Viimeisellä viikolla jatketaan interpoloinnin maailmassa ja tutustutaan erityisesti geostatisen interpoloinnin maailmaan.
Interpolointi suoritetaan determistisellä- tai geostatistisella menetelmällä. Deterministinen malli perustuu ennustettavan pisteen ympäristön mitattuihin arvoihin tai matemaattisiin funktioihin, joilla määritetään ennustuspinnan muoto.Geostatinen interpolointi hyödyntää matemaattisten mallien lisäksi tilastollisia malleja, jotka huomioivat spatiaalisen autokorrelaation (Holopainen, 2015). Spatiaalisessa autokorrelaatio on ajatus siitä, että sijainniltaan toisiaan lähellä olevat arvot ovat todennäköisemmin lähellä toistensa arvoja, kuin kauempana olevien pisteiden arvot (Burrough, 1987). Deterministinen interpolointi ei taas tunnista tätä autokorrelaatiota.
Geostatisilla menetelmän avulla saadaan ennustuspinnan lisäksi tieto ennusteen luotettavuudesta (Holopainen, 2015). Geostatinen interpolointi perustuu semivariogrammiin, jonka avutta tutkitaan autokorrelaation ominaisuuksia ja olemassaoloa (Holopainen, 2015). Semivariogrammista nähdään, miten esimerkiksi etäisyyden kasvaessa spatiaalinen autokorrelaatio heikkenee, eli milloin ja miten varianssi kasvaa.
