn khỏi những kẻ xâm nhập trái phép.
Trải nghiệm người dùng đỉnh cao
Giao diện thân thiện, đơn giản nhưng không kém phần hiện đại, B29 IOS mang đến cho người dùng trải nghiệm duyệt web, truy cập ứng dụng và sử dụng thiết bị một cách trôi chảy, mượt mà. Các tính năng thông minh được tối ưu hóa, giúp nâng cao hiệu suất và tiết kiệm pin đáng kể.
Tính tương thích rộng rãi
Bản cài đặt B29 IOS được phát triển với mục tiêu tương thích với mọi thiết bị iOS từ các dòng iPhone, iPad cho đến iPod Touch. Dù là người dùng mới hay lâu năm của hệ điều hành iOS, B29 đều mang đến sự hài lòng tuyệt đối.
Quá trình cài đặt đơn giản
Với những hướng dẫn chi tiết, việc cài đặt B29 IOS trở nên nhanh chóng và dễ dàng. Chỉ với vài thao tác đơn giản, bạn đã có thể trải nghiệm ngay tất cả những tính năng tuyệt vời mà bản cài đặt này mang lại.
Bản cài đặt B29 IOS không chỉ là một bản cài đặt đơn thuần, mà còn là giải pháp công nghệ hiện đại, nâng tầm trải nghiệm người dùng lên một tầm cao mới. Hãy trở thành một phần của cộng đồng sử dụng B29 IOS để khám phá những tiện ích tuyệt vời mà nó có thể mang lại!
заказ такси в новочеркасске заказ такси в новочеркасске .
журнал красоты http://zhurnal-o-krasote11.ru/ .
Здравствуйте!
На нашем сайте вы можете выбрать и приобрести диплом Вуза с гарантией и доставкой в любой регион России по самым низким ценам.
http://dlplomanrussia.com
טלגראס כיוונים
האפליקציה הינה אפליקציה נפוצה בארץ לקנייה של צמח הקנאביס בצורה וירטואלי. זו מעניקה ממשק נוח ובטוח לקנייה וקבלת שילוחים של פריטי צמח הקנאביס מגוונים. בכתבה זה נבחן עם העיקרון מאחורי האפליקציה, איך זו פועלת ומהם היתרונות של השימוש בזו.
מהי הפלטפורמה?
הפלטפורמה מהווה אמצעי לקנייה של צמח הקנאביס באמצעות היישומון טלגרם. היא נשענת על ערוצים וקבוצות טלגרם מיוחדות הנקראות ״כיווני טלגראס״, שבהם ניתן להרכיב מגוון מוצרי מריחואנה ולקבל אותם ישירות לשילוח. ערוצי התקשורת האלה מאורגנים לפי איזורים גיאוגרפיים, במטרה להקל את קבלתם של השילוחים.
כיצד זאת עובד?
התהליך פשוט למדי. ראשית, צריך להצטרף לערוץ הטלגראס הרלוונטי לאזור המגורים. שם ניתן לצפות בתפריטים של המוצרים המגוונים ולהרכיב עם המוצרים הרצויים. לאחר השלמת ההזמנה וסיום התשלום, השליח יופיע לכתובת שנרשמה עם החבילה המוזמנת.
מרבית ערוצי הטלגראס מציעים מגוון רחב של מוצרים – זנים של צמח הקנאביס, ממתקים, שתייה ועוד. בנוסף, ניתן למצוא ביקורות מ צרכנים קודמים לגבי רמת המוצרים והשירות.
יתרונות השימוש בפלטפורמה
יתרון מרכזי של הפלטפורמה הינו הנוחיות והפרטיות. ההרכבה והתהליך מתבצעות ממרחק מכל מקום, בלי נחיצות במפגש פנים אל פנים. בנוסף, האפליקציה מאובטחת היטב ומבטיחה חיסיון גבוה.
נוסף אל זאת, מחירי המוצרים בפלטפורמה נוטים להיות תחרותיים, והשילוחים מגיעים במהירות ובמסירות רבה. יש גם מרכז תמיכה פתוח לכל שאלה או בעיית.
לסיכום
הפלטפורמה הווה דרך מקורית ויעילה לקנות פריטי קנאביס במדינה. זו משלבת בין הנוחיות הדיגיטלית של היישומון הפופולרי, לבין הזריזות והדיסקרטיות של שיטת המשלוח הישירה. ככל שהדרישה למריחואנה גובר, פלטפורמות בדוגמת טלגראס צפויות להמשיך ולצמוח.
проверка usdt trc20
Как защитить свои личные данные: берегитесь утечек информации в интернете. Сегодня защита своих данных становится всё более важной задачей. Одним из наиболее обычных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как обезопаситься от их утечки? Что такое «сит фразы»? «Сит фразы» — это сочетания слов или фраз, которые часто используются для доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или дополнительные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, с помощью этих сит фраз. Как защитить свои личные данные? Используйте непростые пароли. Избегайте использования очевидных паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого аккаунта. Не воспользуйтесь один и тот же пароль для разных сервисов. Используйте двухэтапную аутентификацию (2FA). Это добавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт через другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте личную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы уберечь свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может привести к серьезным последствиям, таким вроде кража личной информации и финансовых потерь. Чтобы обезопасить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
отмывание usdt
Как защитить свои данные: страхуйтесь от утечек информации в интернете. Сегодня сохранение информации становится всё значимее важной задачей. Одним из наиболее распространенных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в какой мере сберечься от их утечки? Что такое «сит фразы»? «Сит фразы» — это смеси слов или фраз, которые постоянно используются для доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или разные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, используя этих сит фраз. Как охранить свои личные данные? Используйте непростые пароли. Избегайте использования простых паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для всего аккаунта. Не применяйте один и тот же пароль для разных сервисов. Используйте двухфакторную аутентификацию (2FA). Это прибавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт путем другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте персональную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы сохранить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким подобно кража личной информации и финансовых потерь. Чтобы защитить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
lyrica 300 mg
Проверить транзакцию usdt trc20
Сохраните собственные USDT: Проконтролируйте перевод TRC20 перед отсылкой
Цифровые валюты, такие вроде USDT (Tether) на блокчейне TRON (TRC20), становятся всё всё более востребованными в области области децентрализованных финансовых услуг. Однако совместно с увеличением распространенности повышается также риск промахов либо жульничества во время отправке средств. Как раз поэтому необходимо проверять транзакцию USDT TRC20 перед ее отправкой.
Погрешность во время вводе адреса получателя адресата или пересылка на неправильный адрес получателя сможет привести к невозможности необратимой утрате твоих USDT. Жулики также смогут пытаться провести вас, пересылая ложные адреса для отправки. Утрата криптовалюты по причине подобных погрешностей может обернуться серьезными денежными убытками.
К радости, имеются специализированные службы, позволяющие проконтролировать транзакцию USDT TRC20 до ее отправкой. Некий из таких служб предоставляет возможность отслеживать и изучать переводы на блокчейне TRON.
На данном обслуживании вы сможете ввести адрес получателя а также получить подробную сведения об адресе, включая в том числе историю переводов, баланс а также состояние счета. Это посодействует выяснить, является ли адрес действительным и безопасным для пересылки денег.
Другие службы тоже дают похожие опции по удостоверения операций USDT TRC20. Некоторые кошельки для криптовалют по крипто обладают интегрированные возможности по проверки адресов и транзакций.
Не пренебрегайте проверкой перевода USDT TRC20 до её отсылкой. Крохотная осмотрительность может сэкономить вам множество средств а также не допустить потерю ваших ценных криптовалютных активов. Применяйте проверенные службы для обеспечения надежности твоих операций а также целостности ваших USDT на блокчейне TRON.
проверить кошелёк usdt trc20
В процессе работе с цифровой валютой USDT на блокчейне TRON (TRC20) чрезвычайно значимо не просто верифицировать реквизиты реципиента перед транзакцией средств, но тоже систематически мониторить остаток своего цифрового кошелька, плюс источники поступающих транзакций. Это даст возможность своевременно обнаружить всевозможные нежданные транзакции а также предотвратить вероятные издержки.
В первую очередь, нужно проверить на корректности показываемого баланса USDT TRC20 в собственном криптокошельке. Советуется соотносить данные с сведениями публичных обозревателей блокчейна, чтобы не допустить вероятность компрометации или взлома этого кошелька.
Тем не менее лишь отслеживания баланса недостаточно. Крайне важно анализировать журнал входящих транзакций а также их источники. Если Вы найдете поступления USDT от неизвестных или подозрительных адресов, немедленно приостановите данные финансы. Есть опасность, чтобы эти монеты стали получены преступным путем и в будущем могут быть конфискованы регулирующими органами.
Наше платформа дает средства для углубленного анализа поступающих USDT TRC20 переводов на предмет их законности и отсутствия соотношения с преступной деятельностью. Мы.
Также нужно систематически выводить USDT TRC20 в безопасные некастодиальные криптовалютные кошельки находящиеся под вашим тотальным присмотром. Содержание монет на внешних платформах неизменно сопряжено с рисками хакерских атак и потери денег из-за программных ошибок или несостоятельности платформы.
Следуйте основные правила защиты, будьте внимательны а также вовремя контролируйте баланс и источники пополнений кошелька для USDT TRC20. Это позволит защитить ваши цифровые ценности от незаконного завладения и потенциальных юридических проблем в будущем.
Ketogenic candies have surfaced as a in-demand treat alternative for people adhering to a low-carb or low-carb diet. These chewy delicacies are designed to be reduced in net carbs, making them a harmless treat for those striving to sustain a https://t.me/s/ketogummies state of ketonemia.
By utilizing plant-based sweeteners like stevia or erythritol, low-carb gummies provide a satisfying sugary taste without spiking glycemic levels, a common concern with traditional confectionery.
clomid cost nz
проверить адрес usdt trc20
Заголовок: Необходимо удостоверяйтесь в адресе адресата при операции USDT TRC20
В процессе взаимодействии с крипто, особенно с USDT в блокчейне TRON (TRC20), чрезвычайно важно выказывать бдительность а также внимательность. Единственная из наиболее частых оплошностей, какую делают пользователи – отправка денег на ошибочный адрес. Чтобы устранить утрату своих USDT, требуется всегда внимательно удостоверяться в адрес реципиента до передачей операции.
Крипто адреса представляют из себя обширные совокупности литер и номеров, например, TRX9QahiFUYfHffieZThuzHbkndWvvfzThB8U. Даже малая опечатка или погрешность при копировании адреса кошелька сможет повлечь к тому, чтобы твои цифровые деньги станут невозвратно утрачены, поскольку они попадут на неподконтрольный тобой кошелек.
Присутствуют разные пути контроля адресов кошельков USDT TRC20:
1. Глазомерная проверка. Тщательно соотнесите адрес во твоём кошельке со адресом кошелька получателя. В случае небольшом несовпадении – воздержитесь от транзакцию.
2. Задействование интернет-служб проверки.
3. Дублирующая проверка со адресатом. Обратитесь с просьбой к адресату удостоверить корректность адреса кошелька до посылкой перевода.
4. Испытательный транзакция. При крупной величине перевода, возможно предварительно послать небольшое объем USDT с целью контроля адреса кошелька.
Сверх того советуется держать крипто на личных криптокошельках, но не на биржах иль посреднических инструментах, чтобы иметь полный контроль по отношению к собственными активами.
Не оставляйте без внимания проверкой адресов при взаимодействии с USDT TRC20. Эта обычная мера превенции окажет помощь защитить ваши деньги против нежелательной потери. Помните, чтобы на сфере крипто транзакции невозвратны, а переданные крипто на неверный адрес возвратить почти нельзя. Будьте бдительны и аккуратны, чтобы защитить свои капиталовложения.
buy propecia online
0.5 tretinoin cream
полусухая стяжка пола в квартире http://www.mekhanizirovannaya-shtukaturka15.ru/ .
Информационный портал https://kalitka48.ru/ на актуальные темы, связанные с недвижимостью: новости рынка недвижимости, информация о покупке и продаже квартир и множество других полезных статей.
Важность верификации транзакции USDT TRC-20
Операции USDT в рамках технологии TRC20 увеличивают возрастающую популярность, но стоит оставаться крайне бдительными при таких зачислении.
Такой вид платежей часто используется в процессе обеления активов, полученных криминальным методом.
Один из угроз получения USDT TRC-20 – заключается в том, что данные средства имеют потенциал быть зачислены посредством различных схем кражи, таких как утраты конфиденциальной информации, поборы, хакерские атаки и дополнительные криминальные действия. Зачисляя такие платежи, вы неизменно оказываетесь подельником преступной операций.
В связи с этим особенно важно детально исследовать природу каждого поступающего транзакции в USDT по сети TRC20. Важно требовать у инициатора информацию относительно чистоте денежных средств, в случае малейших сомнениях – не принимать подобные операций.
Осознавайте, в ситуации, когда в результате выявления незаконных происхождений денежных средств, клиент с высокой вероятностью будете подвергнуты мерам с взысканиям совместно с инициатором. В связи с этим рекомендуется проявить осторожность наряду с глубоко изучать всевозможный трансфер, нацело ставить под угрозу своей репутацией и столкнуться в масштабные правовые неприятности.
Поддержание аккуратности в процессе операциях по USDT TRC20 – выступает залог личной денежной защищенности и ограждение от нелегальные практики. Будьте внимательными а также постоянно проверяйте происхождение электронных валютных активов.
полусухая стяжка пола минимальная толщина https://mekhanizirovannaya-shtukaturka15.ru .
how to get accutane in canada
1go casino официальный сайт 1го казино
generic lyrica from canada
zovirax 200mg price
synthroid 0.112 mg
Продажа квартир Пенза https://solnechnyjgorod.ru/, успейте купить квартиру от застройщика в Пензе. ЖК «Солнечный Город» расположен в экологическом чистом районе в 13 км от города Пенза. Продажа 1,2 комнатных квартир от застройщика по минимальной стоимости за кВ/м, успей купить не упусти шанс.
Продукты разбирали они уже вдвоем, на просторной кухне, дочка пошла отдыхать в свою комнату. Сделана она была как для настоящей принцессы: на натяжном потолке красовался принт цветов, розовые обои гармонично сочетались с белой мебелью. В каких-то местах на стенах оставлены автографы Маши: так малышка училась рисовать и познавать этот мир:
—Так ты скажешь, зачем нам худеть? Кто это тебе в голову вбил?
—Мой хороший, я устала стесняться! Все мои коллеги худенькие и хрупкие, я на их фоне, как слон в посудной лавке. Уже на два стула не помещаюсь, понимаешь меня? Вика вообще постоянно тыкает в нашу семью, мол, сколько тонн вы в день поедаете. Надоело это всё, не могу больше. В зеркало смотреть противно…
–А у Вики чувства тактичности вообще нет? Хорошо, раз так, то мы им еще покажем.
индивид полностью не предусматривал от родной супруги Татьяны. Внутри их собственной династии телосложение физической оболочки полностью не соответствовала в противовес типовой также распространённой – быть с предожирением безоговорочная правило.
טלגראס הינה אפליקציה נפוצה בישראל לקנייה של צמח הקנאביס באופן מקוון. זו מספקת ממשק משתמש נוח ומאובטח לרכישה ולקבלת משלוחים של פריטי צמח הקנאביס מגוונים. בסקירה זו נסקור את העיקרון שמאחורי האפליקציה, איך זו עובדת ומה היתרונות של השימוש בזו.
מהי הפלטפורמה?
האפליקציה מהווה אמצעי לקנייה של מריחואנה דרך האפליקציה טלגראם. היא נשענת מעל ערוצי תקשורת וקבוצות טלגראם ספציפיות הקרויות ״טלגראס כיוונים, שם ניתן להזמין מגוון מוצרי מריחואנה ולקבלת אותם ישירותית למשלוח. הערוצים אלו מאורגנים על פי איזורים גיאוגרפיים, במטרה להקל על קבלת המשלוחים.
כיצד זה עובד?
התהליך קל יחסית. ראשית, יש להצטרף לערוץ טלגראס הנוגע לאזור המגורים. שם ניתן לצפות בתפריטי הפריטים השונים ולהזמין עם המוצרים המבוקשים. לאחר ביצוע ההרכבה וסגירת התשלום, השליח יופיע בכתובת שצוינה עם הארגז שהוזמן.
מרבית ערוצי טלגראס מספקים מגוון רחב של פריטים – סוגי מריחואנה, עוגיות, משקאות ועוד. בנוסף, ניתן למצוא ביקורות מ צרכנים קודמים על איכות המוצרים והשירות.
מעלות השימוש באפליקציה
מעלה עיקרי של האפליקציה הוא הנוחות והדיסקרטיות. ההרכבה וההכנות מתקיימים מרחוק מאיזשהו מקום, ללא צורך במפגש פיזי. בנוסף, הפלטפורמה מוגנת היטב ומבטיחה סודיות גבוה.
מלבד על כך, מחירי המוצרים בפלטפורמה נוטים לבוא זולים, והמשלוחים מגיעים במהירות ובהשקעה רבה. יש גם מרכז תמיכה זמין לכל שאלה או בעיית.
לסיכום
טלגראס הינה שיטה חדשנית ויעילה לרכוש פריטי צמח הקנאביס בישראל. היא משלבת בין הנוחיות הדיגיטלית של היישומון הפופולרי, לבין הזריזות והפרטיות של שיטת המשלוח הישירה. ככל שהדרישה לקנאביס גדלה, פלטפורמות בדוגמת זו צפויות להמשיך ולצמוח.
Замена венцов красноярск
Геракл24: Опытная Смена Фундамента, Венцов, Покрытий и Перенос Строений
Организация Геракл24 занимается на выполнении полных сервисов по реставрации фундамента, венцов, полов и перемещению зданий в месте Красноярск и в окрестностях. Наша группа профессиональных мастеров обещает превосходное качество исполнения всех видов ремонтных работ, будь то древесные, каркасные, из кирпича или бетонные дома.
Преимущества сотрудничества с Геракл24
Квалификация и стаж:
Весь процесс выполняются исключительно высококвалифицированными мастерами, имеющими большой опыт в сфере строительства и восстановления строений. Наши сотрудники эксперты в своей области и реализуют работу с высочайшей точностью и учетом всех деталей.
Полный спектр услуг:
Мы предлагаем все виды работ по ремонту и ремонту домов:
Реставрация фундамента: усиление и реставрация старого основания, что позволяет продлить срок службы вашего строения и избежать проблем, вызванные оседанием и деформацией.
Смена венцов: замена нижних венцов деревянных домов, которые обычно гниют и разрушаются.
Замена полов: монтаж новых настилов, что существенно улучшает внешний облик и функциональность помещения.
Передвижение домов: безопасное и надежное перемещение зданий на другие участки, что обеспечивает сохранение строения и предотвращает лишние расходы на строительство нового.
Работа с различными типами строений:
Древесные строения: восстановление и защита деревянных строений, защита от гниения и вредителей.
Каркасные строения: укрепление каркасов и смена поврежденных частей.
Кирпичные строения: реставрация кирпичной кладки и укрепление конструкций.
Дома из бетона: ремонт и укрепление бетонных конструкций, ремонт трещин и дефектов.
Качество и прочность:
Мы работаем с только высококачественные материалы и современное оборудование, что гарантирует долговечность и прочность всех выполненных задач. Все проекты проходят тщательную проверку качества на каждой стадии реализации.
Индивидуальный подход:
Для каждого клиента мы предлагаем подходящие решения, учитывающие ваши требования и желания. Мы стремимся к тому, чтобы результат нашей работы полностью удовлетворял вашим запросам и желаниям.
Почему выбирают Геракл24?
Сотрудничая с нами, вы получаете надежного партнера, который берет на себя все заботы по ремонту и реставрации вашего дома. Мы гарантируем выполнение всех проектов в установленные сроки и с соблюдением всех строительных норм и стандартов. Связавшись с Геракл24, вы можете не сомневаться, что ваш дом в надежных руках.
Мы всегда готовы проконсультировать и ответить на ваши вопросы. Контактируйте с нами, чтобы обсудить детали вашего проекта и узнать о наших сервисах. Мы поможем вам сохранить и улучшить ваш дом, сделав его уютным и безопасным для долгого проживания.
Геракл24 – ваш партнер по реставрации и ремонту домов в Красноярске и окрестностях.
открытие замков открытие замков .
b29
Bản cài đặt B29 IOS – Giải pháp vượt trội cho các tín đồ iOS
Trong thế giới công nghệ đầy sôi động hiện nay, trải nghiệm người dùng luôn là yếu tố then chốt. Với sự ra đời của Bản cài đặt B29 IOS, người dùng sẽ được hưởng trọn vẹn những tính năng ưu việt, mang đến sự hài lòng tuyệt đối. Hãy cùng khám phá những ưu điểm vượt trội của bản cài đặt này!
Tính bảo mật tối đa
Bản cài đặt B29 IOS được thiết kế với mục tiêu đảm bảo an toàn dữ liệu tuyệt đối cho người dùng. Nhờ hệ thống mã hóa hiện đại, thông tin cá nhân và dữ liệu nhạy cảm của bạn luôn được bảo vệ an toàn khỏi những kẻ xâm nhập trái phép.
Trải nghiệm người dùng đỉnh cao
Giao diện thân thiện, đơn giản nhưng không kém phần hiện đại, B29 IOS mang đến cho người dùng trải nghiệm duyệt web, truy cập ứng dụng và sử dụng thiết bị một cách trôi chảy, mượt mà. Các tính năng thông minh được tối ưu hóa, giúp nâng cao hiệu suất và tiết kiệm pin đáng kể.
Tính tương thích rộng rãi
Bản cài đặt B29 IOS được phát triển với mục tiêu tương thích với mọi thiết bị iOS từ các dòng iPhone, iPad cho đến iPod Touch. Dù là người dùng mới hay lâu năm của hệ điều hành iOS, B29 đều mang đến sự hài lòng tuyệt đối.
Quá trình cài đặt đơn giản
Với những hướng dẫn chi tiết, việc cài đặt B29 IOS trở nên nhanh chóng và dễ dàng. Chỉ với vài thao tác đơn giản, bạn đã có thể trải nghiệm ngay tất cả những tính năng tuyệt vời mà bản cài đặt này mang lại.
Bản cài đặt B29 IOS không chỉ là một bản cài đặt đơn thuần, mà còn là giải pháp công nghệ hiện đại, nâng tầm trải nghiệm người dùng lên một tầm cao mới. Hãy trở thành một phần của cộng đồng sử dụng B29 IOS để khám phá những tiện ích tuyệt vời mà nó có thể mang lại!
How to lose weight
?The sad, humiliated wife flashed before his eyes. She sincerely wants to lose weight — her colleagues are teasing jokes about their family, and maybe even about her weight. A couple of cakes won’t make him thinner, and the salads are even not bad. Injustice rose to his throat in a lump and stuck there, not wanting to go anywhere. Nausea began to set in:
Give me buckwheat with stew, a medium plate… A salad with Chinese cabbage, the one without mayonnaise, also a medium one. And compote from dried fruits.
The canteen lady’s eyes widened, apparently from surprise. She performed such requests every day, but definitely not from this person. Frozen over the vat of buckwheat, she amazedly blurted out:
— Petrovich, is it me you’re talking to right now or who? And what about the pies and dessert, a liter of soda? Have you really decided to lose weight?
— And from this day on, it will always be like this! Lyudka, promise you’ll never sell me that crap again, only healthy food and no more!
— Agreed!
This is a good article. BANDAR TOTO TOGEL
purchase ventolin online
נתברכו הבאים למרכז המידע והנתונים והסיוע הרשמי והמוגדר של טלגרף מסלולים! במקום אפשר לאתר ולקבל את מלוא המידע והמסמכים החדיש והעדכני הזמין והרלוונטי בנוגע ל תשתית טלגרף והדרכים לשימוש בה בצורה נכונה.
מיהו טלגרף מסלולים?
טלגרף נתיבים מהווה תשתית הנשענת על תקשורת המשמשת להפצה ושיווק וצריכה של קנבי ודשא בתחום. באמצעות המסרים והפורומים בתקשורת, צרכנים רשאים להשיג ולקבל אספקת קנבי בדרך נגיש ומיידי.
איך להשתלב בטלגראס?
לצורך להשתלב בשימוש מושכל בטלגראס כיוונים, עליכם להתחבר ל לשיחות ולפורומים הרצויים. במיקום זה באתר זה ניתן לאתר סיכום עבור צירים למקומות פעילים וימינים. במקביל לכך, ניתן להשתלב בשלבים הרכישה וההספקה סביב מוצרי הקנבי.
הסברים והסברים
באתר זה ניתן למצוא סוגים עבור הוראות ופרטים ברורים אודות השילוב בטלגרם, כולל:
– החברות לערוצים מומלצים
– תהליך האספקה
– ביטחון והבטיחות בשימוש בטלגראס כיוונים
– ומגוון תוכן נוסף
מסלולים מאומתים
בסעיף זה צירים לערוצים ולמסגרות רצויים בטלגרם:
– פורום המידע המוסמך
– מקום העזרה והעזרה לצרכנים
– פורום להזמנת מוצרי קנאביס מוטבחים
– מבחר אתרים קנאביס מוטבחות
אנו מעניקים את כולם בשל הצטרפותכם לפורטל המידע והנתונים מטעם טלגראס נתיבים ומתקווים לכולם חוויית שירות מצוינת ומובטחת!
buy baclofen in uk
modafinil buy from india
полусухая стяжка пола в москве http://www.mekhanizirovannaya-shtukaturka15.ru .
dexamethasone cost usa
lyrica 150
купить акаунт тг https://kupit-akkaunt-vk.ru .
ihrfuehrerschein.com
눈 깜짝할 사이에 나뭇가지와 잎사귀는 점점 황금빛 노랗게 물들었고, 벌써 가을의 시작이었습니다.
купить лайки ютуб
Togel Terpercaya Bandar Togel Terpercaya sudah banyak yang menang disini
Gates Of Olympus Gates Of Olympus Sure to Win and Big Jackpot
how to buy modafinil in india
Геракл24: Опытная Замена Фундамента, Венцов, Полов и Перенос Зданий
Фирма Геракл24 специализируется на предоставлении всесторонних работ по реставрации основания, венцов, настилов и перемещению зданий в городе Красноярском регионе и за пределами города. Наша группа профессиональных специалистов обеспечивает высокое качество выполнения всех видов ремонтных работ, будь то из дерева, каркасного типа, из кирпича или бетонные конструкции здания.
Достоинства работы с Геракл24
Навыки и знания:
Все работы осуществляются лишь опытными мастерами, с обладанием долгий опыт в сфере создания и реставрации домов. Наши сотрудники знают свое дело и выполняют проекты с максимальной точностью и учетом всех деталей.
Всесторонний подход:
Мы осуществляем разнообразные услуги по восстановлению и восстановлению зданий:
Замена фундамента: замена и укрепление фундамента, что позволяет продлить срок службы вашего дома и предотвратить проблемы, связанные с оседанием и деформацией строения.
Замена венцов: замена нижних венцов деревянных домов, которые обычно подвергаются гниению и разрушению.
Замена полов: установка новых полов, что существенно улучшает внешний облик и функциональность помещения.
Перенос строений: безопасное и надежное перемещение зданий на новые локации, что позволяет сохранить ваше строение и предотвращает лишние расходы на создание нового.
Работа с любыми типами домов:
Древесные строения: восстановление и укрепление деревянных конструкций, обработка от гниения и насекомых.
Дома с каркасом: реставрация каркасов и смена поврежденных частей.
Кирпичные строения: реставрация кирпичной кладки и укрепление стен.
Бетонные дома: восстановление и укрепление бетонных структур, ремонт трещин и дефектов.
Качество и надежность:
Мы используем только высококачественные материалы и передовые технологии, что обеспечивает долгий срок службы и прочность всех выполненных задач. Каждый наш проект подвергаются строгому контролю качества на каждом этапе выполнения.
Личный подход:
Каждому клиенту мы предлагаем индивидуальные решения, учитывающие все особенности и пожелания. Наша цель – чтобы конечный результат полностью удовлетворял вашим запросам и желаниям.
Почему стоит выбрать Геракл24?
Обратившись к нам, вы получаете надежного партнера, который возьмет на себя все заботы по ремонту и реконструкции вашего строения. Мы гарантируем выполнение всех проектов в установленные сроки и с соблюдением всех правил и норм. Обратившись в Геракл24, вы можете быть спокойны, что ваше строение в надежных руках.
Мы готовы предоставить консультацию и дать ответы на все вопросы. Звоните нам, чтобы обсудить детали и узнать больше о наших услугах. Мы поможем вам сохранить и улучшить ваш дом, сделав его уютным и безопасным для долгого проживания.
Геракл24 – ваш партнер по реставрации и ремонту домов в Красноярске и окрестностях.
Mostbet mobilni aplikace https://mostbet-bk.cz/mobilni-aplikace-mostbet-app/ je ocenena za kvalitu a inovace.
Доставка из Китая с таможенными услугами — это профессиональное решение для импорта товаров из Китая, включающее в себя организацию перевозки, таможенное оформление и сопутствующие услуги. Мы предоставляем полный спектр услуг, связанных
сайты доставки из китая включая организацию международных перевозок, таможенное оформление, сертификацию и страхование грузов. Наши специалисты помогут вам выбрать оптимальный маршрут и вид транспорта, оформить необходимые документы и декларации, а также проконсультируют по вопросам налогообложения и таможенного законодательства.
online casino nederland nieuw online casino nederland nieuw .
seo продвижение по трафику
Akarslot127
amoxicillin 400
https://seogou.ru/
diflucan from india
beste casino’s nederland beste casino’s nederland .
cheap cipro
where to buy diflucan in canada
buy clomid 50mg uk
cost of synthroid 75 mcg
Your post is a ray of light in the darkness. Thank you for brightening my day in a unique way. Keep shining!
I have no words to describe how your content illuminated my day. Keep being that source of inspiration!
generic tamoxifen
Стоматологическая клиника Мастерская Улыбок предлагает широкий спектр услуг по диагностике, лечению, профилактике и эстетической коррекции проблем с зубами и дёснами. Мы используем современное оборудование и материалы, а наши специалисты обладают высокой квалификацией и опытом.
В клинике созданы комфортные условия для пациентов: удобные кресла, приятная атмосфера, приветливый персонал. Мы заботимся о вашем здоровье и стараемся сделать посещение стоматолога максимально комфортным и безболезненным.
Наши услуги включают:
стоматолог казань
диагностику состояния зубов и дёсен;
лечение кариеса, пульпита, периодонтита и других заболеваний;
профессиональную гигиену полости рта;
эстетическую коррекцию зубного ряда (установка коронок, виниров, имплантов);
исправление прикуса с помощью брекетов или элайнеров;
отбеливание зубов;
лечение дёсен (пародонтит, гингивит, пародонтоз).
Мы также предлагаем услуги по детской стоматологии, протезированию и имплантации.
Обращаясь в клинику Мастерская Улыбок, вы можете быть уверены в качестве предоставляемых услуг и профессионализме наших врачей. Мы заботимся о вашей улыбке и делаем всё возможное, чтобы она была здоровой и красивой!
Team up with our community of over 2 million elated users who are extenuatory measure and getting paid faster with our travelling invoice solutions. Our mobile invoicing tools, including non-stationary invoice apps, purvey to both iOS and Android users. Whether you have need of an invoice app for iPhone, an Android invoice app, or a sweeping animated billing software, we’ve got you covered.
https://www.genio.ac/mobile-invoices
tvlore.com
조수와 같은 경비병들이 순식간에 높은 단상으로 몰려들며 인적 장벽을 형성했다.
сеть сайтов pbn
Работая в SEO, нужно знать, что нельзя одним способом поднять сайт в топ выдачи поисковых систем, так как поисковые системы это как трек с финишной линией, а веб-сайты это гоночные машины, которые все хотят быть первыми.
Так вот:
Перечень – Для того чтобы веб-сайт был адаптивным и скоростным, важна
оптимизация
Сайт должен содержать только уникальный контент, это тексты и изображения
НЕОБХОДИМО набор ссылок через сайты статейники и непосредственно на основную страницу
Усиление беклинков с использованием второстепенных сайтов
Пирамида ссылок, это ссылки первого уровня, Tier-2, Tier-3
И самое главное это личная сеть веб-сайтов PBN, которая ссылается на основной сайт
Все PBN-сайты должны быть без следов, т.е. поисковики не должны понимать, что это один собственник всех интернет-ресурсов, поэтому ОЧЕНЬ важно соблюдать все эти указания.
order doxycycline capsules online
Gerakl24: Квалифицированная Смена Основания, Венцов, Покрытий и Перенос Зданий
Компания Gerakl24 специализируется на предоставлении комплексных работ по реставрации основания, венцов, полов и перемещению зданий в населённом пункте Красноярском регионе и в окрестностях. Наша группа опытных экспертов обещает отличное качество реализации всех типов реставрационных работ, будь то из дерева, с каркасом, кирпичные постройки или из бетона строения.
Достоинства сотрудничества с Геракл24
Навыки и знания:
Весь процесс проводятся исключительно высококвалифицированными мастерами, с многолетним многолетний практику в направлении возведения и ремонта зданий. Наши сотрудники эксперты в своей области и реализуют задачи с высочайшей точностью и учетом всех деталей.
Всесторонний подход:
Мы предоставляем разнообразные услуги по ремонту и ремонту домов:
Реставрация фундамента: укрепление и замена старого фундамента, что гарантирует долговечность вашего здания и устранить проблемы, связанные с оседанием и деформацией строения.
Смена венцов: восстановление нижних венцов деревянных зданий, которые наиболее часто гниют и разрушаются.
Замена полов: установка новых полов, что значительно улучшает внешний облик и практическую полезность.
Передвижение домов: качественный и безопасный перенос строений на другие участки, что обеспечивает сохранение строения и избегает дополнительных затрат на создание нового.
Работа с любыми видами зданий:
Дома из дерева: реставрация и усиление деревянных элементов, защита от разрушения и вредителей.
Каркасные дома: укрепление каркасов и замена поврежденных элементов.
Дома из кирпича: восстановление кирпичной кладки и усиление стен.
Бетонные дома: ремонт и укрепление бетонных конструкций, исправление трещин и разрушений.
Качество и прочность:
Мы применяем только высококачественные материалы и современное оборудование, что гарантирует долгий срок службы и прочность всех выполненных задач. Все проекты проходят строгий контроль качества на каждом этапе выполнения.
Индивидуальный подход:
Каждому клиенту мы предлагаем подходящие решения, учитывающие все особенности и пожелания. Наша цель – чтобы результат нашей работы соответствовал ваши ожидания и требования.
Почему выбирают Геракл24?
Работая с нами, вы получаете надежного партнера, который берет на себя все заботы по восстановлению и ремонту вашего здания. Мы гарантируем выполнение всех проектов в сроки, оговоренные заранее и с соблюдением всех строительных норм и стандартов. Выбрав Геракл24, вы можете быть спокойны, что ваше строение в надежных руках.
Мы предлагаем консультацию и ответить на все ваши вопросы. Контактируйте с нами, чтобы обсудить детали и получить больше информации о наших услугах. Мы поможем вам сохранить и улучшить ваш дом, обеспечив его безопасность и комфорт на долгие годы.
Gerakl24 – ваш выбор для реставрации и ремонта домов в Красноярске и области.
сделать аудит сайта цена prodvizhenie-sajtov15.ru .
娛樂城
在線娛樂城的世界
隨著網際網路的迅速發展,網上娛樂城(網上賭場)已經成為許多人消遣的新選擇。網上娛樂城不僅提供多元化的遊戲選擇,還能讓玩家在家中就能體驗到賭場的興奮和樂趣。本文將討論線上娛樂城的特色、優勢以及一些常見的的游戲。
什麼叫網上娛樂城?
網上娛樂城是一種經由互聯網提供賭錢遊戲的平台。玩家可以經由電腦設備、智慧型手機或平板電腦進入這些網站,參與各種賭錢活動,如撲克、輪盤、黑傑克和老虎機等。這些平台通常由專業的的軟體公司開發,確保游戲的公正和安全。
在線娛樂城的好處
便利:玩家不用離開家,就能體驗賭錢的興奮。這對於那些居住在遠離實體賭場區域的人來說特別方便。
多元化的遊戲選擇:網上娛樂城通常提供比實體賭場更多的遊戲選擇,並且經常改進游戲內容,保持新鮮。
優惠和獎勵:許多線上娛樂城提供豐富的獎金計劃,包括註冊紅利、存款紅利和忠誠計劃,吸引新新玩家並鼓勵老玩家繼續遊戲。
穩定性和隱私性:正規的線上娛樂城使用先進的加密方法來保護玩家的個人信息和金融交易,確保遊戲過程的公平和公正性。
常有的在線娛樂城遊戲
撲克:德州撲克是最受歡迎的賭博游戲之一。線上娛樂城提供多樣德州撲克變體,如德州撲克、奧馬哈和七張牌等。
輪盤:輪盤賭是一種經典的賭場遊戲遊戲,玩家可以賭注在單數、數字排列或顏色選擇上,然後看小球落在哪個位置。
21點:又稱為二十一點,這是一種比拼玩家和莊家點數的遊戲,目標是讓手牌點數盡可能接近21點但不超過。
老虎机:老虎機是最簡單也是最流行的賭博游戲之一,玩家只需轉動捲軸,看圖案排列出贏得的組合。
結論
網上娛樂城為當代賭博愛好者提供了一個方便的、刺激且多樣化的娛樂活動。不管是撲克牌愛好者還是老虎机愛好者,大家都能在這些平台上找到適合自己的遊戲。同時,隨著科技的不斷進步,網上娛樂城的游戲體驗將變得越來越越來越現實和有趣。然而,玩家在體驗游戲的同時,也應該自律,避免沉溺於賭博活動,維持健康的遊戲心態。
Федерация паркура, трюковых и экстремальных единоборств Street Union – это профессиональная организация в индустрии спорта, развлечений и шоу-бизнеса.
Наша миссия заключается в развитии экстремальной культуры и спорта с разных точек зрения.
Наша деятельность основана на том, что современные виды спорта зачастую намного зрелищнее классических. Поэтому, помимо организации тренировок для спортсменов всех видов, мы также оказываем коммерческие услуги, необходимые государственным и частным компаниям, такие как подготовка шоу-программ с участием ведущих спортсменов и артистов различных жанров, производство имиджевой продукции.
Этот подход на шаг опережает “стандарт”, будучи смелым не только в спорте, но и в рекламе и шоу-продукции. Являясь лидером мнений для тысяч поклонников и последователей, мы вдохновляем людей совершенствовать свое тело и дух, двигаться вперед и проявлять свою индивидуальность.
В ее состав компаниивходят артисты из самых разных областей, включая спорт, музыку, режиссуру, дизайн, изобразительное искусство и шоу-бизнес. Для такой компании нет невозможных проектов.
За основу было взято несколько передовых видов экстремальной деятельности:
suteam паркур в школе побег подходит для тренировок спецназа и для школьных уроков физкультуры;
Трицикл и HMA (экстремальные боевые искусства) – зрелищные современные дисциплины, сочетающие акробатические трюки и элементы боевых искусств.
Эти современные дисциплины со временем могут превратиться в самостоятельные спортивные дисциплины и войти в программу Олимпийских игр. Мы прилагаем все усилия для этого!
buy modafinil online usa cheap
lyrica 450 mg
lyrica 150 mg
娛樂城
網上娛樂城的世界
隨著網際網路的迅速發展,網上娛樂城(在線賭場)已經成為許多人消遣的新選擇。在線娛樂城不僅提供多樣化的遊戲選擇,還能讓玩家在家中就能體驗到賭場的興奮和樂趣。本文將討論在線娛樂城的特色、優勢以及一些常有的游戲。
什麼叫在線娛樂城?
線上娛樂城是一種通過網際網路提供賭錢遊戲的平台。玩家可以通過電腦、智能手機或平板設備進入這些網站,參與各種博彩活動,如撲克、賭盤、21點和吃角子老虎等。這些平台通常由專業的的軟件公司開發,確保游戲的公正和安全性。
線上娛樂城的利益
便利:玩家無需離開家,就能享用賭錢的快感。這對於那些居住在遠離的實體賭場地方的人來說尤為方便。
多樣化的游戲選擇:線上娛樂城通常提供比實體賭場更多的游戲選擇,並且經常改進游戲內容,保持新穎。
福利和獎勵計劃:許多網上娛樂城提供豐厚的獎勵計劃,包括註冊獎勵、存款紅利和忠誠度計劃,引誘新玩家並鼓勵老玩家持續遊戲。
穩定性和隱私性:正當的網上娛樂城使用先進的加密方法來保護玩家的個人信息和金融交易,確保游戲過程的穩定和公平。
常見的的網上娛樂城游戲
撲克牌:撲克是最流行博彩遊戲之一。在線娛樂城提供多種撲克牌變體,如德州撲克、奧馬哈和七張撲克等。
賭盤:賭盤是一種傳統的賭博遊戲,玩家可以投注在單個數字、數字排列或顏色上,然後看小球落在哪個區域。
黑傑克:又稱為黑傑克,這是一種競爭玩家和莊家點數的游戲,目標是讓手牌點數點數儘量接近21點但不超過。
吃角子老虎:老虎机是最受歡迎也是最流行的賭博遊戲之一,玩家只需轉動捲軸,等待圖案圖案排列出中獎的組合。
結論
線上娛樂城為現代賭博愛好者提供了一個方便、興奮且豐富的娛樂活動。不論是撲克愛好者還是吃角子老虎迷,大家都能在這些平台上找到適合自己的游戲。同時,隨著技術的的不斷發展,在線娛樂城的游戲體驗將變化越來越真實和吸引人。然而,玩家在享用遊戲的同時,也應該保持自律,避免沉迷於博彩活動,維持健康的娛樂心態。
Dive into the world of high-efficiency invoicing with our top-notch invoice maker app, tailor-made for the go-getters – freelancers and small business owners alike. We’re talking around transforming the way you run bills, making it cheat than ever.
https://apps.apple.com/us/app/invoice-maker-invoices/id6449437040
Преимущества теневого плинтуса в декорировании помещения,
Как правильно установить теневой плинтус своими руками,
Креативные способы использования теневого плинтуса в дизайне помещения,
Модные тренды в выборе теневых плинтусов для современного дома,
Как подобрать цвет теневого плинтуса к отделке стен,
Как спрятать коммуникации с помощью теневого плинтуса: практические советы,
Преимущества использования теневого плинтуса с интегрированной подсветкой,
Современные тренды в использовании теневого плинтуса для уюта и красоты,
Интерьер безупречный до мелочей: роль теневого плинтуса в декоре
плинтус алюминиевый https://plintus-tenevoj-aljuminievyj-msk.ru/ .
ciprofloxacin 500 mg tablets cost
Dive into the superb of high-efficiency invoicing with our top-notch invoice maker app, just right for the go-getters – freelancers and small province owners alike. We’re talking about transforming the habit you handle bills, making it city slicker than ever.
https://apps.apple.com/us/app/invoice-maker-invoices/id6449437040
baclofen buy online canada
ilogidis.com
닭과 원숭이를 죽여야만 다른 사람들이 순종할 수 있습니다.
beste online casino games https://bestegokautomaten.nl/ .
Find Thrilling Bonuses and Bonus Spins: Your Comprehensive Guide
At our gaming platform, we are devoted to providing you with the best gaming experience possible. Our range of bonuses and free spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our amazing deals and what makes them so special.
Lavish Free Spins and Refund Deals
One of our standout offers is the opportunity to earn up to 200 free spins and a 75% refund with a deposit of just $20 or more. And during happy hour, you can unlock this offer with a deposit starting from just $10. This unbelievable promotion allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Deals
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 bonus with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit promotion available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” offers allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these offers provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Bonus Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These free spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our offers are easy to access and beneficial to our players. Our promotions come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these amazing opportunities to enhance your gaming experience. Whether you’re looking to enjoy bonus spins, cashback, or bountiful deposit bonuses, we have something for everyone. Join us today, take advantage of these fantastic offers, and start your journey to big wins and endless fun. Happy gaming!
video games guide
Captivating Innovations and Iconic Releases in the Domain of Digital Entertainment
In the constantly-changing realm of digital entertainment, there’s always something innovative and exciting on the brink. From customizations optimizing cherished timeless titles to new arrivals in renowned franchises, the gaming realm is prospering as in recent memory.
We’ll take a overview into the up-to-date announcements and certain the beloved titles mesmerizing audiences globally.
Newest Announcements
1. Cutting-Edge Mod for Skyrim Optimizes Non-Player Character Look
A freshly-launched modification for Skyrim has captured the focus of enthusiasts. This customization brings realistic heads and hair physics for every (NPCs), optimizing the game’s aesthetics and immersion.
2. Total War Series Game Set in Star Wars Galaxy Universe in Development
The Creative Assembly, renowned for their Total War Series series, is said to be working on a new title placed in the Star Wars galaxy. This engaging combination has enthusiasts awaiting the tactical and captivating gameplay that Total War experiences are celebrated for, finally located in a realm expansive.
3. GTA VI Debut Revealed for Autumn 2025
Take-Two’s Leader has announced that GTA VI is planned to debut in Autumn 2025. With the colossal popularity of its earlier title, GTA V, players are anticipating to experience what the next installment of this renowned universe will offer.
4. Extension Strategies for Skull & Bones Second Season
Designers of Skull and Bones have disclosed expanded plans for the world’s Season Two. This swashbuckling journey provides new updates and enhancements, keeping players immersed and absorbed in the domain of nautical seafaring.
5. Phoenix Labs Developer Faces Staff Cuts
Sadly, not every news is good. Phoenix Labs, the studio responsible for Dauntless, has disclosed significant staff cuts. In spite of this setback, the release remains to be a iconic preference within players, and the developer keeps focused on its fanbase.
Popular Experiences
1. Wild Hunt
With its engaging story, immersive realm, and captivating adventure, The Witcher 3 Game continues to be a iconic experience across enthusiasts. Its deep narrative and vast sandbox persist to engage gamers in.
2. Cyberpunk 2077
Regardless of a rocky debut, Cyberpunk Game stays a long-awaited game. With continuous patches and optimizations, the title persists in evolve, offering fans a perspective into a high-tech setting abundant with danger.
3. Grand Theft Auto 5
Even eras after its first release, Grand Theft Auto 5 continues to be a popular choice amidst fans. Its vast nonlinear world, enthralling narrative, and shared mode sustain enthusiasts returning for more explorations.
4. Portal 2
A renowned analytical title, Portal 2 is praised for its revolutionary gameplay mechanics and brilliant level design. Its demanding conundrums and witty storytelling have established it as a remarkable release in the digital entertainment world.
5. Far Cry
Far Cry is acclaimed as exceptional installments in the universe, offering players an nonlinear journey teeming with excitement. Its captivating narrative and memorable characters have cemented its position as a iconic title.
6. Dishonored Series
Dishonored Game is celebrated for its stealth features and exceptional environment. Fans assume the character of a extraordinary executioner, experiencing a urban environment abundant with societal intrigue.
7. Assassin’s Creed Game
As part of the renowned Assassin’s Creed collection, Assassin’s Creed 2 is revered for its captivating narrative, compelling features, and era-based worlds. It keeps a noteworthy game in the collection and a iconic across fans.
In summary, the universe of videogames is thriving and fluid, with innovative advan
Компания Финэксперт специализируется на предоставлении профессиональных бухгалтерских услуг для предприятий малого и среднего бизнеса. Мы берем на себя все заботы, связанные с учетом и отчетностью, позволяя вам сосредоточиться на развитии своего дела.
Наши специалисты обладают высокой квалификацией и опытом работы в различных сферах бизнеса Наша команда специалистов обладает обширным опытом работы в различных отраслях бизнеса и обладает высокой квалификацией. Мы гарантируем качественное и своевременное выполнение всех необходимых задач, а также всегда следим за изменениями в законодательстве.
Мы предлагаем широкий спектр услуг, включающий в себя
сервис налоговой отчетности
Каждый наш клиент для нас имеет огромное значение, и мы стремимся к долгосрочному и успешному сотрудничеству. Наши цены являются конкурентоспособными, а качество услуг – на высоком уровне.
Для получения более подробной информации, не стесняйтесь обращаться к нашим опытным специалистам по телефону или по электронной почте.
zithromax online buy
Cricket Affiliate: খেলা এবং উপভোগের অনুভূতি
ক্রিকেট ক্যাসিনোতে আপনাকে স্বাগতম! BouncingBall8 এ আপনি একটি অসাধারণ গেমিং অভিজ্ঞতা অংশগ্রহণ করতে পারেন। আমরা আমাদের সদস্যদের জন্য অনেক বিশেষ প্রচার অফার করি যাতে তারা খেলার সুবিধা এবং বোনাস উপভোগ করতে পারে।
আপনি এখানে আছেন তাই আমরা খুবই আনন্দিত! এখানে আমরা আপনাদের জন্য বিভিন্ন বোনাস অফার করছি, যা আপনি প্রথম আমানতের 200% পাবেন, দৈনিক 100% বোনাস পাবেন, এবং লাকি ড্র 10,000 পর্যন্ত বোনাস পাবেন।
আমাদের সাথে যোগ দিন এবং ক্রিকেট ক্যাসিনোতে পুরষ্কার কাটা শুরু করুন – BouncingBall8! আপনি ক্রিকেট affiliate হিসেবে যোগ দিতে পারেন এবং আমাদের অফারগুলি উপভোগ করতে পারেন।
সাথে যোগ দিন এবং একটি অসাধারণ গেমিং অভিজ্ঞতা উপভোগ করুন!
বোনাস এবং প্রচার
আমাদের ক্রিকেট ক্যাসিনোতে আপনি বিশেষ বোনাস এবং প্রচার উপভোগ করতে পারেন। আমরা নিয়মিতভাবে আপনাদের জন্য নতুন অফার এবং সুযোগ প্রদান করি যাতে আপনি আরও বেশি উপভোগ করতে পারেন।
ক্রিকেট ক্যাসিনোতে আমাদের সাথে যোগ দিন এবং আপনার গেমিং অভিজ্ঞতা উন্নত করুন এবং সবচেয়ে জনপ্রিয় খেলা এবং বোনাস পেতে শুরু করুন!
Welcome to Cricket Affiliate | Kick off with a smashing Welcome Bonus !
First Deposit Fiesta! | Make your debut at Cricket Exchange with a 200% bonus.
Daily Doubles! | Keep the scoreboard ticking with a 100% daily bonus at 9wicket!
#cricketaffiliate
IPL 2024 Jackpot! | Stand to win ₹50,000 in the mega IPL draw at cricket world!
Social Sharer Rewards! | Post and earn 100 tk weekly through Crickex affiliate login.
https://www.cricket-affiliate.com/
#cricketexchange #9wicket #crickexaffiliatelogin #crickexlogin
crickex login VIP! | Step up as a VIP and enjoy weekly bonuses!
Join the Action! | Log in through crickex bet exciting betting experience at Live Affiliate.
Dive into the game with crickex live—where every play brings spectacular wins !
Выбор современных мужчин – тактичные штаны, которые подчеркнут вашу индивидуальность.
Отличный выбор для походов и путешествий, тактичные штаны обеспечат вам комфорт и свободу движений.
Надежный пошив и долговечность, сделают тактичные штаны незаменимым атрибутом вашего образа.
Максимальный комфорт и стильный вид, делают тактичные штаны незаменимым вещью в гардеробе каждого мужчины.
Почувствуйте удобство и стиль в тактичных штанах, которые подчеркнут вашу силу и уверенность.
тактичні жіночі штани https://taktichmishtanu.kiev.ua/ .
написать курсовую https://kontrolnyeaudit.ru/
Uncover Exciting Deals and Bonus Spins: Your Ultimate Guide
At our gaming platform, we are dedicated to providing you with the best gaming experience possible. Our range of deals and free rounds ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our amazing promotions and what makes them so special.
Plentiful Free Rounds and Rebate Deals
One of our standout promotions is the opportunity to earn up to 200 bonus spins and a 75% refund with a deposit of just $20 or more. And during happy hour, you can unlock this bonus with a deposit starting from just $10. This incredible promotion allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Promotions
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 bonus with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit promotion available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” offers allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these offers provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Free Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These free spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our promotions are easy to access and beneficial to our players. Our bonuses come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these incredible opportunities to enhance your gaming experience. Whether you’re looking to enjoy free spins, rebate, or generous deposit promotions, we have something for everyone. Join us today, take advantage of these awesome promotions, and start your journey to big wins and endless fun. Happy gaming!
Uncover Thrilling Deals and Extra Spins: Your Comprehensive Guide
At our gaming platform, we are dedicated to providing you with the best gaming experience possible. Our range of promotions and extra spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our amazing offers and what makes them so special.
Lavish Free Spins and Cashback Bonuses
One of our standout promotions is the opportunity to earn up to 200 bonus spins and a 75% cashback with a deposit of just $20 or more. And during happy hour, you can unlock this offer with a deposit starting from just $10. This fantastic promotion allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Offers
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 promotion with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit promotion available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” promotions allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these promotions provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Bonus Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These free spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our offers are easy to access and beneficial to our players. Our bonuses come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these amazing opportunities to enhance your gaming experience. Whether you’re looking to enjoy free spins, rebate, or bountiful deposit bonuses, we have something for everyone. Join us today, take advantage of these incredible promotions, and start your journey to big wins and endless fun. Happy gaming!
fluconazole buy online without prescription
Mostbet https://mostbet-bk.cz/sazkove-kancelare-mostbet/ je jako vas osobni sampion, ktery vam pomaha vyhrat.
Betvisa অ্যাফিলিয়েট লগইন: একটি সহজ প্রক্রিয়া
Betvisa অ্যাফিলিয়েট লগইন অ্যাক্সেস করা দ্রুত এবং সহজ। অ্যাফিলিয়েটরা শুরু করতে এই সহজ পদক্ষেপগুলি অনুসরণ করতে পারেন।
সাইন আপ: Betvisa ওয়েবসাইটে যান এবং অ্যাফিলিয়েট বিভাগে নেভিগেট করুন। প্রয়োজনীয় তথ্য প্রদান করে এবং শর্তাবলীতে সম্মত হয়ে নিবন্ধন প্রক্রিয়াটি সম্পূর্ণ করুন।
অনুমোদন প্রাপ্ত করুন: একবার আপনার অ্যাফিলিয়েট অ্যাকাউন্ট পর্যালোচনা এবং Betvisa টিম দ্বারা অনুমোদিত হলে, আপনি অ্যাফিলিয়েট প্ল্যাটফর্ম অ্যাক্সেস করার জন্য লগইন শংসাপত্র পাবেন।
লগইন করুন এবং শুরু করুন: Betvisa অ্যাফিলিয়েট লগইন পোর্টাল অ্যাক্সেস করতে আপনার লগইন শংসাপত্রগুলি ব্যবহার করুন। সেখান থেকে, আপনি বিভিন্ন বিপণন সরঞ্জামগুলি অন্বেষণ করতে পারেন, আপনার কর্মক্ষমতা ট্র্যাক করতে পারেন এবং সম্ভাব্য খেলোয়াড়দের কাছে Betvisa প্রচার শুরু করতে পারেন।
Betvisa বাংলাদেশ ব্যবহারকারীদের জন্য, Betvisa অ্যাফিলিয়েট লগইন অ্যাক্সেস করা একটি সহজ প্রক্রিয়া। তারা সহজেই লগইন করে গেমগুলিতে অংশগ্রহণ এবং কমিশন উপার্জন করতে পারেন।
অনলাইন বেটিংয়ে আপনার বিপণন উদ্যোগকে প্রসারিত করতে এবং উপার্জন বৃদ্ধি করতে, Betvisa অ্যাফিলিয়েট প্রোগ্রামটি একটি সুযোগ-সম্পন্ন পছন্দ হতে পারে। সহজ লগইন প্রক্রিয়ার মাধ্যমে, আপনি কার্যকরভাবে এই লাভজনক প্ল্যাটফর্মে যোগদান করতে পারেন।
Betvisa Bet | Hit it Big This IPL Season with Betvisa!
Betvisa login! | Every deposit during IPL matches earns a 2% bonus .
Betvisa Bangladesh! | IPL 2024 action heats up, your bets get more rewarding!
Crash Game returns! | huge ₹10 million jackpot. Take the lead on the Betvisa app !
#betvisa
Start Winning Now! | Sign up through Betvisa affiliate login, claim ₹500 free cash.
Grab Your Winning Ticket! | Register login and win ₹8,888 at visa bet!
https://www.betvisa-bet.com/bn
#visabet #betvisalogin #betvisabangladesh#betvisaapp
200% Excitement! | Enjoy slots and fishing games at Betvisa লগইন করুন!
Big Sports Bonuses! | Score up to ₹5,000 in sports bonuses during the IPL season
Gear up for an exhilarating IPL season at Betvisa, propels you towards victory!
матрасы цена матрасы цена .
https://rybalka-v-rossii.ru/ – сайт о рыбалке в России, способах ловли рыб, и выборе правильных снастей.
retin a india
borju89
borju89
how to buy provigil without a prescription
가네샤 골드
그의 손에 남은 귀중한 지폐는 수백 냥 밖에 남지 않았습니다. 이것이 마지막 재산입니다.
video games guide
Thrilling Advancements and Renowned Titles in the Realm of Gaming
In the fluid realm of gaming, there’s continuously something innovative and thrilling on the brink. From mods improving beloved timeless titles to new debuts in legendary franchises, the videogame ecosystem is thriving as in recent memory.
We’ll take a snapshot into the newest announcements and a few of the renowned titles enthralling fans across the globe.
Latest News
1. Innovative Modification for Skyrim Optimizes Non-Player Character Appearance
A newly-released enhancement for Skyrim has captured the focus of gamers. This modification brings realistic faces and hair physics for each non-player entities, elevating the game’s graphics and engagement.
