
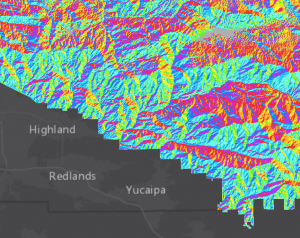
Kuva 1. Kolmannen tuntitehtävän mukaan ArcGIS Pro:lla luotu rasterimuotoinen kartta (Lähde: Esri Academy – Preparing Data for a Suitability Model)
Kun ensimmäinen viikko painottui laajalti vektorimuotoisiin aineistoihin ja niiden kanssa työskentelemiseen, niin toinen viikko painottui luontaisesti rasteriaineistojen muokkauksiin sekä analyyseihin. Koen rasterianalyysien olevan hieman hankalampia kuin vektorianalyysien. Rasteriaineistot koostuvat useista ominaisuustietoa sisältävistä pikseleistä, jotka määräävät koollaan aineiston resoluution. Vektoriaineistoissa kohteet kuvataan pikseleiden sijaan pisteinä, viivoina tai polygoneina ja ne pitävät sisällään enemmän ominaisuustietoa, joka tekee niistä omasta mielestäni suoraviivaisempia analysoinnin kohteita.
Rasterimuotoisten aineistojen analyysit koostuvat jopa hyvin kompleksisista työvaiheista, jotka seuraavat tarkasti toisiaan ja muodostavat ns. työvaiheiden ketjuja (function chain). Kävimme luennolla läpi juurikin kuinka työvaiheita (ja työvaiheiden ketuja) voidaan tallettaa ArcGIS Pro:ssa eräänlaisiksi pohjamalleiksi (template). Ne auttavat ensinnäkin työvaiheiden seuraamisessa, mutta myös nopeuttavat työskentelyä paljon. Kävimme luennolla lisäksi läpi rasteriaineistojen visualisointia, värivalintojen tärkeyttä, sekä eri rasteriaineistojen esitysmalleja. Rasteriaineistoja laatiessa on turvallista luottaa ns. “intuitiivisiin väreihin” ja käyttää universaalisesti tunnettuja värejä symboloimaan eri kohteita. Lisäksi voidaan miettiä esitetäänkö tiettyä ilmiötä esimerkiksi luokittelemalla vai gradientilla. Tälle viikolle on siis luultavasti tiedossa kivoja ja esteettisesti miellyttäviä karttoja, jos viikkotehtävien tekeminen ei tuota suurempia ongelmia.
Ensimmäinen Esri Academy:n tehtävä (Processing Raster Data Using ArcGIS Pro) perehdytti rasteridatan käsittelyyn ja rasterityökalujen käyttöön. Kävimme tehtävässä pääasiassa läpi juurikin työvaiheiden ketjun muodostamista (kuva 1), sekä ketjun käyttämistä pohjamallina. ArcGIS:ssä on iso liuta erilaisia algoritmeja, joiden avulla voidaan tuottaa, käsitellä ja visualisoida rasteridataa. Pää meni välillä näistä kaikista toiminnoista pyörälle, ja vaatii kyllä hetken että ne siirtyvät säilömuistiin. Tehtävässä käsiteltiin kahta eri vuosina (2013 & 2015) otettua satelliittikuvaa samalta alueelta. Tarkoituksena oli tutkia vuosien välistä normalisoitua kasvillisuusindeksiä (NDVI, Normalized Difference Vegetation Index) ja sen avulla kasvillisuuden muutosta.
