
Tällä viikolla jatkettiin rasterianalyysien parissa <3
Ensimmäisessä tehtävässä tehtiin yksinkertainen soveltuvuusanalyysi, jossa yhdistettiin valmistettuja binääriaineistoja sopivan pinnan luomiseksi. Pinnan tuli täyttää halutut kriteerit. Binäärisessä tasoaa on kaksi arvoa:0 ja 1. Myöhemmin lopulliselle mallille tehdään herkkyys- ja virheanalyysi.
Ensin lähtöaineistoa käsiteltiin ja niille tehtiin analyyseja, sekä muokkauksia. Käyttämällä aspect työkalua lähtöaineistosta saadaan ikään kuin kaikki irti, eli se saadaan yksityiskohtaiseen muotoon. Tämän jälkeen käytettiin tuttua reclassify työkalua, jonka avulla tehtiin uusi analyysi ja kaikki tasot yhdistettiin yhdeksi binääriseksi tasoksi kertomalla ne keskenään. Työkalun avulla rasterin pikseleiden arvot voidaan muuntaa uusiksi arvoiksi, jolloin syntyy uusi rasteriainesto.
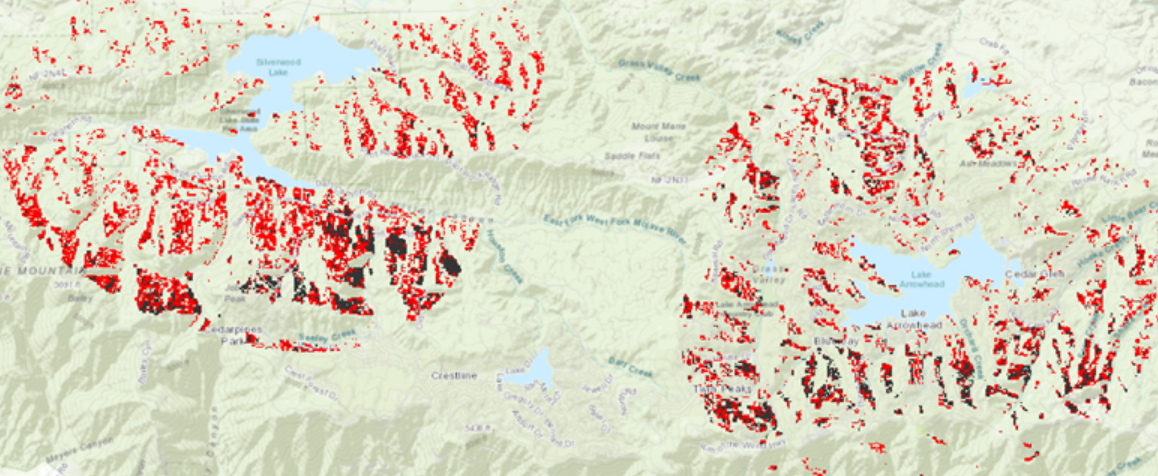
Tämän jälkeen tuloksia analysoidaan käyttämällä herkyys- ja virheanalyysiä. Herkkyysanalyysissä muutetaan yhtä parametria ja testataan kuinka herkkä soveltuvuusanalyysi on muutokselle. Ensin testattiin mallin herkkyyttä muokkaamalla muunnosparametriä CanopyTrans tason reclassify (2) työkalusta. Tässä kohtaa tarkistettiin hyväksyttävän alueen vähimmäisarvo. Lopputloksessa (kuva 1) kartassa punaisella näkyy soveltuuus- ja herkkyyspintojen erot.
Tarkastellessani tuloksia huomasin, että soveltuvuutta kuvaavassa tasossa on vähemmän soluja, jotka nähdään sopivina. Jotta solu on sopiva, on kaikkien kriteerien täytyttävä yksitäisessä solussa.
Virheanalyysissä tarkastellaan kuinka paljon lähtöaineisto vaikuttaa soveltuvuusanalyysiin. Virheen vaikutusta voidaan analysoida lisäämällä tai vähentämällä (esim. + tai – 1 metri) arvoja soluista. Tämä tehtiin poistamalla Elevation datan muuttuja ja laittamalla paikalle DEM-lähdetietojoukko, joka yhdistettiin aspect työkaluun.