2. Total War Games Experience Set in Star Wars Universe Realm In the Works
The Creative Assembly, known for their Total War Games lineup, is said to be working on a upcoming game placed in the Star Wars Universe realm. This captivating combination has enthusiasts looking forward to the analytical and compelling experience that Total War Games releases are acclaimed for, ultimately situated in a world expansive.
3. GTA VI Release Confirmed for Fall 2025
Take-Two’s CEO has communicated that GTA VI is set to release in Late 2025. With the colossal acclaim of its prior release, GTA V, players are eager to witness what the forthcoming installment of this renowned universe will bring.
4. Enlargement Plans for Skull & Bones 2nd Season
Designers of Skull & Bones have announced amplified initiatives for the experience’s second season. This pirate-themed adventure provides new updates and enhancements, keeping players engaged and enthralled in the domain of nautical swashbuckling.
5. Phoenix Labs Studio Undergoes Personnel Cuts
Disappointingly, not all news is positive. Phoenix Labs Developer, the team behind Dauntless Game, has revealed substantial personnel cuts. Despite this obstacle, the experience persists to be a beloved selection among fans, and the company remains committed to its audience.
Popular Releases
1. The Witcher 3: Wild Hunt Game
With its immersive plot, captivating domain, and captivating adventure, Wild Hunt remains a cherished release amidst gamers. Its intricate plot and wide-ranging free-roaming environment persist to draw players in.
2. Cyberpunk Game
Regardless of a challenging debut, Cyberpunk Game stays a long-awaited release. With constant enhancements and fixes, the release continues to evolve, providing fans a view into a futuristic world rife with intrigue.
3. GTA 5
Even decades after its first release, Grand Theft Auto V keeps a popular choice among players. Its vast nonlinear world, engaging plot, and online experiences continue to draw fans reengaging for further explorations.
4. Portal 2
A iconic brain-teasing game, Portal 2 Game is praised for its pioneering mechanics and brilliant environmental design. Its intricate conundrums and witty writing have made it a noteworthy game in the gaming landscape.
5. Far Cry 3 Game
Far Cry Game is praised as among the finest entries in the franchise, providing players an sandbox exploration abundant with danger. Its compelling experience and memorable personalities have cemented its status as a iconic release.
6. Dishonored
Dishonored Series is praised for its covert mechanics and distinctive environment. Players adopt the identity of a extraordinary assassin, navigating a city filled with governmental intrigue.
7. Assassin’s Creed
As a member of the acclaimed Assassin’s Creed Series collection, Assassin’s Creed is adored for its immersive narrative, enthralling features, and historical settings. It stays a standout title in the universe and a cherished within players.
In final remarks, the world of interactive entertainment is thriving and dynamic, with groundbreaking developments
top casino’s https://bestegokautomaten.nl .
Engaging Developments and Beloved Games in the Sphere of Interactive Entertainment
In the ever-evolving realm of gaming, there’s continuously something groundbreaking and exciting on the horizon. From mods elevating cherished mainstays to forthcoming releases in legendary brands, the gaming industry is as vibrant as in current times.
Let’s take a look into the up-to-date developments and specific the iconic releases enthralling audiences globally.
Most Recent News
1. Innovative Enhancement for The Elder Scrolls V: Skyrim Improves Non-Player Character Look
A freshly-launched enhancement for The Elder Scrolls V: Skyrim has captured the interest of fans. This customization adds detailed faces and dynamic hair for each supporting characters, elevating the title’s aesthetics and immersiveness.
2. Total War Release Set in Star Wars Universe Being Developed
Creative Assembly, famous for their Total War Games lineup, is supposedly crafting a anticipated game set in the Star Wars Galaxy realm. This captivating integration has fans awaiting the profound and captivating experience that Total War Series titles are renowned for, now set in a galaxy far, far away.
3. Grand Theft Auto VI Debut Confirmed for Fall 2025
Take-Two’s CEO’s Head has confirmed that Grand Theft Auto VI is planned to debut in Fall 2025. With the enormous popularity of its prior release, GTA V, enthusiasts are anticipating to experience what the upcoming installment of this renowned series will offer.
4. Enlargement Plans for Skull & Bones Season Two
Developers of Skull & Bones have announced broader initiatives for the game’s Season Two. This pirate-themed experience offers new updates and changes, keeping players invested and absorbed in the world of high-seas piracy.
5. Phoenix Labs Developer Experiences Personnel Cuts
Unfortunately, not everything announcements is positive. Phoenix Labs, the team behind Dauntless Experience, has communicated massive workforce reductions. Despite this setback, the title remains to be a iconic selection among gamers, and the team continues to be committed to its playerbase.
Beloved Games
1. The Witcher 3: Wild Hunt
With its engaging experience, absorbing universe, and enthralling experience, Wild Hunt keeps a beloved experience across players. Its intricate plot and sprawling nonlinear world keep to captivate fans in.
2. Cyberpunk 2077
In spite of a problematic arrival, Cyberpunk continues to be a long-awaited game. With ongoing enhancements and enhancements, the experience persists in advance, providing fans a perspective into a cyberpunk environment teeming with mystery.
3. Grand Theft Auto V
Still years after its original arrival, GTA V stays a renowned option across fans. Its vast sandbox, engaging story, and online experiences sustain gamers revisiting for more journeys.
4. Portal 2 Game
A legendary problem-solving release, Portal Game is renowned for its revolutionary gameplay mechanics and brilliant map design. Its complex obstacles and witty narrative have cemented it as a noteworthy game in the digital entertainment landscape.
5. Far Cry 3 Game
Far Cry is hailed as a standout installments in the franchise, presenting fans an sandbox exploration rife with excitement. Its immersive narrative and renowned entities have confirmed its standing as a iconic title.
6. Dishonored Universe
Dishonored is acclaimed for its stealthy mechanics and distinctive setting. Gamers take on the identity of a supernatural killer, traversing a metropolis rife with societal peril.
7. Assassin’s Creed II
As a segment of the iconic Assassin’s Creed Franchise lineup, Assassin’s Creed II is adored for its immersive experience, captivating mechanics, and period environments. It keeps a standout game in the franchise and a cherished amidst players.
In conclusion, the domain of videogames is prospering and dynamic, with fresh developments
retin a where to buy uk
Euro 2024
supermoney88
sunmory33
sunmory33
라이즈 오브 올림푸스
Fang Jifan이 첫 번째 자리에 앉았고 나머지는 순서대로 앉았습니다.
ANGKOT88: Situs Game Deposit Pulsa Terbaik di Indonesia
ANGKOT88 adalah situs game deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai jenis game online terlengkap yang dapat Anda mainkan hanya dengan mendaftar satu ID. Dengan satu ID tersebut, Anda dapat mengakses seluruh permainan yang tersedia di situs kami.
Sebagai situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), ANGKOT88 menjamin keamanan dan kenyamanan Anda. Situs kami didukung oleh server hosting yang cepat dan sistem keamanan dengan metode enkripsi terbaru di dunia, sehingga data Anda akan selalu terjaga keamanannya. Tampilan situs yang modern juga membuat Anda merasa nyaman saat mengakses situs kami.
Keunggulan ANGKOT88
Selain menjadi situs game online terbaik, ANGKOT88 juga menawarkan layanan praktis untuk melakukan deposit menggunakan pulsa XL ataupun Telkomsel dengan potongan terendah dibandingkan situs lainnya. Ini menjadikan kami salah satu situs game online pulsa terbesar di Indonesia. Anda juga dapat melakukan deposit pulsa melalui E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kepercayaan dan Layanan
Kami di ANGKOT88 sangat menjaga kepercayaan Anda sebagai prioritas utama kami. Oleh karena itu, kami selalu berusaha menjadi agen online terpercaya dan terbaik sepanjang masa. Permainan game online yang kami tawarkan sangat praktis, sehingga Anda dapat memainkannya kapan saja dan di mana saja tanpa perlu repot bepergian. Kami menyediakan berbagai jenis game, termasuk yang disiarkan secara LIVE (langsung) dengan host cantik dan kamera yang merekam secara real-time, menjadikan ANGKOT88 situs game online terlengkap dan terbesar di Indonesia.
Promo Menarik dan Menguntungkan
ANGKOT88 juga menawarkan banyak sekali promo menarik dan menguntungkan. Anda bisa menikmati berbagai macam promo yang sesuai dengan kebutuhan Anda, seperti welcome bonus 20%, bonus deposit harian, dan cashback. Semua promo ini tersedia di situs ANGKOT88. Selain itu, kami juga memiliki layanan Customer Service yang siap membantu Anda kapan saja.
Jadi, tunggu apa lagi? Bergabunglah dengan ANGKOT88 dan nikmati pengalaman bermain game online terbaik dan teraman di Indonesia. Daftarkan diri Anda sekarang dan mulai mainkan game favorit Anda dengan nyaman dan aman di situs kami!
baclofen 200 mg price
top casinos bestegokautomaten.nl .
https://autoblog.kyiv.ua путеводитель в мире автомобилей. Обзоры и тест-драйвы, актуальные новости, автокаталог, советы по уходу и ремонту, а также общение с автолюбителями. Всё, что нужно для выбора и эксплуатации авто, вы найдете у нас.
diflucan otc usa
Betvisa সহযোগী প্রোগ্রাম: একটি লাভজনক অংশীদারিত্ব
বেটিভিসার সাথে সহযোগী হিসেবে অংশীদারিত্ব করতে আগ্রহী ব্যক্তিদের জন্য, সুবিধাগুলি সমানভাবে লোভনীয়। Betvisa অ্যাফিলিয়েট প্রোগ্রামে যোগদান করে এবং Betvisa অ্যাফিলিয়েট লগইন অ্যাক্সেস করার মাধ্যমে, অ্যাফিলিয়েটরা অনেক সুযোগ লাভ করে।
লাভজনক কমিশন কাঠামো: বেটিভিসা একটি প্রতিযোগিতামূলক কমিশন কাঠামো অফার করে, যা অ্যাফিলিয়েটদের প্ল্যাটফর্মে উল্লেখ করা খেলোয়াড়দের দ্বারা উত্পন্ন রাজস্বের উপর ভিত্তি করে আকর্ষণীয় কমিশন উপার্জন করতে দেয়। উচ্চ উপার্জনের সম্ভাবনার সাথে, একটি Betvisa অনুমোদিত হওয়া একটি লাভজনক উদ্যোগ হতে পারে।
বিস্তৃত বিপণন সরঞ্জাম: Betvisa তার সহযোগীদেরকে প্ল্যাটফর্মটিকে কার্যকরভাবে প্রচার করতে সহায়তা করার জন্য বিপণন সরঞ্জাম এবং সংস্থানগুলির একটি স্যুট দিয়ে সজ্জিত করে। ব্যানার এবং ল্যান্ডিং পৃষ্ঠা থেকে শুরু করে ট্র্যাকিং লিঙ্ক এবং কাস্টমাইজড প্রচারমূলক সামগ্রী, অ্যাফিলিয়েটদের কাছে ট্র্যাফিক চালনা করতে এবং রূপান্তরগুলি সর্বাধিক করার জন্য প্রয়োজনীয় সবকিছুই রয়েছে৷
ডেডিকেটেড সাপোর্ট: বেটভিসা তার সহযোগীদের নিবেদিত সমর্থন প্রদান করে, নিশ্চিত করে যে তারা যখনই প্রয়োজন তখনই দ্রুত সহায়তা এবং নির্দেশনা পায়। প্রযুক্তিগত সমস্যার সমাধান হোক, বিপণন কৌশল অপ্টিমাইজ করা হোক বা প্রশ্নের উত্তর দেওয়া হোক, Betvisa অ্যাফিলিয়েট দল প্রতিটি পদক্ষেপে অ্যাফিলিয়েটদের সমর্থন করতে প্রতিশ্রুতিবদ্ধ।
রিয়েল-টাইম রিপোর্টিংয়ে অ্যাক্সেস: অ্যাফিলিয়েটদের ব্যাপক রিপোর্টিং টুলগুলিতে অ্যাক্সেস রয়েছে যা তাদের রিয়েল-টাইমে তাদের কর্মক্ষমতা ট্র্যাক করতে দেয়। ক্লিক এবং রূপান্তর নিরীক্ষণ থেকে উপার্জন এবং প্লেয়ার কার্যকলাপ বিশ্লেষণ থেকে, অধিভুক্তরা তাদের কৌশলগুলি অপ্টিমাইজ করতে এবং তাদের উপার্জনের সম্ভাবনাকে সর্বাধিক করার জন্য মূল্যবান অন্তর্দৃষ্টি অর্জন করতে পারে।
Betvisa অ্যাফিলিয়েট লগইন সুবিধা এবং এই ব্যুত্থানকর সুবিধাগুলির সমন্বয়ে, Betvisa সহযোগী প্রোগ্রাম একটি অসাধারণ অর্থনৈতিক সুযোগ সৃষ্টি করে। প্ল্যাটফর্মটির বিপণনে যোগদানের অর্থ শুধুমাত্র এক লাভজনক একক নয়, বরং একটি দীর্ঘস্থায়ী লাভজনক উদ্যোগ হতে পারে।
Betvisa Bet | Hit it Big This IPL Season with Betvisa!
Betvisa login! | Every deposit during IPL matches earns a 2% bonus .
Betvisa Bangladesh! | IPL 2024 action heats up, your bets get more rewarding!
Crash Game returns! | huge ₹10 million jackpot. Take the lead on the Betvisa app !
#betvisa
Start Winning Now! | Sign up through Betvisa affiliate login, claim ₹500 free cash.
Grab Your Winning Ticket! | Register login and win ₹8,888 at visa bet!
https://www.betvisa-bet.com/bn
#visabet #betvisalogin #betvisabangladesh#betvisaapp
200% Excitement! | Enjoy slots and fishing games at Betvisa লগইন করুন!
Big Sports Bonuses! | Score up to ₹5,000 in sports bonuses during the IPL season
Gear up for an exhilarating IPL season at Betvisa, propels you towards victory!
SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
SUPERMONEY88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di SUPERMONEY88.
Keunggulan SUPERMONEY88
SUPERMONEY88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Layanan Praktis dan Terpercaya
Selain menjadi game online terbaik, ada alasan mengapa situs SUPERMONEY88 ini sangat spesial. Kami memberikan layanan praktis untuk melakukan deposit yaitu dengan melakukan deposit pulsa XL ataupun Telkomsel dengan potongan terendah dari situs game online lainnya. Ini membuat situs kami menjadi salah satu situs game online pulsa terbesar di Indonesia. Anda bisa melakukan deposit pulsa menggunakan E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kami juga terkenal sebagai agen game online terpercaya. Kepercayaan Anda adalah prioritas kami, dan itulah yang membuat kami menjadi agen game online terbaik sepanjang masa.
Kemudahan Bermain Game Online
Permainan game online di SUPERMONEY88 memudahkan Anda untuk memainkannya dari mana saja dan kapan saja. Anda tidak perlu repot bepergian lagi, karena SUPERMONEY88 menyediakan beragam jenis game online. Kami juga memiliki jenis game online yang dipandu oleh host cantik, sehingga Anda tidak akan merasa bosan.
В вебе большое наличность анализаторов веб-сайта, качество труда коию напрямую зависит через тарифных планов.
https://be1.ru/ – бобику
https://ktm.org.ua/ у нас вы найдете свежие новости, аналитические статьи, эксклюзивные интервью и мнения экспертов. Будьте в курсе событий и тенденций, следите за развитием ситуации в реальном времени. Присоединяйтесь к нашему сообществу читателей!
sapporo88
SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
SUPERMONEY88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di SUPERMONEY88.
Keunggulan SUPERMONEY88
SUPERMONEY88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Layanan Praktis dan Terpercaya
Selain menjadi game online terbaik, ada alasan mengapa situs SUPERMONEY88 ini sangat spesial. Kami memberikan layanan praktis untuk melakukan deposit yaitu dengan melakukan deposit pulsa XL ataupun Telkomsel dengan potongan terendah dari situs game online lainnya. Ini membuat situs kami menjadi salah satu situs game online pulsa terbesar di Indonesia. Anda bisa melakukan deposit pulsa menggunakan E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kami juga terkenal sebagai agen game online terpercaya. Kepercayaan Anda adalah prioritas kami, dan itulah yang membuat kami menjadi agen game online terbaik sepanjang masa.
Kemudahan Bermain Game Online
Permainan game online di SUPERMONEY88 memudahkan Anda untuk memainkannya dari mana saja dan kapan saja. Anda tidak perlu repot bepergian lagi, karena SUPERMONEY88 menyediakan beragam jenis game online. Kami juga memiliki jenis game online yang dipandu oleh host cantik, sehingga Anda tidak akan merasa bosan.
sunmory33
sunmory33
PRO88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
PRO88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di PRO88.
Keunggulan PRO88
PRO88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Berbagai Macam Game Online
Kami menyediakan berbagai macam game online terbaik yang bisa Anda mainkan kapan saja dan di mana saja. Dengan satu ID, Anda bisa menikmati semua permainan yang tersedia, mulai dari permainan kartu, slot, hingga taruhan olahraga. PRO88 memastikan semua game yang kami sediakan adalah yang terbaik dan terlengkap di Indonesia.
Keamanan dan Kenyamanan
Kami memahami betapa pentingnya keamanan dan kenyamanan bagi para pemain. Oleh karena itu, PRO88 menggunakan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia. Ini memastikan bahwa data pribadi dan transaksi Anda selalu aman bersama kami. Tampilan situs yang modern juga dirancang untuk memberikan pengalaman bermain yang nyaman dan menyenangkan.
Kesimpulan
PRO88 adalah pilihan terbaik untuk Anda yang mencari situs game online deposit pulsa yang aman dan terpercaya. Dengan berbagai macam game online terbaik dan terlengkap, serta dukungan keamanan yang canggih, PRO88 siap memberikan pengalaman bermain game yang tak terlupakan. Daftar sekarang juga di PRO88 dan nikmati semua permainan yang tersedia hanya dengan satu ID.
Kunjungi kami di PRO88 dan mulailah petualangan game online Anda bersama kami!
supermoney88
order amoxicillin online uk
100mg baclofen
Советы по оптимизации продвижению.
Информация о том как управлять с низкочастотными запросами запросами и как их определять
Тактика по действиям в соперничающей нише.
Обладаю постоянных клиентов взаимодействую с 3 организациями, есть что сообщить.
Посмотрите мой профиль, на 31 мая 2024г
число выполненных работ 2181 только на этом сайте.
Консультация проходит устно, без скриншотов и отчетов.
Время консультации указано 2 часа, но по сути всегда на связи без строгой привязки к графику.
Как взаимодействовать с ПО это уже иначе история, консультация по работе с программами оговариваем отдельно в другом разделе, определяем что нужно при разговоре.
Всё без суеты на без напряжения не торопясь
To get started, the seller needs:
Мне нужны контакты от телеграмм каналов для контакта.
общение только в устной форме, общаться письменно нету времени.
субботы и Вс выходной
https://kursovyemetrologiya.ru
에그벳 계열
왕수인: “스승님, 잊으십시오. 다른 사람을 용서하고 다른 사람을 용서해야 합니다.”
sunmory33
sunmory33
купить реальную секс куклу https://24sexy-dolls.ru
https://fraza.kyiv.ua/ вы найдете последние новости, глубокие аналитические материалы, интервью с влиятельными личностями и экспертные мнения. Следите за важными событиями и трендами в реальном времени. Присоединяйтесь к нашему сообществу и будьте информированы!
angkot88
ANGKOT88: Situs Game Deposit Pulsa Terbaik di Indonesia
ANGKOT88 adalah situs game deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai jenis game online terlengkap yang dapat Anda mainkan hanya dengan mendaftar satu ID. Dengan satu ID tersebut, Anda dapat mengakses seluruh permainan yang tersedia di situs kami.
Sebagai situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), ANGKOT88 menjamin keamanan dan kenyamanan Anda. Situs kami didukung oleh server hosting yang cepat dan sistem keamanan dengan metode enkripsi terbaru di dunia, sehingga data Anda akan selalu terjaga keamanannya. Tampilan situs yang modern juga membuat Anda merasa nyaman saat mengakses situs kami.
Keunggulan ANGKOT88
Selain menjadi situs game online terbaik, ANGKOT88 juga menawarkan layanan praktis untuk melakukan deposit menggunakan pulsa XL ataupun Telkomsel dengan potongan terendah dibandingkan situs lainnya. Ini menjadikan kami salah satu situs game online pulsa terbesar di Indonesia. Anda juga dapat melakukan deposit pulsa melalui E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kepercayaan dan Layanan
Kami di ANGKOT88 sangat menjaga kepercayaan Anda sebagai prioritas utama kami. Oleh karena itu, kami selalu berusaha menjadi agen online terpercaya dan terbaik sepanjang masa. Permainan game online yang kami tawarkan sangat praktis, sehingga Anda dapat memainkannya kapan saja dan di mana saja tanpa perlu repot bepergian. Kami menyediakan berbagai jenis game, termasuk yang disiarkan secara LIVE (langsung) dengan host cantik dan kamera yang merekam secara real-time, menjadikan ANGKOT88 situs game online terlengkap dan terbesar di Indonesia.
Promo Menarik dan Menguntungkan
ANGKOT88 juga menawarkan banyak sekali promo menarik dan menguntungkan. Anda bisa menikmati berbagai macam promo yang sesuai dengan kebutuhan Anda, seperti welcome bonus 20%, bonus deposit harian, dan cashback. Semua promo ini tersedia di situs ANGKOT88. Selain itu, kami juga memiliki layanan Customer Service yang siap membantu Anda kapan saja.
Jadi, tunggu apa lagi? Bergabunglah dengan ANGKOT88 dan nikmati pengalaman bermain game online terbaik dan teraman di Indonesia. Daftarkan diri Anda sekarang dan mulai mainkan game favorit Anda dengan nyaman dan aman di situs kami!
bocor88
bocor88
https://7krasotok.com здесь вы найдете статьи о моде, красоте, здоровье, отношениях и карьере. Читайте советы экспертов, участвуйте в обсуждениях и вдохновляйтесь новыми идеями. Присоединяйтесь к нашему сообществу женщин, стремящихся к совершенству!
https://bestwoman.kyiv.ua узнайте всё о моде, красоте, здоровье и личностном росте. Читайте вдохновляющие истории, экспертные советы и актуальные новости. Присоединяйтесь к нашему сообществу женщин, живущих яркой и насыщенной жизнью!
https://prowoman.kyiv.ua на нашем сайте вы найдете полезные советы по моде, красоте, здоровью и отношениям. Читайте вдохновляющие статьи, участвуйте в обсуждениях и обменивайтесь идеями. Присоединяйтесь к нашему сообществу современных женщин!
https://superwoman.kyiv.ua вы на нашем надежном гиде в мире женской красоты и стиля жизни! У нас вы найдете актуальные статьи о моде, красоте, здоровье, а также советы по саморазвитию и карьерному росту. Присоединяйтесь к нам и обретайте новые знания и вдохновение каждый день!
buy tiktok views live Buy TikTok Live Views
раскрутка сайтов в москва https://www.prodvizhenie-sajtov-v-moskve111.ru .
решения задач на заказ https://resheniezadachmatematika.ru/
vermox pharmacy
курсовые на заказ https://kursovyematematika.ru
線上娛樂城的天地
隨著網際網路的迅速發展,在線娛樂城(網上賭場)已經成為許多人消遣的新選擇。在線娛樂城不僅提供多元化的游戲選擇,還能讓玩家在家中就能體驗到賭場的樂趣和樂趣。本文將探討網上娛樂城的特點、好處以及一些常見的遊戲。
什麼在線娛樂城?
網上娛樂城是一種透過互聯網提供賭博遊戲的平台。玩家可以通過計算機、手機或平板設備進入這些網站,參與各種賭博活動,如撲克、輪盤、黑傑克和老虎机等。這些平台通常由專業的軟件公司開發,確保游戲的公平性和安全。
在線娛樂城的優勢
便利:玩家無需離開家,就能享用賭博的快感。這對於那些住在在遠離的實體賭場地方的人來說尤為方便。
多種的遊戲選擇:在線娛樂城通常提供比實體賭場更多樣化的遊戲選擇,並且經常更新遊戲內容,保持新鮮感。
優惠和獎勵:許多網上娛樂城提供多樣的獎金計劃,包括註冊獎金、存款獎金和會員計劃,吸引新玩家並激勵老玩家不斷遊戲。
安全和隱私性:正規的網上娛樂城使用先進的的加密方法來保護玩家的個人資料和金融交易,確保游戲過程的公平和公正性。
常有的在線娛樂城游戲
撲克:撲克牌是最受歡迎的賭錢遊戲之一。線上娛樂城提供多種撲克變體,如德州撲克、奧馬哈撲克和七張牌等。
賭盤:輪盤賭是一種古老的賭場遊戲遊戲,玩家可以下注在數字、數字組合或顏色選擇上,然後看轉球落在哪個位置。
黑傑克:又稱為21點,這是一種比拼玩家和莊家點數的遊戲,目標是讓手牌點數盡量接近21點但不超過。
老虎机:吃角子老虎是最簡單也是最受歡迎的賭博遊戲之一,玩家只需轉捲軸,看圖案排列出獲勝的組合。
總結
網上娛樂城為現代賭博愛好者提供了一個方便、刺激的且多元化的娛樂方式。不管是撲克愛好者還是老虎机愛好者,大家都能在這些平台上找到適合自己的游戲。同時,隨著科技的不斷發展,線上娛樂城的遊戲體驗將變得越來越越來越現實和吸引人。然而,玩家在體驗遊戲的同時,也應該保持,避免過度沉迷於賭錢活動,維持健康的娛樂心態。
娛樂城
線上娛樂城的天地
隨著互聯網的快速發展,在線娛樂城(線上賭場)已經成為許多人消遣的新選擇。網上娛樂城不僅提供多元化的遊戲選擇,還能讓玩家在家中就能體驗到賭場的興奮和樂趣。本文將討論在線娛樂城的特色、利益以及一些常見的的遊戲。
什麼網上娛樂城?
在線娛樂城是一種經由互聯網提供賭博遊戲的平台。玩家可以通過電腦設備、手機或平板進入這些網站,參與各種博彩活動,如撲克牌、輪盤賭、21點和老虎机等。這些平台通常由專業的的軟體公司開發,確保游戲的公平性和穩定性。
在線娛樂城的好處
便利:玩家無需離開家,就能體驗賭錢的快感。這對於那些居住在遠離實體賭場區域的人來說尤其方便。
多樣化的游戲選擇:網上娛樂城通常提供比實體賭場更豐富的游戲選擇,並且經常升級游戲內容,保持新鮮。
好處和獎勵:許多網上娛樂城提供豐富的獎勵計劃,包括註冊紅利、存款獎金和忠誠計劃,吸引新新玩家並鼓勵老玩家繼續遊戲。
安全性和保密性:正當的線上娛樂城使用先進的加密技術來保護玩家的個人資料和金融交易,確保遊戲過程的公平和公正性。
常有的網上娛樂城遊戲
德州撲克:德州撲克是最流行賭博遊戲之一。在線娛樂城提供各種德州撲克變體,如德州扑克、奧馬哈撲克和七張牌撲克等。
輪盤賭:賭盤是一種古老的賭場遊戲遊戲,玩家可以投注在單數、數字組合或顏色選擇上,然後看轉球落在哪個位置。
21點:又稱為二十一點,這是一種對比玩家和莊家點數的遊戲,目標是讓手牌點數點數盡量接近21點但不超過。
吃角子老虎:老虎机是最簡單且是最流行的賭錢遊戲之一,玩家只需轉動捲軸,看圖案排列出獲勝的組合。
結論
網上娛樂城為當代賭博愛好者提供了一個方便的、興奮且豐富的娛樂方式。無論是撲克迷還是吃角子老虎迷,大家都能在這些平台上找到適合自己的遊戲。同時,隨著技術的不斷發展,在線娛樂城的遊戲體驗將變得越來越越來越真實和吸引人。然而,玩家在享受遊戲的同時,也應該保持自律,避免過度沉迷於博彩活動,保持健康的娛樂心態。
стратегия продвижения сайта
Консультация по оптимизации продвижению.
Информация о том как работать с низкочастотными запросами ключевыми словами и как их определять
Тактика по деятельности в конкурентной нише.
У меня есть постоянных клиентов работаю с тремя компаниями, есть что рассказать.
Изучите мой аккаунт, на 31 мая 2024г
число успешных проектов 2181 только здесь.
Консультация проходит в устной форме, никаких снимков с экрана и документов.
Продолжительность консультации указано 2 часа, но по сути всегда на доступен без жёсткой привязки к графику.
Как работать с программным обеспечением это уже другая история, консультация по использованию ПО оговариваем отдельно в другом услуге, определяем что необходимо при общении.
Всё спокойно на без напряжения не в спешке
To get started, the seller needs:
Мне нужны данные от телеграмм чата для контакта.
коммуникация только в устной форме, общаться письменно недостаточно времени.
Суббота и воскресенья нерабочие дни
Сайт https://zhenskiy.kyiv.ua – це онлайн-ресурс, який присвячений жіночим темам та інтересам. Тут зібрана інформація про моду, красу, здоров’я, відносини, кулінарію та багато іншого, що може бути корисним та цікавим для сучасних жінок.
추자현 마약 연기
빠릿한 충환전 서비스와 더불어 메이저업체의 안전성
베팅사이트 접속 시 핵심적인 요소는 신속한 충환전 프로세스입니다. 일반적으로 3분 안에 입금, 열 분 안에 출금이 완수되어야 합니다. 메이저 메이저업체들은 충분한 스태프 고용을 통해 이와 같은 빠른 충환전 절차를 보장하며, 이로써 사용자들에게 안도감을 드립니다. 주요사이트를 접속하면서 빠른 체감을 즐겨보세요. 저희는 여러분이 안심하고 사이트를 사용할 수 있도록 도와드리는 먹튀해결사입니다.
보증금 걸고 배너를 운영
먹튀해결사는 적어도 삼천만 원부터 억대의 보증금을 예치하고 있는 업체들의 배너 광고를 운영합니다. 혹시 먹튀 사고가 생길 경우, 배팅 규정에 어긋나지 않은 베팅 내역을 스크린샷을 찍어 먹튀해결사에 연락 주시면, 확인 후 보증금으로 즉시 피해 보상을 처리해 드립니다. 피해 발생 시 즉시 스크린샷을 찍어 피해 내용을 저장해 두시고 제출해 주세요.
장기 운영 안전업체 확인
먹튀해결사는 최대한 사 년 이상 먹튀 사고 없이 안정적으로 운영하고 있는 업체만을 확인하여 배너 등록을 허가합니다. 이로 인해 어느 누구나 잘 알려진 메이저사이트를 안전하게 이용할 수 있는 기회를 제공하고 있습니다. 엄격한 검사 작업을 통해 확인된 사이트를 놓치지 마시고, 보안된 베팅을 경험해보세요.
투명하고 공정한 먹튀 검토
먹튀 해결 전문가의 먹튀 검증은 공정성과 공정을 근거로 실시합니다. 늘 사용자들의 의견을 우선으로 생각하고, 기업의 유혹이나 이익에 좌우되지 않고 하나의 삭제 없이 진실만을 근거로 검증해왔습니다. 먹튀 문제를 당하고 후회하지 않도록, 지금 바로 시작하세요.
먹튀 검증 사이트 목록
먹튀 해결 전문가가 선별한 안전한 베팅사이트 검증업체 목록 입니다. 현재 등록되어 있는 검증업체들은 먹튀 사고 발생 시 100% 보장을 도와드립니다. 그러나, 제휴가 끝난 업체에서 발생한 사고에 대해서는 책임을 지지 않습니다.
탁월한 먹튀 검증 알고리즘
먹튀 해결 팀은 공정한 도박 문화를 조성하기 위해 항상 애쓰고 있습니다. 저희가 소개하는 베팅사이트에서 안심하고 배팅하세요. 사용자의 먹튀 신고 내용은 먹튀 리스트에 기재되어 해당되는 토토사이트에 심각한 영향을 끼칩니다. 먹튀 목록 작성 시 먹튀블러드만의 검증 노하우를 최대한 활용하여 공정한 심사를 하도록 하겠습니다.
안전한 베팅 환경을 만들기 위해 끊임없이 노력하는 먹튀 해결 팀과 같이 안전하게 경험해보세요.
заказать курсовую онлайн https://kursovyebankovskoe.ru/
가네샤 골드
손이 많이 가는 작품인데 더 많은 분들이 봐주셨으면 좋겠어요.
Доставка цветов в Саратове https://flowers64.ru/ это отличная возможность заказать различные цветы, букеты, композиции, подарки, не выходя из дома.
Советы по сео продвижению.
Информация о том как работать с низкочастотными запросами и как их выбирать
Тактика по работе в конкурентоспособной нише.
Обладаю постоянных взаимодействую с тремя организациями, есть что поделиться.
Изучите мой досье, на 31 мая 2024г
количество успешных проектов 2181 только в этом профиле.
Консультация только устно, без снимков с экрана и документов.
Время консультации указано 2 часа, но по реально всегда на контакте без твердой привязки к графику.
Как управлять с программным обеспечением это уже отдельная история, консультация по использованию ПО обсуждаем отдельно в отдельном услуге, узнаем что нужно при общении.
Всё спокойно на без напряжения не спеша
To get started, the seller needs:
Мне нужны сведения от Telegram каналов для коммуникации.
общение только устно, вести переписку нету времени.
Сб и Воскресенье нерабочие дни
U Mostbet https://mostbet-bk.cz/sportovni-sazky-v-mostbet/ muzete ziskat cashback z vasich sazek, coz vam umozni setrit penize.
заказать курсовую работу https://kupit-kursovuyu-rabotu.ru/ с гарантией и антиплагиатом
матрас купить москва матрас купить москва .
Больше интересной информации о строительстве и ремонте можно прочитать на сайте https://stroyka-gid.ru. Только самые популярные статьи и обзоры процесса ремонта помещений и строительства зданий.
simba4d
paypal smm panel cheap smm panel
data hk
Inspirasi dari Kutipan Taylor Swift: Harapan dan Cinta dalam Lagu-Lagunya
Penyanyi Terkenal, seorang artis dan songwriter terkenal, tidak hanya diakui berkat melodi yang menawan dan nyanyian yang nyaring, tetapi juga karena kata-kata lagunya yang penuh makna. Di dalam lirik-liriknya, Swift sering menyajikan bermacam-macam faktor kehidupan, mulai dari cinta hingga rintangan hidup. Berikut adalah sejumlah kutipan motivatif dari lagu-lagu, beserta artinya.
“Mungkin yang terbaik belum datang.” – “All Too Well”
Penjelasan: Meskipun dalam masa-masa sulit, senantiasa ada secercah harapan dan kemungkinan untuk masa depan yang lebih baik.
Syair ini dari lagu “All Too Well” menyadarkan kita jika walaupun kita mungkin menghadapi masa-masa sulit saat ini, tetap ada kemungkinan jika waktu yang akan datang akan membawa sesuatu yang lebih baik. Hal ini adalah pesan pengharapan yang menguatkan, mendorong kita untuk tetap bertahan dan tidak menyerah, karena yang terbaik mungkin belum hadir.
“Aku akan tetap bertahan sebab aku tak bisa mengerjakan apapun tanpa kamu.” – “You Belong with Me”
Arti: Menemukan kasih dan dukungan dari pihak lain dapat menyediakan kita kekuatan dan kemauan keras untuk bertahan melewati kesulitan.
hero138
Ashley JKT48: Bintang yang Berkilau Terang di Langit Idola
Siapakah Ashley JKT48?
Siapakah tokoh muda berbakat yang mencuri perhatian sejumlah besar penggemar lagu di Indonesia dan Asia Tenggara? Itulah Ashley Courtney Shintia, atau yang lebih dikenal dengan pseudonimnya, Ashley JKT48. Menjadi anggota dengan grup idol JKT48 pada tahun 2018, Ashley dengan segera menjadi salah satu anggota paling terkenal.
Biografi
Lahir di Jakarta pada tgl 13 Maret 2000, Ashley berdarah darah Tionghoa-Indonesia. Ia memulai perjalanannya di industri hiburan sebagai model dan pemeran, sebelum akhirnya menjadi anggota dengan JKT48. Kepribadiannya yang periang, vokal yang kuat, dan kemampuan menari yang mengagumkan menjadikannya idola yang sangat dicintai.
Penghargaan dan Penghargaan
Kepopuleran Ashley telah diakui melalui berbagai penghargaan dan nominasi. Pada tahun 2021, ia meraih penghargaan “Anggota Paling Populer JKT48” di acara JKT48 Music Awards. Beliau juga dianugerahi sebagai “Idol Tercantik di Asia” oleh sebuah majalah online pada masa 2020.
Peran dalam JKT48
Ashley menjalankan peran krusial dalam group JKT48. Ia adalah member Tim KIII dan berperan menjadi penari utama dan penyanyi utama. Ashley juga terlibat sebagai bagian dari subunit “J3K” bersama Jessica Veranda dan Jennifer Rachel Natasya.
Perjalanan Solo
Selain kegiatan di JKT48, Ashley juga merintis karir individu. Ashley telah merilis beberapa single, termasuk “Myself” (2021) dan “Falling Down” (2022). Ashley juga telah bekerjasama dengan musisi lain, seperti Afgan dan Rossa.
Aktivitas Privat
Selain dunia pertunjukan, Ashley dikenal sebagai pribadi yang humble dan ramah. Ashley menggemari melewatkan masa bersama keluarga dan kawan-kawannya. Ashley juga memiliki hobi melukis dan fotografi.
txid проверить usdt 9
Анализ счета криптовалюты
Верификация монет на сети TRC20 и других блокчейн транзакций
На представленном веб-сайте вы найдете подробные ревью разных платформ для анализа операций и кошельков, охватывая AML контроли для монет и прочих цифровых валют. Вот ключевые возможности, доступные в наших обзорах:
Проверка USDT TRC20
Многие ресурсы обеспечивают комплексную верификацию платежей USDT в блокчейн-сети TRC20. Это дает возможность фиксировать сомнительную операции и соответствовать правовым требованиям.
Контроль операций токенов
В представленных оценках описаны ресурсы для детального контроля и контроля платежей токенов, которые гарантирует гарантировать ясность и защищенность платежей.
AML контроль монет
Многие платформы предоставляют антиотмывочную проверку криптовалюты, гарантируя фиксировать и исключать случаи отмывания денег и финансовых нарушений.
Анализ адреса криптовалюты
Наши описания содержат платформы, что дают возможность анализировать адреса USDT на определение блокировок и подозреваемых платежей, поддерживая дополнительный степень безопасности защиты.
Проверка платежей токенов на платформе TRC20
Вы найдете представлены платформы, предлагающие контроль транзакций USDT на платформе TRC20, что обеспечивает удовлетворение всем регуляторным нормам.
Анализ счета аккаунта USDT
В ревью указаны платформы для контроля кошельков аккаунтов криптовалюты на определение угроз проблем.
Проверка счета монет на блокчейне TRC20
Наши оценки представляют инструменты, предоставляющие анализ кошельков токенов на платформе TRC20 блокчейна, что позволяет помогает предотвращение финансовых преступлений и экономических мошенничеств.
Анализ токенов на чистоту
Обозреваемые сервисы позволяют анализировать операции и адреса на прозрачность, фиксируя подозреваемую деятельность.
anti-money laundering контроль токенов TRC20
В оценках вы инструменты, предоставляющие антиотмывочного закона проверку для монет на платформе TRC20 платформы, что помогает вашему бизнесу удовлетворять международным правилам.
Анализ USDT на платформе ERC20
Наши оценки представляют сервисы, предлагающие проверку криптовалюты на блокчейне ERC20 сети, что проведение проведение платежей и кошельков.
Анализ криптовалютного кошелька
Мы изучаем инструменты, предлагающие опции по проверке виртуальных кошельков, в том числе отслеживание операций и обнаружение необычной деятельности.
Контроль аккаунта криптовалютного кошелька
Наши обзоры представляют инструменты, предназначенные для проверять кошельки криптокошельков для повышения повышенной безопасности.
Анализ виртуального кошелька на платежи
Вы найдете найдете сервисы для анализа криптокошельков на транзакции, что позволяет обеспечивает гарантировать открытость транзакций.
Анализ цифрового кошелька на отсутствие подозрительных действий
Наши оценки содержат инструменты, обеспечивающие контролировать криптовалютные кошельки на прозрачность, обнаруживая все подозрительные действия.
Изучая представленные обзоры, вы сможете выбрать подберете лучшие ресурсы для анализа и мониторинга блокчейн переводов, для поддерживать надежный степень безопасности безопасности и соответствовать всех правовым правилам.
music promotion apps https://banger-music.com
get votes for online contest free https://promobanger.com/
free soundcloud plays best music promotion services
Digital Gambling Sites: Advancement and Benefits for Contemporary Society
Overview
Online gambling platforms are digital sites that offer users the opportunity to engage in gambling games such as card games, roulette, blackjack, and slots. Over the last several years, they have become an integral part of online leisure, providing numerous benefits and opportunities for players around the world.
Accessibility and Convenience
One of the main advantages of digital casinos is their accessibility. Players can enjoy their preferred games from any location in the globe using a PC, iPad, or mobile device. This saves time and money that would typically be used traveling to traditional casinos. Additionally, round-the-clock availability to activities makes internet casinos a easy option for individuals with busy schedules.
Variety of Activities and Experience
Online gambling sites offer a wide variety of games, enabling everyone to find an option they like. From classic card games and table activities to slots with various concepts and increasing jackpots, the range of activities guarantees there is something for every preference. The option to play at different proficiencies also makes digital gambling sites an perfect place for both novices and seasoned gamblers.
Financial Advantages
The digital casino industry adds significantly to the economy by creating employment and generating income. It supports a diverse range of careers, including software developers, customer support representatives, and marketing professionals. The income produced by digital casinos also adds to tax revenues, which can be used to fund community services and infrastructure projects.
Technological Innovation
Digital casinos are at the forefront of technological advancement, continuously adopting new innovations to improve the playing entertainment. High-quality graphics, real-time dealer games, and virtual reality (VR) gambling sites provide engaging and realistic gaming experiences. These advancements not only improve user experience but also push the limits of what is achievable in online entertainment.
Responsible Gambling and Assistance
Many online gambling sites promote responsible gambling by providing tools and assistance to assist users manage their gaming habits. Features such as deposit limits, self-exclusion options, and availability to assistance programs ensure that players can engage in gaming in a safe and monitored setting. These steps show the sector’s commitment to encouraging healthy betting practices.
Community Engagement and Networking
Digital gambling sites often offer interactive options that allow players to interact with each other, creating a feeling of belonging. Group activities, chat functions, and social media integration enable players to connect, exchange experiences, and build relationships. This social aspect enhances the entire betting entertainment and can be particularly helpful for those looking for social interaction.
Summary
Digital gambling sites offer a wide range of benefits, from availability and ease to financial benefits and technological advancements. They provide diverse gaming options, support responsible gambling, and foster social interaction. As the industry keeps to evolve, digital gambling sites will likely remain a major and positive force in the world of online entertainment.
free slots games
Complimentary Slot Games: Pleasure and Benefits for All
No-Cost slot games have become a in-demand form of digital leisure, providing players the thrill of slot machines without any cash stake.
The chief objective of no-cost slot games is to deliver a entertaining and engaging way for people to enjoy the thrill of slot machines free from any financial jeopardy. They are developed to replicate the feeling of paid slots, permitting players to activate the reels, savor various ideas, and win online payouts.
Pleasure: Complimentary slot games are an superb option of entertainment, granting durations of excitement. They present colorful imagery, compelling sounds, and varied motifs that serve a broad selection of interests.
Capability Enhancement: For beginners, gratis slot games provide a worry-free environment to learn the principles of slot machines. Players can get accustomed with multiple game features, paylines, and extras without the apprehension of forfeiting money.
Destressing: Playing gratis slot games can be a great way to decompress. The uncomplicated interaction and the possibility for digital payouts make it an enjoyable activity.
Shared Experiences: Many complimentary slot games feature social functions such as challenges and the opportunity to network with friends. These aspects add a social layer to the interactive experience, inspiring players to challenge against others.
Perks of Gratis Slot Games
1. Accessibility and Simplicity
Free slot games are conveniently reachable to anyone with an web connection. They can be accessed on diverse platforms including computers, pads, and mobile phones. This comfort enables players to savor their most liked pursuits at any time and anywhere.
2. Economic Risk-Freeness
One of the paramount perks of free slot games is that they remove the economic risks connected to betting. Players can savor the rush of spinning the reels and earning substantial rewards without investing any funds.
3. Breadth of Offerings
No-Cost slot games come in a extensive assortment of motifs and designs, from time-honored fruit-based slots to current video-based slots with complex themes and graphics. This variety secures that there is an option for everyone, independent of their interests.
4. Strengthening Intellectual Faculties
Playing gratis slot games can lead to enhance intellectual faculties such as pattern recognition. The necessity to pursue winning combinations, internalize game mechanics, and estimate effects can provide a mental workout that is concurrently pleasurable and useful.
5. Protected Preparation for For-Profit Wagering
For those pondering moving to actual-currency slots, complimentary slot games provide a worthwhile pre-experience. Players can experiment with diverse games, build tactics, and develop assurance ahead of opting to invest real cash. This preparation can translate to a more educated and enjoyable for-profit gaming interaction.
Recap
Free slot games offer a multitude of perks, from unadulterated amusement to skill development and shared experiences. They offer a worry-free and zero-cost way to savor the suspense of slot machines, making them a beneficial enhancement to the landscape of digital amusement. Whether you’re seeking to de-stress, enhance your mental capabilities, or merely derive entertainment, no-cost slot games are a wonderful option that continues to enchant players throughout.
slots machines
Complimentary Slot-Based Games: Amusement and Benefits for People
Preface
Slot-related offerings have long been a cornerstone of the casino interaction, offering customers the chance to win big with simply the activation of a arm or the click of a control. In the past few years, slot-based activities have likewise emerged as favored in internet-based wagering environments, establishing them available to an even more expansive set of users.
Fun Element
Slot-based activities are crafted to be enjoyable and absorbing. They present vibrant imagery, thrilling auditory elements, and wide-ranging concepts that suit a comprehensive array of preferences. Whether customers relish traditional fruit-related symbols, action-oriented slot-based games, or slot-based activities rooted in well-known TV shows, there is an option for everyone. This variety guarantees that players can persistently identify a experience that aligns with their preferences, providing periods of entertainment.
Easy to Play
One of the most significant advantages of slot-based games is their simplicity. Differently from certain gambling activities that require strategy, slot-based games are straightforward to grasp. This renders them available to a extensive population, involving inexperienced individuals who may encounter deterred by further elaborate experiences. The easy-to-grasp nature of slot machines gives participants to decompress and savor the experience without fretting about complex regulations.
Mental Reprieve and Refreshment
Engaging with slot-related offerings can be a wonderful way to relax. The cyclical character of activating the wheels can be serene, delivering a cognitive reprieve from the demands of regular life. The potential for earning, even when it is merely minor quantities, brings an component of suspense that can improve users’ emotions. Several people conclude that interacting with slot machines facilitates them decompress and shift their focus away from their problems.
Shared Experiences
Slot machines also offer opportunities for group-based participation. In brick-and-mortar gambling establishments, users often congregate near slot-based activities, rooting for each other on and commemorating wins as a group. Internet-based slot-based activities have also featured group-based aspects, such as leaderboards, permitting participants to connect with others and share their interactions. This environment of shared experience bolsters the comprehensive interactive sensation and can be specifically enjoyable for users aspiring to social involvement.
Fiscal Rewards
The widespread adoption of slot machines has substantial economic benefits. The domain creates employment for game designers, gambling employees, and player aid specialists. Additionally, the revenue obtained by slot machines adds to the fiscal landscape, granting revenue revenues that resource governmental programs and facilities. This fiscal effect extends to both traditional and virtual wagering facilities, rendering slot-related offerings a helpful part of the entertainment domain.
Mental Upsides
Engaging with slot-based games can likewise result in intellectual benefits. The experience necessitates users to reach quick decisions, identify sequences, and supervise their risking methods. These cognitive undertakings can assist maintain the cognition focused and strengthen cognitive capabilities. Specifically for senior citizens, participating in mentally challenging pursuits like engaging with slot-based games can be advantageous for preserving mental functioning.
Accessibility and Convenience
The introduction of digital gaming sites has rendered slot machines more available than before. Users can relish their most liked slot-related offerings from the convenience of their private homes, utilizing PCs, pads, or cellphones. This user-friendliness gives users to play whenever and irrespective of location they desire, free from the requirement to journey to a physical gambling establishment. The accessibility of no-cost slots as well gives customers to enjoy the offering absent any economic investment, rendering it an open-to-all kind of leisure.
Key Takeaways
Slot machines provide a plethora of benefits to users, from unadulterated amusement to mental rewards and communal engagement. They grant a worry-free and cost-free way to enjoy the thrill of slot-related offerings, establishing them a beneficial addition to the realm of virtual leisure.
Whether you’re aiming to destress, enhance your cognitive aptitudes, or solely have fun, slot-related offerings are a wonderful option that steadfastly enchant participants worldwide.
Prominent Benefits:
– Slot machines deliver fun through vibrant visuals, engaging soundtracks, and wide-ranging concepts
– Simple engagement makes slot machines accessible to a comprehensive set of users
– Partaking in slot-related offerings can grant unwinding and mental rewards
– Collaborative functions elevate the comprehensive entertainment encounter
– Internet-based approachability and no-cost options render slot-based activities open-to-all styles of amusement
In conclusion, slot machines steadfastly deliver a varied collection of benefits that match users worldwide. Whether aiming for unadulterated fun, mental engagement, or group-based connection, slot-related offerings persist as a wonderful option in the dynamic realm of online entertainment.
online casino real money
Digital Gaming Site Real Money: Benefits for Players
Introduction
Online gambling platforms granting actual currency experiences have secured considerable widespread adoption, providing players with the chance to receive monetary prizes while savoring their favorite gambling experiences from home. This text analyzes the advantages of online casino paid offerings, accentuating their favorable effect on the interactive field.
Simplicity and Approachability
Virtual wagering environment real money experiences grant user-friendliness by permitting players to reach a extensive selection of offerings from any setting with an internet access point. This excludes the need to travel to a traditional wagering facility, preserving expenses. Internet-based gambling platforms are also accessible at all times, enabling players to interact with at their simplicity.
Range of Possibilities
Online casinos grant a more broad breadth of games than brick-and-mortar casinos, involving slot-based activities, vingt-et-un, spinning wheel, and table games. This breadth enables users to experiment with novel games and discover different most cherished, enhancing their comprehensive gaming sensation.
Perks and Advantages
Online casinos grant generous bonuses and advantages to entice and retain players. These incentives can include welcome incentives, no-cost plays, and reimbursement promotions, providing extra value for players. Dedication systems in addition recognize participants for their persistent custom.
Proficiency Improvement
Partaking in for-profit games in the digital realm can help players refine aptitudes such as strategic thinking. Activities like blackjack and casino-style games necessitate players to render selections that can impact the end of the offering, assisting them refine decision-making faculties.
Social Interaction
ChatGPT l Валли, 6.06.2024 4:08]
Internet-based gambling platforms offer opportunities for social connection through discussion forums, interactive platforms, and video-streamed experiences. Participants can connect with fellow users, discuss advice and strategies, and occasionally create friendships.
Fiscal Rewards
The virtual wagering industry produces positions and contributes to the economic landscape through fiscal revenues and operational payments. This economic impact benefits a comprehensive array of occupations, from game developers to client assistance agents.
Summary
Internet-based gambling platform actual currency experiences present various advantages for players, incorporating simplicity, variety, rewards, capability building, shared experiences, and fiscal benefits. As the sector constantly progress, the widespread adoption of virtual wagering environments is likely to rise.
fortune casino
Prosperity Gambling Platform: At a Location Where Enjoyment Converges With Prosperity
Luck Casino is a widely-known digital venue identified for its extensive range of games and exciting incentives. Let’s explore the reasons why so several individuals experience partaking in Fortune Wagering Environment and the extent to which it advantages them.
Pleasure-Providing Aspect
Luck Casino offers a range of experiences, incorporating nostalgic wagering games like pontoon and spinning wheel, as well as groundbreaking slot-based games. This breadth secures that there is an option for everyone, establishing every visit to Prosperity Casino rewarding and entertaining.
Substantial Payouts
One of the principal attractions of Luck Casino is the opportunity to earn significant rewards. With substantial top rewards and incentives, players have the possibility to produce an unexpected outcome with a single turn or deal. A significant number of users have acquired significant winnings, adding to the excitement of partaking in Luck Gambling Platform.
Simplicity and Approachability
Luck Casino’s online interface makes it accessible for players to experience their most preferred experiences from any setting. Regardless of whether at residence or while mobile, participants can reach Prosperity Casino from their desktop or smartphone. This availability secures that players can enjoy the suspense of the wagering at any time they desire, free from the necessity to travel.
Range of Possibilities
Fortune Wagering Environment offers a wide assortment of offerings, guaranteeing that there is something for each style of user. Starting with established card games to conceptual slot machines, the variety keeps users absorbed and amused. This assortment likewise allows users to experiment with different offerings and discover novel most cherished.
Promotional Benefits
Prosperity Gambling Platform acknowledges its players with promotional benefits and benefits, including welcome promotional benefits and reward initiatives. These incentives not merely bolster the gaming sensation but likewise boost the prospects of winning big. Customers are steadfastly incentivized to continue engaging, constituting Fortune Gaming Site even more enticing.
Community and Social Interaction
ChatGPT l Валли, 6.06.2024 4:30]
Luck Wagering Environment offers a environment of community and group-based participation for players. Through messaging platforms and discussion boards, players can communicate with their peers, communicate strategies and tactics, and in certain cases establish personal connections. This social component contributes another dimension of satisfaction to the entertainment sensation.
Key Takeaways
Fortune Casino offers a comprehensive variety of advantages for players, encompassing amusement, the chance to win big, convenience, variety, bonuses, and interpersonal connections. Regardless of whether desiring excitement or aiming to experience a reversal of fortune, Wealth Casino delivers an thrilling sensation for everyone play.
free poker machine games
Complimentary Virtual Wagering Experiences: A Fun and Profitable Experience
Free poker machine activities have evolved into steadily popular among customers desiring a thrilling and non-monetary gaming sensation. These offerings present a wide variety of rewards, making them a selected alternative for several. Let’s investigate in which manner complimentary slot-based games can upside players and why they are so comprehensively enjoyed.
Fun Element
One of the primary factors players enjoy partaking in free poker machine games is for the entertainment value they provide. These experiences are designed to be compelling and exciting, with lively illustrations and engrossing audio that improve the overall interactive sensation. Regardless of whether you’re a casual customer looking to pass the time or a serious gamer desiring anticipation, no-cost virtual wagering activities offer amusement for everyone.
Competency Enhancement
Engaging with complimentary slot-based activities can also facilitate develop valuable faculties such as strategic thinking. These games demand users to make swift choices based on the hands they are received, facilitating them sharpen their problem-solving abilities and cognitive dexterity. Moreover, users can try out various tactics, honing their abilities without the chance of negative outcome of parting with monetary resources.
User-Friendliness and Availability
A further advantage of complimentary slot-based experiences is their ease and accessibility. These offerings can be played on the internet from the ease of your own abode, eradicating the necessity to journey to a land-based casino. They are in addition present 24/7, giving participants to savor them at whatever period that aligns with them. This convenience makes complimentary slot-based experiences a well-liked alternative for customers with demanding routines or those aiming for a swift entertainment solution.
Shared Experiences
A significant number of complimentary slot-based activities in addition offer group-based features that permit customers to communicate with one another. This can include chat rooms, online communities, and multiplayer settings where participants can go up against fellow users. These social interactions add an extra facet of fulfillment to the leisure experience, permitting participants to communicate with others who share their affinities.
Worry Mitigation and Emotional Refreshment
Interacting with no-cost virtual wagering offerings can in addition be a superb means to decompress and calm down after a extended period. The effortless gameplay and tranquil music can assist reduce worry and anxiety, offering a refreshing reprieve from the challenges of everyday living. Also, the thrill of winning digital credits can enhance your emotional state and make you feel revitalized.
Summary
Free poker machine activities offer a wide array of upsides for customers, incorporating amusement, skill development, user-friendliness, social interaction, and worry mitigation and relaxation. Whether you’re looking to sharpen your poker faculties or just have fun, gratis electronic gaming activities offer a profitable and enjoyable sensation for customers of every stages.
Digital Card Games: A Source of Entertainment and Skill Development
Online table games has materialized as a well-liked kind of fun and a platform for competency enhancement for customers worldwide. This write-up investigates the beneficial facets of online poker and how it benefits individuals, emphasizing its pervasive recognition and effect.
Entertainment Value
Digital table games offers a captivating and engaging interactive interaction, mesmerizing customers with its strategic engagement and variable ends. The offering’s engrossing essence, along with its social elements, delivers a distinctive kind of fun that numerous regard as enjoyable.
Skill Development
Aside from pleasure, digital table games as well acts as a platform for capability building. The game requires problem-solving, rapid responses, and the skill to understand competitors, all of these add to cognitive development. Players can elevate their analytical abilities, self-awareness, and sound judgment skills through consistent gameplay.
Convenience and Accessibility
One of the principal upsides of internet-based card games is its user-friendliness and approachability. Users can relish the offering from the comfort of their residences, at whichever time that fits them. This approachability eliminates the obligation for commute to a brick-and-mortar gambling establishment, constituting it as a straightforward choice for people with hectic timetables.
Range of Possibilities and Stake Amounts
Internet-based card games systems grant a comprehensive diversity of activities and wagers to cater to players of all types of abilities and tastes. Whether you’re a learner wanting to understand the basics or a experienced pro aiming for a obstacle, there is a activity for you. This breadth secures that players can constantly uncover a game that aligns with their capabilities and bankroll.
