Muutoksia malliin: uusi pyydystystapa sekä priorioletusten päivittäminen
Pyydystystavan muutoksen huomioiminen mallissa
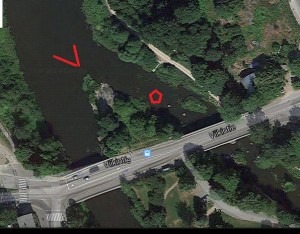
Päivän 16 kohdalla tapahtui tutkimusasetelman kannalta mielenkiintoinen muutos, kun datan lähteeksi joelle lisättiin Taimenruuvin lisäksi Taimenrysä, joka sijaitsee joen haaraumassa suunnilleen kuvan osoittamalla tavalla.
Kuva 1. Pyydysten sijainnit
Tämä tietysti vaikuttaa oleellisesti päivittäisen saalismäärän jakaumaan. Koko mallimme rakenne on karkeasti kuvattuna suunnilleen seuraavanlainen:
N & p -> n , n & q -> x
N = lähtevien taimenten kokonaismäärä
p = päivittäinen lähtötodennäköisyys
n = päivittäisten lähtijöiden lukumäärä
q = pyydystystodennäköisyys
x = pyydystettyjen taimenten lukumäärä
Eli kokonaislukumäärä ja päivittäinen lähtötodennäköisyys määräävät päivittäisten lähtijöiden lukumäärän jakauman, joka taas yhdessä pyydystystodennäköisyyden kanssa määrittää kiinnijääneiden lukumäärän jakaumaan. Tämä hierarkisen rakenteen ansiosta pyydykseen jääneiden kalojen lukumäärä päivittää esimerkiksi arviotamme kokonaislukumäärästä (N).
Taimenrysän tullessa peliin mukaan, täytyy pyydystystodennäköisyys määrittää uudestaan. Rysä ja ruuvi eivät vaikuta toistensa toimintaan, mutta sama kala ei voi jäädä kiinni molempiin. Siis:
P(kala jää ruuviin TAI rysään) = P(kala jää rysään) + P(kala jää ruuviin) – P(kala jää ruuviin JA rysään)
BUGS-koodilla tämä näyttää seuraavalta. (En käy läpi koodin yksityiskohtia; jos BUGS ei sinua kiinnnosta, siirry alas muuttointensiteettiä käsittelevään kappaleeseen!)
# Total cathability
q <- q_f + q_s – q_f * q_s
#separate catchabilities for both catching methods
# a=number of recaptures
# b=number of marked smolts not recaptured on the next day
# q_s=catchability of the smolt screw
q_s~dbeta(alpha,beta)
alpha<-(2 + sum(a[1:m[2]]))
beta<-(8 + sum(b[1:m[2]]))
# q_f=catchability of the fyke, that has been operational from day 15
q_f~dbeta(alpha2,beta2)
alpha2<-(2+(sum(a2[15:m[2]])))
beta2<-(8+(sum(b[15:m[2]])))
Nyt kun pyyntitodennäköisyys on uudelleenmääritelty, täytyy vielä mallissa huomioida, että muutos tapahtui tiettynä päivänä. Toteutimme tämän step-funktion avulla seuraavasti:
for(i in 1:m[1]) {
.
.
.
# catchability changed from day 16
lambda[i] <- q_s*n[i]*step(15-i) + q*n[i]*step(i-16)
# x[i] = the daily catch (num. of fish caught at day i)
x[i]~dpois(lambda[i])
}
Data näyttää mallissa nyt seuraavalta:
list(m=c(60,20))
x[] a[] a2[] b[]
0 0 0 0
0 0 0 0
0 0 0 0
1 0 0 0
2 0 0 0
2 0 0 3
0 0 0 2
0 0 0 0
0 0 0 0
1 0 0 0
1 0 0 1
1 0 0 1
0 0 0 1
2 0 0 0
1 0 0 2
1 0 0 1
1 0 0 1
1 0 0 1
2 0 0 1
5 0 0 3
Muuttointensiteettiä koskevan priorioletuksen päivittäminen
Yhtenä oleellisena haasteena – sekä tarkkailuaikana kokonaisuudessaan Vantaanjoesta mereen siirtyvien smolttien totaalin posterioriestimoinnissa, että seuraavan päivän muuttomäärän estimoinnissa – on määrittää, kuinka muuttointensiteetti vaihtuu päivien kuluessa. Tämän suhteen asiantuntijatietoon perustuvana priorina käytettiin arviota, jonka mukaan a) muutto lähtee (luonnon olosuhteissa) toden teolla käyntiin noin 7 celsius -asteessa sekä b) muutto saavuttaa huippunsa 8 asteen tienoilla. Arvelimme intensiteetin huipun tämän perusteella saavutettavan siis jo seurannan alkuvaiheilla hahmotellen, että päivittäiset muuttomäärät laskevat huipun saavutettuaan hitaammin kuin olivat nousseet, hiipuen pikkuhiljaa lähtötasolle seurannan loppuessa noin 60 päivän jälkeen. Oletamme, että kaikki joessa majailevat smoltit lähtevät liikkeelle seuranta-ajan kuluessa. Tämä olettamus tuskin kirjaimellisesti pitää paikkansa, sillä jo ensimmäisinä päivinä saimme haaviin muutamia havaintoja, mikä antaa ymmärtää, että oletettavasti smoltteja on kulkenut vanhankaupunginkosken ohi jo ennen seurannan aloittamista.
