
- Päivä: 20
- Smoltteja saatu yhteensä: 21
Tässä postauksessa esittelemme lyhyesti uuden mallin antamia tuloksi. Mallin nykytilasta voit lukea tarkemmin täältä: https://blogs.helsinki.fi/taimenlaskenta/?p=32
Tärkeät rakenteelliset muutokset malliin ovat: 1) toisen pyydyksen (taimenrysä) huomioiminen, sekä 2) muuttointensiteetin jakauman uudelleenarviointi. Muuttointensiteettiä, eli todennäköisyyttä muuttaa tiettynä päivänä, mallinnetaan nyt log-normaalin jakauman sijaan tasajakaumalla ja normaalijakaumalla. Syyt muutoksiin löytyvät ylläviitatusta postauksesta.
Lisäksi päivitimme asiantuntijaprioriamme muuttajien kokonaismäärän odotusarvosta. Meillä on nyt käytössä kolme asiantuntija-arviota, jotka ovat ’5000’, ’1940’ ja ’alle 1000’. Optimistisesti tulkitsimme alle 1000 tarkoittamaan 999 ja saimme näin kokonaislukumäärän priorijakauman odotusarvoksi (5000+1980+999) / 3 = 2600 ja keskihajonnaksi sd(5000,1980,999) = 2000. Mallina tälle priorille on edelleen kokonaisluvuiksi pyöristetty normaalijakauma, joka on katkaistu tuottamaan ainoastaan positiivisia arvoja.
Sitten tuloksiin!
Malli 1. normaalimalli muuttointensiteetille
Taulukko 1: mallin 1 antamat estimaatit taimenten kokonaismäärän jakauman tunnusluvuille
| mean | sd | MC error | 95% conf | |
| N | 1086.0 | 814.3 | 18.81 | 219 – 3307 |
Kuvio 1: kokonaismäärän posteriori-jakauma mallissa 1
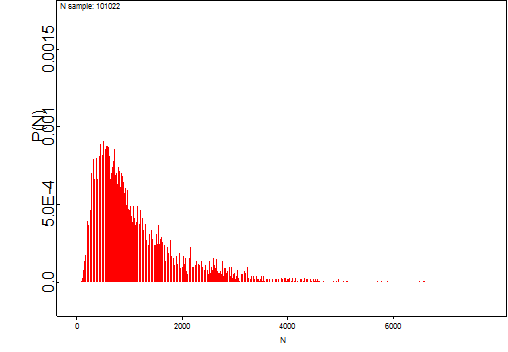
Normaalimalli lähtemisintensiteetille tuottaa taimenten kokonaismäärän odotusarvon piste-estimaatiksi 1086 kappaletta, jolle 95% luottamusväli on 219 – 3307. Luonnollisesti uusi pienempi asiantuntijapriori vetää odotusarvoa alaspäin. Myöskään data ei toistaiseksi tue normaalioletusta lähtemisintensiteetille kovinkaan hyvin, sillä taimenia on pyydystetty tasaisen pieniä määriä, minkä johdosta tasajakaumapriori lähtemistodennäköisyydelle tuottaa (vielä toistaiseksi) suuremman estimaatin kokonaislukumäärälle, kuin normaalipriori. Tästä lisää alempana.
Taulukko 2: Kokonaispyydystettävyys mallissa 1.
| mean | sd | MC error | 95% conf | |
| q | 0.139 | 0.074 | 0.001 | 0.034 – 0.318 |
Kokonaispyydystettävyyden estimaatti on mallissa 0.139, eli odotamme, että 13.9% kaloista joutuu jompaankumpaan pyydykseen. Toistaiseksi pyydykset eivät tosin ole onnistuneet uudelleenpyydystämään ainuttakaan 17 merkatusta kalasta, joten pyydysten pyydystettävyys päivittyy priorioletuksista jatkuvasti huonompaan suuntaan. Tämän(kin) johdosta kokonaismäärän odotusarvon estimaatti tulee todennäköisesti päivittymään suuremmaksi tulevina päivinä, kun dataa saadaan lisää.
Malli 2. Vantaanjoesta muuttavien smolttien totaalin posterioriestimaatti, kun muuttointensiteettien oletetaan noudattavan tasajakaumaa päivien funktiona.
Olettaen muuttointensiteetin seuraavan tasajakaumaa saadaan seuraava posteriorijakauma seurantajakson aikana muuttavien smolttien kokonaismääräksi N.