Ensimmäisessä tehtävässä luotiin Inverse Distance Weighted (IDW) ja Kriging -interpoloinnit. IDW-interpoloinnissa pisteen arvo johdetaan läheisten havaintopisteiden arvoista. Tässä menetelmässä määritettävälle pisteelle asetetaan paino, jonka määrä riippuu pisteen etäisyydestä toiseen tuntemattomaan pisteeseen. Mitä lähempänä estimoitavaa kohtaa havaintopiste sijaitsee, sitä voimakkaammin sen arvo vaikuttaa estimoitavan pisteen arvoon (Andik, 2015). Kriging-interpoloinnin perusajatuksena on, että analysoimalla ja mallintamalla spatiaalisen vaihtelun, voidaan kullekin havaintopisteelle määrätä optimaalinen paino ennustuspintaa laskettaessa (Holopainen, 2015).
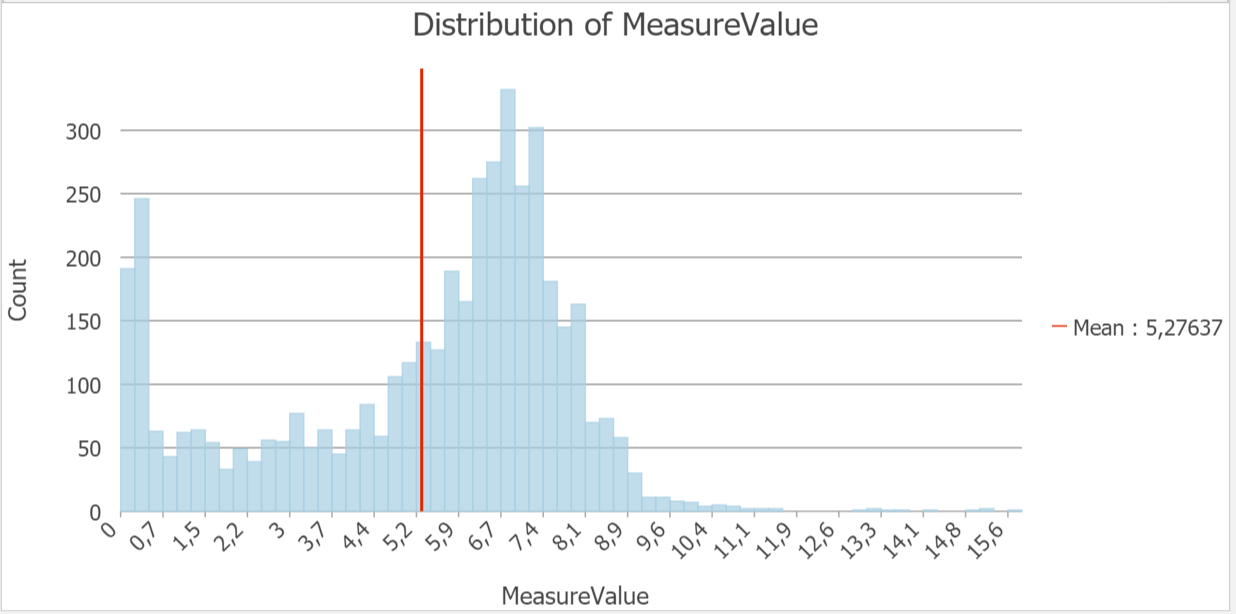
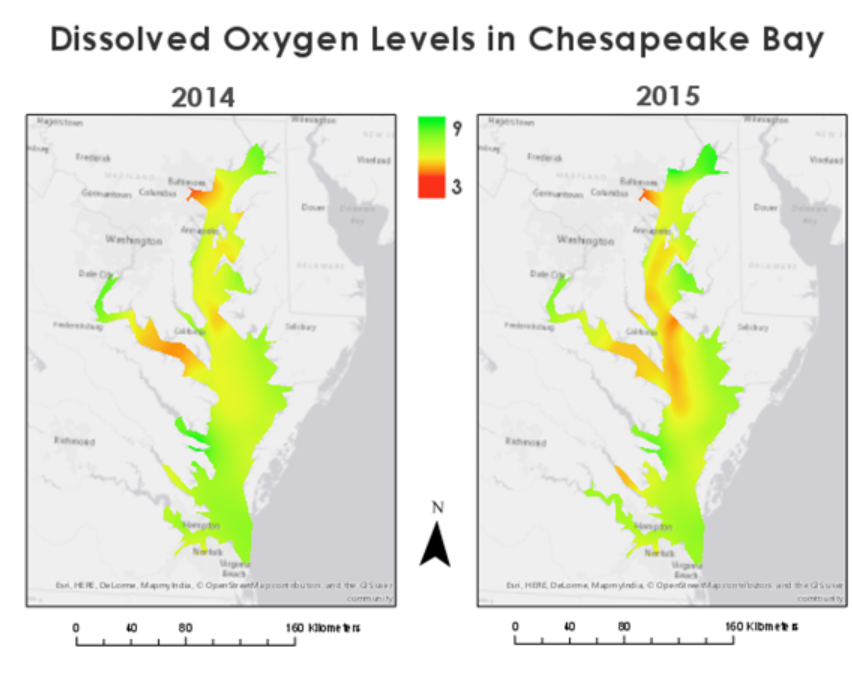
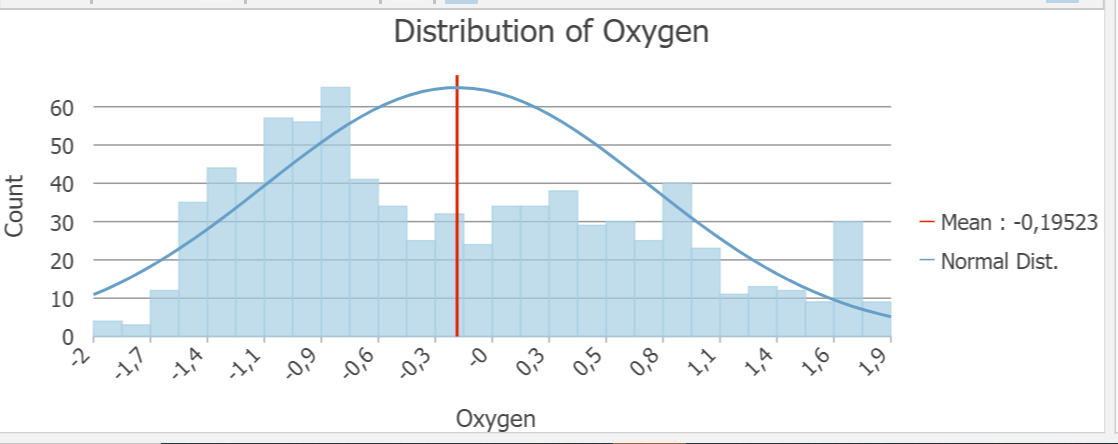
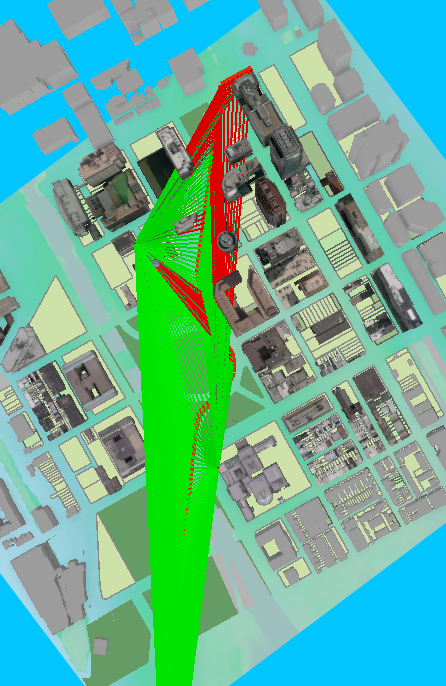
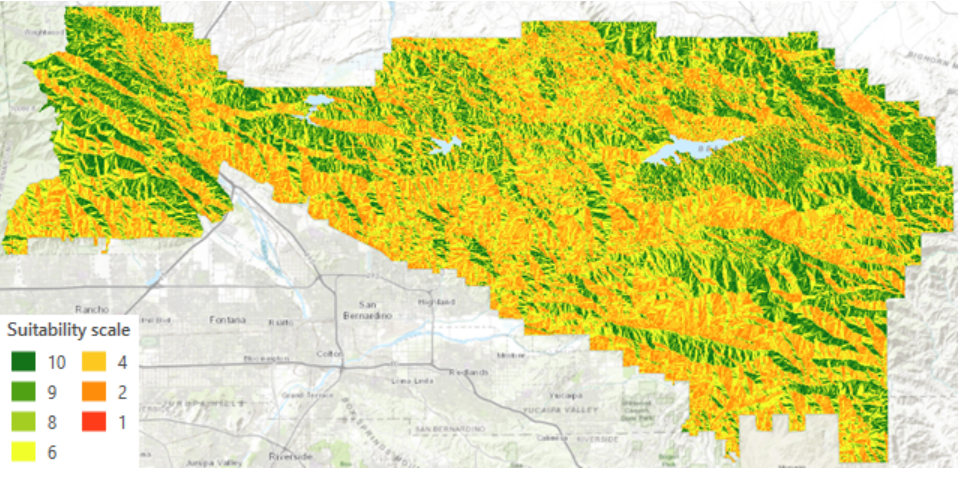
Tehtävän datana toimi kuukausien lämpötilamittauksia Afrikasta ja Lähi-Idästä. Ensin tehtävässä tutustuttiin dataan histogrammin avulla. Interpolointimenetemlät toimivat parhaiten, kun data on jormaalisti jakautunut. Tämän vuoksi interpoloinneissa käytettiin mittauksia elokuulta. Seuraavaksi luotiin pinta, jossa ennustettiin lämpötila-arvoja käyttämällä IDW interpolointia. Tämä tehtiin Geostatistical Wizard työkalun avulla, jolla voidaan valita haluttu interpolointimenetelmä ja muokata sen parametrejä. Työkalussa naapuruustyyppi vaihdettiin smoothiksi, jolloin ennustepinta on tasaisempi ja vähemmän rosoinen (kuva 1).
