
Tällä viikolla tutustuimme erilaisiin korkeusmalleille tehtäviin analyyseihin ja muunnoksiin. Luennolla kertasimme muun muassa mitä korkeusmallit ovat (DEM, DTM ja DSM) ja miten niitä tuotetaan. Lisäksi tutustuimme korkeusmallien tietorakenteisiin ja puhuimme hieman interpoloinnista, jota voi luontaisesti soveltaa myös korkeusmalleihin. Täysin uusia käsitteitä tällä viikolla oli korkeusprofiilin konveksisuus ja konkaavisuus, joita käytetään kuvaamaan pinnan viettoa. Konveksi profiili on kupera ja konkaavi profiili on kovera. Tähän kaikkeen liittyen työpajoissa tehtiin kaksi eri tehtävää. Tehtävät tuntuivat suhteellisen helpoille ja niitä oli ihan mukava tehdä.
Ensimmäisessä tehtävässä (Terrain Analysis Using ArcGIS Pro) harjoiteltiin pääasiassa slope, hillshade ja aspect -tasojen tekoa. Slope kuvaa rinteen jyrkkyyttä eli korkeuspinnan vieton suuntaa. Se lasketaan joko asteina tai prosentteina ja saa informaatiota ympäröivien solujen korkeustiedoista. Aspect kuvaa puolestaan rinteen suuntaa/sijoittumista. Aspect on hyödyllinen, kun tutkitaan ilmakehän ilmiöiden vaikutusta alueeseen (esimerkiksi miten aurinko tai tuulet vaikuttavat). Aspect on myös kytköksissä ympäröiviin soluihin. Tämän takia rajatun alueen reunojen solut voivat antaa vääristynyttä tietoa, sillä niillä on ympärillä vähemmän soluja, joista ottaa informaatiota. Rinteiden viettoa ja suuntaa voidaan myös määrittää hillshade -työkalun avulla, jolla tehdään alueesta varjostuskuva. Tästä lisää myöhemmin 🙂
Eli tehtävänantona oli etsiä potentiaalisia alueita viinitarhalle San Diegossa. Kriteereitä oli kolme: “elevation above 200 meters”, “slope between 1.5 percent and 15 percent” ja “some southern exposure”. Tällä kertaa aloitin tehtävän kiinnittämällä huomiota metadataan, koska tuntuu että en ole aikaisemmilla viikoilla tätä oikein tutkinut. Esri Academyn tehtävät sisältävät suoraan kaikki tarvittavat datasetit, ja välistä jää siis tarkempi aineistoon tutustuminen. Tehtävien suorittaminen voi tämän takia äkkiä muuttua vain aivottomaksi klikkailemiseksi (niinkuin tämän viikon toisessa tehtävässä tuntui käyvän). Käytimme tehtävässä datana NED:n (National Elevation Dataset) korkeusmallia, jotka jakaa ja tuottaa USGS (United States Geological Survey). Ennen tehtävän tekemistä tutustuttiin myös datassa käytettyihin yksiköihin ja koordinaatistoon, jotta näiden kanssa ei syntyisi kiusallisia virheitä.
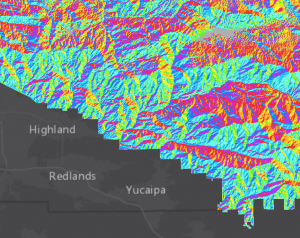
Tehtävä suoritettiin binäärisenä analyysinä raster calculator -työkalulla. Yhdistimme kaikki aikaisemmin luetellut ehdot ja saimme jotakuinkin tällaisen funktion: (“sd_elevation” > 200) & (“sd_slope” >= 1.5) & (“sd_slope” <= 15) & (“sd_aspect” >= 112.5) & (“sd_aspect” <= 247.5). Tässä kohtaa ArcGIS kaatui ensimmäistä kertaa koko kurssin aikana. Onneksi tiedostosta löytyi tuore backup ja pääsin jatkamaan siitä mihin jäinkin. Funktio teki tehtävänsä, jonka jälkeen meillä oli kartalla kaikki potentiaaliset alueet, jotka täyttävät viinitarhan rakentamisen ehdot. Lopputuloksen visualisoin tehtävänannon mukaan. Tuntuu että tehtävät rakastavat väriä “mars red”, joka nyt myös tälläkin kartalla (kuva 1) loistaa läsnäolollaan. Käytin tällä kertaa enemmän aikaa ArcGIS:n toimintojen tutkimiseen ja sain jopa luotua tuloksista jonkun näköisen kartan pohjoisnuolineen ja mittakaavoineen. Legendan tekeminen tuotti vielä paljon vaikeuksia, mutta olen nyt hieman viisaampi tämän suhteen ja pienellä harjoittelulla saan varmasti kasaan varteenotettavan kartan.