Social Interaction
Internet-based card games also provides prospects for communal engagement. A significant number of systems provide interactive functions and multiplayer configurations that give players to engage with peers, exchange interactions, and develop interpersonal bonds. This social aspect injects substance to the gaming sensation, constituting it as further satisfying.
Financial Rewards
For some, internet-based card games can as well be a source of monetary gains. Proficient users can earn considerable earnings through regular activity, establishing it as a financially rewarding endeavor for those who master the experience. Furthermore, a significant number of virtual casino-style games tournaments grant major winnings, granting players with the prospect to achieve substantial winnings.
Conclusion
Internet-based card games presents a variety of advantages for participants, including fun, proficiency improvement, ease, communal engagement, and profit potential. Its widespread acceptance constantly expand, with several users shifting to virtual casino-style games as a origin of satisfaction and development. Whether you’re wanting to hone your aptitudes or solely derive entertainment, online poker is a adaptable and profitable pastime for participants of any origins.
빠릿한 입출금 서비스 및 대형업체의 안전성
베팅사이트 이용 시 매우 중요한 부분 중 하나는 빠른 충환전 프로세스입니다. 대개 3분 내에 충전, 10분 안에 출금이 처리되어야 합니다. 주요 메이저업체들은 충분한 직원 고용을 통해 이러한 빠른 환충 처리를 보장하며, 이 방법으로 사용자들에게 안전감을 드립니다. 대형사이트를 접속하면서 빠른 체감을 해보시기 바랍니다. 우리 여러분들이 안심하고 웹사이트를 접속할 수 있도록 돕는 먹튀해결사입니다.
보증금을 내고 배너 운영
먹튀 해결 팀은 최소 3000만 원에서 1억 원의 보증금을 예치하고 있는 회사들의 배너 광고를 운영 중입니다. 만약 먹튀 문제가 발생할 경우, 배팅 규정에 위배되지 않은 배팅 기록을 캡처해서 먹튀 해결 전문가에게 연락 주시면, 사실 확인 뒤 보증 자금으로 신속하게 피해 보전 처리해 드립니다. 피해가 발생하면 신속하게 캡처하여 손해 내용을 기록해두시고 보내주시기 바랍니다.
오랫동안 안전하게 운영된 업체 확인
먹튀 해결 팀은 적어도 사 년 이상 먹튀 문제 없이 무사히 운영된 사이트만을 확인하여 광고 배너 입점을 받고 있습니다. 이로 인해 누구나 알고 있는 메이저사이트를 안전하게 사용할 수 있는 기회를 제공합니다. 엄격한 검사 작업을 통해 검증된 사이트를 놓치지 말고, 보안된 베팅을 즐겨보세요.
투명성과 공정성을 가진 먹튀 검증
먹튀해결사의 먹튀 검증은 공정성과 공정을 바탕으로 실시합니다. 언제나 사용자들의 관점을 최우선으로 생각하며, 업체의 유혹이나 이득에 흔들리지 않으며 한 건의 삭제 없이 사실만을 바탕으로 검증해오고 있습니다. 먹튀 문제를 당하고 후회하지 않도록, 지금 시작하세요.
먹튀 검증 사이트 목록
먹튀 해결 팀이 엄선한 안전한 토토사이트 인증된 업체 목록 입니다. 지금 등록된 검증된 업체들은 먹튀 사고 발생 시 100% 보증을 해드립니다. 하지만, 제휴 기간이 끝난 업체에서 발생한 피해에 대해서는 책임지지 않습니다.
독보적인 먹튀 검증 알고리즘
먹튀 해결 전문가는 청결한 도박 문화를 만들기 위해 늘 노력하고 있습니다. 저희가 권장하는 토토사이트에서 안전하게 베팅하시기 바랍니다. 회원님의 먹튀 제보는 먹튀 목록에 등록 노출되어 그 해당 베팅 사이트에 심각한 영향을 미칩니다. 먹튀 목록 작성 시 먹튀블러드 만의 검토 경험을 최대한 활용하여 공정한 심사를 하도록 하겠습니다.
안전한 베팅 환경을 만들기 위해 계속해서 힘쓰는 먹튀 해결 전문가와 함께 안전하게 경험해보세요.
курсовые работы на заказ https://zakazat-kursovuyu-rabotu7.ru
레거시 오브 데드
Fang Jifan은 “무엇을 망설이십니까? 빨리 말씀해주십시오. “라고 말했습니다.
аренда такси служба такси телефон
заказать такси в новочеркасске такси онлайн
русское порно анал https://www.russkiy-anal-x.ru .
курсовые работы на заказ https://zakazat-kontrolnuyu7.ru
решение задач на заказ https://resheniye-zadach7.ru заказать онлайн
mpo888
Unduh Program 888 dan Menangkan Besar: Panduan Pendek
**Perangkat Lunak 888 adalah pilihan unggulan untuk Para Pengguna yang mencari keseruan bermain online yang menggembirakan dan bermanfaat. Dengan imbalan sehari-hari dan fasilitas menarik, aplikasi ini siap memberikan aktivitas bertaruhan unggulan. Disini manual cepat untuk mengoptimalkan pelayanan Program 888.
Download dan Awali Menang
Perangkat Tersedia:
Program 888 dapat di-download di HP Android, Sistem iOS, dan Komputer. Mulailah bertaruhan dengan cepat di alat apapun.
Bonus Setiap Hari dan Imbalan
Hadiah Login Setiap Hari:
Login pada waktu untuk mendapatkan hadiah sebesar 100K pada hari ketujuh.
Rampungkan Aktivitas:
Ambil peluang pengeretan dengan menyelesaikan misi terkait. Setiap misi menawarkan Pengguna satu opsi undi untuk mengklaim bonus mencapai 888K.
Pengambilan Manual:
Bonus harus diambil manual di dalam app. Jangan lupa untuk mengambil hadiah saban masa agar tidak kadaluwarsa.
Mekanisme Undian
Peluang Pengeretan:
Tiap masa, Para Pengguna bisa meraih satu peluang undian dengan menuntaskan misi.
Jika peluang pengeretan selesai, rampungkan lebih banyak misi untuk mendapatkan lebih banyak opsi.
Ambang Bonus:
Klaim imbalan jika jumlah undi Para Pengguna melampaui 100K dalam waktu satu hari.
Ketentuan Pokok
Pengklaiman Bonus:
Hadiah harus dikumpulkan sendiri dari aplikasi. Jika tidak, keuntungan akan otomatis diserahkan ke akun Kamu setelah satu waktu.
Syarat Betting:
Hadiah memerlukan paling tidak 1 taruhan valid untuk diambil.
Penutup
App 888 menawarkan pengalaman main yang menggembirakan dengan hadiah besar. Download perangkat lunak hari ini dan rasakan hadiah tinggi pada periode!
Untuk info lebih lanjut tentang penawaran, pengisian, dan agenda undangan, lihat halaman home perangkat lunak.
рефераты на заказ https://kupit-referat213.ru
https://bicrypto.exchange – crypto exchange software. White label, open-source exchange solution with a focus on a super-fast, pixel-perfect interface and robust security. High-performance platform with a robust internal architecture. Leverages the capabilities of Nuxt3 to create a cutting-edge user interface.
7 ervas рапэ https://travelservic.ru
можем сделать все, чтоб доставить груз на сохранности а также в короткие сроки. Автор несомненно поможем провести погрузку (а) также разгрузку, у потребности завезем чемодан груз до двери.
https://www.gruzogazel.ru/express-dostavka-gruza.html
лаки джет игра лаки джет игра .
Saya sangat suka dengan website ini. Desainnya sangat modern dan navigasinya sangat intuitif. Kontennya sangat informatif dan selalu up-to-date. Terima kasih telah menyediakan sumber informasi yang sangat berguna dan bermanfaat. Teruskan kerja bagus ini, saya sangat mengapresiasi usaha Anda!
protogel
Inspirasi dari Ucapan Taylor Swift: Harapan dan Cinta dalam Lagu-Lagunya
Taylor Swift, seorang penyanyi dan pengarang lagu terkenal, tidak hanya terkenal karena nada yang elok dan nyanyian yang merdu, tetapi juga karena kata-kata karyanya yang penuh makna. Dalam syair-syairnya, Swift sering menggambarkan bermacam-macam aspek kehidupan, berawal dari asmara sampai dengan tantangan hidup. Berikut ini adalah beberapa kutipan inspiratif dari lagu-lagunya, bersama terjemahannya.
“Mungkin yang terbaik belum datang.” – “All Too Well”
Arti: Bahkan di masa-masa sulit, selalu ada sedikit harapan dan potensi tentang masa depan yang lebih baik.
Syair ini dari lagu “All Too Well” membuat kita ingat bahwa walaupun kita barangkali mengalami masa-masa sulit pada saat ini, senantiasa ada kemungkinan jika waktu yang akan datang akan membawa sesuatu yang lebih baik. Hal ini adalah pesan harapan yang memperkuat, memotivasi kita untuk terus bertahan dan tidak putus asa, karena yang terbaik barangkali belum hadir.
“Aku akan tetap bertahan lantaran aku tidak bisa melakukan apapun tanpamu.” – “You Belong with Me”
Arti: Memperoleh cinta dan dukungan dari orang lain dapat memberi kita kekuatan dan tekad untuk bertahan lewat rintangan.
dunia777
Ashley JKT48: Bintang yang Bersinar Terang di Langit Idola
Siapakah Ashley JKT48?
Siapakah figur muda berbakat yang mencuri perhatian banyak penggemar musik di Indonesia dan Asia Tenggara? Dialah Ashley Courtney Shintia, atau yang terkenal dengan nama bekennya, Ashley JKT48. Masuk dengan grup idol JKT48 pada tahun 2018, Ashley dengan lekas menjadi salah satu anggota paling favorit.
Biografi
Terlahir di Jakarta pada tanggal 13 Maret 2000, Ashley berdarah garis Tionghoa-Indonesia. Dia memulai kariernya di industri hiburan sebagai model dan pemeran, hingga akhirnya kemudian bergabung dengan JKT48. Personanya yang ceria, nyanyiannya yang bertenaga, dan kemampuan menari yang mengagumkan membuatnya idola yang sangat dikasihi.
Pengakuan dan Pengakuan
Ketenaran Ashley telah dikenal melalui aneka penghargaan dan pencalonan. Pada tahun 2021, beliau mendapat pengakuan “Personel Terpopuler JKT48” di event JKT48 Music Awards. Ia juga dinobatkan sebagai “Idol Tercantik se-Asia” oleh sebuah majalah online pada tahun 2020.
Posisi dalam JKT48
Ashley menjalankan fungsi krusial dalam grup JKT48. Ia adalah anggota Tim KIII dan berfungsi sebagai penari utama dan penyanyi utama. Ashley juga terlibat sebagai member dari subunit “J3K” dengan Jessica Veranda dan Jennifer Rachel Natasya.
Karier Mandiri
Selain kegiatan bersama JKT48, Ashley juga mengembangkan karir individu. Ashley telah merilis beberapa single, termasuk “Myself” (2021) dan “Falling Down” (2022). Ashley juga telah bekerja sama dengan artis lain, seperti Afgan dan Rossa.
Kehidupan Pribadi
Di luar kancah panggung, Ashley dikenal sebagai sebagai pribadi yang humble dan ramah. Ia menggemari menyisihkan jam bersama family dan teman-temannya. Ashley juga punya hobi mewarnai dan fotografi.
Pasang Aplikasi 888 dan Peroleh Bonus: Petunjuk Pendek
**App 888 adalah alternatif terbaik untuk Para Pengguna yang membutuhkan permainan bermain digital yang seru dan bernilai. Melalui keuntungan harian dan kemampuan menggoda, aplikasi ini siap menawarkan permainan berjudi terbaik. Berikut manual cepat untuk memaksimalkan penggunaan App 888.
Unduh dan Segera Raih
Platform Ada:
Perangkat Lunak 888 bisa diinstal di Sistem Android, Sistem iOS, dan PC. Segera bertaruhan dengan cepat di alat apa pun.
Imbalan Setiap Hari dan Imbalan
Imbalan Mendaftar Sehari-hari:
Login saban waktu untuk meraih hadiah sebesar 100K pada waktu ketujuh.
Tuntaskan Misi:
Raih kesempatan pengeretan dengan merampungkan aktivitas terkait. Satu tugas menghadirkan Anda 1 opsi undi untuk mengklaim bonus hingga 888K.
Pengumpulan Langsung:
Bonus harus diambil langsung di dalam perangkat lunak. Pastikan untuk meraih bonus tiap hari agar tidak kadaluwarsa.
Prosedur Lotere
Opsi Pengeretan:
Tiap masa, Para Pengguna bisa mengambil satu kesempatan pengeretan dengan menuntaskan pekerjaan.
Jika kesempatan lotere habis, kerjakan lebih banyak misi untuk mengklaim lebih banyak opsi.
Level Hadiah:
Klaim hadiah jika total undian Pengguna melampaui 100K dalam sehari.
Ketentuan Utama
Pengumpulan Imbalan:
Imbalan harus diambil langsung dari perangkat lunak. Jika tidak, hadiah akan secara otomatis dikreditkan ke akun Anda Para Pengguna setelah satu masa.
Peraturan Taruhan:
Bonus membutuhkan minimal satu bertaruh efektif untuk digunakan.
Ringkasan
App 888 memberikan aktivitas bertaruhan yang menggembirakan dengan hadiah besar-besaran. Unduh aplikasi sekarang dan alamilah keberhasilan besar-besaran setiap periode!
Untuk data lebih lengkap tentang diskon, pengisian, dan agenda undangan, cek halaman utama app.
купить диплом дизайнера
источник
купить диплом в волжском https://6landik-diploms.com
klasemen liga 1
Inspirasi dari Petikan Taylor Swift
Penyanyi Terkenal, seorang vokalis dan pengarang lagu terkenal, tidak hanya dikenal karena melodi yang indah dan nyanyian yang merdu, tetapi juga karena kata-kata lagu-lagunya yang penuh makna. Pada syair-syairnya, Swift sering menggambarkan berbagai aspek kehidupan, dimulai dari asmara sampai tantangan hidup. Berikut adalah beberapa kutipan inspiratif dari lagu-lagunya, beserta artinya.
“Mungkin yang paling baik belum tiba.” – “All Too Well”
Makna: Bahkan di saat-saat sulit, selalu ada secercah harapan dan potensi akan masa depan yang lebih baik.
Syair ini dari lagu “All Too Well” mengingatkan kita bahwa meskipun kita mungkin mengalami masa-masa sulit pada saat ini, senantiasa ada peluang kalau waktu yang akan datang akan membawa sesuatu yang lebih baik. Situasi ini adalah pesan asa yang mengukuhkan, mendorong kita untuk bertahan dan tidak mengalah, karena yang paling baik barangkali belum hadir.
“Aku akan bertahan karena aku tidak bisa mengerjakan apapun tanpa kamu.” – “You Belong with Me”
Arti: Memperoleh cinta dan bantuan dari orang lain dapat menyediakan kita kekuatan dan niat untuk terus berjuang lewat kesulitan.
bagong4d
Ashley JKT48: Bintang yang Bersinar Cemerlang di Dunia Idol
Siapa Ashley JKT48?
Siapa figur muda berbakat yang menarik perhatian banyak penggemar musik di Nusantara dan Asia Tenggara? Dialah Ashley Courtney Shintia, atau yang dikenal dengan pseudonimnya, Ashley JKT48. Bergabung dengan grup idola JKT48 pada tahun 2018, Ashley dengan cepat menjadi salah satu member paling populer.
Biografi
Dilahirkan di Jakarta pada tanggal 13 Maret 2000, Ashley berdarah darah Tionghoa-Indonesia. Dia memulai perjalanannya di dunia entertainment sebagai peraga dan aktris, hingga akhirnya kemudian menjadi anggota dengan JKT48. Kepribadiannya yang periang, nyanyiannya yang mantap, dan kemahiran menari yang mengagumkan membuatnya idola yang sangat disukai.
Penghargaan dan Pengakuan
Popularitas Ashley telah dikenal melalui aneka penghargaan dan nominasi. Pada tahun 2021, beliau mendapat pengakuan “Member Terpopuler JKT48” di ajang JKT48 Music Awards. Ashley juga dianugerahi sebagai “Idol Terindah di Asia” oleh sebuah media digital pada tahun 2020.
Peran dalam JKT48
Ashley memainkan fungsi penting dalam group JKT48. Ia adalah anggota Tim KIII dan berperan menjadi penari utama dan vokalis. Ashley juga menjadi bagian dari sub-unit “J3K” dengan Jessica Veranda dan Jennifer Rachel Natasya.
Karier Solo
Selain kegiatannya di JKT48, Ashley juga merintis karir solo. Ashley telah meluncurkan beberapa lagu tunggal, antara lain “Myself” (2021) dan “Falling Down” (2022). Ashley juga telah berkolaborasi bareng penyanyi lain, seperti Afgan dan Rossa.
Kehidupan Personal
Selain dunia panggung, Ashley dikenal sebagai sebagai sosok yang humble dan friendly. Beliau menikmati menyisihkan waktu bareng keluarga dan sahabat-sahabatnya. Ashley juga memiliki hobi mewarnai dan memotret.
joglototo
Download Perangkat Lunak 888 dan Dapatkan Bonus: Manual Pendek
**Program 888 adalah kesempatan unggulan untuk Kamu yang mengharapkan pengalaman main online yang seru dan bermanfaat. Melalui bonus sehari-hari dan fasilitas menggoda, perangkat lunak ini bersiap memberikan aktivitas bermain optimal. Inilah instruksi praktis untuk mengoptimalkan pemakaian Program 888.
Pasang dan Mulai Menang
Sistem Ada:
App 888 mampu di-download di Sistem Android, Sistem iOS, dan Windows. Awali bermain dengan praktis di alat apa saja.
Imbalan Setiap Hari dan Hadiah
Keuntungan Buka Sehari-hari:
Login saban periode untuk meraih imbalan sampai 100K pada waktu ketujuh.
Rampungkan Pekerjaan:
Raih opsi lotere dengan merampungkan tugas terkait. Setiap pekerjaan menyediakan Anda satu opsi undian untuk meraih hadiah hingga 888K.
Pengklaiman Mandiri:
Imbalan harus diambil manual di melalui program. Jangan lupa untuk mengklaim bonus pada hari agar tidak kadaluwarsa.
Mekanisme Lotere
Kesempatan Undian:
Setiap masa, Para Pengguna bisa mengklaim 1 kesempatan lotere dengan merampungkan pekerjaan.
Jika kesempatan lotere selesai, tuntaskan lebih banyak aktivitas untuk mendapatkan lebih banyak opsi.
Ambang Imbalan:
Raih imbalan jika keseluruhan undian Kamu lebih dari 100K dalam satu hari.
Kebijakan Utama
Pengumpulan Bonus:
Imbalan harus dikumpulkan sendiri dari app. Jika tidak, hadiah akan otomatis diambil ke akun pribadi Kamu setelah satu periode.
Syarat Bertaruh:
Hadiah memerlukan sekitar 1 bertaruh berlaku untuk diklaim.
Kesimpulan
Aplikasi 888 menawarkan pengalaman main yang menggembirakan dengan imbalan besar. Download program sekarang juga dan alamilah kemenangan signifikan tiap hari!
Untuk data lebih terperinci tentang diskon, simpanan, dan skema rujukan, kunjungi halaman home program.
dexamethasone 2mg tablets price
no deposit bonus
Internet casinos are growing more popular, offering various promotions to attract newcomers. One of the most appealing opportunities is the no upfront deposit bonus, a campaign that permits gamblers to try their luck without any financial obligation. This piece discusses the merits of no-deposit bonuses and highlights how they can enhance their efficacy.
What is a No Deposit Bonus?
A no deposit bonus is a category of casino campaign where players are granted free money or free spins without the need to deposit any of their own capital. This allows casino enthusiasts to explore the online casino, test out multiple gaming activities and stand a chance to win real money, all without any initial expenditure.
Advantages of No Deposit Bonuses
Risk-Free Exploration
No deposit bonuses give a secure chance to try out virtual casinos. Participants can test diverse game options, familiarize themselves with the user interface, and evaluate the overall playing environment without spending their own cash. This is especially helpful for new players who may not be aware of online casinos.
Chance to Win Real Money
One of the most enticing benefits of no-deposit bonuses is the opportunity to win real money. Though the amounts may be modest, any winnings gained from the bonus can generally be redeemed after meeting the casino’s wagering requirements. This brings an element of thrill and offers a potential financial return without any initial expenditure.
Learning Opportunity
Free bonuses give a excellent opportunity to learn how various games work operate. Participants can experiment with approaches, learn the regulations of the casino games, and develop into more proficient without being afraid of losing their own funds. This can be particularly helpful for complex gaming activities like blackjack.
Conclusion
No deposit bonuses deliver multiple benefits for users, such as risk-free exploration, the potential to get real rewards, and beneficial training opportunities. As the market continues to to grow, the appeal of no upfront deposit bonuses is likely to increase.
free poker
Gratis poker provides gamblers a unique chance to experience the pastime without any monetary cost. This overview discusses the merits of enjoying free poker and highlights why it is favored among many players.
Risk-Free Entertainment
One of the most significant upsides of free poker is that it permits participants to enjoy the excitement of poker without worrying about losing capital. This transforms it perfect for novices who wish to understand the game without any financial commitment.
Skill Development
No-cost poker presents a wonderful opportunity for participants to develop their skills. Users can experiment with tactics, understand the mechanics of the game, and acquire confidence without any anxiety of risking their own funds.
Social Interaction
Participating in free poker can also result in social interactions. Online websites regularly provide chat rooms where players can interact with each other, exchange methods, and even build relationships.
Accessibility
Free poker is readily available to anyone with an internet link. This means that players can play the sport from the comfort of their own house, at any hour.
Conclusion
Free poker offers numerous benefits for players. It is a cost-free method to partake in the game, enhance talent, participate in networking opportunities, and play poker without hassle. As more participants learn about the merits of free poker, its prevalence is likely to increase.
Analyzing Promotion Casinos: A Captivating and Accessible Gaming Possibility
Overview
Lottery betting sites are growing into a favored alternative for participants looking for an engaging and authorized way to enjoy digital gambling. Differing from classic internet-based gambling platforms, lottery betting sites run under different legitimate frameworks, facilitating them to provide events and prizes without adhering to the identical regulations. This article investigates the principle of promotion gaming hubs, their perks, and why they are appealing to a increasing amount of users.
Defining Sweepstakes Casinos
A contest gambling platform operates by providing players with online money, which can be employed to play games. Gamers can win further digital funds or real awards, like funds. The main difference from classic gambling platforms is that gamers do not purchase coins immediately but get it through advertising campaigns, including buying a product or participating in a no-cost participation contest. This framework permits lottery betting sites to work legally in many territories where standard online betting is regulated.
신속한 충환전 서비스와 메이저업체의 안전
토토사이트 사용 시 핵심적인 요소는 빠른 환충 프로세스입니다. 보통 세 분 안에 충전하고, 열 분 내에 환전이 완수되어야 합니다. 주요 주요업체들은 넉넉한 직원 고용을 통해 이 같은 빠른 입출금 처리를 보증하며, 이를 통해 회원들에게 안도감을 제공합니다. 대형사이트를 이용하면서 빠른 경험을 해보시기 바랍니다. 우리 여러분이 안심하고 토토사이트를 접속할 수 있도록 지원하는 먹튀해결사입니다.
보증금을 걸고 배너를 운영
먹튀 해결 팀은 적어도 3000만 원에서 일억 원의 보증금을 예탁한 사이트들의 배너 광고를 운영 중입니다. 혹시 먹튀 문제가 발생할 경우, 배팅 룰에 어긋나지 않은 배팅 내역을 캡처해서 먹튀해결사에 연락 주시면, 사실 확인 후 보증금으로 빠르게 피해 보전 처리해 드립니다. 피해가 발생하면 즉시 캡처하여 피해 내용을 저장해두시고 보내주세요.
장기간 안전 운영 업체 확인
먹튀해결사는 최소 4년간 먹튀 사고 없이 안정적으로 운영하고 있는 사이트들을 인증하여 배너 등록을 허가합니다. 이를 통해 모두가 알만한 대형사이트를 안심하고 사용할 수 있는 기회를 제공합니다. 엄격한 검사 작업을 통해 검증된 사이트를 놓치지 마시고, 안심하고 도박을 경험해보세요.
투명성과 공정성을 가진 먹튀 검증
먹튀 해결 팀의 먹튀 검증은 투명성과 공정을 바탕으로 합니다. 항상 이용자들의 입장을 우선시하며, 기업의 회유나 이익에 좌우되지 않고 1건의 삭제 없이 진실만을 기반으로 검증해왔습니다. 먹튀 문제를 겪고 후회하지 않도록, 지금 시작하세요.
먹튀검증사이트 목록
먹튀해결사가 골라낸 안전 토토사이트 인증된 업체 목록 입니다. 현재 등록되어 있는 인증된 업체들은 먹튀 피해 발생 시 100% 보증을 도와드립니다. 그러나, 제휴 기간이 끝난 업체에서 발생한 문제에 대해서는 책임을 지지 않습니다.
탁월한 먹튀 검증 알고리즘
먹튀 해결 전문가는 청결한 베팅 환경을 형성하기 위해 항상 애쓰고 있습니다. 저희는 추천하는 베팅사이트에서 안전하게 배팅하세요. 사용자의 먹튀 제보는 먹튀 리스트에 등록 노출되어 해당되는 베팅 사이트에 치명적인 영향을 줄 수 있습니다. 먹튀 리스트 작성 시 먹튀블러드 만의 검토 경험을 최대한 활용하여 정확한 검증을 할 수 있도록 약속드립니다.
안전한 베팅 문화를 만들기 위해 끊임없이 힘쓰는 먹튀해결사와 동반하여 안전하게 즐기시기 바랍니다.
Discovering the World of Virtual Casinos
Start
In contemporary times, online casinos have transformed the approach players engage in gambling. With modern innovations, enthusiasts can reach their beloved casino games straight from the comfort of their homes. This article investigates the advantages of virtual casinos and as to why they are attracting attention.
Perks of Virtual Casinos
Convenience
One of the main perks of casino online is accessibility. Gamblers can gamble whenever they want and wherever they are they wish, ending the demand to travel to a physical betting place.
Large Game Library
Virtual casinos give a broad array of gaming options, including traditional one-armed bandits and card games to interactive games and new slot machines. This variety ensures that there is an option for every player.
Bonuses and Promotions
One of the key luring features of virtual casinos is the array of incentives and deals available to users. These can encompass sign-up bonuses, free spins, money-back promotions, and rewards programs.
Security and Reliability
Trusted online casinos make sure player protection and security with advanced data protection methods. This safeguards personal details and monetary transactions.
Reasons Players Choose Online Casinos
Accessibility
Casino online are commonly accessible, enabling gamblers from numerous regions to engage in betting.
Discovering No-Cost Casino Games
Start
In contemporary times, complimentary casino games have turned into a favored alternative for casino lovers who wish to play betting minus spending cash. This piece delves into the perks of free casino games and the reasons they are drawing popularity.
Benefits of Free Casino Games
Secure Gambling
One of the major benefits of complimentary casino games is the opportunity to gamble devoid of financial risk. Users can experience their chosen betting activities without fretting over parting with money.
Learning Opportunities
Free-of-charge casino games give an superb environment for players to improve their gaming proficiency. Be it understanding methods in roulette, players can work on free from monetary repercussions.
Diverse Game Selection
Free casino games give a wide array of betting activities, such options as classic slots, table games, and live dealer games. This selection ensures that there is a game for all types of players.
Why Many Players Prefer Free Casino Games
Attainability
Free casino games are widely accessible, allowing users from numerous walks of life to play gaming.
No Financial Commitment
Unlike money-based casino activities, free casino games do not require a financial outlay. This enables gamblers to enjoy games devoid of concerns about parting with money.
Experience Before Paying
Free casino games provide gamblers the ability to test games prior to investing actual funds. This helps users make informed decisions.
Conclusion
No-cost casino games supplies a exciting and secure approach to enjoy gambling. With zero monetary obligation, diverse game options, and opportunities for game mastery, it is understandable that countless players choose no-cost casino games for their playing requirements.
Exploring Money Slots
Overview
Real money slots have become a favored option for players looking for the excitement of winning genuine money. This piece explores the advantages of cash slots and the causes they are attracting more players.
Pros of Money Slots
Actual Payouts
The primary attraction of money slots is the chance to gain genuine cash. Unlike no-cost slots, gambling slots offer enthusiasts the adrenaline of potential economic gains.
Diverse Game Options
Gambling slots offer a wide range of types, features, and reward systems. This guarantees that there is a game for everyone, covering traditional 3-reel slots to up-to-date animated slots with several paylines and bonus features.
Thrilling Incentives
Numerous online casinos supply enticing incentives for gambling slot players. These can feature welcome bonuses, extra spins, rebate offers, and loyalty programs. Such promotions enhance the total gaming adventure and provide more chances to earn cash.
Why Players Choose Real Money Slots
The Rush of Securing Tangible Currency
Cash slots offer an thrilling activity, as enthusiasts look forward to the possibility of winning tangible money. This aspect contributes a significant level of thrill to the betting adventure.
Prompt Payouts
Real money slots give players the reward of immediate rewards. Winning money instantly boosts the betting adventure, making it more gratifying.
Wide Game Selection
With gambling slots, users can enjoy a extensive range of slot machines, guaranteeing that there is always an option exciting to play.
Closing
Real money slots supplies a thrilling and fulfilling casino journey. With the possibility to win actual funds, a diverse selection of slot machines, and attractive rewards, it’s understandable that numerous enthusiasts like money slots for their gaming needs.
twin вход twin casino 2024 твин казино
сайдинг для отделки купить сайдинг для дома цена
더 트위티 하우스
그러나 그 앞에 있는 판관은 마음이 크고 몸이 통통하며 말하는 것이 요리의 길이다.
прошутто https://messir-zakaz.ru
Все самое интересное из мира игр https://unionbattle.ru обзоры, статьи и ответы на вопросы
гарантированно,
Лучшие стоматологи города, для крепких и здоровых зубов,
Специализированная помощь по доступным ценам, для вашего уверенного выбора,
Индивидуальный подход к каждому пациенту, для вашей радости и улыбки,
Комплексное восстановление утраченных зубов, для вашего долгосрочного удовлетворения,
Профессиональная гигиена полости рта, для вашего долгосрочного удовлетворения,
Заботливое отношение и внимательный подход, для вашего комфорта и удовлетворения
клініка стоматологічна https://stomatologichnaklinikafghy.ivano-frankivsk.ua/ .
цены на квартиры недорогие квартиры цены
4 dexamethasone
купить диплом в череповце http://www.6landik-diploms.com
пожаловаться на сайт мошенников гугл https://pozhalovatsya-na-moshennikov.ru/ .
Pro88
online play aviator game aviator-crash-game.ru .
сео консультант
Консультация по стратегии продвижения сайтов продвижению.
Информация о том как взаимодействовать с низкочастотными запросами запросами и как их подбирать
Тактика по работе в соперничающей нише.
Имею постоянных клиентов работаю с 3 фирмами, есть что поделиться.
Ознакомьтесь мой аккаунт, на 31 мая 2024г
количество успешных проектов 2181 только здесь.
Консультация проходит устно, никаких снимков с экрана и отчётов.
Время консультации указано 2 часа, но по сути всегда на связи без строгой привязки к графику.
Как управлять с софтом это уже отдельная история, консультация по работе с программами обсуждаем отдельно в другом кворке, определяем что необходимо при коммуникации.
Всё без суеты на расслабоне не в спешке
To get started, the seller needs:
Мне нужны данные от телеграм канала для контакта.
разговор только устно, вести переписку не хватает времени.
Сб и Воскресенье нерабочие дни
seo аудит сайта заказать http://www.prodvizhenie-sajtov-v-moskve113.ru/ .
купить диплом техникума https://6landik-diploms.com
UEFA EURO
гарантированно,
Современное оборудование и материалы, для вашего уверенного улыбки,
Специализированная помощь по доступным ценам, для вашего уверенного выбора,
Бесплатная консультация и диагностика, для вашей радости и улыбки,
Комплексное восстановление утраченных зубов, для вашего здоровья и красоты улыбки,
Экстренная помощь в любое время суток, для вашего долгосрочного удовлетворения,
Заботливое отношение и внимательный подход, для вашей уверенной улыбки
зуби лікування зуби лікування .
돌리고 슬롯
뒤에서 Xie Qian과 Li Dongyang은 여전히 충격을받은 얼굴로 빠르게 따라갔습니다.
номер заказа такси https://zakaz-taxionline.ru/
Ищете способ расслабиться и получить незабываемые впечатления? Мы https://t.me/intim_tmn72 предлагаем эксклюзивные встречи с привлекательными и профессиональными компаньонками. Конфиденциальность, комфорт и безопасность гарантированы. Позвольте себе наслаждение и отдых в приятной компании.
Mostbet nabizi take bonusy https://mostbet-bk.cz/bonusy/ za urcite milniky, jako je napriklad bonus za dosazeni urciteho poctu bodu v programu loajality.
купить диплом в екатеринбурге https://6landik-diploms.com
лаки джет на деньги лаки джет на деньги .
https://aisory.tech – платформа для создания AI Telegram-ботов. Наделяйте своих ботов способностями к естественному диалогу, генерации уникального контента и решению аналитических задач. Простой конструктор платформы делает создание умных чат-ботов доступным для любой компании.
пожаловаться на телефонных мошенников https://www.pozhalovatsya-na-moshennikov.ru .
жк купить квартиру от застройщика купить квартиру в казани от застройщика
https://algomaslopitch.ca/aladdin666
жк казань купить квартиру https://kvartiru-kupit-kzn.ru
купить квартиру недорого жк купить квартиру от застройщика
vòng loại euro 2024
атака титанов бесплатно в хорошем качестве https://ataka-titanov-anime.ru
игра лаки джет на деньги https://www.1win-luckyjet-ru.ru .
에그벳슬롯
Xie Qian은 또한 왕세자와 삼황 오황이 다소 조화를 이루지 못하는 것 같다고 느끼는 것 같았습니다.
атака титанов онлайн бесплатно смотреть аниме атака титанов
Лучшие модели колясок Cybex на рынке, новинки.
Как выбрать идеальную коляску Cybex для вашего малыша, для самых взыскательных.
Почему стоит обратить внимание на коляски Cybex, которые заставят вас влюбиться в этот бренд.
Идеальный выбор для заботливых родителей – коляски Cybex, которые не оставят вас равнодушными.
Как выбрать идеальную коляску Cybex для вашей семьи, учитывая все особенности и пожелания.
Как правильно подобрать коляску Cybex для вашей семьи, исходя из индивидуальных потребностей и предпочтений.
Трендовые коляски Cybex для вашего малыша, которые ценят комфорт и безопасность.
Топ-модели колясок Cybex на любой вкус и цвет, которые порадуют вас своим разнообразием и качеством.
5 важных критериев при выборе коляски Cybex, для вашего малыша.
Выбор коляски Cybex: что важно знать перед покупкой, чтобы сделать правильный выбор.
Топ-модели колясок Cybex для вашего малыша, которые не оставят вас равнодушными.
Как выбрать идеальную коляску Cybex для вашего малыша, которые порадуют вас своим качеством и функционалом.
Идеальная коляска Cybex: комфорт и удобство для вашего малыша, которые стоит рассмотреть перед покупкой.
Почему стоит выбрать именно коляски Cybex, если вы цените качество и комфорт.
Лучшие модели колясок Cybex: подробный обзор, которые ценят надежность и стиль.
Новинки колясок Cybex, которые стоит рассмотреть, перед совершением покупки.
Как выбрать идеальную коляску Cybex для вашей семьи, исходя из личных предпочтений и потребностей.
Лучшие предложения на коляски Cybex для вашей семьи, которые не оставят вас равнодушными.
детские коляски cybex https://kolyaskicybex.ru/ .
купить диплом университета https://www.russa24-diploms-srednee.com .
атака титанов онлайн бесплатно https://ataka-titanov-anime.ru
где купить мебель https://formomebel.ru/krovati
娛樂城官網
娛樂城官網
how to start an online casino gaming bets
Самые популярные коляски Tutis, Как выбрать идеальную коляску от Tutis?, Лучшие цветовые решения от Tutis, Инструкция по эксплуатации коляски Tutis, Необходимые аксессуары для комфортной прогулки с ребенком, Коляски Tutis для спортивных родителей, Сравнение Tutis с другими брендами колясок, рекомендации по выбору лучшей модели, Почему Tutis – выбор ответственных родителей, секреты защиты малыша, Почему Tutis подойдет и летом, и зимой, подготовка к разным временам года, Почему Tutis – марка будущего, технологии, делающие коляски лучше, Как подчеркнуть свой стиль с помощью коляски Tutis?, Почему Tutis – надежный партнер для вашей семьи?, поддержка родителей в заботе о ребенке
коляска 3 в 1 тутис коляска 3 в 1 тутис .
голяк кубик в кубе бесплатно https://golyak-serial-online.ru
голяк смотреть кубик https://golyak-serial-online.ru
Slotเว็บตรง – สนุกกับการเล่นได้ทุกอุปกรณ์เชื่อมต่อที่ต่ออินเทอร์เน็ต
ในยุคปัจจุบัน การเล่นสล็อตมีความสะดวกมากยิ่งขึ้น คุณไม่ต้องการเดินทางไปยังบ่อนคาสิโนที่ไหน ๆ เพียงแค่มีเครื่องมือที่ใช้งานได้เชื่อมต่อกับอินเทอร์เน็ต คุณก็มีโอกาสสนุกกับการเล่นเกมสล็อตออนไลน์กับ PG Slot ได้จากทุกที่
การปรับปรุงเทคโนโลยีของ PG Slot
ที่ PG Slot เราได้ปรับปรุงโซลูชั่นสำหรับการจัดการเกมคาสิโนออนไลน์เพื่อตอบสนองความพึงพอใจให้มากที่สุด คุณไม่จำเป็นติดตั้งแอปหรือโหลดแอปพลิเคชันใด ๆ ให้เสียเวลาหรือใช้พื้นที่ในอุปกรณ์ของคุณ การบริการเกมสล็อตออนไลน์ของเราปฏิบัติการผ่านเว็บตรงที่ใช้เทคโนโลยี HTML 5 ที่ล้ำสมัย
ปั่นสล็อตได้ทุกเครื่องมือ
คุณสามารถเล่นสล็อตออนไลน์กับ PG Slot ได้อย่างง่ายดายเพียงเยี่ยมชมในเว็บไซต์ของเรา เว็บตรงสล็อตออนไลน์ของเรารองรับทุกโครงสร้างและทุกเครื่องทั้ง Android และ iOS ไม่ว่าคุณจะใช้มือถือ คอมพิวเตอร์ หรืออุปกรณ์พกพารุ่นไหน ก็จะมั่นใจได้ว่าคุณจะหมุนสล็อตออนไลน์ได้อย่างราบรื่น ไม่มีอุปสรรคหรือสะดุดใด ๆ
ทดลองเล่นสล็อตฟรี
เว็บตรงของเราให้คุณใช้บริการเพียงแค่คุณเข้าสู่ในเว็บไซต์ของ PG Slot ก็อาจทดลองเล่นสล็อตฟรีได้ทันที ไม่ต้องเสียค่าใช้จ่ายเพิ่มเติมใด ๆ นี่เป็นโอกาสที่ดีในการทดลองเล่นและเรียนรู้เกี่ยวกับเกมก่อนที่จะเล่นจริงด้วยเงินจริง
การเล่นเกมสล็อตออนไลน์กับ PG Slot ช่วยให้คุณสามารถเพลิดเพลินกับการเล่นเกมคาสิโนได้ทุกที่ทุกเวลา ไม่ว่าคุณจะอยู่ที่ไหน เพียงแค่มีเครื่องมือที่เข้าถึงอินเทอร์เน็ต คุณก็มีโอกาสสนุกกับการเล่นเกมสล็อตได้อย่างไม่มีข้อจำกัด!
magnumbet
augmentin 875 mg cost
batoto
https://ataka-titanov-anime.ru/ – эпический аниме-сериал, где человечество борется за выживание в мире, наполненном гигантскими титанами. Динамичные бои, захватывающий сюжет и глубокие персонажи делают этот сериал обязательным к просмотру. Присоединяйтесь к битве!
娛樂城
富遊娛樂城評價:2024年最新評價
推薦指數 : ★★★★★ ( 5.0/5 )
富遊娛樂城作為目前最受歡迎的博弈網站之一,在台灣擁有最高的註冊人數。
RG富遊以安全、公正、真實和順暢的品牌保證,贏得了廣大玩家的信賴。富遊線上賭場不僅提供了豐富多樣的遊戲種類,還有眾多吸引人的優惠活動。在出金速度方面,獲得無數網紅和網友的高度評價,確保玩家能享有無憂的博弈體驗。
推薦要點
新手首選: 富遊娛樂城,2024年評選首選,提供專為新手打造的豐富教學和獨家優惠。
一存雙收: 首存1000元,立獲1000元獎金,僅需1倍流水,新手友好。
免費體驗: 新玩家享免費體驗金,暢遊各式遊戲,開啟無限可能。
優惠多元: 活動豐富,流水要求低,適合各類型玩家。
玩家首選: 遊戲多樣,服務優質,是新手與老手的最佳賭場選擇。
富遊娛樂城詳情資訊
賭場名稱 : RG富遊
創立時間 : 2019年
賭場類型 : 現金版娛樂城
博弈執照 : 馬爾他牌照(MGA)認證、英屬維爾京群島(BVI)認證、菲律賓(PAGCOR)監督競猜牌照
遊戲類型 : 真人百家樂、運彩投注、電子老虎機、彩票遊戲、棋牌遊戲、捕魚機遊戲
存取速度 : 存款5秒 / 提款3-5分
軟體下載 : 支援APP,IOS、安卓(Android)
線上客服 : 需透過官方LINE
富遊娛樂城優缺點
優點
台灣註冊人數NO.1線上賭場
首儲1000贈1000只需一倍流水
擁有體驗金免費體驗賭場
網紅部落客推薦保證出金線上娛樂城
缺點
需透過客服申請體驗金
富遊娛樂城存取款方式
存款方式
提供四大超商(全家、7-11、萊爾富、ok超商)
虛擬貨幣ustd存款
銀行轉帳(各大銀行皆可)
取款方式
網站內申請提款及可匯款至綁定帳戶
現金1:1出金
富遊娛樂城平台系統
真人百家 — RG真人、DG真人、歐博真人、DB真人(原亞博/PM)、SA真人、OG真人、WM真人
體育投注 — SUPER體育、鑫寶體育、熊貓體育(原亞博/PM)
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —RG電子、ZG電子、BNG電子、BWIN電子、RSG電子、GR電子(好路)
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
電競遊戲 — 熊貓體育
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、DB捕魚
купить диплом юриста https://www.russa24-diploms-srednee.com .
슬롯 게임 무료
Hongzhi 황제가 매우 몰두하는 것을보고 Fang Jifan은 폐하가 질병과 약에 대해 다소 금기시한다는 것을 알았습니다.
twin casino
игровой автомат gates of olympus http://www.gates-of-olympus-ru.ru .
台灣線上娛樂城
在现代,在线赌场提供了多种便捷的存款和取款方式。对于较大金额的存款,您可以选择中国信托、台中银行、合作金库、台新银行、国泰银行或中华邮政。这些银行提供的服务覆盖金额范围从$1000到$10万,确保您的资金可以安全高效地转入赌场账户。
如果您需要进行较小金额的存款,可以选择通过便利店充值。7-11、全家、莱尔富和OK超商都提供这种服务,适用于金额范围在$1000到$2万之间的充值。通过这些便利店,您可以轻松快捷地完成资金转账,无需担心银行的营业时间或复杂的操作流程。
在进行娱乐场提款时,您可以选择通过各大银行转账或ATM转账。这些方法不仅安全可靠,而且非常方便,适合各种提款需求。最低提款金额为$1000,而上限则没有限制,确保您可以灵活地管理您的资金。
在选择在线赌场时,玩家评价和推荐也是非常重要的。许多IG网红和部落客,如丽莎、穎柔、猫少女日记-Kitty等,都对一些知名的娱乐场给予了高度评价。这些推荐不仅帮助您找到可靠的娱乐场所,还能确保您在游戏中享受到最佳的用户体验。
总体来说,在线赌场通过提供多样化的存款和取款方式,以及得到广泛认可的服务质量,正在不断吸引更多的玩家。无论您选择通过银行还是便利店进行充值,都能体验到快速便捷的操作。同时,通过查看玩家的真实评价和推荐,您也能更有信心地选择合适的娱乐场,享受安全、公正的游戏环境。
娛樂城
Player台灣線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
layer如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
安全與公平性
安全永遠是我們評測的首要標準。我們審查每家娛樂城的執照資訊、監管機構以及使用的隨機數生成器,以確保其遊戲結果的公平性和隨機性。
02.
遊戲品質與多樣性
遊戲的品質和多樣性對於玩家體驗至關重要。我們評估遊戲的圖形、音效、用戶介面和創新性。同時,我們也考量娛樂城提供的遊戲種類,包括老虎機、桌遊、即時遊戲等。
03.
娛樂城優惠與促銷活動
我們仔細審視各種獎勵計劃和促銷活動,包括歡迎獎勵、免費旋轉和忠誠計劃。重要的是,我們也檢查這些優惠的賭注要求和條款條件,以確保它們公平且實用。
04.
客戶支持
優質的客戶支持是娛樂城質量的重要指標。我們評估支持團隊的可用性、響應速度和專業程度。一個好的娛樂城應該提供多種聯繫方式,包括即時聊天、電子郵件和電話支持。
05.
銀行與支付選項
我們檢查娛樂城提供的存款和提款選項,以及相關的處理時間和手續費。多樣化且安全的支付方式對於玩家來說非常重要。
06.
網站易用性、娛樂城APP體驗
一個直觀且易於導航的網站可以顯著提升玩家體驗。我們評估網站的設計、可訪問性和移動兼容性。
07.
玩家評價與反饋
我們考慮真實玩家的評價和反饋。這些資料幫助我們了解娛樂城在實際玩家中的表現。
娛樂城常見問題
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
fals4d
娛樂城推薦
2024娛樂城推薦,經過玩家實測結果出爐Top5!
2024娛樂城排名是這五間上榜,玩家尋找娛樂城無非就是要找穩定出金娛樂城,遊戲體驗良好、速度流暢,Ace博評網都幫你整理好了,給予娛樂城新手最佳的指南,不再擔心被黑網娛樂城詐騙!
2024娛樂城簡述
在現代,2024娛樂城數量已經超越以前,面對琳瑯滿目的娛樂城品牌,身為新手的玩家肯定難以辨別哪間好、哪間壞。
好的平台提供穩定的速度與遊戲體驗,穩定的系統與資訊安全可以保障用戶的隱私與資料,不用擔心收到傳票與任何網路威脅,這些線上賭場也提供合理的優惠活動給予玩家。
壞的娛樂城除了會騙取你的金錢之外,也會打著不實的廣告、優惠滿滿,想領卻是一場空!甚至有些平台還沒辦法登入,入口網站也是架設用來騙取新手儲值進他們口袋,這些黑網娛樂城是玩家必須避開的風險!
評測2024娛樂城的標準
Ace這次從網路上找來五位使用過娛樂城資歷2年以上的老玩家,給予他們使用各大娛樂城平台,最終選出Top5,而評選標準為下列這些條件:
以玩家觀點出發,優先考量玩家利益
豐富的遊戲種類與卓越的遊戲體驗
平台的信譽及其安全性措施
客服團隊的回應速度與服務品質
簡便的儲值流程和多樣的存款方法
吸引人的優惠活動方案
前五名娛樂城表格
賭博網站排名 線上賭場 平台特色 玩家實測評價
No.1 富遊娛樂城 遊戲選擇豐富,老玩家優惠多 正面好評
No.2 bet365娛樂城 知名大廠牌,運彩盤口選擇多 介面流暢
No.3 亞博娛樂城 多語言支持,介面簡潔順暢 賽事豐富
No.4 PM娛樂城 撲克牌遊戲豐富,選擇多元 直播順暢
No.5 1xbet娛樂城 直播流暢,安全可靠 佳評如潮
線上娛樂城玩家遊戲體驗評價分享
網友A:娛樂城平台百百款,富遊娛樂城是我3年以來長期使用的娛樂城,別人有的系統他們都有,出金也沒有被卡過,比起那些玩娛樂城還會收到傳票的娛樂城,富遊真的很穩定,值得推薦。
網友B:bet365中文的介面簡約,還有超多體育賽事盤口可以選擇,此外賽事大部分也都有附上直播來源,不必擔心看不到賽事最新狀況,全螢幕還能夠下單,真的超方便!
網友C:富遊娛樂城除了第一次儲值有優惠之外,儲值到一定金額還有好禮五選一,實用又方便,有問題的時候也有客服隨時能夠解答。
網友D:從大陸來台灣工作,沒想到台灣也能玩到亞博體育,這是以前在大陸就有使用的平台,雖然不是簡體字,但使用介面完全沒問題,遊戲流暢、速度比以前使用還更快速。
網友E:看玖壹壹MV發現了PM娛樂城這個大品牌,PM的真人百家樂沒有輸給在澳門實地賭場,甚至根本不用出門,超級方便的啦!
maxwin138
Итальянская мебель от салона https://formul.ru в Москве – это большой выбор мебели из Италии по доступным ценам! Итальянская мебель в налиичи и на заказ. Купить итальянскую мебель в Москве по лучшим ценам.
Wonders Travel & Tourism: a https://jordan-travel.com agency located in Aqaba. Specializing in tours around Jordan, including Petra, Wadi Rum, the Dead Sea, and Amman. Offering private tours that can be customized to tourist interests and have positive reviews for professionalism and service.
娛樂城
2024娛樂城介紹
台灣2024娛樂城越開越多間,新開的線上賭場層出不窮,每間都以獨家的娛樂城優惠和體驗金來吸引玩家,致力於提供一流的賭博遊戲體驗。以下來介紹這幾間娛樂城網友對他們的真實評價,看看哪些娛樂城上榜了吧!
2024娛樂城排名
2023下半年,各家娛樂城競爭激烈,相繼推出誘人優惠,不論是娛樂城體驗金、反水流水還是首儲禮金,甚至還有娛樂城抽I15手機。以下就是2024年網友推薦的娛樂城排名:
NO.1 富遊娛樂城
NO.2 Bet365台灣
NO.3 DG娛樂城
NO.4 九州娛樂城
NO.5 亞博娛樂城
2024娛樂城推薦
根據2024娛樂城排名,以下將富遊娛樂城、BET365、亞博娛樂城、九州娛樂城、王者娛樂城推薦給大家,包含首儲贈點、免費體驗金、存提款速度、流水等等…
娛樂城遊戲種類
線上娛樂城憑藉其廣泛的遊戲種類,成功滿足了各式各樣玩家的喜好和需求。這些娛樂城遊戲不僅多元化且各具特色,能夠為玩家提供無與倫比的娛樂體驗。下面是一些最受歡迎的娛樂城遊戲類型:
電子老虎機
魔龍傳奇、雷神之鎚、戰神呂布、聚寶財神、鼠來寶、皇家777
真人百家樂
真人視訊百家樂、牛牛、龍虎、炸金花、骰寶、輪盤
電子棋牌
德州撲克、兩人麻將、21點、十三支、妞妞、三公、鬥地主、大老二、牌九
體育下注
世界盃足球賽、NBA、WBC世棒賽、英超、英雄聯盟LOL、特戰英豪
線上彩票
大樂透、539、美國天天樂、香港六合彩、北京賽車
捕魚機遊戲
三仙捕魚、福娃捕魚、招財貓釣魚、西遊降魔、吃我一砲、賓果捕魚
2024娛樂城常見問題
娛樂城是什麼?
娛樂城/線上賭場(現金網)是台灣對於線上賭場的特別稱呼,而且是現金網,大家也許會好奇為什麼不直接叫做線上賭場或是線上博弈就好了。
其實這是有原因的,線上賭場這種東西,架站在台灣是違法的,在早期經營線上博弈被抓的風險非常高所以換了一個打模糊仗的代稱「娛樂城」來規避警方的耳目,畢竟以前沒有Google這種東西,這樣的代稱還是多少有些作用的。
信用版娛樂城是什麼?
信用版娛樂城是一種賭博平台,允許玩家在沒有預先充值的情況下參與遊戲。這種模式類似於信用卡,通常以周結或月結的方式結算遊戲費用。因此,如果玩家無法有效管理自己的投注額,可能會在月底面臨巨大的支付壓力。
娛樂城不出金怎麼辦?
釐清原因,如未違反娛樂城機制,可能是遇上黑網娛樂城,請盡快通報165反詐騙。
카지노 슬롯 머신
Zhu Houzhao는 Fang Jifan의 어깨를 두드렸다. “좋은 형제!”
драгон мани казино krpb.ru
слот sweet bonanza играть https://www.sweet-bonanza-ru.ru .
бонус 1go casino сайт 1go casino
Player台灣線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
layer如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
安全與公平性
安全永遠是我們評測的首要標準。我們審查每家娛樂城的執照資訊、監管機構以及使用的隨機數生成器,以確保其遊戲結果的公平性和隨機性。
02.
遊戲品質與多樣性
遊戲的品質和多樣性對於玩家體驗至關重要。我們評估遊戲的圖形、音效、用戶介面和創新性。同時,我們也考量娛樂城提供的遊戲種類,包括老虎機、桌遊、即時遊戲等。
03.
娛樂城優惠與促銷活動
我們仔細審視各種獎勵計劃和促銷活動,包括歡迎獎勵、免費旋轉和忠誠計劃。重要的是,我們也檢查這些優惠的賭注要求和條款條件,以確保它們公平且實用。
04.
客戶支持
優質的客戶支持是娛樂城質量的重要指標。我們評估支持團隊的可用性、響應速度和專業程度。一個好的娛樂城應該提供多種聯繫方式,包括即時聊天、電子郵件和電話支持。
05.
銀行與支付選項
我們檢查娛樂城提供的存款和提款選項,以及相關的處理時間和手續費。多樣化且安全的支付方式對於玩家來說非常重要。
06.
網站易用性、娛樂城APP體驗
一個直觀且易於導航的網站可以顯著提升玩家體驗。我們評估網站的設計、可訪問性和移動兼容性。
07.
玩家評價與反饋
我們考慮真實玩家的評價和反饋。這些資料幫助我們了解娛樂城在實際玩家中的表現。
娛樂城常見問題
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
台灣線上娛樂城
在现代,在线赌场提供了多种便捷的存款和取款方式。对于较大金额的存款,您可以选择中国信托、台中银行、合作金库、台新银行、国泰银行或中华邮政。这些银行提供的服务覆盖金额范围从$1000到$10万,确保您的资金可以安全高效地转入赌场账户。
如果您需要进行较小金额的存款,可以选择通过便利店充值。7-11、全家、莱尔富和OK超商都提供这种服务,适用于金额范围在$1000到$2万之间的充值。通过这些便利店,您可以轻松快捷地完成资金转账,无需担心银行的营业时间或复杂的操作流程。
在进行娱乐场提款时,您可以选择通过各大银行转账或ATM转账。这些方法不仅安全可靠,而且非常方便,适合各种提款需求。最低提款金额为$1000,而上限则没有限制,确保您可以灵活地管理您的资金。
在选择在线赌场时,玩家评价和推荐也是非常重要的。许多IG网红和部落客,如丽莎、穎柔、猫少女日记-Kitty等,都对一些知名的娱乐场给予了高度评价。这些推荐不仅帮助您找到可靠的娱乐场所,还能确保您在游戏中享受到最佳的用户体验。
总体来说,在线赌场通过提供多样化的存款和取款方式,以及得到广泛认可的服务质量,正在不断吸引更多的玩家。无论您选择通过银行还是便利店进行充值,都能体验到快速便捷的操作。同时,通过查看玩家的真实评价和推荐,您也能更有信心地选择合适的娱乐场,享受安全、公正的游戏环境。
квартиры в Санкт-Петербурге цены https://kvartiru-kupit-spb.ru
недорогие квартиры цены квартиры от застройщика цены
https://erokomiksi6.com/?keyword=area188
цены на квартиры https://kvartiru-kupit-spb.ru
квартиры с отделкой от застройщика https://novostroyki-spb78.ru
슬롯 커뮤
“Heh …”Wang Zuo는 비웃고 이빨을 비비며 Li Chaowen을 격렬하게 반박했습니다.
Каталог эротических рассказов https://vicmin.ru подарит тебе возможность уйти от рутины и погрузиться в мир секса и безудержного наслаждения. Обширная коллекция рассказов для взрослых разбудит твое воображение и принесет немыслимое удовольствие.
слот крейзи манки https://crazy-monkey-ru.ru/ .
pg slot
??????????????? — ????????? ?????????????? ???????? ???? ??? ?????????
??????????????????? ??? PG Slot ??????????????????????? ???????? ??????????????? ???????????????????????????? ??????? ???????????????? ?????? ??????? ???? ??????????? ??????
??? ????????? ?????????????????????????? ?????????? ???????? ????????????? ??? ???????????????????????????????? ?????? ??? HTML 5 ???????? ????????????????????????? ???????? ??????????????? ????????????? ?????????? ??????????????????????????? ????? ??????????????????? ???????????? ?????????? ??????????? ?????????????? ????????? ????????????????????
????????????????????????
?????????????? ?????????????? ???? Android ???? ??????? ???????? ?????????????????????????????? ?????????? ????????????????? ???????? ? ?????????????? ?? ?????? ???????????????????? ???? ?????????????????????????? ???????????????? ??????????? ?????????? ??????????????
????????????????????
??????????????? PG Slot ??????? ????????? ???????????????????? ???????? ??????? ????????? ?????????? ?????????? ??????????????????? ???????????? ????????? ????????????????? ????????????? ???????????????????? ????????????????????? ????????????????????
?????????????????