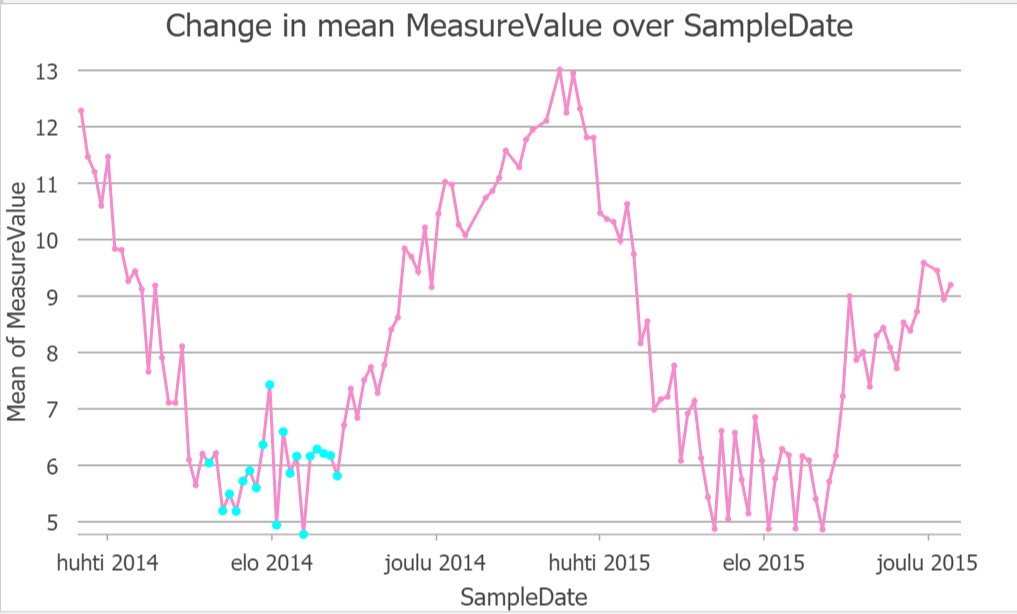
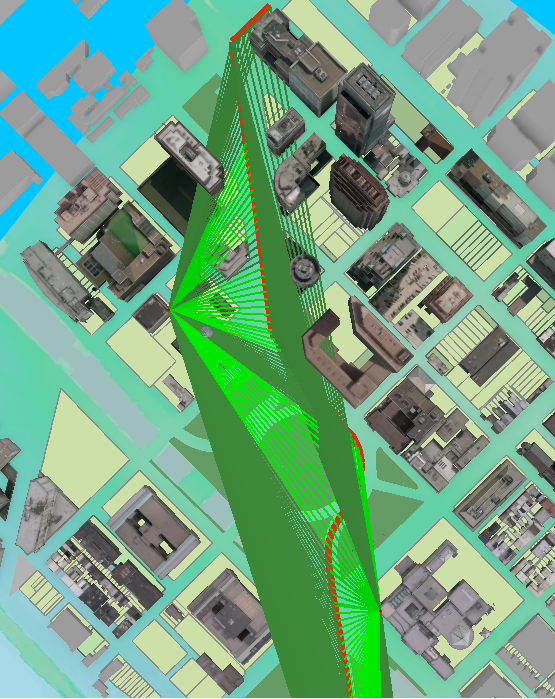
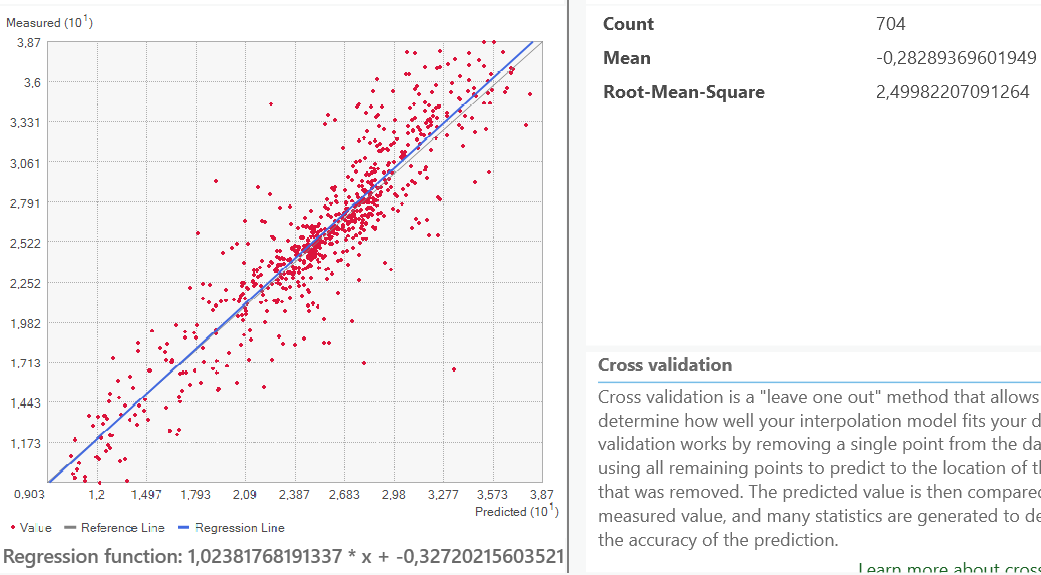
Seuraavaksi tehtiin toinen IDW interpolointi, mutta optimoitu (kuva 2). Työkalulla voi myös vaihtaa interpoloinni voimaa. Jos voima on 0, on kaikilla naapuruston painoilla sama paino. Mitä korkeampi voima on, sitä nopeammin painot pienenevät etäisyyden muuttuessa. Geostatistical Wizard työkalulla voidaan kuvaajan avulla tutkia interpoloinnin luotettavuutta, kun siinä Siinä poistetaan yksi piste kerrallaan tietojoukosta ja jäljellä olevien pisteiden avulla ennustetaan poistetun pisteen arvo. Jos interpolointimalli on luotettava, jäljellä olevien pisteiden tulisi ennustaa tarkasti poistetun pisteen arvo. Kuvaajasta 1 näemme, keskiarvon, joka kertoo meille jos malli on liian vinossa ja ennustaa liian korkeita tai matalia arvoja. Keskiarvo on parhaimmillaan, kun se on lähellä 0. Näemme myös keskiarvon neliön. Mitä lähempänä se on 0, sitä luotettavampi malli on. Seuraavaksi interpolointeja vertailtiin käyttämällä cross validation työkalua. Työkalulla näemme, miten optimisoidun IDW-interpoloinnin keskiarvon neliö on pienempi kuin toisen interpoloinnin, jolloin se on malleista luotettavampi.