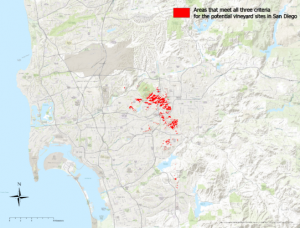
Kuva 1. Potentiaaliset alueet viinitarhalle. (Lähde: Esri Academy – Terrain Analysis Using ArcGIS Pro)
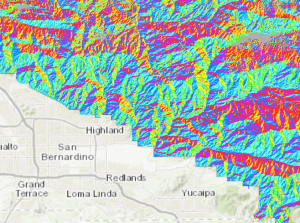
Seuraavaksi teimme hieman lisävisualisointia, jota varten käytimme resoluutiolta pienempää dataa. Loimme sen avulla hillshade-tason, korkeuskäyrät ja teimme tietynlaisen näkyvyysanalyysin (viewshed). Näille kaikille löytyi oikeastaan suorat komennot tai työkalut ArcGIS:stä. Hillshade -työkalulla voidaan luoda realistisen näköinen mallinnus alueen pinnanmuodoista (kuva 3). Saatu tulos ilmentää miltä pinta näyttäisi, jos se valastaisiin jollain valonlähteellä. Valonlähteen suunta eli atsimuutti ja valon lähteen korkeus eli altitudi vaikuttaa tulokseen suuresti. Yleensä atsimuuttia kuvataan 351 asteesta, eli valonlähde on luoteessa. Tämän on todettu olevan kaikille helpoin tapa lukea hillshade dataa, vaikka oikeasti valonlähde (auringonvalo) paistaa vain harvoihin paikkoihin tästä suunnasta. Luennolla kannustettiin kokeilemaan hillshaden -tason luomista toisella atsimuutilla ja näinpä siis tein. 🙂 Loin tason, jonka atsimuutti on 135 eli valonlähde tulee kaakosta (kuva 2).


Kuva 2. Vasemmalla atsimuutti on 315 astetta, oikealla se on 135 astetta. Tulkitsisin itse kuvia aivan erilailla. Kun atsimuutti on 135 astetta, maanpinnan painaumat näyttävät ainakin omiin silmiin kohoumilta. Tässä tilanteessa alakulman vesistöalue näyttää tasangolta tai jopa sandurilta.
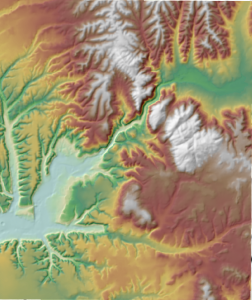
Kuva 3. Hillshade -taso, jonka päällä alkuperäinen korkeusmalli, jonka läpinäkyvyyttä ja visualisointia (värejä) on muokattu.
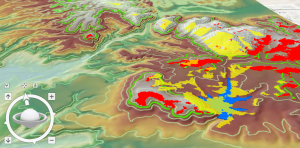
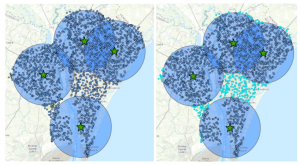
Lisäsimme seuraavaksi tuotokseen korkeuskäyrät (kuva 4) niille suunnitellulla työkalulla ja teimme eräänlaisen näkyvyysanalyysin. Näkyvyysanalyysin (viewshed) avulla saadaan määritettyä solut, jotka voidaan nähdä tietystä tarkastelupisteestä. Tässä tilanteessa haluttiin määritellä solut, joista on hyvä näkyvyys Murray-tekojärvelle. Analyysin tuloksena saatiin hieman epämääräisen näköinen visualisointi tästä kaikesta (kuva 5). Tajusin tässä vaiheessa, että olisin voinut visualisoida lopputuloksen haluamallani tavalla, eikä tehtäviä olisi tarvinnut noudattaa niin tarkasti. Yritin tehdä myös lopputuloksesta jonkinnäköistä karttaa, mutta legendan luominen osoittautui taas sen verran hankalaksi että jouduin luovuttamaan. Analysoimme lopuksi tuloksia myös 3D-kartan avulla, joka sattuukin olemaan tämän blogipostauksen epävirallinen kansikuva.
