Tässä raportissa keskityn enemmän ensimmäiseen tehtävään, koska toisessa tehtävässä ArcGIS ei lopettanut kaatumista…
Tällä viikolla tutustutaan erilaisiin korkeusmalleille tehtäviin analyyseihin ja muunnoksiin. Korkeusmalli, eli maastomalli on digitaalinentasopinta, joka on koosutu interpoloiduista korkeuspisteistä. Korkeusmallien yleistermi on DEM (digital elevation model), mutta se erityisesti korkeuden esitysmuoto. Muita aineistoja ovat DTM maastomalli (digital terrain model), johon kuuluu kaikki maanpintaan kuuluvat aineistot ja DSM (digital surface model) jossa otetaan mukaan esim. Puiden ja rakennusten korkeus.
Korkeusmallia kuvataan tietyllä tesselaatiolla, eli solujen peittämällä pinnalla jossa solut ei mene päällekkäin. Korkeusmalleissa tesselaatioita on yleensä kahdenlaisia; säännöllisiin nelikulmioihin perustuba rasteriaineisto tai epäsäännöllisen kokoisiin komiovektoriaineistoihin (Holopainen, 2015). Hila-aineisto on tyypillinen vektorimuotoinen aineisto, jossa on rivejä ja sarakkeita säännöllisessä ruudukossa. Se sisältää myös atribuuttitaulukon, mitä