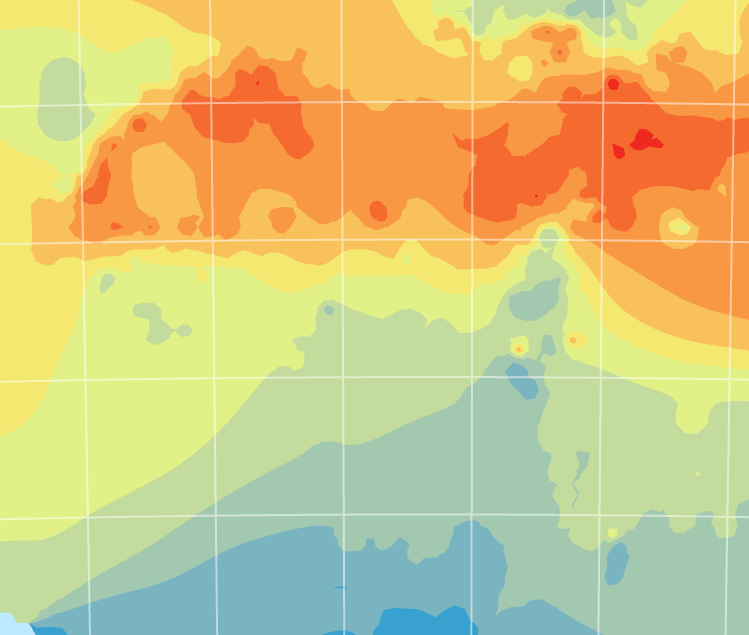
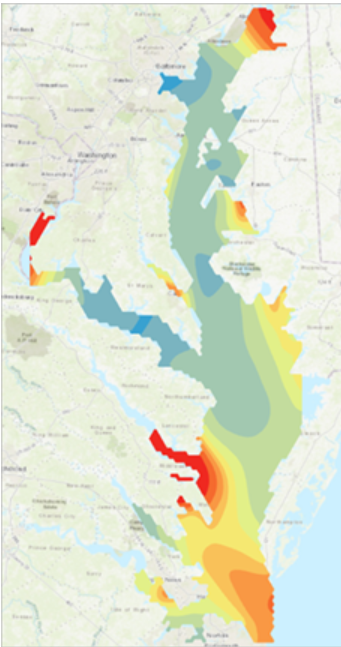
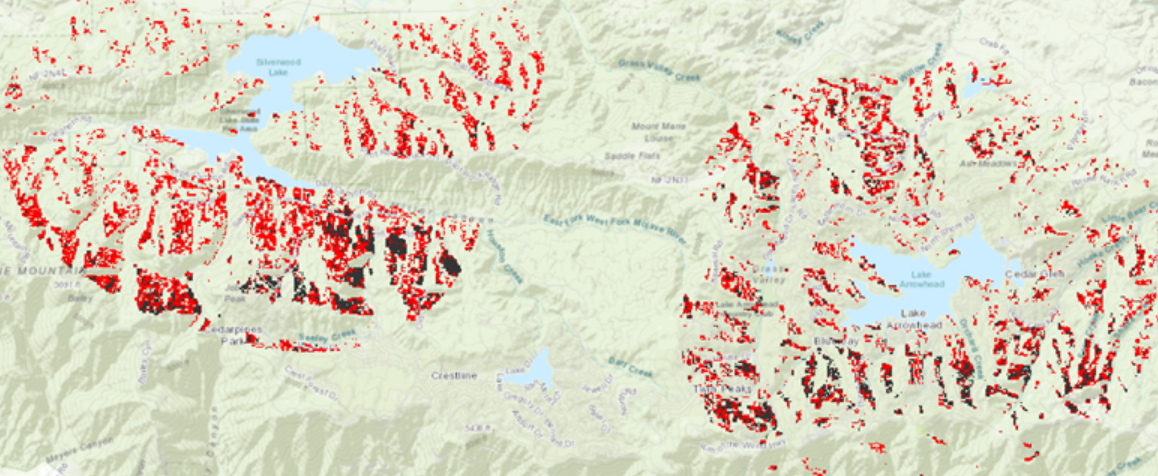
Seuraavaksi Geostatistical Wizard työkalulla suoritettiin kaksi Kriging-interpolointi, jolla koitettiin saavuttaa tarkempi mallinnus. Tämän interpoloinnin tulos oli huomattavasti yksinkertaisempi kuin IDW. Luotiin myös toinen Kriging-interpolointi, jossa malli optimoitiin ja naapuruston luokkakoko vaihdettiin kahdeksaan suuntaan (kuva 3). Yleensä luokkakoko on vain neljä. Nostamalla luokkakoko varmistetaan, että naapureita etsitään kaikkiin suuntiin ja lähellä olevilla pisterykelmillä ei ole kaikkea vaikutusta ennustettuun arvoon. Interpolointeja vertailtiin taas cross validation –työkalulla ja huomattiin, että toinen 8 luokkakoon interpolointi on luotettavampi kuin ensimmäinen interpolointi. Molemmat Kriging-interpoloinnit ovat luotettavampia, kuin IDW.
