
Multilingual NMT with an attention bridge model
Machine translation can also be used as an extrinsic measure for the quality of intermediate representations. Assuming that we require some level of language understanding to perform proper translation, we can approximate the NLU abilities by looking at translation accuracy. Moreover, we can study the possibility to translate between unseen language pairs through an intermediate representation. This is typically called zero-shot translation.
First of all, we were interested in the performance of the modular multilingual architecture with the attention-bridge as described in the model development section. Using the attention bridge as a cross-lingual bottleneck, we expect that increasingly generic representations emerge when training with multiple languages. This should support translation in general and zero-shot performance in particular.

The table above summarizes translation performance in terms of BLEU scores on the multi30k dataset. The first column is a sanity check showing that the attention bridge architecture works even though the intermediate bottleneck hurts the performance somewhat.
The column in the middle summarizes scores for multilingual English-centric models (English being either the source or the target language). The most important takeaway is that zero-shot translation capabilities require additional monolingual training data to trigger a proper cross-lingual abstraction. The explanation for this is that English-centric models do not generalize well to unseen language pairs as the training signal is very consistent in always having English as either source or target language. The same problem happens in fully-shared models with language labels. Including monolingual data, we can see that zero-shot translation is getting quite close to the supervised models.
The third column shows the positive effect of multilingual training. Basically all language directions benefit from multilingual data and the scores go up compared to bilingual baselines. Note that monolingual data still helps to push performance, which indicates that this, again, improves the intermediate shared representations.