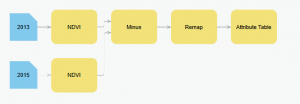
Kuva 1. Ensimmäisen viikkotehtävän työvaiheiden ketju eli “function chain” (Lähde: Esri Academy – Processing Raster Data Using ArcGIS Pro)
Loimme ensin NDVI-tasot satelliittikuvista, jonka jälkeen vähensimme ne toisistaan. Tuloksena saatu tasojen erotus kuvaa muutosta vuosien välillä. Tämän jälkeen annoimme datalle uusia arvoja “remap” -työkalun avulla: arvo 1 kuvaa “muutosta” ja arvo 0 kuvaa “ei muutosta”. Loimme tämän perusteella tasolle atribuuttitaulukon. Ilmiön visualisointi tapahtui punaviher-gradientilla, joka lopuksi sai vain “punaisena” esiintyviä arvoja. Eli punainen väri kartalla (kuva 2) kuvaa vuosien 2013 & 2015 välistä muutosta kasvillisuuden suhteen. Toivon todella, että tein tehtävän oikein. Hämmennystä aiheutti, kun tehtävän annossa puhuttiin “keltaisista alueista”, jotka mallintavat kasvillisuuden muutosta. Eikö tämä ole juuri toisinpäin? Punaisella/vihreällä merkityt alueet kuvaavat muutosta ja keltaisella värillä kuvataan aluetta, joka ei ole muuttunu. Toisaalta saamassani lopputuloksessa ei ole muuta väriä kuin punainen, joten saattaa hyvinkin olla että taas on jotain mennyt harmillisesti pieleen.
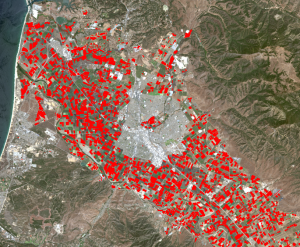
Kuva 2. Ensimmäisen tehtävän lopputulos kartalla. (Lähde: Esri Academy – Processing Raster Data Using ArcGIS Pro)
Toinen tehtävä (Introduction to Suitability Modeling) tuotti aluksi hieman hämmennystä, sillä tehtävässä nostettiin esiin monta uutta käsitettä. Päätin jättää tämän informaatiopläjäyksen muhimaan hetkeksi mieleen ja palasin tehtävän pariin muutaman päivän tauon jälkeen. Luulen, että ymmärrän tehtävää nyt paremmin. Eli pähkinänkuoressa “suitability modeling” (tietynlainen soveltuvuus mallintaminen/soveltuvuusanalyysi) on prosessi, jossa yhdistellään erilaisia kriteeripohjaisia aineistoja, jotta saataisiin määritettyä tarkastellulle ilmiölle optimaalinen sijainti. Tehtävässä lueteltiin ainakin kolmenlaisia mallintamistapoja: “binary”, “weighted” ja “fuzzy”. Keskeisenä konseptina oli opetella ymmärtämään rasteriaineistojen ominaisuuksia, jolloin voidaan myös ymmärtää koko “suitability modeling” -prosessia (kuva 3).
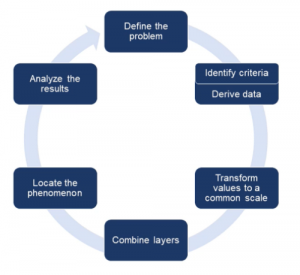
Kuva 3. Miten “suitability modeling” -prosessia tulisi lähestyä. (Lähde: Esri Academy – Introduction to Suitability Modeling)
Kolmannessa tehtävässä (Preparing Data for a Suitability Model) pääsimme laittamaan opitun käytäntöön. Tehtävänantona oli määritellä valkopäämerikotkan esiintymisen kannalta optimaalisia alueita San Bernardinon luonnonpuistossa. Optimaalisille alueille oli paljon kriteereitä, joiden kaikkien oli toteuduttava (taulukko 1). Tehtävä suoritettiin kokonaan työvaiheiden ketjun avulla (kuva 4). Tämä osoittautui nopeaksi keinoksi analysoida dataa, sekä luoda uusia aineistoja sen pohjalta. Koska käsiteltäviä aineistoja oli tehtävässä paljon, oli prosessia helpompi hallita ketjun avulla. Aineistoja pystyi yhdistämään muutamalla klikkauksella haluttuihin toimintoihin, jotka “run” -komennolla suorittivat halutun toiminnon datalle (kuva 5).
