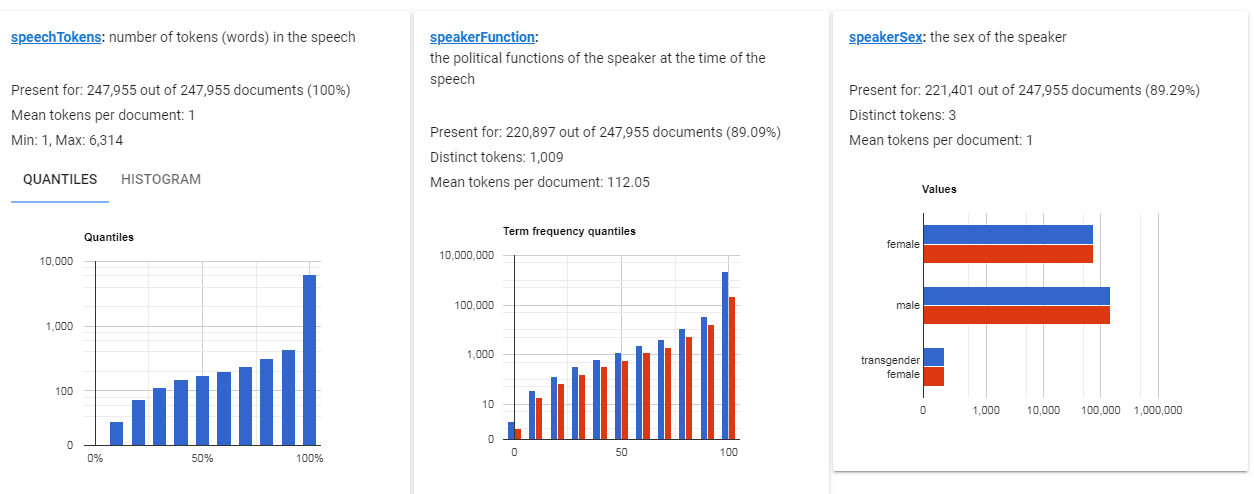
Wehave a huge dataset to explore ‒ 247,955 documents of the parliamentary debates translations , in original language and in English from 1999 till 2017. All the documents include speaker information such as name, country, date of birth, gender, function and also date of the speech and even link to the video (who has ever watched it?).
So, we need to decide what to do with all of these data and how to find something significant among the plethora of speeches. We have started with dozens of questions and discussed its until we narrowed them to our main question.
How does the European Parliament talk about ‘the future’ and ‘the past’?
Why we have chosen this perspective? Because it is universal and creates a framework for discussing over issues even vital values and notions. We want to analyze how MEPs speak about the past and the future and what ideas they connect with such a broad and essential concepts.
We are also going to investigate how these ideas change over time, how do they differ between political parties, fractions, ages, genders, geographical regions, etc?
How we intend to achieve our goal? As we are an interdisciplinary team, each of us can contribute their competencies to the overall result and this helps us to set a list of methods we will use:
Sentiment Analysis
Topic model
Construction grammar network keyword extraction
Word embedding
Collocation
Word frequency trends
Follow our blog to know first our key findings and our methodology and don’t forget to follow us on Twitter.
View from the Uni cafeteria. Not bad, one might say.
And so it’s a wrap on day 4 of Digital Humanities Hackathon 2019. After Friday’s presentation, in which we introduced our preliminary research plan and the research question itself, it was clear that we needed to do some serious reformulating. Today we have continued to work hard on finetuning the research question and the actual research.
As was mentioned on Friday’s post, the Genre and Style group decided to go on a new path with regards to our focus and the way of going about it. Our research stems from a (newly-found) interest in exploring firstly, what named entities can be found in 18th century publications, and secondly, whether genre-classification of these texts can be done on the basis of possible patterns that clusters of named entities comprise. At the moment, the named entities we are placing our primary focus on are proper nouns referring to people. However, further elaborations and updates on this can be expected on the blog as the group’s work proceeds.
