COMHIS Collective will organise a demo-session on “Analysing eighteenth-century key-terms and phrases using ECCO and ESTC” at the British Society for Eighteenth-Century Studies annual conference at Oxford (4-6 January 2017).
Our slot is on Friday, 6th January at 11:00-12.30 (in the “Session Two”, Number 88). All welcome!
What we plan to do in this session is to introduce our workflows to explore Eighteenth Century-Collections Online (ECCO) and English Short-Title Catalogue (ESTC). In the future, our workflows will be made available as publicly usable tools. However, we want to give you an early, hands-on sneak peek at what we’re doing even before things coalesce to that point [read below to get at least a vague understanding of what is possible]. The idea of our text and data mining tools is that they serve different eighteenth-century scholars and historians in particular. Thus, the opportunity to organise this session and to get the BSECS people to test these tools and to comment on their use is very welcome to us.
********
In order for us to plan our session so that we can interact with the audience as much as possible, we would like you to propose certain general subjects (e.g. “politeness”, “justice” …) or more focused topics (e.g. “political economy”, “modern honour”… ) or particular key-terms (e.g. “petticoat”, “periwig”…) by tweeting them with hashtags #bsecs17 #comhis before 20.12.2016.
So, if your suggestion for a topic to be explored in our session is “human nature”, your tweet would read: human nature #bsecs17 #comhis …
We welcome as many suggestions as you would like to make (no limits per tweeter). There are few technical parameters that need to be taken into consideration when deciding what topics and key-terms function best for demonstration purposes. Most importantly, the queries need to be large enough and distinguishable to function in “big data