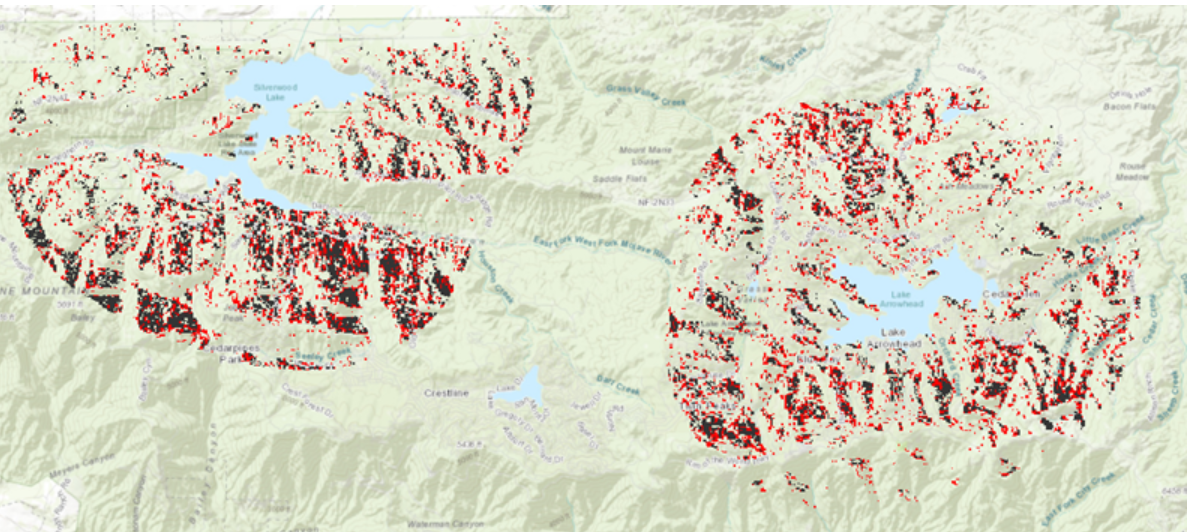
Lopuksi kartta visualisoitiin (kuva 2) niin, että 0 arvon solut ovat värittömiä ja muut punaisia. Kartassa näkyy sopivuus- ja herkkyysintojen muutokset punaisella. Karttaa tarkastellessa huomasin, että ErrorDifference tasossa on vähemmän optimaalisia soluja.
Toisessa tehtävässä valmisteltiin dataa painotettua soveltuvuusmallia varten. Painotetussa soveltuvuusmallissa aineisto luokitellaan asteikolle, jossa suurin arvo kuvaa parasta soveltuvuutta. Tässä tehtävässä tasot uudelleen luokiteltiin arvoihin 1-10 lopullista analyysiä varten. Uudelleenluokitus tapahtui käyttämällä tuttua reclassify työkalua, jossa jokainen solu sai jonkin arvon. Rescale By Function työkalua käytettiin määrittämään suurin asteikon arvo jokaiselle tasolle, jonka haluttiin täyttävän jokin kriteeri. Työkalussa pystyi asettamaan haluttuja parametreja. Tutuksi tuli myös binäärimaskin (?) lisääminen datalle. Sen avulla voidaan poistaa tai peittää ei haluttuja alueita (arvo=0) datasta. Maskin avulla voidaan myös parantaa datan käsittelyaikaa.
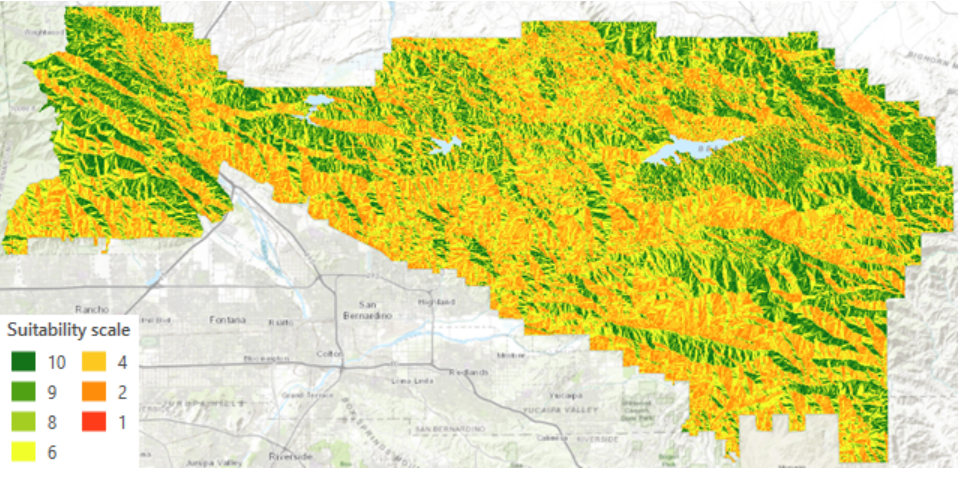
Tehtävän loppuvaiheessa ArcGIS kaatui jatkuvaksi, joten havainnollistava karttaesitys on otettu tehtävän ohjeista (kuva 3). Kartassa näemme hyvin luokituksen 1-10 tasot, jotka kuvaavat soveltuvuutta eri sävyillä. Kuvan 3 kartta havainnollistaa vain yhtä tasoa.