Ennen kaikkea yllä tehdyn priorioletuksen b) perusteella päätimme arvioida yksittäisen smoltin todennäköisyyttä lähteä liikkeelle päivänä i vahvasti oikealle vinolla funktiolla. Tämän kaltaista jakaumamuotoa voitaisiin lähteä approksimoimaan esim. jonkinlaisella muunnelmalla Pareto-, Gamma- tai lognormaalijakaumasta. Päädyimme lognormaalin kaltaiseen funktioon, jonka varmistimme täyttävän todennäköisyysjakauman määritelmän määrittelyjoukossaan jakamalla funktion antamat arvot kaikkien arvojen summalla.
Havaitsimme kuitenkin pian, että lognormaalijakaumalla tullaan olettaneeksi aivan liian suuren osuuden smolteista lähteneen liikkeelle seurannan alkupäivinä. Tämän oletuksen seurauksena yksittäisten päivien muuttoestimaatit vaikuttivat liian korkeilta jo havaituille päiville. Samaisesta syystä totaaliestimaatti vaikutti arvioivan todellista muuttomäärää alakanttiin. Uumoilimme, että muuttohuippu ollaan vasta saavuttamassa ja joko että 1) kasvu huipulle tultaessa ei ole niin jyrkkään – ainakaan seurannan ensimmäisinä päivinä – kuin lognormaalijakauma olettaa, tai 2) että kasvu on vielä jyrkempää, mutta täysin äkillistä. Ehkäpä tiettyjen biologisten ennakkoehtojen kuten sopivan lämpötilan ja valonmäärän osuessa kohdalle, lukemattomat smoltit lähtevät liikkeelle samanaikaisesti.