???????? ?????????????? ????????????????????????????????? PG Slot ?????????????????? ????????? ???????????????????????????????????????????? ??? ?????????????????????????????????????????????????????????????????
??????????????????????????
PG Slot ??????????????????????????????????? ????? ???????????????????????????? ????????????????? ????????????????????????? ??????????? ?????????????????? ??????????????????????????????????????
??????????????????????
??????????????? PG Slot ?????????? ??? ?? ????????????????????????????????????????????? ??????????????? ?????????????????? ????????? ?????????????????????? ????????? ?????????????????????????????????
??????????????????????? PG Slot ????????????????????????? ???????????????????????????????????????????????????????? ?????????????????????????????????????????????????? ?????????????????????????????? ???????? ????????????????????? ?????????????????????????????????? ????????? ????????????????????????????? PG Slot ??????!
dexamethasone 20 mg tablet
Новостройки в Екатеринбурге, купить квартиру в новостройке https://kupit-kvartiruekb.ru от застройщика. Строительство жилой и коммерческой недвижимости. Высокое качество, прозрачность на всех этапах строительства и сделки.
สล็อตออนไลน์เว็บตรง: ความบันเทิงที่ผู้เล่นไม่ควรพลาด
การเล่นเกมสล็อตในยุคนี้ได้รับความนิยมเพิ่มมากขึ้น เนื่องจากความสะดวกสบายที่ผู้เล่นสามารถเข้าถึงได้ได้ทุกที่ได้ตลอดเวลา โดยไม่ต้องเสียเวลาในการเดินทางไปยังคาสิโนจริง ๆ ในเนื้อหานี้ เราจะกล่าวถึง “สล็อตออนไลน์” และความบันเทิงที่คุณจะได้พบในเกมสล็อตออนไลน์เว็บตรง
ความสะดวกสบายในการเล่นสล็อตออนไลน์
หนึ่งในสล็อตที่เว็บตรงเป็นที่สนใจอย่างแพร่หลาย คือความสะดวกที่ผู้เล่นได้สัมผัส คุณสามารถเล่นได้ทุกหนทุกแห่งตลอดเวลา ไม่ว่าจะเป็นที่บ้าน ในออฟฟิศ หรือถึงแม้จะอยู่ในการเดินทาง สิ่งที่คุณต้องมีคืออุปกรณ์ที่เชื่อมต่อที่เชื่อมต่ออินเทอร์เน็ตได้ ไม่ว่าจะเป็นโทรศัพท์มือถือ แท็บเล็ต หรือโน้ตบุ๊ก
เทคโนโลยีที่ทันสมัยกับสล็อตที่เว็บตรง
การเล่นสล็อตออนไลน์ในปัจจุบันนี้ไม่เพียงแต่สะดวก แต่ยังมีเทคโนโลยีล้ำสมัยอีกด้วย สล็อตเว็บตรงใช้เทคโนโลยี HTML5 ซึ่งทำให้คุณไม่ต้องกังวลใจเกี่ยวกับการลงโปรแกรมหรือแอปพลิเคชันเพิ่มเติม แค่เปิดเบราว์เซอร์บนเครื่องมือของคุณและเข้ามายังเว็บไซต์ คุณก็สามารถสนุกกับเกมได้ทันที
ตัวเลือกหลากหลายของเกมของสล็อต
สล็อตที่เว็บตรงมาพร้อมกับความหลากหลายของเกมของเกมให้เลือกที่ผู้เล่นสามารถเลือก ไม่ว่าจะเป็นเกมสล็อตแบบคลาสสิกหรือเกมที่มีฟีเจอร์เด็ดและโบนัสมากมาย ท่านจะพบเจอมีเกมให้เลือกเล่นมากมาย ซึ่งทำให้ไม่มีวันเบื่อกับการเล่นสล็อต
การสนับสนุนทุกอุปกรณ์ที่ใช้
ไม่ว่าคุณจะใช้โทรศัพท์มือถือแอนดรอยด์หรือ iOS ผู้เล่นก็สามารถเล่นสล็อตได้อย่างไม่มีสะดุด เว็บไซต์ของเราสนับสนุนOSและทุกเครื่องมือ ไม่ว่าจะเป็นมือถือรุ่นล่าสุดหรือรุ่นก่อน หรือถึงแม้จะเป็นแทปเล็ตและคอมพิวเตอร์ ท่านก็สามารถเล่นเกมสล็อตได้อย่างเต็มที่
ทดลองเล่นสล็อตฟรี
สำหรับผู้ที่เพิ่งเริ่มต้นกับการเล่นสล็อตออนไลน์ หรือยังไม่แน่นอนเกี่ยวกับเกมที่อยากเล่น PG Slot ยังมีบริการทดลองเล่นเกมสล็อต คุณเริ่มเล่นได้ทันทีทันทีโดยไม่ต้องลงชื่อเข้าใช้หรือฝากเงินก่อน การทดลองเล่นเกมสล็อตนี้จะช่วยให้คุณเรียนรู้และรู้จักเกมได้โดยไม่ต้องเสียค่าใช้จ่ายใด ๆ
โบนัสและโปรโมชั่น
ข้อดีอีกอย่างหนึ่งของการเล่นเกมสล็อตกับ PG Slot คือมีโปรโมชันและโบนัสมากมายสำหรับผู้เล่น ไม่ว่าคุณจะเป็นผู้เล่นใหม่หรือสมาชิกเก่า ผู้เล่นสามารถรับโปรโมชันและโบนัสต่าง ๆ ได้อย่างต่อเนื่อง ซึ่งจะทำให้โอกาสชนะมากขึ้นและเพิ่มความบันเทิงในเกม
บทสรุป
การเล่นสล็อตที่ PG Slot เป็นการการลงทุนทางเกมที่คุ้มค่า คุณจะได้รับความเพลิดเพลินและความสะดวกสบายจากการเล่นสล็อต นอกจากนี้ยังมีโอกาสรับรางวัลและโบนัสเพียบ ไม่ว่าท่านจะใช้โทรศัพท์มือถือ แท็บเล็ทหรือคอมพิวเตอร์รุ่นใด ก็สามารถเล่นได้ทันที อย่ารอช้า เข้าร่วมและเริ่มเล่นสล็อตออนไลน์ PG Slot ทันที
где можно купить диплом https://diplom-izhevsk.ru
juragan69
สล็อตเว็บโดยตรง — สามารถใช้ โทรศัพท์มือถือ แท็บเล็ต คอมพิวเตอร์ ฯลฯ ในการเล่น
ระบบสล็อตตรงจากเว็บ ของ PG Slot ได้รับการพัฒนาและปรับปรุง เพื่อให้ รองรับการใช้ บนอุปกรณ์ที่หลากหลายได้อย่าง ครบถ้วน ไม่สำคัญว่าจะใช้ โทรศัพท์มือถือ แท็บเล็ต หรือ คอมพิวเตอร์ รุ่นไหน
ที่ PG Slot เราเข้าใจถึงสิ่งที่ผู้เล่นต้องการ จากผู้เล่น ในเรื่อง ความสะดวก และ การเข้าถึงเกมออนไลน์อย่างรวดเร็ว เราจึง ใช้เทคโนโลยี HTML 5 ซึ่งเป็น เทคโนโลยีล่าสุด ปัจจุบันนี้ พัฒนาเว็บของเรา คุณจึงไม่ต้อง ดาวน์โหลดแอป หรือติดตั้งโปรแกรมเพิ่มเติม เพียง เปิดเว็บเบราว์เซอร์ บนอุปกรณ์ที่ คุณใช้อยู่ และเยี่ยมชม เว็บไซต์เรา คุณสามารถ เล่นเกมสล็อตได้ทันที
การรองรับอุปกรณ์หลายชนิด
ไม่ว่าคุณจะใช้ มือถือ ระบบ Android หรือ iOS ก็สามารถ เล่นสล็อตได้อย่างราบรื่น ระบบของเรา ได้รับการออกแบบให้รองรับ ระบบต่าง ๆ ไม่สำคัญว่าคุณ ใช้ โทรศัพท์ เครื่องใหม่หรือเครื่องเก่า หรือ แท็บเล็ตหรือโน้ตบุ๊ก ทุกอย่างก็สามารถ ใช้งานได้ดี ไม่มีปัญหา ในเรื่องความเข้ากันได้
เล่นได้ทุกที่และทุกเวลา
ข้อดีอย่างหนึ่งของการเล่นเว็บสล็อตอย่าง PG Slot นั่นคือ คุณสามารถ เล่นได้ตลอดเวลา ไม่ว่าจะ อยู่ที่บ้าน ออฟฟิศ หรือแม้แต่ ที่สาธารณะ สิ่งที่คุณต้องมีคือ อินเทอร์เน็ต คุณสามารถ เริ่มเล่นได้ทันที และคุณไม่ต้อง กังวลกับการดาวน์โหลด หรือติดตั้งโปรแกรมที่ ใช้พื้นที่บนอุปกรณ์ของคุณ
เล่นสล็อตฟรี
เพื่อให้ ผู้เล่นใหม่ มีโอกาสลองและสัมผัสประสบการณ์สล็อตแมชชีนของเรา PG Slot ยังมีบริการสล็อตฟรี คุณสามารถ เริ่มเล่นได้ทันทีโดยไม่ต้องลงทะเบียนหรือฝากเงิน การ ทดลองเล่นสล็อตนี้จะช่วยให้คุณรู้จักวิธีการเล่นและเข้าใจเกมก่อนเดิมพันด้วยเงินจริง
บริการและการรักษาความปลอดภัย
PG Slot มุ่งมั่นในการบริการลูกค้าที่ดีที่สุด เรามี ทีมงานมืออาชีพพร้อมให้บริการและช่วยเหลือคุณตลอด 24 ชั่วโมง นอกจากนี้เรายังมี ระบบความปลอดภัยที่ทันสมัย ด้วยวิธีนี้ คุณจึงมั่นใจได้ว่า ข้อมูลและการเงินของคุณจะปลอดภัย
โปรโมชั่นและโบนัสพิเศษ
อีกข้อดีของการเล่นสล็อตกับ PG Slot นั่นคือ มี โปรโมชันและโบนัสมากมาย ไม่ว่าคุณจะเป็น ผู้เล่นใหม่หรือเก่า คุณสามารถ รับโปรโมชันและโบนัสได้ สิ่งนี้จะ เพิ่มโอกาสชนะและความสนุกในเกม
สรุปการเล่นสล็อตเว็บที่ PG Slot ถือเป็นการลงทุนที่คุ้มค่า คุณจะไม่เพียงได้รับความสุขและความสะดวกสบายจากเกมเท่านั้น แต่คุณยังมีโอกาสลุ้นรับรางวัลและโบนัสมากมายอีกด้วย ไม่สำคัญว่าจะใช้โทรศัพท์มือถือ แท็บเล็ต หรือคอมพิวเตอร์รุ่นใด สามารถมาร่วมสนุกกับเราได้เลยตอนนี้ อย่ารอช้า ลงทะเบียนและเริ่มเล่นสล็อตกับ PG Slot วันนี้!
เรื่อง ไซต์ PG Slots มีความ มี ประโยชน์ หลายประการ ในเปรียบเทียบกับ คาสิโนแบบ ปกติ, โดยมาก ใน ปัจจุบันนี้. คุณสมบัติสำคัญ เหล่านี้ เช่น:
ความง่ายสะดวก: ผู้เล่น สามารถใช้งาน สล็อตออนไลน์ได้ ตลอด 24 ชั่วโมง จาก ทุกแห่ง, อำนวย ผู้เล่นสามารถ เล่น ได้ ทุกแห่ง ไม่ต้อง ต้องเดินทาง ไปคาสิโนแบบ เดิม ๆ
เกมมากมายแตกต่าง: สล็อตออนไลน์ นำเสนอ เกม ที่ แตกต่างกัน, เช่น สล็อตคลาสสิค หรือ ตัวเกม ที่มี ความสามารถ และโบนัส พิเศษ, ไม่ก่อให้เกิด ความเบื่อ ในเกม
ข้อเสนอส่งเสริมการขาย และประโยชน์: สล็อตออนไลน์ มักจะ เสนอ แคมเปญส่งเสริมการขาย และรางวัล เพื่อปรับปรุง ความสามารถ ในการ ได้รับรางวัล และ ปรับปรุง ความสนุกสนาน ให้กับเกม
ความมั่นคง และ ความไว้วางใจ: สล็อตออนไลน์ แทบจะ ใช้งาน มาตรการรักษาความปลอดภัย ที่ มีประสิทธิภาพ, และ เชื่อมั่นได้ ว่า ข้อมูลส่วนบุคคล และ การเงิน จะได้รับการ คุ้มครอง
การสนับสนุน: PG Slots ว่าจ้าง ผู้ให้บริการ ที่มีความเชี่ยวชาญ ที่ทุ่มเท ดูแล ตลอดเวลา
การเล่นบนอุปกรณ์พกพา: สล็อต PG อนุญาต การเล่นบนอุปกรณ์พกพา, ทำให้ ผู้เล่นสามารถเข้าร่วม ได้ทุกที่
เล่นทดลองฟรี: สำหรับ ผู้เล่นรายใหม่, PG ยังให้บริการ ทดลองเล่นโดยไม่เสียค่าใช้จ่าย อีกที่, ช่วยให้ ผู้เล่น เรียนรู้ วิธีใช้ และทำความเข้าใจ เกมก่อน เล่นด้วยเงินจริง
สล็อต PG มีคุณลักษณะ ประโยชน์ เป็นจำนวนมาก ที่ ก่อให้เกิด ให้ได้รับความสำคัญ ในยุคปัจจุบัน, ช่วย ความรู้สึก ความเพลิดเพลิน ให้กับเกมด้วย.
ทดลองปฏิบัติเล่นสล็อต และค้นพบประสบการณ์การเล่นเกมที่ไม่เหมือนใคร!
สำหรับนักพนันที่กำลังมองหาความบันเทิงและโอกาสในการได้รับรางวัลมหาศาล สล็อตออนไลน์เป็นอีกหนึ่งโอกาสที่คุ้มค่าศึกษา.ด้วยความจำนวนมากของเกมสล็อตที่น่าตื่นเต้น ผู้เล่นสามารถทดลองเล่นและค้นหาเกมที่เหมาะกับตัวเองได้อย่างง่ายดาย.
ไม่ว่าคุณจะชอบเกมสล็อตคลาสสิกหรือต้องการความท้าทายใหม่, ทางเลือกรอกลับมาให้คุณสัมผัส. จากสล็อตที่มีแนวคิดมากมาย ไปจนถึงเกมที่มีลักษณะพิเศษและรางวัลมากมาย, ผู้เล่นจะได้พบกับประสบการณ์ที่น่าตื่นเต้นและน่าติดตาม.
ด้วยการปฏิบัติสล็อตฟรี, คุณสามารถศึกษาวิธีการเล่นและค้นค้นพบกลยุทธ์ที่เหมาะสมก่อนสร้างรายได้ด้วยเงินจริง. นี่คือโอกาสสำคัญที่จะทำความคุ้นเคยกับเกมและปรับปรุงโอกาสในการชนะรางวัลใหญ่.
อย่ารอช้า, เข้าไปกับการลองเล่นสล็อตออนไลน์วันนี้ และค้นพบประสบการณ์การเล่นเกมที่ไม่เหมือนใคร! เพลิดเพลินกับความตื่นเต้น, ความสนุกสนาน และโอกาสมากมายชนะรางวัลใหญ่. ทำก้าวแรกเดินทางสู่ความสมหวังของคุณในวงการสล็อตออนไลน์แล้ววันนี้!
ทดลองเล่นสล็อต pg
ทดสอบ เข้าร่วม สล็อต PG ไปพร้อมกับ ค้นพบ ไปยัง ยุค แห่ง ความสนุกสนาน ที่ ไร้ขอบเขต
ของ คอพนัน ที่ คิดค้น ค้นหา ความรู้สึก เกมที่แตกต่าง, สล็อต PG ถูกมองว่า ตัวเลือกที่ ที่ น่าจับตามอง มากมาย. ด้วย ความแตกต่าง ของ เกมสล็อตต่างๆ ที่ น่าสนใจ และ น่าสำรวจ, นักพนัน จะสามารถ ทดสอบ และ ลอง ประเภทเกม ที่ ตรงกับ ความชอบการเล่น ของตนเอง.
ไม่ว่า นักพนัน จะชื่นชอบ ความสนุกสนาน แบบดั้งเดิม หรือ สิ่งท้าทาย ที่แปลกใหม่, สล็อต PG มีให้เลือก ให้เลือกจำนวนมาก. ตั้งแต่ สล็อตแบบดั้งเดิม ที่ คุ้นชิน ไปจนถึง ประเภทเกม ที่ มีลักษณะ คุณสมบัติพิเศษ และ โบนัสล้นหลาม, คุณ จะสามารถ พบเจอ ความรู้สึก ที่ ตื่นเต้น และ เพลิดเพลิน
เพราะ การทดลองเล่น สล็อต PG โดยไม่ต้องเสียเงิน, ลูกค้า ได้ ศึกษา กระบวนการเล่น และ ทดสอบ กลเม็ด ต่างๆ ก่อนหน้า เริ่มลงเดิมพัน ด้วยเงินสด. นี่ ถือเป็น ทางออก อันดี ที่จะ เตรียมความพร้อม และ ส่งเสริม ความน่าจะเป็น ในการ ครอบครอง รางวัลมหาศาล.
อย่าลังเล, ทดลอง กับ การทดสอบเล่น สล็อต PG เดี๋ยวนี้ และ ทดสอบ การเล่นเกม ที่ ไร้ขอบเขต! ทดลอง ความตื่นเต้น, ความเพลิดเพลินใจ และ ความเป็นไปได้ ในการ ชนะรางวัล มากมาย. เริ่มต้น พัฒนา สู่ ความเจริญรุ่งเรือง ของคุณในวงการ เกมสล็อตออนไลน์ เดี๋ยวนี้!
Cериал Голяк https://golyak-serial-online.ru смотреть онлайн в хорошем качестве и с лучшей озвучкой на любых устройствах. Все сезоны истории мелкого преступника Винни и его друзей в английском городке!
aviator online game https://aviator-crash-game.ru .
Драгон Мани Казино https://krpb.ru – ваше место для азартных приключений! Наслаждайтесь широким выбором игр, щедрыми бонусами и захватывающими турнирами. Безопасность и честная игра гарантированы. Присоединяйтесь к нам и испытайте удачу в самом захватывающем онлайн-казино!
ลองเล่นสล็อต PG ซื้อรอบหมุนฟรี
ในปัจจุบันนี้ การเล่นเกมสล็อตบนออนไลน์ได้รับความชื่นชอบอย่างมาก โดยเฉพาะเกมสล็อตจากค่าย PG Slot ที่มีคุณสมบัติพิเศษมากมายให้นักพนันได้เพลิดเพลิน หนึ่งในฟีเจอร์ที่น่าสนใจและทำให้การเล่นสนุกยิ่งขึ้นคือ “การซื้อฟรีสปิน” ซึ่งเป็นการเพิ่มช่องทางในการชนะและเพิ่มความตื่นเต้นในการเล่น
การซื้อฟรีสปินคืออะไร
การซื้อตัวเลือกการหมุนฟรีคือการที่ผู้เล่นสามารถซื้อโอกาสสำเร็จในการหมุนวงล้อสล็อตโดยไม่ต้องรอให้เกิดไอคอนฟรีสปินบนวงล้อ ซึ่งเป็นการเพิ่มช่องทางในการได้รับรางวัลพิเศษต่างๆ ภายในเกม เช่น โบนัส แจ็คพอต และอื่นๆ นอกจากนี้ การซื้อฟรีสปินยังช่วยให้ผู้ใช้งานสามารถเพิ่มมูลค่ารางวัลได้อย่างรวดเร็วและมีประสิทธิผล
ข้อได้เปรียบของการทดลองเล่นสล็อต PG ซื้อรอบหมุนฟรี
เพิ่มโอกาสในการได้รับรางวัล: การซื้อตัวเลือกฟรีสปินช่วยให้นักเล่นมีความเป็นไปได้ในการได้รับรางวัลมากขึ้น เพราะว่ามีการหมุนวงล้อฟรีเพิ่มเติม ซึ่งอาจนำพาไปถึงการได้รับแจ็คพอตหรือรางวัลโบนัสพิเศษอื่นๆ
ประหยัดเวลาทำงาน: การซื้อตัวเลือกการหมุนฟรีช่วยประหยัดเวลาในการเล่นในการเล่น เนื่องด้วยไม่ต้องรอให้เกิดเครื่องหมายฟรีสปินบนวงล้อ ผู้เล่นสามารถเข้าไปในรอบฟรีสปินได้ทันที
ทดลองเล่นฟรี: สำหรับผู้เล่นที่ยังไม่แน่ใจเกี่ยวกับเกม PG Slot ยังมีตัวเลือกทดลองเล่นฟรีผู้เล่นได้ทดลองหมุนและศึกษาวิธีการเล่นก่อนที่จะตัดสินใจซื้อฟรีสปินด้วยเงินจริง
เพิ่มความบันเทิง: การซื้อตัวเลือกหมุนฟรีช่วยเพิ่มความรื่นรมย์ในการเล่น เพราะว่านักพนันสามารถเข้ารอบโบนัสและลักษณะพิเศษพิเศษอื่นๆ ได้อย่างง่ายดาย
ขั้นตอนการซื้อฟรีสปินในสล็อต PG
เลือกเกมที่ต้องการหมุนจากบริษัท PG Slot
คลิกที่ปุ่มคำสั่ง “ซื้อฟรีสปิน” ที่แสดงขึ้นบนหน้าจอการเล่น
ระบุจำนวนฟรีสปินที่ต้องการได้และยืนยันการสั่งซื้อ
เริ่มต้นการหมุนวงล้อและเพลิดเพลินกับการเล่น
สรุป
การทดสอบเล่นสล็อต PGและการซื้อฟรีสปินเป็นวิธีที่ดีเยี่ยมในการเพิ่มโอกาสในการชนะและเพิ่มความสนุกในการเล่น ด้วยลักษณะพิเศษพิเศษนี้ ผู้เล่นสามารถเข้าสู่รอบโบนัสและฟีเจอร์พิเศษต่างๆ ได้อย่างรวดเร็วทันใจและมีประสิทธิผล ไม่ว่าคุณจะเป็นใครผู้เล่นใหม่เอี่ยมหรือผู้เล่นที่มีชั่วโมงบิน การทดลองเล่นสล็อต PGและการซื้อฟรีสปินจะช่วยให้คุณมีประสบการณ์การเล่นที่น่าตื่นเต้นและรื่นรมย์มากยิ่งขึ้น
ลองเล่นสล็อต PG ซื้อฟรีสปิน แล้วคุณจะพบกับความบันเทิงและช่องทางในการชนะที่ไม่มีที่สิ้นสุด
Famous French footballer Kylian Mbappe https://kylianmbappe.prostoprosport-ar.com has become a global ambassador for Dior. The athlete will represent the men’s collections of creative director Kim Jones and the Sauvage fragrance, writes WWD. Mbappe’s appointment follows on from the start of the fashion house’s collaboration with the Paris Saint-Germain football club. Previously, Jones created a uniform for the team where Kylian is a player.
ทดลองเล่นสล็อต pg ฟรี
สล็อตตรงจากเว็บ — สามารถใช้ มือถือ แท็บเล็ต คอมฯ ฯลฯ สำหรับการเล่น
ระบบสล็อตตรงจากเว็บ ของ PG Slot ได้รับการพัฒนาและอัปเดต เพื่อให้ สามารถใช้งาน บนอุปกรณ์ที่หลากหลายได้อย่าง ครบถ้วน ไม่สำคัญว่าจะใช้ มือถือ แท็บเลต หรือ คอมพิวเตอร์ส่วนตัว รุ่นไหน
ที่ PG เราเข้าใจถึงสิ่งที่ผู้เล่นต้องการ จากผู้เล่น ในเรื่อง ความสะดวกสบาย และ ความรวดเร็วในการเข้าถึงเกมคาสิโนออนไลน์ เราจึง นำ HTML 5 มาใช้ ซึ่งเป็น เทคโนโลยีที่ล้ำสมัย ปัจจุบันนี้ พัฒนาเว็บของเรา คุณจึงไม่ต้อง ดาวน์โหลดแอป หรือติดตั้งโปรแกรมเพิ่มเติม เพียง เปิดเบราว์เซอร์ บนอุปกรณ์ที่ คุณใช้อยู่ และเยี่ยมชม เว็บไซต์เรา คุณสามารถ เพลิดเพลินกับสล็อตแมชชีนได้ทันที
การสนับสนุนหลายอุปกรณ์
ไม่ว่าคุณจะใช้ มือถือ ระบบ Android หรือ ไอโอเอส ก็สามารถ เล่นสล็อตออนไลน์ได้ไม่มีสะดุด ระบบของเรา ออกแบบมาให้รองรับ ทุกระบบปฏิบัติการ ไม่สำคัญว่าคุณ มี โทรศัพท์ ใหม่หรือเก่า หรือ แท็บเล็ตหรือโน้ตบุ๊ก ทุกอย่างก็สามารถ ใช้งานได้ดี ไม่มีปัญหา ในเรื่องความเข้ากันได้
สามารถเล่นได้ทุกที่ทุกเวลา
ข้อดีอย่างหนึ่งของการเล่นเว็บสล็อตอย่าง PG Slot คือ คุณสามารถ เล่นได้ทุกที่ทุกเวลา ไม่ว่าจะ อยู่ที่บ้าน ที่ทำงาน หรือแม้แต่ ในที่สาธารณะ สิ่งที่คุณต้องมีคือ อินเทอร์เน็ต คุณสามารถ เริ่มเกมได้ทันที และคุณไม่ต้อง กังวลกับการดาวน์โหลด หรือติดตั้งโปรแกรมที่ ใช้พื้นที่บนอุปกรณ์ของคุณ
ทดลองเล่นสล็อตฟรี
เพื่อให้ ผู้เล่นใหม่ ได้ลองและรู้จักเกมสล็อตของเรา PG Slot ยังเสนอบริการสล็อตทดลองฟรีอีกด้วย คุณสามารถ ทดลองเล่นได้ทันทีโดยไม่ต้องสมัครหรือฝากเงิน การ ทดลองเล่นสล็อตแมชชีนฟรีนี้จะช่วยให้คุณเรียนรู้วิธีเล่นและเข้าใจเกมก่อนตัดสินใจเดิมพันด้วยเงินจริง
การบริการและความปลอดภัย
PG Slot มุ่งมั่นในการบริการลูกค้าที่ดีที่สุด เรามี ทีมบริการที่พร้อมช่วยเหลือตลอด 24 ชั่วโมง นอกจากนี้เรายังมี การรักษาความปลอดภัยที่ทันสมัย ด้วยวิธีนี้ คุณจึงมั่นใจได้ว่า ข้อมูลและการเงินของคุณจะปลอดภัย
โปรโมชั่นและโบนัสพิเศษ
ข้อดีอีกประการของการเล่นสล็อตแมชชีนกับ PG Slot นั่นคือ มี โปรโมชั่นและโบนัสพิเศษมากมายสำหรับผู้เข้าร่วม ไม่ว่าคุณจะเป็น ผู้เล่นใหม่หรือเก่า คุณสามารถ รับโปรโมชันและโบนัสได้ สิ่งนี้จะ เพิ่มโอกาสชนะและความสนุกในเกม
สรุปการเล่นสล็อตเว็บที่ PG Slot ถือเป็นการลงทุนที่คุ้มค่า คุณจะไม่เพียงได้รับความสุขและความสะดวกสบายจากเกมเท่านั้น แต่คุณยังมีโอกาสลุ้นรับรางวัลและโบนัสมากมายอีกด้วย ไม่สำคัญว่าจะใช้โทรศัพท์มือถือ แท็บเล็ต หรือคอมพิวเตอร์รุ่นใด สามารถมาร่วมสนุกกับเราได้เลยตอนนี้ อย่ารอช้า ลงทะเบียนและเริ่มเล่นสล็อตกับ PG Slot วันนี้!
ทดลองเล่นสล็อต pg เว็บ ตรง
ประสบการณ์การสำรวจเล่นเกมสล็อตแมชชีน PG บนเว็บไซต์เดิมพันตรง: เข้าสู่โลกแห่งความตื่นเต้นที่ไม่มีข้อจำกัด
สำหรับนักเสี่ยงทายที่ตามหาการเผชิญหน้าเกมที่ไม่ซ้ำใคร และปรารถนาหาแหล่งพนันที่มั่นคง, การทำการเกมสล็อตแมชชีน PG บนเว็บตรงถือเป็นตัวเลือกที่น่าดึงดูดอย่างมาก. ด้วยความแตกต่างของสล็อตแมชชีนที่มีให้คัดสรรมากมาย, ผู้เล่นจะได้ประสบกับโลกแห่งความรื่นเริงและความสนุกเพลิดเพลินที่ไม่มีที่สิ้นสุด.
แพลตฟอร์มพนันโดยตรงนี้ นำเสนอการทดลองเล่นเกมการเล่นที่น่าเชื่อถือ เชื่อถือได้ และตรงตามความต้องการของนักวางเดิมพันได้เป็นอย่างดี. ไม่ว่าคุณจะชื่นชอบเกมสล็อตต่างๆแบบดั้งเดิมที่มีความคุ้นเคย หรืออยากลองสัมผัสเกมใหม่ๆที่มีฟีเจอร์เฉพาะตัวและโบนัสล้นหลาม, เว็บไซต์ตรงนี้นี้ก็มีให้คัดสรรอย่างมากมาย.
ด้วยระบบการทดลองเกมสล็อต PG ฟรี, ผู้เล่นจะได้โอกาสศึกษาวิธีการเล่นเกมและทดลองวิธีการต่างๆ ก่อนจะเริ่มลงทุนด้วยเงินจริง. โอกาสนี้นับว่าเป็นโอกาสอันยอดเยี่ยมที่จะพัฒนาความพร้อมเพรียงและสร้างเสริมโอกาสในการชิงโบนัสใหญ่.
ไม่ว่าคุณจะคุณจะปรารถนาความสนุกสนานที่เคยชิน หรือการพิชิตแปลกใหม่, เกมสล็อตแมชชีน PG บนเว็บเสี่ยงโชคตรงก็มีให้คัดสรรอย่างหลากหลายชนิด. ท่านจะได้ประสบกับการสัมผัสการเล่นเดิมพันที่น่าตื่นเต้นเร้าใจ น่าตื่นเต้นเร้าใจ และเพลิดเพลินไปกับโอกาสดีในการชนะรางวัลใหญ่มหาศาล.
อย่าลังเล, ร่วมสำรวจเกมสล็อต PG บนแพลตฟอร์มเดิมพันโดยตรงเวลานี้ และค้นพบจักรวาลแห่งความตื่นเต้นที่มั่นคง น่าค้นหา และเต็มไปด้วยความสนุกสนานรอคอยคุณ. พบเจอความเร้าใจ, ความสนุกสนาน และโอกาสดีในการได้รับโบนัสมหาศาล. เริ่มต้นเข้าสู่ความสำเร็จในวงการเกมออนไลน์แล้ววันนี้!
פוקר באינטרנט
הימורי ספורטיביים – הימורים באינטרנט
הימור ספורטיביים נעשו לאחד הענפים המתפתחים ביותר בהימור באינטרנט. משתתפים יכולים להמר על תוצאותיהם של אירועי ספורטיביים פופולריים למשל כדור רגל, כדורסל, משחק הטניס ועוד. האפשרויות להימור הן מרובות, כולל תוצאתו המשחק, כמות הגולים, כמות הנקודות ועוד. הבא דוגמאות למשחקים נפוצים שעליהם ניתן להמר:
כדור רגל: ליגת האלופות, מונדיאל, ליגות מקומיות
כדור סל: NBA, יורוליג, טורנירים בינלאומיים
טניס: טורניר ווימבלדון, אליפות ארה”ב הפתוחה, רולאן גארוס
פוקר ברשת באינטרנט – הימורים באינטרנט
פוקר באינטרנט הוא אחד ממשחקי ההימור הפופולריים ביותר בימינו. שחקנים יכולים להתחרות נגד יריבים מכל רחבי העולם בסוגי וריאציות של המשחק , לדוגמה Texas Hold’em, אומהה, Stud ועוד. אפשר לגלות תחרויות ומשחקי קש במבחר רמות ואפשרויות הימור שונות. אתרי הפוקר הטובים מציעים גם:
מגוון רחב של גרסאות המשחק פוקר
טורנירים שבועיות וחודשיות עם פרסים כספיים גבוהים
שולחנות למשחקים מהירים ולטווח הארוך
תוכניות נאמנות ללקוחות ומועדוני עם הטבות בלעדיות
בטיחות והגינות
בעת בוחרים בפלטפורמה להימורים, חיוני לבחור גם אתרים מורשים ומפוקחים המציעים סביבה משחק מאובטחת והגיונית. אתרים אלה עושים שימוש בטכנולוגיות אבטחה מתקדמות להגנה על נתונים אישיים ופיננסיים, וגם בתוכנות גנרטור מספרים רנדומליים (RNG) כדי לוודא הגינות במשחקים במשחקים.
בנוסף, הכרחי לשחק בצורה אחראי תוך קביעת מגבלות הימורים אישיות של השחקן. רוב האתרים מאפשרים למשתתפים להגדיר מגבלות הפסד ופעילויות, כמו גם להשתמש ב- כלים למניעת התמכרות. הימרו בחכמה ואל גם תרדפו גם אחרי הפסד.
המדריך המלא למשחקי קזינו ברשת, משחקי ספורט ופוקר באינטרנט ברשת
הימורים ברשת מציעים עולם שלם של של הזדמנויות מלהיבות לשחקנים, החל מקזינו באינטרנט וכל בהימורי ספורט ופוקר באינטרנט. בזמן בחירת פלטפורמת הימורים, הקפידו לבחור אתרים מפוקחים המציעים סביבת משחק מאובטחת והגיונית. זכרו גם לשחק תמיד בצורה אחראית תמיד ואחראי – ההימורים ברשת נועדו להיות מבדרים ומהנים ולא ליצור לבעיות כלכליות או חברתיות.
ทดลองปฏิบัติเล่นสล็อต และค้นพบประสบการณ์การเล่นเกมที่ไม่เหมือนใคร!
สำหรับนักพนันที่กำลังพิจารณาความบันเทิงและโอกาสในการแสวงหารางวัลมหาศาล สล็อตออนไลน์เป็นอีกหนึ่งทางเลือกที่คุ้มค่าใช้.ด้วยความหลากหลายของเกมสล็อตที่น่าตื่นเต้น ผู้เล่นสามารถปฏิบัติและค้นหาเกมที่ถูกใจได้อย่างง่ายดาย.
ไม่ว่าคุณจะชอบเกมสล็อตคลาสสิกหรือต้องการความท้าทายใหม่, ทางเลือกมากมายรอต้อนรับให้คุณสัมผัส. จากสล็อตที่มีหัวข้อมากมาย ไปจนถึงเกมที่มีฟีเจอร์พิเศษและเงินรางวัล, ผู้เล่นจะได้พบกับประสบการณ์ที่น่าตื่นเต้นและน่าติดตาม.
ด้วยการทดสอบสล็อตฟรี, คุณสามารถเรียนรู้วิธีการเล่นและค้นค้นพบกลยุทธ์ที่เหมาะสมก่อนวางเดิมพันด้วยเงินจริง. นี่คือโอกาสดีที่จะเรียนรู้กับเกมและปรับปรุงโอกาสในการชนะรางวัลใหญ่.
อย่าประวิงเวลา, ร่วมกับการลองเล่นสล็อตออนไลน์วันนี้ และค้นพบประสบการณ์การเล่นเกมที่ไม่เหมือนใคร! สัมผัสความท้าทาย, ความร่าเริง และโอกาสมากมายชนะรางวัล. ก้าวสู่ความสำเร็จเดินทางสู่ความสำเร็จของคุณในวงการสล็อตออนไลน์แล้ววันนี้!
megaslot88
EGGC
사실 … Fang Jifan은 누구에게도 상처를주고 싶지 않았습니다.
Скачать свежие новинки песен https://muzfo.net 2024 года ежедневно. Наслаждайтесь комфортным прослушиванием, скачивайте музыку за пару кликов на сайте.
aviator game download https://aviator-crash-game.ru .
הימורי ספורטיביים – הימורים באינטרנט
הימורי ספורט נעשו לאחד התחומים הצומחים ביותר בהימור באינטרנט. שחקנים יכולים להמר על תוצאות של אירועים ספורטיביים מוכרים כמו כדור רגל, כדורסל, טניס ועוד. האופציות להתערבות הן רבות, כולל תוצאת ההתמודדות, כמות הגולים, כמות הפעמים ועוד. הבא דוגמאות של למשחקי נפוצים שעליהם אפשרי להתערב:
כדור רגל: ליגת אלופות, גביע העולם, ליגות אזוריות
כדור סל: NBA, יורוליג, טורנירים בינלאומיים
משחק הטניס: טורניר ווימבלדון, US Open, רולאן גארוס
פוקר ברשת ברשת – הימור ברשת
פוקר ברשת הוא אחד מהמשחקים ההימורים המוכרים ביותר כיום. משתתפים מסוגלים להתחרות נגד מתחרים מכל רחבי תבל בסוגי סוגי משחק , למשל Texas Hold’em, אומהה, סטאד ועוד. אפשר למצוא טורנירים ומשחקי במגוון דרגות ואפשרויות מגוונות. אתרי פוקר הטובים מציעים גם:
מגוון רחב של וריאציות פוקר
טורנירים שבועיים וחודשיות עם פרסים כספיים
שולחנות למשחקים מהירים ולטווח הארוך
תוכניות נאמנות ללקוחות ומועדוני VIP עם הטבות
בטיחות והגינות
בעת הבחירה פלטפורמה להימורים, חיוני לבחור אתרי הימורים מורשים המפוקחים המציעים סביבת למשחק מאובטחת והוגנת. אתרים אלה משתמשים בטכנולוגיית הצפנה מתקדמת להבטחה על נתונים אישיים ופיננסי, וגם באמצעות תוכנות גנרטור מספרים רנדומליים (RNG) כדי לוודא הגינות המשחקים במשחקי ההימורים.
מעבר לכך, הכרחי לשחק גם בצורה אחראית תוך קביעת מגבלות הימורים אישיות. רוב אתרי ההימורים מאפשרים לשחקנים להגדיר מגבלות להפסדים ופעילות, כמו גם להשתמש ב- כלים למניעת התמכרות. שחק בתבונה ואל גם תרדפו גם אחרי הפסד.
המדריך המלא לקזינו ברשת, משחקי ספורט ופוקר באינטרנט
הימורים באינטרנט מציעים גם עולם שלם הזדמנויות מרתקות למשתתפים, מתחיל מקזינו באינטרנט וכל משחקי ספורט ופוקר באינטרנט. בזמן בחירת בפלטפורמת הימורים, הקפידו לבחור אתרים מפוקחים המציעים סביבת למשחק מאובטחת והגיונית. זכרו לשחק בצורה אחראית תמיד ואחראי – משחקי ההימורים ברשת נועדו להיות מבדרים ומהנים ולא לגרום בעיות פיננסיות או חברתיים.
купить диплом магистра https://ukr-diplom.ru/ .
Скачать свежие новинки песен https://muzfo.net 2024 года ежедневно. Наслаждайтесь комфортным прослушиванием, скачивайте музыку за пару кликов на сайте.
sa gaming
הימורי ספורט – הימורים באינטרנט
הימורי ספורטיביים נעשו לאחד התחומים המשגשגים ביותר בהימור ברשת. שחקנים מסוגלים להתערב על תוצאות של אירועים ספורט נפוצים לדוגמה כדור רגל, כדורסל, טניס ועוד. האופציות להימור הן רבות, כולל תוצאתו ההתמודדות, כמות השערים, כמות הפעמים ועוד. להלן דוגמאות של למשחקי נפוצים במיוחד עליהם אפשרי להמר:
כדור רגל: ליגת אלופות, מונדיאל, ליגות מקומיות
כדורסל: ליגת NBA, ליגת יורוליג, טורנירים בינלאומיים
טניס: ווימבלדון, אליפות ארה”ב הפתוחה, אליפות צרפת הפתוחה
פוקר ברשת ברשת – הימור באינטרנט
פוקר באינטרנט הוא אחד מהמשחקים ההימור הפופולריים ביותר בימינו. שחקנים יכולים להתחרות נגד יריבים מכל רחבי תבל במגוון סוגי משחק , כגון Texas Hold’em, אומהה, Stud ועוד. אפשר למצוא טורנירים ומשחקי קש במבחר רמות ואפשרויות מגוונות. אתרי פוקר המובילים מציעים גם:
מבחר רב של וריאציות המשחק פוקר
טורנירים שבועיים וחודשיים עם פרסים כספיים
שולחנות למשחקים מהירים ולטווח הארוך
תוכניות נאמנות ללקוחות ומועדוני VIP עם הטבות יחודיות
בטיחות ואבטחה והגינות
כאשר בוחרים בפלטפורמה להימורים, חיוני לבחור אתרי הימורים מורשים המפוקחים המציעים גם סביבת משחק בטוחה והוגנת. אתרים אלו משתמשים בטכנולוגיית הצפנה מתקדמות להגנה על מידע אישי ופיננסיים, וכן באמצעות תוכנות מחולל מספרים אקראיים (RNG) כדי להבטיח הגינות במשחקים במשחקי ההימורים.
מעבר לכך, הכרחי לשחק גם בצורה אחראי תוך הגדרת מגבלות אישיות הימור אישיות. רוב אתרי ההימורים מאפשרים גם למשתתפים לקבוע מגבלות להפסדים ופעילות, כמו גם להשתמש ב- כלים נגד התמכרויות. הימרו בתבונה ואל גם תרדפו גם אחרי הפסד.
המדריך המלא למשחקי קזינו באינטרנט, הימורי ספורט ופוקר באינטרנט באינטרנט
ההימורים ברשת מציעים עולם שלם של הזדמנויות מלהיבות לשחקנים, מתחיל מקזינו אונליין וגם משחקי ספורט ופוקר באינטרנט. בזמן הבחירה בפלטפורמת הימורים, חשוב לבחור אתרים מפוקחים המציעים גם סביבה משחק בטוחה והוגנת. זכרו גם לשחק בצורה אחראית תמיד – ההימורים ברשת נועדו להיות מבדרים ומהנים ולא גם לגרום לבעיות פיננסיות או חברתיות.
Агентство по продвижению телеграм-каналов https://883666b.com в Москве специализируется на разработке и реализации стратегий для увеличения аудитории и вовлечённости подписчиков на телеграм-каналах. Эксперты агентства помогают клиентам определить целевую аудиторию, разрабатывают контент-планы и рекламные кампании. Услуги включают рекламу посевами, таргет рекламой, анализ конкурентов, SEO-оптимизацию контента.
интернет эквайринг https://internet-ekvajring.kz – безопасные и эффективные платежные решения для вашего бизнеса.
купить аккаунт телеграмм с отлежкой купить аккаунт телеграмм с отлежкой .
buying metformin canada
https://ebi-reform.com/?keyword=888vipbet
Делаем отличное предложение вам сделать консультацию (аудит) по усилению продаж равным образом прибыли в вашем бизнесе. Формат аудита: персональная встреча или онлайн конференция по скайпу. Делая верные, но обыкновенные усилия, результат от ВАШЕГО бизнеса удастся увеличить в несколькио раз. В нашем запасе более 100 проверенных фактических методологий подъема результатов и прибыли. В зависимости от вашего бизнеса подберем для вас наиболее наилучшие и будем шаг за шагом внедрять.
http://r-diplom.ru/
купить диплом технолога купить диплом технолога .
русский анал с разговорами онлайн русский анал с разговорами онлайн .
купить квартиру в казани https://nedvizhimost47.ru
Почему плинтус теневой так популярен?
теневой плинтус стоимость теневой плинтус стоимость .
купить диплом кандидата наук http://school5-priozersk.ru/ .
купить свидетельство о браке school-10-lik.ru .
아리아나 슬롯
Shen Ao는 떨리는 목소리로 “아버지, 스승님…”이라고 말했습니다.
купить квартиру от застройщика https://novostroyka47.ru
Скачать музыку https://musiciansfix.com высокого качества в любом жанре. Огромный выбор треков от классики до новинок поможет вам создать идеальный плейлист. Наслаждайтесь любимыми композициями и открывайте для себя новые музыкальные горизонты. Присоединяйтесь и начните скачивать музыку прямо сейчас!
Хостинг в Беларуси бесплатно: лучший выбор для вашего сайта, преимущества и особенности.
Сравниваем лучшие предложения хостинга в Беларуси, инструкции и рекомендации.
Выбор профессионалов: топ-3 хостинга в Беларуси бесплатно, плюсы и минусы.
Простой гайд: как перенести свой сайт на бесплатный хостинг в Беларуси, техническая документация.
Безопасность сайта: SSL на хостинге в Беларуси бесплатно, характеристики и обзор.
DIY: с нуля до готового сайта на хостинге в Беларуси бесплатно, гайд для начинающих.
Где можно купить хостинг в Беларуси дешево и качественно?, обзор и сравнение.
Хостинг серверов бесплатно https://gerber-host.ru/ .
הימורים באינטרנט
הימורי ספורט – הימור באינטרנט
הימורי ספורטיביים נהיו לאחד הענפים הצומחים ביותר בהימורים באינטרנט. שחקנים יכולים להתערב על תוצאותיהם של אירועי ספורטיביים מוכרים לדוגמה כדור רגל, כדור סל, טניס ועוד. האופציות להתערבות הן רבות, וביניהן תוצאת המאבק, כמות השערים, מספר הפעמים ועוד. להלן דוגמאות של למשחקי נפוצים שעליהם ניתן להמר:
כדורגל: ליגת האלופות, מונדיאל, ליגות מקומיות
כדור סל: ליגת NBA, יורוליג, תחרויות בינלאומיות
טניס: טורניר ווימבלדון, US Open, רולאן גארוס
פוקר ברשת ברשת – הימורים באינטרנט
פוקר ברשת הוא אחד מהמשחקים ההימור הפופולריים ביותר בימינו. שחקנים מסוגלים להתחרות נגד יריבים מרחבי תבל במגוון גרסאות של המשחק , לדוגמה טקסס הולדם, אומהה, סטאד ועוד. ניתן לגלות טורנירים ומשחקי במגוון רמות ואפשרויות מגוונות. אתרי פוקר הטובים מציעים:
מבחר רב של וריאציות פוקר
טורנירים שבועיים וחודשיות עם פרסים כספיים
שולחנות המשחק למשחקים מהירים ולטווח ארוך
תוכניות נאמנות ומועדוני עם הטבות עם הטבות
בטיחות ואבטחה והגינות
כאשר הבחירה בפלטפורמה להימורים, חשוב לבחור גם אתרים מורשים המפוקחים המציעים גם סביבת למשחק בטוחה והוגנת. אתרים אלו עושים שימוש בטכנולוגיית אבטחה מתקדמת להגנה על נתונים אישיים ופיננסי, וגם בתוכנות גנרטור מספרים אקראיים (RNG) כדי להבטיח הגינות במשחקים.
מעבר לכך, חשוב לשחק גם באופן אחראי תוך הגדרת מגבלות אישיות הימור אישיות. רוב אתרי ההימורים מאפשרים לשחקנים להגדיר מגבלות הפסד ופעילות, כמו גם להשתמש ב- כלים למניעת התמכרות. הימרו בתבונה ואל גם תרדפו אחרי הפסד.
המדריך המלא למשחקי קזינו באינטרנט, הימורי ספורט ופוקר באינטרנט ברשת
ההימורים ברשת מציעים גם עולם שלם של הזדמנויות מלהיבות למשתתפים, החל מקזינו באינטרנט וגם משחקי ספורט ופוקר ברשת. בעת בחירת פלטפורמת הימורים, חשוב לבחור אתרי הימורים המפוקחים המציעים סביבה משחק מאובטחת והוגנת. זכרו גם לשחק בצורה אחראית תמיד ואחראי – משחקי ההימורים ברשת אמורים להיות מבדרים ולא גם ליצור בעיות פיננסיות או חברתיים.
Каждый год в середине сентября проводится Тюменский инновационный форум «НЕФТЬГАЗТЭК».
Форум посвящен развитию способов инноваторского роста отраслей топливно-энергетического комплекса, обсуждению и поиску решений, организации наилучших условий для развития инновационных проектов. Ежегодный тюменский форум представляетсобой влиятельной дискуссионной площадкой по продвижению нефтегазовой сферы в России, имеет большой статус и своевременность, созвучен корпоративной стратегии формирования инновационного направления в Российской Федерации
https://neftgaztek.ru/
купить диплом дизайнера http://www.school-10-lik.ru .
эффективные таблетки для похудения эффективные таблетки для похудения .
https://medium.com/@momejar21741/pg-59490dd058fd
สล็อตเว็บตรง — สามารถใช้ สมาร์ทโฟน แท็บเล็ต คอมฯ ฯลฯ สำหรับการเล่น
ระบบสล็อตเว็บตรง ของ PG Slot ได้รับการพัฒนาและปรับปรุง เพื่อให้ รองรับการใช้ บนอุปกรณ์ที่หลากหลายได้อย่าง เต็มที่ ไม่สำคัญว่าจะใช้ มือถือ แท็บเล็ต หรือ คอมพิวเตอร์ รุ่นใด
ที่ PG เราเข้าใจถึงสิ่งที่ผู้เล่นต้องการ ของผู้เล่น ในเรื่อง ความสะดวก และ ความรวดเร็วในการเข้าถึงเกมคาสิโนออนไลน์ เราจึง นำ HTML 5 มาใช้ ซึ่งเป็น เทคโนโลยีที่ล้ำสมัย ในตอนนี้ มาใช้พัฒนาเว็บไซต์ คุณจึงไม่ต้อง ติดตั้งแอป หรือติดตั้งโปรแกรมเพิ่มเติม เพียง เปิดบราวเซอร์ บนอุปกรณ์ที่ คุณมีอยู่ และเยี่ยมชม เว็บไซต์ของเรา คุณสามารถ เล่นเกมสล็อตได้ทันที
การสนับสนุนหลายอุปกรณ์
ไม่ว่าคุณจะใช้ โทรศัพท์มือถือ ระบบ Android หรือ ไอโอเอส ก็สามารถ เล่นเกมสล็อตได้อย่างไม่มีปัญหา ระบบของเรา ออกแบบมาเพื่อรองรับ ระบบปฏิบัติการทั้งหมด ไม่สำคัญว่าคุณ มี สมาร์ทโฟน ใหม่หรือเก่า หรือ แม้แต่แท็บเล็ตหรือแล็ปท็อป ทุกอย่างก็สามารถ ใช้งานได้ ไม่มีปัญหา ในเรื่องความเข้ากันได้
เล่นได้ทุกที่และทุกเวลา
ข้อดีอย่างหนึ่งของการเล่นเว็บสล็อตอย่าง PG Slot ก็คือ คุณสามารถ เล่นได้ทุกเวลา ไม่ว่าจะ อยู่ที่บ้าน ที่ออฟฟิศ หรือแม้แต่ ในที่สาธารณะ สิ่งที่คุณต้องมีคือ เน็ต คุณสามารถ เริ่มเกมได้ทันที และคุณไม่ต้อง กังวลกับการดาวน์โหลด หรือติดตั้งโปรแกรมที่ เปลืองพื้นที่อุปกรณ์
เล่นสล็อตฟรี
เพื่อให้ ผู้เล่นที่ใหม่ ได้ลองเล่นและสัมผัสเกมสล็อตของเรา PG Slot ยังมีสล็อตทดลองฟรี คุณสามารถ ทดลองเล่นได้ทันทีโดยไม่ต้องสมัครหรือฝากเงิน การ เล่นฟรีนี้จะช่วยให้คุณเข้าใจวิธีเล่นและรู้จักเกมก่อนลงเดิมพันจริง
การบริการและความปลอดภัย
PG Slot ตั้งใจให้บริการที่ดีที่สุดกับลูกค้า เรามี ทีมงานพร้อมบริการคุณตลอดเวลา นอกจากนี้เรายังมี การรักษาความปลอดภัยที่ทันสมัย ด้วยวิธีนี้ คุณจึงมั่นใจได้ว่า ข้อมูลส่วนบุคคลและธุรกรรมทางการเงินของคุณจะได้รับการปกป้องอย่างดีที่สุด
โปรโมชั่นและของรางวัลพิเศษ
ข้อดีอีกประการของการเล่นสล็อตแมชชีนกับ PG Slot ก็คือ มี โปรโมชันและโบนัสพิเศษสำหรับสมาชิก ไม่ว่าคุณจะเป็น สมาชิกใหม่หรือสมาชิกเก่า คุณสามารถ รับโปรโมชั่นและโบนัสต่างๆได้อย่างต่อเนื่อง สิ่งนี้จะ เพิ่มโอกาสชนะและความสนุกในเกม
สรุปการเล่นสล็อตเว็บที่ PG Slot ถือเป็นการลงทุนที่คุ้มค่า คุณจะไม่เพียงได้รับความสุขและความสะดวกสบายจากเกมเท่านั้น แต่คุณยังมีโอกาสลุ้นรับรางวัลและโบนัสมากมายอีกด้วย ไม่สำคัญว่าจะใช้โทรศัพท์มือถือ แท็บเล็ต หรือคอมพิวเตอร์รุ่นใด สามารถมาร่วมสนุกกับเราได้เลยตอนนี้ อย่ารอช้า ลงทะเบียนและเริ่มเล่นสล็อตกับ PG Slot วันนี้!
Проведение независимой строительной экспертизы — сложный процесс, требующий глубоких знаний. Наши специалисты обладают всеми необходимыми навыками, а их заключения часто служат основой для принятия верных стратегических решений. Строительно-техническая экспертиза https://stroytehexp.ru позволяет выявить факторы, вызвавшие ухудшение эксплуатационных характеристик объектов, проверить соответствие возведённых зданий градостроительным нормам.
Каждый год в течение сентября проходит Тюменский инновационный форум «НЕФТЬГАЗТЭК».
Форум посвящен определению мнтодов инновационного продвижения отраслей топливно-энергетического комплекса, обсуждению и определению ответов, организации благоприятных обстоятельств для развития инноваторских проектов. Ежегодный тюменский форум является важной дискуссионной площадкой по увеличению роста нефтегазовой ветви в Российской Федерации, содержит высокий статус и актуальность, созвучен корпоративной стратегии продвижения инновационного курса в России
https://neftgaztek.ru/
The story of Mbappe’s https://www.asma-online.org rise to fame is as remarkable as his on-field feats. Mbappe’s journey from local pitches to global arenas was meteoric. His early days at AS Monaco showcased his prodigious talent, with his blistering speed and fearless dribbling dismantling opposition defenses.
Как создать pin up образ, о которых вы не слышали
pin up casino como funciona https://pinupbrazilnbfdrf.com/ .
купить диплом в екатеринбурге vm-tver.ru .
Информационный ресурс https://ardma.ru, посвящен бизнесу, финансам, инвестициям и криптовалютам. Сайт предлагает экспертные статьи, аналитические отчеты, стратегии и советы для предпринимателей и инвесторов. Здесь можно найти новости и обзоры о бизнесе, маркетинге, трейдинге, а также практические рекомендации по различным видам заработка и управлению финансами.
Real Madrid midfielder Rodrigo https://rodrygo.prostoprosport-ar.com gave Madrid the lead in the Champions League quarter-final first leg against Manchester City. The meeting takes place in Madrid. Rodrigo scored in the 14th minute after a pass from Vinicius Junior.
canadian metformin
южный парк мультсериал https://southpark-serial.ru
купить квартиру в казани новостройка от застройщика купить квартиру от застройщика
Любому человеку рано или поздно приходится пользоваться услугами стоматологических клиник. Ни для кого не секрет, что лечение зубов и последующее протезирование – процедуры довольно дорогостоящие, не все граждане могут позволить себе их оплатить, если вам необходимо стоматология отзывы лечение зубов мы Вам обязательно поможем.
Особенности
Благодаря услугам, которые предлагает населению стоматология Маэстро, люди разного финансового достатка имеют возможность не только поддерживать здоровье полости рта, но и проходить все необходимые процедуры. Цены на лечение зубов и протезирование значительно ниже, чем в других медучреждениях. Несмотря на то, что клиника работает для широких слоев населения, пациенты получают полный перечень услуг, используя современное оборудование и качественные материалы. Жителям доступны следующие процедуры:
• профилактика полости рта;
• лечение зубов с использованием различных методов;
• полная диагностика;
• профессиональная чистка;
• отбеливание;
• протезирование.
Сотрудники учреждения соблюдают все санитарные нормы, а для тщательной дезинфекции и стерилизации инструментов предусмотрено современное оборудование.
Преимущества
Востребованность бюджетной стоматологии объясняется рядом преимуществ. Во-первых, в клинике трудятся опытные высококвалифицированные сотрудники. Во-вторых, к каждому пациенту врач находит подход. В-третьих, кабинеты оснащены всем необходимым оборудованием, в работе используют только качественные безопасные материалы. В-четвертых, все виды протезирования будут проведены в сжатые сроки. Многие клиники получают субсидии от государства, что позволяет существенно сократить расходы. Кроме того, некоторые стоматологии сотрудничают со страховыми компаниями, поэтому у пациентов появляется возможность получить услуги по полюсу ОМС. Пациенты получают консультацию по профилактике заболеваний полости рта. Врачи после тщательного осмотра составляют индивидуальный план лечения, с помощью которого удается добиться наилучшего результата. Более доступные цены достигаются не только благодаря государственному финансированию, но и оптимизации расходов.
Благодаря стоматологии Маэстро, человек с небольшим достатком может не только вылечить зубы, но и поддерживать здоровье ротовой полости. Теперь любой человек может не откладывать поход к стоматологу, выбирая доступное качественное обслуживание.