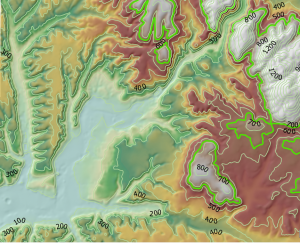
Kuva 4. Korkeuskäyrät
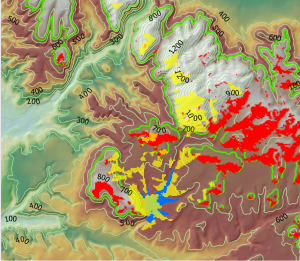
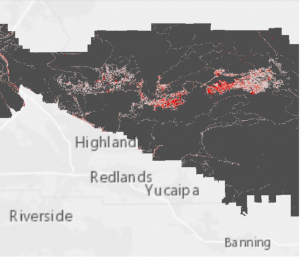
Kuva 5. Kuvassa punaisella potentiaaliset viinitarha-alueet, sinisellä Murray-tekojärvi ja keltaisella näkyvyysanalyysin tuloksena saadut alueet. Kartalla oranssit alueet täyttävät kaikki viinitarhan rakentamiseen annetut ehdot sekä tarjoavat hyvän näköalan tekojärvelle.
Tämän jälkeen oli aika viikon toiselle tehtävälle (Predict Floods with Unit Hydrographs), jossa pääsimme tekemään hydrologista mallinnusta. Tehtävässä tehtiin eräänlaista tulvakartoitusta Vermontissa sijaitsevalle Stowen kaupungille. Tehtävän toteutus oli kummallinen ja erosi muiden tehtävien formaatista. ArcGIS toimi suoraan tietynlaisena portaalina tehtävän tekemiselle ja eri työvaiheet sekä työkalut ponnahtivat valmiina esiin ArcGIS:ssä omalle näytölle. Tämän takia tehtävän tekeminen tuntui hieman epäluonnolliselle. Tuntui ettei oikein mitään jäänyt mieleen, kun vain seurasi työvaiheita sokeana eikä päässyt ajattelemaan omilla aivoilla.
Tehtävä alkoi “sink” -alueiden eli kuoppien paikantamisella ja poistamisella. Kuoppia esiintyy joissain DEM-malleissa ja ne ovat nimensä mukaisesti alueita, joiden elevaatio on alhainen niitä ympäröiviin soluihin verrattuna. Tällaiset kuopat ovat problemaattisia hydrologisessa mallinnuksessa, sillä vesi ei pääse valumaan kuopasta pois, ja tämä voi aiheuttaa tuloksissa erilaisia virheitä. Kun saimme kuopat poistettua, saimme uuden (kuopattoman) DEM-mallin, jota käytimme työskentelyn pohjana. Tästä lähti käyntiin monivaiheinen työsarja, jota ei enää edes meinaa muistaa. Määrittelimme seuraavaksi veden virtauksen suuntaa alueella (jotta saisimme selville valuma-alueen) ja tuloksena oli kiva värikäs kartta (kuva 6).

Kuva 6. Veden virtausta kuvaava rasteritaso. (Flow direction) (Lähde: Esri Academy – Predict Floods with Unit Hydrographs)
Valuma-aluetta varten on myös tiedettävä laskujoen sijainti. Tämän määritettiin kumulatiivisten virtaamien ja useiden eri työkalujen avulla. Kun tämä oli tiedossa, saatiin muodostettua valuma-alue (kuva 7), joka kuvaa kaikkea sitä vesimäärää mikä kulkee alueelta laskujokeen. Valuma-alue on melkein koko Stowen kaupungin rajojen kokoinen ja jo nyt voidaan spekuloida suurten sademäärien tuottavan tulvia alueella. Seuraavana tehtävänä on laskea kuinka nopeasti vesi virtaa laskujokeen vertikaalisen nousun avulla. Tätä varten loimme alueelle tutun ja turvallisen slope-tason (kuva 8). Veden virtauksen nopeus saatiin nyt määritettyä slope-tasolla ja kumulatiivisella virtaamalla (kuva 9).