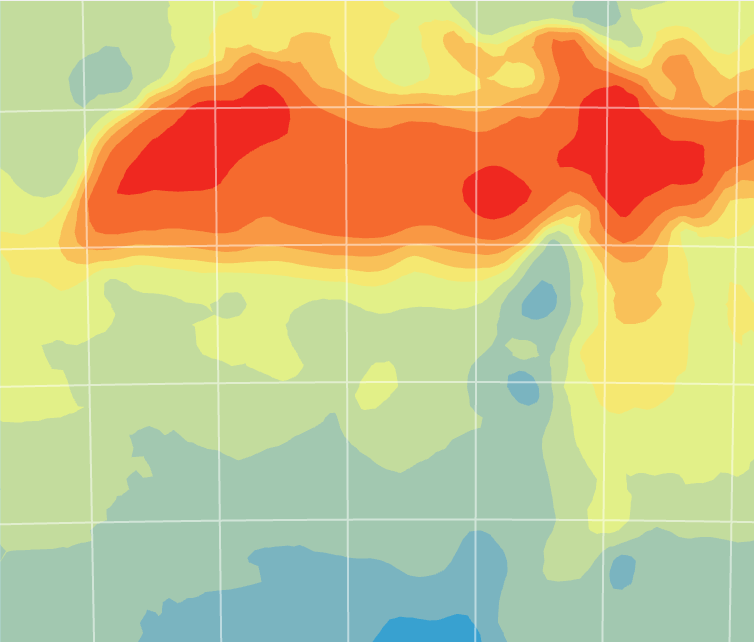
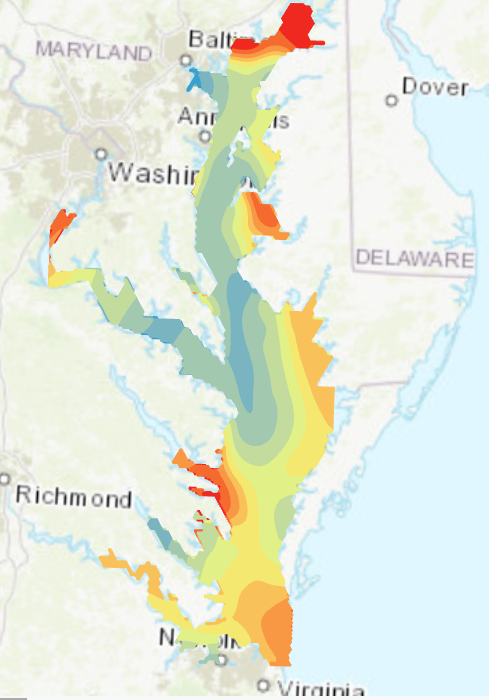
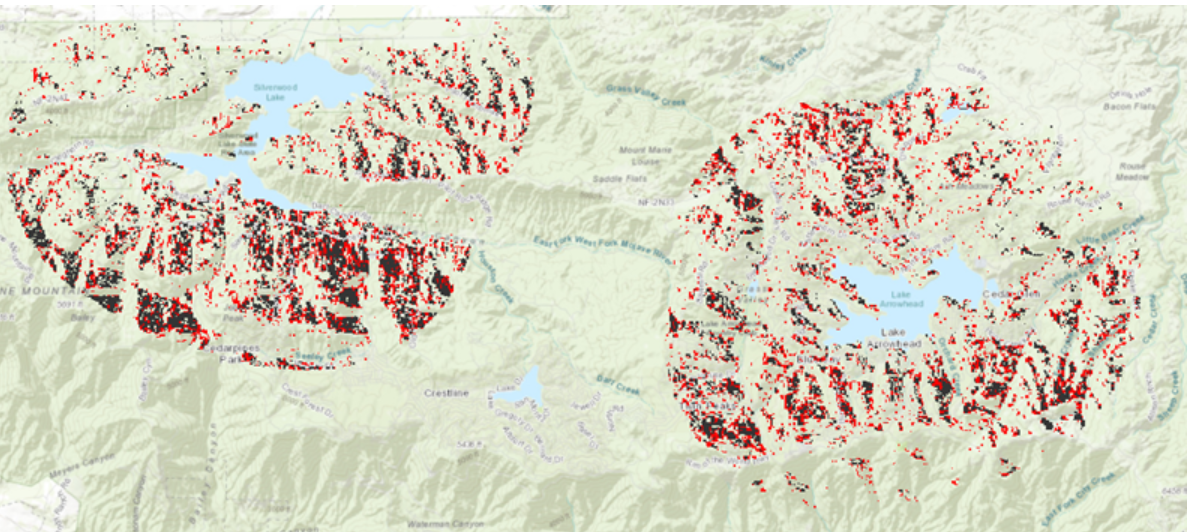
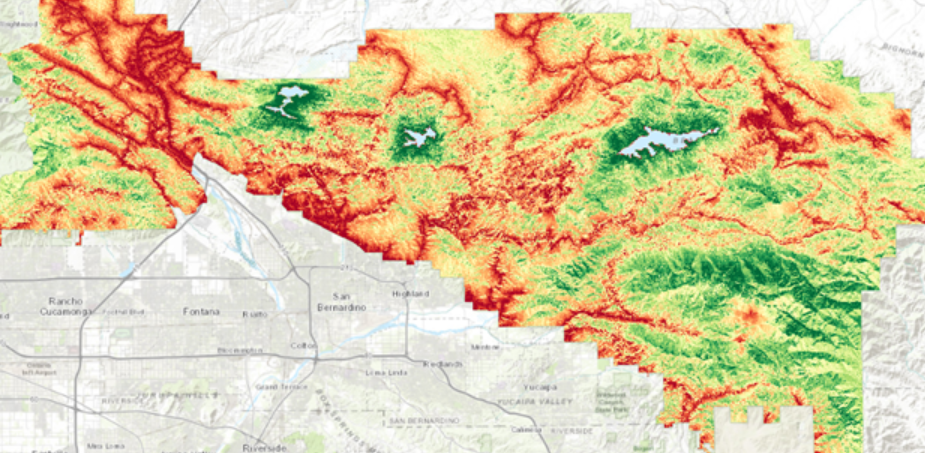
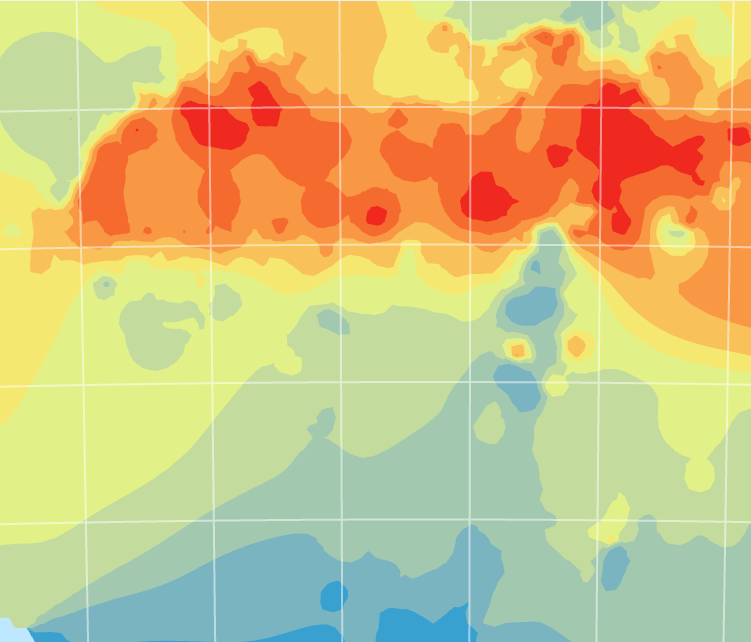
Lopuksi tehtävässä luotiin virhekartta (kuva 4), jolla mallinnetaan mallin epävarmuutta ja luotettavuutta. Virhekartan tummilla arvoilla on suurempi epävarmuus ja vaaleilla korkeampi luotettavuus. Kartasta näemme, miten suurimmat epävarmuudet ovat merialueilla. Tämä käy järkeen, koska näillä alueilla ei ollut mittauspisteitä. Kuva 5 kuvaa lopullista luotettavinta interpolointia.