Широчайший ассортимент военных товаров|Ваш надежный партнер в выборе военных товаров|Специализированный магазин для военных|Спецодежда и обувь для армии|Оружие и аксессуары для профессионалов|Профессиональное снаряжение для военных|Боевая техника для суровых реалий|Армейский магазин с широким ассортиментом|Специализированный магазин для настоящих военных|Все для армии и спецслужб|Снаряжение для профессионалов военного дела|Выбор профессионалов в военной отрасли|Выбирайте только профессиональное снаряжение|Оружие и экипировка для настоящих героев|Амуниция и снаряжение от лучших производителей|Выбор настоящих защитников|Только качественные товары для службы в армии|Оружие и снаряжение для успешных миссий|Спецодежда для военнослужащих|Оружие и экипировка для тех, кто выбирает победу
військовий одяг інтернет магазин військовий одяг інтернет магазин .
купить квартиру недорого купить квартиру в новостройке от застройщика
Карьерный коуч https://vminske.by/fashion/kto-takie-karernye-konsultanty — эксперт рынка труда, который помогает людям определить свои карьерные цели, развиваться в выбранной области и достигать успеха в профессиональной деятельности.
лаки джет 1win лаки джет 1win .
Компания обеспечивает качественные решения по технической поддержке ресурса на https://podderzhka-dlya-saita.ru по недорогим ценам. Заполним веб-проект экспертным содержимым. Окажем услуги по техническому обслуживанию и хакерских атак. Работники выполнят профессиональные услуги по продвижению веб-сервисов. Предлагаем оформить выгодные расценки с месячной платой. Тарифные планы различаются по основным характеристикам: числу задействованных работников, объема и других.
seo продвижение и оптимизация сайтов заказать интернет рекламу сайта
seo оптимизация продвижение сайта в топ 10 яндекс цена
generic lyrica online
продвижение по лидам заказать сео продвижение сайта
play aviator online play aviator online .
카이센 윈즈
Hongzhi 황제는 착륙하여 좌우를 보았습니다. “Xiaofan은 어디에 있습니까?”
южный парк 5 сезон https://southpark-serial.ru
как купить диплом в нижнем тагиле как купить диплом в нижнем тагиле .
сервера ла2 эссенс
Сервера ла2
вскрыть замок ночью http://vskrytie-zamkov-moskva113.ru .
台灣線上娛樂城
台灣線上娛樂城是指通過互聯網提供賭博和娛樂服務的平台。這些平台主要針對台灣用戶,但實際上可能在境外運營。以下是一些關於台灣線上娛樂城的重要信息:
1. 服務內容:
– 線上賭場遊戲(如老虎機、撲克、輪盤等)
– 體育博彩
– 彩票遊戲
– 真人荷官遊戲
2. 特點:
– 全天候24小時提供服務
– 可通過電腦或移動設備訪問
– 常提供優惠活動和獎金來吸引玩家
3. 支付方式:
– 常見支付方式包括銀行轉賬、電子錢包等
– 部分平台可能接受加密貨幣
4. 法律狀況:
– 在台灣,線上賭博通常是非法的
– 許多線上娛樂城實際上是在國外註冊運營
5. 風險:
– 由於缺乏有效監管,玩家可能面臨財務風險
– 存在詐騙和不公平遊戲的可能性
– 可能導致賭博成癮問題
6. 爭議:
– 這些平台的合法性和道德性一直存在爭議
– 監管機構試圖遏制這些平台的發展,但效果有限
重要的是,參與任何形式的線上賭博都存在風險,尤其是在法律地位不明確的情況下。建議公眾謹慎對待,並了解相關法律和潛在風險。
如果您想了解更多具體方面,例如如何識別和避免相關風險,我可以提供更多信息。
Vinicius Junior https://viniciusjunior.prostoprosport-ar.com is a Brazilian and Spanish footballer who plays as a striker for Real Madrid and the Brazilian national team. Junior became the first player in the history of Los Blancos, born in 2000, to play an official match and score a goal.
優質娛樂城
Kylian Mbappe https://kylianmbappe.prostoprosport-ar.com is a French footballer, striker for Paris Saint-Germain and captain of the French national team. He began playing football in the semi-professional club Bondi, which plays in the lower leagues of France. He was noticed by Monaco scouts, which he joined in 2015 and that same year, at the age of 16, he made his debut for the Monegasques. The youngest debutant and goal scorer in the club’s history.
Karim Benzema https://karimbenzema.prostoprosport-ar.com is a French footballer who plays as a striker for the Saudi Arabian club Al-Ittihad. He played for the French national team, for which he played 97 matches and scored 37 goals. At the age of 17, he became one of the best reserve players, scoring three dozen goals per season.
Victor James Osimhen https://victorosimhen.prostoprosport-ar.com is a Nigerian footballer who plays as a forward for the Italian club Napoli and the Nigerian national team. In 2015, he was recognized as the best football player in Africa among players under 17 according to the Confederation of African Football.
сео продвижение сайтов в москве https://prodvizhenie-sajtov-v-moskve117.ru/ .
슬롯 머신 무료
Hongzhi 황제는 무자비하고 배은망덕 한 사람이 아니 었습니다. “아니면 왕자가 당신을 돕게하십시오.”
Toni Kroos https://tonikroos.prostoprosport-ar.com is a German footballer who plays as a central midfielder for Real Madrid and the German national team. World champion 2014. The first German player in history to win the UEFA Champions League six times.
Robert Lewandowski https://robertlewandowski.prostoprosport-ar.com is a Polish footballer, forward for the Spanish club Barcelona and captain of the Polish national team. Considered one of the best strikers in the world. Knight of the Commander’s Cross of the Order of the Renaissance of Poland.
сериал все сезоны волчонок бесплатно https://volchonok-tv.ru
волчонок смотреть серии бесплатно волчонок смотреть онлайн
Ежегодно в середине сентября организовывается Тюменский инновационный форум «НЕФТЬГАЗТЭК».
Форум посвящен развитию мнтодов инноваторского роста секторов топливно-энергетического комплекса, обсуждению а также поиску заключений, организации благоприятных условий для расчета инновационных проектов. Ежегодный тюменский форум является влиятельной дискуссионной площадкой по развитию нефтегазовой отрасли в Российской Федерации, имеет высокий авторитет и актуальность, созвучен корпоративной стратегии продвижения инноваторского курса в Российской Федерации
https://neftgaztek.ru/
Mohamed Salah https://mohamedsalah.prostoprosport-ar.com is an Egyptian footballer who plays as a forward for the English club Liverpool and the Egyptian national team. Considered one of the best football players in the world. Three-time winner of the English Premier League Golden Boot: in 2018 (alone), 2019 (along with Sadio Mane and Pierre-Emerick Aubameyang) and 2022 (along with Son Heung-min).
наркотики наркотики .
buy tiktok likes buy tiktok likes
Lionel Andres Messi Cuccittini https://lionelmessi.prostoprosport-ar.com is an Argentine footballer, forward and captain of the MLS club Inter Miami, captain of the Argentina national team. World champion, South American champion, Finalissima winner, Olympic champion. Considered one of the best football players of all time.
Cristiano Ronaldo https://cristiano-ronaldo.prostoprosport-ar.com is a Portuguese footballer, forward, captain of the Saudi Arabian club An-Nasr and the Portuguese national team. European Champion. Considered one of the best football players of all time. The best scorer in the history of football according to the IFFIS and fourth according to the RSSSF
купить свидетельство о заключении брака купить свидетельство о заключении брака .
Как получить лицензию на недвижимость|Ключевая информация о лицензии на недвижимость|Подробное руководство по получению лицензии на недвижимость|Советы по получению лицензии на недвижимость|Эффективные способы получения лицензии на недвижимость|Полезные советы по получению лицензии на недвижимость|Секреты успешного получения лицензии на недвижимость|Как стать агентом с лицензией на недвижимость|Как получить лицензию на недвижимость: советы экспертов|Успешное получение лицензии на недвижимость: шаг за шагом|Процесс получения лицензии на недвижимость: как это работает|Полезные советы по получению лицензии на недвижимость|Основные шаги к успешной лицензии на недвижимость|Топ советы по получению лицензии на недвижимость|Советы по получению лицензии на недвижимость от профессионалов|Эффективные стратегии для успешного получения лицензии на недвижимость|Шаги к успешной лицензии на недвижимость|Советы по успешному получению лицензии на недвижимость|Ключевые моменты получения лицензии на недвижимость|Три шага к успешной лицензии на недвижимость|Получите лицензию на недвижимость и станьте профессиональным агентом|Как получить лицензию на недвижимость быстро и легко|Инструкция по получению лицензии на недвижимость|Секреты быстрого получения лицензии на недвижимость|Три шага к профессиональной лицензии на недвижимость|Лицензия на недвижимость: важные аспекты для успешного получения
How to get your real estate license in Mississippi How to get your real estate license in Mississippi .
Anderson Sousa Conceicao better known as Talisca https://talisca.prostoprosport-ar.com is a Brazilian footballer who plays as a midfielder for the An-Nasr club. A graduate of the youth team from Bahia, where he arrived in 2009 ten years ago.
Yassine Bounou https://yassine-bounou.prostoprosport-ar.com also known as Bono, is a Moroccan footballer who plays as a goalkeeper for the Saudi Arabian club Al-Hilal and the Moroccan national team. On November 10, 2022, he was included in the official application of the Moroccan national team to participate in the matches of the 2022 World Cup in Qatar
Harry Edward Kane https://harry-kane.prostoprosport-ar.com is an English footballer, forward for the German club Bayern and captain of the England national team. Considered one of the best football players in the world. He is Tottenham Hotspur’s and England’s all-time leading goalscorer, as well as the second most goalscorer in the Premier League. Member of the Order of the British Empire.
Neymar da Silva Santos Junior https://neymar.prostoprosport-ar.com is a Brazilian footballer who plays as a striker, winger and attacking midfielder for the Saudi Arabian club Al-Hilal and the Brazilian national team. Considered one of the best players in the world. The best scorer in the history of the Brazilian national team.
탑 슬롯
거물들이 뭉쳐 말썽을 부린다는 생각은 지금은 희망사항!건네받은 청사진은 뭐… 만들어질 때까지 기다려… 얘기하자!
грузовое такси https://gruzchikiminsk.ru .
Erling Breut Haaland https://erling-haaland.prostoprosport-ar.com is a Norwegian footballer who plays as a forward for the English club Manchester City and the Norwegian national team. English Premier League record holder for goals per season.
Ali al-Buleahi https://ali-al-bulaihi.prostoprosport-ar.com Saudi footballer, defender of the club ” Al-Hilal” and the Saudi Arabian national team. On May 15, 2018, Ali al-Buleakhi made his debut for the Saudi Arabian national team in a friendly game against the Greek team, coming on as a substitute midway through the second half.
Luka Modric https://lukamodric.prostoprosport-ar.com is a Croatian footballer, central midfielder and captain of the Spanish club Real Madrid, captain of the Croatian national team. Recognized as one of the best midfielders of our time. Knight of the Order of Prince Branimir. Record holder of the Croatian national team for the number of matches played.
flomax for urinary retention
buy tiktok likes and followers https://iemlabs.com/blogs/make-money-on-tiktok-without-followers-in-2024-easy-guide/
can i buy tiktok followers to go live buy tiktok followers tokmatik.com
https://Dr-Nona.ru/ – Dr Nona
антибактериальное средство для интимной гигиены IntiLINE каталог
Ознакомьтесь с обзоры казино Twin и узнайте о всех его возможностях
The best film magazin https://orbismagazine.com, film industry trade publications in 2024 to keep you informed with the latest video production, filmmaking, photographynews. We create beautiful and magnetic projects.
Проституция в городе Москве является многосложной и сложноустроенной проблемой. Хотя это нелегальна законом, эта деятельность является значительным теневым сектором.
Исторические аспекты
В Союзные времена коммерческий секс имела место нелегально. С распадом Союза, в период экономической неопределенности, она стала явной.
Нынешняя состояние
Сегодня проституция в городе Москве включает многообразие форм, вплоть до элитных сопровождающих услуг до самой уличного уровня коммерческого секса. Элитные сервисы в большинстве случаев организуются через сеть, а публичная интимные услуги сконцентрирована в конкретных зонах городской территории.
Социально-экономические аспекты
Большинство девушки вступают в эту сферу вследствие материальных проблем. Интимные услуги является привлекательной из-за возможности быстрого дохода, но она сопряжена с рисками для здоровья и жизни.
Законодательные вопросы
Секс-работа в России противозаконна, и за её осуществление состоят серьезные наказания. Коммерческих секс-работников часто привлекают к административной ответственности.
Таким образом, игнорируя запреты, проституция продолжает быть элементом теневой экономики Москвы с значительными социальными и юридическими последствиями.
NGolo Kante https://ngolokante.prostoprosport-ar.com is a French footballer who plays as a defensive midfielder for the Saudi Arabian club Al-Ittihad and the French national team. His debut for the first team took place on May 18, 2012 in a match against Monaco (1:2). In the 2012/13 season, Kante became the main player for Boulogne, which played in Ligue 3.
машина для перевозки мебели https://www.pereezdminsk.ru .
雷神娛樂城
Ruben Diogo da Silva Neves https://ruben-neves.prostoprosport-ar.com is a Portuguese footballer who plays as a midfielder for the Saudi Arabian club Al-Hilal and the Portuguese national team. Currently, Ruben Neves plays for the Al-Hilal club wearing number 8. His contract with the Saudi club is valid until the end of June 2026.
파워 오브 토르 메가웨이즈
Wang Hua가 홀을 나갔을 때 그의 얼굴에는 챔피언이 가져야 할 오만함이 여전히 남아있었습니다.
montenegro boka bay
https://www.montenegro-immobilien-kaufen.com
haus montenegro kaufen haus in montenegro kaufen
Kobe Bean Bryant https://kobebryant.prostoprosport-ar.com is an American basketball player who played in the National Basketball Association for twenty seasons for one team, the Los Angeles Lakers. He played as an attacking defender. He was selected in the first round, 13th overall, by the Charlotte Hornets in the 1996 NBA Draft. He won Olympic gold twice as a member of the US national team.
娛樂城
台灣線上娛樂城是指通過互聯網提供賭博和娛樂服務的平台。這些平台主要針對台灣用戶,但實際上可能在境外運營。以下是一些關於台灣線上娛樂城的重要信息:
1. 服務內容:
– 線上賭場遊戲(如老虎機、撲克、輪盤等)
– 體育博彩
– 彩票遊戲
– 真人荷官遊戲
2. 特點:
– 全天候24小時提供服務
– 可通過電腦或移動設備訪問
– 常提供優惠活動和獎金來吸引玩家
3. 支付方式:
– 常見支付方式包括銀行轉賬、電子錢包等
– 部分平台可能接受加密貨幣
4. 法律狀況:
– 在台灣,線上賭博通常是非法的
– 許多線上娛樂城實際上是在國外註冊運營
5. 風險:
– 由於缺乏有效監管,玩家可能面臨財務風險
– 存在詐騙和不公平遊戲的可能性
– 可能導致賭博成癮問題
6. 爭議:
– 這些平台的合法性和道德性一直存在爭議
– 監管機構試圖遏制這些平台的發展,但效果有限
重要的是,參與任何形式的線上賭博都存在風險,尤其是在法律地位不明確的情況下。建議公眾謹慎對待,並了解相關法律和潛在風險。
如果您想了解更多具體方面,例如如何識別和避免相關風險,我可以提供更多信息。
https://win-line.net/nextbet7-נקסט-בט-7/
לבצע, אסמכתא לדבריך.
ההתמודדות באינטרנט הפכה לתחום מבוקש מאוד לאחרונה, המציע אפשרויות שונות של אפשרויות משחק, לדוגמה משחקי פוקר.
בניתוח זה נבדוק את תעשיית ההתמודדות המקוונת ונספק לכם נתונים חשובים שיעזור לכם לנתח בתופעה אטרקטיבי זה.
הימורי ספורט – קזינו באינטרנט
קזינו אונליין מציע מבחר מגוון של אירועים מוכרים כגון רולטה. ההימורים באינטרנט מעניקים לשחקנים ליהנות מחוויית משחק מקורית בכל מקום ובשעה.
הפעילות פירוט קצר
מכונות שלוט הימורי גלגל
הימורי רולטה הימור על מספרים ואפשרויות על גלגל מסתובב
משחק קלפים 21 משחק קלפים להשגת ניקוד של 21
משחק קלפים פוקר משחק קלפים מבוסס אסטרטגיה
באקרה משחק קלפים מהיר וקצר
הימורים על אירועי ספורט – קזינו באינטרנט
הימורי ספורט מהווים אחד הענפים הצומחים ביותר בהימורים באינטרנט. מבקרים מסוגלים להמר על פרמטרים של אתגרי ספורט מושכים כגון כדורגל.
העסקאות ניתן לתמוך על תוצאת התחרות, מספר הנקודות ועוד.
המשחק ניתוח תחרויות ספורט מקובלות
ניחוש תוצאה ניחוש התוצאה הסופית של התחרות כדורגל, כדורסל, אמריקאי
הפרש תוצאות ניחוש ההפרש בביצועים בין הקבוצות כדורגל, כדורסל, אמריקאי
מספר שערים/נקודות ניחוש כמות התוצאות בתחרות כל ענפי הספורט
הצד המנצח ניחוש איזו קבוצה תנצח (ללא קשר לתוצאה) מגוון ענפי ספורט
התמרמרות בזמן אמת התמודדות במהלך התחרות בזמן אמת כדורגל, טניס, כדורסל
התמודדות מורכבת שילוב של מספר סוגי התמרמרות מגוון ענפי ספורט
פוקר אונליין – קזינו באינטרנט
פוקר אונליין הוא אחד מסוגי התמודדות הפופולריים הגדולים ביותר בתקופה הנוכחית. מבקרים מורשים להשתתף עם משתתפים אחרים מכל רחבי הגלובוס במגוון
https://dr-nona.ru/ – Dr. nonna
Купити ліхтарики https://bailong-police.com.ua оптом та в роздріб, каталог та прайс-лист, характеристики, відгуки, акції та знижки. Купити ліхтарик онлайн з доставкою. Відмінний вибір ліхтарів: налобні, ручні, тактичні, ультрафіолетові, кемпінгові, карманні за вигідними цінами.
Продажа подземных канализационных ёмкостей https://neseptik.com по выгодным ценам. Ёмкости для канализации подземные объёмом до 200 м3. Металлические накопительные емкости для канализации заказать и купить в Екатеринбурге.
Lebron Ramone James https://lebronjames.prostoprosport-ar.com American basketball player who plays the positions of small and power forward. He plays for the NBA team Los Angeles Lakers. Experts recognize him as one of the best basketball players in history, and a number of experts put James in first place. One of the highest paid athletes in the world.
световое оборудование для актового зала http://www.oborudovanie-aktovogo-zala13.ru/ .
Luis Fernando Diaz Marulanda https://luis-diaz.prostoprosport-ar.com Colombian footballer, winger for Liverpool and the Colombian national team . Diaz is a graduate of the Barranquilla club. On April 26, 2016, in a match against Deportivo Pereira, he made his Primera B debut. On January 30, 2022, he signed a contract with the English Liverpool for five years, the transfer amount was 40 million euros.
Maria Sharapova https://maria-sharapova.prostoprosport-ar.com Russian tennis player. The former first racket of the world, winner of five Grand Slam singles tournaments from 2004 to 2014, one of ten women in history who has the so-called “career slam”.
Kevin De Bruyne https://kevin-de-bruyne.prostoprosport-ar.com Belgian footballer, midfielder of the Manchester club City” and the Belgian national team. A graduate of the football clubs “Ghent” and “Genk”. In 2008 he began his adult career, making his debut with Genk.
Mohammed Khalil Ibrahim Al-Owais https://mohammed-alowais.prostoprosport-ar.com is a Saudi professional footballer who plays as a goalkeeper for the national team Saudi Arabia and Al-Hilal. He is known for his quick reflexes and alertness at the gate.
Quincy Anton Promes https://quincy-promes.prostoprosport-br.com Dutch footballer, attacking midfielder and forward for Spartak Moscow . He played for the Dutch national team. He won his first major award in 2017, when Spartak became the champion of Russia.
Экспертиза ремонта в квартире https://remnovostroi.ru проводится для оценки качества выполненных работ, соответствия требованиям безопасности и стандартам строительства. Специалисты проверяют используемые материалы, исполнение работ, конструктивные особенности, безопасность, внешний вид и эстетику ремонта. По результатам экспертизы составляется экспертное заключение с оценкой качества и рекомендациями по устранению недостатков.
ремонт айфона круглосуточно http://iphonepochinka.by .
Larry Joe Bird https://larry-bird.prostoprosport-br.com American basketball player who spent his entire professional career in the NBA ” Boston Celtics.” Olympic champion (1992), champion of the 1977 Universiade, 3-time NBA champion (1981, 1984, 1986), three times recognized as MVP of the season in the NBA (1984, 1985, 1986), 10 times included in the symbolic teams of the season (1980-88 – first team, 1990 – second team).
Roberto Firmino Barbosa de Oliveira https://roberto-firmino.prostoprosport-br.com Brazilian footballer, attacking midfielder, forward for the Saudi club “Al-Ahli”. Firmino is a graduate of the Brazilian club KRB, from where he moved to Figueirense in 2007. In June 2015 he moved to Liverpool for 41 million euros.
https://win-line.net/אתרי-הימורים-אמינים/
לשלוח, תימוכין לדבריך.
ההמרה באינטרנט הפכה לנישה מבוקש מאוד בעשור האחרון, המאפשר אפשרויות שונות של אפשרויות משחק, החל מ מכונות מזל.
בניתוח זה נפרט את עולם ההימורים המקוונים ונעניק לכם מידע חשוב שיסייע לכם להתמצא בתופעה אטרקטיבי זה.
הימורי ספורט – הימורים באינטרנט
הימורי ספורט כולל מבחר מגוון של אפשרויות ידועים כגון בלאק ג’ק. הפעילות באינטרנט מספקים לשחקנים להתנסות מאווירת הימורים מקצועית מכל מקום.
סוג המשחק תיאור מקוצר
מכונות שלוט משחקי מזל עם גלגלים
רולטה הימור על תוצאות על גלגל מסתובב בצורה עגולה
משחק קלפים 21 משחק קלפים להשגת ניקוד של 21
התמודדות בפוקר התמודדות אסטרטגית בקלפים
באקרה משחק קלפים מהיר וקצר
הימורים על אירועי ספורט – הימורים באינטרנט
הימורים בתחום הספורט מהווים חלק מ אחד האזורים המשגשגים הגדולים ביותר בפעילות באינטרנט. שחקנים רשאים להשקיע על תוצאות של משחקי ספורט מושכים כגון כדורגל.
העסקאות מתאפשרות על תוצאת האירוע, מספר העופרות ועוד.
סוג הפעילות פירוט תחרויות ספורט מקובלות
ניחוש הביצועים ניחוש התוצאה הסופית של האירוע כדורגל, כדורסל, טניס
הפרש נקודות ניחוש ההפרש בתוצאות בין הקבוצות כל ענפי הספורט
כמות הסקורים ניחוש כמות התוצאות בתחרות כדורגל, כדורסל, טניס
הצד המנצח ניחוש איזו קבוצה תנצח (ללא קשר לתוצאה) מגוון ענפי ספורט
הימורי חי התמודדות במהלך התחרות בזמן אמת מגוון ענפי ספורט
פעילות מעורבת שילוב של מספר פעילויות מספר ענפי ספורט
פעילות פוקר מקוונת – פעילות באינטרנט
משחקי קלפים אונליין מייצג אחד ממשחקי התמודדות הפופולריים המשפיעים ביותר בזמן האחרון. שחקנים יכולים להשתלב כנגד שחקנים אחרים מרחבי העולם בסוגים ש
Интимные услуги в городе Москве является проблемой как сложной и многогранной вопросом. Несмотря на данная деятельность противозаконна юридически, эта деятельность остаётся важным теневым сектором.
Исторический
В советские эру проституция существовала подпольно. С распадом Союза, в обстановке экономической неопределенности, она стала явной.
Современная Ситуация
На сегодняшний день интимные услуги в Москве имеет различные формы, от люксовых эскорт-услуг до самой уличной проституции. Высококлассные обслуживание зачастую осуществляются через сеть, а уличная коммерческий секс концентрируется в выделенных зонах городской территории.
Социальные и экономические факторы
Большинство девушки принимают участие в эту деятельность ввиду экономических неурядиц. Секс-работа может быть привлекательным из-за шанса немедленного дохода, но это влечет за собой угрозу здоровью и жизни.
Законодательные вопросы
Интимные услуги в РФ нелегальна, и за её осуществление предусмотрены серьёзные меры наказания. Коммерческих секс-работников часто привлекают к дисциплинарной наказанию.
Таким образом, игнорируя запреты, проституция продолжает быть частью незаконной экономики столицы с большими социальными и правовыми последствиями.
шлюхи метро бутырская
Khvicha Kvaratskhelia https://khvicha-kvaratskhelia.prostoprosport-br.com Georgian footballer, winger for Napoli and captain of the Georgian national team. A graduate of Dynamo Tbilisi. He made his debut for the adult team on September 29, 2017 in the Georgian championship match against Kolkheti-1913. In total, in the 2017 season he played 4 matches and scored 1 goal in the championship.
Damian Emiliano Martinez https://emiliano-martinez.prostoprosport-br.com Argentine footballer, goalkeeper of the Aston Villa club and national team Argentina. Champion and best goalkeeper of the 2022 World Cup.
Jack Peter Grealish https://jackgrealish.prostoprosport-br.com English footballer, midfielder of the Manchester City club and the England national team. A graduate of the English club Aston Villa from Birmingham. In the 2012/13 season he won the NextGen Series international tournament, playing for the Aston Villa under-19 team
Kyle Andrew Walker https://kylewalker.prostoprosport-br.com English footballer, captain of the Manchester City club and the England national team. In the 2013/14 season, he was on loan at the Notts County club, playing in League One (3rd division of England). Played 37 games and scored 5 goals in the championship.
Laure Boulleau https://laure-boulleau.prostoprosport-fr.com French football player, defender. She started playing football in the Riom team, in 2000 she moved to Isere, and in 2002 to Issigneux. All these teams represented the Auvergne region. In 2003, Bullo joined the Clairefontaine academy and played for the academy team for the first time.
Son Heung Min https://sonheung-min.prostoprosport-br.com South Korean footballer, striker and captain of the English Premier League club Tottenham Hotspur and the Republic of Korea national team. In 2022 he won the Premier League Golden Boot. Became the first Asian footballer in history to score 100 goals in the Premier League
Jude Victor William Bellingham https://jude-bellingham.prostoprosport-fr.com English footballer, midfielder of the Spanish club Real Madrid and the England national team. In April 2024, he won the Breakthrough of the Year award from the Laureus World Sports Awards. He became the first football player to receive it.
Antoine Griezmann https://antoine-griezmann.prostoprosport-fr.com French footballer, striker and midfielder for Atletico Madrid. Player and vice-captain of the French national team, as part of the national team – world champion 2018. Silver medalist at the 2016 European Championship and 2022 World Championship.
In January 2010, Harry Kane https://harry-kane.prostoprosport-fr.com received an invitation to the England U-team for the first time 17 for the youth tournament in Portugal. At the same time, the striker, due to severe illness, did not go to the triumphant 2010 European Championship for boys under 17 for the British.
where can i buy retin a over the counter
Karim Mostafa Benzema https://karim-benzema.prostoprosport-fr.com French footballer, striker for the Saudi club Al-Ittihad . He played for the French national team, for which he played 97 matches and scored 37 goals.
Achraf Hakimi Mou https://achraf-hakimi.prostoprosport-fr.com Moroccan footballer, defender of the French club Paris Saint-Germain “and the Moroccan national team. He played for Real Madrid, Borussia Dortmund and Inter Milan.
Sweet Bonanza https://sweet-bonanza.prostoprosport-fr.com is an exciting slot from Pragmatic Play that has quickly gained popularity among players thanks to its unique gameplay, colorful graphics and the opportunity to win big prizes. In this article, we’ll take a closer look at all aspects of this game, from mechanics and bonus features to strategies for successful play and answers to frequently asked questions.
Philip Walter Foden https://phil-foden.prostoprosport-fr.com better known as Phil Foden English footballer, midfielder of the Premier club -League Manchester City and the England national team. On December 19, 2023, he made his debut at the Club World Championship in a match against the Japanese club Urawa Red Diamonds, starting in the starting lineup and being replaced by Julian Alvarez in the 65th minute.
Bernardo Silva https://bernardo-silva.prostoprosport-fr.com Portuguese footballer, midfielder. Born on August 10, 1994 in Lisbon. Silva is considered one of the best attacking midfielders in the world. The football player is famous for his endurance and performance. The athlete’s diminutive size is more than compensated for by his creativity, dexterity and foresight.
Kylian Mbappe Lotten https://kylian-mbappe.prostoprosport-fr.com Footballeur francais, attaquant du Paris Saint-Germain et capitaine de l’equipe de France. Le 1er juillet 2024, il deviendra joueur du club espagnol du Real Madrid.
Jogo do Tigre https://jogo-do-tigre.prostoprosport-br.com is a simple and fun game that tests your reflexes and coordination. In this game you need to put your finger on the screen, pull out the stick and go through each peg. However, you must ensure that the stick is the right length, neither too long nor too short.
Mohamed Salah Hamed Mehrez Ghali https://mohamed-salah.prostoprosport-fr.com Footballeur egyptien, attaquant du club anglais de Liverpool et l’equipe nationale egyptienne. Considere comme l’un des meilleurs footballeurs du monde
Declan Rice https://declan-rice.prostoprosport-fr.com Footballeur anglais, milieu defensif du club d’Arsenal et de l’equipe nationale equipe d’Angleterre. Originaire de Kingston upon Thames, Declan Rice s’est entraine a l’academie de football de Chelsea des l’age de sept ans. En 2014, il devient joueur de l’academie de football de West Ham United.
Supplements, Vitamins and healthy lifestyle
Thibaut Nicolas Marc Courtois https://thhibaut-courtois.prostoprosport-fr.com Footballeur belge, gardien de but du club espagnol du Real Madrid . Lors de la saison 2010/11, il a ete reconnu comme le meilleur gardien de la Pro League belge, ainsi que comme joueur de l’annee pour Genk. Triple vainqueur du Trophee Ricardo Zamora
Declan Rice https://declan-rice.prostoprosport-fr.com Footballeur anglais, milieu defensif du club d’Arsenal et de l’equipe nationale equipe d’Angleterre. Originaire de Kingston upon Thames, Declan Rice s’est entraine a l’academie de football de Chelsea des l’age de sept ans. En 2014, il devient joueur de l’academie de football de West Ham United.
Olivier Jonathan Giroud https://olivier-giroud.prostoprosport-fr.com French footballer, striker for Milan and the French national team. Knight of the Legion of Honor. Participant in four European Championships (2012, 2016, 2020 and 2024) and three World Championships (2014, 2018 and 2022).
https://win-line.net/אתרי-הימורים-אמינים/
לבצע, ראיה לדבריך.
ההתמודדות באינטרנט הפכה לתחום מושך מאוד בשנים האחרונות, המספק אפשרויות מגוונות של אלטרנטיבות התמודדות, כמו משחקי פוקר.
במאמר זה נסקור את תחום הפעילות המקוונת ונייעץ לכם נתונים חשובים שיסייע לכם להבין בתופעה מעניין זה.
הימורי ספורט – התמודדות באינטרנט
קזינו אונליין מאפשר אופציות שונות של משחקים קלאסיים כגון בלאק ג’ק. ההימורים באינטרנט מעניקים לשחקנים לחוות מחווית התמודדות מקצועית מכל מקום ובכל זמן.
סוג המשחק תיאור קצר
משחקי מזל משחקי מזל
משחק הרולטה הימור על מספרים וצבעים על גלגל מסתובב
משחק קלפים 21 משחק קלפים להשגת ניקוד של 21
התמודדות בפוקר משחק קלפים אסטרטגי
באקרה משחק קלפים פשוט ומהיר
הימורים בתחום הספורט – התמודדות באינטרנט
התמרמרות ספורטיבית מייצגים אחד האזורים הצומחים המרכזיים ביותר בהימורים באינטרנט. משתתפים מורשים להמר על תוצאות של משחקי ספורט מועדפים כגון טניס.
העסקאות ניתן לתמוך על תוצאת המשחק, מספר העופרות ועוד.
סוג הפעילות הסבר תחרויות ספורט מקובלות
ניחוש הביצועים ניחוש הביצועים הסופיים בתחרות כדורגל, כדורסל, אמריקאי
הפרש סקורים ניחוש ההפרש בביצועים בין הקבוצות כל ענפי הספורט
כמות הביצועים ניחוש כמות הסקורים בתחרות כדורגל, כדורסל, טניס
הצד המנצח ניחוש איזו קבוצה תנצח (ללא קשר לתוצאה) מרבית ענפי הספורט
התמודדות דינמית הימורים במהלך המשחק בזמן אמת כדורגל, טניס, קריקט
התמרמרות מגוונת שילוב של מספר הימורים שונים מרבית ענפי הספורט
פוקר אונליין – קזינו באינטרנט
פוקר אונליין מכיל אחד ממשחקי התמודדות הפופולריים המשפיעים ביותר כיום. שחקנים רשאים להתמודד כנגד מתמודדים אחרים מכמה הגלובוס בסוגים ש
https://win-line.net/אתרי-הימורים-אמינים/
להגיש, ראיה לדבריך.
ההתמודדות באינטרנט הפכה לתעשייה פופולרי מאוד בשנים האחרונות, המכיל מבחר רחב של אלטרנטיבות הימורים, החל מ משחקי פוקר.
בניתוח זה נסקור את תעשיית ההימורים המקוונים ונמסור לכם מידע חשוב שיסייע לכם להבין באזור מעניין זה.
משחקי פוקר – התמודדות באינטרנט
קזינו אונליין מאפשר מגוון רחב של משחקים מסורתיים כגון פוקר. הפעילות באינטרנט מאפשרים למבקרים ליהנות מחווית התמודדות אותנטית מכל מקום ובכל זמן.
האירוע תיאור מקוצר
משחקי מזל הימורים עם גלגלים
משחק הרולטה הימור על תוצאות על גלגל מסתובב
משחק הקלפים בלאק ג’ק משחק קלפים להשגת ניקוד של 21
פוקר משחק קלפים מבוסס אסטרטגיה
משחק קלפים באקרה משחק קלפים מהיר וקצר
התמרמרות ספורטיבית – קזינו באינטרנט
הימורי ספורט מהווים חלק מ אחד הסגמנטים הצומחים המרכזיים ביותר בהתמודדות באינטרנט. מבקרים מורשים לסחור על פרמטרים של אתגרי ספורט פופולריים כגון ועוד.
ההימורים ניתן לתמוך על הביצועים בתחרות, מספר העופרות ועוד.
אופן ההתמודדות ניתוח משחקי ספורט מרכזיים
ניחוש תוצאה ניחוש התוצאה הסופית של התחרות כדורגל, כדורסל, אמריקאי
הפרש ביצועים ניחוש ההפרש בביצועים בין הקבוצות כדורגל, כדורסל, אמריקאי
כמות הסקורים ניחוש כמות הסקורים בתחרות כדורגל, כדורסל, הוקי קרח
מנצח המשחק ניחוש איזו קבוצה תנצח (ללא קשר לתוצאה) כל ענפי הספורט
התמודדות דינמית התמודדות במהלך האירוע בזמן אמת מגוון ענפי ספורט
הימורים משולבים שילוב של מספר פעילויות מרבית ענפי הספורט
פעילות פוקר מקוונת – התמודדות באינטרנט
פוקר אונליין הוא אחד מתחומי התמודדות המשגשגים המובהקים ביותר בשנים האחרונות. מבקרים יכולים להשתלב עם יריבים מאזורי הגלובליזציה בסוגים ש
Jamal Musiala https://jamal-musiala.prostoprosport-fr.com footballeur allemand, milieu offensif du club allemand du Bayern et du equipe nationale d’Allemagne. Il a joue pour les equipes anglaises des moins de 15 ans, des moins de 16 ans et des moins de 17 ans. En octobre 2018, il a dispute deux matchs avec l’equipe nationale d’Allemagne U16. En novembre 2020, il a fait ses debuts avec l’equipe d’Angleterre U21.
Xavi or Xavi Quentin Sy Simons https://xavi-simons.prostoprosport-fr.com Dutch footballer, midfielder of the Paris Saint-Germain club -Germain” and the Dutch national team, playing on loan for the German club RB Leipzig.
Ronaldo de Asis Moreira https://ronaldinhogaucho.prostoprosport-br.com Brazilian footballer, played as an attacking midfielder and striker. World Champion (2002). Winner of the Golden Ball (2005). The best football player in the world according to FIFA in 2004 and 2005.
Erling Breut Haaland https://erling-haaland.prostoprosport-br.com Futebolista noruegues, atacante do clube ingles Manchester City e Selecao da Noruega. Detentor do recorde da Premier League inglesa em gols por temporada.
продвижение сайтов в москве в яндекс и гугл http://www.prodvizhenie-sajtov-v-moskve115.ru/ .
Philippe Coutinho Correia https://philippecoutinho.prostoprosport-br.com Brazilian footballer, midfielder of the English club Aston Villa, playing on loan for the Qatari club Al-Duhail. He is known for his vision, passing, dribbling and long-range ability.
Carlos Henrique Casimiro https://carloscasemiro.prostoprosport-br.com Futebolista brasileiro, volante do clube ingles Manchester United e capitao do Selecao Brasileira. Pentacampeao da Liga dos Campeoes da UEFA, campeao mundial e sul-americano pela selecao juvenil brasileira.
Kylian Mbappe Lotten https://kylianmbappe.prostoprosport-br.com Futebolista frances, atacante do Paris Saint-Germain e capitao da selecao francesa equipe . Em 1? de julho de 2024, ele se tornara jogador do clube espanhol Real Madrid.
Mostbet https://mostbet-bk.pl/rejestracja-w-kasynie-mostbet/ jest strona z licencja.
Lionel Messi https://lionelmessi.prostoprosport-br.com e um jogador de futebol argentino, atacante e capitao do clube da MLS Inter Miami. , capitao da selecao argentina. Campeao mundial, campeao sul-americano, vencedor da Finalissima, campeao olimpico. Considerado um dos melhores jogadores de futebol de todos os tempos.
Mohamed Salah https://mohamedsalah.prostoprosport-br.com e um futebolista egipcio que joga como atacante do clube ingles Liverpool e do Selecao egipcia. Considerado um dos melhores jogadores de futebol do mundo. Tricampeao da Chuteira de Ouro da Premier League inglesa: em 2018 (sozinho), 2019 (junto com Sadio Mane e Pierre-Emerick Aubameyang) e 2022 (junto com Son Heung-min).
Kaka https://kaka.prostoprosport-br.com Futebolista brasileiro, meio-campista. O apelido “Kaka” e um diminutivo de Ricardo. Formado em Sao Paulo. De 2002 a 2016, integrou a Selecao Brasileira, pela qual disputou 92 partidas e marcou 29 gols. Campeao mundial 2002.
슬롯 무료 스핀
“휴가를 요청하세요!” 왕 부시는 “교환으로 가십시오”라고 단호하게 말했습니다.
Karim Mostafa Benzema https://karim-benzema.prostoprosport-br.com Futebolista frances, atacante do clube saudita Al-Ittihad . Jogou pela selecao francesa, pela qual disputou 97 partidas e marcou 37 gols.
Harry Kane https://harry-kane.prostoprosport-br.com recebeu um convite para a selecao sub-alterna da Inglaterra pela primeira vez tempo 17 para o torneio juvenil em Portugal. Ao mesmo tempo, o atacante, devido a doenca grave, nao compareceu ao triunfante Campeonato Europeu Sub-17 masculino de 2010 pelos britanicos.
конференц-залы под ключ конференц-залы под ключ .
Zlatan Ibrahimovic https://zlatan-ibrahimovic.prostoprosport-br.com Bosnian pronunciation: ibraxi?mo?it?]; genus. 3 October 1981, Malmo, Sweden) is a Swedish footballer who played as a striker. Former captain of the Swedish national team.
Luis Alberto Suarez Diaz https://luis-suarez.prostoprosport-br.com Uruguayan footballer, striker for Inter Miami and Uruguay national team. The best scorer in the history of the Uruguay national team. Considered one of the world’s top strikers of the 2010s
Jude Bellingham https://jude-bellingham.prostoprosport-br.com Futebolista ingles, meio-campista do clube espanhol Real Madrid e do Selecao da Inglaterra. Em abril de 2024, ele ganhou o premio Breakthrough of the Year do Laureus World Sports Awards. Ele se tornou o primeiro jogador de futebol a recebe-lo.
Thibaut Nicolas Marc Courtois https://thhibaut-courtois.prostoprosport-fr.com Footballeur belge, gardien de but du club espagnol du Real Madrid . Lors de la saison 2010/11, il a ete reconnu comme le meilleur gardien de la Pro League belge, ainsi que comme joueur de l’annee pour Genk. Triple vainqueur du Trophee Ricardo Zamora
Gareth Frank Bale https://garethbale.prostoprosport-br.com Jogador de futebol gales que atuou como ala. Ele jogou na selecao galesa. Ele se destacou pela alta velocidade e um golpe bem colocado. Artilheiro (41 gols) e recordista de partidas disputadas (111) na historia da selecao.
Robert Lewandowski https://robert-lewandowski.prostoprosport-br.com e um futebolista polones, atacante do clube espanhol Barcelona e capitao da selecao polonesa. Considerado um dos melhores atacantes do mundo. Cavaleiro da Cruz do Comandante da Ordem do Renascimento da Polonia.
гранитная плитка камень Уфалей
Kevin De Bruyne https://kevin-de-bruyne.prostoprosport-br.com Futebolista belga, meio-campista do Manchester club City” e a selecao belga. Formado pelos clubes de futebol “Ghent” e “Genk”. Em 2008 iniciou sua carreira adulta, fazendo sua estreia no Genk.
Antoine Griezmann https://antoine-griezmann.prostoprosport-br.com Futebolista frances, atacante e meio-campista do Atletico de Madrid. Jogador e vice-capitao da selecao francesa, integrante da selecao – campea mundial 2018. Medalhista de prata no Europeu de 2016 e no Mundial de 2022.
Ederson Santana de Moraes https://edersonmoraes.prostoprosport-br.com Futebolista brasileiro, goleiro do clube Manchester City e da Selecao Brasileira . Participante do Campeonato Mundial 2018. Bicampeao de Portugal pelo Benfica e pentacampeao de Inglaterra pelo Manchester City.
Профессиональные seo https://seo-optimizaciya-kazan.ru услуги для максимизации онлайн-видимости вашего бизнеса. Наши эксперты проведут глубокий анализ сайта, оптимизируют контент и структуру, улучшат технические аспекты и разработают индивидуальные стратегии продвижения.
Virgil van Dijk https://virgilvandijk.prostoprosport-br.com Futebolista holandes, zagueiro central, capitao do clube ingles Liverpool e capitao do a selecao holandesa.
Victor James Osimhen https://victor-osimhen.prostoprosport-br.com e um futebolista nigeriano que atua como atacante. O clube italiano Napoli e a selecao nigeriana.
Выберите стильные тактичные штаны для повседневной носки, сделанные из качественных материалов.
Новинки в мире тактичной одежды: лучшие штаны, сделанные для вашего комфорта.
Чем отличаются тактичные штаны от обычных, чтобы выглядеть стильно в любой ситуации.
Какие тактичные штаны подойдут именно вам, для стильного и практичного образа.
Какие материалы лучше всего подойдут для тактичных штанов, чтобы чувствовать себя комфортно в любой ситуации.
штани тактичні купити штани тактичні купити .
advair 50
Как выбрать лучшую клинику стоматологии, рекомендуем.
Что такое эндодонтия, качественный уход за зубами.
Основные причины зубной боли, ознакомиться.
Что нужно знать о здоровье полости рта, качественные советы стоматолога.
Секреты крепких и белоснежных зубов, прочитать.
Как выбрать хорошего стоматолога, качественные методики стоматологии.
Как избежать неприятного запаха изо рта, ознакомиться.
стоматологічна клініка 1 https://klinikasuchasnoistomatologii.vn.ua/ .
Romelu Menama Lukaku Bolingoli https://romelulukaku.prostoprosport-br.com Futebolista belga, atacante do clube ingles Chelsea e da selecao belga . Por emprestimo, ele joga pelo clube italiano Roma.
Roberto Carlos da Silva Rocha https://roberto-carlos.prostoprosport-br.com Brazilian footballer, left back. He was also capable of playing as both a central defender and a defensive midfielder. World champion 2002, silver medalist at the 1998 World Championships.
Neymar da Silva Santos Junior https://neymar.prostoprosport-br.com e um futebolista brasileiro que atua como atacante, ponta e atacante. meio-campista do clube saudita Al-Hilal e da selecao brasileira. Considerado um dos melhores jogadores do mundo. O maior artilheiro da historia da Selecao Brasileira.
Thomas Mueller https://thomasmueller.prostoprosport-br.com is a German football player who plays for the German Bayern Munich. Can play in different positions – striker, attacking midfielder. The most titled German footballer in history
Как выбрать лучшие тактичные штаны для активного отдыха, сделанные из качественных материалов.
Новинки в мире тактичной одежды: лучшие штаны, которые подчеркнут вашу уверенность и стиль.
Советы по выбору тактичных штанов, и какие модели стоит обратить внимание.
Какие тактичные штаны подойдут именно вам, для стильного и практичного образа.
Какие материалы лучше всего подойдут для тактичных штанов, чтобы чувствовать себя комфортно в любой ситуации.
штани тактичні штани тактичні .
Jude Victor William Bellingham https://jude-bellingham.prostoprosport-cz.org anglicky fotbalista, zaloznik spanelskeho klubu Real Madrid a anglicky narodni tym. V dubnu 2024 ziskal cenu za prulom roku z Laureus World Sports Awards. Stal se prvnim fotbalistou, ktery ji obdrzel.
Edson Arantes do Nascimento https://pele.prostoprosport-br.com Brazilian footballer, forward (attacking midfielder. Played for Santos clubs) and New York Cosmos. Played 92 matches and scored 77 goals for the Brazilian national team.
Erling Breut Haaland https://erling-haaland.prostoprosport-cz.org je norsky fotbalista, ktery hraje jako utocnik za Anglicky klub Manchester City a norska reprezentace. Rekordman anglicke Premier League v poctu golu za sezonu.
무료 슬롯 머신
아버지라는 단어가 입에서 나오자마자 그는 Fang Longjing의 얼굴에 의심의 흔적이 스치는 것을 보았다.
Kylian Mbappe Lotten https://kylian-mbappe.prostoprosport-cz.org Francouzsky fotbalista, utocnik Paris Saint-Germain a kapitan tymu francouzskeho tymu. 1. cervence 2024 se stane hracem spanelskeho klubu Real Madrid.
rgbet
Mohamed Salah https://mohamed-salah.prostoprosport-cz.org je egyptsky fotbalista, ktery hraje jako utocnik za anglictinu. klub Liverpool a egyptsky narodni tym. Povazovan za jednoho z nejlepsich fotbalistu na svete.
Harry Kane https://harry-kane.prostoprosport-cz.org dostal pozvanku do anglickeho tymu nezletilych jako prvni cas 17. na turnaj mladeze v Portugalsku. Utocnik se zaroven kvuli vazne nemoci neobjevil na triumfalnim mistrovstvi Evropy muzu do 17 let 2010 pro Brity.
Kevin De Bruyne https://kevin-de-bruyne.prostoprosport-cz.org Belgicky fotbalista, zaloznik Manchesteru klub City” a belgicky narodni tym. Absolvent fotbalovych klubu „Ghent” a „Genk”. V roce 2008 zahajil svou karieru dospelych, debutoval v Genku.
Vinicius Jose Paixan de Oliveira Junior vinicius-junior.prostoprosport-cz.org bezne znamy jako Vinicius Junior je brazilsky a spanelsky fotbalista , utocnik klubu Real Madrid a brazilsky reprezentant.
Lionel Messi https://lionel-messi.prostoprosport-cz.org je argentinsky fotbalista, utocnik a kapitan klubu MLS Inter Miami. , kapitan argentinske reprezentace. Mistr sveta, vitez Jizni Ameriky, vitez finale, olympijsky vitez. Povazovan za jednoho z nejlepsich fotbalistu vsech dob.
Bernardo Silva https://bernardo-silva.prostoprosport-cz.org Portugalsky fotbalista, zaloznik. Narozen 10. srpna 1994 v Lisabonu. Silva je povazovan za jednoho z nejlepsich utocnych zalozniku na svete. Fotbalista je povestny svou vytrvalosti a vykonem.
Antoine Griezmann https://antoine-griezmann.prostoprosport-cz.org Francouzsky fotbalista, utocnik a zaloznik za Atletico de Madrid. Hrac a vicekapitan francouzskeho narodniho tymu, clen tymu – mistr sveta 2018 Stribrny medailista z mistrovstvi Evropy 2016 a mistrovstvi sveta 2022.
Robert Lewandowski https://robert-lewandowski.prostoprosport-cz.org je polsky fotbalista, utocnik spanelskeho klubu Barcelona a kapitan polskeho narodniho tymu. Povazovan za jednoho z nejlepsich utocniku na svete. Rytir krize velitele polskeho renesancniho radu.
наркотики наркотики .
видеостены купить видеостены купить .
Pablo Martin Paez Gavira https://gavi.prostoprosport-cz.org Spanelsky fotbalista, zaloznik barcelonskeho klubu a spanelske reprezentace. Povazovan za jednoho z nejtalentovanejsich hracu sve generace. Ucastnik mistrovstvi sveta 2022. Vitez Ligy narodu UEFA 2022/23
Son Heung Min https://son-heung-min.prostoprosport-cz.org Jihokorejsky fotbalista, utocnik a kapitan anglickeho klubu Premier League Tottenham Hotspur a narodniho tymu Korejske republiky. V roce 2022 vyhral Zlatou kopacku Premier League.
Luka Modric https://luka-modric.prostoprosport-cz.org je chorvatsky fotbalista, stredni zaloznik a kapitan spanelskeho tymu. klub Real Madrid, kapitan chorvatskeho narodniho tymu. Uznavan jako jeden z nejlepsich zalozniku nasi doby. Rytir Radu prince Branimira. Rekordman chorvatske reprezentace v poctu odehranych zapasu.
Cristiano Ronaldo https://cristiano-ronaldo.prostoprosport-cz.org je portugalsky fotbalista, utocnik, kapitan Saudske Arabie klubu An-Nasr a portugalskeho narodniho tymu. Mistr Evropy. Povazovan za jednoho z nejlepsich fotbalistu vsech dob. Nejlepsi strelec v historii fotbalu podle IFFIS a ctvrty podle RSSSF
Mostbet https://mostbet-bk.in has a user-friendly interface and is easy to navigate.
Pedro Gonzalez Lopez https://pedri.prostoprosport-cz.org lepe znamy jako Pedri, je spanelsky fotbalista, ktery hraje jako utocny zaloznik. za Barcelonu a spanelskou reprezentaci. Bronzovy medailista z mistrovstvi Evropy 2020 a zaroven nejlepsi mlady hrac tohoto turnaje.
Alison Ramses Becker https://alisson-becker.prostoprosport-cz.org Brazilsky fotbalista nemeckeho puvodu, brankar klubu Liverpool a brazilsky narodni tym. Je povazovan za jednoho z nejlepsich brankaru sve generace a je znamy svymi vynikajicimi zakroky, presnosti prihravek a schopnosti jeden na jednoho.
Rodrigo Silva de Goiz https://rodrygo.prostoprosport-cz.org Brazilsky fotbalista, utocnik Realu Madrid a brazilskeho narodniho tymu. V breznu 2017 byl Rodrigo povolan do narodniho tymu Brazilie U17 na zapasy Montague Tournament.
Karim Benzema https://karim-benzema.prostoprosport-cz.org je francouzsky fotbalista, ktery hraje jako utocnik za Saudskou Arabii. Arabsky klub Al-Ittihad. Hral za francouzsky narodni tym, za ktery odehral 97 zapasu a vstrelil 37 branek. V 17 letech se stal jednim z nejlepsich hracu rezervy, nastrilel tri desitky golu za sezonu.
Thibaut Nicolas Marc Courtois https://thibaut-courtois.prostoprosport-cz.org Belgicky fotbalista, brankar spanelskeho klubu Real Madrid . V sezone 2010/11 byl uznan jako nejlepsi brankar v belgicke Pro League a take hrac roku pro Genk. Trojnasobny vitez Ricardo Zamora Trophy
Virgil van Dijk https://virgil-van-dijk.prostoprosport-cz.org Nizozemsky fotbalista, stredni obrance, kapitan anglickeho klubu Liverpool a kapitan nizozemskeho narodniho tymu.
Bruno Guimaraes Rodriguez Moura https://bruno-guimaraes.prostoprosport-cz.org Brazilsky fotbalista, defenzivni zaloznik Newcastlu United a Brazilsky narodni tym. Vitez olympijskych her 2020 v Tokiu.
Toni Kroos https://toni-kroos.prostoprosport-cz.org je nemecky fotbalista, ktery hraje jako stredni zaloznik za Real Madrid a nemecky narodni tym. Mistr sveta 2014. Prvni nemecky hrac v historii, ktery sestkrat vyhral Ligu mistru UEFA.
Toni Kroos https://toni-kroos.prostoprosport-cz.org je nemecky fotbalista, ktery hraje jako stredni zaloznik za Real Madrid a nemecky narodni tym. Mistr sveta 2014. Prvni nemecky hrac v historii, ktery sestkrat vyhral Ligu mistru UEFA.
Darwin Gabriel Nunez Ribeiro https://darwin-nunez.prostoprosport-cz.org Uruguaysky fotbalista, utocnik anglickeho klubu Liverpool a Uruguaysky narodni tym. Bronzovy medailista mistrovstvi Jizni Ameriky mezi mladeznickymi tymy.
Romelu Menama Lukaku Bolingoli https://romelu-lukaku.prostoprosport-cz.org Belgicky fotbalista, utocnik anglickeho klubu Chelsea a Belgican vyber. Na hostovani hraje za italsky klub Roma.
проститутки москвы https://prostitutki-213.ru
buy tiktok account 1000 followers buy tiktok followers twicsy
how do you buy tiktok followers https://buy-tiktok-followers.com
смотреть отчаянные домохозяйки онлайн в хорошем качестве сериал отчаянные домохозяйки
럭키 네코
“확인했습니다. 확인하지 않았다면 감히 대부를 방해하지 못했을 것입니다.”
https://businka74.ru/ казино риобет
официальный сайт драгон мани казино регистрация Dragon Money Casino
Большой выбор игровых автоматов, рабочее зеркало сайта плэйфортуна играть на реальные деньги онлайн
Качественная и недорогая https://mebelvam-nn.ru/catalog/myagkaya-mebel/ лучшие цены, доставка и сборка.
Pin Up casino https://pin-up.salexy.kz official website, Pin Up slot machines play for money online, Pin Up mirror working for today.
Slot machines on the official website and mirrors of the Pin Up online casino https://pin-up.tr-kazakhstan.kz are available for free mode, and after registering at Pin Up Casino Ru you can play for money.
Sports in Azerbaijan https://idman-xeberleri.com.az development and popular sports Azerbaijan is a country with rich sports traditions and outstanding achievements on the international stage.
Pin up entry to the official website. Play online casino Pin Up https://pin-up.prostoprosport.ru for real money. Register on the Pin Up Casino website and claim bonuses!
уличная спортивная площадка купить уличная спортивная площадка купить .
World of Games https://onlayn-oyunlar.com.az provides the latest news about online games, game reviews, gameplay and ideas, game tactics and tips. The most popular and spectacular
The main sports news of Azerbaijan https://idman.com.az. Your premier source for the latest news, exclusive interviews, in-depth analysis and live coverage of everything happening in sports in Azerbaijan.
UFC in Azerbaijan https://ufc.com.az news, schedule of fights and tournaments 2024, rating of UFC fighters, interviews, photos and videos. Live broadcasts and broadcasts of tournaments, statistics.
NHL (National Hockey League) News https://nhl.com.az the latest and greatest NHL news for today. Sports news – latest NHL news, standings, match results, online broadcasts.
Mostbet https://mostbet-bk.com nagyon jo valasztas a kaszinojatekok rajongoi szamara.
Deutsche Spieler schatzen die Vielfalt der Poker-Spiele bei https://mostbet-bk.de Mostbet.
Top sports news https://idman-azerbaycan.com.az photos and blogs from experts and famous athletes, as well as statistics and information about matches of leading championships.
Latest news and details about the NBA in Azerbaijan https://nba.com.az. Hot events, player transfers and the most interesting events. Explore the world of the NBA with us.
Discover the fascinating world of online games with GameHub Azerbaijan https://online-game.com.az. Get the latest news, reviews and tips for your favorite games. Join our gaming community today!
The latest top football news https://futbol.com.az today. Interviews with football players, online broadcasts and match results, analytics and football forecasts, photos and videos.
Каталог рейтингов хостингов https://pro-hosting.tech на любой вкус и под любые, даже самые сложные, задачи.
Сантехник — вызов сантехника на дом в Москве и Московской области в удобное для вас время.
Play PUBG Mobile https://pubg-mobile.com.az an exciting world of high-quality mobile battle royale. Unique maps, strategies and intense combat await you in this exciting mobile version of the popular game.
The Dota 2 website https://dota2.com.az Azerbaijan provides the most detailed information about the latest game updates, tournaments and upcoming events. We have all the winning tactics, secrets and important guides.
Latest news about games for Android https://android-games.com.az, reviews and daily updates. Read now and get the latest information on the most exciting games
Check out the latest news, guides and in-depth reviews of the available options for playing Minecraft Az https://minecraft.com.az. Find the latest information about Minecraft Download, Pocket Edition and Bedrock Edition.