In order to study zero-shot translation in more detail, we also systematically trained multilingual models that exclude specific language pairs. The following plot illustrates the results in terms of BLEU scores:
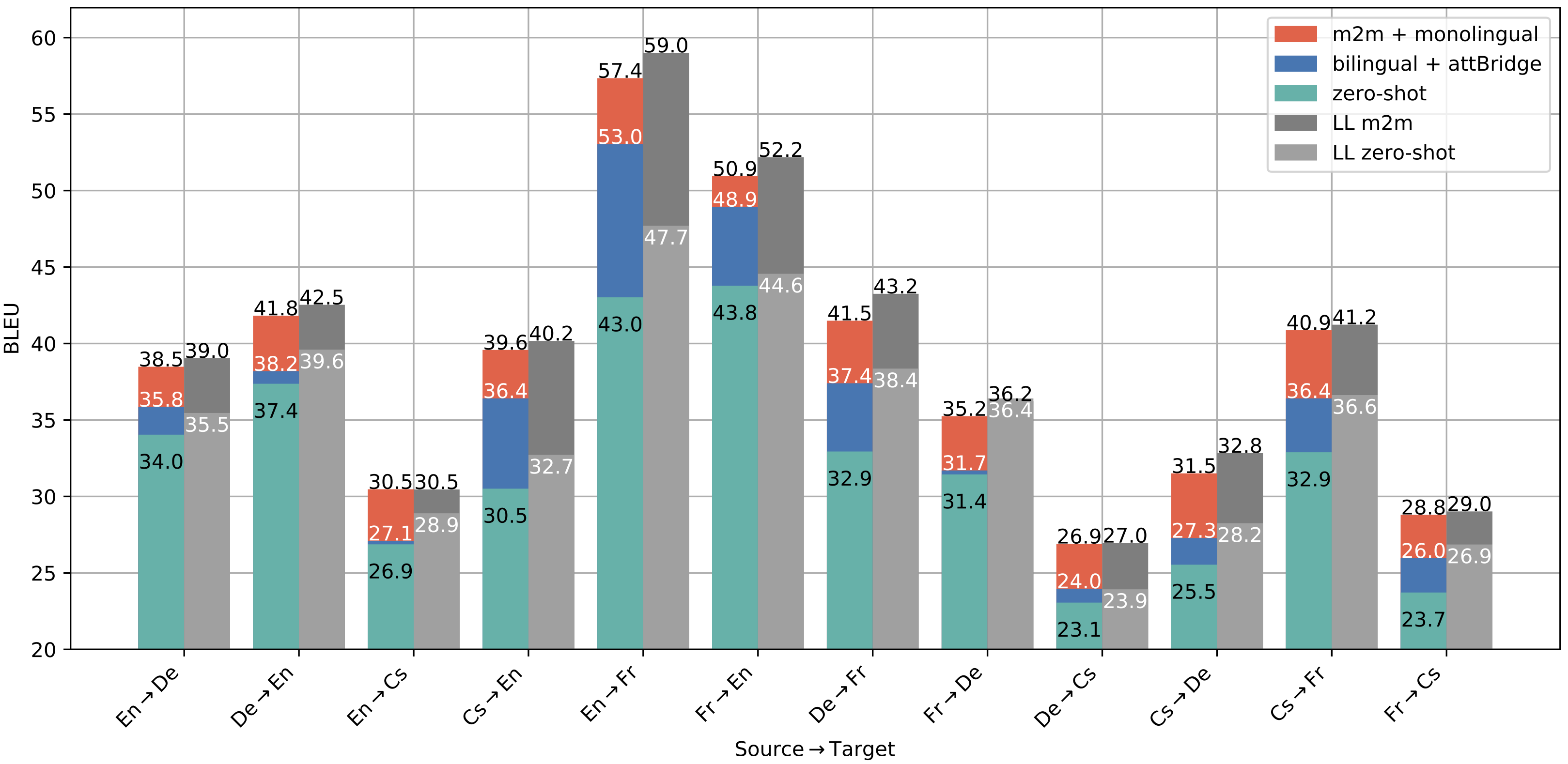
Again, zero-shot translation performance comes very close to the supervised bilingual baseline in most cases, which is very promising. Furthermore, we can see again the positive effect of multilingual training pushing the performance above bilingual baselines in all cases.
In comparison to a fully-shared transformer model with language labels (grey bars), the performance is lower for the attention-bridge architecture in both, zero-shot and many-to-many settings but the differences are small. Naturally, fully-shared networks can better utilize cross-lingual knowledge avoiding the restricted bottleneck in our attention-bridge model. However, the attention-bridge seems to be capable of encoding the essential information to perform similarly well in a highly modular setup.
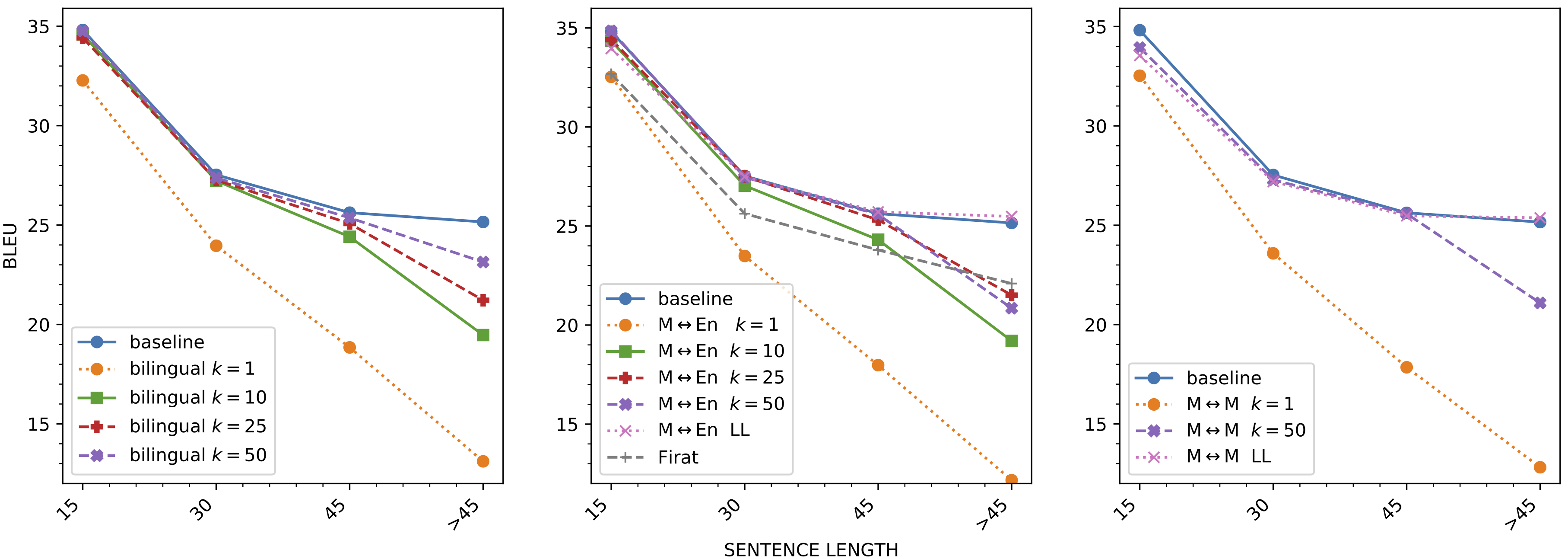
The fixed size of the attention bridge is another reason for the performance difference. The plots above clearly show that the difference between the fully-shared baselines and the comparable attention-bridge model are due to the drop in performance on long sentences (45 tokens and more).
The plot also compares different bridge sizes. Controlling the capacity of the cross-lingual bottleneck is important. Using one single attention head is clearly not enough to support translation. This is the same for bilingual, English-centric and many-to-many settings.
Note that the attention-bridge model was not designed to improve translation performance. The main purpose is to facilitate representation learning and, for this, the fixed size of the intermediate layer is an advantage as we have already discussed in the section on downstream tasks. However, the modularity is attractive and parameter sharing can be optimized in various ways to facilitate translation performance, too.