approach”. For example, “petticoat” is ok, but “condom” not so much. However, you need not to worry about these parameters of your suggestion. There are plenty of otherwise good key-terms and subjects that for technical or semantic reasons cannot be used in this type of analysis. We would like to demonstrate this as well. So, the more suggestions we have by 20th of December 2016 the better (of course, we have a long list of things that interest us as well, but then you’ll end up listening to stuff related to Bernard Mandeville and David Hume…). So, if you tweet your suggestions for subjects or key-terms to be explored before 20th of December 2016 we will have enough time to prepare for the session.
There will also be time for a hands-on part in our session, so if you bring a laptop with you (and the wireless connection at the college works), you can also do some of your own exploration of your favorite topics, although we will not have time to run many of the more time consuming calculations and the more complex analysis will be done with suggestions taken from twitter.
************
Here are some snippets of what our analysis of “human nature” might include (explanation of the workflows and different graphs will take place in Oxford on 6th of January 2017).
 Plenty of search options to choose from.
Plenty of search options to choose from.
 OCR issues with ECCO need to be taken into consideration.
OCR issues with ECCO need to be taken into consideration.
 Rstudio is a convenient analysis environment…
Rstudio is a convenient analysis environment…
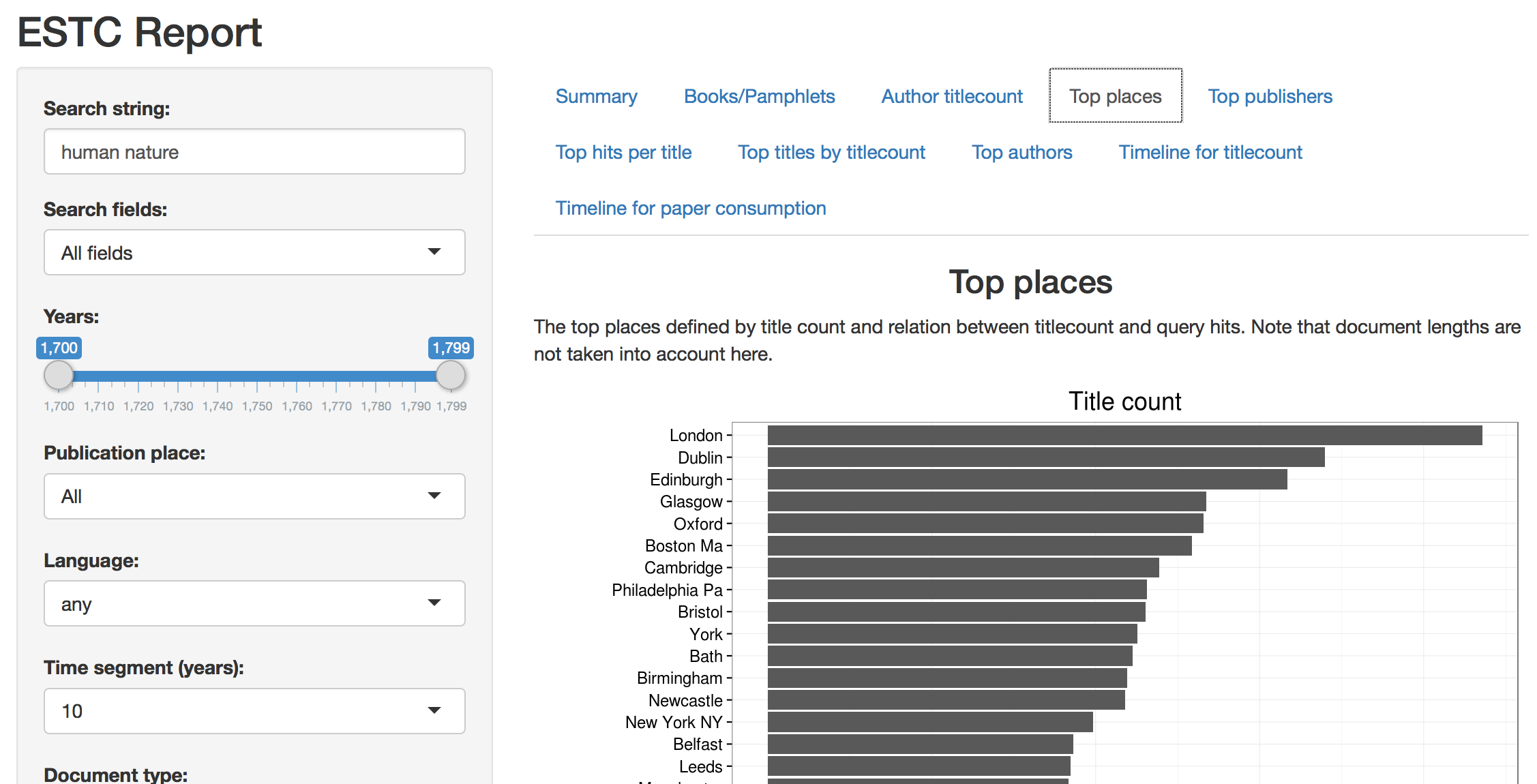 … but we have also shiny app user interfaces to make things even simpler.
… but we have also shiny app user interfaces to make things even simpler.
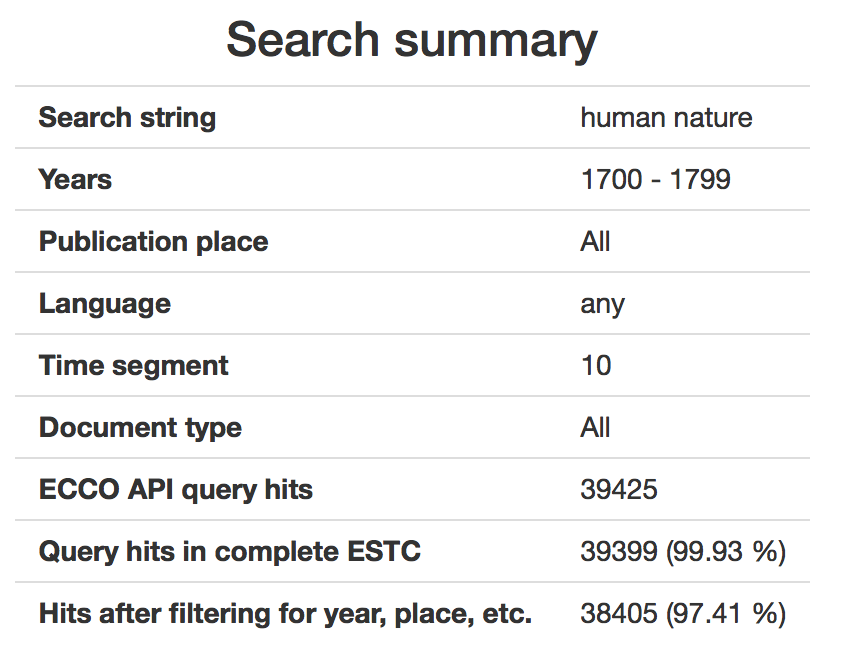 The trick is to focus on the ESTC metadata, clean it up and use that for statistical analysis.