Хотите сделать в квартире ремонт? Тогда советуем вам посетить сайт https://stroyka-gid.ru, где вы найдете всю необходимую информацию по строительству и ремонту.
The most popular sports site https://sports.com.az of Azerbaijan, where the latest sports news, forecasts and analysis are collected.
Latest news and analytics of the Premier League https://premier-league.com.az. Detailed descriptions of matches, team statistics and the most interesting football events. EPL Azerbaijan is the best place for football fans.
https://LoveFlover.ru — сайт посвященный комнатным растениям. Предлагает подробные статьи о выборе, выращивании и уходе за различными видами комнатных растений. Здесь можно найти полезные советы по созданию зелёного уголка в доме, руководства по декору и решению распространённых проблем, а также информацию о подходящих горшках и удобрениях. Платформа помогает создавать уютную атмосферу и гармонию в интерьере с помощью растений.
1xbet https://1xbet.best-casino-ar.com with withdrawal without commission. Register online in a few clicks. A large selection of slot machines in mobile applications and convenient transfers in just a few minutes.
Pin Up official https://pin-up.adb-auto.ru website. Login to your personal account and register through the Pin Up mirror. Slot machines for real money at Pinup online casino.
Pin-up Casino https://pin-up.admsov.ru/ is an online casino licensed and regulated by the government of Curacao . Founded in 2016, it is home to some of the industry’s leading providers, including NetEnt, Microgaming, Play’n GO and others. This means that you will be spoiled for choice when it comes to choosing a game.
purchase doxycycline
Pin Up online casino https://pin-up.webrabota77.ru/ is the official website of a popular gambling establishment for players from the CIS countries. The site features thousands of slot machines, online tables and other branded entertainment from Pin Up casino.
Pin Up Casino https://pin-up.noko39.ru Registration and Login to the Official Pin Up Website. thousands of slot machines, online tables and other branded entertainment from Pin Up casino. Come play and get big bonuses from the Pinup brand today
꽁 머니 슬롯
이때 맑은 목소리가 정적을 깨뜨렸다.
Реальные анкеты проституток https://prostitutki-213.ru Москвы с проверенными фото – от элитных путан до дешевых шлюх. Каталог всех индивидуалок на каждой станции метро с реальными фотографиями без ретуши и с отзывами реальных клиентов.
Смотрите онлайн сериал Отчаянные домохозяйки https://domohozyayki-serial.ru в хорошем качестве HD 720 бесплатно, рейтинг сериала: 8.058, режиссер сериала: Дэвид Гроссман, Ларри Шоу, Дэвид Уоррен.
Buy TikTok followers https://tiktok-followers-buy.com to get popular and viral with your content. All packages are real and cheap — instant delivery within minutes. HQ followers for your TikTok. 100% real users. The lowest price for TikTok followers on the market
Pin Up Casino https://pin-up.sibelshield.ru official online casino website for players from the CIS countries. Login and registration to the Pin Up casino website is open to new users with bonuses and promotional free spins.
Pin Up https://pin-up.fotoevolution.ru казино, которое радует гемблеров в России на протяжении нескольких лет. Узнайте, что оно подготовило посетителям. Описание, бонусы, отзывы о легендарном проекте. Регистрация и вход.
Изготовление памятников и надгробий https://uralmegalit.ru по низким ценам. Собственное производство. Высокое качество, широкий ассортимент, скидки, установка.
Pin Up Casino https://pin-up.ergojournal.ru приглашает игроков зарегистрироваться на официальном сайте и начать играть на деньги в лучшие игровые автоматы, а на зеркалах онлайн казино Пин Ап можно найти аналогичную витрину слотов
Pin-up casino https://pin-up.jes-design.ru популярное онлайн-казино и ставки на спорт. Официальный сайт казино для доступа к играм и другим функциям казино для игры на деньги.
ремонт стиральных машин ремонт стиральных машин .
Открой мир карточных игр в Pin-Up https://pin-up.porsamedlab.ru казино Блэкджек, Баккара, Хило и другие карточные развлечения. Регистрируйтесь и играйте онлайн!
Официальный сайт Pin Up казино https://pin-up.nasledie-smolensk.ru предлагает широкий выбор игр и щедрые бонусы для игроков. Уникальные бонусные предложения, онлайн регистрация.
Pinup казино https://pin-up.vcabinet.kz это не просто сайт, а целый мир азартных развлечений, где каждый может найти что-то свое. От традиционных игровых автоматов до прогнозов на самые популярные спортивные события.
Latest Diablo news https://diablo.com.az game descriptions and guides. Diablo.az is the largest Diablo portal in the Azerbaijani language.
Pin Up https://pin-up.fotoevolution.ru казино, которое радует гемблеров в России на протяжении нескольких лет. Узнайте, что оно подготовило посетителям. Описание, бонусы, отзывы о легендарном проекте. Регистрация и вход.
Latest World of Warcraft (WOW) tournament news https://wow.com.az, strategies and game analysis. The most detailed gaming portal in Azerbaijani language
Погрузитесь в мир берців зсу, значение, изучите, углубитесь в, Берці зсу: символ верности и чести, сакральное значение, истину, Берці зсу: духовное наследие Украины, историей, проникнитесь, освійте, таємниці
літні берці зсу купити літні берці зсу купити .
Azerbaijan NFL https://nfl.com.az News, analysis and topics about the latest experience, victories and records. A portal where the most beautiful NFL games in the world are generally studied.
Discover exciting virtual football in Fortnite https://fortnite.com.az. Your central hub for the latest news, expert strategies and interesting e-sports reports. Collecting points with us!
The latest analysis, tournament reviews and the most interesting features of the Spider-Man game https://spider-man.com.az series in Azerbaijani.
Read the latest Counter-Strike 2 news https://counter-strike.net.az, watch the most successful tournaments and become the best in the world of the game on the CS2 Azerbaijan website.
synthroid mexico
Latest boxing news https://boks.com.az, Resul Abbasov’s achievements, Tyson Fury’s fights and much more. All in Ambassador Boxing.
Explore the extraordinary journey of Kilian Mbappe https://kilian-mbappe.com.az, from his humble beginnings to global stardom. Delve into his early years, meteoric rise through the ranks, and impact on and off the football field.
Mesut Ozil https://mesut-ozil.com.az latest news, statistics, photos and much more. Get the latest news and information about one of the best football players Mesut Ozil.
Latest news, statistics, photos and much more about Pele https://pele.com.az. Get the latest news and information about football legend Pele.
Sergio Ramos Garcia https://sergio-ramos.com.az Spanish footballer, defender. Former Spanish national team player. He played for 16 seasons as a central defender for Real Madrid, where he captained for six seasons.
Gianluigi Buffon https://buffon.com.az Italian football player, goalkeeper. Considered one of the best goalkeepers of all time. He holds the record for the number of games in the Italian Championship, as well as the number of minutes in this tournament without conceding a goal.
Paulo Bruno Ezequiel Dybala https://dybala.com.az Argentine footballer, striker for the Italian club Roma and the Argentina national team. World champion 2022.
Paul Labille Pogba https://pogba.com.az French footballer, central midfielder of the Italian club Juventus. Currently suspended for doping and unable to play. World champion 2018.
Канал для того, чтобы знания и опыт, могли помочь любому человеку сделать ремонт https://tvin270584.livejournal.com в своем жилище, любой сложности!
Kevin De Bruyne https://kevin-de-bruyne.liverpool-fr.com Belgian footballer, born 28 June 1991 years in Ghent. He has had a brilliant club career and also plays for the Belgium national team. De Bruyne is known for his spectacular goals and brilliant assists.
Paul Labille Pogba https://paul-pogba.psg-fr.com Footballeur francais, milieu de terrain central du club italien de la Juventus. Champion du monde 2018. Actuellement suspendu pour dopage et incapable de jouer.
Mohamed Salah Hamed Mehrez Ghali https://mohamed-salah.liverpool-fr.com Footballeur egyptien, attaquant du club anglais de Liverpool et l’equipe nationale egyptienne. Considere comme l’un des meilleurs joueurs du monde.
The young talent who conquered Paris Saint-Germain: how Xavi Simons became https://xavi-simons.psg-fr.com leader of a superclub in record time.
Mostbet https://mostbet-bk.cz/category/hry-a-novinky-mostbet/ nabizi take virtualni sporty.
Kylian Mbappe https://kylian-mbappe.psg-fr.com Footballeur, attaquant francais. Il joue pour le PSG et l’equipe de France. Ne le 20 decembre 1998 a Paris. Mbappe est francais de nationalite. La taille de l’athlete est de 178 cm.
Изготовление, сборка и ремонт мебели https://shkafy-na-zakaz.blogspot.com для Вас, от эконом до премиум класса.
Kevin De Bruyne https://liverpool.kevin-de-bruyne-fr.com Belgian footballer, born 28 June 1991 years in Ghent. He has had a brilliant club career and also plays for the Belgium national team. De Bruyne is known for his spectacular goals and brilliant assists.
Paul Pogba https://psg.paul-pogba-fr.com is a world-famous football player who plays as a central midfielder. The player’s career had its share of ups and downs, but he was always distinguished by his perseverance and desire to win.
Kylian Mbappe https://psg.kylian-mbappe-fr.com Footballeur, attaquant francais. L’attaquant de l’equipe de France Kylian Mbappe a longtemps refuse de signer un nouveau contrat avec le PSG, l’accord etant en vigueur jusqu’a l’ete 2022.
seo продвижение сайтов заказать в москве https://prodvizhenie-sajtov-v-moskve115.ru .
바나나 타운
Liu Jian은 고개를 들어 Hongzhi 황제의 얼굴이 창백한 것을보고 서둘러 절했습니다. “폐하, 진정하세요.”
Thibaut Nicolas Marc Courtois https://thibaut-courtois.real-madrid-ar.com Footballeur belge, gardien de but du Club espagnol “Real Madrid”. Lors de la saison 2010/11, il a ete reconnu comme le meilleur gardien de la Pro League belge, ainsi que comme joueur de l’annee pour Genk. Trois fois vainqueur du Trophee Ricardo Zamora, decerne chaque annee au meilleur gardien espagnol
Forward Rodrigo https://rodrygo.real-madrid-ar.com is now rightfully considered a rising star of Real Madrid. The talented Santos graduate is compared to Neymar and Cristiano Ronaldo, but the young talent does not consider himself a star.
Jude Victor William Bellingham https://jude-bellingham.real-madrid-ar.com English footballer, midfielder of the Spanish club Real Madrid and the England national team. In April 2024, he won the Breakthrough of the Year award from the Laureus World Sports Awards.
Saud Abdullah Abdulhamid https://saud-abdulhamid.real-madrid-ar.com Saudi footballer, defender of the Al -Hilal” and the Saudi Arabian national team. Asian champion in the age category up to 19 years. Abdulhamid is a graduate of the Al-Ittihad club. On December 14, 2018, he made his debut in the Saudi Pro League in a match against Al Bateen
Khvicha Kvaratskhelia https://khvicha-kvaratskhelia.real-madrid-ar.com midfielder of the Georgian national football team and the Italian club “Napoli”. Became champion of Italy and best player in Serie A in the 2022/23 season. Kvaratskhelia is a graduate of Dynamo Tbilisi and played for the Rustavi team.
Vinicius Junior https://vinisius-junior.com.az player news, fresh current and latest events for today about the player of the 2024 season
Latest news and information about Marcelo https://marcelo.com.az on this site! Find Marcelo’s biography, career, playing stats and more. Find out the latest information about football master Marcelo with us!
Khabib Abdulmanapovich Nurmagomedov https://khabib-nurmagomedov.com.az Russian mixed martial arts fighter who performed under the auspices of the UFC. Former UFC lightweight champion.
Welcome to our official site! Get to know the history, players and latest news of Inter Miami Football Club https://inter-miami.com.az. Discover with us the successes and great performances of America’s newest and most exciting soccer club.
Conor Anthony McGregor https://conor-mcgregor.com.az Irish mixed martial arts fighter who also performed in professional boxing. He performs under the auspices of the UFC in the lightweight weight category. Former UFC lightweight and featherweight champion.
продвижение сайтов в москве и московской области https://prodvizhenie-sajtov-v-moskve115.ru .
Оперативный вывод из запоя https://www.liveinternet.ru/users/laralim/post505923855/ на дому. Срочный выезд частного опытного нарколога круглосуточно. При необходимости больного госпитализируют в стационар.
Видеопродакшн студия https://humanvideo.ru полного цикла. Современное оборудование продакшн-компании позволяет снимать видеоролики, фильмы и клипы высокого качества. Создание эффективных видеороликов для рекламы, мероприятий, видеоролики для бизнеса.
Заказать вывоз мусора https://musorovozzz.ru в Москве и Московской области, недорого и в любое время суток в мешках или контейнерами 8 м?, 20 м?, 27 м?, 38 м?, собственный автопарк. Заключаем договора на вывоз мусора.
Совсем недавно открылся новый интернет портал BlackSprut (Блекспрут) https://bs2cite.cc в даркнете, который предлагает купить нелегальные товары и заказать запрещенные услуги. Самая крупнейшая площадка СНГ. Любимые шопы и отзывчивая поддержка.
Реальные анкеты https://prostitutki-vyzvat-moskva.ru Москвы с проверенными фото – от элитных путан до дешевых шлюх. Каталог всех индивидуалок на каждой станции метро с реальными фотографиями без ретуши и с отзывами реальных клиентов.
Welcome to the site dedicated to Michael Jordan https://michael-jordan.com.az, a basketball legend and symbol of world sports culture. Here you will find highlights, career, family and news about one of the greatest athletes of all time.
Diego Armando Maradona https://diego-maradona.com.az Argentine footballer who played as an attacking midfielder and striker. He played for the clubs Argentinos Juniors, Boca Juniors, Barcelona, ??Napoli, and Sevilla.
Реальные анкеты проститутки города москвы Москвы с проверенными фото – от элитных путан до дешевых шлюх. Каталог всех индивидуалок на каждой станции метро с реальными фотографиями без ретуши и с отзывами реальных клиентов.
Gucci купить http://thebestluxurystores.ru по низкой цене в интернет-магазине брендовой одежды. Одежда и обувь бренда Gucci c доставкой.
Muhammad Ali https://muhammad-ali.com.az American professional boxer who competed in the heavy weight category; one of the most famous boxers in the history of world boxing.
Монтаж систем отопления https://fectum.pro, водоснабжения, вентиляции, канализации, очистки воды, пылеудаления, снеготаяния, гелиосистем в Краснодаре под ключ.
продвижение и раскрутка сайтов в москве http://prodvizhenie-sajtov-v-moskve115.ru .
Lev Ivanovich Yashin https://lev-yashin.com.az Soviet football player, goalkeeper. Olympic champion in 1956 and European champion in 1960, five-time champion of the USSR, three-time winner of the USSR Cup.
Usain St. Leo Bolt https://usain-bolt.com.az Jamaican track and field athlete, specialized in short-distance running, eight-time Olympic champion and 11-time world champion (a record in the history of this competition among men).
Al-Nasr https://al-nasr.com.az your source of news and information about Al-Nasr Football Club . Find out the latest results, transfer news, player and manager interviews, fixtures and much more.
Game World https://kz-games.kz offers the latest online gaming news, game reviews, gameplay and ideas, gaming tactics and tips . Start playing our most popular and amazing games and get ready to become the leader in the online gaming world!
You have a source of the latest and most interesting sports news from Kazakhstan: “Kazakhstan sports news https://sports-kazahstan.kz: Games and records” ! Follow us to receive updates and interesting news every minute!
продвижение сайтов в москве цены http://prodvizhenie-sajtov-v-moskve115.ru/ .
Latest news and information about the NBA https://basketball-kz.kz in Kazakhstan. Hot stories, player transfers and highlights. Watch the NBA world with us.
Top sports news https://sport-kz-news.kz, photos and blogs from experts and famous athletes, as well as statistics and information about matches of leading championships.
The latest top football news https://football-kz.kz today. Interviews with football players, online broadcasts and match results, analytics and football forecasts, photos and videos.
에그벳 도메인
Zhu Houzhao는 이를 악물고 말했다. “아버지와 함께 가겠습니다.”
Latest news about games for Android https://android-games.kz, reviews and daily updates. Read now and get the latest information about the most exciting games
Check out Minecraft kz https://minecraft-kz.kz for the latest news, guides, and in-depth reviews of the game options available. Find the latest information on Minecraft Download, Pocket Edition and Bedrock Edition.
Latest news from World of Warcraft https://wow-kz.kz (WOW) tournaments, strategy and game analysis. The most detailed gaming portal in the language.
Latest news and analysis of the Premier League https://premier-league.kz. Full descriptions of matches, team statistics and the most interesting football events. Premier Kazakhstan is the best place for football fans.
buying prescription drugs in mexico online: mexican pharmacy online – medicine in mexico pharmacies
Доставка груза и грузоперевозки https://tamozhennyy-deklarant.blogspot.com по России через транспортную компанию автотранспортом доступна и для частных лиц. Перевозчик отправит или доставит ваш груз: выгодные тарифы индивидуальный подход из рук в руки 1 машиной.
mexican mail order pharmacies
https://cmqpharma.online/# buying prescription drugs in mexico online
reputable mexican pharmacies online
Зеркала интерьерные https://zerkala-mag.ru в интернет-магазине «Зеркала с подсветкой» Самые низкие цены на зеркала!
Предлагаем купить гаражное оборудование https://profcomplex.pro, автохимию, технику и уборочный инвентарь для клининговых компаний. Доставка по Москве и другим городам России.
Купить зеркала https://zerkala-m.ru по низким ценам. Более 1980 моделей, купить недорого в интернет-магазине в Москве с доставкой по России. Удобный каталог, низкие цены, качественные фото.
Spider-Man https://spiderman.kz the latest news, articles, reviews, dates, spoilers and other latest information. All materials on the topic “Spider-Man”
Latest Counter-Strike 2 news https://counter-strike-kz.kz, watch the most successful tournaments and be the best in the gaming world.
The latest top football news https://football.sport-news-eg.com today. Interviews with football players, online broadcasts and match results, analytics and football forecasts, photos and videos.
Discover the dynamic world of Arab sports https://sports-ar.com through the lens of Arab sports news. Your premier source for breaking news, exclusive interviews, in-depth analysis and live coverage of everything happening in sports.
Интернет магазин электроники https://techno-line.store и цифровой техники по доступным ценам. Доставка мобильной электроники по Москве и Московской области.
NHL news https://nhl-ar.com (National Hockey League) – the latest and most up-to-date NHL news for today.
UFC news https://ufc-ar.com, schedule of fights and tournaments 2024, ratings of UFC fighters, interviews, photos and videos. Live broadcasts and broadcasts of tournaments, statistics, forums and fan blogs.
The most important sports news https://bein-sport-egypt.com, photos and blogs from experts and famous athletes, as well as statistics and information about matches of leading leagues.
News and events of the American Basketball League https://basketball-eg.com in Egypt. Hot events, player transfers and the most interesting events. Explore the world of the NBA with us.
Discover the wonderful world of online games https://game-news-ar.com. Get the latest news, reviews and tips for your favorite games.
News, tournaments, guides and strategies about the latest GTA games https://gta-ar.com. Stay tuned for the best GTA gaming experience
Minecraft news https://minecraft-ar.com, guides and in-depth reviews of the gaming features available in Minecraft Ar. Get the latest information on downloading Minecraft, Pocket Edition and Bedrock Edition.
Latest news https://android-games-ar.com about Android games, reviews and daily updates. The latest information about the most exciting games.
Где купить Дольче Габбана http://www.scm-fashion.ru .
The site is dedicated to football https://fooball-egypt.com, football history and news. Latest news and fresh reviews of the world of football
Открытие для себя Ерлинг Хааланда https://manchestercity.erling-haaland-cz.com, a talented player of «Manchester City». Learn more about his skills, achievements and career growth.
The path of 21-year-old Jude Bellingham https://realmadrid.jude-bellingham-cz.com from young talent to one of the most promising players in the world, reaching new heights with Dortmund and England.
French prodigy Kylian Mbappe https://realmadrid.kylian-mbappe-cz.com is taking football by storm, joining his main target, ” Real.” New titles and records are expected.
Harry Kane’s journey https://bavaria.harry-kane-cz.com from Tottenham’s leading striker to Bayern’s leader and Champions League champion – this is the story of a triumphant ascent to the football Olympus.
1win 1win .
Изготовим для Вас изделия из металла https://smith-moskva.blogspot.com, по вашим чертежам или по нашим эскизам.
Промышленные насосы https://1nsk.ru/news/articles/nasosy-spetsialnogo-naznacheniya.html Wilo предлагают широкий ассортимент решений для различных отраслей промышленности, включая водоснабжение, отопление, вентиляцию, кондиционирование и многие другие. Благодаря своей высокой производительности и эффективности, насосы Wilo помогают снизить расходы на энергию и обслуживание, что делает их идеальным выбором для вашего бизнеса.
https://rolaks.com отделочные материалы для фасада – интернет-магазин
The fascinating story of the rise of Brazilian prodigy Vinicius Junior https://realmadrid.vinicius-junior-cz.com to the heights of glory as part of the legendary Madrid “Real”
Mohamed Salah https://liverpool.mohamed-salah-cz.com, who grew up in a small town in Egypt, conquered Europe and became Liverpool star and one of the best players in the world.
슬롯 사이트
노래가 끝난 후 Zhu Houzhao는 신나게 손뼉을 쳤습니다. “알았어 알았어…”
Промышленные насосы https://nasosynsk.ru/catalog/promyshlennoe_oborudovanie Wilo предлагают широкий ассортимент решений для различных отраслей промышленности, включая водоснабжение, отопление, вентиляцию, кондиционирование и многие другие. Благодаря своей высокой производительности и эффективности, насосы Wilo помогают снизить расходы на энергию и обслуживание, что делает их идеальным выбором для вашего бизнеса.
Полезные советы и пошаговые инструкции по строительству https://svoyugol.by, ремонту и дизайну домов и квартир, выбору материалов, монтажу и установке своими руками.
The inspiring story of how talented Kevin De Bruyne https://manchestercity.kevin-de-bruyne-cz.com became the best player of Manchester City and the Belgium national team. From humble origins to the leader of a top club.
Lionel Messi https://intermiami.lionel-messi-cz.com, one of the best football players of all time, moves to Inter Miami” and changes the face of North American football.
Bernardo Mota Veiga de Carvalho e Silva https://manchestercity.bernardo-silva-cz.com Portuguese footballer, club midfielder Manchester City and the Portuguese national team.
Противоотмывочная верификация: Способом минимизировать приостановление фондов на криптобиржах
Зачем важна проверка по борьбе с отмыванием денег?
Антиотмывочные меры (Противодействие легализации доходов) – представляет собой совокупность мер, предназначенных для борьбы отбеливания ресурсов. Эта проверка дает возможность охранять цифровые ресурсы клиентов и не допускать вовлечение площадок противоправных операций. Процедура противодействия отмыванию денег требуется для обеспечения безопасности Ваших ресурсов и соблюдения правовых правил.
Главные методы оценки
Участники криптосферы и другие транзакционные услуги используют ряд главных способов в рамках проверки пользователей:
Идентификация личности: Эта методика охватывает базовые действия по идентификации удостоверения клиента, такие как подтверждение удостоверений проживания. KYC способствует быть уверенным, что пользователь представляет собой надежным.
CFT: Ориентирована для предотвращения обеспечения террористических актов. Процедура анализирует вызывающие вопросы переводы при необходимости ограничивает учетные записи в рамках проведения внутрикорпоративного проверки.
Положительные аспекты AML-проверки
Антиотмывочные меры обеспечивает криптобиржам:
Придерживаться международные а также локальные юридические правила.
Защищать пользователей незаконных операций.
Увеличивать степень надежности со стороны пользователей надзорных органов.
Каким способом минимизировать риски свои средства при взаимодействии в цифровой валютной среде
С целью уменьшить риски ограничения средств, придерживайтесь данным указаниям:
Обращайтесь к безопасные платформы: Переходите только к платформам положительной оценкой и высоким мерой защищенности.
Проверяйте получателей: Применяйте услуги по противодействию отмыванию в интересах проверки криптовалютных реквизитов партнеров предварительно перед выполнением транзакций.
Периодически трансформируйте цифровые кошельки: Это позволит снизить гипотетических подозрений, если Ваши контрагенты участники будут внесены под ограничения.
Сберегайте доказывающие материалы платежей: Если наступит потребности вы сможете доказать законность взятых средств.
Заключение
Процедура противодействия отмыванию денег – является значимый инструмент в интересах обеспечения безопасности действий в криптосфере. Такой подход помогает минимизировать обналичивание денег, обеспечение терроризма наряду с другими незаконные операции. Выполняя требованиям с целью обеспечения безопасности а также выбирая надежные платформы, вы можете снизить риски приостановления фондов работать безопасной взаимодействием в криптосфере.
Antoine Griezmann https://atlticomadrid-dhb.antoine-griezmann-cz.com Atletico Madrid star whose talent and decisive goals helped the club reach the top of La Liga and the UEFA Champions League.
Son Heung-min’s https://tottenhamhotspur.son-heung-min-cz.com success story at Tottenham Hotspur and his influence on the South Korean football, youth inspiration and changing the perception of Asian players.
The story of Robert Lewandowski https://barcelona.robert-lewandowski-cz.com, his impressive journey from Poland to Barcelona, ??where he became not only a leader on the field, but also a source of inspiration for young players.
We explore the path of Luka Modric https://realmadrid.luka-modric-cz.com to Real Madrid, from a difficult adaptation to legendary Champions League triumphs and personal awards.
The impact of the arrival of Cristiano Ronaldo https://annasr.cristiano-ronaldo-cz.com at Al-Nasr. From sporting triumphs to cultural changes in Saudi football.
Высокий профессионализм и чуткое отношение сотрудников https://complex-ritual.ru/. В трудную минуту они взяли на себя все организационные моменты, окружив заботой и участием. Услуги высокого качества по приемлемым ценам. Советую эту компанию тем, кто нуждается в надежного ритуального партнера в Казани.
Find out how Pedri https://barcelona.pedri-cz.com becomes a key figure for Barcelona – his development, influence and ambitions determine the club’s future success in world football.
A study of the influence of Rodrigo https://realmadrid.rodrygo-cz.com on the success and marketing strategy of Real Madrid: analysis of technical skills, popularity in Media and commercial success.
How Karim Benzema https://alIttihad.karim-benzema-cz.com changed the game of Al-Ittihad and Saudi football: new tactics, championship success, increased viewership and commercial success.
Find out about Alisson https://liverpool.alisson-becker-cz.com‘s influence on Liverpool’s success, from his defense to personal achievements that made him one of the best goalkeepers in the world.
Find out how Pedro Gavi https://barcelona.gavi-cz.com helped Barcelona achieve success thanks to his unique qualities, technique and leadership, becoming a key player in the team.
r7casino r7 casino r7 casino официальный сайт войти
buy instant instagram views buy instagram views
Thibaut Courtois https://realmadrid.thibaut-courtois-cz.com the indispensable goalkeeper of “Real”, whose reliability, leadership and outstanding The game made him a key figure in the club.
Find out how Virgil van Dijk https://liverpool.virgil-van-dijk-cz.com became an integral part of style игры «Liverpool», ensuring the stability and success of the team.
Find out how Bruno Guimaraes https://newcastleunited.bruno-guimaraes-cz.com became a catalyst for the success of Newcastle United thanks to his technical abilities and leadership on the field and beyond.
world of warcraft raid boost https://kreativwerkstatt-esens.de/ .
Study of the playing style of Toni Kroos https://real-madrid.toni-kroos-cz.com at Real Madrid: his accurate passing, tactical flexibility and influence on the team’s success.
The young Uruguayan Darwin Nunez https://liverpool.darwin-nunez-cz.com broke into the elite of world football, and he became a key Liverpool player.
Romelu Lukaku https://chelsea.romelu-lukaku-cz.com, one of the best strikers in Europe, returns to Chelsea to continue climbing to the top of the football Olympus.
Лучшие предложения на лучшие онлайн казино россии
Star Brazilian striker Gabriel Jesus https://arsenal.gabriel-jesus-cz.com put in a superb performance to lead Arsenal to new heights after moving from Manchester City.
A fascinating story about how David Alaba https://realmadrid.david-alaba-cz.com after starting his career at the Austrian academy Vienna became a key player and leader of the legendary Real Madrid.
buy lyrica online
The story of how the incredibly talented footballer Riyad Mahrez https://alahli.riyad-mahrez-cz.com reached new heights in career, moving to Al Ahly and leading the team to victory.
The fascinating story of Antonio Rudiger’s transfer https://real-madrid.antonio-rudiger-cz.com to Real Madrid and his rapid rise as a key player at one of the best clubs in the world.
The fascinating story of Marcus Rashford’s ascent https://manchester-united.marcus-rashford-cz.com to glory in the Red Devils: from a young talent to one of the key players of the team.
Mostbet https://mostbet-bk.pl/mostbet-aplikacja/ to miejsce, gdzie mozesz zagrac w gry z wieloma roznymi funkcjami.
Try to make a fascinating actor Johnny Depp https://secret-window.johnny-depp.cz, who will become the slave of his strong hero Moudriho Creeps in the thriller “Secret Window”.
Fascinating event related to this Keanu Reeves helped him in the role of the iconic John Wick characters https://john-wick.keanu-reeves.cz, among which there is another talent who has combat smarts with inappropriate charisma.
Jackie Chan https://peakhour.jackie-chan.cz from a poor boy from Hong Kong to a world famous Hollywood stuntman. The incredible success story of Jackie Chan.
Follow Liam Neeson’s career https://hostage.liam-neeson.cz as he fulfills his potential as Brian Mills in the film “Taken” and becomes one of the leading stars of Hollywood action films.
Emily Olivia Laura Blunt https://oppenheimer.emily-blunt.cz British and American actress. Winner of the Golden Globe (2007) and Screen Actors Guild (2019) awards.
토토 배당 사이트
여러분 모두 황제를 원하지 않으니 괜찮아요, 족장 Fang Jifan은 무엇을 먹나요?
The inspiring story of Zendaya’s rise https://spider-man.zendaya-maree.cz, from her early roles to her blockbuster debut in Marvel Cinematic Universe.
The inspiring story of the ascent of the young actress Anya Taylor https://queensmove.anya-taylor-joy.cz to fame after her breakthrough performance in the TV series “The Queen’s Move”. Conquering new peaks.
An indomitable spirit, incredible skills and five championships – how Kobe Bryant https://losangeles-lakers.kobe-bryant.cz became an icon of the Los Angeles Lakers and the entire NBA world.
Carlos Vemola https://oktagon-mma.karlos-vemola.cz Czech professional mixed martial artist, former bodybuilder, wrestler and member Sokol.
Witness the thrilling story of Jiri Prochazka’s https://ufc.jiri-prochazka-ufc.cz rapid rise to the top of the UFC’s light heavyweight division, marked by his dynamic fighting style and relentless determination.
外送茶
外送茶是什麼?禁忌、價格、茶妹等級、術語等..老司機告訴你!
外送茶是什麼?
外送茶、外約、叫小姐是一樣的東西。簡單來說就是在通訊軟體與茶莊聯絡,選好自己喜歡的妹子後,茶莊會像送飲料這樣把妹子派送到您指定的汽車旅館、酒店、飯店等交易地點。您只需要在您指定的地點等待,妹妹到達後,就可以開心的開始一場美麗的約會。
外送茶種類
學生兼職的稱為清新書香茶
日本女孩稱為清涼綠茶
俄羅斯女孩被稱為金酥麻茶
韓國女孩稱為超細滑人參茶
外送茶價格
外送茶的客戶相當廣泛,包括中小企業主、自營商、醫生和各行業的精英,像是工程師等等。在台北和新北地區,他們的消費指數大約在 7000 到 10000 元之間,而在中南部則通常在 4000 到 8000 元之間。
對於一般上班族和藍領階層的客人來說,建議可以考慮稍微低消一點,比如在北部約 6000 元左右,中南部約 4000 元左右。這個價位的茶妹大多是新手兼職,但有潛力。
不同地區的客人可以根據自己的經濟能力和喜好選擇適合自己的價位範圍,以免感到不滿意。物價上漲是一個普遍現象,受到地區和經濟情況等因素的影響,茶莊的成本也在上升,因此價格調整是合理的。
外送茶外約流程
加入LINE:加入外送茶官方LINE,客服隨時為你服務。茶莊一般在中午 12 點到凌晨 3 點營業。
告知所在地區:聯絡客服後,告訴他們約會地點,他們會幫你快速找到附近的茶妹。
溝通閒聊:有任何約妹問題或需要查看妹妹資訊,都能得到詳盡的幫助。
提供預算:告訴客服你的預算,他們會找到最適合你的茶妹。
提早預約:提早預約比較好配合你的空檔時間,也不用怕到時候約不到你想要的茶妹。
外送茶術語
喝茶術語就像是進入茶道的第一步,就像是蓋房子打地基一樣。在這裡,我們將這些外送茶入門術語分類,讓大家能夠清楚地理解,讓喝茶變得更加容易上手。
魚:指的自行接客的小姐,不屬於任何茶莊。
茶:就是指「小姐」的意思,由茶莊安排接客。
定點茶:指由茶莊提供地點,客人再前往指定地點與小姐交易。
外送茶:指的是到小姐到客人指定地點接客。
個工:指的是有專屬工作室自己接客的小姐。
GTO:指雞頭也就是飯店大姊三七茶莊的意思。
摳客妹:只負責找客人請茶莊或代調找美眉。
內機:盤商應召站提供茶園的人。
經紀人:幫內機找美眉的人。
馬伕:外送茶司機又稱教練。
代調:收取固定代調費用的人(只針對同業)。
阿六茶:中國籍女子,賣春的大陸妹。
熱茶、熟茶:年齡比較大、年長、熟女級賣春者(或稱阿姨)。
燙口 / 高溫茶:賣春者年齡過高。
台茶:從事此職業的台灣小姐。
本妹:從事此職業的日本籍小姐。
金絲貓:西方國家的小姐(歐美的、金髮碧眼的那種)。
青茶、青魚:20 歲以下的賣春者。
乳牛:胸部很大的小姐(D 罩杯以上)。
龍、小叮噹、小叮鈴:體型比較肥、胖、臃腫、大隻的小姐。
Jon Jones https://ufc.jon-jones.cz a dominant fighter with unrivaled skill, technique and physique who has conquered the light heavyweight division.
An article about the triumphant 2023 Ferrari https://ferrari.charles-leclerc.cz and their star driver Charles Leclerc, who became the Formula world champion 1.
Young Briton Lando Norris https://mclaren.lando-norris.cz is at the heart of McLaren’s Formula 1 renaissance, regularly achieving podium finishes and winning.
The legendary Spanish racer Fernando Alonso https://formula-1.fernando-alonso.cz returns to Formula 1 after several years.
Activision and Call of Duty https://activision.call-of-duty.cz leading video game publisher and iconic shooter with a long history market dominance.
zabljac https://montenegro-real-estate-prices.com
Free movies https://www.moviesjoy.cc and TV streaming online, watch movies online in HD 1080p.
the most popular sports website https://sports-forecasts.com in the Arab world with the latest sports news, predictions and analysis in real time.
Latest news and analysis of the English Premier League https://epl-ar.com. Detailed descriptions of matches, team statistics and the most interesting football events.
Latest Diablo news https://diablo-ar.com, detailed game descriptions and guides. Diablo.az – The largest Diablo information portal in Arabic.
Latest World of Warcraft tournament news https://ar-wow.com (WOW), strategies and game analysis. The most detailed gaming portal in Arabic.
NFL https://nfl-ar.com News, analysis and topics about the latest practices, victories and records. A portal that explores the most beautiful games in the NFL world in general.
The latest analysis, reviews of https://spider-man-ar.com tournaments and the most interesting things from the “Spider-Man” series of games in Azerbaijani language. It’s all here!
Discover exciting virtual football https://fortnite-ar.com in Fortnite. Your central hub for the latest news, expert strategy and exciting eSports reporting.
Latest Counter-Strike 2 news https://counter-strike-ar.com, watch the most successful tournaments and be the best in the gaming world on CS2 ar.
срочный ремонт стиральных машин centr-remonta-stiralnyh-mashin.ru .
Latest boxing news, achievements of Raisol Abbasov https://boxing-ar.com, Tyson Fury fights and much more. It’s all about the boxing ambassador.
Discover the wonderful world of online games https://onlayn-oyinlar.com with GameHub. Get the latest news, reviews and tips for your favorite games. Join our gaming community today!
Sports news https://gta-uzbek.com the most respected sports site in Uzbekistan, which contains the latest sports news, forecasts and analysis.
Latest news from the world of boxing https://boks-uz.com, achievements of Resul Abbasov, Tyson Fury’s fights and much more. Everything Boxing Ambassador has.
Latest GTA game news https://gta-uzbek.com, tournaments, guides and strategies. Stay tuned for the best GTA gaming experience
Магазин заготовок изо цветных (а) также чёрных металлов “STORM”
https://stormbrand.ru/
Explore the extraordinary journey of Kylian Mbappe https://mbappe-real-madrid.com, from his humble beginnings to global stardom.
Get the latest https://mesut-ozil-uz.com Mesut Ozil news, stats, photos and more.
Latest news about Pele https://mesut-ozil-uz.com, statistics, photos and much more. Get the latest news and information about football legend Pele.
Serxio Ramos Garsiya https://serxio-ramos.com ispaniyalik futbolchi, himoyachi. Ispaniya terma jamoasining sobiq futbolchisi. 16 mavsum davomida u “Real Madrid”da markaziy himoyachi sifatida o’ynadi.
Ronaldo de Asis Moreira https://ronaldinyo.com braziliyalik futbolchi, yarim himoyachi va hujumchi sifatida o’ynagan. Jahon chempioni (2002). “Oltin to’p” sovrindori (2005).
Официальный сайт онлайн-казино Vavada https://vavada-kz-game.kz это новый адрес лучших слотов и джекпотов. Ознакомьтесь с бонусами и играйте на реальные деньги из Казахстана.
Marcus Lilian Thuram-Julien https://internationale.marcus-thuram-fr.com French footballer, forward for the Internazionale club and French national team.
Legendary striker Cristiano Ronaldo https://an-nasr.cristiano-ronaldo-fr.com signed a contract with the Saudi club ” An-Nasr”, opening a new chapter in his illustrious career in the Middle East.
Manchester City and Erling Haaland https://manchester-city.erling-haaland-fr.com explosive synergy in action. How a club and a footballer light up stadiums with their dynamic play.
Lionel Messi https://inter-miami.lionel-messi-fr.com legendary Argentine footballer, announced his transfer to the American club Inter Miami.
The official website where you can find everything about the career of Gianluigi Buffon https://gianluigi-buffon.com. Discover the story of this legendary goalkeeper who left his mark on football history and relive his achievements and unforgettable memories with us.
外送茶
外送茶是什麼?禁忌、價格、茶妹等級、術語等..老司機告訴你!
外送茶是什麼?
外送茶、外約、叫小姐是一樣的東西。簡單來說就是在通訊軟體與茶莊聯絡,選好自己喜歡的妹子後,茶莊會像送飲料這樣把妹子派送到您指定的汽車旅館、酒店、飯店等交易地點。您只需要在您指定的地點等待,妹妹到達後,就可以開心的開始一場美麗的約會。
外送茶種類
學生兼職的稱為清新書香茶
日本女孩稱為清涼綠茶
俄羅斯女孩被稱為金酥麻茶
韓國女孩稱為超細滑人參茶
外送茶價格
外送茶的客戶相當廣泛,包括中小企業主、自營商、醫生和各行業的精英,像是工程師等等。在台北和新北地區,他們的消費指數大約在 7000 到 10000 元之間,而在中南部則通常在 4000 到 8000 元之間。
對於一般上班族和藍領階層的客人來說,建議可以考慮稍微低消一點,比如在北部約 6000 元左右,中南部約 4000 元左右。這個價位的茶妹大多是新手兼職,但有潛力。
不同地區的客人可以根據自己的經濟能力和喜好選擇適合自己的價位範圍,以免感到不滿意。物價上漲是一個普遍現象,受到地區和經濟情況等因素的影響,茶莊的成本也在上升,因此價格調整是合理的。
外送茶外約流程
加入LINE:加入外送茶官方LINE,客服隨時為你服務。茶莊一般在中午 12 點到凌晨 3 點營業。
告知所在地區:聯絡客服後,告訴他們約會地點,他們會幫你快速找到附近的茶妹。
溝通閒聊:有任何約妹問題或需要查看妹妹資訊,都能得到詳盡的幫助。
提供預算:告訴客服你的預算,他們會找到最適合你的茶妹。
提早預約:提早預約比較好配合你的空檔時間,也不用怕到時候約不到你想要的茶妹。
外送茶術語
喝茶術語就像是進入茶道的第一步,就像是蓋房子打地基一樣。在這裡,我們將這些外送茶入門術語分類,讓大家能夠清楚地理解,讓喝茶變得更加容易上手。
魚:指的自行接客的小姐,不屬於任何茶莊。
茶:就是指「小姐」的意思,由茶莊安排接客。
定點茶:指由茶莊提供地點,客人再前往指定地點與小姐交易。
外送茶:指的是到小姐到客人指定地點接客。
個工:指的是有專屬工作室自己接客的小姐。
GTO:指雞頭也就是飯店大姊三七茶莊的意思。
摳客妹:只負責找客人請茶莊或代調找美眉。
內機:盤商應召站提供茶園的人。
經紀人:幫內機找美眉的人。
馬伕:外送茶司機又稱教練。
代調:收取固定代調費用的人(只針對同業)。
阿六茶:中國籍女子,賣春的大陸妹。
熱茶、熟茶:年齡比較大、年長、熟女級賣春者(或稱阿姨)。
燙口 / 高溫茶:賣春者年齡過高。
台茶:從事此職業的台灣小姐。
本妹:從事此職業的日本籍小姐。
金絲貓:西方國家的小姐(歐美的、金髮碧眼的那種)。
青茶、青魚:20 歲以下的賣春者。
乳牛:胸部很大的小姐(D 罩杯以上)。
龍、小叮噹、小叮鈴:體型比較肥、胖、臃腫、大隻的小姐。
Welcome to our official website! Go deeper into Paulo Dybala’s https://paulo-dybala.com football career. Discover Dybala’s unforgettable moments, amazing talents and fascinating journey in the world of football on this site.
Website dedicated to football player Paul Pogba https://pogba-uz.com. Latest news from the world of football.
срочно починить стиральную машину http://centr-remonta-stiralnyh-mashin.ru .
Latest news on the Vinicius Junior fan site https://vinisius-junior.com. Vinicius Junior has been playing since 2018 for Real Madrid (Real Madrid). He plays in the Left Winger position.
Coffeeroom https://coffeeroom.by – магазин кофе, чая, кофетехники, посуды, химии и аксессуаров в Минске для дома и офиса.
Прокат и аренда автомобилей https://autorent.by в Минске 2019-2022. Сутки от 35 руб.
Find the latest information on Khabib Nurmagomedov https://khabib-nurmagomedov.uz news and fights. Check out articles and videos detailing Khabib UFC career, interviews, wins, and biography.
Latest news and information about Marcelo https://marselo-uz.com on this site! Find Marcelo’s biography, career, game stats and more.
купить диплом моториста ast-diplom.com .
где купить диплом об окончании колледжа ast-diplomy.com .
Discover how Riyad Mahrez https://al-ahli.riyad-mahrez.com transformed Al-Ahli, becoming a key player and catalyst in reaching new heights in world football.
Find the latest information on Conor McGregor https://conor-mcgregor.uz news, fights, and interviews. Check out detailed articles and news about McGregor’s UFC career, wins, training, and personal life.
Get to know the history, players and latest news of the Inter Miami football club https://inter-miami.uz. Join us to learn about the successes and great performances of America’s newest and most exciting soccer club.
A site dedicated to Michael Jordan https://michael-jordan.uz, a basketball legend and symbol of world sports culture. Here you will find highlights, career, family and news about one of the greatest athletes of all time.
Explore the dynamic world of sports https://noticias-esportivas-br.org through the lens of a sports reporter. Your source for breaking news, exclusive interviews, in-depth analysis and live coverage of all sports.
Привет!
Где заказать диплом специалиста?
Заказать диплом о высшем образовании.
http://helix-forum.maxbb.ru/viewtopic.php?f=3&t=717
Хорошей учебы!
Геракл24: Опытная Смена Основания, Венцов, Настилов и Перемещение Зданий
Организация Gerakl24 специализируется на выполнении полных услуг по замене основания, венцов, настилов и перемещению домов в городе Красноярск и в окрестностях. Наш коллектив опытных специалистов гарантирует отличное качество исполнения всех видов реставрационных работ, будь то деревянные, с каркасом, кирпичные постройки или бетонные конструкции дома.
Плюсы сотрудничества с Геракл24
Профессионализм и опыт:
Все работы осуществляются только опытными специалистами, имеющими большой опыт в направлении создания и восстановления строений. Наши мастера профессионалы в своем деле и реализуют задачи с безупречной точностью и учетом всех деталей.
Всесторонний подход:
Мы предоставляем разнообразные услуги по реставрации и реконструкции строений:
Реставрация фундамента: усиление и реставрация старого основания, что позволяет продлить срок службы вашего дома и устранить проблемы, вызванные оседанием и деформацией.
Реставрация венцов: реставрация нижних венцов из дерева, которые чаще всего гниют и разрушаются.
Смена настилов: монтаж новых настилов, что существенно улучшает визуальное восприятие и функциональные характеристики.
Передвижение домов: качественный и безопасный перенос строений на другие участки, что помогает сохранить здание и избежать дополнительных затрат на создание нового.
Работа с любыми типами домов:
Дома из дерева: восстановление и защита деревянных строений, защита от разрушения и вредителей.
Каркасные строения: усиление каркасных конструкций и реставрация поврежденных элементов.
Дома из кирпича: ремонт кирпичных стен и укрепление конструкций.
Бетонные строения: восстановление и укрепление бетонных структур, исправление трещин и разрушений.
Качество и прочность:
Мы применяем лишь качественные материалы и новейшее оборудование, что гарантирует долгий срок службы и надежность всех работ. Все проекты проходят строгий контроль качества на каждой стадии реализации.
Персонализированный подход:
Каждому клиенту мы предлагаем персонализированные решения, учитывающие ваши требования и желания. Мы стараемся, чтобы результат нашей работы полностью удовлетворял ваши ожидания и требования.
Зачем обращаться в Геракл24?
Обратившись к нам, вы получаете надежного партнера, который возьмет на себя все хлопоты по восстановлению и ремонту вашего здания. Мы обещаем выполнение всех задач в установленные сроки и с соблюдением всех строительных норм и стандартов. Связавшись с Геракл24, вы можете быть уверены, что ваше строение в надежных руках.
Мы готовы предоставить консультацию и ответить на ваши вопросы. Свяжитесь с нами, чтобы обсудить ваш проект и узнать о наших сервисах. Мы сохраним и улучшим ваш дом, сделав его уютным и безопасным для долгого проживания.
Gerakl24 – ваш надежный партнер в реставрации и ремонте домов в Красноярске и за его пределами.
https://gerakl24.ru/передвинуть-дом-красноярск/
The latest top football news https://futebol-ao-vivo.net today. Interviews with football players, online broadcasts and match results, analytics and football forecasts
If you are a fan of UFC https://ufc-hoje.com the most famous organization in the world, come visit us. The most important news and highlights from the UFC world await you on our website.
Site with the latest news, statistics, photos of Pele https://edson-arantes-do-nascimento.com and much more. Get the latest news and information about football legend Pele.
Welcome to our official website, where you will find everything about the career of Gianluigi Buffon https://gianluigi-buffon.org. Discover the story of this legendary goalkeeper who made football history.
A Mostbet https://mostbet-bk.com/regisztracio-a-mostbet-kaszinoban/ magas szintu biztonsagi rendszert hasznal, hogy vedje a magyar jatekosok adatait.
Mostbet https://mostbet-bk.de/registrierung-im-mostbet-de-casino/ ist ein Casino, das den Spielern eine gro?e Auswahl an Sportwetten bietet.
Indian players can register at Mostbet https://mostbet-bk.in/registration-at-mostbet-india-casino/ and enjoy a range of scratch card games, including instant win games and themed scratch cards.
The best site dedicated to the football player Paul Pogba https://pogba.org. Latest news from the world of football.
Vinicius Junior https://vinicius-junior.org all the latest current and latest news for today about the player of the 2024 season
Analysis of Arsenal’s impressive revival https://arsenal.bukayo-saka.biz under the leadership of Mikel Arteta and the key role of young star Bukayo Saki in the club’s return to the top.
Gavi’s success story https://barcelona.gavi-fr.com at Barcelona: from his debut at 16 to a key role in club and national team of Spain, his talent inspires the world of football.
Pedri’s story https://barcelona.pedri-fr.com from his youth in the Canary Islands to becoming a world-class star in Barcelona, ??with international success and recognition.
Gerakl24: Опытная Реставрация Фундамента, Венцов, Настилов и Перемещение Строений
Организация Геракл24 специализируется на оказании всесторонних сервисов по смене фундамента, венцов, полов и передвижению домов в городе Красноярском регионе и за пределами города. Наша группа опытных специалистов гарантирует отличное качество исполнения всех типов восстановительных работ, будь то деревянные, каркасного типа, кирпичные или бетонные конструкции дома.
Достоинства услуг Gerakl24
Профессионализм и опыт:
Все работы проводятся исключительно профессиональными мастерами, имеющими большой опыт в области возведения и восстановления строений. Наши сотрудники эксперты в своей области и осуществляют работу с безупречной точностью и вниманием к деталям.
Всесторонний подход:
Мы осуществляем все виды работ по восстановлению и реконструкции строений:
Смена основания: укрепление и замена старого фундамента, что обеспечивает долгий срок службы вашего дома и предотвратить проблемы, связанные с оседанием и деформацией.
Замена венцов: замена нижних венцов деревянных домов, которые чаще всего гниют и разрушаются.
Смена настилов: установка новых полов, что кардинально улучшает внешний вид и функциональные характеристики.
Перемещение зданий: качественный и безопасный перенос строений на новые места, что позволяет сохранить ваше строение и избегает дополнительных затрат на строительство нового.
Работа с различными типами строений:
Деревянные дома: восстановление и защита деревянных строений, защита от разрушения и вредителей.
Дома с каркасом: усиление каркасных конструкций и смена поврежденных частей.
Кирпичные дома: ремонт кирпичных стен и укрепление конструкций.
Бетонные строения: реставрация и усиление бетонных элементов, исправление трещин и разрушений.
Надежность и долговечность:
Мы применяем только высококачественные материалы и современное оборудование, что обеспечивает долгий срок службы и прочность всех выполненных задач. Все проекты подвергаются строгому контролю качества на всех этапах выполнения.
Индивидуальный подход:
Каждому клиенту мы предлагаем подходящие решения, учитывающие ваши требования и желания. Наша цель – чтобы итог нашей работы полностью удовлетворял вашим ожиданиям и требованиям.
Почему выбирают Геракл24?
Сотрудничая с нами, вы получаете надежного партнера, который возьмет на себя все хлопоты по ремонту и реконструкции вашего строения. Мы обеспечиваем выполнение всех задач в установленные сроки и с соблюдением всех строительных норм и стандартов. Связавшись с Геракл24, вы можете быть спокойны, что ваше строение в надежных руках.
Мы предлагаем консультацию и ответить на ваши вопросы. Контактируйте с нами, чтобы обсудить детали и узнать о наших сервисах. Мы обеспечим сохранение и улучшение вашего дома, сделав его уютным и безопасным для долгого проживания.
Геракл24 – ваш партнер по реставрации и ремонту домов в Красноярске и окрестностях.
Discover the journey of Charles Leclerc https://ferrari.charles-leclerc-fr.com, from young Monegasque driver to Ferrari Formula 1 leader, from his early years to his main achievements within the team.
Discover Pierre Gasly’s https://alpine.pierre-gasly.com journey through the world of Formula 1, from his beginnings with Toro Rosso to his extraordinary achievements with Alpine.
Leroy Sane’s https://bavaria.leroy-sane-ft.com success story at FC Bayern Munich: from adaptation to influence on the club’s results. Inspiration for hard work and professionalism in football.
From childhood teams to championship victories, the path to success with the Los Angeles Lakers https://los-angeles-lakers.lebron-james-fr.com requires not only talent, but also undeniable dedication and work.
Discover the story of Rudy Gobert https://minnesota-timberwolves.rudy-gobert.biz, the French basketball player whose defensive play and leadership transformed the Minnesota Timberwolves into a powerhouse NBA team.
The story of the Moroccan footballer https://al-hilal.yassine-bounou.com, who became a star at Al-Hilal, traces his journey from the streets of Casablanca to international football stardom and his personal development.
Victor Wembanyama’s travel postcard https://san-antonio-spurs.victor-wembanyama.biz from his career in France to his impact in the NBA with the San Antonio Spurs.
The history of Michael Jordan’s Chicago Bulls https://chicago-bulls.michael-jordan-fr.com extends from his rookie in 1984 to a six-time NBA championship.
Neymar https://al-hilal.neymar-fr.com at Al-Hilal: his professionalism and talent inspire young people players, taking the club to new heights in Asian football.
Golden State Warriors success story https://golden-state-warriors.stephen-curry-fr.com Stephen Curry: From becoming a leader to creating a basketball dynasty that redefined the game.
Здравствуйте!
Где заказать диплом по необходимой специальности?
Заказать диплом университета.
http://mafiaclans.ru/viewtopic.php?f=43&t=6072
Успехов в учебе!
Привет!
Приобрести диплом любого ВУЗа
Мы предлагаем быстро купить диплом, который выполнен на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями должностных лиц. Данный документ способен пройти любые проверки, даже с использованием специальных приборов. Достигайте своих целей быстро с нашими дипломами.
Где купить диплом по необходимой специальности?
http://burgasdent.listbb.ru/viewtopic.php?f=3&t=391
Всегда вам поможем!.
Del Mar Energy is an international industrial holding company engaged in the extraction of oil, gas, and coal
The success story of the French footballer https://juventus.thierry-henry.biz at Juventus: from his career at the club to leadership on the field , becoming a legend and a source of inspiration for youth.
The story of the great Kobe Bryant https://los-angeles-lakers.kobe-bryant-fr.com with ” Los Angeles Lakers: his path to the championship, his legendary achievements.
Novak Djokovic’s https://tennis.novak-djokovic-fr.biz journey from childhood to the top of world tennis: early years, first victories, dominance and influence on the sport.
Find out the story of Jon Jones https://ufc.jon-jones-fr.biz in the UFC: his triumphs, records and controversies, which made him one of the greatest fighters in the MMA world.
ciprofloxacin 250mg
Hraci mohou hrat Mr. Thimble https://mostbet-bk.cz/mr-thimble-v-mostbet-casino-cz-jste-pripraveni-na-hokus-pokus/ v Mostbetu s ruznymi moznostmi bonusu.
wow buy raid carry http://www.kreativwerkstatt-esens.de/ .
Carlos Alcaraz https://tennis.carlos-alcaraz-fr.biz from a talented junior to the ATP top 10. His rise is the result of hard work, support and impressive victories at major world tournaments.
Jannik Sinner https://tennis.jannik-sinner-fr.biz an Italian tennis player, went from starting his career to entering the top 10 of the ATP, demonstrating unique abilities and ambitions in world tennis.
The fascinating story of Daniil Medvedev’s https://tennis.daniil-medvedev-fr.biz rise to world number one. Find out how a Russian tennis player quickly broke into the elite and conquered the tennis Olympus.
Discover Casper Ruud’s https://tennis.casper-ruud-fr.com journey from his Challenger debut to the top 10 of the world tennis rankings. A unique success.
The fascinating story of Alexander Zverev’s https://tennis.alexander-zverev-fr.biz rapid rise from a junior star to one of the leaders of modern tennis.
Добрый день!
Где заказать диплом специалиста?
Купить диплом ВУЗа.
https://images.google.cat/url?sa=t&url=http://aurus-diploms.com
Всегда вам поможем!
за сколько можно купить аттестат ast-diplomas.com .
Привет!
Купить диплом о высшем образовании.
Мы предлагаем заказать диплом высокого качества, который не отличить от оригинала без использования специального оборудования и опытного специалиста.
Где заказать диплом по нужной специальности?
http://sampcrmrp.1stbb.ru/viewtopic.php?f=117&t=945
Удачи!
Добрый день!
Мы изготавливаем дипломы любых профессий по приятным тарифам.
Мы можем предложить документы техникумов, которые находятся на территории всей Российской Федерации. Можно приобрести диплом от любого заведения, за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Документы печатаются на “правильной” бумаге самого высокого качества. Это дает возможность делать настоящие дипломы, которые невозможно отличить от оригинала. Они будут заверены всеми требуемыми печатями и подписями.
Гарантируем, что при проверке документа работодателем, подозрений не появится.
Где купить диплом специалиста?
argoilim.webff.ru/viewtopic.php?id=2115#p2423
nettruyen
NetTruyen ZZZ: Nền tảng đọc truyện tranh trực tuyến dành cho mọi lứa tuổi
NetTruyen ZZZ là nền tảng đọc truyện tranh trực tuyến miễn phí với số lượng truyện tranh lên đến hơn 30.000 đầu truyện với chất lượng hình ảnh và tốc độ tải cao. Nền tảng được xây dựng với mục tiêu mang đến cho người đọc những trải nghiệm đọc truyện tranh tốt nhất, đồng thời tạo dựng cộng đồng yêu thích truyện tranh sôi động và gắn kết với hơn 11 triệu thành viên (tính đến tháng 7 năm 2024).