ei taas löydy rasteri aineistosta. Tyypillisin näistä kahdesta on rastereihin perustuvat korkeusaineistot. Muita korkeusaineistoja on epäsäännöllinen kolmioverkko (TIN-malli) ja korkeuskäyräaineistot. TIN-mallissa pisteet yhdistetään kolmioksi, jolloin saadaan tieto esimerkiksi rinteen jyrkkyydestä kun nähdään kolmion pinnan kaltevuus.
Ensimmäisessä tehtävässä tutustuttiin korkeusmallien käsittelemiseen ja luotiin binäärinen soveltuvuusmalli optimaalisen sijainnin löytämiseksi. Sijainnin tuli täyttää rinteen jyrkyyteen ja avautumissuuntaan liittyviä kriteerejä. Tehtävä aloitettiin vetämällä korkeusdataa sisältävä taso pohjakartan päälle ja käytettiin transparency työkalua, jonka avulla saatiin säädettyä korkeusdatatason läpinäkyvyys 40%:iin. Tällöin oli mahdollista nähdä Montgomery field sd_elevation rasterin läpi. Korkeuspinnan kaltevuus lasketaan solun x ja sen naapurisolun korkeuseron muutoksen avulla ja muutosta kuvataan prosentteina tai asteina.
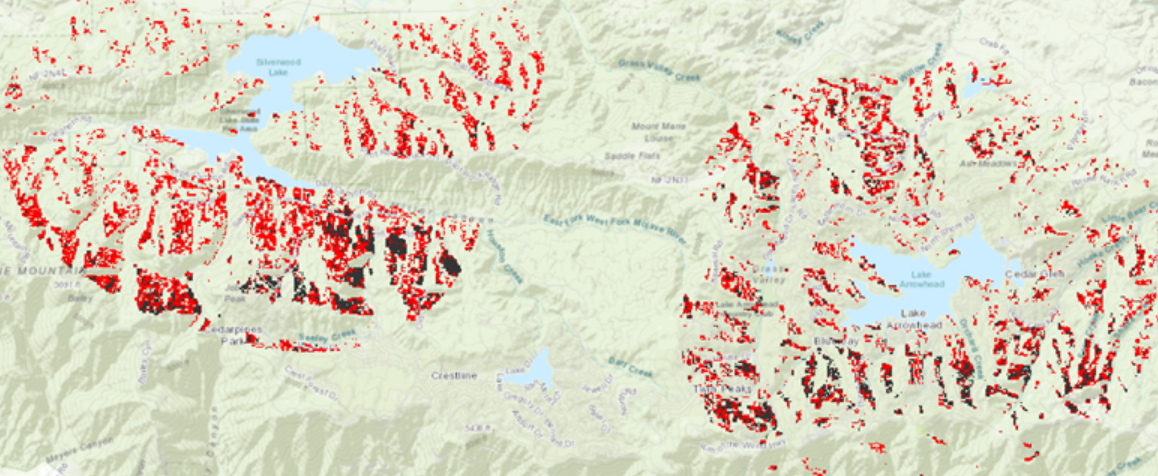
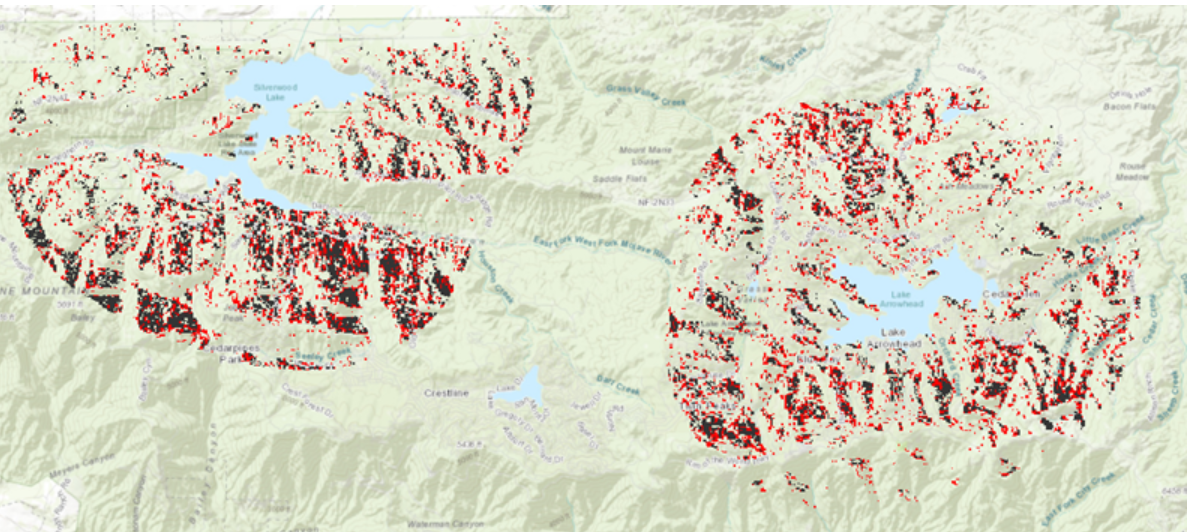
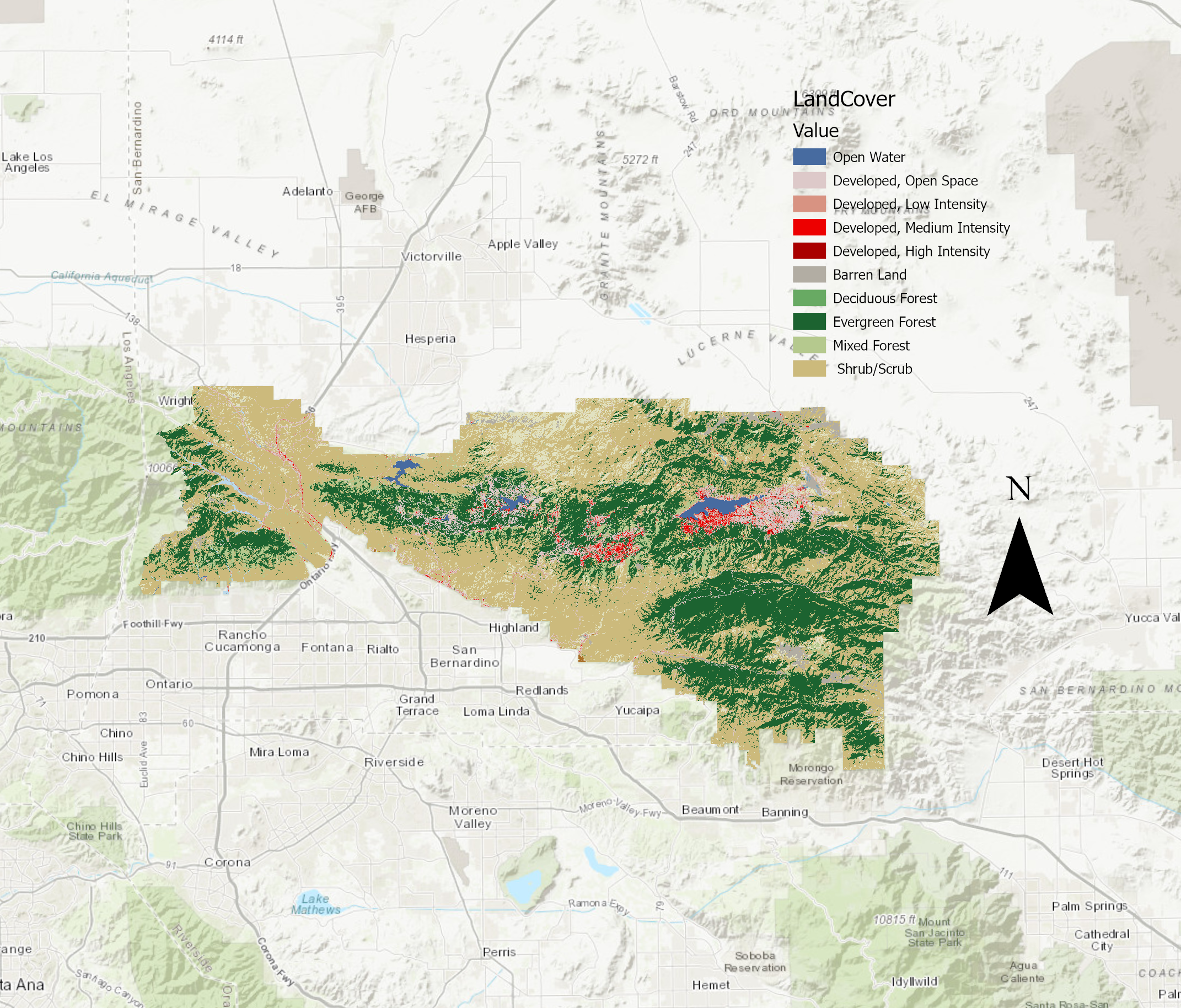
