
Tässä blogipostauksessa pohdin laskentaprojektiamme yleisesti, siihen liittyvää omaa oppimistani, sekä muutamaa projektin yksityiskohtaa, jotka tässä vaiheessa mietityttävät minua.
Olemme nyt puuhastelleet Vantaanjoen meritaimenkannan arvioinnin kanssa muutaman viikon, ja on selvää, että mielekkään projektin parissa työskentely tarjoaa loistavan tilaisuuden oppia. Olen todella iloinen siitä, että projektia suoritetaan suurilta osin ryhmätyönä ja siinä on mukana paljon eritaustaisia ihmisiä. Tämä tarjoaa jokaiselle hyvän mahdollisuuden oppia toisiltaan. Itselläni on tausta tilastotieteessä ja koen aina hyödylliseksi jos saan tilaisuuden selittää muille sellaisia teoreettisia peruskäsitteitä, jotka minulla pitäisi olla jo hyvin hallussa. Tämä on hyvä tapa varmistaa, että olen todella itse ymmärtänyt kyseiset asiat ja samalla tilaisuus syventää omaa ymmärrystäni niihin. Tieto on paljon hyödyllisempää, jos sen osaa selkeästi välittää eteenpäin, joten kaikki kokemus oman tiedon jakamisesta on minusta arvokasta.
Käytännöllisen projektin kanssa työskentely on myös tarjonnut mahdollisuuden peilata omaa osaamistaan ‘tosielämän tilanteiden’ valossa. Toisaalta keksiessään ratkaisuja projektin osaongelmiin voi tyytyväisenä huomata oppineensa jotain viimeisen kolmen vuoden aikana yliopistolla, mutta toisaalta taas joidenkin asioiden kanssa ymmärtää, että teorian soveltaminen käytäntöön ei ole helppo eikä itsestäänselvä harppaus. Välillä on vaikeaa tunnistaa miten käytännön ongelma muotoillaan matemaattisesti, vaikka ongelma tuntuisikin yksinkertaiselta. Käytännössä tutuilla ongelmilla on aina päällä uudenlaiset vaatteet.

The definition of e on a T-shirt
Koen saaneeni paljon apua projektin biologisen ja tietoteknisen puolen asioihin muilta projektilaisilta. Käyttämämme BUGS -ohjelmisto oli minulle jokseenkin tuttu ennen projektia, mutta nyt koen, että muiden avulla olen saanut hyvän otteen ohjelmasta ja olen kiinnostunut oppimaan lisää mallidiagnostiikasta ja muista ohjelmiston tarjoamista ominaisuuksista. Erityisesti minua mietityttää esimerkiksi se, minkälaisia työkaluja on olemassa eri mallien vertailuun ja miten parhaiten vertailla erilaisten priorien vaikutusta posteriorijakaumiin. Tähän liittyen myös teoria priorijakaumien valinnasta kiinnostaa.
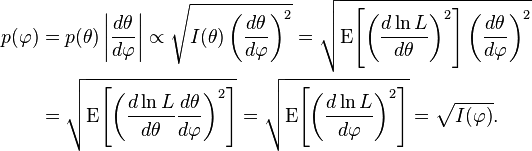
Jeffreys prior
Yksi haastavimmista osista mallia on ollut kalojen muuttointensiteetin mallintaminen, jota kuvataan mallissa kalojen todennäköisyytenä lähteä liikkeellee tiettynä päivänä. Tämän mallinosan suunnittelu alkoi yksinkertaisesta diskreetistä tasajakaumapriorista, eteni siitä ’normaalin’ näköiseen pistetodennäköisyysfunktioon ja tästä edelleen ’log-normaaliin’ pistetodennäköisyysfunktioon. Pidimme alunperin jälkimmäistä ’parhaana’ ja ’realistisimpana’ priorivalintana, sillä se vaikutti sopivan yhteen vaelluksen dynamiikasta kertovat asiantuntijatiedon kanssa.
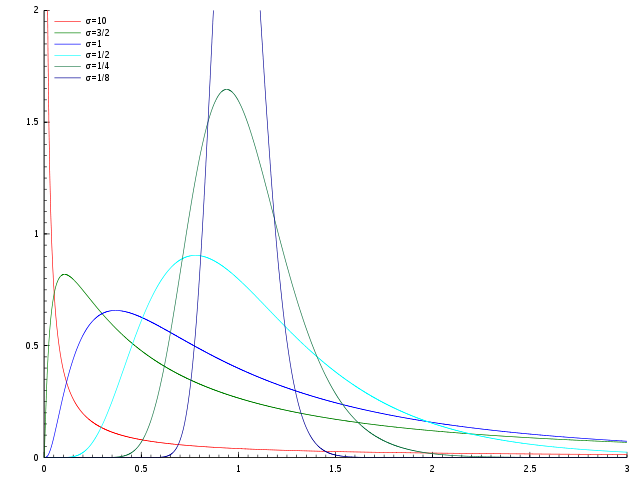
log-Normal distribution
Vaikutti kuitenkin siltä, ettei kyseinen priorivalinta saanut mallia käyttäytymään haluamallamme tavalla; lähtöintensiteetin huippu ajoittui ei-haluttuun kohtaan. Kyseinen priorivalinta vaikutti myös huomattavasti tuloksiin; ajattelen tämän johtuvan ainakin osittain siitä, että lähtöintensiteetin jakauma ei päivity mallissa kovinkaan nopeasti, sillä se kuvaa vaelluksen kulkua yli kaikkien vaelluspäivien ja alussa on tietysti dataa vain ensimmäisistä päivistä. Yritän hakea tästä epäonnistumisesta opetusta. Meillä ei ollut kovinkaan paljoa tietoa ilmiöstä ja silti valitsimme melko informatiivisen priorin. Lisäksi tiesimme, ettei data tulisi päivittämään tätä priorijakaumaa kovinkaan tehokkaasti. Ehkäpä voidaan yleisesti sanoa, että tällaisessa tilanteessa tulisi valita epäinformatiivisempi priori?