

Kuva 1. Maistiainen tämän viikon tehtävistä. Taustalla vihreällä valkopäämerikotkalle suotuisat asuinalueet.
Kolmas viikko jatkui edellisen viikon soveltuvuusanalyyseistä. Tuolloin valmisteltu data voidaan nyt vihdoin koota yhteen ja määrittää San Bernardinon luonnonpuistossa alueet, joilla Yhdysvaltain kansallislintua tullaan todennäköisimmin tapaamaan (kuva 1). Luennolla puolestaan tutustuimme mm. metatietoon, muuttujiin sekä niiden ominaisuustaulukoihin ja koordinaatistoihin paikkatietojärjestelmissä. Lisäksi kävimme läpi rasteriaineistojen käsittelyssä olennaisia työkaluja, joista useampaa käytimme myös tämän viikon tehtävissä. Tällä viikolla ongelmaa tuntui tuottavan erityisesti valtava uuden tiedon määrä, sekä Esri Academyn käsitteiden ja konseptien järkevä kääntäminen suomen kielelle. Tiedon määrän takia tuntuu myös, että raportista tuli vähän turhan pitkä. Valkoisen paperin kammo ei auttanut asiaa, kun oma käsitys oleellisesta ja epäolennaisesta hämärtyi sen vaikutuksesta.
| Criteria | Dataset |
| Far from developed areas | Land cover raster |
|
Not too densely or sparsely covered by forest (ranging from 20 percent to 60 percent) |
Tree canopy raster |
| Close to lakes (fewer than 2 miles) | Major lake polygons |
| Located on northeast-facing aspects | DEM raster (digitaalinen korkeusmalli) |
Taulukko 1. Valkopäämerikotkan esiintymisen kannalta optimaalisten alueiden kriteerit ja niiden käsittelyyn tarvittavat aineistot. Lähde: (Esri Academy – Creating a Simple Suitability Model)
Pääsimme siis ensimmäisessä tehtävässä takaisin binäärisen soveltuvuusanalyysin pariin. Analyysin avulla määritämme valkopäämerikotkalle suotuisia asuinpaikkoja tiettyjen kriteerien perusteella (taulukko 1). Tehtävänannossa kerratiin ja syvennyttiin binäärisiin (binary) ja painotettuihin (weighted) soveltuvuusanalyyseihin. Kuten viime viikolla todettiin, binäärisessä analyysissä uudelleen luokitellaan solujen arvot binäärilukujen 0 ja 1 avulla. Tällöin luku 1 saa arvon “meets the criteria” ja luku 0 saa arvon “doesn’t meet the criteria”. Painotetun (weighted) soveltuvuusanalyysin avulla puolestaan annetaan eri painoarvot prosentteina eri rasterikartoille sen perusteella millainen lopputulos halutaan. Eli mitä korkeampi arvo, sen enemmän painoarvoa tasolla on. Tätä harjoittelimme myös viikon viimeisessä tehtävässä. Alapuolella havainnollistava kuva kyseisestä weighted overlay -prosessista.
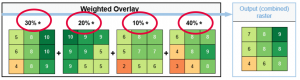
Kuva 2. Weighted overlay -prosessia havainnollistava kuva. (Lähde: Luentodiat)
Tehtävänannossa painotettiin binäärisen analyysin kätevyyttä, kun halutaan määrittää soluja, jotka täyttävät kokonaan halutut vaatimukset. Binäärisiä rastereita voidaankin käyttää ns. “maskina” tai “maskirastereina”. Näiden avulla pystytään peittämään analyysin kannalta ei-halutut tai soveltumattomat alueet. Valkopäämerikotka esimerkissä maskina voitaidaan käyttää järviä mallintavaa rasteritasoa, ja peittää järvi-alueet antamalla niille arvo 0. Järvien pinta-alueita ei tarvita tarkastelussa, sillä nämä alueet eivät sovellu valkopäämerikotkan asuinalueiksi ja siksi ne on hyvä peittää. Vaikka binääriset soveltuvuusanalyysit ovat käteviä ja helppoja, niitä ei voi käyttää jos halutaan mallintaa jatkuvaa skaalaa. Tällöin on hyvä käyttää esimerkiksi “weighted” tai “fuzzy” -malleja.
