
Joulun lähestyessä saapuu myös tämän kurssin viimeinen kerta. Täytynee sanoa, että kurssin aikana olen huomannut suurta kehitystä GIS:iin liittyvien asioiden ymmärtämisessä, eivätkä tehtävät tunnu enää niin ”etäisiltä” ja monimutkaisilta. Tällä kertaa kurssitehtäviä oli kaksi, joista ensimmäinen sujui mutkitta ja toisen kanssa kävin pientä taistelua, jonka voin omaksi ilokseni kertoa päättyneen voittoon!
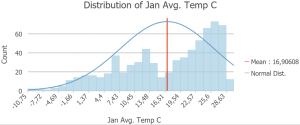
Ensimmäisessä tehtävässä tutustuttiin lämpötilan interpolointiin Afrikassa. Datassa oli näytteitä ympäri Afrikan maanosaa, joista jokaisessa oli kuukauden keskilämpötila. Näistä tehtiin aluksi histogrammeja (kuva 1) ja vertailtiin esimerkiksi tammikuun ja elokuun lämpötiloja, joista huomattiin, että elokuussa jakauma oli normaalimpi.
Tämän jälkeen tehtiin analyysi, joka ennustaa lämpötiloja ympäri Afrikkaa ja Lähi-itää. Tämä onnistuu geostatiikalla, joka perustuu siihen, että asiat ovat mitä todennäköisimmin samankaltaisia kuin sitä lähellä olevat mitatut arvot. Tähän käytetään Geostatistical Wizard -toimintoa, joka sisältää useita interpolointi keinoja, mutta ensiksi käytetään IDW:tä (Inverse Distance Weighting), joka on yksi simppeleimmistä interpoloinnin metodeista.
Alussa on tärkeää, että datoissa käytetään samoja projektoreita, jotta lämpötilojen ennustaminen olisi spatiaalisesti mahdollisimman paikkansa pitävä. IDW interpoloinnilla tehtiin sekä Smooth että Smooth Optimized. Jotta näistä kahdesta tiedettäisiin kumpi on luotettavampi, verrataan niiden Root-Mean-Square:a Cross Validationillä, sillä mitä lähempänä nollaa luku on, sitä luotettavampi se on. Tässä tehtävässä paremmaksi osoittautui Smooth Optimized.
Toisena käytetään Kriging –metodia, joka on huomattavasti vähemmän yksinkertaisempi, kuin aikaisempi IDW, sillä painoarvot lasketaan sekä näytteiden välisistä riippuvuuksista että kohteiden välisisistä riippuvuuksista. Jälleen verrataan Cross Validationillä Kriging Default ja Kriging Modified, joista huomataankin, että niiden arvot ovat hyvin samankaltaisia, mutta erottavana tekijänä voidaan pitää Root-Mean-Square:a, jolloin paremmaksi valitaan Kriging Modified.
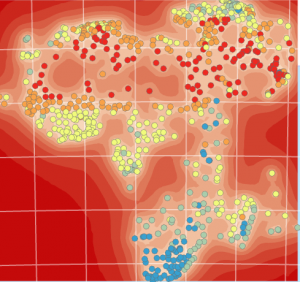
Äsken luotua Kriging Modified –layeria tarkatellaan Standard Error –toiminnolla (kuva 2), joka kertoo epävarmuudet ennustetuissa arvoissa spatiaalisesti. Kuvassa näkyvät tummanpunaiset alueet ovat niitä, joilla epävarmuus on suurinta. Tässä voidaan nähdä selkeä ero mantereen ja meren välillä, joka johtuu suurimmaksi osaksi siitä, että merestä ei ole otettu näytteitä tätä dataa varten.
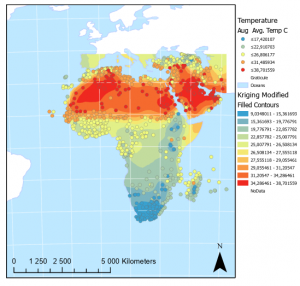
Ensimmäinen tehtävä saatiin lopulliseen muotoonsa kuten kuvassa 3. Kuten ehkä oletettavaa on, päiväntasaajalla on selkeästi lämpimin alue.
Toisessa tehtävässä selviteltiin interpoloinnin avulla lämpötilojen jakautumista kaupungissa ja vielä tarkemmin vanhemman väestön keskuudessa. Näin tiedostetaan alueet, joissa ikääntyneet ihmiset saattavat olla riskin alaisia lämpöaaltojen aikaan. Urbaaneilla alueilla lämpötilat saattavat nousta hyvinkin korkealle kuumina aikoina. Tähän vaikuttavat esimerkiksi pinnat kaupungeissa, jotka imevät itseensä lämpöä sekä kasvillisuuden vähäisyys. Kaupunkien ympärillä saattaa esiintyä Heat Island –ilmiö. Tästä voi lukea lisää esimerkiksi osoitteesta https://www.epa.gov/heatislands/learn-about-heat-islands.
