Kurssin viimeinen viikko jatkui interpolointien parissa. Vedimme tällä viikolla viivan determinististen sekä geostatististen interpolointien välille, ja käsittelimme niiden eroavaisuuksia. Viime viikko keskittyi pääasiassa deterministisiin interpolointimenetelmiin, kuten IDW- ja Kernel-interpolointiin. Deterministinen interpolointi ei hyödynnä tilastotiedettä samalla tavalla kuin geostatistinen interpolointi, vaan rakentuu lähinnä vierekkäisten mittauspisteiden arvojen perusteella. Geostatistinen interpolointi ottaa puolestaan kattavammin huomioon muuttujien spatiaalisen vaihtelun. Interpolointi painottuu tällöin spatiaaliseen autokorrelaatioon ja tilastotieteeseen. Spatiaalisen autokorrelaation ideana on, että kohteet jotka ovat lähekkäin toisiaan, ovat enemmän riippuvaisia toisistaan kuin kaukana sijaitsevat kohteet. Spatiaalinen tilastotiede (johon geostatistinen interpolointi pohjautuu) olettaakin, että tällaista riippuvuutta esiintyy luonnossa. Menetelmä mahdollistaa siksi myös virhemarginaalien tarkastelun, ja tulosten validiteetin kattavamman arvioinnin.
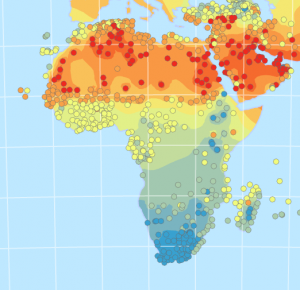
Viikon harjoitustehtävät painottuivat pääasiassa geostatistiseen kriging-interpolointiin. Vertasimme ensimmäisessä tehtävässä (Interpolate temperatures using the Geostatistical Wizard) IDW- ja kriging-interpolointia. Toisin sanoen tutkimme miten deterministinen interpolointi ja geostatistinen interpolointi käytännössä eroavat keskenään ja mitä samankaltaisuuksia niillä mahdollisesti on. Kriging-interpolointi huomioi spatiaalisen autokorrelaation voimakkuutta ja ulottumista, jolloin sen avulla voidaan myös laskea todennäköisyyksiä, virheitä sekä luotettavuutta. Sanoisin siis hypoteesina jo nyt, että kriging-interpolointi osoittautuu tehtävässä “paremmaksi” menetelmäksi tulosten tarkasteluun. Vertailimme tehtävässä näitä kahta menetelmää interpoloimalla dataa Afrikassa tehdyistä lämpötila mittauksista.
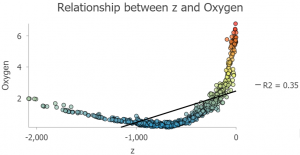
Ensin loimme datan perusteella histogrammin lämpötilamittauksista, sillä lämpötilojen jakautumista on helpompi tutkia sen avulla. Tämä työvaihe tuli tutuksi jo viime viikon harjoitustehtävissä. Histogrammia tutkiessa voidaankin huomata, että elokuun lämpötilat seuraavat aika hyvin normaalijakaumaa, jolloin myös geostatistinen interpolointi on kaikista tehokkainta. (Pakko myöntää etten vieläkään pienen pohtimisen jälkeen ole täysin varma miksi interpolointi on tällöin tehokkainta, näin kuitenkin todettiin tehtävässä.) Tämän havainnon jälkeen suoritimme ensin IDW-interpoloinnin elokuussa mitatuilla arvoilla. Suoritimme kaksi IDW-interpolointia, joista toista on optimoitu dataan sopivammaksi muuttamalla tiettyjä parametreja (kuva 1).
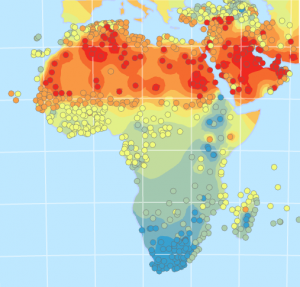
Kuva 1. Vasemmalla on IDW smooth -taso ja oikealla IDW Smooth Optimized -taso. (Lähde: Esri Academy – Interpolate temperatures using the Geostatistical Wizard)
Kuten kuvasta 1 voidaan todeta, punaiset alueet (eli korkeimmat lämpötila estimaatit) kattavat nyt kartalla laajemman alueen. Tasot ovat muuten hyvin samanlaisia ja on hyvin vaikea spontaanisti sanoa, kumpi näistä on luotettavampi. Tutkimme siksi tuloksia seuraavaksi ristiinvalidoinnin avulla. Keskityimme tarkkailemaan tasojen neliöllistä keskiarvoa (root mean square). Mitä lähempänä keskiarvo on nollaa, sen täsmällisempi taso on. Nopean ristiinvalidoinnin perusteella voidaankin sanoa, että IDW Smooth Optimized -tasolla on pienempi virhemarginaali ja sitä voidaan siksi pitää luotettavampana.