Tehtävässä olennaisinta oli viime viikolla valmistellun datan yhdistäminen. Tasot yhdistettiin “suitability surface” -tasoksi, joka mallintaa kaikkia kriteerejä samanaikaisesti, ja jonka avulla voidaan nyt määritellä valkopäämerikotkalle optimaaliset asuinalueet. Data koottiin yhteen “raster calculator“ -työkalun avulla. Yhdistämisessä käytetään kertolaskua, sillä mikä vain luku kertaa 0 on 0. Näin saadaan kaikki halutut kriteerit esiintymään samanaikaisesti. Tasojen yhdistäminen tapahtui lähinnä modelbuilderissä eli muokkasimme työvaiheketjua (kuva 3) lisäilen sinne työvaiheita. Kun suoritimme ketjuun lisätyt työvaiheet “run” -komennolla, saimme vihdoin tason, joka mallintaa parhaimpia alueita. En pitänyt siitä, millaiseksi tehtävä käski karttaa tekemään, joten päätin visualisoida sopivat alueeet tummanvihreällä (kuva 4).
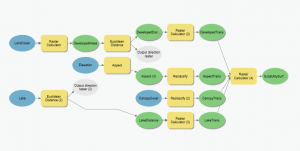
Kuva 3. Ensimmäisen tehtävän työvaiheketju. Lähde: (Esri Academy – Creating a Simple Suitability Model)
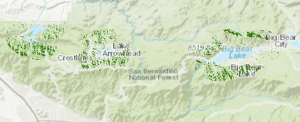
Kuva 4. Binäärisellä soveltuvuusanalyysillä määritellyt kohteet. Tummanvihreät alueet ovat valkopäämerikotkan esiintymisen kannalta optimaalisia alueita San Bernardinon luonnonpuistossa.
Tutustuimme samassa tehtävässä käsitteisiin “sensitivity analysis” ja “error analysis”, jotka ovat relevantteja myös viimeisen tehtävän yhteydessä. Herkkyysanalyysillä määritetään kuinka suuri – tai millainen vaikutus – lopulliseen dataan on, jos muutetaan jotain mallin parametreistä. Parametriä muutetaan työvaiheketjussa, jonka jälkeen ketju suoritetaan uudestaan “run” -komennolla. Vaikutuksen arviointi tapahtuu visuaalisesti saaduista tuloksista. Jos tulos eroaa paljon alkuperäisestä, on se korkeasti sensitiivinen kyseiselle parametrille. Suoritimme herkkyysanalyysin tehtävässä modifioimalla CanopyTrans -layeria. Muutimme erästä luokkaa latvustonpeitettä kuvaavassa tasossa kymmenellä yksiköllä.
Virheanalyysissä tutkitaan miten alkuperäisten datasettien (esimerkiksi niiden arvojen) virheet vaikuttavat lopputulokseen. Kun virhe on “istutettu” modelbuilderin avulla, suoritetaan taas komennot ja analysoidaan lopputulosta visuaalisesti. Jos lopputulos on suuresti muuttunut, on hyvä vaihtaa datasettiä tai miettiä uudelleen miten alkuperäistä tulosta on tulkittava. Suoritimme virheanalyysin niin, että poistimme “elevation” -tason ja korvasimme sen “DEM_error” -tasolla, joka on harjoitusta varta vasten laadittu eri arvoja sisältävä taso. DEM:iä eli korkeusmallia voi muuttaa esimerkiksi +/- 1 metrin. Tällä muutoksella ei ollut suuresti vaikutusta verrattuna alkuperäiseen tulokseen.
Toisessa tehtävässä pääsimme käyttämään painotettua (weighted) soveltuvuusanalyysiä. Tutkimme aivan samaa ilmiötä kuin aikaisemmin eli valkopäämerikotkalle optimaalisia asuinalueita metsästetään vieläkin. Latasimme datan Esri Academysta, joka sisälsi jo puolilleen valmiin työvaiheketjun. Käytimme “reclassify” -työkalua melkeinpä kaikkiin datan rasteritasoihin, jotta saisimme ne muokattua kriteerien mukaisiksi (taulukko 1). Esimerkiksi annoimme työkalun avulla skaalalla 1-10 niille soluille suurimmat arvot, joiden latvustopeite on lähellä 45%. Tämän avulla kriteeri “Not too densely or sparsely covered by forest” täyttyy. Kun tasoja oltiin muokattu kriteerien mukaisiksi, suoritimme työvaiheketjun ja pääsimme tutkimaan saatuja tuloksia (kuva 5).