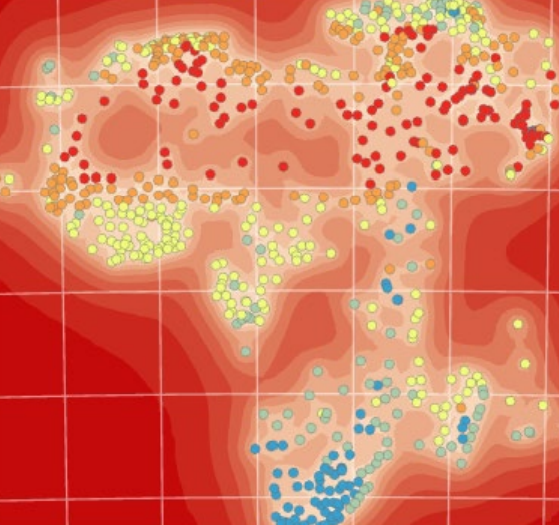
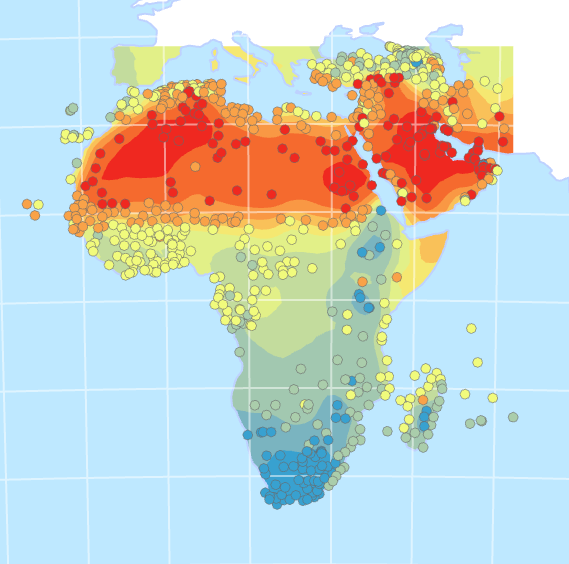
Toisessa tehtävässä interpoloimalla etsittiin Madisonin kaupungista korkean lämpötilan alueita, joissa oli riskiryhmäläisiä. Histogrammin avulla paikannettiin korkeimpien lämpötilojen löytyvät kaupungin keskustasta. Seuraavaksi Geostatistical Wizard työkalulla tehtiin yksinkertainen Kringing-interpolointi (kuva 6), jossa asetettiin halutut parametrit ja mallinnus optimoitiin. Cross validation ikkunan error kohdasta näki, miten malli tasoittaa arvoja, eli aliarvioi suuria arvoja ja yliarvioi pieniä. Tässä tapauksessa tasoitus ei ollut suurta. Ikkunan normal QQ plot kohdasta näki, että mallinnuksen ennustus seuraa normaalia jakaumaa.
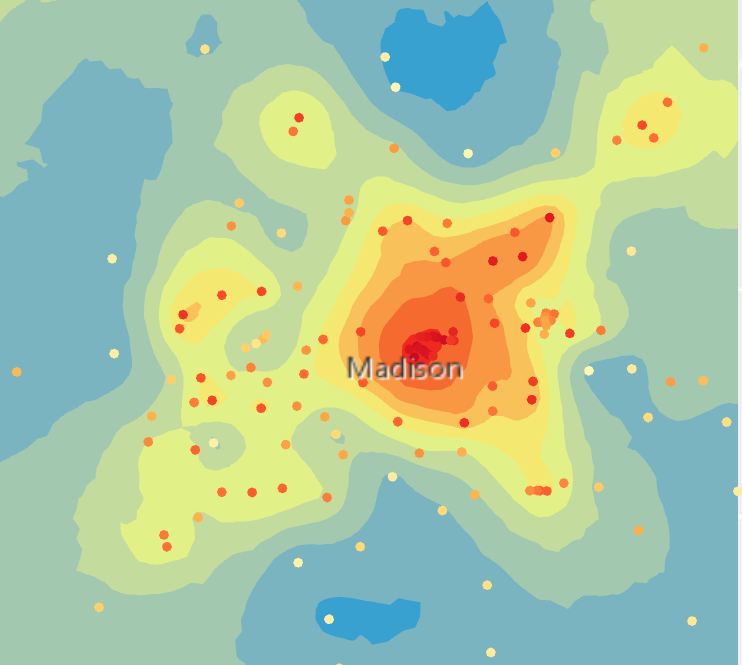
Seuraavaksi lämpötiloja mallinneettiin käyttämällä hienostuneempaa empirical Bayesian kriging (EBK) -interpolointia (kuva 7). EBK-interpolointi eroaa muista Kriging-interpoloinneista siten, että se jakaa aineiston pienempiin osiin ja tekee jokaiselle osiolle oman semivariogrammin. Tällä tavalla lokaaleja muutoksia pystytään paremmin mallintamaan (Gunarathna et al. 2016). Parametrejä muutettiin niin, että osajoukon koko oli 50, joka määrää pisteiden määrän kussakin osajoukossa. Tällä varmistettiin, että semivariogrammit arvioidaan riittävän paikallisella tasolla, mutta säilytetään tarpeeksi pisteitä osajoukoissa, jotta semivariogrammin parametrejä voidaan arvioida luotettavasti. Cross validation -ikkunan arvot osoittivat, että EBK-interpolointi on luotettavampi, kuin simple Kriging -interpolointi. Error valikosta näkyi, että tämäkin malli tasoitti arvoja hieman.