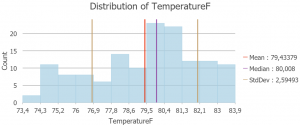
Aluksi aineistosta tehtiin histogrammi, jota voi tarkemmin katsoa kuvasta 4. Poikkiviivat histogrammissa edustavat keskiarvoa, mediaania ja keskihajontaa.
Seuraavaksi keskitytään taas interpolointiin ja tarkemmin Kriging sekä EBK –metodeihin. Kuten ensimmäisessä tehtävässä, taas vertaillaan näiden kahden tulosta toisiinsa ja valitaan se, joka sopii paremmin tehtävään. EBK metodin interpolointi tulos on tarkempi, erityisesti standard errorsia vertaillessa. EBK käy yleisestikin ottaen silloin, kun käsitellään pieniä aineistoja, kuten tässä tehtävässä. Suurin ero näiden kahden metodin välillä on se, että EBK:ssa ei tarvitse määritellä/laskea erikseen semivariogrammia, kuten muissa kriging metodeissa, vaan sen oletetaan automaattisesta olevan kuten ennustettu ( Täältä lisää tästä ). Kummastakin metodista tosin voidaan huomata, että kaupunki keskusta on alue, jossa lämpeneminen on pahimmillaan.
Seuraavaksi karttaan lisätään uusi rasterilayer, josta nähdään läpäisemättömät alueet. Tähän käytetään ArcGis:istä haettavaa dataa nimeltä ”USA NLCD Impervious Surface Time Series”, joka kattaa koko Yhdysvallat, minkä vuoksi käytetään Exract by Mask-toimintoa, jolla saadaan rasteriaineisto vain meidän rajaamalle alueelle. Näin saadaan datasta huomattavasti pienempi.
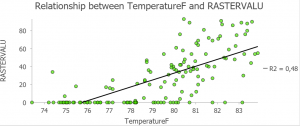
Jotta saadaan vielä selville, että läpäisemättömille tasoilla ja lämpötilojen kohoamisella urbaanilla alueella on riippuvuutta, selvitetään tämä tekemällä kuvaaja, josta voidaan tulkita riippuvuutta paremmin. Aluksi pitää kuitenkin saada näytepisteiden ja läpäisemättömän layerin arvot samaan uuteen layeriin, jonka voi tehdä Exract Values to Points -toiminnolla. Tästä voidaan jatkaa edelleen Scatter Plotin tekoon (kuva 5). Kuvaajasta huomataan selkeä positiivinen riippuvuus lämpötilan ja läpäisemättömän pinnan välillä.
Seuraavaksi käytetään EBK Regression Prediction –toimintoa, jotta voidaan hyöydyntää läpäisemättömiä pintoja selittävänä muuttuja lämpötilamittausten interpoloinnissa. Aiempaan kahteen Kriging-metodiin verrattuna, uusi layer on hyvin samanlainen, mutta siinä on enemmän tarkkuutta.
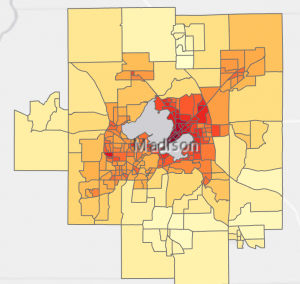
Kun meillä on interpoloinnilla saadut lämpötilaoletukset, voidaan niistä laskea keskiarvo jokaiselle korttelille. Ensiksi pitää saada Zonal Statistics as Table –toiminnolla kortteleihin lämpötilan keskiarvo, jonka jälkeen tämä attribuuttitaulukko voidaan liittää korttelilayeriin. Lopputulos on kuvan 6 mukainen. Kuten siitä nähdään, kaupungin keskiosissa on kaikista kuuminta.
Tehtävän tarkoitus oli nähdä kuumien kortteleiden lisäksi niiden iäkkäät asukkaat. Lopputulosta voidaan analysoida vielä Select Layer by Attribute avulla ja lisätään sinne ehdoiksi, että korttelin lämpötilan keskiarvon on oltava isompi kuin 81 fahrenheittia ja korttelissa on oltava yli 65 asukkaita enemmän kuin 100 000. Työkalu hakee meille kuvan 7 mukaiset alueet. (Esrin ohjeissa oli hieman vähemmän alueita, en tiedä onko vika minussa, vai ohjeissa :D)
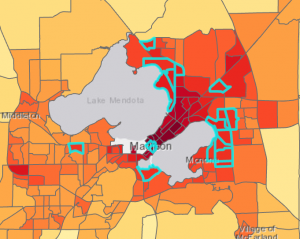
Kuvan 7 tietoja voitaisiin hyödyntää esimerkiksi ennakoimaan tulevien lämpöaaltojen vaikutusta terveydenhuoltoon. Jos kaupungissa on useita sairaaloita, keskustan alueella olevat sairaalat voisivat lisätä resurssejaan aikoina, jolloin on erityisen kuuma, sillä lähtökohtaisesti iäkkäämpi väestö kärsii kuumuudesta enemmän. Kaupallisella puolella tätä tietoa voitaisiin käyttää esimerkiksi markkinointiin. Yrityksen, jotka tarjoavat esimerkiksi lämpöilmapumppuja voisivat kohdentaa markkinointinsa näille alueille.