
Multilingual NMT and downstream tasks
The beauty of pre-trained language models is the ability to provide information that can be useful for other downstream tasks. Neural translation models can be used in the same way and, for example, the encoder of a pre-trained translation model can be used to obtain contextualized embeddings in the same way as masked or causal language models can do.
The vision of FoTran is to see whether multilingual training signals are effective for improved generalizations leading to more abstract representations that better support complex reasoning tasks. The attention bridge model introduced in sub-project 1 was designed to create such cross-lingual representation that would directly be applicable in unrelated downstream tasks. The fixed size of the shared layer makes it possible to use the representation as is without pooling or other types of manipulations. However note that pooling is still needed if the size becomes too big.
Our initial experiments with the model revealed that multilingual training is, indeed, beneficial in downstream tasks compared to bilingual baselines. Evaluations on SentEval demonstrate the affect of multilinguality:

Probing tasks mostly support this impression as well as we can see in the plots for SentEval tasks below. However, the picture is a bit mixed, which is not very surprising as many probing tasks look at surface-based linguistic features that may differ a lot across languages and a multilingual cross-lingual representation may confuse the classifier rather than supporting it.
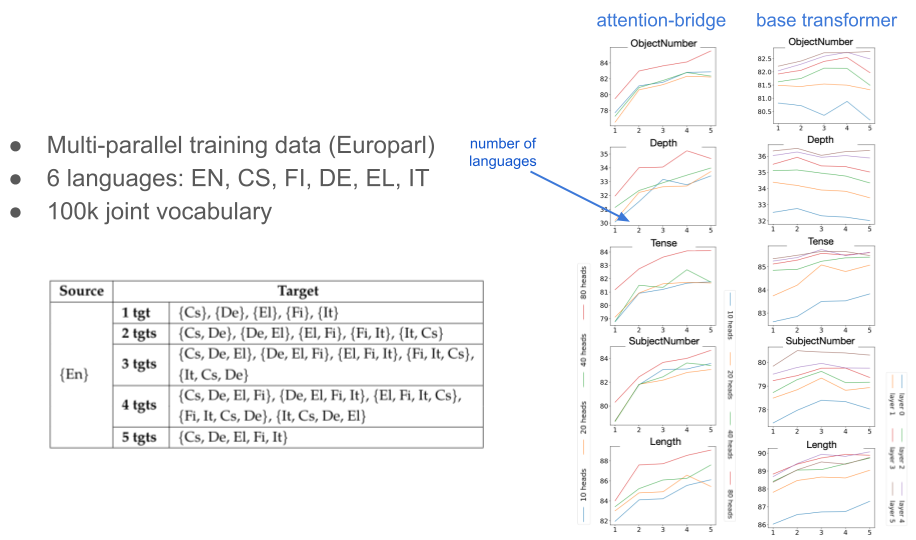
In comparison to base transformers, the attention bridge model seem to benefit more from multilinguality supporting the positive effect of the explicit cross-lingual bottleneck that the attention bridge creates.
The effect of parameter sharing
Moving to the MAMMOTH framework, we can more systematically study the effect of parameter sharing. To motivate the importance of architectural decisions, we ran a systematic comparison of translation models with different levels of parameter sharing, here on the encoder side only. To study the effect of multilinguality, we ran a controlled experiment with increasing language coverage coming from the English-centric data collection in OPUS-100.
The first test is on cross-lingual natural language inference tasks (XNLI):
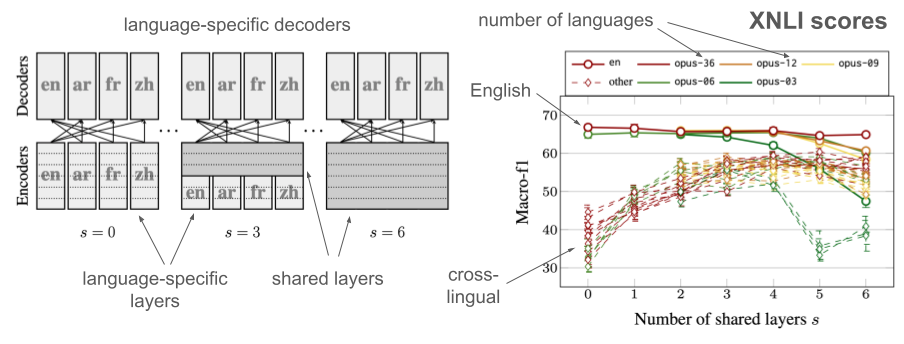
The results show that full parameter sharing is not necessary and can even be detrimental, both, in supervised and cross-lingual settings. For cross-lingual tests, we can clearly see the benefits of parameter sharing but only up to a certain point. This is good news for multilingual models and modular architectures in general.
We also looked at language specific NLU tasks collected in benchmarks for English, Arabic, Chinese and French. The following plots show normalized average scores with different levels of parameter sharing:
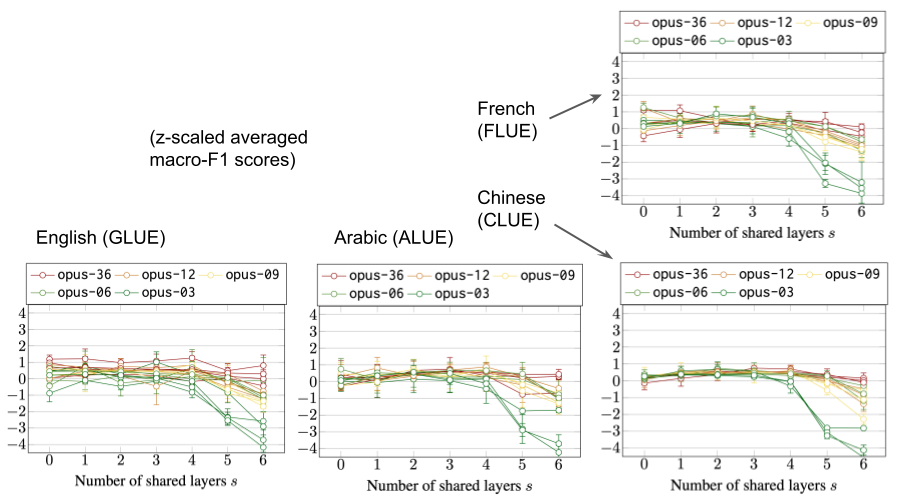
Similar to XNLI, we can see again that full parameter sharing is not optimal but partial sharing works well. However, contrary to our believes, we cannot see any consistent increase of representational power when adding languages to the mixture. This is in contradiction with out earlier findings on SentEval downstream tasks and the vanilla attention bridge model. More detailed studies would be needed to investigate the behavior of multilingual models with respect to monolingual reasoning tasks.
Robustness of NLU benchmarks
At the same time as we were looking at downstream tasks, we also realized that many benchmarks are not very robust. Working on natural language inference (NLI), we saw surprising results when manipulating data sets while running standard models to predict the correct class for complex reasoning tasks. This led to a series of diagnostics that can and should be applied to NLU benchmarks before drawing general conclusions about the capabilities of language models to understand natural languages.