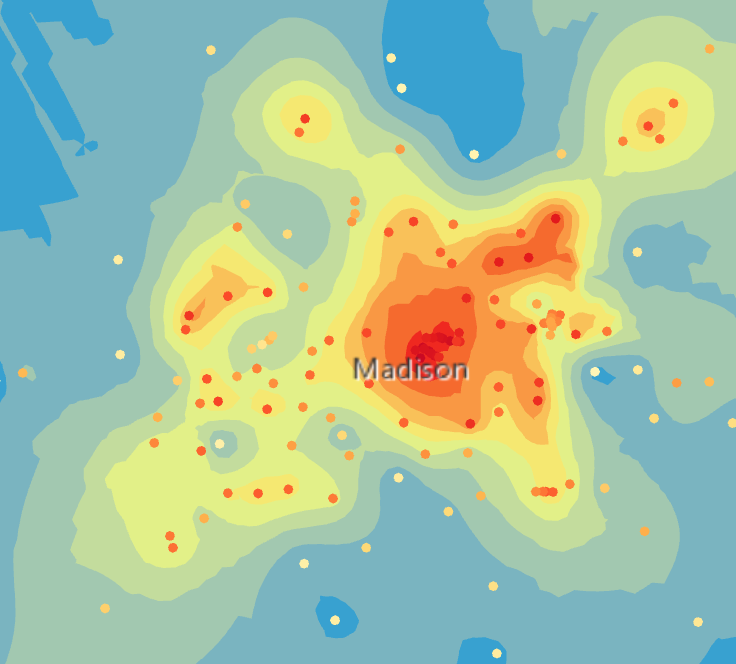
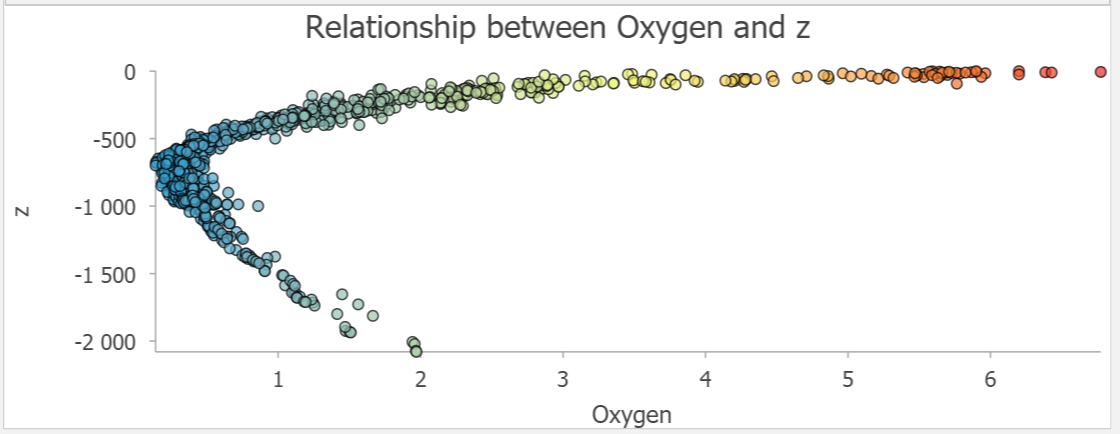
Seuraavaksi käytettiin Extract By Mask –työkalua, kun kartalle lisättiin rasteritaso ja poistettiin siitä vettä läpäisemättömät alueet. Tämän tason ja sen kuvaajan avulla pystyttiin vertailemaan läpäisemättömien pintojen ja mitatun lämpötilan välillä. Kuvaajasta nähtiin, että muuttujien välinen suhde on lineaarinen. Seuraavaksi käytettiin EBK Regression Prediction –työkalua lämpötilamittausten interpolointiin käyttämällä läpäisemättömiä pintoja selvittävänä muuttujana. Tämän jälkeen EBK: n regressio-ennustetta verrattiin aikaisempiin interpolointeihin ja huomattiin, että regressio-ennuste oli tarkempi, kuin aikaisemmat Kriging-interpoloinnit.