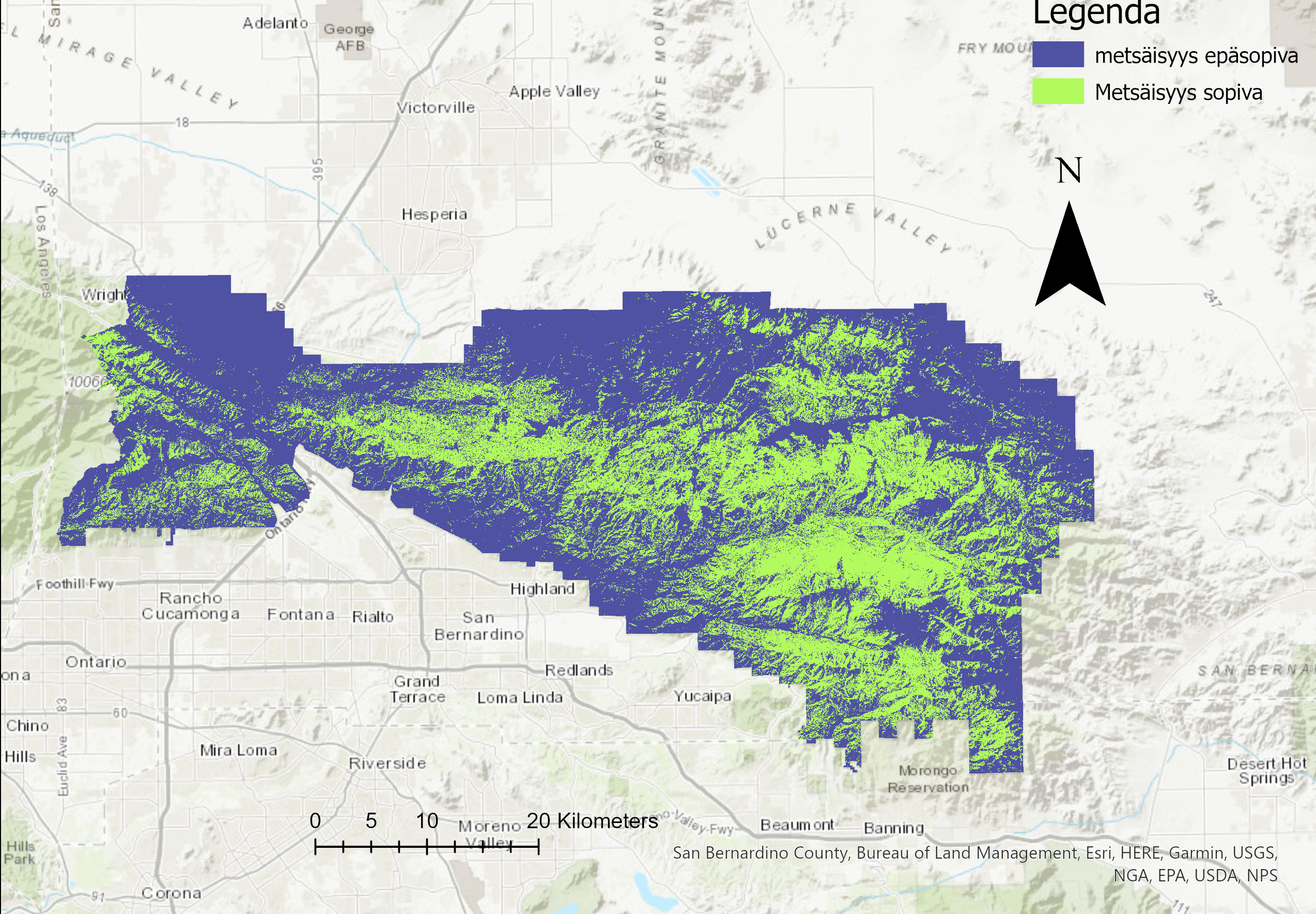
Korkeustiedosta voidaan laskea topografisia tunnuksia, kuten rinteen jyrkkyyttä tai suuntaa (Holopainen, 2015). Geoprocessing työvaiheessa opin käyttämään slope työkalua, joka kuvaa rinteen jyrkkyyttä. Se on yksi korkeusmallien tyypillisistä paikkatietotyökaluista. Työkalussa asetettiin halutut parametrit ja luotiin uusi taso, joka näyttää jyrkemmät rinteet tummalla väriskaalalla. Opin myös käyttämään aspect työkalua, joka kuvaa rinteen avautumissuuntaa (kuva 1). Avautumissuunta laskettiin samalla tavalla kuin slope työkalussa. Aspectin arvot soluille lasketaan 0°-360° välillä, missä pohjoinen on 0°, itä 90°, etelä 180° ja länsi 270°. Solut, jotka sisältävät tasaista aluetta saavat arvon -1. Slope työkalulla luotiin uusi taso, jossa eri värein kuvattiin pikseleissä olevien rinteiden suuntaa. Näiden vaiheiden jälkeen tehtiin sopivuusanalyysi, joka visualisoitiin. Kartassa (kuva 2) punaisella on kuvattu ne alueet, jotka täyttävät kaikki analyysin kriteerit.


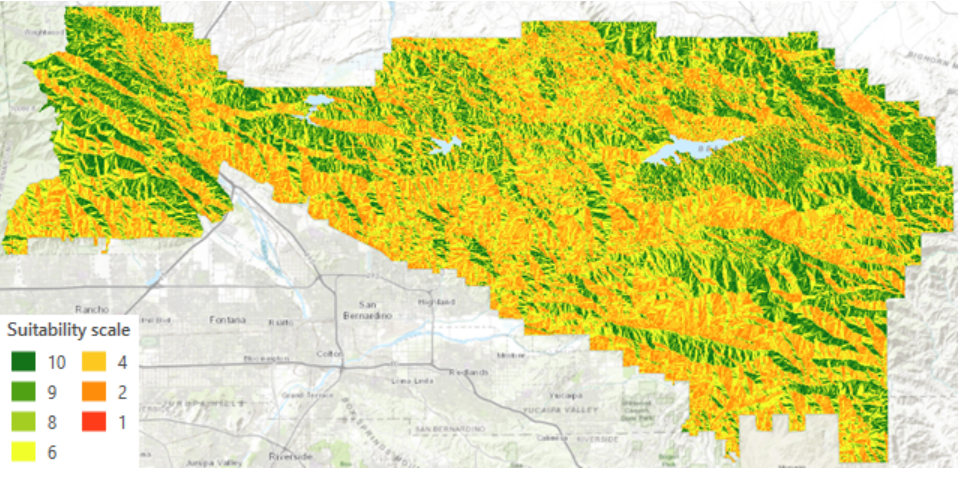
