
Thanks to Mikkeli University Consortium help, the National Library of Finland was present at the DH 2019 conference in Utrecht. The conference is organized by the The Alliance of Digital Humanities Organizations (ADHO), and organized annually, usually every other year in Europe or in Americas. Netherlands was a good choice of venue, since the National Library of Netherlands is doing excellent work with the library lab development as with the researcher-in-residence program, having then much of calls for visiting them, as we got to hear in the library labs session during one lunch break. At building library labs pre-conference workshop we had a paper, outlining current work we do with the researchers (morning coffees, data clinics etc) and briefly outlining the possible future directions for improving tools and services forwards.
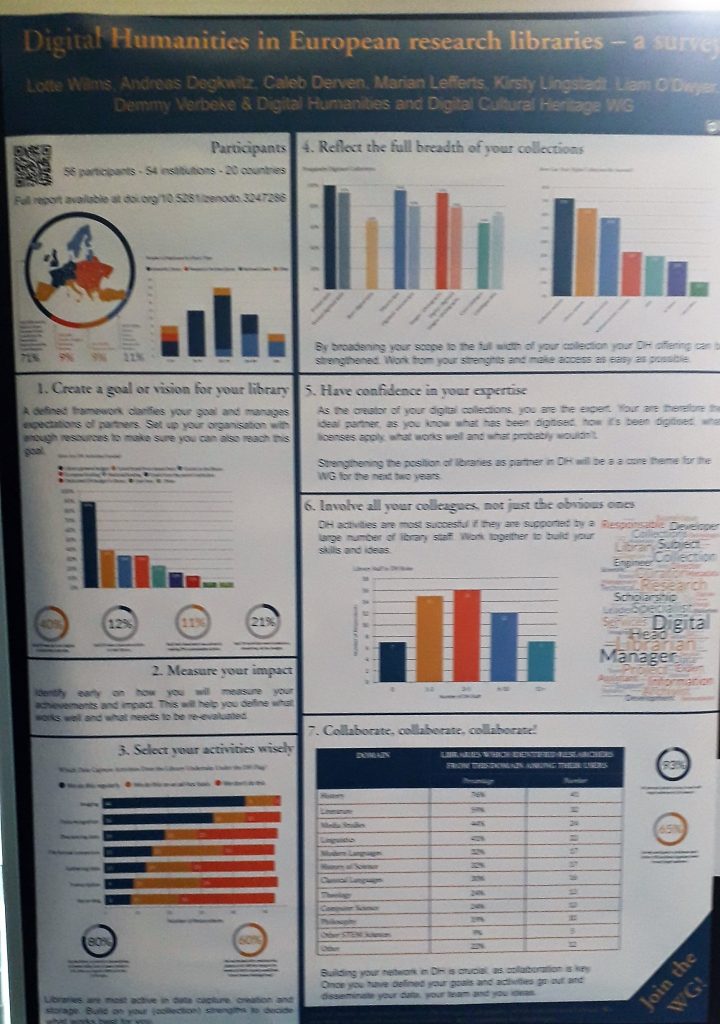
A poster of recent survey done about DH in European Research Libraries
About the conference
Conference was large and very popular, at the very last minute the participant amount grew to the bit over 1000 so the venue was packed. This despite there were four parallel tracks that nicely divided the participants to the different locations of the venue. The conference venue was a music hall, with halls and rooms for 30-1000 people in different wings within the hall. Usually it was just simplest to experience a session in full to secure a spot there where you wanted it.

Researchers, scholars, academics, go!
I tended to pick most of the long paper sessions, where there were academics from various universities and research institutes from all over the world. Also the fields of studies varied: data, quantitative and qualitative, machine learning used and also with many different languages and collections were targeted. Mostly digital, but also mentions of microfilm were there.
The multitude of tracks meant that there was a cornucopia of good sessions to choose from, and regardless it felt that you were missing out something after picking some session, but that is how it usually goes in these events.
One side discussion in Twitter occurred on the woes of the lack of digitisation. The situation in countries is naturally varies, some have got some millions of pages of their collections digitized and some are only starting their way.
Most striking feature of the discussion of newspaper digitisation at #dh2019 so far is the low percentage of newspapers so far digitised – between about 4% and 6.5% various colleagues suggest.
— Andrew Prescott (@Ajprescott) July 10, 2019
Heard a few , as expected, mentions of the OCR quality, and at least one, quick remark of the post correction of OCR. Newspapers, books, libraries, archives of many kinds were used (even if not all of them were named). One interesting one was the Impresso project, which talks about “newspapers as an Eldorado”, that with an addition to the NewsEye and READ (Transcribus) development could be that even more in the future.
Again impressed by the work of @ImpressoProject as presented by @maudehrmann with shout-out to CfP for conference 'Digitised newspapers – a new Eldorado for historians ?' https://t.co/WUwOCZw5pX #DH2019
— Martijn Kleppe (@MartijnKleppe) July 10, 2019
Lots of libraries were developing platforms, where the machine learning capabilities are part of the solution given to the researchers, British Library had ‘Curatr’ where there was word embeddings that work in the background, and allow reseacher to make their own small subcorpora of their research question as the tools were integrated within the presentation system. There also one main feature was to be able to variate between distant reading and close reading – you could get back to the original page which could explain why certain thing was included to the search results. Then there was authorship verification work, work with dictionaries and DH, maps, image capturing of various material types, segmentation, fake news, multi-language woes (i.e. why quite much of research is done on English corpora?) . But also to the concrete, how to get the new generation to read, how the collections should be put available online and combine different media? What kind of features would be needed from the newspaper collections, which initiated an ad-hoc meetup on Friday to collect the researcher needs and work on those onwards in the coming DH2020 conference and between.
![]()
Finland
Finnish universities were present quite well in the conference. Comhis group had several papers and posters that talked about utilizing the national bibliography, or newspaper collections. They tweeted the slides and abstracts for anyone to utilize:
All the slides & abstracts of our group’s six #dh2019 papers and a poster can be found here: https://t.co/P2A5sPykol Thanks everyone for a great conference! #helsinkiDH
— Helsinki Computational History Group (@COMHISgroup) July 12, 2019
and the interesting ways how you can utilize the digitisation process metadata in novel ways to show and tell the changes in newspaper landscape.
If you'd have wanted to see my presentation on analysing the material dimensions of newspapers but didn't fit, the presentation is at https://t.co/tJB8b5JFDm. It isn't completely parseable without the talk, but I'm happy to answer questions #DH2019
— Eetu Mäkelä (@jiemakel) July 11, 2019
University of Turku had also Comhis and Oceanic Exchanges related papers presented.
Trans-Atlantic Platform panel set to begin in #DH2019 conference @TiVre_Utrecht – @SuomenAkatemia #DIGIHUM programme represented by @MilaOiva & @hannusalmi @UniTurku pic.twitter.com/YBJqIrYKsT
— Risto Vilkko (@RistoVilkko) July 10, 2019