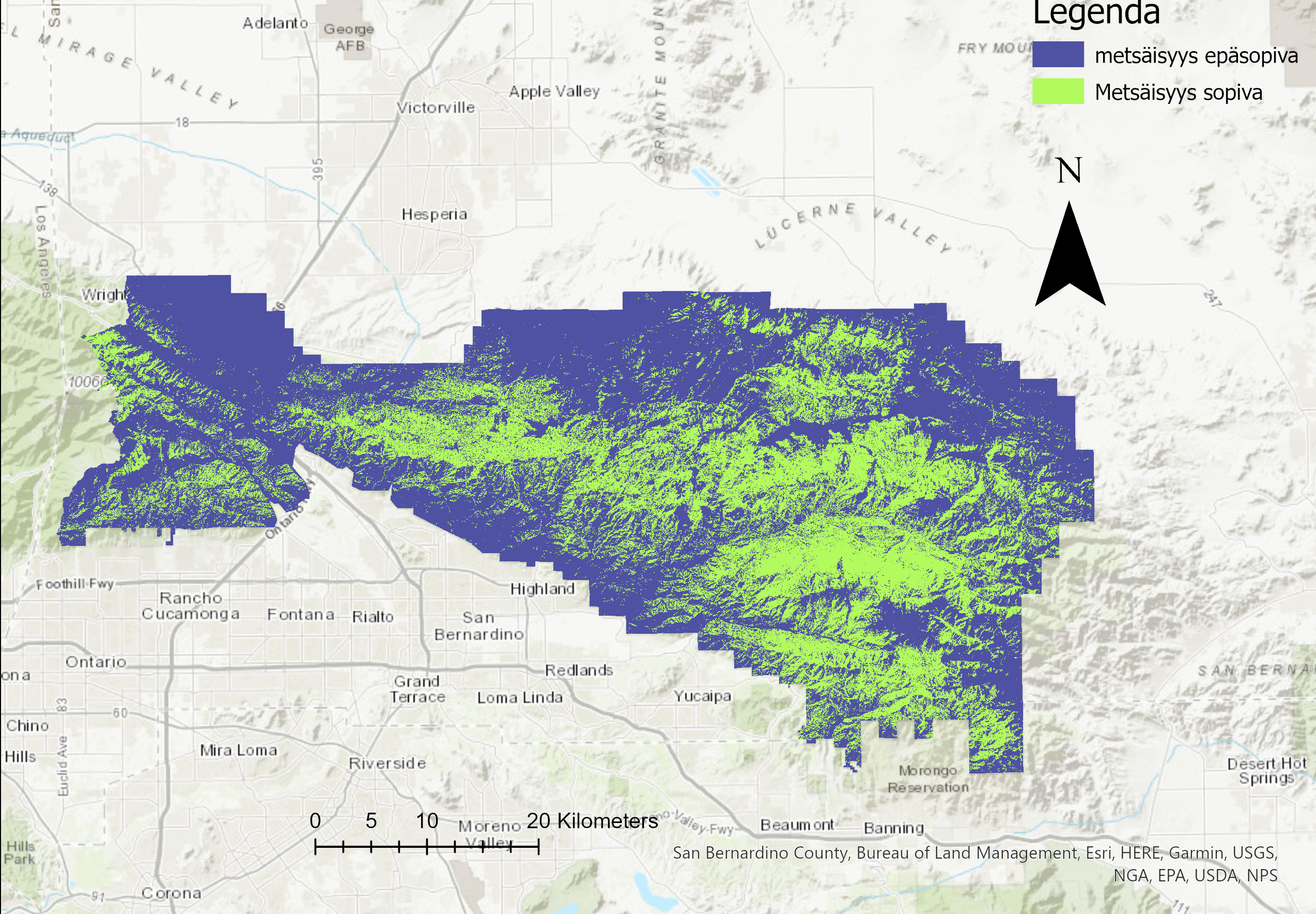
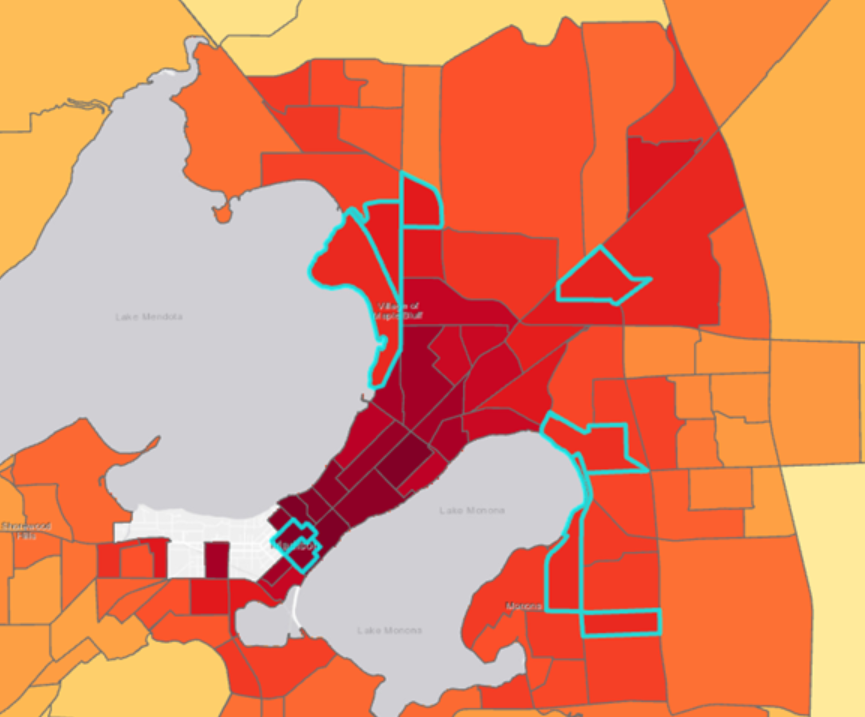
Lopuksi lämpötilaa ennustettiin jokaisessa kaupungin blokkiryhmässä. Tästä näimme jälleen, että korkeimmat lämpötilat ovat kaupungin keskustassa. Lopuksi tehtiin kysely, jolla löydettiin korkean lämpötilan ja riskiryhmäläisten blokit. Tähän käytettiin Select Layer by Attribute työkalua. Kriteerien perusteella kaupungista löytyi 5 sopivaa blokkia (kuva 8).
Ja näin koko kurssi on tullut päätöksen. Mielestäni kurssi oli kokonaisuutena onnistunut ja opin monia uusia hyödyllisiä taitoja. Uskon, että tulevaisuudessa pystyn soveltamaan uusia opittuja asioista monipuolisesti.
Viittaukset:
Andik, H., Eslami, H. Evaluate the spatial variability of EC and TDS in groundwater of Dez irrigation network. Journal of Scientific Research and Development. 2015; 2 (5) 95-98.
Burrough, P. A. 1987. Principles of Geographical Information Systems for Land Resources Assessment. Monographs on Soil and Resources Survey No 12. Oxford Science Publications. 194 s.
Gunarathna, M & Nirmanee, K & Kumari, M. (2016). Are Geostatistical Interpolation Methods Better than Deterministic Interpolation Methods in Mapping Salinity of Groundwater?. International Journal of Research and Innovations in Earth Science Volume 3, Issue 3, ISSN (Online) : 2394-1375.
Holopainen et al. (toim.). (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7.