Seuraavaksi tehtävässä käytettiin hillshade, contour lines ja viewshed työkaluja, joiden avulla visualisoitiin pienempää aluetta. Hillshade työkalulla luotiin uusi mustavalkokuva taso, jolla on mahdollista kuvata maan realistisia muotoja valaisemalla pintaa tietystä kulmasta. Valon sijainti määritetään valon suunnan ja tulokulman mukaan. Sijainnin määrittämisen jälkeen työkalu käyttää slope ja aspect dataa päättääkseen, miten kirkkaasti kukin pikseli valaistaan. Kirkkaus vaihtelee 0 (pimein) – 255 (kirkkain) akselilla. Hillshade tason päälle luotiin varjo reliefi efekti, jonka avulla voidaan visualisoida maan muotoja eri väreillä. Tämä tehdään, koska hillshade on mustavalkokuva ja vain valaisee alueen. Seuraavaksi käytettiin contour lines työkalua, jonka avulla rajattiin korkeuskriteerejä kattavia alueita (kuva 3). Työkalulla yhdistetään samanarvoisia pintoja luomalla viivoja, jotka näyttävät jatkuvan ilmiön esim. korkeuden arvojen muutosnopeuden. Mitä lähempänä viivat ovat toisiaan, sitä nopeampaa muutos on. Viivat myös kulkevat tietyn intervallivälin esim. 5 metrin mukaan.