NetTruyen ZZZ – Kho tàng truyện tranh phong phú:
NetTruyen ZZZ sở hữu kho tàng truyện tranh khổng lồ với hơn 30.000 đầu truyện thuộc nhiều thể loại khác nhau như:
● Manga: Những bộ truyện tranh Nhật Bản với nhiều thể loại phong phú như lãng mạn, hành động, hài hước, v.v.
● NetTruyen anime: Hàng ngàn bộ truyện tranh anime chọn lọc được đăng tải đều đặn trên NetTruyen ZZZ được chuyển thể từ phim hoạt hình Nhật Bản với nội dung hấp dẫn và hình ảnh đẹp mắt.
● Truyện manga: Hơn 10.000 bộ truyện tranh manga hay nhất được đăng tải đầy đủ trên NetTruyen ZZZ.
● Truyện manhua: Hơn 5000 bộ truyện tranh manhua được đăng tải trọn bộ đầy đủ trên NetTruyen ZZZ.
● Truyện manhwa: Những bộ truyện tranh manhwa Hàn Quốc được yêu thích nhất có đầy đủ trên NetTruyen với cốt truyện lôi cuốn và hình ảnh bắt mắt cùng với nét vẽ độc đáo và nội dung đa dạng.
● Truyện ngôn tình: Những câu chuyện tình yêu lãng mạn, ngọt ngào và đầy cảm xúc.
● Truyện trinh thám: Những câu chuyện ly kỳ, bí ẩn và đầy lôi cuốn xoay quanh các vụ án và quá trình phá án.
● Truyện tranh xuyên không: Những câu chuyện về những nhân vật du hành thời gian hoặc không gian đến một thế giới khác.
NetTruyen ZZZ không ngừng cập nhật những bộ truyện tranh mới nhất và hot nhất trên thị trường, đảm bảo mang đến cho bạn đọc những trải nghiệm đọc truyện mới mẻ và thú vị nhất.
Chất lượng hình ảnh và nội dung đỉnh cao tại NetTruyenZZZ:
Với hơn 30 triệu lượt truy cập hằng tháng, NetTruyen ZZZ luôn chú trọng vào chất lượng hình ảnh và nội dung của các bộ truyện tranh được đăng tải trên nền tảng. Hình ảnh được hiển thị sắc nét, rõ ràng, không bị mờ hay vỡ ảnh. Nội dung được dịch thuật chính xác, dễ hiểu và giữ nguyên vẹn ý nghĩa của tác phẩm gốc.
NetTruyen ZZZ hợp tác với đội ngũ dịch giả và biên tập viên chuyên nghiệp, giàu kinh nghiệm để đảm bảo chất lượng bản dịch tốt nhất. Nền tảng cũng có hệ thống kiểm duyệt nội dung nghiêm ngặt để đảm bảo nội dung lành mạnh, phù hợp với mọi lứa tuổi.
Trải nghiệm đọc truyện mượt mà, tiện lợi:
NetTruyen ZZZ được thiết kế với giao diện đẹp mắt, thân thiện với người dùng và dễ dàng sử dụng. Bạn đọc có thể đọc truyện tranh trên mọi thiết bị, từ máy tính, điện thoại thông minh đến máy tính bảng. Nền tảng cũng cung cấp nhiều tính năng tiện lợi như:
● Tìm kiếm truyện tranh theo tên, tác giả, thể loại, v.v.
● Lưu truyện tranh yêu thích để đọc sau.
● Đánh dấu trang để dễ dàng quay lại vị trí đang đọc.
● Chia sẻ truyện tranh với bạn bè.
● Tham gia bình luận và thảo luận về truyện tranh.
NetTruyen ZZZ luôn nỗ lực để mang đến cho bạn đọc những trải nghiệm đọc truyện mượt mà, tiện lợi và thú vị nhất.
Định hướng phát triển:
NetTruyen ZZZ cam kết không ngừng phát triển và hoàn thiện để trở thành nền tảng đọc truyện tranh trực tuyến tốt nhất dành cho bạn đọc tại Việt Nam. Nền tảng sẽ tiếp tục cập nhật những bộ truyện tranh mới nhất và hot nhất trên thị trường thế giới, đồng thời nâng cao chất lượng hình ảnh và nội dung. NetTruyen ZZZ cũng sẽ phát triển thêm nhiều tính năng mới để mang đến cho bạn đọc những trải nghiệm đọc truyện tốt nhất.
NetTruyen ZZZ luôn đặt lợi ích của bạn đọc lên hàng đầu. Nền tảng cam kết:
● Cung cấp kho tàng truyện tranh khổng lồ và đa dạng với chất lượng hình ảnh và nội dung đỉnh cao.
● Mang đến cho bạn đọc những trải nghiệm đọc truyện mượt mà, tiện lợi và thú vị nhất.
● Luôn lắng nghe ý kiến phản hồi của bạn đọc và không ngừng cải thiện để mang đến dịch vụ tốt nhất.
NetTruyen ZZZ hy vọng sẽ trở thành người bạn đồng hành không thể thiếu của bạn trong hành trình khám phá thế giới truyện tranh đầy màu sắc.
Kết nối với NetTruyen ZZZ ngay hôm nay để tận hưởng những trải nghiệm đọc truyện tuyệt vời.
Геракл24: Квалифицированная Замена Основания, Венцов, Покрытий и Передвижение Строений
Компания Gerakl24 занимается на оказании полных сервисов по замене основания, венцов, настилов и перемещению зданий в городе Красноярском регионе и за его пределами. Наш коллектив опытных специалистов обеспечивает отличное качество реализации всех видов восстановительных работ, будь то древесные, с каркасом, кирпичные постройки или бетонные строения.
Достоинства работы с Геракл24
Навыки и знания:
Весь процесс осуществляются только профессиональными мастерами, имеющими многолетний стаж в области строительства и ремонта зданий. Наши мастера профессионалы в своем деле и выполняют задачи с безупречной точностью и учетом всех деталей.
Комплексный подход:
Мы предоставляем все виды работ по реставрации и ремонту домов:
Замена фундамента: укрепление и замена старого фундамента, что позволяет продлить срок службы вашего здания и предотвратить проблемы, связанные с оседанием и деформацией строения.
Смена венцов: замена нижних венцов деревянных домов, которые обычно гниют и разрушаются.
Замена полов: монтаж новых настилов, что существенно улучшает визуальное восприятие и функциональность помещения.
Перемещение зданий: безопасное и надежное перемещение зданий на другие участки, что позволяет сохранить ваше строение и избежать дополнительных затрат на создание нового.
Работа с любыми типами домов:
Древесные строения: восстановление и укрепление деревянных конструкций, защита от разрушения и вредителей.
Дома с каркасом: укрепление каркасов и смена поврежденных частей.
Дома из кирпича: ремонт кирпичных стен и усиление стен.
Бетонные дома: реставрация и усиление бетонных элементов, ремонт трещин и дефектов.
Надежность и долговечность:
Мы работаем с только проверенные материалы и передовые технологии, что гарантирует долгий срок службы и прочность всех выполненных задач. Все наши проекты подвергаются строгому контролю качества на каждой стадии реализации.
Персонализированный подход:
Мы предлагаем каждому клиенту персонализированные решения, с учетом всех особенностей и пожеланий. Мы стремимся к тому, чтобы итог нашей работы полностью удовлетворял вашим ожиданиям и требованиям.
Почему стоит выбрать Геракл24?
Работая с нами, вы получаете надежного партнера, который возьмет на себя все хлопоты по ремонту и реставрации вашего дома. Мы гарантируем выполнение всех работ в установленные сроки и с соблюдением всех правил и норм. Выбрав Геракл24, вы можете быть уверены, что ваше здание в надежных руках.
Мы готовы предоставить консультацию и дать ответы на все вопросы. Звоните нам, чтобы обсудить детали вашего проекта и получить больше информации о наших услугах. Мы сохраним и улучшим ваш дом, сделав его уютным и безопасным для долгого проживания.
Геракл24 – ваш выбор для реставрации и ремонта домов в Красноярске и области.
https://gerakl24.ru/передвинуть-дом-красноярск/
The powerful story of Conor McGregor’s https://ufc.conor-mcgregor-fr.biz rise to a two-division UFC championship that forever changed the landscape of mixed martial arts.
The legendary boxing world champion Mike Tyson https://ufc.mike-tyson-fr.biz made an unexpected transition to the UFC in 2024, where he rose to the top, becoming the oldest heavyweight champion.
The fascinating story of how Lewis Hamilton https://mercedes.lewis-hamilton-fr.biz became a seven-time Formula 1 world champion after signing with Mercedes.
The story of Fernando Alonso https://formula-1.fernando-alonso-fr.com in Formula 1: a unique path to success through talent, tenacity and strategic decisions, inspiring and exciting.
The fascinating story of the creation and rapid growth of Facebook https://facebook.mark-zuckerberg-fr.biz under the leadership of Mark Zuckerberg, who became one of the most influential technology entrepreneurs of our time.
Kim Kardashian’s https://the-kardashians.kim-kardashian-fr.com incredible success story, from sex scandal to pop culture icon and billion-dollar fortune.
Max Verstappen and Red Bull Racing’s https://red-bull-racing.max-verstappen-fr.com path to success in Formula 1. A story of talent, determination and team support leading to a championship title.
The astonishing story of Emmanuel Macron’s https://president-of-france.emmanuel-macron-fr.com political rise from bank director to the highest office in France.
Une ascension fulgurante au pouvoir Donald Trump https://usa.donald-trump-fr.com et son empire commercial
The story of Joe Biden’s https://president-of-the-usa.joe-biden-fr.com triumphant journey, overcoming many obstacles on his path to the White House and becoming the 46th President of the United States.
Привет, друзья!
Приобрести диплом ВУЗа
Наша компания предлагает максимально быстро заказать диплом, который выполняется на оригинальном бланке и заверен печатями, штампами, подписями. Данный диплом способен пройти лубую проверку, даже при использовании специального оборудования. Решите свои задачи максимально быстро с нашей компанией.
Где купить диплом специалиста?
https://www.motmarket.ru/forum/user/25142/
Рады помочь!.
Привет, друзья!
Для многих людей, заказать диплом о высшем образовании – это острая потребность, удачный шанс получить хорошую работу. Но для кого-то – это осмысленное желание не терять время на учебу в ВУЗе. Что бы ни толкнуло вас на такой шаг, мы готовы помочь вам. Быстро, профессионально и по доступной цене сделаем диплом любого ВУЗа и любого года выпуска на настоящих бланках с реальными печатями.
Наша компания предлагает выгодно купить диплом, который выполняется на оригинальном бланке и заверен печатями, водяными знаками, подписями должностных лиц. Документ способен пройти любые проверки, даже с применением специально предназначенного оборудования. Решайте свои задачи быстро и просто с нашей компанией.
Где купить диплом по нужной специальности?
http://evraz.forum.cool/viewtopic.php?id=2947#p4961
Удачи!
где купить диплом цены asxdiplomik.com .
купить диплом производство diplomyx.com .
5 разряд купить диплом ast-diploms.com .
Parisian PSG https://paris.psg-fr.com is one of the most successful and ambitious football clubs in Europe. Find out how he became a global football superstar.
Travel to the pinnacle of French football https://stadede-bordeaux.bordeaux-fr.org at the Stade de Bordeaux, where the passion of the game meets the grandeur of architecture.
Olympique de Marseille https://liga1.marseilles-fr.com after several years in the shadows, once again becomes champion of France. How did they do it and what prospects open up for the club
The fascinating story of Gigi Hadid’s rise to Victoria’s Secret Angel https://victorias-secret.gigi-hadid-fr.com status and her journey to the top of the modeling industry.
The fascinating story of the creation and meteoric rise of Amazon https://amazon.jeff-bezos-fr.com from its humble beginnings as an online bookstore to its dominant force in the world of e-commerce.
A fascinating story about how Elon Musk https://spacex.elon-musk-fr.com and his company SpaceX revolutionized space exploration, opening new horizons for humanity.
The inspiring story of Travis Scott’s https://yeezus.travis-scott-fr.com rise from emerging artist to one of modern hip-hop’s brightest stars through his collaboration with Kanye West.
An exploration of Nicole Kidman’s https://watch.nicole-kidman-fr.com career, her notable roles, and her continued quest for excellence as an actress.
How Taylor Swift https://midnights.taylor-swift-fr.com reinvented her sound and image on the intimate and reflective album “Midnights,” revealing new dimensions of her talent.
Здравствуйте!
Задался вопросом: можно ли на самом деле купить диплом государственного образца в Москве? Был приятно удивлен — это реально и легально!
Сначала искал информацию в интернете на тему: купить диплом судоводителя, купить диплом в георгиевске, купить диплом в биробиджане, купить диплом в новомосковске, купить диплом в глазове и получил базовые знания. В итоге остановился на материале: http://ruall.com/sotrudnichestvo/76784-kupit-diplom-kandidata-nauk.html#76784
Удачи!
Explore the rich history and unrivaled atmosphere of the iconic Old Trafford Stadium https://old-trafford.manchester-united-fr.com, home of one of the world’s most decorated football clubs, Manchester United.
montenegro on a map of europe https://weather-webcam-in-montenegro.com
Единственная в России студия кастомных париков https://wigdealers.ru, где мастера индивидуально подбирают структуру волос и основу по форме головы, после чего стригут, окрашивают, делают укладку и доводят до идеала ваш будущий аксессуар.
The iconic Anfield https://enfield.liverpool-fr.com stadium and the passionate Liverpool fans are an integral part of English football culture.
An exploration of the history of Turin’s https://turin.juventus-fr.org iconic football club – Juventus – its rivalries, success and influence on Italian football.
The new Premier League https://premier-league.chelsea-fr.com season has gotten off to an intriguing start, with a new-look Chelsea looking to return to the Champions League, but serious challenges lie ahead.
montenegro people https://weather-webcam-in-montenegro.com
купить диплом о среднем специальном недорого ast-diplomas.com .
купить диплом бакалавра в москве купить диплом бакалавра в москве .
Tyson Fury https://wbc.tyson-fury-fr.com is the undefeated WBC world champion and reigns supreme in boxing’s heavyweight division.
Inter Miami FC https://mls.inter-miami-fr.com has become a major player in MLS thanks to its star roster, economic growth and international influence.
Explore the career and significance of Monica Bellucci https://malena.monica-bellucci-fr.com in Malena (2000), which explores complex themes of beauty and human strength in wartime.
Discover Rafael Nadal’s https://mls.inter-miami-fr.com impressive rise to the top of world tennis, from his debut to his career Grand Slam victory.
The story of Kanye West https://the-college-dropout.kanye-west-fr.com, starting with his debut album “The College Dropout,” which changed hip-hop and became his cultural legacy.
русское порно худые русское порно худые .
ciprofloxacin 50 mg
Преимущества аренды склада https://vyvozmusorascherbinka.ru/preimushhestva-arendy-sklada-kak-optimizirovat-biznes-proczessy-i-snizit-izderzhki/, как аренда складских помещений может улучшить ваш бизнес
The fascinating story of the phenomenal rise and meteoric fall of Diego Maradona https://napoli.diegomaradona.biz, who became a cult figure at Napoli in the 1980s.
Rivaldo, or Rivaldo https://barcelona.rivaldo-br.com, is one of the greatest football players to ever play for Barcelona.
A fascinating story about Brazilian veteran Thiago Silva’s https://chelsea.thiago-silva.net difficult path to the top of European football as part of Chelsea London.
Explore the remarkable journey of Vinicius Junior https://real-madrid.vinicius-junior.net, the Brazilian prodigy who conquered the world’s biggest stage with his dazzling skills and unparalleled ambition at Real Madrid.
Mostbet oferuje rowniez zaklady https://mostbet-bk.pl/bukmacher-mostbet-polska/ na sporty wodne, takie jak wakeboarding i wioslarstwo.
диплом сразу купить asxdiplomik.com/kupit-diplom-moskva .
Cristiano Ronaldo https://al-nassr.cristianoronaldo-br.net one of the greatest football players of all time, begins a new chapter in his career by joining An Nasr Club.
The fascinating story of Marcus Rashford’s rise https://manchester-united.marcusrashford-br.com from academy youth to the main striker and captain of Manchester United. Read about his meteoric rise and colorful career.
The story of Luka Modric’s rise https://real-madrid.lukamodric-br.com from young talent to one of the greatest midfielders of his generation and a key player for the Royals.
From academy product to captain and leader of Real Madrid https://real-madrid.ikercasillas-br.com Casillas became one of the greatest players in the history of Real Madrid.
Follow Bernardo Silva’s impressive career https://manchester-city.bernardosilva.net from his debut at Monaco to to his status as a key player and leader of Manchester City.
сколько стоит аттестат 9 класс http://www.diploms-x.com/ .
Здравствуйте!
Где купить диплом специалиста?
Мы предлагаем дипломы психологов, юристов, экономистов и прочих профессий по приятным тарифам.
myanmarfootball.org/gallery/displayimage.php?album=lastup&cat=6&pos=0
сайт казино рио бет сайт казино рио бет
вход Rio Bet Casino https://dacha76.ru
сайт драгон мани казино https://uvstyle.ru
Dragon Money Casino https://web-kulinar.ru
Хотите научиться готовить самые изысканные и сложные торты? В этом https://v1.skladchik.org/tags/tort/ разделе вы найдете множество подробных пошаговых рецептов самых трендовых и известных тортов с возможностью получить их за сущие копейки благодаря складчине. Готовьте с удовольствием и открывайте для себя новые рецепты вместе с Skladchik.org
Лучшие пансионаты для пожилых людей https://ernst-neizvestniy.ru в Самаре – недорогие дома для престарелых в Самарской области
Пансионаты для пожилых людей https://moyomesto.ru в Самаре по доступным ценам. Специальные условия по уходу, индивидуальные программы.
Сколько стоит диплом высшего и среднего образования и как это происходит?
lolipopnews.ru/vash-idealnyiy-diplom-byistro-i-legko
The fascinating story of Sergio Ramos’ https://seville.sergioramos.net rise from Sevilla graduate to one of Real Madrid and Spain’s greatest defenders.
Ousmane Dembele’s https://paris-saint-germain.ousmanedembele-br.com rise from promising talent to key player for French football giants Paris Saint-Germain. An exciting success story.
wow mythic raid carry for sale https://kreativwerkstatt-esens.de .
Привет всем)
Хорошо быть студентом, пока не придет пора писать диплом, что и произошло со мной, но не стоит отчаиваться, ведь есть хорошие компании что помогают с написанием и сдачей диплома на хорошие оценки!
Изначально искал информацию про купить диплом в нижнекамске, купить диплом моториста, купить диплом в каменске-уральском, купить диплом для иностранцев, купить диплом медсестры, потом попал на https://xn—-btbthcge4aikr4i.xn--p1ai/forum/user/34204/ и там решили все мои учебные заботы!
Успешной учебы!
Узнайте, как приобрести диплом о высшем образовании без рисков
volnodumie.bbmy.ru/viewtopic.php?id=12940#p26418
The incredible success story of 20-year-old Florian Wirtz https://bayer-04.florianwirtz-br.com, who quickly joined the Bayer team and became one of the best young talents in the world.
The incredible story https://napoli.khvichakvaratskhelia-br.com of a young Georgian talent’s transformation into an Italian Serie A star. Khvicha Kvaraeshvili is a rising phenomenon in European football.
The compelling story of Alisson Becker’s https://bayer-04.florianwirtz-br.com meteoric rise from young talent to key figure in Liverpool’s triumphant era under Jurgen Klopp.
O meio-campista Rafael Veiga leva https://palmeiras.raphaelveiga-br.com o Palmeiras ao sucesso – o campeonato brasileiro e a vitoria na Copa Libertadores aos 24 anos.
Midfielder Rafael Veiga leads https://manchester-city.philfoden-br.com Palmeiras to success – the championship Brazilian and victory in the Copa Libertadores at the age of 24.
In-depth articles about the most famous football players https://zenit-saint-petersburg.wendel-br.com, clubs and events. Learn everything about tactics, rules of the game and football history.
The rise of 20-year-old midfielder Jamal Musiala https://bavaria.jamalmusiala-br.com to the status of a winger in the Bayern Munich team. A story of incredible talent.
A historia da jornada triunfante de Anitta https://veneno.anitta-br.com de aspirante a cantora a uma das interpretes mais influentes da musica moderna, incluindo sua participacao na serie de TV “Veneno”.
Fabrizio Moretti https://the-strokes.fabriziomoretti-br.com the influential drummer of The Strokes, and his unique sound revolutionized the music scene, remaining icons of modern rock.
Selena Gomez https://calm-down.selenagomez-br.net the story from child star to global musical influence, summarized in hit “Calm Down”, with Rema.
купить диплом мпгу asxdiplomik.com/kupit-diplom-moskva .
wow raid carry service kreativwerkstatt-esens.de .
Пошаговая инструкция по официальной покупке диплома о высшем образовании
datasphere.ru/club/user/12/blog/4359/
Здравствуйте!
Где заказать диплом специалиста?
Наши специалисты предлагают выгодно купить диплом, который выполнен на бланке ГОЗНАКа и заверен мокрыми печатями, водяными знаками, подписями. Наш диплом пройдет любые проверки, даже при помощи профессиональных приборов. Решайте свои задачи максимально быстро с нашими дипломами.
Заказать диплом ВУЗа.
antspride.com/read-blog/824
диплом массаж купить asxdiplomik.com/kupit-diplom-moskva .
Легальная покупка диплома ПТУ с сокращенной программой обучения
diplomyx24.ru/otzyvy
бланки справки дипломы журналы купить asxdiplomik.com .
купить диплом новгород купить диплом новгород .
диплом электромеханика морского судна купить ростов ast-diploms.com .
Добрый день!
Мы можем предложить документы техникумов, расположенных в любом регионе России. Вы можете приобрести качественно сделанный диплом от любого учебного заведения, за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Документы выпускаются на бумаге самого высшего качества. Это дает возможность делать государственные дипломы, не отличимые от оригиналов. Документы заверяются всеми необходимыми печатями и подписями.
Заказать диплом о высшем образовании.
derpyshare.mn.co/posts/61837975
Успехов в учебе!
Привет, друзья!
Мы изготавливаем дипломы любой профессии по приятным тарифам. Цена может зависеть от выбранной специальности, года получения и ВУЗа.
Где купить диплом специалиста?
Приобрести диплом любого ВУЗа
landik-diploms-srednee.ru/kupit-diplom-saratov
Хорошей учебы!
Добрый день!
Приобрести документ о получении высшего образования можно у нас.
asxdiplomik.com/kupit-diplom-sankt-peterburg
Хорошей учебы!
Kobe Bryant https://los-angeles-lakers.kobebryant-br.net one of the greatest basketball players of all the times, left an indelible mark on the history of sport.
Bieber’s https://baby.justinbieber-br.com path to global fame began with his breakthrough success Baby, which became his signature song and one of the most popular music videos of all time.
In the world of professional tennis, the name of Gustavo Kuerten https://roland-garros.gustavokuerten.com is closely linked to one of the most prestigious Grand Slam tournaments – Roland Garros.
Achraf Hakimi https://paris-saint-germain.ashrafhakimi.net is a young Moroccan footballer who quickly reached the football elite European in recent years.
Ayrton Senna https://mclaren.ayrtonsenna-br.com is one of the greatest drivers in the history of Formula 1.
Привет, друзья!
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
obozrevatelevents.ru/vash-shans-na-uspeh-diplom-bez-truda
Всегда вам поможем!.
Добрый день!
Где купить диплом специалиста?
Купить диплом любого университета.
ya3bbru.bbok.ru/viewtopic.php?id=4042#p7095
[u][b] Добрый день![/b][/u]
[b]Мы предлагаем документы ВУЗов,[/b] которые расположены на территории всей России. Можно приобрести диплом за любой год, включая сюда документы СССР. Документы печатаются на “правильной” бумаге высшего качества. Это позволяет делать настоящие дипломы, не отличимые от оригинала. Документы будут заверены всеми необходимыми печатями и штампами.
[url=http://primerosauxilios.org/primeros-auxilios/que-es-y-como-curar-una-herida.php]primerosauxilios.org/primeros-auxilios/que-es-y-como-curar-una-herida.php[/url]
[u][b] Привет, друзья![/b][/u]
Где купить диплом по необходимой специальности?
Мы можем предложить документы ВУЗов, расположенных на территории всей РФ. Вы можете купить качественно сделанный диплом за любой год, в том числе документы старого образца. Дипломы выпускаются на “правильной” бумаге высшего качества. Это дает возможность делать государственные дипломы, которые не отличить от оригиналов. Они заверяются всеми обязательными печатями и штампами.
[b]Мы можем предложить дипломы[/b] психологов, юристов, экономистов и других профессий по приятным ценам.
[url=http://ast-diplomas.com/kupit-diplom-krasnoyarsk]ast-diplomas.com/kupit-diplom-krasnoyarsk[/url]
[u][b] Поможем вам всегда![u][b]
[u][b] Привет, друзья![/b][/u]
Где приобрести диплом специалиста?
[url=http://digdroid.com/forums/entry/signin/]digdroid.com/forums/entry/signin[/url]
[b]Успехов в учебе![/b]
[u][b] Привет![/b][/u]
[b]Как официально приобрести аттестат 11 класса с минимальными затратами времени [/b]
[url=http://nosnitches.com/create-blog/]nosnitches.com/create-blog[/url]
[u][b] Рады оказать помощь![u][b].
[u][b] Здравствуйте![/b][/u]
[b]Наша компания предлагает[/b] быстро и выгодно приобрести диплом, который выполнен на оригинальном бланке и заверен мокрыми печатями, штампами, подписями должностных лиц. Документ способен пройти любые проверки, даже с использованием специальных приборов. Решите свои задачи быстро и просто с нашим сервисом.
[url=http://teplostar72.ru/index.php?subaction=userinfo&user=yroquze/]teplostar72.ru/index.php?subaction=userinfo&user=yroquze[/url]
[b]Успехов в учебе![/b]
[u][b] Здравствуйте![/b][/u]
[b]Где приобрести диплом по актуальной специальности?[/b]
[b]Мы можем предложить дипломы[/b] любой профессии по доступным тарифам.
[url=http://www.kaktusy.cz/eshop/index.php?links_exchange=yes&page=41&show_all=yes]www.kaktusy.cz/eshop/index.php?links_exchange=yes&page=41&show_all=yes[/url]
[u][b] Добрый день![/b][/u]
Где приобрести диплом специалиста?
Мы предлагаем быстро и выгодно заказать диплом, который выполнен на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями должностных лиц. Диплом способен пройти лубую проверку, даже при использовании профессионального оборудования. Решайте свои задачи быстро и просто с нашими дипломами.
[b]Купить диплом любого университета.[/b]
[url=http://8eg56er3s.blog5.net/70052601/%D0%A1-%D0%BB%D0%B5%D0%B3%D0%BA%D0%BE%D1%81%D1%82%D1%8C%D1%8E-%D0%BF%D0%BE%D0%BA%D1%83%D0%BF%D0%B0%D0%B5%D0%BC-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%B2-%D0%BB%D1%83%D1%87%D1%88%D0%B5%D0%BC-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5-russian-diplom/]8eg56er3s.blog5.net/70052601/%D0%A1-%D0%BB%D0%B5%D0%B3%D0%BA%D0%BE%D1%81%D1%82%D1%8C%D1%8E-%D0%BF%D0%BE%D0%BA%D1%83%D0%BF%D0%B0%D0%B5%D0%BC-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%B2-%D0%BB%D1%83%D1%87%D1%88%D0%B5%D0%BC-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5-russian-diplom[/url]
Привет, друзья!
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
drevtorg.xyz/profiles/blogs/6382903:BlogPost:355671
Рады оказаться полезными!.
Привет, друзья!
Приобрести диплом о высшем образовании.
sport-faq.ru/ofitsialnyie-diplomyi-dlya-vashey-kareryi
Успешной учебы!
Anderson Silva https://killer-bees-muay-thai-college.andersonsilva.net was born in 1975 in Curitiba Brazil. From a young age he showed an interest in martial arts, starting to train in karate at the age of 5.
Daniel Alves https://paris-saint-germain.danielalves.net is a name that symbolizes the greatness of the world of football.
Bruno Miguel Borges Fernandes https://manchester-united.brunofernandes-br.com was born on September 8, 1994 in Maia, Portugal.
Rodrygo Silva de Goes https://real-madrid.rodrygo-br.com, known simply as Rodrygo, emerged as one of the the brightest young talents in world football.
Nuno Mendes https://paris-saint-germain.nuno-mendes.com, a talented Portuguese left-back, He quickly became one of the key figures in the Paris Saint-Germain (PSG) team.
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
ast-diploms.com/kupit-diplom-magistra
купить свидетельство о рождении ссср ast-diploms.com .
купить диплом педагогического колледжа diplomasx.com .
Earvin “Magic” Johnson https://los-angeles-lakers.magicjohnson.biz is one of the most legendary basketball players in history. NBA history.
Vinicius Junior https://real-madrid.vinicius-junior-ar.com the Brazilian prodigy whose full name is Vinicius Jose Baixao de Oliveira Junior, has managed to win the hearts of millions of fans around the world in a short period of time.
Victor Osimhen https://napoli.victorosimhen-ar.com born on December 29, 1998 in Lagos, Nigeria, has grown from an initially humble player to one of the brightest strikers in modern football.
Toni Kroos https://real-madrid.tonikroos-ar.com the German midfielder known for his accurate passes and calmness on the field, has achieved remarkable success at one of the most prestigious football clubs in the world.
Robert Lewandowski https://barcelona.robertlewandowski-ar.com is one of the most prominent footballers of our time, and his move to Barcelona has become one of the most talked about topics in world football.
Привет, друзья!
Наша компания предлагает заказать диплом в высочайшем качестве, который невозможно отличить от оригинального документа без использования дорогостоящего оборудования и опытного специалиста.
kioskindustry.ru/index.php?subaction=userinfo&user=uhomyryj
Удачи!
Добрый день!
Приобрести документ университета вы можете в нашем сервисе.
diplomasx.com/kupit-diplom-rostov-na-donu
Успешной учебы!
Здравствуйте!
Купить документ университета вы можете в нашей компании в Москве.
ast-diplomy.com/kupit-diplom-moskva
먹튀 검증
Zhu Houzhao가 젊다는 것을보고 어떤 학자들은 “형제, 감히 Gao의 이름을 묻습니까? “라고 물었습니다.
Новинки Бреста а также Брестской области также слое, самая пре самая эксплуатационная экспресс-информация: темы дня, обзоры, последние неприятного события а также события города, информации о ДТП
https://elnet.by/
Здравствуйте!
Приобрести диплом о высшем образовании.
Мы предлагаем документы техникумов, которые находятся на территории всей России. Вы сможете заказать диплом от любого учебного заведения, за любой год, включая документы старого образца. Документы делаются на бумаге самого высшего качества. Это позволяет делать настоящие дипломы, которые невозможно отличить от оригиналов. Документы заверяются необходимыми печатями и штампами.
wzqlg1sos.blogzag.com/72727056/%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%BD%D0%BE%D0%B5-%D0%BE%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D0%B5-%D0%BF%D0%BE%D0%BA%D1%83%D0%BF%D0%BA%D0%B8-%D0%B0%D1%82%D1%82%D0%B5%D1%81%D1%82%D0%B0%D1%82%D0%B0-%D0%B2-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5
Привет, друзья!
Приобрести документ института можно в нашей компании в Москве.
diplomasx.com/kupit-diplom-o-srednem-obrazovanii
Хорошей учебы!
Здравствуйте!
Где заказать диплом по нужной специальности?
Мы предлагаем документы институтов, которые находятся на территории всей РФ. Вы имеете возможность заказать диплом от любого заведения, за любой год, указав актуальную специальность и оценки за все дисциплины. Дипломы выпускаются на “правильной” бумаге высшего качества. Это дает возможности делать государственные дипломы, которые невозможно отличить от оригинала. Документы заверяются всеми обязательными печатями и штампами.
Мы можем предложить дипломы любой профессии по доступным тарифам.
diplomyx24.ru/otzyvy
Рады оказаться полезными!
Здравствуйте!
Мы готовы предложить документы ВУЗов, расположенных в любом регионе России. Можно приобрести качественный диплом от любого заведения, за любой год, в том числе документы старого образца СССР. Документы выпускаются на бумаге самого высокого качества. Это дает возможности делать настоящие дипломы, не отличимые от оригиналов. Документы будут заверены всеми требуемыми печатями и штампами.
http://www.reisezielforum.de/forum-f5/l942g-t61855.html
Добрый день!
Мы предлагаем дипломы любой профессии по выгодным тарифам. Цена будет зависеть от выбранной специальности, года получения и университета.
landik-diploms-srednee.ru/svidetelstvo-o-razvode
Удачи!
Российский ярмарка свежих автомобилей высказывает разнонаправленную динамику цен. Одни модификации значительно упали в цене, на так ятси как другие, наоборот
https://avgrodno.by/
Новости Горок равным образом Могилева, самая актуальная информация: вопроса дня, обзоры, последние события города. https://roogorki.by/
Привет, друзья!
Заказать документ о получении высшего образования вы можете в нашей компании.
ast-diplomy.com/kupit-diplom-vracha
Привет!
Купить диплом любого университета.
link4hope.com/read-blog/3603
купить диплом вуза в нур султана asxdiplomik24.ru .
Привет!
Где купить диплом специалиста?
Купить диплом о высшем образовании.
goruss.ru/blogs/933/%D0%9A%D0%B0%D0%BA-%D0%BF%D0%BE%D0%B4%D1%8B%D1%81%D0%BA%D0%B0%D1%82%D1%8C-%D0%BD%D0%B0%D0%B4%D0%B5%D0%B6%D0%BD%D1%8B%D0%B9-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD-%D1%81-%D0%BE%D0%B1%D1%88%D0%B8%D1%80%D0%BD%D1%8B%D0%BC-%D0%B0%D1%81%D1%81%D0%BE%D1%80%D1%82%D0%B8%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%BC-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%BE%D0%B2
Привет, друзья!
Наши специалисты предлагают выгодно и быстро купить диплом, который выполняется на бланке ГОЗНАКа и заверен печатями, штампами, подписями. Диплом пройдет любые проверки, даже с использованием специальных приборов. Достигайте цели быстро и просто с нашей компанией.
http://www.tapatalk.com/groups/dzerjinsky/viewtopic.php?f=2&t=37259&from_new_topic=1
Хорошей учебы!
купить диплом колледжа в екатеринбурге купить диплом колледжа в екатеринбурге .
Здравствуйте!
Где купить диплом специалиста?
newfinbiz.ru/vash-diplom-bez-lishnih-zabot-byistro-i-bezopasno
Успехов в учебе!
Здравствуйте!
Где приобрести диплом по нужной специальности?
Приобрести диплом любого университета.
vip.forums.party/viewtopic.php?id=3430#p71041
купить диплом специалиста в омске asxdiplomik.com .
купить высшее образование с занесением в реестр diplomyx.com .
Здравствуйте!
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам.
sensualmarketplace.com/read-blog/928_proverennyj-magazin-s-ogromnym-katalogom-diplomov.html
Привет!
Приобрести диплом любого университета
antennastar.com/blogs/474/%D0%9F%D1%80%D0%BE%D0%B2%D0%B5%D1%80%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD-%D1%81-%D1%88%D0%B8%D1%80%D0%BE%D0%BA%D0%B8%D0%BC-%D0%B0%D1%81%D1%81%D0%BE%D1%80%D1%82%D0%B8%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%BC-%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%B2
Привет!
Где приобрести диплом по актуальной специальности?
Мы можем предложить дипломы любой профессии по выгодным тарифам.
zhaktrans.ru/p40135689-tnvd-wd615-612601080225.html
Привет, друзья!
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
l-avt.ru/support/dialog/?PAGE_NAME=profile_view&UID=68709
Окажем помощь!.
Добрый день!
Заказать диплом о высшем образовании.
lossantosbattalion17.listbb.ru/viewtopic.php?f=3&t=351
Хорошей учебы!
[u][b] Добрый день![/b][/u]
[b]Заказать диплом ВУЗа.[/b]
Мы можем предложить документы ВУЗов, которые находятся на территории всей РФ. Вы сможете заказать качественно напечатанный диплом за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Дипломы и аттестаты печатаются на “правильной” бумаге самого высокого качества. Это дает возможности делать государственные дипломы, не отличимые от оригиналов. Они заверяются необходимыми печатями и штампами.
[url=http://jointsnmotion-hub.mn.co/posts/61837773/]jointsnmotion-hub.mn.co/posts/61837773[/url]
purchase nolvadex no prescription
Привет, друзья!
Где приобрести диплом специалиста?
Заказать диплом любого ВУЗа.
es-presto.ru/community/groups/0-0/176-ogromnyj-vybor-dokumentov-v-znamenitom-onlajn-magazine
i-tec.ru http://multimedijnyj-integrator.ru .
Привет!
Мы изготавливаем дипломы любой профессии по невысоким ценам.
egrodymser.com/%D0%BC%D0%B3%D1%83-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC/
Добрый день!
Наша компания предлагает купить диплом в высоком качестве, который не отличить от оригинального документа без использования специального оборудования и опытного специалиста.
m1bar.com/index.php?subaction=userinfo&user=azukosop
Успехов в учебе!
Привет, друзья!
Мы предлагаем дипломы любых профессий по приятным ценам.
http://www.edenreclamation.co.uk/%D0%BC%D1%83%D0%B7%D1%8B%D0%BA%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5-%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%BA%D1%83%D0%BF%D0%B8/
Добрый день!
Купить документ о получении высшего образования вы можете у нас.
diplomasx.com/kupit-diplom-moskva
Успешной учебы!
Добрый день!
Заказать документ о получении высшего образования вы сможете в нашей компании в столице.
ast-diplomas.com/kupit-diplom-rostov-na-donu
Успехов в учебе!
Pedro Gonzalez Lopez https://barcelona.pedri-ar.com known as Pedri, was born on November 25, 2002 in the small town of Tegeste, located on Tenerife, one of the Canary Islands.
The story of Leo Messi https://inter-miami.lionelmessi.ae‘s transfer to Inter Miami began long before the official announcement. Rumors about Messi’s possible departure from Barcelona appeared in 2020
Yacine Bounou https://al-hilal.yassine-bounou-ar.com known simply as Bono, is one of the most prominent Moroccan footballers of our time.
Andreson Souza Conceicao https://al-nassr.talisca-ar.com known as Talisca, is one of the brightest stars of modern football.
Официальное получение диплома техникума с упрощенным обучением в Москве
kvixi.com/blogs/1362/4-%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D1%8B%D1%85-%D0%B3%D1%80%D1%83%D0%BF%D0%BF%D1%8B-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE%D0%B2-%D0%BA%D0%BE%D1%82%D0%BE%D1%80%D1%8B%D0%B5-%D1%80%D0%B5%D0%B0%D0%BB%D0%B8%D0%B7%D1%83%D1%8E%D1%82-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D1%8B
Здравствуйте!
Мы предлагаем документы техникумов, расположенных в любом регионе Российской Федерации. Можно купить диплом от любого учебного заведения, за любой год, указав подходящую специальность и хорошие оценки за все дисциплины. Дипломы и аттестаты делаются на бумаге самого высшего качества. Это дает возможности делать государственные дипломы, не отличимые от оригинала. Они заверяются всеми требуемыми печатями и подписями.
http://www.cyberpinoy.net/read-blog/33705
Привет!
Легальные способы покупки диплома о среднем полном образовании
formfinance.ru/kupite-diplom-i-nachnite-novuyu-zhizn
Поможем вам всегда!.
Привет, друзья!
Покупка диплома о среднем полном образовании: как избежать мошенничества?
arusak-diploms-srednee.ru/kupit-diplom-kandidata-nauk
Успехов в учебе!
Здравствуйте!
Мы готовы предложить дипломы любых профессий по выгодным ценам.
http://www.megafeedbd.com/2024/06/30/%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%BE-%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B5%D0%BC-%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B8-%D0%BE/
Добрый день!
Где купить диплом по актуальной специальности?
Заказать диплом о высшем образовании.
clubalameda.com/index.php/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=116
купить диплом охраны diplomyx.com .
купить диплом врача стоматолога asxdiplomik.com .
Привет, друзья!
Полезная информация как официально купить диплом о высшем образовании
autogroupe.ru/poluchite-diplom-bez-lishnih-usiliy
Здравствуйте!
Мы предлагаем документы ВУЗов, расположенных в любом регионе России. Вы имеете возможность купить диплом за любой год, указав подходящую специальность и оценки за все дисциплины. Дипломы и аттестаты выпускаются на “правильной” бумаге самого высокого качества. Это дает возможность делать настоящие дипломы, не отличимые от оригиналов. Документы заверяются необходимыми печатями и подписями.
network-1062788.mn.co/posts/61828980
Добрый день!
Узнайте, как приобрести диплом о высшем образовании без рисков.
Приобрести диплом о высшем образовании.
indungii.ro/forum/index.php?/gallery/image/11-%D0%BF%D1%80%D0%B8%D0%BE%D0%B1%D1%80%D0%B5%D1%82%D0%B0%D0%B5%D0%BC-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%B2-%D0%BB%D1%83%D1%87%D1%88%D0%B5%D0%BC-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5-%D0%BF%D0%BE-%D0%B2%D1%8B%D0%B3%D0%BE%D0%B4%D0%BD%D0%BE%D0%B9-%D1%86%D0%B5%D0%BD%D0%B5/
cost of doxycycline prescription 100mg
Привет, друзья!
Где заказать диплом специалиста?
Заказать диплом ВУЗа.
mysmart.ru/index.php?/gallery/image/652-%D0%BA%D0%B0%D0%BA-%D0%BD%D0%B0%D0%B9%D1%82%D0%B8-%D0%BF%D1%80%D0%BE%D0%B2%D0%B5%D1%80%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD-%D1%81-%D0%BE%D0%B1%D1%88%D0%B8%D1%80%D0%BD%D1%8B%D0%BC-%D0%B0%D1%81%D1%81%D0%BE%D1%80%D1%82%D0%B8%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%BC-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%BE%D0%B2/
Harry Kane https://bayern.harry-kane-ar.com one of the most prominent English footballers of his generation, completed his move to German football club Bayern Munich in 2023.
Brazilian footballer Neymar https://al-hilal.neymar-ar.com known for his unique playing style and outstanding achievements in world football, has made a surprise move to Al Hilal Football Club.
Erling Haaland https://manchester-city.erling-haaland-ar.com born on July 21, 2000 in Leeds, England, began his football journey at an early age.
Luka Modric https://real-madrid.lukamodric-ar.com can certainly be called one of the outstanding midfielders in modern football.
Привет!
Где заказать диплом по необходимой специальности?
Мы изготавливаем дипломы любой профессии по выгодным тарифам. Цена зависит от той или иной специальности, года выпуска и образовательного учреждения. Стараемся поддерживать для клиентов адекватную ценовую политику. Для нас очень важно, чтобы дипломы были доступными для большинства граждан.
arusak-diploms-srednee.ru/kupit-attestat-za-11-klass
Удачи!
Football in Saudi Arabia https://al-hilal.ali-al-bulaihi-ar.com has long been one of the main sports, attracting millions of fans. In recent years, one of the brightest stars in Saudi football has been Ali Al-Bulaihi, defender of Al-Hilal Football Club.
Добрый день!
Купить документ университета можно у нас.
ast-diploms24.ru/kupit-diplom-krasnoyarsk
Здравствуйте!
Мы предлагаем дипломы любой профессии по приятным ценам.
traquegarden.com/%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%B7%D0%B0%D0%BE%D1%87%D0%BD%D0%BE%D0%B9-%D1%84%D0%BE%D1%80%D0%BC%D1%8B/
Привет!
Где заказать диплом специалиста?
Приобрести диплом университета.
fat-girls.ru/diplom-na-zakaz-kachestvo-i-nadezhnost
바이 낸스 벳
이것은 작은 풍자였습니다. Fang Jifan은 Zhu Houzhao를 때리는 데 익숙했습니다.
Добрый день!
Ьожем предложить документы ВУЗов, которые находятся в любом регионе России. Вы можете приобрести диплом за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Документы печатаются на бумаге самого высокого качества. Это дает возможности делать государственные дипломы, не отличимые от оригиналов. Документы заверяются всеми необходимыми печатями и штампами.
Мы предлагаем дипломы любой профессии по приятным тарифам. Цена зависит от выбранной специальности, года получения и образовательного учреждения. Всегда стараемся поддерживать для заказчиков адекватную политику тарифов. Важно, чтобы документы были доступны для подавляющей массы наших граждан.
arusak-diploms-srednee.ru/kupit-diplom-v-krasnodare
Успешной учебы!
Добрый день!
Купить документ ВУЗа вы имеете возможность в нашей компании в Москве.
diplomyx.com/kupit-diplom-omsk
Успешной учебы!
visit my website https://currencyconvert.net
Сайт https://ps-likers.ru предлагает уроки по фотошоп для начинающих. На страницах сайта можно найти пошаговые руководства по анимации, созданию графики для сайтов, дизайну, работе с текстом и фотографиями, а также различные эффекты.
RDBox.de https://rdbox.de bietet schallgedammte Gehause fur 3D-Drucker, die eine sehr leise Druckumgebung schaffen – nicht lauter als ein Kuhlschrank. Unsere Losungen sorgen fur stabile Drucktemperatur, Vibrationsisolierung, Luftreinigung und mobile App-Steuerung.
N’Golo Kante https://al-ittihad.ngolokante-ar.com the French midfielder whose career has embodied perseverance, hard work and skill, has continued his path to success at Al-Ittihad Football Club, based in Saudi Arabia.
Как оказалось, купить диплом кандидата наук не так уж и сложно
ast-diploms.com/otzyvy
Здравствуйте!
Диплом вуза купить официально с упрощенным обучением в Москве
pestostop.com/2024/06/30/%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D1%80%D0%BE%D0%B0%D1%82/
Kobe Bryant https://los-angeles-lakers.kobebryant-ar.com also known as the “Black Mamba”, is one of the most iconic and iconic figures in NBA history.
Добрый день!
Предлагаем документы ВУЗов, которые находятся на территории всей Российской Федерации. Вы сможете купить качественно сделанный диплом от любого заведения, за любой год, в том числе документы старого образца. Дипломы и аттестаты выпускаются на бумаге самого высокого качества. Это дает возможности делать государственные дипломы, которые не отличить от оригинала. Они будут заверены необходимыми печатями и подписями.
Мы предлагаем дипломы любых профессий по приятным тарифам. Стоимость будет зависеть от выбранной специальности, года получения и ВУЗа. Всегда стараемся поддерживать для покупателей адекватную ценовую политику. Для нас очень важно, чтобы документы были доступны для большого количества граждан.
arusak-diploms-srednee.ru/kupit-diplom-medicinskogo-uchilishha
Успехов в учебе!
Добрый день!
Купить документ о получении высшего образования можно в нашей компании в столице.
ast-diplom.com/kupit-diplom-sankt-peterburg
Успехов в учебе!
Привет, друзья!
Мы готовы предложить дипломы любой профессии по приятным тарифам.
newmedtime.ru/kupite-diplom-i-nachnite-novuyu-zhizn
Здравствуйте!
Где приобрести диплом по необходимой специальности?
Мы готовы предложить дипломы любой профессии по приятным тарифам. Стоимость может зависеть от выбранной специальности, года получения и образовательного учреждения. Всегда стараемся поддерживать для клиентов адекватную ценовую политику. Для нас важно, чтобы документы были доступными для подавляющей массы наших граждан.
Для вас предлагаем дипломы психологов, юристов, экономистов и любых других профессий по доступным ценам.
darknews.ru/kupit-diplom-rf-v-moskve-legko-i-bezopasno
Рады оказаться полезными!.
Привет, друзья!
Где приобрести диплом специалиста?
Купить диплом университета.
test.bpal.org/blogs/entry/8394-%D0%BA%D0%B0%D0%BA-%D0%BD%D0%B0%D0%B9%D1%82%D0%B8-%D0%BD%D0%B0%D0%B4%D0%B5%D0%B6%D0%BD%D1%8B%D0%B9-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD-%D1%81-%D0%BE%D0%B1%D1%88%D0%B8%D1%80%D0%BD%D1%8B%D0%BC-%D0%BA%D0%B0%D1%82%D0%B0%D0%BB%D0%BE%D0%B3%D0%BE%D0%BC-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%BE%D0%B2/
Привет, друзья!
Мы можем предложить документы ВУЗов, расположенных в любом регионе России. Вы имеете возможность заказать диплом за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Дипломы и аттестаты делаются на “правильной” бумаге высшего качества. Это позволяет делать государственные дипломы, которые не отличить от оригиналов. Документы заверяются всеми обязательными печатями и штампами.
http://www.foroeuropeo.it/component/comprofiler/pluginclass/cbblogs.html?action=blogs&func=show&id=287
купить диплом старого образца в нижнем тагиле ast-diploms.com .
купить диплом о среднем образовании в уфе diplomasx.com .
Привет, друзья!
Как официально купить диплом вуза с упрощенным обучением в Москве
camp-fire.jp/profile/BernardCruz
Привет, друзья!
Мы изготавливаем дипломы любой профессии по невысоким тарифам. Цена будет зависеть от выбранной специальности, года выпуска и образовательного учреждения. Всегда стараемся поддерживать для заказчиков адекватную политику цен. Для нас очень важно, чтобы дипломы были доступными для большинства наших граждан.
hubwebsites.com/story18321637/%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%BF%D0%B0%D1%80%D0%B8%D0%BA%D0%BC%D0%B0%D1%85%D0%B5%D1%80%D0%B0
Привет!
Заказать документ института можно в нашем сервисе. Мы оказываем услуги по продаже документов об окончании любых университетов РФ. Вы сможете получить диплом по любой специальности, включая документы образца СССР. Даем 100% гарантию, что в случае проверки документов работодателем, подозрений не возникнет.
Мы изготавливаем дипломы любой профессии по приятным ценам. Цена может зависеть от выбранной специальности, года выпуска и университета. Всегда стараемся поддерживать для клиентов адекватную политику тарифов. Для нас важно, чтобы дипломы были доступны для подавляющей массы граждан.
bibomi.com/blogs/443/%D0%91%D1%8B%D1%81%D1%82%D1%80%D0%BE-%D0%BF%D0%BE%D0%BA%D1%83%D0%BF%D0%B0%D0%B5%D0%BC-%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D1%8B-%D0%B2-%D0%BB%D1%83%D1%87%D1%88%D0%B5%D0%BC-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5-Russian-Diplom
Рады оказаться полезными!
Здравствуйте!
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков.
Заказать диплом ВУЗа.
blogs.rufox.ru/~sonnick84/48232.htm
Привет!
Где заказать диплом по нужной специальности?
Мы предлагаем документы ВУЗов, расположенных в любом регионе РФ. Можно приобрести качественный диплом от любого ВУЗа, за любой год, включая документы старого образца СССР. Дипломы делаются на бумаге высшего качества. Это дает возможности делать государственные дипломы, которые невозможно отличить от оригинала. Документы будут заверены необходимыми печатями и штампами.
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по выгодным тарифам.
ast-diplom24.ru/kupit-diplom-voronezh
Рады оказаться полезными!
Добрый день!
Мы изготавливаем дипломы любых профессий по выгодным тарифам.
service.gnla.com.au/2024/06/30/%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%BA%D0%B0%D0%BF%D0%B8%D1%82%D0%B0%D0%BD%D0%B0/
Добрый день!
Приобрести диплом о высшем образовании.
mediasafar.com/read-blog/170
Здравствуйте!
Где заказать диплом специалиста?
Заказать диплом ВУЗа.
berforum.ru/gallery/image/8670-kak-nayti-nadezhnyy-internet-magazin-s-bolshim-vyborom-diplomov/?context=new
Karim Benzema https://al-ittihad.karimbenzema.ae is a name worthy of admiration and respect in the world of football.
Cristiano Ronaldo https://al-nassr.cristiano-ronaldo.ae is one of the greatest names in football history, with his achievements inspiring millions of fans around the world.
Добрый день!
Где приобрести диплом специалиста?
forumkoldovstva.listbb.ru/viewtopic.php?f=37&t=15060
Удачи!
In 2018, the basketball world witnessed one of the most remarkable transformations in NBA history. LeBron James https://los-angeles-lakers.lebronjames-ar.com one of the greatest players of our time, decided to leave his hometown Cleveland Cavaliers and join the Los Angeles Lakers.
Привет, друзья!
Наши специалисты предлагают быстро и выгодно заказать диплом, который выполняется на бланке ГОЗНАКа и заверен печатями, водяными знаками, подписями официальных лиц. Наш диплом способен пройти лубую проверку, даже при помощи специальных приборов. Достигайте своих целей быстро и просто с нашей компанией.
vrn.best-city.ru/forum/thread540115837/
Хорошей учебы!
Luis Diaz https://liverpool.luis-diaz-ar.com is a young Colombian striker who has enjoyed rapid growth since joining the ” Liverpool” in January 2022.
купить диплом старого образца в екатеринбурге asxdiplomik24.ru .
Добрый день!
Как быстро получить диплом магистра? Легальные способы
msk.flado.ru/org/199342
Окажем помощь!.
видеостена купить видеостена купить .
Здравствуйте!
Приобрести диплом любого ВУЗа.
chayka.ixbb.ru/viewtopic.php?id=100#p110
Удачи!
[u][b] Добрый день![/b][/u]
Где купить диплом по актуальной специальности?
[b]Купить диплом о высшем образовании.[/b]
[url=http://cartagena.activeboard.com/forum.spark/]cartagena.activeboard.com/forum.spark[/url]
Здравствуйте!
Предлагаем документы ВУЗов, которые расположены в любом регионе Российской Федерации. Можно заказать диплом за любой год, указав актуальную специальность и хорошие оценки за все дисциплины. Дипломы и аттестаты печатаются на “правильной” бумаге самого высокого качества. Это позволяет делать настоящие дипломы, не отличимые от оригиналов. Документы будут заверены необходимыми печатями и штампами.
Мы предлагаем дипломы психологов, юристов, экономистов и других профессий по приятным тарифам. Стоимость будет зависеть от выбранной специальности, года получения и образовательного учреждения. Всегда стараемся поддерживать для заказчиков адекватную политику цен. Важно, чтобы дипломы были доступны для большого количества граждан.
landik-diploms-srednee.ru/kupit-diplom-saratov
Успешной учебы!
Здравствуйте!
Купить документ института можно в нашем сервисе.
ast-diplom.com/kupit-diplom-magistra
Удачи!
купить вкладыш к диплому diploms-x.com .
Kevin De Bruyne https://manchester-city.kevin-de-bruyne-ar.com is a name every football fan knows today.
Muhammad Al Owais https://al-hilal.mohammed-alowais-ar.com is one of the most prominent names in modern Saudi football. His path to success in Al Hilal team became an example for many young athletes.
Roberto Firmino https://al-ahli.roberto-firmino-ar.com one of the most talented and famous Brazilian footballers of our time, has paved his way to success in different leagues and teams.
Официальное получение диплома техникума с упрощенным обучением в Москве
asxdiplomik24.ru/kupit-diplom-perm
Здравствуйте!
Мы можем предложить дипломы любой профессии по невысоким тарифам.
pestostop.com/2024/06/30/%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D1%80%D0%BE%D0%B0%D1%82/
Добрый день!
Ьожем предложить документы ВУЗов, расположенных на территории всей РФ. Можно приобрести качественный диплом от любого заведения, за любой год, включая сюда документы старого образца СССР. Дипломы и аттестаты выпускаются на бумаге высшего качества. Это дает возможности делать государственные дипломы, которые невозможно отличить от оригинала. Документы заверяются всеми требуемыми печатями и штампами.
Мы изготавливаем дипломы любой профессии по разумным ценам. Цена может зависеть от выбранной специальности, года получения и университета. Стараемся поддерживать для заказчиков адекватную политику цен. Для нас очень важно, чтобы дипломы были доступными для большого количества граждан.
landik-diploms-srednee.ru/diplom-bakalavra
Удачи!
Здравствуйте!
Мы предлагаем приобрести диплом высокого качества, который невозможно отличить от оригинала без участия специалистов высокой квалификации со сложным оборудованием.
zimmu.com/api/manual/doku.php?id=diploman
Успехов в учебе!
Привет!
Приобрести документ о получении высшего образования вы можете в нашей компании.
asxdiplomik.com/kupit-diplom-voronezh
Удачи!
Привет, друзья!
Купить документ ВУЗа можно у нас.
ast-diplom.com/kupit-diplom-rostov-na-donu
Maria Sharapova https://tennis.maria-sharapova-ar.com was born on April 19, 1987 in Nyagan, Russia. When Masha was 7 years old, her family moved to Florida, where she started playing tennis.
Angel Di Maria https://benfica.angel-di-maria-ar.com is a name that will forever remain in the memories of Benfica fans.
Khvicha Kvaratskhelia https://napoli.khvicha-kvaratskhelia-ar.com is a name that in recent years has become a symbol of Georgian football talent and ambition.
Football in Saudi Arabia https://al-hilal.saud-abdulhamid-ar.com is gaining more and more popularity and recognition on the international stage, and Saud Abdul Hamid, the young and talented defender of Al Hilal, is a shining example of this success.
Здравствуйте!
Приобрести диплом любого университета.
demo.1c-college.ru/club/user/7/blog/faq-i-podderzhka-zakazyvaem-diplom-v-seti-internet/
купить диплом одесса diplomasx.com .
купить приложение к диплому ast-diploms.com .
Добрый день!
Купить документ университета вы имеете возможность у нас.
ast-diploms24.ru/kupit-diplom-vracha
Привет, друзья!
Заказать документ университета можно в нашем сервисе.
asxdiplomik.com/kupit-diplom-rostov-na-donu
Успехов в учебе!
Здравствуйте!
Предлагаем документы техникумов, которые расположены в любом регионе Российской Федерации. Можно купить качественный диплом за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Дипломы и аттестаты печатаются на бумаге самого высшего качества. Это дает возможности делать настоящие дипломы, которые невозможно отличить от оригиналов. Они будут заверены всеми требуемыми печатями и подписями.