The trick is to focus on the ESTC metadata, clean it up and use that for statistical analysis.
 This graph is a timeline of titles that include the hit (“human nature”) in the document. NB! we can also limit the queries in various ways, for example, so that the analysis only includes those documents where “human nature” is mentioned 5 or 10 times.
This graph is a timeline of titles that include the hit (“human nature”) in the document. NB! we can also limit the queries in various ways, for example, so that the analysis only includes those documents where “human nature” is mentioned 5 or 10 times.
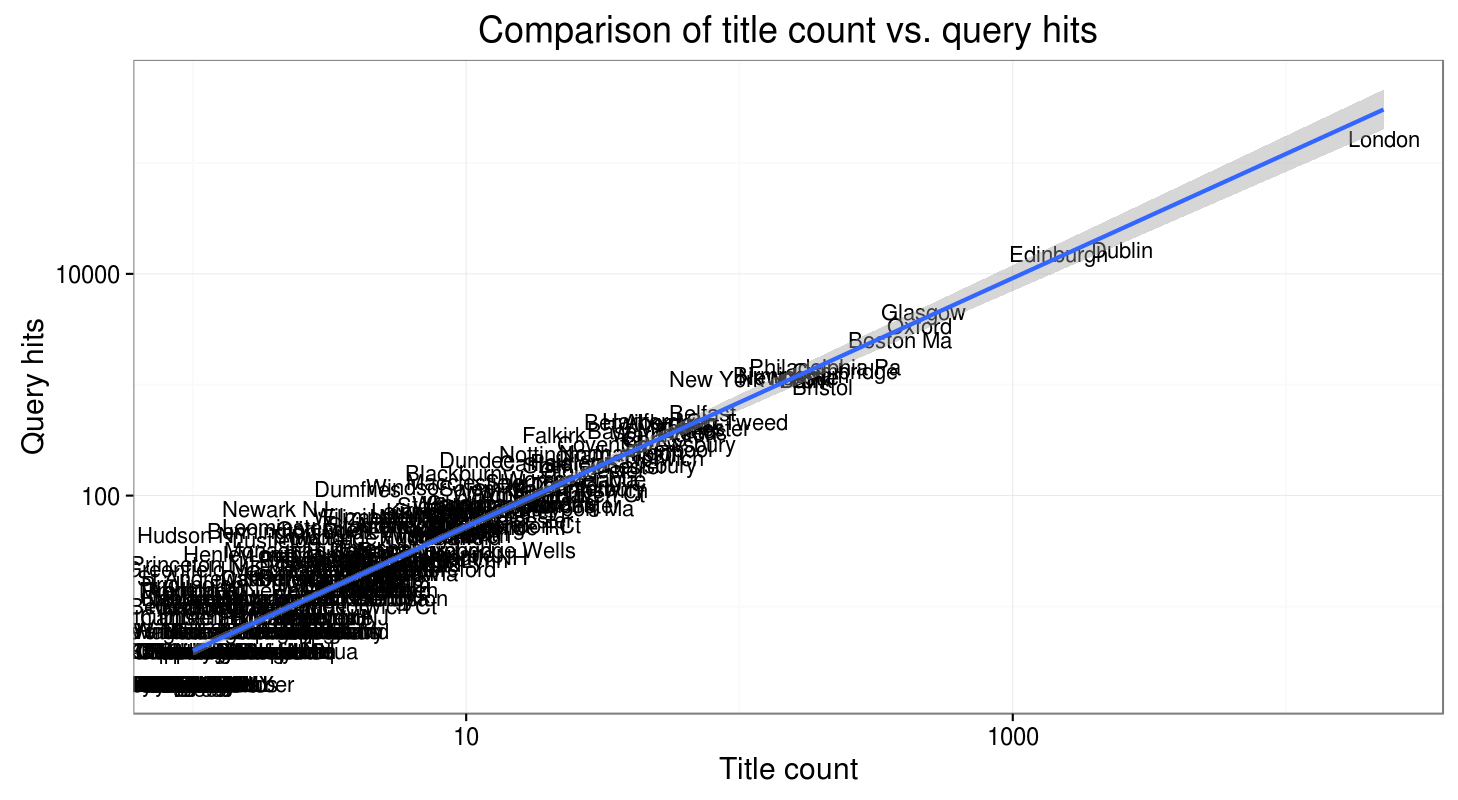 Places of publication of documents that include particular hits can also be analysed in different ways. This is a comparison between places of publication focusing