
Wehave a huge dataset to explore ‒ 247,955 documents of the parliamentary debates translations , in original language and in English from 1999 till 2017. All the documents include speaker information such as name, country, date of birth, gender, function and also date of the speech and even link to the video (who has ever watched it?).
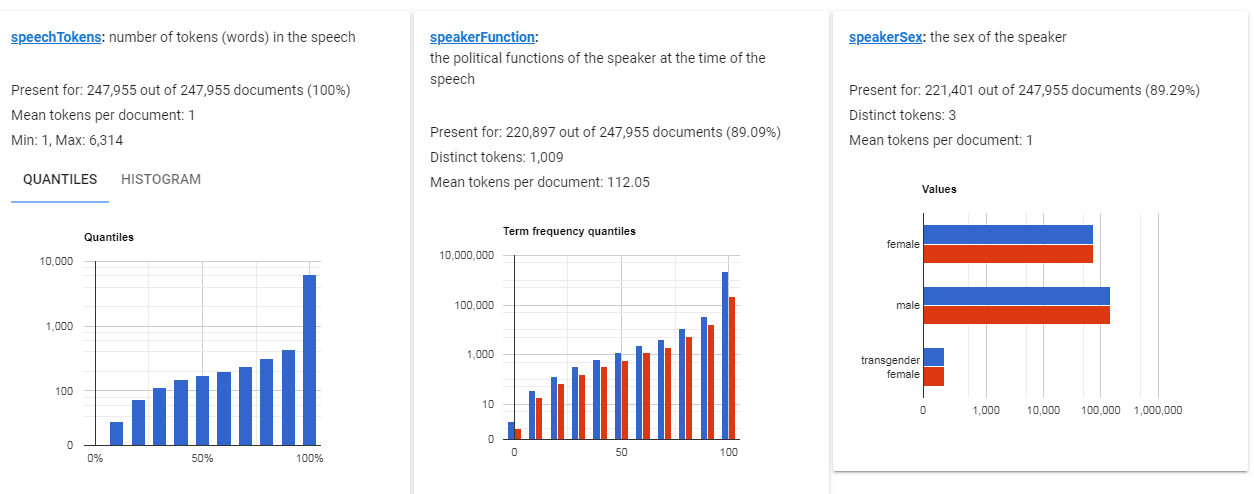
So, we need to decide what to do with all of these data and how to find something significant among the plethora of speeches. We have started with dozens of questions and discussed its until we narrowed them to our main question.
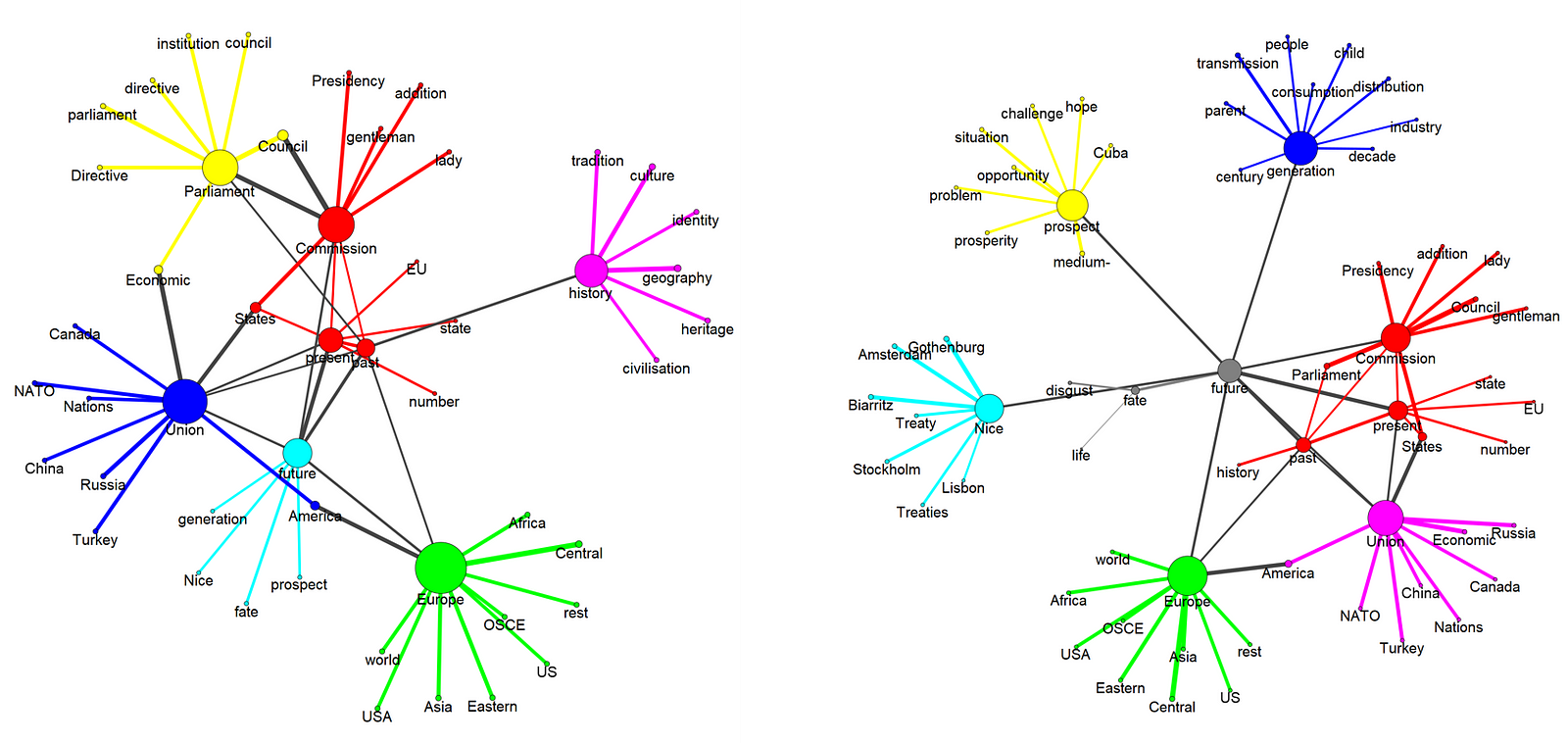
How does the European Parliament talk about ‘the future’ and ‘the past’?
Why we have chosen this perspective? Because it is universal and creates a framework for discussing over issues even vital values and notions. We want to analyze how MEPs speak about the past and the future and what ideas they connect with such a broad and essential concepts.
We are also going to investigate how these ideas change over time, how do they differ between political parties, fractions, ages, genders, geographical regions, etc?

How we intend to achieve our goal? As we are an interdisciplinary team, each of us can contribute their competencies to the overall result and this helps us to set a list of methods we will use:
- Sentiment Analysis
- Topic model
- Construction grammar network keyword extraction
- Word embedding
- Collocation
- Word frequency trends
Follow our blog to know first our key findings and our methodology and don’t forget to follow us on Twitter.