| Criteria | Dataset |
| Far from developed areas | Land cover raster |
|
Not too densely or sparsely covered by forest (ranging from 20 percent to 60 percent) |
Tree canopy raster |
| Close to lakes (fewer than 2 miles) | Major lake polygons |
| Located on northeast-facing aspects | DEM raster (digitaalinen korkeusmalli) |
Taulukko 1. Valkopäämerikotkan esiintymisen kannalta optimaalisten alueiden kriteerit ja niiden käsittelyyn tarvittavat aineistot. Lähde: (Esri Academy – Preparing Data for a Suitability Model)
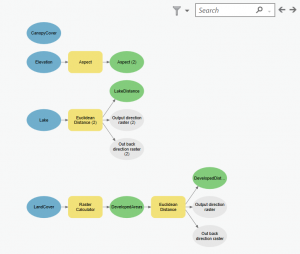
Kuva 4. Kolmannen viikkotehtävän työvaiheiden ketju (Lähde: Esri Academy – Preparing Data for a Suitability Model)
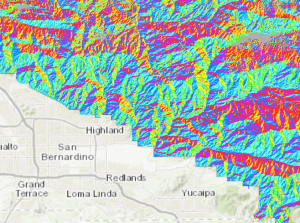
Kuva. 5 Kriteerien perusteella muokattu digitaalinen korkeusmalli (DEM). Värit havainnollistavat rinteen suuntaa. (Lähde: Esri Academy – Preparing Data for a Suitability Model)
Hämmennyin hetkeksi kun tehtävä loppui kuin seinään, mutta se jatkui seuraavassa viikkotehtävässä (Transforming Data for a Simple Suitability Model). Kolmannen tehtävän jäljiltä olimme saaneet aikaan kriteereitä mallintavat tasot (ns. “derived data”), joiden perusteella aineistoa oli vielä muokattava pidemmälle, että saataisiin selville optimaaliset alueet. Käytimme tässä “binary suitability modeling” -prosessia, jonka keskeinen idea oli siis antaa pikseleille/soluille binäärisiä arvoja: arvo 1 “suitable” ja arvo 0 “unsuitable”. Teimme kyseisen soveltavuusanalyysin kaikille tehtävän aineistoille. Lopputuloksena saatiin 4 erilaista tasoa, jotka täyttävät annetut kriteerit. Seuraavan viikon rasterianalyysi tehtävissä jatkamme aineiston kanssa työskentelemistä ja luultavasti yhdistämme aineistot yhdeksi suureksi kokonaisuudeksi.
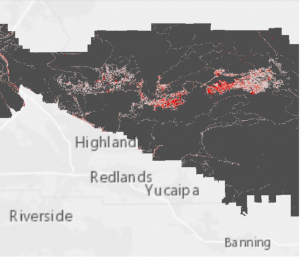
Kuva 6. Tässä esimerkki “Land cover” -aineistosta, jota on muokattu niin, että annetut kriteerit toteutuvat. Kuvassa tummat alueet (“undeveloped areas”) toteuttavat annetut kriteerit, kun taas punaiset alueet (“developed areas”) kuvaavat kaupunki- ja teollisuusalueita. (Lähde: Esri Academy – Transforming Data for a Simple Suitability Model)
Lähteet
Holopainen et al. (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7.
Tehtävälähteet ja data
-
- https://www.esri.com/training/catalog/57e19a8eed0f3a861c100985/processing-raster-data-using-arcgis-pro/
- https://www.esri.com/training/catalog/5c08179b7351db0c2ab3fbf4/introduction-to-suitability-modeling/
- https://www.esri.com/training/catalog/5cad01dd9b1f4010cad9abc4/preparing-data-for-a-suitability-model/
- https://www.esri.com/training/catalog/5cad01b39b1f4010cad9ab56/transforming-data-for-a-simple-suitability-model/