The group members doing their thing.
In addition to this, the day consisted mainly of independent work; the computer scientists among us were busy with, for example, compiling sample sets of the data retrieved from ECCO so that the applicability and accuracy of the named entity recognition (NER) algorithm can be examined. Further elaboration of that can maybe be expected in tomorrow’s post. While waiting to get our hands on the quantitative results in the making, others conducted various preparational work, such as literature review on articles discussing genres in early modern English texts as well as NER and text mining. Feels good to have this show on the road!
The day shall end with popcorn and a group viewing of the season finale of Game of Thrones in the ComHis group’s office. So as you can understand, I gotta go now.
This post is written by Annika Pensola,a first year student in the Master’s Programme in English Studies, Faculty of Arts in the University of Helsinki. Currently feeling inspired by the international and multidisciplinary composition of the hackathon and excited for its results.
A quick update on the Genre and Style group in the DHH19. The discussion sessions yesterday ran late, so this post arrives with a small delay.
Day 3 of the hackathon (or day 2 of the blog) has been a great example of why these gatherings can lead to unexpected results — we started the day with one question in mind, but along the way decided on something quite different. In our group we are trying to use digital humanities tools to study the variations in genre and style in 18th century digitized English texts.
On Friday, we had to come up with a formulated research question and a plan for our research based on this. A well-formulated plan would naturally keep us in focus, and help us do solid and reasonable work during the week.
Our task for Friday
This is not of course how our team works! 🙂 We arrived this morning diligently — at 9.15 AM — to study the genres in relation to gender. However by 10.15 we had found out that out of all the texts available to us, a very small proportion was written by women (less than 5%). This would make it quite difficult to compare with other texts.
Additionally, we have been made aware that the metadata on the texts is pretty simple and unreliable, and the OCR quality of the texts makes it difficult to do many types of comparisons (although many analyses work surprisingly well even for bad quality texts).
So, we started thinking once again, how could we compare these texts and how could we get to the genre within these texts. Now we already knew each other a bit, what we were interested in, and what we could do, and could more comfortably discuss an interesting topic to study.
So, by 11.15 we came up with a different topic — what if we could look at 18th century texts as a type of network, with similar texts connected to each other. Texts on the same topics would mention the same people and would be discovered by these means. In this case, we could talk about genres independently of the metadata that had uncertain quality and were marked up quite unevenly.
Named Entity Recognition finds entities from text through various heuristics and algorithms.
By 12.15 we were testing Named-Entity-Recognizers on the old texts, and by 13.15 we had almost forgotten to eat lunch because of it. Eventually we came up with a plan that seemed to make sense from a humanities perspective, seemed to be feasible technologically, and most importantly seemed within reach of our group and interesting enough to try to do.
So, by 14.15, we had come up with a research strategy and ran initial tests, and by 15.15, we were ready with our slides for a presentation. We got some tough (but necessary) questions from the instructors and the audience, and got a good way to move forward. Now, unless basic steps of the plan fail, we would each have something interesting to do with the data.
Our research question.
We planned to have a working meeting after the presentations at 16.15, but walking through the outdoors even briefly — it was 18 degrees of warmth outside (i.e. feels like 30!), this turned into a meeting in the park, which gradually moved into more informal discussions (see illustration below).
The overtime working team avoiding being captured on the photo.
So, within just a few hours, we explored a lot of data, came up with another research plan, formulated it, and made plans for next week. Having gotten to know each other over some time already, discussing also plans and topics has become easier and easier — also looks like we should get some very interesting results!
So, turbulent times in the hackathon. Catch up with us here next week* with more info!
Kirnu roller coaster in Linnanmäki amusement park in Helsinki
*- Technically, even this post is cheating, since we have been given strict instructions not to do any work during the weekend. However, as we prepare our minds for the week ahead, it’s good give a quick overview of where we got.