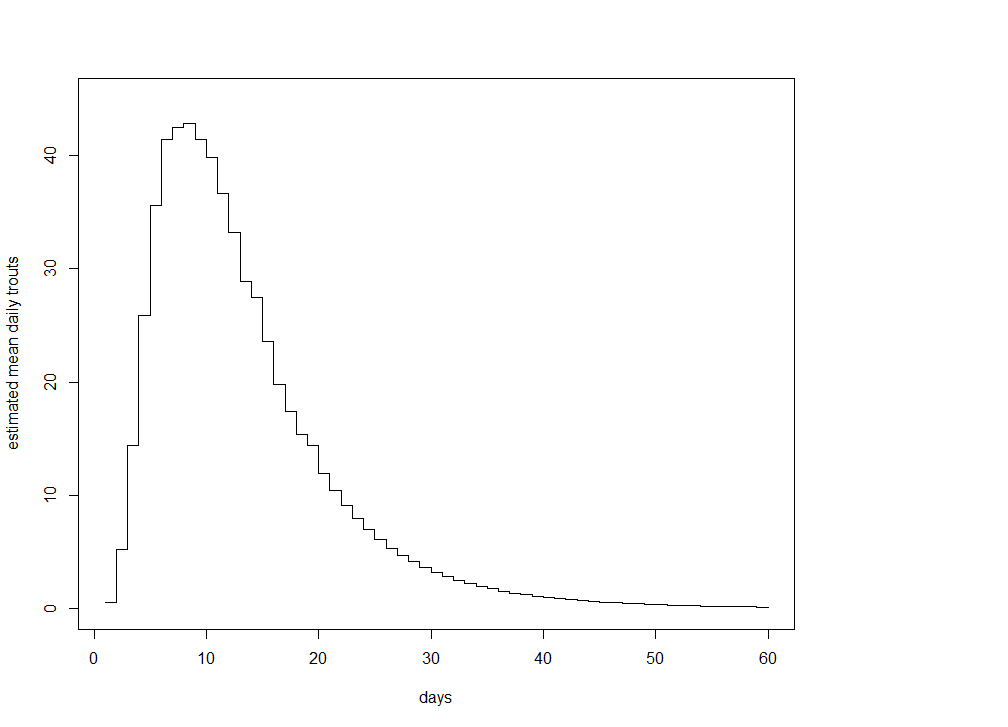
Kuvio 1. Smolttien ennustetut odotusarvoiset muuttomäärät päivien funktiona mallivalinnalla lognormaali
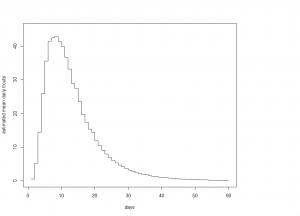
Kuten kuviosta 1 havaitsee, mallioletuksella lognormaali smolttien muuton huipun pitäisi jo olla takanapäin, sillä tänään 29.5. olemme päivässä nro 21. Tämä on ristiriidassa asiantuntijatiedon kanssa, jonka mukaan muuttaminen saavuttaa huippunsa noin kahdeksassa asteessa, mikä lämpötila saavutettiin eilen. Samaisesta syystä mallin estimoima suhteellinen muuttaneiden osuus kaikista joen smolteista vaikuttaa liian korkealta.
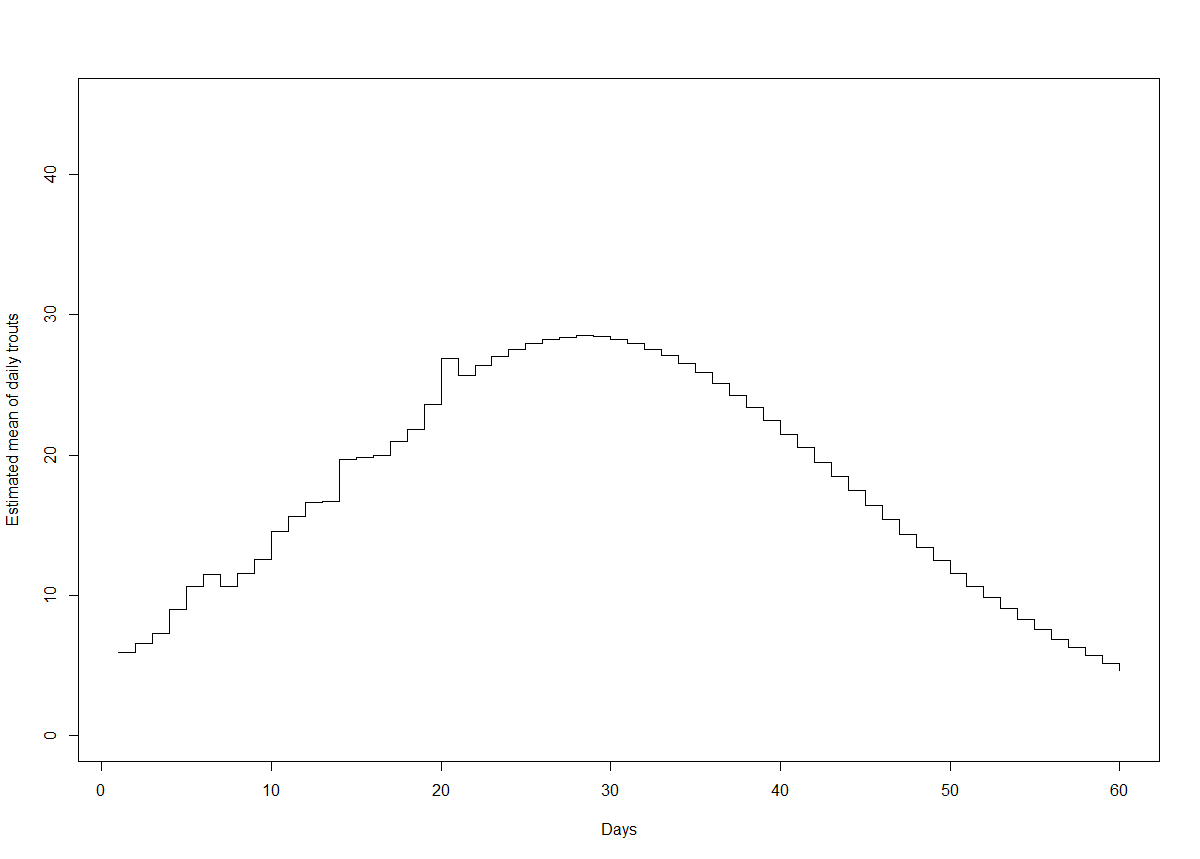
Korjausliikkeenä em. haasteeseen 1) päätimme muuttaa oletustamme muuttointensiteetistä. Lähdimme mallintamaan asiaa kahdella vaihtoehtoisella tavalla. Ensinnäkin datavetoisesti olettaen muuttotodennäköisyyden vakioksi yli päivien (ts P[i] = 1/60). Toiseksi olettaen jakauman normaaliseksi saavuttaen huippunsa odotusarvoisesti 25 päivän kohdalla. Saimme seuraavat estimaatit päiväkohtaisille muuttomäärien odotusarvoille:
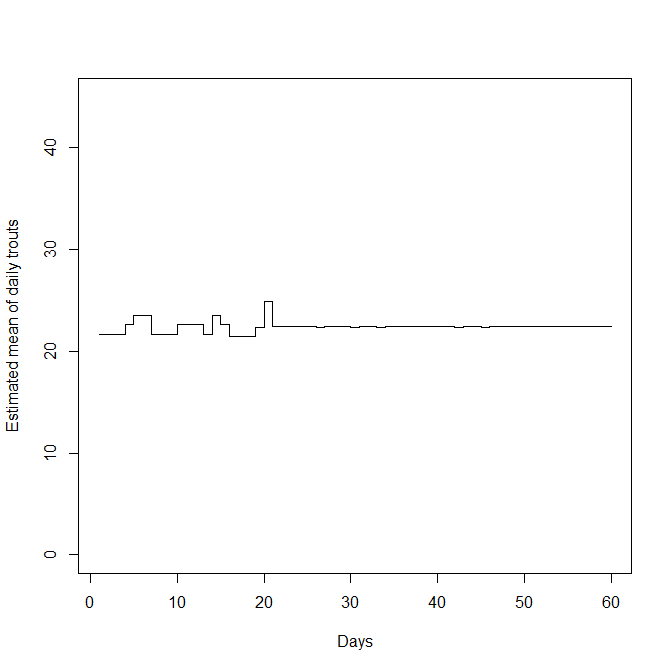
Kuvio 2. Smolttien ennustetut odotusarvoiset muuttomäärät päivien funktiona mallivalinnalla tasajakauma ja normaalijakauma