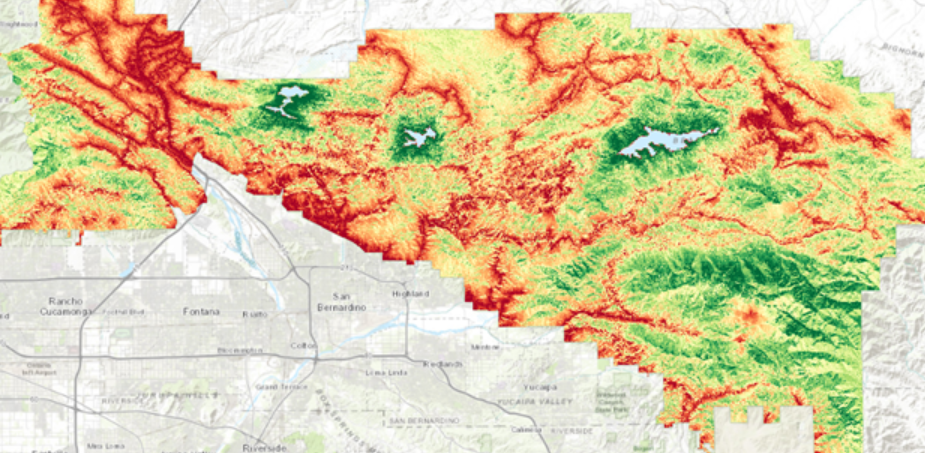
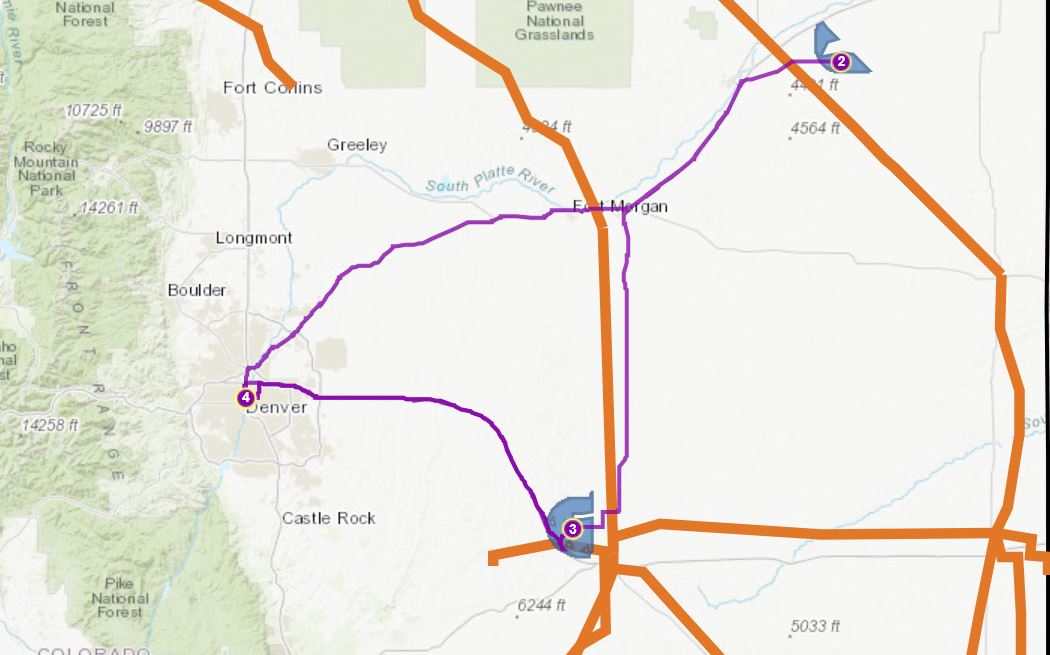
Lopuksi etsittiin sopivaa sijaintia näkyvyyden suhteen (kuva 4). Tällöin käytettiin viewshed työkalua, jonka avulla voidaan identifioida syöttörasterin näkyvät solut jotka näkyvät useasta pisteestä. Jokainen ulostulorasteri saa tarkkailupisteiden määrää kuvaavan arvon, jotka luokitellaan “näkyvä” ja “ei näkyvä”. Näkyvyys lasketaan arvioimalla solujen korkeudet paikallisten horisonttien löytämiseksi. Lopuksi visualisoidaan 3D kartta (kuva 5), jossa näkyy kaikki halutut kriteerit. Tämä tehtiin vaihtamalla 2D kartan (kuva 4) koordinaattisysteemiä.