IDW-tasojen tutkailun jälkeen siirryimme kriging-interpolointiin. Geostatistisen luonteen takia kriging-interpolointi tarjoaa paljon enemmän tunnuslukuja ja muuttujia, joiden avulla datan luotettavuutta voidaan tutkia. Tehtävässä lueteltiinkin pitkä lista eri parametreja ja niiden vaikutuksia interpoloinnin tulokseen. Tämä oli omasta mielestäni erittäin hyödyllistä ja auttoi ymmärtämään interpolointi-prosessia edes jonkin verran syvemmin. Suoritimme siis kaksi kriging interpolointia: kriging default ja kriging modified. Alkuperäistä interpolointia modifioitiin mm. optimoimalla ja määrittämällä sen “sector type” niin, ettei yksittäisen suunnan naapureilla olisi yhtä isoa vaikutusta tuloksessa.
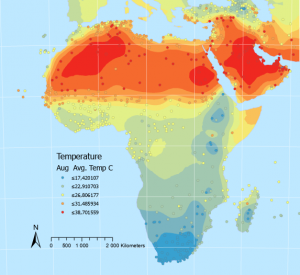 Kuva 2. Interpoloinnin tuloksena saatu Kriging modified -taso, josta on laadittu lämpötiloja mallintava kartta. (Lähde: Esri Academy – Interpolate temperatures using the Geostatistical Wizard)
Kuva 2. Interpoloinnin tuloksena saatu Kriging modified -taso, josta on laadittu lämpötiloja mallintava kartta. (Lähde: Esri Academy – Interpolate temperatures using the Geostatistical Wizard)
Tämän jälkeen vertailimme tasoja ristiinvalidoinnin avulla. Tasojen tunnusluvut olivat niin lähellä toisiaan, ettei tässä tapauksessa ollut kirkkaan selvää kumpi on luotettavampi. Kriging modified -tasolla oli kuitenkin hieman parempi neliöllinen keskiarvo, ja tämän perusteella valitsimme sen kriging default -tason sijaan. Kun näitä molempia tasoja verrattiin puolestaan aikaisempaan IDW Smooth Optimized -tasoon, huomattiin että kriging-interpoloinnilla saadut tulokset olivat kaiken kaikkiaan tarkempia. Ihan viimeisenä laadimme vielä kriging modified -tasolle näppärän virhekartan (kuva 3), joka kuvaa interpoloinnin luotettavuutta eri puolilla karttaa.
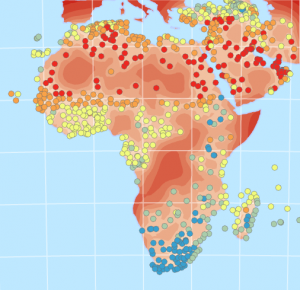 Kuva 3. Virhekartta. (Lähde: Esri Academy – Interpolate temperatures using the Geostatistical Wizard)
Kuva 3. Virhekartta. (Lähde: Esri Academy – Interpolate temperatures using the Geostatistical Wizard)
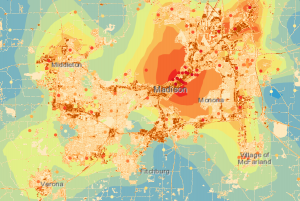
Toisessa harjoitustehtävässä (Analyze Urban Heat Using Kriging) tutkimme lämpösaarekeilmiötä Madisonin kaupungissa, Wisconsinissa, ja sen vaikutusta kaupungissa asuviin – varsinkin riskiryhmään kuuluviin vanhempiin asukkaisiin. Tehtävässä hankalinta oli ehkäpä termien ja konseptien järkevä kääntäminen suomen kielelle. Käytimme tässäkin tehtävässä apuna kriging-interpolointia ja aloitimme ensin luomalla datan pohjalta histogrammin (kuva 4), jotta voitaisiin määrittää onko lämpösaarekeilmiö alueella edes todellinen. Nopean tarkastelun jälkeen voidaan todeta, että lämpösaarekeilmiö on havaittavissa, sillä alimmat lämpötilat sijoittuvat kaupunkia ympäröiville alueille ja korkeimmat lämpötilat kaupungin keskusalueille.