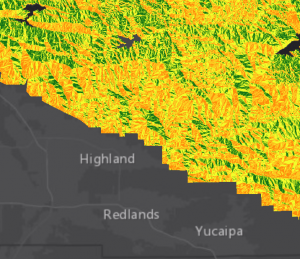
Kuva 5. Kriteerien perusteella muokattu “aspect” -taso, joka kuvaa rinteen suuntaa.
Tästä jatkoimme sitten seuraavassa tehtävässä kuten binäärisen soveltuvuusanalyysin kanssa eli yhdistimme äskettäin “reclassify” -työkalulla muokatut tasot. Tasot yhdistettiin painotetun soveltuvuusanalyysin mukaisesti antamalla niille eri prosentteihin pohjautuvia arvoja. Analyysiä tehdessä pitää muistaa, että arvojen yhteenlaskettu osuus ei tule ylittää 100%. Kun eri tasot oltiin yhdistetty modelbuilderin avulla, saatiin yhteinen rasteritaso “suitability surface”. Skaalasimme rasteritason arvot käyttäen “percent clip” -skaalausta, joka poimii prosenttuaalisesti suurimmat ja pienimmät arvot, ja tekee niiden välissä oleville arvoille lineaarisen skaalauksen. Lopputulos oli ainakin subjektiivisesti sanottuna miellyttävän näköinen (kuva 6).
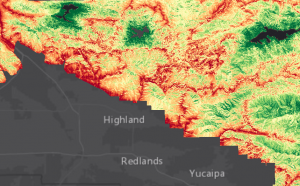
Kuva 6. Painotetulla (weighted) soveltuvuusanalyysillä määritellyt kohteet. Tummanvihreät alueet ovat valkopäämerikotkan esiintymisen kannalta optimaalisia alueita San Bernardinon luonnonpuistossa. Lähde: (Esri Academy – Creating a Weighted Suitability Model)
Tämän jälkeen suoritimme herkkyys- ja virheanalyysin tulokselle. Teimme tämän kutakuinkin samalla taktiikalla kuin binäärisen soveltuvuusanalyysin kanssa. Toki prosessit erosivat toisistaan hieman, sillä painotettu soveltuvuusanalyysi skaalautuu jatkuvasti, kun taas binäärinen analyysi ei. Tässä tilanteessa herkkyysanalyysi voidaan toteuttaa muuttamalla joko yksittäistä parametriä, tai sitten jonkun tason painotuksen arvoa. Kahta tasoa muutetaan niin, että tasojen yhteenlaskettu prosenttiosuus on silti 100%. Muutimme “Developed areas” -tason arvoa luvusta 0.3 lukuun 0.2. Koska käytimme “weighted sum” -työkalua, ei kaikkien yhteenlaskettujen prosenttiosuuksien tarvinnut olla 100%. Virheanalyysin teimme samallalailla kuin binäärisessä soveltuvuusanalyysissä eli muuttamalla DEM-rasteria DEM_error -rasteriksi. Kummassakaan tapauksessa lopputulos ei juuuri muuttunut. Solujen välisten arvojen magnitudi muutui hieman ja tämä ilmeni esimerkiksi alueiden värien tummumisena. Vaikutuksesta värierot kasvoivat, ja omasta mielestäni kartta näyttää nyt hieman dramaattisemmalta. Tarkkasilmäiset huomaavat tämän eron kuvissa 7 ja 8. Voidaan siis sanoa, että mallin herkkyys muutoksille (ainakin näiden muuttujien suhteen) on matala.
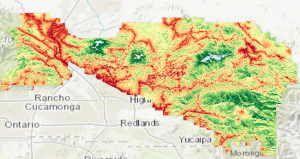

Kuva 7 ja 8. Yläpuolella on alkuperäinen “suitability surface” ja alapuolella on herkkyysanalyysin tuloksena saatu “sensitivity surface”.
Lähteet
Holopainen et al. (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7.
MAA-221 Geoinformatiikan menetelmät 2 (syksy 2020) luentodiat, Opettaja Petteri Muukkonen
Tehtävälähteet ja data
1.https://www.esri.com/training/catalog/5cad02009b1f4010cad9abdc/creating-a-simple-suitability-model/
2.https://www.esri.com/training/catalog/5cbf7e046b7be962098492f4/transforming-data-for-a-weighted-suitability-model/
3.https://www.esri.com/training/catalog/5cbf7e336b7be96209849309/creating-a-weighted-suitability-model/