on query hits and title count of “human nature”. We can for example sort documents based on their type (books vs. pamphlets), format (4to, 8vo..) and base our analysis on paper consumption, if you are into that sort of thing. For book historians: the cleaning of ESTC metadata is not quite finished yet, but the idea is that we can make efficient searches based on the extracted and cleaned up information of the imprints as well soon.
Places of publication of documents that include particular hits can also be analysed in different ways. This is a comparison between places of publication focusing on query hits and title count of “human nature”. We can for example sort documents based on their type (books vs. pamphlets), format (4to, 8vo..) and base our analysis on paper consumption, if you are into that sort of thing. For book historians: the cleaning of ESTC metadata is not quite finished yet, but the idea is that we can make efficient searches based on the extracted and cleaned up information of the imprints as well soon.
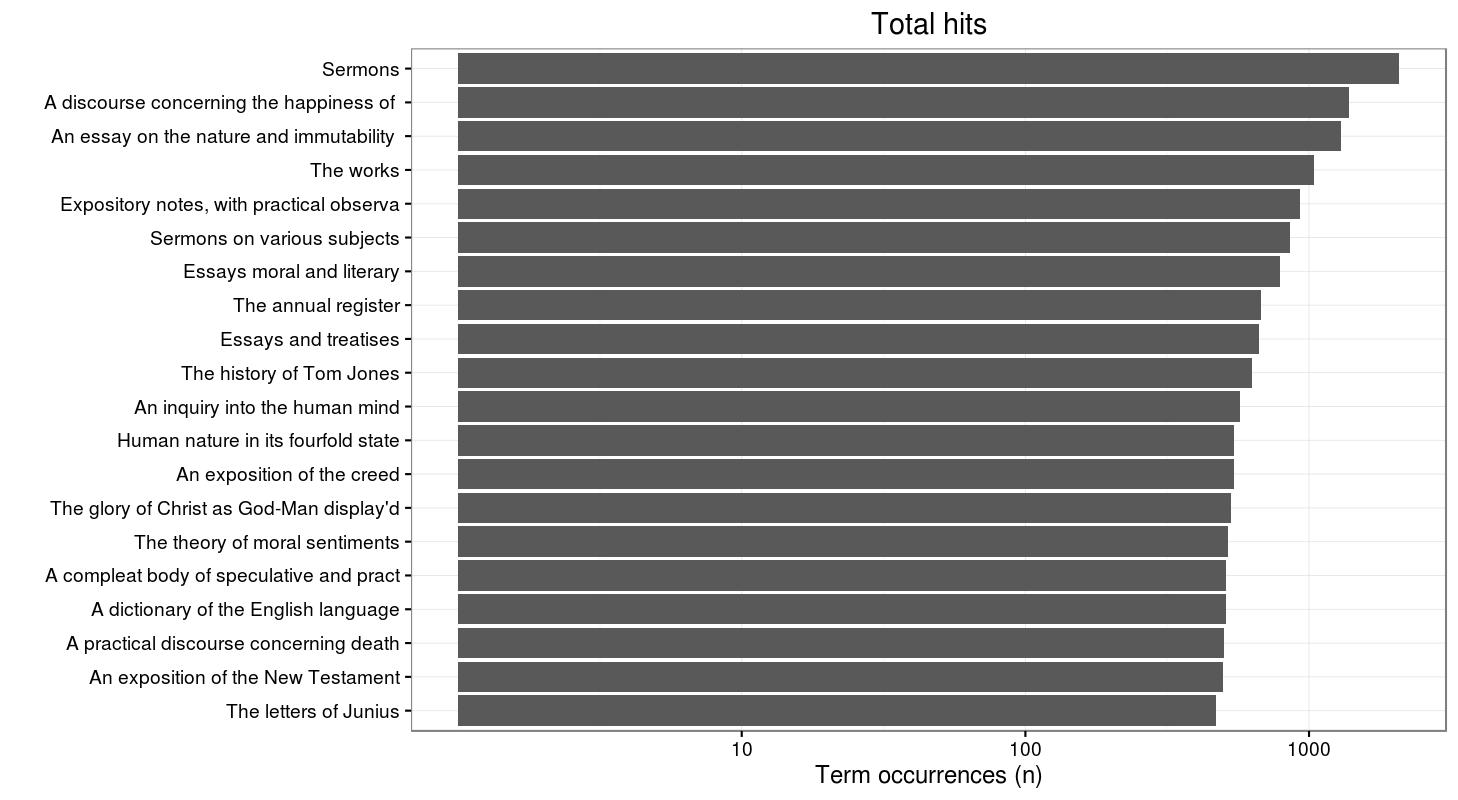 Top-titles that include particular hits can be analysed in multiple ways. This graph includes all the printed editions of a particular title in which “human nature” features as a term and it is found in ECCO.
Top-titles that include particular hits can be analysed in multiple ways. This graph includes all the printed editions of a particular title in which “human nature” features as a term and it is found in ECCO.