The impact of parameter sharing in modular NMT
The attention bridge model takes modularity to an extreme where knowledge transfer across languages is limited to a fixed-size bottleneck. In order to study the effect of parameter sharing and different types of modular translation models, we developed MAMMOTH. It provides a framework for experiments with modular, massively multilingual encoder-decoder models with various features to support architectures with different levels of sharing parameters across tasks, languages or selected languages only.
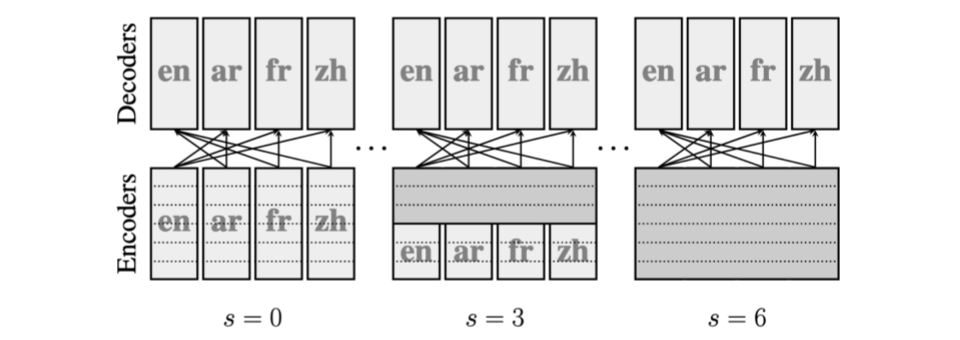
We started with a systematic test of models that share parts of the encoder and trained increasingly multilingual models on English-centric data from OPUS-100. The architecture is a simple transformer encoder-decoder model with 6 layers in encoder and in the decoder without any bridge. The shared layers are shared across all source languages:
We trained models with the same hyper-parameters and tested the translation performance in supervised and zero-shot translation directions. Note that we explicitly focused on language diversity in the language selection. The following plots show BLEU scores with increasing levels of parameter sharing for models of up to 36 languages:
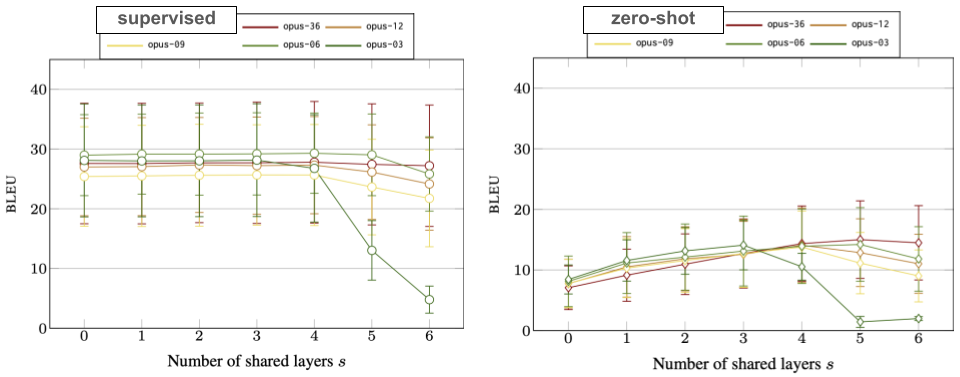
The main take-away is that modularity works and can even be beneficial compared to fully-shared models. In the supervised case, we can see some detrimental outcomes when sharing more than 4 layers in our 6-layer model. In the literature, this is often referred to as the “curse of multilinguality” and we can certainly see the negative effects of interference with our diverse set of languages. Even more interesting is the zero-shot translation case. As expected, we can see the benefits of parameter sharing but only up to a certain point. Leaving some capacity to language specific parameters is beneficial at least in our experiments. This is especially the case for smaller sets where all languages are rather distant from each other, whereas bigger sets necessarily contain more languages with stronger linguistic connections that would benefit from joint encoding.

