
 Natural language understanding (NLU) is the “holy grail” of computational linguistics and a long-term goal in research on artificial intelligence. Found in Translation (FoTran) is an ERC funded project running from 2018 to 2024 within the language technology research group at the University of Helsinki. The goal of the project is to develop neural language and translation models trained on implicit information given by large collections of human translations. The main hypothesis in FoTran is that increasing amounts of linguistic diversity in training will lead to stronger abstractions and ultimately to language-agnostic meaning representations. We study the use of machine translation as a training objective and investigate the effect on neural embeddings and downstream applications. The project is led by Jörg Tiedemann and runs within the Department of Digital Humanities.
Natural language understanding (NLU) is the “holy grail” of computational linguistics and a long-term goal in research on artificial intelligence. Found in Translation (FoTran) is an ERC funded project running from 2018 to 2024 within the language technology research group at the University of Helsinki. The goal of the project is to develop neural language and translation models trained on implicit information given by large collections of human translations. The main hypothesis in FoTran is that increasing amounts of linguistic diversity in training will lead to stronger abstractions and ultimately to language-agnostic meaning representations. We study the use of machine translation as a training objective and investigate the effect on neural embeddings and downstream applications. The project is led by Jörg Tiedemann and runs within the Department of Digital Humanities.
Aims and objectives
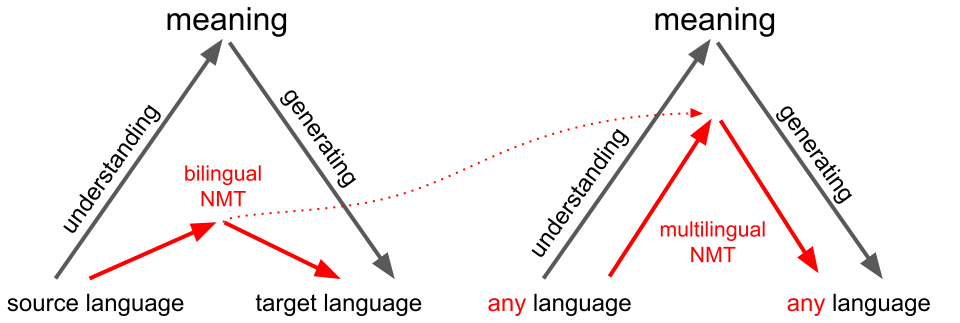
The overall goal of FoTran is to develop effective multilingual language encoders that find language-agnostic meaning representations through what we call “cross-lingual grounding”. The idea is that translations are aligned through meaning and that neural translation models will learn some kind of mapping to abstract representations that reflect the essential information needed to be translated across languages. Furthermore, we assume that multilingual translation models are forced to generalize more than bilingual models due to the linguistic variation that needs to be covered by one single model. FoTran tries to study the influence of linguistic diversity on representation learning when scaling to a large number of languages.
Project setup
Neural translation models serve as the backbone for FoTran. In the project we build massively multilingual models and study their internal structures, representations they learn and how they affect downstream applications.
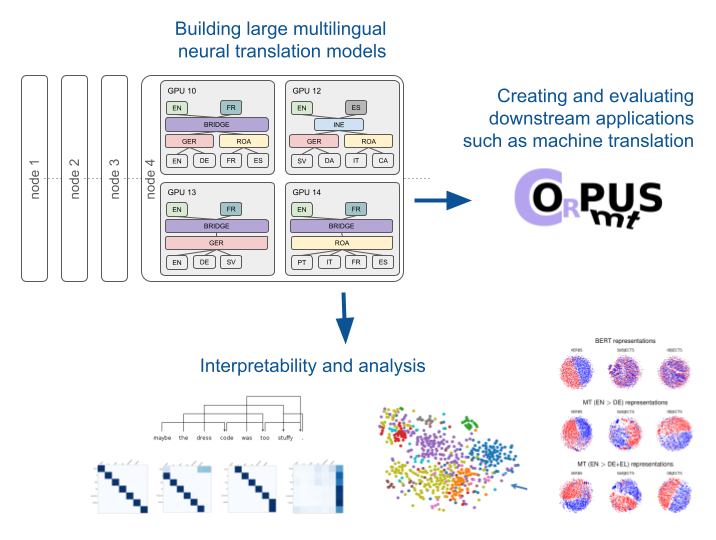
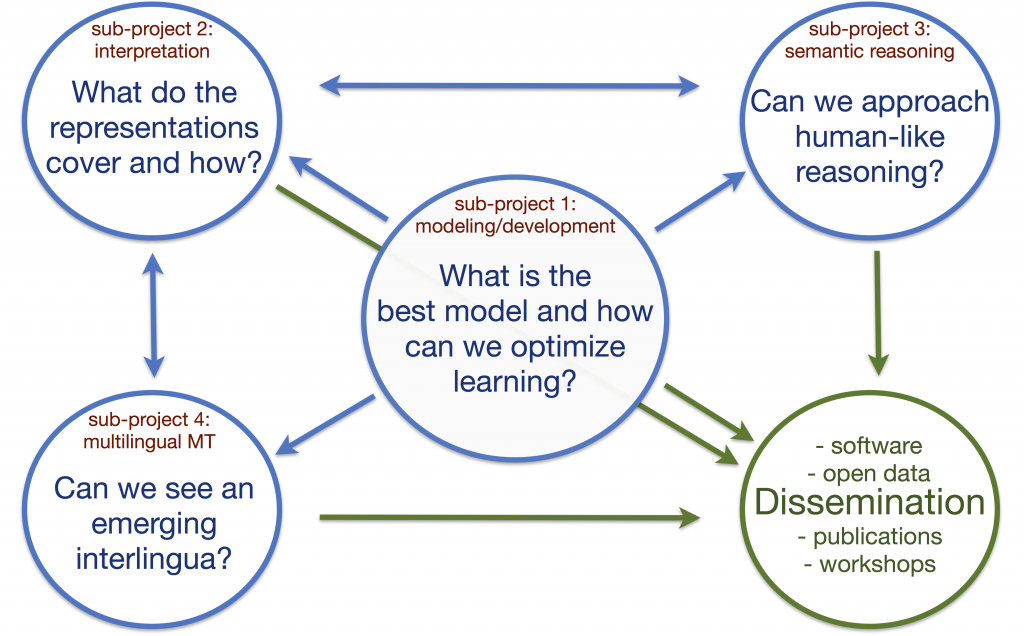
The project is divided into 4 sub-projects. At the core is model development (sub-project 1), a necessary task that facilitates the studies we want to carry out. In sub-project 2, we emphasize intrinsic evaluation and the interpretation of the representations that emerge from our models when training with different kinds of data. Sub-projects 3 and 4 focus on extrinsic evaluation and the application of language representations in down-stream tasks such as machine translation (sub-project 4) and other tasks that require some kind semantic reasoning (sub-project 3). The following picture illustrates the interactions between the various sub-projects and the research questions we ask.
Read more about our research in the overview pages of the sub-projects:
We also organized a number of dissemination events and were actively collaborating with various external researchers.