The basic idea we tested is to apply various kinds of data corruptions to test the impact on common benchmark results such as MNLI. We found out that classification performance can be surprisingly robust even if we remove essential information from the data. The figure above illustrates the procedure:
- remove words of a certain type from training and/or test data
- train NLI classifiers on various variants and combinations of data sets
- evaluate and analyze the differences that come out of the various setups
The table above shows that removing even content words alters accuracy surprisingly little, which hints on over-fitting effects and spurious features that trigger decisions. A small-scale study on human performance with corrupted data shows that successful reasoning is seriously damaged with such types of data manipulations, but the models seem to suffer relatively little in comparison.
At first sight, one may expect that lexical features may cause this effect. However, the plot on the top-right shows that there is no clear correlation between accuracy and lexical overlap between original and corrupted data. But that does not disprove the potential risk of lexical overfitting.
Similar observations and issues with, especially, NLI have been observed by other researchers. Stress-testing and breaking NLI became a popular enterprise. Together with our data corruption techniques, we recommend to run a set of sanity checks and diagnostics to assess the quality of any NLI benchmark, including word-shuffling, hypothesis-only baselines, premise-hypothesis-swapping and our word-class dropping.

In follow-up work, we then looked at different NLU benchmarks and studied the effect of data corruption on the GLUE tasks. Above, the plots show the reduction in accuracy when removing words of certain word classes from the test data, the training data and both data sets, respectively. Rows correspond to different tasks and columns to selected word classes. We can see that nouns have overall the biggest impact, which could be expected, but there are certainly significant differences between the tasks.
Running diagnostics like this, is a useful way to understand the quality of benchmarks and provides insights about the level of generality we can expect from each of the tasks.
References
- Alessandro Raganato, Raúl Vázquez, Mathias Creutz, and Jörg Tiedemann. 2019. An Evaluation of Language-Agnostic Inner-Attention-Based Representations in Machine Translation. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), pages 27–32, Florence, Italy. Association for Computational Linguistics.
- Raúl Vázquez, Alessandro Raganato, Mathias Creutz, and Jörg Tiedemann. 2020. A Systematic Study of Inner-Attention-Based Sentence Representations in Multilingual Neural Machine Translation. Computational Linguistics, 46(2):387–424.
- Michele Boggia, Stig-Arne Grönroos, Niki Loppi, Timothee Mickus, Alessandro Raganato, Jörg Tiedemann, and Raúl Vázquez. 2023. Dozens of Translation Directions or Millions of Shared Parameters? Comparing Two Types of Multilinguality in Modular Machine Translation. In Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), pages 238–247, Tórshavn, Faroe Islands. University of Tartu Library.
- David Mareček, Hande Celikkanat, Miikka Silfverberg, Vinit Ravishankar, Jörg Tiedemann. 2020. Are Multilingual Neural Machine Translation Models Better at Capturing Linguistic Features? In The Prague Bulletin of Mathematical Linguistics, pages 143-162
- Aarne Talman, Marianna Apidianaki, Stergios Chatzikyriakidis, and Jörg Tiedemann. 2021. NLI Data Sanity Check: Assessing the Effect of Data Corruption on Model Performance. In Proceedings of the 23rd Nordic Conference on Computational Linguistics (NoDaLiDa), pages 276–287, Reykjavik, Iceland (Online). Linköping University Electronic Press, Sweden.
- Aarne Talman and Stergios Chatzikyriakidis. 2019. Testing the Generalization Power of Neural Network Models across NLI Benchmarks. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 85–94, Florence, Italy. Association for Computational Linguistics.
- Aarne Talman, Marianna Apidianaki, Stergios Chatzikyriakidis, and Jörg Tiedemann. 2022. How Does Data Corruption Affect Natural Language Understanding Models? A Study on GLUE datasets. In Proceedings of the 11th Joint Conference on Lexical and Computational Semantics, pages 226–233, Seattle, Washington. Association for Computational Linguistics.