The impact on language similarity on modularity raises another question about partial parameter sharing. MAMMOTH allows to define language groups for which parameters will be shared (see illustration above). This functionality enables hierarchical architectures, where language-specific, language-group specific and language agnostic parameters can be combined in a single network. They can be combined with different types of encoder-decoder bridges and with that, MAMMOTH provides a flexible toolkit to experiment with many options.
Scaling up and scaling down
An important requirement of multilingual frameworks is that they need to scale, both in terms of overall size and also in terms of language coverage. In order to make practical use of the modular systems implemented in MAMMOTH, we need to make sure that training scales well with increasing numbers of modules and languages covered. A modular massively multilingual model needs to be trained in a distributed multi-node environment and, due to the potential complexity of the architecture, we need to ensure that task assignments and inter-node communication is optimized. MAMMOTH implements various features that facilitate the task assignments and manages the necessary communication while backpropagating and updating model parameters in multi-task training schedules.
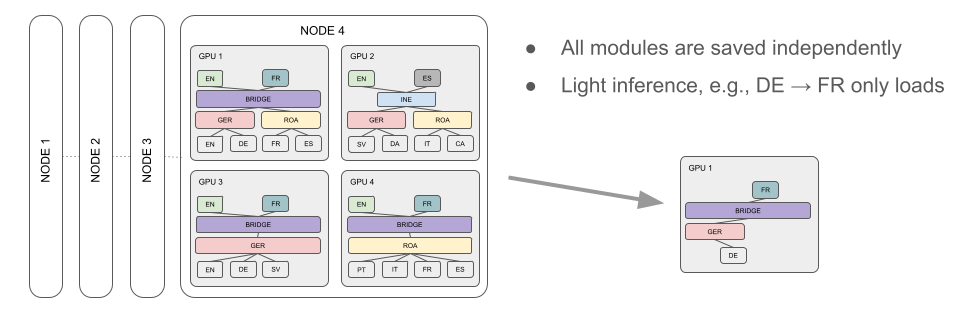
Even with small modules, the overall parameter size will grow but the network remains sparse due to the pre-defined modularity. This is a nice feature that enables down-sizing at inference time. Only necessary modules need to be loaded and inference becomes cheap as only a small fraction of the entire network will be used. All components are saved separately and can be loaded on demand for tasks they are needed.