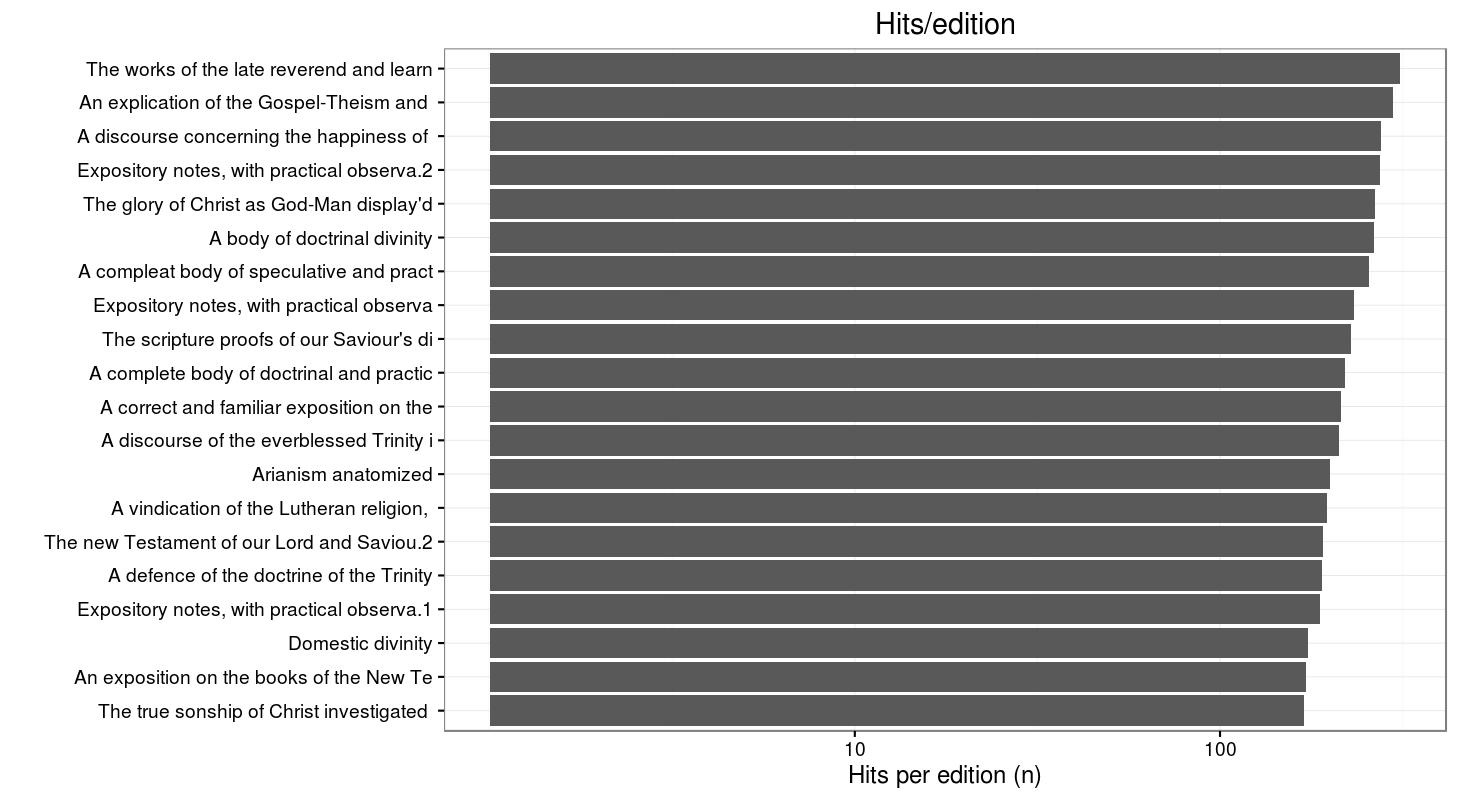 In this graph we have a top-list of hits / edition of titles that include “human nature” in the text, meaning that it is a listing of the titles where the term “human nature” is mentioned most often in ECCO (compared to the previous graph, reprints and different editions are excluded here). This will not solve all our questions about human understanding and passions, but it is an interesting point of departure for further questions.
In this graph we have a top-list of hits / edition of titles that include “human nature” in the text, meaning that it is a listing of the titles where the term “human nature” is mentioned most often in ECCO (compared to the previous graph, reprints and different editions are excluded here). This will not solve all our questions about human understanding and passions, but it is an interesting point of departure for further questions.