Toisessa tehtävässä harjoiteltiin hydrologista mallinnusta, joka pohjautuu DEM aineistoon. Tarkemmin mallinnettiin pintavesien valuntaa ja nopeutta. Tärkeintä mallinnuksessa on hydrologisesti korjattu korkeusmalli. Mallin on hyvä olla grid-muodossa, koska silloin sille on helppo tehdä esimerkiksi naapuruusanalyyseja. Korkeusmallissa voi olla erilaisia virheitä, kuten kuoppia. Kuoppia voi esiintyä luonnostaan, mutta ne usein ovat vain virheitä datassa Tätä harjoiteltiin tehtävässä käyttämällä flow direction työkalua, jonka avulla voi paikantaa alueet joihin vesi ei pysty enää virtaamaan. Tämän jälkeen kuopat voi paikantaa sink työkalulla ja poistaa käyttämällä fill toimintoa, jolla kuopat “peitetään”. Peiton jälkeen muodostui uusi DEM, jossa kuoppia sisältävät solut saivat alueen korkeusdatasta matalimman arvon.
Seuraavaksi tehtävässä keskityttiin valuma-alueen rajaukseen. Tärkeä osa hydrologista mallinnusta on veden virtauksen mallintaminen, jota voi muun muassa tehdä flow direction työkalulla. Kun ruudun viettosuunta naapuriruutuun nähden tunnetaan voidaan päätellä mihin ruutuun vesi virtaa ruudusta x. Voidaan myös päätellä kuinka monesta ja mistä ruudusta vesi virtaa ruutuun x.
Tehtävässä flow direction työkalulla luotiin välikerros, jossa rajattiin vedenjakaja-alueita. Ne määritettiin virtaussuunnan (rasteritaso) ja uoman purkupisteen avulla. Itse purkupisteet voidaan löytää käyttämällä flow accumulation työkalua. Watershed työkalu on toinen yleinen virtauksen mallintamiseen käytetty työkalu, jolla määriteltiin veden laskupisteeseen laskevat vesistöt.
Kun vedenjakaja-alue oli määritelty pystyttiin määrittämään veden virtausnopeus luomalla uusi rasteripinta, jonka tuli täyttää haluttuja kriteerejä. Virtausnopeuteen vaikuttaa rinteen jyrkkyys ja virtauksen akkumulaatio. Tähän käytettiin ensimmäisestä tehtävästä tuttua slope työkalua. Seuraavaksi määriteltiin veden virtausnopeutta luomalla isokronikartta (vakioaikaerokäyrä), jossa mitattiin kulunutta aikaa pisteestä a pisteeseen b.
Tässä vaiheessa ArcGIS kaatui jatkuvasti, enkä saanut tehtävää tehtyä loppuun. Luin kuitenkin ohjeet loppuun asti, jolloin opin käytetyistä menetelmistä. kaatuilemisesta huolimatta tästä viikosta jäi ihan hyvä fiilis! Koen oppineeni paljon, mutta voisin tulevaisuudessa pohtia enemmän työkalujen käyttöä esimerkiksi muihin tarkoituksiin.
Ensi viikkoon 🙂
Viittaukset:
Holopainen et al. (toim.). (2015). Geoinformatiikka luonnonvarojen hallinnassa. Helsingin yliopiston metsätieteiden laitoksen julkaisuja 7.