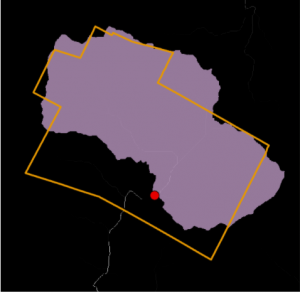
Kuva 7. Stowen valuma-alue tumman lilalla, kaupungin rajat oranssilla ja laskujoki näkyy kuvassa valkoisena.
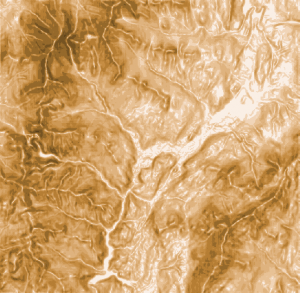
Kuva 8. Slope-taso. Tummat alueet kartalla ovat jyrkempiä.
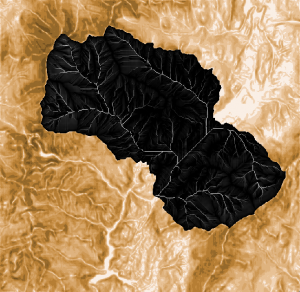
Kuva 9. Veden virtauksen nopeus. (Tummemmat värit edustavat hitaampaa virtausta ja vaaleammat nopeampaa virtausta). Tästä kuvasta ei tule ilmi, mutta virtaus on nopeinta joissa, jotka kulkevat Stowen kaupungin läpi.
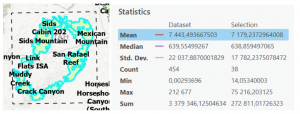
Näiden työvaiheiden jälkeen rupesimme luomaan isopleettikarttaa, joka kuvaa kuinka kauan vedellä kestää virrata tietyille alueille. Veden virtausaika saadaan selville jakamalla virtauksen pituus sen nopeudella. Käytimme tässä “flow length” -työkalua. Lopputuloksena oli taso, jonka rastereissa on tieto siitä, kuinka kauan vedellä kestää virrata rasterista laskujokeen. Arvot vaihtelivat välillä 0 – 47 000 eli vedellä kestää virrata paikoittain 0 sekunnista noin 13 tuntiin. Lopuksi käytimme “reclassify” -työkalua, jonka avulla saimme lopputuloksesta kasattua isopleettikartan (kuva 10). Ihan viimeisenä kasasimme kokoon taulukon tästä kaikesta (taulukko 1), jonka luomisprosessista en nyt enempää aijo selittää. Olisi joku kerta kiva sukeltaa vielä bonustehtävien pariin, mutta tuntuu että jo näiden tehtävien tekemisessä menee useita tunteja. Ehkä tekeminen nopeutuu kun ArcGIS tulee tutummaksi.
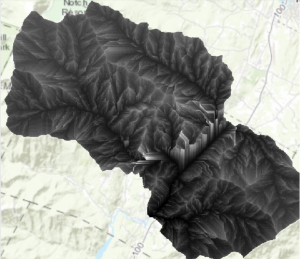
Kuva 10. Tadaa! Valmis isopleettikartta virtausajoista (joka näyttää vähän hiili-möhkäleeltä) Tummemmat alueet edustavat lyhyempiä virtausaikoja ja vaaleammat alueet pidempiä.
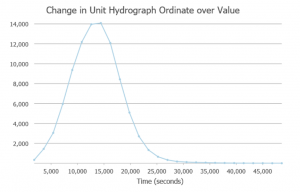
Taulukko 1. Y-akselin tunniste jäi kuvasta jostain syystä pois. Y-akseli kuvaa siis: “Discharge at outlet per unit of excess rainfall (square meters per second)”.
Lähteet
Holopainen et al. (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7.
Tehtävälähteet
Terrain Analysis Using ArcGIS Pro https://www.esri.com/training/catalog/57630436851d31e02a43f18f/terrain-analysis-using-arcgis-pro/
Predict Floods with Unit Hydrographs https://www.esri.com/training/catalog/598a43865bed191d3a9bc732/predict-floods-with-unit-hydrographs/



{kind=link}