
In FoTran, we are interested in analyzing the neural language and translation models to understand their inner workings, how they pick up information and how that information is stored in the network. The distributed nature of neural models make it difficult to disentangle the information flow and interpretibility and explainability of predictions and generated output is a challenging task. In general, we can distinguish between intrinsic and extrinsic studies that may be hypothesis-driven or data-driven/explorative in nature. In sub-project 2 we focus on the intrinsic analyses of network parameters whereas sub-project 3 looks at the analyses by means of downstream and probing tasks. Here are some highlights of our research.
Language embeddings
Fully-shared translation models with language labels are interesting as they learn language embeddings in some high-dimensional space from raw data. Similar to the initial character-level language model, language spaces that emerge from training encoder-decoder models for translation show reasonable clusters as we can see at the following t-SNE plot from a model trained on Bible translations covering over 900 languages.

Bjerva et. al (2019) and Östling & Kurfali (2023) look into more details about what such language embeddings really represent.
Analyzing transformers
We were the first to analyze transformer parameters looking at the contextualized embeddings learnt from translation data and the attention patterns that emerge.
![]()
We observed that attention is often very sparse producing highly regular patterns such as the once shown above. These insights led to the possibility of replacing trainable attention heads with fixed patterns, effectively reducing model size and supporting low-resource scenarios with a valuable prior.
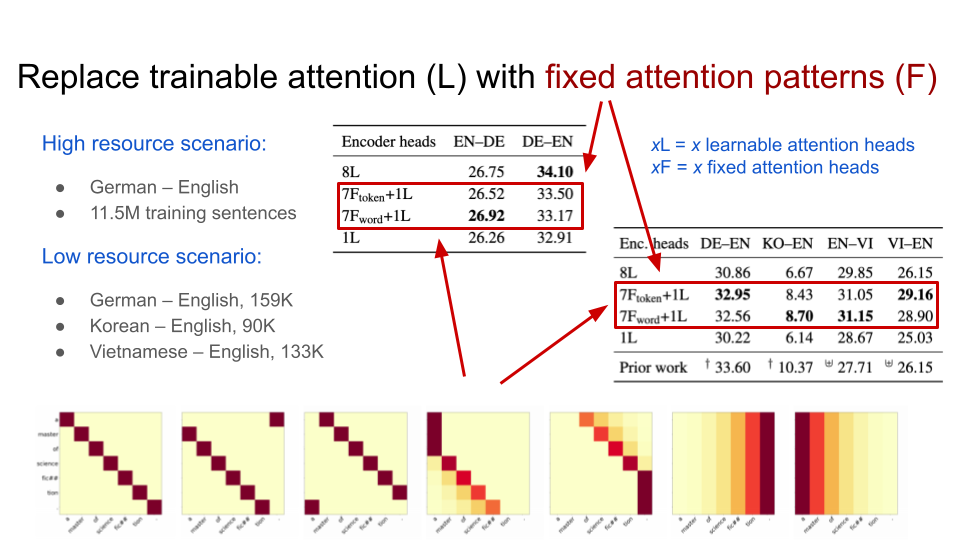
Comparing language and translation models
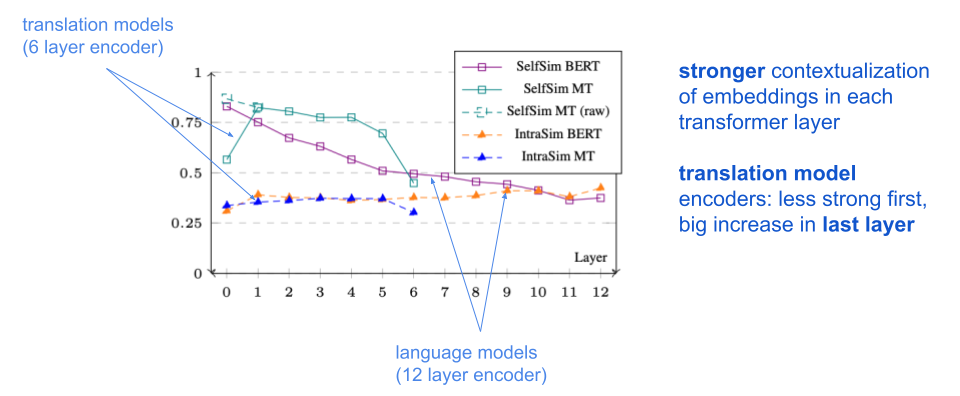
Pre-trained neural language models appeared shortly after the start of the FoTran project and changed the NLP landscape. Turning our attention to a comparison between language and translation models was a natural adjustment. Masked language models and translation model encoders show surprising difference in the representations they learn and we looked at contextualization of the embeddings in particular using measures of self-similarity (SelfSim) and intra-sentential similarity (IntraSim), see Ethayarajh (2019) for more details.