Multi-tasking
MAMMOTH is not restricted to translation tasks. The beauty of the modular setup is that we can also add other types of tasks to the mixture by adding dedicated encoder or decoder modules that read or generate certain other types of input and output. For example, we can add an audio encoder module as an alternative way of processing input data, which can then be trained to transcribe or translate into text of any language that is supported by the model. We experimented with a simple speech-to-text translation model using the attention-bridge architecture and could show that multi-task training with text-to-text and speech-to-text tasks is beneficial for creating end-to-end speech translation models.

We are currently testing the integration of other sequence-to-sequence tasks in the MAMMOTH framework such as text simplification and definition generation. Many directions can be explored in the future, for example zero-shot text simplification across languages or modalities.
Open machine translation
Part of the missions of Fotran is also to provide open data, tools and resources that will push research and development of transparent and openly available applications with a high language coverage. For many years, we have collected and prepared parallel data sets for research in machine translation. OPUS is the major hub of public resources with an increasing coverage in terms of domains and languages.
A lot of effort has been put into streamlining the process of training machine translation models and the procedures typically start with data preparation. From OPUS resources we compiled a highly multilingual dataset, the Tatoeba Translation Challenge, that can directly be used to systematically train bilingual and multilingual translation models.

Based on OPUS and the Tatoeba Translation Challenge we also created an ecosystem for MT training and model distribution. OPUS-MT provides thousands of translation models covering hundreds of languages and we are constantly improving the quality and coverage. A majority of our models is also available from the popular model hub at Hugging Face, making integration and use easy and straightforward.
Many of our models are multilingual and we try to systematically build translation systems with different language coverage and model sizes. This allows us to inspect the potential cross-lingual transfer and also pitfalls of multilinguality in more detail. Evaluation is at the core of such studies and, therefore, we created a dashboard for MT models to quickly obtain an overview of model performance with different benchmarks and evaluation metrics.

The OPUS-MT dashboard is an invaluable resource for tracking the progress and also a very good hub for selecting appropriate models for specific needs. Translation output can also be inspected and compared with competing systems. We will continuously develop the resource to contribute to the landscape of open machine translation.
References
- Raúl Vázquez, Alessandro Raganato, Mathias Creutz, and Jörg Tiedemann. 2020. A Systematic Study of Inner-Attention-Based Sentence Representations in Multilingual Neural Machine Translation. Computational Linguistics, 46(2):387–424.
- Michele Boggia, Stig-Arne Grönroos, Niki Loppi, Timothee Mickus, Alessandro Raganato, Jörg Tiedemann, and Raúl Vázquez. 2023. Dozens of Translation Directions or Millions of Shared Parameters? Comparing Two Types of Multilinguality in Modular Machine Translation. In Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), pages 238–247, Tórshavn, Faroe Islands. University of Tartu Library.
- Raúl Vázquez, Mikko Aulamo, Umut Sulubacak, and Jörg Tiedemann. 2020. The University of Helsinki Submission to the IWSLT2020 Offline SpeechTranslation Task. In Proceedings of the 17th International Conference on Spoken Language Translation, pages 95–102, Online. Association for Computational Linguistics.
- Jörg Tiedemann. 2020. The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT. In Proceedings of the Fifth Conference on Machine Translation, pages 1174–1182, Online. Association for Computational Linguistics.
- Jörg Tiedemann and Ona de Gibert. 2023. The OPUS-MT Dashboard – A Toolkit for a Systematic Evaluation of Open Machine Translation Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 315–327, Toronto, Canada. Association for Computational Linguistics.
- Jörg Tiedemann, Mikko Aulamo, Daria Bakshandaeva, Michele Boggia, Stig-Arne Grönroos, Tommi Nieminen, Alessandro Raganato, Yves Scherrer, Raúl Vázquez and Sami Virpioj. 2023. Democratizing neural machine translation with OPUS-MT. Language Resources & Evaluation (2023).