This blog post was written by Peeter Tinits, a last year PhD student at Tallinn University and a digital humanities grunt in University of Tartu, in Estonia. Attending the hackathon from abroad for the learnings and the funs.
This blog post is also published on Medium (19/5/2019): https://medium.com/@GenreAndStyle
The Helsinki Digital Humanities Hackathon or DHH is celebrating its fifth year. The week and a half long hackathon brings together researchers and students from computer science, data science, the humanities and social science to work on an interdisciplinary research project. This year DHH welcomed international participants to take part in the event!
In the series of blog posts coming this week from our Genre and Style in Early Modern Publications group, we will recap our experience in the hackathon (including all triumphs and tribulations) with short introductions of ourselves, so stay tuned!
The event started on Wednesday 15th of May with general introductions and division into groups. The day begun with brainstorming and formulating a research question and getting to know each other on the side. Today, on the second day of the hackathon, we continued our brainstorming actions while getting familiar with our eighteenth century publications data. At this point we don’t have a specific research question to present to you yet, but we have been spitballing with ideas about genres and gender, e.g. to compare female and male authors’ style of writing and possibly creating some kind of classifier that predicts the gender of the author of the publication.
Our day started with a little tea-on-laptop incident, but the laptop survived!
We continued with extracting the data from ECCO database through the Octavo API and faced some hiccups with the server crashing a few times but that certainly did not discourage us and we continue to work hard on the this. Next, we are planning on creating some simple statistics of the data in order to explore it more efficiently.
At the end of the day we were treated with an interesting lecture about 4D Modeling and SBIM by Anthony Caldwell from HumTech UCLA.
This is our first hackathon and we are looking forward to the coming days with excitement!
This blog post was written by Selina Lehtoranta, a first year Data Science master’s student from University of Helsinki, Faculty of Science and Veera Oksala, a first year student in the Master’s Programme in English Studies, Faculty of Arts in the University of Helsinki.
First we were given the magic nametags which provide us the endless coffee at the cafeteria. Digital Humanities Hackathon 2019 has started. Then we were put in a small room full of strangers. Those strangers would not be strangers for long for we would study Brexit on transnational social media for the next couple of weeks.
Turns out we come from all over the world; China, India, US, Finland, Russia. We come from different educational backgrounds and most of us know nothing of studying social media. But we fear not – we have the support of our group leaders Daria, Joe and Steven, the data team and the general organizers.
But what is digital humanities? It is a field of studies that combines humanities and social sciences with computational methods to solve issues that interest humanities and social sciences researchers. The possibilities are endless. Not only can humanists now study larger datasets than before, the computer scientists can tackle humanities interests. We can study the digital world or use new methods to study history. On the other hand we all need to learn to work together.
Haven’t you always wanted to draw the wall full of mind maps? Well, we got to do that!
What is interesting about the Brexit phenomenon on Twitter during the spring of 2019? The due date of the UK’s separation from EU came and went and was postponed. Each of us took a stand one at the time and wrote on the wall what would be interesting to study about this phenomenon. Some of us were interested in applying specific methods to the data, some of us were interested in abstract contexts related to Brexit.
The brainstorming session was full of forgotten words, new concepts and methods explained. It was also full of new connections between subjects that none of us could see on our own. The session also caused a lot of anxiety, as the amount of new information was overwhelming. Taking a small break seemed to help to focus, as did voicing concerns and sharing the feelings we had.
Dealing with social media data raises a lot of ethical questions. Where do we draw the line what information has been willingly given to be seen and used? How do we anonymize the information we are using?
Deciding on one approach deemed hard. We all had so many ideas on what could be interesting in the data that making tough decisions on what to do seemed impossible. But once we all felt comfortable enough to voice their opinions we are making our way towards an actual research.
Next up – the research plan. Follow our journey in this blog and on Twitter with the hashtags #dhh19 & #brexit.
Written by Sonja Sipponen, MA student of general history at the University of Helsinki.