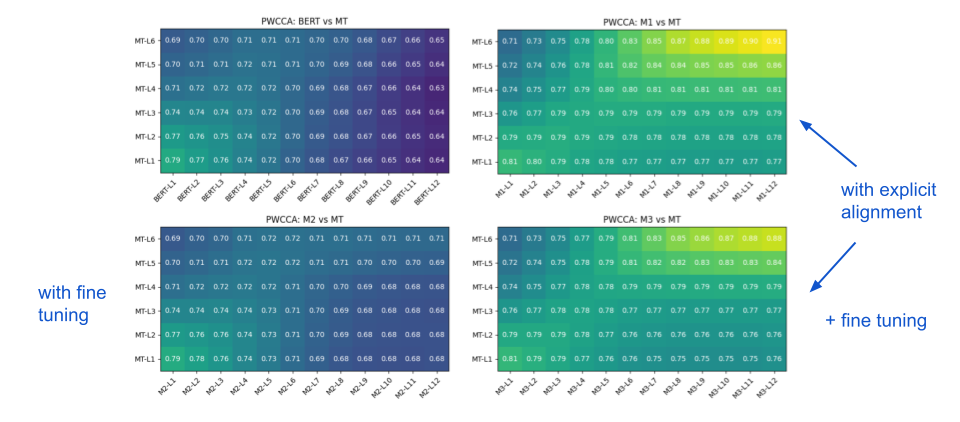
However, turning a pre-trained masked language model into a translation encoder is possible through fine-tuning and alignment. Representation Similarity Analysis (RSA) and Projection-Weighted Canonical Correlation Analysis (PWCCA) show the effect of such a transformation.
Training dynamics
Another interesting observation is the differences in training dynamics between translation and language models of different kinds. We measured loss change allocations (LCA) in encoder-decoder models and compared them to masked and causal language models.
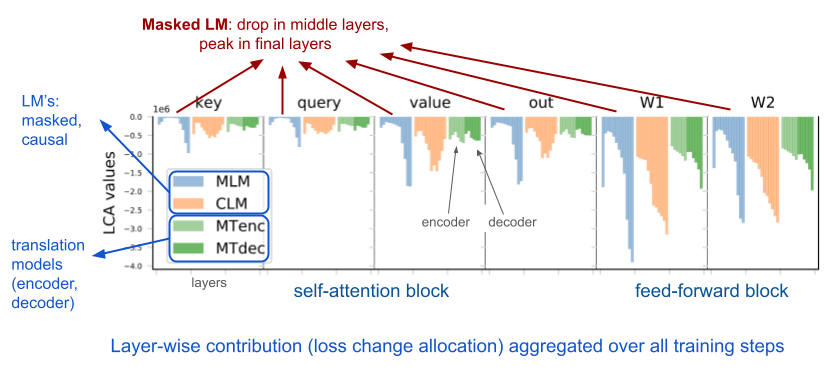
Interesting differences appear depending on the training objectives applied. Middle layers in masked language models contribute less to the optimization of the loss function whereas translation models are more balanced. Causal language models are somewhat in between and reflect quite well the behavior of the translation model decoder, which is quite natural as they both represent generative components. The overall contribution of the feed-forward block is also remarkable. This demonstrates that a lot of adjustments need to be made in that component especially in upper layers.