Taulukko 3. Vantaanjoesta muuttavien smolttien kokonaismäärän posteriorijakauma.
| Mean | Sd | MC_error | val2.5pc | median | val97.5pc | start | sample | |
| N | 1346.0 | 873.5 | 9.441 | 364.0 | 1105.0 | 3694.0 | 66301 | 2827470 |
Kuvio 2. Muuttavien smolttien kokonaismäärän posteriorijakauma
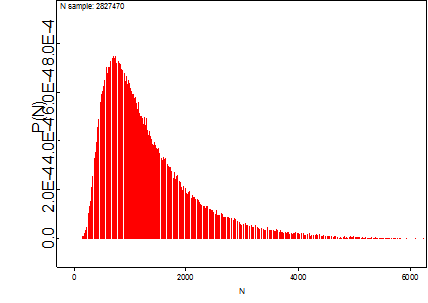
Paras yksittäinen posterioriestimaatti liikkuu jossain reilun tuhannen paikkeilla. Mielestäni tämä vaikuttaa uskottavalla yksittäiseltä arviolta. Voidaan kuitenkin todeta, että arvio smolttien kokonaismäärästä on vielä kovin epävarma. 95% todennäköisyydellä totaali olisi mallin perusteella välillä (360; 3700).
Samaan hengenvetoon voidaan kyseenalaistaa, onko posterioriarvio riittävän epävarma? Aineistoa on nimittäin saatu kovin vähän, eikä sen ja prioritiedon valossa uskaltaisi välttämättä mennä väittämään, ettei smoltteja varmasti muuta esimerkiksi yli 6000. Itse en menisi tästä takuuseen: hyvin paljon nimittäin riippuu tehdyistä mallioletuksista. Kenties luotettavin arvio saataisiinkin keskiarvoistamalla posterioriestimaatit yli rakennettujen mallien. Palataan asiaan myöhemmässä blogipostauksessa.
Näkisin mallivalinnassa esiintyvän kaksi erityisen suurta epävarmuustekijää: 1) mitä jakaumaa smolttien muuttointensiteetti (ajan funktiona) noudattaa (ks. viimeisin mallit -osion blogipostaus)? sekä 2) mikä on ruuvin ja rysän pyydystystodennäköisyys?
Molempien suhteen priorioletuksemme päivittyy koko ajan melko vinhaa vauhtia. Ensimmäistä koskien olemme joutuneet jo luopumaan epärealistiseksi todetusta lognormaalijakaumasta: kyseinen priorioletus asetti liian paljon todennäköisyysmassaa ensimmäisten havaintopäivien kohdalle. Jälkimmäistä koskien oletuksemme ovat siirtyneet vahvasti kohti heikompaa pyydystettävyyttä, mikä on varsin perusteltua, sillä vielä emme nimittäin ole saaneet yhtään smolttia uudelleenpyydettyä. Lähtökohtainen joka viidennen smoltin jääminen ruuviin on muuttunut noin 7% odotusarvoksi kunkin pyydyksen pyydystettävyydelle. Kenties tämän suhteen beta-jakauma priorimme oli turhan informatiivinen vastatessaan kymmentä pseudosmolttihavaintoa.
Taulukko 4. Posterioriestimaatti yhteenlasketulle (ts. smoltti jää rysään TAI ruuviin) pyydystettävyydelle
| Mean | Sd | MC_error | val2.5pc | median | val97.5pc | start | sample | |
| q | 0.1248 | 0.0666 | 5.534E-4 | 0.03345 | 0.1122 | 0.2854 | 152121 | 2570010 |
Pyydystettävyyden estimointia tulisi parantaa varsinkin suhteessa rysän ja ruuvin suhteelliseen pyydystehoon. Nythän oletamme rysän ja ruuvin saalistavan samalla teholla: oletus, jonka paikkansapitävyydelle ei ole juuri perusteita. Samanaikaisesti pyydystettävyystehot päivittyvät ainoastaan uudelleenpyydettyjen smolttien aineistolla. Voidaan kuitenkin hyvin olettaa, että kaikki (muutkin kuin merkatut smoltit) kalat tuovat mukanaan informaatiota pyydystettävyydestä jäädessään kuhunkin pyydykseen. Jos esimerkiksi alkaisi vaikuttaa siltä, että yhteen pyydykseen jää kaksi kertaa niin paljon kaloja kuin toiseen, tulisi mallin kyetä päivittämään pyydysten suhteellisia tehoja havainnon mukaisesti. Tämä voitaisiin kenties tehdä laskemalla aineiston mukaan päivitettävät painot pyydyskohtaisille todennäköisyyksille. Näiden painojen keskiarvon tulisi olla 1. Jatkossa tämän näkökulman huomioimista on syytä edelleen kehittää.