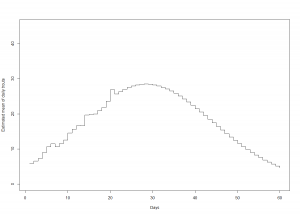
Nähdäksemme kyseisillä mallivalinnoilla on realistisemmat oletukset jo mereen muuttaneiden smolttien suhteellisesta osuudesta. Datavetoisella tasajakaumapriorilla saamme suhteessa havaittujen smolttien aineistossa esiintyneeseen tasaiseen trendiin perustellun oloisia estimaatteja. Normaalijakaumaoletuksella muuttohuippu on vasta edessä, minkä lisäksi pienempi osuus smolteista oletetaan jo muuttaneen kuin lognomaalioletuksella.
Edellä arveltiin, että menneiden tutkimusten perusteella saattaisi käydä niin, että muutto tapahtuu muutamassa harppauksessa sitten, kun se lähtee käyntiin. Näin ollen päivien yli oletetun muuttointensiteetin jakaumaan saattaa olla perusteltua tehdä yhä joitain kyseiset arviot paremmin huomioonottavia muokkauksia. Esimerkiksi voitaisiin olettaa, että muutto on tasaista (sitä kuvaa tasajakauma) tiettyyn päivään asti, jolloin jakauman muoto muuttuu ikään kuin kategorisena muuttointensiteetin tilan muutoksena. Tämä voidaan sisällyttää malliin olettamalla eri muuttoajanjaksoille (korkea / alhainen intensiteetti) omat niitä parhaiten kuvaavat todennäköisyysjakaumat esimerkiksi edellä jo esiintyneen step -funktion logiikkaa hyödyntäen.