Kolmannessa tehtävässä yhdistettiin toisessa tehtävässä uudelleenluokitellut tasot yhdeksi tasoksi, jossa sopivuutta kuvattiin asteikolla 1-10. Tasojen yhdistämiseksi käytettiin Weighted Sum työkalua, jossa tasot lisättiin yhteen, toisin kun binäärisessä mallissa tasot kerrottiin yhteen. Lisättäessä lasketaan yhteen kunkin tason solujen arvot. Weighted sum työkalulle asetettiin haluttuja parametreja. Tehtävässä uutena asiana tuli soveltuvuuspinnan venytystyypin muokkaaminen parempaa kartan visualisointia varten.
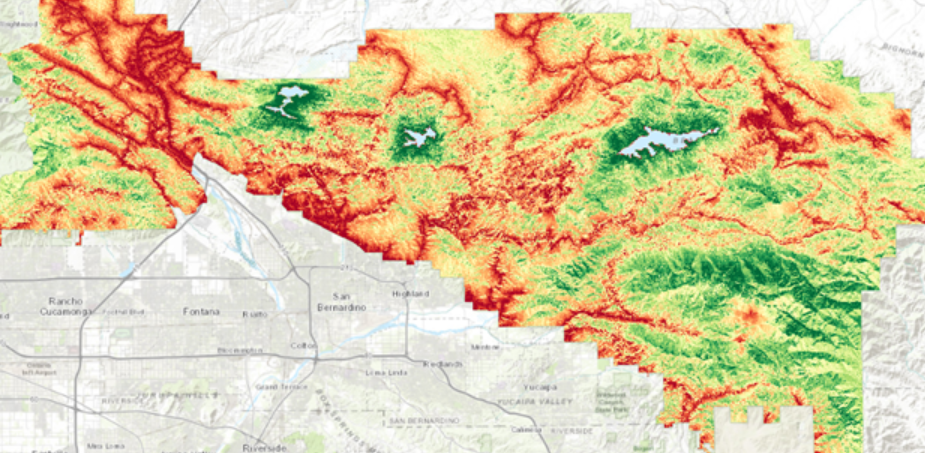
Seuraavaksi lopulliselle mallille tehtiin virhe- ja herkkyysanalyysi. Painotetun soveltuvuusmallin herkkyyttä voidaan analysoida muuttaalla jotakin muunnostyökalun painoa tai yhtä parametria. Tässä tehtävässä muutettiin painoa, eikä parametria niin kuin ensimmäisessä tehtävässä. Tämän jälkeen malli voidaan suorittaa uudelleen ja tuloksia voi tarkastella silmämääräisesti. Jos tulokset muuttuvat huomattavasti painon tai parametrin muututtua katsotaan mallin olevan erittäin herkkä. Tässä kohtaa opin myös käyttämään ArcGIS:in swipe efektiä, jolla pystyi arvioimaan herkkyyden muutosta tarkastelemalla kahta tasoa samaan aikaan. Virhettä taas analysoitiin samalla tavalla kuin ensimmäisessä tehtävässä (kuva 4.). Lopuksi data visualisointiin ja muutoksia arvioitiin käyttämällä swipe efektiä.
Koen tällä viikolla oppineeni paljon käytännön teoriaa. Tehtävät olivat sopivan haastavia ja ArcGIS kaatui vain kerran <3. Uskon, että pystyn tulevaisuudessa yhdistelemään monipuolisesti aikaisemmilla viikoilla opittuja asioita.
Till nästa vecka!