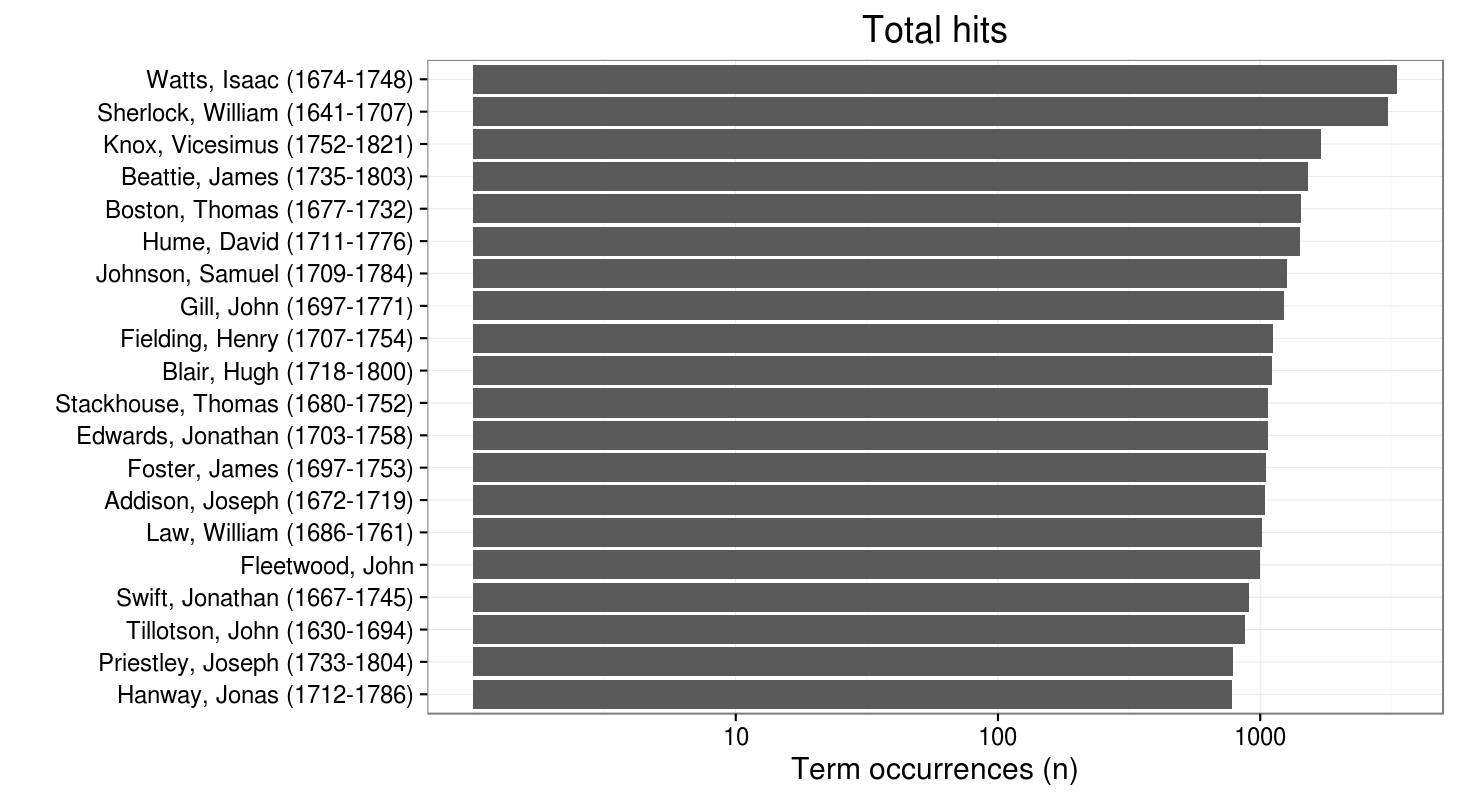 We chose to include this graph of top-hit of authors that includes all the editions of titles with a hit on “human nature”, because David Hume did not make the more focused top hits/edition list…
We chose to include this graph of top-hit of authors that includes all the editions of titles with a hit on “human nature”, because David Hume did not make the more focused top hits/edition list…
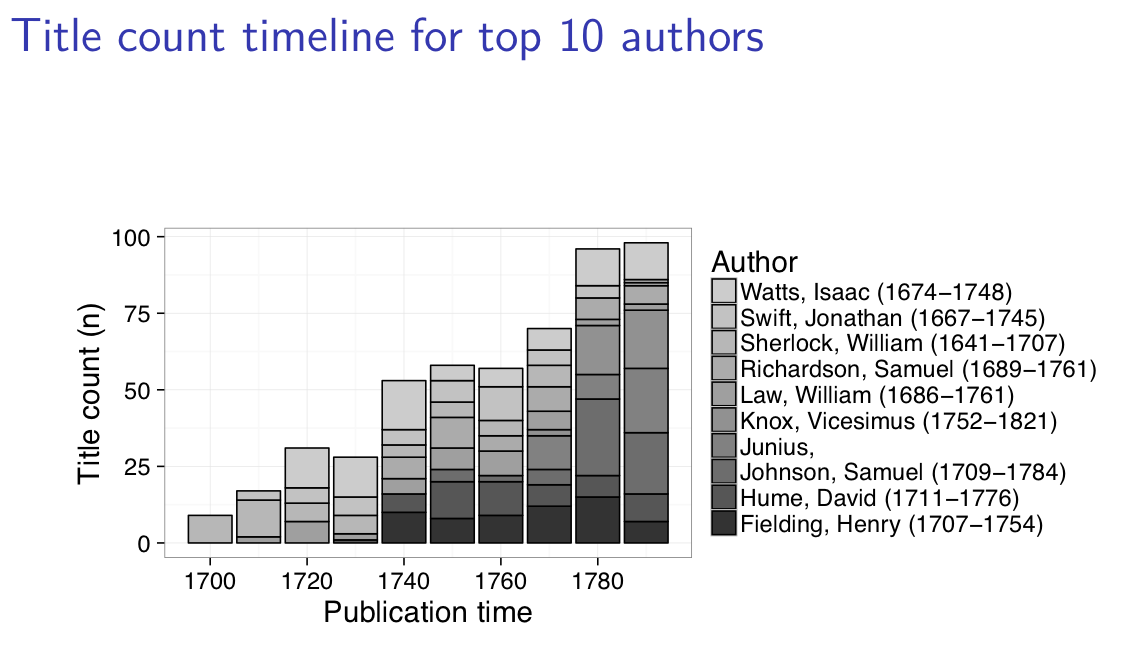 Timeline count of top authors in this graph is modified so that it includes only those documents in which “human nature” is mentioned at least 10 times.
Timeline count of top authors in this graph is modified so that it includes only those documents in which “human nature” is mentioned at least 10 times.
 We can also look at collocations (co-occurring terms) of “human nature” in ECCO data and put this information to use.
We can also look at collocations (co-occurring terms) of “human nature” in ECCO data and put this information to use.
 We can, for example, take “human nature” as a baseline term and then compare other terms and their development in time. This can be done based on co-occurring terms in the whole document or in the same paragraph. Here we are looking at the analysis of whole document and witnessing the rise of sympathy and benevolence (although pride still trumps them both).
We can, for example, take “human nature” as a baseline term and then compare other terms and their development in time. This can be done based on co-occurring terms in the whole document or in the same paragraph. Here we are looking at the analysis of whole document and witnessing the rise of sympathy and benevolence (although pride still trumps them both).