Looking at the loss change allocation over time, we can also see the effect of strong activities in upper layers. Naturally, the biggest changes happen in the beginning after some warmup period. Masked language models seem to oscillate for a slightly longer time but this may be a scaling effect as well.
Aggregating LCA over individual attention heads is also interesting. In general, change allocations are quite evenly distributed but it also looks like certain heads do the heavy lifting in active layers.
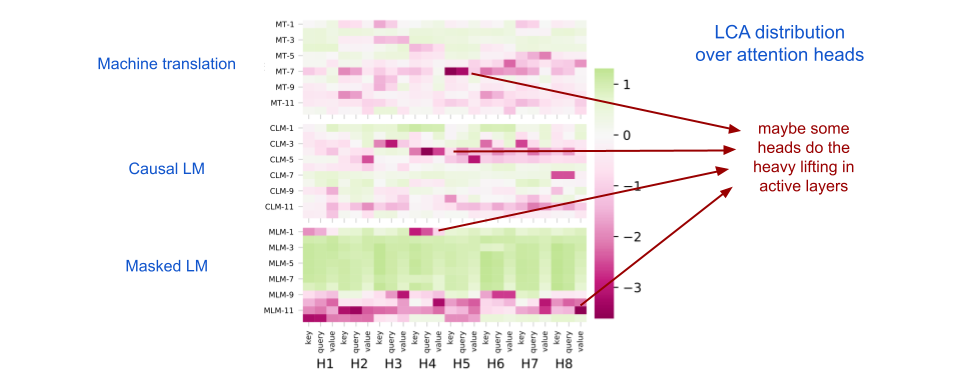
Looking at those insights, it can be useful to re-think model architectures and training schedules. LCA provides valuable information that could lead to more efficient model design and training procedures.
Disentangle representations
One of the most interesting questions in interpretability studies is to find out what kind of information is encoded in neural language models and where. Can we identify the components that represent certain specific attributes or types of linguistic knowledge? We applied a de-biasing technique based on iterative nullspace projection that tries to identify a projection that removes information from pre-trained embeddings that can be used by a linear classifier to detect such information (see Ravfogel at el., 2020 for more information).
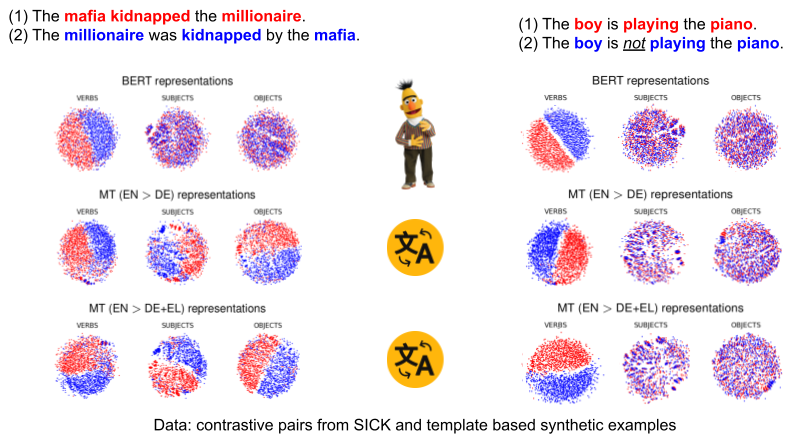
We conducted an experiment to study the imprint of passivization and negation on contextualized embeddings (in English), comparing masked language models and translation encoders. Looking at the plots above, we can see that translation encoders clearly mark passivization information at verbs, subjects and objects whereas BERT seems to put it on verbs only. This may indicate that the voice feature is more important across positions in translation tasks then it would be in masked word prediction. Changing or adding target languages may affect the situation but our limited experiment did not clearly show any patterns. Negation, however, seems to be mainly attached to verbs in both cases, masked language modeling and translation.