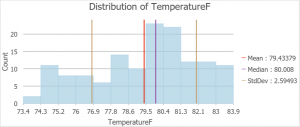
Kuva 4. Histogrammi datasta. (Lähde: Esri Academy – Analyze Urban Heat Using Kriging)
Tämän jälkeen suoritimme ensin (simple) kriging-interpoloinnin. Säädimme interpoloinnin parametrejä niin, että virhemarginaali olisi mahdollisimman pieni. Myös interpoloinnin tulosta tarkastellessa voidaan todeta, että lämpösaarekeilmiö on todellinen (kuva 5). Tehtävässä olennaista oli simple kriging -interpoloinnin vertaaminen bayesian kriging -interpolointiin. Näin lyhyesti selitettynä geostatinen interpolointi pohjautuu semivariogrammeihin (ilmaisevat riippuvuuden määrää datassa). Bayesian kriging -menetelmässä data jaetaan pieniin osiin, ja jokaiselle osalle luodaan oma semivariogrammi yhden koko datan kattavan semivariogrammin sijaan. Näin saadaan vielä tarkempi mallinnus datasta, jossa on yleensä pienemmät virhemarginaalit (kuva 5).
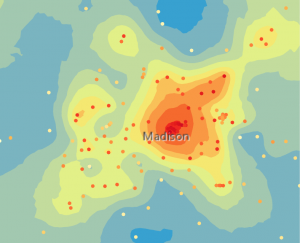
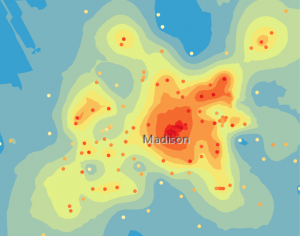
Kuva 5. Vasemmalla simple kriging -interpolointi ja oikealla empirical bayesian kriging -interpolointi. (Lähde: Esri Academy – Analyze Urban Heat Using Kriging)
Seuraavassa työvaiheessa käytimme EBK (empirical bayesian kriging) regression –työkalua. Tämän avulla sisällytimme interpolointiin dataa vettä läpäisemättömistä pinnoista, kuten asfaltoiduista teistä ja parkkipaikoista. Leikkasimme samalla myös tarpeetonta dataa extract by mask -työkalulla. Teimme datasta pistekaavion (kuva 6), joka osoittaa kytköksen mitattujen lämpötilojen ja vettä läpäisemättömien pintojen osuuksista. Pintojen huono absorptio ja suuri albedo vaikuttavat paikallisesti lämpötilaan sitä nostaen. Siksi mitä enemmän vettä läpäisemättömiä pintoja on, sitä korkeammat ovat mitatut lämpötilat.
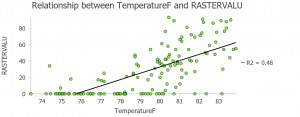 Kuva 6. Pistekaavio vettä läpäisemättömien pintojen ja lämpötilojen suhteesta. (Lähde: Esri Academy – Analyze Urban Heat Using Kriging)
Kuva 6. Pistekaavio vettä läpäisemättömien pintojen ja lämpötilojen suhteesta. (Lähde: Esri Academy – Analyze Urban Heat Using Kriging)
Pääsimme tekemään tehtävässä myös paljon ristiinvalidointia, kun päätimme mitä kriging-interpoloinnilla saaduista tuloksista on paras käyttää datan syvempään tarkasteluun. Kun olimme valinneet luotettavimman tuloksen, yhdistimme siihen dataa kaupungin alueista ja tutkimme millä alueilla lämpösaarekeilmiö on voimakkainta. Näihin alueisiin tai niin sanottuihin “blokkeihin” oli sidottuna dataa myös alueen asukkaista. Tämän perusteella pystyimme identifioimaan alueet, joilla riskiryhmään kuuluvien asukkaiden osuus on huomattava. Valitsimme alueet valintatyökalun avulla ja annoimme ehdoiksi “mean is greater than 81” ja “densityover65 is greater than 100000”. Nän ArcGIS määritti alueet, joilla lämpötilan keskiarvo on yli 81 fahrenheitia ja 65-vuotiaiden asukkaiden asukastiheys on enemmän kuin 100000 (kuva 7).
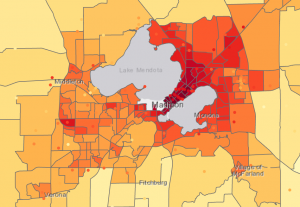
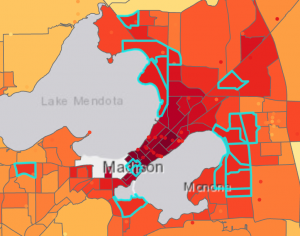
Kuva 7. Yhdistetty data. Oikealla sinisellä alueet, jotka määritetiin valintatyökalulla. (Lähde: Esri Academy – Analyze Urban Heat Using Kriging)
Lähteet
Holopainen et al. (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7.
Tehtävälähteet
Interpolate temperatures using the Geostatistical Wizard https://www.arcgis.com/sharing/rest/content/items/0eb5f9204170449da8230fe6a887e053/data
Analyze Urban Heat Using Kriging https://www.esri.com/training/catalog/5b4e36a842cbd2069a939171/analyze-urban-heat-using-kriging/