 One of the more experimental part of the tool development for ECCO use is a vector space model that compares the contexts of two different terms and how closely they resemble each other. What this graph suggests is that the uses of “human nature” and “dignity” are consistently approaching each other during the eighteenth century. Further methods to confirm this and give more depth to the analysis are being developed and we hope to tell you more about this and other aspects of our work not mentioned in this overview in January! So, show up on Friday, 6th January at 11:00-12.30 (in the “Session Two”, Number 88), “Analysing eighteenth-century key-terms and phrases using ECCO and ESTC” by COMHIS Collective.
One of the more experimental part of the tool development for ECCO use is a vector space model that compares the contexts of two different terms and how closely they resemble each other. What this graph suggests is that the uses of “human nature” and “dignity” are consistently approaching each other during the eighteenth century. Further methods to confirm this and give more depth to the analysis are being developed and we hope to tell you more about this and other aspects of our work not mentioned in this overview in January! So, show up on Friday, 6th January at 11:00-12.30 (in the “Session Two”, Number 88), “Analysing eighteenth-century key-terms and phrases using ECCO and ESTC” by COMHIS Collective.
**************
The key-players in our expanding group are currently: Mikko Tolonen, Leo Lahti, Eetu Mäkelä, Ville Vaara, Jani Marjanen, Antti Kanner and Hege Roivainen. We like to think of ourselves as a collective, so the group is by no means limited to these individuals. What unites us is the enthusiasm for new ways to analyse early modern books, pamphlets and newspapers.