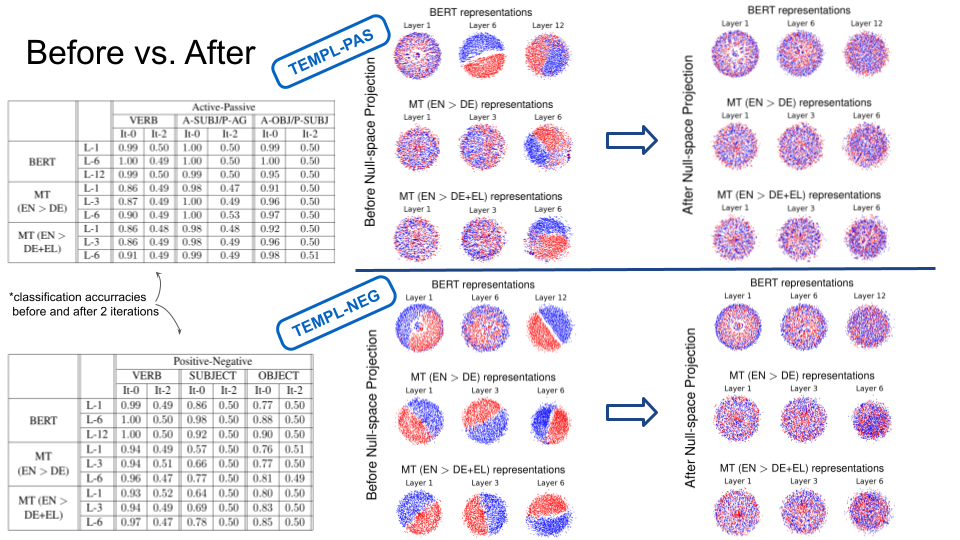
The nullspace projection procedure seems to be very effective in removing those specific properties as we can see in the plots above. From all layers, the distinction between the contrastive alternatives is basically gone, demonstrating the possibility to disentangle the contextual representations with a simple projection technique. However, the projection matrix is not easily ported across datasets, which shows the remaining difficulties in finding principled ways of extracting specific linguistic information from the complex knowledge structure incorporated in deep neural networks.
References
- Johannes Bjerva, Robert Östling, Maria Han Veiga, Jörg Tiedemann, and Isabelle Augenstein. 2019. What Do Language Representations Really Represent?. Computational Linguistics, 45(2):381–389.
- Robert Östling and Murathan Kurfali, 2023 Language Embeddings Sometimes Contain Typological Generalizations. In: Computational Linguistics, 45(2): 1003-1051.
- Kawin Ethayarajh. 2019. How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 55–65, Hong Kong, China. Association for Computational Linguistics.
- Alessandro Raganato and Jörg Tiedemann. 2018. An Analysis of Encoder Representations in Transformer-Based Machine Translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 287–297, Brussels, Belgium. Association for Computational Linguistics.
- Alessandro Raganato, Yves Scherrer, and Jörg Tiedemann. 2020. Fixed Encoder Self-Attention Patterns in Transformer-Based Machine Translation. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 556–568, Online. Association for Computational Linguistics.
- Raúl Vázquez, Hande Celikkanat, Mathias Creutz, and Jörg Tiedemann. 2021. On the differences between BERT and MT encoder spaces and how to address them in translation tasks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: Student Research Workshop, pages 337–347, Online. Association for Computational Linguistics.
- Raúl Vázquez, Hande Celikkanat, Vinit Ravishankar, Mathias Creutz, and Jörg Tiedemann. 2022. A Closer Look at Parameter Contributions When Training Neural Language and Translation Models. In Proceedings of the 29th International Conference on Computational Linguistics, pages 4788–4800, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. 2020. Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7237–7256, Online. Association for Computational Linguistics.
- Hande Celikkanat, Sami Virpioja, Jörg Tiedemann, and Marianna Apidianaki. 2020. Controlling the Imprint of Passivization and Negation in Contextualized Representations. In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 136–148, Online. Association for Computational Linguistics.