
Continuous multilinguality with language embeddings
The starting point was the multilingual character-level language model implemented by Robert Östling in 2016. Adding language tokens to the recurrent neural language model made it possible to learn language embeddings from massively multilingual training data.
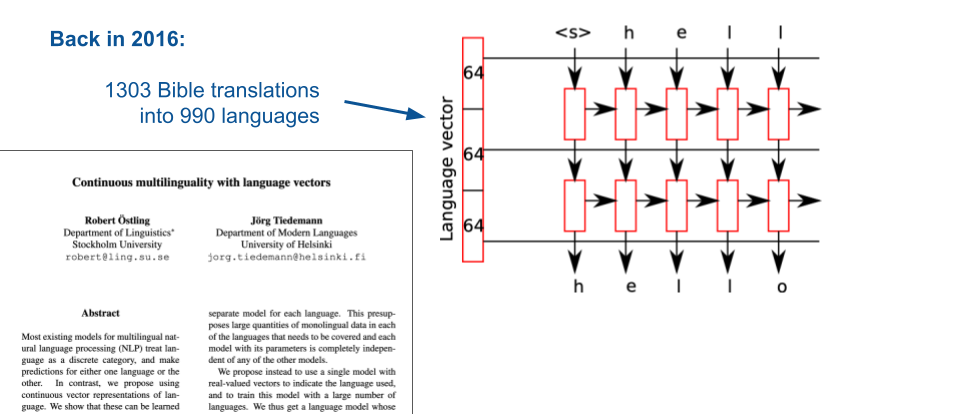
The emerging embedding space of language IDs can be used to find interesting language clusters or force the model to generate specific languages. More interestingly, those embeddings can also be combined to mix languages and interpolations between language embeddings reflect a continuum between them.

Nowadays, we could call the use of language tokens as an early variant of prompting that influences the output of the generative model.
At the same time, language tokens have been proposed for encoder-decoder models with an application to machine translation. This simple trick enables multilingual translation models without modifications in the architecture and completely shared parameters.
The attention bridge model
In FoTran, we are mainly interested in the representations that a neural translation model learns from raw data. According to our hypothesis, we expect higher levels of abstractions with increased linguistic diversity in the training data. In order to test this hypothesis, we need a scalable architecture that can be trained with massively multilingual data sets. Additionally, we want to force the model to generalize over all included languages in order to create language-agnostic meaning representations in the long run, which can be used for advanced types of reasoning.
Therefore, we implemented a modular architecture that creates a special shared layer that will function as a bottleneck bridging all languages that are read and generated by language-specific encoder and decoder modules. This so-called “attention bridge” is implemented as a fixed-size self-attention layer between encoder and decoder components. A schematic overview of the architecture is shown below:

The fixed size enables the direct use of those intermediate representations in downstream tasks without additional pooling. The model is also capable of zero-shot machine translation (i.e. translation between languages for which no explicit examples were seen in training) without language labels demonstrating the cross-lingual abstractions that the attention bridge can obtain.
MAMMOTH – A framework for modular machine translation
The attention bridge model has several short comings. First of all, the fixed-size shared layer is not powerful enough to capture all cross-lingual signals that can help to transfer knowledge between languages and, especially small bridges, suffer from a significant drop in translation performance compared to fully shared models. Secondly, the initial implementation did not scale very well because training could not easily be distributed in a multi-node setup. In addition, many alternative variants of modularity and partial parameter sharing have been proposed in the meantime.
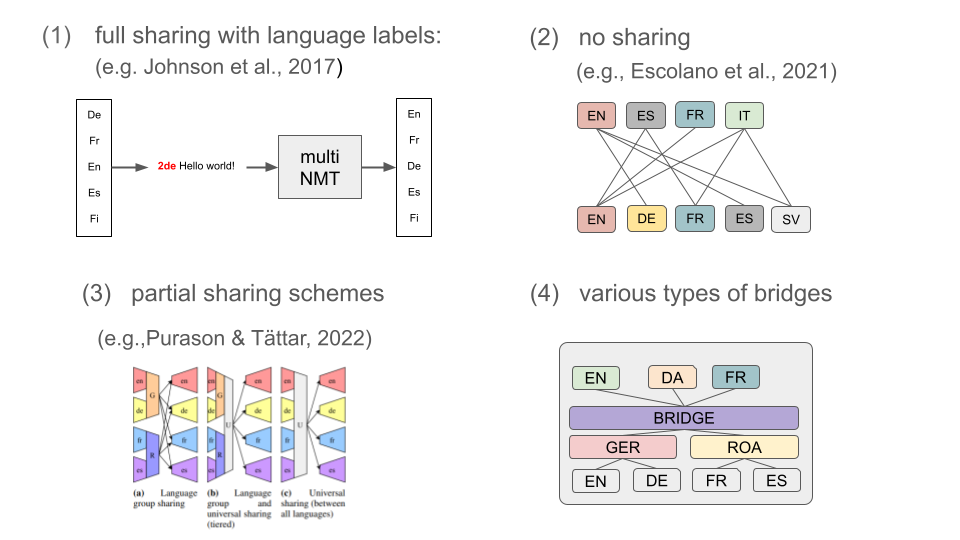
Therefore, we decided to generalize the implementation into a flexible framework that includes a comprehensive number of features to build massively multilingual modular sequence-to-sequence models. This framework was named MAMMOTH – a toolkit for Massively Multilingual Modular Open Translation @ Helsinki. Special care is taken to support scalability. Tasks and modules can be distributed over large compute clusters and the toolkit takes care of the setup and communication during training. The final goal is to train a massively multilingual flagship model that makes extensive use of the modular nature of the architecture. Below is a schematic plan for the flagship development:

References
- Robert Östling and Jörg Tiedemann. 2017. Continuous multilinguality with language vectors. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 644–649, Valencia, Spain. Association for Computational Linguistics.
- Raúl Vázquez, Alessandro Raganato, Jörg Tiedemann, and Mathias Creutz. 2019. Multilingual NMT with a Language-Independent Attention Bridge. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), pages 33–39, Florence, Italy. Association for Computational Linguistics.
- Raúl Vázquez, Michele Boggia, Alessandro Raganato, Niki A. Loppi, Stig-Arne Grönroos, and Jörg Tiedemann. 2022. Latest Development in the FoTran Project – Scaling Up Language Coverage in Neural Machine Translation Using Distributed Training with Language-Specific Components. In Proceedings of the 23rd Annual Conference of the European Association for Machine Translation, pages 311–312, Ghent, Belgium. European Association for Machine Translation.
- Michele Boggia, Stig-Arne Grönroos, Niki Loppi, Timothee Mickus, Alessandro Raganato, Jörg Tiedemann, and Raúl Vázquez. 2023. Dozens of Translation Directions or Millions of Shared Parameters? Comparing Two Types of Multilinguality in Modular Machine Translation. In Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), pages 238–247, Tórshavn, Faroe Islands. University of Tartu Library.
-
Mickus, T., Grönroos, S-A., Attieh, J., Boggia, M., De Gibert, O., Ji, S., Loppi, N. A., Raganato, A., Vázquez, R. & Tiedemann, J., 2024. MAMMOTH: Massively Multilingual Modular Open Translation @ Helsinki, In: Aletras, N. & De Clercq, O. (eds.). Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. Kerrville: The Association for Computational Linguistics, p. 127-136
Software
MAMMOTH – Massively Multilingual Modular Open Translation @ Helsinki [GitHub][ReadTheDocs]