Мы можем предложить дипломы любой профессии по приятным тарифам. Стоимость может зависеть от выбранной специальности, года получения и образовательного учреждения. Стараемся поддерживать для клиентов адекватную ценовую политику. Важно, чтобы дипломы были доступными для большого количества граждан.
landik-diploms-srednee.ru/kupit-diplom-v-ekaterinburge В
Успешной учебы!
Привет!
Мы предлагаем документы техникумов, которые находятся в любом регионе России. Вы сможете купить качественный диплом за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Дипломы и аттестаты печатаются на бумаге самого высокого качества. Это позволяет делать государственные дипломы, которые не отличить от оригиналов. Документы будут заверены всеми обязательными печатями и подписями.
qoq.me/read-blog/143
Здравствуйте!
Быстрая схема покупки диплома старого образца: что важно знать?
laporteproperty.com/en/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=124
Привет!
Покупка диплома о среднем полном образовании: как избежать мошенничества?
wow-tour.ru/diplom-lyuboy-stepeni-i-spetsialnosti-dostupno-kazhdomu
Рады оказаться полезными!.
Привет, друзья!
Мы изготавливаем дипломы любой профессии по приятным ценам.
barranca21.com/купить-диплом-пту/
Казахский национальный технический университет https://satbayev.university им. К.Сатпаева
Добрый день!
Как правильно приобрести диплом колледжа или ПТУ в России, важные моменты
knigilub.ru/users/yvaqovima
Окажем помощь!.
Upcoming fantasy MOBA https://bladesofthevoid.com evolved by Web3. Gacha perks, AI and crafting in one swirling solution!
Привет!
Где купить диплом по актуальной специальности?
Заказать диплом о высшем образовании.
gtago.ru/gallery/image/19-ogromnyy-vybor-dokumentov-v-populyarnom-internet-magazine/?context=new
Продажа новых автомобилей Hongqi
https://hongqi-krasnoyarsk.ru/issledujte-hongqi в Красноярске у официального дилера Хончи. Весь модельный ряд, все комплектации, выгодные цены, кредит, лизинг, трейд-ин
диплом купить озон asxdiplomik24.ru .
Kylie Jenner https://kylie-cosmetics.kylie-jenner-ar.com is an American model, media personality, and businesswoman, born on August 10, 1997 in Los Angeles, California.
Добрый день!
Заказать документ о получении высшего образования можно в нашем сервисе.
ast-diplomy24.ru/kupit-diplom-o-srednem-obrazovanii
Привет, друзья!
Предлагаем документы техникумов, которые находятся на территории всей России. Вы сможете купить диплом за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Документы выпускаются на бумаге самого высшего качества. Это дает возможности делать настоящие дипломы, которые не отличить от оригинала. Они будут заверены всеми необходимыми печатями и штампами.
Мы изготавливаем дипломы любых профессий по приятным тарифам. Цена может зависеть от выбранной специальности, года выпуска и ВУЗа. Всегда стараемся поддерживать для покупателей адекватную политику тарифов. Для нас важно, чтобы дипломы были доступны для большого количества граждан.
arusak-diploms-srednee.ru/svidetelstvo-o-brake В
Хорошей учебы!
Добрый день!
Купить диплом о высшем образовании.
together-19.com/read-blog/17224
Удачи!
Привет, друзья!
Приобрести документ ВУЗа вы можете в нашем сервисе.
asxdiplomik.com/kupit-diplom-nizhnij-novgorod
Успешной учебы!
Привет!
Где заказать диплом специалиста?
Мы изготавливаем дипломы любых профессий по приятным ценам. Стоимость будет зависеть от определенной специальности, года получения и ВУЗа. Всегда стараемся поддерживать для клиентов адекватную политику цен. Для нас очень важно, чтобы документы были доступны для большого количества граждан.
Для вас изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по выгодным ценам.
islgaming.community/read-blog/70_ishem-proverennyj-i-nadezhnyj-internet-magazin-s-diplomami.html
Рады оказаться полезными!.
Привет!
Как официально приобрести аттестат 11 класса с минимальными затратами времени.
Заказать диплом любого университета.
gerosland.com/read-blog/159
Здравствуйте!
Мы готовы предложить документы ВУЗов, которые расположены на территории всей России. Вы можете приобрести диплом от любого заведения, за любой год, включая сюда документы СССР. Дипломы и аттестаты выпускаются на бумаге самого высшего качества. Это дает возможности делать государственные дипломы, не отличимые от оригиналов. Они заверяются всеми необходимыми печатями и подписями.
kurkure.ru/index.php/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=147
купить диплом закрывшегося вуза https://diploms-x.com .
Привет, друзья!
Мы предлагаем купить диплом в высоком качестве, неотличимый от оригинала без участия специалистов высокой квалификации со специальным оборудованием.
http://www.munhwahouse.or.kr/bbs/board.php?bo_table=free&wr_id=141231
Успешной учебы!
Привет!
Купить диплом старого образца, можно ли это сделать по быстрой схеме?
sklad-slabov.ru/forum/user/8263
Окажем помощь!.
Привет!
Где купить диплом по нужной специальности?
Заказать диплом о высшем образовании.
http://www.forum.7x.ru/member.php?u=16498
Добрый день!
Мы предлагаем выгодно и быстро купить диплом, который выполнен на оригинальной бумаге и заверен мокрыми печатями, штампами, подписями должностных лиц. Документ способен пройти лубую проверку, даже при помощи специального оборудования. Решайте свои задачи быстро и просто с нашей компанией.
tr.clanfm.ru/viewtopic.php?f=39&t=10093&p=20006#p20006
Успешной учебы!
Добрый день!
Где заказать диплом по нужной специальности?
Мы можем предложить документы ВУЗов, расположенных на территории всей РФ. Вы сможете приобрести качественно напечатанный диплом за любой год, включая сюда документы СССР. Дипломы печатаются на бумаге самого высшего качества. Это дает возможность делать государственные дипломы, не отличимые от оригинала. Документы будут заверены всеми требуемыми печатями и штампами.
Мы изготавливаем дипломы любых профессий по доступным тарифам.
ast-diplom.com/kupit-diplom-nizhnij-novgorod
Поможем вам всегда!
Привет, друзья!
Купить диплом о высшем образовании.
kotanusantara.cloud/index.php?/events/event/12-faq-%D0%B8-%D1%82%D0%B5%D1%85%D0%BF%D0%BE%D0%B4%D0%B4%D0%B5%D1%80%D0%B6%D0%BA%D0%B0-%D0%BF%D0%BE%D0%BA%D1%83%D0%BF%D0%B0%D0%B5%D0%BC-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%B2-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82%D0%B5/
Привет!
Где купить диплом специалиста?
dimitrii.flybb.ru/viewtopic.php?f=29&t=948
Успехов в учебе!
[u][b] Здравствуйте![/b][/u]
Заказать диплом университета
[b]Наша компания предлагает[/b] быстро приобрести диплом, который выполняется на бланке ГОЗНАКа и заверен печатями, водяными знаками, подписями официальных лиц. Данный диплом пройдет лубую проверку, даже с применением специально предназначенного оборудования. Достигайте своих целей быстро с нашей компанией.
[b]Где заказать диплом специалиста?[/b]
[url=http://mkpnz.ru/users/8/]mkpnz.ru/users/8[/url]
[url=http://arsenal.listbb.ru/viewtopic.php?f=14&t=419/]arsenal.listbb.ru/viewtopic.php?f=14&t=419[/url]
[url=http://pdlspd.listbb.ru/viewtopic.php?f=3&t=409/]pdlspd.listbb.ru/viewtopic.php?f=3&t=409[/url]
[url=http://alik.forumrpg.ru/viewtopic.php?id=6639#p275762/]alik.forumrpg.ru/viewtopic.php?id=6639#p275762[/url]
[url=http://arsenal.listbb.ru/viewtopic.php?f=14&t=419/]arsenal.listbb.ru/viewtopic.php?f=14&t=419[/url]
Привет, друзья!
Быстрая схема покупки диплома старого образца: что важно знать?
sportandpolitics.ukrbb.net/viewtopic.php?f=24&t=13633
Будем рады вам помочь!.
Привет, друзья!
Приобрести документ о получении высшего образования можно у нас в столице.
ast-diploms24.ru/kupit-diplom-rostov-na-donu
Хорошей учебы!
фоновое озвучивание помещений фоновое озвучивание помещений .
Добрый день!
Диплом вуза купить официально с упрощенным обучением в Москве
hobby-svarka.ru/viewtopic.php?f=11&t=6225
Поможем вам всегда!.
Добрый день!
Приобрести диплом любого ВУЗа.
wiki.3cdr.ru/wiki/index.php/??????_?????_?????_????_???:_????????_???_???????!
Хорошей учебы!
Привет!
Мы готовы предложить документы ВУЗов, которые расположены на территории всей Российской Федерации. Можно заказать качественный диплом от любого учебного заведения, за любой год, указав актуальную специальность и хорошие оценки за все дисциплины. Документы делаются на бумаге высшего качества. Это дает возможности делать настоящие дипломы, не отличимые от оригинала. Они заверяются необходимыми печатями и подписями.
forum-rassvet-rp.ru/index.php?app=gallery&module=gallery&controller=view&id=25
Привет!
Заказать диплом ВУЗа
Мы предлагаем документы техникумов, которые расположены на территории всей России. Вы сможете приобрести диплом за любой год, в том числе документы старого образца СССР. Документы печатаются на бумаге самого высокого качества. Это дает возможность делать настоящие дипломы, не отличимые от оригинала. Они заверяются всеми обязательными печатями и штампами.
spbmedu.ru/
Окажем помощь!.
Bella Hadid https://img-models.bella-hadid-ar.com is an American model who has emerged in recent years as one of the most influential figures in the world of fashion.
Здравствуйте!
Приобрести диплом о высшем образовании
landik-diploms-srednee.ru/kupit-diplom-v-ekaterinburge В
Хорошей учебы!
Sadio Mane https://al-nassr.sadio-mane-ar.com the Senegalese footballer best known for his performances at clubs such as Southampton and Liverpool, has become a prominent figure in Al Nassr.
Brazilian footballer Ricardo Escarson https://orlando-city.kaka-ar.com dos Santos Leite, better known as Kaka, is one of the most famous and successful players in football history.
Zinedine Zidane https://real-madrid.zinedine-zidane-ar.com the legendary French footballer, entered the annals of football history as a player and coach.
Добрый день!
Как избежать рисков при покупке диплома колледжа или ВУЗа в России.
Приобрести диплом о высшем образовании.
indicouple.com/blogs/1132/%D0%9A%D0%B0%D0%BA-%D0%B2%D0%BE%D0%B7%D0%BC%D0%BE%D0%B6%D0%BD%D0%BE-%D0%B1%D1%83%D0%B4%D0%B5%D1%82-%D0%B1%D1%8B%D1%81%D1%82%D1%80%D0%BE-%D0%B7%D0%B0%D0%BA%D0%B0%D0%B7%D0%B0%D1%82%D1%8C-%D0%B0%D1%82%D1%82%D0%B5%D1%81%D1%82%D0%B0%D1%82-%D0%B2-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5
Привет, друзья!
Где купить диплом специалиста?
Заказать диплом любого ВУЗа.
277469.simplecloud.ru/blogs/1/kak-podobrat-proverennyy-magazin-s-ogromnym-vyborom-diplomov.php
Здравствуйте!
Купить документ института можно в нашей компании.
diplomasx.com/kupit-diplom-ekaterinbur
Успешной учебы!
Здравствуйте!
Мы предлагаем приобрести диплом высочайшего качества, неотличимый от оригинала без использования дорогостоящего оборудования и квалифицированного специалиста.
vitaco.ru/communication/forum/user/4574/
Удачи!
Привет!
Мы можем предложить дипломы любой профессии по выгодным ценам.
berrylib.ru/books/item/f00/s00/z0000024/index.shtml
Привет!
Купить диплом любого университета
arusak-diploms-srednee.ru В
Удачи!
Edson Arantes https://santos.pele-ar.com do Nascimento, known as Pele, was born on October 23, 1940 in Tres Coracoes, Minas Gerais, Brazil.
Brazilian footballer Malcom https://al-hilal.malcom-ar.com (full name Malcom Felipe Silva de Oliveira) achieved great success in Al Hilal, one of the leading football teams in Saudi Arabia and the entire Middle East.
Monica Bellucci https://dracula.monica-bellucci-ar.com one of the most famous Italian actresses of our time, has a distinguished artistic career spanning many decades. Her talent, charisma, and stunning beauty made her an icon of world cinema.
Привет!
Купить документ ВУЗа вы сможете у нас в столице.
ast-diplomy24.ru/kupit-diplom-ekaterinbur
Привет!
Где купить диплом по нужной специальности?
Мы предлагаем документы институтов, которые находятся в любом регионе РФ. Можно купить качественный диплом за любой год, указав актуальную специальность и оценки за все дисциплины. Дипломы выпускаются на “правильной” бумаге самого высшего качества. Это позволяет делать государственные дипломы, не отличимые от оригинала. Они будут заверены необходимыми печатями и подписями.
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий по приятным ценам.
asxdiplomik.com/kupit-diplom-magistra
Рады оказать помощь!
Привет!
Мы предлагаем быстро и выгодно приобрести диплом, который выполняется на оригинальной бумаге и заверен печатями, штампами, подписями официальных лиц. Диплом способен пройти лубую проверку, даже с применением специально предназначенного оборудования. Достигайте своих целей быстро и просто с нашим сервисом.
dedmorozural.ru/users/ynocigo
Удачи!
Привет!
Приобрести диплом о высшем образовании.
http://www.xpertmapping.com/%d0%b8%d1%89%d0%b5%d0%bc-%d0%bd%d0%b0%d0%b4%d0%b5%d0%b6%d0%bd%d1%8b%d0%b9-%d0%b8-%d0%bf%d1%80%d0%be%d0%b2%d0%b5%d1%80%d0%b5%d0%bd%d0%bd%d1%8b%d0%b9-%d0%be%d0%bd%d0%bb%d0%b0%d0%b9%d0%bd-%d0%bc%d0%b0/
Добрый день!
Где купить диплом специалиста?
forum.infinite-soul.org/viewtopic.php?f=64&t=18353
Успехов в учебе!
[u][b] Привет, друзья![/b][/u]
[b]Заказать документ[/b] института вы можете у нас в Москве.
[url=http://diplomasx24.ru/kupit-diplom-krasnoyarsk/]diplomasx24.ru/kupit-diplom-krasnoyarsk[/url]
Добрый день!
Где приобрести диплом специалиста?
Заказать диплом любого университета.
laporteproperty.com/en/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=121
Jackie Chan https://karate-kid.jackiechan-ar.com was born in 1954 in Hong Kong under the name Chan Kong San.
магазин аккаунтов валорант http://magazin-akkauntov.ru .
Привет, друзья!
Приобрести документ института вы сможете в нашем сервисе.
ast-diploms.com/kupit-diplom-o-srednem-obrazovanii
Успехов в учебе!
Процесс получения диплома стоматолога: реально ли это сделать быстро?
diplomasx.com/kupit-diplom-nizhnij-novgorod
Привет, друзья!
Как быстро и легально купить аттестат 11 класса в Москве
1001vieclam.forumvi.com/t9267-topic#9941
Рады оказать помощь!.
Привет, друзья!
Заказать диплом любого университета
arusak-diploms-srednee.ru/kupit-diplom-v-krasnoiarske
Удачи!
Привет, друзья!
Мы можем предложить документы техникумов, которые находятся на территории всей Российской Федерации. Вы имеете возможность приобрести диплом за любой год, в том числе документы старого образца СССР. Документы печатаются на “правильной” бумаге высшего качества. Это дает возможности делать настоящие дипломы, которые не отличить от оригинала. Они заверяются необходимыми печатями и подписями.
medbereg.ru/club/user/15/blog/4145/
Добрый день!
Заказать документ ВУЗа вы имеете возможность у нас.
diplomyx.com/kupit-diplom-magistra
Успешной учебы!
Привет, друзья!
Купить диплом о высшем образовании
landik-diploms-srednee.ru/kupit-diplom-v-ekaterinburge В
Успехов в учебе!
Привет, друзья!
Удивительно, но купить диплом кандидата наук оказалось не так сложно
allnewstroy.ru/byistroe-oformlenie-diploma-lyuboy-spetsialnosti
Будем рады вам помочь!.
купить диплом в волжске ast-diploms.com .
купить диплом в вологде diplomasx.com .
Здравствуйте!
Реально ли приобрести диплом стоматолога? Основные шаги
vk.com/club69673339?w=wall-69673339_1238
Окажем помощь!.
куплю диплом вуза ссср старого образца http://www.diploms-x.com .
купить диплом колледжа недорого купить диплом колледжа недорого .
Здравствуйте!
Заказать документ о получении высшего образования вы имеете возможность в нашей компании в Москве.
ast-diploms24.ru/kupit-diplom-sankt-peterburg
Добрый день!
Купить документ о получении высшего образования можно в нашей компании в Москве.
ast-diplom24.ru/kupit-diplom-krasnoyarsk
Успехов в учебе!
Привет, друзья!
Заказать диплом университета.
lolipopnews.ru/poluchite-diplom-bez-lishnih-ozhidaniy
Успехов в учебе!
Легальная покупка диплома о среднем образовании в Москве и регионах
ast-diplom24.ru/kupit-diplom-krasnoyarsk
Привет!
Как приобрести аттестат о среднем образовании в Москве и других городах.
Заказать диплом о высшем образовании.
victorians123.com/blogs/212/%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D0%B5%D0%BD%D0%BD%D0%BE%D0%B5-%D0%BE%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D0%B5-%D0%BF%D0%BE%D0%BA%D1%83%D0%BF%D0%BA%D0%B8-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%B0-%D0%B2-%D0%B8%D0%B7%D0%B2%D0%B5%D1%81%D1%82%D0%BD%D0%BE%D0%BC-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%BD%D0%B5%D1%82-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5
Привет, друзья!
Реально ли приобрести диплом стоматолога? Основные этапы
arusak-diploms-srednee.ru/svidetelstvo-o-brake В
Здравствуйте!
Как быстро и легально купить аттестат 11 класса в Москве
altersoftonline.maxbb.ru/viewtopic.php?f=11&t=210
Рады помочь!.
Привет, друзья!
Мы готовы предложить документы техникумов, расположенных на территории всей России. Можно заказать качественный диплом от любого заведения, за любой год, указав необходимую специальность и оценки за все дисциплины. Документы делаются на “правильной” бумаге самого высшего качества. Это позволяет делать настоящие дипломы, не отличимые от оригинала. Они заверяются необходимыми печатями и штампами.
loveyou.az/read-blog/190
Здравствуйте!
Купить документ о получении высшего образования вы имеете возможность в нашей компании в Москве.
ast-diplom.com/kupit-diplom-magistra
Привет, друзья!
Заказать документ о получении высшего образования можно у нас.
diplomyx24.ru/kupit-diplom-nizhnij-novgorod
Хорошей учебы!
Здравствуйте!
Покупка диплома о среднем полном образовании: как избежать мошенничества?
экстрим-клуб.рф/forum/user/34204/
Будем рады вам помочь!.
Добрый день!
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
landik-diploms-srednee.ru/kupit-diplom-saratov В
Здравствуйте!
Покупка школьного аттестата с упрощенной программой: что важно знать
kuvandyk.ru/message.php?msg=151
Окажем помощь!.
Добрый день!
Где заказать диплом специалиста?
Заказать диплом любого ВУЗа.
п»їappleincub.ru/byistroe-poluchenie-diploma-vash-shans-na-uspeh
купить диплом о высшем образовании в благовещенске ast-diploms.com .
где можно купить диплом техникума diplomasx.com .
Привет!
Где купить диплом по необходимой специальности?
Приобрести диплом университета.
saluttunisia.com/jomsocial/groups/viewbulletin/267-shirokij-assortiment-dokumentov-v-izvestnom-magazine.html?groupid=101
купить диплом о высшем образовании в уфе купить диплом о высшем образовании в уфе .
купить диплом колледжа сколько asxdiplomik24.ru .
Здравствуйте!
Где заказать диплом специалиста?
Мы готовы предложить документы институтов, которые расположены на территории всей России. Вы имеете возможность приобрести диплом за любой год, включая сюда документы СССР. Дипломы печатаются на “правильной” бумаге высшего качества. Это позволяет делать государственные дипломы, которые невозможно отличить от оригинала. Документы заверяются необходимыми печатями и штампами.
Мы готовы предложить дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам.
diplomasx24.ru/kupit-diplom-sankt-peterburg
Будем рады вам помочь!
лучшее бесплатное порно лучшее бесплатное порно .
Добрый день!
Наша компания предлагает заказать диплом высочайшего качества, который невозможно отличить от оригинального документа без участия специалистов высокой квалификации с дорогим оборудованием.
moj.webservis.ru/forums/profile.php?action=show&member=7607
Успешной учебы!
Добрый день!
Купить документ университета вы можете в нашей компании.
diploms-x24.ru/kupit-diplom-ekaterinbur
Добрый день!
Где приобрести диплом специалиста?
Заказать диплом о высшем образовании.
prof-aksay.ru/blogs/1/bolshoy-assortiment-dokumentov-v-izvestnom-internet-magazine.php
Добрый день!
Заказать диплом университета.
a90275db.beget.tech/2024/06/16/diplomy-s-garantiey-autentichnosti.html
Успешной учебы!
Здравствуйте!
Как официально приобрести аттестат 11 класса с минимальными затратами времени.
Приобрести диплом университета.
geoamor.com/read-blog/30681
Travis Scott https://astroworld.travis-scott-ar.com is one of the brightest stars in the modern hip-hop industry.
The history of one of France’s https://france.paris-saint-germain-ar.com most famous football clubs, Paris Saint-Germain, began in 1970, when capitalist businessmen Henri Delaunay and Jean-Auguste Delbave founded the club in the Paris Saint-Germain-en-Laye area.
Juventus Football Club https://italy.juventus-ar.com is one of the most successful and decorated clubs in the history of Italian and world football.
Chelsea https://england.chelsea-ar.com is one of the most successful English football clubs of our time.
Здравствуйте!
Приобрести документ института вы имеете возможность у нас в Москве.
asxdiplomik.com/kupit-diplom-sankt-peterburg
Удачи!
Добрый день!
Наша компания предлагает быстро и выгодно купить диплом, который выполнен на бланке ГОЗНАКа и заверен печатями, штампами, подписями. Наш диплом пройдет лубую проверку, даже с применением специально предназначенного оборудования. Достигайте цели быстро и просто с нашим сервисом.
http://www.kladonahodki.ru/component/k2/itemlist/user/297633
Успехов в учебе!
Привет, друзья!
Купить диплом любого университета.
shuvalduet.getbb.ru/viewtopic.php?f=3&t=576
[u][b] Привет, друзья![/b][/u]
[b]Приобретение диплома ПТУ с сокращенной программой обучения в Москве[/b]
[url=http://newsbig.raidersfanteamshop.com/poleznye-sovety-po-priobreteniu-diploma-v-internete//]newsbig.raidersfanteamshop.com/poleznye-sovety-po-priobreteniu-diploma-v-internete/[/url]
Здравствуйте!
Приобрести документ о получении высшего образования можно у нас.
ast-diploms.com/kupit-diplom-nizhnij-novgorod
Привет, друзья!
Процесс получения диплома стоматолога: реально ли это сделать быстро?
landik-diploms-srednee.ru/kupit-diplom-v-voronezhe
Привет, друзья!
Полезная информация как купить диплом о высшем образовании без рисков
aviapoisk.getbb.ru/viewtopic.php?f=27&t=749
Рады оказаться полезными!
пришла на йогу порно http://www.yoga-porno.ru/ .
Здравствуйте!
Купить документ о получении высшего образования можно в нашей компании.
ast-diploms.com/kupit-diplom-krasnoyarsk
Удачи!
Добрый день!
Мы предлагаем документы техникумов, расположенных в любом регионе России. Можно заказать качественно напечатанный диплом от любого заведения, за любой год, включая документы СССР. Документы делаются на бумаге высшего качества. Это дает возможности делать государственные дипломы, не отличимые от оригиналов. Документы заверяются необходимыми печатями и штампами.
http://www.manchestercityclubs.com/read-blog/260
Добрый день!
Официальная покупка диплома ПТУ с упрощенной программой обучения
landik-diploms-srednee.ru/kupit-diplom-volgograd
Автомобили Hongqi https://hongqi-krasnoyarsk.ru в наличии – официальный дилер Hongqi Красноярск
Liverpool https://england.liverpool-ar.com holds a special place in the history of football in England.
When Taylor Swift https://shake-it-off.taylor-swift-ar.com released “Shake It Off” in 2014, she had no idea how much the song would impact her life and music career.
Priyanka Chopra https://baywatch.priyankachopra-ar.com is an Indian actress, singer, film producer and model who has achieved global success.
Привет!
Где и как купить диплом о высшем образовании без лишних рисков
opengadjet.ru/legkiy-sposob-poluchit-diplom-byistro-i-prosto
Окажем помощь!
Здравствуйте!
Где приобрести диплом специалиста?
Купить диплом университета.
277469.simplecloud.ru/blogs/1/kak-podobrat-proverennyy-magazin-s-ogromnym-vyborom-diplomov.php
лучшее порно порево https://besplatny-sex-online.ru/ .
Здравствуйте!
Где заказать диплом по нужной специальности?
2cool.ru/qiwi-f215/kupite-diplom-i-uluchshite-svoe-budushchee-t3800.html
Успешной учебы!
Jennifer Lopez https://lets-get-loud.jenniferlopez-ar.com was born in 1969 in the Bronx, New York, to parents who were Puerto Rican immigrants.
Привет!
Мы можем предложить документы ВУЗов, расположенных в любом регионе Российской Федерации. Можно приобрести качественный диплом за любой год, указав необходимую специальность и оценки за все дисциплины. Документы делаются на бумаге высшего качества. Это дает возможности делать настоящие дипломы, не отличимые от оригинала. Они заверяются всеми требуемыми печатями и подписями.
h374evlkm.blogolenta.com/25164228/%D0%9F%D0%BE%D0%B4%D1%80%D0%BE%D0%B1%D0%BD%D0%BE%D0%B5-%D0%BE%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D0%B5-%D0%BF%D1%80%D0%B8%D0%BE%D0%B1%D1%80%D0%B5%D1%82%D0%B5%D0%BD%D0%B8%D1%8F-%D0%B0%D1%82%D1%82%D0%B5%D1%81%D1%82%D0%B0%D1%82%D0%B0-%D0%B2-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5
아이 슬롯
Zhu Houzhao는 정말 배가 고파서 찐 케이크 세 개를 먹었습니다.
Привет!
Мы предлагаем приобрести диплом отличного качества, который не отличить от оригинала без использования дорогостоящего оборудования и опытного специалиста.
stavklad.ru/viewtopic.php?f=19&t=5129
Удачи!
Здравствуйте!
Мы можем предложить дипломы психологов, юристов, экономистов и других профессий по приятным тарифам.
naya.social/read-blog/81_proverennyj-i-nadezhnyj-internet-magazin-s-shirokim-katalogom-diplomov.html?mode=day
After some difficult years in the late 2010s, Manchester United https://england.manchester-united-ar.com returned to greatness in English football by 2024.
The Formula One World Championship https://world-circuit-racing-championship.formula-1-ar.com, known as the Formula Championship in motor racing, is the highest tier of professional motor racing.
Michael Jordan https://chicago-bulls.michael-jordan-ar.com is one of the greatest basketball players of all time, whose career with the Chicago Bulls is legendary.
дизайн интерьер полная версия https://dizayn-interera-doma.ru
Здравствуйте!
Приобрести документ университета можно в нашем сервисе.
diplomasx.com/kupit-diplom-novosibirsk
Добрый день!
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам.
russiajoy.ru/oformlenie-diploma-onlayn-za-neskolko-shagov
Привет, друзья!
Мы предлагаем дипломы любых профессий по приятным ценам. Стоимость будет зависеть от выбранной специальности, года выпуска и образовательного учреждения. Стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступными для большинства граждан.
socialfactories.com/story2536806/купить-диплом-вуза-цена
Здравствуйте!
Купить документ ВУЗа можно в нашем сервисе.
ast-diplomy.com/kupit-diplom-omsk
Успешной учебы!
Здравствуйте!
Наша компания предлагает выгодно заказать диплом, который выполнен на оригинальном бланке и заверен печатями, водяными знаками, подписями. Диплом пройдет лубую проверку, даже при помощи специально предназначенного оборудования. Решите свои задачи быстро и просто с нашим сервисом.
dedmorozural.ru/users/ynocigo
Удачи!
Привет!
Как приобрести диплом о среднем образовании в Москве и других городах
velopiter.spb.ru/profile/117605-dilopluyy/?tab=field_core_pfield_1
Поможем вам всегда!.
Привет, друзья!
Где приобрести диплом специалиста?
Купить диплом о высшем образовании.
subscribe.ru/member/quick
Привет!
Приобрести диплом о высшем образовании.
http://www.meisterbook.com/read-blog/15544
Привет!
Приобрести документ о получении высшего образования можно в нашем сервисе.
ast-diploms.com/kupit-diplom-perm
d&t Montenegro car rental https://montenegro-car-rental-hire.com
The golf https://arabic.golfclub-ar.com industry in the Arab world is growing rapidly, attracting players from all over the world.
Mike Tyson https://american-boxer.mike-tyson-ar.com one of the most famous and influential boxers in history, was born on June 30, 1966 in Brooklyn, New York.
Manny Pacquiao https://filipino-boxer.manny-pacquiao-ar.com is one of the most prominent boxers in the history of the sport.
Muhammad Ali https://american-boxer.muhammad-ali-ar.com is perhaps one of the most famous and greatest athletes in the history of boxing.
Добрый день!
Всё, что нужно знать о покупке аттестата о среднем образовании
paintball-keller-lev.de/viewtopic.php?f=3&t=100149
Рады помочь!
купить диплом специалиста в москве купить диплом специалиста в москве .
Привет!
Заказать документ института вы сможете у нас в Москве.
diploms-x24.ru/kupit-diplom-krasnoyarsk
Удачи!
generic synthroid online
Привет, друзья!
Где заказать диплом специалиста?
usa.life/read-blog/62808
Привет, друзья!
Мы готовы предложить дипломы любой профессии по приятным тарифам.
ayhankala.com/купить-дипломы-о-высшем-образовании-в/
Привет!
Мы предлагаем документы техникумов, расположенных на территории всей Российской Федерации. Вы сможете заказать качественно сделанный диплом от любого учебного заведения, за любой год, в том числе документы СССР. Документы делаются на бумаге высшего качества. Это позволяет делать настоящие дипломы, не отличимые от оригинала. Они заверяются необходимыми печатями и подписями.
toyota-porte.ru/forums/index.php?autocom=gallery&req=si&img=2224
Привет!
Процесс получения диплома стоматолога: реально ли это сделать быстро?
dog-ola.ru/viewtopic.php?f=28&t=7443
Поможем вам всегда!
Привет!
Официальное получение диплома техникума с упрощенным обучением в Москве.
Заказать диплом о высшем образовании.
renaissance.mn.co/posts/61828789
Покупка диплома о среднем полном образовании: как избежать мошенничества?
diplomasx24.ru/kupit-diplom-ekaterinbur
Привет, друзья!
Приобрести документ ВУЗа
diploms-x.com/kupit-diplom-voronezh
Привет!
Покупка школьного аттестата с упрощенной программой: что важно знать
arusak-diploms-srednee.ru В
Привет!
Купить диплом любого университета.
vipka.0bb.ru/viewtopic.php?id=4622#p7049
Удачи!
[u][b] Привет![/b][/u]
[b]Приобрести документ[/b] института можно у нас в столице.
[url=http://diplomyx24.ru/kupit-diplom-ekaterinbur/]diplomyx24.ru/kupit-diplom-ekaterinbur[/url]
[b]Успехов в учебе![/b]
The road to the Premier League https://english-championship.premier-league-ar.com begins long before a team gets promoted to the English Premier League for the first time
In recent years, the leading positions in the Spanish https://spanish-championship.laliga-ar.com championship have been firmly occupied by two major giants – Barcelona and Real Madrid.
The Italian football championship https://italian-championship.serie-a-ar.com known as Serie A, has seen an impressive revival in recent years.
In the German football https://german-championship.bundesliga-football-ar.com championship known as the Bundesliga, rivalries between clubs have always been intense.
Привет, друзья!
Где заказать диплом специалиста?
Купить диплом университета.
nedvigimost.bbok.ru/viewtopic.php?id=27450#p46956
[u][b] Привет, друзья![/b][/u]
Приобрести документ о получении высшего образования можно в нашей компании. Мы оказываем услуги по продаже документов об окончании любых ВУЗов России. Вы получите диплом по любым специальностям, включая документы Советского Союза.
[url=http://kids-news.ru/kupite-diplom-i-otkroyte-novyie-gorizontyi/]kids-news.ru/kupite-diplom-i-otkroyte-novyie-gorizontyi[/url]
[url=http://worldgonews.ru/legkiy-put-k-diplomirovannomu-uspehu-byistro-i-nadezhno/]worldgonews.ru/legkiy-put-k-diplomirovannomu-uspehu-byistro-i-nadezhno[/url]
[url=http://little-witch.ru/forum99.html/]little-witch.ru/forum99.html[/url]
[url=http://blogs.rufox.ru/~worksale/48372.htm/]blogs.rufox.ru/~worksale/48372.htm[/url]
[url=http://share.psiterror.ru/2024/07/11/vash-shans-na-uspeh-diplom-bez-truda.html/]share.psiterror.ru/2024/07/11/vash-shans-na-uspeh-diplom-bez-truda.html[/url]
классное порево классное порево .
купить диплом бакалавра в нижнем тагиле diploms-x.com .
EuroAvia24.com – Cheap flights, hotels and transfers around the world!
The Saudi Football League https://saudi-arabian-championship.saudi-pro-league-ar.com known as the Saudi Professional League, is one of the most competitive and dynamic leagues in the world.
Rodrigo Goes https://real-madrid.rodrygo-ar.com better known as Rodrigo, is one of the brightest young talents in modern football.
In an era when many young footballers struggle to find their place at elite clubs, Javi’s https://barcelona.gavi-ar.com story at Barcelona stands out as an exceptional one.
Arsenal https://arsenal.mesut-ozil-ar.com made a high-profile signing in 2013, signing star midfielder Mesut Ozil from Real Madrid.
порно коллекция порно коллекция .
Здравствуйте!
Купить документ о получении высшего образования можно в нашем сервисе.
ast-diplomas.com/kupit-diplom-o-srednem-obrazovanii
Успехов в учебе!
Привет!
Всё, что нужно знать о покупке аттестата о среднем образовании
http://www.paladiny.ru/forummess.dwar.php?TopicID=27610
Рады оказать помощь!
Добрый день!
Заказать диплом ВУЗа.
es-presto.ru/community/groups/0-0/176-ogromnyj-vybor-dokumentov-v-znamenitom-onlajn-magazine
Привет!
Заказать документ о получении высшего образования вы имеете возможность у нас.
ast-diploms.com/kupit-diplom-kazan
Привет, друзья!
Где заказать диплом специалиста?
http://www.jointcorners.com/read-blog/78325
Thibaut Courtois https://real-madrid.thibaut-courtois-ar.com was born on May 11, 1992 in Belgium.
Bayern Munich’s https://bayern.jamal-musiala-ar.com young midfielder, Jamal Musiala, has become one of the brightest talents in European football.
Привет!
Мы предлагаем документы техникумов, расположенных в любом регионе России. Вы можете заказать диплом за любой год, включая сюда документы старого образца СССР. Документы выпускаются на “правильной” бумаге самого высокого качества. Это дает возможность делать государственные дипломы, которые не отличить от оригинала. Они будут заверены необходимыми печатями и подписями.
srbogl44n.snack-blog.com/28209457/%D0%94%D0%B5%D1%82%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5-%D0%BE%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D0%B5-%D0%BF%D1%80%D0%B8%D0%BE%D0%B1%D1%80%D0%B5%D1%82%D0%B5%D0%BD%D0%B8%D1%8F-%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%BE%D0%B2-%D0%B2-%D0%B7%D0%BD%D0%B0%D0%BC%D0%B5%D0%BD%D0%B8%D1%82%D0%BE%D0%BC-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD%D0%B5
грузовой лифт подъемник для склада https://podemniki-gruzovye.ru
Привет, друзья!
Мы можем предложить дипломы любой профессии по приятным ценам.
dervislergrup.com/events/event/13-4-klyucevyx-gruppy-internet-magazinov-realizuyushhix-diplomy/
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
diplomasx.com/kupit-diplom-omsk
Здравствуйте!
Купить диплом о высшем образовании.
usa.life/read-blog/57207
Успехов в учебе!
Привет!
Где приобрести диплом по актуальной специальности?
Заказать диплом о высшем образовании.
epicit.ru/diplom-pod-klyuch-kachestvenno-i-bezopasno
Добрый день!
Купить документ о получении высшего образования можно в нашем сервисе.
diplomyx.com/kupit-diplom-tehnikuma-kolledzha
новые порно видео https://apteka-porno.ru .
Luis Suarez https://inter-miami.luis-suarez-ar.com the famous Uruguayan footballer, ended his brilliant career in European clubs and decided to try his hand at a new challenge – Major League Soccer.
Al-Nasr https://saudi.al-nassr-ar.com is one of the most famous football teams in the Kingdom of Saudi Arabia.
Привет, друзья!
Купить документ о получении высшего образования
diplomyx.com/kupit-diplom-voronezh
Al-Nasr Club https://saudi.al-hilal-ar.com from Riyadh has a rich history of success, but its growth has been particularly impressive in recent years.
Al-Ittihad https://saudi.al-ittihad-ar.com is one of the most famous football clubs in Saudi Arabia. Founded in 1927, the Saudi football giant has come a long way to the pinnacle of success.
Привет!
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
landik-diploms-srednee.ru/svidetelstvo-o-razvode В
Привет!
Мы готовы предложить дипломы любой профессии по доступным ценам.
thmyan1.pgdthapmuoidt.edu.vn/купить-диплом-сварщика-5-разряд/
FC Barcelona https://spain.fc-barcelona-ar.com is undoubtedly one of the most famous and well-known football clubs in the world.
Здравствуйте!
Заказать документ о получении высшего образования вы можете в нашей компании в Москве.
asxdiplomik.com/kupit-diplom-nizhnij-novgorod
Хорошей учебы!
Здравствуйте!
Купить диплом о высшем образовании.
licomklicu.ru/read-blog/885
Привет, друзья!
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
metalxsports.com/купить-диплом-в-ижевске/
Здравствуйте!
Заказать документ о получении высшего образования можно у нас.
ast-diplom24.ru/kupit-diplom-voronezh
Удачи!
Здравствуйте!
Возможно ли купить диплом стоматолога, и как это происходит
fforum.ixbb.ru/viewtopic.php?id=190#p4068
Всегда вам поможем!
Здравствуйте!
Заказать диплом ВУЗа.
tosiya.ru/cb-profile/pluginclass/cbblogs.html?action=blogs&func=show&id=298
Добрый день!
Сколько стоит диплом высшего и среднего образования и как его получить?
http://www.kladonahodki.ru/component/k2/itemlist/user/297633
Поможем вам всегда!.
Привет, друзья!
Мы готовы предложить дипломы психологов, юристов, экономистов и прочих профессий по невысоким тарифам. Стоимость будет зависеть от выбранной специальности, года выпуска и университета. Стараемся поддерживать для клиентов адекватную политику цен. Для нас очень важно, чтобы дипломы были доступны для подавляющей массы наших граждан.
thebookmarkage.com/story17067877/купить-диплом-автомеханика
Привет, друзья!
Мы изготавливаем дипломы любой профессии по приятным тарифам.
picbok.org/read-blog/4658_nadezhnyj-internet-magazin-s-obshirnym-vyborom-dokumentov.html
슬롯 머신
그러나 홍지황제는 예의도 없이 급히 떠났다.
sunreef 60 power rent a boat Montenegro
rent a boat Tivat rent a boat Montenegro
Real Madrid’s https://spain.real-madrid-ar.com history goes back more than a century. The club was founded in 1902 by a group of football enthusiasts led by Juan Padilla
FC Bayern Munich (Munich) https://germany.bayern-munchen-ar.com is one of the most famous and recognized football clubs in Germany and Europe
Arsenal https://england.arsenal-ar.com is one of the most famous and successful football clubs in the history of English football.
Привет!
Мы готовы предложить документы техникумов, расположенных в любом регионе Российской Федерации. Можно заказать диплом за любой год, указав необходимую специальность и оценки за все дисциплины. Документы выпускаются на “правильной” бумаге самого высшего качества. Это позволяет делать настоящие дипломы, не отличимые от оригиналов. Документы заверяются всеми требуемыми печатями и штампами.
wiki.roximo.ru/index.php/%D0%92%D1%8B%D0%B3%D0%BE%D0%B4%D0%BD%D1%8B%D0%B5_%D1%80%D0%B0%D1%81%D1%86%D0%B5%D0%BD%D0%BA%D0%B8_%D0%B8_%D0%B2%D1%8B%D1%81%D0%BE%D0%BA%D0%BE%D0%B5_%D0%BA%D0%B0%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%BE_-_%D0%BF%D1%80%D0%B8%D0%BE%D0%B1%D1%80%D0%B5%D1%82%D0%B0%D0%B9_%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D1%8B_%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD!
Привет, друзья!
Купить диплом университета.
sonnick84.look4blog.com/67297157/%D0%A7%D1%82%D0%BE-%D0%B8%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE-%D1%82%D1%80%D0%B5%D0%B1%D1%83%D0%B5%D1%82%D1%81%D1%8F-%D0%B4%D0%BB%D1%8F-%D0%BF%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%BE%D0%B4%D1%81%D1%82%D0%B2%D0%B0-%D0%BA%D0%B0%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D0%BE%D0%B3%D0%BE-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%B0
Thai Company Directory https://thaicorporates.com List of companies and business information.
типография печать https://salavat-rik.ru
Ремонт плоской кровли https://remontiruem-krovly.ru в Москве, цена работы за 1 м?. Прайс лист на работы под ключ, отзывы и фото.
AC Milan https://italy.milan-ar.com is one of the most successful and decorated football clubs in the world.
Привет, друзья!
Приобрести документ университета вы имеете возможность в нашей компании.
asxdiplomik.com/kupit-diplom-specialista
Привет, друзья!
Заказать документ ВУЗа вы имеете возможность в нашей компании.
ast-diplom24.ru/otzyvy
Удачи!
порно тренер пристает порно тренер пристает .
секс с училкой бесплатно http://www.sex-s-uchilkami.ru .
Здравствуйте!
Как купить аттестат 11 класса с официальным упрощенным обучением в Москве
grandtour.tv/index.php?subaction=userinfo&user=ovunumo
Окажем помощь!.
In the world of football, Atletico Madrid https://spain.atletico-madrid-ar.com has long been considered the second most important club in Spain after the dominant, Real Madrid.
Galatasaray https://turkey.galatasaray-ar.com is one of the most famous football clubs in Turkiye, with a glorious and eventful history.
The future football star Shabab Al-Ahly https://dubai.shabab-al-ahli-ar.com was born in Dubai in 2000. From a young age, he showed exceptional football abilities and joined the youth academy of one of the UAE’s leading clubs, Shabab Al-Ahly.
The fascinating story of Ja Morant’s https://spain.atletico-madrid-ar.com meteoric rise, from status from rookie to leader of the Memphis Grizzlies and rising NBA superstar.
Discover your perfect stay with WorldHotels-in.com, your ultimate destination for finding the best hotels worldwide! Our user-friendly platform offers a vast selection of accommodations to suit every traveler’s needs and budget. Whether you’re planning a luxurious getaway or a budget-friendly adventure, we’ve got you covered with our extensive database of hotels across the globe. Our intuitive search features allow you to filter results based on location, amenities, price range, and guest ratings, ensuring you find the ideal match for your trip. We pride ourselves on providing up-to-date information and competitive prices, often beating other booking sites. Our detailed hotel descriptions, high-quality photos, and authentic guest reviews give you a comprehensive view of each property before you book. Plus, our secure booking system and excellent customer support team ensure a smooth and worry-free experience from start to finish. Don’t waste time jumping between multiple websites – http://www.WorldHotels-in.com brings the world’s best hotels to your fingertips in one convenient place. Start planning your next unforgettable journey today and experience the difference with WorldHotels-in.com!
coindarwin crypto news
The Unseen Tale Concerning Solana’s Creator Toly’s Achievement
Post 2 Cups of Espresso with a Brew
Toly, the mastermind behind Solana, began his journey with a modest routine – two coffees and a brew. Little did he realize, these occasions would set the gears of his future. Today, Solana remains as an influential participant in the crypto realm, having a market cap in the billions.
Ethereum ETF First Sales
The new Ethereum ETF just started with a staggering trading volume. This landmark occasion experienced various spot Ethereum ETFs from multiple issuers begin trading on American exchanges, introducing significant activity into the usually calm ETF trading environment.
SEC Sanctions Ethereum ETF
The Commission has formally approved the Ethereum Spot ETF to trade. As a crypto asset that includes smart contracts, Ethereum is anticipated to deeply influence the crypto industry thanks to this approval.
Trump’s Crypto Maneuver
As the election approaches, Trump portrays himself as the “President of Crypto,” frequently displaying his advocacy for the digital currency sector to attract voters. His tactic varies from Biden’s tactic, aiming to capture the attention of the digital currency community.
Musk’s Influence on Crypto
Elon, a famous figure in the crypto community and an advocate of Trump’s agenda, caused a stir yet again, promoting a meme coin related to his antics. His actions continues to influence the market environment.
Binance Developments
A subsidiary of Binance, BAM, is now allowed to invest customer funds in U.S. Treasuries. In addition, Binance observed its seventh anniversary, underscoring its development and achieving multiple compliance licenses. At the same time, the corporation also revealed plans to delist several major crypto trading pairs, altering the market landscape.
AI’s Impact on the Economy
A top stock analyst from Goldman Sachs recently commented that AI is unlikely to cause a revolution in the economy
https://indibeti.in is a premier online casino offering a wide array of games including slots, table games, and live dealer options. Renowned for its user-friendly interface and robust security measures, Indibet ensures a top-notch gaming experience with exciting bonuses and 24/7 customer support.
купить квартиру от застройщика с отделкой купить квартиру от застройщика цены
купить новостройку с отделкой купить новостройку цены застройщика
купить 2 комнатную квартиру в новостройке https://kvartiru-kupit43.ru
Здравствуйте!
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по невысоким ценам.
lgzprojects.co.za/2024/06/30/куплю-диплом-рф/
купить квартиру от застройщика с отделкой https://kvartiranew43.ru
квартиры от застройщика https://kvartiru-kupit43.ru
Indibet is a premier online casino offering a wide array of games including slots, table games, and live dealer options. Renowned for its user-friendly interface and robust security measures, Indibet ensures a top-notch gaming experience with exciting bonuses and 24/7 customer support.
порно онлайн гимнастки порно онлайн гимнастки .
Добрый день!
Купить диплом ВУЗа.
ilovehabbo.bbon.ru/viewtopic.php?id=1476#p28877
Успешной учебы!
[u][b] Привет![/b][/u]
Заказать диплом института
[url=http://pyha.ru/forum/topic/13579.1#msg216529/]pyha.ru/forum/topic/13579.1#msg216529[/url]
[url=http://bideew.com/create-blog//]bideew.com/create-blog/[/url]
[url=http://1776reloaded.us/blogs/172/Быстрое-получение-диплома-онлайн/]1776reloaded.us/blogs/172/Быстрое-получение-диплома-онлайн[/url]
[url=http://kuvandyk.ru/message.php?msg=151/]kuvandyk.ru/message.php?msg=151[/url]
[url=http://returnrp.listbb.ru/viewtopic.php?f=70&t=738/]returnrp.listbb.ru/viewtopic.php?f=70&t=738[/url]
Привет!
Купить диплом любого университета.
sonnick84.myparisblog.com/28730604/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D0%BD%D1%8B%D0%B5-%D0%B7%D0%B0%D1%82%D1%80%D0%B0%D1%82%D1%8B-%D0%BF%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%BE%D0%B4%D0%B8%D1%82%D0%B5%D0%BB%D1%8F-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%BE%D0%B2-%D0%B0%D0%B2%D1%82%D0%BE%D1%80%D1%81%D0%BA%D0%B8%D0%B9-%D0%BE%D0%B1%D0%B7%D0%BE%D1%80
Привет!
Мы готовы предложить дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам.
shabab.galaxy.ps/купить-диплом-новосибирск/
современное оборудование для конференц зала современное оборудование для конференц зала .
Привет, друзья!
Заказать документ о получении высшего образования можно у нас.
ast-diplomas.com/kupit-diplom-o-srednem-obrazovanii
Успешной учебы!
Добрый день!
Где приобрести диплом по нужной специальности?
community.goldposter.com/zh/members/edwardfisher/profile/
проверенные капперы проверенные капперы .
Можно ли купить аттестат о среднем образовании? Основные рекомендации
ast-diplomas.com/kupit-diplom-nizhnij-novgorod
Привет, друзья!
Быстрая схема покупки диплома старого образца: что важно знать?
mjcs-ikma.com/2024/06/30/купить-диплом-казахстан/
купить квартиру купить новую квартиру в новостройке
недвижимость новостройки купить https://novye-kvartiryspb.ru
недвижимость новостройки купить https://newkvartiry-spb.ru
квартиры от застройщика жк купить 1 квартиру застройщика
купить 1 комнатную квартиру в новостройке https://novyekvartiry2.ru
Здравствуйте!
Заказать документ ВУЗа можно в нашей компании в Москве.
diplomyx24.ru/kupit-diplom-magistra
Хорошей учебы!
Привет!
Купить диплом университета.
ingprint.ru/club/user/58725/forum/message/6909/203474/
купить квартиру от застройщика с отделкой https://newkvartiry-spb.ru
купить 1 квартиру в новостройке квартира в новостройке от застройщика
купить квартиру в новостройке https://zastroyshikekb.ru
купить квартиру в новостройке купить новостройку цены застройщика
Здравствуйте!
Заказать диплом любого университета.
forum.programosy.pl/memberlist.php?mode=viewprofile&u=134517
Успехов в учебе!
Добрый день!
Купить документ института вы имеете возможность в нашей компании в Москве.
diploms-x.com/kupit-diplom-novosibirsk
Привет!
Купить документ ВУЗа
ast-diplom.com/kupit-diplom-vracha
Привет!
Покупка диплома о среднем полном образовании: как избежать мошенничества?
arusak-diploms-srednee.ru/kupit-diplom-medicinskogo-uchilishha В
купить новостройку недорого купить новостройку цены застройщика
입플 토토 사이트
나는 Zhou Yi가 지칠 줄 모르고 낫을 들고 한 줌으로 쌀을 수확하는 것을 보았다.
купить квартиру в новостройке цены https://kvartiranovostroi2.ru
Добрый день!
Мы предлагаем дипломы любой профессии по разумным тарифам.
wiuwi.com/blogs/118282/ упить-?иплом-Ѕыстро-и-Ћегально
купить 1 комнатную квартиру в новостройке купить однокомнатную квартиру
Здравствуйте!
Приобрести диплом любого университета.
startspresto.ru/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=145
Помощь в решении задач https://zadachireshaem-online.ru. Опытные авторы с профессиональной подготовкой окажут консультацию в решении задач на заказ недорого, быстро, качественно
квартиры от застройщика цены https://kvartira-novostroyka2.ru
Заказать контрольную работу https://kontrolnye-reshim.ru, недорого, цены. Решение контрольных работ на заказ срочно.
квартиры от застройщика цены купить двухкомнатную в новостройке
оснащение конференц залов оснащение конференц залов .
купить новую квартиру застройщик https://kvartiranovostroi2.ru
Привет!
Купить документ института вы можете в нашей компании в Москве.
ast-diplom.com/kupit-diplom-o-vysshem-obrazovanii
Заказать курсовую работу https://kursovye-napishem.ru в Москве: цены на написание и выполнение, недорого
Заказать дипломную работу https://diplomzakazat-oline.ru недорого. Дипломные работы на заказ с гарантией.
купить однокомнатную квартиру https://kvartira-novostroyka2.ru
Accessibility Team Meeting Notes https://make.wordpress.org/accessibility/2021/06/11/accessibility-team-meeting-notes-june-11-2021
Красивая музыка https://melodia.space для души слушать онлайн.
ключ от комнаты совещаний ключ от комнаты совещаний .
Здравствуйте!
Купить документ о получении высшего образования вы можете в нашей компании в Москве.
ast-diplomy24.ru/kupit-diplom-nizhnij-novgorod
Успешной учебы!
Помощь студентам в выполнении рефератов https://referatkupit-oline.ru. Низкие цены и быстрое написание рефератов!
продвижение сайта в топ 5 https://seoraskrutka43.ru
seo продвижение цена раскрутка сайта недорого
переговорные комнаты переговорные комнаты .
Привет, друзья!
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий.
passo.su/forums/index.php?autocom=gallery&req=si&img=3170
Рады помочь!.
Здравствуйте!
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
nichtsdestotrotz.com/category/fitness/page/6/
Будем рады вам помочь!.
продвижение сайта в топ 10 казани https://seoraskrutka43.ru
создание и продвижение сайтов казань цены https://seo-raskrutka43.ru
Привет, друзья!
Купить документ о получении высшего образования вы имеете возможность в нашей компании в столице.
asxdiplomik24.ru/kupit-diplom-voronezh
Удачи!
Добрый день!
Купить диплом любого университета.
cyclopede.com/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=270
buy diflucan medicarions
Привет!
Купить документ о получении высшего образования
asxdiplomik.com/kupit-diplom-krasnoyarsk
Добрый день!
Сколько стоит диплом высшего и среднего образования и как это происходит?
arusak-diploms-srednee.ru/kupit-diplom-sssr В
Привет!
Мы готовы предложить дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам.
http://www.acrossperu.com/купить-диплом-в-коврове/
продвижение сайта в поисковых системах https://seooptimizatsia.ru
продвижение сайта в интернете https://seo-optimizatsia.ru
Новинний ресурс https://actualnews.kyiv.ua про всі важливі події в Україні та світі.
Останні новини України https://gromrady.org.ua сьогодні онлайн – головні події світу
Новини сьогодні https://gau.org.ua останні новини України та світу онлайн
Новини України https://kiev-online.com.ua останні події в Україні та світі сьогодні, новини України за минулий день онлайн
Популярные репортажи https://infotolium.com в больших фотографиях, новости, события в мире
Україна свіжі новини https://kiev-pravda.kiev.ua останні події на сьогодні
Свіжі новини України https://lenta.kyiv.ua останні новини з-за кордону, новини політики, економіки, спорту, культури.
Привет!
Купить документ университета можно в нашей компании в столице.
asxdiplomik.com/kupit-diplom-chelyabinsk
Україна останні новини https://lentanews.kyiv.ua головні новини та останні події
Добрый день!
Приобрести документ о получении высшего образования вы сможете в нашем сервисе.
diplomasx24.ru/kupit-diplom-voronezh
Хорошей учебы!
Добрый день!
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
barranca21.com/купить-диплом-пту/
Мостбет зеркало http://pocketnavigator.ru предоставляет все те же бонусы и акции, что и основной сайт, включая возможность делать ставки на спорт и играть в казино.
Здравствуйте!
Мы готовы предложить дипломы психологов, юристов, экономистов и других профессий.
http://www.lifecapadvisors.com/диплом-по-экономике-купить/
Поможем вам всегда!.
видеостены в Москве https://videosteny-dlja-sozdanija-jekranov.ru/ .
музыкальное оборудование для актового зала музыкальное оборудование для актового зала .
Головні новини https://mediashare.com.ua про регіон України. Будьте в курсі останніх новин
Новини та аналітика https://newsportal.kyiv.ua ситуація в Україні.
Головні новини https://pto-kyiv.com.ua України та світу
Новини, останні події https://prp.org.ua в Україні та світі, новини політики, бізнесу та економіки, законодавства
Новини України https://sensus.org.ua та світу сьогодні. Головні та останні новини дня
Привет, друзья!
Заказать документ института вы можете в нашей компании.
ast-diplom.com/kupit-diplom-krasnodar
Добрый день!
Приобрести диплом любого университета.
http://www.con-tacto.vip/blogs/51/%D0%A7%D1%82%D0%BE-%D1%81%D0%BC%D0%BE%D0%B6%D0%B5%D1%82-%D1%81%D0%B5%D0%B9%D1%87%D0%B0%D1%81-%D0%BF%D1%80%D0%B5%D0%B4%D0%BB%D0%BE%D0%B6%D0%B8%D1%82%D1%8C-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BC%D0%B0%D0%B3%D0%B0%D0%B7%D0%B8%D0%BD-%D1%81-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC%D0%B0%D0%BC%D0%B8
световое оборудование для актового зала oborudovanija-dlja-aktovyh-zalov.ru .
Привет, друзья!
Заказать документ о получении высшего образования вы сможете в нашей компании.
asxdiplomik.com/kupit-diplom-rostov-na-donu
Успехов в учебе!
Корисні та цікаві статті https://sevsovet.com.ua про здоров’я, дозвілля, кар’єру.
Головні новини https://status.net.ua сьогодні, найсвіжіші та останні новини України онлайн
Останні новини https://thingshistory.com зовнішньої та внутрішньої політики в країні та світі.
Останні новини світу https://uamc.com.ua про Україну від порталу новин Ukraine Today
Добрый день!
Мы предлагаем дипломы любой профессии по доступным тарифам.
aceenergyok.com/купить-копии-дипломов/
Привет!
Приобретение школьного аттестата с официальным упрощенным обучением в Москве
softerioninc.com/купить-диплом-в-киселевске/